Abstract
Most existing image retrieval methods separately retrieve single images, such as a scene, content, or object, from a single database. However, for general purposes, target databases for image retrieval can include multiple subjects because it is not easy to predict which subject is entered. In this paper, we propose that image retrieval can be performed in practical applications by combining multiple databases. To deal with multi-subject image retrieval (MSIR), image embedding is generated through the fusion of scene- and object-level features, which are based on Detection Transformer (DETR) and a random patch generator with a deep-learning network, respectively. To utilize these feature vectors for image retrieval, two bags-of-visual-words (BoVWs) were used as feature embeddings because they are simply integrated with preservation of the characteristics of both features. A fusion strategy between the two BoVWs was proposed in three stages. Experiments were conducted to compare the proposed method with previous methods on conventional single-subject datasets and multi-subject datasets. The results validated that the proposed fused feature embeddings are effective for MSIR.
1. Introduction
Image retrieval is a problem of searching for images related to a given query image in a large database. The existing image retrieval studies mainly dealt with content-based image retrieval (CBIR) [1,2,3] or instance retrieval, which is based on the similarity of visual content between images. Recently, object-based image retrieval (OBIR) problems [4,5,6] have been introduced for splice detection, as shown in Figure 1.

Figure 1.
The example of single-subject and multi-subject image retrieval. The image on the left is the query image and the image on the right side of the arrow is the retrieved image. The green box means that it is the right image for the purpose of the search. The red box means that the image is not suitable for search purposes. Contrary to single-subject image retrieval that searches a single topic such as content, instance, and object at once, multi-subject image retrieval deals with multiple topics in the same framework.
Deep learning networks based on convolutional neural networks (CNNs) are used for computer vision tasks such as image classification and object recognition. They are pre-trained on large datasets such as ImageNet [7] or Microsoft Common Objects in Context (MS COCO) [8]. These pre-trained networks demonstrate excellent image representation capabilities and are used as backbone networks in various computer vision tasks, such as image retrieval and instance segmentation. In CBIR, a feature map extracted from a pre-trained network is used as a global feature to calculate the similarity between the images. In instance retrieval, refs. [2,9,10] images are represented by embeddings based on a variation of global features. However, in OBIR, image retrieval is performed based on local features extracted from object detection models such as Faster-RCNN [11] or HoG [12]. This is because the image is represented based on object information excluding the background of the image. Existing image retrieval methods are mostly optimized for single-subject datasets. In the case of a database consisting of multi-subject images, or if the purpose of retrieval is complicated, both the scene and object information are required. While the conventional image retrieval methods have only optimized information for the specific target subject, we propose multi-subject image retrieval (MSIR) utilizing image representation by combining object and scene information. Several image retrieval studies propose image embedding combining features representing different aspects. The feature fusion methods generate distinctive descriptors to incorporate various information and to improve the performance of image retrieval. However, previous fusion methods only used local, global, and deep-learning features. We propose fusion strategy utilizing object and scene-level feature embeddings to represent image information that is appropriate for MSIR tasks.
To generate image embeddings for MSIR, we used two ‘bag of visual words’ (BoVW) models [13,14,15] representing object- and scene-level information. The first BoVW, for extracting object-level local feature vectors, used the Detection Transformer (DETR) [16] model. DETR can generate object embeddings corresponding to target objects in an image using the attention mechanism. Object embedding is generated based on the COCO dataset [8], which was used for the training and evaluation of object recognition models. Class embedding, which is extracted from the output vector of DETR via a multi-layer perceptron (MLP), is used for a better representation of object embeddings. The second BoVW, for scene-level features, was generated using a random patch generator [17] and image classification network pre-trained on ImageNet. As the random patches have local information including objects or a background, scene-level local features are obtained by inputting each patch into the image classification network.
In conclusion, we propose an image embedding that combines object- and scene-level feature embeddings to improve the performance in MSIR. We divide the BoVW method into three stages. We generate image embeddings, which are combined local features, codebooks, or histograms. We compare the performances of the image retrieval approaches on various single-subject and multi-subject datasets, as shown in Figure 1, and show that the proposed fusion method of image embeddings performs better than the existing image retrieval methods in the multi-subject dataset.
To summarize, our paper has the following contributions:
- We introduce a new problem, multi-subject image retrieval (MSIR), searching for images from a multi-subject database composed of complex and diverse images.
- We propose an image embedding that combines object- and scene-level feature embeddings extracted using BoVW-based models.
- Our method shows better performance in MSIR compared with the existing methods.
2. Related Work
The content-based image retrival (CBIR), a steady and predominantly treated study, is a problem of finding images with visual content similar to a given query image. The scale-invariant feature transform (SIFT) [18] was combined with the bag-of-words (BoW) model and used for image retrieval and classification. BoW is the proposed model for modeling documents. Because a document is divided into words, the document can be represented as a single histogram by using the frequency of words. Bag-of-visual-words (BoVW) [13,14,15] is a method of dividing images into visual words and utilizing the generated histogram as an image representation in Figure 2. SIFT is used to generate local features used as visual words. Since AlexNet [19] has achieved significantly higher recognition accuracy on ILSRVC 2012, image retrieval research began to focus on deep learning-based methods [20,21,22,23,24,25], especially using convolutional neural networks (CNNs). CNN has outperformed hand-crafted features in many computer vision tasks. For image retrieval, it also shows competitive performance while using shorter feature vectors compared to BoVW models. In this work, we use pre-trained CNNs for comparative experiments with proposed methods.
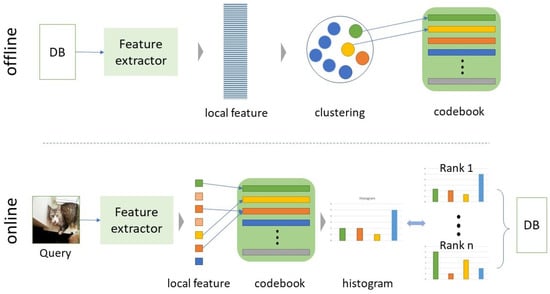
Figure 2.
The pipeline of BoVW for image retrieval.
Image retrieval may be classified into various types according to the purpose. This study focuses specifically on CBIR, instance retrieval, and object-based image retrieval (OBIR). Instance retrieval [24,26,27,28,29] is a problem of searching for images containing the same scenes and landmarks taken in different views, illumination, and occlusions for given query images with specific scenes and landmarks. Oxford5k and Paris6k are the most popular landmark dataset used by numerous image retrieval methods to date. Unlike previous datasets, which have only 4–5 similar images per class, such as Holidays [30] and UKBench [31], they have more than 100 similar images per class. However, the problem is that there are incorrect cases of image annotation. So, the revised version of them, the ROxford and RParis datasets [2] are presented to solve this problem. In this paper, ROxford and RParis are used for experiments. As a CNN-based global descriptor that shows excellent performance on those datasets, we select two descriptors: regional max-pooling (R-MAC) [10] and generalized mean-pooling (GeM) [9], which are applied to feature maps obtained from pre-trained CNNs, respectively. They are widely used to conduct the research and evaluation of instance retrieval on the Oxford5k and Paris6k datasets. R-MAC and R-GeM show good performance in various benchmarks [2,3,9].
Several image retrieval studies re-learn networks for the specific purpose and database. Radenovic et al. [9] and Gordo et al. [10] use constant and triplet loss functions to re-learn the network, respectively. NetVLAD [32] uses GPS information and street-view images to re-learn the network. The combination of multiple global descriptors [33] is designed to implement the ensemble effect of several previously proposed global descriptors, and it similarly generates a descriptor through re-learning. In contrast to the fine-tuning methods as explained above, the method of using a pre-trained network on ImageNet [34] for direct image retrieval is used for our method, which is called the off-the-shelf method.
Depending on the type and diversity of the database, retrieval may not be successful by simply comparing the visual features of the image once. To address this problem, several studies have been conducted on visual re-ranking methods [35,36,37] that correct initial image retrieval results. Query Expansion [2,26,38] further refines the existing expression of the query image using the information of the top image obtained from the initial search. Geometric context verification [39] compares the query and retrieved images with the geometric context of the local feature to determine the incorrectly found images. In K-nearest neighbors (K-NN)-based re-ranking [40], only those that are one of the K-NN of the query and include the query as K-NN from among the searched top images are extracted. Diffusion-based re-ranking was originally proposed for the purpose of using a manifold, but it was successfully applied to image retrieval [41] and achieved good results for several benchmarks. Recently, a method using contextual similarity aggregation with the self-attention of a transformer encoder has been proposed [36]. This method is robust to the image retrieval method that uses other feature representations because it is not directly related to the original features.
Chen et al. [4] approach splicing detection [6,42] from an image search perspective. Object Embeddings for Spliced Image Retrieval (OE-SIR) was proposed to define spliced image retrieval (SIR), in which the authentic image of a query image in the database is found when given a spliced query image. If the existing image search technique focuses on finding near-duplicate images or images pointing to the same landmark, then SIR finds the authentic image used in the query image manipulation. Currently, the query image and authentic image often have completely different backgrounds; therefore, the local feature is more suitable for SIR than the previously used global feature. Because most spliced images use authentic image objects (e.g., animals, faces, and logos) for image manipulation, OE-SIR extracts object-level representations of each object in the image through object detection. The performance was improved by using classification embeddings for object-level feature extraction. In our work, we also used object-level feature embeddings to retrieve images based on existing objects without considering the background scene.
Global and local features have different advantages and disadvantages. In certain situations, they are combined to increase retrieval performance complementally. The SIFT feature [18] extracts keypoints from the image and represent them only in the gradient magnitudes and orientations. HSV-SIFT [43], HueSIFT [44], and OpponentSIFT [45] combined the conventional SIFT and color descriptors to improve the representation ability. Zhang et al. [46], Deng et al. [47], and Zheng et al. [48] propose a descriptor with richer information through the fusion of local and global features. In this study, we propose an image embedding combining object and scene-level feature embeddings, which are not considered in previous studies.
Similar to our approach, Almazán et al. [49] presented an approach that starts from a strong pre-trained model, and adapts it to tackle multiple retrieval tasks concurrently, using only unlabeled images from the different task domains. It adopts an adaptor structure that extends a pre-trained model to enable multiple adaptors to learn different domains, and integrates them into a single integrated representation suitable for multiple retrieval tasks. It employs a strategy to fuse various representations with networks for practical visual models, but a separate learning process is needed for convergence with adaptors for each representation.
3. Methods
The method can be divided into offline and online procedures, as shown in Figure 3. In the offline section, the object and scene-level local features are extracted from all images in the dataset, respectively. The local feature extracts a codebook, which is the visual words of the dataset, through the clustering method. Finally, each image of a given dataset is represented by a single histogram, which is the distribution of visual words. In the process of generating a single histogram, image embedding, we propose a strategy to fuse local features, codebooks, or histograms expressed in different aspects. In the online section, local features are extracted from a given query image. The histogram is extracted using the local features and the pre-generated codebook. The image embeddings of query images are compared to the pre-extracted image embeddings of a dataset, and are sorted sequentially based on similarities. Finally, the top N similar images are considered as retrieved images.

Figure 3.
Algorithm flowchart for proposed image embedding.
Two different feature extractors were used to extract object-level and scene-level feature vectors, simultaneously. For object-level features, DETR [16] is used, as shown in Figure 4. DETR is a deep-learning network composed of a CNN and an encoder–decoder of a transformer, and produces output vectors for an input image. First, the pre-trained CNN extracts feature map representing the input image. The feature map is flattened and positional encoding is added. Second, the encoder extracts hidden state from the vector. The encoder consists of the self-attention and feed-forward-network (FFN) modules. The attention mechanism used in a self-attention module is defined as follows:
where Q is query, K is key, and V is value. is the scaling factor. The input consists of queries and keys of dimension , and values of dimension . We compute the dot products of the query with all keys, divide each by , and apply a softmax function to obtain the weights on the values.
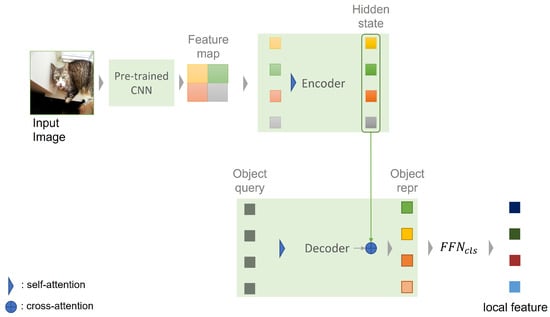
Figure 4.
The pipeline of object-level feature extraction.
The attention mechanism computes the similarity between queries and keys, and reflects the calculated relationship to the hidden state. In this process, the encoder separates each instance and attends object information except the background. Third, the decoder generates object representations from object queries, which are learnt positional encodings. The decoder consists of self-attention, cross-attention, and FFN modules. Cross attention calculates the similarity between the object queries and the hidden state of encoder. In this process, each object query indicates to a different instance and attends to object extremities, as shown in Figure 5. As a result, DETR extracts multiple object representations from the input image. The object representations describe the object information of the image, except for the background. Instead of SIFT being used to extract local feature, DETR is utilized as a local feature extractor. Because codebook and histogram generated by DETR consist of discriminative object features, we utilize the histogram generated by DETR and BoVW as the object-level feature embeddings of given images.

Figure 5.
The visualization of weights of decoder. Each object query points to a different instance.
Class embeddings and weighted histograms were applied to generate distinctive object embeddings. The output vector of DETR was used as an input to the MLP for object classification and bounding box regression. As shown in Figure 6, the output vector of MLP used for classification prediction is called class embedding. Inspired by the work of Chen et al. [4], instead of the transformer’s output vector, class embedding was used for object embedding to improve the performance of image retrieval. The transformer’s output vector was used to embed bounding box regression and object classification. In particular, because bounding box regression mainly utilizes the extremit information of objects, such as legs and heads, only limited object information was used for classification compared to class embedding, which focuses on the overall information of objects. Therefore, class embedding, which represents object information well, was used as the object embedding for object-level features.
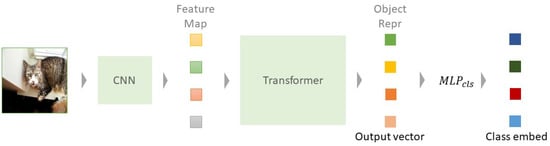
Figure 6.
The overview of class embedding. This is generated after the transformer’s output vector has passed through the MLP.
The weighted histogram in Figure 7 reflects the object class confidence of object embedding. Similar to the bounding box shown in the query image, each object embedding may correspond to an object or a non-object region. However, in the existing histogram, all of the object embeddings have the same weight, as shown in Figure 7a. Because object embeddings with low confidence in generating object-level features can be viewed as outliers, confidence should be reflected in the histogram generation process, such that the object embedding corresponding to the actual object can have a higher weight. As shown in Figure 7b, the distribution of the weighted histogram was more suitable as an object-level feature because the codewords representing the objects are emphasized more than other non-object codewords. The weighted histogram can generate more significant object-level features by reflecting the confidence of object embedding.
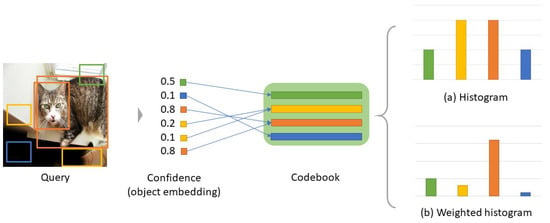
Figure 7.
The overview of weighted histogram. Weights are applied when computing the histogram according to the confidence of each region.
A scene-level feature was generated using the feature vectors obtained by generating M patches from an image through a random patch generator [17], and passing each patch through a CNN, as shown in Figure 8. As each patch can have either object or background information, in contrast to DETR, it can be viewed as a content-level feature that represents the overall information of the image. The fusion of image embeddings for MSIR was generated by the integration of object- and scene-level features, as introduced above. We propose a fusion strategy in three stages: (i) feature vector-level fusion (ii) codebook-level fusion, and (iii) histogram-level fusion between the DETR-based BoVW and random patch-based BoVW, as shown in Figure 9. In feature vector-level fusion, scene and object-level feature vectors are combined and used to generate a codebook by clustering the combined feature vectors. As clustering is performed based on the distance between feature vectors without labeling, codewords, which are representative values of K clusters, can simultaneously include scene- and object-level characteristics. In codebook-level fusion, codebooks from DETR and random patch-based BoVWs are combined. In feature vector-level fusion, an imbalance of object- and scene-level codewords may occur depending on the ratio of images in the database and extracted local feature vectors, whereas in codebook level fusion, both codewords have the same proportion. Histogram-level fusion fuses histograms of the occurrences of visual words. This fusion strategy has the advantage of a better representation of image content, such as scenes or objects if the codebook is generated from a larger and more diverse database.
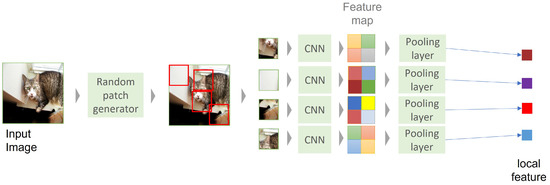
Figure 8.
The pipeline of scene-level feature extraction.

Figure 9.
The overview of feature fusion methods. We combine local feature, codebook, and histogram representing different aspects. We state these as feature-, codebook- and histogram-level.
4. Experiments
Various experiments were conducted to compare the performance of the previous image retrieval methods and the proposed method on single-subject and multi-subject datasets. As a single-subject dataset, the MS COCO [8], aerial image dataset (AID) [50], and Paris6K and Oxford5K [2] datasets, which predominantly include object, scene, and landmark images, respectively, were used. MS COCO is typically used for the training and evaluation of object recognition models, and consists of 80 object classes. Many images in the COCO dataset include multiple classes of objects. However, image retrieval performance is mainly measured by a single class match of a query image with the retrieved images. Images with multiple classes were unsuitable for evaluation. Therefore, images in which only objects of a single class exist in COCO were selected, where 1025 images composed of a single class from 5000 verification images were used as query images, and 24,186 images out of 118,287 images were reorganized as a database for search. AID consists of 30 aerial scene classes, and 50 images per class were used as query images. A database consisting of 170 images per class was used for the search. Paris6K and Oxford5K are each composed of 12 landmark classes. Five images per class were used as query images, and a database of 100 images per class was used for the search.
Our implementation follows the practice in [16,51]. The image is resized to 800 × 800 resolution, which was the shortest size that DETR used for the object recognition process. The image for scene-level feature embedding extracts multiple random patches of 224 × 224 resolution, which follows the practice in [51]. The backbone for feature extraction is with the ImgeNet-pretrained ResNet model from TORCHVISION with frozen batchnorm layers. Specifically, the ResNet-101 model is used for all the experiments. For scene-level feature embeddings, we applied a pooling layer to the feature map of ResNet. The corresponding models with average pooling, regional max-pooling [10], and GeM pooling [9] are called ResNet, R-MAC, and R-GeM, respectively. In all tables, the CNN-based global feature has 2048 dimensions, which follow, in practice, [51]; BoVW- and Mix BoVW-based feature embeddings have 1000 dimensions. The number of local features for object-level feature embeddings used for generating codebook and histogram is 100, which follow the practice in [16]. The number of local features for scene-level feature embeddings is the same as the object-level feature embeddings for comparison. All hyperparameters are empirically set in consideration of a trade-off between complexity and performance.
We fine-tune revised DETR which is an added linear layer with AdamW [52] for class embedding. The clustering method for codebook is a k-means clustering algorithm from the KMeans of SKLEARN library. We extract global feature, object, and scene-level feature embeddings using PYTORCH, OPENCV, and PYTHON, versions 1.12.1, 4.6.0, and 3.8.8, respectively, on an Intel I7 CPU with an Nvidia RTX 3090 GPU. We calculated the similarity between image embeddings extracted from a given query image and database. The retrieved images were then sorted in descending order by similarity. At this time, the cosine similarity was used for calculating the similarity, which is defined as follows:
where q is an image embedding of a given query image, x are the image embeddings of the database.
Image retrieval performance was measured using the evaluation metric, which is defined as follows:
where N is the number of retrieved images. i means the rank of the retrieved image. is the indicator function. is the object class of the retrieved image with rank i, and is the object class of a given query image. is a weight parameter of rank i, which is defined as follows:
The top N-rank retrieved images with high similarity were used to measure the performance. When is equal to , the indicator function returns 1; otherwise, it returns 0. We utilize the weight parameter , which gives a higher value to higher rank images. In other words, if the rank is close to 1, the is high, and if the rank is close to N, the is low. It is normalized to the sum of all weights, such that the accuracy has a value of between 0 and 100. If the object classes of all retrieved images are equal to , the score is 100 and the opposite is 0. The results of all tables in the paper have the same configuration; for comparison, N is set to 100, and the accuracy described is measured using Equation (3).
4.1. Single Subject Image Retrieval
In Table 1, the performance of image retrieval using previous methods such as SIFT-based BoVW [14], ResNet [51], R-MAC [10], R-GeM [9], and our method using DETR-based BoVW and random-based BoVW are compared. Image retrieval in the COCO dataset can be regarded as OBIR, which searches for images containing the same object as the query image. As shown in Figure 10, the object-level feature in DETR-based BoVW performed better than other image retrieval methods in OBIR. Because SIFT [18] extracts feature vectors without distinguishing between objects and backgrounds, the image embedding of SIFT-based BoVW exhibited low performance in OBIR. The global features of ResNet or scene-level features of random patch-based BoVW could not represent object information effectively when the query image and database had complex backgrounds, or when the objects were small or occluded; therefore, the detection of the scene-level features performed poorly. Contrarily, in the AID, and Paris6K and Oxford5K datasets, the global- and scene-level features that represent scene information performed well, as shown in Figure 10. R-MAC performs well on the COCO and Oxford datasets. In R-MAC, the feature map of CNNs is truncated to different sizes and applies max pooling to multiple regions to improve the image representation ability. R-GeM shows the best results on both AID, Paris6k, and Oxford5k. Owing to GeM pooling and whitening being performed as a post-processing step, it is enabled as an image representation that is suitable for instance retrieval.

Table 1.
Comparison of accuracy in a single-subject dataset. The bold and underline mean the best and second accuracy for each dataset, respectively.

Figure 10.
The results of image retrieval for single-subject datasets.
4.2. Multi-Subject Image Retrieval
We applied the proposed method, which combines object- and scene-level features based on the BoVW framework to MSIR, and compared it with other image retrieval methods. In Table 2, C, A, P, and O indicate the COCO, AID, Paris6K, and Oxford5K datasets, respectively. The multi-subject dataset comprises a combination of these single-subject datasets. To avoid data imbalance, five images per class were selected as query images, and 100 images were used as a search database. The feature, codebook, and histogram indicate the fusion of the feature vector, codebook, and histogram levels, respectively.
Table 2.
Comparison of accuracy in a multi-subject dataset. The bold and underline mean the best and second accuracy for each dataset, respectively.
In the MSIR, R-MAC and R-GeM performed worse in contrast to single-subject datasets. Images with similar backgrounds but different object classes often appear in multi-subject datasets. As the conventional retrieval methods cannot completely discriminate a background and objects, images with similar backgrounds behave as distractors, which results in poor performance. DETR-based BoVW has low performance, even if all the datasets used in the experiment contain object images. DETR has excellent object representation ability, but low scene representation ability. Therefore, the local features of the DETR generated for the scene image interfere with the creation of an intact codebook and cause a decrease in the overall performance. The proposed method showed better performance for all combinations of multi-subject datasets. In particular, histogram-based fusion shows the best performance in all cases, because the image embedding of histogram level fusion can effectively reflect both object-level and scene-level information. The codebook and feature vector-based fusion methods also showed significantly better performances compared to other methods in the C+P and C+P+O datasets.
We divided the BoVW method into three stages to generate different image embeddings. As shown in Table 2, the image embedding of histogram-level performs well in all multi-subject databases. Image embeddings of codebook- and feature-levels performed relatively poorly, as object and scene-information can be imbalanced during the fusion process. However, in most cases, the proposed methods performed better than the traditional methods. The image embedding of the histogram-level has distinct and balanced scene and object information, and presents the best results compared to the other descriptors. In addition, since the two histograms are simply concatenated, the fusion process requires little resources. Figure 11 shows an example of the image retrieval results of the global feature and fusion embeddings proposed in this study. As the existing global feature searches for images with greater emphasis on scene information, such as grass, tree, and sky, images with other objects or landmarks in similar scenes were retrieved. As the proposed fusion embedding is based on both object- and scene-level features, it is evident that images with similar scenes, including same-category objects, were retrieved.

Figure 11.
The results of CNN and fusion image embedding. The image on the left is the query image and the image on the right side of the arrow is the retrieved image.
4.3. Ablation Study
Table 3 summarizes the ablation study results for the proposed image retrieval method. Class embedding shows significantly better performance in image retrieval for the COCO dataset because the object-level embedding included the overall information of the objects in the image. The weighted histogram selected vectors that do not represent objects accurately among the N object embeddings extracted from DETR, and through this, a histogram was generated by considering object embeddings. However, in the case of scene-based or multi-subject datasets, most class embeddings were regarded as outliers. Therefore, it is evident that the performance was reduced by adversely affecting the generation of histograms. Therefore, even though the weighted histogram was effective for object embedding when applied to object-level datasets such as COCO, it was not applied to image embedding for MSIR.
Table 3.
The ablation study of class embedding and weighted histogram. The bold means the best accuracy for each dataset.
In Table 4, the performance of image retrieval according to the object-level codebooks, generated from DETR, is summarized. Multi-subject and COCO codebooks were generated using the target multi-subject and COCO datasets, respectively. The COCO codebook showed a better performance than the multi-subject codebook for all cases in the MSIR dataset and fusion strategy because it used a relatively large number of diverse object embeddings; however, it did not include the hindering of object embeddings from the scene images of multi-subject datasets. Thus, the COCO dataset or a similar large and diverse dataset is more useful for generating object-level feature embeddings than the target dataset.
Table 4.
The ablation study of codebooks generated using Mutli-subject and COCO datasets.
5. Conclusions
In this study, we proposed a MSIR method by fusing image embeddings from object-level and scene-level features. These were generated by applying BoVW to local features from DETR and random patches, respectively. Class embedding and weighted histograms were used to better represent object-level features. Thereafter, the fusion strategy for the object- and scene-level features, was introduced in three stages. Experiments were performed on single-subject and multi-subject datasets to characterize existing image retrieval methods and to evaluate the performance of the proposed method. Among the fusion methods, the histogram-level fusion method showed the best results, owing to the generation of more representative codebooks. In the ablation study, class embedding and object-level embedding using the COCO dataset yielded more effective results. The proposed image retrieval method performed better in MSIR because the proposed image embedding method manages scene and object information simultaneously.
Author Contributions
Conceptualization, Y.H.; Methodology, C.-G.B.; Software, C.-G.B. and D.P.; Data curation, D.P. and R.-Y.J.; Writing—original draft, Y.H.; Supervision, M.-S.C.; Project administration, R.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by a Research and Development project, Building a DataAI-based Problem-solving System of Korea Institute of Science and Technology (KISTI), South Korea, under Grant K-22-L04-C05-S01.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
We have used open datasets that are available in public.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zheng, L.; Yang, Y.; Tian, Q. SIFT Meets CNN: A Decade Survey of Instance Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1224–1244. [Google Scholar] [CrossRef] [PubMed]
- Radenovic, F.; Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 5706–5715. [Google Scholar]
- Gkelios, S.; Sophokleous, A.; Plakias, S.; Boutalis, Y.; Chatzichristofis, S.A. Deep convolutional features for image retrieval. Expert Syst. Appl. 2021, 177, 114940. [Google Scholar] [CrossRef]
- Chen, B.C.; Wu, Z.; Davis, L.S.; Lim, S.N. Efficient Object Embedding for Spliced Image Retrieval. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Nashville, TN, USA, 2021; pp. 14960–14970. [Google Scholar]
- Zhou, P.; Chen, B.C.; Han, X.; Najibi, M.; Shrivastava, A.; Lim, S.N.; Davis, L. Generate, Segment, and Refine: Towards Generic Manipulation Segmentation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 13058–13065. [Google Scholar] [CrossRef]
- Huh, M.; Liu, A.; Owens, A.; Efros, A.A. Fighting Fake News: Image Splice Detection via Learned Self-Consistency. In Computer Vision—ECCV 2018; Springer International Publishing: Cham, Switzerland, 2018; Volume 11215, pp. 106–124. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Radenovic, F.; Tolias, G.; Chum, O. Fine-Tuning CNN Image Retrieval with No Human Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1655–1668. [Google Scholar] [CrossRef] [PubMed]
- Gordo, A.; Almazán, J.; Revaud, J.; Larlus, D. End-to-End Learning of Deep Visual Representations for Image Retrieval. Int. J. Comput. Vis. 2017, 124, 237–254. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Csurka, G.; Bray, C.; Dance, C.; Fan, L. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision, ECCV, Prague, Czech Republic, 11–14 May 2004; pp. 1–22. [Google Scholar]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 2, pp. 1470–1477. [Google Scholar]
- Fei-Fei, L.; Perona, P. A Bayesian hierarchical model for learning natural scene categories. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 524–531. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Iakovidou, C.; Anagnostopoulos, N.; Kapoutsis, A.; Boutalis, Y.; Lux, M.; Chatzichristofis, S. Localizing global descriptors for content-based image retrieval. Eurasip J. Adv. Signal Process. 2015, 2015, 80. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 806–813. [Google Scholar]
- Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural codes for image retrieval. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 584–599. [Google Scholar]
- Yue-Hei Ng, J.; Yang, F.; Davis, L.S. Exploiting local features from deep networks for image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 53–61. [Google Scholar]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2015, arXiv:1511.05879. [Google Scholar]
- Kalantidis, Y.; Mellina, C.; Osindero, S. Cross-dimensional weighting for aggregated deep convolutional features. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 685–701. [Google Scholar]
- Gordo, A.; Almazán, J.; Revaud, J.; Larlus, D. Deep image retrieval: Learning global representations for image search. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 241–257. [Google Scholar]
- Chum, O.; Philbin, J.; Sivic, J.; Isard, M.; Zisserman, A. Total recall: Automatic query expansion with a generative feature model for object retrieval. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Perd’och, M.; Chum, O.; Matas, J. Efficient representation of local geometry for large scale object retrieval. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 9–16. [Google Scholar]
- Tolias, G.; Jégou, H. Visual query expansion with or without geometry: Refining local descriptors by feature aggregation. Pattern Recognit. 2014, 47, 3466–3476. [Google Scholar] [CrossRef]
- Babenko, A.; Lempitsky, V. Aggregating deep convolutional features for image retrieval. arXiv 2015, arXiv:1510.07493. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. Hamming embedding and weak geometric consistency for large scale image search. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 304–317. [Google Scholar]
- Nister, D.; Stewenius, H. Scalable recognition with a vocabulary tree. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2161–2168. [Google Scholar]
- Arandjelovic, R.; Gronát, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Jun, H.; Ko, B.; Kim, Y.; Kim, I.; Kim, J. Combination of Multiple Global Descriptors for Image Retrieval. arXiv 2019, arXiv:1903.10663. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Lee, S.; Seong, H.; Lee, S.; Kim, E. Correlation Verification for Image Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 5364–5374. [Google Scholar]
- Ouyang, J.; Wu, H.; Wang, M.; Zhou, W.; Li, H. Contextual Similarity Aggregation with Self-Attention for Visual Re-Ranking. Adv. Neural Inf. Process. Syst. 2021, 34, 3135–3148. [Google Scholar]
- Nguyen, X.B.; Bui, D.T.; Duong, C.N.; Bui, T.D.; Luu, K. Clusformer: A Transformer based Clustering Approach to Unsupervised Large-scale Face and Visual Landmark Recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Nashville, TN, USA, 2021; pp. 10842–10851. [Google Scholar]
- Chum, O.; Mikulík, A.; Perdoch, M.; Matas, J. Total recall II: Query expansion revisited. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 889–896. [Google Scholar]
- Cao, B.; Araujo, A.; Sim, J. Unifying Deep Local and Global Features for Image Search. In Computer Vision—ECCV 2020; Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12365, pp. 726–743. [Google Scholar]
- Shen, X.; Lin, Z.; Brandt, J.; Avidan, S.; Wu, Y. Object retrieval and localization with spatially-constrained similarity measure and k-NN re-ranking. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3013–3020. [Google Scholar]
- Bai, S.; Bai, X.; Tian, Q.; Latecki, L.J. Regularized Diffusion Process for Visual Retrieval. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3967–3973. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Learning Rich Features for Image Manipulation Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1053–1061. [Google Scholar]
- Bosch, A.; Zisserman, A.; Munoz, X. Scene classification using a hybrid generative/discriminative approach. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 712–727. [Google Scholar] [CrossRef] [PubMed]
- Van de Weijer, J.; Gevers, T.; Bagdanov, A.D. Boosting color saliency in image feature detection. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 28, 150–156. [Google Scholar] [CrossRef] [PubMed]
- Van De Sande, K.; Gevers, T.; Snoek, C. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1582–1596. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Yang, M.; Cour, T.; Yu, K.; Metaxas, D.N. Query specific fusion for image retrieval. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 660–673. [Google Scholar]
- Deng, C.; Ji, R.; Liu, W.; Tao, D.; Gao, X. Visual reranking through weakly supervised multi-graph learning. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 2–8 December 2013; pp. 2600–2607. [Google Scholar]
- Zheng, L.; Wang, S.; Tian, L.; He, F.; Liu, Z.; Tian, Q. Query-adaptive late fusion for image search and person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1741–1750. [Google Scholar]
- Almazán, J.; Ko, B.; Gu, G.; Larlus, D.; Kalantidis, Y. Granularity-Aware Adaptation for Image Retrieval Over Multiple Tasks. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 389–406. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’16), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).