


An Anomaly Detection Framework for Twitter Data

 ,
,  ,
,  ,
,
Abstract
1. Introduction
- Collected 44,162 tweets using Tweepy API and created a dataset (available at https://github.com/sandpoonia/Twitter_Anomaly accessed on 18 September 2022).
- Performed topic modeling using NMF and LDA to obtain the most dominant tweets.
- Created a query set using most frequent words detected by topic modeling.
- BERT model deployed for anomaly detection.
- Two case study evaluated using the proposed framework.
2. Literature Review
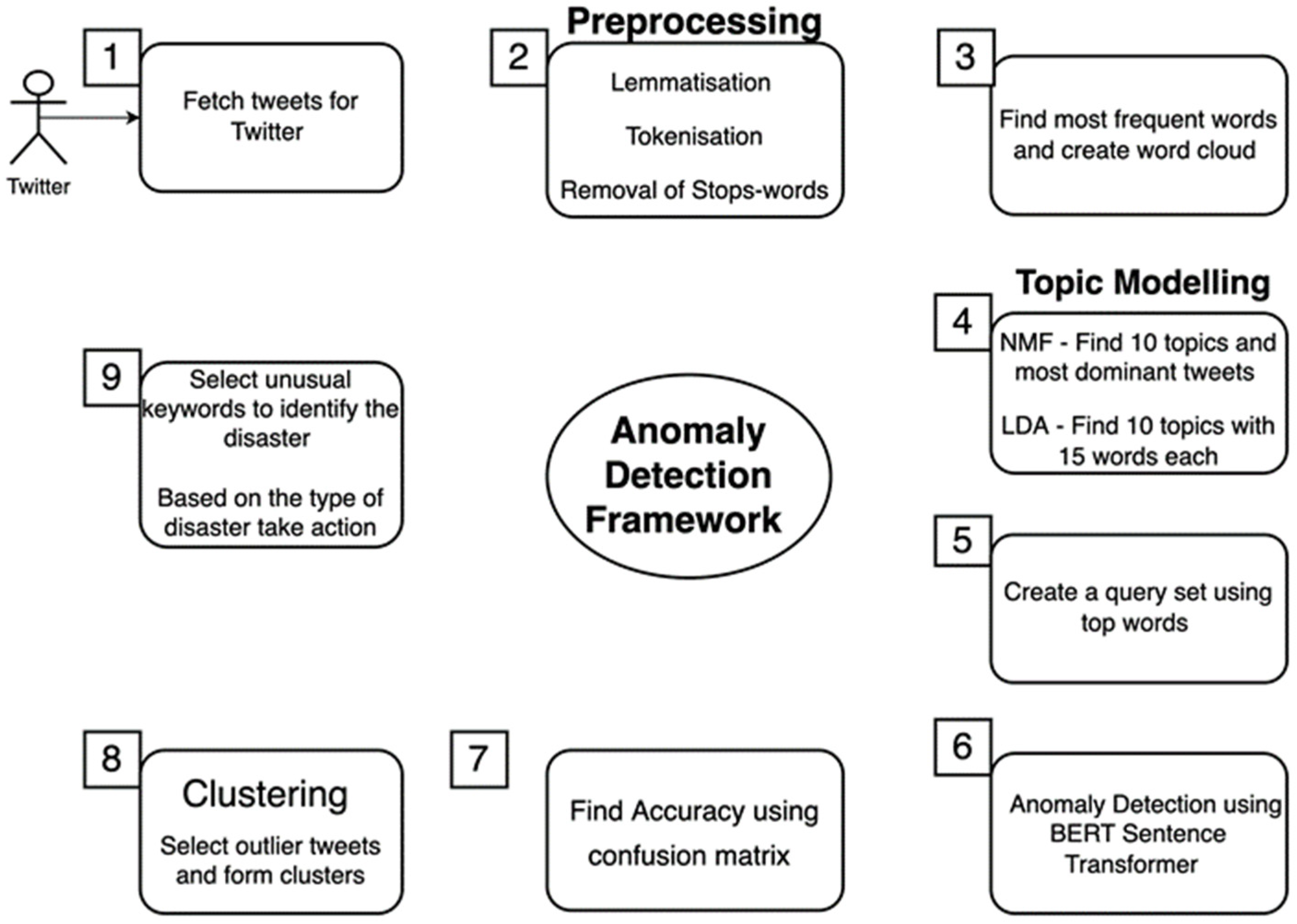
3. Social Media Data Analysis and Anomaly Detection
- Collection of tweets from Twitter
- Pre-processing of data
- Topic modeling
- Collect the most frequently used words using topic modeling
- Anomaly detection
- Clustering using K-means
3.1. Collection of Tweet Dataset from Twitter
3.2. Pre-Processing of Data
3.3. Topic Modeling
- Topic modeling using NMF. This method is based on the dominant score of each topic, which is used to select topics with a higher score to form a query set. It involves finding the top 10 topics from the entire dataset, and each topic with the 15 most similar words. It obtains the leading topic for each tweet and finds the most relevant topic for each tweet. Based on the dominant score of each topic with each tweet, its finds the most dominant topics, which are ordinary tweets. These tweets are used to find anomalies in a new set of tweet datasets. The most dominant tweets from the entire dataset are selected that are most relevant to the above ten topics. Table 4 shows the top 10 topics; each has 15 words. Table 5 shows the sample’s most dominant tweets.
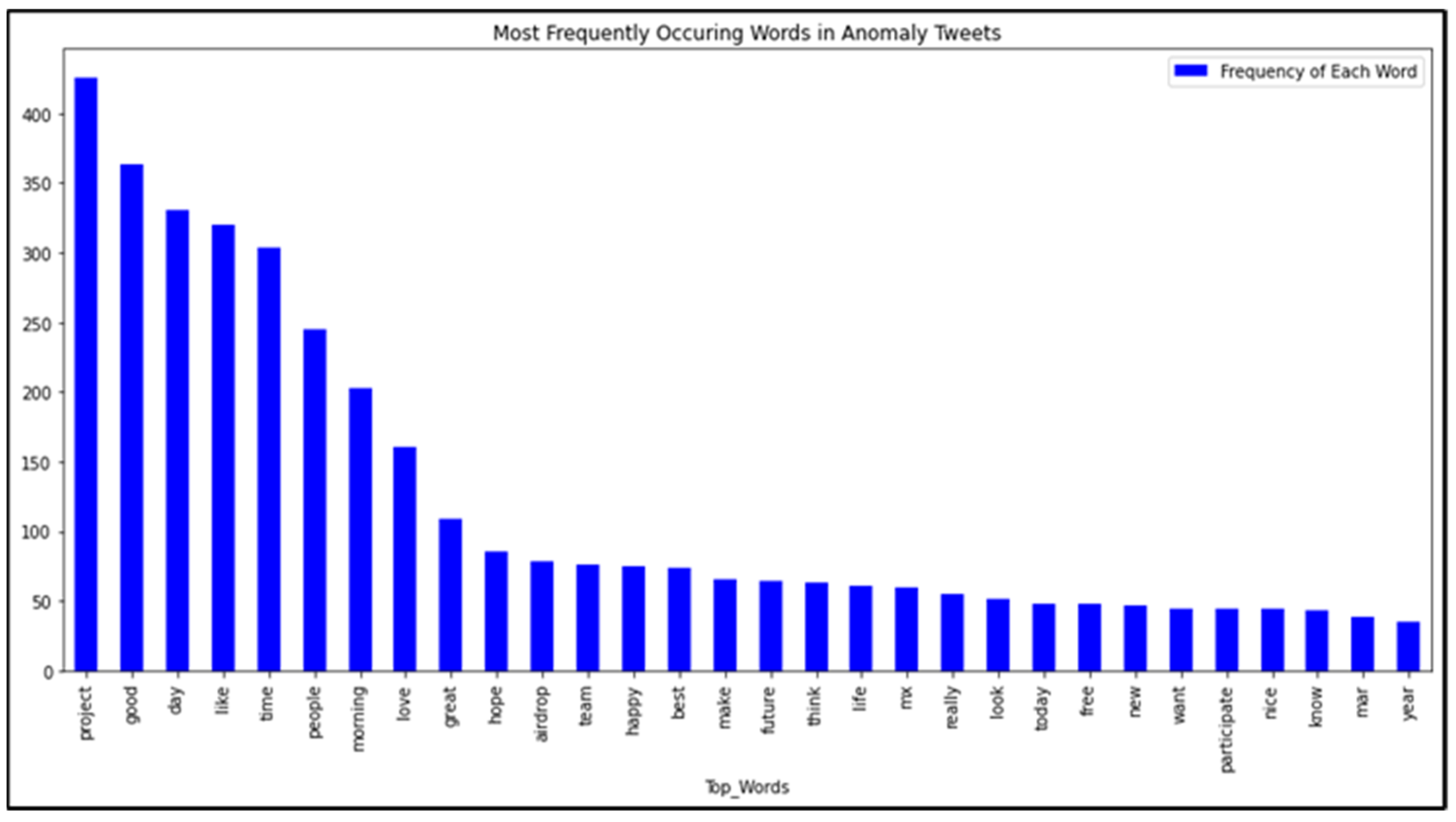
- Topic modeling using LDA. This method is based on the weightage of each word in each topic. The top 10 topics from the entire dataset are found; each topic has 15 of the most similar words with their weightage. The most weighted topics are used to create a query string. Here most frequently used topics identified by topic modeling were: know, food, happy, fan, like, thank you, people, nice, really, time, great, love, today, strong, day, good morning, always, think, look, want, best, help, never, please, and make.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No. | Topic |
|---|---|
| 1 | know time people want make think see even go still say take would thing never |
| 2 | good morning good morning dawn good dawn drink beautiful luck ka nice happy today water look everyone |
| 3 | like look like feel feel like would like sound act something looking lol unity seems really |
| 4 | one person one best another also right ever give best made top many buy last two |
| 5 | love much always thank listen radio would playing happy channel unity fall art give birthday |
| 6 | day nice every happy got today morning last great ka hope another beautiful drink start |
| 7 | get check shopee get shopee free airdrop mx mar mx get airdrop mar rm soon mexcglobal participate well |
| 8 | project best great team hope happy future nft labor really crypto thank community strong amazing |
| 9 | need really help please stop india learn programming go much freelance hope unity business engagement |
| 10 | new nft come india year live check news season start design next song update token |
| S. No. | Tweet No. | Tweets |
|---|---|---|
| 1 | Tweet1389 | wonderful project best quality project currently running market hopefully project get success |
| 2 | Tweet2841 | Shiba incredibly awesome project managed experienced promoter great success potential join get benefited airdrop electroshiba |
| 3 | Tweet4824 | interesting project definitely going huge thank giving u great opportunity hope I’ll get reward from event project get moon giveaways airdrop |
| 4 | Tweet18770 | aaronok answer question like anime unlike anime really emotionally attached anime main character understand motif that’s like alliance despite refiner one fav |
| 5 | Tweet16857 | go ward half-hour early check bed select one disease prepared well guy allotted one bed make sure someone prepared test well |
| 6 | Tweet12258 | specifically, Noida newsroom one Mumbai well |
| 7 | Tweet15844 | buddy telling truth people rate last obviously toxic one solo one them why yall misunderstanding |
| 8 | Tweet10068 | bunch known corrupt people unite one-man spare effort ridicule blackmail attempt assassinate character blindly follow one man Marcus |
| 9 | Tweet18946 | happy see people masked getting grocery today last week one store wearing one |
| 10 | Tweet9550 | bunch known corrupt people unite one-man spare attempt assassinate character blindly follow one man Marcus aurelias |
3.4. Anomaly Detection
- Use a different set of tweets related to any disaster, analyze each tweet and assign, as usual, or anomaly tweet by human annotation.
- Compare each tweet of a new set of tweets with the query set and find the cosine similarity score for each tweet. The similarity score of each tweet is compared with the threshold value, and tweets are categorized as normal and anomalous tweets.
- Compare the actual type of tweet with predicted values and find the accuracy score with the help of a confusion matrix.
3.5. Clustering Using K-Means
4. Case Study 1—Corona Virus Tweet Dataset
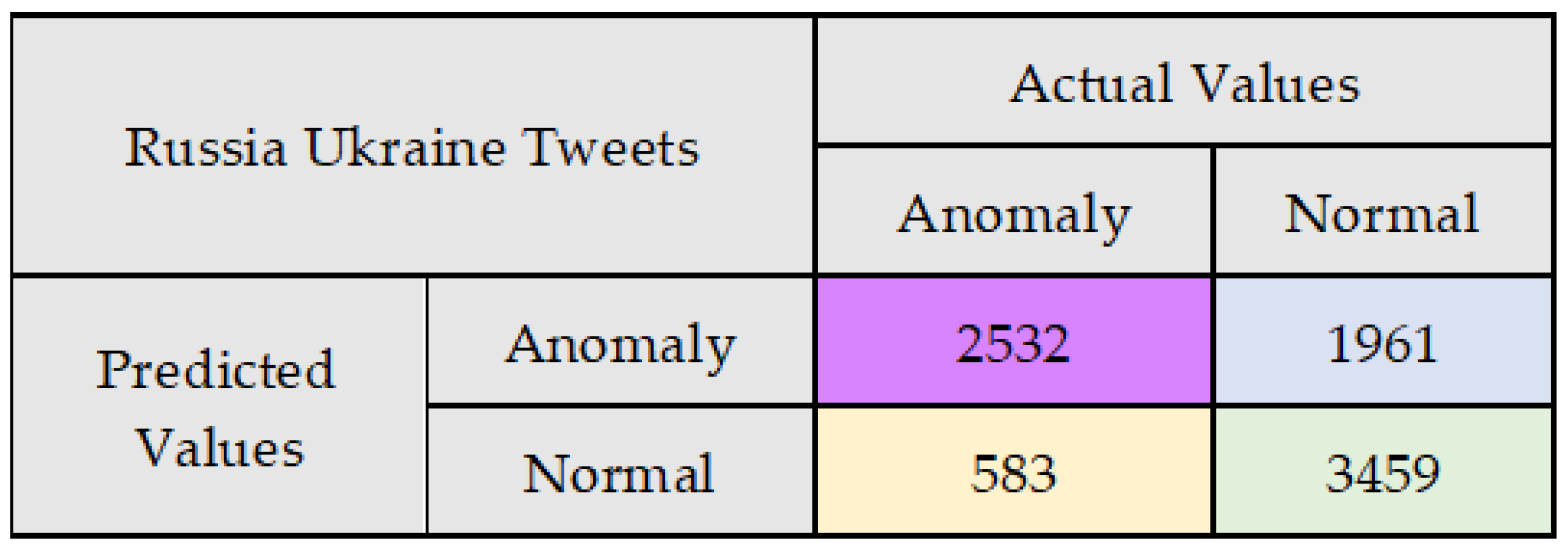
5. Case Study 2—Russia Ukraine Tweet Dataset
6. Discussion and Limitation of This Study
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guarino, A.; Malandrino, D.; Zaccagnino, R. An automatic mechanism to provide privacy awareness and control over unwittingly dissemination of online private information. Comput. Netw. 2022, 202, 108614. [Google Scholar] [CrossRef]
- Mao, H.; Shuai, X.; Kapadia, A. Loose tweets: An analysis of privacy leaks on twitter. In Proceedings of the 10th Annual ACM Workshop on Privacy in the Electronic Society, Chicago, IL, USA, 17 October 2011; pp. 1–12. [Google Scholar]
- Yu, R.; Qiu, H.; Wen, Z.; Lin, C.; Liu, Y. A survey on social media anomaly detection. ACM SIGKDD Explorations. Newsletter 2016, 18, 1–14. [Google Scholar]
- Savage, D.; Zhang, X.; Yu, X.; Chou, P.; Wang, Q. Anomaly detection in online social networks. Soc. Netw. 2014, 39, 62–70. [Google Scholar] [CrossRef]
- Casalino, G.; Castiello, C.; del Buono, N.; Mencar, C. A framework for intelligent Twitter data analysis with non-negative matrix factorization. Int. J. Web Inf. Syst. 2018, 14, 334–356. [Google Scholar] [CrossRef]
- Hawkins, D.M. Identification of Outliers; Chapman and Hall: London, UK, 1980; Volume 11. [Google Scholar]
- Ahmed, M.; Mahmood, A.N.; Hu, J. A survey of network anomaly detection techniques. J. Netw. Comput. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Patcha, A.; Park, J.M. An overview of anomaly detection techniques: Existing solutions and latest technological trends. Comput. Netw. 2007, 51, 3448–3470. [Google Scholar] [CrossRef]
- Alatawi, T.; Aljuhani, A. Anomaly detection framework in fog-to-things communication for industrial internet of things. Comput. Mater. Contin. 2022, 73, 1067–1086. [Google Scholar] [CrossRef]
- Ragab, M.; Sabir, M.F.S. Arithmetic optimization with deep learning-enabled anomaly detection in smart city. Comput. Mater. Contin. 2022, 73, 381–395. [Google Scholar]
- Zhao, J.; Zeng, P.; Chen, C.; Dong, Z.; Han, J. Deep learning anomaly detection based on hierarchical status-connection features in networked control systems. Intell. Autom. Soft Comput. 2021, 30, 337–350. [Google Scholar] [CrossRef]
- Saqaeeyan, S.; Haj, H.; Amirkhani, H. A Novel Probabilistic Hybrid Model to Detect Anomaly in Smart Homes. CMES-Comput. Model. Eng. Sci. 2019, 121, 815–834. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, C.; He, S.; Gu, Y.; Alfarraj, O.; Abugabah, A. Loguad: Log unsupervised anomaly detection based on word2vec. Comput. Syst. Sci. Eng. 2022, 41, 1207–1222. [Google Scholar] [CrossRef]
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment analysis and topic modeling on tweets about online education during COVID-19. Appl. Sci. 2021, 11, 8438. [Google Scholar] [CrossRef]
- Lyu, J.C.; le Han, E.; Luli, G.K. COVID-19 vaccine-related discussion on Twitter: Topic modeling and sentiment analysis. J. Med. Internet Res. 2021, 23, e24435. [Google Scholar] [CrossRef] [PubMed]
- Amen, B.; Faiza, S.; Do, T.T. Big data directed acyclic graph model for real-time COVID-19 twitter stream detection. Pattern Recognit. 2022, 123, 108404. [Google Scholar] [CrossRef] [PubMed]
- Yousefinaghani, S.; Dara, R.; Mubareka, S.; Sharif, S. Prediction of COVID-19 waves using social media and Google search: A case study of the US and Canada. Front. Public Health 2021, 9, 656635. [Google Scholar] [CrossRef]
- Kabir, M.Y.; Madria, S. EMOCOV: Machine learning for emotion detection, analysis and visualization using COVID-19 tweets. Online Soc. Netw. Media 2021, 23, 100135. [Google Scholar] [CrossRef]
- Gharavi, E.; Nazemi, N.; Dadgostari, F. Early outbreak detection for proactive crisis management using twitter data: COVID-19 a case study in the US. arXiv 2020, arXiv:2005.00475. [Google Scholar]
- Tam, N.T.; Weidlich, M.; Zheng, B.; Yin, H.; Hung, N.Q.V.; Stantic, B. From anomaly detection to rumour detection using data streams of social platforms. Proc. VLDB Endow. 2019, 12, 1016–1029. [Google Scholar] [CrossRef]
- Xu, Z.; Huang, X.; Zhao, Y.; Dong, Y.; Li, J. Contrastive Attributed Network Anomaly Detection with Data Augmentation. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Cham, Switzerland, 2022; pp. 444–457. [Google Scholar]
- Hoeltgebaum, H.; Adams, N.; Fernandes, C. Estimation, Forecasting, and Anomaly Detection for Nonstationary Streams Using Adaptive Estimation. IEEE Trans. Cybern. 2021, 52, 7956–7967. [Google Scholar] [CrossRef]
- Nanda, G.; Douglas, K.A.; Waller, D.R.; Merzdorf, H.E.; Goldwasser, D. Analyzing large collections of open-ended feedback from MOOC learners using LDA topic modeling and qualitative analysis. IEEE Trans. Learn. Technol. 2021, 14, 146–160. [Google Scholar] [CrossRef]
- Farkhod, A.; Abdusalomov, A.; Makhmudov, F.; Cho, Y.I. LDA-Based Topic Modeling Sentiment Analysis Using Topic/Document/Sentence (TDS) Model. Appl. Sci. 2021, 11, 11091. [Google Scholar] [CrossRef]
- Kim, M.; Kim, D. A Suggestion on the LDA-Based Topic Modeling Technique Based on ElasticSearch for Indexing Academic Research Results. Appl. Sci. 2022, 12, 3118. [Google Scholar] [CrossRef]
- Bastani, K.; Namavari, H.; Shaffer, J. Latent Dirichlet allocation (LDA) for topic modeling of the CFPB consumer complaints. Expert Syst. Appl. 2019, 127, 256–271. [Google Scholar] [CrossRef]
- Xie, R.; Chu, S.K.W.; Chiu, D.K.W.; Wang, Y. Exploring public response to COVID-19 on Weibo with LDA topic modeling and sentiment analysis. Data Inf. Manag. 2021, 5, 86–99. [Google Scholar] [CrossRef]
- Abuzayed, A.; Al-Khalifa, H. BERT for Arabic topic modeling: An experimental study on BERTopic technique. Procedia Comput. Sci. 2021, 189, 191–194. [Google Scholar] [CrossRef]
- Jónsson, E.; Stolee, J. An evaluation of topic modelling techniques for twitter. In Proceedings of the 53th Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; short papers. pp. 489–494. [Google Scholar]
- Casalino, G.; Grilli, L.; Guarino, A.; Schicchi, D.; Taibi, D. Intelligent knowledge understanding from students questionnaires: A case study. In International Workshop on Higher Education Learning Methodologies and Technologies Online; Springer: Cham, Switzerland, 2021; pp. 74–86. [Google Scholar]











| Author [Ref.] | Activity | Technique Used | Data Source | Description | Applications |
|---|---|---|---|---|---|
| Tam et al. [20] | Social media analysis | Graph-based approach. | Social platforms | Multimodal approach used to detect anomalies in posts, users and hashtags. | Rumour Detection |
| Xu et al. [21] | Siamese graph neural network with a contrastive loss | Amazon, Flickr, Facebook, Enron, Twitter dataset | Data augmentation approach used to model human knowledge and employed use reconstruction loss to obtain anomaly scores | Network Anomaly Detection | |
| Hoeltgebaum et al. [22] | Penalized-regression model | Streaming data | Proposed a real-time adaptive component | Estimation, Forecasting, and Anomaly Detection | |
| Nanda et al. [23] | LDA for topic modeling | LDA | Survey | Identified MOOC learning experience from learners | Massive open online course |
| Farkhod et al. [24] | Topic/Document/Sentence (TDS) Model | IMDB dataset | Topic-based sentiment analysis performed | Sentiment analysis | |
| Kim and Kim [25] | ElasticSearch | Not applicable | Topic-based LDA model (to improve supervised learning) were deployed to extract the features of academic papers | Indexing Academic Research Results | |
| Bastani et al. [26] | LDA | CFPB dataset | Developed an LDA based decision support system | Analysis of consumer complaints | |
| Xie et al. [27] | LDA | Weibo posts | Deployed LDA for topics modeling and performed sentiment analysis | Public opinion about COVID-19 on Weibo | |
| Abuzayed and Al-Khalifa [28] | NMF for topic modeling | BERTopic | Arabic language | BERTopic deployed for Arabic Language models | Topic modeling for Arabic language |
| Tweets | Location | Created on |
|---|---|---|
| After all the headaches I am finally able to leave Singapore and head back to Malaysia But first some Chwee Kueh at the lounge Basically its steamed rice cake with preserved radish sprinkled on top Never tried this until I’m in Singapore Love it | Malaysia | 25 April 2022 23:59 |
| origins I remember while I was in the car with my mom, I thought about the concept that reality could end at any moment scared the shit out of me so much that I cried so hard that my mom had to pull over and I threw up it was all sparked by this image btw | Pakistan | 24 March 2022 23:59 |
| Today love yourself as you are unique and brave and full of love | Chennai, India | 25 February 2022 23:59 |
| People should think about the fact that official US policy prohibits assassination of the one person causing a war but slaughtering soldiers and others by the thousands is OK | Singapore | 12 January 2022 23:47 |
| He said Climate leader Because like winter summer and rainy season our BCM won’t come out of his house If he comes out it becomes a climate Looking at the whole picture here Ajit Pawar is controlling the cabinet orders from Bade Shaheb Only for namesake Uddhav is CM | India | 13 November 2012 23:46 |
| S. No. | Word | Frequency |
|---|---|---|
| 1 | like | 3601 |
| 2 | good | 2460 |
| 3 | day | 2062 |
| 4 | know | 1882 |
| 5 | time | 1873 |
| 6 | make | 1696 |
| 7 | love | 1643 |
| 8 | people | 1618 |
| 9 | need | 1540 |
| 10 | want | 1525 |
| good | thanks | think | beautiful |
| morning | best | always | blessed |
| India | future | love | friend |
| information | great | life | birthday |
| like | health | know | hope |
| happy | water | day | actually |
| photo | team | people | new |
| social | life | need | listen |
| well | future | everyone | dream |
| world | truth | nice | sorry |
| Tweets | Location | Created on |
|---|---|---|
| Hindu Pfizer is in another deadlock with the GOI They continue to insist they will only provide their vaccine if the company wa | Delhi, India | 22 May 2021 |
| Pfizers COVID-19 vaccine can now can be stored at conventional refrigerator temperatures for up to a month as per Health | Barcelona | 19 May 2021 |
| PublicHealth CUPHD is hosting COVID-19 walk-in vaccination clinics each Friday from 830 AM400 PM wPfizer Moderna and Johnson amp | Urbana, IL | 9 June 2021 |
| Can a COVID-19 vaccine make me sick with COVID-19 NO COVID-19 vaccines contain the live virus that causes COVID-19 | Broadway Brooklyn | 1 March 2018 |
| My Grandmommy was very sick with pneumonia last month amp got over it slowly I was so worried shed catch COVID-19 | $RayeStreams | 28 April 2019 |
| Tweets | Location | Created on |
|---|---|---|
| Russians remind me of the dynamic between dogs when one is obviously kinda dumb and goofy. | Russia | 01 June 2022 |
| Iraq and Afghanistan were thousands of km away. Afghanistan and Iraq were defeated militarily very quickly, it was the insurgency that was the problem. | Belgium | 02 June 2022 |
| news project good whitepaper also clear hope project successful future also hope community grow even bigger | Russia | 28 March 2022 |
| Trump was impeached for taking congressionally-approved taxpayer money and extorting Ukraine | US | 01 June 2022 |
| amazing sexy quiet heartwarming cool really good rapper love way bare face way walk rapping savage man look funny fineeeeeyou like basketball like | US | 24 April 2022 |
| Recall | Precision | F1 Score | Accuracy | |
|---|---|---|---|---|
| Case Study 1 | 0.7981 | 0.8210 | 0.8093 | 0.7857 |
| Case Study 2 | 0.8128 | 0.5635 | 0.665 | 0.7019 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, S.; Khan, M.B.; Hasanat, M.H.A.; Saudagar, A.K.J.; AlTameem, A.; AlKhathami, M. An Anomaly Detection Framework for Twitter Data. Appl. Sci. 2022, 12, 11059. https://doi.org/10.3390/app122111059
Kumar S, Khan MB, Hasanat MHA, Saudagar AKJ, AlTameem A, AlKhathami M. An Anomaly Detection Framework for Twitter Data. Applied Sciences. 2022; 12(21):11059. https://doi.org/10.3390/app122111059
Chicago/Turabian StyleKumar, Sandeep, Muhammad Badruddin Khan, Mozaherul Hoque Abul Hasanat, Abdul Khader Jilani Saudagar, Abdullah AlTameem, and Mohammed AlKhathami. 2022. "An Anomaly Detection Framework for Twitter Data" Applied Sciences 12, no. 21: 11059. https://doi.org/10.3390/app122111059
APA StyleKumar, S., Khan, M. B., Hasanat, M. H. A., Saudagar, A. K. J., AlTameem, A., & AlKhathami, M. (2022). An Anomaly Detection Framework for Twitter Data. Applied Sciences, 12(21), 11059. https://doi.org/10.3390/app122111059