Appendix A
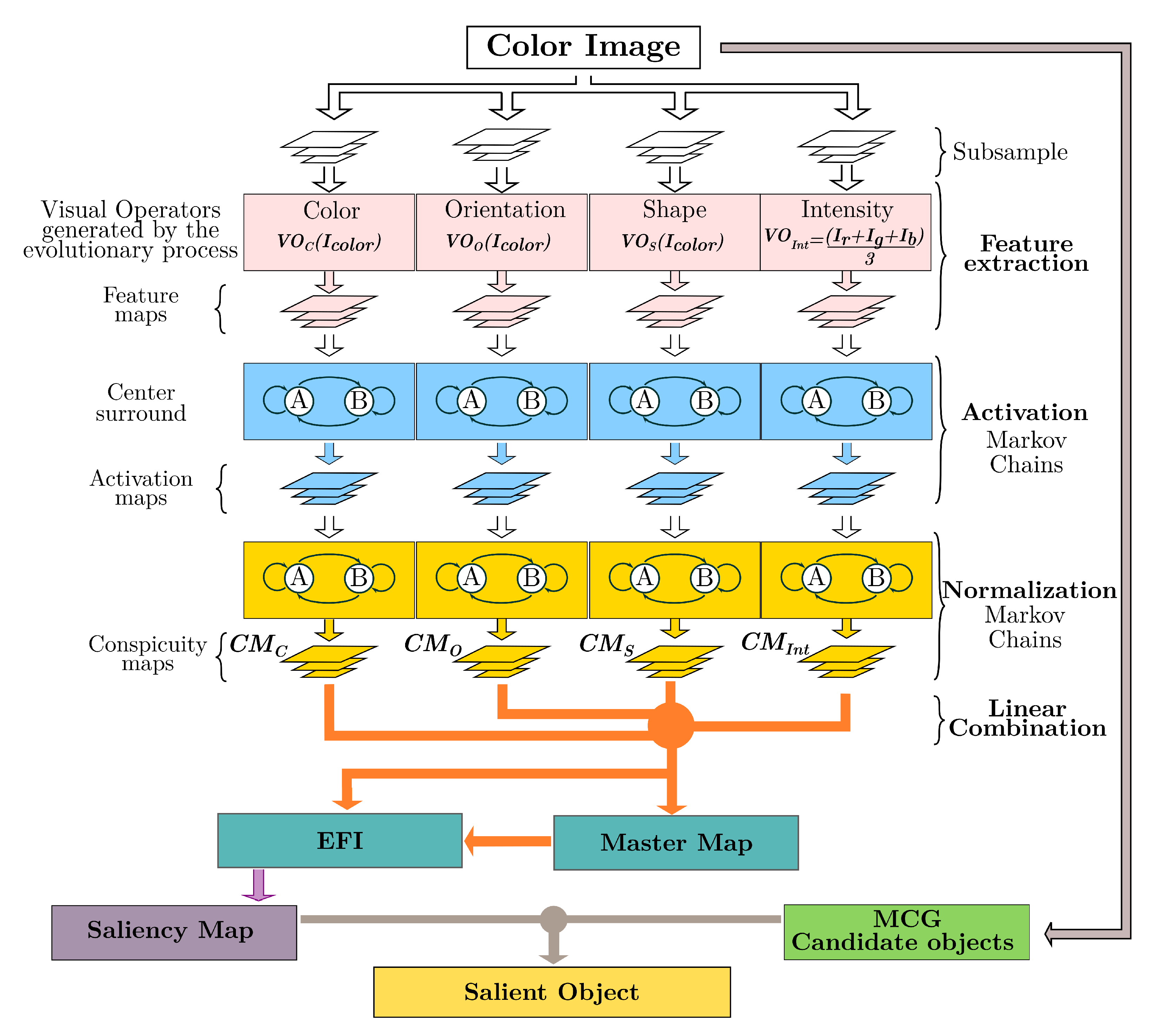
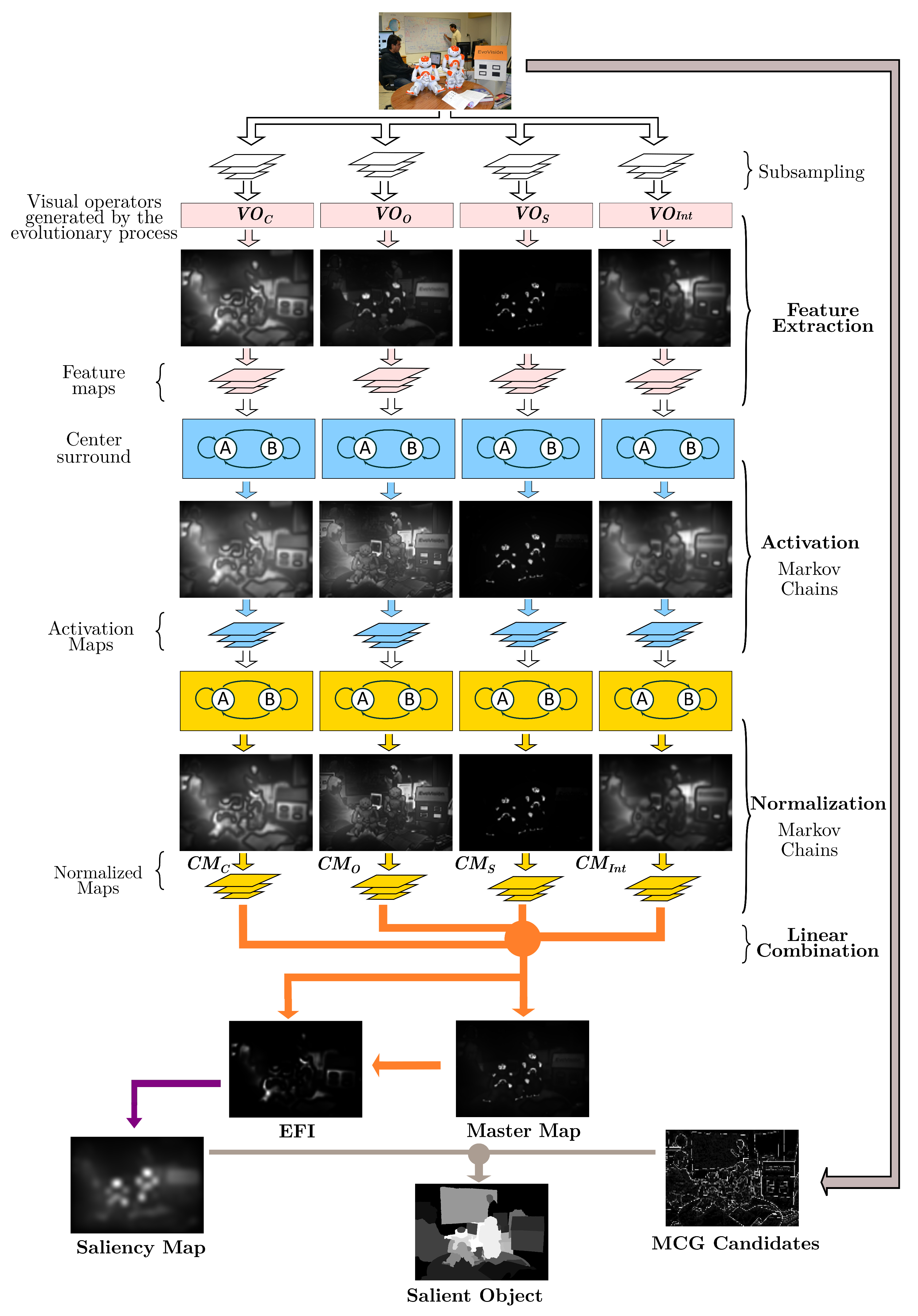
In the present work, we integrate the GBVS algorithm into the ADS; since the functions were defined manually, we would like to incorporate learning. By evolving its dimensions, the BP paradigm enhanced the GBVS methodology with automated design capabilities. This nature-inspired technique, in turn, increased its performance by endowing it with the ability to learn, as shown in
Figure 1.
In addition, we use the approach presented in [
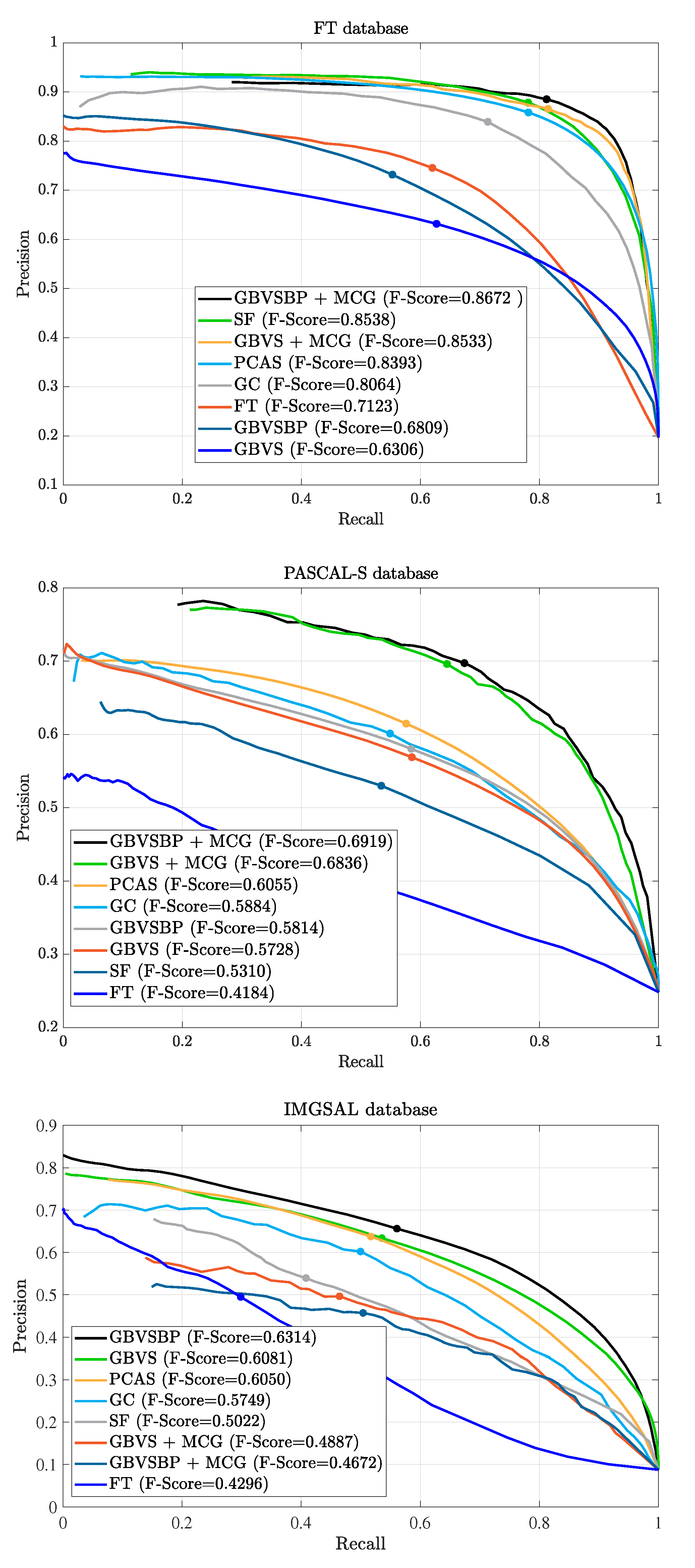
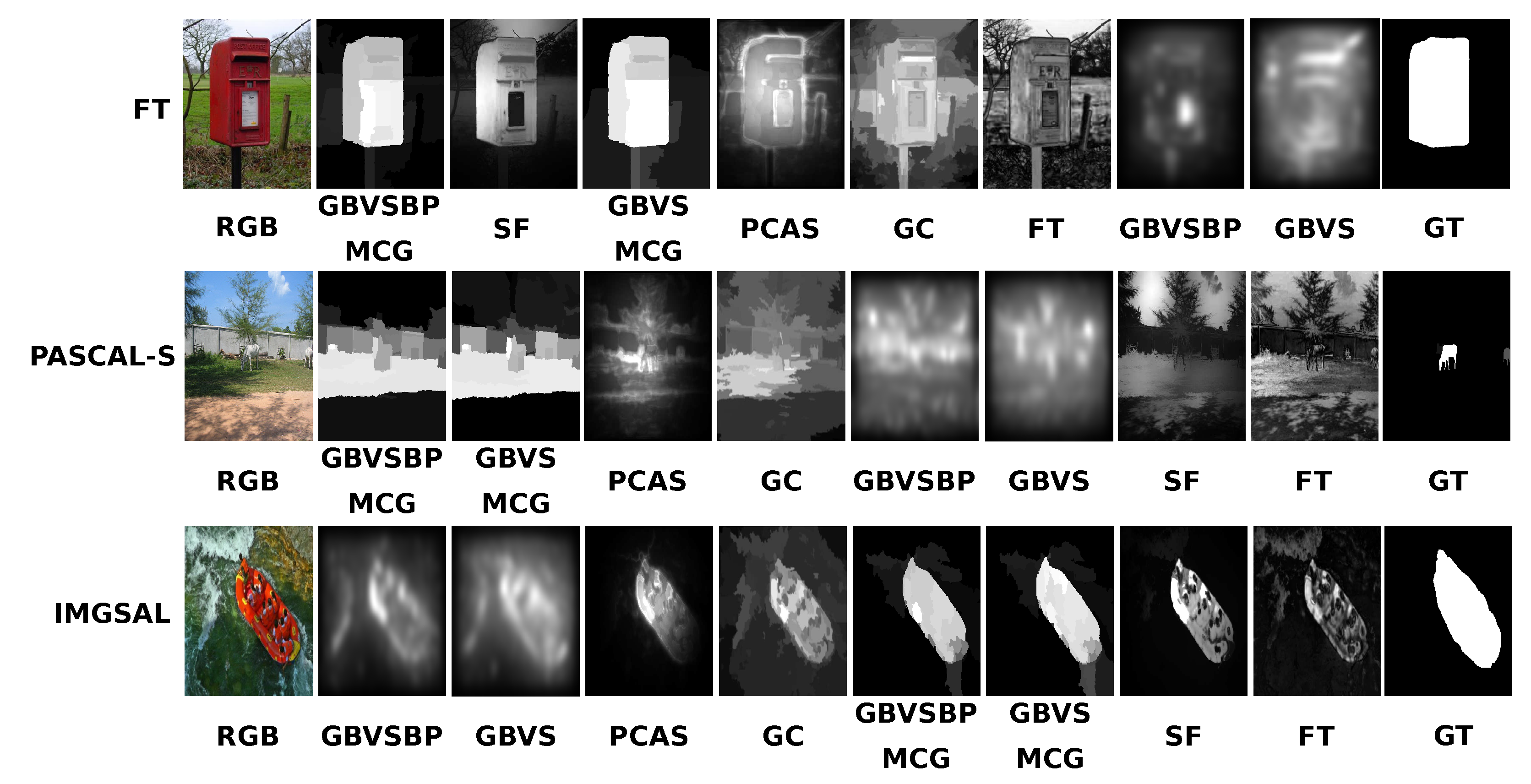
30], where the authors introduced a segmentation algorithm called MCG. The fusion of an optimized GBVS+MCG presents superior results if ground truth is accurate while testing object detection algorithms in the SOD benchmark.
As discussed in the previous chapter, the GBVS has several stages. As part of the integration with the BP, the GBVS underwent several changes. These transformations start with feature extraction, where two new color maps, HSV and CMYK, are extracted for each subsampling level.
The DKColor and Orientation dimensions are now dynamic, and a new dimension, ‘shape’, is added. The BP tree model comes into play, using the orientation subtree in the dimension of the same name, the DKColor dimension transforms to use the Color subtree, and finally, we add Form as a feature dimension through the shape subtree. A final transformation occurs later with a fourth subtree, charged with integrating features to the output as post-processing enhancement.
These changes allow GBVS to optimize its dimensions concerning image processing. This evolution of the GBVS also includes its merger with the MCG algorithm, which underwent a series of modifications.
Firstly, the segmentation mechanism and extraction of MCG characteristics are isolated, separating its operation from the flow of the evolutionary cycle. This division represents a saving of at least five times the time required, without loss in performance, by the MCG to process an image. We achieved this by storing each result in a file each time the image enters the evaluation of an individual generated by BP. We illustrate the execution times before and after its application below.
The time required for each image takes approximately 40 s (1 s for GBVS, 4 s for integration, and 35 for MCG) on average. A complete run requires 30 generations with 30 individuals to develop a solution, and each individual must process each of the images in the training set. In a hypothetical example with 120 images for training, there would be an execution time of
and this time considers a single processing core.
Now, when studying the MCG algorithm, we realize that the output of each processed image does not change, and therefore it is not necessary to generate it more than once. We limit the processing of the images by the MCG to only once for each image, saving computational resources and improving the overall consumption by the evolutionary cycle. This idea brings as a consequence that with the same hardware components, the PC will only take the following time:
for 120 images, the available processing time would be
in total on average, representing an improvement of approximately 89% compared to the initial method. Since this work implies improvements in the functioning of the ADS model, it is necessary to explain in situ the changes we made to it. In this section, we describe the pseudocode algorithms of the brain programming of the new artificial dorsal route based on the one developed by [
5].
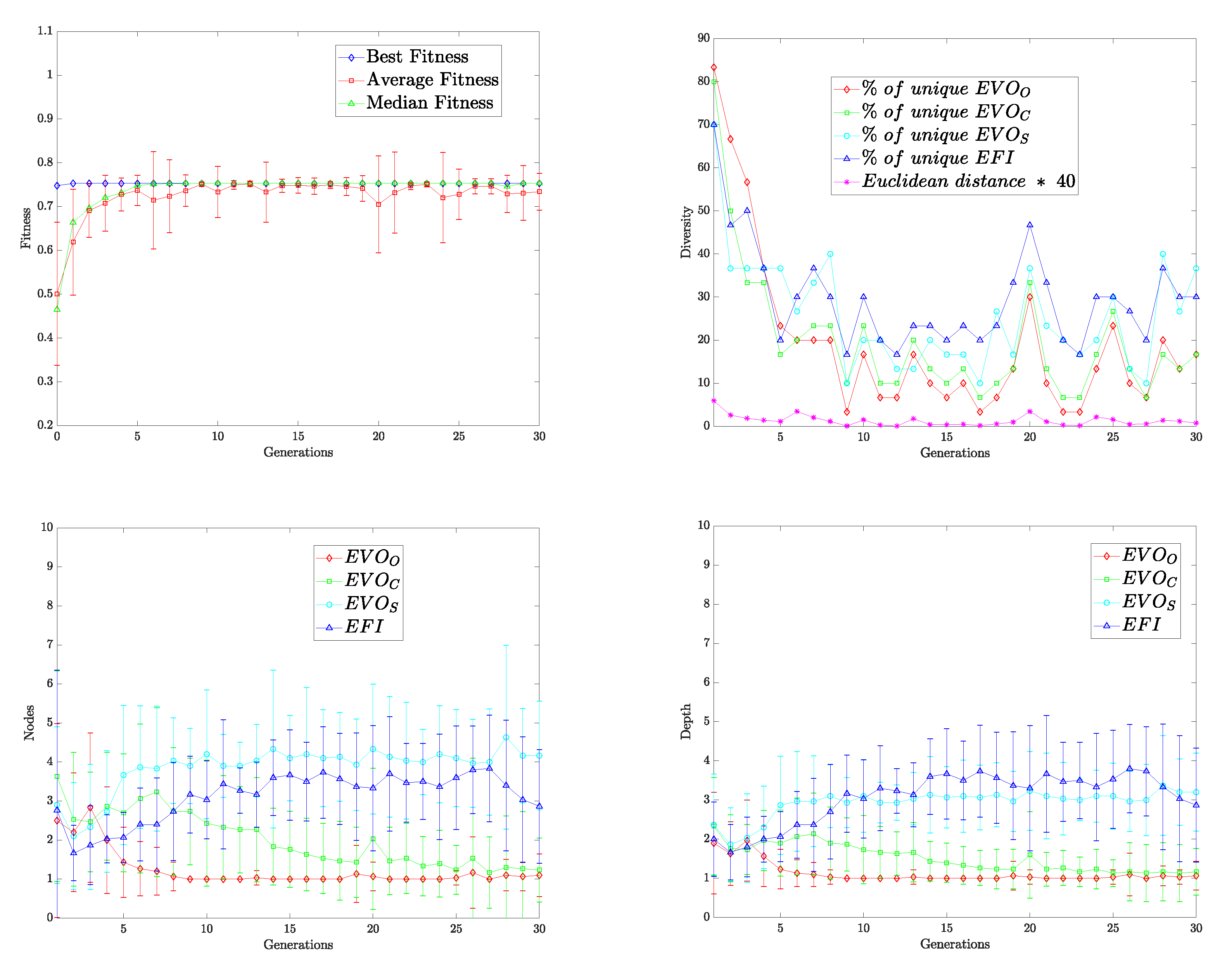
We detail the evolutionary process in the Algorithm A1. We initialize GP variables between lines (1–6). The sets of functions and terminals of the three dimensions (orientation, color, and shape), and the function corresponding to the integration of features (7–14) are declared. Then we create the first generation of individuals in the population (15). In line 16, we initiate the reference list of training images. GP starts the cycle (17). The conditional if has a negative value only in the first loop; its function is to create a new generation from the current one (18–29).
After the pop individuals, we calculate their fitness—each fitness value is initialized to “0” (30). The cycle responsible for calculating aptitude begins (31). On line 32, the values of are initialized to “0”. The second cycle (33) begins, which is responsible for calculating the fitness of the individual whose index is i for each image in the list . To achieve this, executing the salobj_test_img (Algorithm A2) returns a proto-object (34). Then, this pro-object compares with the corresponding binary image (35), and the result corresponds to the fitness value of the individual i in the image j. We store results in , and at the end of the loop, the average of all fitness values is calculated (37). We preserve the individual with the best average fitness up to that moment at the end of each GP cycle (39).
The second cycle creates new generations of the population (18–29). The array (19) is emptied. Then (20) several individuals represented by pop_size and discriminated by a roulette selection method based on the fitness value of each individual in the population are assigned to . The higher the aptitude, the greater the chance of being selected. The array is also emptied (21), and a cycle is in charge of generating the new individuals from the parent individuals (22). The first step is to choose the genetic operation to perform through a roulette selection. The operations are chromosome-crossover, chromosome-mutation, gene-crossover, and gene-mutation. These genetic operators have a probability defined in the initialization (23). Genetic-crossover operators produce two child individuals from two parents, while mutation operators produce one child individual from the parent. We store these generated individuals in (25), and once the generation ends, these individuals replace those of the previous generation (27). Only the best individuals from a generation pass on to the next (28).
Algorithm A2 takes care of generating the proto-object. The first step is initializing the parameters necessary for executing the GBVS (1). Next, the salience map is obtained in
gbvsResult (Algorithm A3) (2). This algorithm is responsible for using an individual generated by the GP to process the input image and convert it into a salience map and store it in
salMap (3). The masks, candidate segments, segment numbers and MCG features are stored in
masks,
maskCCs,
numSegs,
mcg_feats respectively (Algorithm A4) (4). The previous algorithm segments the input image and generates an array of candidate segments according to the input image and the mode (second parameter) to accomplish it. This process consumes many resources, executed only once per image, and its result turns into a file for its next use. This strategy is possible because it always returns the same individual result for each image. The features and array indexes of the MCG masks are stored in
curFeats,
maskIdx respectively (4). This algorithm uses the GBVS bulge map and the segments generated by the MCG to highlight those segments that coincide with the most bulge areas of the GBVS map. On the next 2 lines, readjustments are made to the array data
masks,
mcg_feats (6–7). In the array
allFeats, we store the features extracted from the MCG (8) for future computation. For the extraction of labels (
labels) and their probabilities (
probs), we apply a pre-trained tree model with saliency maps of the GBVS to the characteristics of the MCG (9). The labels are ordered from highest to lowest for later use (10). We reset the label index array in the next five lines (11–15). Next, the best masks of the MCG are extracted (16). In the next three lines, we execute rescaling processes and grayscale conversions of the final mask (17–19).
| Algorithm A1 Evolving GBVS with BP |
Purpose: Create a population of individuals. Each individual is made up of a minimum of 4 functions. The GBVS+MCG uses these functions, and the fitness function uses their results to determine the best individual.
Input:
Variables:max_level: Maximum number of levels any tree can have. max_trees: Number of trees (genes) that an individual (chromosome) must have. prob_chrom_cross: Probability of applying a chromosome crossover. prob_chrom_mut: Probability of applying a chromosome mutation. pop: An array with all individuals in the population. : A structure that saves the selected individuals as parents. : An array that holds one or two new individuals, the product of some genetic operator applied to selected members of the current population. new_pop: An array containing the individuals of the new population generation. It is the same size as pop. : An array of image pairs used for training. The first is an RGB image, and the second is a binary image representing the RGB image’s proto-object. : An array of image pairs used for training. The first is an RGB image, and the second is a binary image representing the RGB image’s proto-object. fitness: An array that stores the average fitness values for each individual. : An array that stores the fitness values of a single individual. , , , : List of function sets regarding Orientation (O), Color (C), Shape (S), and Feature Integration (FI). data_base_train: Number of cycles/generations in the evolutionary process.
Output:- 1:
max_level ← 9 - 2:
max_trees ← 4 - 3:
prob_chrom_cross ← 0.8 - 4:
prob_chrom_mut ← 0.2 - 5:
prob_gen_cross ← 0.8 - 6:
prob_gen_mut ← 0.2 - 7:
{Orientation functions} - 8:
{Color Features} - 9:
{Form Functions} - 10:
{Feature Integration Functions} - 11:
{Orientation Terminals} - 12:
{Color Terminals} - 13:
{Form Terminals} - 14:
{Feature Integration Terminals} - 15:
pop - 16:
Load(data_base_train) - 17:
for (gen ← 1 to num_gen) do - 18:
if gen ≠ 1 then - 19:
.Clear() - 20:
Roulette(pop,fitness,pop.size) - 21:
.Clear() - 22:
while (.length <.length) do - 23:
operator ← Roulette_Op(prob_chrom_cross,prob_chrom_mut,prob_gen_cross, prob_gen_mut) - 24:
i ←.length - 25:
.Add(Apply_Gen_Op(operator,,i)) - 26:
end while - 27:
pop ← - 28:
pop.Add(best_ind) - 29:
end if - 30:
fitness ← 0 - 31:
for (i ← 1 to pop.length) do - 32:
0 - 33:
for (j ← 1 to .length ) do - 34:
proto ← salobj_test_img([j,1],pop[i]) - 35:
[j] ← Calc_Proto_Fitness(pop[i], [j,2]) - 36:
end for - 37:
fitness[i] ← Mean() - 38:
end for - 39:
best_ind ← Get_Best(pop, fitness, best_ind) - 40:
end for - 41:
return best_ind
|
| Algorithm A2 salobj_test_img |
Purpose
Inputimg: Image or image path. param: Contains parameters for the algorithm. forest: A pre-trained model for calculating the highest level characteristics. This model requires training the GBVS bulge maps or some other fixation prediction algorithm. imgName: Name of the image to use.
Output- 1:
gbvsParam ← makeGBVSParams() - 2:
gbvsResult ← gbvs_init(img, param.ind) - 3:
salMap ← gbvsResult.master_map - 4:
[masks,maskCCs,numSegs,mcg_feats] ← compute_mcg(img, ’accurate’, imgName, param) - 5:
[curFeats, maskIdx] ← computeFeatures(maskCCs, salMap, [], param) - 6:
masks ← masks(:,:,maskIdx) - 7:
mcg_feats ← single(mcg_feats(maskIdx, :)) - 8:
allFeats ← [curFeats, mcg_feats] - 9:
[labels, probs] ← forestApply(allFeats, forest) - 10:
[labels, index] ← sort(labels, 1, ’descend’) - 11:
sizeK ← param.topK - 12:
if (sizeK > length(index)) then - 13:
sizeK ← length(index) - 14:
end if - 15:
index ← index(1:sizeK) - 16:
topMasks ← masks(:,:,index) - 17:
scores ← reshape((labels(index)/param.nbins), [1 1 sizeK]) - 18:
finalMask ← topMasks .* repmat(scores, [imgH, imgW, 1]) - 19:
finalMask ← mat2gray(sum(finalMask, 3)) - 20:
return finalMask
|
| Algorithm A3 gbvs_init |
Purpose
Input
Output- 1:
params ← makeGBVSParams - 2:
params.channels ← ’DIOS’ - 3:
params.gaborangles ← [ 0, 45, 90, 135 ] - 4:
params.levels ← 4 - 5:
params.tol ← 0.003 - 6:
params.salmapmaxsize ← round( max(size(img))/8 ) - 7:
params.ind ← ind - 8:
params.gp ← 1 - 9:
params.shapeWeight ← 1 - 10:
out ← gbvs(img, params) - 11:
return out
|
Algorithm A3 is in charge of initializing the execution parameters of the GBVS and executing it. The default parameters of the algorithm (1) are stored in
param. Next, the channels (dimensions for the GP) to be used are chosen (2). The Gabor angles to use, the subsampling levels, the tolerance level of the eigenvector equilibrium mechanism, and the minimum subsampling size are established (3–6). The individual generated by the GP is also stored as well as the control variables and weights (7–9). Finally, we obtain the GBVS result for the input image (10).
| Algorithm A4 compute_mcg |
Purpose
Inputimg: Image or image path. mode: MCG execution mode. imgName: Name of the image to use. param: MCG execution parameters.
Outputmasks: Contains the masks of the MCG conversions. maskCCs: Contains the filtered masks of the MCG conversions. numSegs: Number of parts in which the image is segmented. mcg_feats: Contains the characteristics of the MCG result.
- 1:
if exist(char(strcat(’tmp/’,imgName,’.mat’)), ’file’) then - 2:
[masks,maskCCs,numSegs,mcg_feats] ← load(char(strcat(’tmp/’,imgName,’.mat’))) - 3:
else - 4:
[candidates_mcg, mcg_feats] ← im2mcg_simple(img, mode) - 5:
mcg_feats ← mcg_feats(:, [1:3, 6:13, 15:16]) - 6:
numProps ← size(candidates_mcg.scores, 1) - 7:
numProps ← min(numProps, param.maxTestProps) - 8:
masks ← false([size(img, 1), size(img, 2), numProps]) - 9:
scores ← zeros([1 numProps]) - 10:
sorted_scores ← candidates_mcg.scores - 11:
sorted_idx ← [1:numProps] - 12:
scores(1:numProps) ← sorted_scores(1:numProps) - 13:
sorted_idx ← sorted_idx(1:numProps) - 14:
mcg_feats ← [mcg_feats(sorted_idx, :), scores’] - 15:
props ← candidates_mcg.labels(sorted_idx) - 16:
for (curProp ← 1 to numProps) do - 17:
masks(:,:,curProp) ← ismember(candidates_mcg.superpixels, props{curProp}) - 18:
end for - 19:
[masks, validMasks, maskCCs] ← filterMasks(masks, param.minArea) - 20:
mcg_feats ← mcg_feats(validMasks, :) - 21:
numSegs ← size(masks, 3) save(char(strcat(’tmp/’,imgName,’.mat’)),’masks’,’maskCCs’,’numSegs’,’mcg_feats’) - 22:
end if - 23:
return [masks,maskCCs,numSegs,mcg_feats]
|
Algorithm A4 is in charge of converting the image into segments and characteristics of the MCG. Regarding the first two lines, the MCG verifies the existence of values corresponding to the image processing (1–2). This step is necessary to save the MCG time to process an image (approximately 30 s according to [
30]). The MCG then processes the image to extract candidate segments and MCG features (4–6). The following five lines are used to process the MCG results (7–11). The scores and characteristics are readjusted (12–14) in the following three lines. Then the MCG results are converted into masks (15–18), filtered, and saved to a file (19–21). Finally, the masks, candidates, segment numbers, and features are returned (23).
Algorithm A5 is responsible for calculating the salience map of an image. Some constants necessary for executing the GBVS are established in the initial line, such as the weight matrix and the Gabor filters. This information is stored in a file for each image dimension to be processed and reused while keeping dimensions (1). In the following line, we extract the feature maps of the image. It is in this phase that the individual generated by the GP is used and stored param (Algorithm A6) (2). Then the activation maps are calculated for each feature map (3). These maps are then normalized (4). Next, each channel’s average of the feature maps is calculated (5). Next, the characteristics are added through the channels (6). Then the part of the individual corresponding to the integration of characteristics is added to the resulting salience map (33). This sum is blurred and finally returned (38).
Algorithm A6 extracts the features from the input image using the individual generated by the GP. In the initial line, an array is established with the subsampling levels of the image starting at two because one would be the image with the original dimensions. The next 11 lines of the algorithm are dedicated to the subsampling of the different channels of three color spaces (RGB, CMYK, and HSV) (2–12). In the array rawfeatmaps the feature maps of each of the channels are saved (orientation (Algorithm A7), color (Algorithm A8), shape (Algorithm A9) and intensity) for each of the levels (17). These maps result from applying the individual generated from the GP to each training image. Finally, these maps are returned (22).
Algorithm A7 is in charge of extracting the characteristics corresponding to the orientation channel. The subsampling index is stored in the initial line, which is then used to access the corresponding color channels for each level (1). The following 11 lines are used to store the different channels of the color spaces at each level that will be used later as terminals in evaluating the individual in the image (2–12). The result of this evaluation is stored and returned later (13–14).
Algorithm A8 is in charge of extracting the characteristics corresponding to the color. In the three initial lines, the three channels of the RGB color space of the input image (1–3) are regrouped. This channel also uses the DKL color space, which is obtained from the function rgb2dkl (4). In the following lines, this color space’s three channels are distributed (5–7). The subsampling index is assigned (8) to be then used to access the terminals that correspond to the channels of each color space used (11–20). The individual is then evaluated, stored, and returned (21–22).
Algorithm A9 is in charge of extracting the characteristics corresponding to the shape. The subsampling index is stored in the initial line, which is then used to access the corresponding color channels for each level (1). The following lines group together the three channels of the RGB color space of the input image (2–4). In the following seven lines, the channels of various color spaces are distributed (5–11). The individual is evaluated, stored, and then returned (21–22).
| Algorithm A5 gbvs |
PurposeCompute the GBVS map of an image and place it in master_map. If this image is part of a video sequence, motionInfo should be looped, and the information from the previous frame/image will be used if “flicker” or “motion” channels are used. It is necessary to initialize prevMotionInfo to [] for the first frame.
Inputind: Individual resulting from the evolutionary cycle of the GP. img: Image or image path. (opcional) param: Contains parameters for the algorithm.
Outputmaster_map: It is the GBVS map for the image–resized it is the same size as the image. feat_maps: Contains the final and normalized individual feature maps. map_types: Contains a string description of each map in feat_map (respectively for each index). intermed_maps: Contains all computed intermediate maps along the path (act. & norm.) used to compute feat_maps, which are then combined into master_map. rawfeatmaps: It contains all the feature maps calculated at the different scales. motionInfo: It contains information on the movement of the frames.
- 1:
[grframe,param] ← initGBVS(param,size(img)) - 2:
[rawfeatmaps,motionInfo] ← getFeatureMaps( img , param ) - 3:
allmaps ← getActivationMaps() - 4:
norm_maps ← getNormalizationMaps() - 5:
comb_norm_maps ← getCombinationNormalizationMaps() - 6:
master_map ← getMasterMap() - 7:
if (param.gp = 1) then - 8:
[R,G,B,image] ← mygetrgb( img ) - 9:
image ← imresize( mean(image,3) , param.salmapsize , ’bicubic’) - 10:
R ← imresize( R , param.salmapsize , ’bicubic’) - 11:
G ← imresize( G , param.salmapsize , ’bicubic’) - 12:
B ← imresize( B , param.salmapsize , ’bicubic’) - 13:
[C,M,Y,K] ← rgb2cmyk(R,G,B) - 14:
C ← imresize( C , param.salmapsize , ’bicubic’) - 15:
M ← imresize( M , param.salmapsize , ’bicubic’) - 16:
Y ← imresize( Y , param.salmapsize , ’bicubic’) - 17:
K ← imresize( K , param.salmapsize , ’bicubic’) - 18:
[H,S,V] ← rgb2hsv(img) - 19:
H ← imresize( H , param.salmapsize , ’bicubic’) - 20:
S ← imresize( S , param.salmapsize , ’bicubic’) - 21:
V ← imresize( V , param.salmapsize , ’bicubic’) - 22:
dkl ← rgb2dkl( img ) - 23:
dkl1 ← dkl(:,:,1) - 24:
dkl1 ← imresize( dkl1 , param.salmapsize , ’bicubic’) - 25:
dkl2 ← dkl(:,:,2) - 26:
dkl2 ← imresize( dkl2 , param.salmapsize , ’bicubic’) - 27:
dkl3 ← dkl(:,:,3) - 28:
dkl3 ← imresize( dkl3 , param.salmapsize , ’bicubic’) - 29:
conspicuity1 ← comb_norm_maps{1} - 30:
conspicuity2 ← master_map - 31:
conspicuity3 ← comb_norm_maps{3} - 32:
conspicuity4 ← comb_norm_maps{4} - 33:
master_map ← master_map + eval(param.ind.str(4)) - 34:
end if - 35:
master_map ← attenuateBordersGBVS(master_map,4) - 36:
master_map ← mat2gray(master_map) - 37:
master_map ← getBluredMasterMap() - 38:
return master_map
|
| Algorithm A6 getFeatureMaps |
Purpose
Inputimg: Image or image path. param: Contains parameters for the algorithm. prevMotionInfo: Information of the previous frame/image.
Output- 1:
levels ← [ 2 : param.maxcomputelevel ] - 2:
imgL ← getIntensitySubsamples() - 3:
imgR ← getRedSubsamples() - 4:
imgG ← getGreenSubsamples() - 5:
imgB ← getBlueSubsamples() - 6:
imgC ← getCyanSubsamples() - 7:
imgM ← getMagentaSubsamples() - 8:
imgY ← getYellowSubsamples() - 9:
imgK ← getKeySubsamples() - 10:
imgH ← getHueSubsamples() - 11:
imgS ← getSaturationSubsamples() - 12:
imgV ← getBrightnessSubsamples() - 13:
l ← 0 - 14:
for (i ← 1 to channels) do - 15:
for (j ← 1 to channels[i].numtypes ) do - 16:
for (k ← 1 to levels ) do - 17:
rawfeatmaps[l] ← channelfunc(param,imgLk,imgRk,imgGk,imgBk,ti) - 18:
l ← l + 1 - 19:
end for - 20:
end for - 21:
end for - 22:
return rawfeatmaps
|
| Algorithm A7 OrientationGP |
Purpose
Inputfparam: Channel execution parameters. img: Image subsampled with intensity values. imgR: Red channel of the subsampled image. imgG: Green channel of the subsampled image. imgB: Blue channel of the subsampled image. typeidx: Image subsampling rate.
Output- 1:
n ← typeidx - 2:
R ← imgR - 3:
G ← imgG - 4:
B ← imgB - 5:
C ← fparam.terminals(n).C - 6:
M ← fparam.terminals(n).M - 7:
Y ← fparam.terminals(n).Y - 8:
K ← fparam.terminals(n).K - 9:
H ← fparam.terminals(n).H - 10:
S ← fparam.terminals(n).S - 11:
V ← fparam.terminals(n).V - 12:
imagen ← fparam.terminals(n).V - 13:
out.map ← eval(fparam.ind.str(1)) - 14:
return out
|
| Algorithm A8 dkColorGP |
Purpose
Inputfparam: Channel execution parameters. img: Image subsampled with intensity values. imgR: Red channel of the subsampled image. imgG: Green channel of the subsampled image. imgB: Blue channel of the subsampled image. typeidx: Image subsampling rate.
Output- 1:
rgb ← repmat( imgR , [ 1 1 3 ] ) - 2:
rgb(:,:,2) ← imgG - 3:
rgb(:,:,3) ← imgB - 4:
dkl ← rgb2dkl( rgb ) - 5:
dkl1 ← dkl(:,:,1) - 6:
dkl2 ← dkl(:,:,2) - 7:
dkl3 ← dkl(:,:,3) - 8:
n ← typeidx - 9:
image ← [] - 10:
image ← img - 11:
R ← imgR - 12:
G ← imgG - 13:
B ← imgB - 14:
C ← fparam.terminals(n).C - 15:
M ← fparam.terminals(n).M - 16:
Y ← fparam.terminals(n).Y - 17:
K ← fparam.terminals(n).K - 18:
H ← fparam.terminals(n).H - 19:
S ← fparam.terminals(n).S - 20:
V ← fparam.terminals(n).V - 21:
out.map ← eval(fparam.ind.str(2)) - 22:
return out
|
| Algorithm A9 ShapeGP |
Purpose
Inputfparam: Channel execution parameters. img: Image subsampled with intensity values. imgR: Red channel of the subsampled image. imgG: Green channel of the subsampled image. imgB: Blue channel of the subsampled image. typeidx: Image subsampling rate.
Output- 1:
n ← typeidx - 2:
R ← imgR - 3:
G ← imgG - 4:
B ← imgB - 5:
C ← fparam.terminals(n).C - 6:
M ← fparam.terminals(n).M - 7:
Y ← fparam.terminals(n).Y - 8:
K ← fparam.terminals(n).K - 9:
H ← fparam.terminals(n).H - 10:
S ← fparam.terminals(n).S - 11:
V ← fparam.terminals(n).V - 12:
out.map ← eval(fparam.ind.str(3)) - 13:
return out
|



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



