
Few-Shot Continuous Authentication for Mobile-Based Biometrics



Abstract
:1. Introduction
Motivation and Contribution
- Limited impostor profiles for training:The core challenge of FSAD is the limited availability of seen impostor profiles. However, the models need to be able to detect arbitrary unseen impostors during inference.
- Class imbalance between genuine and impostor data:Since FSAD uses extensive genuine and small impostor data, models inherently suffer from the class-imbalance problem. This can emphasize the genuine class and under-fit the impostor classes, preventing learning the impostor patterns adequately.
- Large intra-class variance of user behavior data:Due to the significant intra-class variance of raw touch sensor data, most touch-gesture authentication solutions have adopted hand-crafted features and conventional machine learning models such as support-vector machine, random forest, etc., which are more noise-robust than learned features [11,12,13,14,23,24,25,26,27,28]. However, hand-crafted features lack refined feature information, making it hard to characterize delicate impostor patterns.
- We formulate continuous mobile-based biometric authentication as a few-shot anomaly detection problem, aiming to enhance the discrimination robustness of the genuine user and seen and unseen impostors.
- We present a sequential data augmentation method, random pattern mixing, which expands the feature space of impostor data, providing synthetic impostor patterns not present in seen impostors.
- We propose the LFP-TCN, which aggregates global and local feature information, characterizing fine-grained impostor patterns from noisy sensor data.
- We demonstrate the continuous authentication based on the decision and score-level fusion, which can effectively improve the authentication performance for longer re-authentication time.
2. Related Works
2.1. Touch-Gesture Features for Authentication
2.2. Deep Anomaly Detection in Mobile-Based Biometrics
2.3. Few-Shot Anomaly Detection
2.4. Data Augmentation for Mobile-Based Biometrics
3. Method
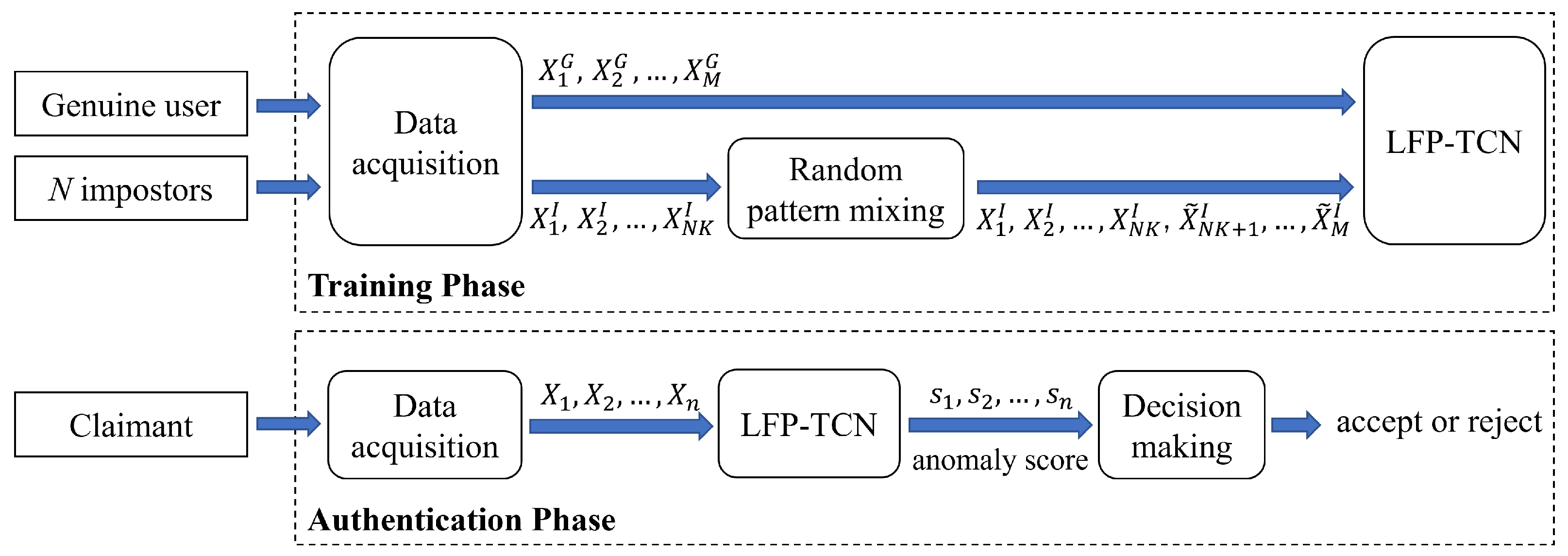
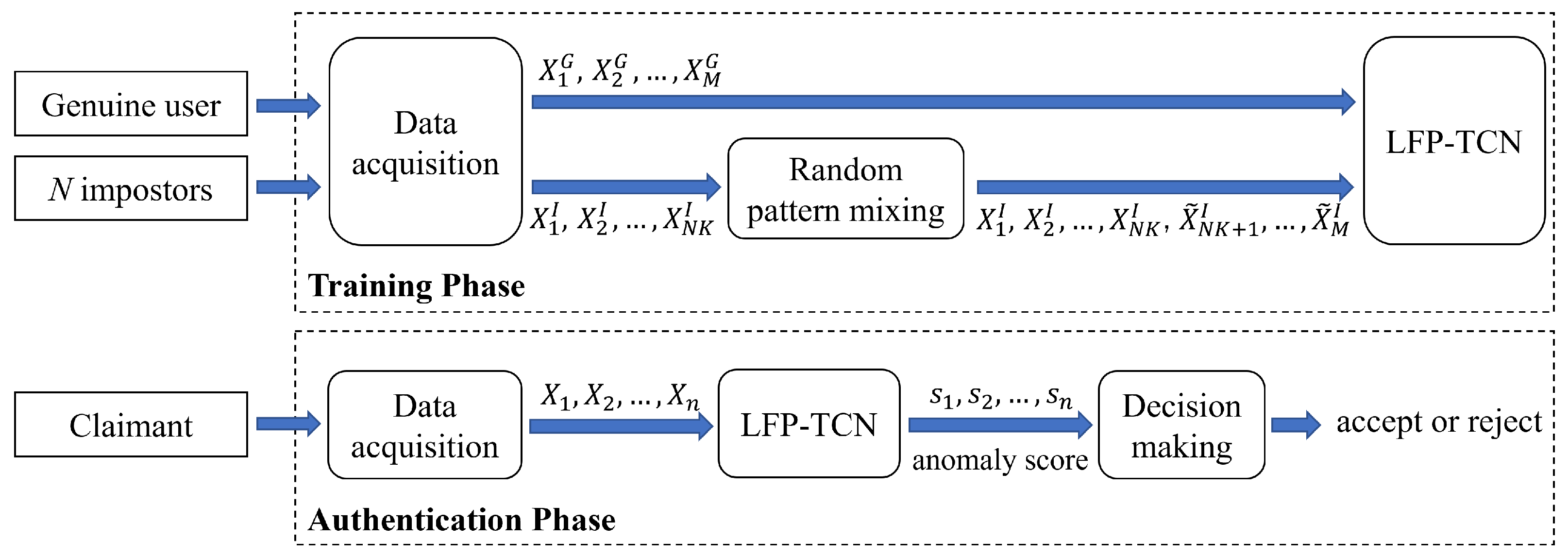
3.1. System Overview
3.2. Random Pattern Mixing
3.2.1. Jittering
3.2.2. Scaling
3.2.3. Permutation
3.2.4. SMOTE
- Random Pattern Mixing
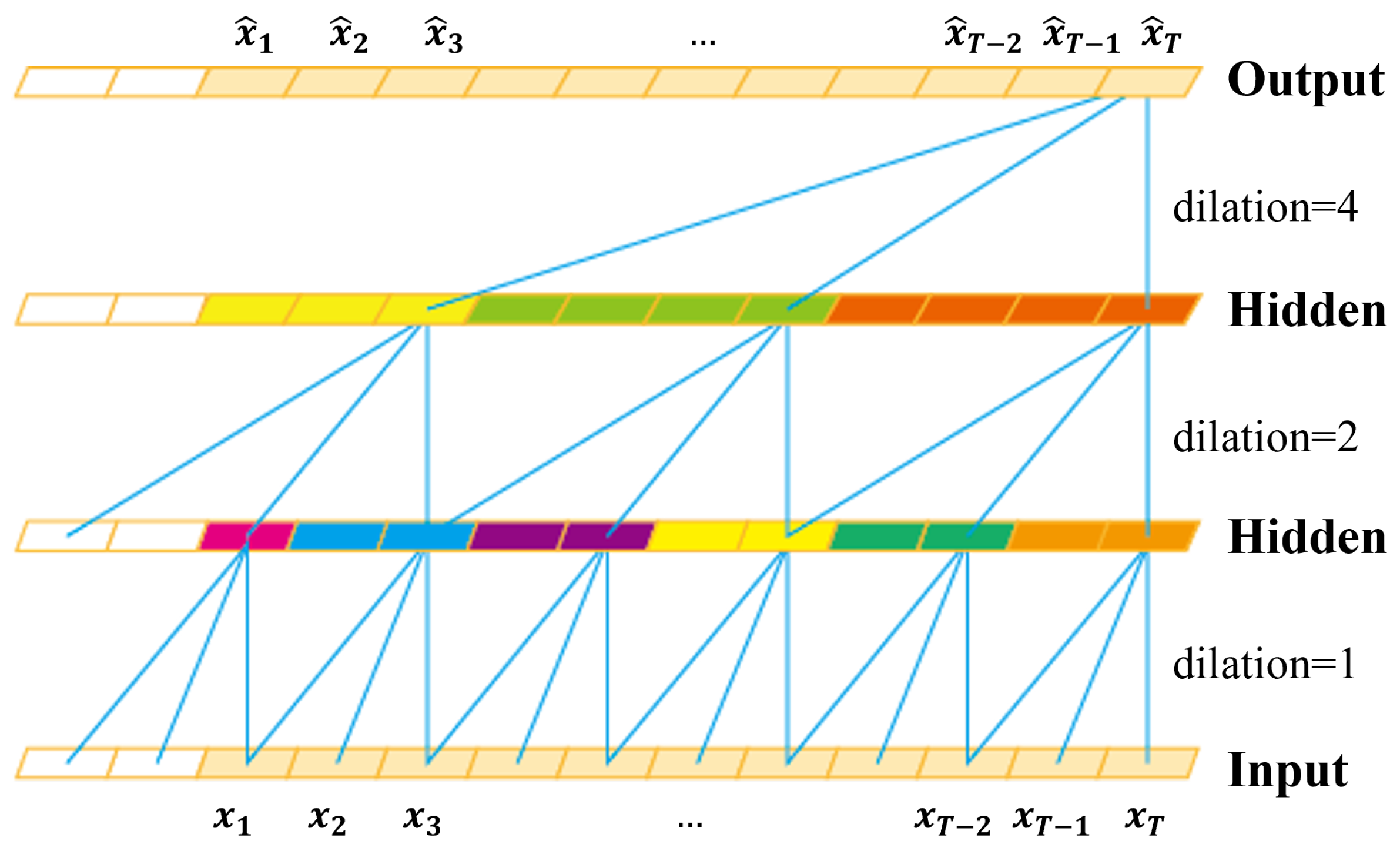
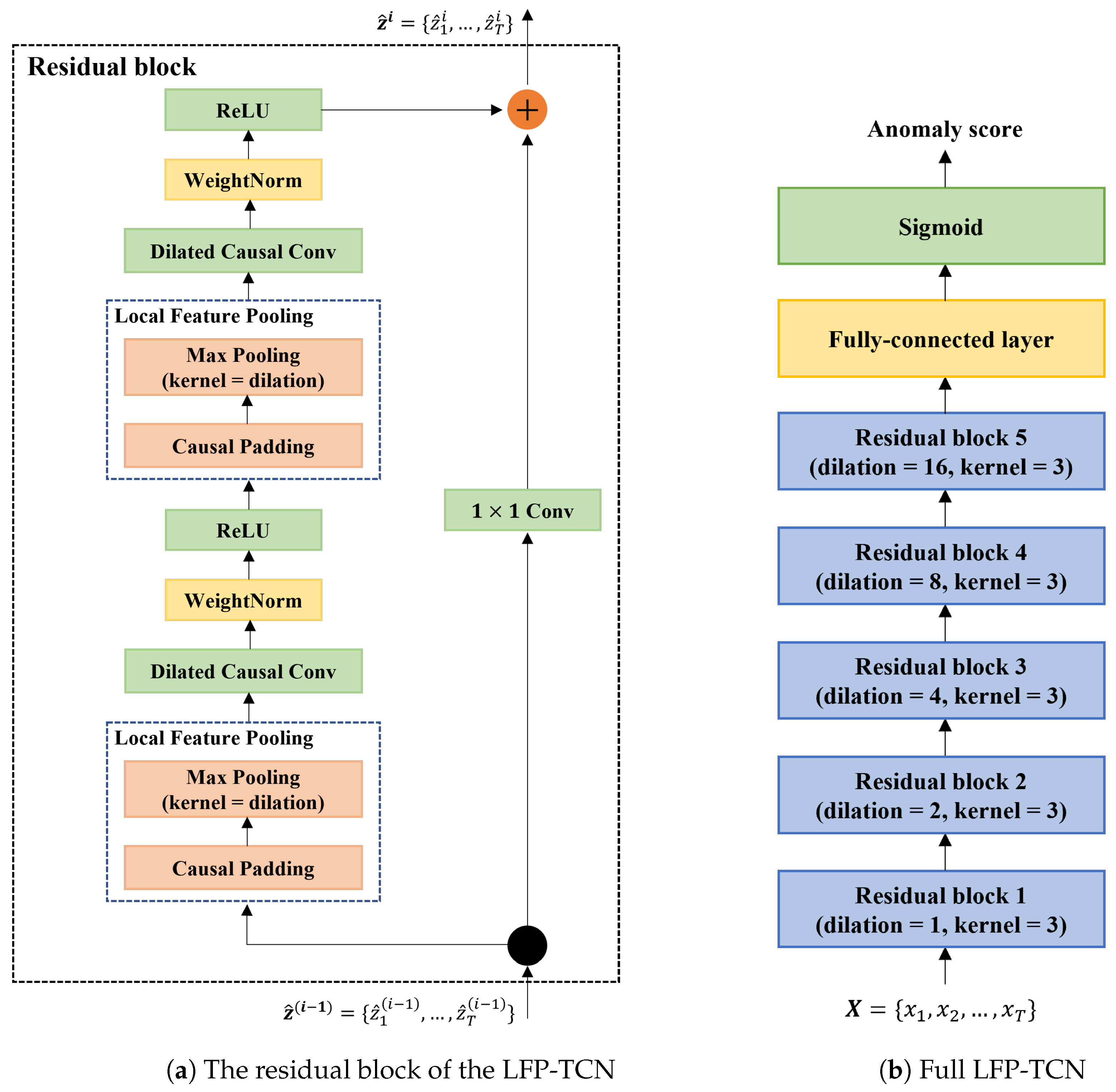
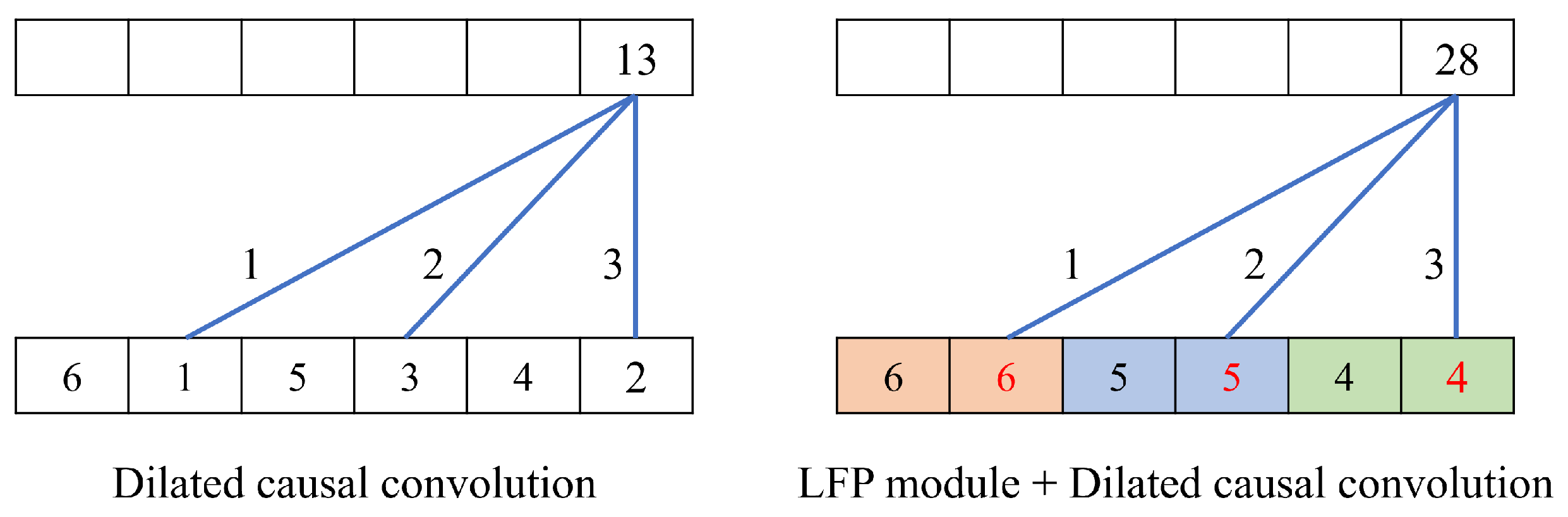
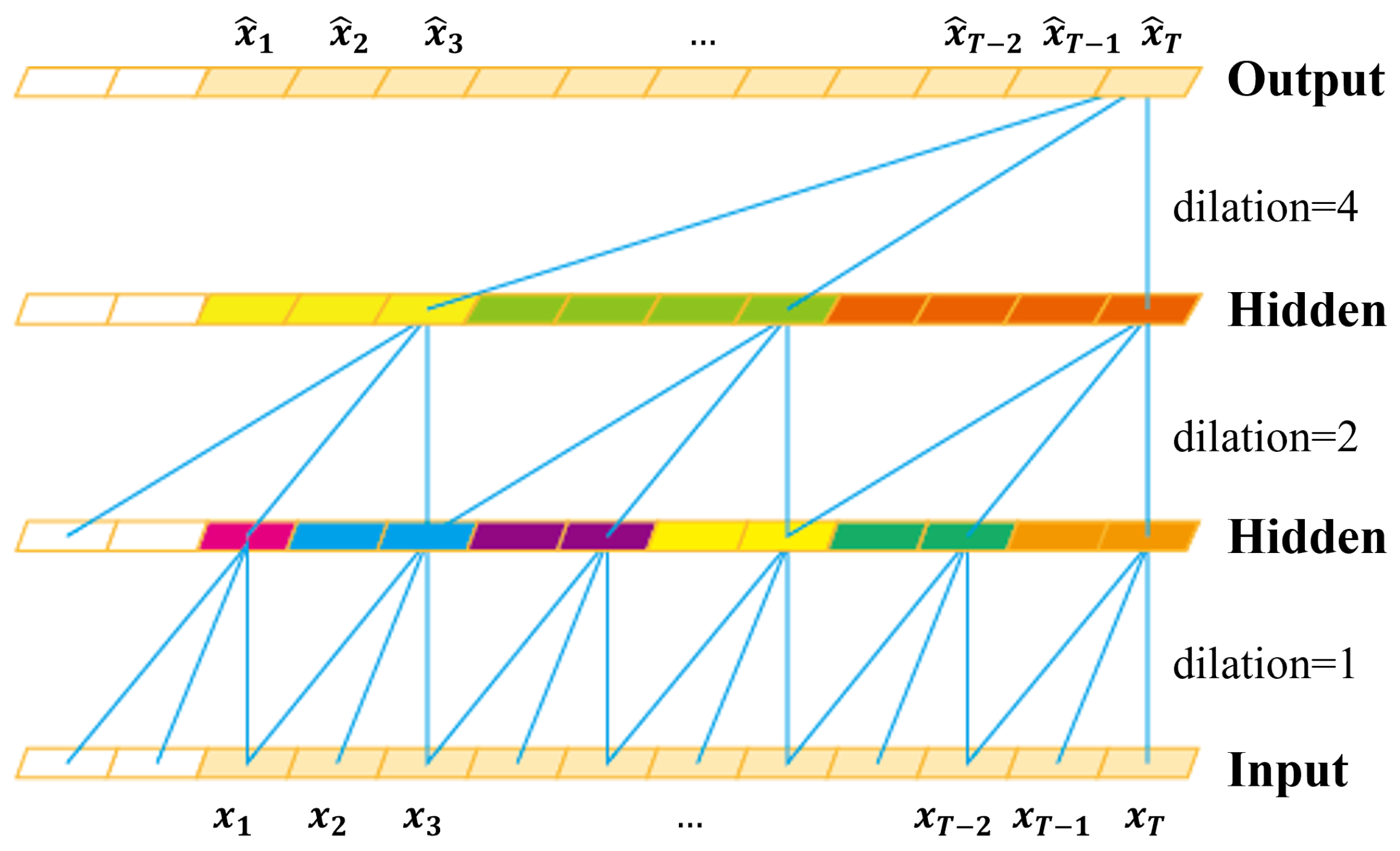
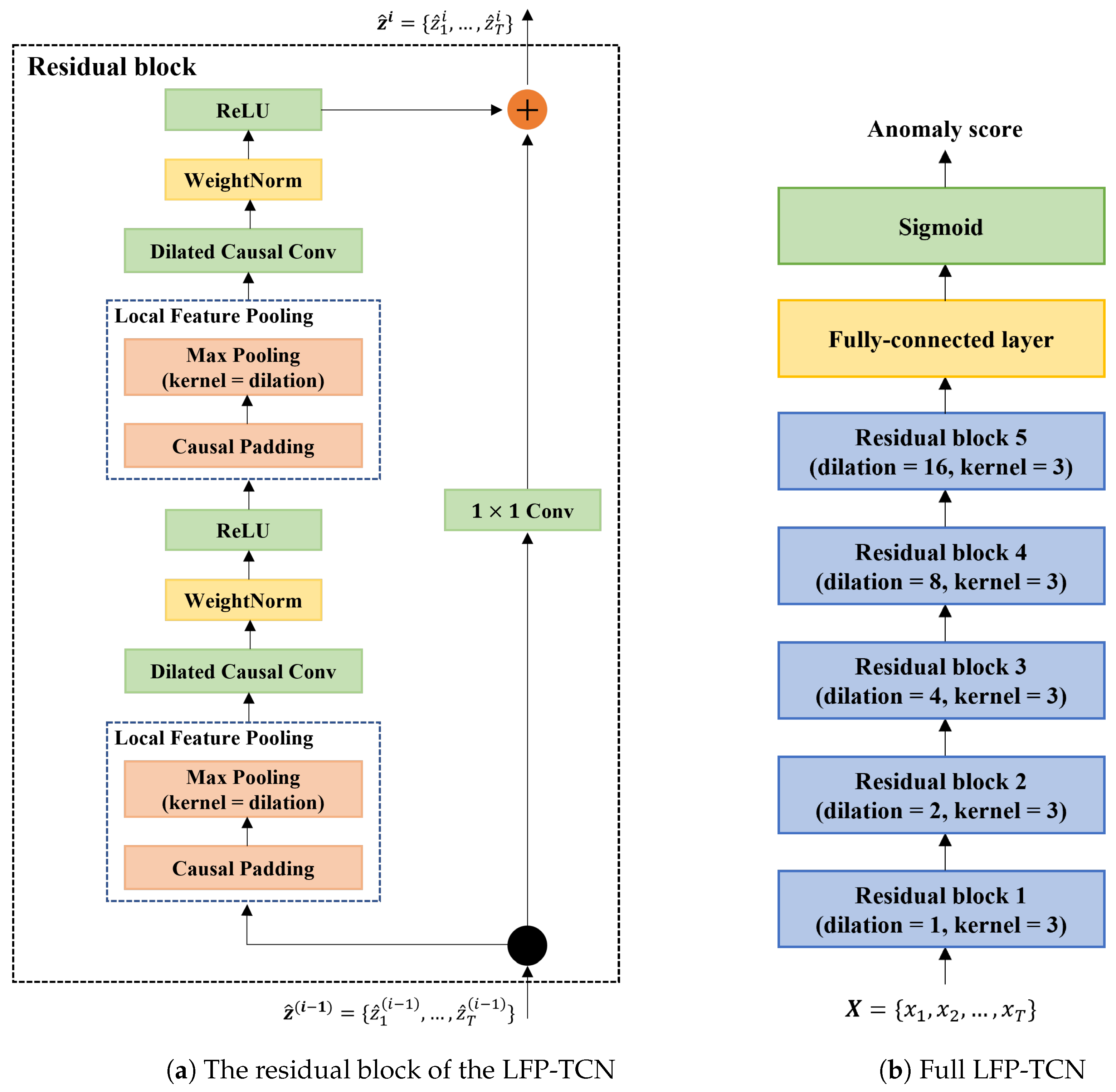
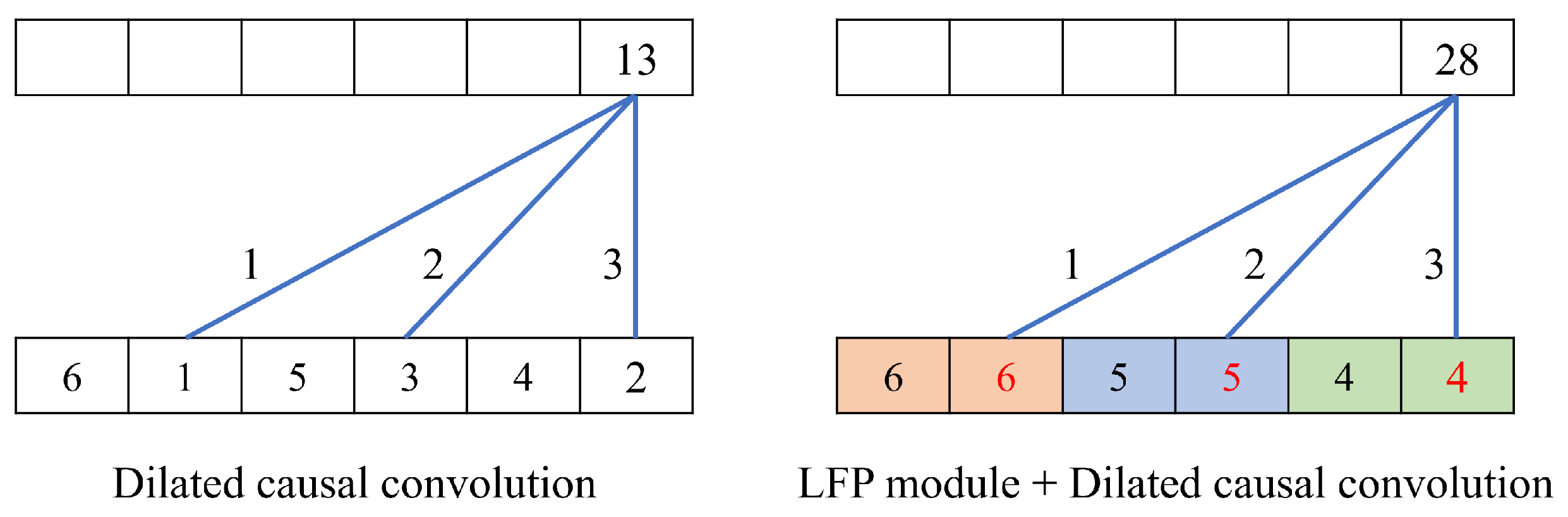
3.3. Local Feature Pooling-Based Temporal Convolution Network (LFP-TCN)
3.4. Decision-Making Mechanism
3.4.1. Decision-Level Fusion
3.4.2. Score-Level Fusion
4. Experiments
4.1. Dataset
- The HMOG dataset [37] is a multimodal dataset containing touch screen, accelerometer, and gyroscope data captured from 100 subjects while doing three tasks, e.g., reading web articles, typing texts, and navigating a map. The dataset comprises 24 sessions (8 sessions for each task) for each subject. The data are captured under sitting and walking situations. We used data of these tasks under sitting situations.
- The BBMAS dataset [38] captures touch screen, accelerometer, and gyroscope data from 117 subjects while typing free and fixed texts. These data are captured under sitting and walking situations. We used only data under the sitting situations. We removed five subjects’ data because of too small a data size, resulting in 112 subjects’ data.
4.2. Experiment Protocol
4.3. Implementation Detail
4.4. Accuracy Metrics
5. Experimental Result
5.1. Effectiveness of the LFP Module
- MLP: 3-layer MLP with neurons of on each layer. We use the ReLU activation function.
- LSTM: 5 stacked LSTM blocks with hidden states of 128. The hidden states at the last time step are fed into the output layer.
- CNN: 10 convolution layers with a kernel size of three. ReLU is used for the activation function. The final feature map is flattened and fed into the output layer. This is equivalent to the below TCN, in which we replace the dilated causal convolution layers with ordinary convolution layers and remove the skip connection.
- TCN: 5 stacked residual blocks in Figure 3 without the LFP module.
- LFE-TCN: the above TCN with the LFE module [34]. The LFE module puts an additional five residual blocks on top of the TCN with the decreasing dilation rate, resulting in 10 stacked residual blocks with the dilation rate in each block.
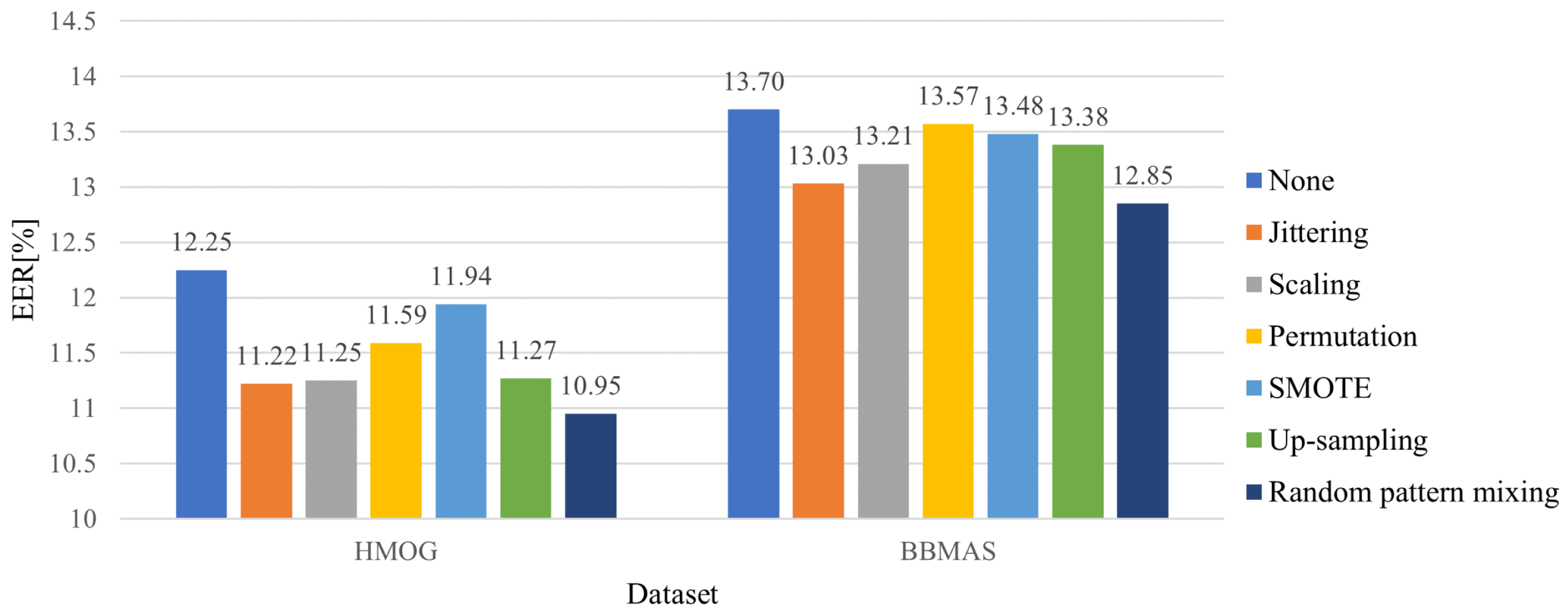
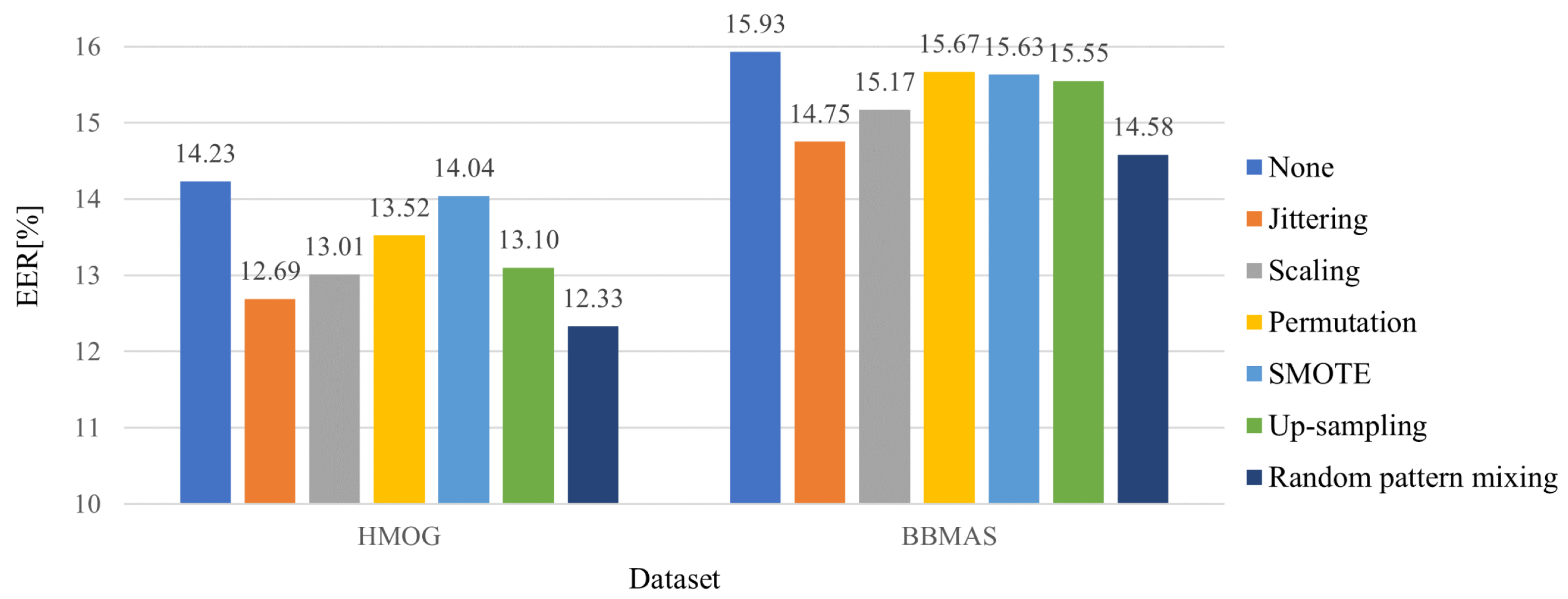
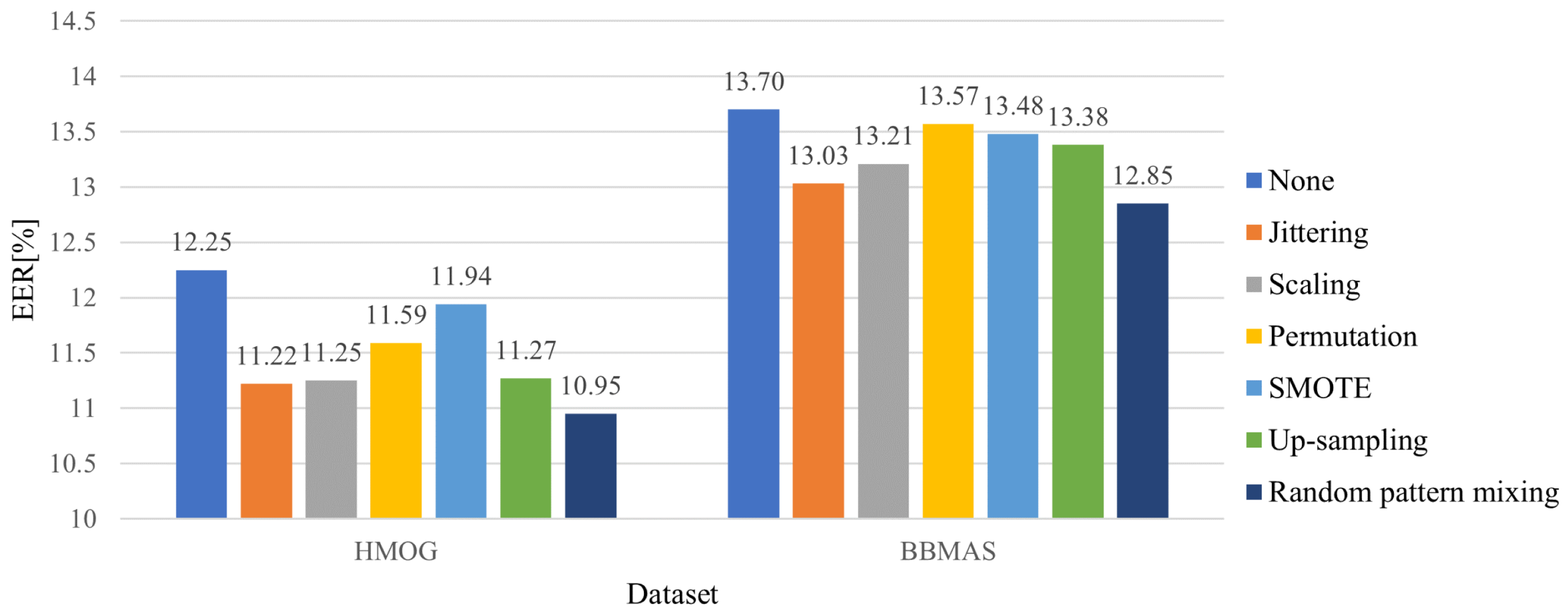
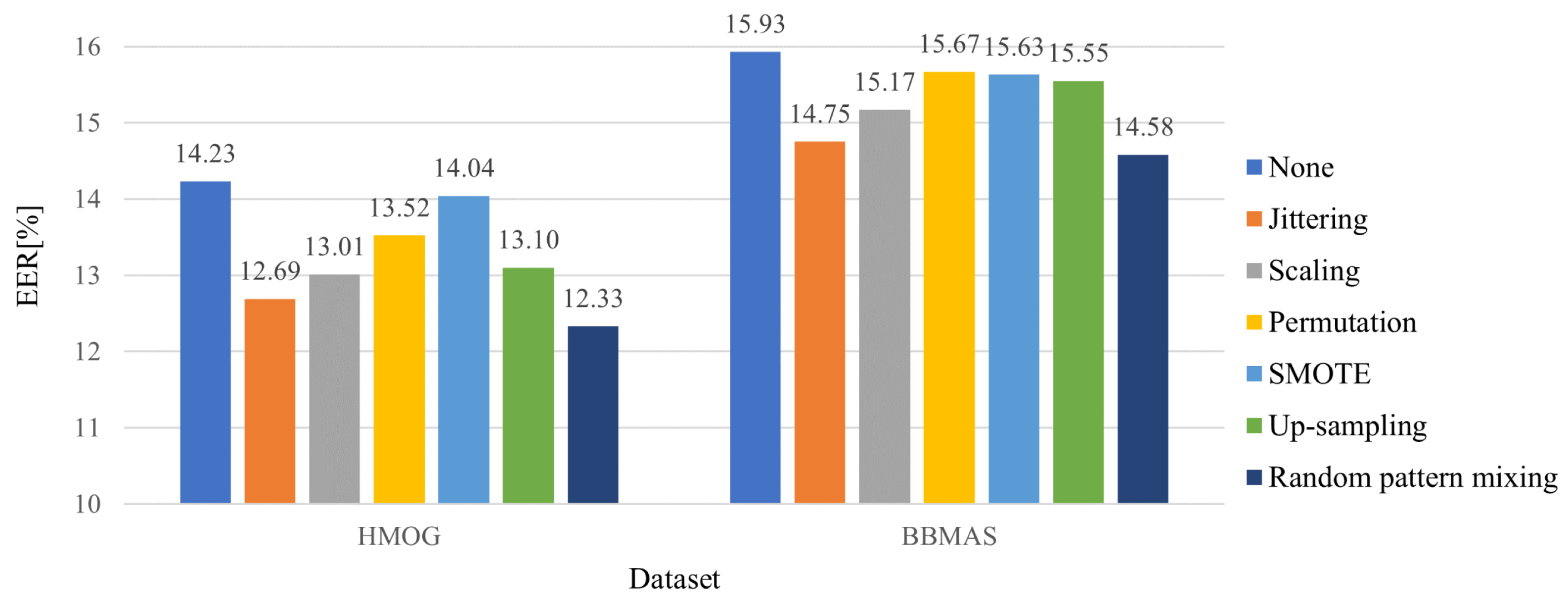
5.2. Effectiveness of the Random Pattern Mixing
5.3. Comparison with State of the Arts
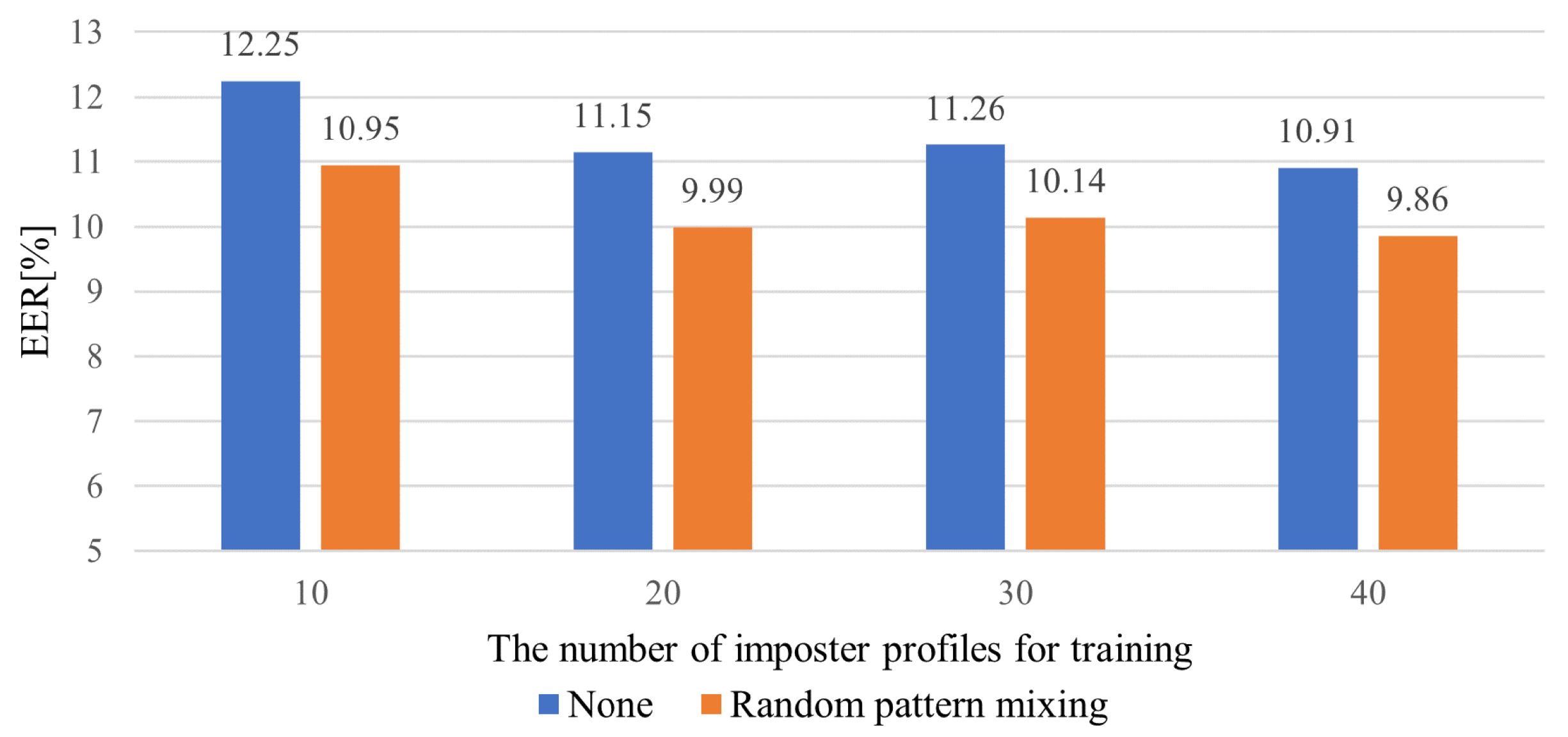
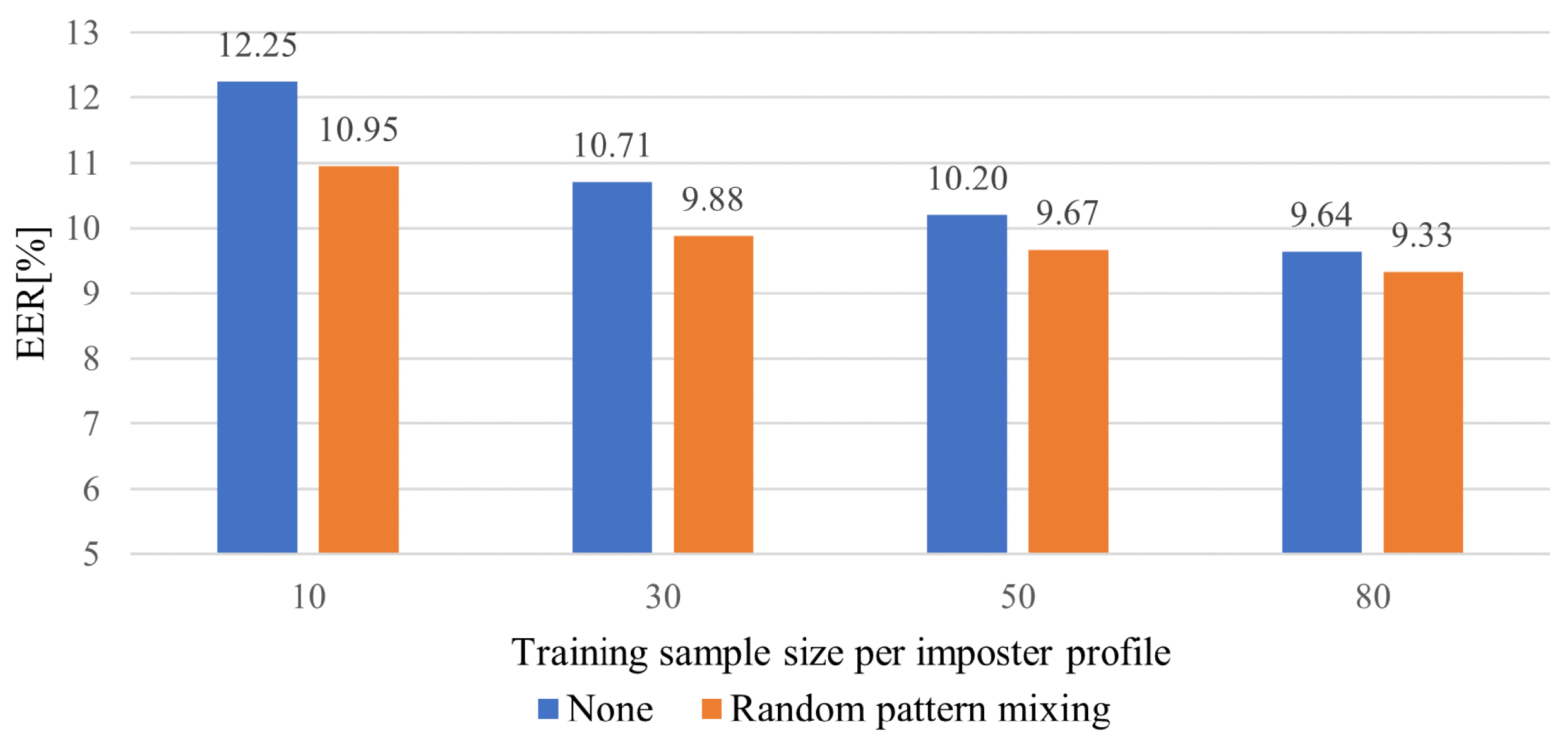
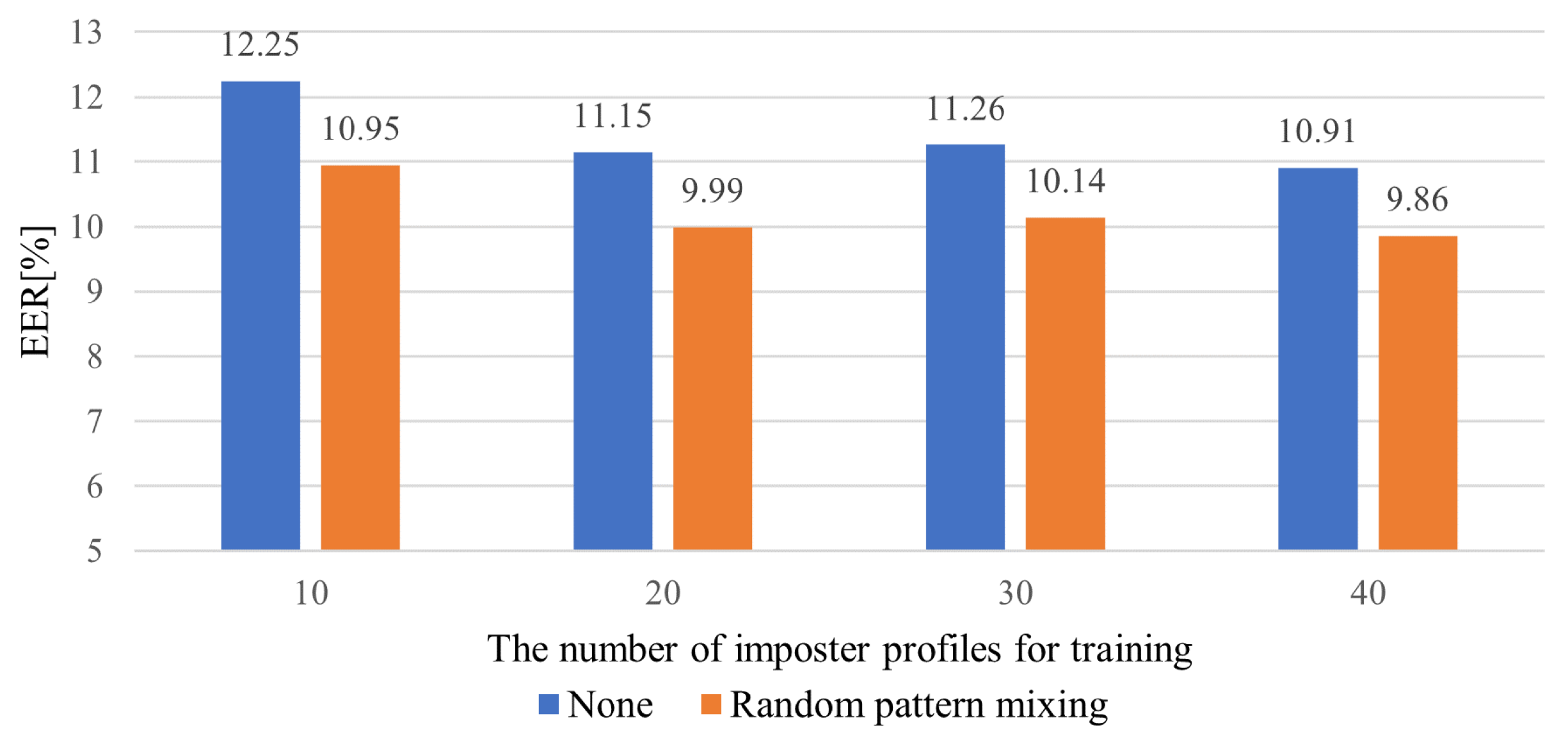
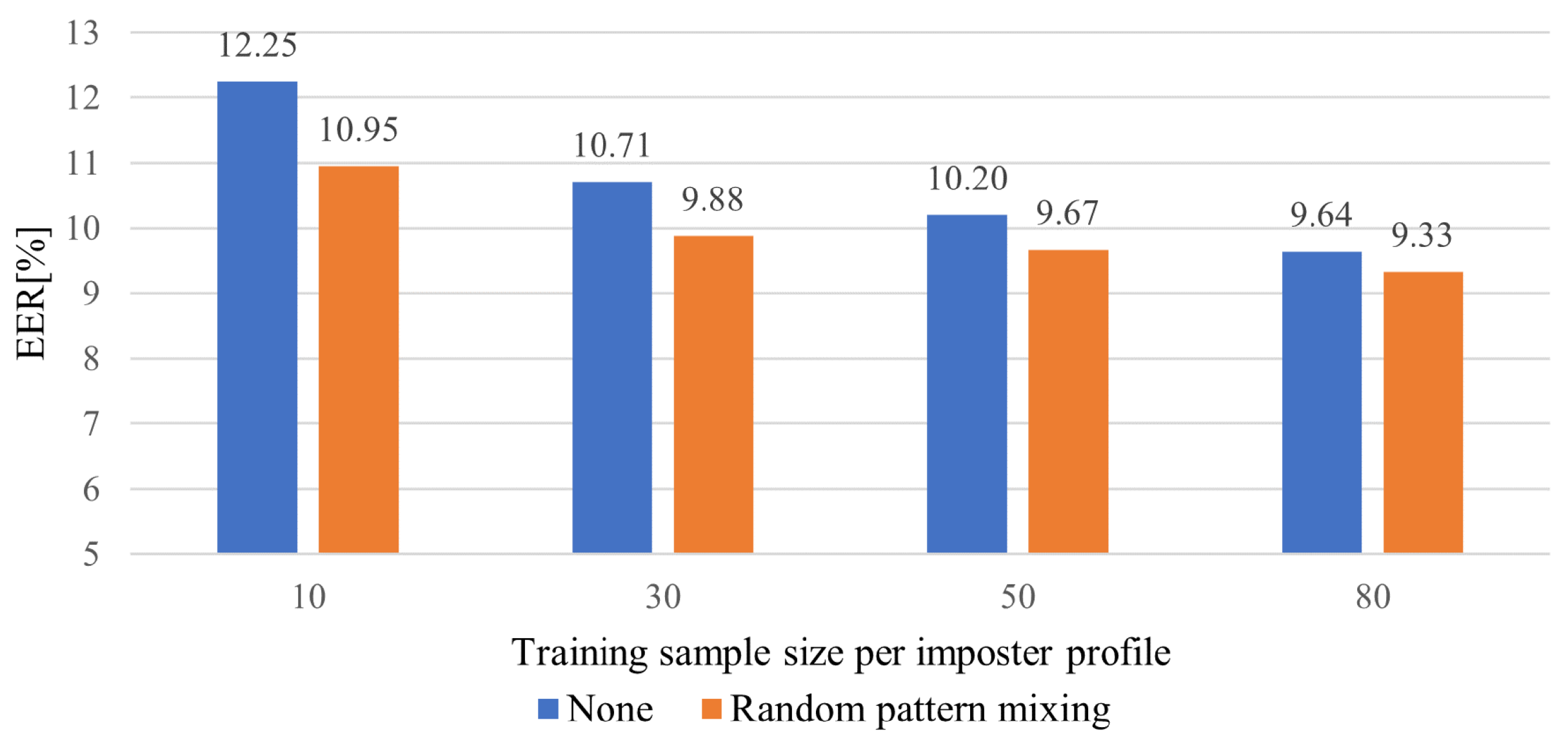
5.4. Impact of the Number of impostor Profiles and Sample Size for Training
5.5. Impact of Re-Authentication Time
5.5.1. Decision and Score-Level Fusion
5.5.2. Sensor-Level Fusion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, X.; Yan, Z.; Zhang, R.; Zhang, P. Attacks and defenses in user authentication systems: A survey. J. Netw. Comput. Appl. 2021, 188, 103080. [Google Scholar] [CrossRef]
- Centeno, M.P.; van Moorsel, A.; Castruccio, S. Smartphone continuous authentication using deep learning autoencoders. In Proceedings of the 2017 15th Annual Conference on Privacy, Security and Trust (PST), Calgary, AB, Canada, 27–29 August 2017; pp. 147–1478. [Google Scholar]
- Giorgi, G.; Saracino, A.; Martinelli, F. Using recurrent neural networks for continuous authentication through gait analysis. Pattern Recognit. Lett. 2021, 147, 157–163. [Google Scholar] [CrossRef]
- Hu, H.; Li, Y.; Zhu, Z.; Zhou, G. CNNAuth: Continuous authentication via two-stream convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Networking, Architecture and Storage (NAS), Chongqing, China, 11–14 October 2018; pp. 1–9. [Google Scholar]
- Li, Y.; Hu, H.; Zhu, Z.; Zhou, G. SCANet: Sensor-based continuous authentication with two-stream convolutional neural networks. ACM Trans. Sens. Netw. 2020, 16, 1–27. [Google Scholar] [CrossRef]
- Li, Y.; Tao, P.; Deng, S.; Zhou, G. DeFFusion: CNN-based Continuous Authentication Using Deep Feature Fusion. ACM Trans. Sens. Netw. 2021, 18, 1–20. [Google Scholar] [CrossRef]
- Deng, S.; Luo, J.; Li, Y. CNN-Based Continuous Authentication on Smartphones with Auto Augmentation Search. In Proceedings of the International Conference on Information and Communications Security, Chongqing, China, 19–21 November 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 169–186. [Google Scholar]
- Amini, S.; Noroozi, V.; Pande, A.; Gupte, S.; Yu, P.S.; Kanich, C. Deepauth: A framework for continuous user re-authentication in mobile apps. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 2027–2035. [Google Scholar]
- Mekruksavanich, S.; Jitpattanakul, A. Deep learning approaches for continuous authentication based on activity patterns using mobile sensing. Sensors 2021, 21, 7519. [Google Scholar] [CrossRef] [PubMed]
- Abuhamad, M.; Abuhmed, T.; Mohaisen, D.; Nyang, D. AUToSen: Deep-learning-based implicit continuous authentication using smartphone sensors. IEEE Internet Things J. 2020, 7, 5008–5020. [Google Scholar] [CrossRef]
- Agrawal, M.; Mehrotra, P.; Kumar, R.; Shah, R.R. Defending Touch-based Continuous Authentication Systems from Active Adversaries Using Generative Adversarial Networks. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–8. [Google Scholar]
- Yang, Y.; Guo, B.; Wang, Z.; Li, M.; Yu, Z.; Zhou, X. BehaveSense: Continuous authentication for security-sensitive mobile apps using behavioral biometrics. Ad Hoc Netw. 2019, 84, 9–18. [Google Scholar] [CrossRef]
- Incel, Ö.D.; Günay, S.; Akan, Y.; Barlas, Y.; Basar, O.E.; Alptekin, G.I.; Isbilen, M. DAKOTA: Sensor and touch screen-based continuous authentication on a mobile banking application. IEEE Access 2021, 9, 38943–38960. [Google Scholar] [CrossRef]
- Volaka, H.C.; Alptekin, G.; Basar, O.E.; Isbilen, M.; Incel, O.D. Towards continuous authentication on mobile phones using deep learning models. Procedia Comput. Sci. 2019, 155, 177–184. [Google Scholar] [CrossRef]
- Li, Y.; Hu, H.; Zhou, G. Using data augmentation in continuous authentication on smartphones. IEEE Internet Things J. 2018, 6, 628–640. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jantawong, P.; Jitpattanakul, A. Enhancement of Sensor-based User Identification using Data Augmentation Techniques. In Proceedings of the 2022 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI DAMT & NCON), Chiang Rai, Thailand, 26–28 January 2022; pp. 333–337. [Google Scholar]
- Benegui, C.; Ionescu, R.T. To augment or not to augment? Data augmentation in user identification based on motion sensors. In Proceedings of the International Conference on Neural Information Processing, Sanur, Indonesia, 8–12 December 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 822–831. [Google Scholar]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; van den Hengel, A. Deep anomaly detection with deviation networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 353–362. [Google Scholar]
- Ding, K.; Zhou, Q.; Tong, H.; Liu, H. Few-shot network anomaly detection via cross-network meta-learning. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2448–2456. [Google Scholar]
- Tian, Y.; Maicas, G.; Pu, L.Z.C.T.; Singh, R.; Verjans, J.W.; Carneiro, G. Few-shot anomaly detection for polyp frames from colonoscopy. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 274–284. [Google Scholar]
- Pang, G.; Ding, C.; Shen, C.; Hengel, A.v.d. Explainable deep few-shot anomaly detection with deviation networks. arXiv 2021, arXiv:2108.00462. [Google Scholar]
- Song, Y.; Cai, Z. Integrating Handcrafted Features with Deep Representations for Smartphone Authentication. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2022, 6, 1–27. [Google Scholar] [CrossRef]
- Keykhaie, S.; Pierre, S. Mobile match on card active authentication using touchscreen biometric. IEEE Trans. Consum. Electron. 2020, 66, 376–385. [Google Scholar] [CrossRef]
- Ooi, S.Y.; Teoh, A.B.J. Touch-stroke dynamics authentication using temporal regression forest. IEEE Signal Process. Lett. 2019, 26, 1001–1005. [Google Scholar] [CrossRef]
- Chang, I.; Low, C.Y.; Choi, S.; Teoh, A.B.J. Kernel deep regression network for touch-stroke dynamics authentication. IEEE Signal Process. Lett. 2018, 25, 1109–1113. [Google Scholar] [CrossRef]
- Buriro, A.; Ricci, F.; Crispo, B. SwipeGAN: Swiping Data Augmentation Using Generative Adversarial Networks for Smartphone User Authentication. In Proceedings of the 3rd ACM Workshop on Wireless Security and Machine Learning, Abu Dhabi, United Arab Emirates, 2 July 2021; pp. 85–90. [Google Scholar]
- Buriro, A.; Crispo, B.; Gupta, S.; Del Frari, F. Dialerauth: A motion-assisted touch-based smartphone user authentication scheme. In Proceedings of the Eighth ACM Conference on Data and Application Security and Privacy, Tempe, AZ, USA, 19–21 March 2018; pp. 267–276. [Google Scholar]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Kim, J.; Kang, P. Draw-a-Deep Pattern: Drawing Pattern-Based Smartphone User Authentication Based on Temporal Convolutional Neural Network. Appl. Sci. 2022, 12, 7590. [Google Scholar] [CrossRef]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Hamaguchi, R.; Fujita, A.; Nemoto, K.; Imaizumi, T.; Hikosaka, S. Effective use of dilated convolutions for segmenting small object instances in remote sensing imagery. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1442–1450. [Google Scholar]
- Park, H.; Yoo, Y.; Seo, G.; Han, D.; Yun, S.; Kwak, N. C3: Concentrated-comprehensive convolution and its application to semantic segmentation. arXiv 2018, arXiv:1812.04920. [Google Scholar]
- Modak, S.K.S.; Jha, V.K. Multibiometric fusion strategy and its applications: A review. Inf. Fusion 2019, 49, 174–204. [Google Scholar] [CrossRef]
- Sitová, Z.; Šeděnka, J.; Yang, Q.; Peng, G.; Zhou, G.; Gasti, P.; Balagani, K.S. HMOG: New behavioral biometric features for continuous authentication of smartphone users. IEEE Trans. Inf. Forensics Secur. 2015, 11, 877–892. [Google Scholar] [CrossRef]
- Belman, A.K.; Wang, L.; Iyengar, S.; Sniatala, P.; Wright, R.; Dora, R.; Baldwin, J.; Jin, Z.; Phoha, V.V. Insights from BB-MAS—A Large Dataset for Typing, Gait and Swipes of the Same Person on Desktop, Tablet and Phone. arXiv 2019, arXiv:1912.02736. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Supervision | Architecture | |
|---|---|---|---|
| Centeno et al. [2] | Acc. 1 | Unsupervised | Autoencoder |
| Giorgi et al. [3] | Acc. 1, Gyro. 2 | Unsupervised | LSTM autoencoder |
| CNNAuth [4] | Acc. 1, Gyro. 2 | Semi-supervised | CNN + PCA 5 + OC-SVM |
| SCANet [5] | Acc. 1, Gyro. 2 | Semi-supervised | CNN + PCA 5 + OC-SVM |
| DeFFusion [6] | Acc. 1, Gyro. 2 | Semi-supervised | CNN + FA 6 + OC-SVM |
| CAuSe [7] | Acc. 1, Gyro. 2, Mag. 3 | Semi-supervised | CNN + PCA 5 + LOF |
| Mekruksavanich et al. [16] | Acc.1, | Fully supervised | CNN |
| Giorgi et al. [3] | Acc. 1, Gyro. 2 | Fully supervised | LSTM |
| DeepAuth [8] | Acc. 1, Gyro. 2 | Fully supervised | LSTM |
| Benegui et al. [17] | Acc. 1, Gyro. 2 | Fully supervised | LSTM/ConvLSTM |
| DeepAuthen [9] | Acc. 1, Gyro. 2, Mag. 3 | Fully supervised | ConvLSTM |
| AUTOSen [10] | Touch. 4, Acc. 1, Gyro. 2, Mag. 3 | Fully supervised | Bidirectional LSTM |
| Sensor | Feature | Data Augmentation Methods | |
|---|---|---|---|
| Agrawal et al. [11] | Touch. 1 | Hand-crafted | GAN generator |
| SWIPEGAN [27] | Touch. 1, Acc. 2 | Hand-crafted | GAN generator |
| DAKOTA [13] | Touch. 1, Acc. 2, Gyro. 3, Mag. 4 | Hand-crafted | SMOTE |
| SensorAuth [15] | Acc. 2, Gyro. 3 | Hand-crafted | Jittering, scaling, permutation, sampling, cropping |
| Mekruksavanich et al. [16] | Acc. 2 | Raw | Jittering, scaling, warping, rotation |
| Benegui et al. [17] | Acc. 2, Gyro. 3 | Raw | Jittering, scaling, warping |
| Giorgi et al. [3] | Acc. 2, Gyro. 3 | Raw | Jittering, scaling, permutation |
| CAuSe [7] | Acc. 2, Gyro. 3, Mag. 4 | Raw | Jittering, scaling, permutation, cropping, warping, rotation |
| Architecture | Dataset | Parameter Size | |
|---|---|---|---|
| HMOG | BBMAS | ||
| MLP | 20.33 | 15.48 | 0.5 M |
| LSTM | 23.55 | 14.09 | 0.6 M |
| CNN | 13.14 | 16.97 | 0.4 M |
| TCN | 12.76 | 14.02 | 0.5 M |
| LFE-TCN | 14.90 | 16.76 | 1.0 M |
| LFP-TCN | 12.25 | 13.70 | 0.5 M |
| Method | Sensor | Feature | Supervision | Dataset | |
|---|---|---|---|---|---|
| HMOG | BBMAS | ||||
| AUToSen [10] | To. 1, Acc. 2, Gyro. 3 | Raw | Fully-supervised | 22.13 | 15.34 |
| DAKOTA [13] | Hand-crafted | Fully supervised | 11.71 | 14.06 | |
| Volaka et al. [14] | Hand-crafted | Fully supervised | 15.59 | 15.04 | |
| Ours | Raw | Weakly supervised | 10.95 | 12.85 | |
| CNNAuth [4] | Acc. 2, Gyro. 3 | Raw | Semi-supervised | 31.60 | 38.11 |
| DeFFusion [6] | Raw | Semi-supervised | 26.40 | 36.55 | |
| Giorgi et al. [3] | Raw | Fully supervised | 26.36 | 23.28 | |
| DeepAuthen [9] | Raw | Fully supervised | 27.29 | 24.86 | |
| Ours | Raw | Weakly supervised | 18.32 | 22.98 | |
| Re-Authentication Time | Decision-Level Fusion | Score-Level Fusion | |
|---|---|---|---|
| Mean-Score | Max-Score | ||
| 1 s | 10.95 | 10.95 | 10.95 |
| 3 s | 9.97 | 8.84 | 8.09 |
| 5 s | 9.15 | 8.00 | 6.98 |
| 7 s | 8.65 | 7.51 | 6.24 |
| 9 s | 8.21 | 7.09 | 5.73 |
| 15 s | 7.21 | 6.26 | 4.81 |
| 19 s | 6.77 | 5.86 | 4.20 |
| 25 s | 6.12 | 5.37 | 3.74 |
| 29 s | 5.86 | 5.11 | 3.55 |
| Re-Authentication Time | Sensor-Level Fusion | Parameter Size |
|---|---|---|
| 1 s | 10.95 | 0.5 M |
| 3 s | 10.20 | 0.7 M |
| 5 s | 9.64 | 0.7 M |
| 7 s | 9.68 | 0.8 M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wagata, K.; Teoh, A.B.J. Few-Shot Continuous Authentication for Mobile-Based Biometrics. Appl. Sci. 2022, 12, 10365. https://doi.org/10.3390/app122010365
Wagata K, Teoh ABJ. Few-Shot Continuous Authentication for Mobile-Based Biometrics. Applied Sciences. 2022; 12(20):10365. https://doi.org/10.3390/app122010365
Chicago/Turabian StyleWagata, Kensuke, and Andrew Beng Jin Teoh. 2022. "Few-Shot Continuous Authentication for Mobile-Based Biometrics" Applied Sciences 12, no. 20: 10365. https://doi.org/10.3390/app122010365
APA StyleWagata, K., & Teoh, A. B. J. (2022). Few-Shot Continuous Authentication for Mobile-Based Biometrics. Applied Sciences, 12(20), 10365. https://doi.org/10.3390/app122010365