


Research on Key Technologies of Super-Resolution Reconstruction of Medium and Long Wave Maritime Infrared Image

Abstract
1. Introduction
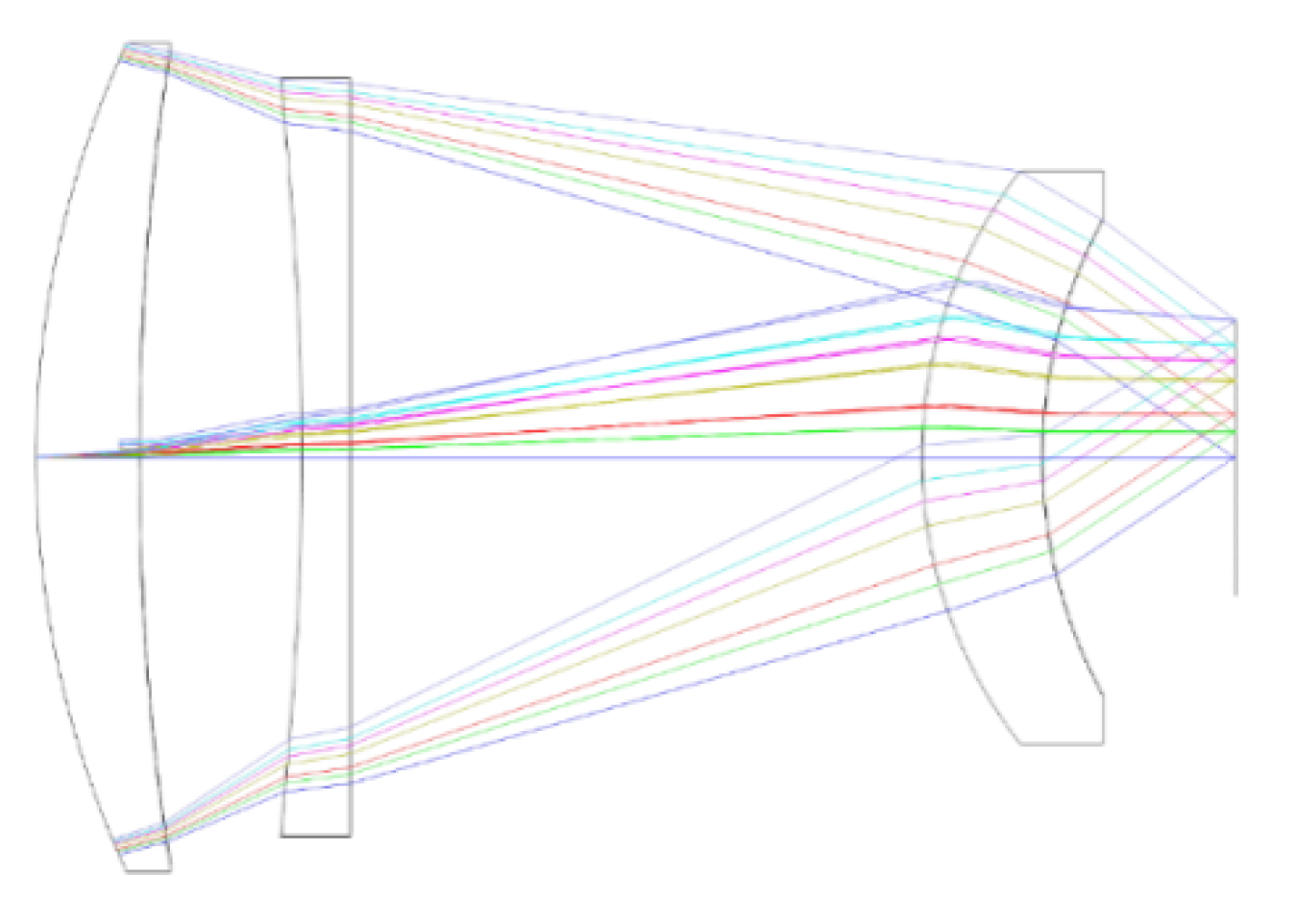
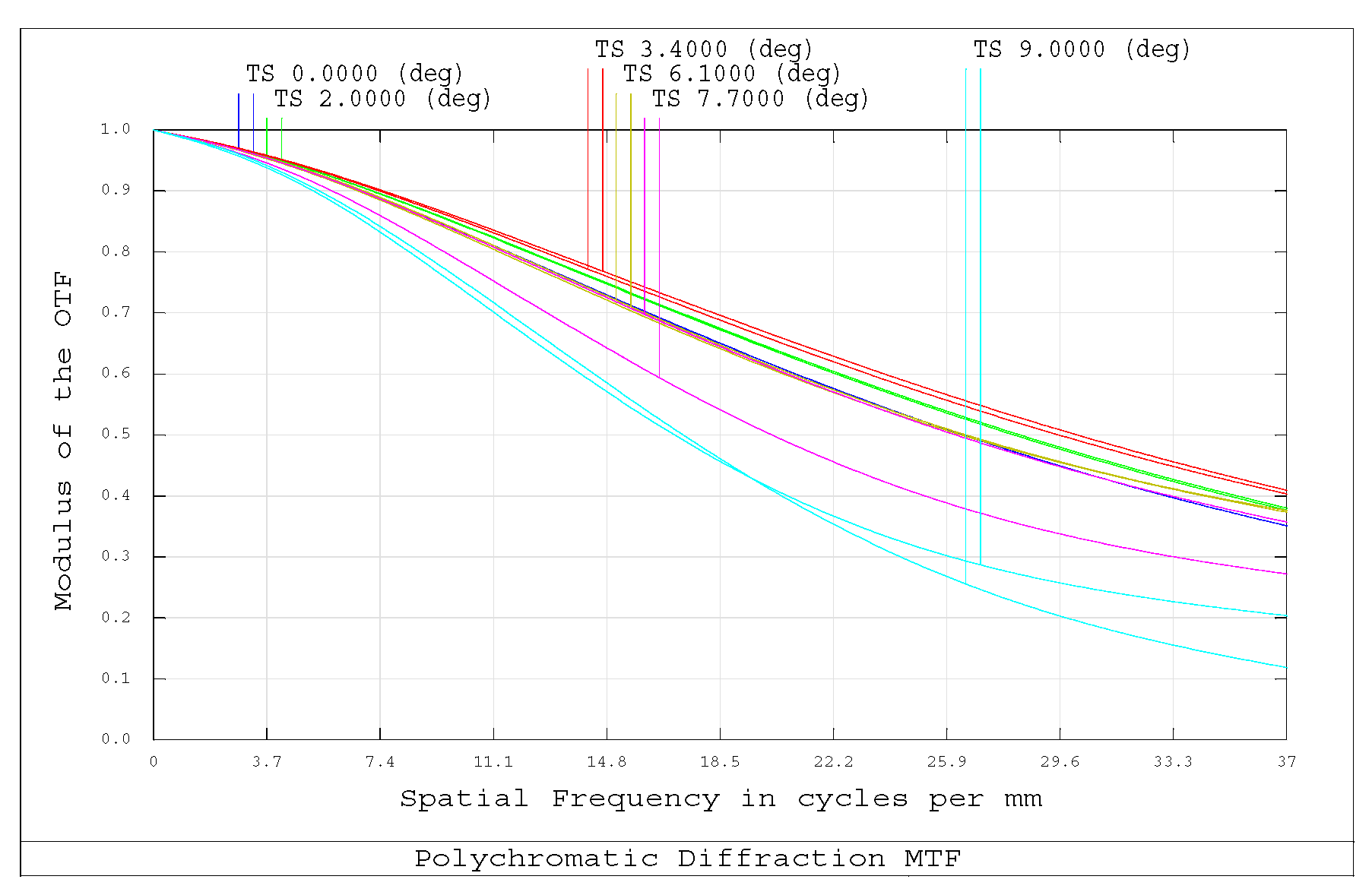
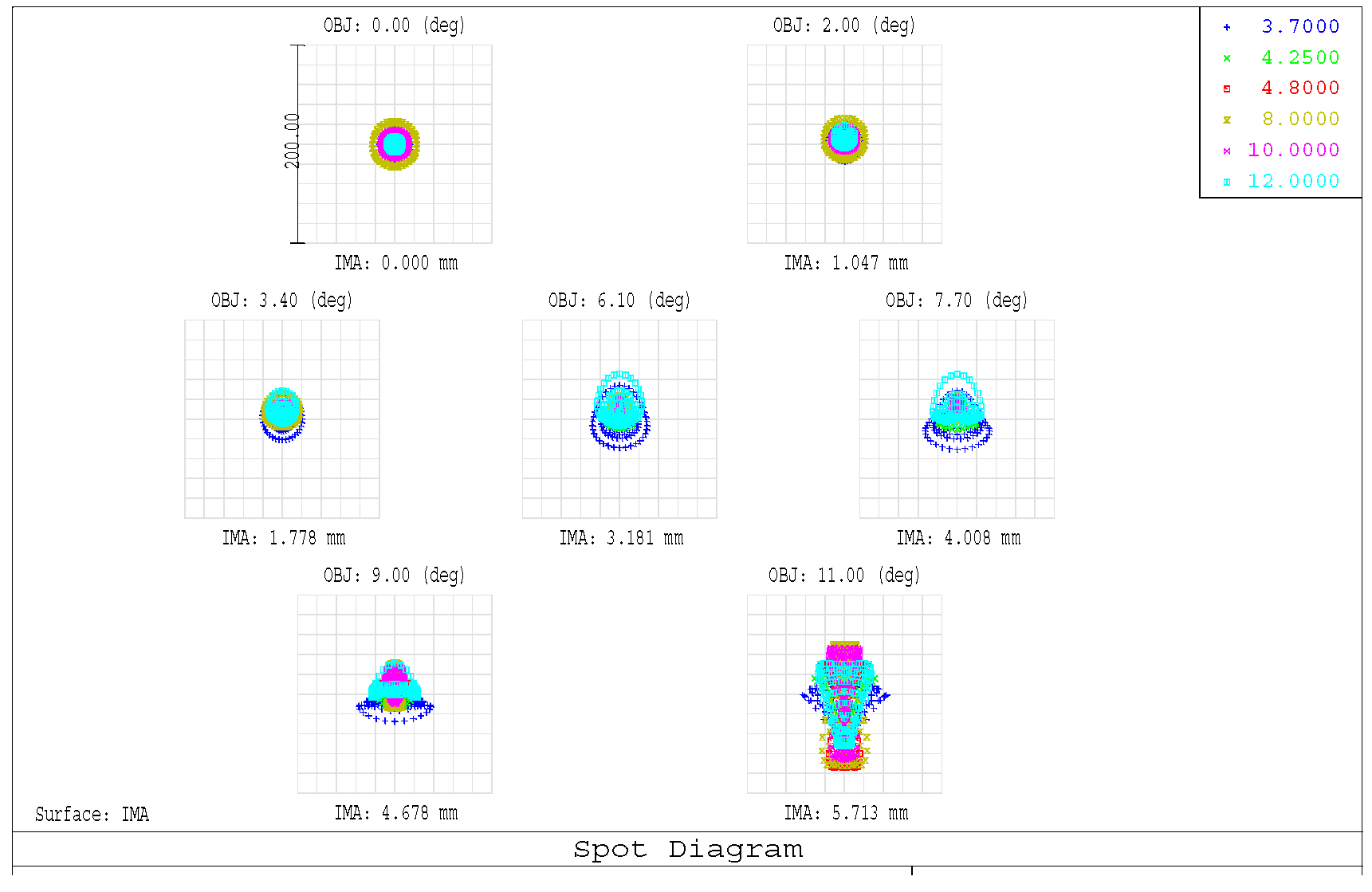
2. The Designed Infrared Optical Imaging System
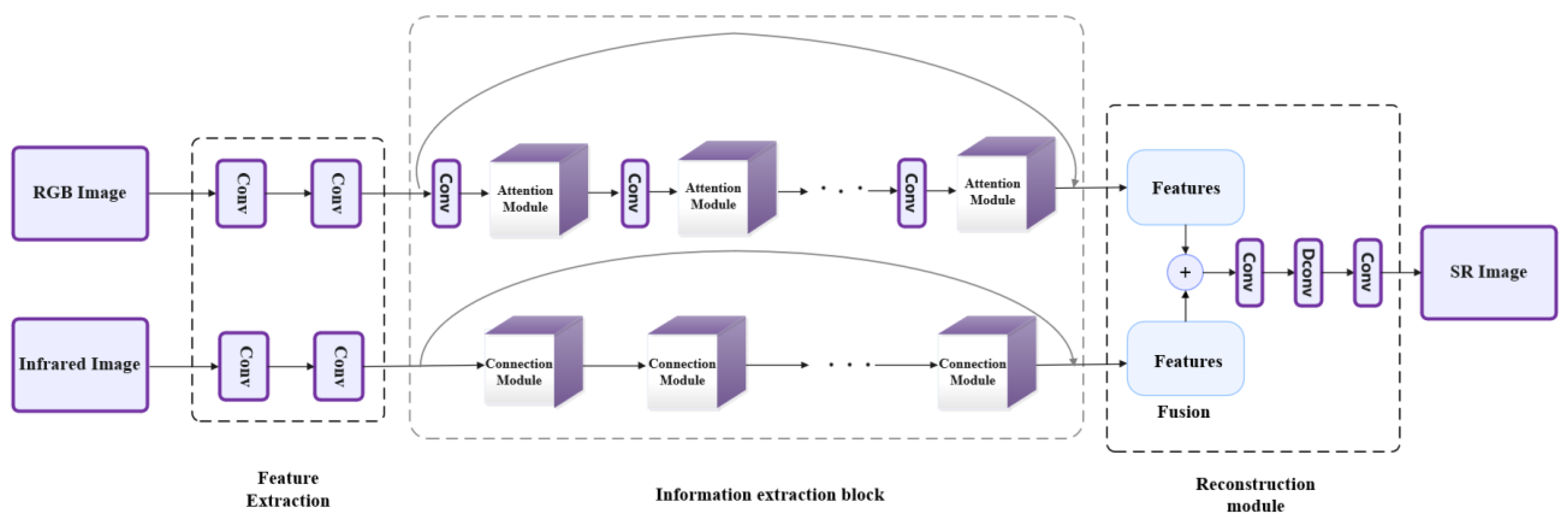
3. The Proposed Network Model
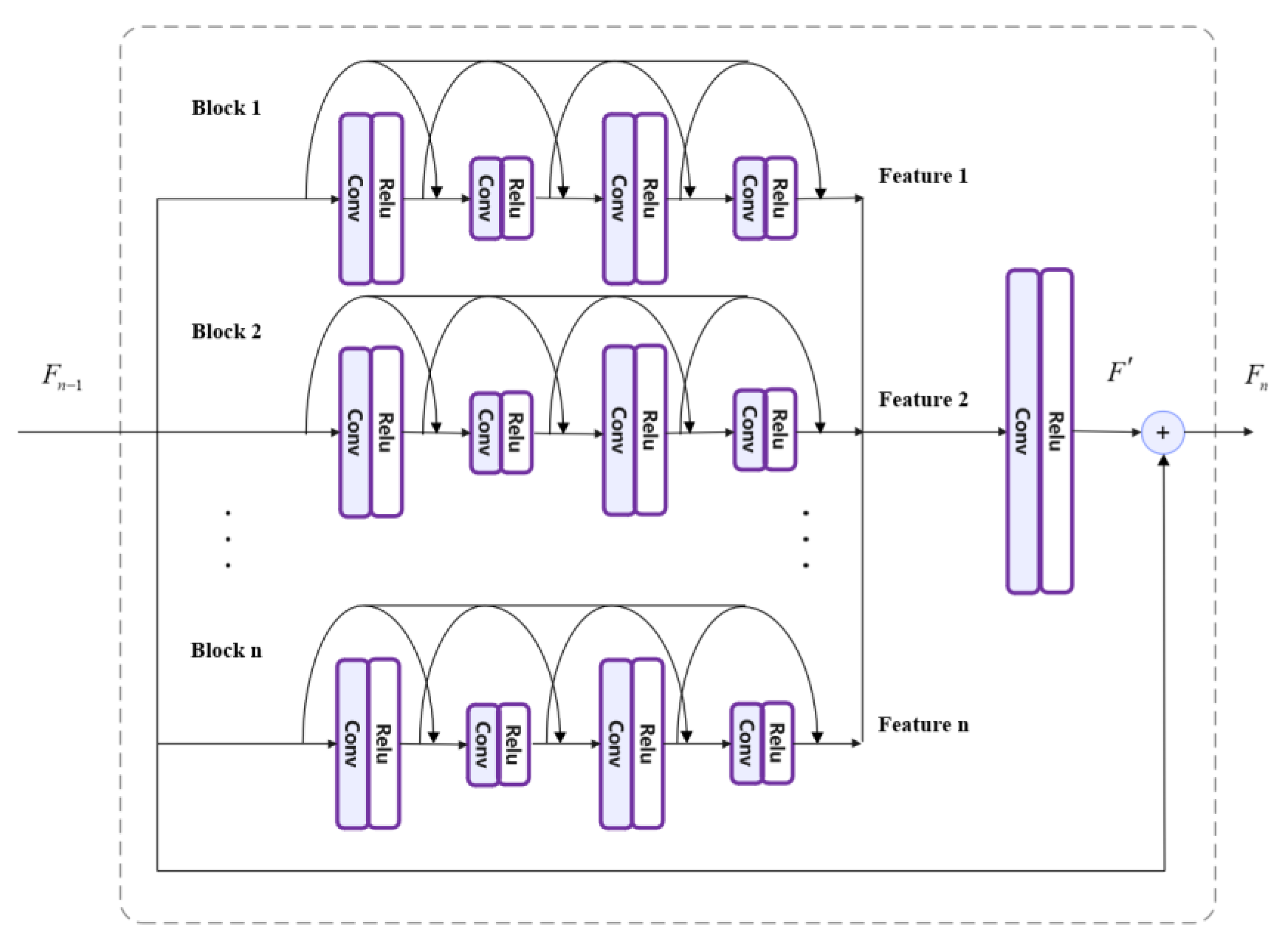
3.1. Feature Extraction Layer
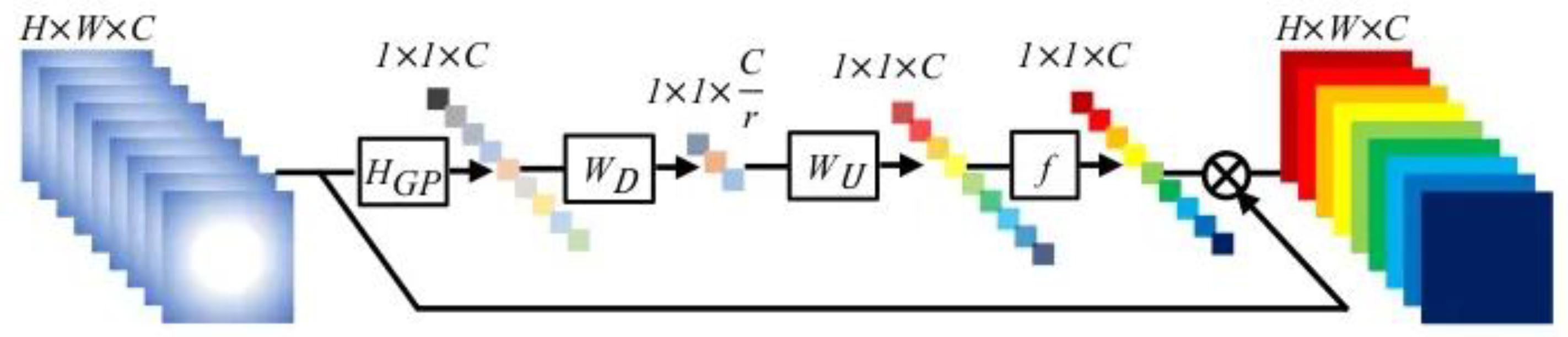
3.2. Information Extraction Layer
3.3. The Reconstruction Layer
3.4. Framework of the Whole Algorithm
- (1).
- Two-line input, one is low resolution IR and the other is registered high-resolution RGB image. First, we use bicubic interpolation to up sample the infrared image to the same size as RGB.
- (2).
- The most IR related channel of the RGB image is selected.
- (3).
- Next, we perform preliminary information extraction on the two images.
- (4).
- Taking the high-resolution RGB image as a guide, the main features such as edge texture are extracted by convolution.
- (5).
- The corresponding low-resolution IR is used to extract the main features such as edge texture by convolution.
- (6).
- Fuse the values of (4) and (5), we compare the fused results with the high-definition IR corresponding to the training and calculate the loss function.
- (7).
- Back propagation is used to update the network weight parameters and to constantly optimize the network model.
- (8).
- We then judge whether all images have been executed. If yes, the training is stopped. If not, loop back to step 1.
- (9).
- Finally, the network model of training optimization is obtained.
4. Experiments and Comparisons
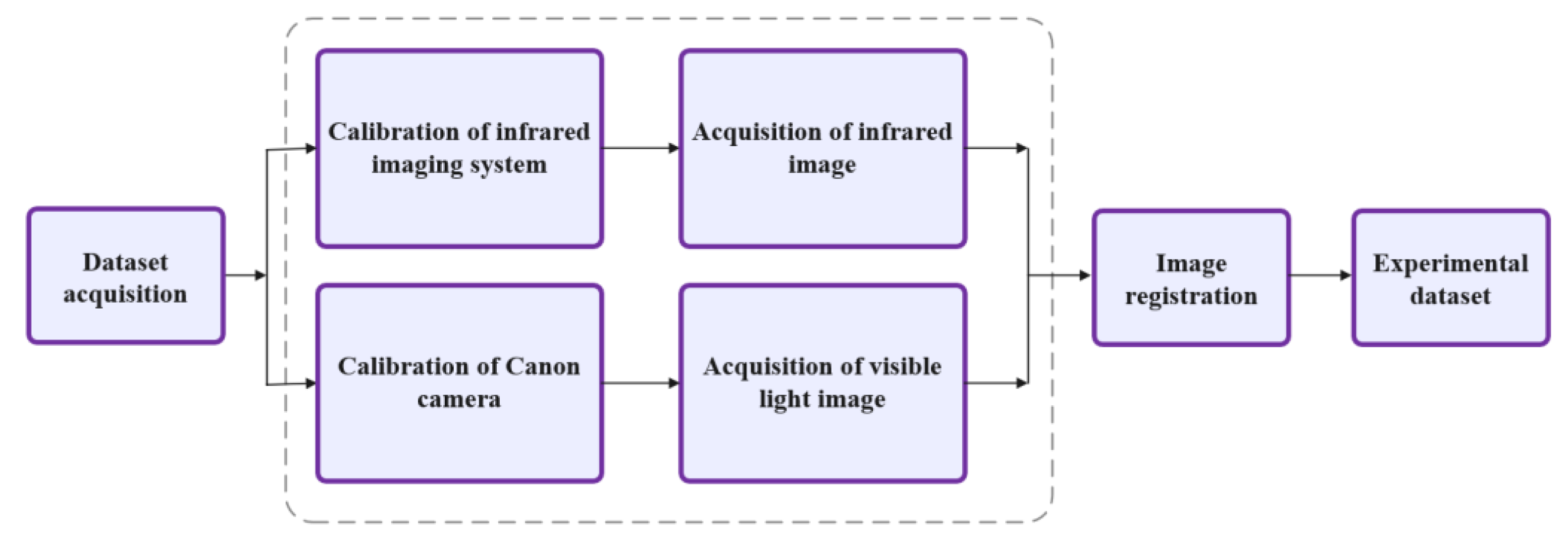
4.1. Experimental Data
4.2. Experimental Setup
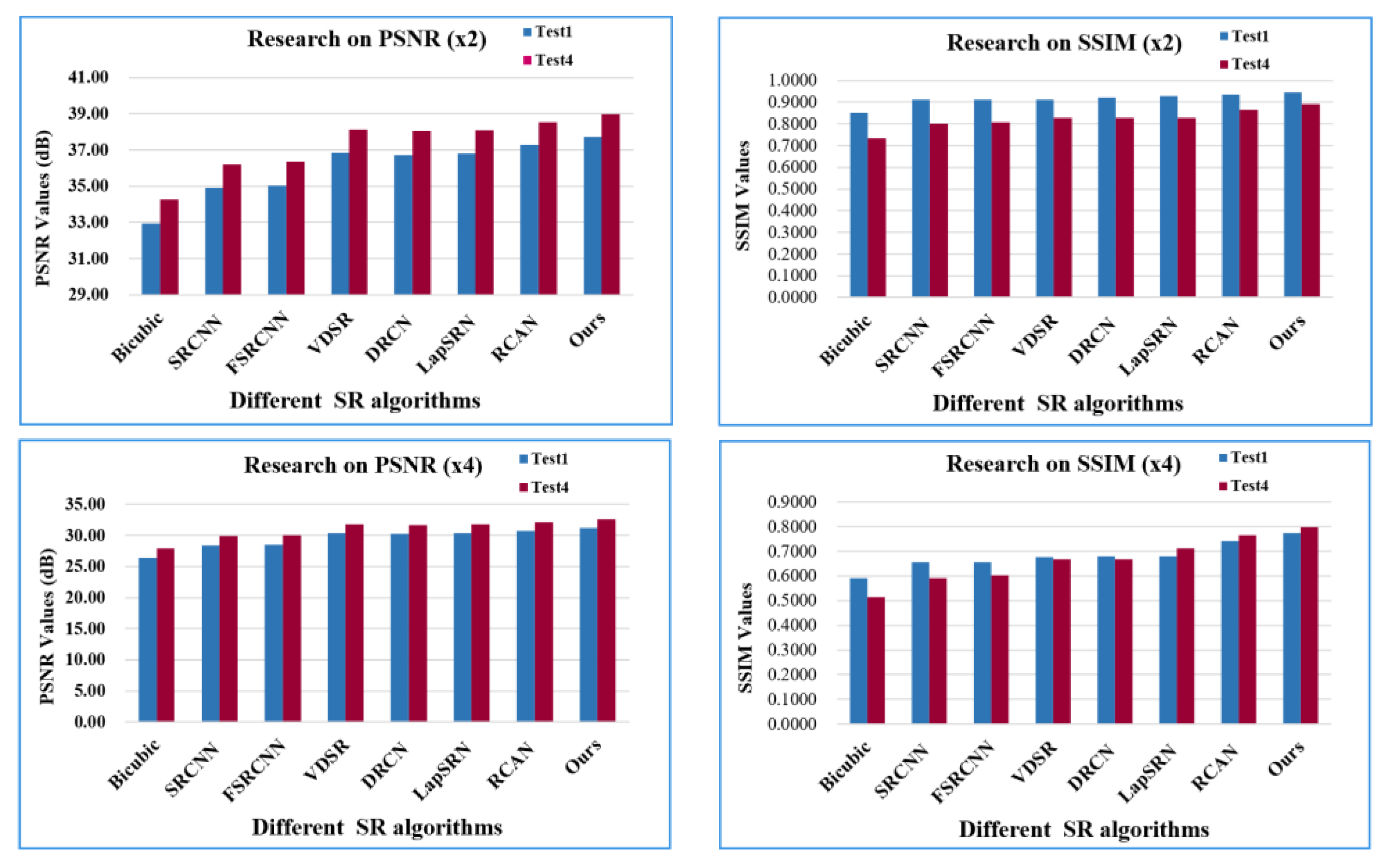
4.3. Experimental Comparison
4.4. Experimental Analysis
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, X.-G.; Wu, X.-M.; Wang, L.; Liang, Q.-Y.; Gu, L.-J.; Liu, F.; Lu, H.-L.; Zhang, Y.; Zhang, M. Distributed optical fiber acoustic sensor for in situ monitoring of marine natural gas hydrates production for the first time in the Shenhu Area. China Geol. 2022, 5, 322–329. [Google Scholar] [CrossRef]
- Zhang, R.; Hong, W.; Wang, X.; Su, J. Color Fusion Method of Infrared Medium and Long Wave Images Based on Helix Mapping of Differential Features. Prog. Laser Optoelectron. 2022, 59, 4. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.H.; Liao, Q. Deep learning for single image super-resolution: A brief review. IEEE Trans. Multimed. 2019, 21, 3106–3121. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Wang, C.; Zhang, Y.; Jiang, H.L.; Li, Y.C.; Jiang, L.; Fu, Q.; Han, L. Research Status and Progress of Super Resolution Imaging Methods. Laser Infrared 2017, 7, 791–798. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze and excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Sakai, Y.; Lu, H.; Tan, J.K.; Kim, H. Recognition of surrounding environment from electric wheelchair videos based on modified YOLOv2. Future Gener. Comput. Syst. 2019, 92, 161. [Google Scholar] [CrossRef]
- Xiang, L.; Yang, S.; Liu, Y.; Li, Q.; Zhu, C. Novel linguistic steganography based on character-level text generation. Mathematics 2020, 8, 1558. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, L.; Tao, J.; Xia, R.; Zhang, Q.; Yang, K.; Xiong, J.; Chen, X. The improved image inpainting algorithm via encoder and similarity constraint. Vis. Comput. 2020, 37, 1691–1705. [Google Scholar] [CrossRef]
- He, S.; Li, Z.; Wang, J.; Xiong, N.N. Intelligent detection for key performance indicators in industrial based cyber-physical systems. IEEE Trans. Ind. Inform. 2020, 17, 5799–5809. [Google Scholar] [CrossRef]
- Lu, W.; Zhang, Y.; Wang, S.; Huang, H.; Liu, Q.; Luo, S. Concept representation by learning explicit and implicit concept couplings. IEEE Intell. Syst. 2020, 36, 6–15. [Google Scholar] [CrossRef]
- Chen, Y.; Phonevilay, V.; Tao, J.; Chen, X.; Xia, R.; Zhang, Q.; Yang, K.; Xiong, J.; Xie, J. The face image super-resolution algorithm based on combined representation learning. Multimed. Tools Appl. 2020, 80, 30839–30861. [Google Scholar] [CrossRef]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Zhang, P.; Lam Edmund, Y. Efficient Dual Attention Mechanism for Single Image Super-Resolution. Inst. Electr. Electron. Eng. 2021, 114, 957–964. [Google Scholar] [CrossRef]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super resolution using dense skip connections. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4809–4817. [Google Scholar]
- Lee, S.; Cho, M.S.; Jung, K.; Kim, J.H. Scene text extraction with edge constraint and text collinearity. In Proceedings of the 20th International Conference on Pattern Recognition, Washington, DC, USA, 23–26 August 2010; pp. 3983–3986. [Google Scholar]
- Morris, N.J.; Avidan, S.; Matusik, W.; Pfister, H. Statistics of infrared images. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–7. [Google Scholar]
- Yang, X.; Xie, T.; Liu, L.; Zhou, D. Image super-resolution reconstruction based on improved Dirac residual network. Multidimens. Syst. Signal Process. 2021, 32, 1065–1082. [Google Scholar] [CrossRef]
- Esmaeilzehi, A.; Ahmad, M.O.; Swamy, M.N.S. A Deep Light-Weight Network for Single Image Super Resolution Using Spatial and Spectral Information. IEEE Trans. Comput. 2021, 7, 409–421. [Google Scholar] [CrossRef]
- Wang, Y.; Perazzi, F.; McWilliams, B.; Sorkine-Hornung, A.; Sorkine-Hornung, O.; Schroers, C. A fully progressive approach to single-image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 17–22 June 2018; pp. 977–986. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training very deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2377–2385. [Google Scholar]
- Chen, Y.; Liu, L.; Phonevilay, V.; Gu, K.; Xia, R.; Xie, J. Image super-resolution reconstruction based on feature map attention mechanism. Appl. Intell. 2021, 51, 4367–4380. [Google Scholar] [CrossRef]
- Soh, J.W.; Cho, S.; Cho, N.I. Meta-transfer learning for zero-shot super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3513–3522. [Google Scholar]
- Timofte, R.; Rothe, R.; Gool, L.V. Seven ways to improve example-based single image super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1865–1873. [Google Scholar]
- Ren, Z.; Zhao, J.; Chen, C.; Lou, Y.; Ma, X.; Tao, P. Rendered image super-resolution reconstruction with multi-channel feature network. Sci. Program. 2022, 2022, 9393589. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment from error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Sheikh, H.R.; Bovik, A.C.; De Veciana, G. An information fidelity criterion for image quality assessment using natural scene statistics. IEEE Trans. Image Process. 2005, 14, 2117–2128. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Index |
|---|---|
| wavelength | 3–12 μm |
| focal length | 30 mm |
| F\# | 0.9 |
| Total length of optical system | 35 mm |
| detector resolution | 640 × 512 |
| pixel size of detector | 15 μm |
| Algorithm | Input | Depth | Residual Structure | Reconstruction | Loss |
|---|---|---|---|---|---|
| SRCNN [4] | LR+Bicubic | 3 | no | - | L2 |
| FSRCNN [5] | LR | 8 | no | - | L2 |
| VDSR [6] | LR+Bicubic | 20 | yes | - | L2 |
| DRCN [7] | LR+Bicubic | 5 | no | - | L2 |
| LapSRN [8] | LR | 24 | yes | Progressive | Charbonnier |
| Dataset | Scale | Bicubic | SRCNN [4] | FSRCNN [5] | VDSR [6] | DRCN [7] | LapSRN [8] | RCAN [9] | Ours |
|---|---|---|---|---|---|---|---|---|---|
| Test1 | 2× | 32.93 | 34.92 | 35.05 | 36.86 | 36.71 | 36.82 | 37.28 | 37.73 |
| Test2 | 2× | 33.24 | 35.33 | 35.47 | 37.28 | 37.13 | 37.25 | 37.66 | 38.12 |
| Test3 | 2× | 33.56 | 35.67 | 35.82 | 37.61 | 37.44 | 37.58 | 37.99 | 38.44 |
| Test4 | 2× | 34.28 | 36.19 | 36.34 | 38.12 | 38.05 | 38.10 | 38.52 | 38.98 |
| Test1 | 3× | 29.82 | 31.83 | 31.96 | 33.75 | 33.62 | 33.73 | 34.18 | 34.63 |
| Test2 | 3× | 30.51 | 32.49 | 32.67 | 34.41 | 34.25 | 34.37 | 34.82 | 35.27 |
| Test3 | 3× | 30.95 | 32.93 | 33.05 | 34.79 | 34.63 | 34.74 | 35.17 | 35.61 |
| Test4 | 3× | 31.46 | 33.43 | 33.57 | 35.38 | 35.22 | 35.36 | 35.73 | 36.19 |
| Test1 | 4× | 26.45 | 28.43 | 28.56 | 30.37 | 30.23 | 30.34 | 30.70 | 31.15 |
| Test2 | 4× | 26.99 | 28.98 | 29.10 | 30.91 | 30.76 | 30.87 | 31.26 | 31.72 |
| Test3 | 4× | 27.53 | 29.52 | 29.66 | 31.47 | 31.32 | 31.43 | 31.61 | 32.06 |
| Test4 | 4× | 27.93 | 29.91 | 30.04 | 31.82 | 31.65 | 31.77 | 32.18 | 32.64 |
| Dataset | Scale | Bicubic | SRCNN [4] | FSRCNN [5] | VDSR [6] | DRCN [7] | LapSRN [8] | RCAN [9] | Ours |
|---|---|---|---|---|---|---|---|---|---|
| Test1 | 2× | 0.8853 | 0.9087 | 0.9134 | 0.9302 | 0.9284 | 0.9299 | 0.9315 | 0.9349 |
| Test2 | 2× | 0.8866 | 0.9100 | 0.9147 | 0.9315 | 0.9297 | 0.9312 | 0.9328 | 0.9362 |
| Test3 | 2× | 0.8949 | 0.9183 | 0.9230 | 0.9398 | 0.9380 | 0.9395 | 0.9411 | 0.9445 |
| Test4 | 2× | 0.8992 | 0.9226 | 0.9273 | 0.9441 | 0.9423 | 0.9438 | 0.9454 | 0.9488 |
| Test1 | 3× | 0.8579 | 0.8813 | 0.8860 | 0.9028 | 0.9010 | 0.9025 | 0.9041 | 0.9075 |
| Test2 | 3× | 0.8623 | 0.8856 | 0.8903 | 0.9071 | 0.9053 | 0.9068 | 0.9084 | 0.9118 |
| Test3 | 3× | 0.8635 | 0.8871 | 0.8917 | 0.9085 | 0.9067 | 0.9082 | 0.9098 | 0.9132 |
| Test4 | 3× | 0.8800 | 0.9032 | 0.9081 | 0.9249 | 0.9231 | 0.9246 | 0.9262 | 0.9296 |
| Test1 | 4× | 0.7747 | 0.7982 | 0.8028 | 0.8196 | 0.8178 | 0.8193 | 0.8209 | 0.8243 |
| Test2 | 4× | 0.7926 | 0.8159 | 0.8206 | 0.8374 | 0.8356 | 0.8371 | 0.8387 | 0.8421 |
| Test3 | 4× | 0.8001 | 0.8236 | 0.8282 | 0.8450 | 0.8432 | 0.8447 | 0.8463 | 0.8497 |
| Test4 | 4× | 0.8056 | 0.8289 | 0.8337 | 0.8505 | 0.8487 | 0.8502 | 0.8518 | 0.8552 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Z.; Zhao, J.; Wang, C.; Ma, X.; Lou, Y.; Wang, P. Research on Key Technologies of Super-Resolution Reconstruction of Medium and Long Wave Maritime Infrared Image. Appl. Sci. 2022, 12, 10871. https://doi.org/10.3390/app122110871
Ren Z, Zhao J, Wang C, Ma X, Lou Y, Wang P. Research on Key Technologies of Super-Resolution Reconstruction of Medium and Long Wave Maritime Infrared Image. Applied Sciences. 2022; 12(21):10871. https://doi.org/10.3390/app122110871
Chicago/Turabian StyleRen, Zhipeng, Jianping Zhao, Chao Wang, Xiaocong Ma, Yan Lou, and Peng Wang. 2022. "Research on Key Technologies of Super-Resolution Reconstruction of Medium and Long Wave Maritime Infrared Image" Applied Sciences 12, no. 21: 10871. https://doi.org/10.3390/app122110871
APA StyleRen, Z., Zhao, J., Wang, C., Ma, X., Lou, Y., & Wang, P. (2022). Research on Key Technologies of Super-Resolution Reconstruction of Medium and Long Wave Maritime Infrared Image. Applied Sciences, 12(21), 10871. https://doi.org/10.3390/app122110871