

A Heterogeneous Machine Learning Ensemble Framework for Malicious Webpage Detection

Abstract
1. Introduction
- To propose an advanced machine learning model that can detect and predict the distribution of malicious codes based on URLs and web content without network data analysis.
- To predict the risk of distribution by detecting malicious code distribution websites to predict cyber threats in advance, rather than simple malicious web detection.
- Defining an advanced feature set based on URL and web content and including the most optimized detection model structure.
- Providing an improved malicious web detection framework with high accuracy through ensemble techniques based on six different machine learning sub-models.
- Providing the performance comparison results of various machine learning models for malicious web detection.
- Providing an automated technology for the detection of malicious webpage such as phishing, malicious code distribution, and via the web in the cyber security field.
- Reducing cyber security damage by predicting the location of malicious code distribution in advance.
2. Related Work
2.1. Heuristic-Based Malicious Website Detection
2.2. Machine Learning-Based Malicious Website Detection
2.3. Malicious Code Distribution Pattern Detection
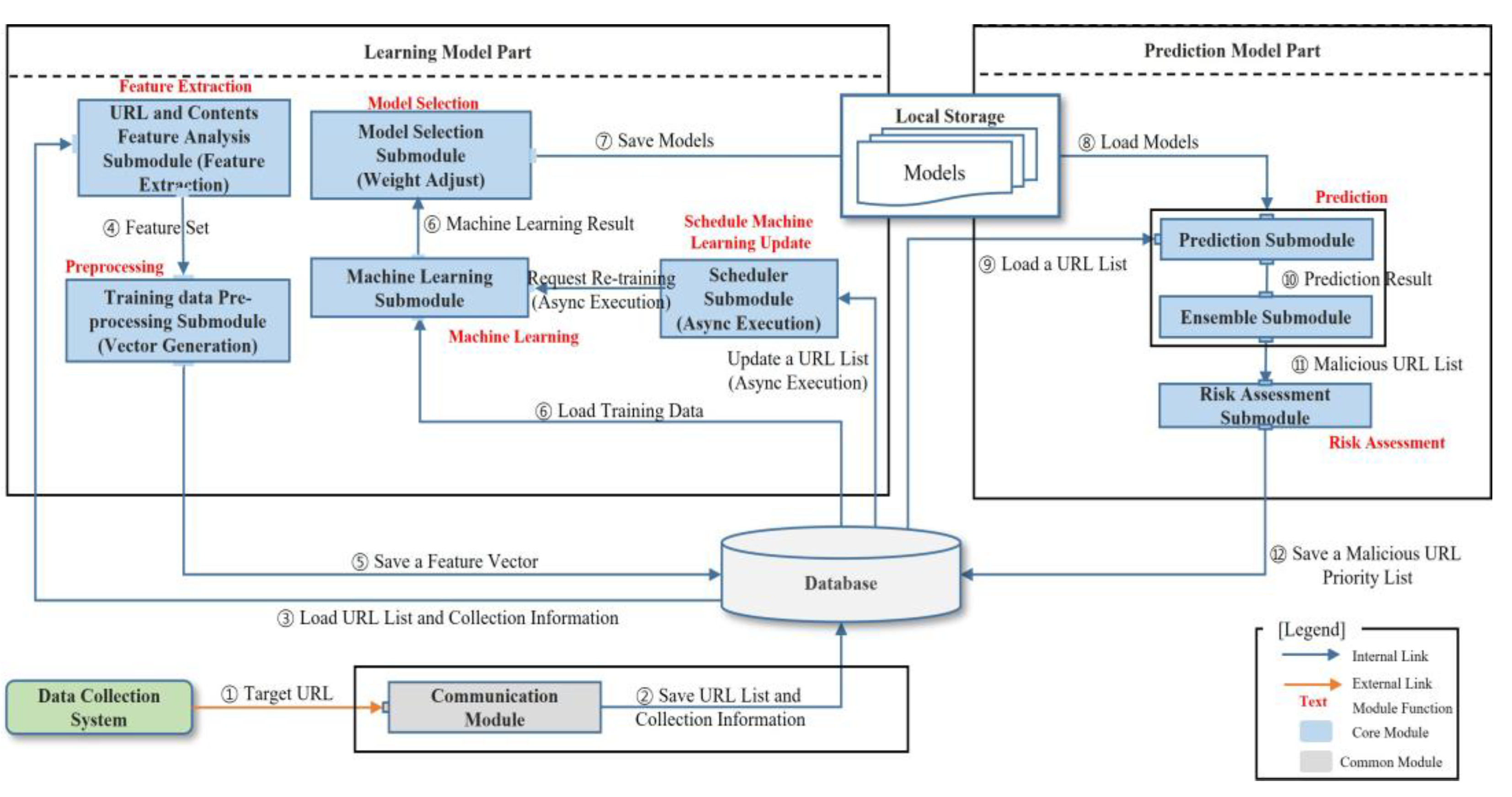
3. Malicious Code Distribution Automation Prediction System (MCDWDS)
3.1. Applying Machine Learning Algorithm for MCDWDS
3.2. Extraction and Pre-Processing of Malicious Code Distribution Web Features
3.3. Machine Learning Model Selection in MCDWDS
- Input a machine learning model generated from the updated learning data;
- Conduct a performance validation of each model and create a ‘Model Information,’ which covers both validation results and performance data;
- Load a ‘Model Information’ of the previously used models;
- Replace the existing models with better models by comparing the previous and updated models.
3.4. Sub-Model Prediction Process
3.5. Ensemble Machine Learning Prediction Results Analysis
- ①
- Input the prediction results for each model.
- ②
- Dynamically calculate weights (model reliability) using the performance values of each model.
- ③
- Calculate the ensemble result of soft voting (using the weighted average) with the weights and performance values of each model.
- ④
4. Experiment and Result
4.1. Dataset
4.2. Classification Results by Machine Learning Models
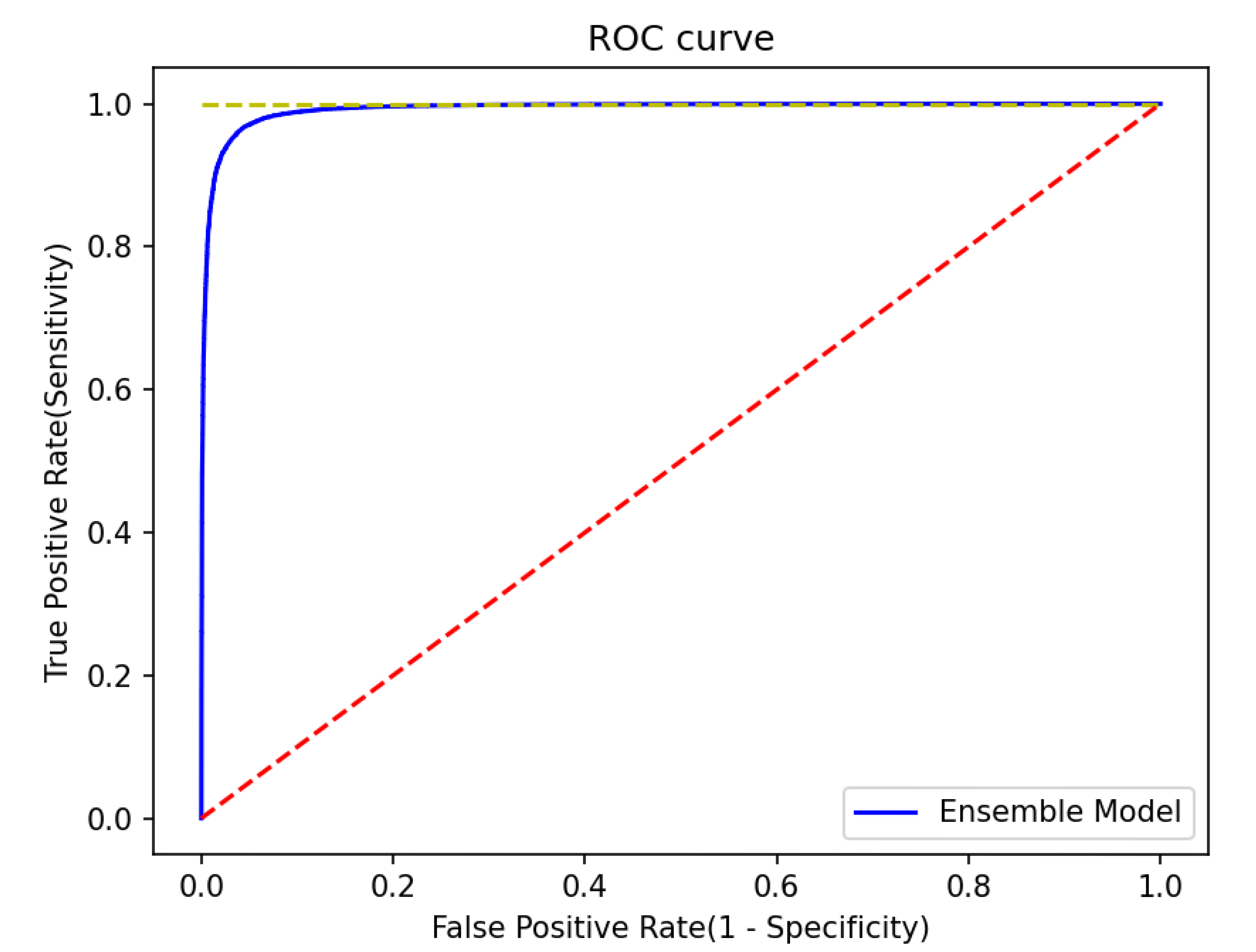
4.3. Prediction Accuracy of the Ensemble Technique
4.4. Validation of Malicious Website Classifications
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kang, H.K.; Shin, S.S.; Kim, D.Y.; Park, S.T. Design and Implementation of Malicious URL Prediction System based on Multiple Machine Learning Algorithms. J. Korea Multimed. Soc. 2020, 23, 1396–1405. [Google Scholar] [CrossRef]
- Le, H.; Pham, Q.; Sahoo, D.; Hoi, S.C.H. URLNet: Learning a URL Representation with Deep Learning for Malicious URL Detection. arXiv preprint 2018, arXiv:1802.03162. [Google Scholar] [CrossRef]
- Patil, D.R.; Patil, J.B. Survey on Malicious Web Pages Detection Techniques. Int. J. u-e-Serv. Sci. Technol. 2015, 8, 195–206. [Google Scholar] [CrossRef]
- Baykara, M.; Gürel, Z.Z. Detection of Phishing Attacks. In Proceedings of the 2018 6th International Symposium on Digital Forensic and Security (ISDFS), Antalya, Turkey, 22–25 March 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Cova, M.; Kruegel, C.; Vigna, G. Detection and Analysis of Drive-by-Download Attacks and Malicious JavaScript Code. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 281–290. [Google Scholar] [CrossRef]
- Singhal, S.; Chawla, U.; Shorey, R. Machine Learning & Concept Drift Based Approach for Malicious Website Detection. In Proceedings of the 2020 International Conference on Communication Systems & Networks (COMSNETS), Bengaluru, India, 7–11 January 2020; pp. 582–585. [Google Scholar] [CrossRef]
- Bhoj, N.; Tripathi, A.; Bisht, G.S.; Dwivedi, A.R.; Pandey, B.; Chhimwal, N. Comparative Analysis of Feature Selection Techniques for Malicious Website Detection in SMOTE Balanced Data. RS Open J. Innov. Commun. Technol. 2021, 2, 1–10. [Google Scholar] [CrossRef]
- Chaiban, A.; Sovilj, D.; Soliman, H.; Salmon, G.; Lin, X. Investigating the Influence of Feature Sources for Malicious Website Detection. Appl. Sci. 2022, 12, 2806. [Google Scholar] [CrossRef]
- Altay, B.; Dokeroglu, T.; Cosar, A. Context-Sensitive and Keyword Density-Based Supervised Machine Learning Techniques for Malicious Webpage Detection. Soft Comput. 2019, 23, 4177–4191. [Google Scholar] [CrossRef]
- Zhuang, W.; Jiang, Q.; Xiong, T. An intelligent anti-phishing strategy model for phishing website detection. In Proceedings of the 2012 32nd International Conference on Distributed Computing Systems Workshops, Macau, China, 18–21 June 2012. [Google Scholar] [CrossRef]
- Invernizzi, L.; Miskovic, S.; Torres, R.; Saha, S.; Lee, S.-J.; Mellia, M.; Kruegel, C.; Vigna, G. Nazca: Detecting Malware Distribution in Large-Scale Networks. NDSS 2014, 14, 23–26. [Google Scholar] [CrossRef]
- Eshete, B.; Kessler, F.B. Effective Analysis, Characterization, and Detection of Malicious Web Pages. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 355–359. [Google Scholar] [CrossRef]
- Tretyakov, K. Machine Learning Techniques in Spam Filtering. In Data Mining Problem-Oriented Seminar; MTAT: Beauvallon, France, 2004; pp. 60–79. Available online: https://courses.cs.ut.ee/2004/dm-seminarspring/uploads/Main/P06.pdf (accessed on 16 January 2022).
- Knuth, D.E. Postscript about NP-hard problems. ACM SIGACT News. 1974, 6, 15–16. [Google Scholar] [CrossRef]
- Beheshti, Z.; Shamsuddin, S.M. A review of population-based meta-heuristic algorithms. Int. J. Adv. Soft Comput. Appl 2013, 5, 1–35. [Google Scholar]
- Aljabri, M.; Alhaidari, F.; Mohammad, R.M.A.; Samiha, M.; Alhamed, D.H.; Altamimi, H.S.; Chrouf, S.M.B. An Assessment of Lexical, Network, and Content-Based Features for Detecting Malicious URLs Using Machine Learning and Deep Learning Models. Comput. Intell. Neurosci. 2022, 2022, 3241216. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.-H.; Yu, L.; Tian, S.-W.; Peng, Y.-F.; Pei, X.-J. Bidirectional LSTM Malicious Webpages Detection Algorithm Based on Convolutional Neural Network and Independent Recurrent Neural Network. Appl. Intell. 2019, 49, 3016–3026. [Google Scholar] [CrossRef]
- Ozker, U.; Sahingoz, O.K. Content Based Phishing Detection with Machine Learning. In Proceedings of the 2020 International Conference on Electrical Engineering (ICEE), Istanbul, Turkey, 25–27 September 2020; pp. 27–32. [Google Scholar] [CrossRef]
- Chatterjee, M.; Namin, A.S. Detecting Phishing Websites through Deep Reinforcement Learning. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; Volume 2, pp. 227–232. [Google Scholar] [CrossRef]
- Vara, K.D.; Dimble, V.S.; Yadav, M.M.; Thorat, A.A. Based on URL Feature Extraction Identify Malicious Website Using Machine Learning Techniques. Int. Res. J. Innov. Eng. Technol. 2022, 6, 144–148. [Google Scholar] [CrossRef]
- Choi, S.Y.; Lim, C.G.; Kim, Y.M. Automated Link Tracing for Classification of Malicious Websites in Malware Distribution Networks. J. Inf. Process. Syst. 2019, 15, 100–115. [Google Scholar] [CrossRef]
- Wang, G.; Stokes, J.W.; Herley, C.; Felstead, D. Detecting Malicious Landing Pages in Malware Distribution Networks. In Proceedings of the 2013 43rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Budapest, Hungary, 24–27 June 2013. [Google Scholar] [CrossRef]
- Salami, H.O.; Ibrahim, R.S.; Yahaya, M.O. Detecting Anomalies in Students' Results Using Decision Trees. Int. J. Mod. Educ. Comput. Sci. 2016, 8, 31–40. [Google Scholar] [CrossRef]
- Desai, A.; Jatakia, J.; Naik, R.; Raul, N. Malicious Web Content Detection Using Machine Leaning. In Proceedings of the 2017 2nd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 19–20 May 2017; pp. 1432–1436. [Google Scholar] [CrossRef]
- Chiramdasu, R.; Srivastava, G.; Bhattacharya, S.; Reddy, P.K.; Reddy Gadekallu, T. Malicious Url Detection Using Logistic Regression. In Proceedings of the 2021 IEEE International Conference on Omni-Layer Intelligent Systems (COINS), Barcelona, Spain, 23–25 August 2021; Volume 2021, pp. 11–16. [Google Scholar] [CrossRef]
- Mokbal, F.M.M.; Dan, W.; Xiaoxi, W.; Wenbin, Z.; Lihua, F. XGBXSS: An Extreme Gradient Boosting Detection Framework for Cross-Site Scripting Attacks Based on Hybrid Feature Selection Approach and Parameters Optimization. J. Inf. Secur. Appl. 2021, 58, 102813. [Google Scholar] [CrossRef]
- Brintha, N.C.; Preethi, C.; Winowlin Jappes, J.T. Exploring Malicious Webpages Using Machine Learning Concept. In Proceedings of the 2021 2nd International Conference for Emerging Technology (INCET), Belagavi, India, 21–23 May 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support vector machine versus random forest for remote sensing image classification: A meta-analysis and systematic review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Akusok, A.; Bjork, K.-M.; Miche, Y.; Lendasse, A. High-Performance Extreme Learning Machines: A Complete toolbox for Big Data Applications. IEEE Access 2015, 3, 1011–1025. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3149–3157. Available online: https://dl.acm.org/doi/10.5555/3294996.3295074 (accessed on 16 January 2022).
- Shamshirband, S.; Chronopoulos, A.T. A new malware detection system using a high performance-ELM method. In Proceedings of the 23rd International Database Applications & Engineering Symposium, Athens, Greece, 10–12 June 2019; pp. 1–10. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | No. | Feature | Description |
|---|---|---|---|
| Lexical-based feature | 1 | IP | • IP address is included in the hostname. |
| 2 | URL Length | • URL length exceeds a given number of characters. | |
| 3 | Short URL | • A long link is reduced to a Short URL. | |
| 4 | HTML Length | • HTML text length. | |
| 5 | @ | • A ‘@’ symbol is included in the URL. | |
| 6 | // | • A URL redirection occurs due to ‘//.’ | |
| 7 | (_), (-) | • A domain name includes symbols such as (_) or (-) that are not recommended by the naming rules. | |
| 8 | HTTPS | • Whether a HTTPS security protocol is used or not. | |
| 9 | Unnecessary Ports | • An ordinary web server uses Port 80 (HTTP) and Port 443 (HTTPS) only. | |
| 10 | HTTPS script in URL | • HTTPS script is included in the sub-domain/domain name. | |
| 11 | HTTPS Validity | • HTTPS certificate validity period is over within a year. | |
| Malicious feature | 12 | Request URL | • Videos, images, and CSS files are loaded from the external URLs. |
| 13 | Window Pop Tag | • Whether a window pop-up command is included. | |
| 14 | Anchor Tag Ratio | • Check a ratio of anchor tags <a href>. Whether a website is linked to another domain. | |
| 15 | HTML Tag Configuration | • Check a ratio of <Meta>, <Script>, and <Link> tags in HTML source code. | |
| 16 | Server Form Handler | • A webpage sending data to a server is an external URL or an ‘about:blank’ page. | |
| 17 | Email Tag | • Whether a “mailto:” tag is functioning. | |
| 18 | WHOIS Lookup | • WHOIS domain is not included in the URL. | |
| 19 | <script> Tag | • Check a ratio of the ‘src’ attribute allowed to link to scripts from an external domain. | |
| HTML/JS-based feature | 20 | Number of Forwarding | • Number of redirects to different URLs. |
| 21 | onMouseOver Script | • Whether a onMouseOver script is included in Javascript. | |
| 22 | Disabled Mouse Right Click | • Whether a “event.button == 2” script is used. | |
| 23 | Pop-up Window | • Whether a pop-up window has a ‘text field’ for data input. | |
| 24 | iFrame | • Whether iframe/frameBorder tag and attribute are used. | |
| Domain-based feature | 25 | Domain Registration Period | • Check the expiration date of a domain using WHOIS DB. • Longer than 6 months is normal but less than 6 months is suspicious. |
| 26 | SSL certificate registration period | • Check the expiration date of an SSL certificate. |
| Type | Dataset | Learning (80%) | Validation (20%) |
|---|---|---|---|
| Malicious URL | 57,504 | 91,996 | 23,000 |
| Benign URL | 57,492 | ||
| Total | 114,996 | 114,996 | |
| Model | Precision | Recall | F1-Score | G-Mean | Accuracy |
|---|---|---|---|---|---|
| Support Vector Machine | 0.6096 | 0.6095 | 0.6093 | 0.60 | 0.61 |
| Decision Tree | 0.9162 | 0.9162 | 0.9161 | 0.91 | 0.91 |
| Random Forest | 0.9511 | 0.951 | 0.951 | 0.95 | 0.95 |
| XGBoost | 0.9499 | 0.9498 | 0.9498 | 0.94 | 0.94 |
| Logistic Regression | 0.9337 | 0.9329 | 0.933 | 0.93 | 0.90 |
| 1D-Convolutional Neural Networks | 0.804 | 0.802 | 0.8018 | 0.80 | 0.80 |
| LGBM | 0.9541 | 0.9546 | 0.9543 | 0.95 | 0.95 |
| HP-ELM | 0.6535 | 0.6774 | 0.6653 | 0.65 | 0.65 |
| Average | 0.8465 | 0.8491 | 0.8475 | 0.84 | 0.83 |
| Ensemble Method | Precision | Recall | F1-Score | G-Mean | Accuracy |
|---|---|---|---|---|---|
| Hard Voting | 0.955 | 0.9549 | 0.9573 | 0.9549 | 0.9548 |
| Soft Voting | 0.8286 | 0.8284 | 0.8284 | 0.8285 | 0.8284 |
| Weighted Soft Voting | 0.9686 | 0.9689 | 0.9688 | 0.9687 | 0.9687 |
| Ensemble Method | Precision | Recall | F1-Score | G-Mean | Accuracy |
|---|---|---|---|---|---|
| AdaBoost | 0.9526 | 0.9504 | 0.9516 | 0.9516 | 0.9516 |
| Reputation Score | Benign URL Results | Malicious URL Results | ||
|---|---|---|---|---|
| False Positive | True Positive | True Negative | False Positive | |
| (Malicious) | (Benign) | (Malicious) | (Benign) | |
| 3 | 213 | 9736 | 981 | 321 |
| 4 | 52 | 0 | 124 | 0 |
| 5 | 41 | 0 | 255 | 0 |
| 6 | 13 | 0 | 200 | 0 |
| 7 | 173 | 1296 | 4059 | 172 |
| 8 | 25 | 0 | 282 | 0 |
| 9 | 46 | 0 | 1359 | 0 |
| 10 | 22 | 0 | 1052 | 0 |
| 11 | 26 | 0 | 1526 | 0 |
| 12 | 1 | 0 | 16 | 0 |
| 13 | 7 | 0 | 209 | 0 |
| 14 | 14 | 0 | 630 | 0 |
| 15 | 0 | 0 | 151 | 0 |
| Total | 633 | 11,032 | 10,844 | 493 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, S.-S.; Ji, S.-G.; Hong, S.-S. A Heterogeneous Machine Learning Ensemble Framework for Malicious Webpage Detection. Appl. Sci. 2022, 12, 12070. https://doi.org/10.3390/app122312070
Shin S-S, Ji S-G, Hong S-S. A Heterogeneous Machine Learning Ensemble Framework for Malicious Webpage Detection. Applied Sciences. 2022; 12(23):12070. https://doi.org/10.3390/app122312070
Chicago/Turabian StyleShin, Sam-Shin, Seung-Goo Ji, and Sung-Sam Hong. 2022. "A Heterogeneous Machine Learning Ensemble Framework for Malicious Webpage Detection" Applied Sciences 12, no. 23: 12070. https://doi.org/10.3390/app122312070
APA StyleShin, S.-S., Ji, S.-G., & Hong, S.-S. (2022). A Heterogeneous Machine Learning Ensemble Framework for Malicious Webpage Detection. Applied Sciences, 12(23), 12070. https://doi.org/10.3390/app122312070