

Small Object Detection in Infrared Images: Learning from Imbalanced Cross-Domain Data via Domain Adaptation


Abstract
1. Introduction
- We propose a framework for small object detection in the infrared domain based on YOLOv5, where target objects can be detected without adding excessive or complex calculations.
- We propose an auxiliary domain classifier with a corresponding training procedure, through which the model can be trained using multi-domain datasets with instance number imbalance.
2. Related Works
2.1. Object Detection
2.2. YOLO
2.3. Small Object Detection
2.4. Infrared Object Detection
2.5. Domain Adaptation
2.6. Knowledge Distillation
3. Materials and Methods
3.1. Model Architecture
3.2. Loss Function
3.2.1. Detection Loss
3.2.2. Domain Loss
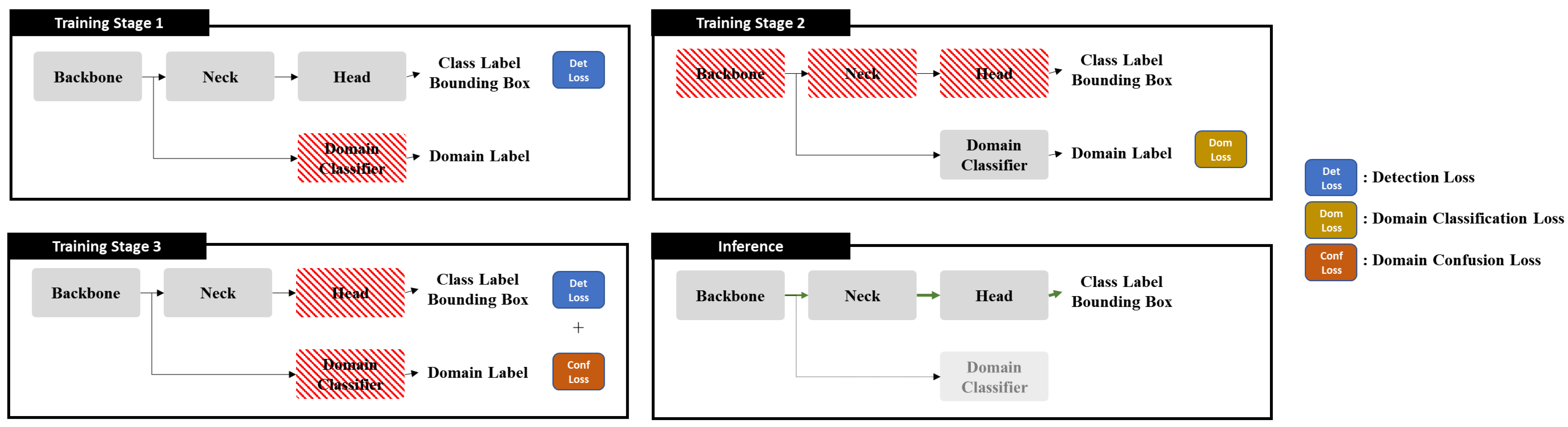
3.3. Training Process
3.4. Datasets
3.4.1. Open Datasets
- Visible Light Datasets: Considering the infrared target application, all visible light images were converted to greyscale via post-processing. For pre-training of the base network, MS COCO [8] was used. Image instances which contained small-sized objects (<30 × 30 pixels) in the vehicle and human (person) categories were chosen. Additionally, the VEDAI [48] and DOTA [49] datasets are used in training. Both datasets are based on aerial imagery containing small objects. Images containing vehicle categories were selected for both training and benchmarks. The size of the target objects were concentrated from 12 × 12 pixels to 25 × 25 pixels.
- Infrared datasets: The Teledyne FLIR Free ADAS Thermal Dataset v2 [47] provides pairs of thermal and visible spectrum images for object detection. Among the instances, images containing people, bikes, cars, buses, and trucks were extracted. The infrared images were additionally annotated as “infrared, real”, and RGB pairs were annotated as “visible light, real” for domain adaptation training.
3.4.2. Synthetic Data Generation
- Synthetic Visible Light Images: Acquiring images and annotating objects are labor-consuming tasks. Although the small target detection datasets in the visible light spectrum are relatively abundant, in such scenarios as aerial surveillance and distant target detection, it is very difficult to generate a dataset for a specific scenario. Therefore, we used Blender to generate synthetic visible-light object detection datasets. Using 3D Google Map data, we simulated real-world terrain and buildings via 3D mesh. The target object images were fused in random locations with automatic annotations of object class and location. Here, 3D models of vehicles were used to obtain more than 20,000 images.
- Synthetic Infrared Images: Capturing infrared images requires professional equipment, making the acquision process very difficult. Although long-wave infrared range (LWIR) images are relatively simple to obtain, obtaining infrared images from other spectra, such as the mid-range infrared range (MWIR), is not an easy task. Therefore, we used the infrared signature simulation software MuSES to render MWIR synthetic images. After giving the material information and environmental conditions to the 3D object modeling software, we placed the object on a grid and rendered corresponding infrared images at each azimuth and elevation angle. The distance between the sensor and object ranged from 20 m to 3 km. Car and tank models were used to obtain object renderings. Additionally, real-world MWIR images were captured using the FLIR A8580 Compact MWIR Camera. A total of 6 scenes comprised of 3000 images were acquired. The simulated infrared target images were fused to these infrared images, yielding a synthetic MWIR dataset.
4. Results and Discussion
4.1. Experiment Environment
4.1.1. Evaluation Criteria
4.1.2. Experimental Results
4.1.3. Ablation Test
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.1093. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Ingham, F.; Poznanski, J.; Fang, J.; Yu, L.; et al. ultralytics/yolov5: v3.1—Bug Fixes and Performance Improvements (v3.1). Zenodo 2020. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Sarda, A.; Dixit, S.; Bhan, A. Object detection for autonomous driving using YOLO [You Only Look Once] algorithm. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1370–1374. [Google Scholar]
- Yi, Z.; Shen, Y.; Zhang, J. An improved tiny-yolov3 pedestrian detection algorithm. Optik 2019, 183, 17–23. [Google Scholar] [CrossRef]
- Chen, W.; Huang, H.; Peng, S.; Zhou, C.; Zhang, C. YOLO-face: A real-time face detector. Vis. Comput. 2020, 37, 805–813. [Google Scholar] [CrossRef]
- Yue, X.; Wang, Q.; He, L.; Li, Y.; Tang, D. Research on Tiny Target Detection Technology of Fabric Defects Based on Improved YOLO. Appl. Sci. 2022, 12, 6823. [Google Scholar] [CrossRef]
- Dos Reis, D.H.; Welfer, D.; De Souza Leite Cuadros, M.A.; Gamarra, D.F.T. Mobile robot navigation using an object recognition software with RGBD images and the YOLO algorithm. Appl. Artif. Intell. 2019, 33, 1290–1305. [Google Scholar] [CrossRef]
- Ju, M.; Luo, H.; Wang, Z.; Hui, B.; Chang, Z. The Application of Improved YOLO V3 in Multi-Scale Target Detection. Appl. Sci. 2019, 9, 3775. [Google Scholar] [CrossRef]
- Teutsch, M.; Kruger, W. Classification of small boats in infrared images for maritime surveillance. In Proceedings of the 2010 International WaterSide Security Conference, Carrara, Italy, 3–5 November 2010; pp. 1–7. [Google Scholar]
- Ma, T.; Yang, Z.; Wang, J.; Sun, S.; Ren, X.; Ahmad, U. Infared small target dection network with generate label and feature mapping. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection snip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3578–3587. [Google Scholar]
- Singh, B.; Najibi, M.; Sharma, A.; Davis, L.S. Scale Normalized Image Pyramids with AutoFocus for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3749–3766. [Google Scholar] [CrossRef] [PubMed]
- Benjumea, A.; Teeti, I.; Cuzzolin, F.; Bradley, A. YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles. arXiv 2021, arXiv:2112.11798. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric contextual modulation for infrared small target detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 950–959. [Google Scholar]
- McIntosh, B.; Venkataramanan, S.; Mahalanobis, A. Infrared Target Detection in Cluttered Environments by Maximization of a Target to Clutter Ratio (TCR) Metric Using a Convolutional Neural Network. IEEE Trans. Aerosp. Electron. Syst. 2020, 57, 485–496. [Google Scholar] [CrossRef]
- Varol, G.; Romero, J.; Martin, X.; Mahmood, N.; Black, M.J.; Laptev, I.; Schmid, C. Learning from synthetic humans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 109–117. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef] [PubMed]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Moran, J.; Haibo, L.; Zhongbo, W.; Miao, H.; Zheng, C.; Bin, H. Improved YOLO V3 algorithm and its application in small target detection. Acta Opt. Sin. 2019, 39, 0715004. [Google Scholar] [CrossRef]
- Xu, Q.; Lin, R.; Yue, H.; Huang, H.; Yang, Y.; Yao, Z. Research on Small Target Detection in Driving Scenarios Based on Improved Yolo Network. IEEE Access 2020, 8, 27574–27583. [Google Scholar] [CrossRef]
- Cui, J.; Hou, X. Transmission line fault detection based on YOLOv4 with attention mechanism. Foreign Electron. Meas. Technol. 2021, 40, 24–29. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Rivest, J.; Fortin, R. Detection of dim targets in digital infrared imagery by morphological image processing. Opt. Eng. 1996, 35, 1886–1893. [Google Scholar] [CrossRef]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. In Signal and Data Processing of Small Targets 1999; SPIE: Bellingham, CA, USA, 1999; pp. 74–83. [Google Scholar]
- Han, J.; Moradi, S.; Faramarzi, I.; Zhang, H.; Zhao, Q.; Zhang, X.; Li, N. Infrared small target detection based on the weighted strengthened local contrast measure. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1670–1674. [Google Scholar] [CrossRef]
- Shao, Y.; Zhang, X.; Chu, H.; Zhang, X.; Zhang, D.; Rao, Y. AIR-YOLOv3: Aerial Infrared Pedestrian Detection via an Improved YOLOv3 with Network Pruning. Appl. Sci. 2022, 12, 3627. [Google Scholar] [CrossRef]
- Liu, X.; Li, F.; Liu, S. Improved SSD infrared image pedestrian detection algorithm. Electro Opt. Control 2020, 20, 42–49. [Google Scholar]
- Dai, X.; Duan, Y.; Hu, J.; Liu, S.; Hu, C.; He, Y.; Chen, D.; Luo, C.; Meng, J. Near infrared nighttime road pedestrians recognition based on convolutional neural network. Infrared Phys. Technol. 2019, 97, 25–32. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Domain adaptation for large-scale sentiment classification: A deep learning approach. In Proceedings of the ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3339–3348. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Strong-weak distribution alignment for adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6956–6965. [Google Scholar]
- He, Z.; Zhang, L. Multi-adversarial faster-rcnn for unrestricted object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6668–6677. [Google Scholar]
- Sasagawa, Y.; Nagahara, H. Yolo in the dark-domain adaptation method for merging multiple models. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 345–359. [Google Scholar]
- Hnewa, M.; Radha, H. Multiscale domain adaptive yolo for cross-domain object detection. arXiv 2021, arXiv:2106.01483. [Google Scholar]
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning efficient object detection models with knowledge distillation. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Han, Y.; Liu, X.; Sheng, Z.; Ren, Y.; Han, X.; You, J.; Liu, R.; Luo, Z. Wasserstein loss-based deep object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 998–999. [Google Scholar]
- FLIR Systems, Inc. Free Flir Thermal Dataset for Algorithm Training. Available online: https://www.flir.com/oem/adas/adas-dataset-agree (accessed on 5 March 2022.).
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLOv3 | YOLOv4 | YOLOv5 | |
|---|---|---|---|
| Neural Network Type | Full convolution | Full convolution | Full convolution |
| Backbone | Darknet-53 | Darknet-53 | CSPDarknet-53 |
| Neck | FPN | PANet | PANet |
| Head | YOLO Layer | YOLO Layer | YOLO Layer |
| Loss Function | Binary Cross-entropy | Binary Cross-entropy | Binary Cross-entropy and Logit Loss Function |
| Dataset | Image Count |
|---|---|
| MS COCO [8] | 3231 |
| FLIR ADAS [47] | 3086 |
| VEDAI [48] | 2538 |
| DOTA [49] | 1680 |
| Generated Visible Light | 21,225 |
| Generated Infrared | 3000 |
| Model | mAP |
|---|---|
| YOLOv5 | 41.3 |
| Faster-RCNN | 31.5 |
| YOLO-Z | 32.4 |
| Proposed | 64.7 |
| Model | mAP |
|---|---|
| YOLOv5 | 39.3 |
| Faster-RCNN | 21.7 |
| YOLO-Z | 26.7 |
| Proposed | 57.5 |
| Model | Task | mAP |
|---|---|---|
| Base Only | Human Detection | 41.3 |
| Base + WL | Human Detection | 43.7 |
| Base + WL + DA | Human Detection | 64.7 |
| Base Only | Vehicle Detection | 39.3 |
| Base + WL | Vehicle Detection | 45.9 |
| Base + WL + DA | Vehicle Detection | 57.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Huh, J.; Park, I.; Bak, J.; Kim, D.; Lee, S. Small Object Detection in Infrared Images: Learning from Imbalanced Cross-Domain Data via Domain Adaptation. Appl. Sci. 2022, 12, 11201. https://doi.org/10.3390/app122111201
Kim J, Huh J, Park I, Bak J, Kim D, Lee S. Small Object Detection in Infrared Images: Learning from Imbalanced Cross-Domain Data via Domain Adaptation. Applied Sciences. 2022; 12(21):11201. https://doi.org/10.3390/app122111201
Chicago/Turabian StyleKim, Jaekyung, Jungwoo Huh, Ingu Park, Junhyeong Bak, Donggeon Kim, and Sanghoon Lee. 2022. "Small Object Detection in Infrared Images: Learning from Imbalanced Cross-Domain Data via Domain Adaptation" Applied Sciences 12, no. 21: 11201. https://doi.org/10.3390/app122111201
APA StyleKim, J., Huh, J., Park, I., Bak, J., Kim, D., & Lee, S. (2022). Small Object Detection in Infrared Images: Learning from Imbalanced Cross-Domain Data via Domain Adaptation. Applied Sciences, 12(21), 11201. https://doi.org/10.3390/app122111201