
Skeleton Motion Recognition Based on Multi-Scale Deep Spatio-Temporal Features




Abstract
:1. Introduction
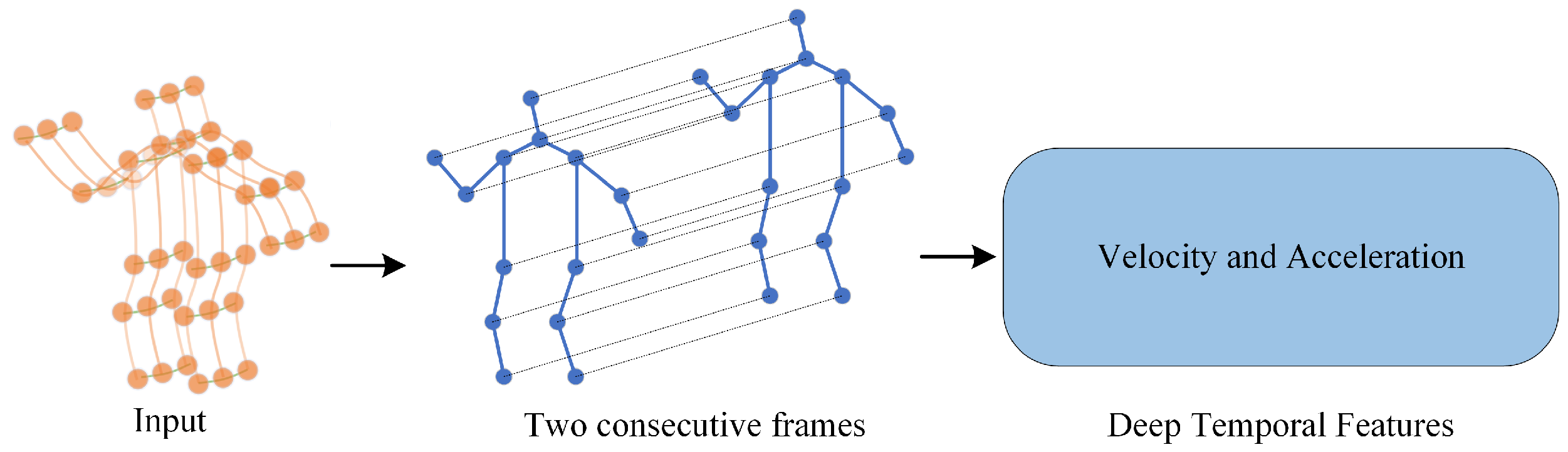
- Feature enhancement: In this paper, a multi-scale time-sampling module is proposed to obtain richer semantic information by varying the number of time frames. In addition, we combine the human skeleton map with the manipulator in robotics and propose a deep spatiotemporal feature extraction module. The module calculates the joint angle, the change of the joint angle, the angular velocity of the joint angle, and the acceleration of the joint angle in the human skeleton map, to make full use of the spatiotemporal features in the human skeleton data.
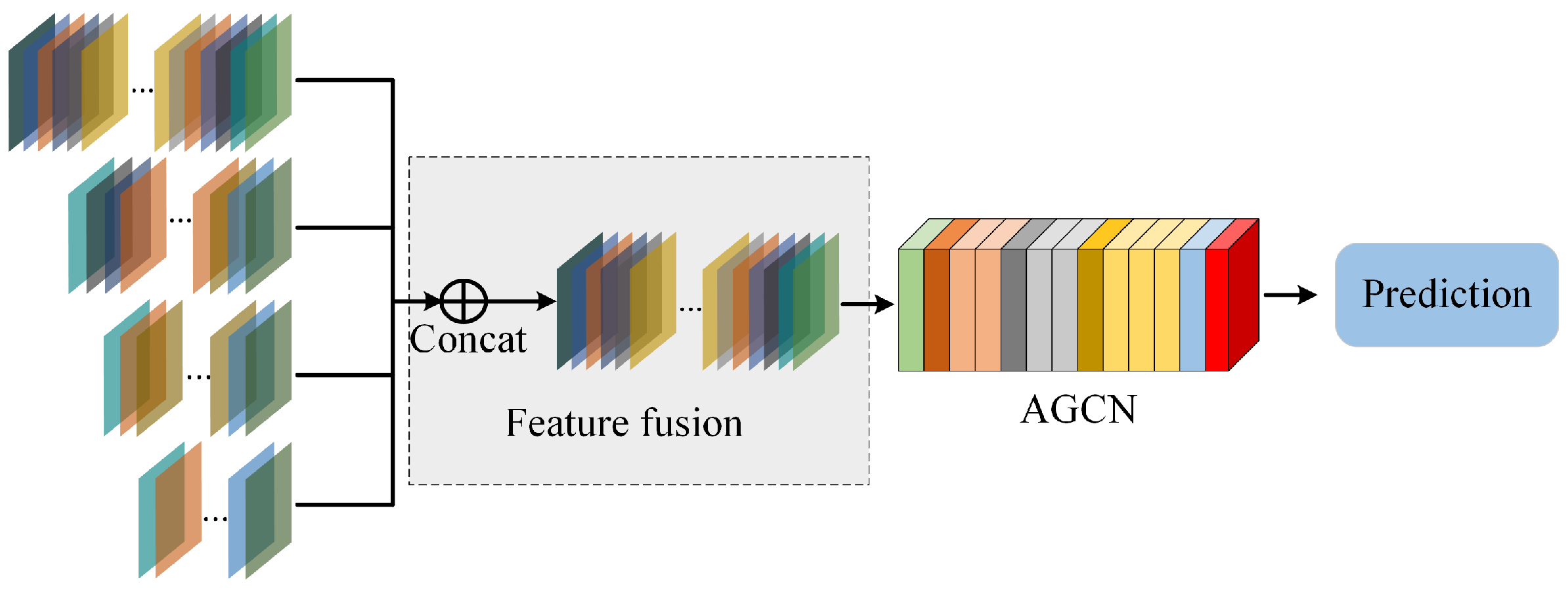
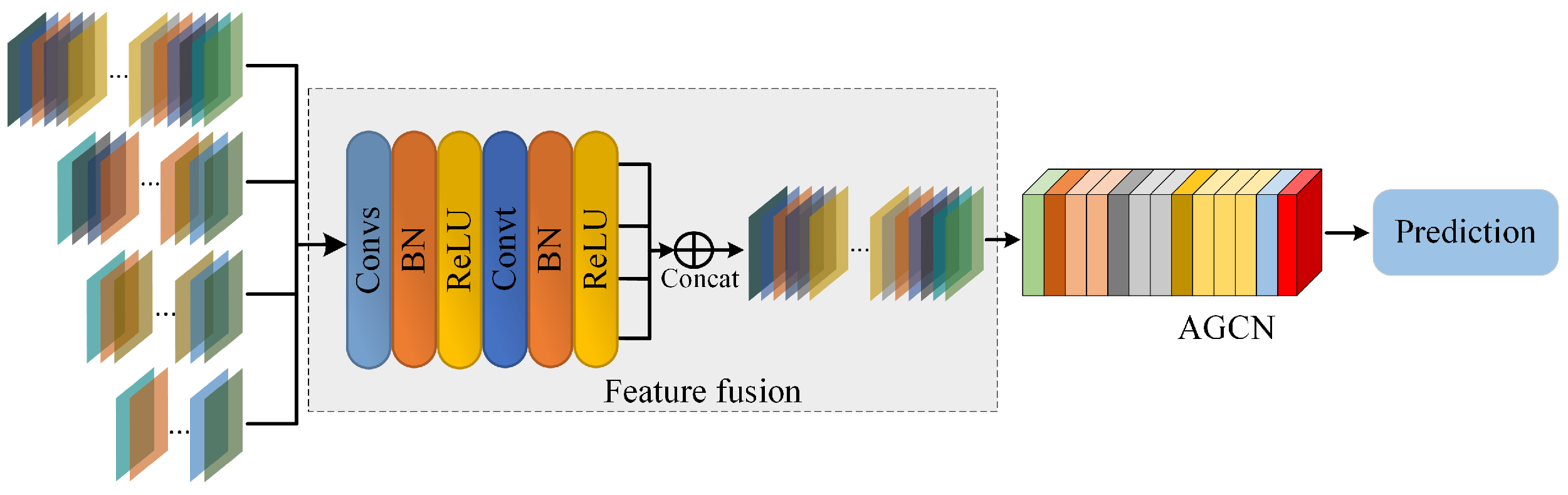
- Structure comparison: For the multi-scale deep spatiotemporal features proposed in this paper, we compare three different feature fusion methods. We introduce these three feature fusion methods in detail in Section 3. Experiments show that the decision-making level fusion method can achieve the best result for the model.
2. Related Works
2.1. Introduction to Manipulators in Robotics
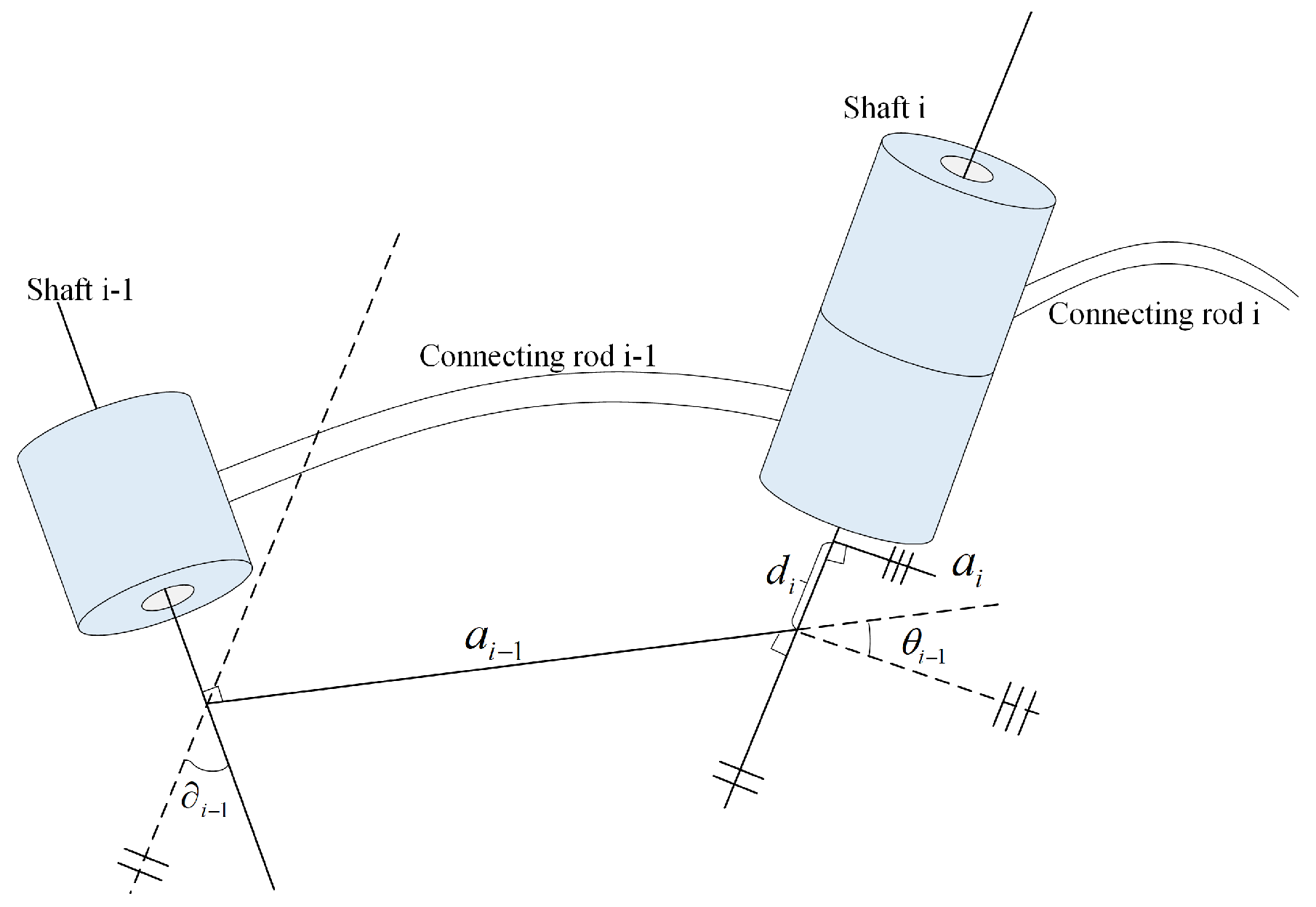
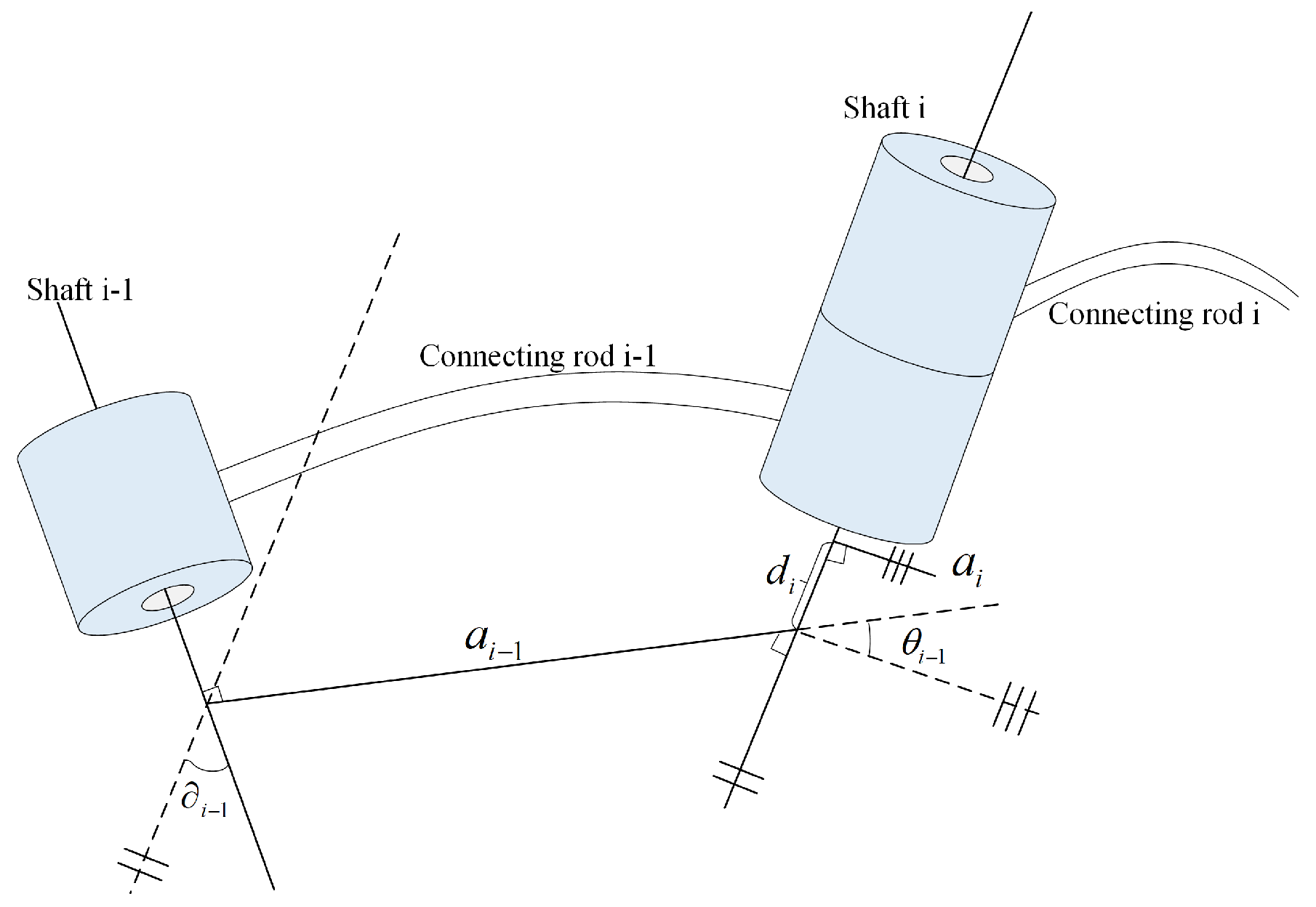
- Four parameters are related to connecting ros [14,15]. The connecting rods are numbered from the fixed base of the operating arm. The fixed base is connecting rod 0, the first movable connecting rod is 1, and so on. The connecting rod at the end of the operating arm is connecting rod n. In Figure 1, the joint axis and the joint axis i, the connecting rod , and the connecting rod i are taken as examples to further illustrate the description of the joint–connecting rod connection.There is a common joint axis between two adjacent connecting rods. The distance along the common axis of two adjacent connecting rods can be described using a parameter called the connecting rod offset. The link offset on the joint axis i is marked as . Another parameter is used to describe the angleof two adjacent connecting rods rotating around the common axis. This parameter is called the joint angle, which is recorded as . Figure 1 shows the interconnected connecting rod and connecting rod i. According to the previous definition, represents the connection relationship between two adjacent connecting rods. The first parameter is the directional distance from the intersection of the common vertical line and the joint axis i to the intersection of the common vertical line and the joint axis i, that is, the link offset . A representation of the method of connecting rod offset is shown in Figure 1. When joint i is a moving joint, the link offset is , which is a variable. The second parameter describing the connection relationship between adjacent connecting rods is the included angle formed by the rotation around the joint axis i between the extension line of and , that is, the joint angle , as shown in Figure 1. In the figure, the straight lines marked with double slashes and triple slashes are parallel lines. When joint i is a rotating joint, the joint angle is a variable.In the above formula, represents the speed of point Q in coordinate system B, and represents the pose information of point Q in coordinate system B at time t. The orientation of coordinate system B relative to coordinate system A changes with time, and the rotation speed of B relative to A is expressed by vector , which indicates that an intuitive method can be used to calculate the point velocity. Two instantaneous quantities are used to represent the vector Q around . The rotation of B is observed from the coordinate system A. When analyzing the acceleration of a rigid body, the linear acceleration and angular acceleration can be obtained by deriving the linear velocity and angular velocity of the rigid body at any instant. The linear acceleration is shown in Equation (2) and angular velocity in Equation (3).From the introduction of relevant knowledge in the above operating arm, we can regard the two arms and two legs of the human body as operating arms. Therefore, we can calculate the angle, linear velocity and angular velocity, linear acceleration, and angular acceleration between adjacent joints.
2.2. Graph Convolutional Networks
3. Proposed Methods
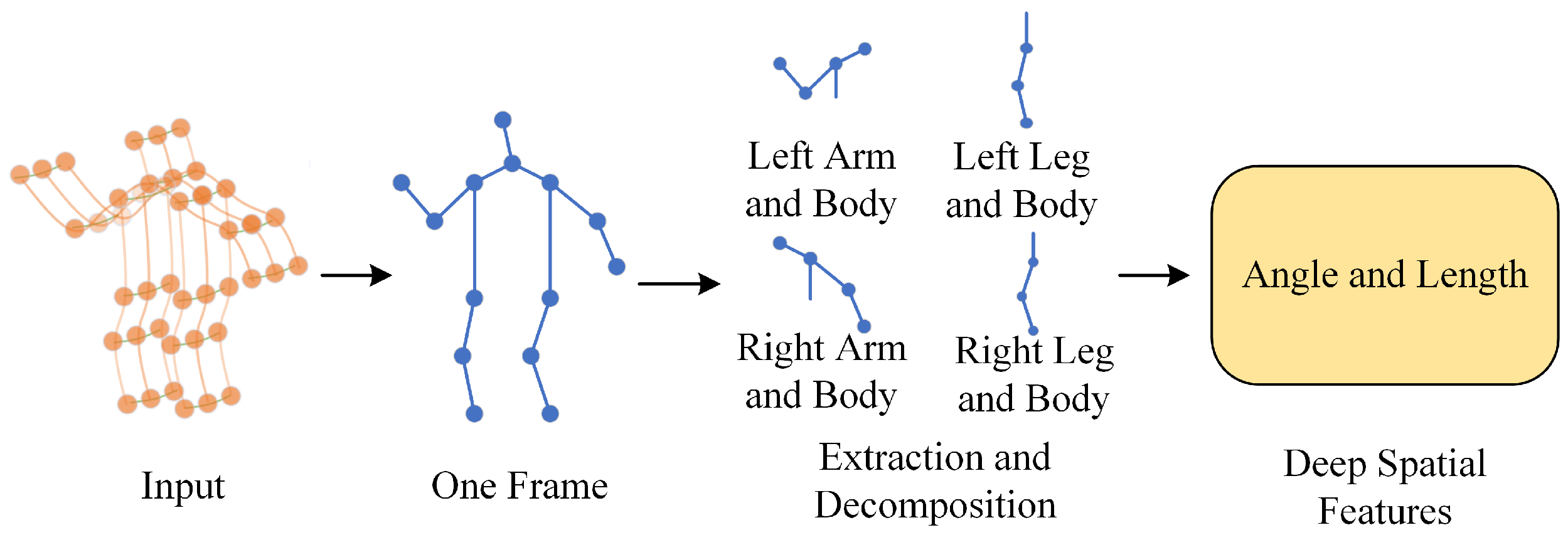
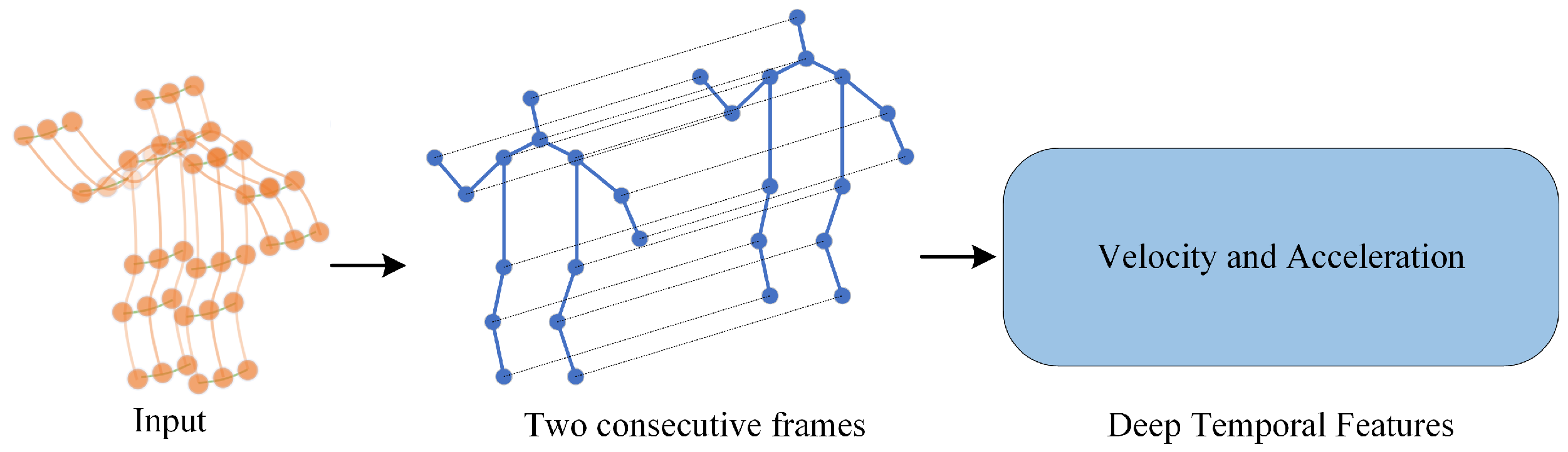
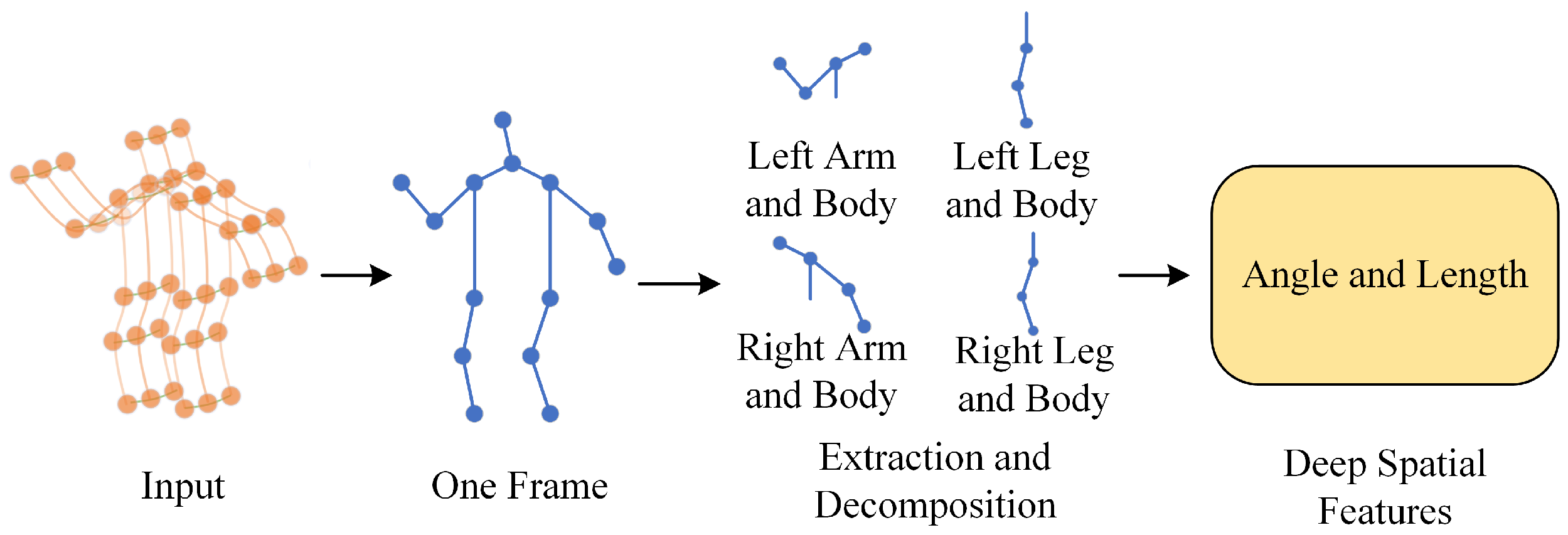
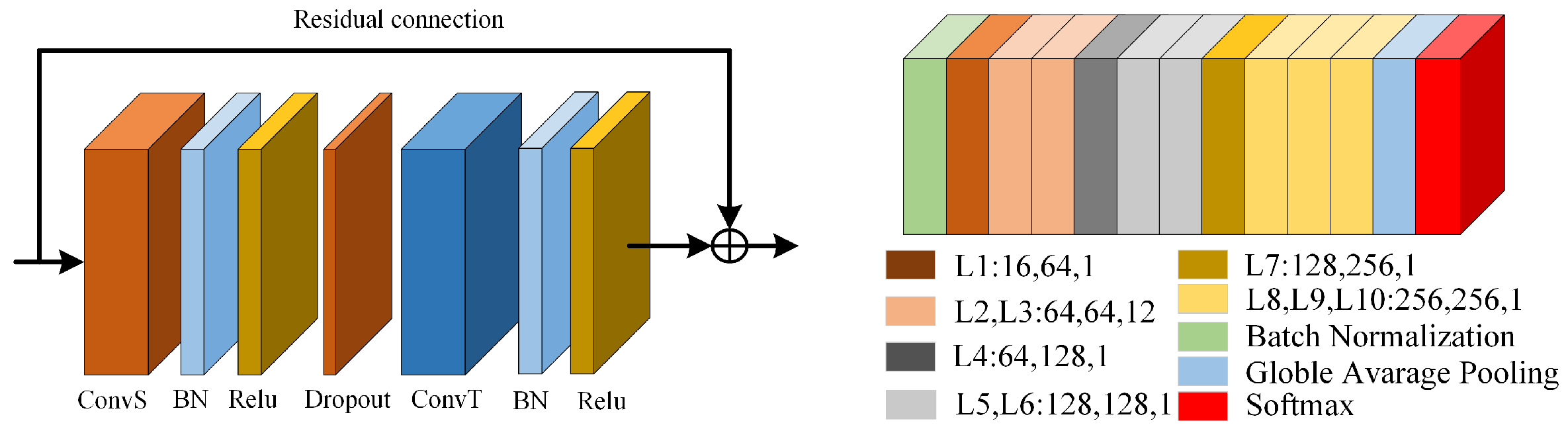
3.1. Deep Spatiotemporal Feature Enhancement Module
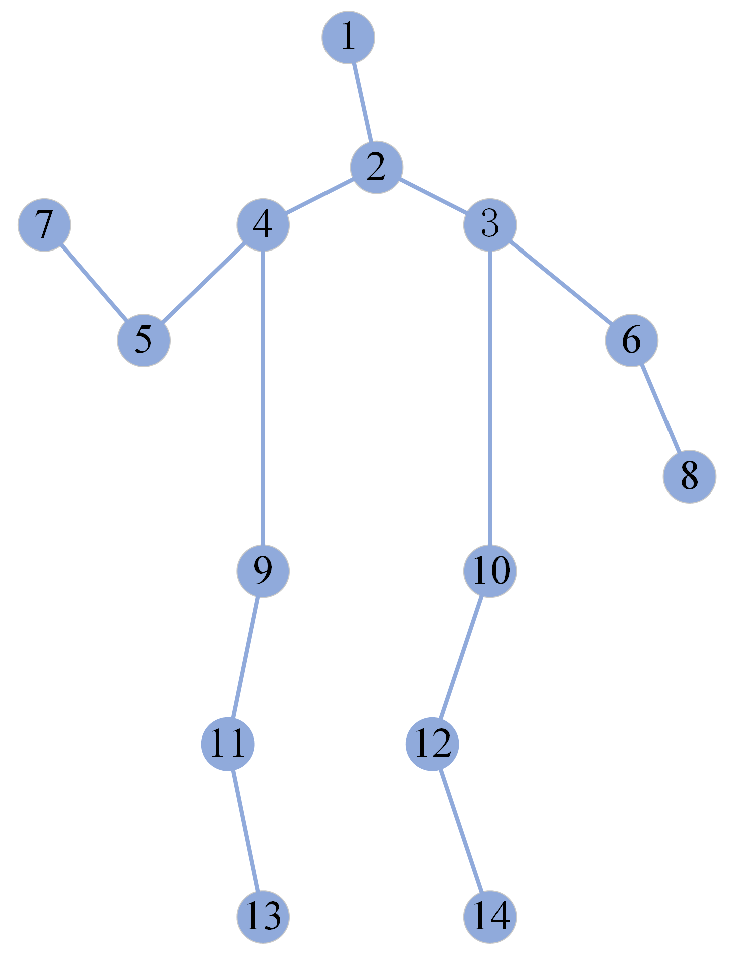
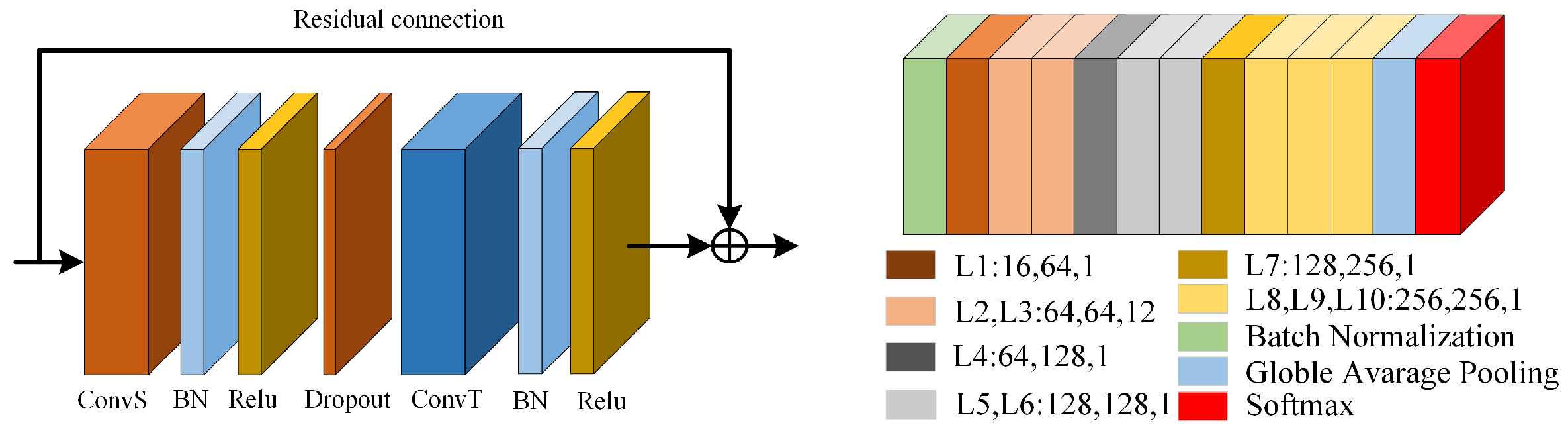
3.1.1. Spatial Feature Extraction Module
3.1.2. Time Feature Extraction Module
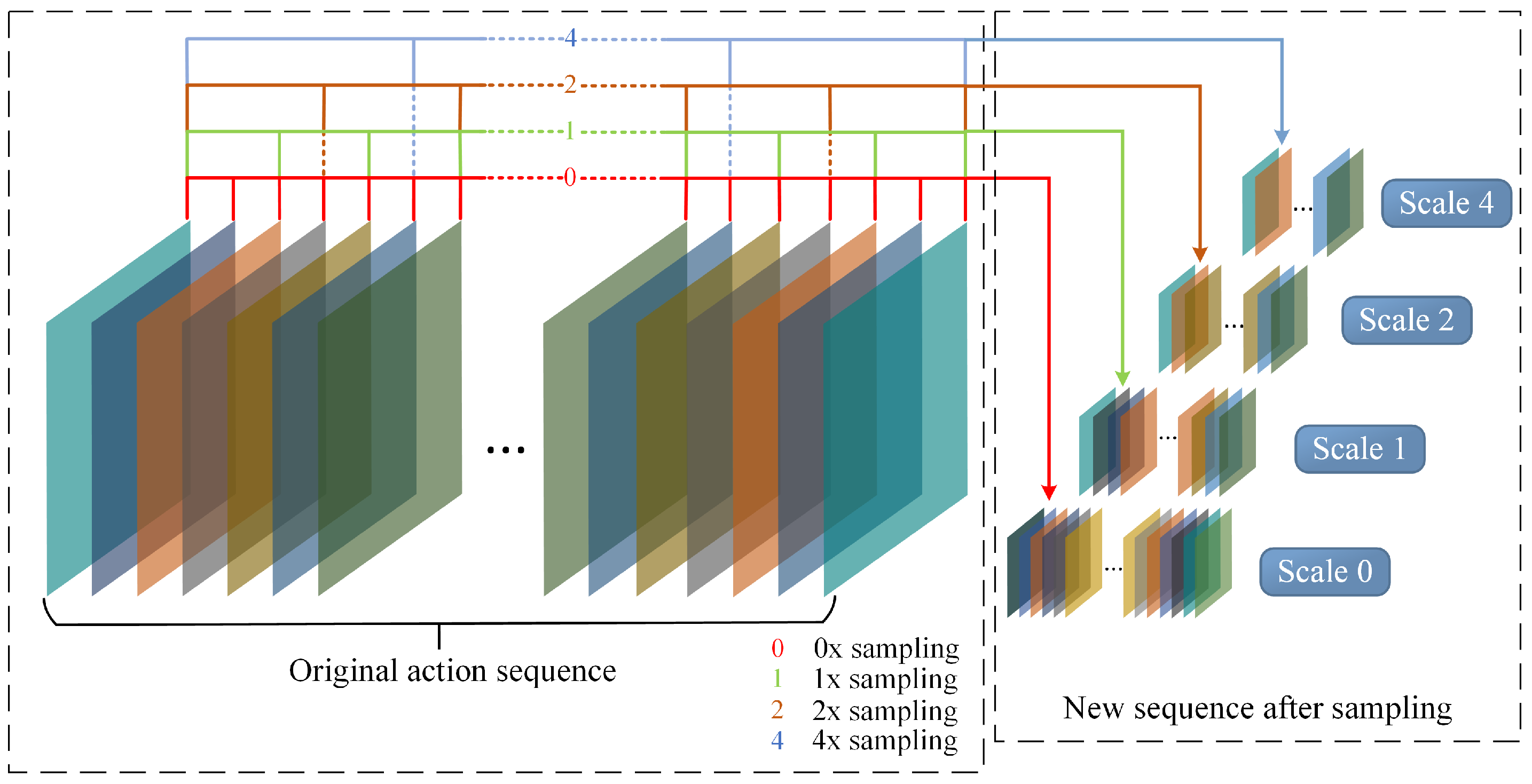
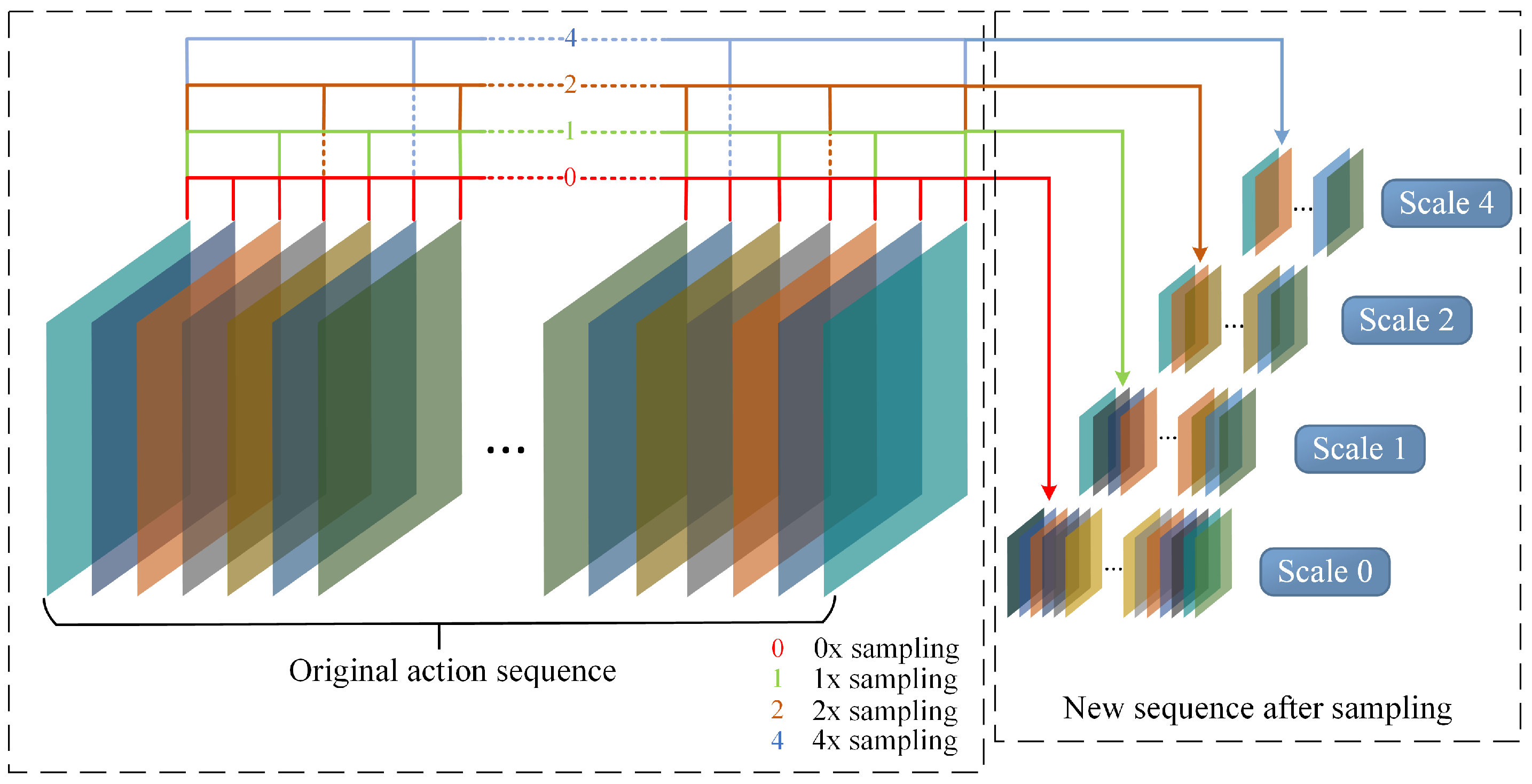
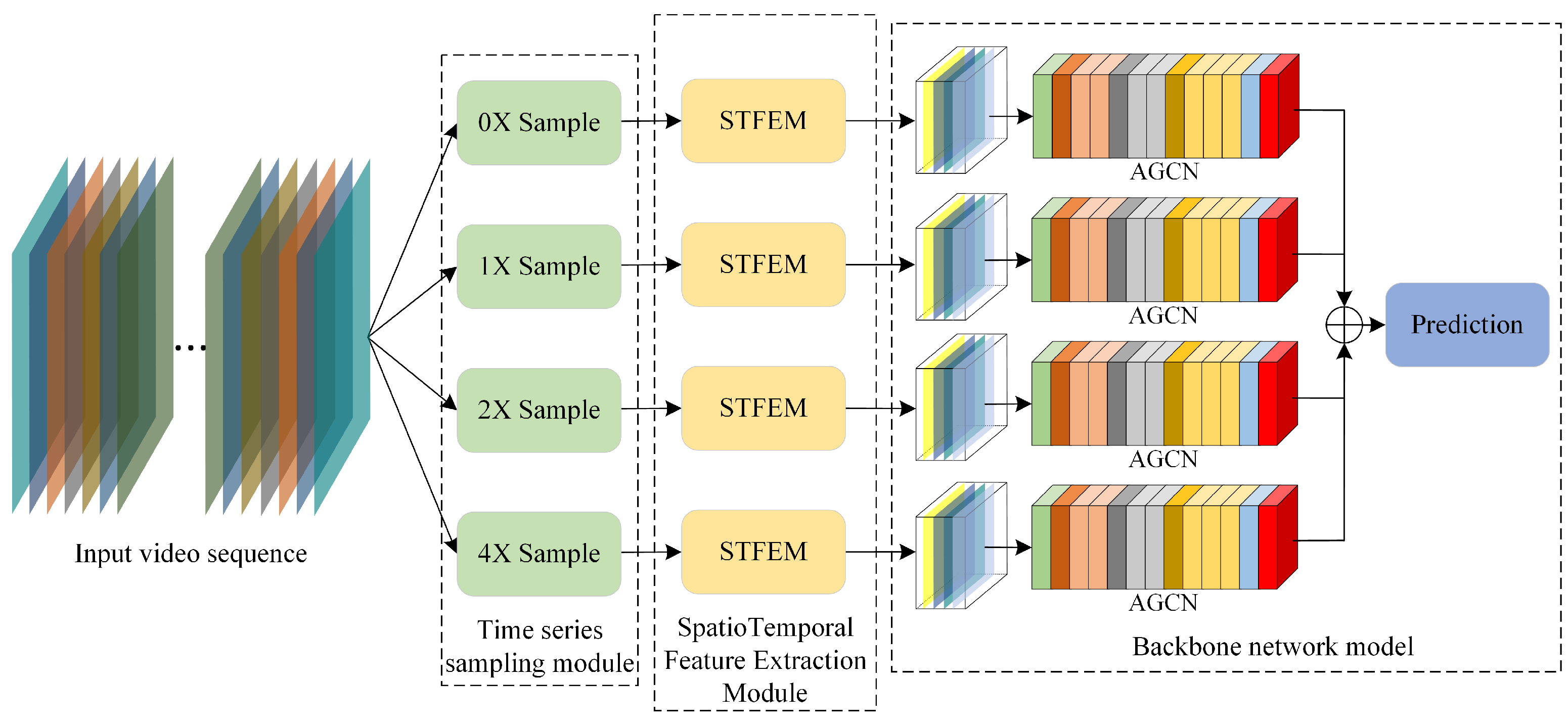
3.2. Time Multi-Scale Sampling Module
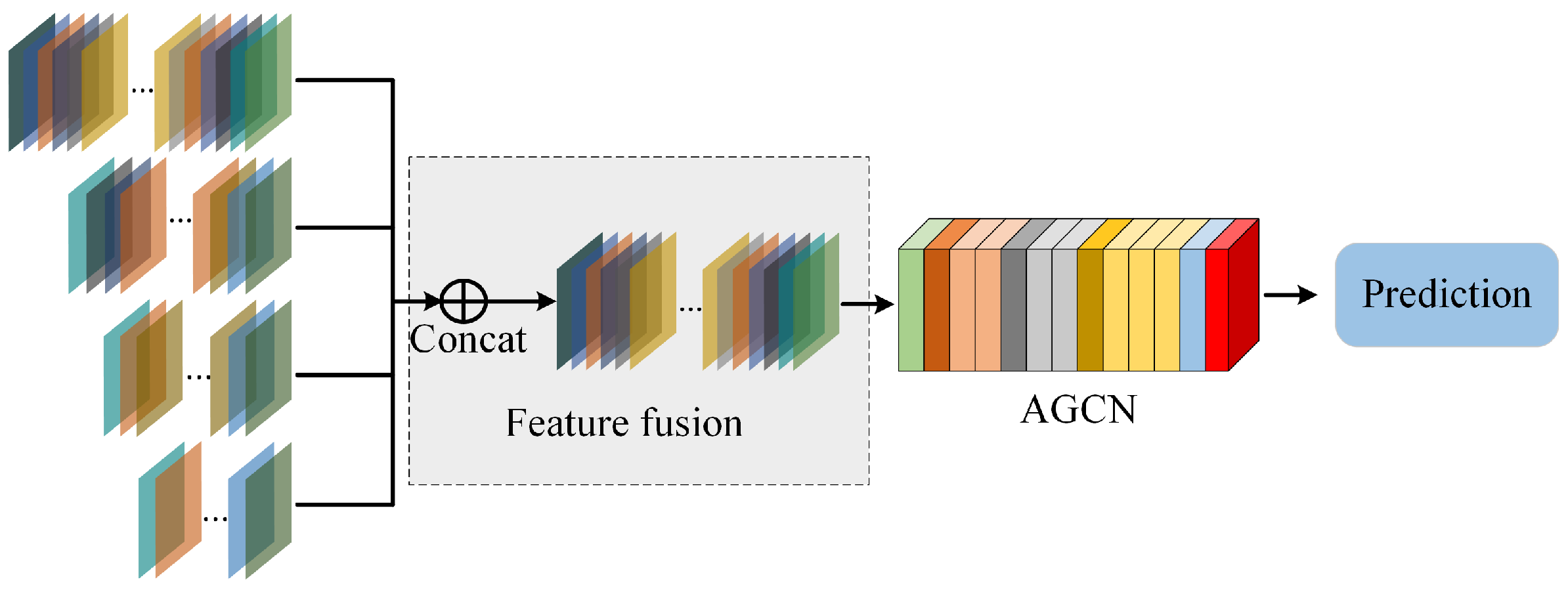
3.3. Selection of Feature Fusion Methods
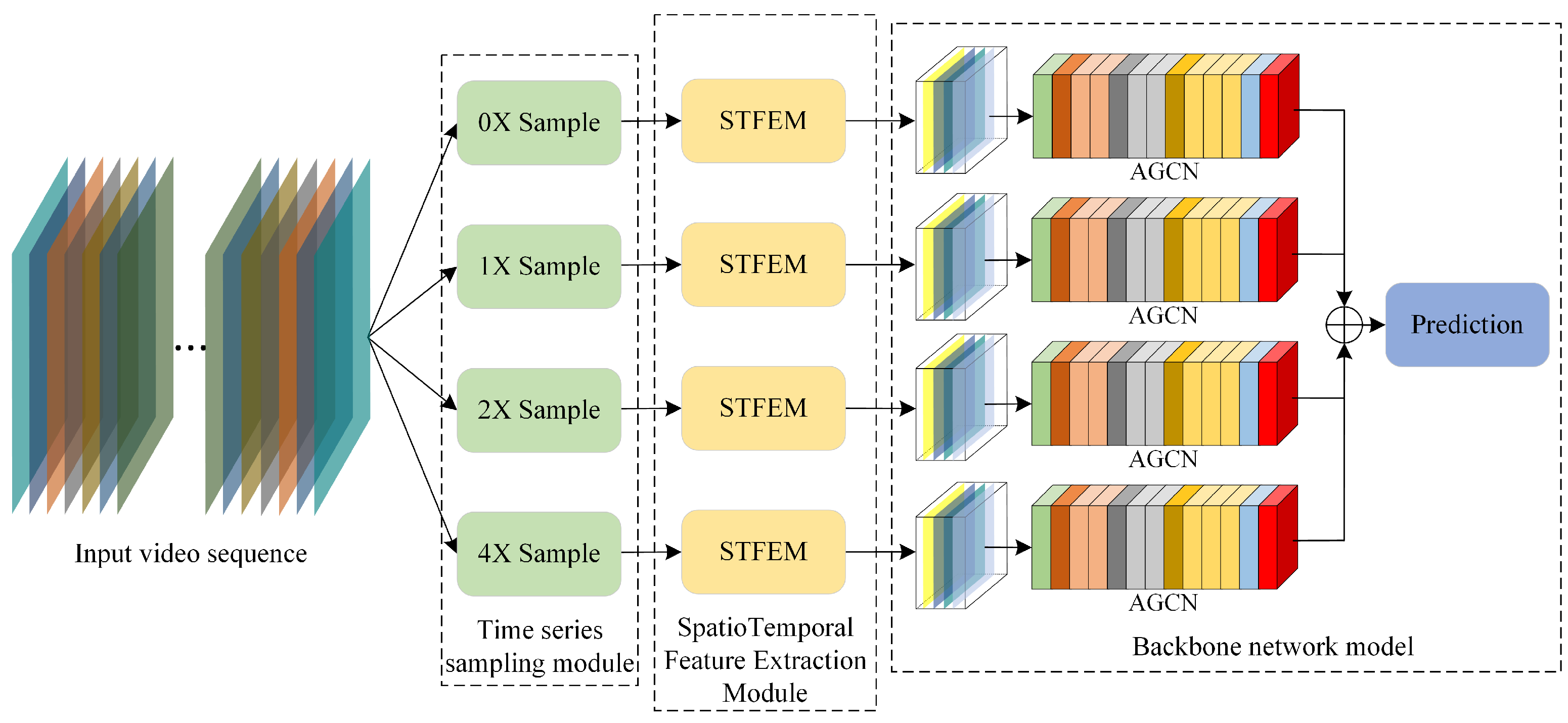
3.4. Skeleton Action Recognition Algorithm Based on Multi-Scale Deep Spatiotemporal Features
4. Experimental Results and Analysis
4.1. Datasets
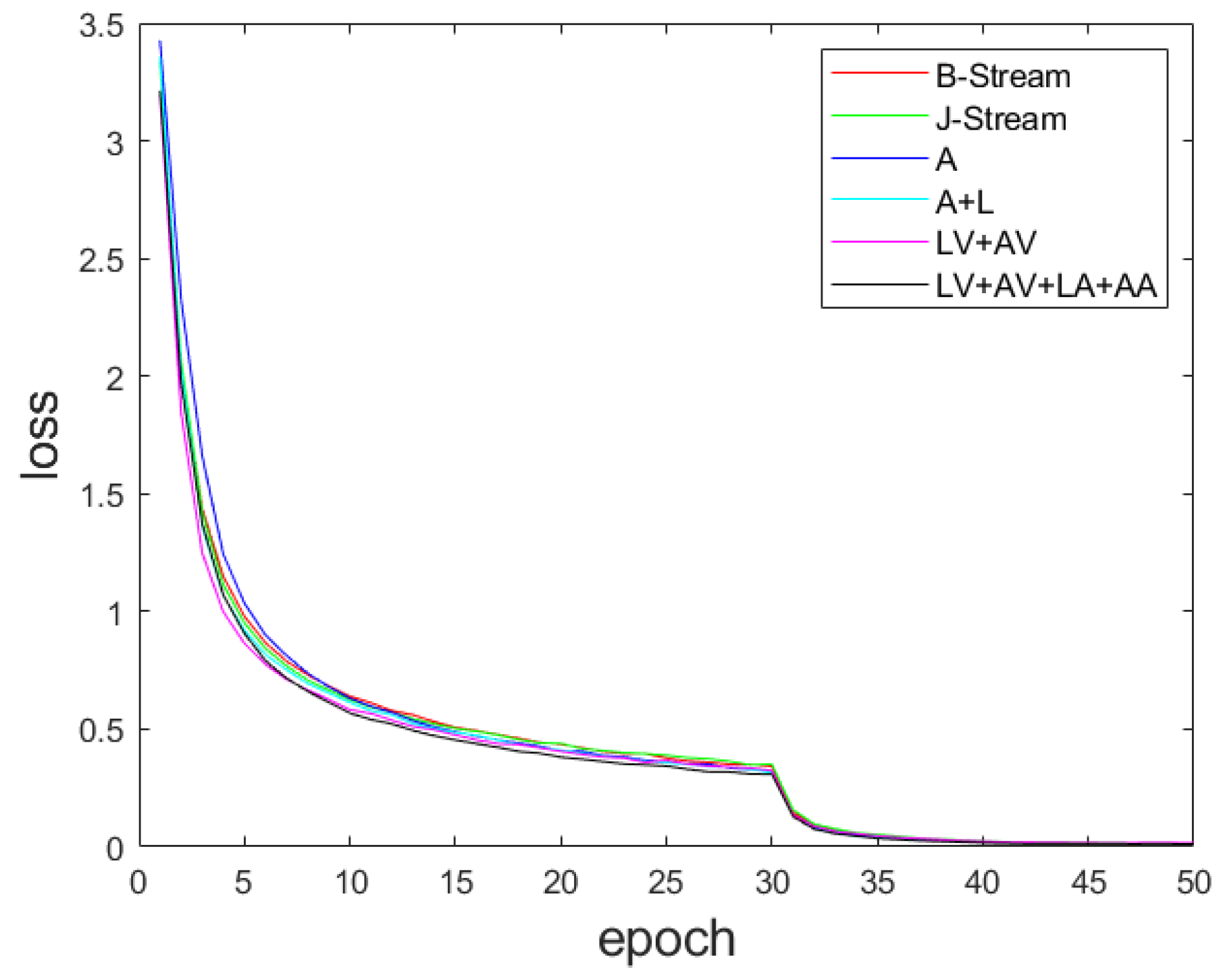
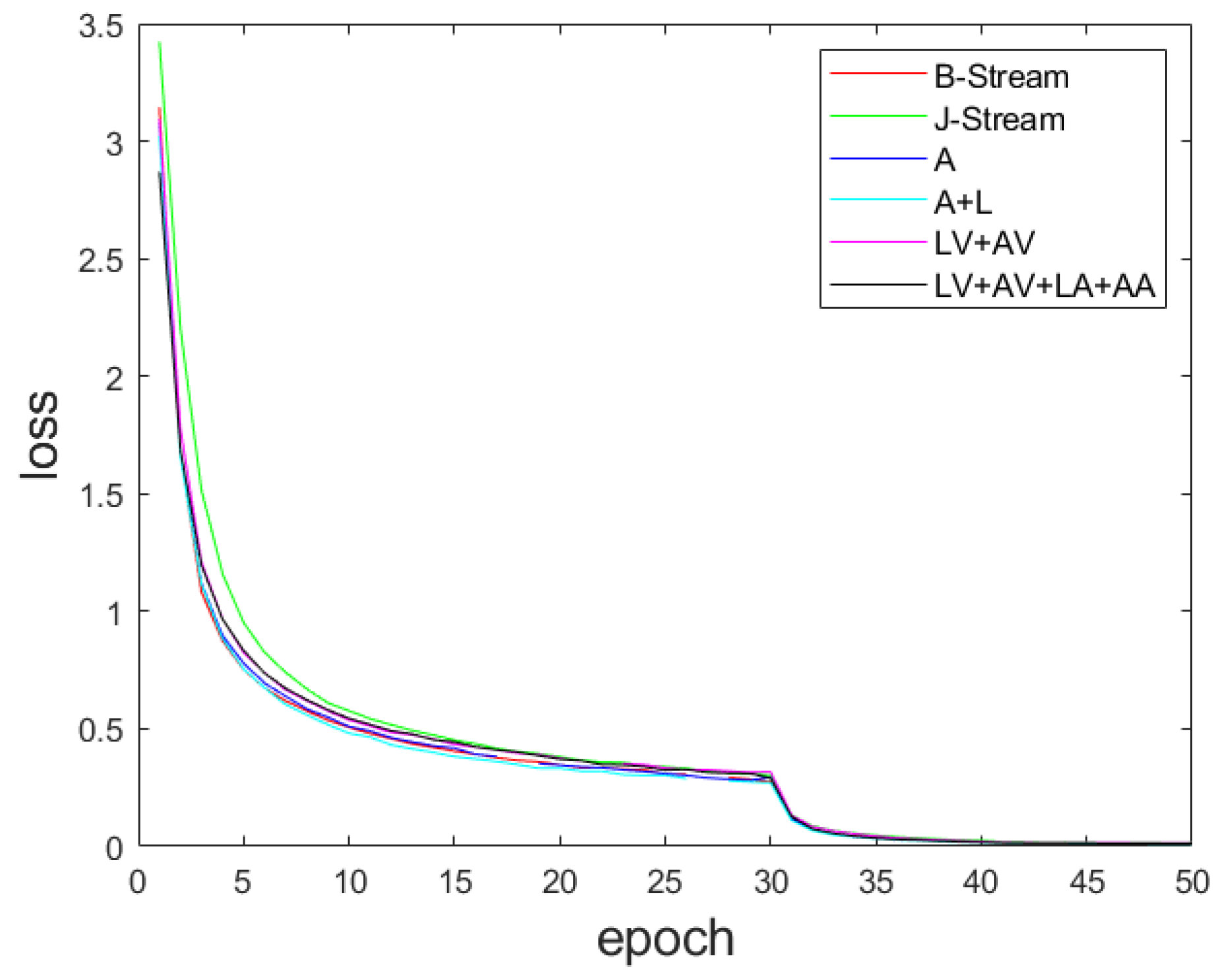
4.2. Training Details
4.3. Effectiveness Comparison of Time Multi-Scale Modules
4.4. Effectiveness Analysis of Deep Spatiotemporal Feature Module
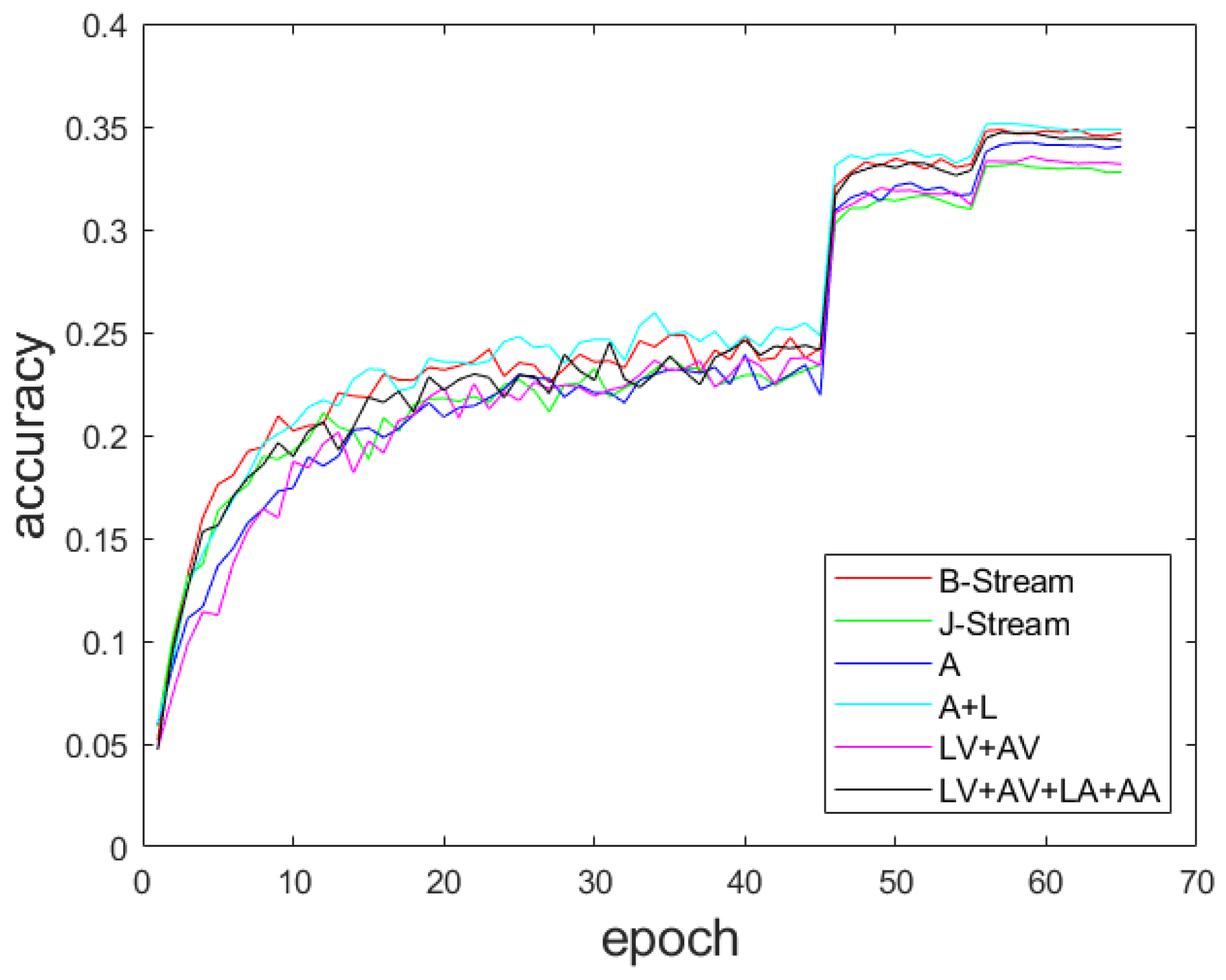
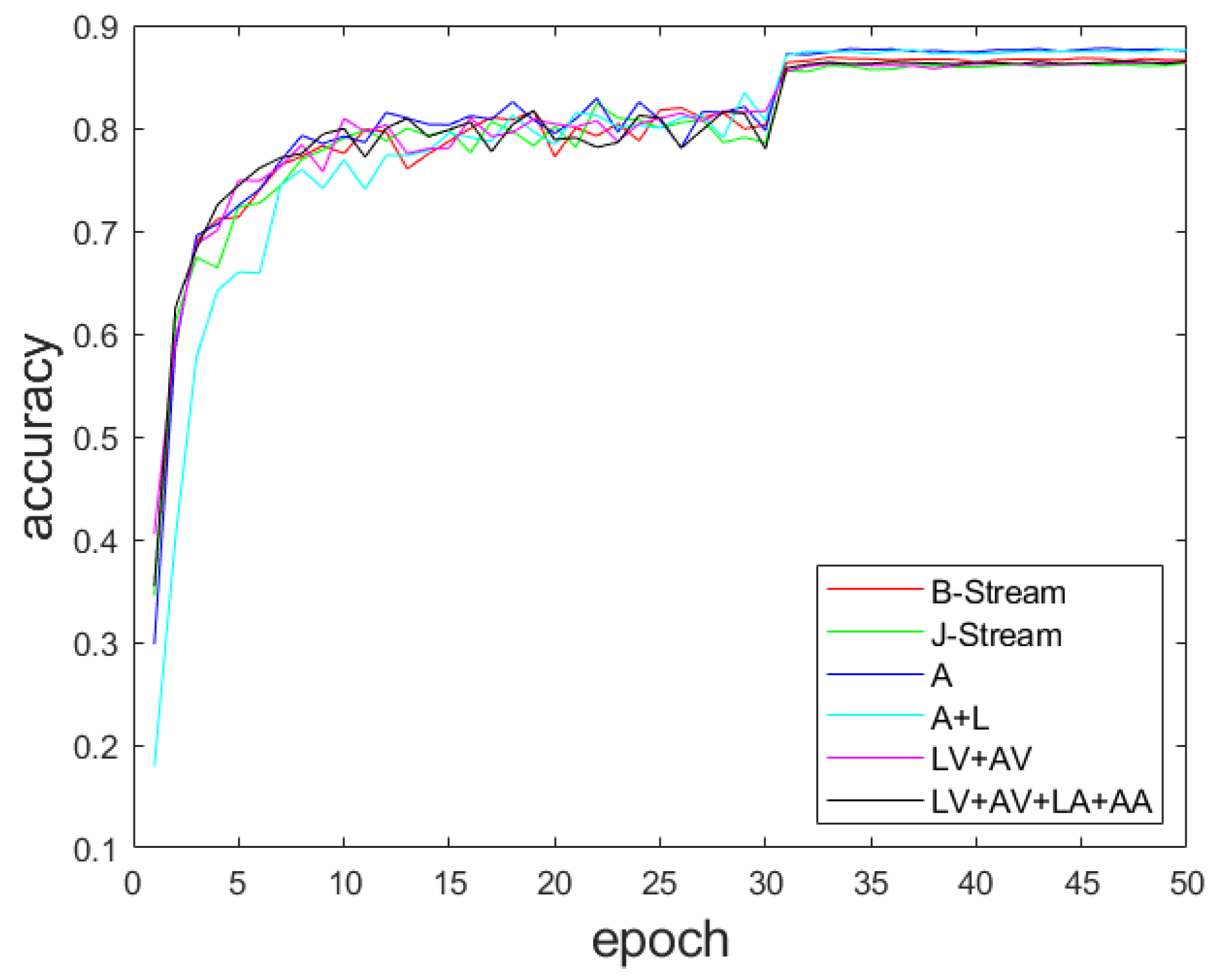
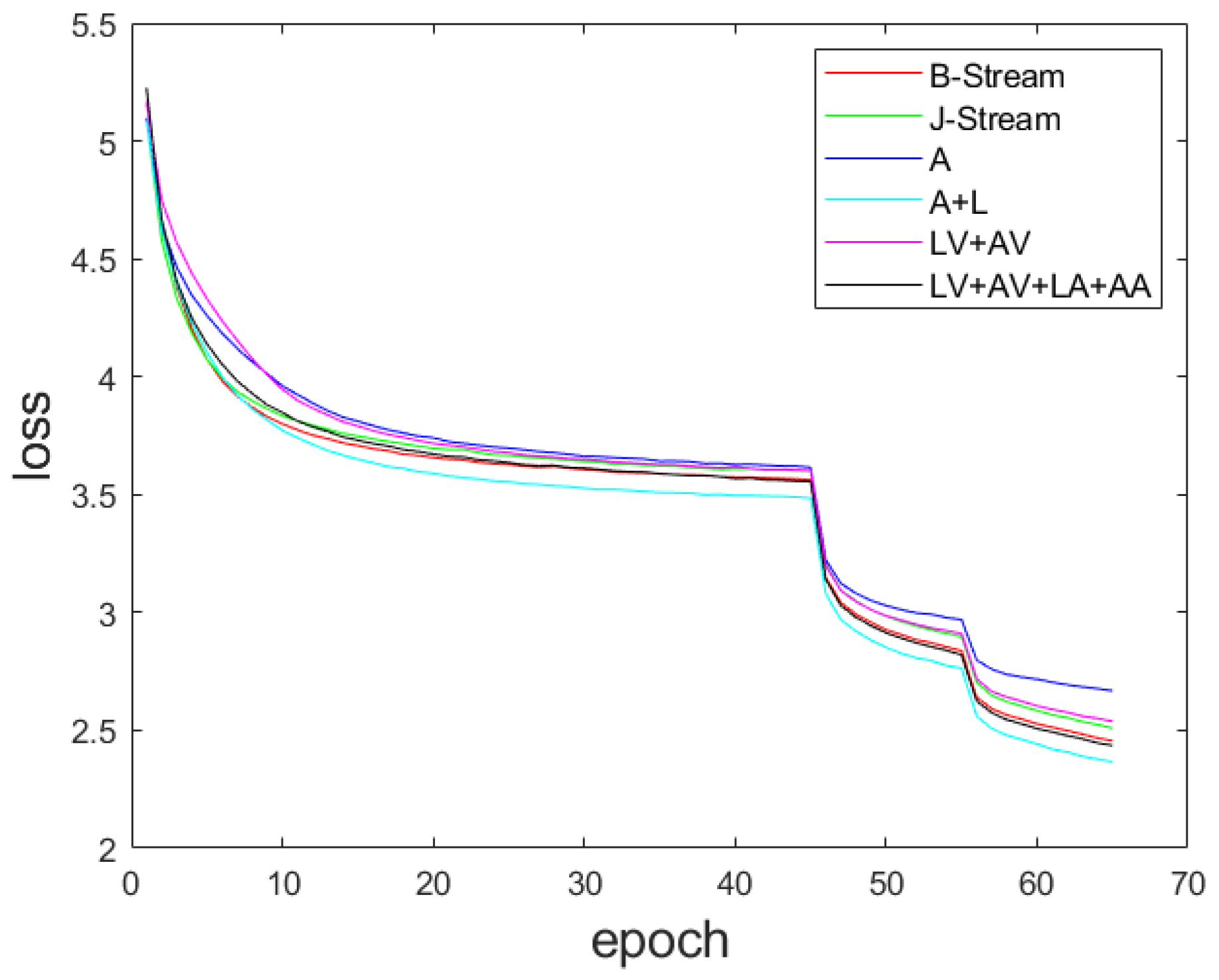
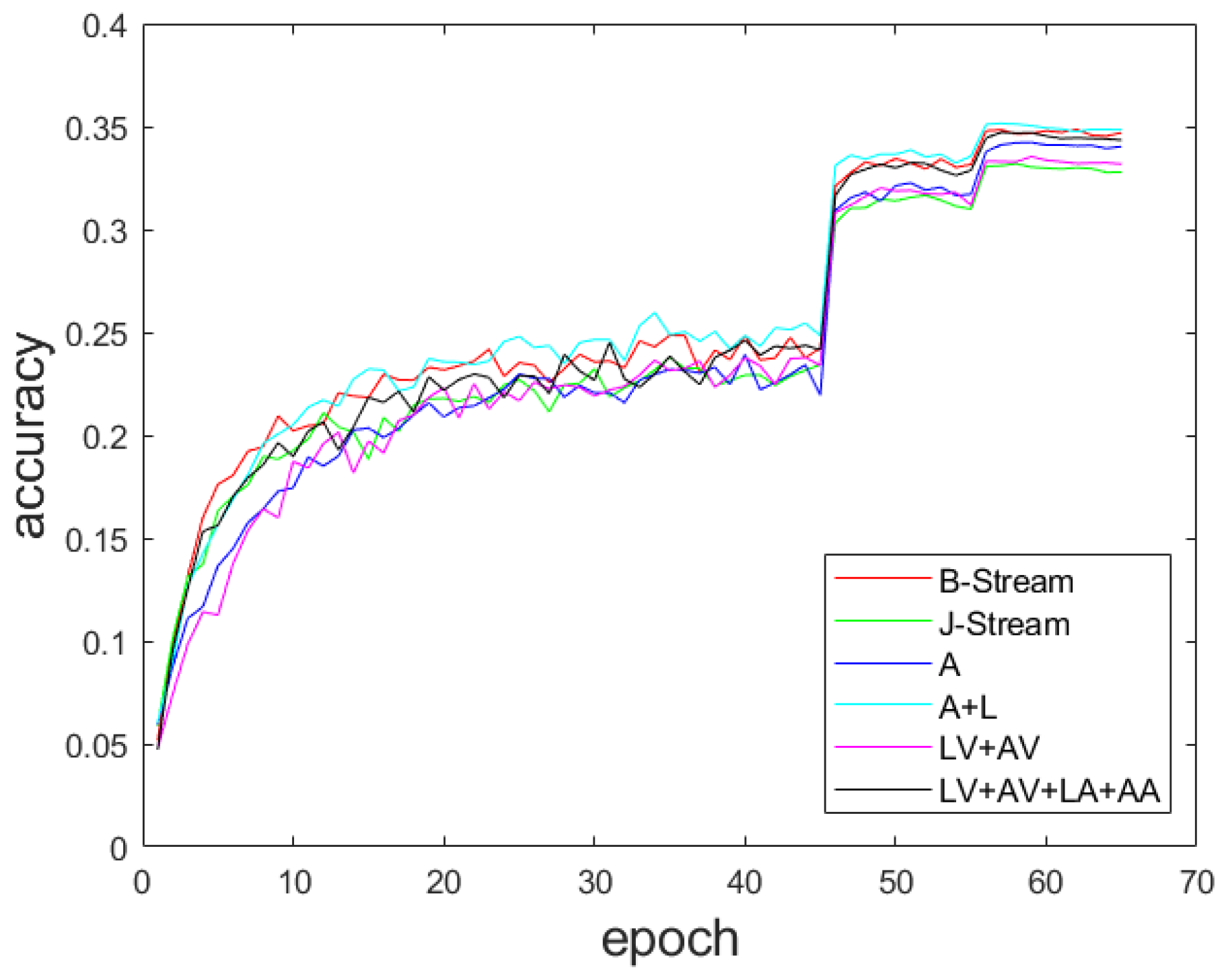
4.5. Comparison of Multi-Scale Feature Fusion Methods
4.6. Comparison with Existing State-of-the-Art Network
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dai, R.; Gao, Y.; Fang, Z.; Jiang, X.; Wang, A.; Zhang, J.; Zhong, C. Unsupervised learning of depth estimation based on attention model and global pose optimization. Signal Process. Image Commun. 2019, 78, 284–292. [Google Scholar] [CrossRef]
- Johansson, G. Visual perception of biological motion and a model for its analysis. Percept. Psychophys. 1973, 14, 201–211. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with directed graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7912–7921. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition. In Proceedings of the Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Thakkar, K.; Narayanan, P.J. Part-based Graph Convolutional Network for Action Recognition. In Proceedings of the 29th British Machine Vision Conference, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition. In Proceedings of the 32nd IEEE Conference on Computer Vision and Patten Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3590–3598. [Google Scholar]
- Craig, J.J. Introduction to Robotics: Mechanics and Control; Pearson Education: San Francisco, CA, USA, 1986. [Google Scholar]
- Hu, K.; Tian, L.; Weng, C.; Weng, L.; Zang, Q.; Xia, M.; Qin, G. Data-Driven Control Algorithm for Snake Manipulator. Appl. Sci. 2021, 11, 8146. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Jin, J.; Qian, M.; Zhang, Y. SUACDNet: Attentional change detection network based on siamese U-shaped structure. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102597. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Xia, M.; Wang, K.; Song, W.; Chen, C.; Li, Y. Non-intrusive load disaggregation based on composite deep long short-term memory network. Expert Syst. Appl. 2020, 160, 113669. [Google Scholar] [CrossRef]
- Xia, M.; Zhang, X.; Weng, L.; Xu, Y. Multi-stage feature constraints learning for age estimation. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2417–2428. [Google Scholar] [CrossRef]
- Xia, M.; Qu, Y.; Lin, H. PANDA: Parallel asymmetric network with double attention for cloud and its shadow detection. J. Appl. Remote. Sens. 2021, 15, 046512. [Google Scholar] [CrossRef]
- Wang, Z.; Xia, M.; Lu, M.; Pan, L.; Liu, J. Parameter Identification in Power Transmission Systems Based on Graph Convolution Network. IEEE Trans. Power Deliv. 2021. [Google Scholar] [CrossRef]
- Chen, J.; Yang, W.; Liu, C.; Yao, L. A Data Augmentation Method for Skeleton-Based Action Recognition with Relative Features. Appl. Sci. 2021, 11, 11481. [Google Scholar] [CrossRef]
- Guo, J.; Liu, H.; Li, X.; Xu, D.; Zhang, Y. An attention enhanced spatial–temporal graph convolutional LSTM network for action recognition in Karate. Appl. Sci. 2021, 11, 8641. [Google Scholar] [CrossRef]
- Hu, K.; Zheng, F.; Weng, L.; Ding, Y.; Jin, J. Action Recognition Algorithm of Spatio–Temporal Differential LSTM Based on Feature Enhancement. Appl. Sci. 2021, 11, 7876. [Google Scholar] [CrossRef]
- Ha, J.; Shin, J.; Park, H.; Paik, J. Action Recognition Network Using Stacked Short-Term Deep Features and Bidirectional Moving Average. Appl. Sci. 2021, 11, 5563. [Google Scholar] [CrossRef]
- Degardin, B.; Proença, H. Human Behavior Analysis: A Survey on Action Recognition. Appl. Sci. 2021, 11, 8324. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peng, W.; Hong, X.; Chen, H.; Zhao, G. Learning graph convolutional network for skeleton-based human action recognition by neural searching. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA; 2020; Volume 34, pp. 2669–2676. [Google Scholar]
- Twinanda, A.P.; Alkan, E.O.; Gangi, A.; de Mathelin, M.; Padoy, N. Data-driven spatio-temporal RGBD feature encoding for action recognition in operating rooms. Int. J. Comput. Assist. Radiol. 2015, 10, 737–747. [Google Scholar] [CrossRef]
- Gammulle, H.; Denman, S.; Sridharan, S.; Fookes, C. Two Stream LSTM: A Deep Fusion Framework for Human Action Recognition. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Kim, T.S.; Reiter, A. Interpretable 3d human action analysis with temporal convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1623–1631. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Trans. Image Process. 2020, 29, 9532–9545. [Google Scholar] [CrossRef]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2117–2126. [Google Scholar]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Skeleton-based action recognition with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 597–600. [Google Scholar]
- Liu, J.; Wang, G.; Hu, P.; Duan, L.Y.; Kot, A.C. Global context-aware attention lstm networks for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1656. [Google Scholar]
- Zheng, W.; Li, L.; Zhang, Z.; Huang, Y.; Wang, L. Relational network for skeleton-based action recognition. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 826–831. [Google Scholar]
- Li, C.; Xie, C.; Zhang, B.; Han, J.; Zhen, X.; Chen, J. Memory attention networks for skeleton-based action recognition. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Tian, Y.; Lu, J.; Li, P.; Zhou, J. Deep progressive reinforcement learning for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5323–5332. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Wang, L. Richly activated graph convolutional network for action recognition with incomplete skeletons. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1–5. [Google Scholar]
- Wang, M.; Ni, B.; Yang, X. Learning multi-view interactional skeleton graph for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Cross-View% | Cross-Subject% | Kinetics% |
|---|---|---|---|
| Scale 0 (J-Stream) | 93.1 | 86.3 | 34.0 |
| Scale 1 | 93.9 | 87.1 | 35.0 |
| Scale 2 | 92.7 | 86.2 | 33.2 |
| Scale 4 | 91.5 | 85.2 | 33.5 |
| Methods | Cross-View% | Cross-Subject% | Kinetics% |
|---|---|---|---|
| B-Stream | 93.3 | 86.7 | 34.3 |
| J-Stream | 93.1 | 86.3 | 34.0 |
| A | 93.5 | 87.5 | 32.8 |
| A + L | 93.7 | 87.6 | 34.9 |
| LV + AV | 93.2 | 86.4 | 33.2 |
| LV + AV + LA + AA | 93.8 | 86.5 | 34.7 |
| Cross-View % | ||
|---|---|---|
| Methods | Accuracy (%) | Times(h) |
| Method 1 | 90.6 | 30.8 |
| Method 2 | 91.5 | 30.9 |
| Method 3 | 95.5 | 98 |
| Cross-Subject % | ||
| Methods | Accuracy (%) | Times(h) |
| Method 1 | 86.5 | 35 |
| Method 2 | 87.0 | 35.2 |
| Method 3 | 89.5 | 106 |
| Kinetics % | ||
| Methods | Accuracy (%) | Times(h) |
| Method 1 | 32.0 | 24.8 |
| Method 2 | 32.1 | 25 |
| Method 3 | 37.1 | 79 |
| Action Type | Frame | Method 1(s) | Method 2(s) | Method 3(s) |
|---|---|---|---|---|
| A10: Clapping | 69 | 1.4 | 1.4 | 1.5 |
| A7: Throw | 86 | 1.5 | 1.5 | 1.6 |
| A27: Jump up | 87 | 1.5 | 1.5 | 1.6 |
| A4: Brush air | 99 | 1.5 | 1.5 | 1.6 |
| A1: Drink water | 103 | 1.5 | 1.5 | 1.6 |
| Action Type | Date | Top-1(%) | Top-5(%) |
|---|---|---|---|
| Feature Encoding [31] | 2015 | 14.9 | 25.8 |
| Deep LSTM [32] | 2016 | 16.4 | 35.3 |
| Temporal ConvNet [33] | 2017 | 20.3 | 40.0 |
| ST-GCN [5] | 2018 | 30.7 | 52.8 |
| 2S-AGCN [6] | 2019 | 36.1 | 58.7 |
| GCN-NAS [30] | 2020 | 37.1 | 60.0 |
| 1s-AAGCN [34] | 2020 | 36.0 | 58.4 |
| 2s-AAGCN [34] | 2020 | 37.4 | 60.4 |
| 4s-AAGCN [34] | 2020 | 37.8 | 61.0 |
| MST-AGCN (ours) | - | 37.1 | 61.0 |
| Methods | Date | Cross-View (%) | Cross-Subject (%) |
|---|---|---|---|
| Deep LSTM [32] | 2016 | 67.3 | 60.7 |
| Temporal ConvNet [33] | 2017 | 83.1 | 74.3 |
| VA-LSTM [35] | 2017 | 87.6 | 79.4 |
| Two-stream CNN [36] | 2017 | 89.3 | 83.2 |
| GCA-LSTM [37] | 2017 | 82.8 | 74.4 |
| ARRN-LATM [38] | 2019 | 89.6 | 81.8 |
| MANs [39] | 2018 | 93.2 | 83.0 |
| ST-GCN [5] | 2018 | 88.3 | 81.5 |
| DPRL + GCNN [40] | 2018 | 81.5 | 83.5 |
| 2S-AGCN [6] | 2019 | 95.1 | 88.5 |
| RA-GCN [41] | 2020 | 93.6 | 87.3 |
| MV-IGNet [42] | 2020 | 96.3 | 89.2 |
| MST-AGCN (ours) | - | 95.5 | 89.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, K.; Ding, Y.; Jin, J.; Weng, L.; Xia, M. Skeleton Motion Recognition Based on Multi-Scale Deep Spatio-Temporal Features. Appl. Sci. 2022, 12, 1028. https://doi.org/10.3390/app12031028
Hu K, Ding Y, Jin J, Weng L, Xia M. Skeleton Motion Recognition Based on Multi-Scale Deep Spatio-Temporal Features. Applied Sciences. 2022; 12(3):1028. https://doi.org/10.3390/app12031028
Chicago/Turabian StyleHu, Kai, Yiwu Ding, Junlan Jin, Liguo Weng, and Min Xia. 2022. "Skeleton Motion Recognition Based on Multi-Scale Deep Spatio-Temporal Features" Applied Sciences 12, no. 3: 1028. https://doi.org/10.3390/app12031028
APA StyleHu, K., Ding, Y., Jin, J., Weng, L., & Xia, M. (2022). Skeleton Motion Recognition Based on Multi-Scale Deep Spatio-Temporal Features. Applied Sciences, 12(3), 1028. https://doi.org/10.3390/app12031028