1. Introduction
Active vibration control is a challenging problem with high-dimensional, high-frequency and complex dynamics. Many conventional vibration controllers have been presented to solve this problem. For instance, PID controllers [
1,
2,
3,
4], which are not very suitable for high-dimensional vibration-control problems, and the determination of the controller parameters requires substantial design effort; LQR controllers [
5,
6,
7], which are suitable for the systems that can be formulated by state-space equations; FxLMS controllers [
8,
9,
10], which require the construction of a reference signal and the identification of a secondary path. It was found that, although these conventional controllers are usually effective, they require substantial engineering effort, design effort and expertise.
A new simple method for vibration-controller design is made possible by using RL. The parameters of the controller are automatically obtained by reinforcement-learning algorithms. Moreover, the new method is a data-driven method, which means that it does not require the physical information of the system, such as the mass matrix, stiffness matrix or damping matrix. Therefore, the new method requires less engineering effort and design effort in comparison with the conventional controller design methods.
Actually, RL has been widely used for building agents to learn complex control in complex environments, and it has achieved some successes in a variety of domains [
11,
12,
13,
14,
15]. Moreover, its applicability has been extended to the vibration-control domain, such as the vibration control of the suspension [
16,
17,
18,
19], manipulator [
20,
21,
22], magneto rheological damper [
23,
24], flexible beam/plate [
25,
26,
27], etc.
In suspension vibration-control problems [
16,
17,
18,
19], the controllers are trained to suppress the vibration caused by road profiles, and they are only validated by numerical simulations. Bucak et al. [
16] used a stochastic actor–critic reinforcement-learning control algorithm to provide control forces to a nonlinear quarter-car active-suspension model subjected to a sinusoidal road profile. The simulation results showed that the new algorithm stabilized the suspension very quickly. Kim et al. [
17] applied the DDPG (deep deterministic policy gradient) algorithm to the vibration-control simulation of a quarter-vehicle active-suspension model. The quarter-vehicle model with a trained agent (controller) was tested at the low-frequency cosine road and step road, which confirmed the effectiveness of the DDPG algorithm. Liu et al. [
18] presented an improved DDPG algorithm using empirical samples, and they applied it to a quarter-vehicle semiactive-suspension vibration-control simulation. The simulation results showed that, compared with the passive suspension, the semiactive suspension with the improved DDPG algorithm could better adapt to various road levels and vehicle speeds. Han et al. [
19] presented a PPO-based vibration-control strategy for a vehicle semiactive-suspension system, in which the designed reward function realizes the dynamic adjustment according to the road-condition changes. The simulation results showed that the body acceleration was reduced by 46.93% under the continuously changing road. These suspension vibration-control studies mainly considered single-input control problems.
In flexible-manipulator control problems [
20,
21,
22], the controllers are trained to suppress the transient vibration, as well as to follow the given trajectories. Ouyang et al. [
20] applied the actor–critic algorithm for a single-link flexible manipulator in an attempt to suppress the vibration due to its flexibility and lightweight structure. In the experiment, when the single link was given a desired position, the reinforcement-learning control could obtain a satisfactory tracking and vibration-suppression performance. He et al. [
21] investigated the actor–critic reinforcement-learning control of a flexible two-link manipulator by a numerical and experimental study. In the simulation and experiment, when the links were given desired trajectories, the reinforcement-learning control had feasibility and stability in suppressing the vibration. Long et al. [
22] presented a combined-vibration-control method for a hybrid-structured flexible manipulator based on sliding-mode control and reinforcement learning. The experimental results showed that the combined control method had good robustness to the tip trajectory and tip-load mass under the condition that the learning parameters of the controller remained unchanged.
In terms of the vibration-control problems of magneto rheological dampers [
23,
24], as the controller was designed based on Q-learning [
28], they are theoretically not suitable for high-dimensional continuous-action spaces. Park et al. [
23] proposed a novel reinforcement-learning method based on Q-learning for the vibration control of a magneto rheological elastomer. The experimental results showed that the proposed method could minimize the vibration level with respect to the tonal disturbance or sine-sweep disturbance. Yuan et al. [
24] proposed a semiactive control strategy of a magneto rheological damper based on the Q-learning algorithm, and the simulation results showed that it was better than simple bang-bang control.
In the vibration-control problems of flexible beams or plates [
25,
26,
27], accurate finite element models are constructed as the simulation environment, and then reinforcement-learning algorithms, such as the soft actor–critic algorithm, DDPG algorithm and multiagent twin delayed DDPG algorithm, are applied to train the vibration controllers. Finally, the well-trained controllers are validated in experiments. The simulation and experimental results demonstrate that the controllers trained by the proposed RL algorithms have better control effects compared with PD control. However, an accurate finite element model is difficult to build for complex vibrating systems, and the proper PD parameters are difficult to estimate.
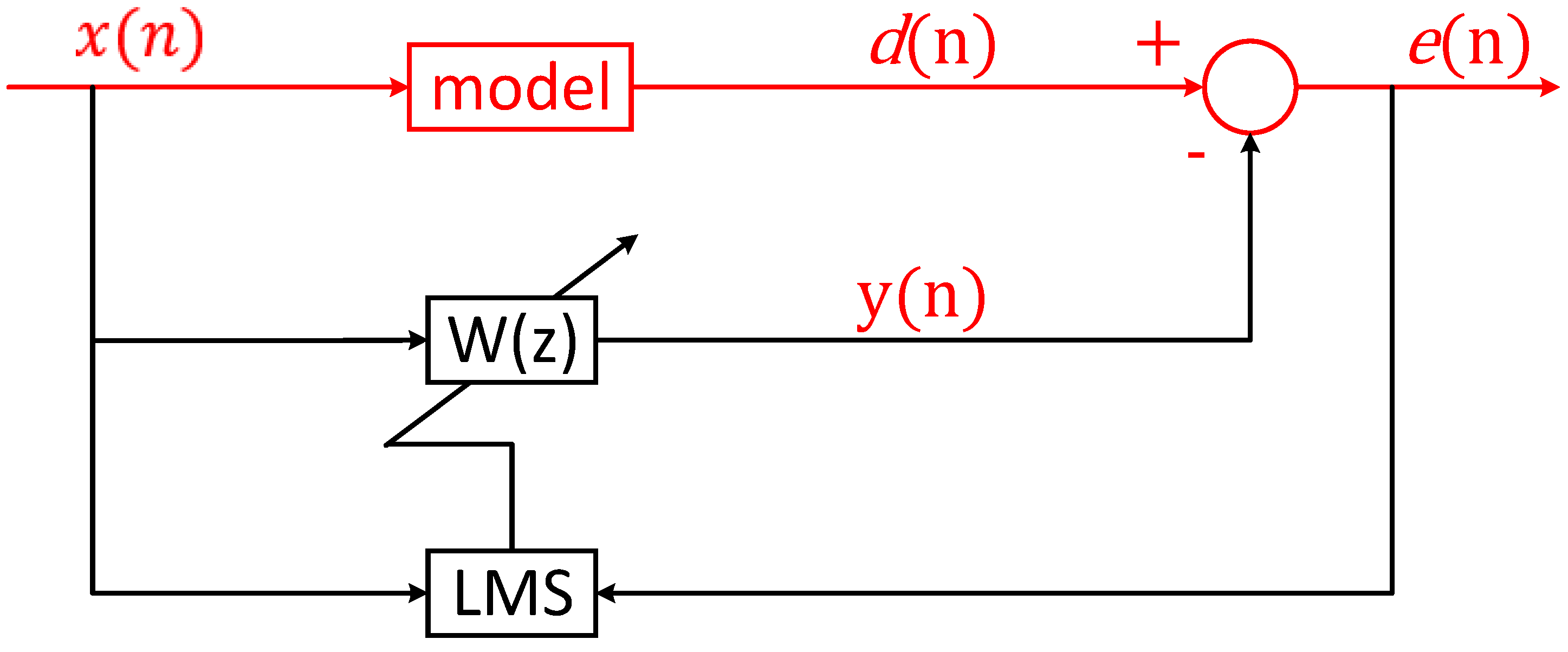
Although RL algorithms were applied in the above vibration-control research, they mainly considered vibration-control problems of low dimension (for instance, the single-input suspension control problem) and simple dynamics, such as link, beam, plate, quarter-car, etc., simulation models. However, this paper solved the multi-input/multi-output real-world vibration-control problem within a frequency range by using RL and an FIR filter, which was inspired by the least-mean-square (LMS) adaptive algorithm. To the best of the authors’ knowledge, this is the first time that the high-dimensional high-frequency vibration-control problem has been solved by using reinforcement learning.
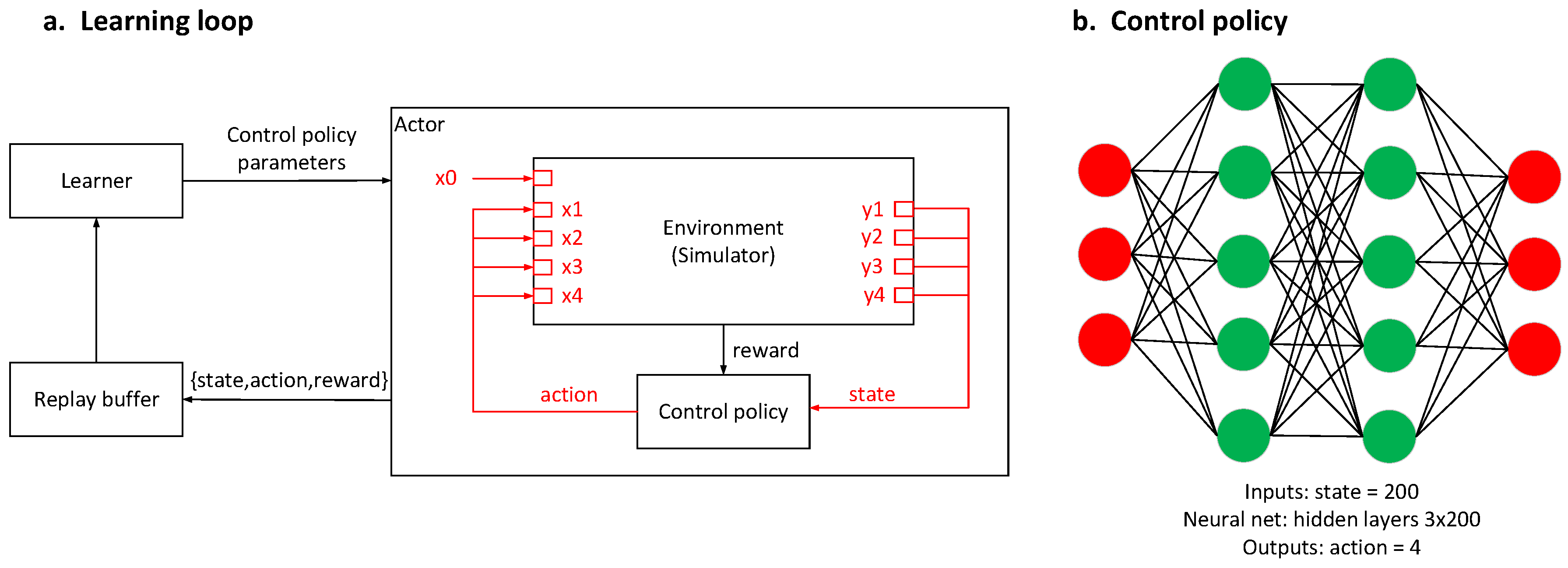
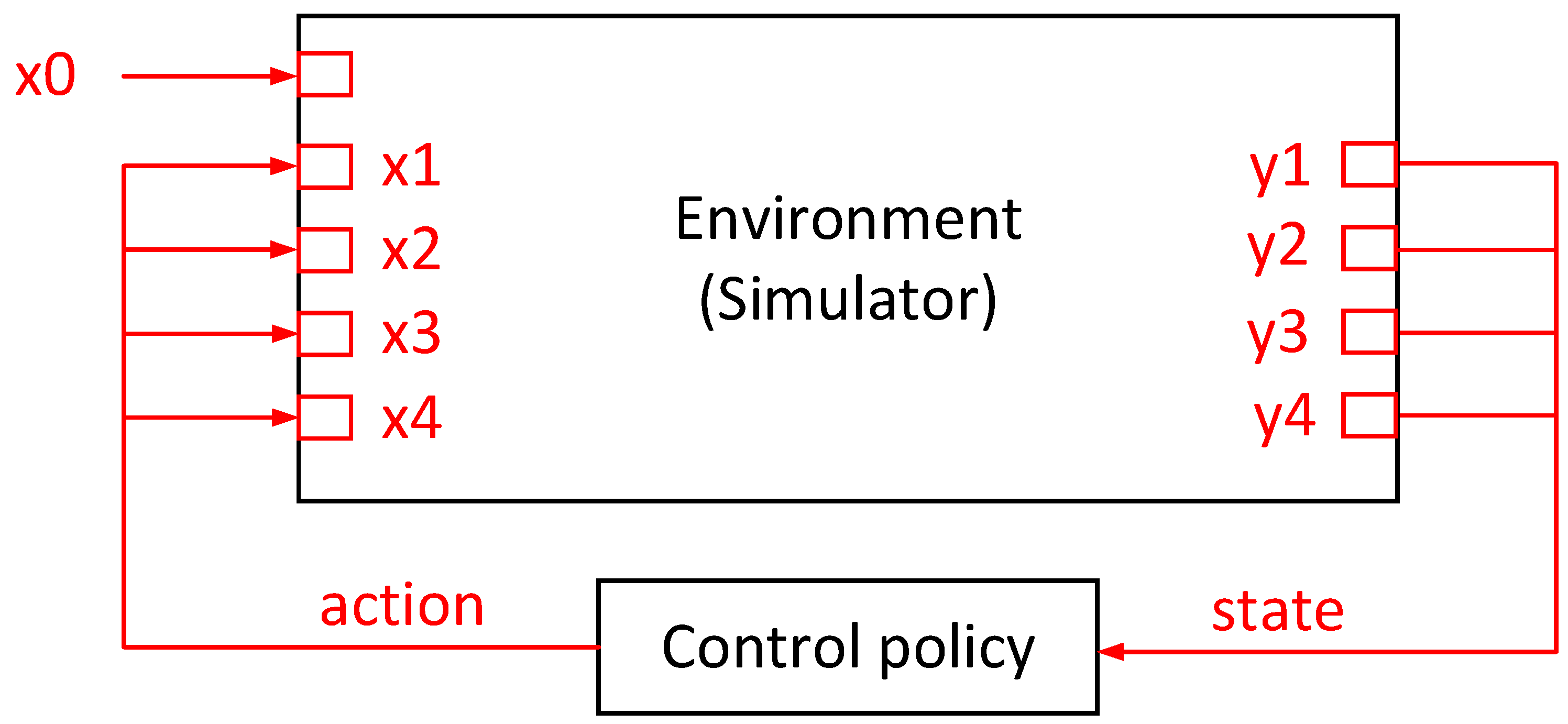
In this paper, the FIR filter was used to establish the transfer-function channels (i.e., the simulator) from the exciter and actuators to the sensors. Then, a reinforcement-learning algorithm interacted with the simulator to find a near-optimal control policy to meet the specified goals. Furthermore, the RL-based controller was verified in high-dimensional high-frequency vibration-control experiments.
The rest of this paper is organized as follow. First, the vibration-control problem is formulated. Second, a new method for a vibration-controller design through RL is presented. Third, the RL-designed vibration controller is experimentally verified. Finally, the conclusions are drawn.
4. Experiment
4.1. Experimental Setup and Procedure
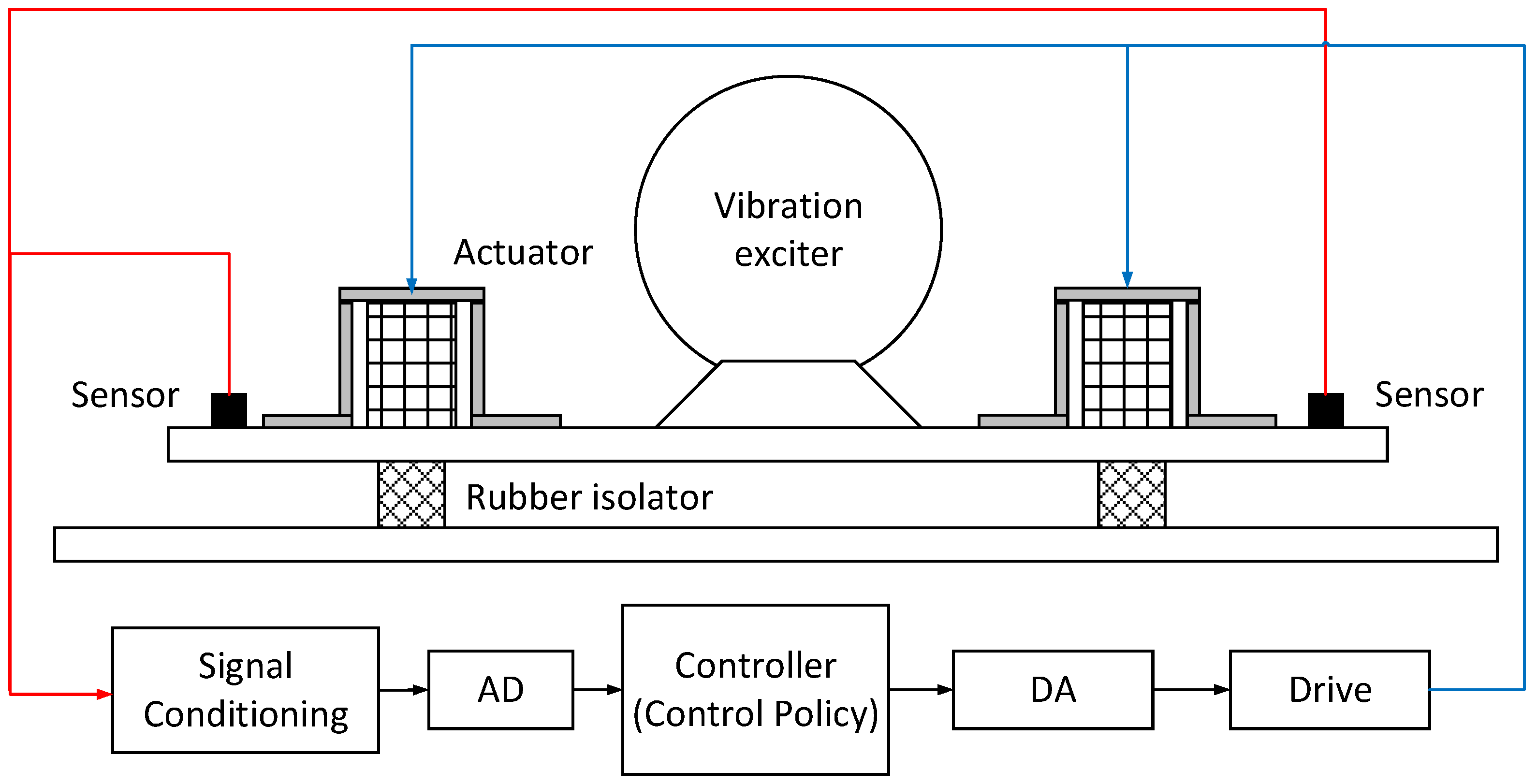
As shown in
Figure 12, the vibration system was supported on the ground by rubber isolators. A vibration exciter was installed on the vibration system to generate the vibration-excitation force. The control system includes the acceleration sensors, signal-conditioning module, AD module, controller, DA module, drive module and electromagnetic actuators. The acceleration sensors measure the system vibration. The well-trained neural network is compiled into binary code, and it is then run on the controller hardware. The controller controls the electromagnetic actuators to reduce the vibration caused by the exciter.
We carried out many different experiments by giving different signals to the vibration exciter. For clarity, three experiments were chosen to be shown.
In Experiment #1, the signal given to the exciter is the superposition of the 52 Hz, 55 Hz and 58 Hz sine signals, and it is the same as that in Simulation #1.
In Experiment #2, the signal given to the exciter is the superposition of the 53 Hz, 56 Hz and 59 Hz sine signals.
In Experiment #3, the signal given to the exciter is the superposition of the 53 Hz, 56 Hz, and 59 Hz sine signals, but its amplitude is completely different from that in Experiment #2.
The parameters of the well-trained neural network were fixed in all the experiments. The controller controls the actuators to reduce the vibration caused by the exciter. In each experiment, the sensor signals were recorded when the controller was turned on or off. Some of the experimental results were chosen to be shown in the following sections.
4.2. Experimental Results and Discussions
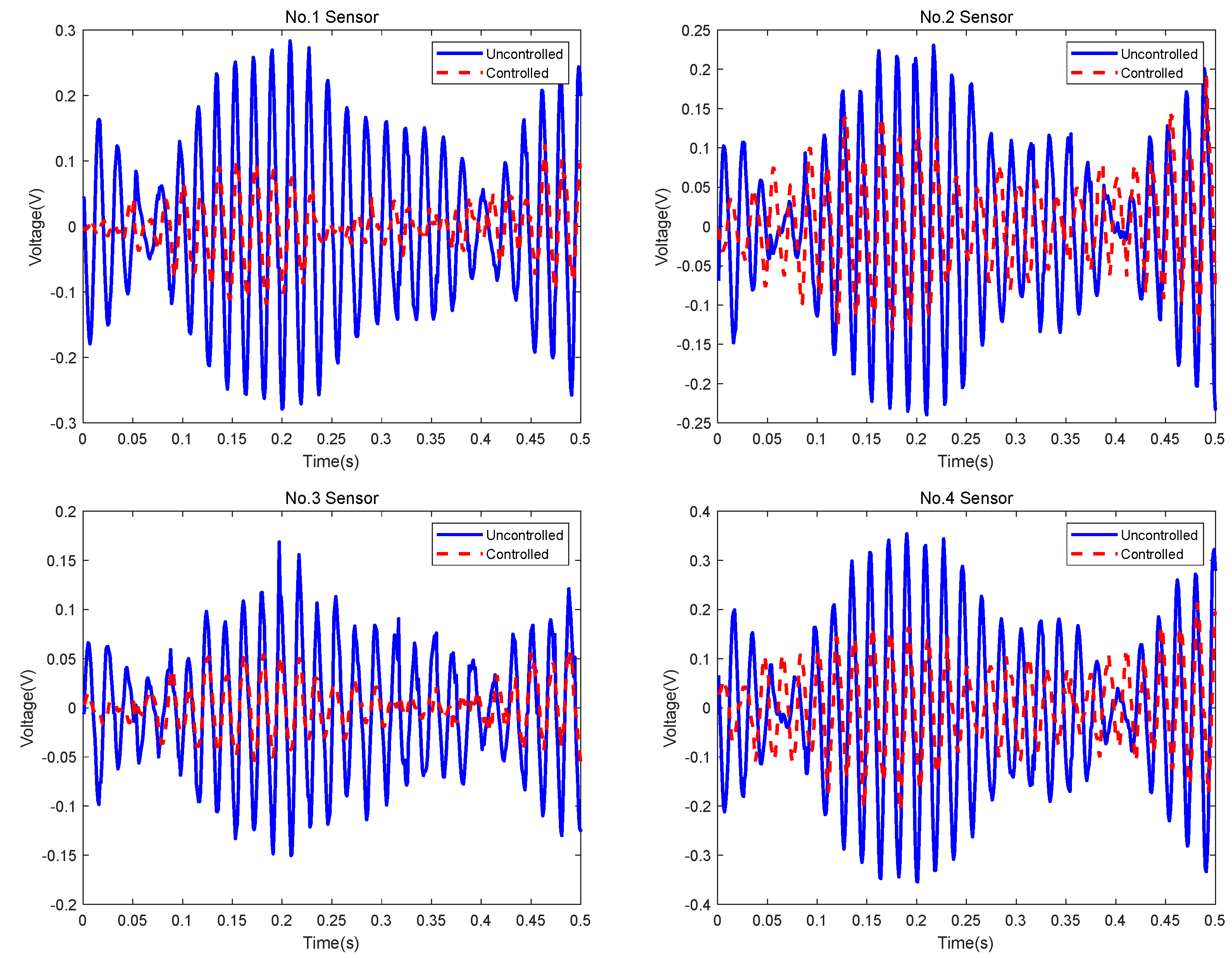
4.2.1. Experiment #1
Figure 13 shows the sensor signals in the time domain. The controlled signals were recorded when the controller was on, and the uncontrolled signals were recorded when the controller was off. Although the controlled signals and uncontrolled signals are shown in the same figure, they were not sampled at the same time. The sampling frequency was 1 kHz. The amount of the total sampled data was more than 30 s. For clarity, a small amount of data is shown in the figures.
Table 3 shows the RMS values of the uncontrolled and controlled sensor signals. The RMS values were calculated based on the total sampled data. It was found that the RMS values were reduced by more than 39%. The vibration reduction can also be seen from the PSD curves of the sensor signals, as shown in
Figure 14.
Table 4 shows the peak values of the PSD curves of the sensor signals. It can be seen that the peak values of the PSD curves at specific frequencies were reduced by more than 47%. Moreover,
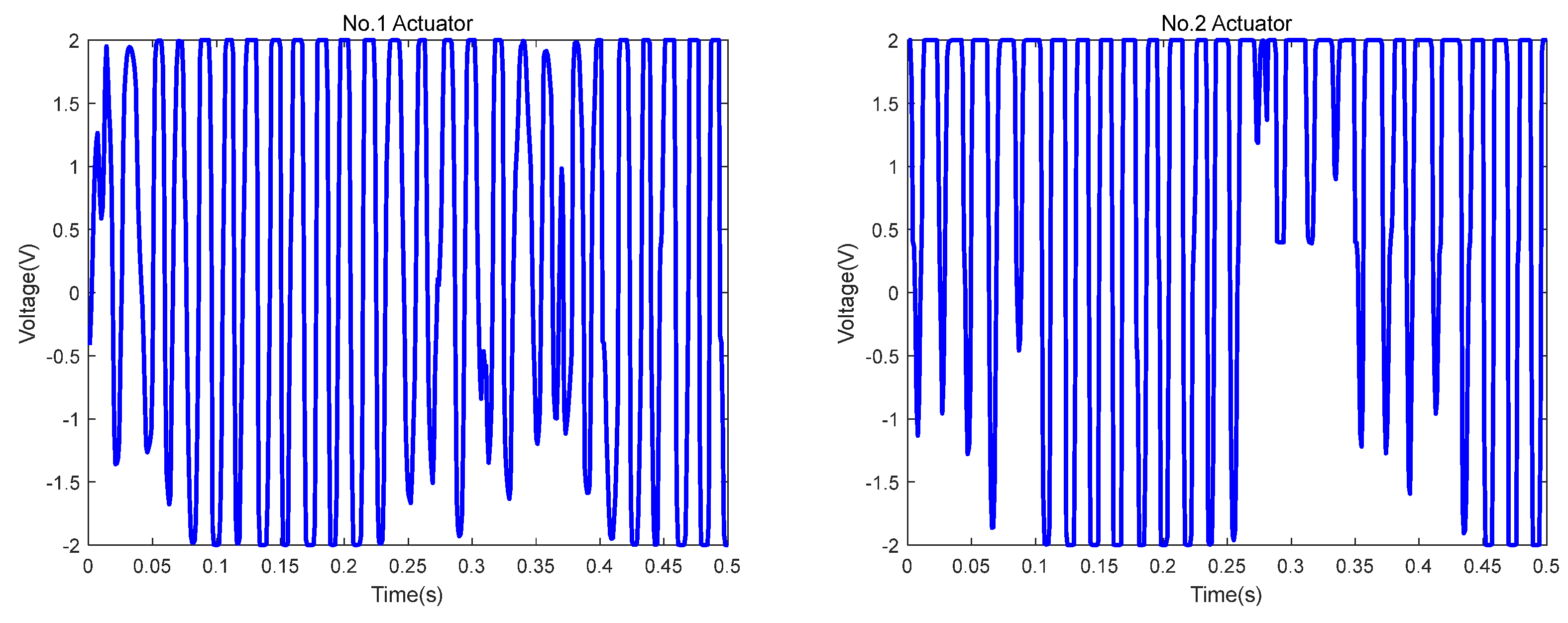
Figure 15 shows that the controller outputs were bounded from −2 V to 2 V.
4.2.2. Experiment #2
Figure 16 shows the sensor signals in the time domain.
Table 5 shows the RMS values of the uncontrolled and controlled sensor signals. It was found that the RMS values were all reduced by more than 40%. The vibration reduction can also be seen from the PSD curves of the sensor signals, as shown in
Figure 17.
Table 6 shows the peak values of the PSD curves of the sensor signals. It can be seen that the peak values of the PSD curves at specific frequencies were nearly all reduced by more than 50%.
4.2.3. Experiment #3
Figure 18 shows the sensor signals in the time domain.
Table 7 shows the RMS values of the uncontrolled and controlled sensor signals. It was found that the RMS values were all reduced by more than 32%. The vibration reduction can also be seen from the PSD curves of the sensor signals, as shown in
Figure 19.
Table 8 shows the peak values of the PSD curves of the sensor signals. It can be seen that the peak values of the PSD curves at specific frequencies were all reduced by more than 52%.
4.3. Comparison of Experimental and Simulation Results
The results of Simulation #1 and Experiment #1 were compared. The physical fidelity of the simulation model, including the simulator and control policy, was validated.
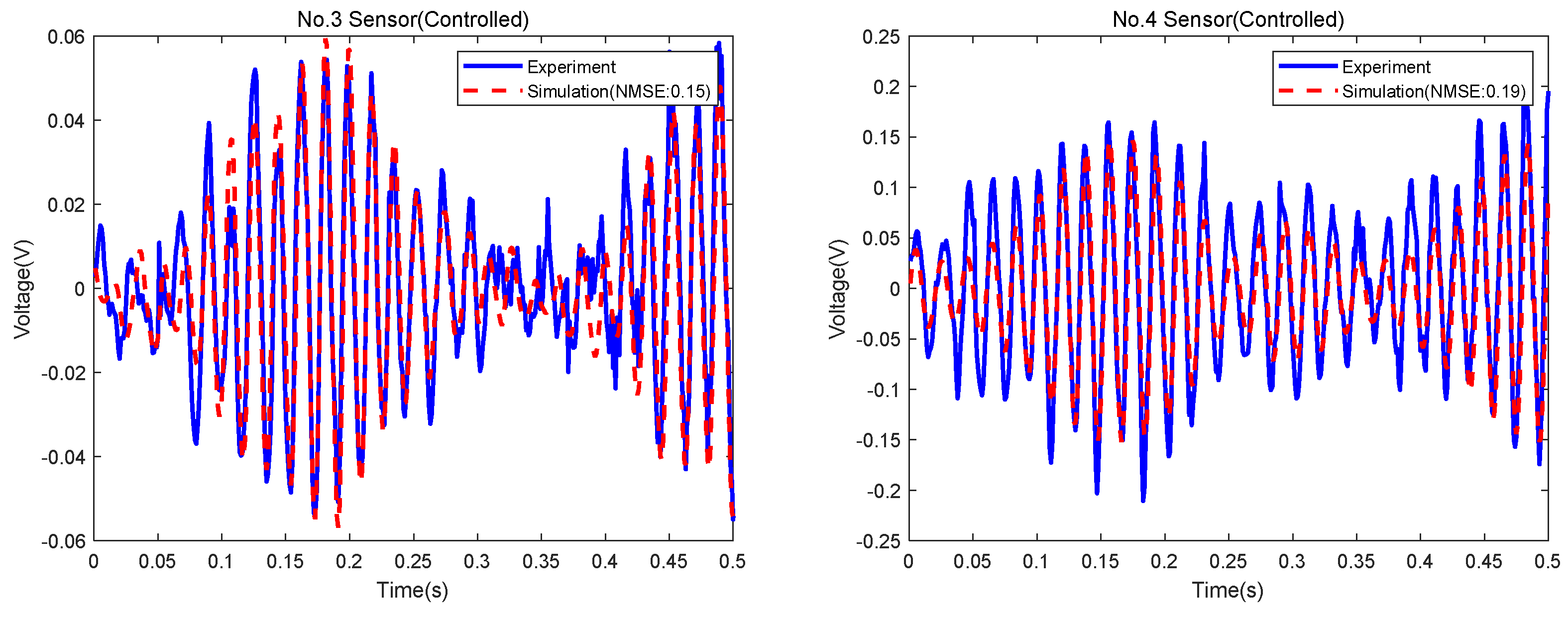
Figure 20 shows the sensor signals obtained by the simulation and experiment. The NMSEs between the experimental and simulation signals from the No. 1 to No. 4 sensors are 14%, 17%, 15% and 19%, respectively.
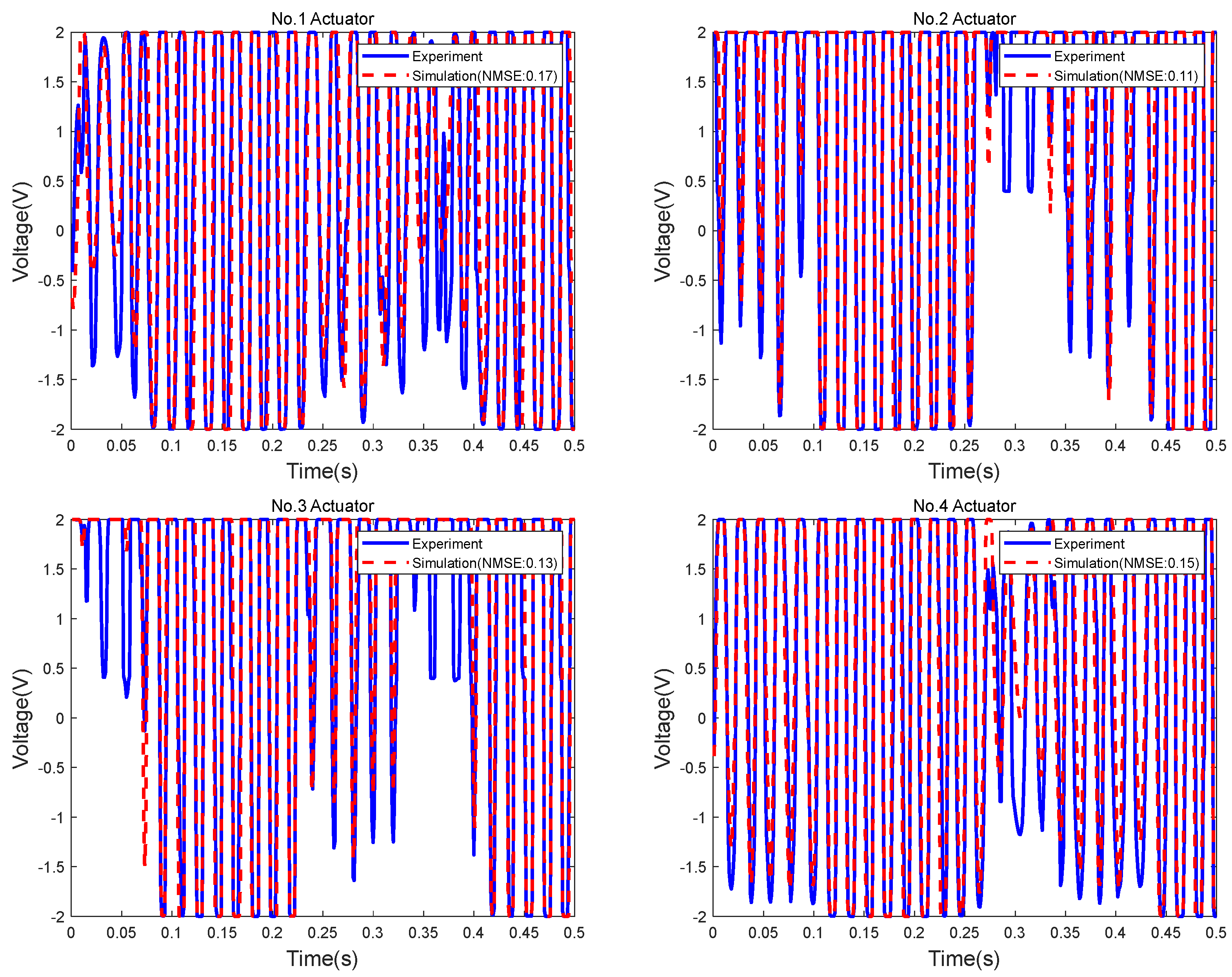
Figure 21 shows the actuator signals obtained by the simulation and experiment. The NMSEs between the experimental and simulation signals from the No. 1 to No. 4 actuators are 17%, 11%, 13% and 15%, respectively.
The errors mainly come from the errors between the real-world vibration system and the simulator, the time delay and signal interference of the electronic components, external disturbances, and so on. However, the errors can be accepted. On the one hand, the errors are smaller than 20%, which can be accepted in most engineering problems. On the other hand, the experiment results also show that the simulation model has enough physical fidelity, and the proposed method for designing the vibration controller is effective and useful.
5. Control-Performance Verification
In order to further verify the effectiveness of the simulator established with the FIR filter, we carried out experiments based on another simulator that was established with dynamics equations. We set up the dynamics equations in the simulation software and trained the proposed RL-based controller, which interacted with the dynamics equations to find the optimal control policy, which was then used in the experiments.
The vibration system shown in
Figure 22 is simplified as a spring–mass–damper system, which can be formulated by ordinary differential equations. The spring–mass–damper system has three degrees of freedom, including vertical motion along the Z-axis, rotation motion along the X-axis, and rotation motion along the Y-axis. The symbol
stands for the control force of the actuator, and
stands for the force of the rubber isolator. The symbol
F denotes the force of the exciter, and its location is determined by the coordinates
. The dynamics equations are obtained at the equilibrium position:
where
denotes the vertical displacement of the mass center;
denotes the rotation angle along the X-axis;
denotes the rotation angle along the Y-axis;
denotes the mass;
and
denote the inertias.
Next, the proposed RL-based controller that interacts with the dynamics equations was trained to find the optimal control policy. Then, the control policy was compiled into binary code and run on the controller hardware in the experiment. We performed the experiments by giving different signals to the vibration exciter. The controlled sensor signals were recorded when the controller was on, and the uncontrolled sensor signals were recorded when the controller was off.
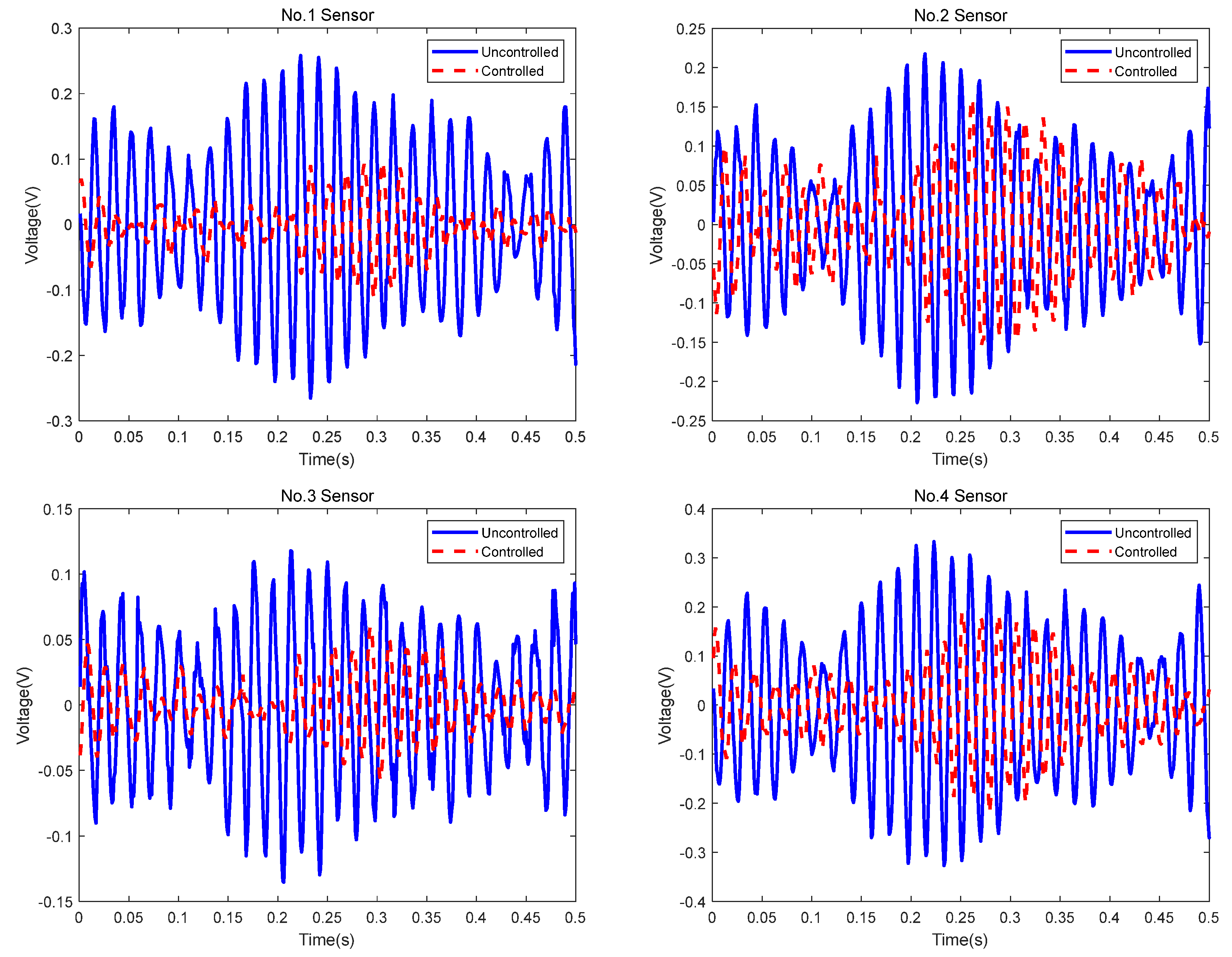
Figure 23 shows the sensor signals when a simple 55 Hz sine signal was given to the exciter. The sampling frequency was 1 kHz. The amount of the total sampled data was more than 30 s. For clarity, a small amount of data is shown.
Table 9 shows the RMS values of the uncontrolled and controlled sensor signals. It was found that the RMS values were increased by more than 53%. The vibration enhancement can also be seen from the PSD curves of the sensor signals, as shown in
Figure 24.
Table 10 shows the peak values of the PSD curves of the sensor signals. It can be seen that the peak values of the PSD curves at specific frequencies were increased by more than 140%.
It was found that the control policy obtained by using the dynamics equations led to the vibration enhancement. In comparison with the control policy obtained by using the FIR filter, which effectively reduces the vibration, the effectiveness of the FIR filter could be verified.
The main reason for the vibration enhancement may be that the dynamics equations can only be used to effectively solve vibration-control problems of low dimension and simple dynamics. The parameters of the dynamic model were carefully verified, such as the mass, stiffness, damping, size, and so on, but it is still much less accurate than the FIR filter. Thus, it is difficult for the RL-based controller to successfully learn an effective control policy from the dynamics equations. To solve this problem, we present an RL-based controller that interacts with the accurate parametric model (FIR filter) instead of dynamics equations. Therefore, the RL-based controller converges more easily, and the vibration can be effectively reduced.
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}