

A Hybrid U-Lossian Deep Learning Network for Screening and Evaluating Parkinson’s Disease
 , ,
, ,
Abstract
1. Introduction
2. State of the Art Review of Signal Analysis Based Approaches for Analyzing Parkinson’s Disease
Overview of Deep Learning Based Approaches to PD Speech Analysis
3. Materials and Methods
3.1. Dataset
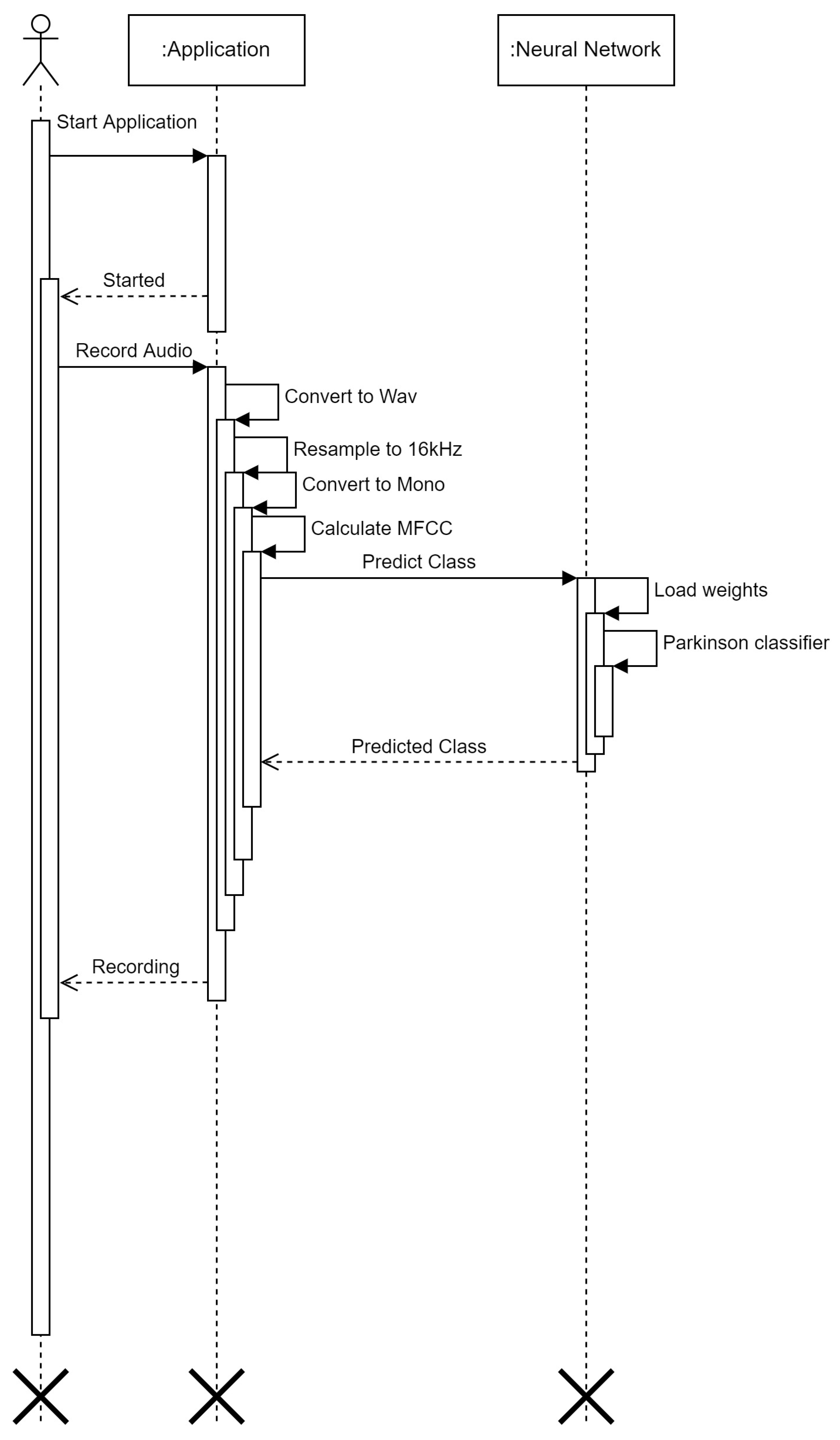
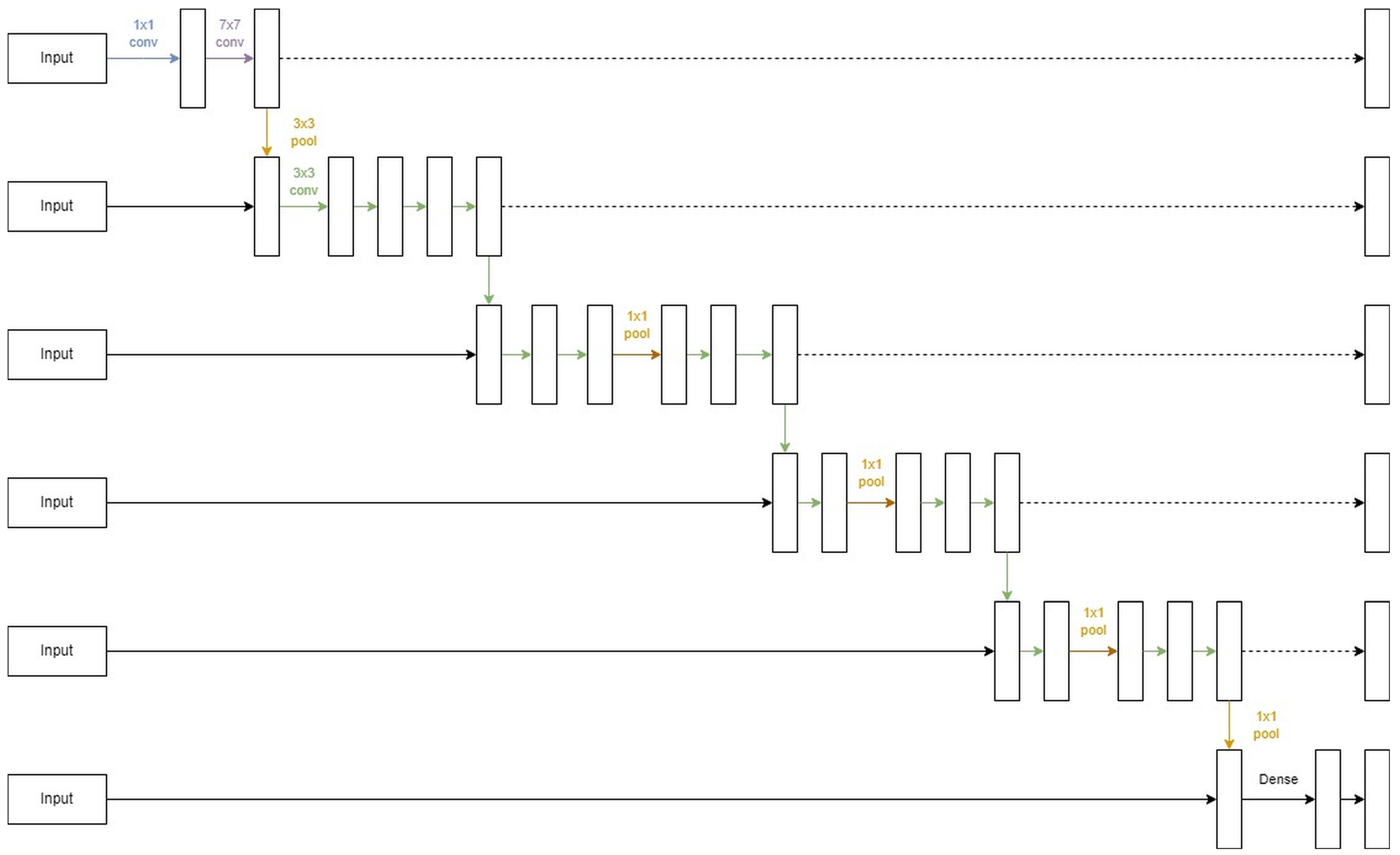
3.2. U-Lossian Deep Learning Network
4. Experimental Validation
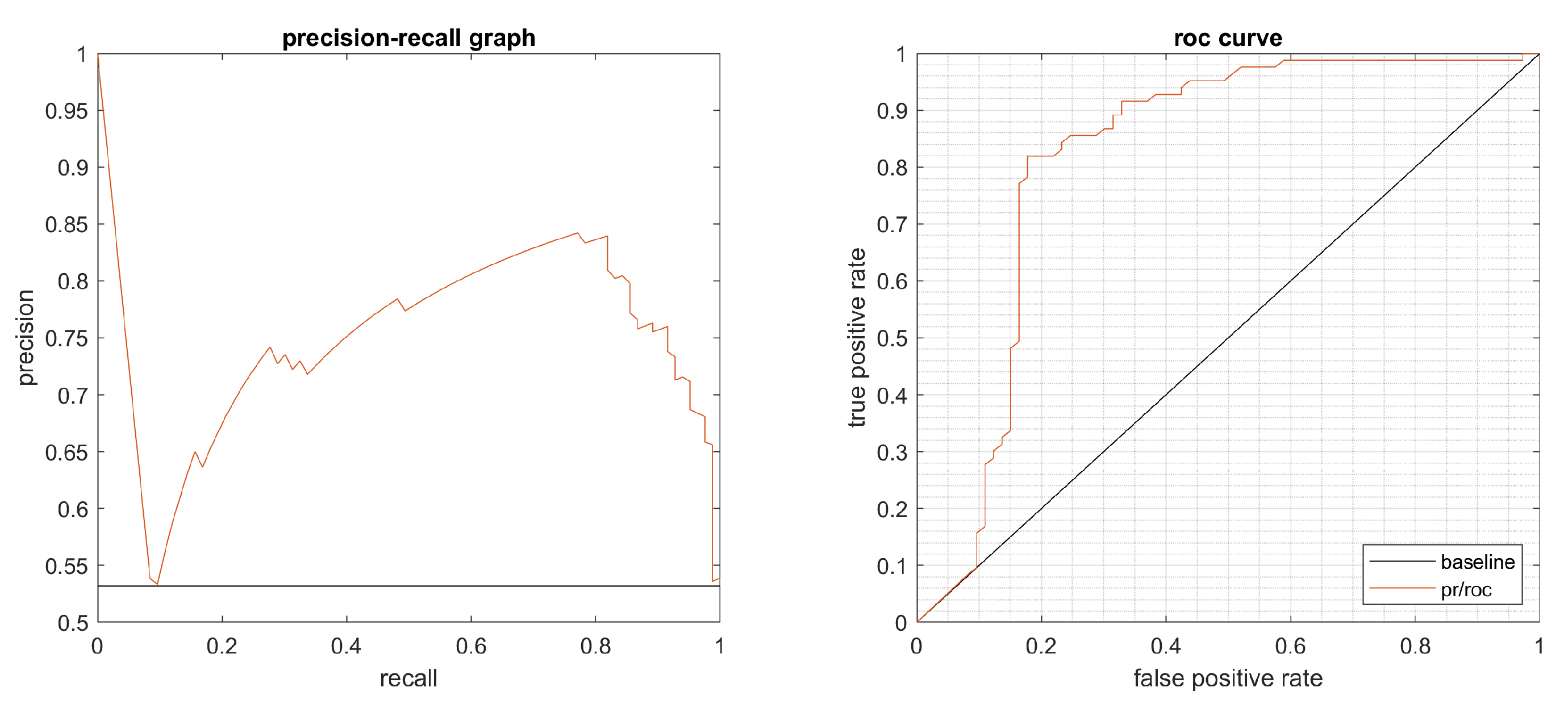
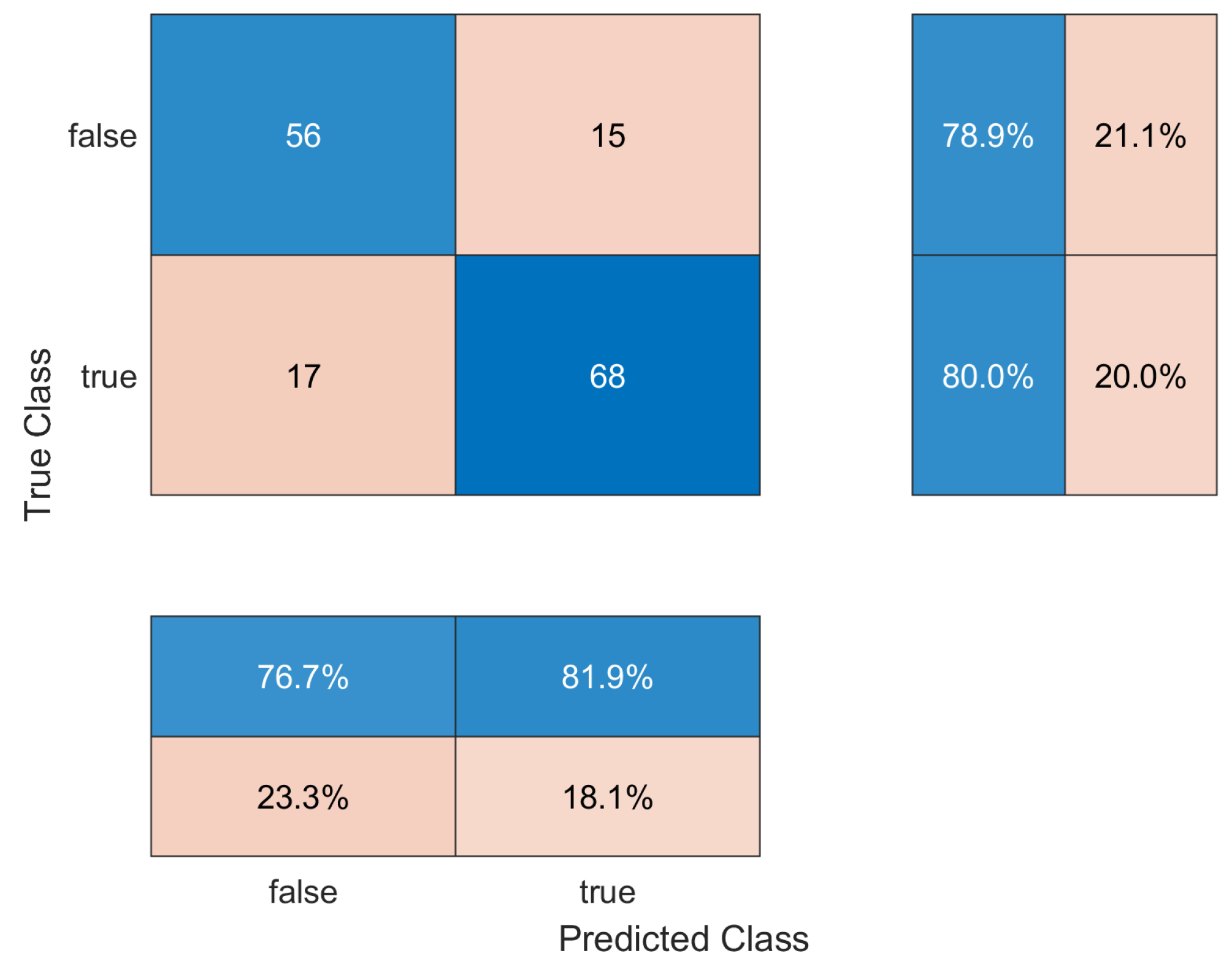
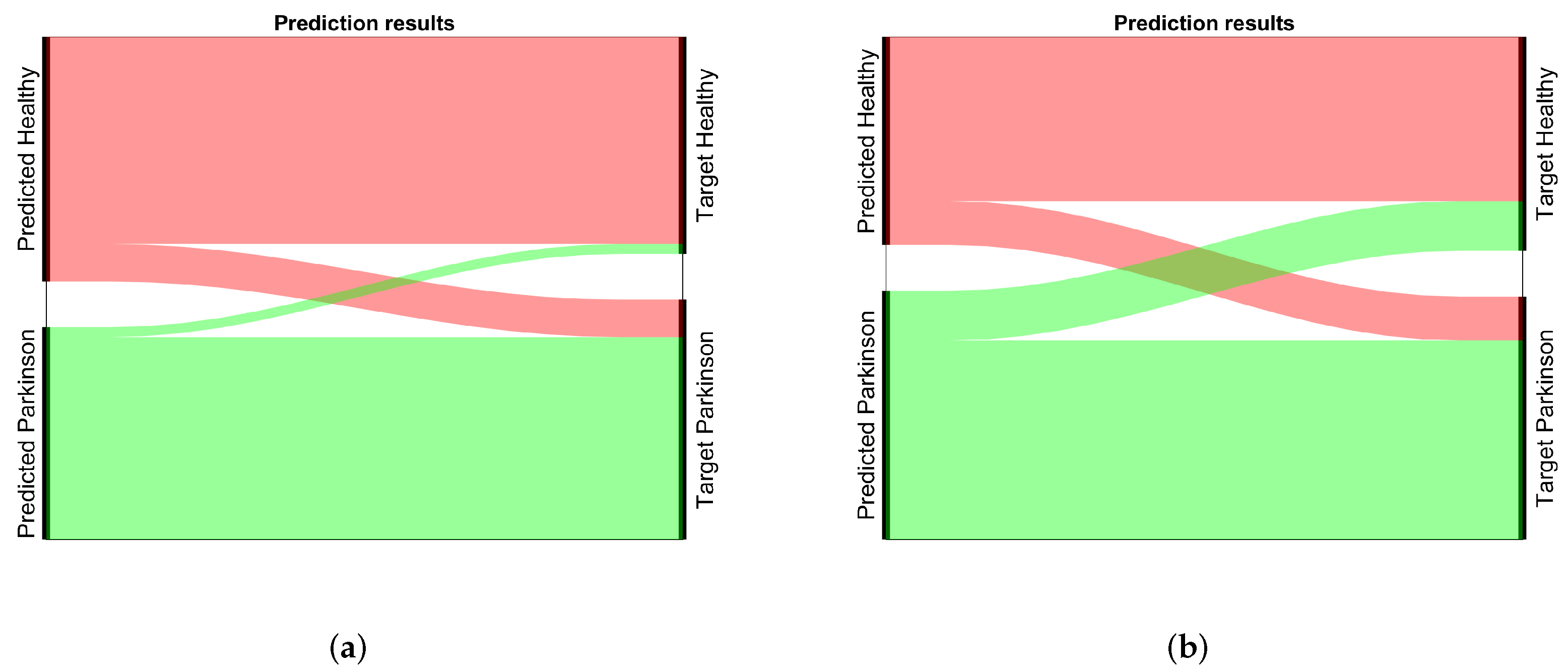
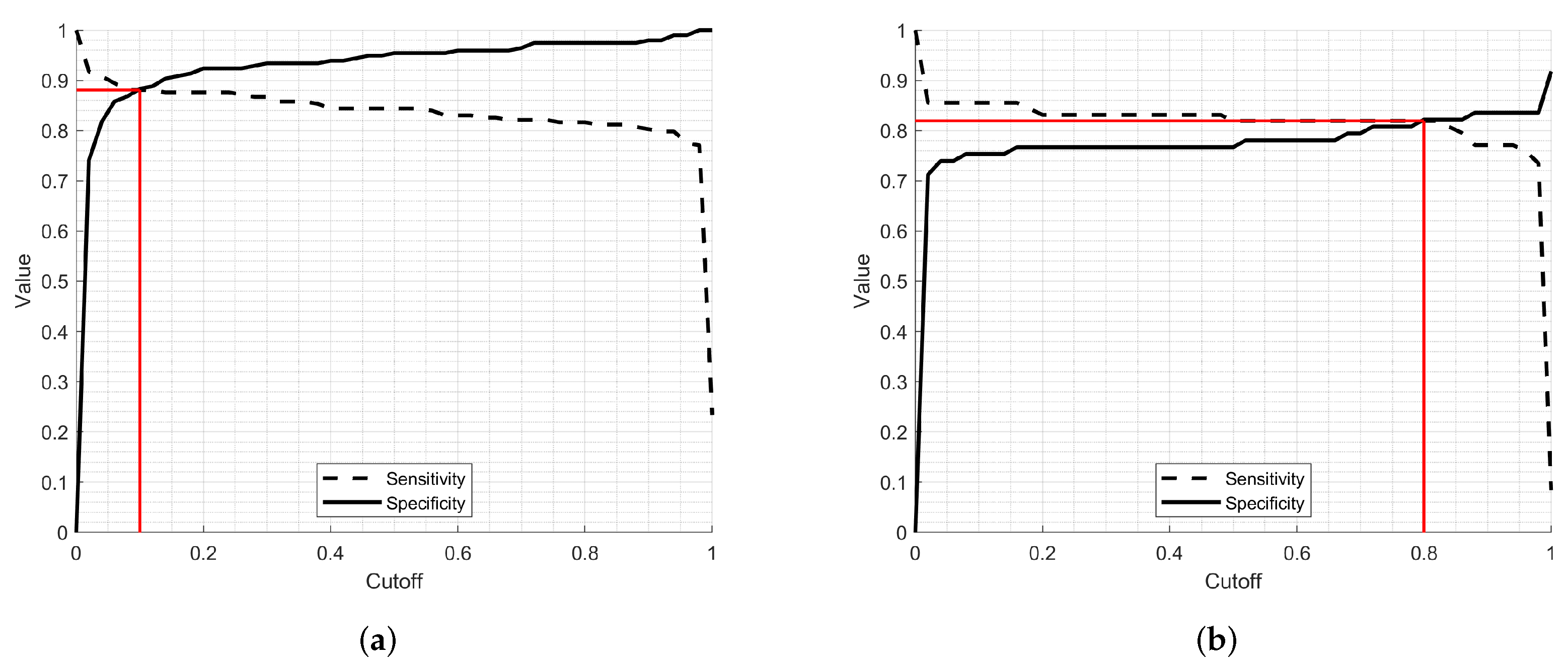
4.1. Performance Evaluation
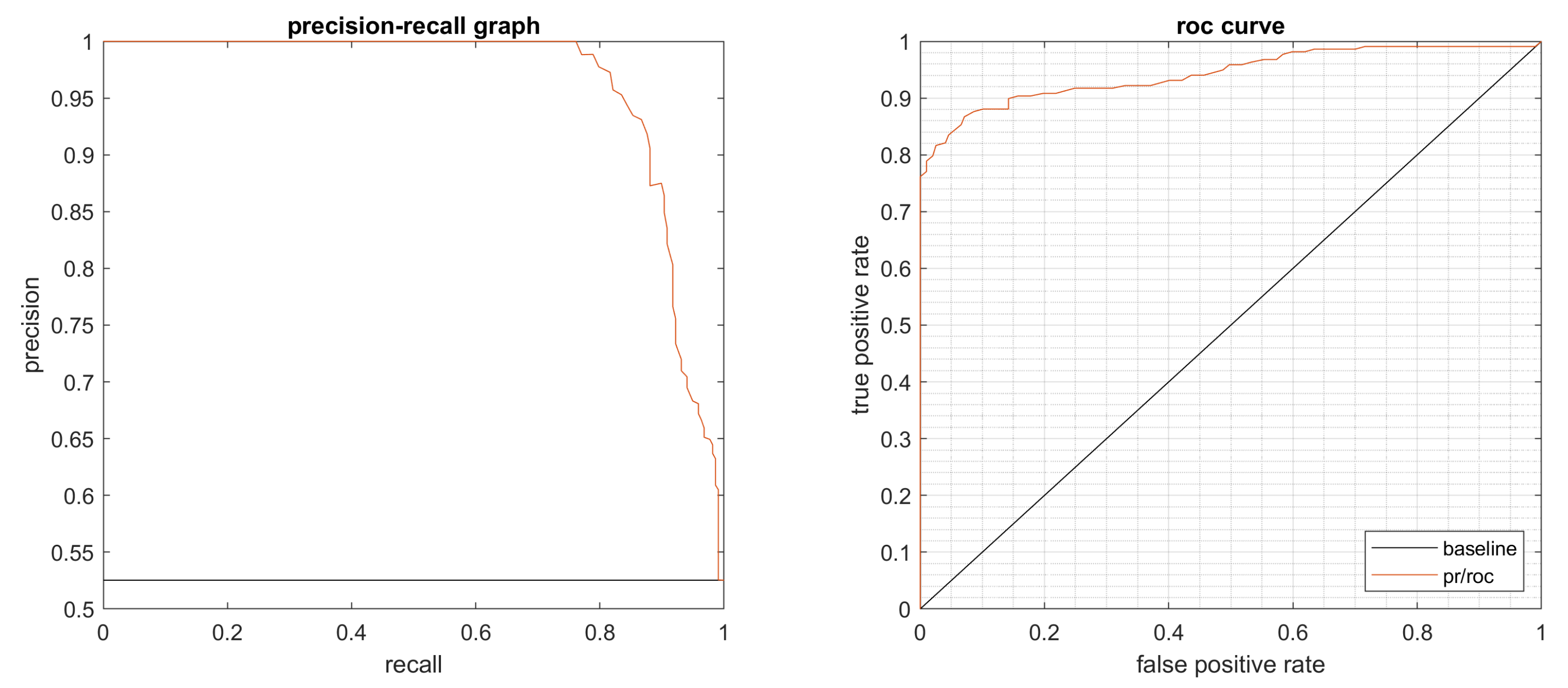
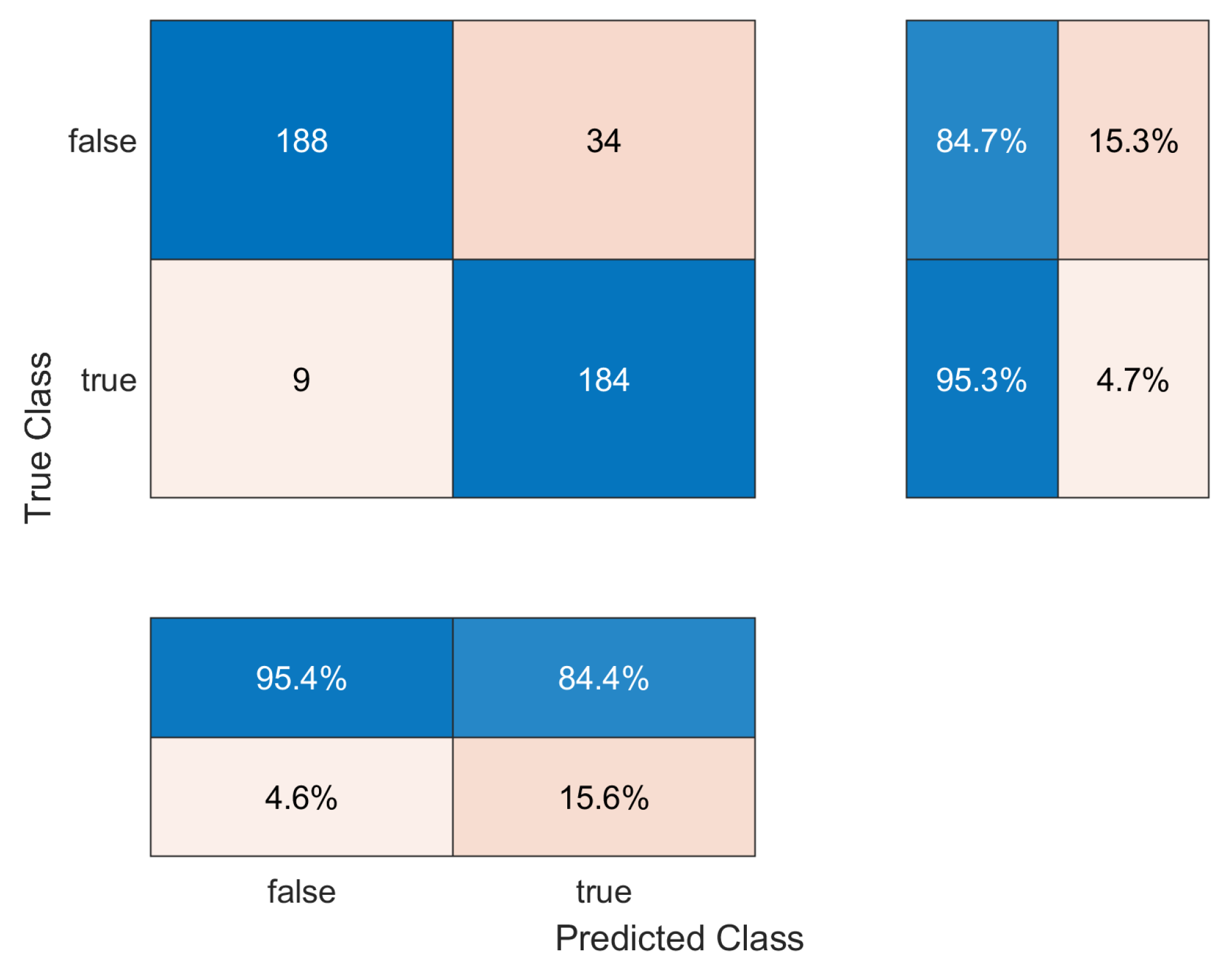
4.2. Results
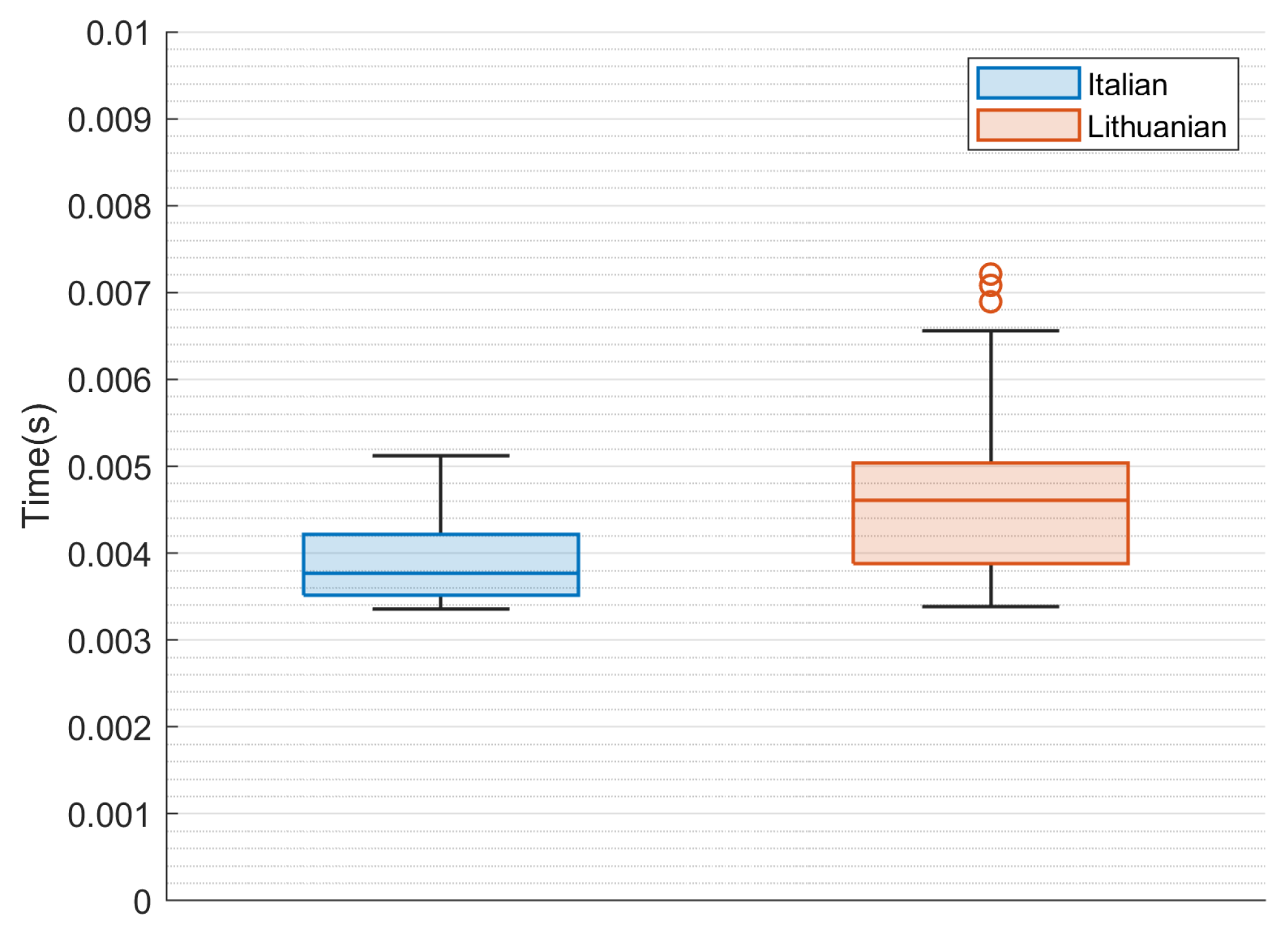
4.3. Statistical Evaluation
4.4. Summary of the Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PD | Parkinson Disease |
| DL | Deep learning |
| HC | Healthy Control |
| TP | True Positive |
| FP | False positive |
| AI | Artificial Intelligence |
| PVI | Parkinson Speech Initiative |
| NMI | Normalized Mutual Information |
| CO | Control |
| KNN | K-Nearest Neighbor |
| AUC | Area Under The Curve |
| ROC | Receiver Operating Characteristics |
| ADAM | Adaptive Moment Estimation |
| EOR | Error Odds Ratio |
| DOR | Diagnostic Odds Ratio |
| MCR | Mis-classification Rate |
| FOR | False omission rate |
| BA | Balanced Accuracy |
| NPV | Negative Predictive Value |
| FDR | False discovery rate |
| NLR | Negative Likelihood Ratio |
| PLR | Positive Likelihood Ratio |
| FPR | False Positive rate |
| FNR | False Negative rate |
| CSI | Critical success index |
References
- Harrison, P.J.; Luciano, S. Incidence of Parkinson’s disease, dementia, cerebrovascular disease and stroke in bipolar disorder compared to other psychiatric disorders: An electronic health records network study of 66 million people. Bipolar Disord. 2021, 23, 454–462. [Google Scholar] [CrossRef] [PubMed]
- Ou, Z.; Pan, J.; Tang, S.; Duan, D.; Yu, D.; Nong, H.; Wang, Z. Global Trends in the Incidence, Prevalence, and Years Lived With Disability of Parkinson’s Disease in 204 Countries/Territories From 1990 to 2019. Front. Public Health 2021, 9, 776847. [Google Scholar] [CrossRef] [PubMed]
- Bloem, B.R.; Okun, M.S.; Klein, C. Parkinson’s disease. Lancet 2021, 397, 2284–2303. [Google Scholar] [CrossRef]
- Gaenslen, A.; Swid, I.; Liepelt-Scarfone, I.; Godau, J.; Berg, D. The patients’ perception of prodromal symptoms before the initial diagnosis of Parkinson’s disease. Mov. Disord. 2021, 26, 653–658. [Google Scholar] [CrossRef] [PubMed]
- Walter, U.; Kleinschmidt, S.; Rimmele, F.; Wunderlich, C.; Gemende, I.; Benecke, R.; Busse, K. Potential impact of self-perceived prodromal symptoms on the early diagnosis of Parkinson’s disease. J. Neurol. 2012, 260, 3077–3085. [Google Scholar] [CrossRef] [PubMed]
- Schrag, A.; Horsfall, L.; Walters, K.; Noyce, A.; Petersen, I. Prediagnostic presentations of Parkinson’s disease in primary care: A case-control study. Lancet Neurol. 2015, 14, 57–64. [Google Scholar] [CrossRef]
- Pont-Sunyer, C.; Hotter, A.; Gaig, C.; Seppi, K.; Compta, Y.; Katzenschlager, R.; Mas, N.; Hofeneder, D.; Brücke, T.; Bayés, A.; et al. The Onset of Nonmotor Symptoms in Parkinson’s disease (The ONSET PDStudy). Mov. Disord. 2015, 30, 229–237. [Google Scholar] [CrossRef]
- Bezard, E.; Gross, C.E.; Brotchie, J.M. Presymptomatic compensation in Parkinson’s disease is not dopamine-mediated. Trends Neurosci. 2003, 26, 215–221. [Google Scholar] [CrossRef]
- Postuma, R.B.; Berg, D.; Stern, M.; Poewe, W.; Olanow, C.W.; Oertel, W.; Obeso, J.; Marek, K.; Litvan, I.; Lang, A.E.; et al. MDS clinical diagnostic criteria for Parkinson’s disease. Mov. Disord. 2015, 30, 1591–1601. [Google Scholar] [CrossRef]
- Mahlknecht, P.; Stockner, H.; Marini, K.; Gasperi, A.; Djamshidian, A.; Willeit, P.; Kiechl, S.; Willeit, J.; Rungger, G.; Poewe, W.; et al. Midbrain hyperechogenicity, hyposmia, mild parkinsonian signs and risk for incident Parkinson’s disease over 10 years: A prospective population-based study. Parkinsonism Relat. Disord. 2020, 70, 51–54. [Google Scholar] [CrossRef]
- Kouba, T.; Illner, V.; Rusz, J. Study protocol for using a smartphone application to investigate speech biomarkers of Parkinson’s disease and other synucleinopathies: SMARTSPEECH. BMJ Open 2022, 12, e059871. [Google Scholar] [CrossRef] [PubMed]
- Duffy, J.R. Motor Speech Disorders. 2019. Available online: https://www.elsevier.com/books/motor-speech-disorders/duffy/978-0-323-53054-5 (accessed on 1 October 2022).
- Mostafa, S.A.; Mustapha, A.; Mohammed, M.A.; Hamed, R.I.; Arunkumar, N.; Abd Ghani, M.K.; Jaber, M.M.; Khaleefah, S.H. Examining multiple feature evaluation and classification methods for improving the diagnosis of Parkinson’s disease. Cogn. Syst. Res. 2019, 54, 90–99. [Google Scholar] [CrossRef]
- Mohammed, M.A.; Elhoseny, M.; Abdulkareem, K.H.; Mostafa, S.A.; Maashi, M.S. A Multi-agent Feature Selection and Hybrid Classification Model for Parkinson’s Disease Diagnosis. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–22. [Google Scholar] [CrossRef]
- Harel, B.; Cannizzaro, M.; Snyder, P.J. Variability in fundamental frequency during speech in prodromal and incipient Parkinson’s disease: A longitudinal case study. Brain Cogn. 2004, 56, 24–29. [Google Scholar] [CrossRef]
- Rusz, J.; Cmejla, R.; Ruzickova, H.; Ruzicka, E. Quantitative acoustic measurements for characterization of speech and voice disorders in early untreated Parkinson’s disease. J. Acoust. Soc. Am. 2011, 129, 350–367. [Google Scholar] [CrossRef]
- Rusz, J.; Hlavnička, J.; Novotný, M.; Tykalová, T.; Pelletier, A.; Montplaisir, J.; Gagnon, J.; Dušek, P.; Galbiati, A.; Marelli, S.; et al. Speech Biomarkers in Rapid Eye Movement Sleep Behavior Disorder and Parkinson Disease. Ann. Neurol. 2021, 90, 62–75. [Google Scholar] [CrossRef]
- Rusz, J.; Hlavnička, J.; Tykalová, T.; Bušková, J.; Ulmanová, O.; Růžička, E.; Šonka, K. Quantitative assessment of motor speech abnormalities in idiopathic rapid eye movement sleep behaviour disorder. Sleep Med. 2016, 19, 141–147. [Google Scholar] [CrossRef]
- Atzori, A.; Carullo, A.; Vallan, A.; Cennamo, V.; Astolfi, A. Parkinson disease voice features for rehabilitation therapy and screening purposes. In Proceedings of the 2019 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Istanbul, Turkey, 26–28 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Dumican, M.; Watts, C. Self-perceptions of speech, voice, and swallowing in motor phenotypes of Parkinson’s disease. Clin. Parkinsonism Relat. Disord. 2020, 3, 100074. [Google Scholar] [CrossRef]
- Brooks, S.; Weston, D.; Greenberg, N. Social and psychological impact of the COVID-19 pandemic on people with Parkinson’s disease: A scoping review. Public Health 2021, 199, 77–86. [Google Scholar] [CrossRef]
- Erdogdu Sakar, B.; Serbes, G.; Sakar, C.O. Analyzing the effectiveness of vocal features in early telediagnosis of Parkinson’s disease. PLoS ONE 2017, 12, e0182428. [Google Scholar] [CrossRef]
- Pah, N.D.; Motin, M.A.; Kumar, D.K. Phonemes based detection of parkinson’s disease for telehealth applications. Sci. Rep. 2022, 12, 9687. [Google Scholar] [CrossRef] [PubMed]
- Rusz, J.; Cmejla, R.; Tykalova, T.; Ruzickova, H.; Klempir, J.; Majerova, V.; Picmausova, J.; Roth, J.; Ruzicka, E. Imprecise vowel articulation as a potential early marker of Parkinson’s disease: Effect of speaking task. J. Acoust. Soc. Am. 2013, 134, 2171–2181. [Google Scholar] [CrossRef] [PubMed]
- Kandl, J.; Moore, J. Parkinson Disease. J. Sing. 2022, 78, 609–612. [Google Scholar] [CrossRef]
- Illner, V.; Sovka, P.; Rusz, J. Validation of freely-available pitch detection algorithms across various noise levels in assessing speech captured by smartphone in Parkinson’s disease. Biomed. Signal Process. Control 2020, 58, 101831. [Google Scholar] [CrossRef]
- Tykalova, T.; Novotny, M.; Ruzicka, E.; Dusek, P.; Rusz, J. Short-term effect of dopaminergic medication on speech in early-stage Parkinson’s disease. NPJ Parkinson’s Dis. 2022, 8, 22. [Google Scholar] [CrossRef] [PubMed]
- Cordella, F.; Paffi, A.; Pallotti, A. Classification-based screening of Parkinson’s disease patients through voice signal. In Proceedings of the 2021 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Lausanne, Switzerland, 23–25 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Almeida, J.S.; Rebouças Filho, P.P.; Carneiro, T.; Wei, W.; Damaševičius, R.; Maskeliūnas, R.; de Albuquerque, V.H.C. Detecting Parkinson’s disease with sustained phonation and speech signals using machine learning techniques. Pattern Recognit. Lett. 2019, 125, 55–62. [Google Scholar] [CrossRef]
- Arora, S.; Tsanas, A. Assessing Parkinson’s Disease at Scale Using Telephone-Recorded Speech: Insights from the Parkinson’s Voice Initiative. Diagnostics 2021, 11, 1892. [Google Scholar] [CrossRef]
- Arora, S.; Baghai-Ravary, L.; Tsanas, A. Developing a large scale population screening tool for the assessment of Parkinson’s disease using telephone-quality voice. J. Acoust. Soc. Am. 2019, 145, 2871–2884. [Google Scholar] [CrossRef]
- Rusz, J.; Hlavnička, J.; Tykalová, T.; Novotný, M.; Dušek, P.; Šonka, K.; Růžička, E. Smartphone Allows Capture of Speech Abnormalities Associated With High Risk of Developing Parkinson’s Disease. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 1495–1507. [Google Scholar] [CrossRef]
- Ehsan, M.T.; Pranto, S.I.; Mamun, K.A. Real-Time Screening of Parkinson’s Disease based on Speech Analysis using Smartphone. In Proceedings of the 2021 10th International IEEE/EMBS Conference on Neural Engineering (NER), Virtual, 4–6 May 2021; pp. 573–576. [Google Scholar] [CrossRef]
- Bot, B.M.; Suver, C.; Neto, E.C.; Kellen, M.; Klein, A.; Bare, C.; Doerr, M.; Pratap, A.; Wilbanks, J.; Dorsey, E.R.; et al. The mPower study, Parkinson disease mobile data collected using ResearchKit. Sci. Data 2016, 3, 160011. [Google Scholar] [CrossRef]
- Zhan, A.; Mohan, S.; Tarolli, C.; Schneider, R.B.; Adams, J.L.; Sharma, S.; Elson, M.J.; Spear, K.L.; Glidden, A.M.; Little, M.A.; et al. Using Smartphones and Machine Learning to Quantify Parkinson Disease Severity. JAMA Neurol. 2018, 75, 876–880. [Google Scholar] [CrossRef] [PubMed]
- Lipsmeier, F.; Taylor, K.I.; Kilchenmann, T.; Wolf, D.; Scotland, A.; Schjodt-Eriksen, J.; Cheng, W.Y.; Fernandez-Garcia, I.; Siebourg-Polster, J.; Jin, L.; et al. Evaluation of smartphone-based testing to generate exploratory outcome measures in a phase 1 Parkinson’s disease clinical trial. Mov. Dis. 2018, 33, 1287–1297. [Google Scholar] [CrossRef] [PubMed]
- Aharonov, O. Toward voice detection for screening rheumatology patients. Indian J. Rheumatol. 2021, 16, 371. [Google Scholar] [CrossRef]
- Pereira, C.R.; Pereira, D.R.; Weber, S.A.T.; Hook, C.; de Albuquerque, V.H.C.; Papa, J.P. A survey on computer-assisted Parkinson’s Disease diagnosis. Artif. Intell. Med. 2019, 95, 48–63. [Google Scholar] [CrossRef]
- Behroozi, M.; Sami, A. A Multiple-Classifier Framework for Parkinson’s Disease Detection Based on Various Vocal Tests. Int. J. Telemed. Appl. 2016, 2016, 6837498. [Google Scholar] [CrossRef]
- Tsanas, A.; Little, M.A.; McSharry, P.E.; Ramig, L.O. Nonlinear speech analysis algorithms mapped to a standard metric achieve clinically useful quantification of average Parkinson’s disease symptom severity. J. R. Soc. Interface 2011, 8, 842–855. [Google Scholar] [CrossRef]
- Perez, C.; Roca, Y.C.; Naranjo, L.; Martin, J. Diagnosis and Tracking of Parkinson’s Disease by using Automatically Extracted Acoustic Features. J. Alzheimers Dis. Park. 2016, 6, 260. [Google Scholar] [CrossRef]
- Pah, N.D.; Motin, M.A.; Kumar, D.K. Voice Analysis for Diagnosis and Monitoring Parkinson’s Disease; Springer: Singapore, 2021. [Google Scholar] [CrossRef]
- Mohammadi, A.G.; Mehralian, P.; Naseri, A.; Sajedi, H. Parkinson’s disease diagnosis: The effect of autoencoders on extracting features from vocal characteristics. Array 2021, 11, 100079. [Google Scholar] [CrossRef]
- Gillivan-Murphy, P.; Miller, N.; Carding, P. Voice Tremor in Parkinson’s Disease: An Acoustic Study. J. Voice 2019, 33, 526–535. [Google Scholar] [CrossRef]
- Akyol, K. Growing and Pruning Based Deep Neural Networks Modeling for Effective Parkinson’s Disease Diagnosis. Comp. Model. Eng. Sci. 2020, 122, 619–632. [Google Scholar] [CrossRef]
- Maskeliūnas, R.; Kulikajevas, A.; Damaševičius, R.; Pribuišis, K.; Ulozaitė-Stanienė, N.; Uloza, V. Lightweight Deep Learning Model for Assessment of Substitution Voicing and Speech after Laryngeal Carcinoma Surgery. Cancers 2022, 14, 2366. [Google Scholar] [CrossRef] [PubMed]
- Tracy, J.M.; Özkanca, Y.; Atkins, D.C.; Hosseini Ghomi, R. Investigating voice as a biomarker: Deep phenotyping methods for early detection of Parkinson’s disease. J. Biomed. Inf. 2020, 104, 103362. [Google Scholar] [CrossRef] [PubMed]
- Ali, L.; Zhu, C.; Zhang, Z.; Liu, Y. Automated Detection of Parkinson’s Disease Based on Multiple Types of Sustained Phonations Using Linear Discriminant Analysis and Genetically Optimized Neural Network. IEEE J. Transl. Eng. Health Med. 2019, 7, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Viswanathan, R.; Arjunan, S.P.; Bingham, A.; Jelfs, B.; Kempster, P.; Raghav, S.; Kumar, D.K. Complexity Measures of Voice Recordings as a Discriminative Tool for Parkinson’s Disease. Biosensors 2019, 10, 1. [Google Scholar] [CrossRef]
- Hireš, M.; Gazda, M.; Drotár, P.; Pah, N.D.; Motin, M.A.; Kumar, D.K. Convolutional neural network ensemble for Parkinson’s disease detection from voice recordings. Comp. Biol. Med. 2022, 141, 105021. [Google Scholar] [CrossRef] [PubMed]
- Polat, K. A Hybrid Approach to Parkinson Disease Classification Using Speech Signal: The Combination of SMOTE and Random Forests. In Proceedings of the 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT), Istanbul, Turkey, 24–26 April 2019. [Google Scholar] [CrossRef]
- Solana-Lavalle, G.; Galán-Hernández, J.C.; Rosas-Romero, R. Automatic Parkinson disease detection at early stages as a pre-diagnosis tool by using classifiers and a small set of vocal features. Biocybern. Biomed. Eng. 2020, 40, 505–516. [Google Scholar] [CrossRef]
- Tuncer, T.; Dogan, S.; Acharya, U.R. Automated detection of Parkinson’s disease using minimum average maximum tree and singular value decomposition method with vowels. Biocybern. Biomed. Eng. 2020, 40, 211–220. [Google Scholar] [CrossRef]
- Pah, N.D.; Motin, M.A.; Kempster, P.; Kumar, D.K. Detecting Effect of Levodopa in Parkinson’s Disease Patients Using Sustained Phonemes. IEEE J. Transl. Eng. Health Med. 2021, 9, 1–9. [Google Scholar] [CrossRef]
- Laganas, C.; Iakovakis, D.; Hadjidimitriou, S.; Charisis, V.; Dias, S.B.; Bostantzopoulou, S.; Katsarou, Z.; Klingelhoefer, L.; Reichmann, H.; Trivedi, D.; et al. Parkinson’s Disease Detection Based on Running Speech Data From Phone Calls. IEEE Trans. Biomed. Eng. 2022, 69, 1573–1584. [Google Scholar] [CrossRef]
- Loh, H.W.; Hong, W.; Ooi, C.P.; Chakraborty, S.; Barua, P.D.; Deo, R.C.; Soar, J.; Palmer, E.E.; Acharya, U.R. Application of Deep Learning Models for Automated Identification of Parkinson’s Disease: A Review (2011–2021). Sensors 2021, 21, 7034. [Google Scholar] [CrossRef]
- Xu, Z.; Shen, B.; Tang, Y.; Wu, J.; Wang, J. Deep Clinical Phenotyping of Parkinson’s Disease: Towards a New Era of Research and Clinical Care. Phenomics 2022, 104, 349–361. [Google Scholar] [CrossRef]
- Krishna, A.; prakash Sahu, S.; Janghel, R.R.; Singh, B.K. Speech Parameter and Deep Learning Based Approach for the Detection of Parkinson’s Disease. In Computer Networks, Big Data and IoT; Springer: Singapore, 2021; pp. 507–517. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, J.; Li, Y.; Wang, P.; Liu, Y. Few-shot learning of Parkinson’s disease speech data with optimal convolution sparse kernel transfer learning. Biomed. Signal Process. Control. 2021, 69, 102850. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, Y.; Li, Y.; Zhou, L.; Qin, L.; Zeng, Y.; Wang, P.; Lei, Y. Deep dual-side learning ensemble model for Parkinson speech recognition. Biomed. Signal Process. Control. 2021, 69, 102849. [Google Scholar] [CrossRef]
- Ouhmida, A.; Terrada, O.; Raihani, A.; Cherradi, B.; Hamida, S. Voice-Based Deep Learning Medical Diagnosis System for Parkinson’s Disease Prediction. In Proceedings of the 2021 International Congress of Advanced Technology and Engineering (ICOTEN), Virtual, 4–5 July 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Hireš, M.; Gazda, M.; Vavrek, L.; Drotár, P. Voice-Specific Augmentations for Parkinson’s Disease Detection Using Deep Convolutional Neural Network. In Proceedings of the 2022 IEEE 20th Jubilee World Symposium on Applied Machine Intelligence and Informatics (SAMI), Poprad, Slovakia, 2–5 March 2022; pp. 213–218. [Google Scholar] [CrossRef]
- Wodzinski, M.; Skalski, A.; Hemmerling, D.; Orozco-Arroyave, J.R.; Nöth, E. Deep Learning Approach to Parkinson’s Disease Detection Using Voice Recordings and Convolutional Neural Network Dedicated to Image Classification. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 717–720. [Google Scholar] [CrossRef]
- Majda-Zdancewicz, E.; Potulska-Chromik, A.; Jakubowski, J.; Nojszewska, M.; Kostera-Pruszczyk, A. Bull. Pol. Acad. Sci. Tech. Sci. 2021, 69, e137347. [Google Scholar] [CrossRef]
- Karaman, O.; Çakın, H.; Alhudhaif, A.; Polat, K. Robust automated Parkinson disease detection based on voice signals with transfer learning. Exp. Syst. Appl. 2021, 178, 115013. [Google Scholar] [CrossRef]
- Narendra, N.; Schuller, B.; Alku, P. The Detection of Parkinson’s Disease From Speech Using Voice Source Information. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1925–1936. [Google Scholar] [CrossRef]
- Anisha, C.; Arulanand, N. Early Prediction of Parkinson’s Disease (PD) Using Ensemble Classifiers. In Proceedings of the 2020 International Conference on Innovative Trends in Information Technology (ICITIIT), Kottayam, India, 13–14 February 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Grover, S.; Bhartia, S.; Akshama; Yadav, A.; Seeja, K.R. Predicting Severity Of Parkinson’s Disease Using Deep Learning. Proc. Comp. Sci. 2018, 132, 1788–1794. [Google Scholar] [CrossRef]
- Mir, W.A.; Nissar, I.; Izharuddin; Rizvi, D.R.; Masood, S.; Hussain, A. Deep Learning-based model for the detection of Parkinson’s disease using voice data. In Proceedings of the 2022 First International Conference on Artificial Intelligence Trends and Pattern Recognition (ICAITPR), Paris, France, 1–3 June 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Rizvi, D.R.; Nissar, I.; Masood, S.; Ahmed, M.; Ahmed, F. An LSTM based Deep learning model for voice-based detection of Parkinsons disease. Int. J. Adv. Sci. Technol. 2020, 29, 337–343. [Google Scholar]
- Quan, C.; Ren, K.; Luo, Z. A Deep Learning Based Method for Parkinson’s Disease Detection Using Dynamic Features of Speech. IEEE Access 2021, 9, 10239–10252. [Google Scholar] [CrossRef]
- Sharanyaa, S.; Renjith, P.N.; Ramesh, K. Exponential delta-AMS features and optimized deep learning for the classification of Parkinsons disease. Crit. Rev. Biomed. Eng. 2022, 50, 1–28. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, Y.; Sun, H.; Shan, H. Parkinson disease detection using energy direction features based on EMD from voice signal. Biocybern. Biomed. Eng. 2021, 41, 127–141. [Google Scholar] [CrossRef]
- Nagasubramanian, G.; Sankayya, M. Multi-Variate vocal data analysis for Detection of Parkinson disease using Deep Learning. Neural Comput. Appl. 2020, 33, 4849–4864. [Google Scholar] [CrossRef]
- Marsili, L.; Rizzo, G.; Colosimo, C. Diagnostic Criteria for Parkinson’s Disease: From James Parkinson to the Concept of Prodromal Disease. Front. Neurol. 2018, 9, 156. [Google Scholar] [CrossRef]
- Dimauro, G.; Girardi, F. Italian Parkinson’s Voice and Speech. 2019. Available online: https://doi.org/10.21227/AW6B-TG17 (accessed on 1 October 2022).
- Dimauro, G.; Di Nicola, V.; Bevilacqua, V.; Caivano, D.; Girardi, F. Assessment of Speech Intelligibility in Parkinson’s Disease Using a Speech-To-Text System. IEEE Access 2017, 5, 22199–22208. [Google Scholar] [CrossRef]
- Tougui, I.; Jilbab, A.; Mhamdi, J.E. Machine Learning Smart System for Parkinson Disease Classification Using the Voice as a Biomarker. Healthc. Inform. Res. 2022, 28, 210–221. [Google Scholar] [CrossRef] [PubMed]
- Sudo, Y.; Itoyama, K.; Nishida, K.; Nakadai, K. Sound event aware environmental sound segmentation with Mask U-Net. Adv. Robot. 2020, 34, 1280–1290. [Google Scholar] [CrossRef]
- Esmaeilpour, M.; Cardinal, P.; Koerich, A.L. From environmental sound representation to robustness of 2D CNN models against adversarial attacks. Appl. Acoust. 2022, 195, 108817. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Cardillo, G. Clinical Test Performance: The Performance of a Clinical Test Based on the Bayes Theorem. 2016. Available online: http://www.mathworks.com/matlabcentral/fileexchange/12705 (accessed on 1 October 2022).
- Clopper, C.J.; Pearson, E.S. The use of confidence or fiducial limits illustrated in the case of the Binomial. Biometrika 1934, 26, 404–413. [Google Scholar] [CrossRef]
- Altman, D.; Machin, D.; Bryant, T.; Gardner, M. (Eds.) Statistics with Confidence, 2nd ed.; BMJ Books: London, UK, 2000. [Google Scholar]
- Mercaldo, N.D.; Lau, K.F.; Zhou, X.H. Confidence intervals for predictive values with an emphasis to case–control studies. Stat. Med. 2007, 26, 2170–2183. [Google Scholar] [CrossRef]
- Matthews, R.A.J. Methods for Assessing the Credibility of Clinical Trial Outcomes. Drug. Inf. J. 2001, 35, 1469–1478. [Google Scholar] [CrossRef]
- Kreiman, J.; Gerratt, B.R. Acoustic Analysis and Voice Quality in Parkinson Disease; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Yang, S.; Wang, F.; Yang, L.; Xu, F.; Luo, M.; Chen, X.; Feng, X.; Zou, X. The physical significance of acoustic parameters and its clinical significance of dysarthria in Parkinson’s disease. Sci. Rep. 2020, 10, 11776. [Google Scholar] [CrossRef] [PubMed]
- Skrabal, D.; Rusz, J.; Novotny, M.; Sonka, K.; Ruzicka, E.; Dusek, P.; Tykalova, T. Articulatory undershoot of vowels in isolated REM sleep behavior disorder and early Parkinson’s disease. npj Parkinson’s Dis. 2022, 8, 137. [Google Scholar] [CrossRef] [PubMed]
- Moro-Velazquez, L.; Gomez-Garcia, J.; Dehak, N.; Godino-Llorente, J.I. New Tools for the Differential Evaluation of Parkinson’s Disease Using Voice and Speech Processing. In Proceedings of the IberSPEECH 2021, Valladolid, Spain, 24–25 March 2021. [Google Scholar] [CrossRef]
- Sakar, B.E.; Isenkul, M.E.; Sakar, C.O.; Sertbas, A.; Gurgen, F.; Delil, S.; Apaydin, H.; Kursun, O. Collection and Analysis of a Parkinson Speech Dataset With Multiple Types of Sound Recordings. IEEE J. Biomed. Health Inform. 2013, 17, 828–834. [Google Scholar] [CrossRef]
- Sakar, C.O.; Serbes, G.; Gunduz, A.; Tunc, H.C.; Nizam, H.; Sakar, B.E.; Tutuncu, M.; Aydin, T.; Isenkul, M.E.; Apaydin, H. A comparative analysis of speech signal processing algorithms for Parkinson’s disease classification and the use of the tunable Q-factor wavelet transform. Appl. Soft Comput. 2019, 74, 255–263. [Google Scholar] [CrossRef]
- Tsanas, A.; Little, M.A.; Fox, C.; Ramig, L.O. Objective Automatic Assessment of Rehabilitative Speech Treatment in Parkinson’s Disease. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 181–190. [Google Scholar] [CrossRef] [PubMed]
- Orozco-Arroyave, J.R.; Arias-Londoño, J.D.; Vargas-Bonilla, J.F.; González-Rátiva, M.C.; Nöth, E. New Spanish speech corpus database for the analysis of people suffering from Parkinson’s disease. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), European Language Resources Association (ELRA). Reykjavik, Iceland, 26–31 May 2014; pp. 342–347. [Google Scholar]
- Li, J.; Jin, M.; Wang, L.; Qin, B.; Wang, K. MDS clinical diagnostic criteria for Parkinson’s disease in China. J. Neurol. 2016, 264, 476–481. [Google Scholar] [CrossRef]
- Berg, D.; Adler, C.H.; Bloem, B.R.; Chan, P.; Gasser, T.; Goetz, C.G.; Halliday, G.; Lang, A.E.; Lewis, S.; Li, Y.; et al. Movement disorder society criteria for clinically established early Parkinson’s disease. Mov. Disord. 2018, 33, 1643–1646. [Google Scholar] [CrossRef]
- Heinzel, S.; Berg, D.; Gasser, T.; Chen, H.; Yao, C.; Postuma, R.B. Update of the MDS research criteria for prodromal Parkinson’s disease. Mov. Disord. 2019, 34, 1464–1470. [Google Scholar] [CrossRef]
- Godino-Llorente, J.I. (Ed.) Automatic Assessment of Parkinsonian Speech; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Logemann, J.A.; Fisher, H.B.; Boshes, B.; Blonsky, E.R. Frequency and Cooccurrence of Vocal Tract Dysfunctions in the Speech of a Large Sample of Parkinson Patients. J. Speech Heari. Disord. 1978, 43, 47–57. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| initial learning rate | |
| min learning rate | |
| scheduler | cosine annealing with warm restarts—200 epochs |
| batch size | 8 |
| optimizer | AdamW |
| Parameter | Value |
|---|---|
| Total params: | 11,692,525 |
| Trainable params: | 11,692,525 |
| Non-trainable params: | 0 |
| Model size (params + buffers): | 44.65 Mb |
| Framework and CUDA overhead: | 1942.21 Mb |
| Total RAM usage: | 1986.86 Mb |
| Floating Point Operations on forward: | 1.70 GFLOPs |
| Multiply-Accumulations on forward: | 850.23 MMACs |
| Direct memory accesses on forward: | 863.85 MDMAs |
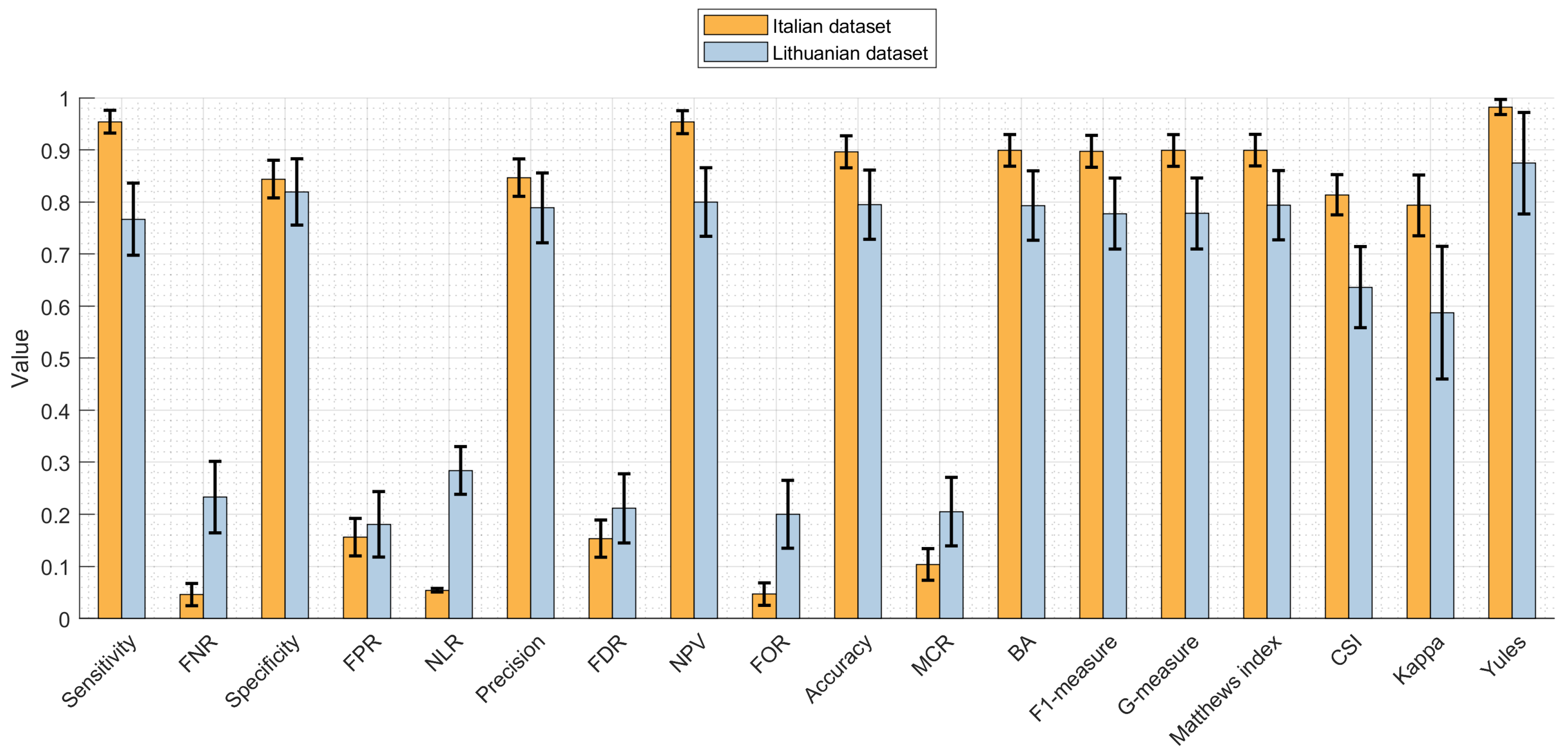
| Parameter | Value (Confidence Range) Italian Dataset | Value (Confidence Range) Lithuanian Dataset |
|---|---|---|
| Sensitivity | 0.9543 (0.9283–0.9720) | 0.7671 (0.6914–0.8300) |
| False Negative rate (FNR) | 0.0457 (0.0285–0.0712) | 0.2329 (0.1706–0.3080) |
| Specificity | 0.8440 (0.8047–0.8771) | 0.8193 (0.7479–0.8753) |
| False Positive rate (FPR) | 0.1560 (0.1231–0.1951) | 0.1807 (0.1255–0.2513) |
| Positive Likelihood Ratio (PLR) | 6.1188 (5.7392–6.5236) | 4.2447 (3.6150–4.9842) |
| Negative Likelihood Ratio (NLR) | 0.0541 (0.0508–0.0577) | 0.2842 (0.2421–0.3338) |
| Precision | 0.8468 (0.8077–0.8796) | 0.7887 (0.7147–0.8489) |
| False discovery rate (FDR) | 0.1532 (0.1206–0.1921) | 0.2113 (0.1518–0.2847) |
| Negative Predictive Value (NPV) | 0.9534 (0.9272–0.9713) | 0.8000 (0.7269–0.8587) |
| False omission rate (FOR) | 0.0466 (0.0292–0.0724) | 0.2000 (0.1420–0.2724) |
| Accuracy | 0.8964 (0.8620–0.9235) | 0.7949 (0.7213–0.8543) |
| Mis-classification Rate (MCR) | 0.1036 (0.0768–0.1377) | 0.2051 (0.1464–0.2780) |
| Balanced Accuracy (BA) | 0.8992 (0.8651–0.9259) | 0.7932 (0.7195–0.8528) |
| F1-measure | 0.8974 (0.8631–0.9244) | 0.7778 (0.7029–0.8393) |
| G-measure (Fowlkes–Mallows index) | 0.8990 (0.8649–0.9258) | 0.7779 (0.7029–0.8394) |
| Matthews index: | 0.8996 (0.8656–0.9263) | 0.7938 (0.7201–0.8533) |
| Critical success index (CSI) | 0.8139 (0.7723–0.8496) | 0.6364 (0.5552–0.7110) |
| Cohen’s Kappa | 0.7935 (0.7351–0.8519) | 0.5874 (0.4599–0.7148) |
| Yule’s coefficient | 0.9825 (0.9628–0.9918) | 0.8745 (0.7453–0.9404) |
| Critical Diagnostic Odds Ratio (DOR) | 1.1326 | 1.2643 |
| Discriminant Power | 2.6066 | 1.4906 |
| Method | Accuracy | Dataset (Language, Availability) |
|---|---|---|
| Sparse kernel transfer learning [59] | 86.72% | UCI repository v.2013 (English, open on request) [91] |
| Linear DL network [68] | 81.67% | Telemonitoring voice dataset (Unspecified, closed) |
| Linear DL network + mRMR feature selection [69] | 99.1% | UCI repository v.2019 (English, open on request) [92] |
| Ensemble classifier [67] | 94.12% | UCI repository v.2019 (English, open on request) [92] |
| Dual-side learning ensemble [60] | 98.41% | LSVT voice rehabilitation dataset [93] |
| LSTM [70] | 97.12% | UCI repository v.2013 (English, open on request) [91] |
| 1D CNN [58] | 87.76% | UCI repository v.2013 (English, open on request) [91] |
| ADCNN [74] | 98.11% | UCI repository v.2013 (English, open on request) [91] |
| Bidirectional LSTM [71] | 75.56% | GYENNO SCIENCE Parkinson Disease Research Center dataset (Chinese, closed) |
| LSTM with SSWA-based attention [72] | 92.5% | Proprietary (Indian, closed) |
| ResNet18 [63] | 91.7% | PC-GITA database (Spanish, open) [94] |
| Alexnet [64] | 91.7% | Dataset of Department of Neurology at the Medical University of Warsaw (Polish, closed) |
| DenseNet161 [65] | 89.75% | mPower PD dataset (English, open) [34] |
| CNN-ANN [61] | 93.10% | Max Little dataset (English, open) |
| Ensemble CNN [62] | 97.3% | PC-GITA database (Spanish, open) [94] |
| CNN with IAIF and QCP [66] | 97.3% | PC-GITA database (Spanish, open) [94] |
| EDF-EMD [73] | 92.59% | Dataset-CPPDD (Chinese, closed) |
| Hybrid U-lossian network (our approach) | 89.64% | LSMU Lithuanian dataset (Lithuanian, open on request) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maskeliūnas, R.; Damaševičius, R.; Kulikajevas, A.; Padervinskis, E.; Pribuišis, K.; Uloza, V. A Hybrid U-Lossian Deep Learning Network for Screening and Evaluating Parkinson’s Disease. Appl. Sci. 2022, 12, 11601. https://doi.org/10.3390/app122211601
Maskeliūnas R, Damaševičius R, Kulikajevas A, Padervinskis E, Pribuišis K, Uloza V. A Hybrid U-Lossian Deep Learning Network for Screening and Evaluating Parkinson’s Disease. Applied Sciences. 2022; 12(22):11601. https://doi.org/10.3390/app122211601
Chicago/Turabian StyleMaskeliūnas, Rytis, Robertas Damaševičius, Audrius Kulikajevas, Evaldas Padervinskis, Kipras Pribuišis, and Virgilijus Uloza. 2022. "A Hybrid U-Lossian Deep Learning Network for Screening and Evaluating Parkinson’s Disease" Applied Sciences 12, no. 22: 11601. https://doi.org/10.3390/app122211601
APA StyleMaskeliūnas, R., Damaševičius, R., Kulikajevas, A., Padervinskis, E., Pribuišis, K., & Uloza, V. (2022). A Hybrid U-Lossian Deep Learning Network for Screening and Evaluating Parkinson’s Disease. Applied Sciences, 12(22), 11601. https://doi.org/10.3390/app122211601