
ACapMed: Automatic Captioning for Medical Imaging


Abstract
:1. Introduction
- A new approach to generate vocabulary for text generation and encoding was constructed from medical concepts and image captions.
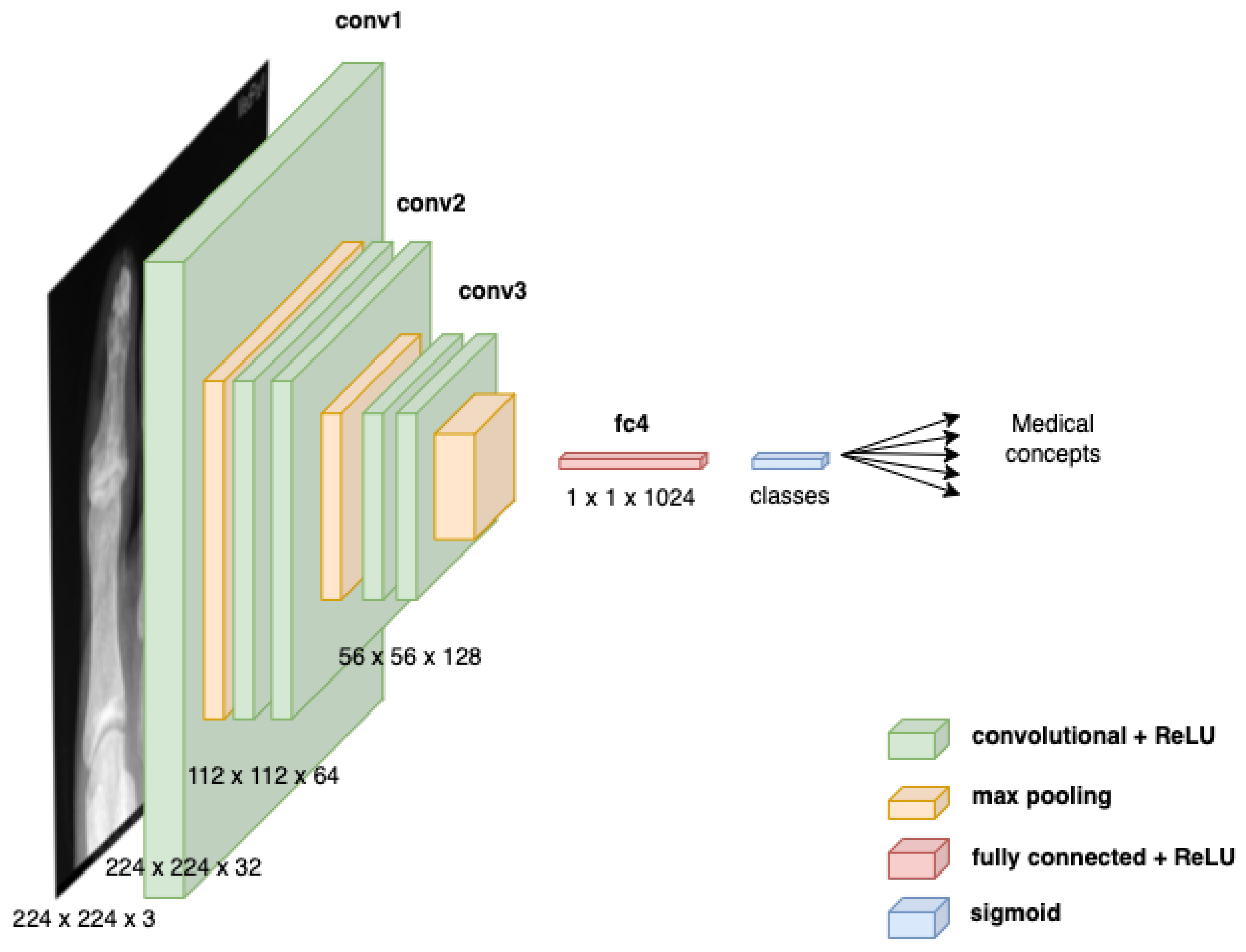
- A multi-label classification MLC model based on VGG-16 is proposed to detect medical concepts from images.
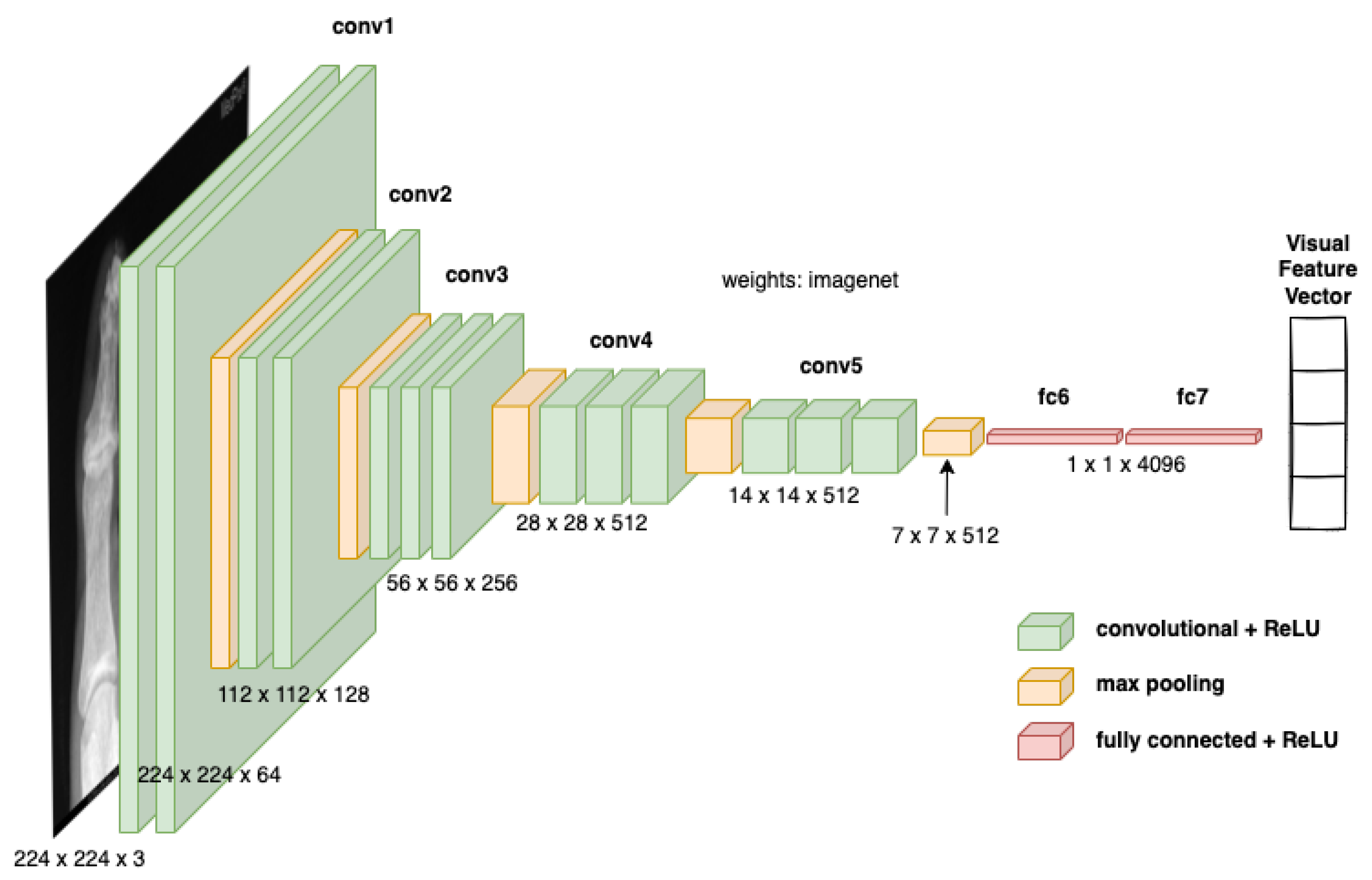
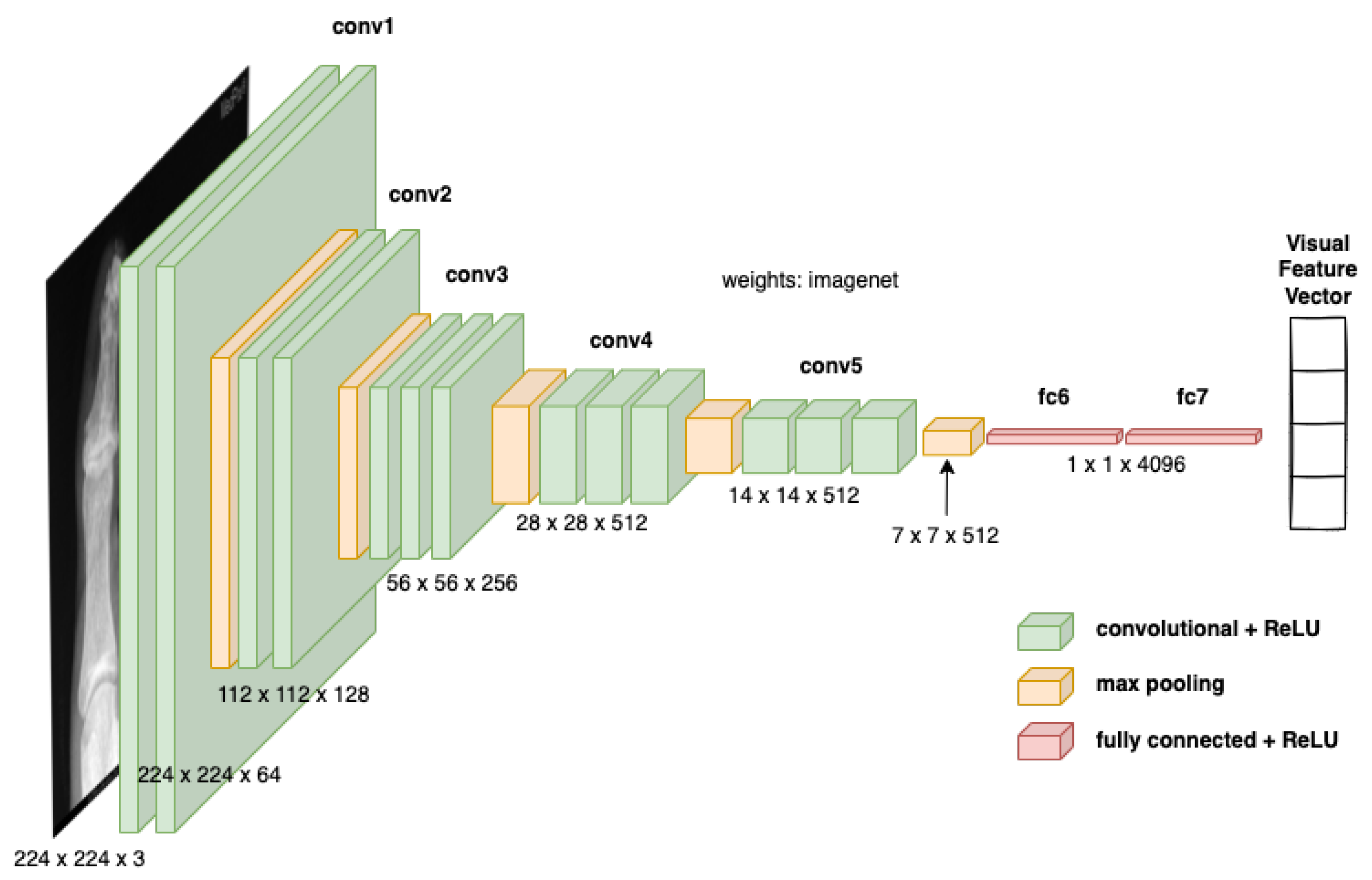
- A pre-trained VGG-16 network was employed to extract visual features from medical images.
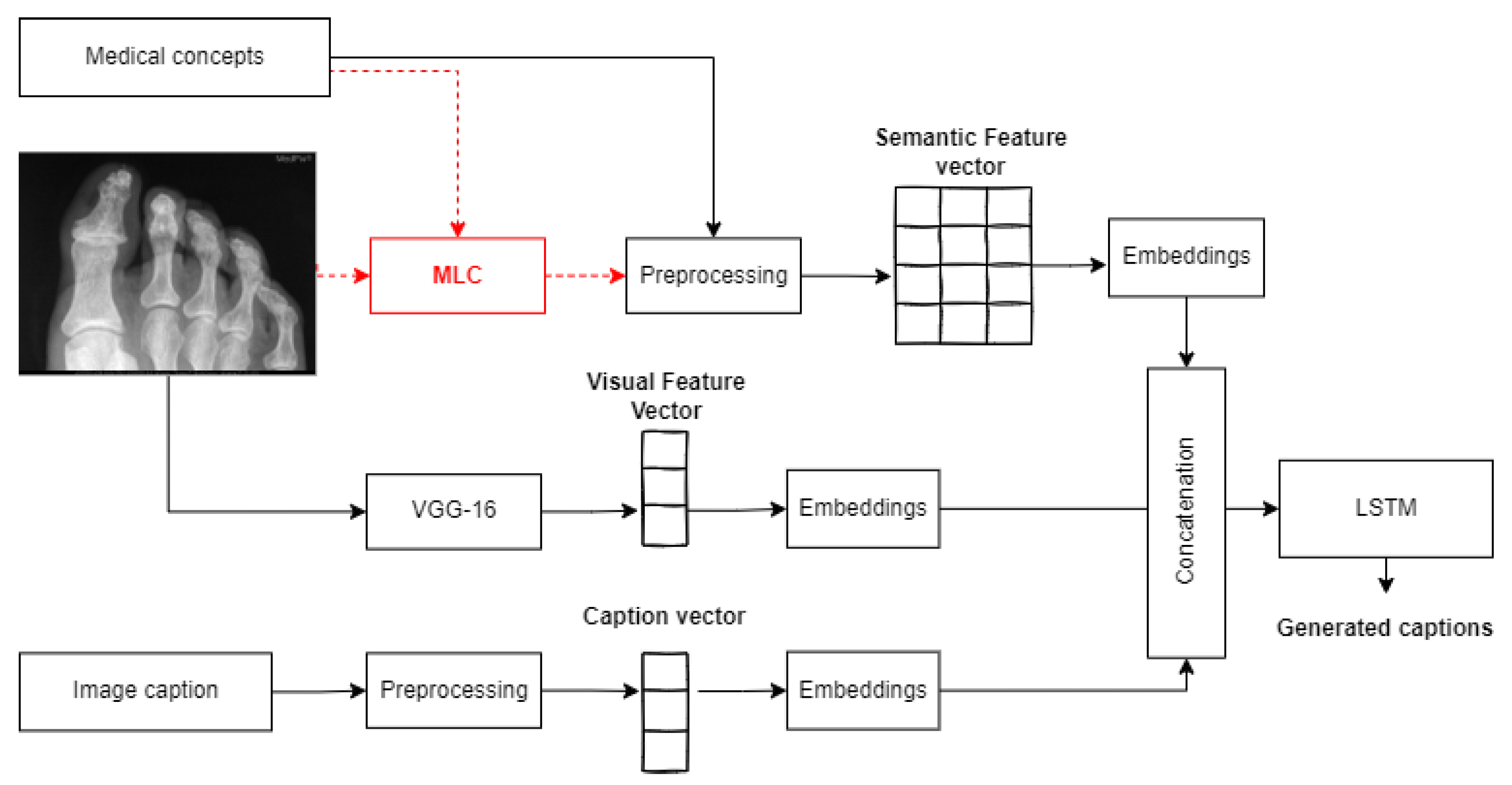
- An end-to-end deep learning-based network was employed for text generation, fusing visual and semantic features extracted from images as well as their associated medical concepts. The model merges different networks: MLC for semantic feature encoding, VGG-16 for visual feature extraction, caption embedding, and an LSTM network for caption generation.
- A beam search was employed alongside LSTM to accurately select the best words among the list of predicted words for caption construction.
- An ablation study was conducted to investigate the impacts of each component of the proposed model in the overall performance.
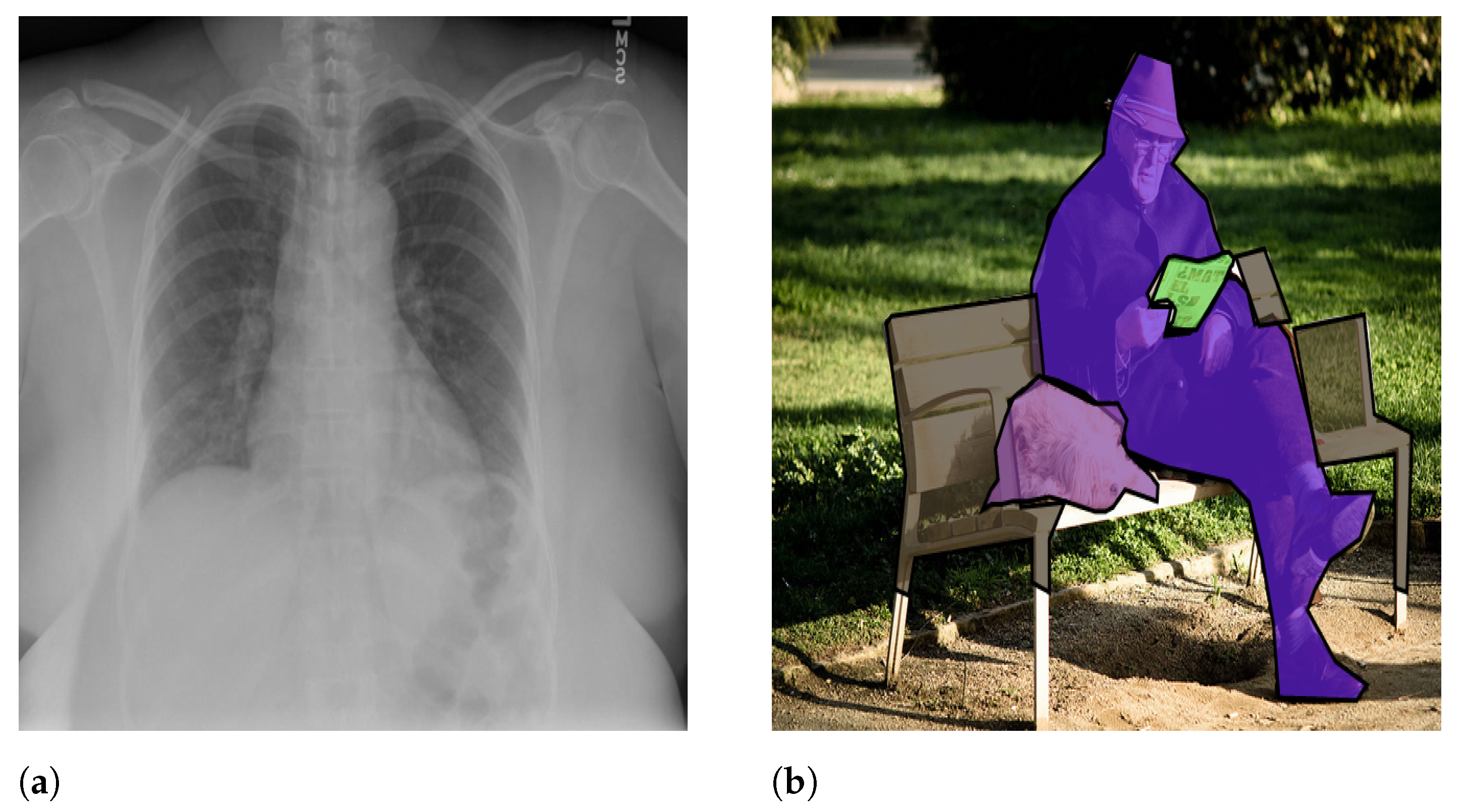
2. Background
- Template-based techniques: Exploit objects or attributes detected from images and use grammar rules and constraints to generate captions [10]. Templates are filled out with specific text that better enhance the distinction between normal and abnormal findings. The generated captions are often small, grammatically correct, and hard-coded, constraining the variety and flexibility of the outputs [3]. For instance, Onita et al. [11] used kernel ridge regression combined with classification to map a given image to words, describing the content from a dictionary; the authors investigated how text and the feature extraction model could influence the captioning performance. They evaluated their proposal on the PadChest dataset (https://bimcv.cipf.es/bimcv-projects/padchest/, accessed on 2 October 2022).
- Retrieval-based techniques: Are based on the retrieval of images visually similar to the input image from a large dataset, and use their captions to construct a new caption for the input image [10]. Retrieved captions are either combined to create a completely new caption or the most similar caption is employed as a substitute for the new caption. For instance, Xuwen Wang [12] proposed using the Lucene Image Retrieval (LIRE) system to extract similar images of given medical images based on their underlying concepts, which were detected using a multi-label classifier and a topic modeling method. Then, semantic annotated concepts were combined with the body parts of images to cluster them into different groups. The proposed technique could be extended to retrieve the most relevant captions of the inputted image from captions of images of its class.
- Deep learning-based techniques: Rely on the end-to-end trainable networks to extract automatic features from images and map them into meaningful text [3]. Since deep learning-based models performed very well for many other domains, this category is the most investigated in image captioning as well. These techniques include encoder–decoder architectures, fully connected networks, and CNNs [10]. The existing methods in the literature are basically inspired by the show-and-tell model [13], an encoder–decoder model for image captioning. The proposed technique is based on a visual feature extractor (the encoder), which is usually a CNN network, and a text generator, which is an RNN network (the decoder). This model is further improved to deal with medical images and to focus on important parts of the image (parts where the most significant features are obtained) using attention mechanisms. For instance, the authors of Zeng et al. [1] proposed detecting lesion areas, extracting automatic visual features from them, diagnosing pathological information, and reporting the findings from medical images using an encoder–decoder architecture. Similarly, Yin et al. [14] employed a deep CNN-based multi-label classifier as the encoder and a hierarchical RNN as the decoder. First, the model detects abnormalities in medical images, which are then used to generate long medical annotations based on an attention mechanism. Likewise, Beddiar et al. [15] exploited the show–attend–tell model [16] (extension of the show-and-tell model, using attention mechanisms) and changed the decoder with a GRU network for medical image captioning. In contrast to encoder–decoder architectures, visual and semantic features were fused and exploited to generate captions in merged models. In general, merged models employ CNN for visual feature extraction and an RNN for textual features. Then, textual and visual features are merged to assign a new caption to a given medical image. Obviously, they constitute a variant of encoder–decoder architecture with the fusion of textual information. For instance, Wang et al. [17] employed a joint representation of image–text pairs calculated using a variational autoencoder model for medical report generation. They used a topic model theory to model semantic topics of images that were exploited, in addition to deep fuzzy logic rules designed based on diagnosis logic, to summarize and interpret abnormalities in medical images. Likewise, Al Duhayyim et al. [18] proposed using encoding and decoding architectures for the generation of effective captions where SSA-based hyperparameter optimizers in both parts were used to attain effective results.
3. Materials and Methods
3.1. Visual Feature Encoding
3.2. Semantic Feature Encoding
3.2.1. Text Pre-Processing
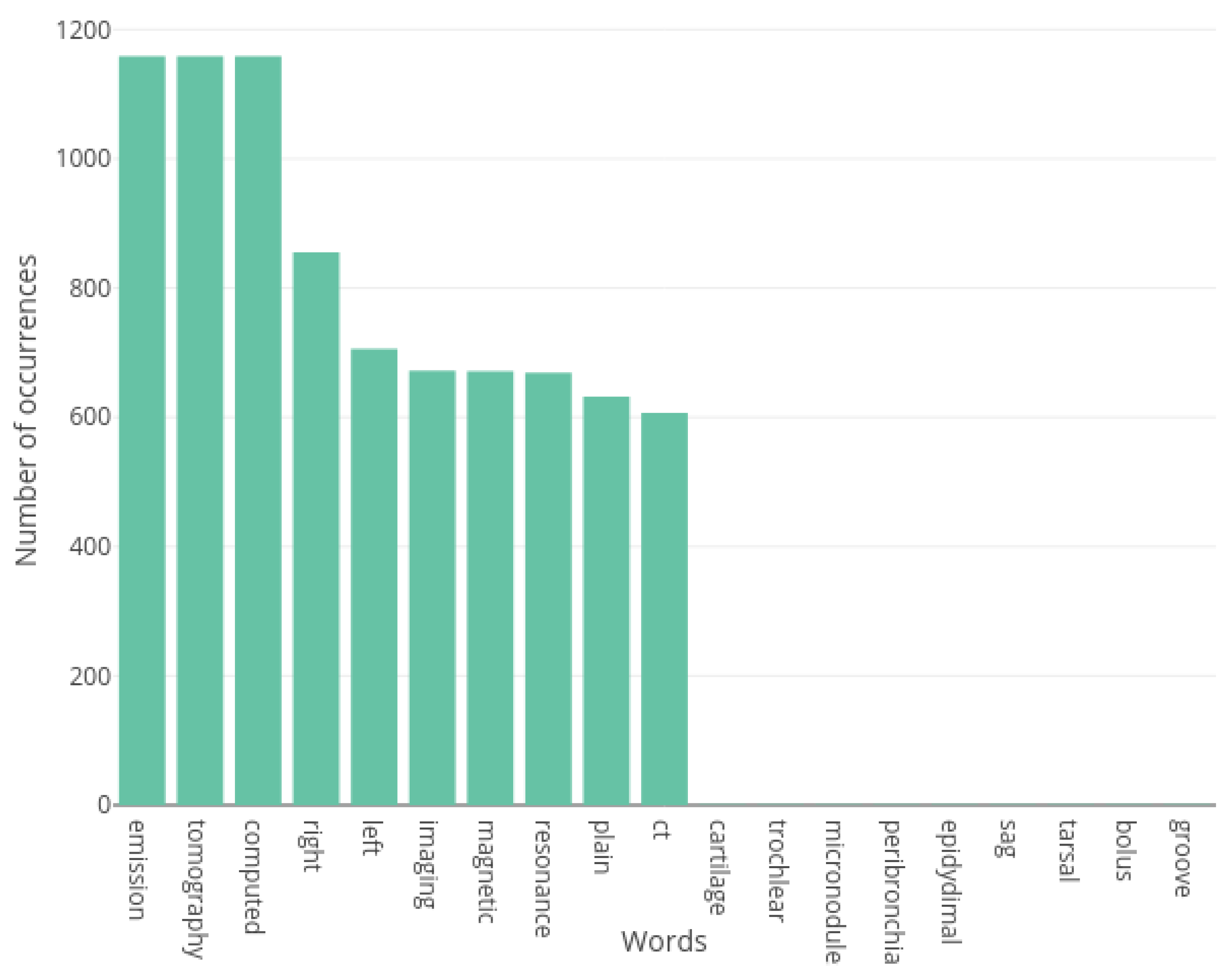
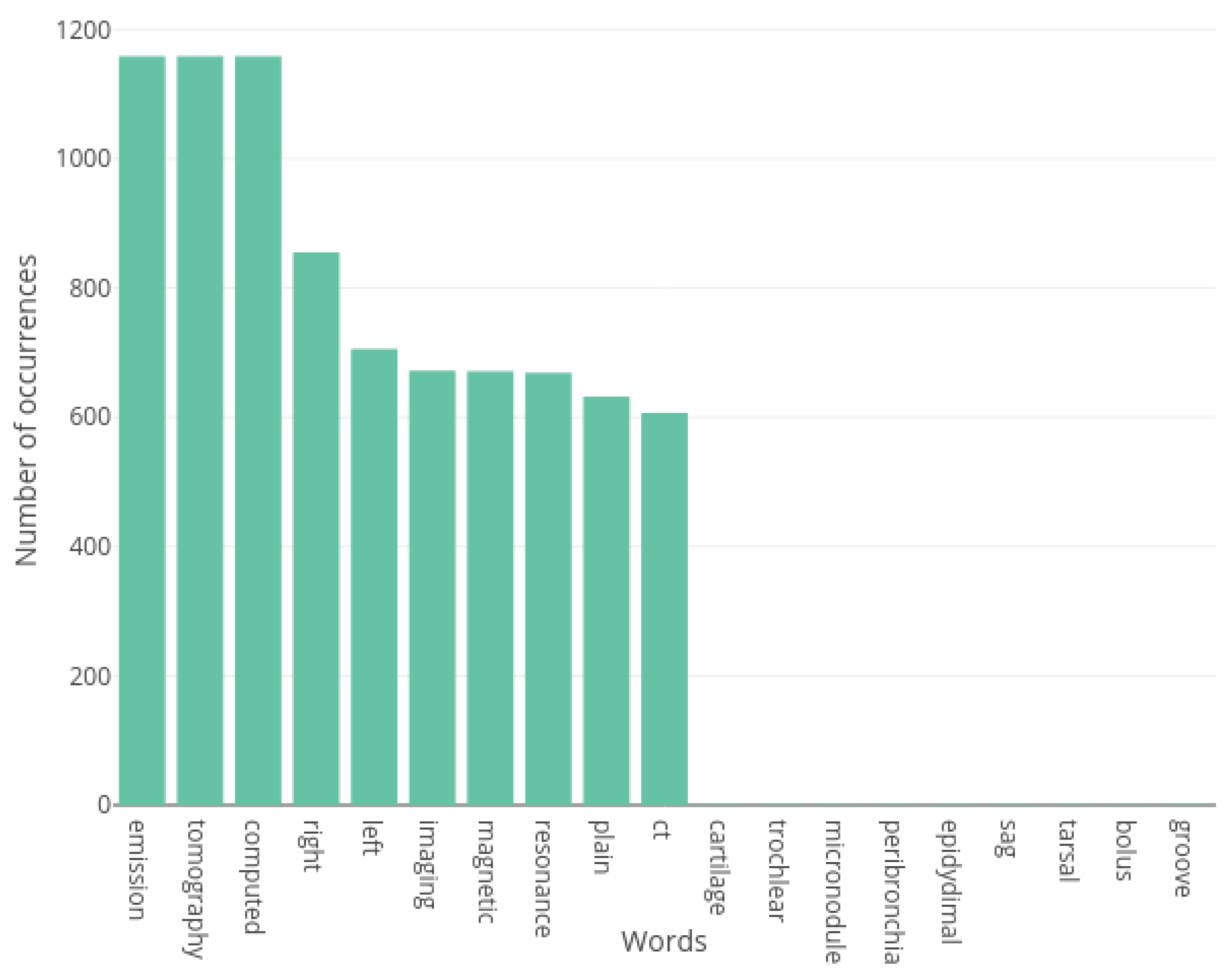
3.2.2. Vocabulary Construction
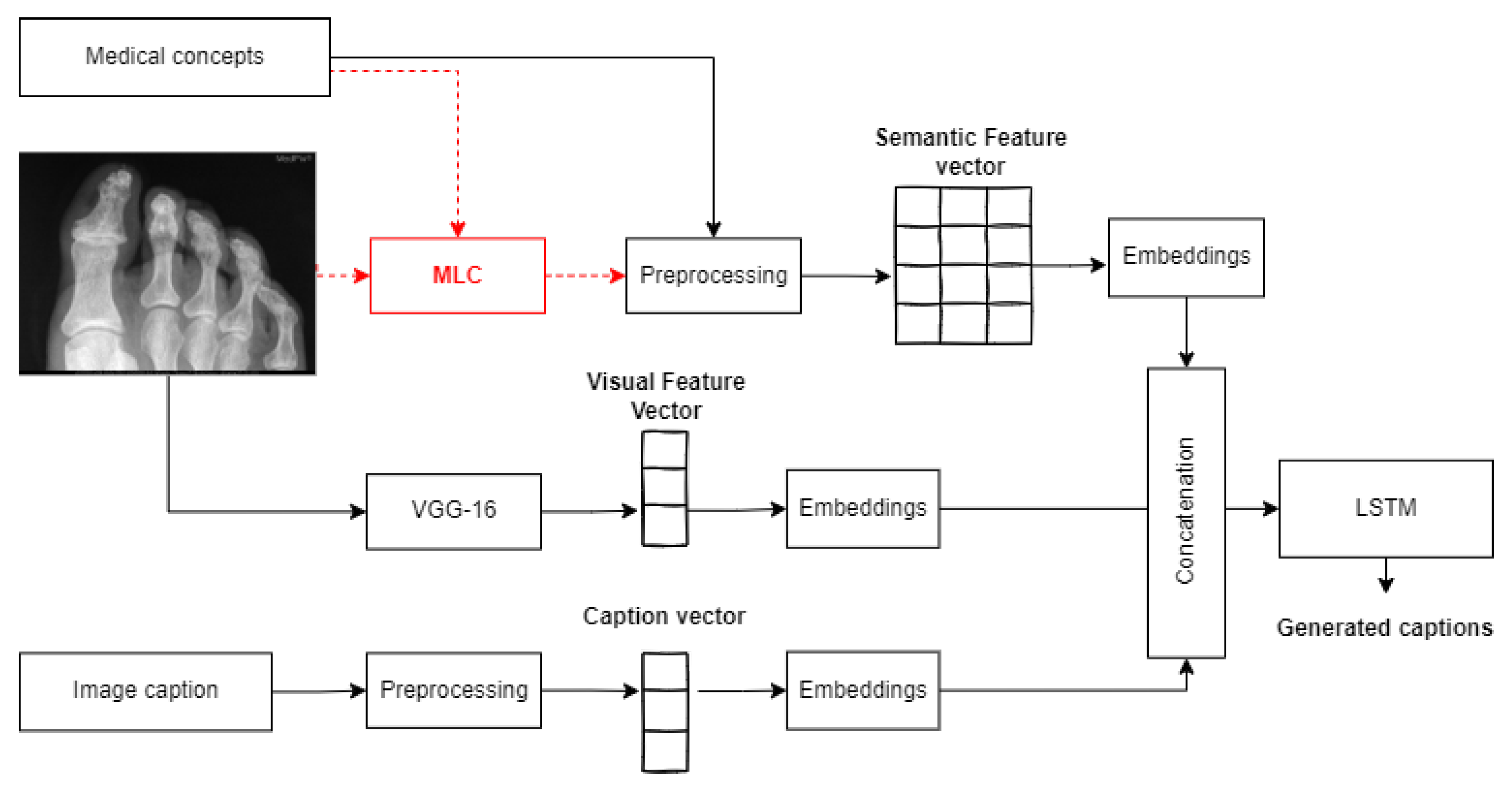
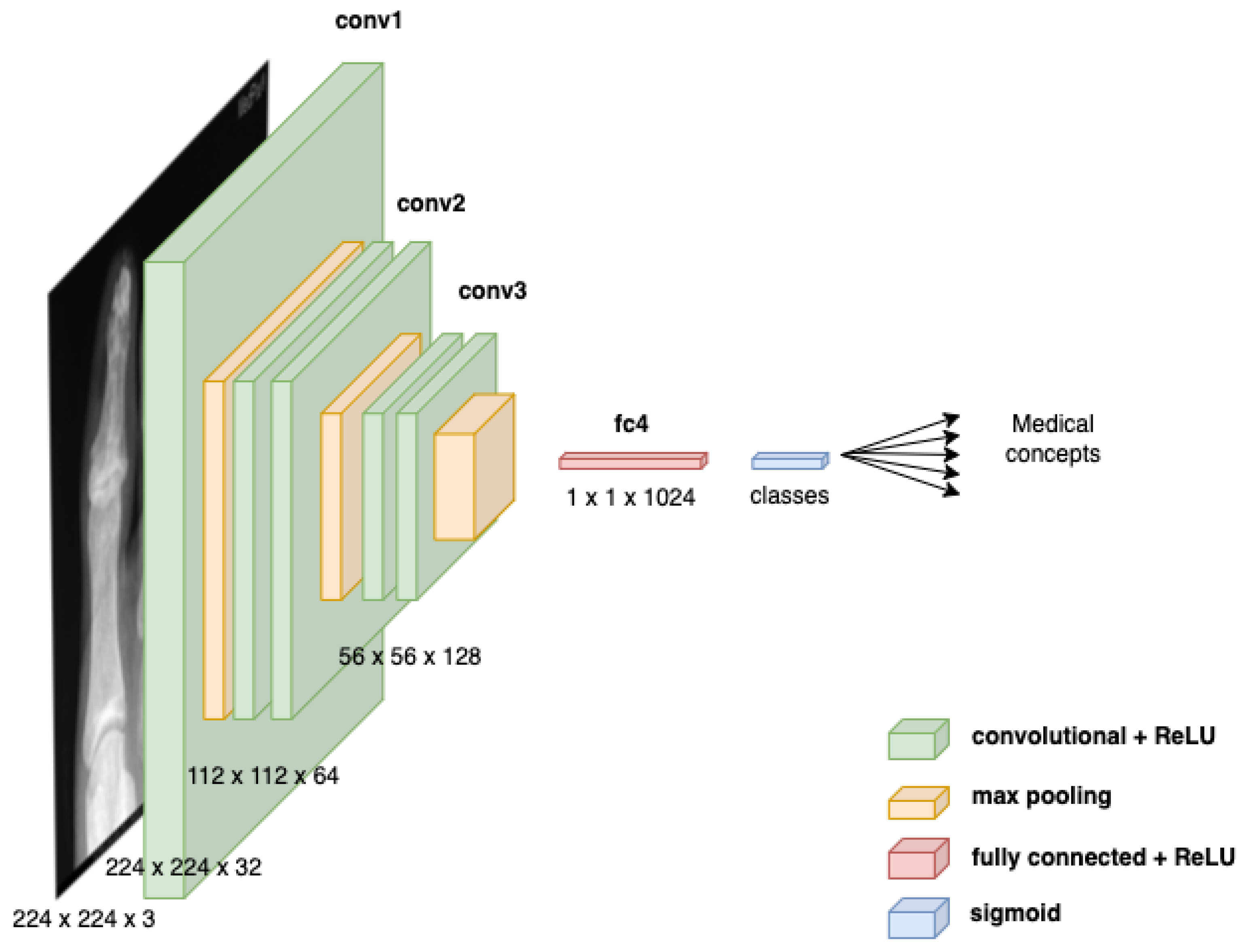
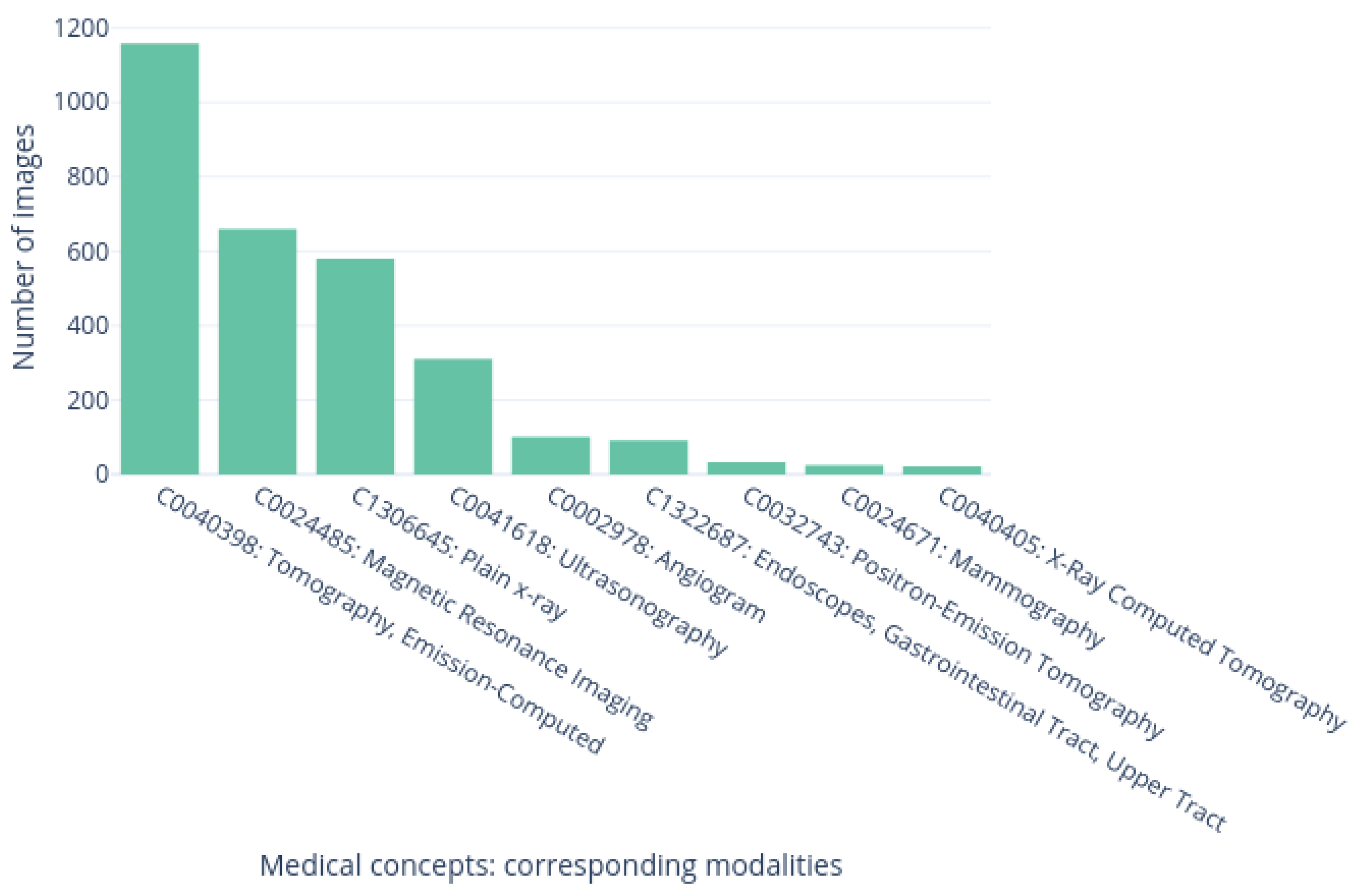
3.2.3. Multi-Label Classification for Medical Concept Detection
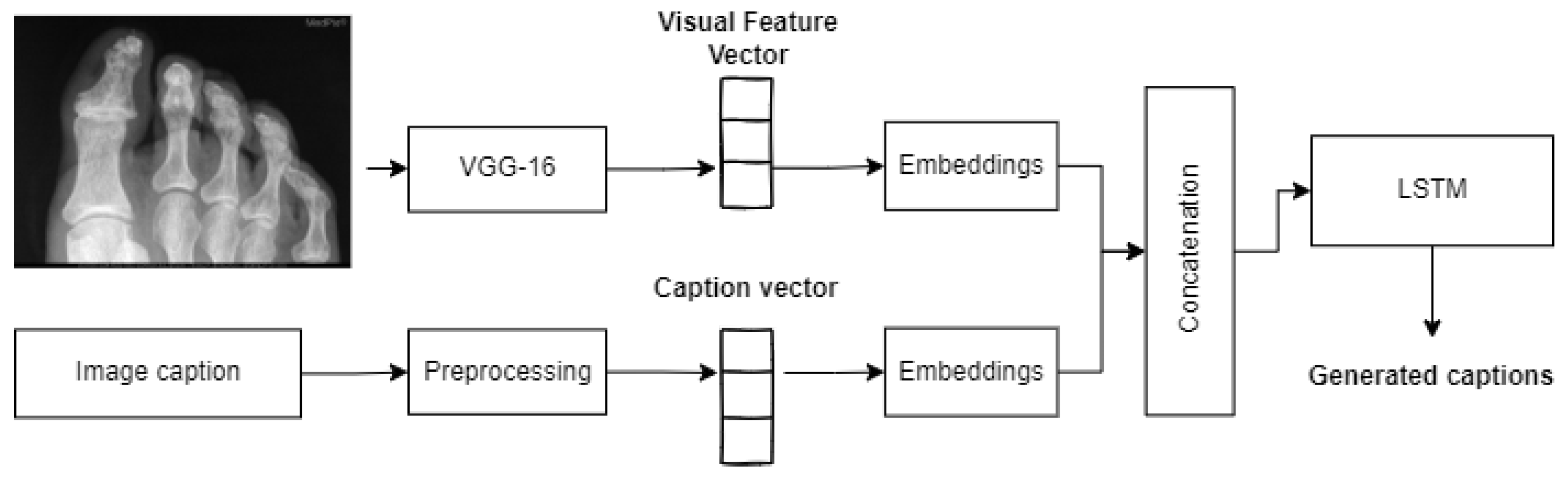
3.3. Captioning Model
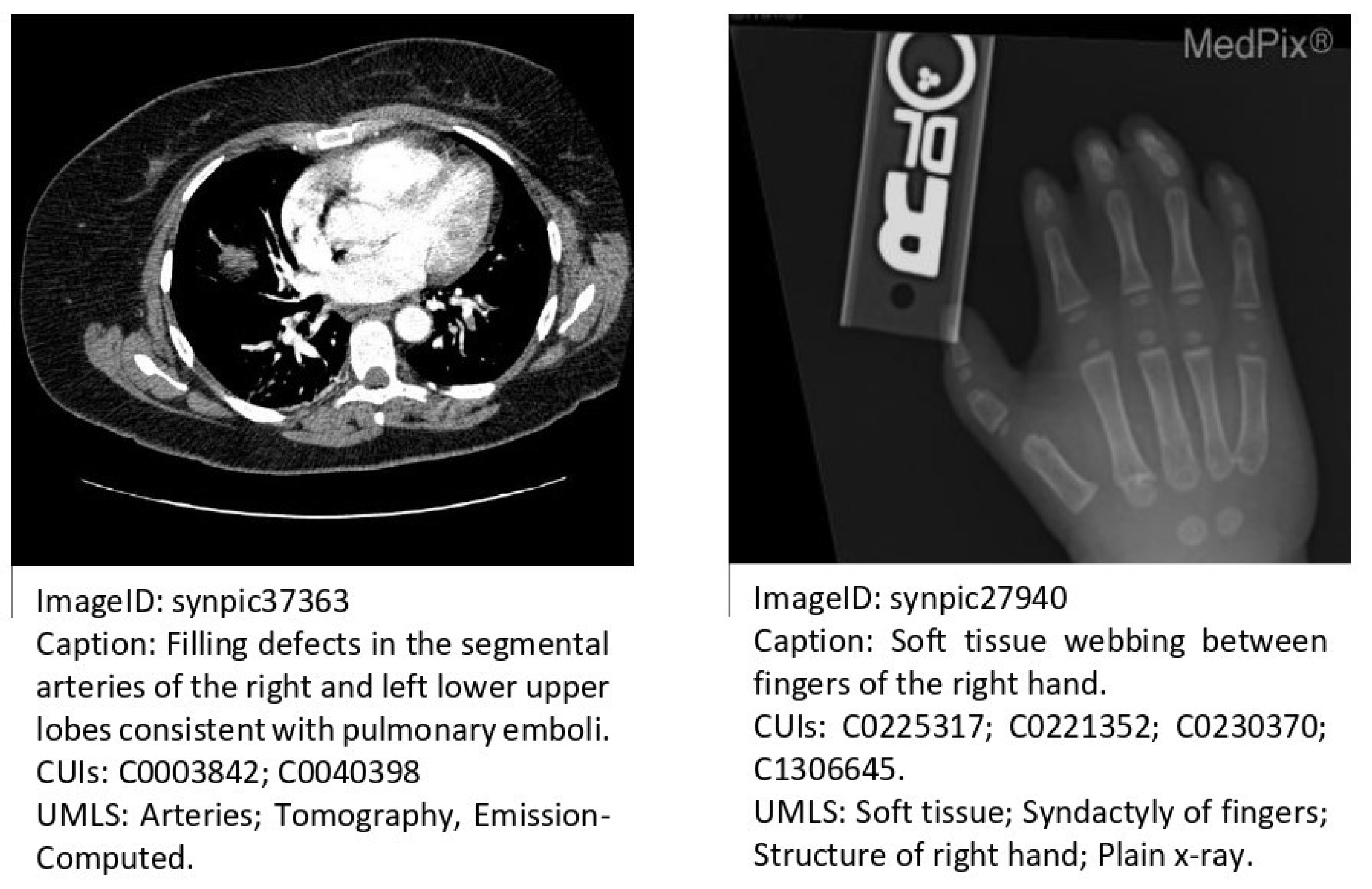
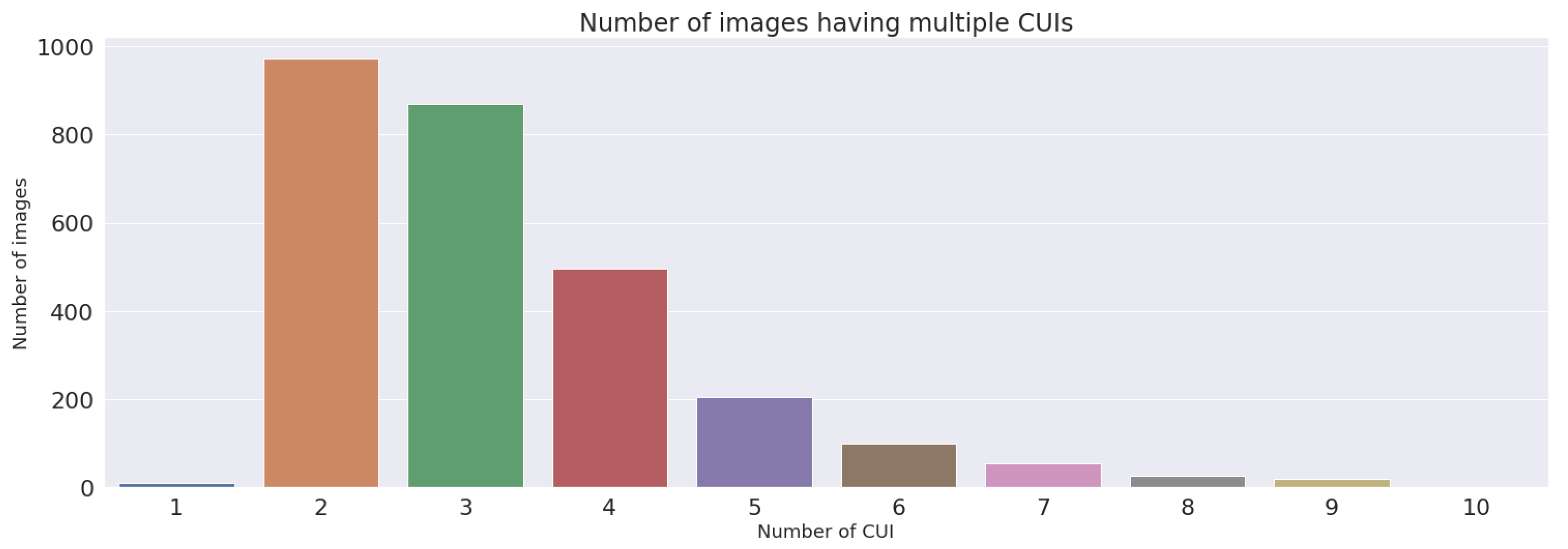
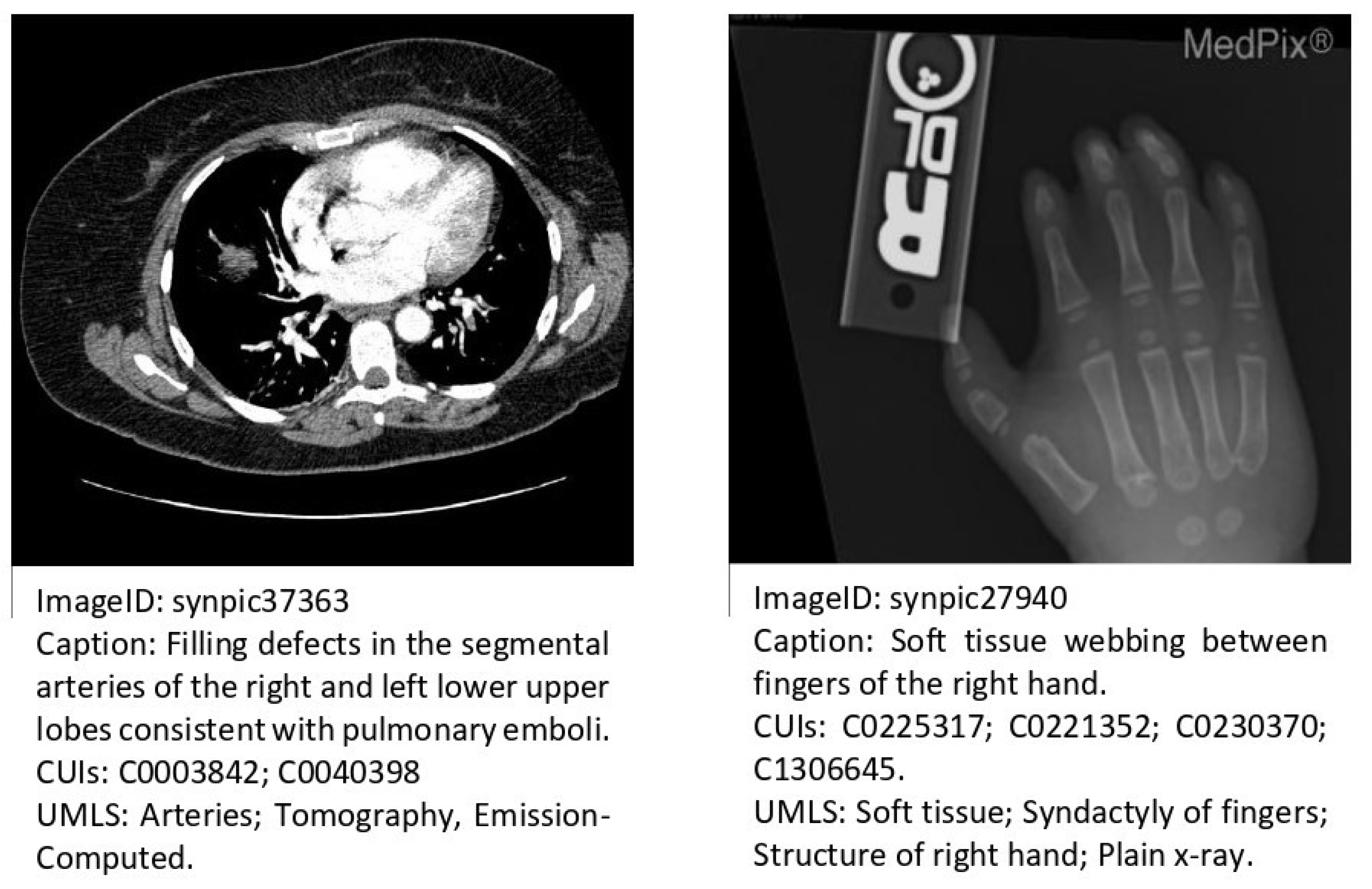
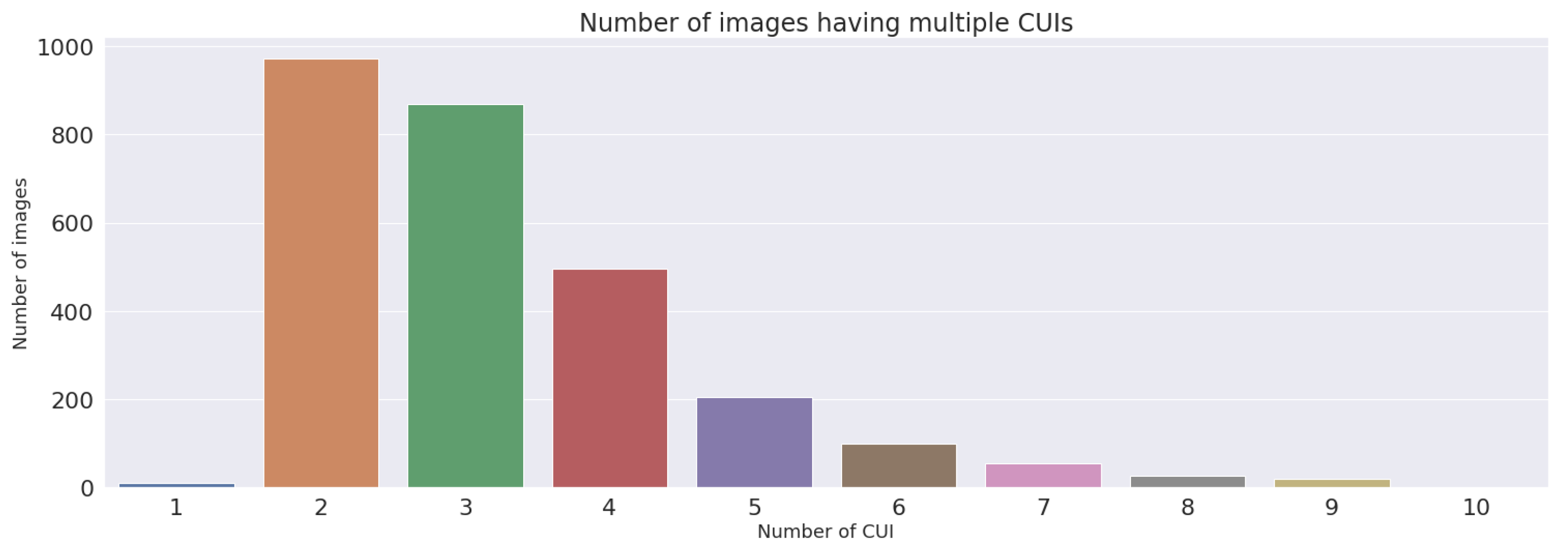
3.4. Dataset
3.5. Evaluation Metrics
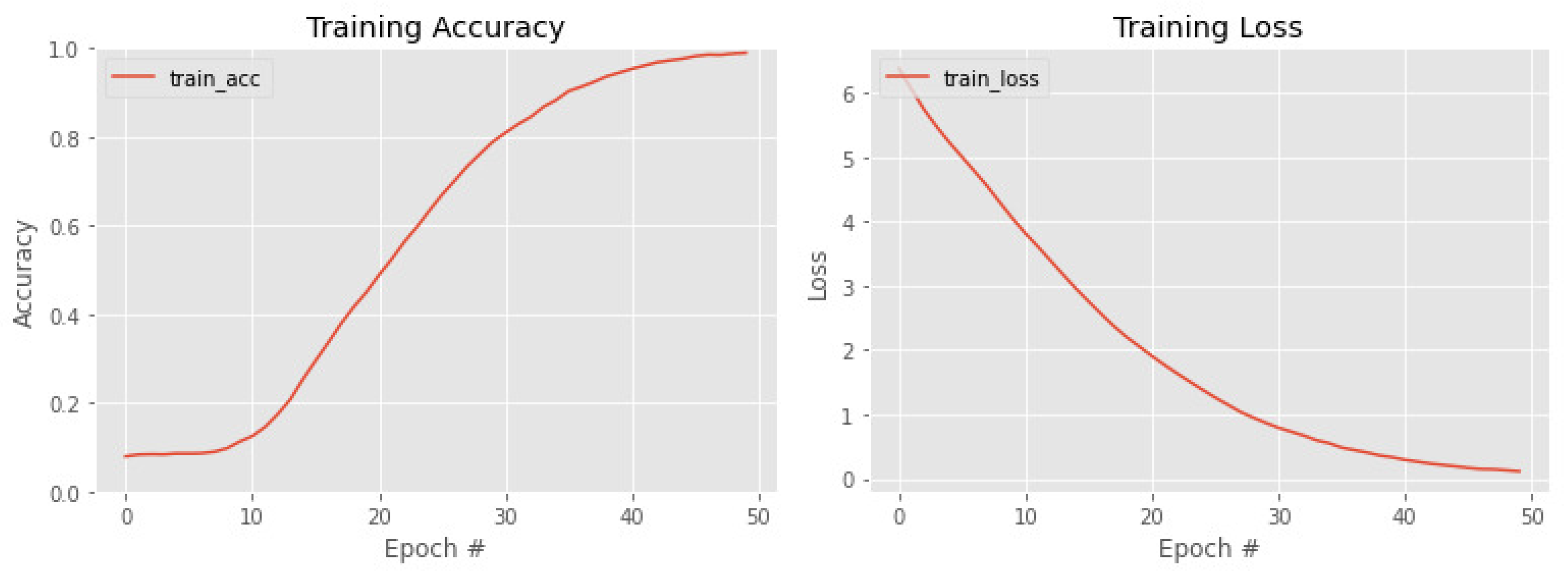
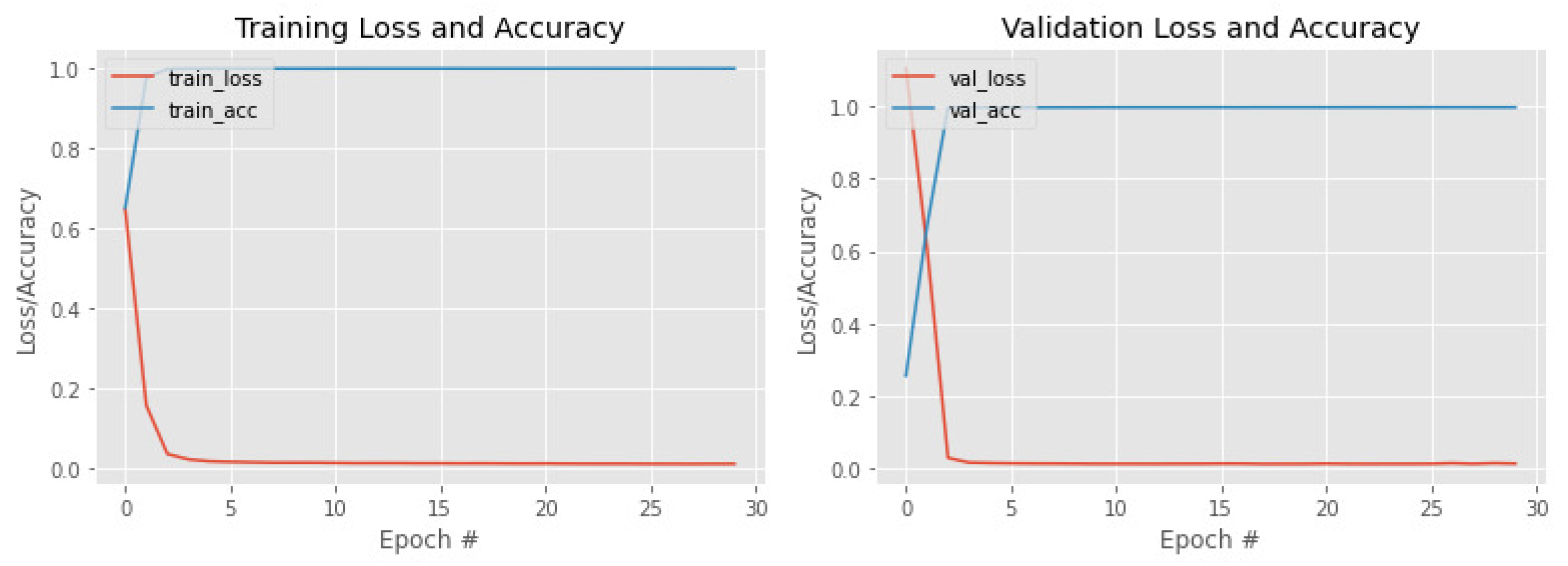
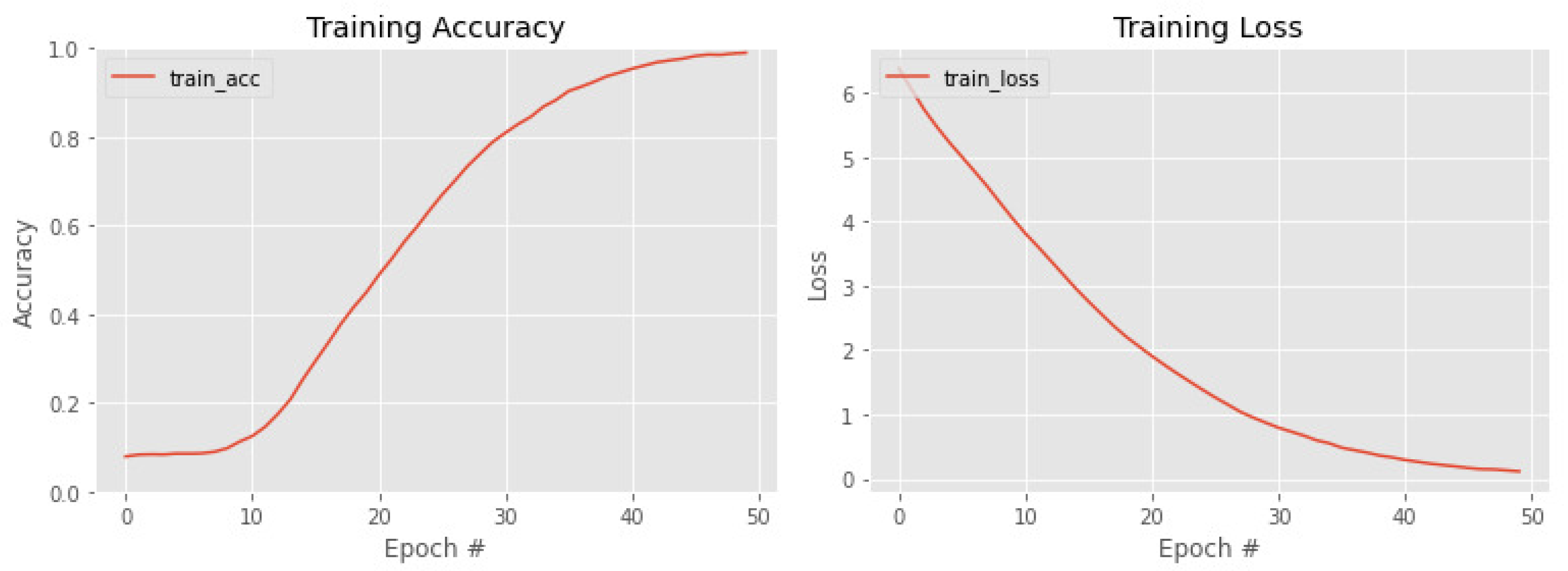
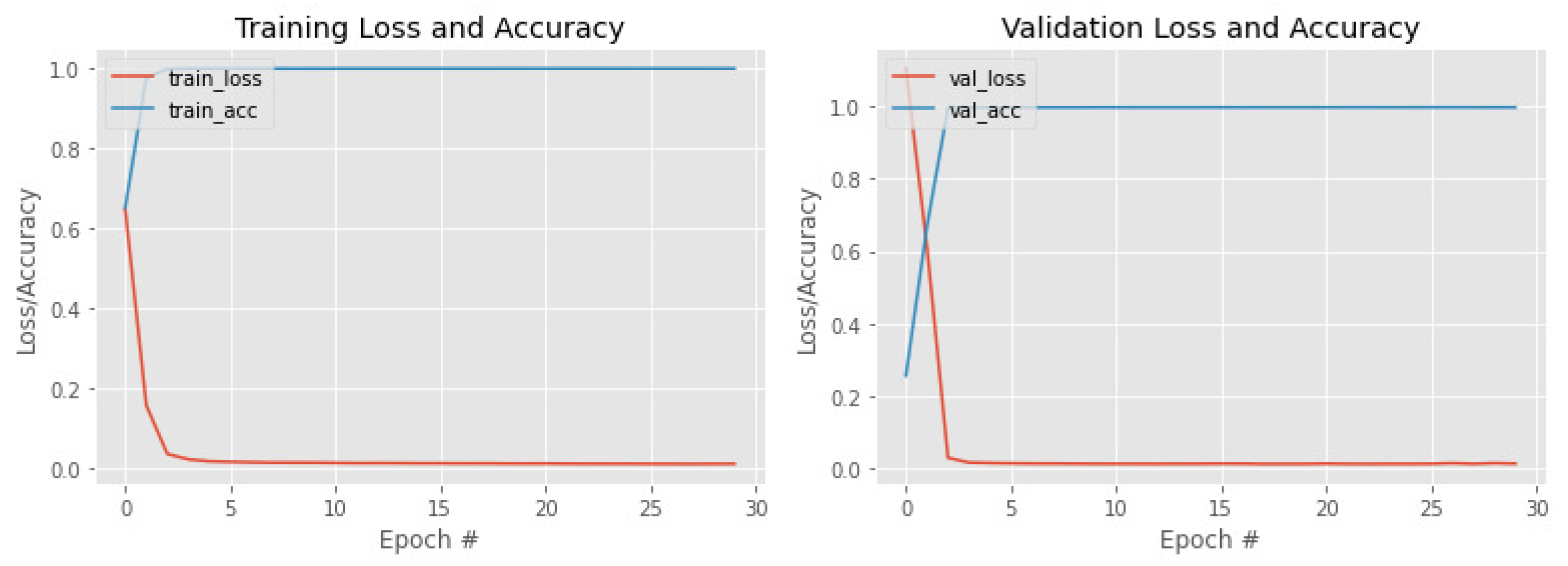
4. Results
Ablation Study
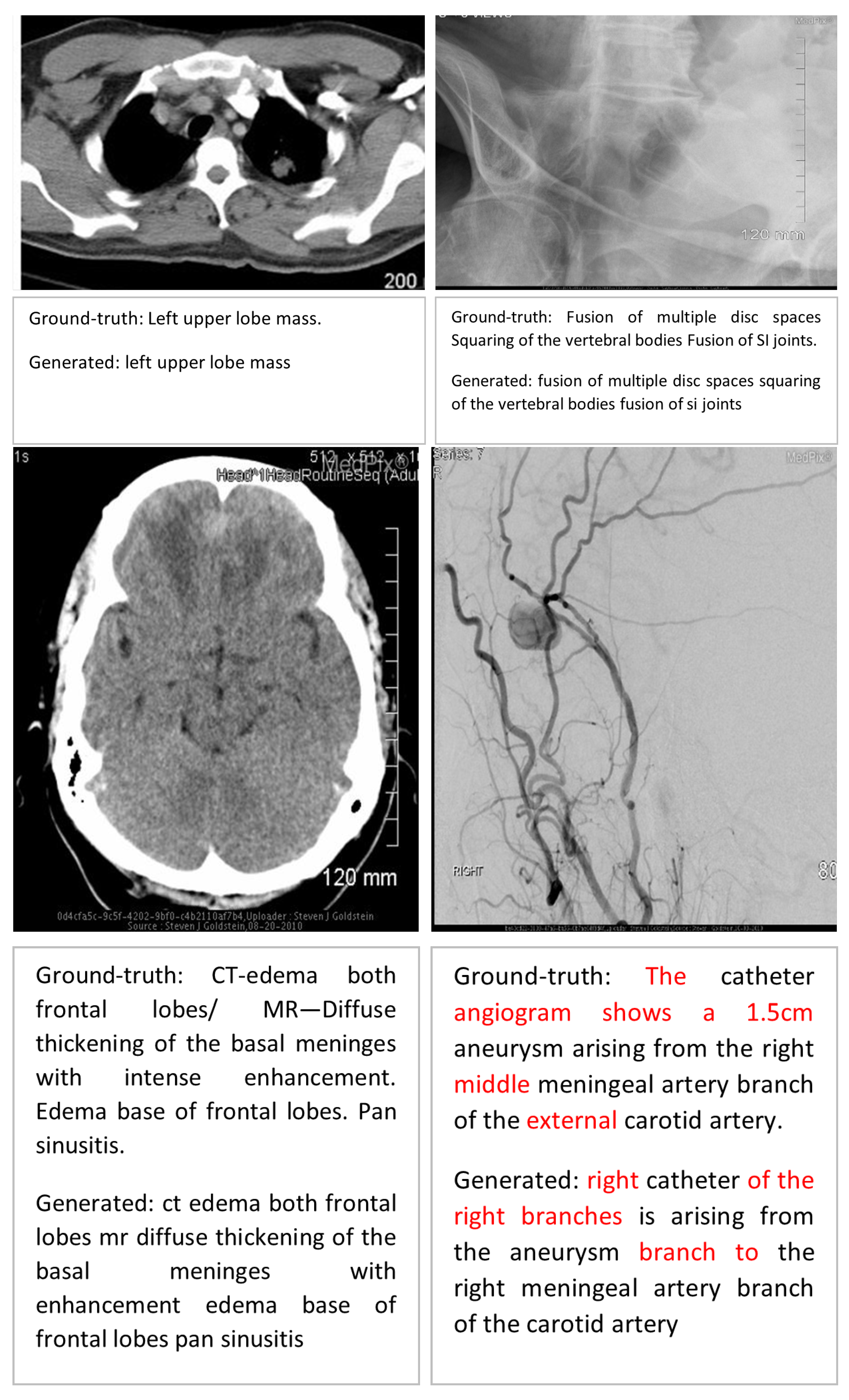
5. Discussion
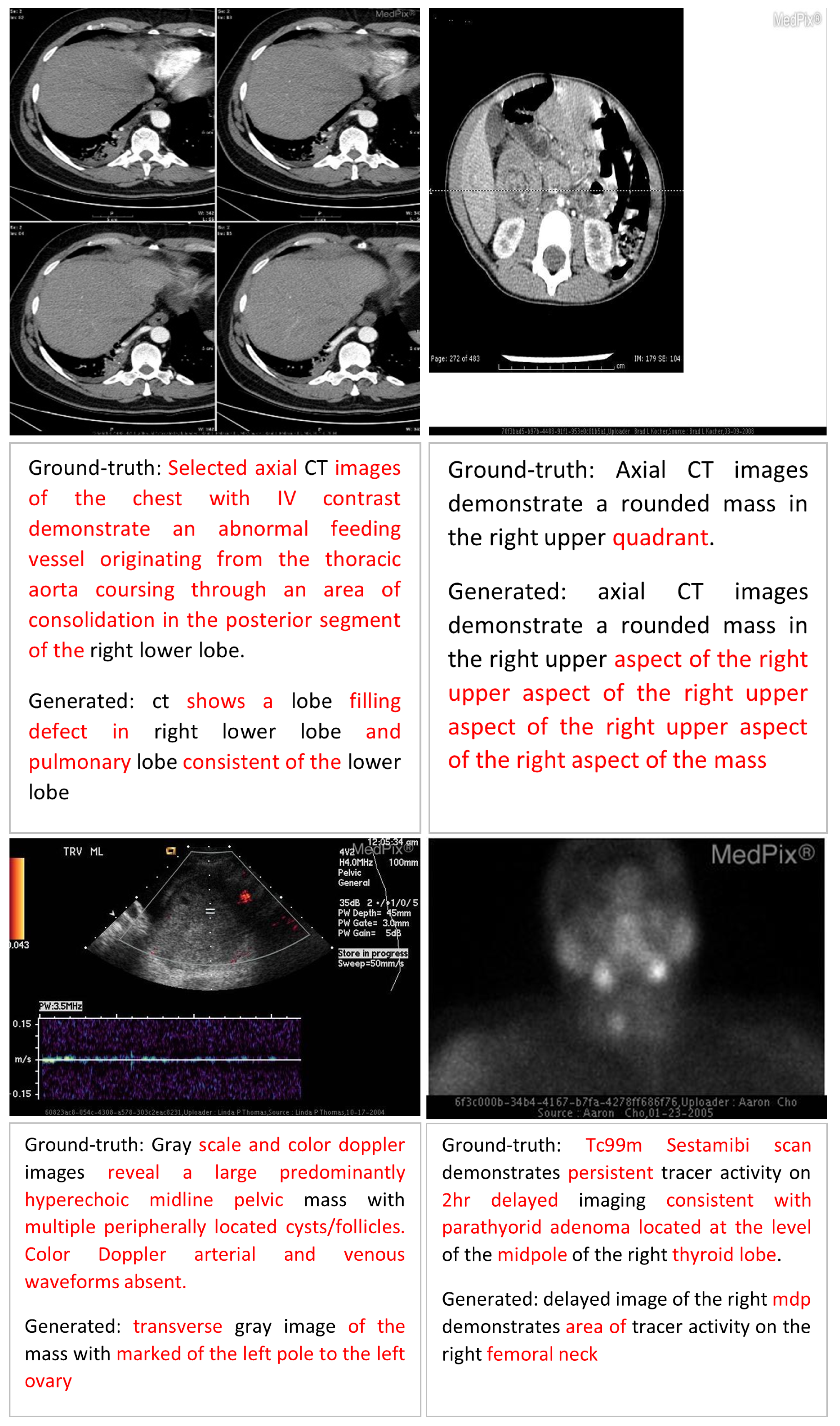
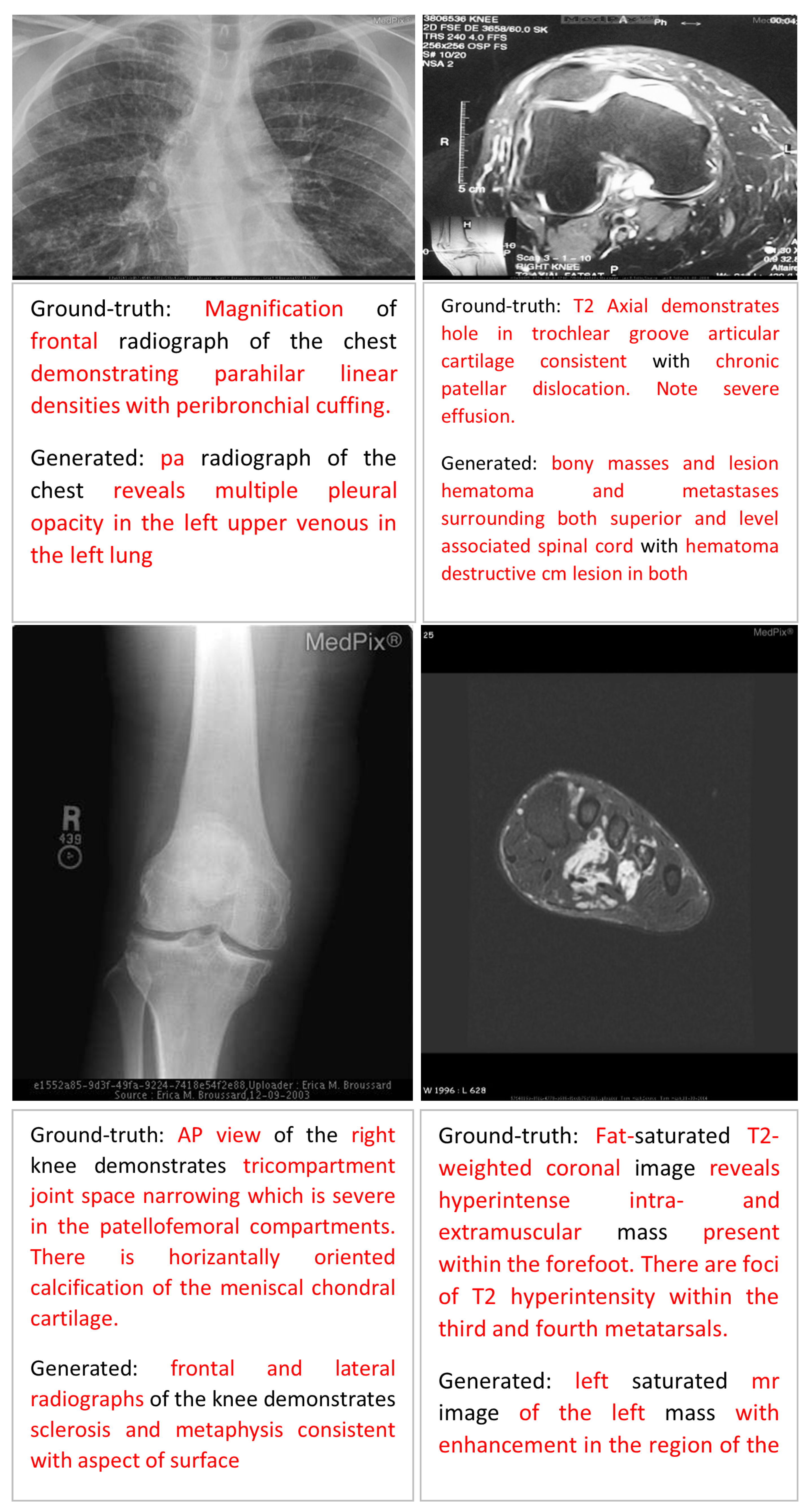
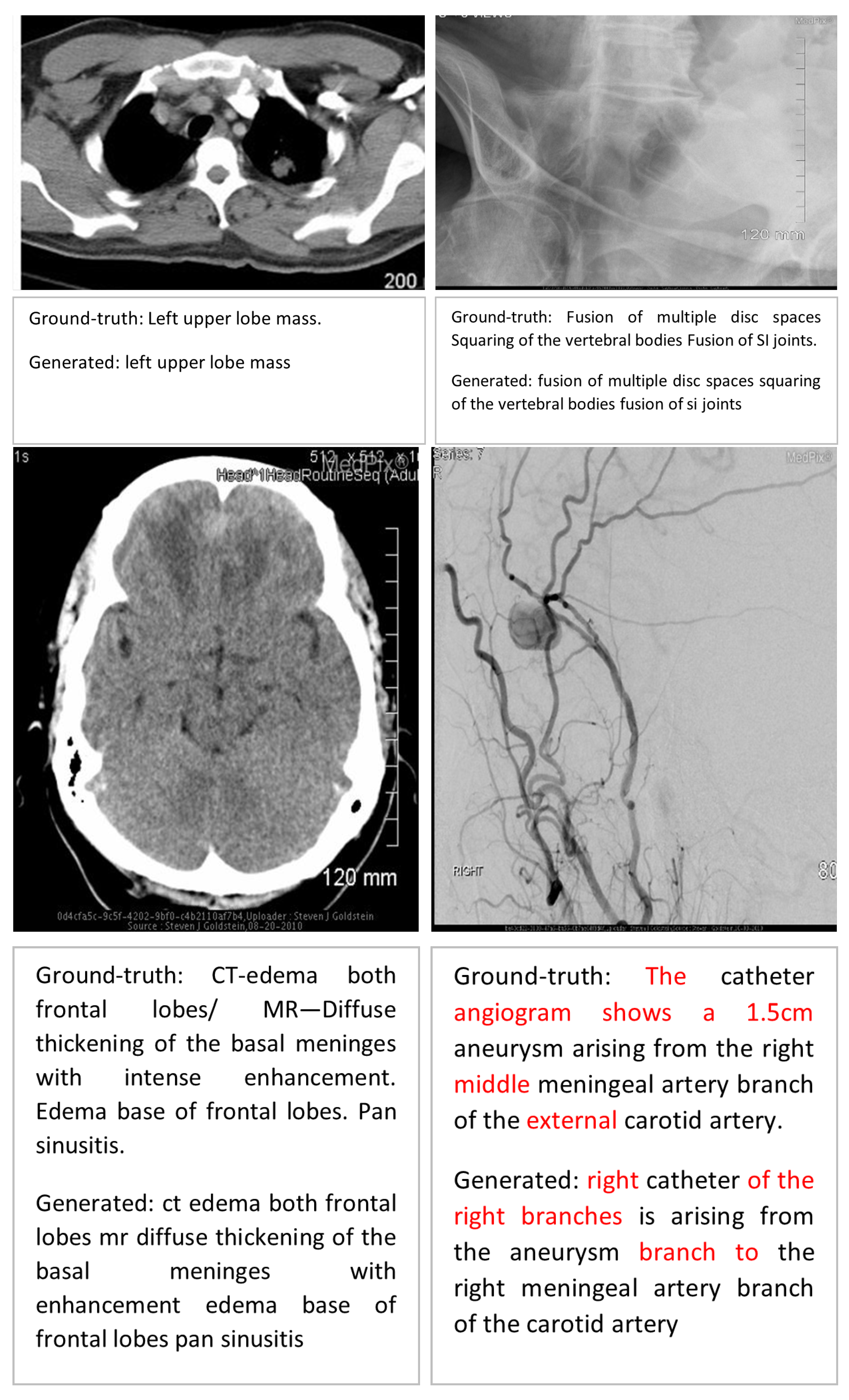
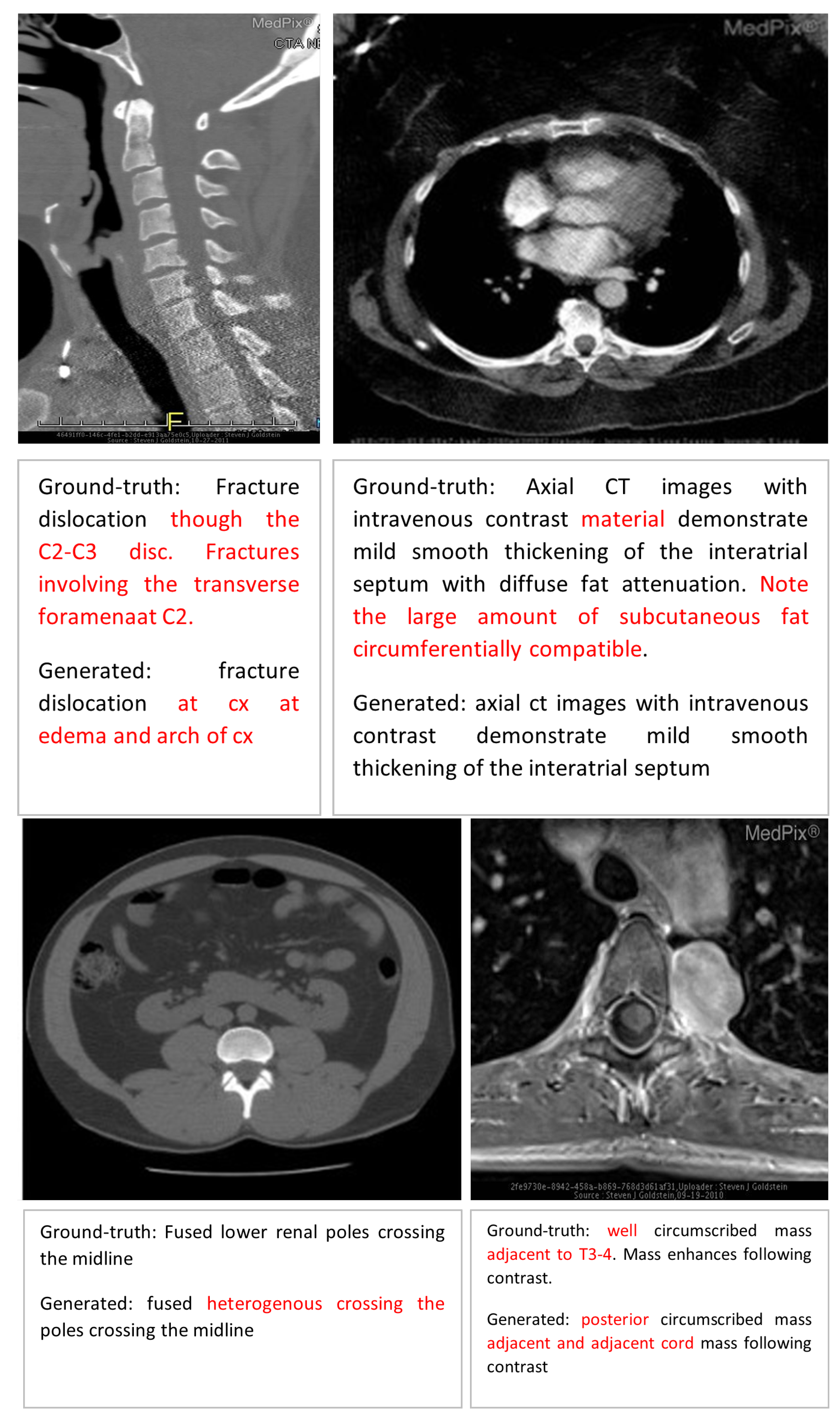
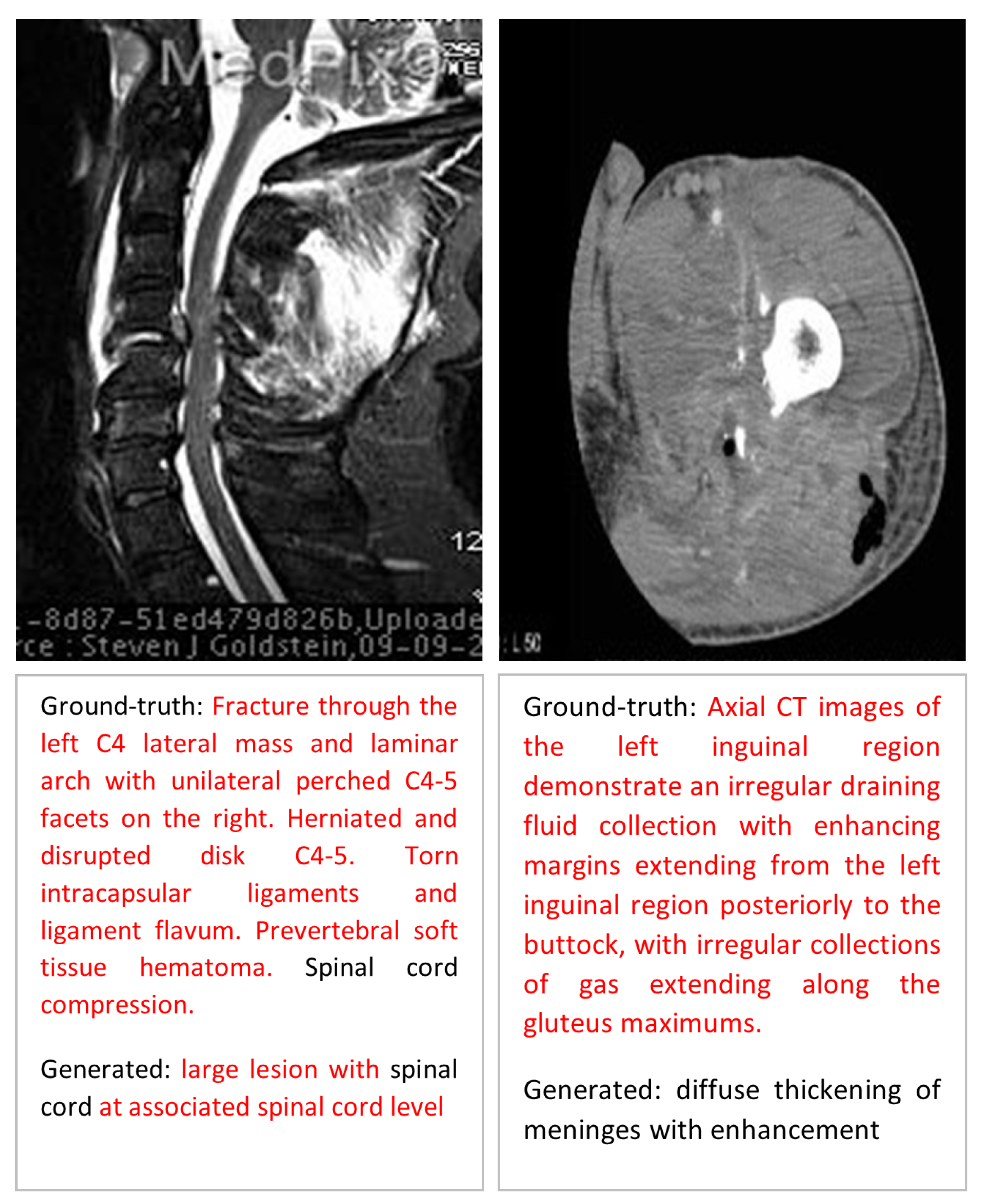
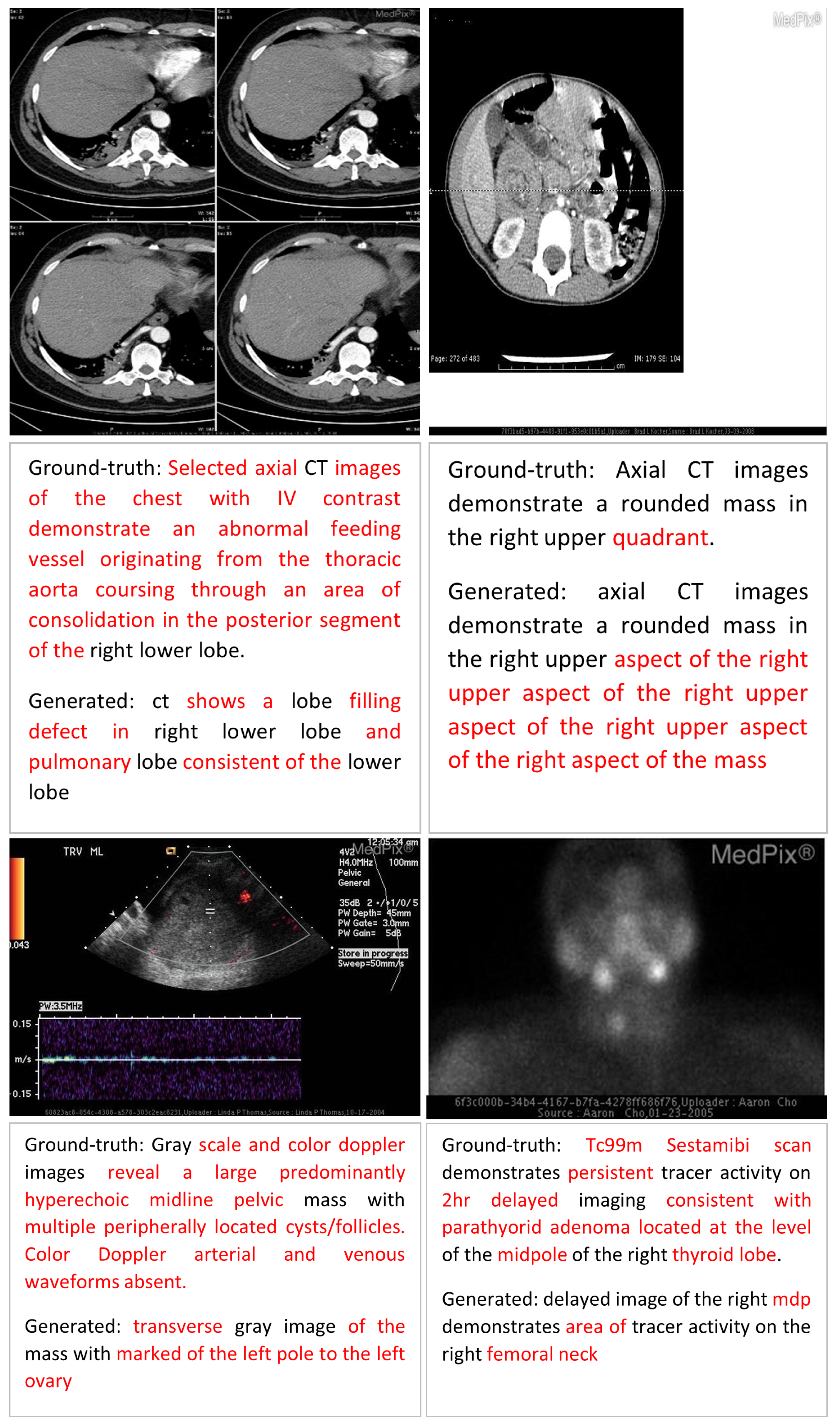
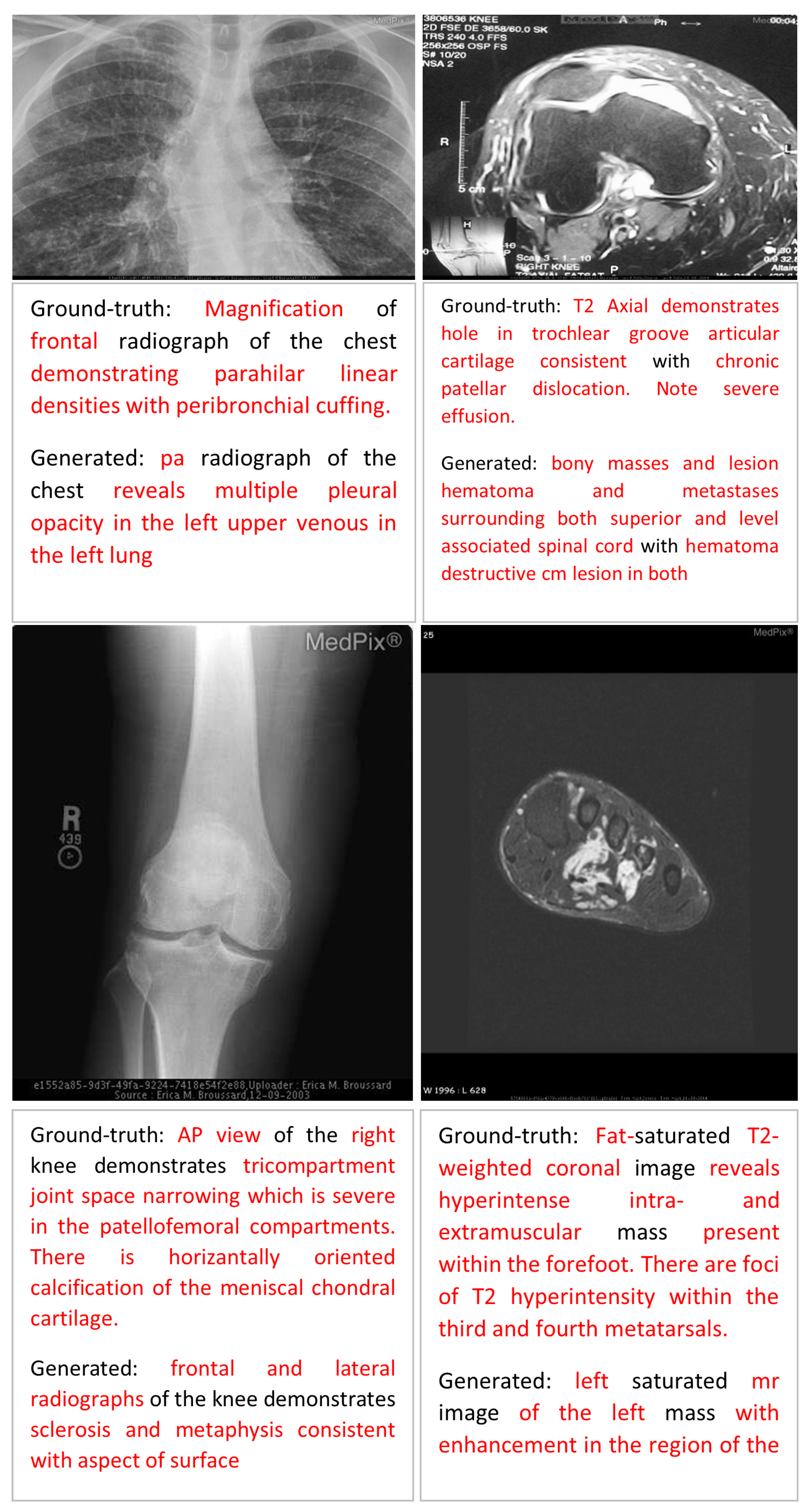
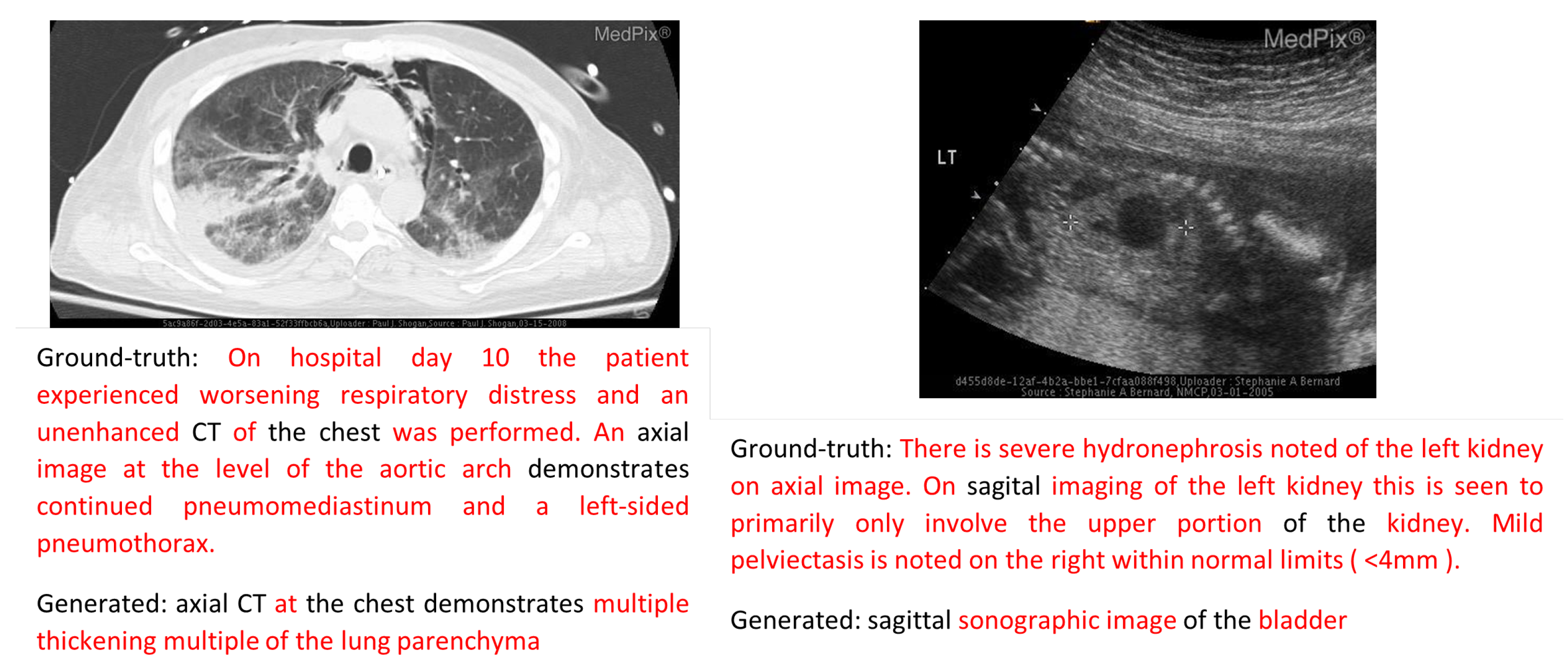
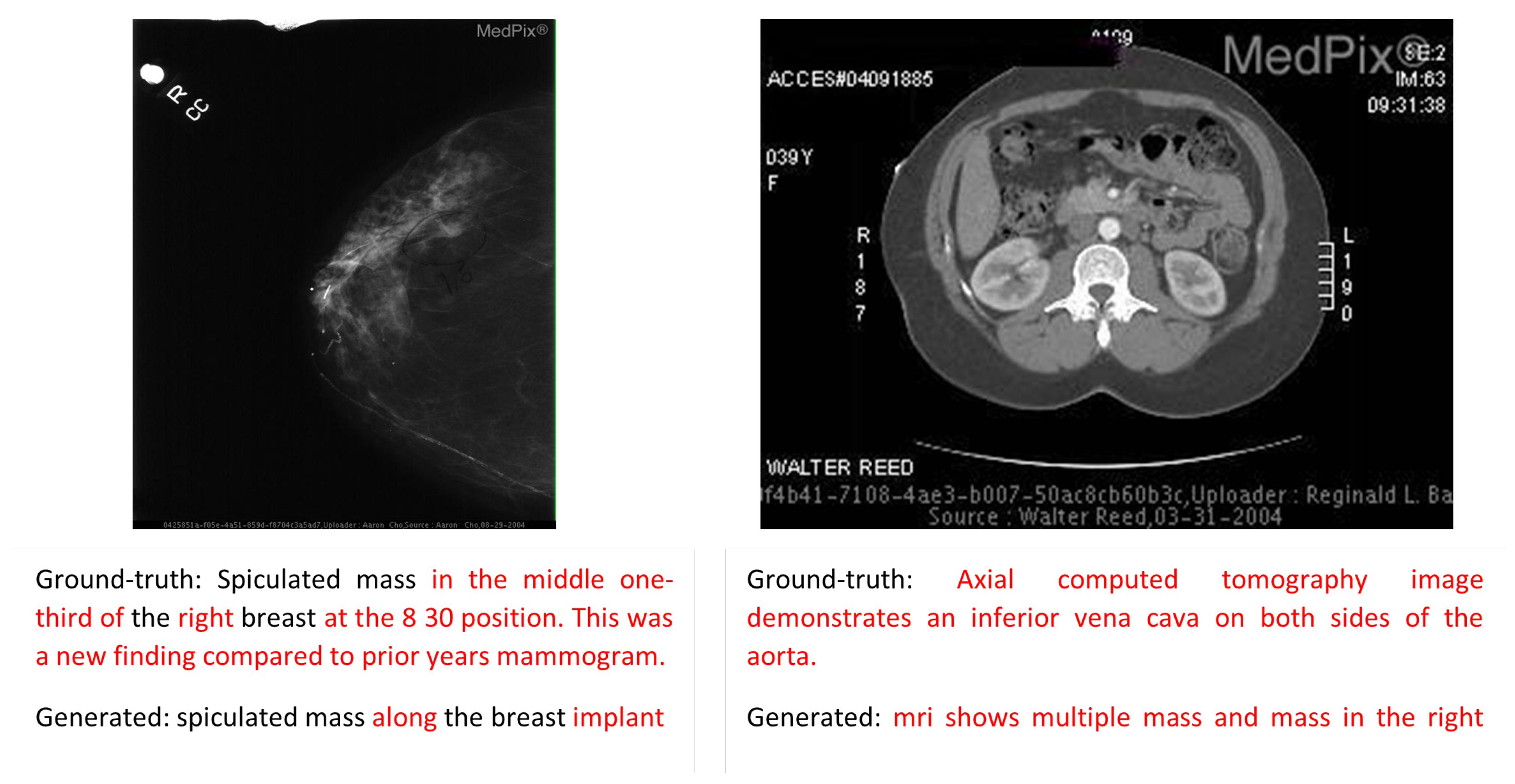
Error Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zeng, X.; Wen, L.; Xu, Y.; Ji, C. Generating diagnostic report for medical image by high-middle-level visual information incorporation on double deep learning models. Comput. Methods Programs Biomed. 2020, 197, 105700. [Google Scholar] [CrossRef]
- Han, Z.; Wei, B.; Xi, X.; Chen, B.; Yin, Y.; Li, S.; Han, Z.; Wei, B.; Xi, X.; Chen, B.; et al. Unifying neural learning and symbolic reasoning for spinal medical report generation. Med. Image Anal. 2021, 67, 101872. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Oussalah, M.; Seppänen, T. Automatic captioning for medical imaging (MIC): A rapid review of literature. Artif. Intell. Rev. 2022. [Google Scholar] [CrossRef] [PubMed]
- Ionescu, B.; Müller, H.; Péteri, R.; Abacha, A.B.; Datla, V.; Hasan, S.A.; Demner-Fushman, D.; Kozlovski, S.; Liauchuk, V.; Cid, Y.D.; et al. Overview of the ImageCLEF 2020: Multimedia Retrieval in Medical, Lifelogging, Nature, and Internet Applications. In Lecture Notes in Computer Science, Proceedings of the Experimental IR Meets Multilinguality, Multimodality, and Interaction CLEF 2020, Virtual, 21–24 September 2020; Springer: Cham, Switzerland, 2020; Volume 12260, pp. 311–341. [Google Scholar]
- Yang, S.; Niu, J.; Wu, J.; Wang, Y.; Liu, X.; Li, Q. Automatic ultrasound image report generation with adaptive multimodal attention mechanism. Neurocomputing 2021, 427, 40–49. [Google Scholar] [CrossRef]
- Li, C.; Liang, X.; Hu, Z.; Xing, E.; Li, C.Y.; Liang, X.; Hu, Z.; Xing, E.P. Hybrid Retrieval-Generation Reinforced Agent for Medical Image Report Generation. In Advances in Neural Information Processing Systems 31 (NIPS 2018), Proceedings of the Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montreal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Kumar, D.; Srivastava, V.; Popescu, D.E.; Hemanth, J.D. Dual-Modal Transformer with Enhanced Inter-and Intra-Modality Interactions for Image Captioning. Appl. Sci. 2022, 12, 6733. [Google Scholar] [CrossRef]
- Chang, Y.H.; Chen, Y.J.; Huang, R.H.; Yu, Y.T. Enhanced Image Captioning with Color Recognition Using Deep Learning Methods. Appl. Sci. 2021, 12, 209. [Google Scholar] [CrossRef]
- Zeng, X.H.; Liu, B.G.; Zhou, M. Understanding and Generating Ultrasound Image Description. J. Comput. Sci. Technol. 2018, 33, 1086–1100. [Google Scholar] [CrossRef]
- Ayesha, H.; Iqbal, S.; Tariq, M.; Abrar, M.; Sanaullah, M.; Abbas, I.; Rehman, A.; Niazi, M.F.K.; Hussain, S. Automatic medical image interpretation: State of the art and future directions. Pattern Recognit. 2021, 114, 107856. [Google Scholar] [CrossRef]
- Onita, D.; Birlutiu, A.; Dinu, L. Towards mapping images to text using deep-learning architectures. Mathematics 2020, 8, 1606. [Google Scholar] [CrossRef]
- Wang, X.; Guo, Z.; Zhang, Y.; Li, J. Medical Image Labelling and Semantic Understanding for Clinical Applications. In Lecture Notes in Computer Science, Proceedings of the Experimental IR Meets Multilinguality, Multimodality, and Interaction CLEF 2019, Lugano, Switzerland, 9–12 September 2019; Springer: Cham, Switzerland, 2019; Volume 11696, pp. 260–270. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Yin, C.; Qian, B.; Wei, J.; Li, X.; Zhang, X.; Li, Y.; Zheng, Q.; Yin, C.; Qian, B.; Wei, J.; et al. Automatic Generation of Medical Imaging Diagnostic Report with Hierarchical Recurrent Neural Network. In Proceedings of the 2019 19th IEEE International Conference on Data Mining (ICDM 2019), Beijing, China, 8–11 November 2019; pp. 728–737. [Google Scholar]
- Beddiar, D.R.; Oussalah, M.; Seppänen, T. Attention-based CNN-GRU model for automatic medical images captioning: ImageCLEF 2021. In Proceedings of the Working Notes of CLEF 2021—Conference and Labs of the Evaluation Forum, CEUR Workshop Proceedings, CEUR-WS.org, Bucharest, Romania, 21–24 September 2021; Volume 2936, pp. 1160–1173. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Wang, X.; Zhang, Y.; Guo, Z.; Li, J. A Computational Framework Towards Medical Image Explanation. In Artificial Intelligence in Medicine: Knowledge Representation and Transparent and Explainable Systems; Springer: Cham, Switzerland, 2019; Volume 11979, pp. 120–131. [Google Scholar]
- Al Duhayyim, M.; Alazwari, S.; Mengash, H.A.; Marzouk, R.; Alzahrani, J.S.; Mahgoub, H.; Althukair, F.; Salama, A.S. Metaheuristics Optimization with Deep Learning Enabled Automated Image Captioning System. Appl. Sci. 2022, 12, 7724. [Google Scholar] [CrossRef]
- Xie, X.; Xiong, Y.; Yu, P.; Li, K.; Zhang, S.; Zhu, Y. Attention-Based Abnormal-Aware Fusion Network for Radiology Report Generation. In Proceedings of the 24th International Conference on Database Systems for Advanced Applications, DASFAA 2019, Chiang Mai, Thailand, 22–25 April 2019; Volume 11448, pp. 448–452. [Google Scholar]
- Li, C.Y.; Liang, X.; Hu, Z.; Xing, E.P. Knowledge-driven encode, retrieve, paraphrase for medical image report generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 8–12 October 2019; Volume 33, pp. 6666–6673. [Google Scholar]
- Zhao, S.; Li, L.; Peng, H.; Yang, Z.; Zhang, J. Image Caption Generation via Unified Retrieval and Generation-Based Method. Appl. Sci. 2020, 10, 6235. [Google Scholar] [CrossRef]
- Pelka, O.; Ben Abacha, A.; García Seco de Herrera, A.; Jacutprakart, J.; Friedrich, C.M.; Müller, H. Overview of the ImageCLEFmed 2021 Concept & Caption Prediction Task. In Proceedings of the CLEF2021 Working Notes, CEUR Workshop Proceedings, CEUR-WS.org, Bucharest, Romania, 21–24 September 2021. [Google Scholar]
- Ionescu, B.; Müller, H.; Peteri, R.; Abacha, A.B.; Sarrouti, M.; Demner-Fushman, D.; Hasan, S.A.; Kozlovski, S.; Liauchuk, V.; Dicente, Y.; et al. Overview of the ImageCLEF 2021: Multimedia Retrieval in Medical, Nature, Internet and Social Media Applications. In LNCS Lecture Notes in Computer Science, Proceedings of the 12th International Conference of the CLEF Association (CLEF 2021), Bucharest, Romania, 21–24 September 2021; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Castro, V.; Pino, P.; Parra, D.; Lobel, H. PUC Chile team at Caption Prediction: ResNet visual encoding and caption classification with Parametric ReLU. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1174–1183. [Google Scholar]
- Wang, X.; Guo, Z.; Xu, C.; Sun, L.; Li, J. ImageSem Group at ImageCLEFmed Caption 2021 Task: Exploring the Clinical Significance of the Textual Descriptions Derived from Medical Images. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1387–1393. [Google Scholar]
- Tsuneda, R.; Asakawa, T.; Aono, M. Kdelab at ImageCLEF 2021: Medical Caption Prediction with Effective Data Pre-processing and Deep Learning. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1365–1374. [Google Scholar]
- Schuit, G.; Castro, V.; Pino, P.; Parra, D.; Lobel, H. PUC Chile team at Concept Detection: K Nearest Neighbors with Perceptual Similarity. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1352–1358. [Google Scholar]
- Jacutprakart, J.; Andrade, F.P.; Cuan, R.; Compean, A.A.; Papanastasiou, G.; de Herrera, A.G.S. NLIP-Essex-ITESM at ImageCLEFcaption 2021 task: Deep Learning-based Information Retrieval and Multi-label Classification towards improving Medical Image Understanding. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1264–1274. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input | Output | Dataset |
|---|---|---|---|
| Template-based method: kernel ridge regression and classification [11] | chest X-ray images | description | PADChest dataset |
| Retrieval-based method: Lucene Image Retrieval (LIRE) + multi-label classification and topic modeling [12] | medical images | description | ImageCLEF + ROCO datasets |
| Deep-learning-based method: show and tell encoder–decoder model [13] | natural images | captions | Pascal VOC 2008, Flickr8k, Flickr30k, MSCOCO |
| Deep-learning-based method: encoder–decoder model [1] | medical images | diagnosis report | IU X-ray + own created dataset |
| Deep-learning-based method: encoder–decoder model with CNN-based multi-label classifier and RNN as decoder [14] | chest X-ray images | medical report | IU X-ray dataset |
| Deep-learning-based method: encoder–decoder with attention, show, attend and tell model [16] | natural images | captions | Flickr8k, Flickr30k and MS COCO |
| Deep-learning-based method: encoder–decoder with attention, decoder with GRU [15] | medical images | descriptions | ImageCLEF 2021 |
| Deep-learning-based method: merge model with a variational auto-encoder [17] | chest X-ray images | medical report | IU X-ray dataset |
| Deep-learning-based method: encoder–decoder with SSA-based hyperparameter optimizer [18] | natural images | captions | MSCOCO and Flick8K |
| Hybrid method: topic-guided attention mechanism [19] | lateral and frontal chest X-ray images | description | IU X-ray dataset |
| Hybrid method: abnormality graph learning with retrieval technique [20] | lateral and frontal chest X-ray images | medical report | IU X-ray dataset |
| Hybrid method: method based on a Retrieval-Generation Reinforced Agent [6] | lateral and frontal chest X-ray images | medical report | IU X-ray + ChexPert dataset |
| Hybrid method: retrieval-based method combined with generation-based method [21] | natural images | captions | MSCOCO |
| (Visual Vector) | (Semantic Vector) | (Text Sequence) | y (Word to Predict) |
|---|---|---|---|
| visual feature | semantic feature | start, | macroscopic |
| visual feature | semantic feature | start, macroscopic, | fat |
| visual feature | semantic feature | start, macroscopic, fat, | containing |
| visual feature | semantic feature | start, macroscopic, fat, containing, | nodule |
| visual feature | semantic feature | start, macroscopic, fat, containing, nodule, | in |
| visual feature | semantic feature | start, macroscopic, fat, containing, nodule, in, | the |
| visual feature | semantic feature | start, macroscopic, fat, containing, nodule, in, the, | right |
| visual feature | semantic feature | start, macroscopic, fat, containing, nodule, in, the, right, | adrenal |
| visual feature | semantic feature | start, macroscopic, fat, containing, nodule, in, the, right, adrenal, | gland |
| visual feature | semantic feature | start, macroscopic, fat, containing, nodule, in, the, right, adrenal, gland, | end |
| Method | BLEU |
|---|---|
| ImageSem [25] | 25.70% |
| IALab_PUC [24] | 51.00% |
| Kdelab [26] | 36.20% |
| ours: MLC + LSTM + Argmax | 41.09% |
| ours: MLC + LSTM + Beam Search 3 | 42.15% |
| ours: MLC + LSTM + Beam Search 5 | 42.28% |
| ours: MLC + LSTM + Beam Search 7 | 41.16% |
| Method | F_measure |
|---|---|
| IALab_PUC [24] | 50.50% |
| ImageSem [25] | 41.90% |
| NLIP-Essex-ITESM [28] | 41.20% |
| Attention-based encoder–decoder [15] | 28.70% |
| Our proposal | 41.80% |
| Method | BLEU |
|---|---|
| ours: LSTM + Argmax | 33.69% |
| ours: LSTM + Beam Search 3 | 36.28% |
| ours: LSTM + Beam Search 5 | 36.23% |
| ours: LSTM + Beam Search 7 | 33.63% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beddiar, D.R.; Oussalah, M.; Seppänen, T.; Jennane, R. ACapMed: Automatic Captioning for Medical Imaging. Appl. Sci. 2022, 12, 11092. https://doi.org/10.3390/app122111092
Beddiar DR, Oussalah M, Seppänen T, Jennane R. ACapMed: Automatic Captioning for Medical Imaging. Applied Sciences. 2022; 12(21):11092. https://doi.org/10.3390/app122111092
Chicago/Turabian StyleBeddiar, Djamila Romaissa, Mourad Oussalah, Tapio Seppänen, and Rachid Jennane. 2022. "ACapMed: Automatic Captioning for Medical Imaging" Applied Sciences 12, no. 21: 11092. https://doi.org/10.3390/app122111092
APA StyleBeddiar, D. R., Oussalah, M., Seppänen, T., & Jennane, R. (2022). ACapMed: Automatic Captioning for Medical Imaging. Applied Sciences, 12(21), 11092. https://doi.org/10.3390/app122111092