

Tool for Parsing Important Data from Web Pages





Abstract
1. Introduction
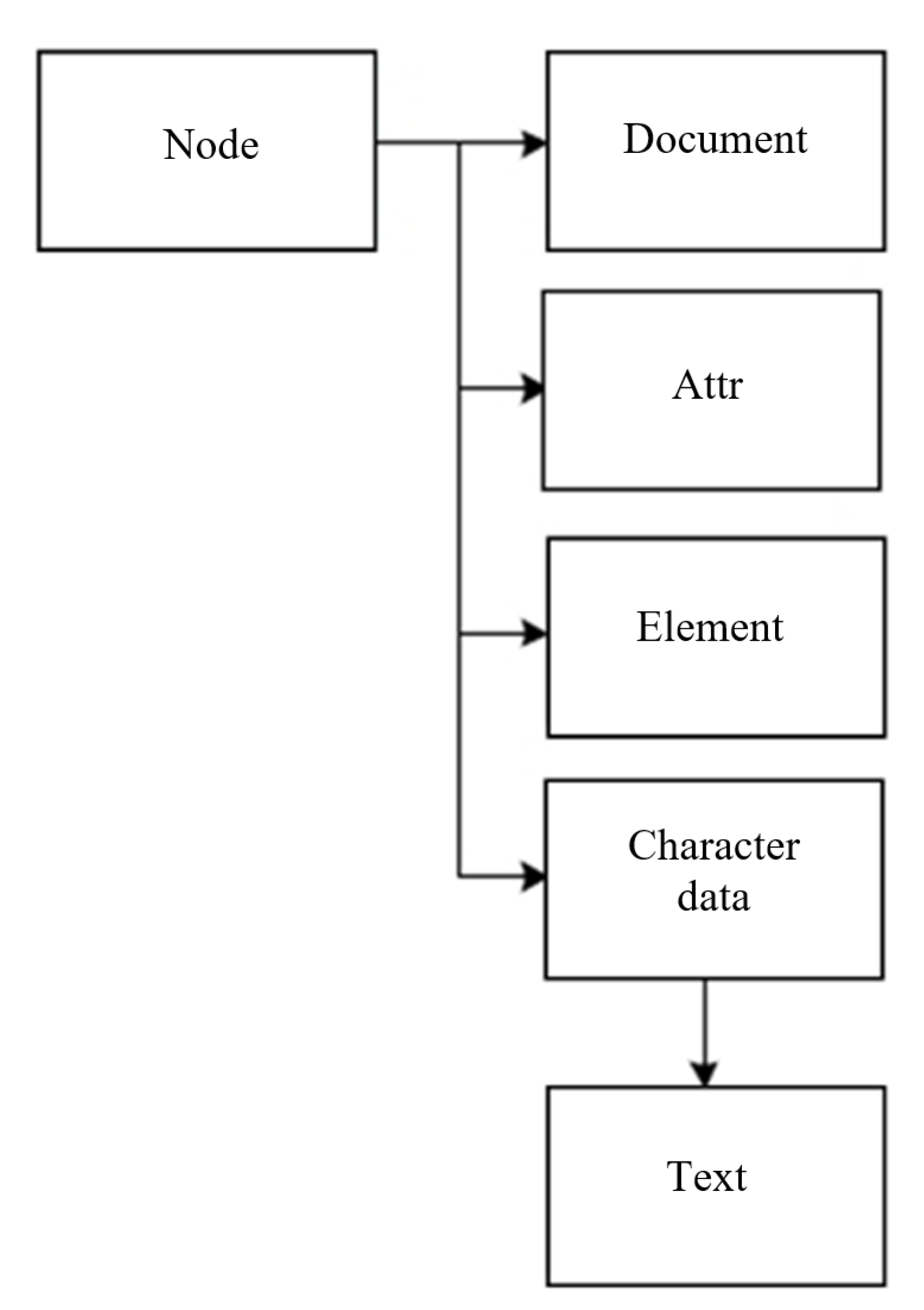
2. Document Object Model
2.1. Markup Language Interface Document Object Model
2.2. DOM Interface Definition
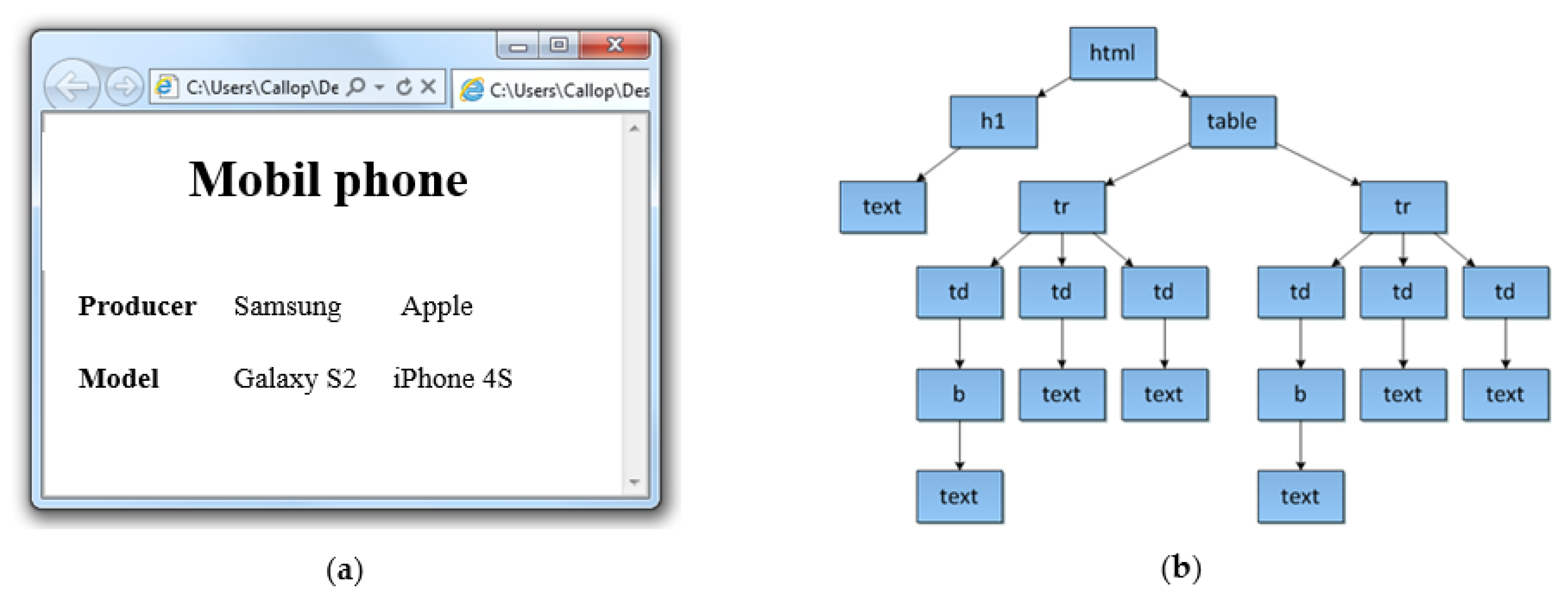
2.3. Document Segmentation Using the DOM
DOM Tree Structure
3. Natural Language Processing
3.1. Understanding Natural Language
- Understanding of thought processes;
- Representation and meaning of language input;
- Knowledge of words.
3.1.1. Phonology and Morphology
- Phonetic rules—for sounds within words;
- Phonemic rules—for variations in pronunciation when words are spoken together;
- Prosodic rules—for fluctuations in strength and intonation throughout the sentence.
3.1.2. Lexicon
3.1.3. Syntax and Semantics
3.1.4. Interview and Purpose
4. Design of an Algorithm for Main Text and Images Extraction from Web Documents
4.1. Combination of DOM and NLP Analysis
4.1.1. Text Extraction
- <div> tag
- <p> tag
- <br> tag
4.1.2. Image Extraction
5. Algorithm for Main Content Extraction from Web Documents
5.1. Identification of the Main Block of the Web Document
- Known element identifier name (e.g., <div id=“main_block”>);
- Character counter;
- Sentence counter.
Image Extraction
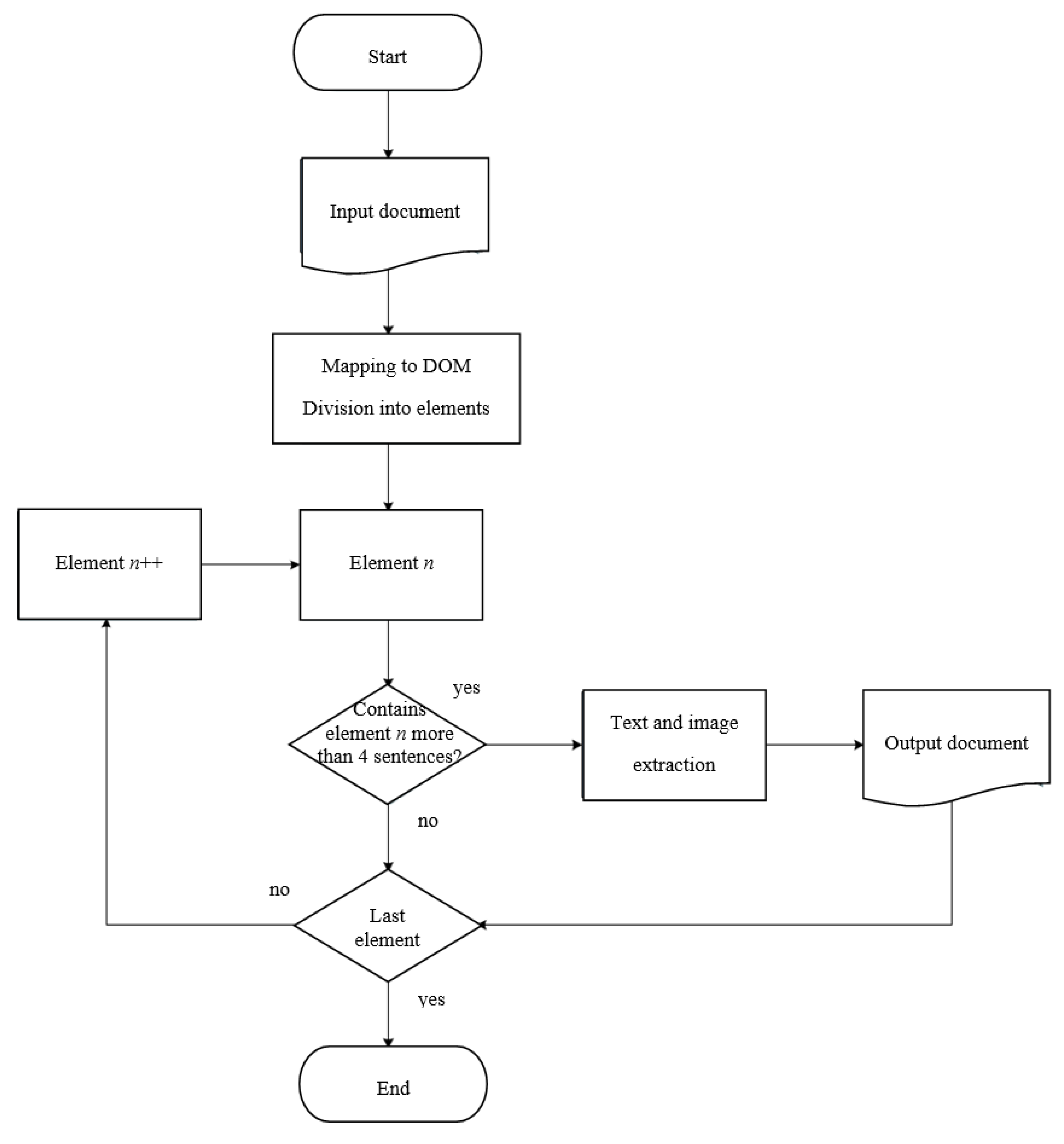
5.2. The Algorithm Proposal
- Loading a document;
- Mapping a document to the DOM;
- Division into elements;
- Scan elements and test them with a specified filter;
- Text and image extraction;
- Save extracted material to external files to verify extraction accuracy.
5.2.1. Loading a Document
- Loading using a URL from external storage;
- Loading from a file on local storage.
5.2.2. Search and Test Elements
- Searching in blocks <div>;
- Extension of the block searching <body>.
5.2.3. Duplication Treatment
5.2.4. Export to External Files
6. Testing of the Algorithm
- Creating a database of web documents;
- Extraction of the main block using an algorithm;
- Analysis of the results.
6.1. Creating a Database of Web Pages
6.2. The Evaluation of the Algorithm
6.3. Comparison of Experimental Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ferrara, E.; De Meo, P.; Fiumara, G.; Baumgartner, R. Web data extraction, applications and techniques: A survey. Knowl.-Based Syst. 2014, 70, 301–323. [Google Scholar] [CrossRef]
- Uzun, E. A Novel Web Scraping Approach Using the Additional Information Obtained from Web Pages. IEEE Access 2020, 8, 61726–61740. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Figueiredo, L.N.L.; de Assis, G.T.; Ferreira, A.A. DERIN: A data extraction method based on rendering information and n-gram. Inf. Process. Manag. 2017, 53, 1120–1138. [Google Scholar] [CrossRef]
- Kushmerick, N. Wrapper Induction for Information Extraction; University of Washington: Seattle, DC, USA, 1997. [Google Scholar]
- Liu, L.; Pu, C.; Han, W. XWRAP: An XML-enabled wrapper construction system for Web information sources. In Proceedings of the 16th International Conference on Data Engineering (Cat. No.00CB37073), San Diego, CA, USA, 29 February–3 March 2000; IEEE Computer Society: Washington, DC, USA, 2000; pp. 611–621. [Google Scholar]
- Das, R.; Turkoglu, I. Creating meaningful data from web logs for improving the impressiveness of a website by using path analysis method. Expert Syst. Appl. 2009, 36, 6635–6644. [Google Scholar] [CrossRef]
- Fazzinga, B.; Flesca, S.; Tagarelli, A. Schema-based Web wrapping. Knowl. Inf. Syst. 2011, 26, 127–173. [Google Scholar] [CrossRef]
- Kao, H.Y.; Lin, S.H.; Ho, J.M.; Chen, M.S. Mining web informative structures and contents based on entropy analysis. IEEE Trans. Knowl. Data Eng. 2004, 16, 41–55. [Google Scholar] [CrossRef]
- Zachariasova, M.; Hudec, R.; Benco, M.; Kamencay, P. Automatic extraction of non-textual information in Web document and their classification. In Proceedings of the 2012 35th International Conference on Telecommunications and Signal Processing (TSP), Prague, Czech Republic, 3–4 July 2012; pp. 753–757. [Google Scholar] [CrossRef]
- Li, Z.; Ng, W.K.; Sun, A. Web data extraction based on structural similarity. Knowl. Inf. Syst. 2005, 8, 438–461. [Google Scholar] [CrossRef]
- Maghdid, H.S. Web News Mining Using New Features: A Comparative Study. IEEE Access 2019, 7, 5626–5641. [Google Scholar] [CrossRef]
- Radilova, M.; Kamencay, P.; Matuska, S.; Benco, M.; Hudec, R. Tool for Optimizing Webpages on a Mobile Phone. In Proceedings of the 2020 43rd International Conference on Telecommunications and Signal Processing (TSP), Milan, Italy, 7–9 July 2020; IEEE: Milan, Italy, 2020; pp. 554–558. [Google Scholar]
- Wood, L. Programming the Web: The W3C DOM specification. IEEE Internet. Comput. 1999, 3, 48–54. [Google Scholar] [CrossRef]
- World Wide Web Consortium. Document Object Model (DOM) Level 1 Specification; World Wide Web Consortium: Cambridge, MA, USA, 1998. [Google Scholar]
- Nadee, W.; Prutsachainimmit, K. Towards data extraction of dynamic content from JavaScript Web applications. In Proceedings of the 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018; pp. 750–754. [Google Scholar] [CrossRef]
- Vineel, G. Web page DOM node characterization and its application to page segmentation. In Proceedings of the IEEE International Conference on Internet Multimedia Services Architecture and Applications (IMSAA), Bangalore, India, 9–11 December 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Luo, J.; Shen, J.; Xie, C. Segmenting the web document with document object model. In Proceedings of the IEEE International Conference on Services Computing (SCC 2004), Shanghai, China, 15–18 September 2004; IEEE: Shanghai, China, 2004; pp. 449–452. [Google Scholar]
- Chowdhury, G.G. Natural language processing. Annu. Rev. Inf. Sci. Technol. 2003, 37, 51–89. [Google Scholar] [CrossRef]
- Liddy, E.D. Natural Language Processing; Syracuse University: New York, NY, USA, 2001. [Google Scholar]
- Savolainen, R.; Kari, J. Placing the Internet in information source horizons. A study of information seeking by Internet users in the context of self-development. Libr. Inf. Sci. Res. 2004, 26, 415–433. [Google Scholar] [CrossRef]
- Shengnan, Z.; Jiawei, W.; Kun, J. A Webpage Segmentation Method Based on Node Information Entropy of DOM Tree. J. Phys. Conf. Ser. 2020, 1624, 032023. [Google Scholar] [CrossRef]
- Joshi, P.M.; Liu, S. Web Document Text and Images Extraction using DOM Analysis and Natural Language Processing. In Proceedings of the 2009 ACM Symposium on Document Engineering, Munich, Germany, 16–18 September 2009; pp. 1–4. [Google Scholar] [CrossRef]
- Alimohammadi, D. Meta-tag: A means to control the process of Web indexing. Online Inf. Rev. 2003, 27, 238–242. [Google Scholar] [CrossRef]
- Gu, M.; Zhu, F.; Guo, Q.; Gu, Y.; Zhou, J.; Qu, W. Towards effective web page classification. In Proceedings of the 2016 International Conference on Behavioral, Economic and Socio-Cultural Computing (BESC), Durham, NC, USA, 11–13 November 2016; pp. 1–2. [Google Scholar] [CrossRef]
- Yu, X.; Jin, Z. Web content information extraction based on DOM tree and statistical information. In Proceedings of the 2017 IEEE 17th International Conference on Communication Technology (ICCT), Chengdu, China, 27–30 October 2017; pp. 1308–1311. [Google Scholar] [CrossRef]
- Utiu, N.; Ionescu, V. Learning Web Content Extraction with DOM Features. In Proceedings of the 2018 IEEE 14th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 6–8 September2018; pp. 5–11. [Google Scholar] [CrossRef]
- Kalra, G.S.; Kathuria, R.S.; Kumar, A. YouTube Video Classification based on Title and Description Text. In Proceedings of the 2019 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), Greater Noida, India, 18–19 October 2019; pp. 74–79. [Google Scholar] [CrossRef]
- Poornima, A.; Priya, K.S. A Comparative Sentiment Analysis of Sentence Embedding Using Machine Learning Techniques. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 493–496. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
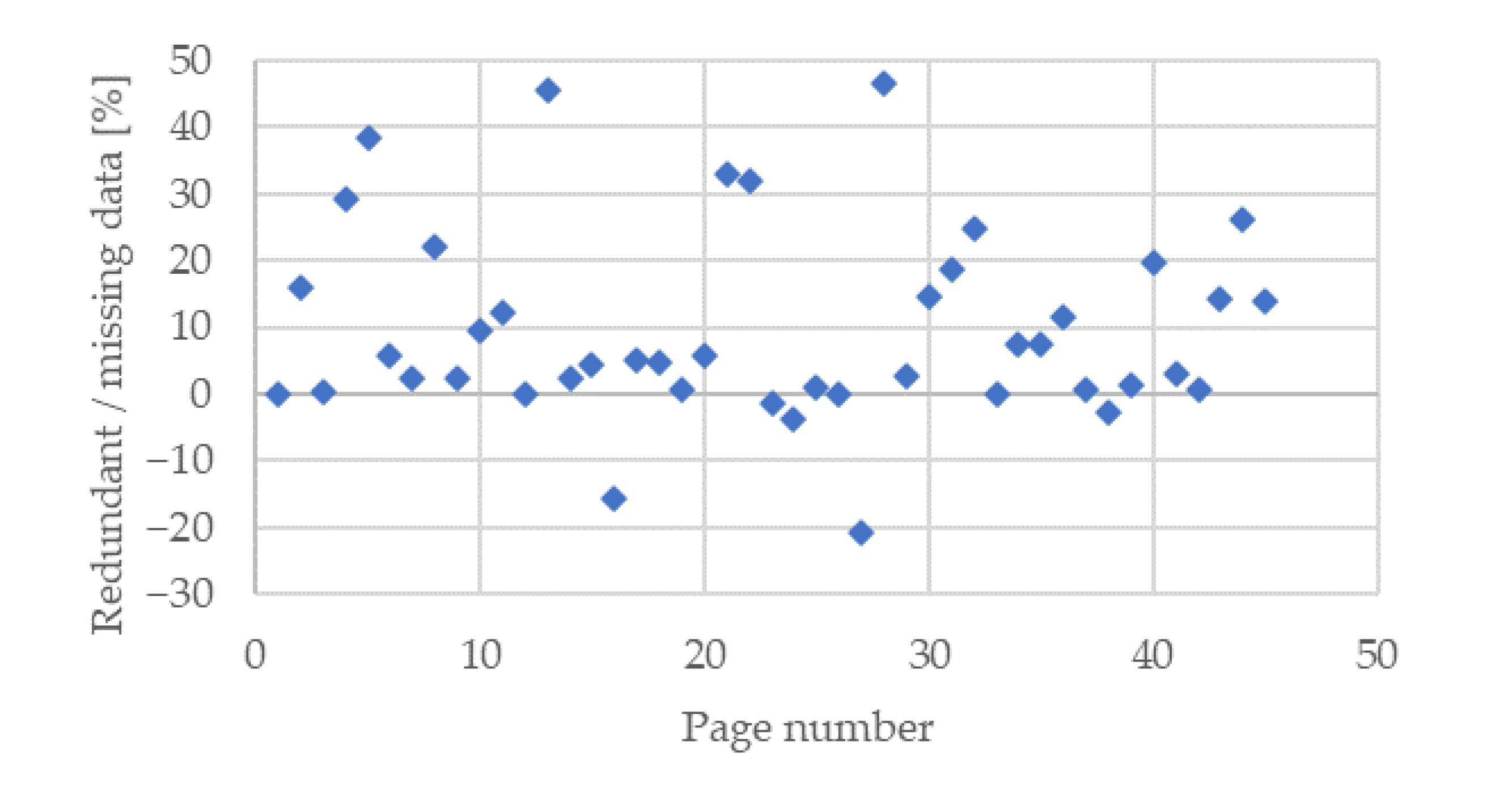
| Number | HTML | Number Char | Difference | |
|---|---|---|---|---|
| Required | Acquired | |||
| 1 | bobobobor.html | 4414 | 4414 | 0.00 |
| 2 | 14bobor.html | 10,360 | 12,008 | 15.91 |
| 3 | bobor-vodny.htm | 7139 | 7165 | 0.36 |
| 4 | ZVIERATA—bobor vodny.htm | 1871 | 2418 | 29.24 |
| 5 | Bobor vodný—Časopis Poľovníctvo a rybárstvo.htm | 1752 | 2423 | 38.30 |
| 6 | Kliešť obyčajný (Ixodes ricinus).html | 9345 | 9896 | 5.90 |
| 7 | Kliešť Takto sa zahryzne Topky sk.html | 2615 | 2678 | 2.41 |
| 8 | Cassovia.sk Kliešte aj v zime. Rozhovory a reportáže.htm | 3982 | 4857 | 21.97 |
| 9 | Kliešte v meste Správy Správy Rodinka.sk.htm | 4447 | 4547 | 2.25 |
| 10 | Kliešte ohrozujú najviac seniorov, chýba im očkovanie—Zdravie a prevencia—zdravie.pravda.sk.htm | 2194 | 2401 | 9.43 |
| 11 | Jedovaté huby.html | 4611 | 5176 | 12.25 |
| 12 | Huby.htm | 1251 | 1251 | 0.00 |
| 13 | Huba mesiaca júl 09—Časopis Poľovníctvo a rybárstvo.htm | 1485 | 2160 | 45.45 |
| 14 | Do lesa s dozimetrom Máme sa báť zbierať huby—Život.sk.htm | 5092 | 5219 | 2.49 |
| 15 | Pozor na huby na tanieri.htm | 2825 | 2951 | 4.46 |
| 16 | Najnovší objav vedcov Dinosaurus s vráskavými očami—ADAM.sk.htm | 1713 | 1443 | −15.76 |
| 17 | www.kutilas.estranky.sk—Dinosaury.htm | 7585 | 7981 | 5.22 |
| 18 | infovekacik.htm | 3044 | 3195 | 4.96 |
| 19 | eQuark.sk—portál pre popularizáciu vedy—Prvý dinosaurus s jedným prstom.htm | 1867 | 1882 | 0.80 |
| 20 | Dinosaurus bol iný, ako sme si pôvodne mysleli Veda a technika-články 16-06-2011 Veda a technika Noviny.sk.htm | 1424 | 1505 | 5.69 |
| 21 | Plameniak ružový ZOO Bojnice.htm | 1000 | 1329 | 32.90 |
| 22 | plameniaky.htm | 1451 | 1914 | 31.91 |
| 23 | Plameniaky na ružovo farbia baktérie a beta karotén Zaujímavosti prievidza.sme.sk.htm | 1882 | 1856 | −1.38 |
| 24 | Hadogenes paucidens.html | 2535 | 2441 | −3.71 |
| 25 | eQuark.sk—portál pre popularizáciu vedy—Jed škorpiónov je vhodný do pesticídov.htm | 1261 | 1276 | 1.19 |
| 26 | História psa Pes-portál.sk.htm | 2195 | 2195 | 0.00 |
| 27 | Poľovníka postrelil pes.htm | 980 | 778 | −20.61 |
| 28 | stvornohykamarat—Plemená psov na C a Č—Český strakatý pes.htm | 1732 | 2538 | 46.54 |
| 29 | Aj pes, ktorý šteká, hryzie. Nebezpečne—Zdravie a prevencia—zdravie.pravda.sk.htm | 6596 | 6771 | 2.65 |
| 30 | DOBERMAN—História dobermana—DOBERMAN3.htm | 5406 | 6198 | 14.65 |
| 31 | Slon africký ZOO Bojnice.htm | 2786 | 3307 | 18.70 |
| 32 | Je zaujímavé aká môže byť príroda že—Fotoalbum—Cicavce—Slon africký.htm | 1793 | 2240 | 24.93 |
| 33 | Ivan Pleško—O slonoch—Slon Africký (Loxodonta Africana).htm | 13,539 | 13,541 | 0.01 |
| 34 | Zvieratká—Suchozemské zvieratá—Slon Africký.htm | 4966 | 5336 | 7.45 |
| 35 | MARŤANKOVIA.htm | 1371 | 1475 | 7.59 |
| 36 | Vyspelá civilizácia mravcov.htm | 14,181 | 15,815 | 11.52 |
| 37 | rad Blankokrídlovce—Mravce.htm | 3203 | 3228 | 0.78 |
| 38 | Mravce používajú antibiotiká. Pestujú huby a spolupracujú s baktériami Biológia veda.sme.sk.htm | 3837 | 3731 | −2.76 |
| 39 | Mravce—etológia, biológia a ich chov—článok zo serveru www.vivarista.sk.htm | 12,426 | 12,578 | 1.22 |
| 40 | Mravce. Blog—Michal Wiezik (blog.sme.sk).htm | 6793 | 8141 | 19.84 |
| 41 | Atlas živočíchov vidlochvost ovocný—Na túru s NATUROU.htm | 2060 | 2126 | 3.20 |
| 42 | Moľa DDD služby.htm | 1478 | 1491 | 0.88 |
| 43 | Vidlochvost Feniklový Motýle Slovenskej republiky.htm | 1763 | 2017 | 14.41 |
| 44 | Babôčka osiková « CASD Liptovský Mikuláš.htm | 1533 | 1937 | 26.35 |
| 45 | Hnedáčik Pyštekový Motýle Slovenskej republiky.htmr.html | 1838 | 2092 | 13.82 |
| Author | Year | Approach | Technique | Classification Accuracy [%] |
|---|---|---|---|---|
| Min Gu, Feng Zhu, Qing Guo, Yanhui Gu, Junsheng Zhou, Weiguang Qu [25] | 2016 | Towards Effective Web Page Classification | SVM | 84.15 |
| Xin Yu, Zhengping Jin [26] | 2017 | Web Content Information Extraction Based on DOM Tree and Statistical Information | DOM, CEDS | 97.90 |
| Nichita Utiu, Vlad-Sebastian Ionescu [27] | 2018 | Learning Web Content Extraction with DOM Features | LR, SVM, DT, RF, MLP | 80.85 |
| Gurjyot Singh Kalra, Ramandeep Singh Kathuria, Amit Kumar [28] | 2019 | YouTube video classification based on title and description text | Random Forest : Decision tree | 98.00 |
| A. Poornima, k. Sathiya Priya [29] | 2020 | A comparative sentiment analysis of sentence embedding using machine learning techniques | Support Vector Machine, Random Forest, Naïve Bayes | 86.00 |
| Martina Radilova, Patrik Kamencay, Robert Hudec, Miroslav Benco, Roman Radil | 2022 | Tool for Parsing Important Data from Web Pages | DOM, NLP | 88.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Radilova, M.; Kamencay, P.; Hudec, R.; Benco, M.; Radil, R. Tool for Parsing Important Data from Web Pages. Appl. Sci. 2022, 12, 12031. https://doi.org/10.3390/app122312031
Radilova M, Kamencay P, Hudec R, Benco M, Radil R. Tool for Parsing Important Data from Web Pages. Applied Sciences. 2022; 12(23):12031. https://doi.org/10.3390/app122312031
Chicago/Turabian StyleRadilova, Martina, Patrik Kamencay, Robert Hudec, Miroslav Benco, and Roman Radil. 2022. "Tool for Parsing Important Data from Web Pages" Applied Sciences 12, no. 23: 12031. https://doi.org/10.3390/app122312031
APA StyleRadilova, M., Kamencay, P., Hudec, R., Benco, M., & Radil, R. (2022). Tool for Parsing Important Data from Web Pages. Applied Sciences, 12(23), 12031. https://doi.org/10.3390/app122312031