
Towards Zero-Shot Flow-Based Cyber-Security Anomaly Detection Framework




Abstract
:1. Introduction
- sketchy data structures are adapted for extracting generic and universal features and are compared with approaches described in the literature,
- the principles of domain adaptation are leveraged to improve classification quality in zero and few-shot scenarios,
- recently published and realistic datasets are used to compare the proposed approach under different scenarios with respect to anomaly detection.
2. Related Work
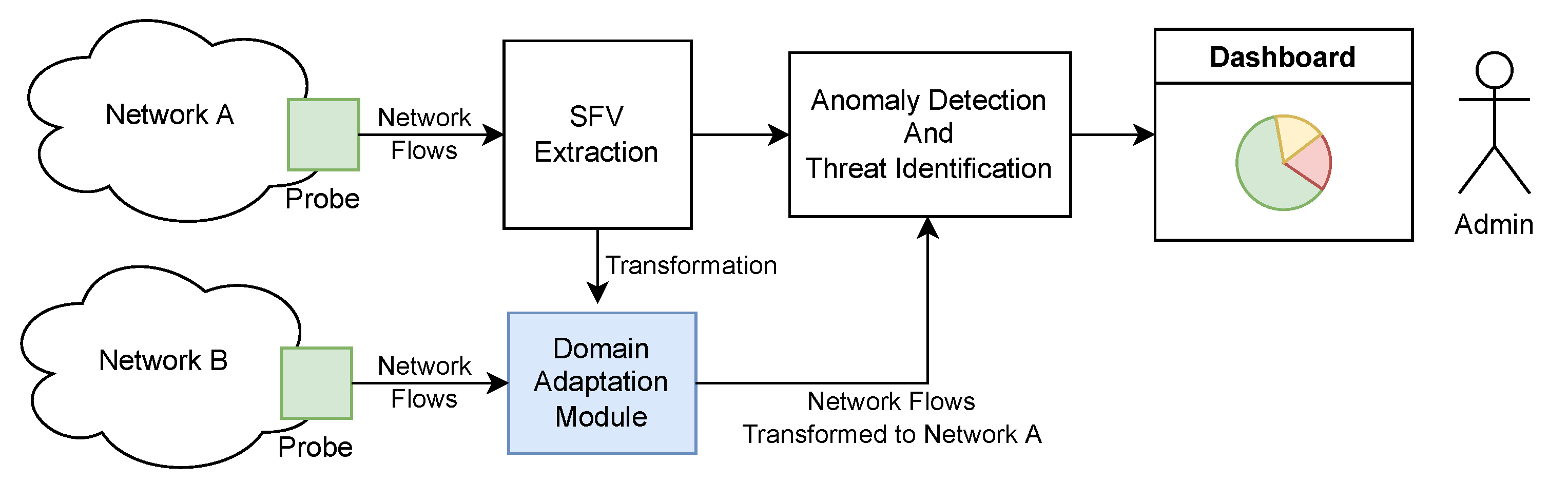
3. Proposed Method
- Network probe, which captures network traffic in the form of network flows,
- Sketchy feature vectors (SFV) extraction, which calculates feature vectors over a predefined time window,
- Anomaly detection and threat identification, which is responsible for detecting anomalies in the observed traffic and categorizing them as a known threat,
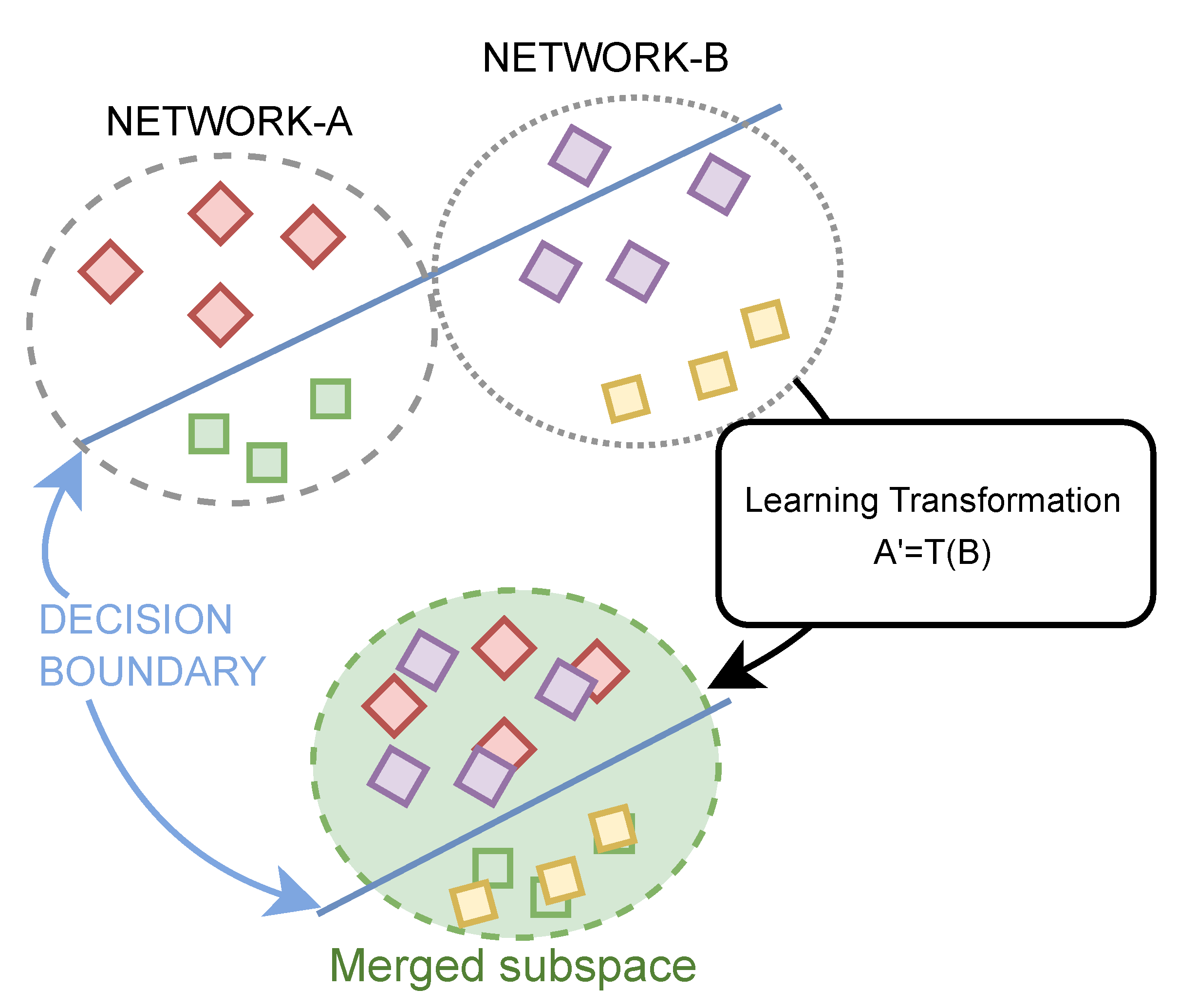
- Domain adaptation module, which is intended to bring the traffic coming from a different network onto a feature space where the anomaly detection and threat classification were trained,
- Dashboard, which is intended to visualize various traffic characteristics for the identified anomalies and threats.
3.1. Flow-Based Data Acquisition
- the number of incoming and outgoing bytes
- IP addresses partaking in the communication
- utilized source and destination ports
- utilized type of protocol (e.g., transmission control protocol (TCP) or user datagram protocol (UDP))
3.2. SFV—Sketchy Feature Vectors Extraction
3.3. Domain Adaptation
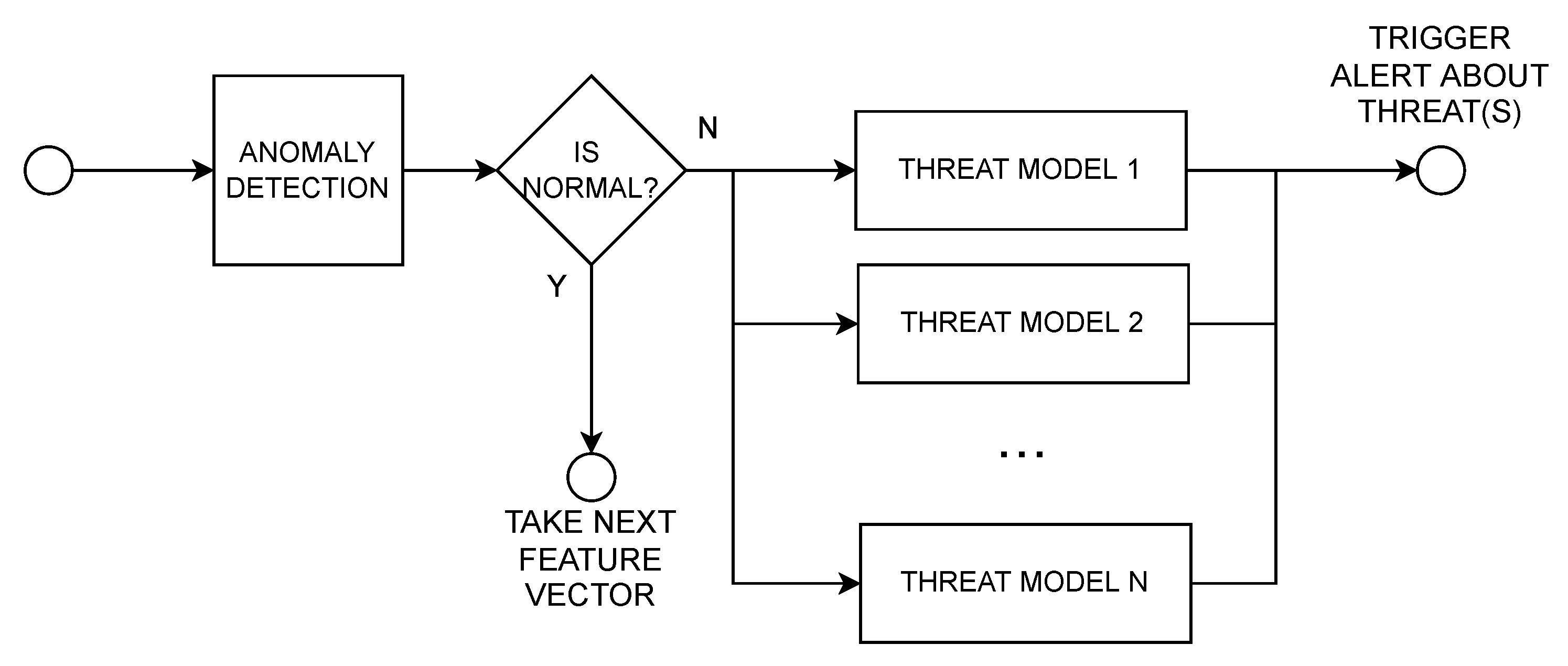
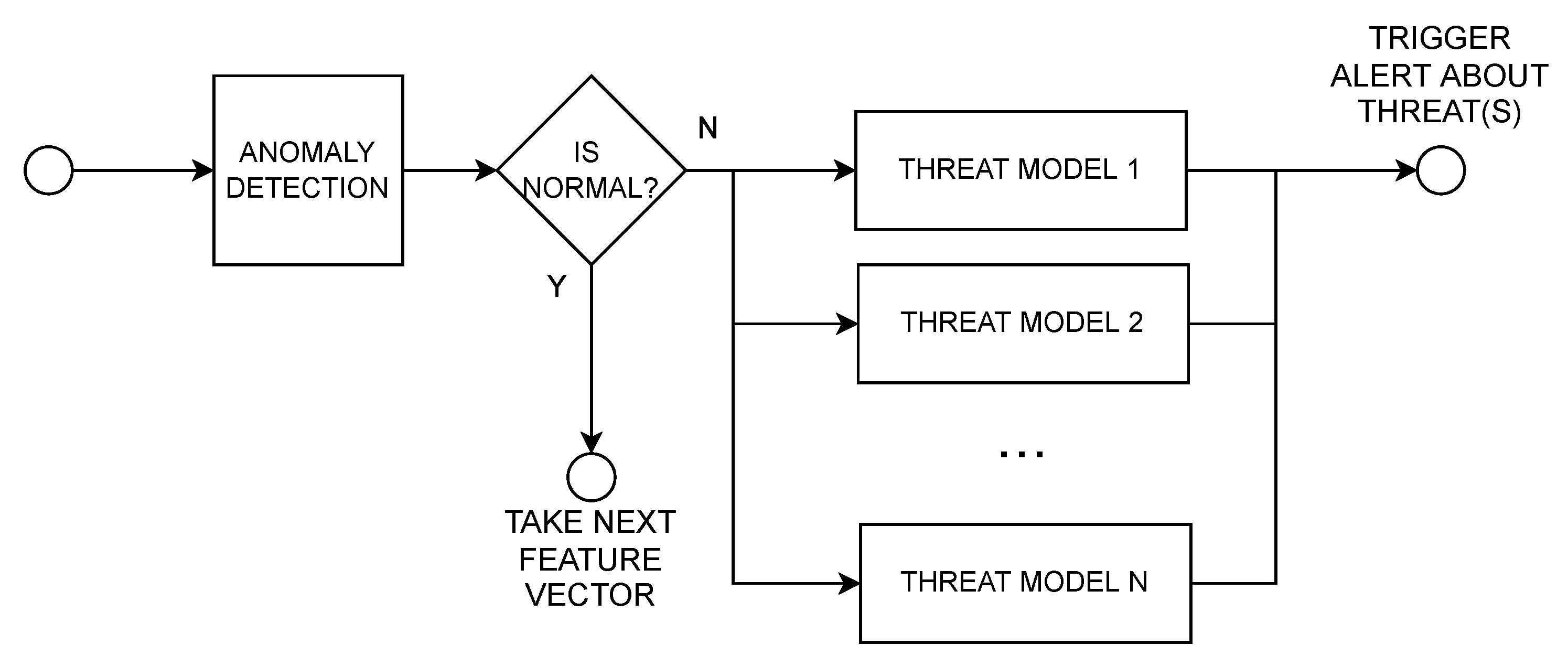
3.4. Anomaly Detection and Threat Identification
4. Experimental Setup
4.1. Experiments
4.2. Datasets Used for Evaluation
4.3. Metrics Used for Evaluation
- communication flows were aggregated into time windows (in this case, 3-min time windows were used).
- for the given time windows, sketchy feature vectors were calculated.
- within the ground-truth communication flows, labels were examined against those predicted; subsequently the TP, TN, FP and FN errors (true and false positives and negatives) were measured.
- lastly, recall, precision, and F1-score metrics were calculated and reported.
4.4. Evaluation Methodology
- First, the effectiveness of the proposed approach was evaluated separately on the IoT-23 and SIMARGL2021 datasets. A classical random split approach was used, where 70% of the data was used for training and the remaining 30% was used during testing. The recall, precision, and F1-score were measured for two cases, namely, anomaly detection and threat identification.
- Subsequently, the transferability capabilities of the proposed approach in a zero-shot manner were measured. The models were trained on the SIMARGL2021 dataset and evaluated on the IoT-23 dataset. The results for two cases were provided, namely, when the domain adaptation module was turned off and on. This enabled highlighting of the importance of domain adaptation for the proposed method.
- Finally, the transferability capabilities were tested using a varying number of samples drawn from the other domain. Specifically, the models were trained on the SIMARGL2021 dataset with N additional samples from IoT-23, and evaluated using the models for the remaining part of the IoT-23 dataset.
5. Results
5.1. Effectiveness Comparison
5.2. Zero-Shot Scenario
5.3. Few-Shot Scenario
5.4. Comparison of Results with Other Methods
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jung, I.; Lim, J.; Kim, H.K. PF-TL: Payload Feature-Based Transfer Learning for Dealing with the Lack of Training Data. Electronics 2021, 10, 1148. [Google Scholar] [CrossRef]
- Zhao, J.; Shetty, S.; Pan, J.W.; Kamhoua, C.; Kwiat, K. Transfer learning for detecting unknown network attacks. Eurasip J. Inf. Secur. 2019, 2019, 1. [Google Scholar] [CrossRef]
- Cremer, F.; Sheehan, B.; Fortmann, M.; Kia, A.N.; Mullins, M.; Murphy, F.; Materne, S. Cyber risk and cybersecurity: A systematic review of data availability. Geneva Pap. Risk Insur.-Issues Pract. 2022, 47, 698–736. [Google Scholar] [CrossRef] [PubMed]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, H.; Liu, P. Tackling Imbalanced Data in Cybersecurity with Transfer Learning: A Case with ROP Payload Detection. arXiv 2021, arXiv:2105.02996. [Google Scholar] [CrossRef]
- Kim, J.; Sim, A.; Kim, J.; Wu, K.; Hahm, J. Improving Botnet Detection with Recurrent Neural Network and Transfer Learning. arXiv 2021, arXiv:2104.12602. [Google Scholar]
- Masum, M.; Shahriar, H. Tl-nid: Deep neural network with transfer learning for network intrusion detection. In Proceedings of the 2020 15th International Conference for Internet Technology and Secured Transactions (ICITST), London, UK, 8–10 December 2020; pp. 1–7. [Google Scholar]
- Xu, M.; Li, X.; Wang, Y.; Luo, B.; Guo, J. Privacy-preserving multisource transfer learning in intrusion detection system. Trans. Emerg. Telecommun. Technol. 2021, 32, e3957. [Google Scholar] [CrossRef]
- Taghiyarrenani, Z.; Fanian, A.; Mahdavi, E.; Mirzaei, A.; Farsi, H. Transfer learning based intrusion detection. In Proceedings of the 2018 8th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 25–26 October 2018; pp. 92–97. [Google Scholar]
- Wang, C.; Mahadevan, S. Heterogeneous domain adaptation using manifold alignment. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Long, M.; Wang, J.; Ding, G.; Pan, S.J.; Philip, S.Y. Adaptation regularization: A general framework for transfer learning. IEEE Trans. Knowl. Data Eng. 2013, 26, 1076–1089. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Qiu, S.; Zhou, S.; Zhang, C. Unknown attack detection based on zero-shot learning. IEEE Access 2020, 8, 193981–193991. [Google Scholar] [CrossRef]
- Qureshi, A.S.; Khan, A.; Shamim, N.; Durad, M.H. Intrusion detection using deep sparse auto-encoder and self-taught learning. Neural Comput. Appl. 2020, 32, 3135–3147. [Google Scholar] [CrossRef]
- Pawlicki, M.; Kozik, R.; Choraś, M. A survey on neural networks for (cyber-) security and (cyber-) security of neural networks. Neurocomputing 2022, 500, 1075–1087. [Google Scholar] [CrossRef]
- Zerhoudi, S.; Granitzer, M.; Garchery, M. Improving intrusion detection systems using zero-shot recognition via graph embeddings. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 790–797. [Google Scholar]
- Ge, M.; Syed, N.F.; Fu, X.; Baig, Z.; Robles-Kelly, A. Towards a deep learning-driven intrusion detection approach for Internet of Things. Comput. Netw. 2021, 186, 107784. [Google Scholar] [CrossRef]
- Kumar, S. MCFT-CNN: Malware classification with fine-tune convolution neural networks using traditional and transfer learning in internet of things. Future Gener. Comput. Syst. 2021, 125, 334–351. [Google Scholar]
- Mehedi, S.T.; Anwar, A.; Rahman, Z.; Ahmed, K.; Rafiqul, I. Dependable Intrusion Detection System for IoT: A Deep Transfer Learning-based Approach. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Singla, A.; Bertino, E.; Verma, D. Preparing network intrusion detection deep learning models with minimal data using adversarial domain adaptation. In Proceedings of the 15th ACM Asia Conference on Computer and Communications Security, Taipei, Taiwan, 1–5 June 2020; pp. 127–140. [Google Scholar]
- Aburakhia, S.; Tayeh, T.; Myers, R.; Shami, A. A transfer learning framework for anomaly detection using model of normality. In Proceedings of the 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 4–7 November 2020; pp. 0055–0061. [Google Scholar]
- Zhang, X.; Gao, L.; Jiang, Y.; Yang, X.; Zheng, J.; Wang, H. A zero-shot intrusion detection method based on regression model. In Proceedings of the 2019 Seventh International Conference on Advanced Cloud and Big Data (CBD), Suzhou, China, 21–22 September 2019; pp. 186–191. [Google Scholar]
- Agarwal, N.; Sondhi, A.; Chopra, K.; Singh, G. Transfer learning: Survey and classification. In Smart Innovations in Communication and Computational Sciences; Springer: Singapore, 2021; pp. 145–155. [Google Scholar]
- Si, T.; He, F.; Zhang, Z.; Duan, Y. Hybrid Contrastive Learning for Unsupervised Person Re-identification. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Stoian, N. Machine Learning for Anomaly Detection in IoT Networks: Malware Analysis on the IoT-23 Data Set. Bachelor’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Choraś, M.; Pawlicki, M. Intrusion detection approach based on optimised artificial neural network. Neurocomputing 2021, 452, 705–715. [Google Scholar] [CrossRef]
- Kozik, R.; Pawlicki, M.; Choraś, M. A new method of hybrid time window embedding with transformer-based traffic data classification in IoT-networked environment. Pattern Anal. Appl. 2021, 24, 1441–1449. [Google Scholar] [CrossRef]
- Singh, A.; Garg, S.; Kaur, R.; Batra, S.; Kumar, N.; Zomaya, A.Y. Probabilistic data structures for big data analytics: A comprehensive review. Knowl.-Based Syst. 2020, 188, 104987. [Google Scholar] [CrossRef]
- Garcia, S.; Parmisano, A.; Erquiaga, M.J. IoT-23: A Labeled Dataset with Malicious and Benign IoT Network Traffic. 2020. Available online: https://www.stratosphereips.org/datasets-iot23 (accessed on 22 September 2022). [CrossRef]
- Mihailescu, M.E.; Mihai, D.; Carabas, M.; Komisarek, M.; Pawlicki, M.; Hołubowicz, W.; Kozik, R. The Proposition and Evaluation of the RoEduNet-SIMARGL2021 Network Intrusion Detection Dataset. Sensors 2021, 21, 4319. [Google Scholar] [CrossRef]
- Wardhani, N.W.S.; Rochayani, M.Y.; Iriany, A.; Sulistyono, A.D.; Lestantyo, P. Cross-validation Metrics for Evaluating Classification Performance on Imbalanced Data. In Proceedings of the 2019 International Conference on Computer, Control, Informatics and its Applications (IC3INA), Tangerang, Indonesia, 23–24 October 2019; pp. 14–18. [Google Scholar] [CrossRef]
- Abdalgawad, N.; Sajun, A.R.; Kaddoura, Y.; Zualkernan, I.; Aloul, F. Generative Deep Learning to Detect Cyberattacks for the IoT-23 Dataset. IEEE Access 2021, 10, 6430–6441. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Class | Recall | Precision | F1-Score |
|---|---|---|---|
| Benign | 0.9980 | 0.9968 | 0.9974 |
| Anomaly | 0.9974 | 0.9984 | 0.9979 |
| CNC | 1.0000 | 0.9957 | 0.9978 |
| DDOS | 1.0000 | 0.8814 | 0.9369 |
| Okiru | 1.0000 | 0.9990 | 0.9995 |
| Torii | 1.0000 | 1.0000 | 1.0000 |
| PortScan | 0.9972 | 0.9954 | 0.9963 |
| Class | Recall | Precision | F1-Score |
|---|---|---|---|
| Benign | 1.0000 | 0.9999 | 1.0000 |
| Anomaly | 0.9716 | 0.9884 | 0.9799 |
| RUDY | 0.9941 | 0.9883 | 0.9912 |
| Slowloris | 0.9947 | 1.0000 | 0.9973 |
| FIN Scan | 0.9710 | 1.0000 | 0.9853 |
| NULL Scan | 0.9761 | 1.0000 | 0.9879 |
| UDP Scan | 0.9907 | 1.0000 | 0.9953 |
| XMAS Scan | 0.9552 | 1.0000 | 0.9771 |
| Scenario | Class | Recall | Precision | F1-Score |
|---|---|---|---|---|
| Without Domain Adaption | Benign | 0.69481 | 0.6295 | 0.66055 |
| Anomaly | 0.66133 | 0.7235 | 0.69102 | |
| With Domain Adaption | Benign | 0.6823 | 0.8450 | 0.7550 |
| Anomaly | 0.7965 | 0.6065 | 0.6886 |
| Samples | Class | Recall | Precision | F1-Score |
|---|---|---|---|---|
| 100 | Benign | 0.9122 | 0.9500 | 0.9307 |
| Anomaly | 0.9478 | 0.9085 | 0.9278 | |
| 500 | Benign | 0.9497 | 0.9730 | 0.9612 |
| Anomaly | 0.9723 | 0.9485 | 0.9603 | |
| 1000 | Benign | 0.9875 | 0.9880 | 0.9878 |
| Anomaly | 0.9880 | 0.9875 | 0.9878 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Komisarek, M.; Kozik, R.; Pawlicki, M.; Choraś, M. Towards Zero-Shot Flow-Based Cyber-Security Anomaly Detection Framework. Appl. Sci. 2022, 12, 9636. https://doi.org/10.3390/app12199636
Komisarek M, Kozik R, Pawlicki M, Choraś M. Towards Zero-Shot Flow-Based Cyber-Security Anomaly Detection Framework. Applied Sciences. 2022; 12(19):9636. https://doi.org/10.3390/app12199636
Chicago/Turabian StyleKomisarek, Mikołaj, Rafał Kozik, Marek Pawlicki, and Michał Choraś. 2022. "Towards Zero-Shot Flow-Based Cyber-Security Anomaly Detection Framework" Applied Sciences 12, no. 19: 9636. https://doi.org/10.3390/app12199636
APA StyleKomisarek, M., Kozik, R., Pawlicki, M., & Choraś, M. (2022). Towards Zero-Shot Flow-Based Cyber-Security Anomaly Detection Framework. Applied Sciences, 12(19), 9636. https://doi.org/10.3390/app12199636