
Recognizing Teachers’ Hand Gestures for Effective Non-Verbal Interaction


Abstract
1. Introduction
2. Related Works
2.1. Hand Gestures in Class
2.2. Recognition of Hand Gestures
3. Proposed Framework
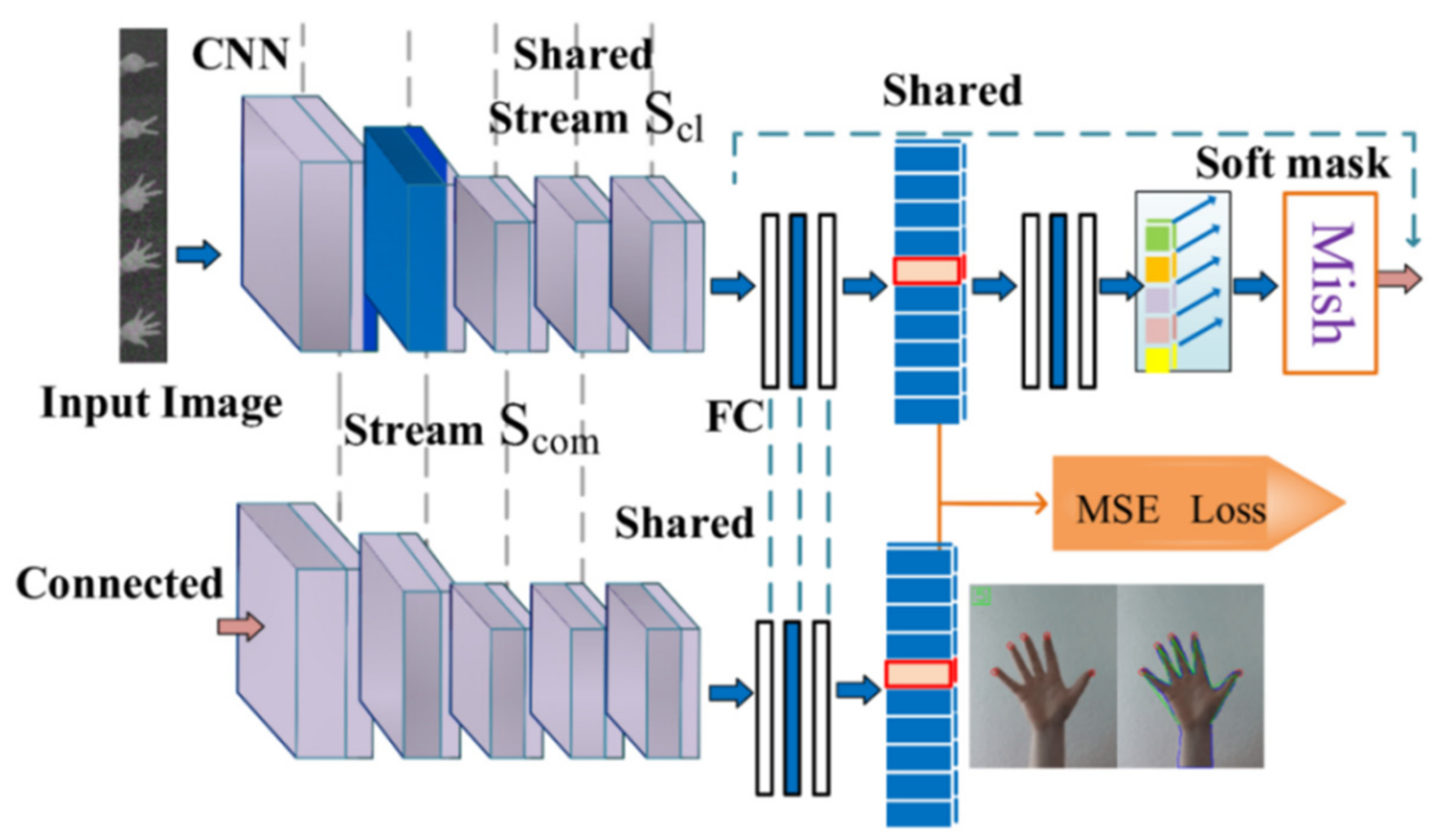
3.1. Shape Detection Based on Illumination Invariance
3.2. Hand Gesture Recognition
3.3. Improved CNN Based on Multi-Scale Feature Fusion
4. Experiments
4.1. Experimental Design
4.2. Datasets
4.3. Algorithms and Evaluation Metrics
4.4. Experimental Results
4.4.1. Detection of Hand Gestures with Complex Backgrounds
4.4.2. Recognition of Hand Gestures with Different Backlights
4.4.3. A Case Study in the Classroom Environment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Paranduk, R.; Karisi, Y. The Effectiveness of Non-Verbal Communication in Teaching and Learning English: A Systematic Review. J. Engl. Cult. Lang. Lit. Educ. 2021, 8, 145–159. [Google Scholar] [CrossRef]
- Brey, E.; Pauker, K. Teachers’ nonverbal behaviors influence children’s stereotypic beliefs. J. Exp. Child Psychol. 2019, 188, 104671. [Google Scholar] [CrossRef] [PubMed]
- Kamiya, N. What Factors Affect Learners’ Ability to Interpret Nonverbal Behaviors in EFL Classrooms? J. Nonverbal Behav. 2019, 43, 283–307. [Google Scholar] [CrossRef]
- Mahmoud, A.G.; Hasan, A.M.; Hassan, N.M. Convolutional neural networks framework for human hand gesture recognition. Bull. Electr. Eng. Inform. 2021, 10, 2223–2230. [Google Scholar] [CrossRef]
- Alibali, M.W.; Nathan, M.J.; Wolfgram, M.S.; Church, R.B.; Jacobs, S.A.; Martinez, C.J.; Knuth, E.J. How Teachers Link Ideas in Mathematics Instruction Using Speech and Gesture: A Corpus Analysis. Cogn. Instr. 2013, 32, 65–100. [Google Scholar] [CrossRef]
- Nathan, M.J.; Yeo, A.; Boncoddo, R.; Hostetter, A.B.; Alibali, M.W. Teachers’ attitudes about gesture for learning and instruction. Gesture 2019, 18, 31–56. [Google Scholar] [CrossRef]
- Berman, S.; Stern, H. Sensors for Gesture Recognition Systems. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2011, 42, 277–290. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Lee, H.-C.; Shih, C.-Y.; Lin, T.-M. Computer-Vision Based Hand Gesture Recognition and Its Application in Iphone. In Advances in Intelligent Systems and Applications-Volume 2; Springer: Berlin/Heidelberg, Germany, 2013; pp. 487–497. [Google Scholar]
- Zhou, H.; Wu, T.; Sun, K.; Zhang, C. Towards High Accuracy Pedestrian Detection on Edge GPUs. Sensors 2022, 22, 5980. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Bai, Y.; Park, S.-Y.; Kim, Y.-S.; Jeong, I.-G.; Ok, S.-Y.; Lee, E.-J. Hand Tracking and Hand Gesture Recognition for Human Computer Interaction. J. Korea Multimed. Soc. 2011, 14, 182–193. [Google Scholar] [CrossRef][Green Version]
- Li, S.Z.; Chu, R.; Liao, S.; Zhang, L. Illumination invariant face recognition using near-infrared images. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 627–639. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Jiang, J.; Li, Y.; Xu, S.; Zhang, X.; Yan, C.; Li, L. A panoramic survey method based on gesture recognition. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 677–681. [Google Scholar]
- Fan, D.; Lu, H.; Xu, S.; Cao, S. Multi-Task and Multi-Modal Learning for RGB Dynamic Gesture Recognition. IEEE Sensors J. 2021, 21, 27026–27036. [Google Scholar] [CrossRef]
- Enfield, N.; Kita, S.; de Ruiter, J. Primary and secondary pragmatic functions of pointing gestures. J. Pragmat. 2007, 39, 1722–1741. [Google Scholar] [CrossRef]
- Rahmat, A. Teachers’ Gesture in Teaching EFL Classroom of Makassar State University. Metathes. J. Engl. Lang. Lit. Teach. 2018, 2, 236–252. [Google Scholar] [CrossRef]
- Aldugom, M.; Fenn, K.; Cook, S.W. Gesture during math instruction specifically benefits learners with high visuospatial working memory capacity. Cogn. Res. Princ. Implic. 2020, 5, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Flevares, L.M.; Perry, M. How many do you see? The use of nonspoken representations in first-grade mathematics lessons. J. Educ. Psychol. 2001, 93, 330. [Google Scholar] [CrossRef]
- Sime, D. What Do Learners Make of Teachers’ Gestures in the Language Classroom? Int. Rev. Appl. Linguist. Lang. Teach. (IRAL) 2006, 44, 211–230. [Google Scholar] [CrossRef]
- Lim, V.F. Analysing the teachers’ use of gestures in the classroom: A systemic functional multimodal discourse analysis approach. Social Semiotics 2019, 29, 83–111. [Google Scholar] [CrossRef]
- Stam, G.; Tellier, M. Gesture helps second and foreign language learning and teaching. In Gesture in Language: Development across the Lifespan; American Psychological Association: Washington, DC, USA, 2022; pp. 335–363. [Google Scholar] [CrossRef]
- Wang, J.; Liu, T.; Wang, X. Human hand gesture recognition with convolutional neural networks for K-12 double-teachers instruction mode classroom. Infrared Phys. Technol. 2020, 111, 103464. [Google Scholar] [CrossRef]
- Yang, M.-T.; Liao, W.-C. Computer-Assisted Culture Learning in an Online Augmented Reality Environment Based on Free-Hand Gesture Interaction. IEEE Trans. Learn. Technol. 2014, 7, 107–117. [Google Scholar] [CrossRef]
- Liu, T.; Chen, Z.; Liu, H.; Zhang, Z.; Chen, Y. Multi-modal hand gesture designing in multi-screen touchable teaching system for human-computer interaction. In Proceedings of the 2nd International Conference on Advances in Image Processing, Chengdu, China, 16–18 June 2018; pp. 198–202. [Google Scholar] [CrossRef]
- Hu, X.; Han, Z.R. Effects of gesture-based match-to-sample instruction via virtual reality technology for Chinese students with autism spectrum disorders. Int. J. Dev. Disabil. 2019, 65, 327–336. [Google Scholar] [CrossRef]
- Rautaray, S.S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2012, 43, 1–54. [Google Scholar] [CrossRef]
- Ghosh, D.K.; Ari, S. On an algorithm for Vision-based hand gesture recognition. Signal, Image and Video Processing 2016, 10, 655–662. [Google Scholar] [CrossRef]
- Lu, W.; Tong, Z.; Chu, J. Dynamic Hand Gesture Recognition with Leap Motion Controller. IEEE Signal Process. Lett. 2016, 23, 1188–1192. [Google Scholar] [CrossRef]
- Fan, H.; Zhu, H. Separation of vehicle detection area using Fourier descriptor under internet of things monitoring. IEEE Access 2018, 6, 47600–47609. [Google Scholar] [CrossRef]
- Hasan, H.; Abdul-Kareem, S. RETRACTED ARTICLE: Static hand gesture recognition using neural networks. Artif. Intell. Rev. 2012, 41, 147–181. [Google Scholar] [CrossRef]
- Wang, Z.; Li, G.; Yang, L. Dynamic Hand Gesture Recognition Based on Micro-Doppler Radar Signatures Using Hidden Gauss–Markov Models. IEEE Geosci. Remote Sens. Lett. 2020, 18, 291–295. [Google Scholar] [CrossRef]
- Zhao, M.; Quek, F.; Wu, X. RIEVL: Recursive induction learning in hand gesture recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1174–1185. [Google Scholar] [CrossRef]
- Ge, S.; Yang, Y.; Lee, T. Hand gesture recognition and tracking based on distributed locally linear embedding. Image Vis. Comput. 2008, 26, 1607–1620. [Google Scholar] [CrossRef]
- Dubey, A.K. Enhanced hand-gesture recognition by improved beetle swarm optimized probabilistic neural network for human–computer interaction. J. Ambient Intell. Humaniz. Comput. 2022, 1–14. [Google Scholar] [CrossRef]
- Li, J.; Li, C.; Han, J.; Shi, Y.; Bian, G.; Zhou, S. Robust Hand Gesture Recognition Using HOG-9ULBP Features and SVM Model. Electronics 2022, 11, 988. [Google Scholar] [CrossRef]
- Ma, D.; Lan, G.; Hassan, M.; Hu, W.; Upama, M.B.; Uddin, A.; Youssef, M. Solargest: Ubiquitous and battery-free gesture recognition using solar cells. In Proceedings of the 25th Annual International Conference on Mobile Computing and Networking, Los Cabos, Mexico, 21–25 October 2019; pp. 1–15. [Google Scholar]
- Montulet, R.; Briassouli, A.; Maastricht, N. Deep Learning for Robust end-to-end Tone Mapping. In Proceedings of the British Machine Vision Conference BMVC, Cardiff, UK, 9–12 September 2019; Volume 2, p. 4. [Google Scholar]
- Li, G.; Tang, H.; Sun, Y.; Kong, J.; Jiang, G.; Jiang, D.; Tao, B.; Xue, S.; Liu, H. Hand gesture recognition based on convolution neural network. Clust. Comput. 2019, 22, 2719–2729. [Google Scholar] [CrossRef]
- Oyedotun, O.; Khashman, A. Deep learning in vision-based static hand gesture recognition. Neural Comput. Appl. 2016, 28, 3941–3951. [Google Scholar] [CrossRef]
- Zhang, D.; Shen, D.; Alzheimer’s Disease Neuroimaging Initiative. Multi-modal multi-task learning for joint prediction of multiple regression and classification variables in Alzheimer’s disease. NeuroImage 2012, 59, 895–907. [Google Scholar] [CrossRef] [PubMed]
- Melo, D.F.Q.; Silva, B.M.C.; Pombo, N.; Xu, L. Internet of Things Assisted Monitoring Using Ultrasound-Based Gesture Recognition Contactless System. IEEE Access 2021, 9, 90185–90194. [Google Scholar] [CrossRef]
- Ewe, E.L.R.; Lee, C.P.; Kwek, L.C.; Lim, K.M. Hand Gesture Recognition via Lightweight VGG16 and Ensemble Classifier. Appl. Sci. 2022, 12, 7643. [Google Scholar] [CrossRef]
- Yeo, H.S.; Lee, B.G.; Lim, H. Hand tracking and gesture recognition system for human-computer interaction using low-cost hardware. Multimed. Tools Appl. 2015, 74, 2687–2715. [Google Scholar] [CrossRef]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Koide, K.; Miura, J. Identification of a specific person using color, height, and gait features for a person following robot. Robot. Auton. Syst. 2016, 84, 76–87. [Google Scholar] [CrossRef]
- Han, Y.; Roig, G.; Geiger, G.; Poggio, T. Scale and translation-invariance for novel objects in human vision. Sci. Rep. 2020, 10, 1411–1413. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, X. Vehicle-logo recognition based on modified HU invariant moments and SVM. Multimed. Tools Appl. 2017, 78, 75–97. [Google Scholar] [CrossRef]
- Hsieh, J.-W.; Chen, L.-C.; Chen, D.-Y. Symmetrical SURF and Its Applications to Vehicle Detection and Vehicle Make and Model Recognition. IEEE Trans. Intell. Transp. Syst. 2014, 15, 6–20. [Google Scholar] [CrossRef]
- Mohanty, A.; Rambhatla, S.S.; Sahay, R.R. Deep gesture: Static hand gesture recognition using CNN. In Proceedings of the International Conference on Computer Vision and Image Processing, Roorkee, India, 26–28 February 2016; pp. 449–461. [Google Scholar]
- Pisharady, P.; Vadakkepat, P.; Loh, A.P. Attention Based Detection and Recognition of Hand Postures against Complex Backgrounds. Int. J. Comput. Vis. 2012, 101, 403–419. [Google Scholar] [CrossRef]
- You, S.H.; Hwang, M.; Kim, K.H.; Cho, C.S. Implementation of an Autostereoscopic Virtual 3D Button in Non-contact Manner Using Simple Deep Learning Network. J. Inf. Process. Syst. 2021, 17, 505–517. [Google Scholar]
- Song, P.; Qi, L.; Qian, X.; Lu, X. Detection of ships in inland river using high-resolution optical satellite imagery based on mixture of deformable part models. J. Parallel Distrib. Comput. 2019, 132, 1–7. [Google Scholar] [CrossRef]
- Espejel-Cabrera, J.; Cervantes, J.; García-Lamont, F.; Castilla, J.S.R.; Jalili, L.D. Mexican sign language segmentation using color based neuronal networks to detect the individual skin color. Expert Syst. Appl. 2021, 183, 115295. [Google Scholar] [CrossRef]
- Sabaghi, A.; Oghbaie, M.; Hashemifard, K.; Akbari, M. Deep Learning meets Liveness Detection: Recent Advancements and Challenges. arXiv 2021, arXiv:2112.14796. [Google Scholar]
- Castaldi, E.; Lunghi, C.; Morrone, M.C. Neuroplasticity in adult human visual cortex. Neurosci. Biobehav. Rev. 2020, 112, 542–552. [Google Scholar] [CrossRef]
- Byun, S.; Lim, H.; Yu, S.; Paik, J. Contrast Enhancement of Mobile Phone Camera Using Multi-Scale Feature Map. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Taoyuan, Taiwan, 28–30 September 2020; pp. 1–2. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Model | Detection Accuracy (%) | Localization Accuracy (%) |
|---|---|---|
| YOLO | 0.919 | 0.61 |
| YOLOv3 | 0.945 | 0.63 |
| Bayesian model | 0.971 | - |
| DPM model | 0.93 | 0.6 |
| HSV skin color model | 0.72 | - |
| Proposed framework | 0.992 | 0.76 |
| Network Model | Average F1 Values (%) | Running Time (s) |
|---|---|---|
| YOLO | 90.96 | 1.204 |
| YOLOv3 | 92.64 | 0.96 |
| Proposed framework | 98.43 | 0.065 |
| Network Model | Recognition Accuracy (%) |
|---|---|
| Proposed framework (32 × 32) | 95.78 |
| Proposed framework (64 × 64) | 95.75 |
| Proposed framework (96 × 96) | 95.77 |
| Proposed framework | 98.65 |
| Network Model | Recognition Accuracy (%) |
|---|---|
| Skin color + CNN | 97.2 |
| CNN+SVM | 98.7 |
| Gaussian model | 94.73 |
| Proposed framework | 99.59 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Z.; Yang, Z.; Xiahou, J.; Xie, T. Recognizing Teachers’ Hand Gestures for Effective Non-Verbal Interaction. Appl. Sci. 2022, 12, 11717. https://doi.org/10.3390/app122211717
Peng Z, Yang Z, Xiahou J, Xie T. Recognizing Teachers’ Hand Gestures for Effective Non-Verbal Interaction. Applied Sciences. 2022; 12(22):11717. https://doi.org/10.3390/app122211717
Chicago/Turabian StylePeng, Zhenlong, Zhidan Yang, Jianbing Xiahou, and Tao Xie. 2022. "Recognizing Teachers’ Hand Gestures for Effective Non-Verbal Interaction" Applied Sciences 12, no. 22: 11717. https://doi.org/10.3390/app122211717
APA StylePeng, Z., Yang, Z., Xiahou, J., & Xie, T. (2022). Recognizing Teachers’ Hand Gestures for Effective Non-Verbal Interaction. Applied Sciences, 12(22), 11717. https://doi.org/10.3390/app122211717