
Chinese Neural Question Generation: Augmenting Knowledge into Multiple Neural Encoders


Abstract
:1. Introduction
- 1.
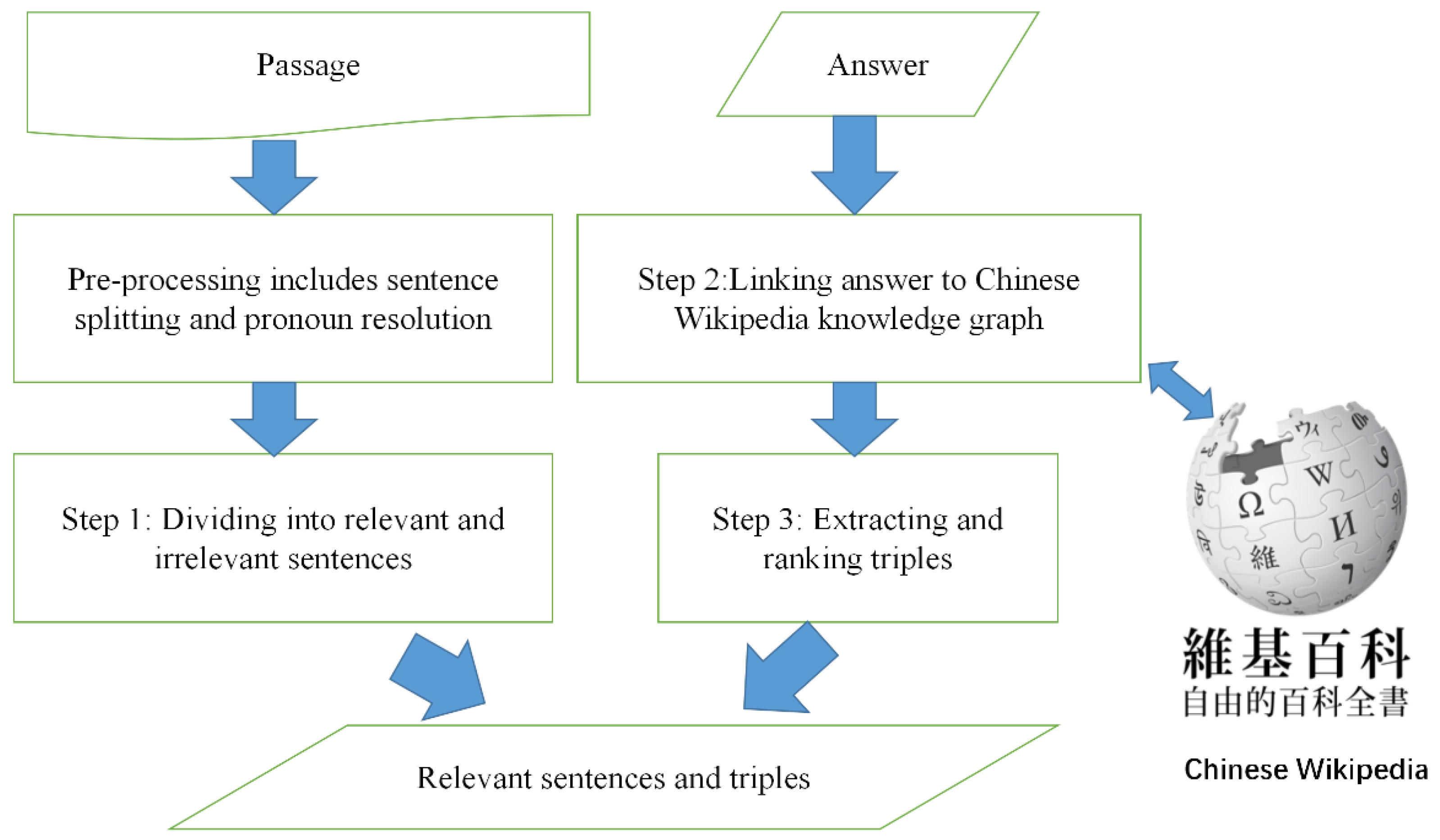
- To address Chinese QG from the long source text issue, we introduced a passage compression step and incorporated Chinese knowledge graphs to compensate for the information loss of the passage compression. This approach was inspired by the extracting relevant sentence step in question generation [15], whose purpose was to minimize question generation complexity from long source texts. However, to reduce the loss of context information from the answer, we incorporated Chinese Wikipedia knowledge to the neural model by extracting and ranking triples based on their text similarity to irrelevant sentences. We investigated the impact of the number of triples used on the system performance.
- 2.
- To improve the answer-focused attention mechanism, we proposed a multi-encoder sequence-to-sequence neural model with a double attention mechanism, where compressed text, triples and answer information have been encoded separately. The global attention mechanism pays attention to each encoder, while the local attention mechanism of each encoder pays attention to each word. Therefore, the answer and its corresponding encoder will be focused. We investigated the impact of different encoding schemas, ranging from one to three encoders, on the system performance. Moreover, inspired by recent success of the Bidirectional Encoder Representations from Transformers (BERT) model in NLP tasks [19,20], we used BERT to encode the text, triples and answer information due to its rich contextual information representation.
- 3.
- We performed comprehensive human evaluation and error analysis. Besides the question acceptability, we introduced a new evaluation metric, called the same question type ratio (SQTR), which measures the ratio of the generated questions that have the same question types as the reference question. Human experts manually analyzed 800 questions from each neural model and annotated each question acceptability and question type. Moreover, an error analysis of the Chinese questions was also performed. This kind of analysis provides valuable insights for future work with respect to how to improve Chinese question generation performance.
2. Related Work
2.1. Paragraph-Level Question Generation
2.2. Answer-Focus Question Generation
2.3. Deep Transfer Learning
3. Our Neural Question Generation Approach
3.1. Passage Compression Step Using the Knowledge Graph
3.2. Multiple Encoders Sequence-To-Sequence Model with Double Attention Mechanism
3.2.1. Multi-Encoders
3.2.2. Double Attention-Based Decoder
4. Experiments
4.1. WebQA Dataset Description
4.2. Comparative Neural Question Generation Models
- 1.
- Trans-Rules: the rule-based Chinese question generation system [7], which transforms a declarative sentence into an interrogative question by using predefined rules. We modified the code so that it can generate questions based on a given passage and the answer.
- 2.
- s2s+ Att: baseline encoder-decoder based seq2seq network with attention mechanism [12].
- 3.
- 4.
- NQG++MP: extends NQG++ model by adding a maxout pointer mechanism with a gated self-attention encoder [16].
- 5.
- NQG++PC: extends NQG++ by adding the passage compression step described in Section 3.1.
- 6.
- BERT-SQG: uses the pre-trained BERT model to encode passage and previous decoded question words and a single fully-connected layer to decode question words based on the hidden state of last token on the last layer in the BERT model [19].
- 7.
- 8.
- Single-encQG: our proposed model with only one BERT encoder compressed passage, answer and triples, and deploys a double attention-based decoder combining with the question word BERT representation.
- 9.
- Multi-encQG +TA/P: our proposed model with two encoders: one BERT encoder for passages and another BERT encoder for triples from the knowledge graph and answer embeddings.
- 10.
- Multi-encQG +PA/T: our proposed model with two encoders: one BERT encoder for passages and answer, and another BERT encoder for triples from the knowledge graph.
- 11.
- Multi-encQG +PT/A: our proposed model with two encoders: one BERT encoder for passages and triples, and another BERT encoder for the answer.
- 12.
- Multi-encQG ++: our proposed model with three encoders for passages, triples and answers, respectively.
- 13.
- Multi-encQG -triples: ablation test; the triple BERT encoder is removed from MultiencQG++.
- 14.
- Multi-encQG-answer: ablation test; the triple Answer BERT encoder is removed from Multi-encQG++.
4.3. Machine Evaluation and Results
4.3.1. Comparison Results with Different Question Generation Models
4.3.2. Ablation Studies
4.4. Case Study
4.5. Human Evaluation and Results
4.6. Error Analysis of Neural Questions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Graesser, A.; Person, N. Question Asking during Tutoring. Am. Educ. Res. J. 1994, 31, 104–137. [Google Scholar] [CrossRef]
- Rus, V.; Cai, Z.; Graesser, A. Experiments on Generating Questions about Facts. In Proceedings of the 8th International Conference on Computational Linguistics and Intelligent Text Processing, Mexico City, Mexico, 18–24 February 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 444–455. [Google Scholar]
- Heilman, M.; Smith, N.A. Good Question! Statistical Ranking for Question Generation. In Proceedings of the Annual Conference of North American Chapter of the Association for Computational Linguistics—Human Language Technologies, Los Angeles, CA, USA, 2–4 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 609–617. [Google Scholar]
- Rus, V.; Wyse, B.; Piwek, P.; Lintean, M.; Stoyanchev, S.; Moldovan, C. Overview of the First Question Generation Shared Task Evaluation Challenge. In Proceedings of the Third Workshop on Question Generation, Pittsburgh, PA, USA, 6 July 2010. [Google Scholar]
- Tang, D.; Duan, N.; Yan, Z.; Zhang, Z.; Zhou, M. Learning to collaborate for question answering and asking. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Li, Y.; Duan, N.; Zhou, B.; Chu, X.; Ouyang, W.; Wang, X.; Zhou, M. Visual Question Generation as Dual Task of Visual Question Answering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Salt Lake City Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6116–6124. [Google Scholar]
- Liu, M.; Rus, V.; Liu, L. Automatic Chinese Factual Question Generation. IEEE Trans. Learn. Technol. 2017, 10, 194–224. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2383–2392. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- See, A.; Liu, P.J.; Manning, C.D. Get to the Point: Summarization with Pointer-Generator Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1073–1083. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2014; pp. 1–15. [Google Scholar]
- Du, X.; Shao, J.; Cardie, C. Learning to Ask: Neural Question Generation for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1342–1352. [Google Scholar]
- Serban, I.V.; García-Durán, A.; Gulcehre, C.; Ahn, S.; Chandar, S.; Courville, A.; Bengio, Y. Generating Factoid Questions with Recurrent Neural Networks: The 30M Factoid Question-Answer Corpus. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL, Berlin, Germany, 7–12 August 2016; pp. 588–598. [Google Scholar]
- Zhou, Q.; Yang, N.; Wei, F.; Tan, C.; Bao, H.; Zhou, M. Neural Question Generation from Text: A Preliminary Study. In Proceedings of the International CCF conference on Natural Language Processing and Chinese Computing, Dalian, China, 8–12 November 2017; pp. 662–671. [Google Scholar]
- Du, X.; Cardie, C. Harvesting paragraph-level question-answer pairs from wikipedia. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1907–1917. [Google Scholar]
- Zhao, Y.; Ni, X.; Ding, Y.; Ke, Q. Paragraph-level Neural Question Generation with Maxout Pointer and Gated Self-attention Networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3901–3910. [Google Scholar]
- Zhao, S.; Ng, H.T. Identification and resolution of Chinese zero pronouns: A machine learning approach. In Proceedings of the 2007 Conference on Empirical Methods in Natural Language Processing, Prague, Czech Republic, 28–30 June 2017; pp. 1309–1318. [Google Scholar]
- Zheng, H.T.; Han, J.; Chen, J.; Sangaiah, A.K. A novel framework for automatic Chinese question generation based on multi-feature neural network model. Comput. Sci. Inf. Syst. 2018, 15, 487–499. [Google Scholar] [CrossRef] [Green Version]
- Chan, Y.-H.; Fan, Y.-C. BERT for Question Generation. In Proceedings of the 12th International Conference on Natural Language Generation, Tokyo, Japan, 29 October–1 November 2019; pp. 173–177. [Google Scholar]
- Zhu, J.; Xia, Y.; Wu, L.; He, D.; Qin, T.; Zhou, W.; Li, H.; Liu, T.-Y. Incorporating BERT into Neural Machine Translation. In Proceedings of the 8th International Conference on Learning Representation, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–18. [Google Scholar]
- Goodfellow, I.J.; Warde-Farley, D.; Mirza, M.; Courville, A.; Bengio, Y. Maxout networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1319–1327. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceeding of the 34th International Conference on Machine Learning, ICML, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Xu, B.; Liang, J.; Xie, C.; Liang, B.; Chen, L.; Xiaohidden, Y. CN-DBpedia2: An Extraction and Verification Framework for Enriching Chinese Encyclopedia Knowledge Base. In Proceedings of the Data Intelligence, South Padre Island, TX, USA, 28–30 June 2019; pp. 244–261. [Google Scholar]
- Wang, H.; Zhang, X. Baidu Baike. Available online: https://www.baike.baidu.com (accessed on 28 November 2021).
- Hudong Baike. Available online: https://www.baike.com (accessed on 28 November 2021).
- Chinese Wikipedia. Available online: https://zh.wikipedia.org (accessed on 28 November 2021).
- Wang, H.; Zhang, X.; Wang, H. A Neural Question Generation System Based on Knowledge Base. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Hohhot, China, August 26–30 2018; pp. 133–142. [Google Scholar]
- Duan, N.; Tang, D.; Chen, P.; Zhou, M. Question Generation for Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 866–874. [Google Scholar]
- Kim, Y.; Lee, H.; Shin, J.; Jung, K. Improving Neural Question Generation Using Answer Separation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Harrison, V.; Walker, M. Neural Generation of Diverse Questions using Answer Focus, Contextual and Linguistic Features. In Proceedings of the International Conference on Natural Language Generation (INLG), Tilburg, The Netherlands, 5–8 November 2018; pp. 296–306. [Google Scholar]
- Sun, X.; Liu, J.; Lyu, Y.; He, W.; Ma, Y.; Wang, S. Answer-focused and Position-aware Neural Question Generation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3930–3939. [Google Scholar]
- Azunre, P. Transfer Learning for Natural Language Processing; Manning Publications: Shelter Island, USA, 2021. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics, ACL, Minneapolis, MI, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, USENIX Associa-tion, OSDI, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 20–26 June 2020; pp. 7871–7880. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.Q.; Li, W.; Liu, P. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1532–4435. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.W. Unified language model pre-training for natural language understanding and generation. In Proceedings of the In Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 13042–13054. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F.; Wang, W.; Yang, N.; Liu, X.; Hon, H.W. Unilmv2: Pseudo-masked language models for unified language model pre-training. In Proceedings of the International Conference on Machine Learning 2020, Shanghai, China, 12–18 July 2020; pp. 642–652. [Google Scholar]
- Li, P.; Li, W.; He, Z.; Wang, X.; Cao, Y.; Zhou, J.; Xu, W. Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Factoid Question Answering. arXiv 2016, arXiv:1607.06275. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online. 6–11 June 2021; pp. 483–498. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-training for Neural Machine Translation. Trans. Assoc. Comput. Linguist. MA 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Huang, C.; Yin, J.; Hou, F. Text Similarity Measurement Combining Word Semantic Information with TF-IDF Method. Chin. J. Comput. 2011, 34, 856–863. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; p. 13. [Google Scholar]
- Li, S.; Zhao, Z.; Hu, R.; Li, W.; Liu, T.; Du, X. Analogical reasoning on Chinese morphological and semantic relations. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 138–143. [Google Scholar]
- t5_in_bert4keras. Available online: https://github.com/bojone/t5_in_bert4keras (accessed on 28 November 2021).
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 76–378. [Google Scholar] [CrossRef]
- Sun, C. Chinese: A Linguistic Introduction; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Liu, B.; Lai, K.; Zhao, M.; He, Y.; Xu, Y.; Niu, D.; Wei, H. Learning to generate questions by learning what not to generate. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1106–1118. [Google Scholar]
- Stasaski, K.; Hearst, M.A. Multiple Choice Question Generation Utilizing An Ontology. In Proceedings of the 12th Workshop on Innovative Use of NLP for Building Educational Applications, Copenhagen, Denmark, 8 September 2018; pp. 303–312. [Google Scholar]
- Kulshreshtha, D.; Belfer, R.; Serban, I.V.; Reddy, S. Back-Training excels Self-Training at Unsupervised Domain Adaptation of Question Generation and Passage Retrieval. In Proceedings of the the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 7064–7078. [Google Scholar]
- Back, S.; Kedia, A.; Chinthakindi, S.C.; Lee, H.; Choo, J. Learning to Generate Questions by Learning to Recover Answer-containing Sentences. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 1516–1529. [Google Scholar]
- Xiao, D.; Zhang, H.; Li, Y.; Sun, Y.; Tian, H.; Wu, H.; Wang, H. Ernie-gen: An enhanced multi-flow pre-training and fine-tuning framework for natural language generation. In Proceedings of the the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20), Yokohama, Japan, 11–17 July 2020; pp. 3997–4003. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
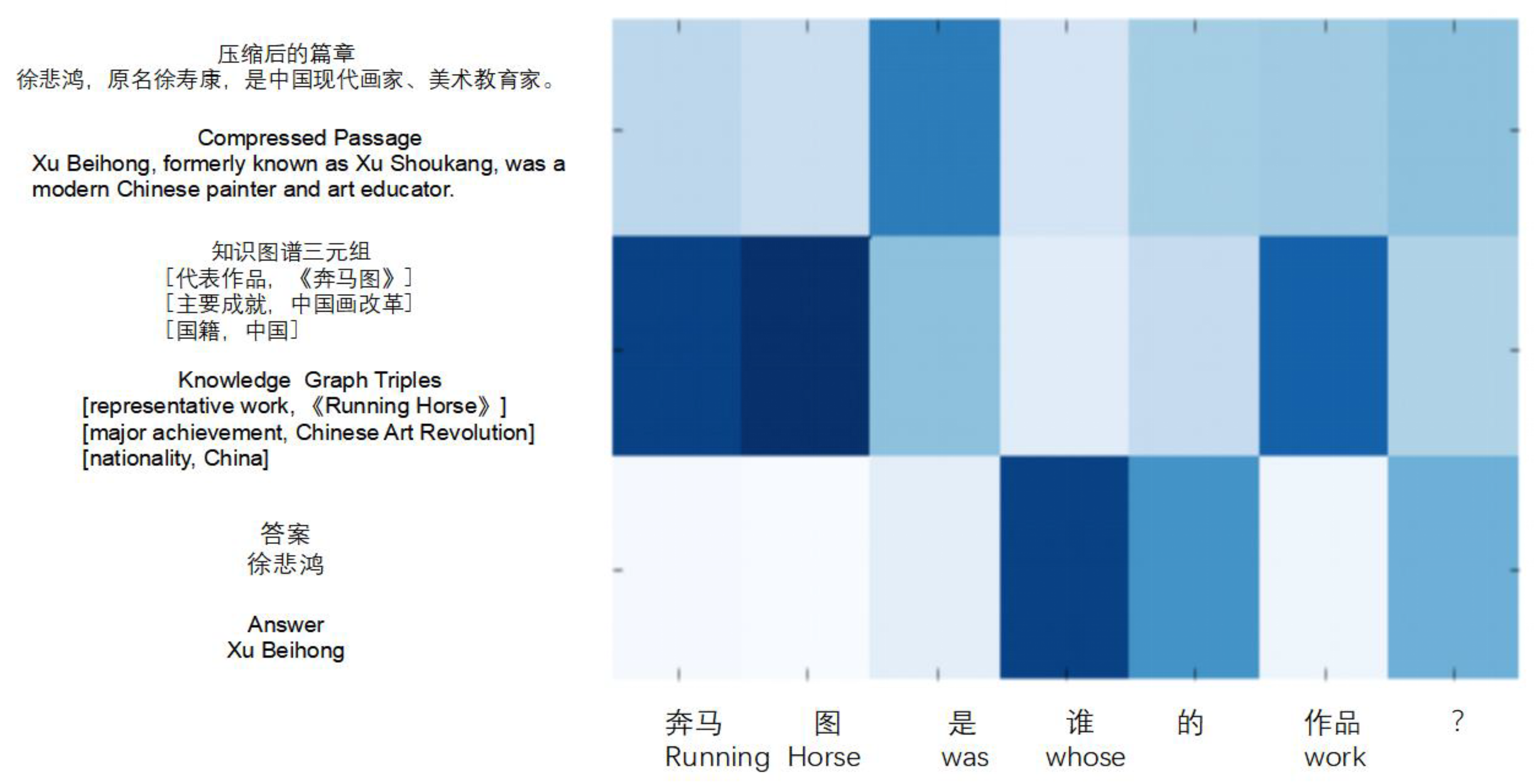
| Example Passage1: 徐悲鸿,原名徐寿康,是中国现代画家、美术教育家。曾留学法国学西画,归国后长期从事美术教育,先后任教于北平国立中央大学艺术系、北平大学艺术学院和北平艺专。擅长人物、走兽、花鸟,主张现实主义,其代表作品有《群马》、《奔马图》、《愚公移山图》。晚年去世后,其夫人将作品1200余件全部捐献给国家。 Xu Beihong, formerly known as Xu Shoukang, was a modern Chinese painter and art educator. He studied in France and studied Western painting, and then engaged in art education for a long time in China as well as taught in the Department of Art of National Central University in Peiping, the School of Art of Peiping University, and the Peiping Art College. He was good at characters, beasts, flowers and birds and advocates realism; his representative works included “Gunma”, “Running Horse”, and “Yugong Yishan”. After he died, his wife donated more than 1200 pieces of his works to the country. |
| Answer: 徐悲鸿 Xu Beihong Reference: “奔马图”是谁画的? |
| Who painted “Running Horse”? Question generated by the baseline: 徐悲鸿在北平任教什么? What did Xu Beihong teach in Peiping? |
| Irrelevant Sentences: 曾留学法国学西画,归国后长期从事美术教育,先后任教于北平国立中央大学艺术系、北平大学艺术学院和北平艺专。擅长人物、走兽、花鸟,主张现实主义,其代表艺术作品有《群马》、《奔马图》、《愚公移山图》。晚年去世后,1200余件作品全部捐献给国家。 |
| He studied in France and studied Western painting, and then engaged in art education for a long time in China and taught in the Department of Art of National Central University in Peiping, the School of Art of Peiping University, and the Peiping Art College. He was good at characters, beasts, flowers and birds, and advocates realism and his representative works included “Gunma”, “Running Horse”, and “Yugong Yishan”. After he died, his wife donated more than 1200 pieces of his works to the country. Relevant Sentences: 徐悲鸿,原名徐寿康,是中国现代画家、美术教育家。 Xu Beihong, formerly known as Xu Shoukang, was a modern Chinese painter and art educator. Top 3 ranked triples from knowledge graph: [徐悲鸿,代表作品,《奔马图》] Xu Beihong, Art work, “Running Horse” [徐悲鸿,主要成就,中国画改革] Xu Beihong, Major achievement, Chinese Art Revolution [徐悲鸿,国籍,中国] Xu Beihong, Nationality, China |
| Dataset | Avg Number of Words Per Passage | Avg Number of Words Per Passage after Compression | Number of Question–Answer Pairs | |
|---|---|---|---|---|
| WebQA | Train | 75.44 | 38.92 | 29,884 |
| Validation | 72.25 | 31.55 | 3735 | |
| Test | 71.89 | 29.75 | 3735 |
| Dataset | Model | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ROUGE-L |
|---|---|---|---|---|---|---|
| WebQA | Trans-Rules | 23.21 | 12.00 | 7.24 | 4.51 | 18.02 |
| s2s+Att | 23.61 | 12.96 | 7.99 | 5.05 | 19.15 | |
| NQG++ | 28.06 | 15.66 | 9.82 | 6.45 | 23.97 | |
| NQG++PC | 24.65 | 13.04 | 8.09 | 6.08 | 21.16 | |
| NQG++MP | 33.32 | 18.78 | 12.65 | 8.12 | 29.05 | |
| BERT-SQR | 34.14 | 20.13 | 13.45 | 8.98 | 30.47 | |
| mT5 | 36.52 | 21.45 | 15.24 | 9.88 | 32.58 | |
| Single-encQG | 30.12 | 15.38 | 9.35 | 4.92 | 25.72 | |
| Multi-encQG+TA/P | 32.52 | 17.75 | 12.05 | 8.08 | 28.85 | |
| Multi-encQG+PA/T | 31.75 | 16.19 | 11.85 | 7.78 | 27.50 | |
| Multi-encQG+PT/A | 34.10 | 19.76 | 13.21 | 8.37 | 30.13 | |
| Multi-encQG++ | 42.19 | 30.15 | 22.71 | 12.18 | 40.28 | |
| Multi-encQG-Triple | 26.85 | 14.58 | 8.58 | 6.94 | 23.78 | |
| Multi-encQG-answer | 23.98 | 13.21 | 8.34 | 5.28 | 20.65 |
| Model | Question |
|---|---|
| Human Reference | “奔马图” 是谁画的?Who painted “Running Horse”? |
| Trans-Rules | Q1: 谁是中国现代画家、美术教育家? Who was a modern Chinese painter and art educator? Error: coping wrong context words |
| s2s+Att | Q2: 艺术作品是什么? What was the art work? Error: Vague |
| NQG++ | Q3: 徐悲鸿北平任教什么? What did Xu Beihong teach in Peiping? Error: Grammatical and repetition errors |
| NQG++MP | Q4: 谁的原名叫徐康寿? Who was known as Xu Shoukang? Error: coping wrong context words |
| BERT-SQG | Q5: 徐寿康是哪位? Who is Xu Shoukang? Error: copying wrong context words |
| Multi-encQG | Q6: 徐悲鸿原名是什么? What was the former name of Xu Beihong? Error: incorrect answer |
| Multi-encQG++ | Q7: 奔马图是谁的作品? Whose artwork was Running Horse? Acceptable |
| Dataset | Model | Acceptance |
|---|---|---|
| WebQA | s2s+Att | 31% |
| NQG++ | 36% | |
| NQG++MP | 39% | |
| BERT-SQG | 40% | |
| mT5 | 42% | |
| Single-encQG | 37% | |
| Multi-encQG++ | 45% |
| Dataset | Model | What (什么) | Who (谁) | Which (哪个) | Where (哪里) | Avg. |
|---|---|---|---|---|---|---|
| WebQA | s2s+Att | 0.625 | 0.636 | 0.599 | 0.393 | 0.563 |
| NQG++ | 0.708 | 0.682 | 0.416 | 0.643 | 0.612 | |
| NQG++MP | 0.724 | 0.658 | 0.611 | 0.464 | 0.614 | |
| BERT-SQG | 0.700 | 0.722 | 0.659 | 0.551 | 0.657 | |
| mT5 | 0.710 | 0.718 | 0.670 | 0.558 | 0.664 | |
| Single-encQG | 0.647 | 0.586 | 0.671 | 0.557 | 0.615 | |
| Multi-encQG++ | 0.770 | 0.703 | 0.701 | 0.685 | 0.715 |
| Deficiency | Description | % |
|---|---|---|
| Does not make sense and isvague | The question is grammatical but too vague to know exactly what it is asking about. Example Passage 2: 鲁智深,小说《水浒传》中重要人物,人称花和尚… (Lu Zhishen, an important figure in the novel “Outlaws of the Marsh”, is known as flower monk.) Triples: (鲁智深 别名 花和尚), (鲁智深 职业 提辖), (鲁智深 主要成就 拳打镇关西) Reference: 谁是《水浒传》里的花和尚?(Who is the flower monk in the “Outlaws of the Marsh”?) System: 水浒传里的花是谁? (Who is the flower from “Heroes of the Marshes”?) | 38.75 |
| Wrong question word | Example Passage 3: 北美洲是世界上湖泊最多的洲同时也是世界上最大的淡水湖区… (North America is the continent with the most lakes in the world and the largest freshwater lake area in the world.) Triples: (北美洲,全称,北亚美利加洲), (北美洲,气候,温带大陆性气候), (北美洲,重要城市,纽约) Reference: 世界上哪洲湖泊最多? (Which continent has the most lakes in the world?) System: 世界上最大的淡水湖是什么? (What is the largest freshwater lake in the world?) | 11.75 |
| Incorrect answer | The answer to the question is not as the same as human reference. Example Passage 3: 1925年3月, 闻一多先生写下了名篇《七子之歌》,其中第五章是“广州湾” (In March 1925, Mr. Wen Yiduo wrote the famous “Song of the Seven Children”, of which the fifth chapter is “Guangzhou Bay”) Triples:(闻一多 出生地 湖北省浠水县), (闻一多 毕业院校 清华大学), (闻一多 职业 现代诗人) (Wen Yiduo birthplace Laishui County, Hubei Province) (Wen Yiduo graduation university) (Wen Yiduo profession modern poet) Reference: 七子之歌是谁写的? Who wrote the Song of the Seven Children? System Question现代诗人是谁? Who was the modern poet? | 2.75 |
| Ungrammatical | The question is not a valid Chinese sentence The answer to the question is not as the same as human reference. Example Passage 3: 李贺有“诗鬼”之称, “是与诗圣”之称杜甫、诗仙”之称李白“、以及“诗佛”王维相齐的唐代著名诗人。 Li He is known as a “Poet Ghost”, one of famous poets in Tang Dynasty including Li Bai is known as “Poetic Fairy”, Du Fu is known as “Poet Immortal”, Li P and Wang Wei, “Poet Buddha”. Triples: (李贺 信仰 道教), (李贺 主要成就 开创“长吉体”诗歌), (李贺 出生地 河南福昌) (Li He Religion Taoism), (Li He main achievement initiating “Chang Ji Style” poetry), (Li He birthplace Fuchang Henan) Reference: 文学史上被称为“诗鬼”的作家是谁? Who is known as “poet ghost” in the history of literature? System Question谁被称为诗鬼称为? Who is known “poet ghost” known? | 1.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Zhang, J. Chinese Neural Question Generation: Augmenting Knowledge into Multiple Neural Encoders. Appl. Sci. 2022, 12, 1032. https://doi.org/10.3390/app12031032
Liu M, Zhang J. Chinese Neural Question Generation: Augmenting Knowledge into Multiple Neural Encoders. Applied Sciences. 2022; 12(3):1032. https://doi.org/10.3390/app12031032
Chicago/Turabian StyleLiu, Ming, and Jinxu Zhang. 2022. "Chinese Neural Question Generation: Augmenting Knowledge into Multiple Neural Encoders" Applied Sciences 12, no. 3: 1032. https://doi.org/10.3390/app12031032
APA StyleLiu, M., & Zhang, J. (2022). Chinese Neural Question Generation: Augmenting Knowledge into Multiple Neural Encoders. Applied Sciences, 12(3), 1032. https://doi.org/10.3390/app12031032