
A Comparison of Hybrid and End-to-End ASR Systems for the IberSpeech-RTVE 2020 Speech-to-Text Transcription Challenge

 , and
, and
Abstract
:1. Introduction
- We firstly studied state-of-the-art techniques for hybrid and end-to-end ASR systems;
- We report the use of data augmentation techniques to improve our Kaldi-based hybrid ASR system presented in the IberSpeech-RTVE 2018 edition [32];
- Then, we evaluated a baseline end-to-end system on a real TV content dataset. We chose PyChain because it is based on the state-of-the-art LF-MMI approach, for which good results have been previously reported;
- Finally, looking to improve the end-to-end ASR system, we propose the use of DAT to learn features invariant to the environmental conditions and TV show format. Thus, we developed a novel improved version of the PyChain baseline including DAT. This implementation allowed us to compare the performance of both end-to-end systems in the case of having low-computational or -speech data resources.
2. Architectures
2.1. DNN-HMM ASR
2.2. End-to-End LF-MMI ASR
2.3. End-to-End LF-MMI ASR Applying Domain Adversarial Training
3. Experimental Setup
3.1. RTVE2020 Database
- Subtitles were generated by means of a re-speaking procedure that sometimes changed the sentences and summarized what had been said, obtaining non-reliable transcriptions;
- Transcriptions were not supervised by humans. Only 109 h from the dev1, dev2, and test partitions contain human-revised transcriptions;
- Timestamps were not properly aligned with the speech signal.
3.2. Other Databases
3.3. Training Setup
- 1.
- Live TV shows: a variety of content for the whole family;
- 2.
- Documentaries: show broadcasts about risky sports, adventure, street reports, and current information in different Spanish regions;
- 3.
- TV game shows: content related to comedy competitions, road safety, or culture dissemination, among others;
- 4.
- Interviews: moderated debates with analysis, political and economic news, and weather information.
3.4. Resources
4. Results
4.1. Hybrid ASR
4.2. End-to-End LF-MMI ASR
5. Related Works
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Chiu, C.C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-art speech recognition with sequence-to-sequence models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar]
- Collobert, R.; Puhrsch, C.; Synnaeve, G. Wav2letter: An end-to-end convnet-based speech recognition system. arXiv 2016, arXiv:1609.03193. [Google Scholar]
- Zeyer, A.; Irie, K.; Schlüter, R.; Ney, H. Improved training of end-to-end attention models for speech recognition. arXiv 2018, arXiv:1805.03294. [Google Scholar]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4945–4949. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Zhang, Y.; Qin, J.; Park, D.S.; Han, W.; Chiu, C.C.; Pang, R.; Le, Q.V.; Wu, Y. Pushing the limits of semi-supervised learning for automatic speech recognition. arXiv 2020, arXiv:2010.10504. [Google Scholar]
- Chen, G.; Chai, S.; Wang, G.; Du, J.; Zhang, W.Q.; Weng, C.; Su, D.; Povey, D.; Trmal, J.; Zhang, J.; et al. GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 h of Transcribed Audio. arXiv 2021, arXiv:2106.06909. [Google Scholar]
- Watanabe, S.; Mandel, M.; Barker, J.; Vincent, E.; Arora, A.; Chang, X.; Khudanpur, S.; Manohar, V.; Povey, D.; Raj, D.; et al. CHiME-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings. arXiv 2020, arXiv:2004.09249. [Google Scholar]
- Andrusenko, A.; Laptev, A.; Medennikov, I. Towards a competitive end-to-end speech recognition for chime-6 dinner party transcription. arXiv 2020, arXiv:2004.10799. [Google Scholar]
- Chan, W.; Park, D.; Lee, C.; Zhang, Y.; Le, Q.; Norouzi, M. SpeechStew: Simply mix all available speech recognition data to train one large neural network. arXiv 2021, arXiv:2104.02133. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Soplin, N.E.Y.; Heymann, J.; Wiesner, M.; Chen, N.; et al. Espnet: End-to-end speech processing toolkit. arXiv 2018, arXiv:1804.00015. [Google Scholar]
- Shao, Y.; Wang, Y.; Povey, D.; Khudanpur, S. PyChain: A Fully Parallelized PyTorch Implementation of LF-MMI for End-to-End ASR. arXiv 2020, arXiv:2005.09824. [Google Scholar]
- Povey, D.; Peddinti, V.; Galvez, D.; Ghahremani, P.; Manohar, V.; Na, X.; Wang, Y.; Khudanpur, S. Purely Sequence-Trained Neural Networks for ASR Based on Lattice-Free MMI; Interspeech: San Francisco, CA, USA, 2016; pp. 2751–2755. [Google Scholar]
- Peddinti, V.; Chen, G.; Manohar, V.; Ko, T.; Povey, D.; Khudanpur, S. JHU ASpIRE System: Robust LVCSR with TDNNS, iVector Adaptation and RNN-LMS. In Proceedings of the IEEE 2015 Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 539–546. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Han, W.; Zhang, Z.; Zhang, Y.; Yu, J.; Chiu, C.C.; Qin, J.; Gulati, A.; Pang, R.; Wu, Y. Contextnet: Improving convolutional neural networks for automatic speech recognition with global context. arXiv 2020, arXiv:2005.03191. [Google Scholar]
- Winata, G.I.; Cahyawijaya, S.; Liu, Z.; Lin, Z.; Madotto, A.; Xu, P.; Fung, P. Learning Fast Adaptation on Cross-Accented Speech Recognition. arXiv 2020, arXiv:eess.AS/2003.01901. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Dhakal, P.; Damacharla, P.; Javaid, A.Y.; Devabhaktuni, V. A near real-time automatic speaker recognition architecture for voice-based user interface. Mach. Learn. Knowl. Extr. 2019, 1, 504–520. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.; Kudina, O.; Halpern, B.M.; Scharenborg, O. Quantifying bias in automatic speech recognition. arXiv 2021, arXiv:2103.15122. [Google Scholar]
- Serdyuk, D.; Audhkhasi, K.; Brakel, P.; Ramabhadran, B.; Thomas, S.; Bengio, Y. Invariant representations for noisy speech recognition. arXiv 2016, arXiv:1612.01928. [Google Scholar]
- Shinohara, Y. Adversarial Multi-Task Learning of Deep Neural Networks for Robust Speech Recognition; Interspeech: San Francisco, CA, USA, 2016; pp. 2369–2372. [Google Scholar]
- Sun, S.; Yeh, C.F.; Hwang, M.Y.; Ostendorf, M.; Xie, L. Domain adversarial training for accented speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4854–4858. [Google Scholar]
- Meng, Z.; Li, J.; Chen, Z.; Zhao, Y.; Mazalov, V.; Gang, Y.; Juang, B.H. Speaker-invariant training via adversarial learning. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5969–5973. [Google Scholar]
- Lleida, E.; Ortega, A.; Miguel, A.; Bazán-Gil, V.; Pérez, C.; Gómez, M.; de Prada, A. Albayzin Evaluation: IberSPEECH-RTVE 2020 Speech to Text Transcription Challenge. 2020. Available online: http://catedrartve.unizar.es/reto2020/EvalPlan-S2T-2020-v1.pdf (accessed on 14 January 2022).
- Perero-Codosero, J.M.; Antón-Martín, J.; Merino, D.T.; Gonzalo, E.L.; Gómez, L.A.H. Exploring Open-Source Deep Learning ASR for Speech-to-Text TV Program Transcription; IberSPEECH: Valladolid, Spain, 2018; pp. 262–266. [Google Scholar]
- Lleida, E.; Ortega, A.; Miguel, A.; Bazán-Gil, V.; Pérez, C.; Gómez, M.; de Prada, A. Albayzin 2018 evaluation: The iberspeech-RTVE challenge on speech technologies for spanish broadcast media. Appl. Sci. 2019, 9, 5412. [Google Scholar] [CrossRef] [Green Version]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Seltzer, M.L.; Khudanpur, S. A study on data augmentation of reverberant speech for robust speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5220–5224. [Google Scholar]
- Ravanelli, M.; Parcollet, T.; Bengio, Y. The pytorch-kaldi speech recognition toolkit. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6465–6469. [Google Scholar]
- Can, D.; Martinez, V.R.; Papadopoulos, P.; Narayanan, S.S. Pykaldi: A python wrapper for kaldi. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5889–5893. [Google Scholar]
- Lleida, E.; Ortega, A.; Miguel, A.; Bazán-Gil, V.; Pérez, C.; Gómez, M.; de Prada, A. RTVE2020 Database Description. 2020. Available online: http://catedrartve.unizar.es/reto2020/RTVE2020DB.pdf (accessed on 14 January 2022).
- Toledano, D.T.; Gómez, L.A.H.; Grande, L.V. Automatic phonetic segmentation. IEEE Trans. Speech Audio Process. 2003, 11, 617–625. [Google Scholar] [CrossRef]
- Kocour, M.; Cámbara, G.; Luque, J.; Bonet, D.; Farrús, M.; Karafiát, M.; Veselỳ, K.; Ĉernockỳ, J. BCN2BRNO: ASR System Fusion for Albayzin 2020 Speech to Text Challenge. arXiv 2021, arXiv:2101.12729. [Google Scholar]
- Alvarez, A.; Arzelus, H.; Torre, I.G.; González-Docasal, A. The Vicomtech Speech Transcription Systems for the Albayzın-RTVE 2020 Speech to Text Transcription Challenge; IberSPEECH: Virtual Valladolid, Spain, 2021; pp. 104–107. [Google Scholar]
- Kriman, S.; Beliaev, S.; Ginsburg, B.; Huang, J.; Kuchaiev, O.; Lavrukhin, V.; Leary, R.; Li, J.; Zhang, Y. Quartznet: Deep automatic speech recognition with 1d time-channel separable convolutions. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual Barcelona, Spain, 4–8 May 2020; pp. 6124–6128. [Google Scholar]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. arXiv 2020, arXiv:2006.11477. [Google Scholar]
- Vyas, A.; Madikeri, S.; Bourlard, H. Comparing CTC and LFMMI for out-of-domain adaptation of wav2vec 2.0 acoustic model. arXiv 2021, arXiv:2104.02558. [Google Scholar]
- Wang, Y.; Li, J.; Wang, H.; Qian, Y.; Wang, C.; Wu, Y. Wav2vec-switch: Contrastive learning from original-noisy speech pairs for robust speech recognition. arXiv 2021, arXiv:2110.04934. [Google Scholar]
- Li, J.; Manohar, V.; Chitkara, P.; Tjandra, A.; Picheny, M.; Zhang, F.; Zhang, X.; Saraf, Y. Accent-Robust Automatic Speech Recognition Using Supervised and Unsupervised Wav2vec Embeddings. arXiv 2021, arXiv:2110.03520. [Google Scholar]
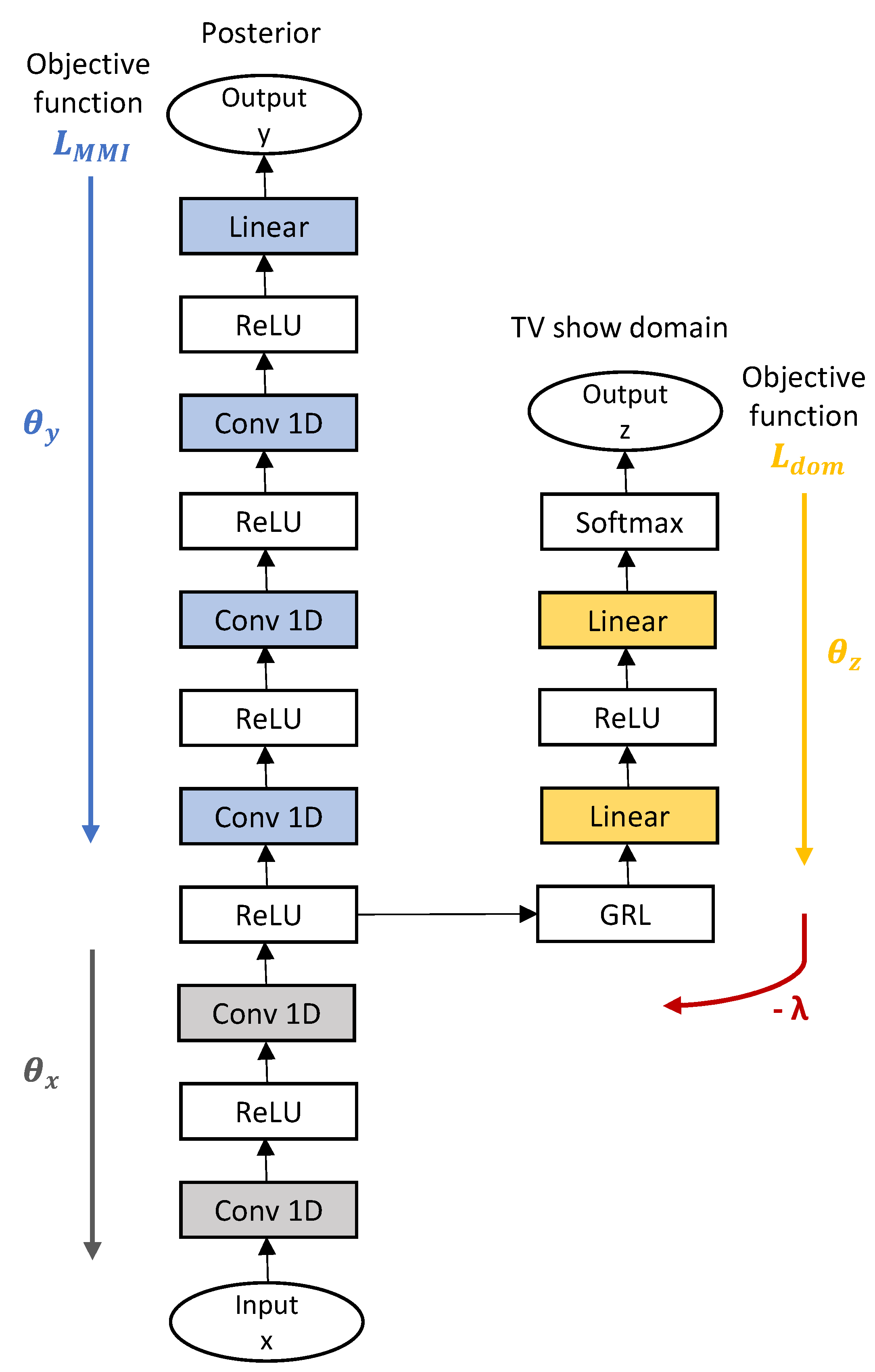


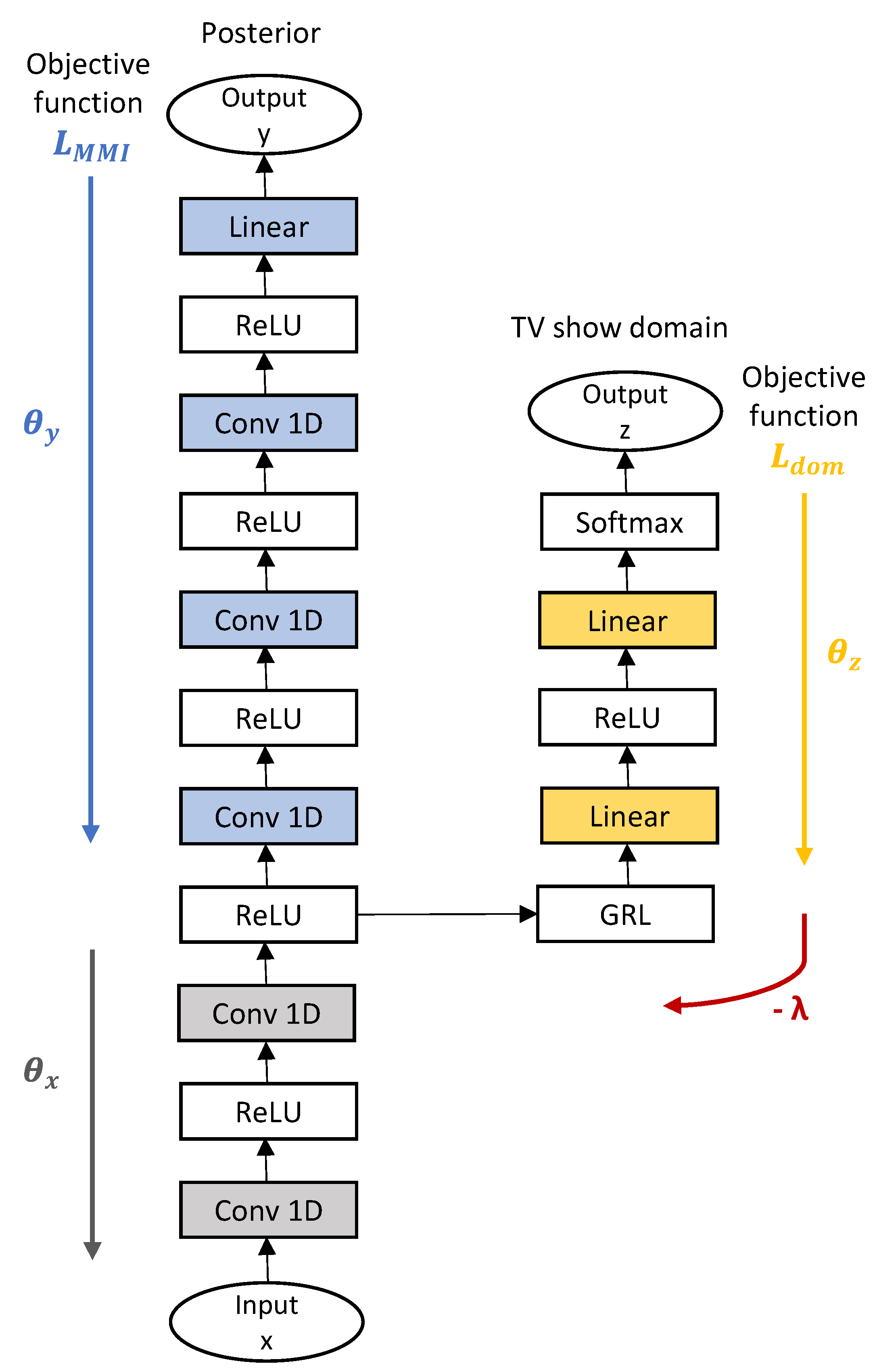{kind=link}
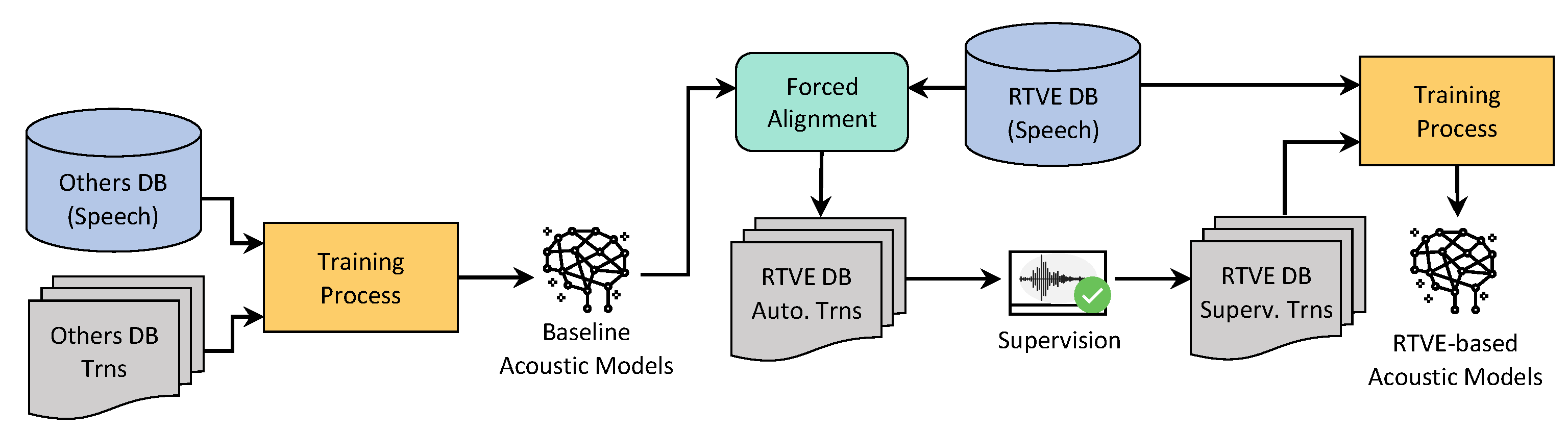{kind=link}
| Class | # of Samples | Examples of TV Shows |
|---|---|---|
| 1. live TV shows | 11,239 | La Mañana |
| 2. documentaries | 4671 | Al filo de lo Imposible, Comando Actualidad, España en Comunidad |
| 3. TV-game shows | 7995 | Arranca en Verde, Dicho y Hecho, Saber y Ganar |
| 4. interviews | 22,194 | Latinoamerica 24H, La Tarde en 24H, Millenium |
| 20H_dev1 | AP_dev1 | CA_dev1 | LM_dev1 | Mill_dev1 | LN24H_dev1 | |
|---|---|---|---|---|---|---|
| Kaldi-based baseline [32] | ||||||
| Reverb. data augmentation | ||||||
| Kaldi-based baseline (RTVE_train100) | ||||||
| PyChain-based baseline | ||||||
| Domain adversarial training |
| RTVE2020_test | |
|---|---|
| Kaldi-based baseline [32] | |
| Reverb. data augmentation | |
| PyChain-based baseline | |
| Domain adversarial training |
| Datasets | Decoding | LM Rescoring |
|---|---|---|
| 20H_dev1 | ||
| AP_dev1 | ||
| CA_dev1 | ||
| LM_dev1 | ||
| Mill_dev1 | ||
| LN24H_dev1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perero-Codosero, J.M.; Espinoza-Cuadros, F.M.; Hernández-Gómez, L.A. A Comparison of Hybrid and End-to-End ASR Systems for the IberSpeech-RTVE 2020 Speech-to-Text Transcription Challenge. Appl. Sci. 2022, 12, 903. https://doi.org/10.3390/app12020903
Perero-Codosero JM, Espinoza-Cuadros FM, Hernández-Gómez LA. A Comparison of Hybrid and End-to-End ASR Systems for the IberSpeech-RTVE 2020 Speech-to-Text Transcription Challenge. Applied Sciences. 2022; 12(2):903. https://doi.org/10.3390/app12020903
Chicago/Turabian StylePerero-Codosero, Juan M., Fernando M. Espinoza-Cuadros, and Luis A. Hernández-Gómez. 2022. "A Comparison of Hybrid and End-to-End ASR Systems for the IberSpeech-RTVE 2020 Speech-to-Text Transcription Challenge" Applied Sciences 12, no. 2: 903. https://doi.org/10.3390/app12020903
APA StylePerero-Codosero, J. M., Espinoza-Cuadros, F. M., & Hernández-Gómez, L. A. (2022). A Comparison of Hybrid and End-to-End ASR Systems for the IberSpeech-RTVE 2020 Speech-to-Text Transcription Challenge. Applied Sciences, 12(2), 903. https://doi.org/10.3390/app12020903