
FDA-SSD: Fast Depth-Assisted Single-Shot MultiBox Detector for 3D Tracking Based on Monocular Vision


Abstract
:1. Introduction
- A method for establishing benchmarks for object tracking with motion parameters (OTMP) was proposed. This dataset is constructed by the image obtained by the monocular camera, the motion trajectory of the monocular camera, the motion trajectory of the sample to be trained, and camera internal parameters. This data set can be used for visual scientific research such as visual slam of indoor dynamic environments, spatial positioning of moving targets, and dynamic target-recognition and classification.
- A network structure of a Fast Depth-Assisted Single-Shot MultiBox Detector was designed. With a data set with depth information (such as the OTMP in this article), the original SSD and the target-depth information were fused to train, enabling the network to learn the correlation between the depth of a target and the feature detectors at various scales. The normalized depth information obtained by combining target-positioning and -tracking algorithms can highly reduce the amount of computing on the SSD network when FDA-SSD is employed for actual detection.
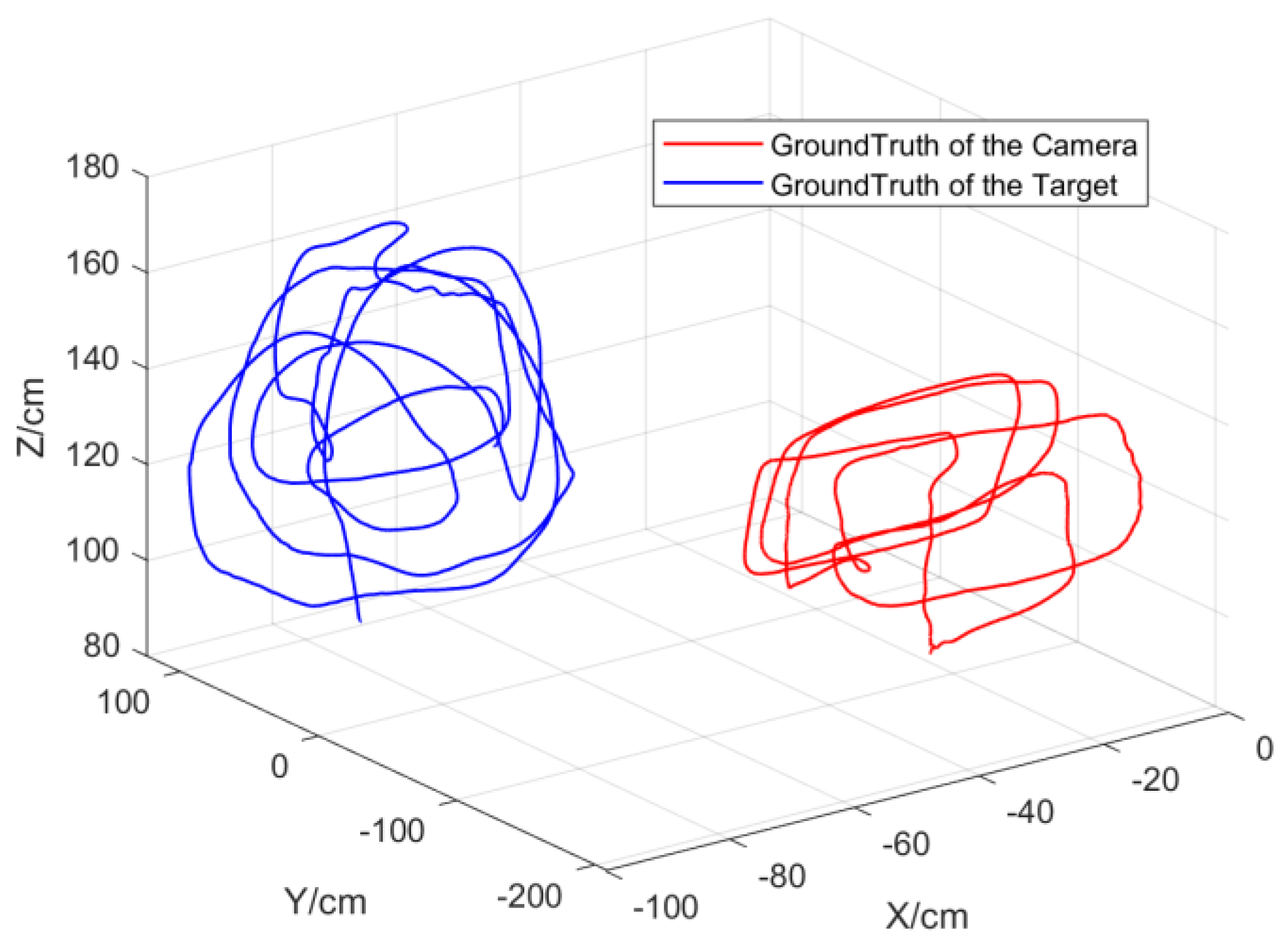
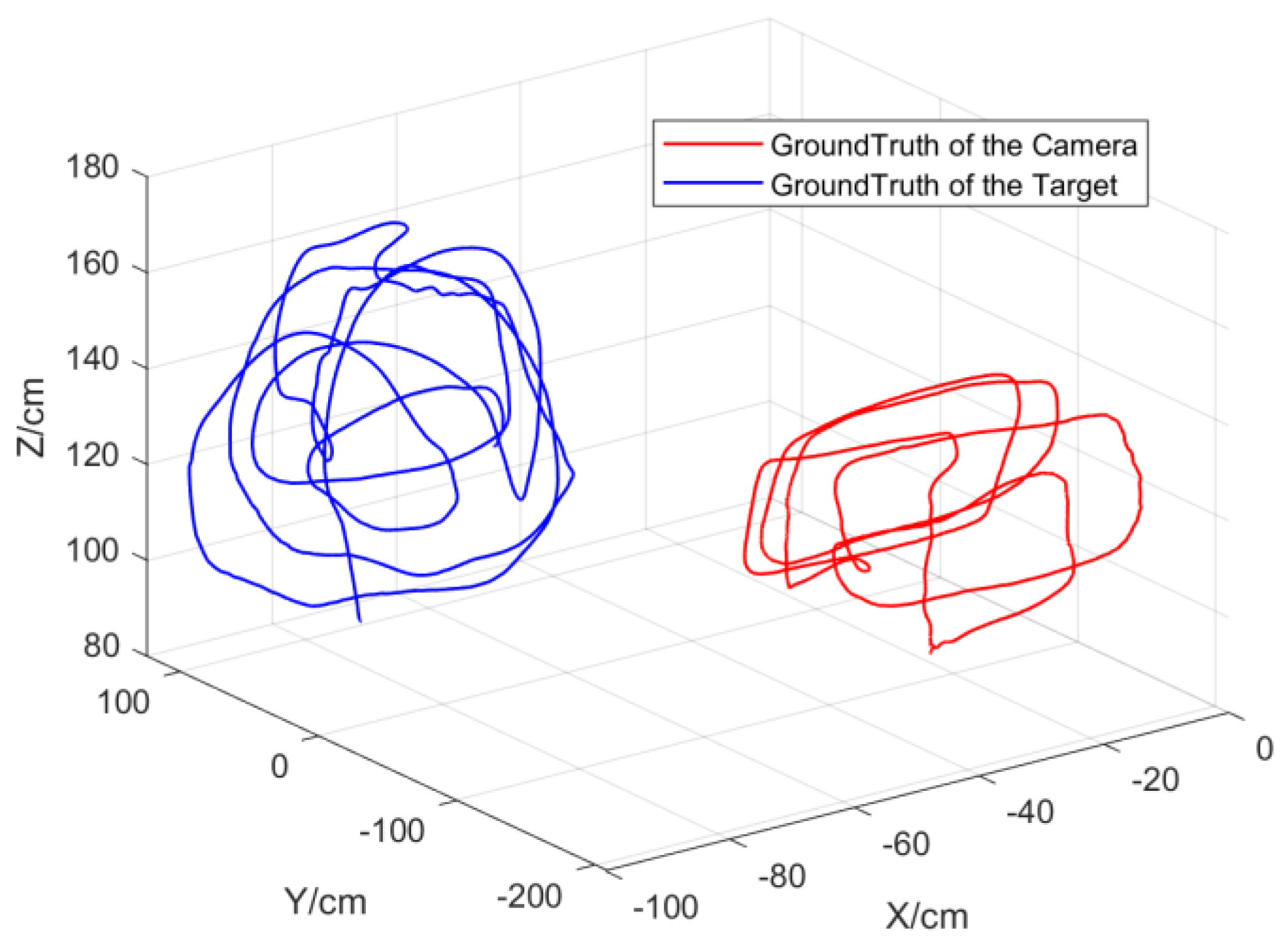
- Based on the FDA-SSD network and the author’s previous work [10], a target-detection-and-tracking algorithm framework for a monocular motion platform was established using the spatial-positioning method of geometric constraints. In this study, multiple sets of indoor target-tracking experiments were conducted with the indoor dynamic capture system as the ground truth. The test data demonstrate that the average RMSE of the tracking trajectory was 4.72 cm, which verifies the effectiveness of the target-tracking algorithm framework.
2. Related Works
2.1. Data Set
2.2. Target-Detection Model in Real-Time 3D Tracking
2.3. Depth Estimation in Monocular Vision
3. Data Set with Motion Parameters
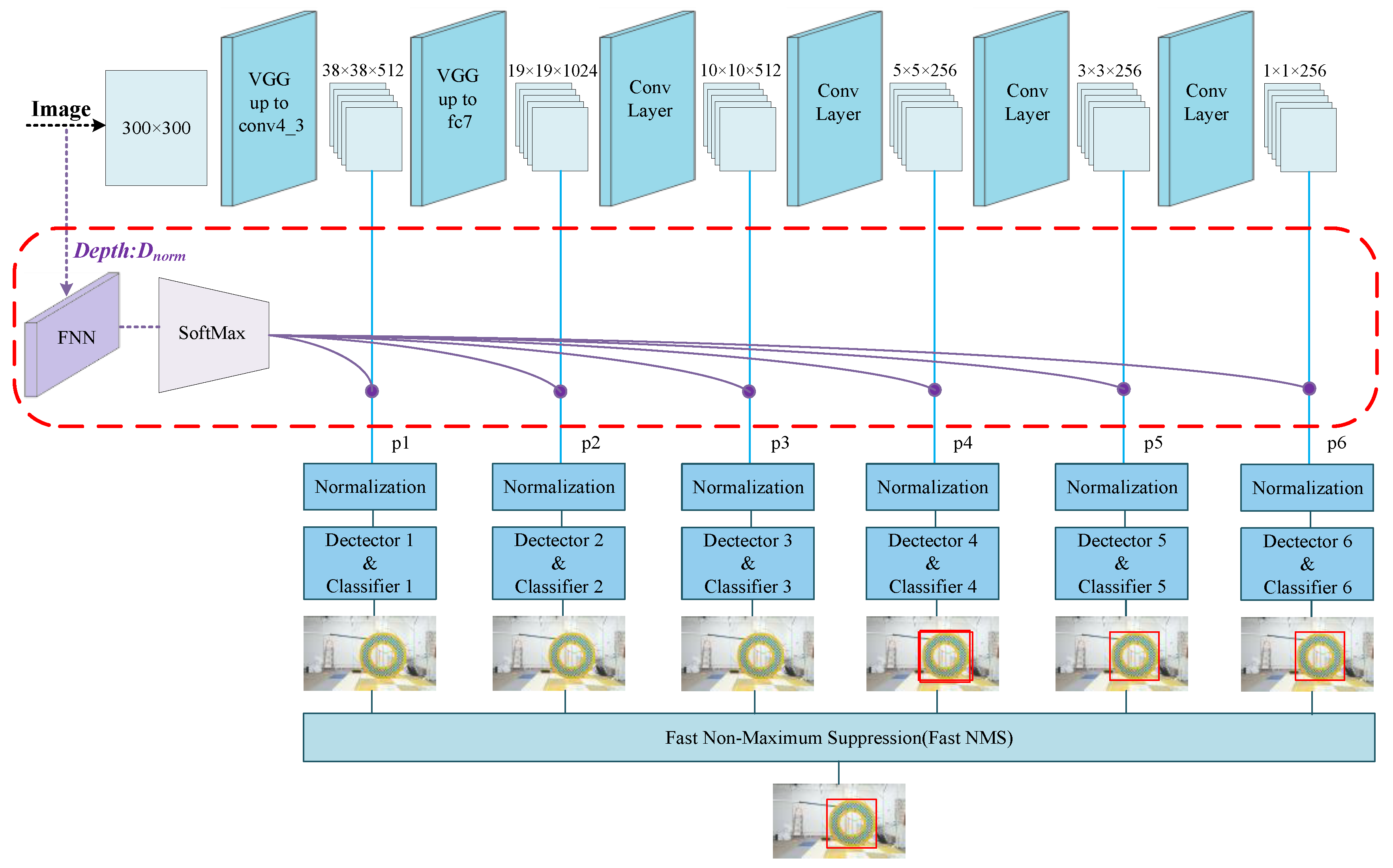
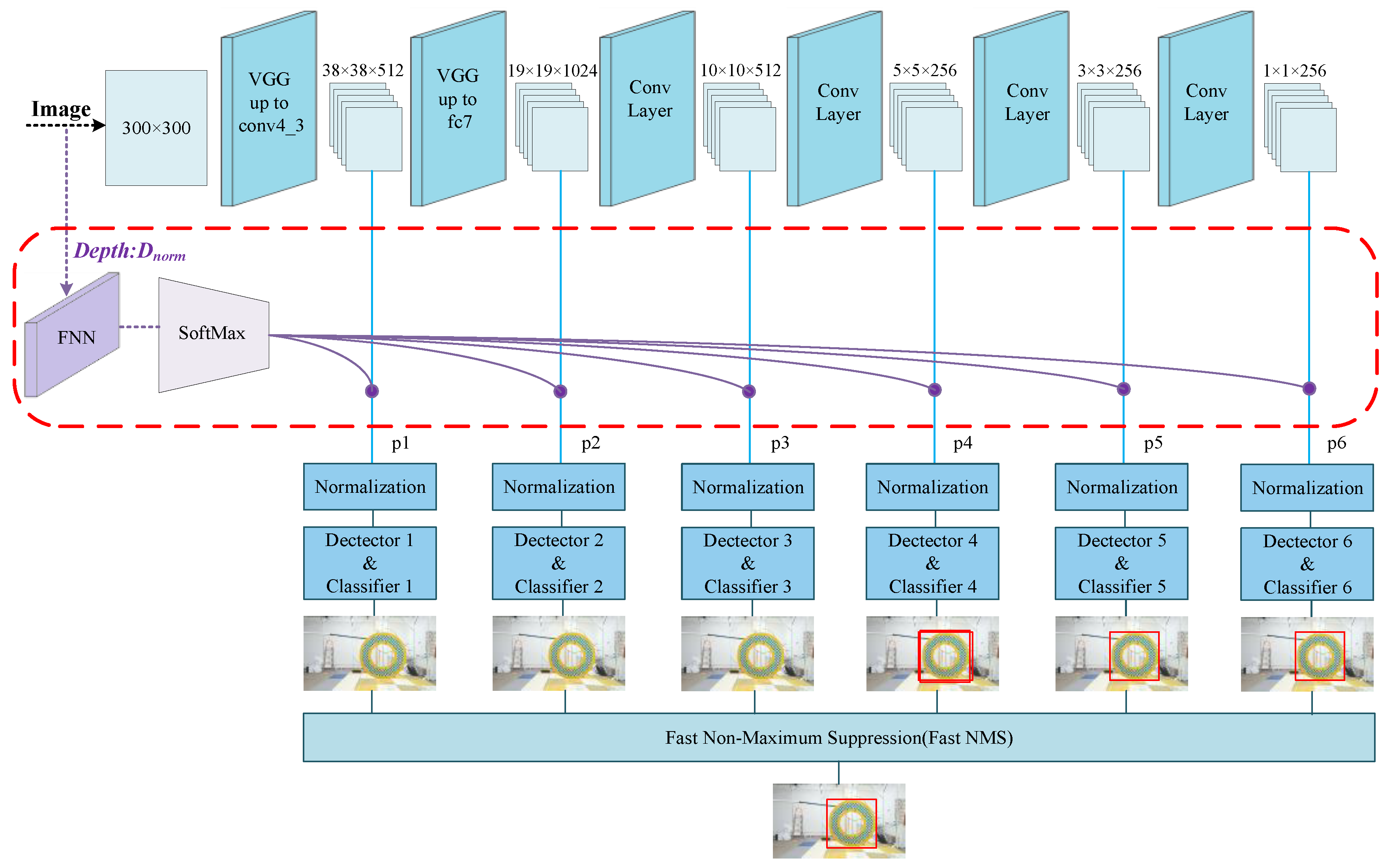
4. FDA-SSD Network
4.1. Improved Model
4.2. Issues Related to Depth Values
- For the FDA-SSD-based detection-and-tracking framework, the detection model has not yet detected the target sample to be tracked when the first frame of the image is given. Therefore, the target depth value cannot be obtained.
- For the Nth frame image, the input depth value is the depth information calculated from the N − 1 frame instead of the current frame.
- The scale of the training sample may not be consistent with the size of the tracking target during visual inspection. The same depth information does not match the same 2D-image scale. Therefore, the algorithm needs to normalize parameters such as the depth and the target scale.
- In most detection and spatial-positioning models, the basis of the 3D-spatial-positioning algorithm is to obtain the detection results of the 2D-projection surface. Therefore, during the process of using the FDA-SSD model, the depth-assisted module was not adapted by default when the first frame of the image was initialized for detection. Instead, detectors at all scales were directly employed to detect the target and obtain the initial-value 2D-tracking anchor frame. Then, the spatial-positioning-and-tracking algorithm in Section 5 was adapted to obtain the initial depth value of the target.
- Given the tracking problem based on real-time video streams, adjacent images have strong relevance. In other words, the positions of the N − 1th frame target and the N frame target are very close in most cases. Therefore, the depth information of the N − 1 frame can be adapted to assist the detection of the Nth frame. There are some extreme situations. For example, the high-speed movement of the target in the radial direction of the camera results in a large gap between the depth values of frame N − 1 and frame N. In this case, we can obtain the movement trend of the target through the target-tracking algorithm and turn on the corresponding scale detector of the corresponding N − 1 frame and its adjacent detectors to expand the scale-detection interval. Concerning general detection, when the depth information of the target moves between two scale detectors, the close FNN output-estimation probabilities and indicates that the target can be detected on both the -th and -th scale detectors. At this point, we can open the two road detectors to perform directory detection.
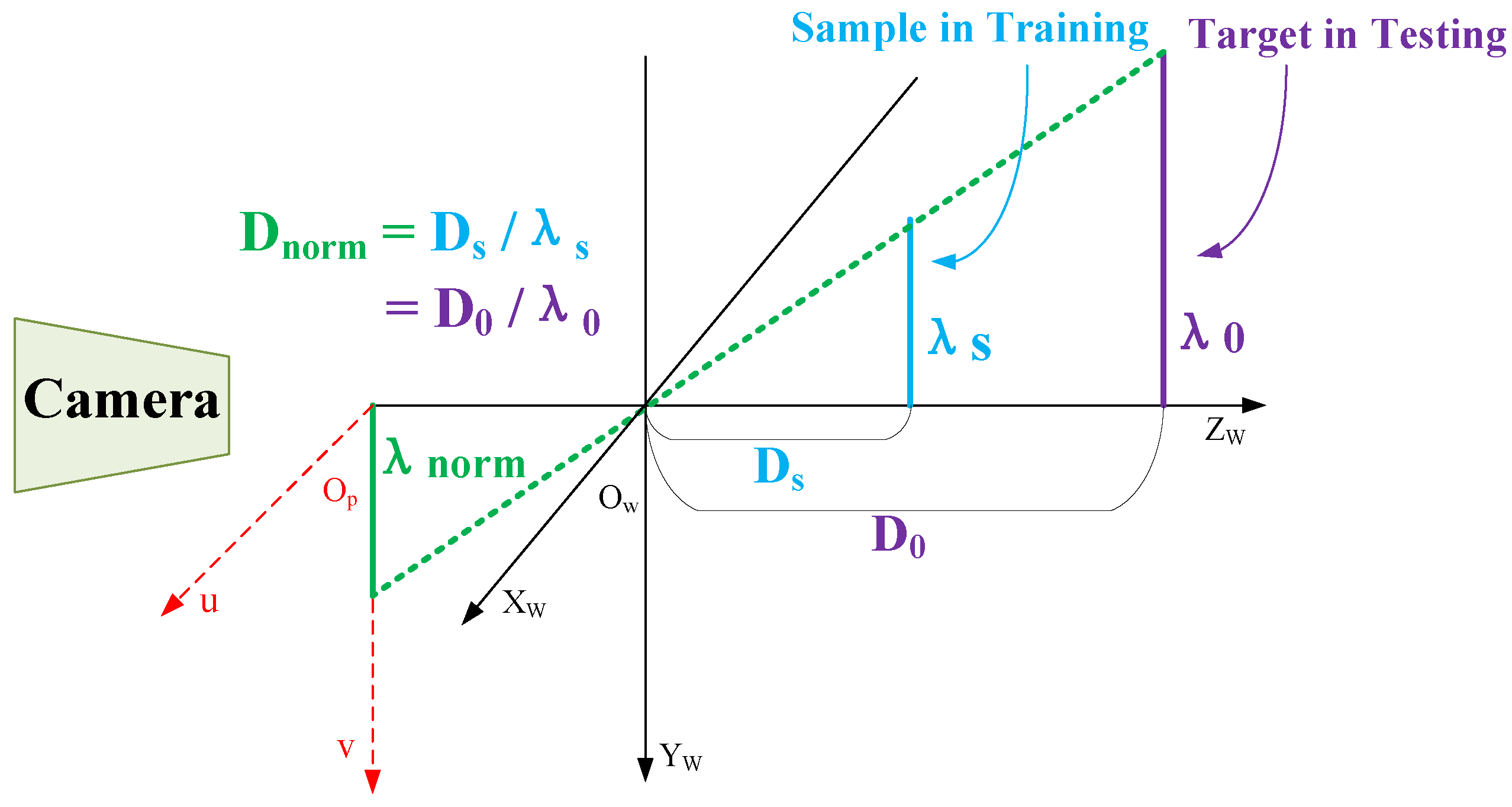
- Since there may be differences between the sample scale and the real target scale in practical applications, similar triangular properties of the projection should be employed to return the depth value to a unified standard, as illustrated in Figure 6.
5. 3D Target Tracking
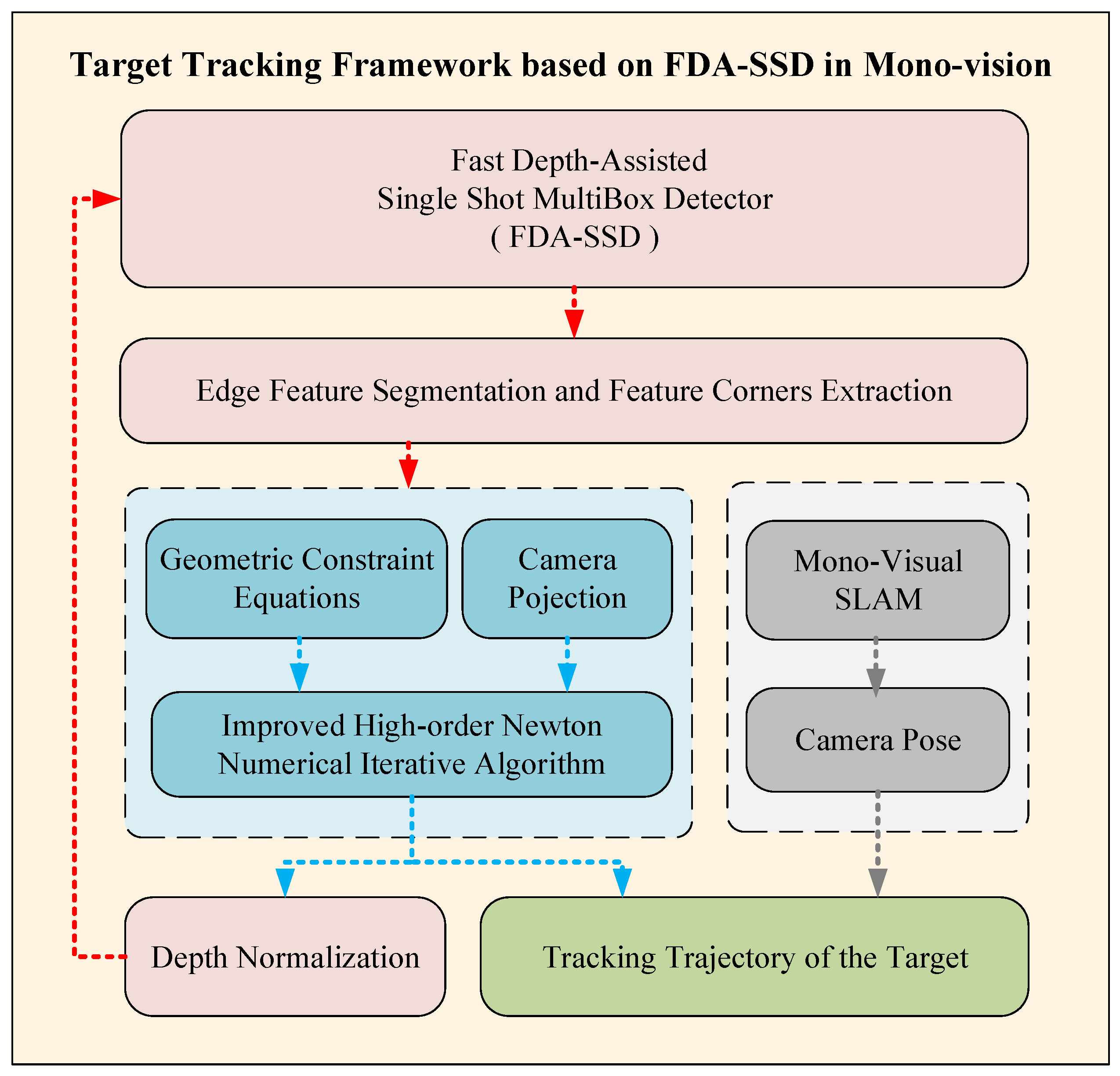
5.1. Overall Framework
- Two-dimensional-detection based on a neural network (red part): The FDA-SSD model was adapted to obtain the anchor frame area of the sample in real-time. Considering the real-time requirements, the key corner points can be extracted according to the typical geometric characteristics of the target, such as triangles, parallelograms, and circles, for use in subsequent positioning algorithms. Finally, the motion information of the target related to the camera in the current frame was employed to extract the depth information of the target relative to the camera, obtain the restored depth value based on the target scale and the sample scale, and feed it back to the input of the FDA-SSD as the reference depth value of the next frame of the image.
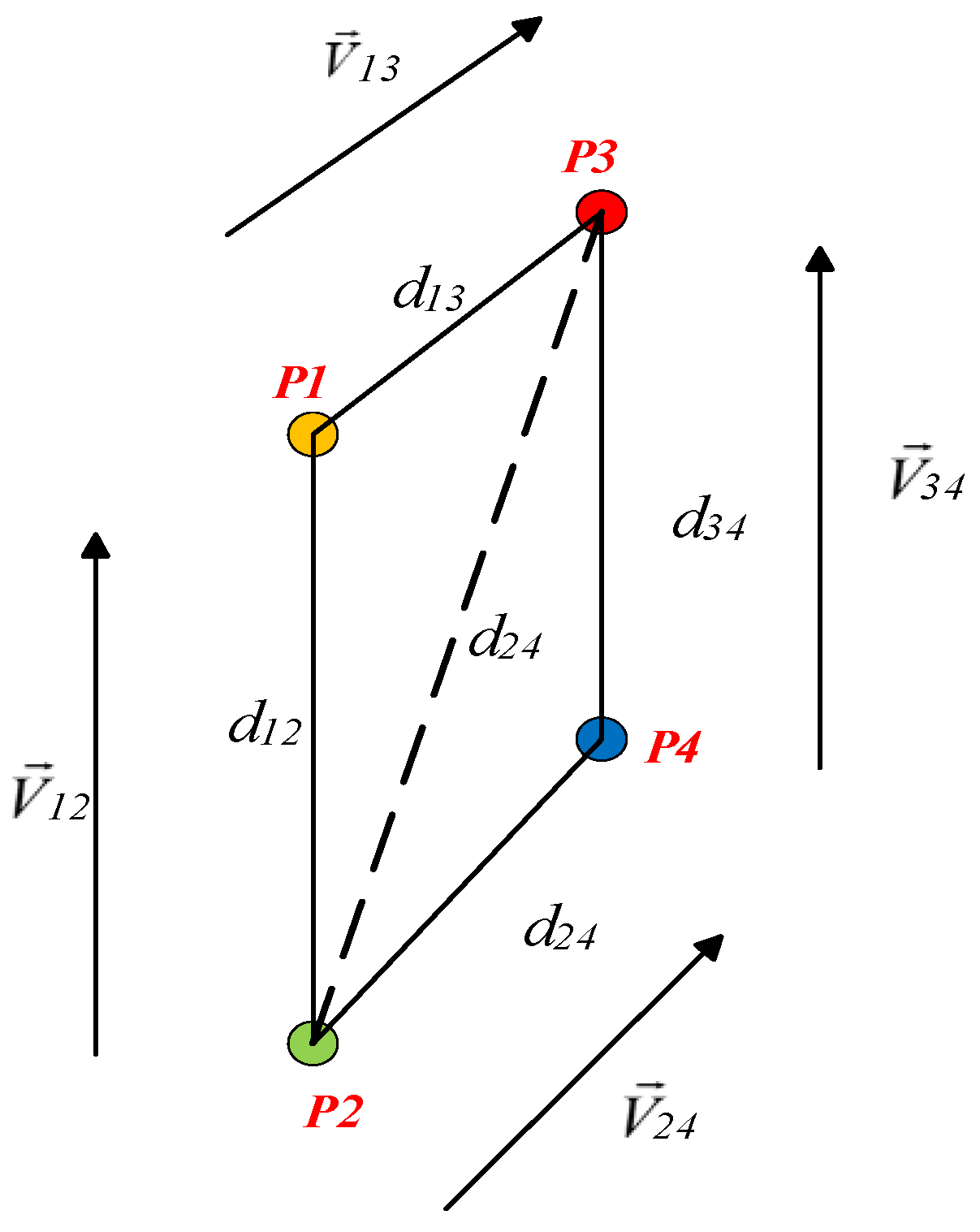
- Three-dimensional-location method based on geometric constraints (blue part): The targets in this article were abstracted as a circle or a parallelogram, and the improved high-order Newton iterative algorithm was used to realize the efficient real-time numerical solution of the depth information of the target feature points. Then, the spatial motion of the target related to the camera was restored using depth information. Finally, the real-space motion trajectory of the target was calculated with the pose of the camera.
- Camera-pose acquisition (gray part): The monocular camera pose can be obtained by open-source visual-slam methods such as VINS [24], ORB-SLAM3 [25], or refer to the author’s previous work [26,27]. This article focuses on two parts, part1 and part2. In the experimental verification of this study, the camera pose was acquired by the motion-capture system. In practical applications, the absolute scale information learning of the target can be obtained by multiple methods such as multi-frame initialization in the monocular vision slam, the baseline of the visual motion platform, and the prior information of the cooperative target.
5.2. Spatial-Positioning Method Based on Geometric Constraints
6. Experiment and Results
6.1. Target = Detection Experiment
6.2. Target-Tracking Experiments
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning Dynamic Siamese Network for Visual Object Tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1763–1771. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Cai, H.; Gan, C.; Wang, T.; Zhang, Z.; Han, S. Once-for-all: Train one network and specialize it for efficient deployment. arXiv 2019, arXiv:1908.09791. [Google Scholar]
- Ma, X.; Wang, Z.; Li, H.; Zhang, P.; Ouyang, W.; Fan, X. Accurate Monocular 3D Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 6851–6860. [Google Scholar]
- Singandhupe, A.; La, H.M. A Review of SLAM Techniques and Security in Autonomous Driving. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 602–607. [Google Scholar]
- Chang, M.-F.; Ramanan, D.; Hays, J.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; et al. Argoverse: 3D Tracking and Forecasting with Rich Maps. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8748–8757. [Google Scholar]
- Hu, H.N.; Cai, Q.Z.; Wang, D.; Lin, J.; Sun, M.; Krahenbuhl, P.; Darrell, T.; Yu, F. Joint monocular 3D vehicle detection and tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5390–5399. [Google Scholar]
- Luo, W.; Yang, B.; Urtasun, R. Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 3569–3577. [Google Scholar]
- Wang, Z.H.; Chen, W.J.; Qin, K.Y. Dynamic Target Tracking and Ingressing of a Small UAV Using Monocular Sensor Based on the Geometric Constraints. Electronics 2021, 10, 1931. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.-H. Online Object Tracking: A Benchmark. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Moudgil, A.; Gandhi, V. Long-Term Visual Object Tracking Benchmark. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2018; pp. 629–645. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Kämäräinen, J.-K.; Danelljan, M.; Zajc, L.Č.; Lukežič, A.; Drbohlav, O.; et al. The Eighth Visual Object Tracking VOT2020 Challenge Results. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 547–601. [Google Scholar]
- Müller, M.; Bibi, A.; Giancola, S.; Alsubaihi, S.; Ghanem, B. TrackingNet: A Large-Scale Dataset and Benchmark for Object Tracking in the Wild. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 300–317. [Google Scholar]
- Dong, X.; Shen, J. Triplet Loss in Siamese Network for Object Tracking. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Munich, Germany, 8–14 September 2018; pp. 459–474. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Joglekar, A.; Joshi, D.; Khemani, R.; Nair, S.; Sahare, S. Depth estimation using monocular camera. Int. J. Comput. Sci. Inf. Technol. 2011, 2, 1758–1763. [Google Scholar]
- Pizzoli, M.; Forster, C.; Scaramuzza, D. REMODE: Probabilistic, monocular dense reconstruction in real time. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2609–2616. [Google Scholar]
- Choi, S.; Min, D.; Ham, B.; Kim, Y.; Oh, C.; Sohn, K. Depth Analogy: Data-Driven Approach for Single Image Depth Estimation Using Gradient Samples. IEEE Trans. Image Process. 2015, 24, 5953–5966. [Google Scholar] [CrossRef] [PubMed]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-scale Convolutional Architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper Depth Prediction with Fully Convolutional Residual Networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar] [CrossRef] [Green Version]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Multi-scale Continuous CRFs as Sequential Deep Networks for Monocular Depth Estimation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5354–5362. [Google Scholar]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Campos, C.; Elvira, R.; Rodriguez, J.J.G.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Wang, Z.H.; Qin, K.Y.; Zhang, T.; Zhu, B. An Intelligent Ground-Air Cooperative Navigation Framework Based on Visual-Aided Method in Indoor Environments. Unmanned Syst. 2021, 9, 237–246. [Google Scholar] [CrossRef]
- Wang, Z.H.; Zhang, T.; Qin, K.Y.; Zhu, B. A vision-aided navigation system by ground-aerial vehicle cooperation for UAV in GNSS-denied environments. In Proceedings of the 2018 IEEE CSAA Guidance, Navigation and Control Conference (CGNCC), Xiamen, China, 10–12 August 2018; pp. 1–6. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP | FPS | Boxes | GPU | Input Resolution |
|---|---|---|---|---|---|
| YOLO v1 | 97.7 | 21.2 | 98 | GTX1060 | 448 × 448 |
| YOLO v2 | 98.9 | 27.4 | 1521 | GTX1060 | 416 × 416 |
| SSD | 98.6 | 24.3 | 8732 | GTX1060 | 300 × 300 |
| FDA-SSD | 98.3 | 28.7 | ~dynamic | GTX1060 | 300 × 300 |
| Axis | X (m) | Y (m) | Z (m) |
|---|---|---|---|
| RMSE | 0.0402 | 0.0326 | 0.0417 |
| Axis | X (m) | Y (m) | Z (m) |
|---|---|---|---|
| RMSE | 0.0392 | 0.0372 | 0.0472 |
| Method | Timing for Detection | Timing for Location | GPU | Input Resolution |
|---|---|---|---|---|
| Yolo v2 | 37.15 ms | 2.63 ms | GTX1060 | 416 × 416 |
| SSD | 41.73 ms | 2.30 ms | GTX1060 | 300 × 300 |
| FDA-SSD | 34.82 ms | 2.55 ms | GTX1060 | 300 × 300 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Yang, S.; Shi, M.; Qin, K. FDA-SSD: Fast Depth-Assisted Single-Shot MultiBox Detector for 3D Tracking Based on Monocular Vision. Appl. Sci. 2022, 12, 1164. https://doi.org/10.3390/app12031164
Wang Z, Yang S, Shi M, Qin K. FDA-SSD: Fast Depth-Assisted Single-Shot MultiBox Detector for 3D Tracking Based on Monocular Vision. Applied Sciences. 2022; 12(3):1164. https://doi.org/10.3390/app12031164
Chicago/Turabian StyleWang, Zihao, Sen Yang, Mengji Shi, and Kaiyu Qin. 2022. "FDA-SSD: Fast Depth-Assisted Single-Shot MultiBox Detector for 3D Tracking Based on Monocular Vision" Applied Sciences 12, no. 3: 1164. https://doi.org/10.3390/app12031164
APA StyleWang, Z., Yang, S., Shi, M., & Qin, K. (2022). FDA-SSD: Fast Depth-Assisted Single-Shot MultiBox Detector for 3D Tracking Based on Monocular Vision. Applied Sciences, 12(3), 1164. https://doi.org/10.3390/app12031164