
Intent Classification and Slot Filling Model for In-Vehicle Services in Korean

 , and
, and
Abstract
:1. Introduction
- We propose a model that learns in-vehicle services situations with diverse domains in Korean that are jointly trained with intent classification and slot-filling.
- To show our model’s effectiveness, we conduct experiments on a mobility domain dataset and show comparable performances on the dataset.
- We show the efficacy of the value-refiner through an ablation study and demonstrate the error types from the model prediction.
2. Related Work
2.1. Task-Oriented Dialogue System
2.2. Pre-Trained Language Models for Dialogue Systems
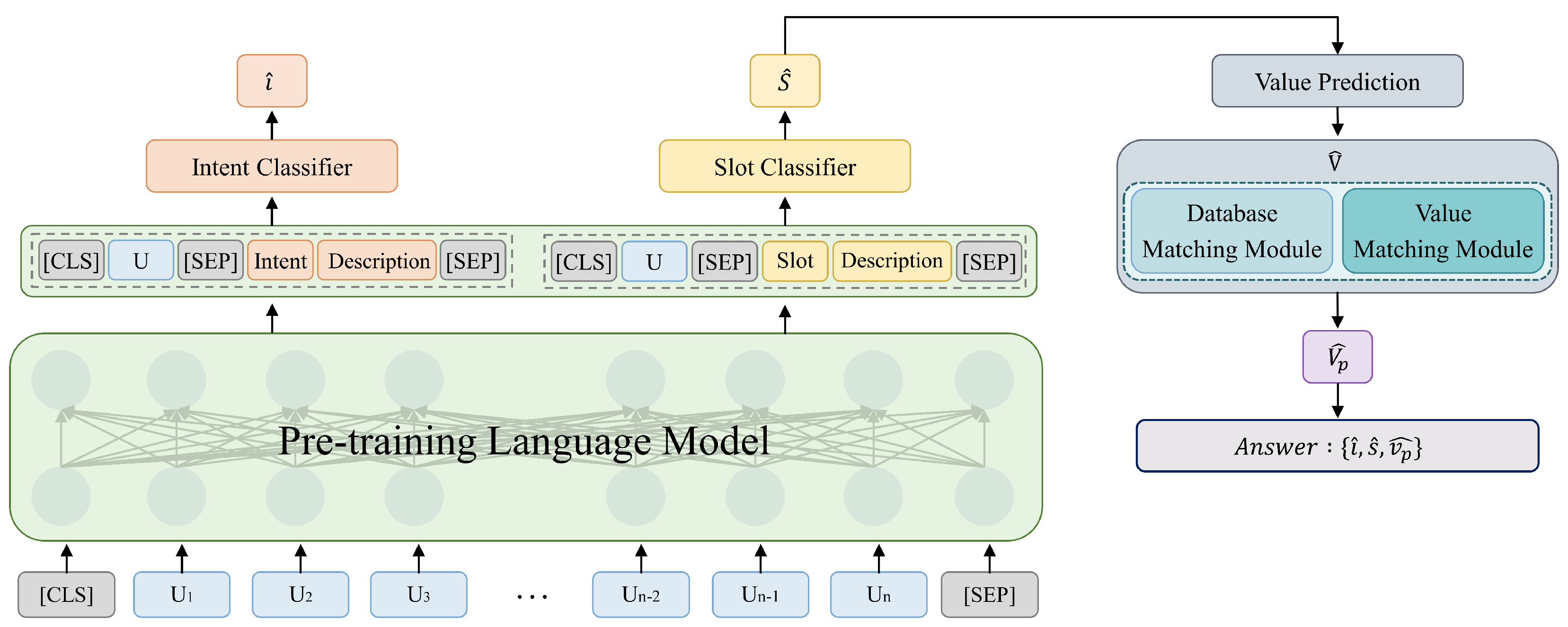
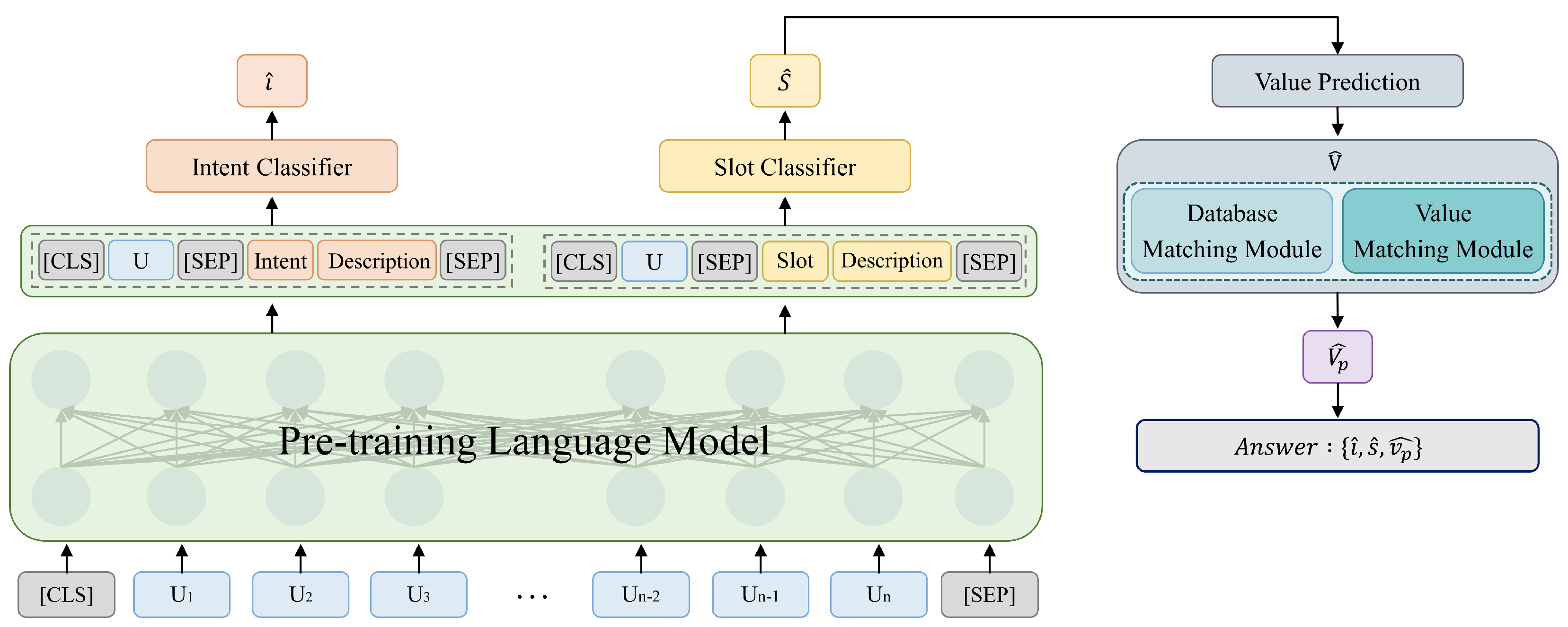
3. Method
3.1. Intent Classifier
3.2. Slot Classifier
3.3. Slot Value Predictor
3.4. Value Refiner
4. Experiments
4.1. Data
4.2. Experimental Setup
4.3. Evaluation Metrics
4.4. Results and Analysis
4.4.1. Main Results
4.4.2. Ablation Study on Value Refiner
5. Discussion
5.1. Qualitative Results on Slot Value Prediction
5.2. Error Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Zhang, Z.; Zhang, Z.; Chen, H.; Zhang, Z. A joint learning framework with bert for spoken language understanding. IEEE Access 2019, 7, 168849–168858. [Google Scholar] [CrossRef]
- Louvan, S.; Magnini, B. Recent Neural Methods on Slot Filling and Intent Classification for Task-Oriented Dialogue Systems: A Survey. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 480–496. [Google Scholar]
- Mesnil, G.; He, X.; Deng, L.; Bengio, Y. Investigation of recurrent-neural-network architectures and learning methods for spoken language understanding. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013; pp. 3771–3775. [Google Scholar]
- Mesnil, G.; Dauphin, Y.; Yao, K.; Bengio, Y.; Deng, L.; Hakkani-Tur, D.; He, X.; Heck, L.; Tur, G.; Yu, D.; et al. Using recurrent neural networks for slot filling in spoken language understanding. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 23, 530–539. [Google Scholar] [CrossRef]
- Liu, B.; Lane, I. Recurrent neural network structured output prediction for spoken language understanding. In Proceedings of the NIPS Workshop on Machine Learning for Spoken Language Understanding and Interactions, Montreal, QC, Canada, 11 December 2015. [Google Scholar]
- Zhang, C.; Li, Y.; Du, N.; Fan, W.; Philip, S.Y. Joint Slot Filling and Intent Detection via Capsule Neural Networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5259–5267. [Google Scholar]
- Wang, Y.; Shen, Y.; Jin, H. A Bi-Model Based RNN Semantic Frame Parsing Model for Intent Detection and Slot Filling. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 309–314. [Google Scholar]
- Lin, Z.; Madotto, A.; Winata, G.I.; Fung, P. MinTL: Minimalist Transfer Learning for Task-Oriented Dialogue Systems. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 3391–3405. [Google Scholar]
- Wu, C.S.; Hoi, S.C.; Socher, R.; Xiong, C. TOD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogue. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 917–929. [Google Scholar]
- Hemphill, C.T.; Godfrey, J.J.; Doddington, G.R. The ATIS Spoken Language Systems Pilot Corpus. In Proceedings of the Speech and Natural Language, St. Louis, PA, USA, 24–27 June 1990. [Google Scholar]
- Coucke, A.; Saade, A.; Ball, A.; Bluche, T.; Caulier, A.; Leroy, D.; Doumouro, C.; Gisselbrecht, T.; Caltagirone, F.; Lavril, T.; et al. Snips voice platform: An embedded spoken language understanding system for private-by-design voice interfaces. arXiv 2018, arXiv:1805.10190. [Google Scholar]
- Schuster, S.; Gupta, S.; Shah, R.; Lewis, M. Cross-lingual Transfer Learning for Multilingual Task Oriented Dialog. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 3795–3805. [Google Scholar]
- Rastogi, A.; Zang, X.; Sunkara, S.; Gupta, R.; Khaitan, P. Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8689–8696. [Google Scholar]
- Budzianowski, P.; Wen, T.H.; Tseng, B.H.; Casanueva, I.; Ultes, S.; Ramadan, O.; Gasic, M. MultiWOZ-A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 5016–5026. [Google Scholar]
- Eric, M.; Krishnan, L.; Charette, F.; Manning, C.D. Key-Value Retrieval Networks for Task-Oriented Dialogue. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, Saarbrucken, Germany, 15–17 August 2017; pp. 37–49. [Google Scholar]
- Abro, W.A.; Qi, G.; Ali, Z.; Feng, Y.; Aamir, M. Multi-turn intent determination and slot filling with neural networks and regular expressions. Knowl.-Based Syst. 2020, 208, 106428. [Google Scholar] [CrossRef]
- Yanli, H. Research on Spoken Language Understanding Based on Deep Learning. Sci. Program. 2021. [Google Scholar] [CrossRef]
- Park, S.; Moon, J.; Kim, S.; Cho, W.I.; Han, J.; Park, J.; Song, C.; Kim, J.; Song, Y.; Oh, T.; et al. KLUE: Korean Language Understanding Evaluation. arXiv 2021, arXiv:2105.09680. [Google Scholar]
- Han, S.; Lim, H. Development of Korean dataset for joint intent classification and slot filling. J. Korea Converg. Soc. 2021, 12, 57–63. [Google Scholar]
- Kim, Y.M.; Lee, T.H.; Na, S.O. Constructing novel datasets for intent detection and ner in a korean healthcare advice system: Guidelines and empirical results. Appl. Intell. 2022, 1–21. [Google Scholar] [CrossRef]
- Yu, D.; He, L.; Zhang, Y.; Du, X.; Pasupat, P.; Li, Q. Few-shot intent classification and slot filling with retrieved examples. arXiv 2021, arXiv:2104.05763. [Google Scholar]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Firdaus, M.; Golchha, H.; Ekbal, A.; Bhattacharyya, P. A deep multi-task model for dialogue act classification, intent detection and slot filling. Cogn. Comput. 2021, 13, 626–645. [Google Scholar] [CrossRef]
- Liu, B.; Lane, I. Attention-based recurrent neural network models for joint intent detection and slot filling. arXiv 2016, arXiv:1609.01454. [Google Scholar]
- Zhang, X.; Wang, H. A joint model of intent determination and slot filling for spoken language understanding. In Proceedings of the IJCAI International Joint Conferences on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; Volume 16, pp. 2993–2999. [Google Scholar]
- Goo, C.W.; Gao, G.; Hsu, Y.K.; Huo, C.L.; Chen, T.C.; Hsu, K.W.; Chen, Y.N. Slot-gated modeling for joint slot filling and intent prediction. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 753–757. [Google Scholar]
- Qin, L.; Che, W.; Li, Y.; Wen, H.; Liu, T. A stack-propagation framework with token-level intent detection for spoken language understanding. arXiv 2019, arXiv:1909.02188. [Google Scholar]
- Chen, Q.; Zhuo, Z.; Wang, W. Bert for joint intent classification and slot filling. arXiv 2019, arXiv:1902.10909. [Google Scholar]
- Jeong, M.S.; Cheong, Y.G. Comparison of Embedding Methods for Intent Detection Based on Semantic Textual Similarity; The Korean Institute of Information Scientists and Engineers: Seoul, Republic of Korea, 2020; pp. 753–755. [Google Scholar]
- Heo, Y.; Kang, S.; Seo, J. Korean Natural Language Generation Using LSTM-based Language Model for Task-Oriented Spoken Dialogue System. Korean Inst. Next Gener. Comput. 2020, 16, 35–50. [Google Scholar]
- So, A.; Park, K.; Lim, H. A study on building korean dialogue corpus for restaurant reservation and recommendation. In Proceedings of the Annual Conference on Human and Language Technology. Human and Language Technology, Tartu, Estonia, 27–29 September 2018; pp. 630–632. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Brier, G.W. Verification of forecasts expressed in terms of probability. Mon. Weather Rev. 1950, 78, 1–3. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Choi, J.; Lee, J. Redefining Korean road name address system to implement the street-based address system. J. Korean Soc. Surv. Geod. Photogramm. Cartogr. 2018, 36, 381–394. [Google Scholar]
- Park, J.H.; Myaeng, S.H. A method for establishing korean multi-word concept boundary harnessing dictionaries and sentence segmentation for constructing concept graph. In Proceedings of the 44th KISS Conference; 2017; Volume 44, pp. 651–653. [Google Scholar]
- Hur, Y.; Son, S.; Shim, M.; Lim, J.; Lim, H. K-EPIC: Entity-Perceived Context Representation in Korean Relation Extraction. Appl. Sci. 2021, 11, 11472. [Google Scholar] [CrossRef]

{kind=link}
| # of Examples | # of Domains | |
|---|---|---|
| Train | 492,000 | 23 |
| Test | 260,991 | 23 |
| Domain | Domain Description | # of Intent |
|---|---|---|
| AVNT | Waypoint | 2 |
| BT | Bluetooth | 12 |
| chitchat | Inconsequential conversation | 8 |
| cluster | Dashboard | 6 |
| embedded | Systems built into car | 45 |
| fatc | Car control | 26 |
| glass | Window and side mirror control | 6 |
| hipass | Hipass | 6 |
| ma | Mobile application | 3 |
| music | Music | 3 |
| navi | Navigation | 2 |
| others | Others | 2 |
| portal | Portal Search | 17 |
| QA | Question and answering | 22 |
| seat | Seat control | 38 |
| settings | Setting control | 17 |
| simple | Simple setting control | 6 |
| sunroof | Sunroof control | 2 |
| trunk | Trunk control | 2 |
| vehicle | Charger control | 2 |
| weather | Weather check | 12 |
| wheel | Wheel heating control | 2 |
| wind | Wind control | 16 |
| Slot Name | Slot Description | # of Slots |
|---|---|---|
| Categorical Slots | ||
| AboutDisplay | In-vehicle display devices, instrument clusters, heads-up displays, lights, lamp | 6328 |
| SettingBar | Settings change control button | 14,475 |
| Non-Categorical Slots | ||
| AlbumName | Search music, song album title when playing music | 453 |
| AMSetting | Radio AM frequency range | 2121 |
| BroadcastStation | The name of the broadcasting station that transmits radio broadcasts and the radio program broadcast from the broadcasting station | 3269 |
| CallTarget | A call target with a dialing function through Bluetooth cell phone linkage | 18,166 |
| Consumables | Automobile interior parts that are worn out and need replacement or continuous inspection | 42,097 |
| Date | Date and time | 33,264 |
| FMSetting | Radio FM frequency range | 2112 |
| GenreName | Music search, music playback, music genre, classification | 449 |
| Region | Address unit, special city, province, city, county, street name, street name | 22,882 |
| SearchPlace | Search place, POI, school, restaurant, gas station, subway station, train station, place, address, frequent places | 4745 |
| SearchRange | Search area, nearby subway station, train station, airport, park, POI | 1877 |
| SettingCheck | Change Settings checkbox | 3819 |
| SettingColor | Setting color to change mood light color | 3629 |
| SettingTarget | Settings Classification Menu | 9869 |
| SettingValue | Setting change value | 10,995 |
| SingerName | Search for music, name of singer, artist when playing music | 1233 |
| SongName | Search music, song title when playing music | 1418 |
| SpecialPlace | Schools, educational institutions, companies, shops, shops, restaurants, gas stations, parking lots, buildings, lakes, complexes, addresses, entrances of apartments, etc. | 1407 |
| Switchgear | Associated devices capable of controlling opening and closing | 9831 |
| System | Safety device system, driving device, system, alarm, mode | 13,022 |
| TemperatureValue | Temperature setting values for air conditioning, air conditioning, and heater inside the vehicle | 3576 |
| Update | Software update | 12,866 |
| WarningLight | Lights up to warn users when the operating status of equipment in the car is abnormal, etc. This is shown in the car cluster. | 3633 |
| Intent Acc. | Slot Acc. | Cat Acc. | Non-Cat EM | Non-Cat F1 | JGA | ||
|---|---|---|---|---|---|---|---|
| KoBERT | 98.50 | - | - | - | - | - | |
| ICO | KLUE-RoBERTa | 97.14 | - | - | - | - | - |
| mBERT | 96.70 | - | - | - | - | - | |
| KoBERT | - | 99.46 | 51.54 | 85.51 | 94.68 | - | |
| SFO | KLUE-RoBERTa | - | 98.47 | 51.57 | 54.00 | 86.88 | - |
| mBERT | - | 98.45 | 51.57 | 78.94 | 91.27 | - | |
| KoBERT | 98.90 | 99.70 | 93.71 | 86.67 | 95.53 | 86.55 | |
| ICO + SFO | KLUE-RoBERTa | 98.98 | 99.45 | 94.29 | 76.41 | 92.84 | 86.42 |
| mBERT | 98.38 | 99.52 | 94.51 | 89.97 | 95.83 | 90.74 |
| PP Type | KoBERT | KLUE-RoBERTa | mBERT |
|---|---|---|---|
| DM + VM | 86.55 | 86.42 | 90.74 |
| DM | 85.91 | 84.82 | 90.54 |
| VM | 83.51 | 83.35 | 87.66 |
| - | 76.95 | 80.55 | 86.38 |
| Utterance | |
|---|---|
| 소프트웨어 버전 업데이트 필요한지 봐줘 Watch if a software version update is necessary | |
| Slot Label | |
| 업데이트 Update | |
| Slot Prediction | |
| KoBERT | 업데이트 Update |
| RoBERTa | 업데이트 Update |
| mBERT | 업데이트 Update |
| Value Label | |
| 소프트웨어 버전 Software version | |
| Value Prediction | |
| KoBERT | 소프트웨어 버 Software ver |
| RoBERTa | 소프트웨어 버 Software ver |
| mBERT | 소프트웨어 버전 Software version |
| Ground-Truth | Slot Value Prediction |
|---|---|
| 도두리로 | 도두리 |
| Doduri-ro | Doduri |
| 우천산업단지로 | 우천산업단지 |
| Ucheonsaneopdanji-ro | Ucheonsaneopdanji |
| 녹산산단 153로 | 녹산산단 153 |
| Noksansandan 153-ro | Noksansandan 153 |
| 학동 11로 | 학동 11 |
| Hakdong 11-ro | Hakdong 11 |
| Ground-Truth | Slot Value Prediction |
|---|---|
| 우리 아파트 어린이집 선생님 | 우리 아파트 어린이집 선생님에 |
| uri apateu eorinijip seonsaengnim | uri apateu eorinijip seonsaengnimE |
| 국제대 | 국제대가 |
| gukjedae | gukjedae Ga |
| 1183 | 1183로 |
| 1183 | 1183ro |
| 유O은 | 유O은이 |
| YooOEun | YooOEunYi |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, J.; Son, S.; Lee, S.; Chun, C.; Park, S.; Hur, Y.; Lim, H. Intent Classification and Slot Filling Model for In-Vehicle Services in Korean. Appl. Sci. 2022, 12, 12438. https://doi.org/10.3390/app122312438
Lim J, Son S, Lee S, Chun C, Park S, Hur Y, Lim H. Intent Classification and Slot Filling Model for In-Vehicle Services in Korean. Applied Sciences. 2022; 12(23):12438. https://doi.org/10.3390/app122312438
Chicago/Turabian StyleLim, Jungwoo, Suhyune Son, Songeun Lee, Changwoo Chun, Sungsoo Park, Yuna Hur, and Heuiseok Lim. 2022. "Intent Classification and Slot Filling Model for In-Vehicle Services in Korean" Applied Sciences 12, no. 23: 12438. https://doi.org/10.3390/app122312438
APA StyleLim, J., Son, S., Lee, S., Chun, C., Park, S., Hur, Y., & Lim, H. (2022). Intent Classification and Slot Filling Model for In-Vehicle Services in Korean. Applied Sciences, 12(23), 12438. https://doi.org/10.3390/app122312438