


Ensemble Learning of Multiple Deep CNNs Using Accuracy-Based Weighted Voting for ASL Recognition

Abstract
1. Introduction
1.1. Problem Statement
1.2. Literature Review
1.3. Contributions and Structure of the Paper
- An ASL Recognition System using Multiple deep CNNs and Accuracy-based weighted voting (ARS-MA) is proposed, which consists of data preprocessing, feature extraction with multiple deep CNNs, and classification.
- Multiple deep CNNs are designed for feature extraction, and an AWV algorithm is proposed for classification.
- Three new datasets for classification are created from the feature extraction results, with two hyperparameters, and , introduced to optimize the accuracy of the AWV algorithm.
- The proposed model recognizes 29 gestures with accuracies of 98.83% for the ASL Alphabet dataset and 98.79% for the ASLA dataset with complex backgrounds.
2. Materials and Methods
2.1. Datasets and Image Preprocessing
2.2. Proposed Model
2.2.1. New Datasets for Classifiers
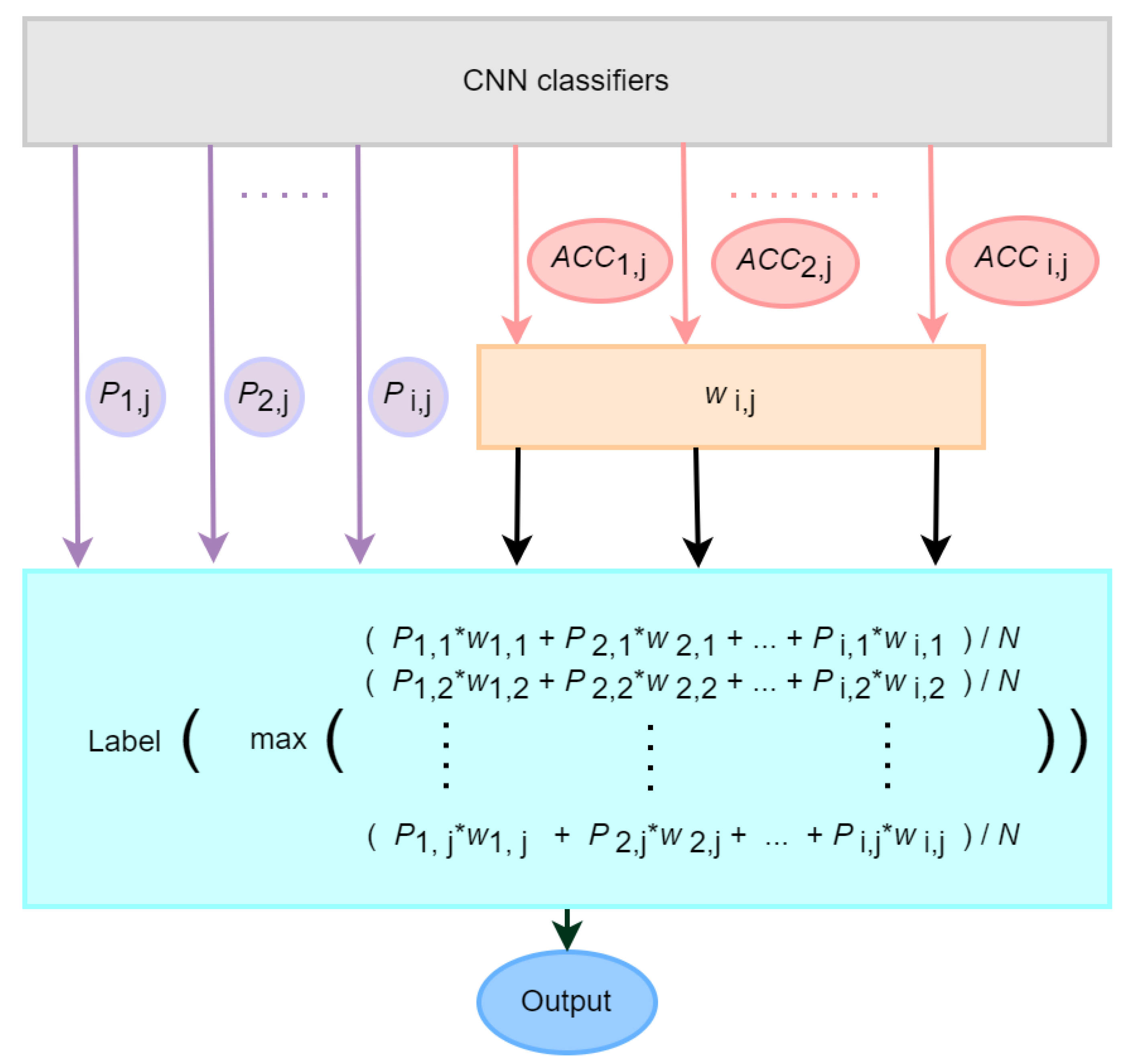
2.2.2. Classification and the Proposed AWV Algorithm
| Algorithm 1. The AWV algorithm for ASL letter recognition ( = 2, = 5). |
| Input: |
| X = [, , …, , …,, , , , …, , …,, ] |
| Output: Y |
| Process: |
| 1) Initialize the weights matrix for memory |
| = W[] |
| = 1 for i = 1, 2, …, 5 and for j = 1, 2, …, 29 |
| 2) Calculate weights |
| For i from 1 to 5 do For j from 1 to 29 do |
| 3) Initialize the values matrix for memory |
| values = V[] |
| = 1 for j = 1, 2, …, 29 |
| 4) Calculate a total of 29 values for the final decision |
| For j from 1 to 29 do = ( values ← |
| 5) Sort a total of 29 values from largest to smallest |
| For j from 1 to 29 do sorted_values = largest_to_smallest_sort(values) |
| 6) Take the class j belonging to the largest value |
| Largest value = sorted_values.take(0) = //take the first largest value Y ← |
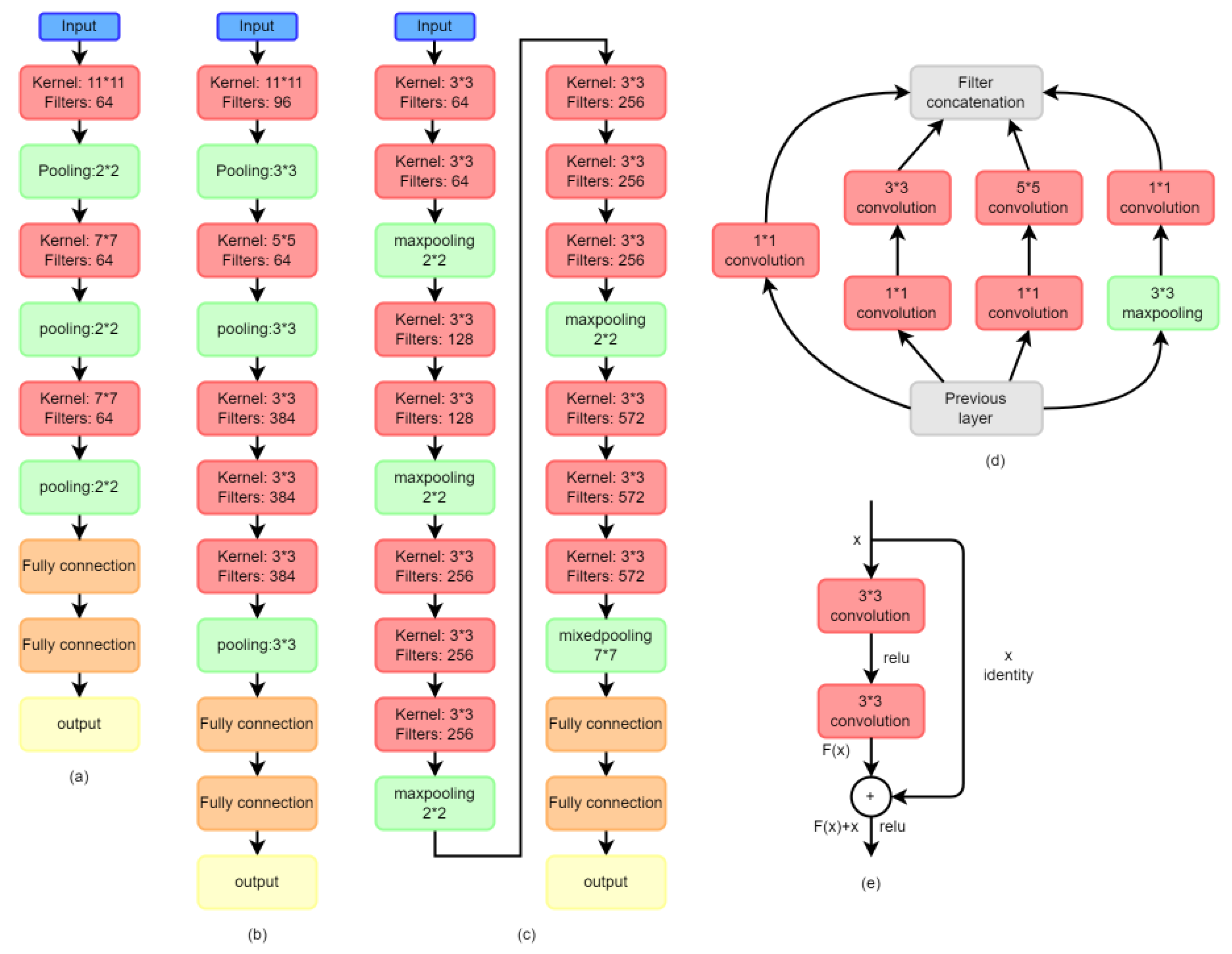
2.2.3. CNN Algorithms
2.3. Evaluation Methods
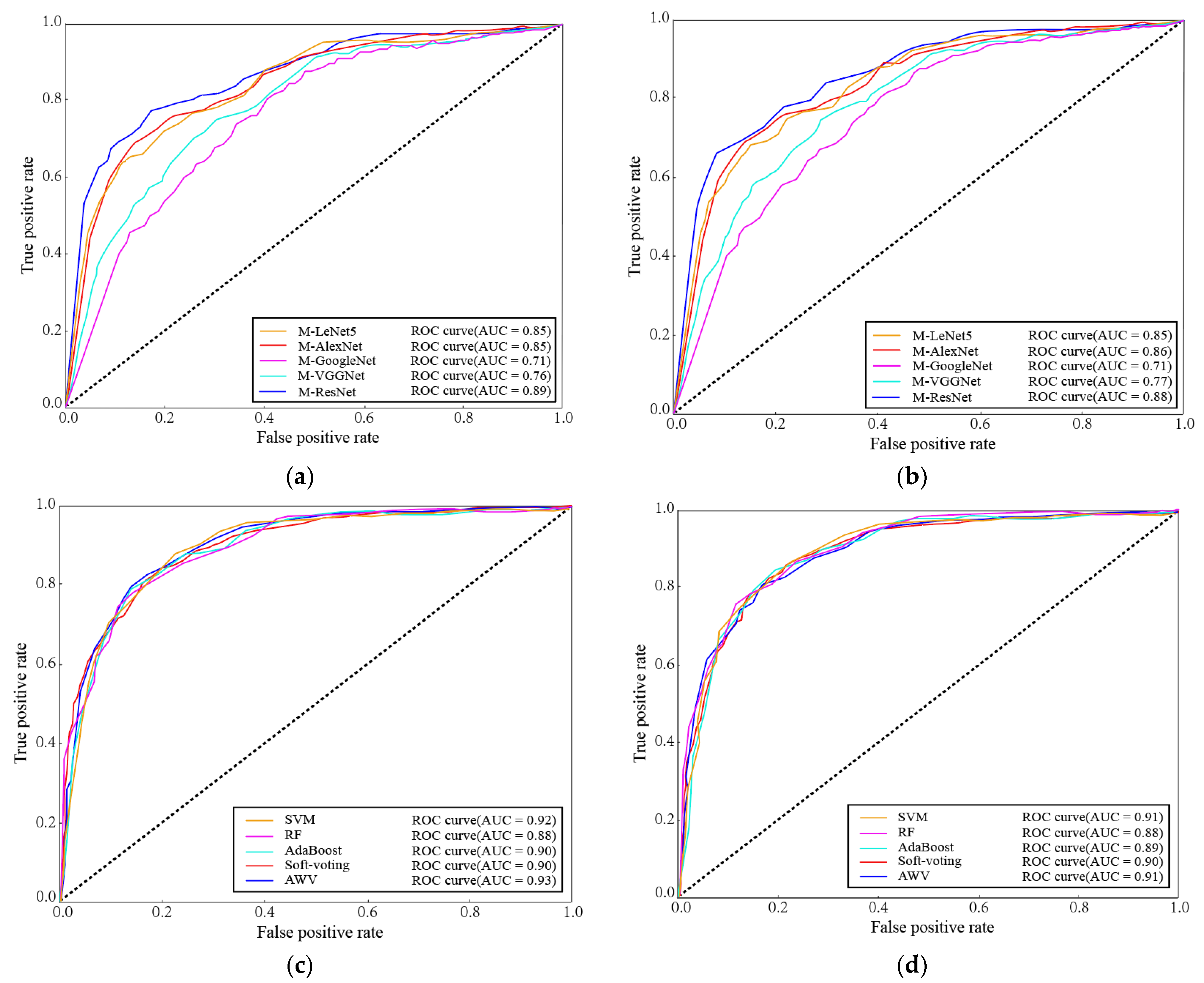
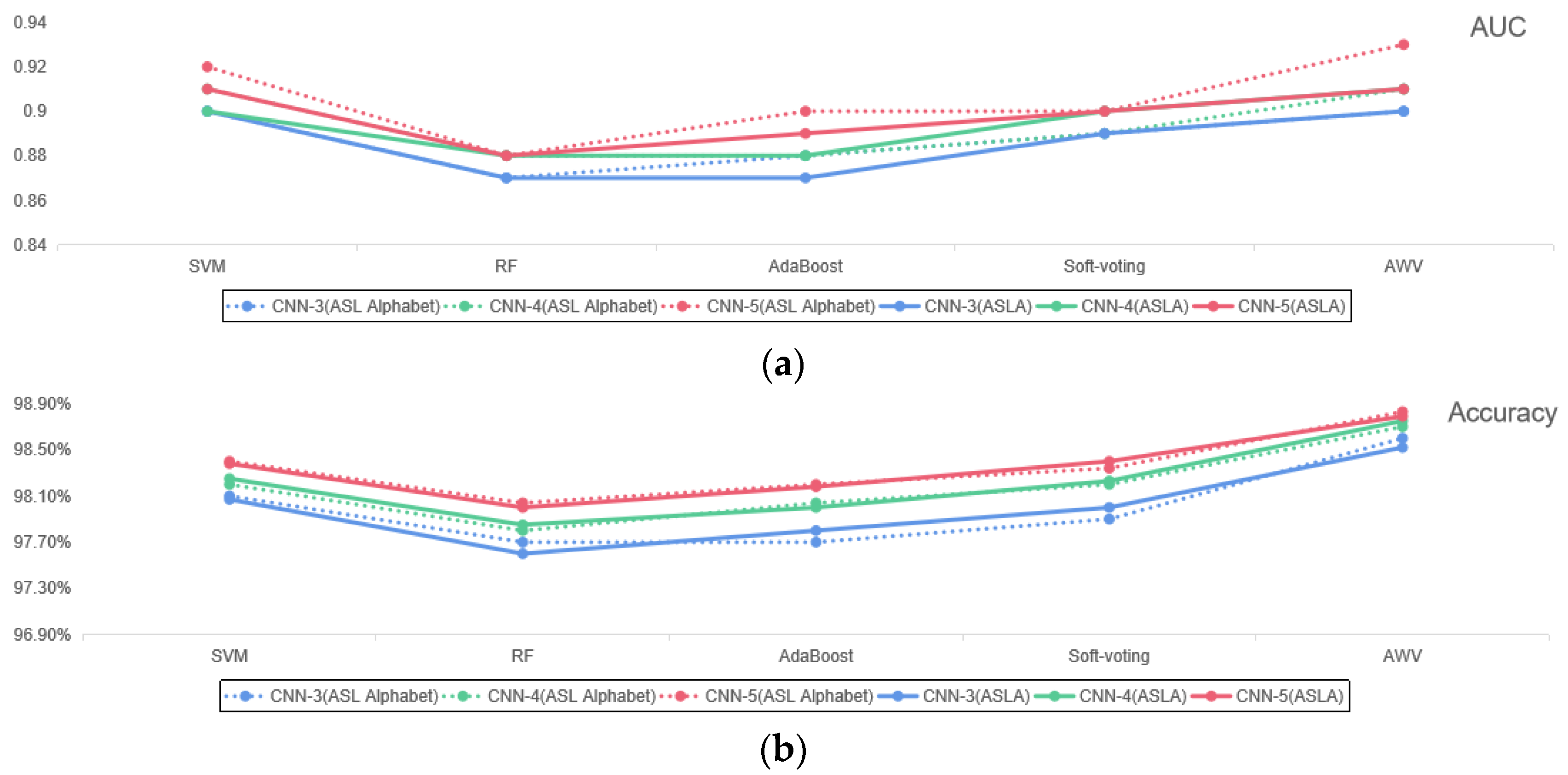
3. Results and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization (WHO). Available online: www.who.int/deafness/world-hearing-day/whd-2018/en (accessed on 1 February 2022).
- Das, P.; Ahmed, T.; Ali, F. Static Hand Gesture Recognition for American Sign Language using Deep Convolutional Neural Network. IEEE Sens. 2020, 11, 2. [Google Scholar]
- Kamal, S.M.; Chen, Y.; Li, S.; Shi, X.; Zheng, J. Technical approaches to Chinese sign language processing: A review. IEEE Access 2019, 7, 96926–96935. [Google Scholar] [CrossRef]
- National Institute on Deafness and Other Communication Disorders (NIDCD). Available online: https://www.nidcd.nih.gov/health/american-sign-language (accessed on 7 June 2022).
- Rastgoo, R.; Kiani, K.; Escalera, S. Sign Language Recognition: A Deep Survey. Expert Syst. Appl. 2020, 164, 113794. [Google Scholar] [CrossRef]
- Guo, Y.; Ge, X.; Yu, M.; Yan, G.; Liu, Y. Automatic recognition method for the repeat size of a weave pattern on a woven fabric image. Text. Res. J. 2018, 89, 2754–2775. [Google Scholar] [CrossRef]
- Yu, M.; Guo, Z.-Q.; Yu, Y.; Wang, Y.; Cen, S.-X. Spatiotemporal Feature Descriptor for Micro-Expression Recognition Using Local Cube Binary Pattern. IEEE Access 2019, 7, 159214–159225. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Kim, H.; Shim, M.; Choi, E. CNN-Based Network Intrusion Detection against Denial-of-Service Attacks. Electronics 2020, 9, 916. [Google Scholar] [CrossRef]
- Halder, A.; Tayade, A. Real-time vernacular sign language recognition using mediapipe and machine learning. ISSN 2021, 2582, 7421. [Google Scholar]
- Chuan, C.H.; Regina, E.; Guardino, C. American sign language recognition using leap motion sensor. In Proceedings of the 2014 13th International Conference on Machine Learning and Applications, Detroit, MI, USA, 3–5 December 2014; pp. 541–544. [Google Scholar]
- Roy, P.P.; Kumar, P.; Kim, B.G. An efficient sign language recognition (SLR) system using Camshift tracker and hidden Markov model (hmm). SN Comput. Sci. 2021, 2, 1–15. [Google Scholar] [CrossRef]
- Ahmed, W.; Chanda, K.; Mitra, S. Vision based Hand Gesture Recognition using Dynamic Time Warping for Indian Sign Language. In Proceedings of the 2016 international conference on information science (ICIS), Dublin, Ireland, 11–14 December 2017; pp. 120–125. [Google Scholar]
- Hasan, M.M.; Srizon, A.Y.; Sayeed, A.; Hasan, M.A.M. Classification of sign language characters by applying a deep convolutional neural network. In Proceedings of the 2020 2nd International Conference on Advanced Information and Communication Technology (ICAICT), Dhaka, Bangladesh, 28–29 November 2020; pp. 434–438. [Google Scholar]
- Pigou, L.; Dieleman, S.; Kindermans, P.J. Sign language recognition using convolutional neural networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 572–578. [Google Scholar]
- Jing, L.; Vahdani, E.; Huenerfauth, M.; Tian, Y. Recognizing American sign language manual signs from RGB-D videos. arXiv 2019. [Google Scholar]
- Huang, J.; Zhou, W.; Li, H.; Li, W. Sign language recognition using 3d convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Multimedia and Expo (ICME), Torino, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Aloysius, N.; Geetha, M.; Nedungadi, P. Incorporating Relative Position Information in Transformer-Based Sign Language Recognition and Translation. IEEE Access 2021, 9, 145929–145942. [Google Scholar] [CrossRef]
- De Coster, M.; Van Herreweghe, M.; Dambre, J. European Language Resources Association (ELRA). Sign language recognition with transformer networks. In Proceedings of the 12th International Conference on Language Resources and Evaluation, Palais du Pharo, France, 11–16 May 2020; pp. 6018–6024. [Google Scholar]
- Du, Y.; Xie, P.; Wang, M.; Hu, X.; Zhao, Z.; Liu, J. Full Transformer Network with Masking Future for Word-Level Sign Language Recognition. Neurocomputing 2022, 500, 115–123. [Google Scholar] [CrossRef]
- Ye, Y.; Tian, Y.; Huenerfauth, M.; Liu, J. Recognizing american sign language gestures from within continuous videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2064–2073. [Google Scholar]
- Yu, X.; Zhang, Z.; Wu, L.; Pang, W.; Chen, H.; Yu, Z.; Li, B. Deep Ensemble Learning for Human Action Recognition in Still Images. Complexity 2020, 2020, 1–23. [Google Scholar] [CrossRef]
- Zaidi, S.; Zela, A.; Elsken, T.; Holmes, C.; Hutter, F.; Teh, Y.W. Neural ensemble search for uncertainty estimation and dataset shift. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2021. [Google Scholar]
- Hao, A.; Min, Y.; Chen, X. Self-mutual distillation learning for continuous sign language recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 11303–11312. [Google Scholar]
- Adaloglou, N.; Chatzis, T. A Comprehensive Study on Deep Learning-based Methods for Sign Language Recognition. IEEE Trans. Multimed. 2022, 24, 1750–1762. [Google Scholar] [CrossRef]
- Kothadiya, D.; Bhatt, C.; Sapariya, K.; Patel, K.; Gil-González, A.-B.; Corchado, J.M. Deepsign: Sign Language Detection and Recognition Using Deep Learning. Electronics 2022, 11, 1780. [Google Scholar] [CrossRef]
- Kania, K.; Markowska-Kaczmar, U. American Sign Language Fingerspelling Recognition Using Wide Residual Networks. In International Conference on Artificial Intelligence and Soft Computing; Springer: Cham, Switzerland, 2018; pp. 97–107. [Google Scholar]
- Bousbai, K.; Merah, M. A Comparative Study of Hand Gestures Recognition Based on MobileNetV2 and ConvNet Models. In Proceedings of the 2019 6th International Conference on Image and Signal Processing and their Applications (ISPA), Mostaganem, Algeria, 24–25 November 2019; pp. 1–6. [Google Scholar]
- Li, Y.; Ma, D.; Yu, Y.; Wei, G.; Zhou, Y. Compact joints encoding for skeleton-based dynamic hand gesture recognition. Comput. Graph. 2021, 97, 191–199. [Google Scholar] [CrossRef]
- Ma, Y.; Xu, T.; Kim, K. Two-Stream Mixed Convolutional Neural Network for American Sign Language Recognition. Sensors 2022, 22, 5959. [Google Scholar] [CrossRef]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Frontiers of Computer Science 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Hrúz, M.; Gruber, I.; Kanis, J.; Boháček, M.; Hlaváč, M.; Krňoul, Z. One Model is Not Enough: Ensembles for Isolated Sign Language Recognition. Sensors 2022, 22, 5043. [Google Scholar] [CrossRef]
- Zhang, B.; Qi, S.; Monkam, P.; Li, C.; Yang, F.; Yao, Y.-D.; Qian, W. Ensemble Learners of Multiple Deep CNNs for Pulmonary Nodules Classification Using CT Images. IEEE Access 2019, 7, 110358–110371. [Google Scholar] [CrossRef]
- ASL Alphabet Dataset. Available online: https://www.kaggle.com/datasets/grassknoted/asl-alphabet (accessed on 27 February 2021).
- ASLA Dataset. Available online: https://www.kaggle.com/datasets/debashishsau/aslamerican-sign-language-aplhabet-dataset (accessed on 27 February 2021).
- Park, K.V.; Oh, K.H.; Jeong, Y.J.; Rhee, J.; Han, M.S.; Han, S.W.; Choi, J. Machine Learning Models for Predicting Hearing Prognosis in Unilateral Idiopathic Sudden Sensorineural Hearing Loss. Clin. Exp. Otorhinolaryngol. 2020, 13, 148–156. [Google Scholar] [CrossRef]
- Karlos, S.; Kostopoulos, G.; Kotsiantis, S. A soft-voting ensemble based co-training scheme using static selection for binary classification problems. Algorithms 2020, 13, 26. [Google Scholar] [CrossRef]
- Yanmei, H.; Bo, W.; Zhaomin, Z. An improved LeNet-5 model for Image Recognition. In Proceedings of the 2020 4th International Conference on Electronic Information Technology and Computer Engineering; Association for Computing Machinery: New York, NY, USA, 2020; pp. 444–448. [Google Scholar] [CrossRef]
- Li, S.; Wang, L.; Li, J.; Yao, Y. Image Classification Algorithm Based on Improved AlexNet. J. Phys. Conf. Ser. 2021, 1813, 012051. [Google Scholar] [CrossRef]
- Zhiqi, Yang. Gesture recognition based on improved VGGNET convolutional neural network. In Proceedings of the IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 1736–1739. [CrossRef]
- Lee, S.-G.; Sung, Y.; Kim, Y.-G.; Cha, E.-Y. Variations of AlexNet and GoogLeNet to Improve Korean Character Recognition Performance. J. Inf. Processing Syst. 2018, 14, 205–217. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? Adv. Neural Inf. Processing Syst. 2018, 31, 2483–2493. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar]
- Cook, J.; Ramadas, V. When to consult precision-recall curves. Stata J. Promot. Commun. Stat. Stata 2020, 20, 131–148. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN Model | Architecture | Kernel Size | Output Shape |
|---|---|---|---|
| M-LeNet | Input | - | 227 × 227 × 1 |
| Convolution_1 | 5 × 5, 64, stride = 2 | 75 × 75 × 64 | |
| Maxpooling_1 | 2 × 2, stride = 2 | 37 × 37 × 64 | |
| Convolution_2 | 5 × 5, 128, stride = 2 | 11 × 11 × 128 | |
| Maxpooling_2 | 2 × 2, stride = 2 | 5 × 5 × 128 | |
| Flatten | - | 3200 | |
| Fully connected_1 | - | 640 | |
| Fully connected_2 | - | 128 | |
| Output | - | 29 |
| CNN Model | Architecture | Kernel Size | Output Shape |
|---|---|---|---|
| M-AlexNet | Input | - | 227 × 227 × 1 |
| Convolution_1 | 11 × 11, 64, stride = 4 | 55 × 55 × 64 | |
| Maxpooling_1 | 3 × 3, stride = 2 | 27 × 27 × 64 | |
| Convolution_2 | 5 × 5, 128, stride = 1 | 27 × 27 × 128 | |
| Maxpooling_2 | 3 × 3, stride = 2 | 13 × 13 × 128 | |
| Convolution_3 | 3 × 3, 256, stride = 1 | 13 × 13 × 256 | |
| Convolution_4 | 3 × 3, 256, stride = 1 | 13 × 13 × 256 | |
| Convolution_5 | 3 × 3, 128, stride = 1 | 13 × 13 × 128 | |
| Maxpooling_5 | 3 × 3, stride = 2 | 6 × 6 × 128 | |
| Flatten | - | 4600 | |
| Fully connected_1 | - | 2096 | |
| Fully connected_2 | - | 2096 | |
| Output | - | 29 |
| CNN Model | Architecture | Kernel Size | Output Shape | |||
|---|---|---|---|---|---|---|
| M-GoogleNet | Input | - | 224 × 224 × 1 | |||
| Convolution_1 | 7 × 7, 64, stride = 2 | 112 × 112 × 64 | ||||
| Maxpooling_1 | 3 × 3, 64, stride = 2 | 56 × 56 × 64 | ||||
| Convolution_2 | 3 × 3, 192, stride = 1 | 56 × 56 × 192 | ||||
| Maxpooling_2 | 3 × 3, 64, stride = 2 | 28 × 28 × 192 | ||||
| Inception_1 | 1 × 1, 64 | 1 × 1, 96 | 1 × 1, 32 | 3 × 3, 32 (MP) | 28 × 28 × 256 | |
| 3 × 3, 128 | 5 × 5, 32 | 1 × 1, 32 | ||||
| Inception_2 | 1 × 1, 128 | 1 × 1, 128 | 1 × 1, 32 | 3 × 3, 64 (MP) | 28 × 28 × 480 | |
| 3 × 3, 192 | 5 × 5, 96 | 1 × 1, 64 | ||||
| Maxpooling_3 | 3*3, stride = 2 | 14 × 14 × 480 | ||||
| Inception_3 | 1 × 1, 192 | 1 × 1, 96 | 1 × 1, 16 | 3 × 3, 64 (MP) | 14 × 14 × 512 | |
| 3 × 3, 208 | 5 × 5, 48 | 1 × 1, 64 | ||||
| Inception_4 | 1 × 1, 160 | 1 × 1, 112 | 1 × 1, 24 | 3 × 3, 64 (MP) | 14 × 14 × 512 | |
| 3 × 3, 224 | 5 × 5, 64 | 1 × 1, 64 | ||||
| Inception_5 | 1 × 1, 128 | 1 × 1, 128 | 1 × 1, 24 | 3 × 3, 64 (MP) | 14 × 14 × 512 | |
| 3 × 3, 256 | 5 × 5, 64 | 1 × 1, 64 | ||||
| Inception_6 | 1 × 1, 112 | 1 × 1, 144 | 1 × 1, 32 | 3 × 3, 64 (MP) | 14 × 14 × 528 | |
| 3 × 3, 288 | 5 × 5, 64 | 1 × 1, 64 | ||||
| Inception_7 | 1 × 1, 256 | 1 × 1, 160 | 1 × 1, 32 | 3 × 3, 128 (MP) | 14 × 14 × 832 | |
| 3 × 3, 320 | 5 × 5, 128 | 1 × 1, 128 | ||||
| Maxpooling_4 | 3 × 3, stride = 2 | 7 × 7 × 832 | ||||
| Inception_8 | 1 × 1, 256 | 1 × 1, 160 | 1 × 1, 32 | 3 × 3, 128 (MP) | 7 × 7 × 832 | |
| 3 × 3, 320 | 5 × 5, 128 | 1 × 1, 128 | ||||
| Inception_9 | 1 × 1, 384 | 1 × 1, 192 | 1 × 1, 48 | 3 × 3, 128 (MP) | 7 × 7 × 1024 | |
| 3 × 3, 384 | 5 × 5, 128 | 1 × 1, 128 | ||||
| Avgpooling_1 | 7 × 7, 1024, stride = 1 | 1 × 1 × 1024 | ||||
| Fully connected_1 | - | 1 × 1 × 1000 | ||||
| Output | - | 29 | ||||
| CNN Model | Architecture | Kernel Size | Output Shape |
|---|---|---|---|
| M-VGGNet | Input | - | 224 × 224 × 1 |
| Convolution_1 | 3 × 3, 64, stride = 2 | 112 × 112 × 64 | |
| Convolution_2 | 3 × 3, 64, stride = 1 | 112 × 112 × 64 | |
| Maxpooling_1 | 2 × 2, stride = 2 | 56 × 56 × 64 | |
| Convolution_3 | 3 × 3, 128, stride = 1 | 56 × 56 × 128 | |
| Convolution_4 | 3 × 3, 128, stride = 1 | 56 × 56 × 128 | |
| Maxpooling_2 | 2 × 2, stride = 2 | 28 × 28 × 128 | |
| Convolution_5 | 3 × 3, 256, stride = 1 | 28 × 28 × 256 | |
| Convolution_6 | 3 × 3, 256, stride = 1 | 28 × 28 × 256 | |
| Convolution_7 | 3 × 3, 256, stride = 1 | 28 × 28 × 256 | |
| Maxpooling_3 | 2 × 2, stride = 2 | 12 × 12 × 256 | |
| Convolution_8 | 3 × 3, 512, stride = 1 | 12 × 12 × 512 | |
| Convolution_9 | 3 × 3, 512, stride = 1 | 12 × 12 × 512 | |
| Convolution_10 | 3 × 3, 512, stride = 1 | 12 × 12 × 512 | |
| Maxpooling_4 | 2 × 2, stride = 2 | 6 × 6 × 512 | |
| Convolution_11 | 3 × 3, 512, stride = 1 | 6 × 6 × 512 | |
| Convolution_12 | 3 × 3, 512, stride = 1 | 6 × 6 × 512 | |
| Convolution_13 | 3 × 3, 512, stride = 1 | 6 × 6 × 512 | |
| Maxpooling_5 | 3 × 3, stride = 2 | 3 × 3 × 512 | |
| Flatten | - | 4600 | |
| Fully connected_1 | - | 4096 | |
| Fully connected_2 | - | 1000 | |
| Output | - | 29 |
| CNN Model | Architecture | Kernel Size | Output Shape |
|---|---|---|---|
| M-ResNet | Input | - | 224 × 224 × 1 |
| Convolution_1 | 7 × 7, 64, stride = 2 | 112 × 112 × 64 | |
| Maxpooling_1 | 3 × 3, stride = 2 | 56 × 56 × 64 | |
| Residual module_1 ×2 | 3 × 3, 128, stride = 13 × 3, 128, stride = 1 | 56 × 56 × 128 | |
| Residual module_2 ×1 | 3 × 3, 256, stride = 23 × 3, 256, stride = 1 | 28 × 28 × 256 | |
| Residual module_3 ×1 | 3 × 3, 256, stride = 13 × 3, 256, stride = 1 | 28 × 28 × 256 | |
| Residual module_4 ×1 | 3 × 3, 256, stride = 23 × 3, 256, stride = 1 | 14 × 14 × 256 | |
| Residual module_5 ×1 | 3 × 3, 256, stride = 13 × 3, 256, stride = 1 | 14 × 14 × 256 | |
| Residual module_6 ×1 | 3 × 3, 512, stride = 23 × 3, 512, stride = 1 | 7 × 7 × 512 | |
| Residual module_7 ×1 | 3 × 3, 512, stride = 13 × 3, 512, stride = 1 | 7 × 7 × 512 | |
| Avgpooling_1 | 7 × 7, stride = 1 | 1 × 1 × 512 | |
| Fully connected_1 | - | 512 | |
| Output | - | 29 |
| CNN Methods | ASL Alphabet | ASLA | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| M-LeNet5 | 94.45% | 94.76% | 94.67% | 94.71% | 93.53% | 95.11% | 94.27% | 94.69% |
| M-AlexNet | 95.56% | 94.46% | 94.38% | 94.42% | 94.61% | 94.11% | 93.87% | 93.99% |
| M-GoogleNet | 96.07% | 91.84% | 90.41% | 91.12% | 95.54% | 90.87% | 90.92% | 90.89% |
| M-VGGNet | 97.39% | 93.48% | 93.74% | 93.61% | 96.86% | 93.78% | 92.69% | 93.18% |
| M-ResNet | 97.76% | 95.42% | 96.13% | 95.77% | 97.27% | 95.61% | 96.33% | 95.97% |
| Final Fusion Classifiers | ASL Alphabet | ASLA | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| SVM | 98.35% | 97.67% | 97.12% | 97.39% | 98.27% | 97.59% | 97.31% | 97.45% |
| RF | 97.96% | 96.32% | 96.27% | 96.29% | 97.89% | 97.56% | 96.22% | 96.89% |
| AdaBoost | 98.11% | 96.12% | 95.78% | 95.95% | 98.04% | 96.24% | 96.51% | 96.37% |
| Soft voting | 98.46% | 97.19% | 96.51% | 96.85% | 98.41% | 96.74% | 96.84% | 96.79% |
| AWV ( = 2, = 5) | 98.83% | 97.98% | 96.94% | 97.46% | 98.79% | 97.61% | 97.59% | 97.60% |
| Accuracy on ASL Alphabet | Accuracy on ASLA | |
|---|---|---|
| 1 | 98.7843% | 98.7432% |
| 2 | 98.8319% | 98.7943% |
| 3 | 98.8317% | 98.7937% |
| 4 | 98.8317% | 98.7942% |
| ASL Alphabet | ASLA | |||
|---|---|---|---|---|
| Accuracy | Average Time/Image | Accuracy | Average Time/Image | |
| 1 | 98.8319% | 0.312 s | 98.7943% | 0.324 s |
| 3 | 98.8327% | 0.282 s | 98.7945% | 0.286 s |
| 5 | 98.8332% | 0.276 s | 98.7946% | 0.279 s |
| 7 | 98.7953% | 0.273 s | 98.7471% | 0.271 s |
| 9 | 98.7139% | 0.270 s | 98.6816% | 0.267 s |
| Types | Authors | Works | Accuracy |
|---|---|---|---|
| Sign Language Recognition | Marek et al., 2022 [31] | Ensembles for Isolated Sign Language Recognition | 73.84% |
| Hao et al., 2021 [23] | Self-mutual distillation learning | 80% | |
| Adaloglou et al., 2022 [24] | Inflated 3D ConvNet with BLSTM | 89.74% | |
| Kayo et al., 2020 [18] | Sign Language Translation with STMC-Transformer | 96.32% | |
| Du et al., 2022 [19] | Full transformer network with masking future | 96.17% | |
| ASL recognition | Kania et al., 2018 [26] | Transfer learning using WRN (Wide Residual Networks) on ASL alphabet | 93.30% |
| Bousbai and Merah, 2019 [27] | Compare custom CNN model and transfer learning using MobileNetV2 on ASLs | 97.06% | |
| Hasan et al., 2020 [13] | Deep learning classification on ASL MNIST dataset | 97.62% | |
| Li et al., 2021 [28] | 2D-CNN with joints encoding hand gesture recognition for 14-class ASL alphabet | 96.31% | |
| Kothadiya et al., 2022 [25] | Four different sequences of LSTM and GRU for ASL recognition | 95.3% | |
| Ma et al., 2022 [29] | Two stream fusion CNN for ASL alphabet recognition | 97.57% | |
| Proposed Work (ARS-MA) | The ARS-MA model on 29 classes of ASL Alphabet and ASLA datasets, respectively | 98.83% (ASL Alphabet) 98.79% (ASLA) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Xu, T.; Han, S.; Kim, K. Ensemble Learning of Multiple Deep CNNs Using Accuracy-Based Weighted Voting for ASL Recognition. Appl. Sci. 2022, 12, 11766. https://doi.org/10.3390/app122211766
Ma Y, Xu T, Han S, Kim K. Ensemble Learning of Multiple Deep CNNs Using Accuracy-Based Weighted Voting for ASL Recognition. Applied Sciences. 2022; 12(22):11766. https://doi.org/10.3390/app122211766
Chicago/Turabian StyleMa, Ying, Tianpei Xu, Seokbung Han, and Kangchul Kim. 2022. "Ensemble Learning of Multiple Deep CNNs Using Accuracy-Based Weighted Voting for ASL Recognition" Applied Sciences 12, no. 22: 11766. https://doi.org/10.3390/app122211766
APA StyleMa, Y., Xu, T., Han, S., & Kim, K. (2022). Ensemble Learning of Multiple Deep CNNs Using Accuracy-Based Weighted Voting for ASL Recognition. Applied Sciences, 12(22), 11766. https://doi.org/10.3390/app122211766