

Ring-Overlap: A Storage Scaling Mechanism for Hyperledger Fabric


Abstract
:1. Introduction
- The mechanism is to realize the storage scaling of the blockchain without increasing too much extra communication overhead;
- It tolerates the failure of some nodes without causing the loss of ledger data, which ensures the reliability of the system;
- It is compatible with the write and query mechanisms of Hyperledger Fabric, and only needs to add tiny extra maintenance mechanism.
2. Background and Related Work
2.1. Shard-Based Blockchain Protocols
2.1.1. Bitcoin-NG
2.1.2. Elastico
2.1.3. OmniLedger
2.1.4. RapidChain
2.2. Related Work
- Cannot increase too much extra communication overhead;
- Tolerates the failure of some nodes without causing the loss of ledger data;
- Only needs to add tiny extra maintenance mechanism.
3. Problem Description
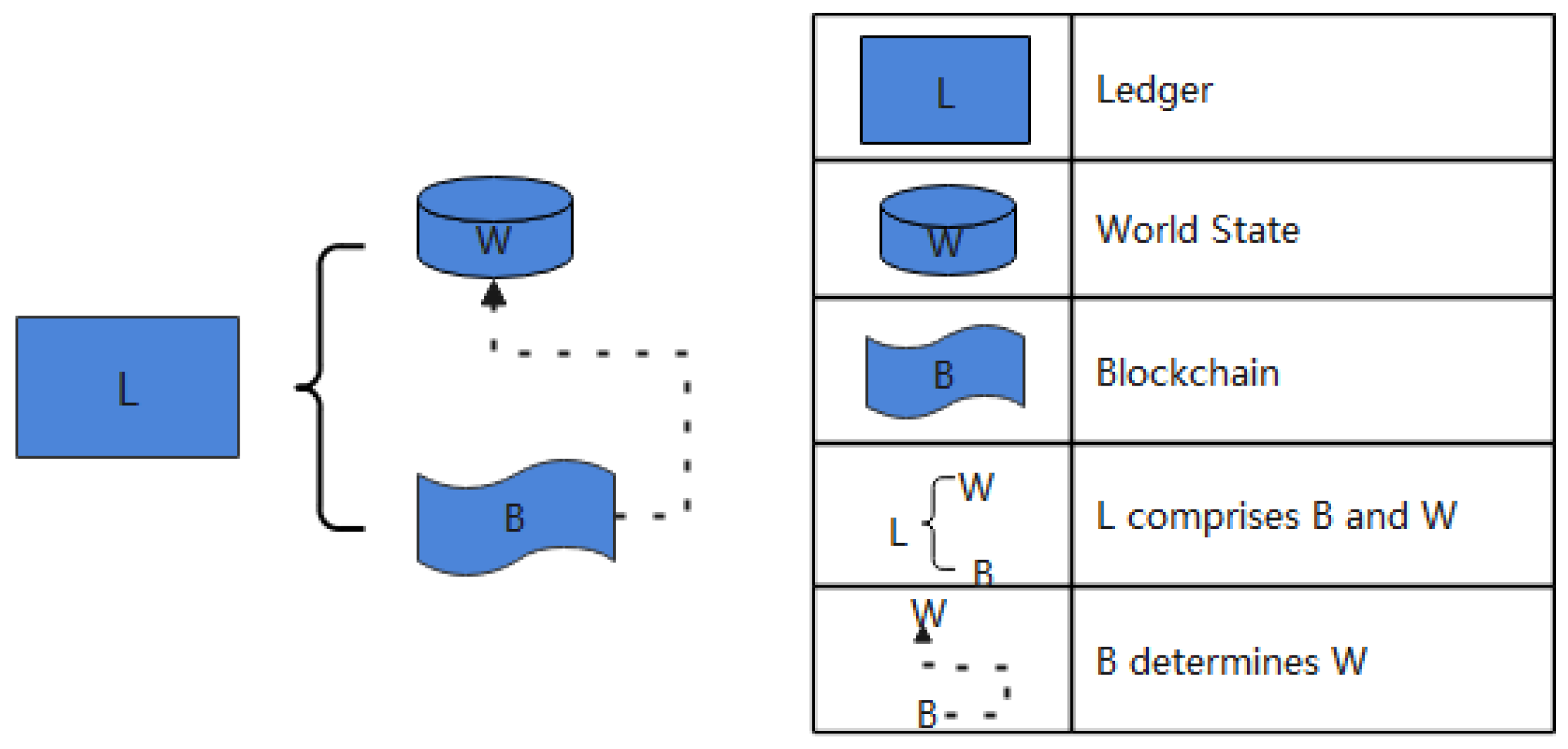
3.1. Double-Shard Model
3.2. Ring-Overlap Storage Model
4. Scheme Design
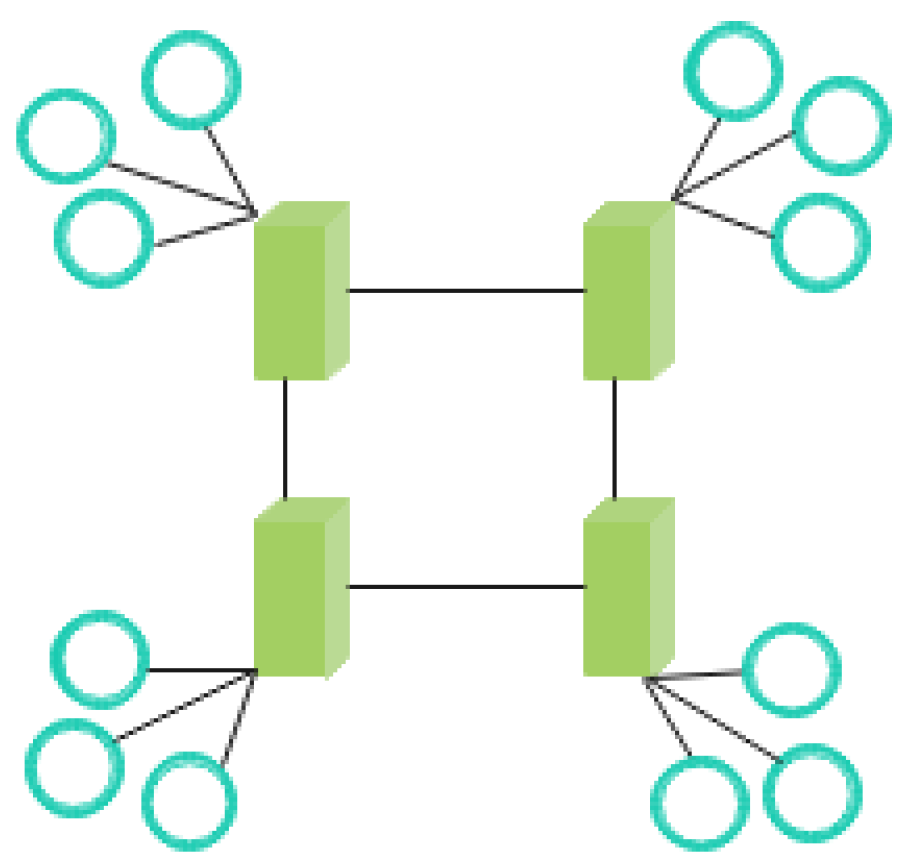
4.1. Cluster Division
4.2. Intra-Cluster Data Storage
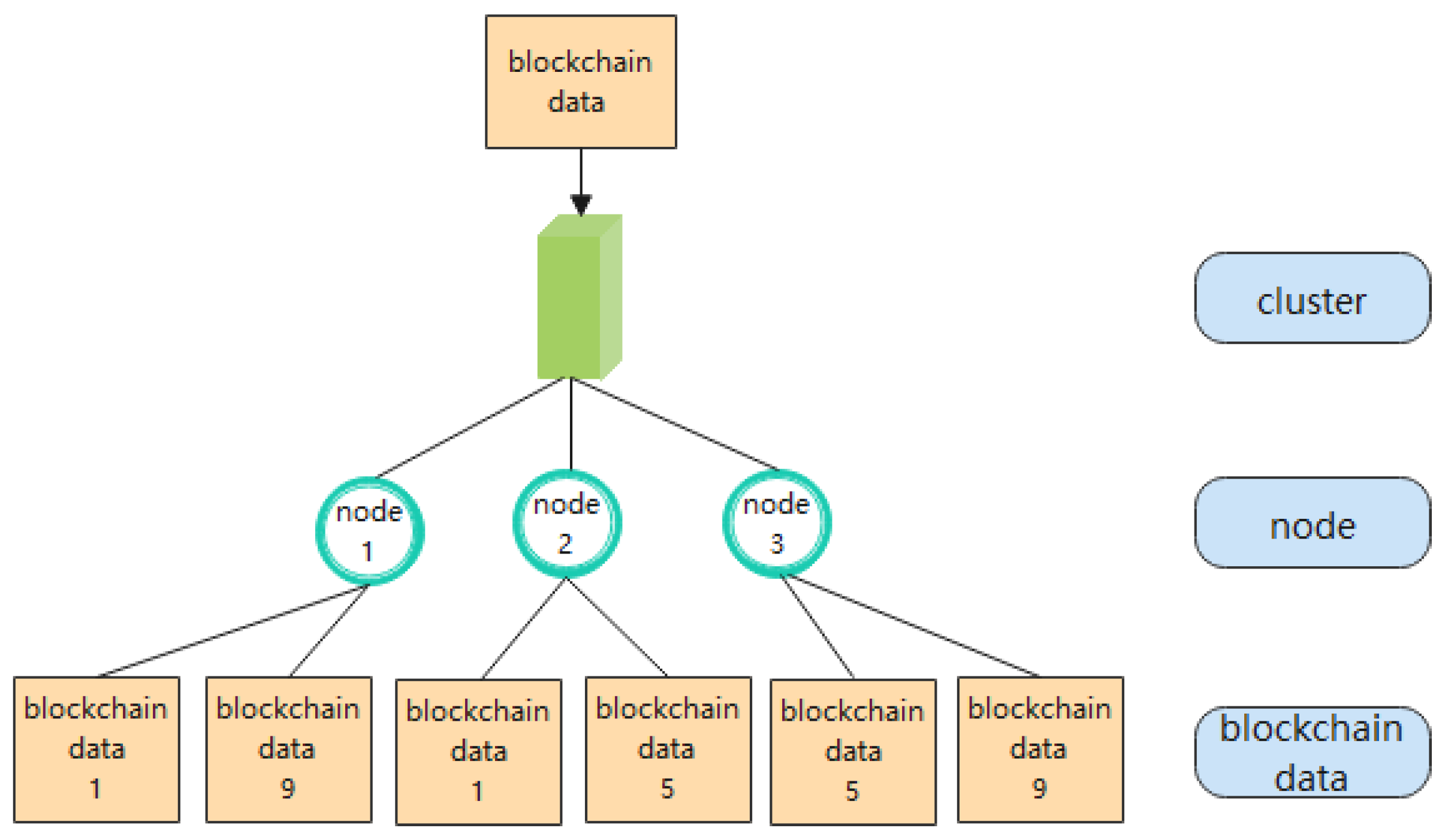
4.3. Storage and Query Mechanism
4.3.1. Storage Process
- The first generated block ID is 1, we can obtain 1⊘4= 1 according to the storage cluster location formula to determine that the block should be stored in cluster 1, then we get l = [(1 − 1)÷4] + 1 = 1 according to the storage node location formula in a single cluster, then l⊘3= 1 and (l + 1)⊘3= 2 to determine that the block should be stored in nodes 1 and 2.
- The next generated block IDs are 2, 3, 4, then according to the storage cluster location formula yields 2⊘4= 2, 3⊘4= 3, 4⊘4= 4, it can be determined that the block should be stored in clusters 2, 3, 4, node storage process is the same as step (1).
- When the generated block ID is 5, so we get 5⊘4 = 1, and it is determined that the block should be stored in cluster 1, with the result that l = [(5 − 1)4] + 1 = 2, then l⊘3= 2, (l + 1)⊘3= 3, it is determined that the block should be stored in nodes 2 and 3.
4.3.2. Query Process
5. Scheme Analysis
5.1. Storage Efficiency Analysis
5.2. Security Analysis
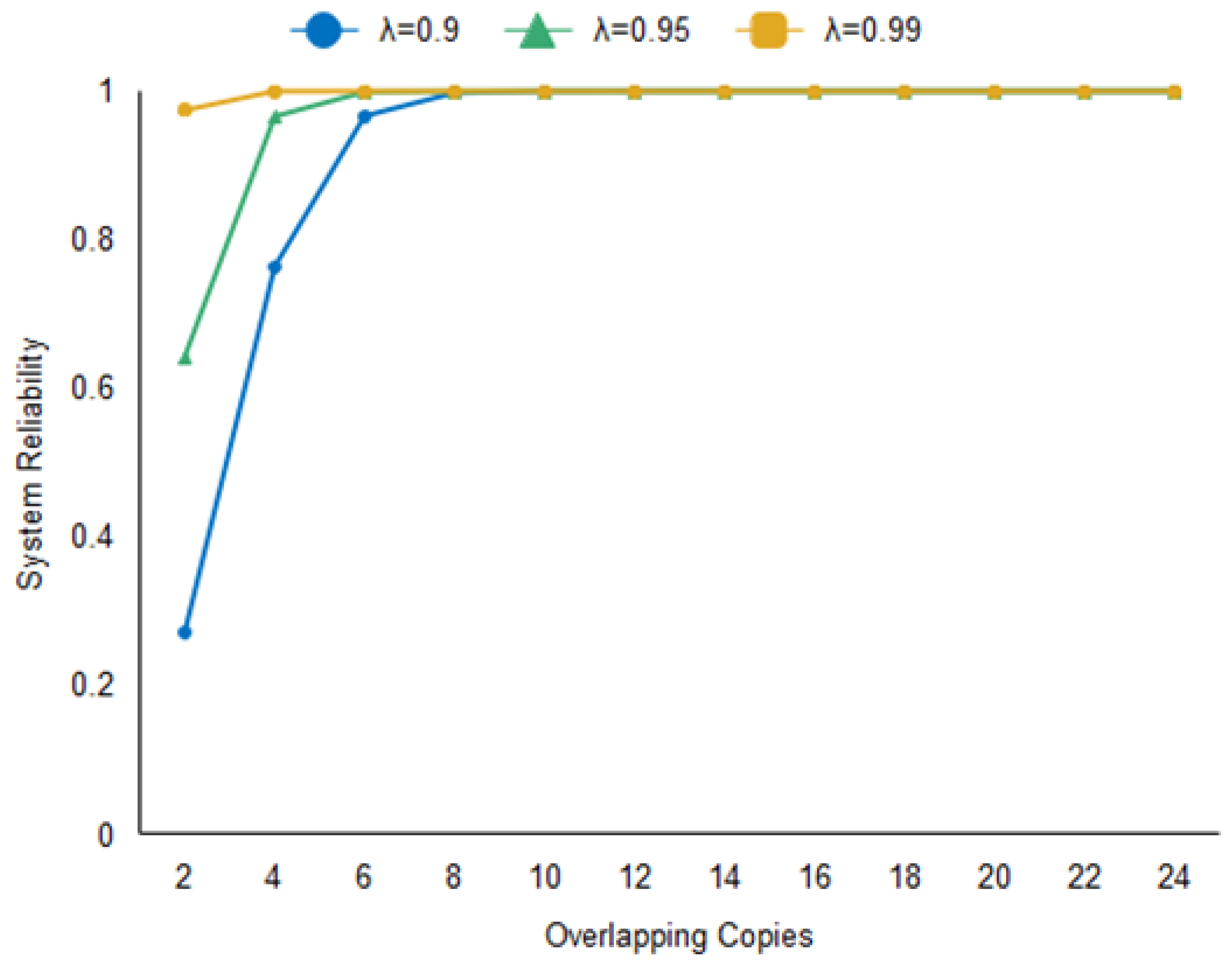
5.2.1. System Reliability
5.2.2. Gossiping Guarantees
5.2.3. Epoch Security
6. Simulation Experiment
6.1. Experimental Setup
6.2. Experimental Design
6.2.1. Experiment 1: Storage Consumed on a Single Node
6.2.2. Experiment 2: Query Efficiency
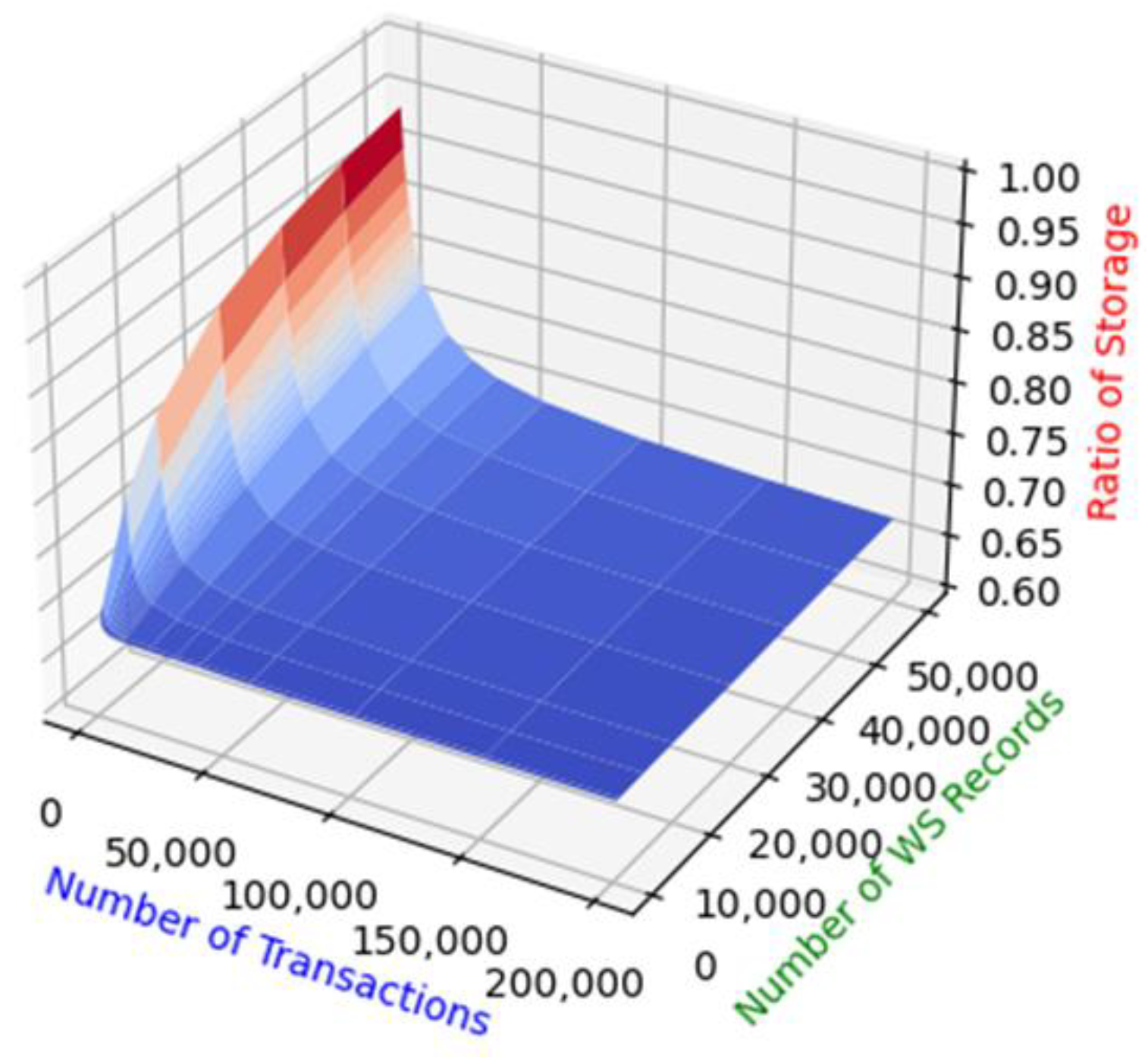
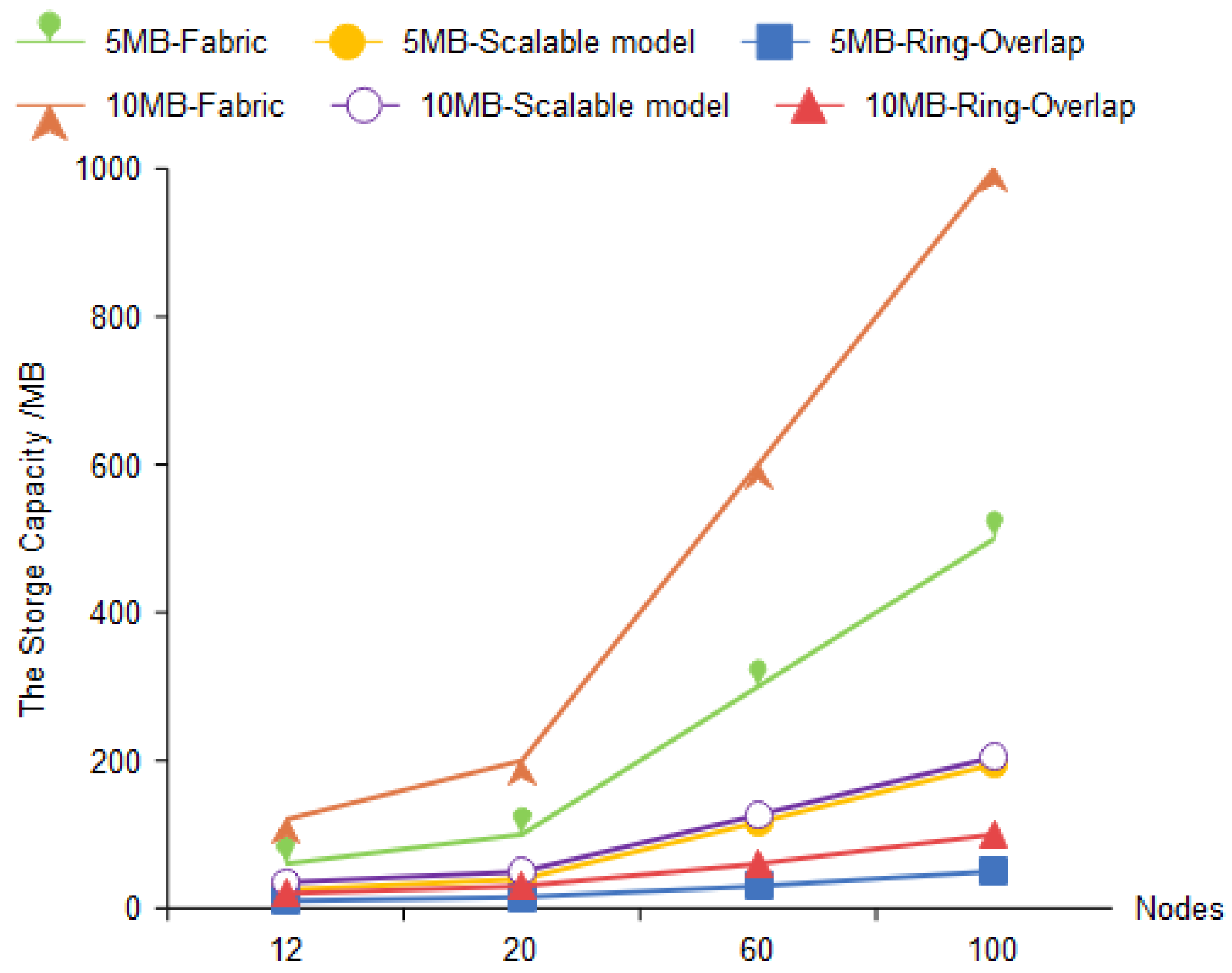
6.2.3. Experiment 3: Storage Cost
6.3. Experimental Result
6.3.1. Experiment 1
6.3.2. Experiment 2
6.3.3. Experiment 3
6.4. Analysis of Experimental Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 22 March 2021).
- Decker, C.; Seidel, J.; Wattenhofer, R. Bitcoin meets strong consistency. In Proceedings of the 17th International Conference on Distributed Computing and Networking (ICDCN ‘16), Singapore, 4–7 January 2016; pp. 1–10. [Google Scholar]
- Gilad, Y.; Hemo, R.; Micali, S.; Vlachos, G.; Zeldovich, N. Algorand: Scaling Byzantine Agreements for Cryptocurrencies. In Proceedings of the 26th Symposium on Operating Systems Principles (SOSP ‘17), Shanghai, China, 28 October 2017; pp. 51–68. [Google Scholar]
- Yu, G.; Wang, X.; Yu, K.; Ni, W.; Zhang, J.A.; Liu, R.P. Survey: Sharding in Blockchains. IEEE Access 2020, 8, 14155–14181. [Google Scholar] [CrossRef]
- Zhang, P.; Zhou, M.; Zhen, J.; Zhang, J. Enhancing Scalability of Trusted Blockchains through Optimal Sharding. In Proceedings of the 2021 IEEE International Conference on Smart Data Services (SMDS), Chicago, IL, USA, 5–10 September 2021; pp. 226–233. [Google Scholar]
- Wang, G. RepShard: Reputation-based Sharding Scheme Achieves Linearly Scaling Efficiency and Security Simultaneously. In Proceedings of the 2020 IEEE International Conference on Blockchain (Blockchain), Rhodes, Greece, 11 December 2020; pp. 237–246. [Google Scholar]
- Underwood, S. Blockchain beyond Bitcoin. Commun. ACM 2016, 59, 15–17. [Google Scholar] [CrossRef]
- Li, C.L.; Zhang, J.; Yang, X.M. Scalable blockchain storage mechanism based on two-layer structure and improved distributed consensus. Supercomput 2022, 78, 4850–4881. [Google Scholar] [CrossRef]
- Liu, W.X.; Zhang, D.H.; Zhao, J.D. Ring-Overlap: A Storage Scaling Mechanism for Consortium Blockchain. In Proceedings of the 2022 International Conference on Service Science (ICSS), Zhuhai, China, 13–15 May 2022; pp. 33–40. [Google Scholar] [CrossRef]
- Min, X.P.; Li, Q.Z.; Kong, L.J.; Zhang, S.D.; Zheng, Y.Q.; Xiao, Z. Permissioned Blockchain Dynamic Consensus Mechanism Based Multi-centers. Chin. J. Comput. 2018, 41, 1005–1020. [Google Scholar]
- Eyal, I.; Gencer, A.E.; Sirer, E.G.; Renesse, R.V. Bitcoin-NG: A Scalable Blockchain Protocol. In Proceedings of the 13th Usenix Conference on Networked Systems Design and Implementation (NSDI’ 16), Santa Clara, CA, USA, 16–18 March 2016; pp. 45–59. [Google Scholar]
- Luu, L.; Narayanan, V.; Zheng, C.D.; Baweja, K.; Gilbert, S.; Saxena, P. A Secure Sharding Protocol for Open Blockchains. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS ‘16), Vienna, Austria, 24–28 October 2016; pp. 17–30. [Google Scholar] [CrossRef]
- Kokoris-Kogias, E.; Jovanovic, P.; Gasser, L.; Gailly, N.; Syta, E.; Ford, B. OmniLedger: A Secure, Scale-Out, Decentralized Ledger via Sharding. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 583–598. [Google Scholar]
- Zamani, M.; Movahedi, M.; Raykova, M. RapidChain: Scaling Blockchain via Full Sharding. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS ‘18), Toronto, ON, Canada, 15–19 October 2018; pp. 931–948. [Google Scholar] [CrossRef]
- Wang, J.P.; Wang, H. Monoxide: Scale out blockchain with asynchronous consensus zones. In Proceedings of the 16th USENIX Conference on Networked Systems Design and Implementation (NSDI’19), Boston, MA, USA, 26–28 February 2019; pp. 95–112. [Google Scholar]
- Danezis, G.; Meiklejohn, S. Centrally Banked Cryptocurrencies. In Proceedings of the 23rd Annual Network & Distributed System Security Symposium (NDSS), San Diego, CA, USA, 21–24 February 2016; pp. 1–14. [Google Scholar]
- Gencer, A.E.; van Renesse, R.; Sirer, E.G. Short paper: Service-oriented sharding for blockchains. In Proceedings of the International Conference on Financial Cryptography and Data Security, Sliema, Malta, 3–7 April 2017; pp. 393–401. [Google Scholar] [CrossRef]
- Nguyen, L.N.; Nguyen, T.D.T.; Dinh, T.N.; Thai, M.T. OptChain: Optimal Transactions Placement for Scalable Blockchain Sharding. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 525–535. [Google Scholar] [CrossRef]
- Niu, J.Y.; Wang, Z.Y.; Gai, F.Y.; Feng, C. Incentive Analysis of Bitcoin-NG, Revisited. ACM SIGMETRICS Perform. Eval. Rev. 2020, 48, 59–60. [Google Scholar] [CrossRef]
- Mao, Z.L.; Liu, Y.N.; Sun, H.P.; Chen, Z. Research on Blockchain Performance Scalability and Security. Netinfo Secur. 2020, 20, 56–64. [Google Scholar]
- Micali, S.; Rabin, M.; Vadhan, S. Verifiable Random Functions. In Proceedings of the 40th Annual Symposium on Foundations of Computer Science (Cat. No.99CB37039), New York, NY, USA, 17–19 October 1999; pp. 120–130. [Google Scholar] [CrossRef]
- Wang, H.; Wang, L.C.; Bai, X.; Liu, Q.H.; Shen, X.Y. Research on Key Technology of Blockchain Privacy Protection and Scalability. J. Xidian Univ. 2020, 47, 28–39. [Google Scholar]
- Zhang, X.H.; Niu, B.N.; Gong, T. Account-based Blockchain Scalable Storage Model. J. Beijing Univ. Aeronaut. Astronaut. 2022, 48, 708–715. [Google Scholar]
- Zheng, P.; Xu, Q.; Zheng, Z.; Zhou, Z.; Yan, Y.; Zhang, H. Meepo: Sharded Consortium Blockchain. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 1847–1852. [Google Scholar] [CrossRef]
- Kim, T.; Lee, S.; Kwon, Y.; Noh, J.; Kim, S.; Cho, S. SELCOM: Selective Compression Scheme for Lightweight Nodes in Blockchain System. IEEE Access 2020, 8, 225613–225626. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, H.P.; Song, X.; Chen, Z. OverlapShard: Overlap-based Sharding Mechanism. In Proceedings of the 2021 IEEE Symposium on Computers and Communications (ISCC), Athens, Greece, 05–08 September 2021; pp. 1–7. [Google Scholar]
- Li, M.; Qin, Y.; Liu, B.; Chu, X. A Multi-node Collaborative Storage Strategy via Clustering in Blockchain Network. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 1275–1280. [Google Scholar]
- Jia, D.Y.; Xin, J.C.; Wang, Z.Q.; Guo, W.; Wang, G.R. Storage Capacity Scalable Model for Blockchain. J. Front. Comput. Sci. Technol. 2018, 12, 525–535. [Google Scholar]
- EI Azzaoui, A.; Choi, M.Y.; Lee, C.H.; Park, J.H. Scalable Lightweight Blockchain-Based Authentication Mechanism for Secure VoIP Communication. Hum.-Cent. Comput. Inf. Sci. 2022, 12, 8. [Google Scholar] [CrossRef]
- Fan, X.; Niu, B.N.; Liu, Z.L. Scalable blockchain storage systems: Research progress and models. Computing 2022, 104, 1497–1524. [Google Scholar] [CrossRef]
- Ren, L.; Ward, P.A.S. Understanding the Transaction Placement Problem in Blockchain Sharding Protocols. In Proceedings of the 2021 IEEE 12th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 27–30 October 2021; pp. 0695–0701. [Google Scholar]
- Fajri, A.I.; Mahananto, F. Hybrid lightning protocol: An approach for blockchain scalability issue. Procedia Comput. Sci. 2022, 197, 437–444. [Google Scholar] [CrossRef]
- Yang, C.L.; Li, X.X.; Li, J.J.; Qian, H.F. Linear Scalability from Sharding and PoS. In Proceedings of the Algorithms and Architectures for Parallel Processing, New York, NY, USA, 2–4 October 2020; pp. 548–562. [Google Scholar]
- Li, M.Y.; Qin, Y.; Liu, B.; Chu, X.W. Enhancing the efficiency and scalability of blockchain through probabilistic verification and clustering. Inf. Processing Manag. 2021, 58, 102650. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Storage Scalable Schemes | Proposer | Main Content |
|---|---|---|
| SSMAB | Zhang et al. [23] | Store stated data in a fully redundant manner to ensure transaction verification; store block data in a sharded manner to reduce redundancy; and implement an economic incentive mechanism to reduce storage consumption while ensuring data availability. |
| Meepo | Zheng et al. [24] | Cross-nesting and cross-call are used to improve the efficiency across shards; a partial cross-call merging strategy is used to handle multi-state dependencies in contract calls and achieve flexibility across shards; a backup algorithm called shadow shard-based recovery is also used to improve the robustness of shards. |
| SELCOM | Kim et al. [25] | To avoid the accumulation of compression results, a selective compression scheme based on checkpoint chains is proposed. An update process is also proposed to prevent the accumulation of checkpoints by merging them. |
| OverlapShard | Liu et al. [26] | By mapping each node to multiple actual shards, the adverse effects of cross-shard transactions are mitigated. To handle cross-shard transactions, virtual slices made up of overlapping nodes can be used. |
| ICIStrategy | Li et al. [27] | Divide all participants into clusters. Each cluster needs to store all of the network’s data, and the nodes in the cluster are not required to maintain data integrity. Storage pressure is alleviated by reducing the amount of data that each participant needs to store, and communication overhead is reduced through collaborative storage and block verification by cluster nodes. |
| ElasticChain | Jia et al. [28] | Which fragments a blockchain replica and stores the fragments in a part of nodes. Validation nodes are added to perform real-time testing of nodes storing data based on data retrievability proof methods, record updated storage node stability values, and then select high-stability nodes to store newly generated data copies. |
| Hops | Frequency |
|---|---|
| 1 | 150 |
| 2 | 52 |
| 3 | 260 |
| 4 | 346 |
| 5 | 173 |
| 6 | 19 |
| Overlapping Block Number s | Storage Rate | Number of Failure Tolerant Nodes |
|---|---|---|
| 2 | 8% | 1 |
| 3 | 12% | 2 |
| 4 | 16% | 3 |
| 5 | 20% | 4 |
| 6 | 24% | 5 |
| 7 | 28% | 6 |
| 8 | 32% | 7 |
| 9 | 36% | 8 |
| 10 | 40% | 9 |
| 11 | 44% | 10 |
| 12 | 48% | 11 |
| 13 | 52% | 12 |
| 14 | 56% | 13 |
| 15 | 60% | 14 |
| 16 | 64% | 15 |
| 17 | 68% | 16 |
| 18 | 72% | 17 |
| 19 | 76% | 18 |
| 20 | 80% | 19 |
| 21 | 84% | 20 |
| 22 | 88% | 21 |
| 23 | 92% | 22 |
| 24 | 96% | 23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Zhang, D.; Mu, C.; Zhao, X.; Zhao, J. Ring-Overlap: A Storage Scaling Mechanism for Hyperledger Fabric. Appl. Sci. 2022, 12, 9568. https://doi.org/10.3390/app12199568
Liu W, Zhang D, Mu C, Zhao X, Zhao J. Ring-Overlap: A Storage Scaling Mechanism for Hyperledger Fabric. Applied Sciences. 2022; 12(19):9568. https://doi.org/10.3390/app12199568
Chicago/Turabian StyleLiu, Wenxuan, Donghong Zhang, Chunxiao Mu, Xiangfu Zhao, and Jindong Zhao. 2022. "Ring-Overlap: A Storage Scaling Mechanism for Hyperledger Fabric" Applied Sciences 12, no. 19: 9568. https://doi.org/10.3390/app12199568
APA StyleLiu, W., Zhang, D., Mu, C., Zhao, X., & Zhao, J. (2022). Ring-Overlap: A Storage Scaling Mechanism for Hyperledger Fabric. Applied Sciences, 12(19), 9568. https://doi.org/10.3390/app12199568