1. Introduction
Speech translation (ST) systems have been traditionally designed under a cascade approach, where independent automatic speech recognition (ASR) and machine translation (MT) components are chained, feeding the ASR output into the MT component, oftentimes with task-specific bridging to optimise component communication [
1,
2,
3]. Although this approach has been the dominant paradigm in the field, cascade speech translation is prone to error propagation, requires the assembly of separate components, and cumulates the latency of its two main components.
With the advent of deep learning approaches, significant results have been achieved with end-to-end neural models, notably in the fields of machine translation [
4,
5] and speech recognition [
6,
7], building on the ability of neural models to jointly learn different aspects of a task. Following the success of these approaches, end-to-end modelling has also been proposed for the speech translation task [
8,
9,
10]. In what follows, we use the terms
direct and
end-to-end interchangeably to denote the process of modelling speech translation with a neural network trained on speech input in the source language and text output in the target language.
While preliminary results with end-to-end systems had shown promise, the initial cascade systems still obtained better results overall on standard evaluation datasets [
11]. One of the main factors for this state of affairs has been the paucity of parallel speech–text corpora, in contrast with the comparatively larger amounts of data available to train separate ASR and MT models, for some language pairs at least. Recent efforts have been made to build parallel corpora suitable for the task, notably the multilingual MuST-C [
12] and Europarl-ST [
13] corpora. As most available data are built around English, which limits experimental variety, [
14] made available the mintzai-ST corpus for Basque–Spanish. This corpus supports further experimentation on languages with a number of marked linguistic properties, such as Basque, notably rich morphology and relatively free word order, which can represent a challenge for natural language processing tasks in general and automated translation in particular [
15,
16].
With newly available ST corpora supporting research and development in the field, recent variants of direct ST models have closed the quality gap with cascade approaches [
17,
18,
19,
20,
21,
22], in terms of automated metrics or manual evaluations on standard datasets [
23,
24]. Nevertheless, additional work is still needed to identify the strengths and weaknesses of end-to-end approaches to the task, and comparative results may fluctuate on standard datasets [
25].
In this paper, we extend the work of [
14] on Basque–Spanish ST and address in more details the comparative merits of cascade and direct approaches on a relatively difficult language pair and dataset. We first explored the characteristics of the mintzai-ST Basque–Spanish corpus, to provide a complete description of the data and present results for the baseline cascade and direct models trained on this corpus. We then describe additional end-to-end variants, which bridge the gap between the two approaches in terms of automated metrics. Finally, we describe the results of manual evaluations comparing the cascade and direct models.
The remainder of this paper is organised as follows:
Section 2 presents related work in the field; in
Section 3, we describe the mintzai-ST corpus, including the data acquisition process and data statistics;
Section 4 describes the different baseline models that were built for Basque–Spanish speech translation, including cascade and end-to-end models;
Section 5 discusses comparative results for the baseline models; in
Section 6, we describe several direct ST model variants and their results on automated metrics;
Section 7 describes the protocol and results of our manual evaluation of the best cascade and end-to-end models, along with the results of targeted evaluations on specific linguistic phenomena and on the impact of relative input difficulty; finally,
Section 8 draws the main conclusions from this work.
2. Related Work
Standard speech-to-text translation systems operate on the basis of separate components for speech recognition and machine translation, feeding the output of the ASR module into the MT component. Chaining these components can be performed by simply selecting the best recognition hypothesis as the input to machine translation, as was often performed with earlier systems via interlingual-based representations [
26,
27]. To optimise cascade processing, other alternatives have been explored over the years, notably via the exploitation of multiple ASR hypotheses [
1,
2] or the adoption of statistical methods and finite-state automata, integrating acoustic and translation models within stochastic transducers [
28,
29]. The issue of error propagation has been also addressed by improving the ASR component [
30], the robustness of the MT component with synthetic ASR recognition errors [
31], or the use of specific features to improve communication between components [
3].
An alternative approach to the speech translation process has focused on performing direct ST via end-to-end artificial neural networks. The first results were obtained with encoder–decoder models coupled with attentions mechanisms [
8,
9,
10]. Although most studies have focused on speech-to-text, end-to-end architectures have also been explored for speech-to-speech translation [
10,
32]. Despite promising initial results, which demonstrated the ability of neural networks to model the ST task in an end-to-end fashion, cascade systems tended to outperform end-to-end systems on standard datasets [
11]. One of the main reasons for this state of affairs was training data scarcity, i.e., the lack of sufficiently large speech-to-text datasets to train direct ST systems, in contrast with the comparatively larger training data for the ASR and MT components, considered separately. Another relevant factor was the need to improve end-to-end ST architectures or training methods for this type of approach.
The first issue has been partially tackled in recent years, with the preparation and distribution of additional ST datasets. Thus, Reference [
33] built and shared a corpus based on 236 h of English speech, from the Librispeech library, aligned with French translations. This corpus was exploited by [
34] to train an end-to-end ST model whose performance closed the gap with that of a conventional cascade model. Another important contribution in terms of ST datasets was the release of MuST-C [
12], based on translated TED talks from English into eight languages, with audio recordings ranging from 385–504 h. An additional multilingual ST corpus, CoVoST [
35,
36], provided coverage for translation from 21 languages into English and from English into 15 languages, with audio recording lengths between 1 h and 364 h.
To extend the coverage of language pairs beyond English, Reference [
13] released the Europarl-ST corpus, prepared from publicly available videos of the European Parliament, covering six languages (English, French, German, Spanish, Portuguese, and Italian) and thirty translation pairs, with volumes of data ranging from 20–89 h of audio recordings. Supporting multilingual ST beyond English also is the TEDx corpus [
37], which covers eight source languages associated with a subset of target languages, with audio recordings ranging from 11–69 h. In [
14], a corpus was prepared to address the under-resourced Basque–Spanish language pair, with 180 h for Basque and 468 h for Spanish; a detailed description of this corpus is provided in
Section 3. Synthetic data have also been exploited for speech translation, for instance by leveraging high-quality MT models on ASR datasets and speech synthesis models on MT corpora [
38].
The second issue for direct ST approaches, namely the improvement of architectural design and training methods, has been addressed via different techniques [
19]. Most current frameworks for ST adapt the Transformer architecture [
5] to the task, mainly via an adaptation of encoder layers to handle the specificities of the audio input, whose usually large number of frames raises issues given the quadratic complexity of the Self-Attention (SA) mechanism. Thus, Reference [
39] proposed a Transformer model, which notably included a 2D attention mechanism to jointly attend to the time and frequency axes of two-dimensional speech spectra input, while [
17,
40] included convolutional layers alongside 2D SA layers. Recently, an alternative framework was proposed by [
22], with decoupled triple supervision signals for acoustic, semantic, and translation processing, improving over the state-of-the-art.
In addition to architectural variant proposals, an important contribution was made by [
34], who demonstrated the usefulness of pretraining the encoder and decoder of their end-to-end model on the ASR and MT tasks, respectively, partially closing the gap with corresponding cascade systems. Their work also demonstrated the positive impact for speech-to-text translation of multi-task training, introduced for end-to-end speech-to-speech translation by [
10]. Leveraging additional resources has led to significant increases in direct ST quality, with approaches such as the application of knowledge distillation using an MT model as the teacher for direct ST training [
18] or the use of meta-learning for knowledge transfer from the ASR and MT tasks to the ST task [
41].
Recently, the use of self-supervised models trained on unlabelled speech, such as Wav2Vec [
42,
43], has demonstrated its potential for the ST task [
20,
44] and offers an interesting alternative considering the lack of labelled data, which hinders research and development in the field. Combining the use of this type of pretrained speech encoder with an additional pretrained text decoder, via minimalist fine-tuning, has been shown to provide further gains on the multilingual ST task [
21]. In
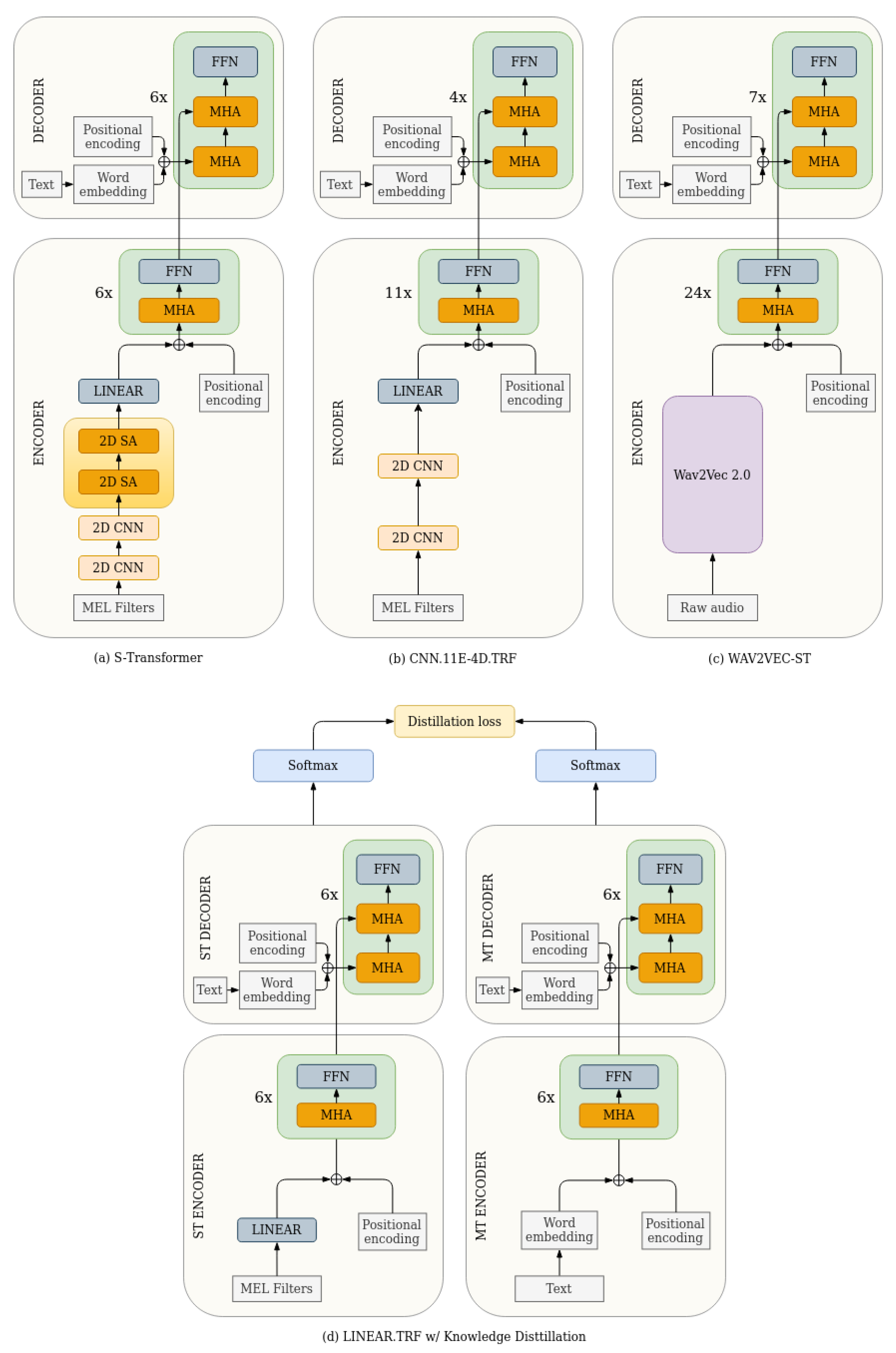
Section 6, we describe the impact of pretrained speech models, along with several representative ST variants, on the mintzai-ST datasets.
Recent improvements in ST modelling have closed the gap between direct and cascade approaches on standard datasets. Thus, whereas the latter outperformed the former in the IWSLT 2019 shared task, results from the 2020 edition featured similar performances overall [
23]. However, results on the 2021 edition of the shared task have again placed cascade ST as the top-performing approach [
25]. Alongside these results, Reference [
24] presented an in-depth comparative study of the two main approaches, in three translation directions, via both automatic and manual evaluations based on professional post-editing and annotation. They concluded that, for the language pairs and datasets in their study at least, the gap between the two approaches can be considered closed, as subtle differences between the two are not sufficient for human evaluators to establish a preference. In
Section 7, we describe a comparative manual evaluation over several cascade and direct ST model variants, with results that diverge from their conclusions.
5. Comparative Baseline Results
We first performed an evaluation centred on cascade models, where a number of variants were prepared based on different ASR approaches or different types and volumes of training data. The variants included:
ASR models trained with either an End-to-End neural model (E2E) or the Kaldi toolkit (KAL);
ASR and MT models trained on either In-Domain data only (IND) or on a combination of in-domain and out-of-domain data (ALL), by integrating the OpenDataEuskadi dataset to train the language and casing models for speech recognition and the translation models for the MT component;
MT models obtained by fine-tuning a model trained on the out-of-domain dataset with the in-domain data, in addition to the models trained on in-domain data only and all available data.
Table 8 shows the results for the cascade variants on the mintzai-ST test sets, in terms of word error rate (WER) and BLEU [
59]. All results in the table were computed with ASR output that included punctuation, generated with the previously mentioned punctuation models. To measure the impact of punctuation on the overall process, differences between BLEU scores obtained with and without punctuation, in that order, are also shown in the table (
PUNC).
Overall, cascade models trained on all data performed significantly better than their in-domain counterparts, with improvements of up to five and 1.6 BLEU points for EU–ES and ES–EU, respectively. These results were mostly due to improvements obtained on the MT components, as was expected from adding significantly larger amounts of training data to the small in-domain datasets. For the ASR components, the impact in terms of WER was minor, with around 0.3 gains in either language, mainly due to the use of the same data for acoustic modelling in all cases.
Punctuation had a significant impact on the results, with systematic improvements of up to 2.6 and 1.5 BLEU points in EU–ES and ES–EU, respectively. This trend is not entirely surprising, since the translation models were trained on data that included punctuation marks; the impact of punctuation was amplified for models trained on larger amounts of data.
Regarding the overall translation quality, as measured in terms of the BLEU scores at least, the results were in line with or higher than typical results in similar tasks [
11]. One explanation for higher marks is the domain specificity of the corpus, with recurrent topics and typical expressions. Nonetheless, the corpus also features challenging characteristics for automated speech translation, such as the use of Basque dialects or the idiosyncratic properties of the two languages at hand.
From the previous evaluation, we selected the best cascade variants based on either in-domain or all data and compared with the end-to-end speech translation models, in both translation directions. The comparative results on the mintzai-ST test sets are shown in
Table 9, where BP indicates the Brevity Penalty computed within the BLEU metric.
The most notable result from this evaluation was the large difference in terms of the BLEU between the cascade and the end-to-end variants under similar conditions, i.e., using only the in-domain data. Under these conditions, the end-to-end variant was outperformed by 12.2 and eight BLEU points in EU–ES and ES–EU, respectively. Since the conditions were similar, with relatively small amounts of training data, this large gap may be attributed to the relative dependency of the baseline end-to-end models on larger volumes of training data. More robust alternative end-to-end ST approaches are explored in the next section.
Interestingly, the end-to-end model produced translations that were closer in length to the human references, as shown by the results in terms of the brevity penalty. Although further analyses of these aspects will be warranted, these results indicate that the end-to-end systems built for these experiments may be modelling aspects of the speech translation process that are not fully captured by their cascade counterparts.
7. Targeted Evaluations of Cascade and Advanced Direct Models
Given the results of the previous sections, we selected the most representative variants to perform a manual evaluation and examine in detail the characteristics of the selected cascade and direct models. Since the results varied significantly between models based strictly on in-domain data and models with access to additional data (where additional data refer to both the datasets described in
Section 4.1 and the data used to independently train the
wav2vec 2.0 models), we selected two different pairs of systems to be compared separately:
In the following sections, we describe the results of the comparative evaluations along different relevant aspects, namely manual ranking, divergences on specific phenomena, and error propagation.
7.1. Manual Ranking Task
This task consisted of a manual evaluation of the translations generated by the different selected systems, previously described, where users were presented the source transcription and two competing translations and had to indicate whether one was preferred or whether they could be considered similar in accuracy and fluency.
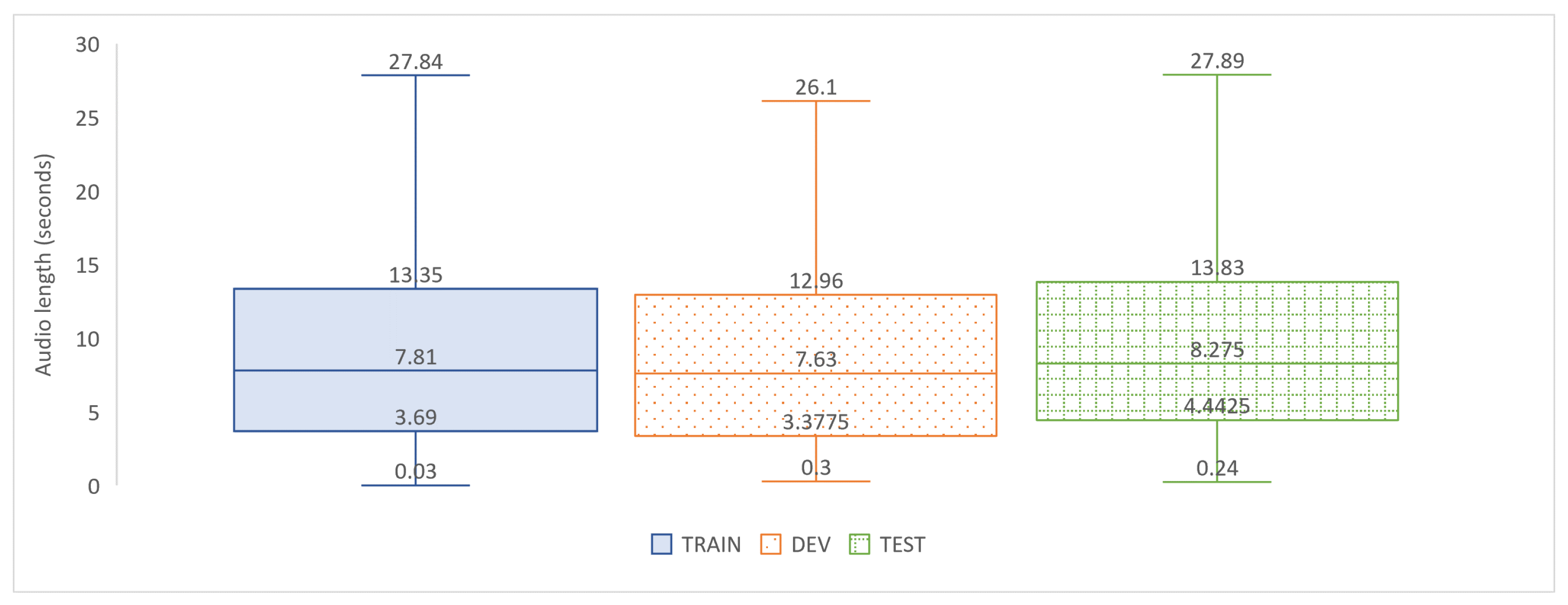
As evaluation data for the task, we extracted new data from the 2019 Sessions of the Basque Parliament, not covered by the mintzai-ST corpus, and sampled 100 representative audio inputs. To select the samples, the content of a complete Session was first translated with each of the four selected ST models. The data were then log-normalised and split into quartiles according to the length of the transcriptions, with 25 samples randomly selected from each quartile to provide a representation of different types of input in terms of duration.
Table 13 indicates the BLEU scores obtained by each model on the selected samples, to be taken as a first indication of the relative translation quality on the samples. The results were in line with the previous indications of relative model strength in terms of metrics, with slightly better scores overall obtained by the cascade models.
For the manual three-way ranking task, two separate groups of users were defined to handle, with the following characteristics:
Group A was tasked with comparing the translations between models trained only on in-domain data, namely cas ind and s-trf.pt.kd. For Spanish to Basque, nine users completed the full evaluation and one user only partially completed the task (forty out of one-hundred). For Basque to Spanish, eight users completed the full evaluation and one user only partially completed the task (twenty-three out of one-hundred);
Group B was tasked with comparing the translations between models trained on additional data, namely cas all and wav2vec-st.pt. For Spanish to Basque, 12 users completed the full evaluation; for Basque to Spanish, 11 users completed the full evaluation.
The evaluators who volunteered for the task were native speakers of Basque and Spanish, but not professional translators. They were provided guidelines on the task itself and on the use of the evaluation environment, which is based on the Appraise system [
64] and provides inter-annotator agreement statistics.
The results of the manual evaluation are shown in
Table 14, with inter-annotator agreement measured in terms of Krippendorff’s alpha [
65], Fleiss’s Kappa [
66], Bennett’ S [
67], and Scott’s Pi [
68] (omitted from the table are the number of cases that were skipped by users, which were none in all cases for Group B and, for Group A, amounted to 2.66% in ES–EU and 0.12% in EU–ES). Overall, translations from the cascade systems were preferred by a large margin for systems trained only on in-domain data, in both translation directions, and in Basque to Spanish for the systems trained on additional data. Only in the latter case, for Spanish to Basque, were the systems considered relatively equal. It also worth noting that between 30% and 40% of the translations, approximately, were considered of equal quality overall.
Inter-annotator agreement was moderate overall and significantly higher in both cases of Basque to Spanish translation, where the differences were larger between the compared systems. The lowest agreement was obtained in the only case where no clear preference was shown for either system, which may be interpreted as a result of the translations being of similar quality overall, without systematic aspects favouring one or the other.
7.2. Divergence on Specific Phenomena
To assess more detailed differences between the cascade and direct approaches, we selected and evaluated translation subsets addressing three different phenomena, after a preliminary manual evaluation of the data to identify aspects that led to divergent translations.
We thus identified all source transcriptions in the test sets that contained: numbers; a specific subset of punctuation marks, namely question, exclamation, and ellipsis marks; named entities introduced by markers in Basque or Spanish corresponding to
Sir,
Madam, or similar, which are almost systematically used to refer to other participants by name in the sessions of the Basque Parliament. The number of identified samples, and BLEU scores for the four selected systems on each subset, are indicated in
Table 15.
On the numbers subset, the end-to-end models performed better overall, although this was mainly due to the fact that numbers were provided in word rather than numeral form by ASR in the cascade system. Additional processes could perform this conversion in a cascade setup, similar to the use of additional processes to insert punctuation marks. The differences in translations of numbers were thus mainly significant to indicate that some of the gains obtained by direct models were related to this variable way of representing numbers in the final translations.
Translations also differed in terms of punctuation, in this case also with higher marks obtained overall by end-to-end models, except for Basque to Spanish with additional data. One of the main reasons for this divergence comes from the limitations of the specific punctuation model used for the cascade system, which only covered commas and periods. In contrast, the end-to-end models exploited the source–target punctuation data directly and could model the whole spectrum of punctuation marks in the datasets.
Finally, the divergences in terms of names were less marked, with slightly better scores with cascade models overall for Basque to Spanish. For Spanish to Basque, nearly identical results were obtained with models trained only on in-domain data and slightly better scores for wav2vec-st.pt against cas all.
Table 16 provides examples of divergent translations between cascade and direct models. Except the punctuation case, which is only correct in the direct translation example, the other examples illustrated divergences that may all be considered correct. The differences nonetheless impacted the BLEU scores on the single references used in these evaluations, an aspect that needs to be factored in when comparing translation models [
16,
24].
7.3. Error Propagation
As previously noted, one of the expected advantages of direct ST models is avoiding the propagation of ASR errors to the MT component, an aspect that was one of the characteristics of earlier cascade systems. To measure this effect, albeit indirectly, we evaluated the translation results on input classified according to the WER scores obtained with the top-performing ASR component described in
Section 4.1.1, with WER scores assumed to reflect the percentage of ASR errors that may impact a cascaded MT model. Clearly, since higher WER scores may be due to audio input that is intrinsically difficult to process for any automated recognition system, cascaded or direct, this evaluation was an approximation explored to determine eventual differences in behaviour between cascade and direct models. For these evaluations, we used the four systems selected in
Section 7.
We first measured the correlation between the WER and BLEU scores for each considered model, to determine the linear relationship between the two scores, if any. Additionally, we measured the correlation between WER and the difference of BLEU scores obtained by the compared cascade and end-to-end models, to determine the relation between WER and performance variation for the two types of models. To account for the fact that WER scores are less reliable on short audio, we filtered all audio whose corresponding transcription consisted of 10 words or less; WER scores were also normalised in the 0–100 range. The results in terms of Pearson correlation coefficients are shown in
Table 17. It is worth noting that negative coefficients between WER and BLEU indicate a positive correlation, since the metrics are reversed in terms of rank interpretation, with a higher WER indicating worse results, while a higher BLEU indicates better results.
For both cascade and direct models, the correlation between the WER and BLEU scores was small overall, with lower marks for ES–EU than for EU–ES. The correlation was comparatively higher between the WER and BLEU scores’ differences, being moderate across the board.
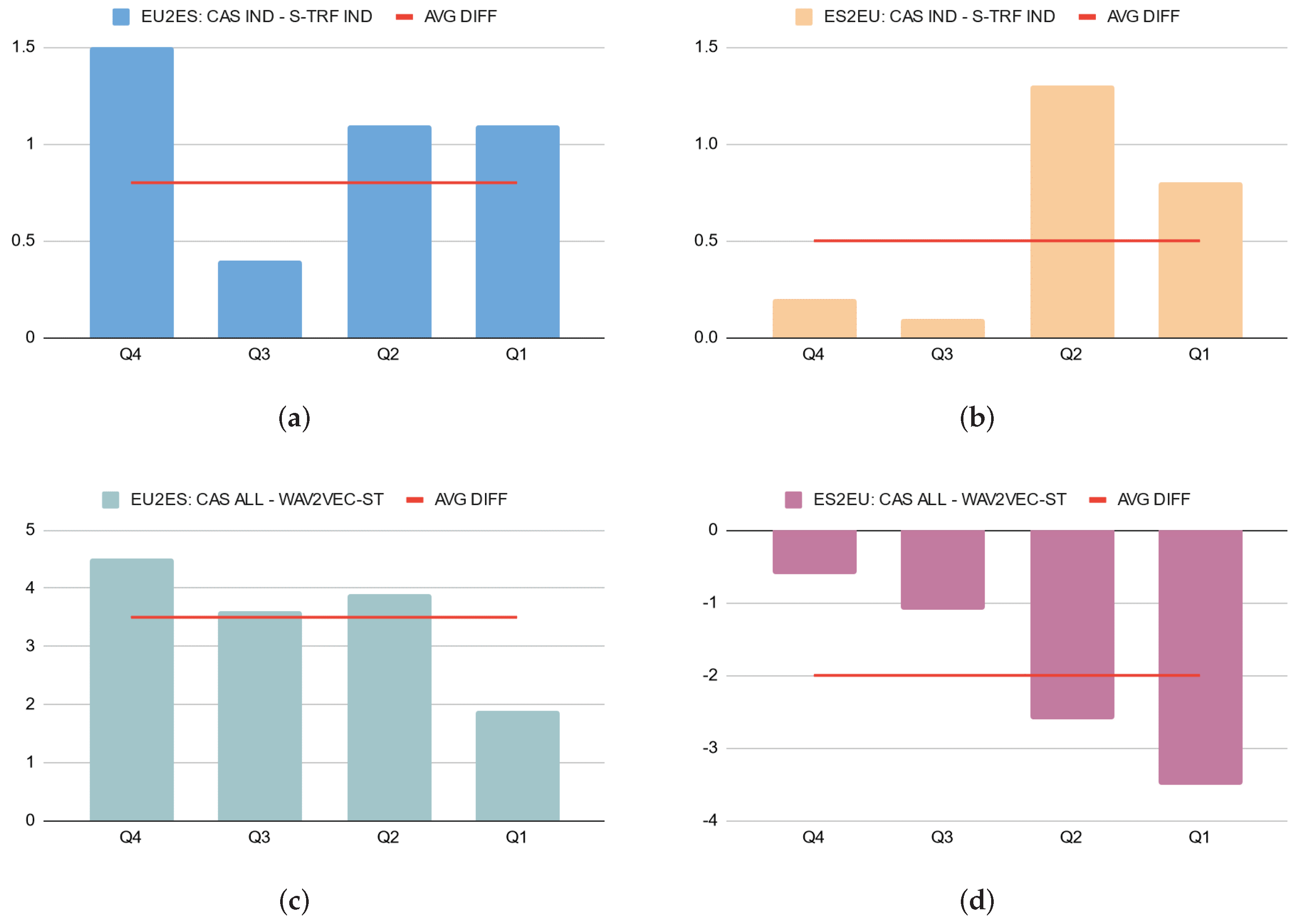
To further evaluate the impact of input difficulty as indicated by the BLEU scores, the test data were further first divided into quartiles according to the WER scores obtained by the ASR component. We then computed the difference in the BLEU scores between paired models on the data in each quartile. The results are shown in
Figure 3.
Under the assumption that higher WER scores would correlate with a larger number of errors that would impact the MT component of cascade models more than they would an end-to-end model, the expectation would be that the difference in BLEU scores is lower than the average where cascade models outperform direct models and higher than average where direct models score better than their cascade counterpart.
With models trained on in-domain data only, for EU–ES (
Figure 3a), only Q3 featured a result under the average difference; in all other quartiles, the difference was larger than average, although the differences on both Q2 and Q1 were lower than with Q4. In ES–EU (
Figure 3b), the tendencies were opposite the expectation, with the cascade model performing markedly better than average compared to the direct model on data associated with a higher WER, i.e., Q2 and Q1.
The results for models trained on additional data were more in line with the assumed impact of data associated with higher WER scores. For EU–ES for instance (
Figure 3c), the positive difference in favour of the cascade model against the direct model was lesser on Q1 and higher on Q4, with Q1 and Q3 in line with the average difference. For ES–EU (
Figure 3d), the direct model scored higher than average compared to the cascade model, with a consistent tendency as the WER scores increased from Q4 to Q1.
The results for this evaluation were thus not uniform, with opposite tendencies for the two pairs of systems depending on their having been trained only on in-domain data or also on additional data. In this case as well, additional references and manual assessments of the audio files in terms of difficulty could help determine the actual tendencies in terms of error propagation. A manual examination of non-literal transcriptions in the test sets would also support a more precise evaluation of WER-related differences between models. These tasks were however beyond the scope of this study and are left for future work.
8. Conclusions
In this work, we presented the results of a case study in Basque–Spanish speech translation, centred on comparative evaluations of cascade and direct approaches to the task.
We first described the mintzai-ST corpus, based on the proceedings of the sessions of the Basque Parliament between 2011 and 2018. We extended the initial description of the corpus in [
14] with a detailed examination of the different alignment and filtering steps, along with an analysis of the data distribution in the corpus.
Different ST models were compared, based on cascade and end-to-end approaches, starting with baseline results that included end-to-end models trained strictly on the source–target data, which resulted in cascade systems significantly outperforming their direct counterparts, with or without additional data.
Several variants of advanced end-to-end models were then prepared, exploiting pretraining and knowledge distillation techniques in particular. As was the case in other studies exploiting these techniques [
18,
34], all advanced variants significantly closed the gap with their cascaded counterparts, in terms of automated metrics, including a variant based on
wav2vec [
63], which outperformed all other models in Spanish to Basque translation. This latter model proved the most efficient in terms of metrics, providing further support to the usefulness of self-supervised training on audio data prior to performing speech translation. The comparison with other models in this study was less direct, however, given the use of large amounts of audio data to pretrain the models. Among other variants, pretraining and knowledge distillation both proved critical to drastically increase the performance of end-to-end models, with the S-Transformer model outperforming similarly trained model variants that featured architectural differences.
To further evaluate the differences between the two main ST approaches, cascade and direct, a manual evaluation was carried out on the translations from the best-performing models in each case. Although between 30% and 40% of the translations overall were considered of similar quality by a panel of native speakers of the two languages, the translations generated by the cascade models were preferred by a significant margin in all but one case, where the preferences were equally distributed. These results complement other comparative manual evaluations such as [
24], though reaching differing conclusions, as in our study and specific evaluation protocol, cascade translations were preferred overall.
We also conducted targeted evaluations along two axes. First, we evaluated divergent translations under the cascade and direct approaches, where the latter approach performed better on numbers and punctuation against the specific cascade models in this study, although in both cases, improvements could be straightforwardly achieved in a cascade approach. Additionally, we compared model result differences according to the WER scores, to measure the potential impact of ASR errors on MT results in a cascade approach and the eventual higher robustness of a direct approach in this respect. The results were inconclusive, with better relative scores for direct models on more difficult input in Basque to Spanish translation, but a reverse tendency in Spanish to Basque.
From this study, it appears that the gap between cascade and direct approaches has been reduced significantly with recent approaches to direct ST modelling, in line with similar findings [
19,
23,
24]. Nonetheless, the cascade models still obtained better results overall in terms of reference-based metrics and manual evaluations, in line with the findings reported in [
25], where cascade models achieved the best results overall on the IWSLT 2021 shared task datasets. It is worth noting that this was the case even under the controlled conditions of our study, where additional audio and translation data were considered to some extent, but with volumes of data largely under what might be exploited in this language pair [
16,
69]. The gap between cascade and direct speech translation models is thus likely to be larger under unrestricted conditions, despite the significant progress achieved with direct models in recent years.
In future work, a more detailed examination of the characteristics of the Basque–Spanish language pair, in terms of syntactic and morphological variation in particular, along with further manual examination of the corpus in terms of literality and audio variation, could shed more light on the respective strengths and limitations of cascade and direct approaches.


 ,
, 

{kind=link}
{kind=link}
{kind=link}