1. Introduction
STEAM education involves the integration of multi-disciplinary instructional design with specific themes. However, teachers trained in a single discipline can hardly meet the requirements of STEAM multi-disciplinary theme design [
1]. As a multi-disciplinary instructional framework, the subject knowledge graph, with its rich semantic relevance, is expected to solve the problem of STEAM multi-disciplinary theme design. However, the current knowledge graph of disciplines is still unable to provide teachers with appropriate STEAM learning topics according to the instructional requirements of the curriculum standards, which leads to serious disconnection of the knowledge system of various disciplines in STEAM education. Therefore, how to effectively support the generation of appropriate STEAM learning topics through the dynamic cutting and completion of the subject knowledge graph has become an important research question.
In recent years, since the tensor decomposition model has flexible computing capability for potential semantic features, it is regarded by researchers as a key algorithm model for developing the learners’ knowledge graph from the basic lower cognitive stages to the higher panoramic cognitive stages [
2]. Presently, the dynamic organization effect of multi-disciplinary learning resources on STEAM learning topics is not appropriate enough, and it has not been found that STEAM teachers can be configured with learning topics that meet the learning requirements of the curriculum standards. The application of the tensor decomposition model in the STEAM multi-disciplinary semantic association and its completion of the panoramic knowledge graph provides relatively ideal support for STEAM learning theme content organization. This method helps single-discipline teachers to organize, discover, configure, and recommend appropriate themes of interdisciplinary learning.
This study had three main objectives:
- (1)
To propose the dynamic generation technology of subject knowledge graph technology, which includes two types of technical solutions: knowledge graph generation based on basic data sets, and STEAM subject knowledge graph completion oriented to curriculum standards in order to achieve flexible STEAM subject generation and design for single-subject teachers.
- (2)
To integrate multiple APIs to conduct multiple trainings on data sets to meet the requirements for entity recognition and semantic modeling of the subject knowledge graph under different personalized learning scenarios. Among them, the conditional random field and tensor decomposition algorithm achieved the best semantic relationship modeling effect.
- (3)
To introduce the high-order singular value decomposition with orthogonal iteration (HO-SVD-OI) for the tensor decomposition algorithm of a penalty function and the high-dimensional orthogonal iteration mechanism to calculate the matches between STEAM learning resources and learners’ cognitive styles in different stages. The simulation results show that the algorithm optimization strategy had good computational performance on the topic coverage of STEAM learning themes.
3. Methodology
This section proposes a dynamic generation method for knowledge graphs of STEAM themes, including three technical processes: the dynamic generation of cross-modal subject knowledge graphs based on natural language processing, dynamic completion of subject knowledge graphs based on the tensor semantic decomposition model, and quality evaluation of subject knowledge graphs for STEAM interdisciplinary curriculum standards.
3.1. Knowledge Graph Generation of STEAM Instructional Themes
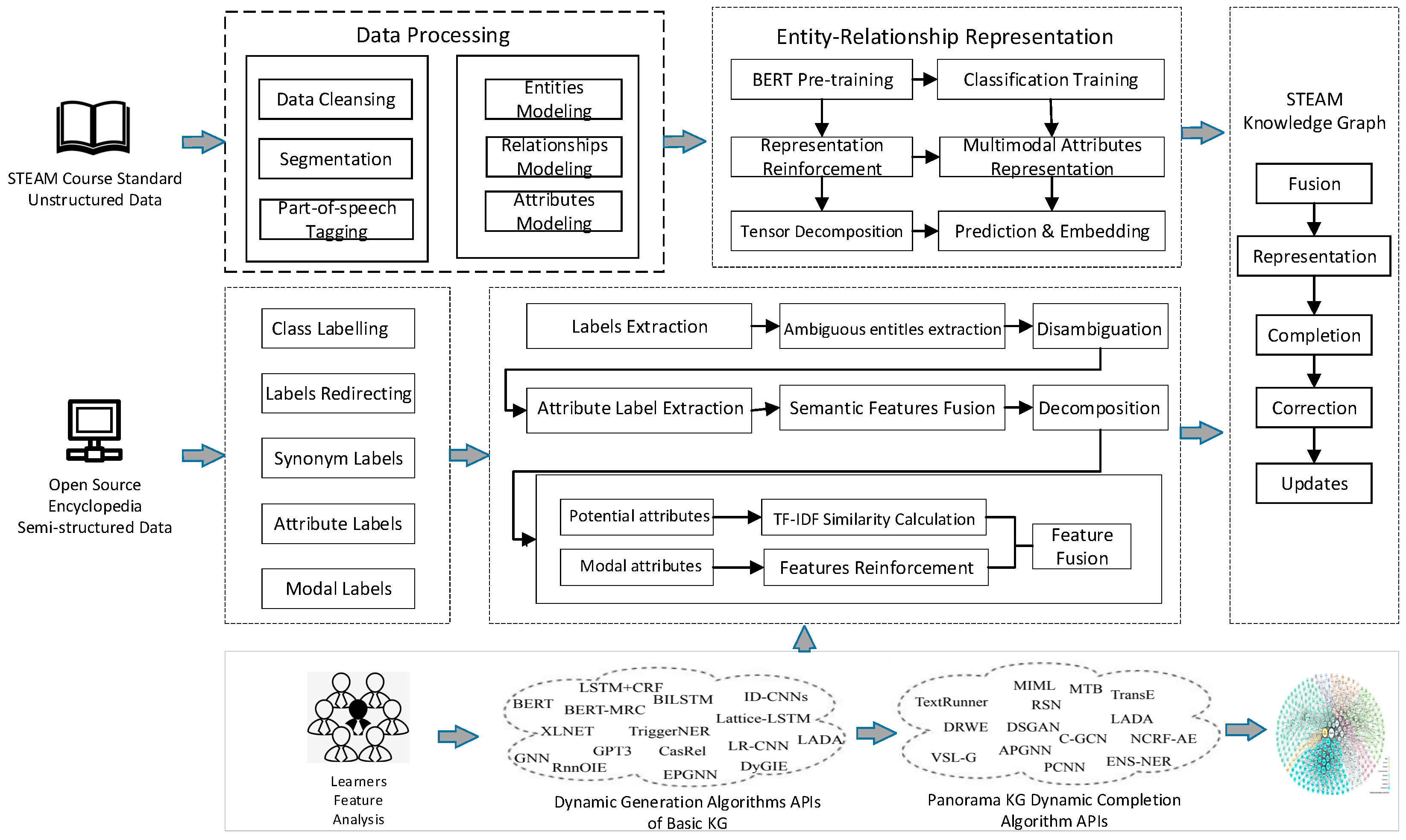
The subject knowledge graph is the key cornerstone of interdisciplinary instructional design for realizing the multi-disciplinary knowledge collaboration of STEAM. Machine learning intelligence, with the semantic annotation of a large-scale knowledge corpus, enables teachers of a single subject to design STEAM learning themes that are appropriate for the curriculum standards. Based on our research of the key technologies of knowledge graphs at home and abroad, this study proposed a dynamic generation framework of STEAM subject knowledge graphs based on a multi-algorithm collaboration, as shown in
Figure 1.
The data set for constructing a STEAM discipline knowledge graph comes from two channels: (1) unstructured data based on national discipline curriculum standards, digital textbooks, and texts; and (2) open-source semi-structured data, such as encyclopedia entries on OpenKG. The knowledge system of unstructured data, such as national discipline curriculum standards and digital textbooks in the atlas, is more precise and rigorous. The open-source encyclopedia entry data are open and collaborative, and its knowledge system in the atlas is more dynamic and extensive. The knowledge systems of the two data channels complement each other, and together they form multi-disciplinary teaching domain knowledge with strong integrity that conforms to the national discipline curriculum standards and academic quality system. At the same time, it also has the same degree of applicability for constructing the methodology of knowledge graphing for a single discipline. From the above technical work summary, it can be seen that unstructured texts on national subject curriculum standards or digital textbooks can be transformed into a structured triplet of subject knowledge graphs only through the BERT model’s neural network attention-mapping mechanism. The process and method of knowledge extraction in this link are relatively mature and also applicable to semi-structured data, such as open-source encyclopedia entry data. Technically, it is still very difficult for us to map the knowledge system space in the cognitive field, which is suitable for learning characteristics in each academic stage. There are two specific possible solutions: (1) Under the metadata design mode of the current subject knowledge graph, the open-source encyclopedia entry data are manually marked, and an unstructured training set that matches the knowledge ability level described in the national subject curriculum standard is built. It provides an excellent, labeled training source for the supervised learning algorithm, but its labor cost is obviously too high. (2) Based on the standardized corpus generated by the curriculum standard or contents of digital textbooks, the remote semi-supervised learning method is employed to generate the semantic data labels of some discipline knowledges. At this time, algorithm intelligence is used to replace heavy repetitive work, reducing the cost of artificial semantic labels for large-scale datasets. However, the semi-supervised learning algorithm cannot ensure that the discipline semantic labels of the training set that was constructed fully comply with the discipline curriculum standards in terms of knowledge compliance. Therefore, strict requirements for accuracy, such as applicability, may affect the further iterative training effect of machine learning algorithms.
The dynamic construction of STEAM’s interdisciplinary knowledge graph is reflected not only in the integration and openness of its encapsulation algorithm library API, but also in its intelligent configurability of the knowledge graph of various disciplines, which is specifically divided into the core stages of multi-disciplinary knowledge fusion, representation, completion, error correction, and update. Multi-discipline knowledge fusion refers to entity alignment and attribute fusion of multi-group and multi-discipline knowledge data. In addition to the above basic tuple elements such as “head entity—relational predicate—tail entity”, the multi-group data processed by the multi-disciplinary knowledge extraction algorithm also contain multi-group knowledge mixed with other language elements, such as time, place, degree modifier, etc. In order to realize the standardized semantic storage, linking, reasoning, etc., of the multi-group knowledge, it is necessary to regularize the tensor decomposition of the mixed elements in the multi-group; the knowledge representation is further matched with the triple representation in the current discipline knowledge graph so as to build a discipline knowledge graph configuration unit with a standardized data format, clear semantic association, and multiple reasoning paths. The representation of multi-disciplinary knowledge refers to the problem of how to map the expression forms of various multi-disciplinary knowledge in different cognitive intelligence fields. The multi-disciplinary knowledge in the learner’s cognitive intelligence development field is represented as symbolic information, and the multi-disciplinary knowledge in the machine’s cognitive learning intelligent field is represented as vectorized information. The disciplinary knowledge graph itself becomes the interface between the knowledge symbolic representation and vectorized representation to meet the needs of knowledge flow and integration in their respective fields. The completion, error correction, and updating of multi-disciplinary knowledge is a mechanism for the collaborative optimization of multi-disciplinary knowledge quality in the process of data fusion and the representation of graph corpus between learners and machines during multi-disciplinary learning. On the one hand, it dynamically updates the semantic relationship of associated conceptual entities among disciplines by encapsulating and integrating various panoramic knowledge graph completion algorithms’ API, and it promotes the configuration and integration of discipline graphs. On the other hand, through the joint training and learning of large-scale corpus semantic data, we can detect the logical fallacy of semantic relations between different entities and update knowledge cooperatively, so as to build a cognitive intelligence dynamic architecture for the appropriate instructional design of STEAM themes.
3.2. Knowledge Graph Completion of STEAM Instructional Themes
The STEAM interdisciplinary knowledge graph has an interdisciplinary and multi-level cognitive development path. It aims to cultivate learners’ multi-clue and multi-dimensional problem-solving thinking and ability. The dynamic completion of the disciplinary knowledge graph provides an intelligent cognitive framework for teachers to carry out interdisciplinary instructional design. It also enables learners to construct multi-personalized meanings for multi-disciplinary learning tasks. The completion of the STEAM knowledge graph refers to using the tensor decomposition model to convert the data of various topic maps that are related to each other or have a learning order (before and after knowledge) into a data form that is easy to be processed by the computer. Next, the semantic relationship between the subject knowledge points is mined to predict and embed the potential semantic relationship between new and old knowledge entities or their attributes. Finally, the intelligent and dynamic completion of the subject knowledge graph is realized. According to the knowledge learning path of different disciplines of STEAM, the completion path of a STEAM knowledge graph also presents multiple dynamics.
Before introducing the tensor decomposition model applied to STEAM knowledge graph embedding, the following symbol definitions were decided:
The knowledge triple is represented by (head entity, relationship type, tail entity), which is denoted as and abbreviated as . The Greek letter represents the three-dimensional knowledge tensor, and the elements in are represented by . The capital letter represents the matrices model, which is used to represent entity sets and relationship type sets, whereas represents the size of the matrices. The lowercase letter represents a vector, where item i is represented by . represents the Tucker product, which is used for the product of the three-dimensional knowledge tensor and matrix. The operator “” represents the product of a vector.
In STEAM multi-disciplinary project-based instruction, the relationships among knowledges are often numerous, and their semantics are connected; in addition, the representation of the relationships is not unique. To simplify the principle introduction, the knowledge semantic relationship is represented as a triple. Taking “Mendel’s Law of Inheritance” as an example, the random combination of dominant genes and recessive genes of organisms determines various traits, and the corresponding probability can be obtained through mathematical modeling. Therefore, its knowledge semantics can be represented by a composite triple (Mendel’s law, mathematical modeling/material basis, and a random combination of probability/DNA genetic information). When it is extended to the tensor model, the knowledge triplet is constructed as a three-dimensional tensor, in which two dimensions are composed of knowledge head and tail entities (such as Mendel’s law or a random combination of probability/DNA genetic information) and the third dimension is the relationship between knowledges (mathematical modeling/material basis).
Take the classic algorithm of the Tucker decomposition [
28] of a tensor model as an example. For the three-dimensional tensor in the subject knowledge graph, the Tucker decomposition can obtain the core tensor and three knowledge matrices, as shown in Formula (1).
Among them, the core tensor G represents the level of semantic relationship between knowledge entities and relationships, which can be used for a potential semantic analysis of knowledge points and knowledge relationships. In essence, tensor decomposition is to decompose the potential semantic relationship of new knowledge through the dimension reduction processing of complex knowledge structures and the dimension reduction algorithm of model structures, so as to generate new knowledge structures that do not exist in the original graph spectrum and to promote the STEAM project to learn multiple observation perspectives and solve multi-clue problems. Therefore, the tensor model is suitable for the dynamic completion of the subject knowledge map, and the semantic relationship cohesion of the subject knowledge is improved through the dynamic embedded model.
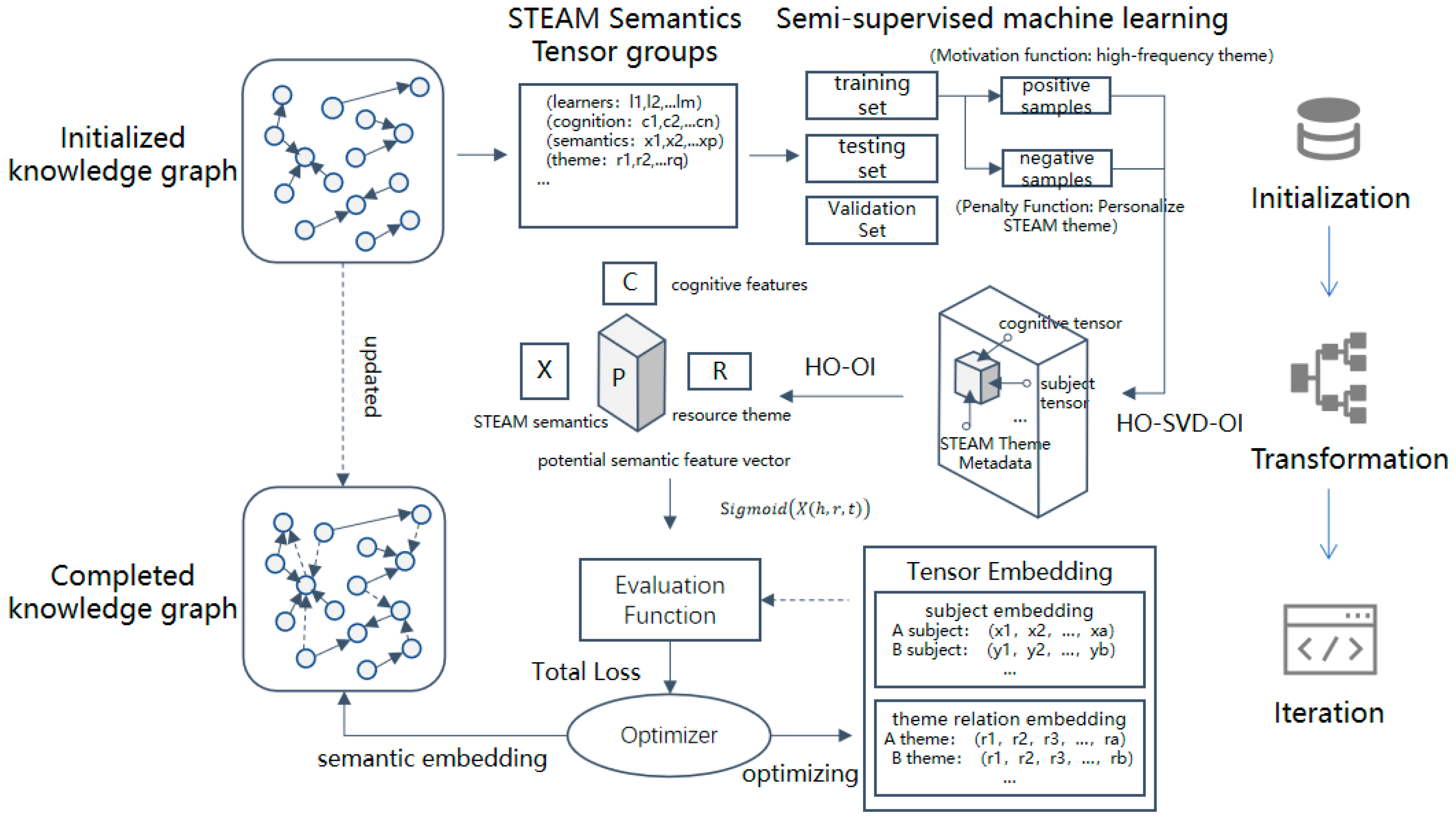
Combined with the tensor decomposition algorithm, this study proposed a dynamic completion model of a STEAM interdisciplinary knowledge graph as shown in
Figure 2. The main idea of the model is to reflect the hidden information of knowledge through tensor decomposition into a low-dimensional matrix, which is used to estimate the incomplete part of the original discipline knowledge graph. The model extracts knowledge triplets from the knowledge graph of a single discipline to form a data set. The positive and negative samples in the data set of a single discipline are constructed into a three-dimensional knowledge tensor, which is decomposed into a low-dimensional knowledge matrix by Tucker and sent to the scoring function. The embedded entities and relationships are constantly updated by the optimizer, and the implicit relationships between knowledges are mined to supplement the STEAM interdisciplinary knowledge graph as a newly generated knowledge connection.
In order to establish relationships among the knowledge entities with unknown relationships, the model uses the replacement method to replace the correct knowledge triplet entities into negative triples. For prediction, the function is used as the activation function to predict the correctness of the triple through probability. For optimization, the model uses the logarithmic likelihood loss function to measure the quality of the model’s prediction.
3.3. Quality Assessment of STEAM Knowledge Graph Based on Curriculum Standards
The matching degree between the subject knowledge system and the subject accomplishment evaluation index in the STEAM curriculum standard is an important indicator for measuring the quality of the generation and completion of the subject knowledge graph. Whether it is the generation of the subject knowledge graph or the dynamic completion of the subject knowledge graph based on different teaching objectives and teaching themes, the quality evaluation index should focus on the teaching connectivity and teaching appropriateness of the map. The teaching connectivity is calculated by the dynamic performance of the interdisciplinary knowledge of the atlas, while the teaching appropriateness is calculated by the cognitive and evaluation matching degree of the discipline curriculum standards related to the STEAM teaching theme of the atlas. Therefore, its quality evaluation methods include the matching degree calculation methods of the knowledge atlas completion performance based on tensor model and the academic quality evaluation indicators based on the discipline curriculum standards. We evaluated whether the constructed discipline knowledge graph had good dynamic embedding performance; that is, whether the discipline knowledge graph met the dynamic embedding of entity relations with multi-modal attributes. The test data selected multi-source heterogeneous data, such as digital education resource library and public service resource metadata, through MRR, Hits@1, Hits@3, and Hits@10 to calculate the matching effect between the subject knowledge graph and the subject curriculum standard knowledge system.
The Mean Reciprocal Rank (MRR) is the average reciprocal ranking of embedded entities in the discipline knowledge graph. The larger the index is, the better the matching effect is, as shown in Formula (2).
Hits@N is the average proportion of triples ranking less than N in the prediction of a STEAM interdisciplinary knowledge link. The larger the index is, the better the matching effect is, as shown in Formula (3).
Conversely, we evaluated whether the constructed subject knowledge graph matched the instructional requirements of the subject curriculum standards of each learning segment, such as whether the generated and completed subject knowledge graph met the teaching objectives, resource organization, and activity design of STEAM teachers based on interdisciplinary curriculum standards while meeting the requirement of providing students with cognitive support, resource recommendations, and learning path planning based on the subject curriculum standards. Therefore, the matching data set of the evaluation method was the text data of the curriculum standards of each discipline of STEAM. Through the knowledge extraction, knowledge annotation, knowledge matching, and other links of the curriculum standard text, the matching degree of the curriculum standard teaching requirements of each discipline can be measured according to the phased output of each link. Specifically, it includes the matching of the subject knowledge graph and the cognitive level of the subject curriculum standard, and the matching of the academic quality with literacy evaluation indicators.
5. Results and Discussion
5.1. Performance Results of Comparison Simulation Experiment
In the training set data, the corresponding TopN list of each learner was calculated by the multi-disciplinary semantic tensor decomposition algorithm HO-SVD-OI in this section. The accuracy recall curve was used to reflect the changing trend of the accuracy of the method in this paper and the mainstream classical algorithm in matching STEAM learning topics with course standards, and the performance gap of different algorithms was reflected by the harmonic mean F1 index [
29]. In this section, we selected the Kmeans IDF algorithm [
30] based on semantic tags and K-means clustering of user access resources, the classical tensor decomposition Co SClu algorithm [
31] based on semantic tag co-occurrence spectrum clustering, and the classical TD algorithm [
32] based on original tensor decomposition as the reference comparison algorithm.
The P-R curve and F1 index curve simulation results of the above four algorithms are shown in
Figure 4. In the P-R curve comparison chart, as the training scale of the data set increased, the accuracy and recall rate of the algorithm showed a reverse proportion change trend. The more the values gathered to the upper right side of the image area, the better the matching effect of the digital learning resources organized by the algorithm on the learner’s knowledge tag. In the F1 index curve comparison chart, the more values gathered above the image area, the higher the accuracy of the learning topics generated by the algorithm for the coverage of multi-disciplinary curriculum standards. In addition, whether it was the HO-SVD-OI algorithm applied in this chapter or the high-dimensional semantic tensor decomposition resource organization matching algorithm based on Kmeans clustering or spectral clustering proposed by our predecessors, its performance was significantly better than that of the simple tensor decomposition algorithm. By observing the F1 index curve, we found that when the scale of STEAM learning topics approached about 20, the four algorithms all achieved the best performance in the coverage accuracy of the STEAM discipline curriculum standard.
5.2. Discussion on Learning Path Based on STEAM Interdisciplinary Knowledge Graph
When learners complete STEAM project learning, they generally have a relatively complete discipline knowledge structure in the lower learning stage. In the context of STEAM interdisciplinary project learning, the dynamic completion of a discipline knowledge graph is essentially a process of personalized meaning construction of learners for high-level learning objects, thus promoting the gradual formation of high-level knowledge and literacy of disciplines.
In the key words knowledge graph of the project theme shown in
Figure 3, the teaching goal of the project is to solve the problem of “the causes of the diversity of pea genetic traits”, while the original knowledge structure of the learners is the relevant scientific principle “Mendelian genetic law conducts mathematical modeling through the probability learned in junior high school, and the expression of biological genetic traits is determined by their DNA”. The new knowledge that learners need to master is that “the deep reason for the establishment of Mendel’s Law is that biological genetic material DNA has the random characteristics of free separation and combination, and the random combination characteristics of genetic material lead to the diversification of genetic traits, thus contributing to the diversity of biological genetics and evolution directions”. The STEAM interdisciplinary knowledge graph supports single-discipline teachers to design project learning path steps as follows:
Step 1: According to the high school biology curriculum standard, the triple of the original knowledge graph is marked as the literacy evaluation index V(ij), indicating the literacy level that learners should reach when learning corresponding knowledge , where i represents the triple knowledge sequence, and j represents the literacy evaluation level sequence.
Step 2: According to the quality evaluation index system of the subject curriculum standards, the subject project teaching topics of different subject quality levels are presented. For example, for the learning needs of mathematical logic computing quality evaluation, teachers can build appropriate mathematical models for learners to deduce and verify the “randomness of biological genetic material combination” according to the quality evaluation index labels (junior high school, mathematics, event probability, mathematical modeling, and problem-solving) and can support learners to understand the essence of problem-solving from the evolution of mathematical variables. For the learning needs of spatial structure analysis literacy, teachers can build “the combination and change law of DNA microstructure in the genetic process” for it through spatial micro-analysis according to the quality evaluation index labels (junior high school, chemistry, structure of life macromolecules, scientific inquiry, macro-identification, and micro-analysis). Different goal orientation will lead to different paths of STEAM project learning activities.
Step 3: When learners choose different ways to organize corresponding discipline project resources, teachers will provide necessary assistance and intervention according to their learning process and learners’ dynamic generation and completion direction of the discipline knowledge graph based on derived theme keywords, adjust the direction and level of learners’ personalized meaning construction, and finally achieve the overall goal of STEAM project teaching that meets the discipline curriculum standards.
6. Conclusions and Future Work
Presently, there are many kinds of mature natural language processing and machine learning algorithms in the computer science field. The application of a single algorithm cannot meet the context or scene adaptability requirements of the entity recognition accuracy and relational semantic modeling of the STEAM interdisciplinary knowledge graph from different perspectives. It is necessary to integrate multiple APIs to conduct multiple trainings on data sets to meet the needs of teachers in a single discipline for the design of STEAM interdisciplinary teaching themes; among them, conditional random field and tensor decomposition algorithms are relatively ideal for semantic relationship modeling. On the one hand, the dynamic generation of a STEAM subject knowledge graph can enable teachers of a single subject to flexibly organize instructional resources and improve teaching efficiency in an intelligent learning environment. On the other hand, a STEAM subject knowledge map can effectively plan personalized learning paths by adapting to learners’ cognitive characteristics, thus broadening learners’ multi-dimensional thinking ability.
Although the traditional tensor decomposition algorithm has good performance for the generation of STEAM multi-disciplinary topics, it is easy to form a STEAM “topic cocoon room” due to the long-term recommendation of high-frequency single discipline themes, which are not conducive to the development of learners’ multiple cognitive abilities. The HO-SVD-OI tensor decomposition algorithm, which introduces a penalty function and high-dimensional orthogonal iteration mechanism, has good computational performance for the matching and coverage of STEAM learning themes and multi-disciplinary curriculum standards; it can effectively eliminate the problem of a “theme cocoon room” in STEAM instructional design. Future research will focus on the interpretability mechanism of knowledge graphs for STEAM interdisciplinary semantic learning.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



