


An Effective Rainfall–Ponding Multi-Step Prediction Model Based on LSTM for Urban Waterlogging Points
Abstract
1. Introduction
2. Rainfall Prediction Model Construction
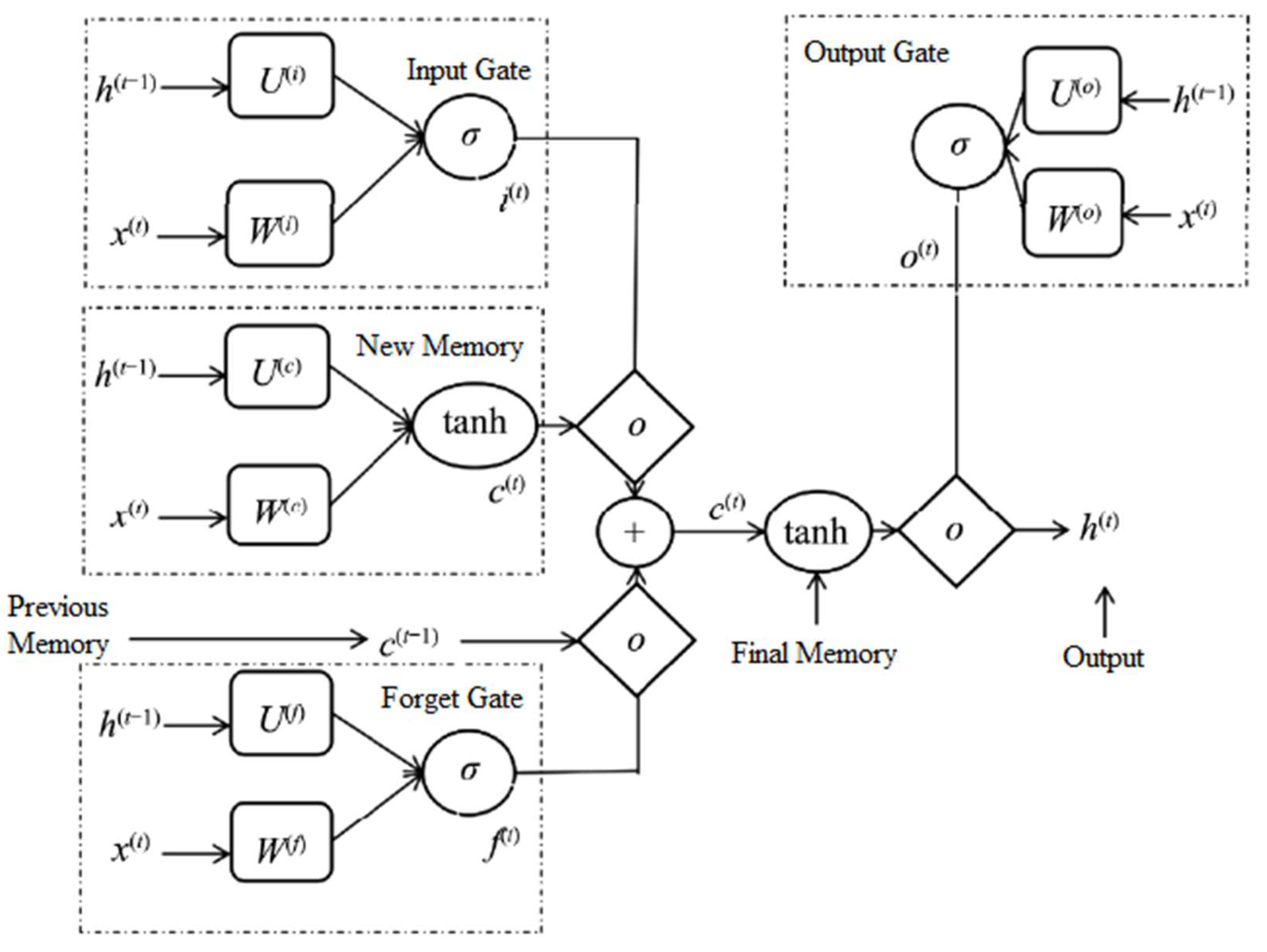
2.1. Modeling Principle
2.2. Prediction Objectives
2.3. Model Framework
2.4. Optimization Algorithm in Model Compilation
3. Case Study
3.1. Study Area and Data Sources
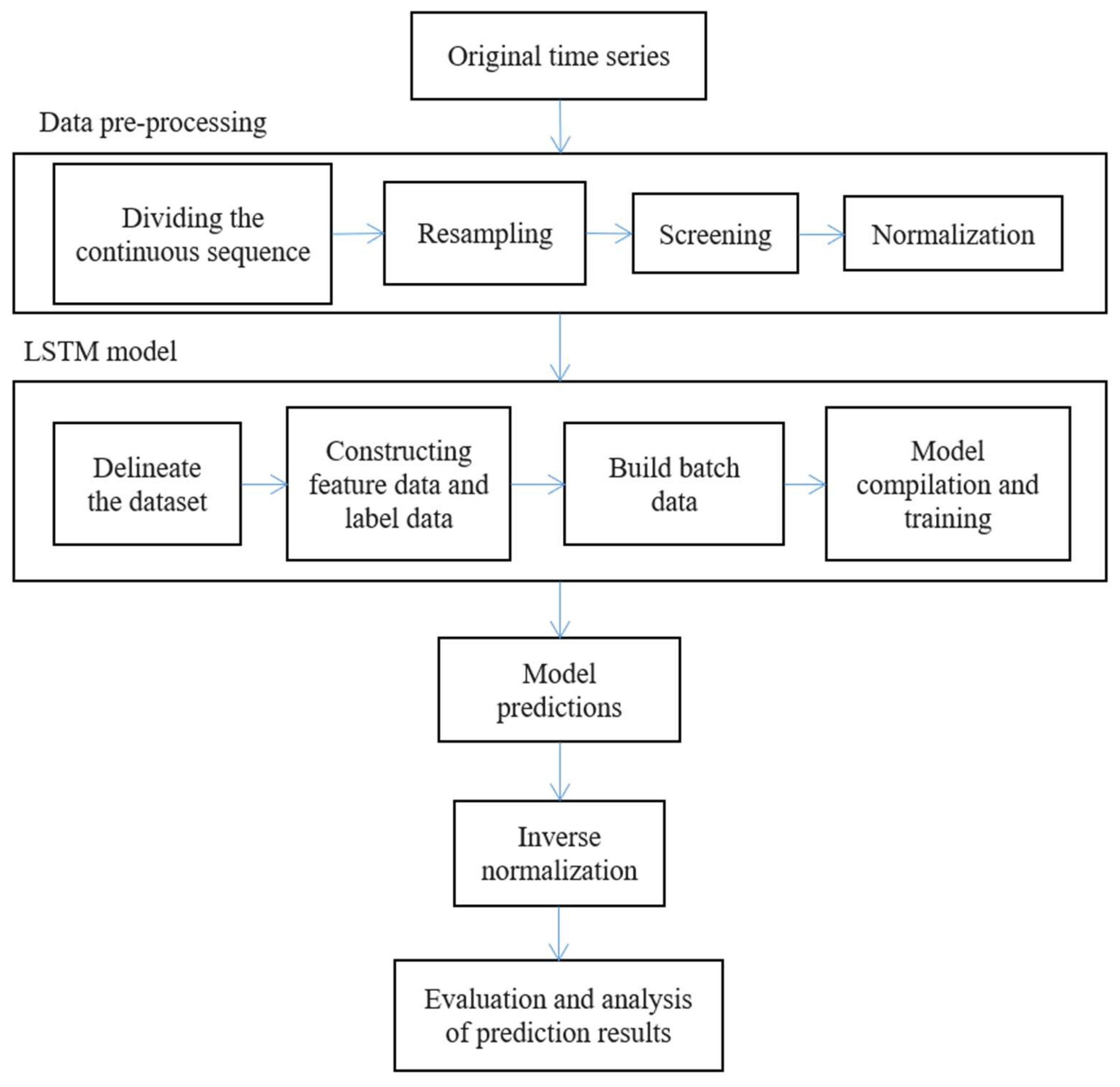
3.2. Data Pre-Processing
3.2.1. Continuous Series Segmentation
3.2.2. Resampling
3.2.3. Screening
3.2.4. Normalization
3.3. Model Training
3.3.1. Defining Labeled Data and Feature Data
3.3.2. Moving Sliding Window
3.4. Hyperparameter Setting
4. Evaluation of Prediction Results
4.1. Prediction Accuracy Index
- Root mean squared error (RMSE)
- 2.
- Mean absolute error (MAE)
- 3.
- Mean absolute percentage error (MAPE)
- 4.
- Nash–Sutcliffe efficiency coefficient (NSE)
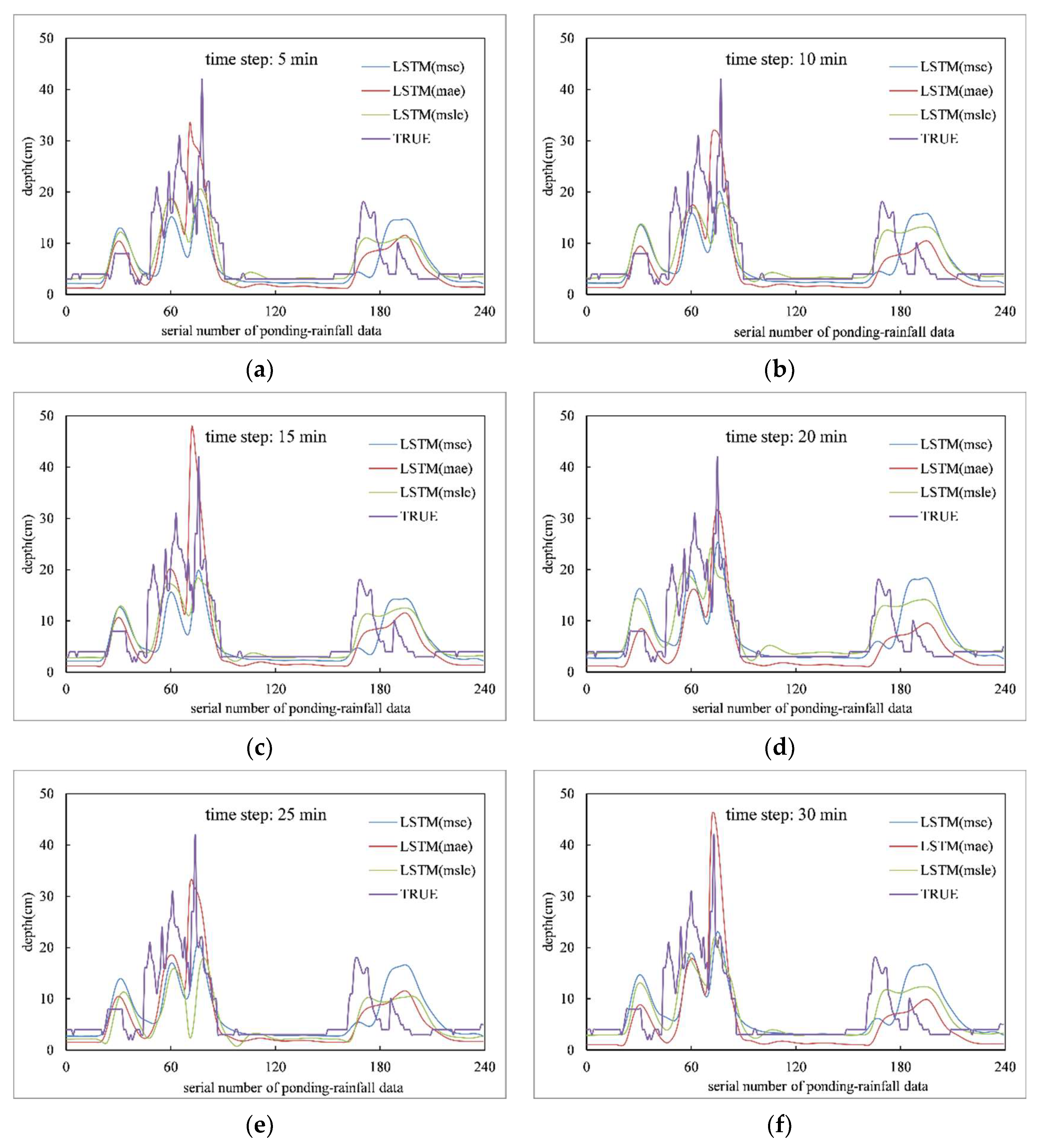
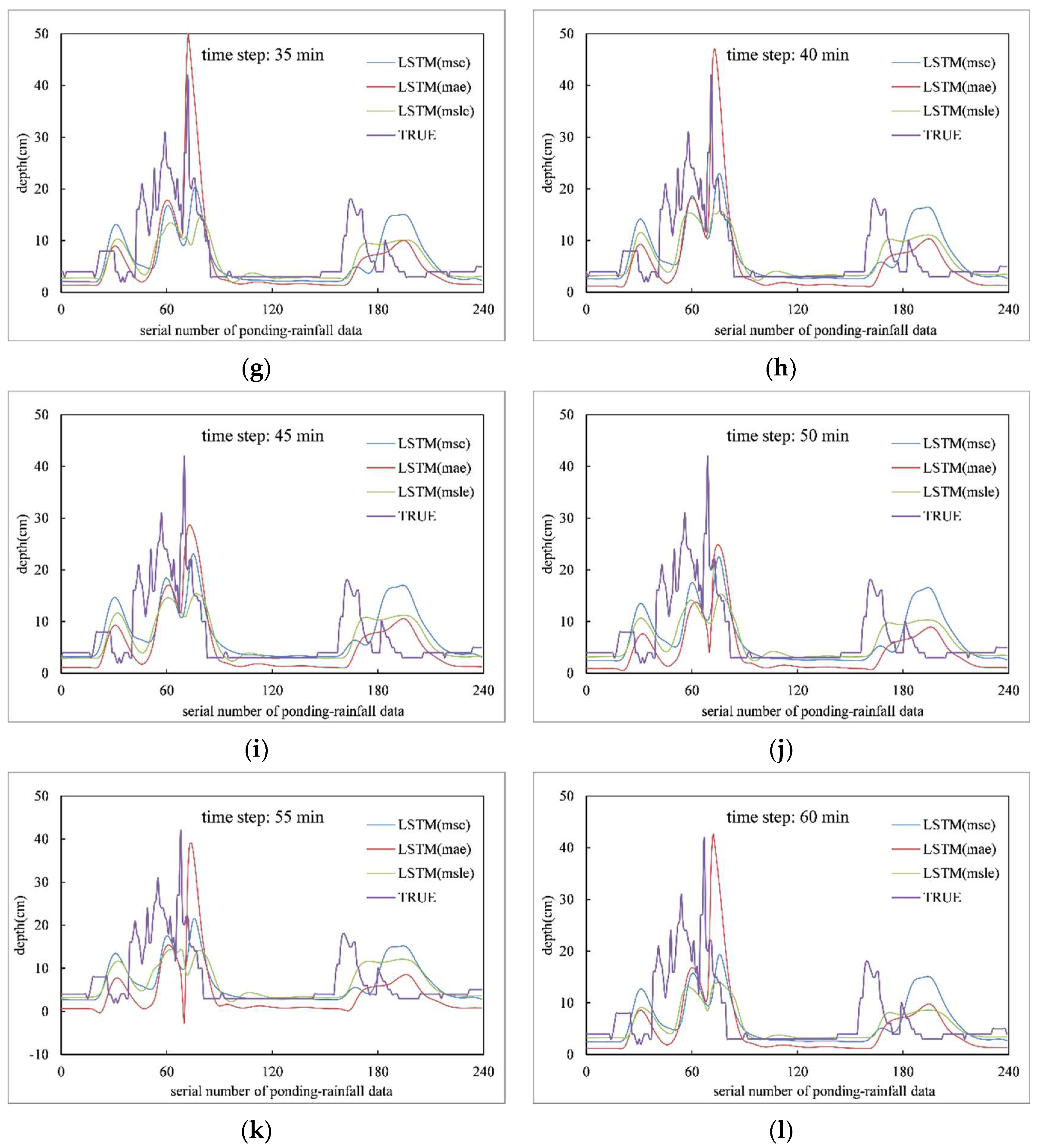
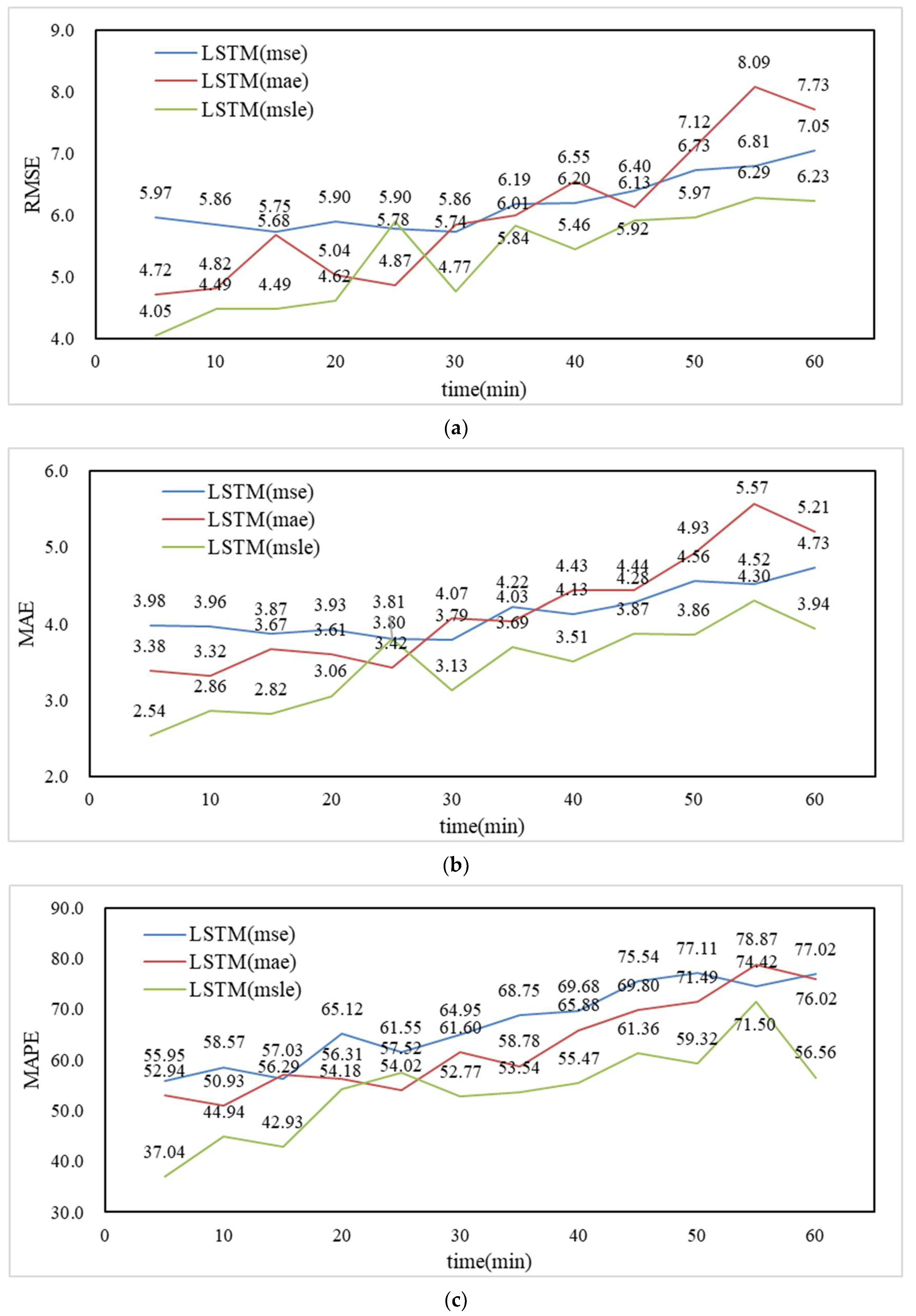
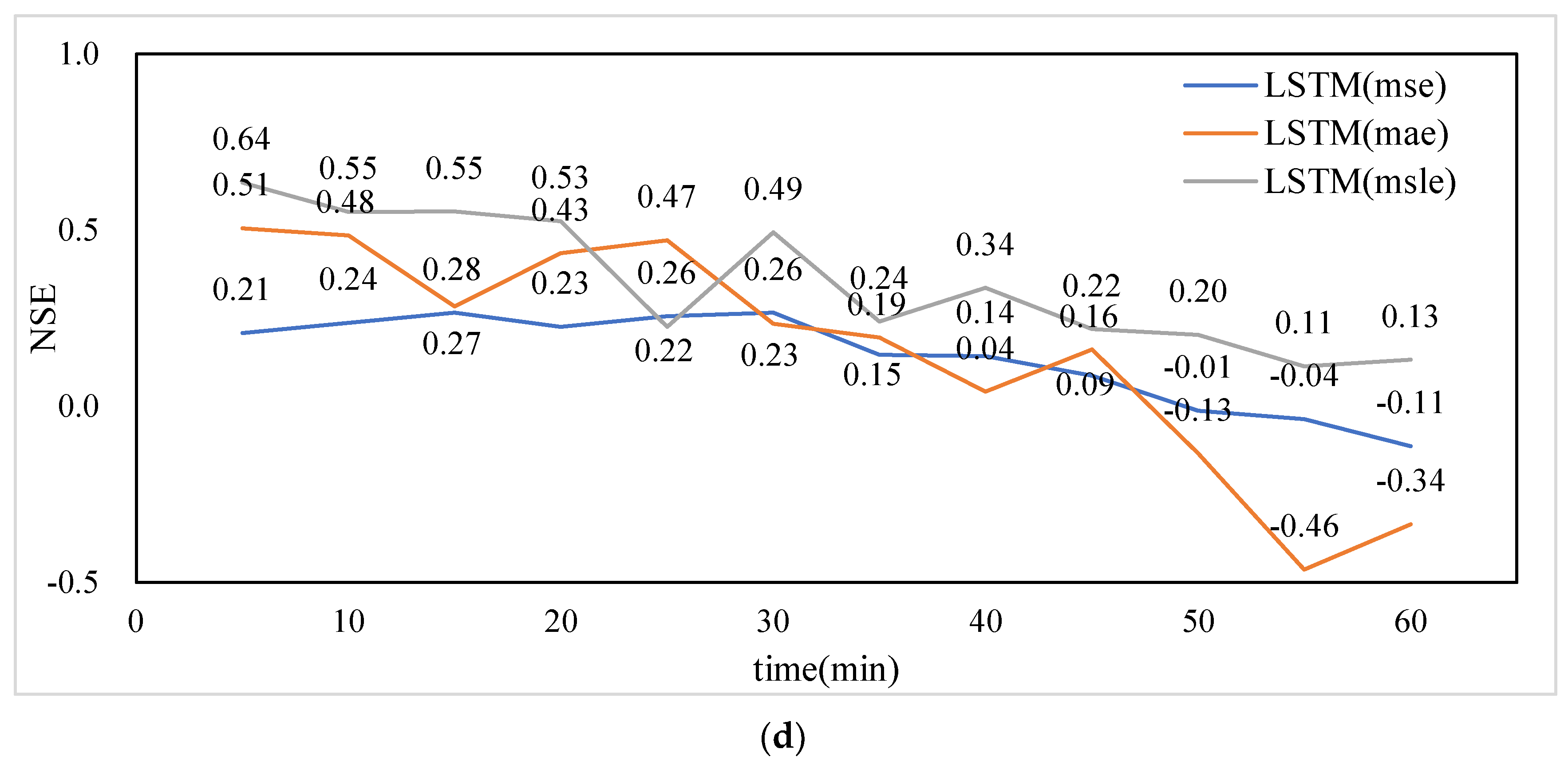
4.2. Analysis of Prediction Results
5. Conclusions
- The LSTM fully exploits the nonlinear relationship between the rainfall data of each rainfall station and the ponding data of individual ponding survey points, and has a good multi-step prediction effect on the future ponding process.
- With the increase of time step, the prediction accuracy of each model decreases to different degrees, and 0–40 min in the future is the time range to achieve better prediction effect.
- The model trained with MSLE as the loss function has high prediction accuracy, but the prediction effect is not good in extreme or special conditions, while the model trained with MAE as the loss function can better predict the excessive ponding depth in special conditions.
- The limitation of our study lies in the fact that the number of positive samples in the data set is relatively small. In future research, we will set about extending the scale of the data set to build a predictive model with better performance. Meanwhile, we will consider other deep learning models, such as convolutional neural networks (CNNs), to improve the prediction of urban flood waterlogging depth.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eduardo, A.A.; Felipe, F.B.; Reinaldo, J.M. A meta-heuristic based on simulated annealing for solving multiple-objective problems in simulation optimization. In Proceedings of the 2004 Winter Simulation Conference, Washington, DC, USA, 5–8 December 2004; pp. 508–513. [Google Scholar]
- Zhongrun, X.; Jun, Y.; Ibrahim, D. A Rainfall-Runoff Model With LSTM-Based Sequence-to-Sequence Learning. Water Resour. Res. 2020, 56, e2019WR025326. [Google Scholar]
- Zou, Q.; Xiong, Q.; Li, Q.; Yi, H.; Yu, Y.; Wu, C. A water quality prediction method based on the multi-time scale bidirectional long short-term memory network. Environ. Sci. Pollut. Res. Int. 2020, 27, 16853–16864. [Google Scholar] [CrossRef] [PubMed]
- Tamiru, H.; Dinka, M.O. Application of ANN and HEC-RAS model for flood inundation mapping in lower Baro Akobo River Basin, Ethiopia. J. Hydrol. Reg. Stud. 2021, 36, 100855. [Google Scholar] [CrossRef]
- Li, J.; Zhu, D.; Li, C. Comparative analysis of BPNN, SVR, LSTM, Random Forest, and LSTM-SVR for conditional simulation of non-Gaussian measured fluctuating wind pressures. Mech. Syst. Signal Process. 2022, 178, 109285. [Google Scholar] [CrossRef]
- Yuhyeok, J.; Kyunghan, M.; Donghyuk, J.; Myoungho, S.; Manbae, H. Comparative study of the artificial neural network with three hyper-parameter optimization methods for the precise LP-EGR estimation using in-cylinder pressure in a turbocharged GDI engine. Appl. Therm. Eng. 2018, 149, 1324–1334. [Google Scholar]
- Dimitri, P.S.; Avi, O. Data-driven modelling: Some past experiences and new approaches. J. Hydroinform. 2008, 10, 3–22. [Google Scholar]
- Chen, Y.; Liu, T.; Ge, Y.; Xia, S.; Yuan, Y.; Li, W.; Xu, H. Examining social vulnerability to flood of affordable housing communities in Nanjing, China: Building long-term disaster resilience of low-income communities. Sustain. Cities Soc. 2021, 71, 102939. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1542. [Google Scholar] [CrossRef]
- Kumar, D.; Singh, A.; Samui, P.; Jha, R.K. Forecasting monthly precipitation using sequential modelling. Hydrol. Sci. J. 2019, 64, 690–700. [Google Scholar] [CrossRef]
- Alipour, A.; Jafarzadegan, K.; Moradkhani, H. Global sensitivity analysis in hydrodynamic modeling and flood inundation mapping. Environ. Model. Softw. 2022, 152, 105398–105412. [Google Scholar] [CrossRef]
- Wei, L.; Amin, K.; Clint, D. High temporal resolution rainfall–runoff modeling using long-short-term-memory (LSTM) networks. Neural Comput. Appl. 2020, 33, 1261–1278. [Google Scholar]
- Nguyen, T.H.T.; Phan, Q.B. Hourly day ahead wind speed forecasting based on a hybrid model of EEMD, CNN-Bi-LSTM embedded with GA optimization. Energy Rep. 2022, 8, 53–60. [Google Scholar] [CrossRef]
- Alberto, D.L.F.; Viviana, M.; Carolina, M. Hydrological Early Warning System Based on a Deep Learning Runoff Model Coupled with a Meteorological Forecast. Water-Sui. 2019, 11, 1808. [Google Scholar]
- Chen, L.; Li, H.Q.; Lei, M.J.; Du, Q.Y. Dongting Lake water level forecast and its relationship with the Three Gorges Dam based on a long short-term memory network. Water 2018, 10, 1389. [Google Scholar]
- Surdiani, Y.; Riewansyah, I.; Arustini, H. Long short term memory (LSTM) recurrent neural network (RNN) for discharge level prediction and forecast in Cimandiri river, Indonesia. IOP Conf. Ser. Earth Environ. Sci. 2019, 299, 1. [Google Scholar]
- Hrnjica, B.; Bonacci, O. Lake level prediction using feed forward and recurrent neural networks. Water Resour. Manag. 2019, 33, 2471. [Google Scholar] [CrossRef]
- Miao, Q.; Pan, B.; Wang, H.; Hsu, K.; Sorooshian, S. Improving monsoon precipitation prediction using combined convolutional and long short term memory neural network. Water 2019, 11, 977. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–runoff modelling using long short-term memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef]
- Xiaohui, Y.; Chen, C.; Xiaohui, L.; Yanbin, Y.; Rana, M.A. Monthly runoff forecasting based on LSTM–ALO model. Stoch. Environ. Res. Risk Assess. 2018, 32, 2199–2212. [Google Scholar]
- Zhang, D.; Lindholm, G.; RAtnaweera, H. Use long short-term memory to enhance Internet of Things for combined sewer overflow monitoring. J. Hydrol. 2018, 556, 409–418. [Google Scholar] [CrossRef]
- Hu, C.; Wu, Q.; Li, H.; Jian, S.; Li, N.; Lou, Z. Deep learning with a long short-term memory networks approach for rainfallrunoff simulation. Water 2018, 10, 1543. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, X.; Yin, L. Research on image classification method based on improved multi-scale relational network. PeerJ Comput. Sci. 2021, 7, e613. [Google Scholar] [CrossRef] [PubMed]
- Chang, T.; Yu, H.; Wang, C.; Chen, A.S. Overland-gully-sewer (2D-1D-1D) urban inundation modeling based on cellular automata framework. J. Hydrol. 2021, 603, 1027001–1027016. [Google Scholar] [CrossRef]
- Liu, B.; Wang, R.; Zhao, G.; Guo, X. Prediction of rock mass parameters in the TBM tunnel based on BP neural network integrated simulated annealing algorithm. Tunn. Undergr. Space Technol. Inc. Trenchless Technol. Res. 2020, 95, 103103–103114. [Google Scholar] [CrossRef]
- Baek, S.; Pyo, J.; Chun, J.A. Prediction of Water Level and Water Quality Using a CNN-LSTM Combined Deep Learning Approach. Water 2020, 12, 3399–3411. [Google Scholar] [CrossRef]
- Tambe, P.P. Selective Maintenance Optimization of a Multi-component System based on Simulated Annealing Algorithm. Procedia Comput. Sci. 2022, 200, 1412–1421. [Google Scholar] [CrossRef]
- Shuai, G.; Yuefei, H.; Shuo, Z.; Jingcheng, H.; Guangqian, W.; Meixin, Z.; Qingsheng, L. Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation. J. Hydrol. 2020, 589, 125188–125198. [Google Scholar]
- Wang, P.; Li, Y.; Yu, P.; Zhang, Y. The analysis of urban flood risk propagation based on the modified susceptible infected recovered model. J. Hydrol. 2021, 603, 127121–127136. [Google Scholar] [CrossRef]
- Wu, X.; Liu, Z.; Yin, L.; Zheng, W.; Song, L.; Tian, J.; Yang, B.; Liu, S. A Haze Prediction Model in Chengdu Based on LSTM. Atmosphere 2021, 12, 1479. [Google Scholar] [CrossRef]
- Wenjun, W.; Junli, L.; Zongyi, H.; Xinxin, Y.; Jie, Z.; Xiu, C.; Hongjiao, Q. Tracking spatio-temporal variation of geo-tagged topics with social media in China: A case study of 2016 hefei rainstorm. Int. J. Disaster Risk Reduct. 2020, 50, 101737–101752. [Google Scholar]
- Lei, X.; Chen, W.; Panahi, M.; Falah, F.; Rahmati, O.; Uuemaa, E.; Kalantari, Z.; Ferreira, C.S.S.; Rezaie, F.; Tiefenbacher, J.P.; et al. Urban flood modeling using deep-learning approaches in Seoul, South Korea. J. Hydrol. 2021, 601, 126684–126696. [Google Scholar] [CrossRef]
- Peng, J.; Zhang, J. Urban flooding risk assessment based on GIS- game theory combination weight: A case study of Zhengzhou City. Int. J. Disaster Risk Reduct. 2022, 77, 103080–103092. [Google Scholar] [CrossRef]
- Bo, W.; Becky, P.Y.L.; Feng, Z.; Guangliang, X. Urban resilience from the lens of social media data: Responses to urban flooding in Nanjing, China. Cities 2020, 106, 102884–102896. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | LSTM (msle) vs. LSTM (mse) | LSTM (msle) vs. LSTM (mae) | LSTM (mse) vs. LSTM (mae) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | MAPE (%) | NSE | RMSE | MAE | MAPE (%) | NSE | RMSE | MAE | MAPE (%) | NSE | |
| 5 min | −1.92 | −1.43 | −18.91 | 0.43 | −0.67 | −0.84 | −15.90 | 0.13 | 1.25 | 0.59 | 3.01 | −0.30 |
| 10 min | −1.37 | −1.10 | −13.64 | 0.31 | −0.32 | −0.46 | −5.99 | 0.07 | 1.04 | 0.64 | 7.64 | −0.25 |
| 15 min | −1.26 | −1.06 | −13.36 | 0.29 | −1.19 | −0.85 | −14.11 | 0.27 | 0.06 | 0.20 | −0.75 | −0.02 |
| 20 min | −1.28 | −0.87 | −10.95 | 0.30 | −0.42 | −0.55 | −2.13 | 0.09 | 0.86 | 0.32 | 8.82 | −0.21 |
| 25 min | 0.12 | 0.01 | −4.03 | −0.03 | 1.03 | 0.39 | 3.50 | −0.25 | 0.91 | 0.38 | 7.52 | −0.22 |
| 30 min | −0.97 | −0.66 | −12.18 | 0.23 | −1.09 | −0.94 | −8.84 | 0.26 | −0.12 | −0.28 | 3.34 | 0.03 |
| 5–30 min average | −1.11 | −0.85 | −12.18 | 0.25 | −0.45 | −0.54 | −7.25 | 0.10 | 0.67 | 0.31 | 4.93 | −0.16 |
| 35 min | −0.35 | −0.53 | −15.21 | 0.09 | −0.17 | −0.34 | −5.24 | 0.05 | 0.18 | 0.19 | 9.97 | −0.05 |
| 40 min | −0.74 | −0.62 | −14.20 | 0.19 | −1.10 | −0.92 | −10.41 | 0.29 | −0.35 | −0.30 | 3.79 | 0.10 |
| 45 min | −0.48 | −0.41 | −14.18 | 0.13 | −0.21 | −0.57 | −8.43 | 0.06 | 0.27 | −0.16 | 5.74 | −0.07 |
| 50 min | −0.76 | −0.70 | −17.79 | 0.22 | −1.15 | −1.07 | −12.17 | 0.34 | −0.39 | −0.37 | 5.62 | 0.12 |
| 55 min | −0.51 | −0.21 | −2.92 | 0.15 | −1.79 | −1.26 | −7.37 | 0.58 | −1.28 | −1.05 | −4.45 | 0.43 |
| 60 min | −0.82 | −0.79 | −20.46 | 0.24 | −1.49 | −1.27 | −19.46 | 0.47 | −0.67 | −0.48 | 1.00 | 0.22 |
| 35–60 min average | −0.61 | −0.54 | −14.13 | 0.17 | −0.99 | −0.91 | −10.51 | 0.30 | −0.38 | −0.36 | 3.61 | 0.12 |
| full time average | −0.86 | −0.70 | −13.15 | 0.21 | −0.72 | −0.72 | −8.88 | 0.20 | 0.15 | −0.03 | 4.27 | −0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhang, W.; Yan, Y.; Li, Z.; Xia, Y.; Song, S. An Effective Rainfall–Ponding Multi-Step Prediction Model Based on LSTM for Urban Waterlogging Points. Appl. Sci. 2022, 12, 12334. https://doi.org/10.3390/app122312334
Liu Y, Zhang W, Yan Y, Li Z, Xia Y, Song S. An Effective Rainfall–Ponding Multi-Step Prediction Model Based on LSTM for Urban Waterlogging Points. Applied Sciences. 2022; 12(23):12334. https://doi.org/10.3390/app122312334
Chicago/Turabian StyleLiu, Yongzhi, Wenting Zhang, Ying Yan, Zhixuan Li, Yulin Xia, and Shuhong Song. 2022. "An Effective Rainfall–Ponding Multi-Step Prediction Model Based on LSTM for Urban Waterlogging Points" Applied Sciences 12, no. 23: 12334. https://doi.org/10.3390/app122312334
APA StyleLiu, Y., Zhang, W., Yan, Y., Li, Z., Xia, Y., & Song, S. (2022). An Effective Rainfall–Ponding Multi-Step Prediction Model Based on LSTM for Urban Waterlogging Points. Applied Sciences, 12(23), 12334. https://doi.org/10.3390/app122312334