
Vehicle-Following Control Based on Deep Reinforcement Learning

Abstract
1. Introduction
- According to the characteristics of vehicle-following in dense urban roads, the vehicle-following process is divided into two stages: start–stop, steady driving. In order to improve the PPO algorithm, a subsection policy optimization algorithm (Subsection-PPO) is proposed to use two different policy networks for training in different following stages.
- The weighted importance sampling method is used instead of the importance sampling method when estimating the objective function.
- In order to evaluate the effectiveness of the Section-PPO method in vehicle-following control, this paper uses the TORCS (The Open Racing Car Simulator) simulation environment to simulate urban traffic flow for verification. The experimental results show that the method has a very good effect in vehicle-following scenarios.
2. Related Work
3. Problem Formulation
3.1. State Space
3.2. Action Space
3.3. Reward Function
- where , . A positive reward is given when the vehicle maintains a safe spacing , , and is the Minimum Time Headway.
- . On vehicle-intensive roads, the vehicle speed is generally less than 30 km/h. In this paper, the maximum speed of the preceding vehicle is set as . Since the vehicle uses the sensor to obtain the current state information, the accuracy and speed are much higher than that of a human driver. Maintaining a similar speed can stably follow the distance to ensure safety. Therefore, the speed of the vehicle is kept as consistent as possible in the experiment.
- is the vehicle acceleration, .
4. Methodology
4.1. Noise
4.2. Proximal Policy Optimization Algorithm
4.3. Subsection-PPO
- start-stop stageThe trajectories generated in this stage are start–stop data.
- steady stage: whenThe trajectories generated in this stage are steady driving data.
5. Experimental Simulation
- The experiment compares the cumulative reward of the Subsection-PPO algorithm proposed in this paper with PPO and DDPG.
- The total distance of vehicle-following by different algorithms while maintaining a safe spacing is compared.
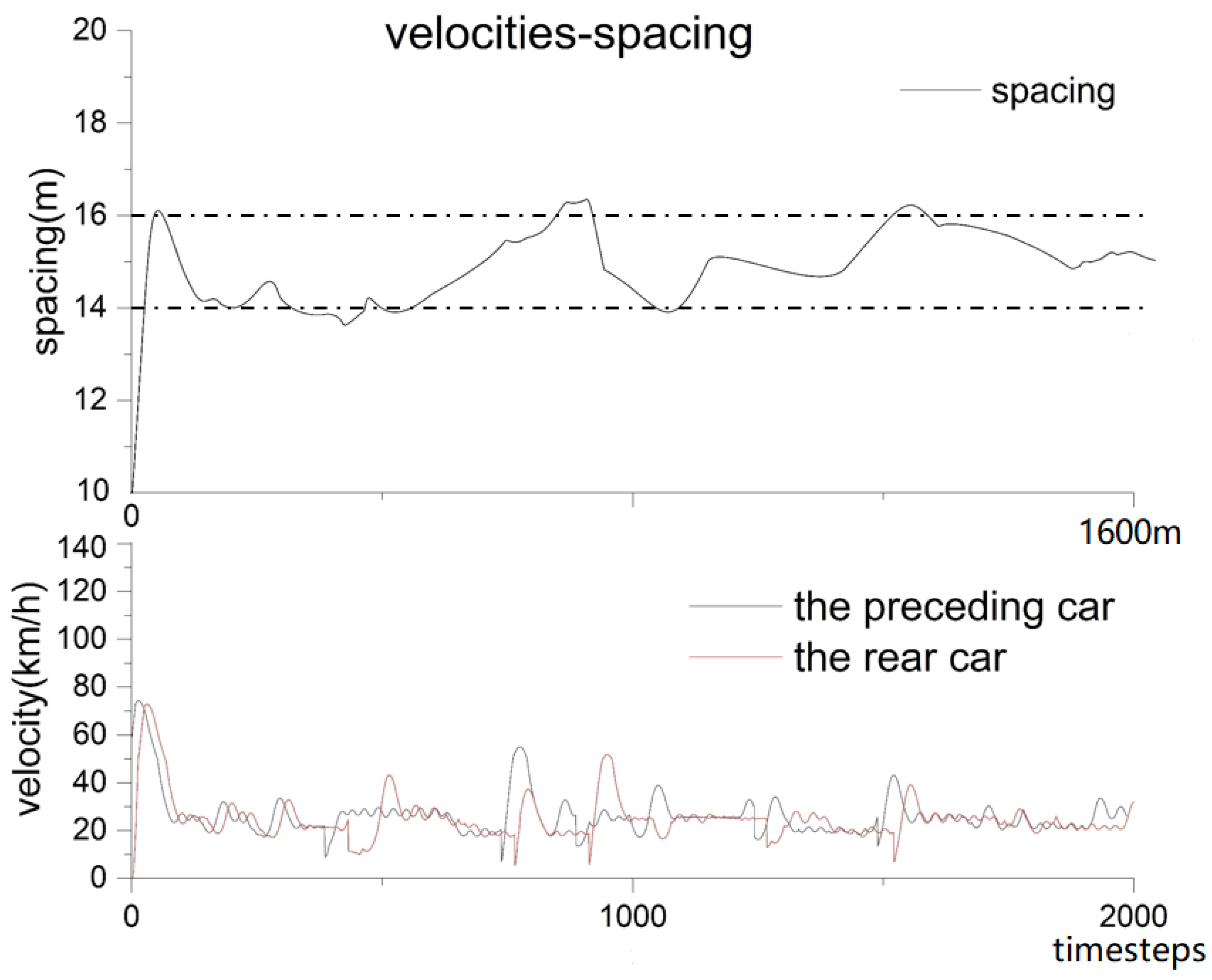
- The effect of the proposed algorithm in vehicle-following control is described using the relationship between speed and distance.
5.1. Hardware Configuration
5.2. Experiment and Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Paschalidis, E.; Choudhury, C.F.; Hess, S. Combining driving simulator and physiological sensor data in a latent variable model to incorporate the effect of stress in car-following behaviour. Anal. Methods Accid. Res. 2019, 22, 100089. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, Q.; Nie, G.; Tian, Y. A multi-objective model predictive control for vehicle adaptive cruise control system based on a new safe distance model. Int. J. Automot. Technol. 2021, 22, 475–487. [Google Scholar] [CrossRef]
- Farag, W. Complex Trajectory Tracking Using PID Control for Autonomous Driving. Int. J. Intell. Transp. Syst. Res. 2019, 18, 356–366. [Google Scholar] [CrossRef]
- Choomuang, R.; Afzulpurkar, N. Hybrid Kalman filter/fuzzy logic based position control of autonomous mobile robot. Int. J. Adv. Robot. Syst. 2005, 2, 20. [Google Scholar] [CrossRef]
- Fayjie, A.R.; Hossain, S.; Oualid, D.; Lee, D.J. Driverless car: Autonomous driving using deep reinforcement learning in urban environment. In Proceedings of the IEEE 2018 15th International Conference on Ubiquitous Robots (UR), Honolulu, HI, USA, 26–30 June 2018; pp. 896–901. [Google Scholar] [CrossRef]
- Colombaroni, C.; Fusco, G.; Isaenko, N. Modeling car following with feed-forward and long-short term memory neural networks. Transp. Res. Procedia 2021, 52, 195–202. [Google Scholar] [CrossRef]
- Bhattacharyya, R.; Wulfe, B.; Phillips, D.; Kuefler, A.; Morton, J.; Senanayake, R.; Kochenderfer, M. Modeling human driving behavior through generative adversarial imitation learning. arXiv 2020, arXiv:2006.06412. [Google Scholar] [CrossRef]
- Lin, Y.; McPhee, J.; Azad, N.L. Longitudinal dynamic versus kinematic models for car-following control using deep reinforcement learning. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1504–1510. [Google Scholar] [CrossRef]
- Pipes, L.A. An operational analysis of traffic dynamics. J. Appl. Phys. 1953, 24, 274–281. [Google Scholar] [CrossRef]
- Gazis, D.C.; Herman, R.; Potts, R.B. Car-following theory of steady-state traffic flow. Oper. Res. 1959, 7, 499–505. [Google Scholar] [CrossRef]
- Cattin, J.; Leclercq, L.; Pereyron, F.; El Faouzi, N.E. Calibration of Gipps’ car-following model for trucks and the impacts on fuel consumption estimation. IET Intell. Transp. Syst. 2019, 13, 367–375. [Google Scholar] [CrossRef]
- Ayres, T.; Li, L.; Schleuning, D.; Young, D. Preferred time-headway of highway drivers. In Proceedings of the ITSC 2001, Oakland, CA, USA, 25–29 August 2001; 2001 IEEE Intelligent Transportation Systems. Proceedings (Cat. No. 01TH8585). pp. 826–829. [Google Scholar] [CrossRef]
- Jamson, A.H.; Merat, N. Surrogate in-vehicle information systems and driver behaviour: Effects of visual and cognitive load in simulated rural driving. Transp. Res. Part F Traffic Psychol. Behav. 2005, 8, 79–96. [Google Scholar] [CrossRef]
- Treiber, M.; Kesting, A. Traffic flow dynamics: data, models and simulation. Phys. Today 2014, 67, 54. [Google Scholar]
- Mathew, T.V.; Ravishankar, K. Neural Network Based Vehicle-Following Model for Mixed Traffic Conditions. Eur. Transp.-Trasp. Eur. 2012, 52, 1–15. [Google Scholar]
- Sharma, O.; Sahoo, N.; Puhan, N. Highway Discretionary Lane Changing Behavior Recognition Using Continuous and Discrete Hidden Markov Model. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 1476–1481. [Google Scholar] [CrossRef]
- Li, L.; Gan, J.; Qu, X.; Mao, P.; Yi, Z.; Ran, B. A novel graph and safety potential field theory-based vehicle platoon formation and optimization method. Appl. Sci. 2021, 11, 958. [Google Scholar] [CrossRef]
- Zhu, W.X.; Zhang, L.D. A new car-following model for autonomous vehicles flow with mean expected velocity field. Phys. A: Stat. Mech. Its Appl. 2018, 492, 2154–2165. [Google Scholar] [CrossRef]
- Li, W.; Chen, T.; Guo, J.; Wang, J. Adaptive car-following control of intelligent electric vehicles. In Proceedings of the 2018 IEEE 4th International Conference on Control Science and Systems Engineering (ICCSSE), Wuhan, China, 21–23 August 2018; pp. 86–89. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, Q.; Wang, J.; Verwer, S.; Dolan, J.M. Lane-change intention estimation for car-following control in autonomous driving. IEEE Trans. Intell. Veh. 2018, 3, 276–286. [Google Scholar] [CrossRef]
- Kamrani, M.; Srinivasan, A.R.; Chakraborty, S.; Khattak, A.J. Applying Markov decision process to understand driving decisions using basic safety messages data. Transp. Res. Part Emerg. Technol. 2020, 115, 102642. [Google Scholar] [CrossRef]
- Guerrieri, M.; Parla, G. Deep learning and yolov3 systems for automatic traffic data measurement by moving car observer technique. Infrastructures 2021, 6, 134. [Google Scholar] [CrossRef]
- Masmoudi, M.; Friji, H.; Ghazzai, H.; Massoud, Y. A Reinforcement Learning Framework for Video Frame-based Autonomous Car-following. IEEE Open J. Intell. Transp. Syst. 2021, 2, 111–127. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, X.; Wang, Y. Human-like autonomous car-following model with deep reinforcement learning. Transp. Res. Part C Emerg. Technol. 2018, 97, 348–368. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning (PMLR), Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Gao, H.; Shi, G.; Xie, G.; Cheng, B. Car-following method based on inverse reinforcement learning for autonomous vehicle decision-making. Int. J. Adv. Robot. Syst. 2018, 15, 1729881418817162. [Google Scholar] [CrossRef]
- Ngoduy, D.; Lee, S.; Treiber, M.; Keyvan-Ekbatani, M.; Vu, H. Langevin method for a continuous stochastic car-following model and its stability conditions. Transp. Res. Part C Emerg. Technol. 2019, 105, 599–610. [Google Scholar] [CrossRef]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar] [CrossRef]
- Kakade, S.; Langford, J. Approximately optimal approximate reinforcement learning. In Proceedings of the 19th International Conference on Machine Learning, Sydney, Australia, 8–12 July 2002. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Range | Description |
|---|---|---|
| Speed along the longitudinal axis of the vehicle (driving direction of the rear vehicle) | ||
| Speed along the longitudinal axis of the vehicle (direction of travel of the vehicle in front) | ||
| Acceleration of rear vehicle | ||
| Spacing between vehicles | ||
| Speed along the Z-axis of the vehicle |
| Action | Range | Description |
|---|---|---|
| Throttle force 0 means not to step on the throttle, 1 means fully depressed. | ||
| Braking force, 0 means no braking, 1 means fully depressed. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Xu, X.; Li, Y.; Zhang, X.; Liu, Y.; Zhang, X. Vehicle-Following Control Based on Deep Reinforcement Learning. Appl. Sci. 2022, 12, 10648. https://doi.org/10.3390/app122010648
Huang Y, Xu X, Li Y, Zhang X, Liu Y, Zhang X. Vehicle-Following Control Based on Deep Reinforcement Learning. Applied Sciences. 2022; 12(20):10648. https://doi.org/10.3390/app122010648
Chicago/Turabian StyleHuang, Yong, Xin Xu, Yong Li, Xinglong Zhang, Yao Liu, and Xiaochuan Zhang. 2022. "Vehicle-Following Control Based on Deep Reinforcement Learning" Applied Sciences 12, no. 20: 10648. https://doi.org/10.3390/app122010648
APA StyleHuang, Y., Xu, X., Li, Y., Zhang, X., Liu, Y., & Zhang, X. (2022). Vehicle-Following Control Based on Deep Reinforcement Learning. Applied Sciences, 12(20), 10648. https://doi.org/10.3390/app122010648