
Robustness, Stability, and Fidelity of Explanations for a Deep Skin Cancer Classification Model



Abstract
:1. Introduction
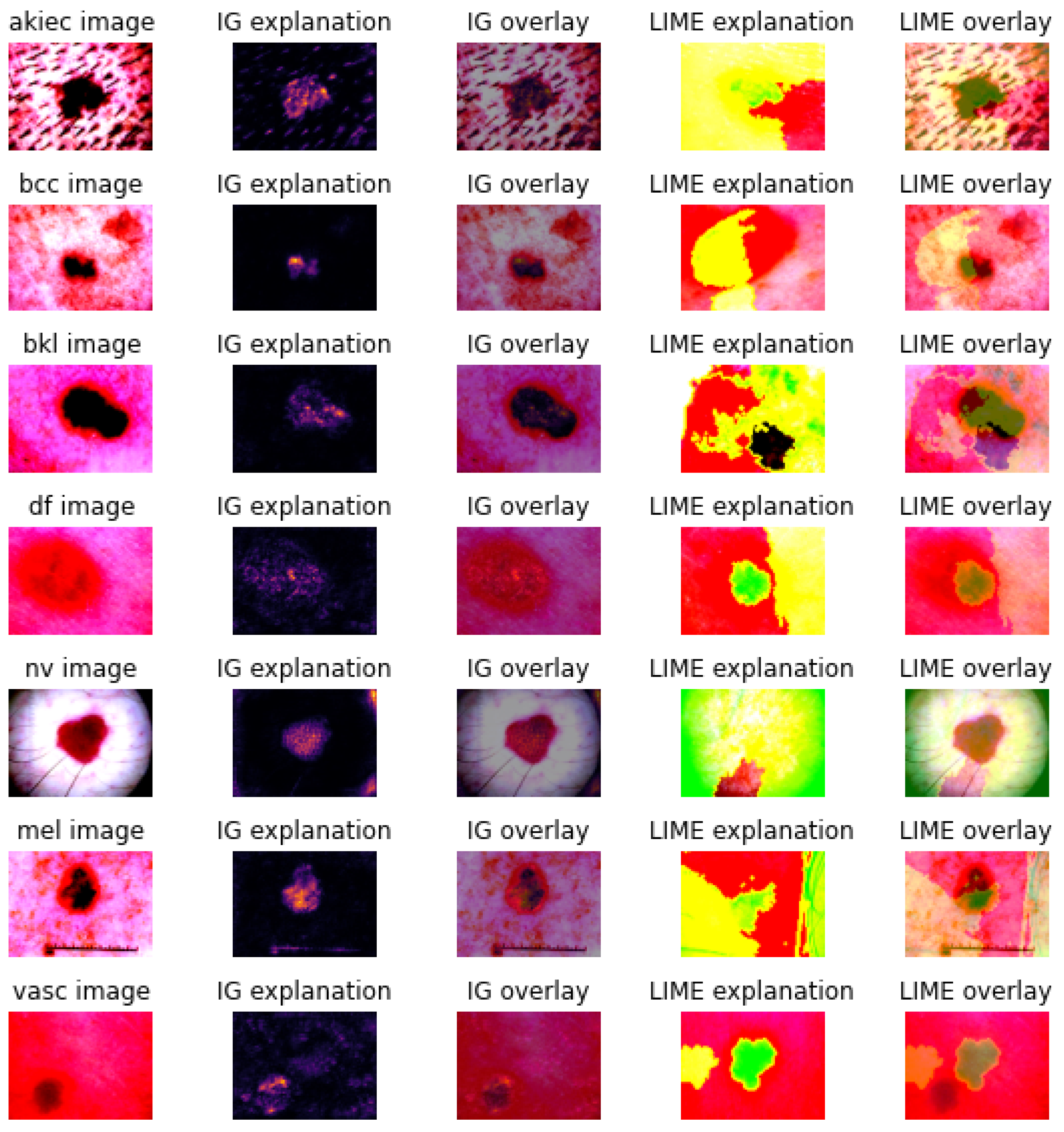
- Integrated gradients [20], which calculate feature attributions to the prediction by accumulating gradients along a path from a baseline instance to the specific instance of interest.
- Local interpretable model-agnostic explanations [21], which build an interpretable surrogate model around the decision space of the CNN model’s prediction in the local neighbourhood of the specific instance of interest.
2. Material and Methods
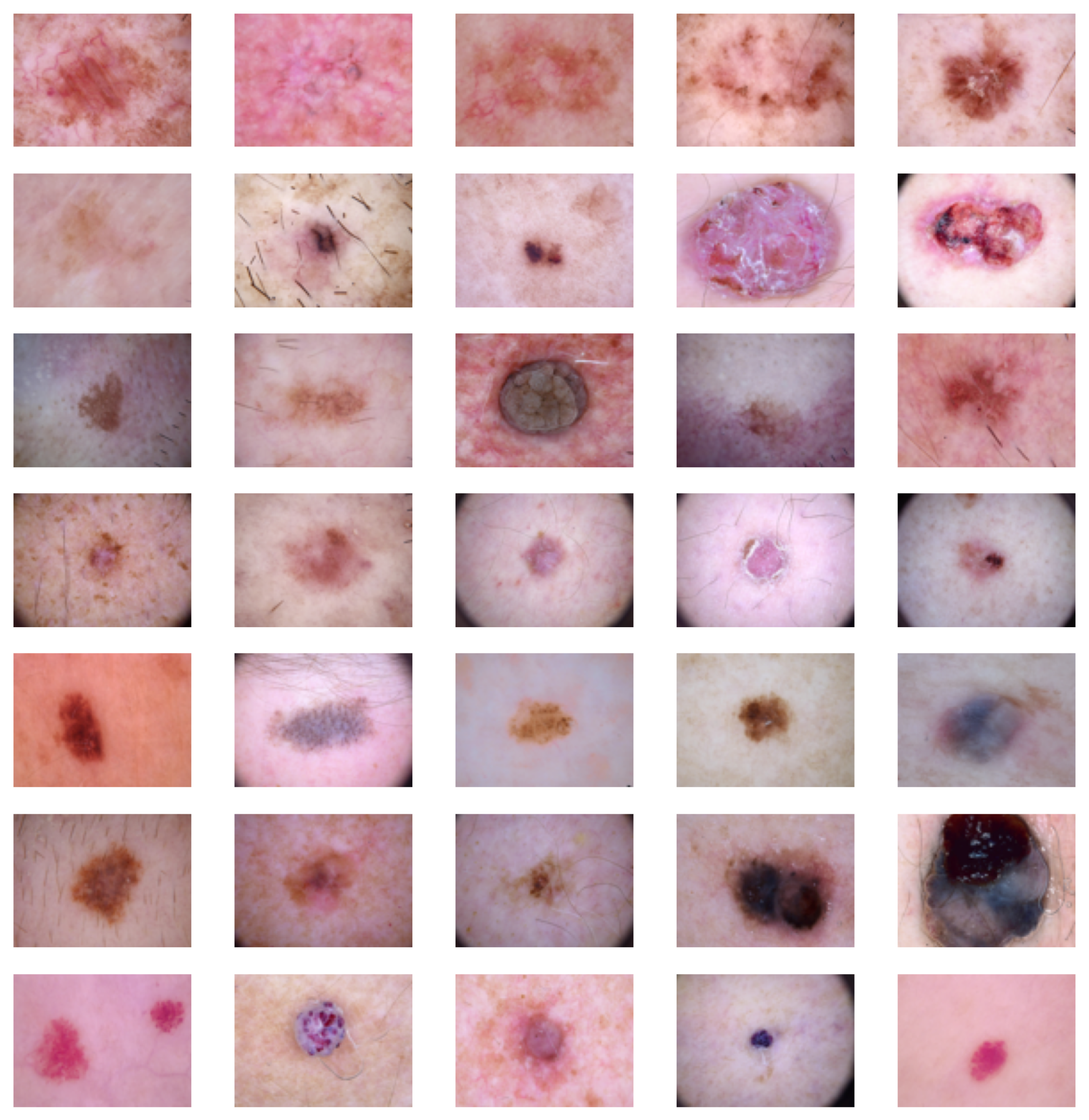
2.1. Data
2.2. Methods
2.2.1. Deep Learning
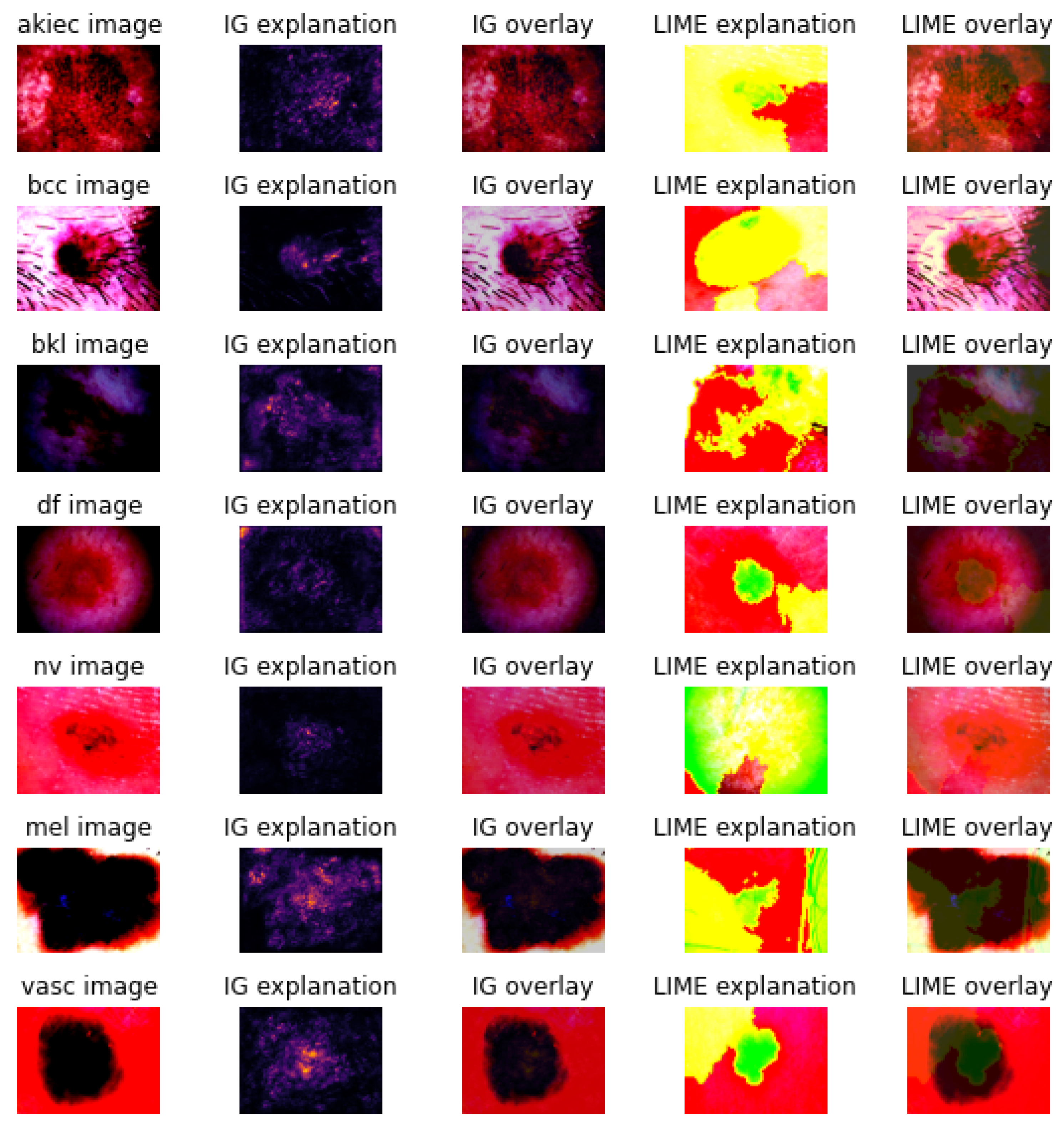
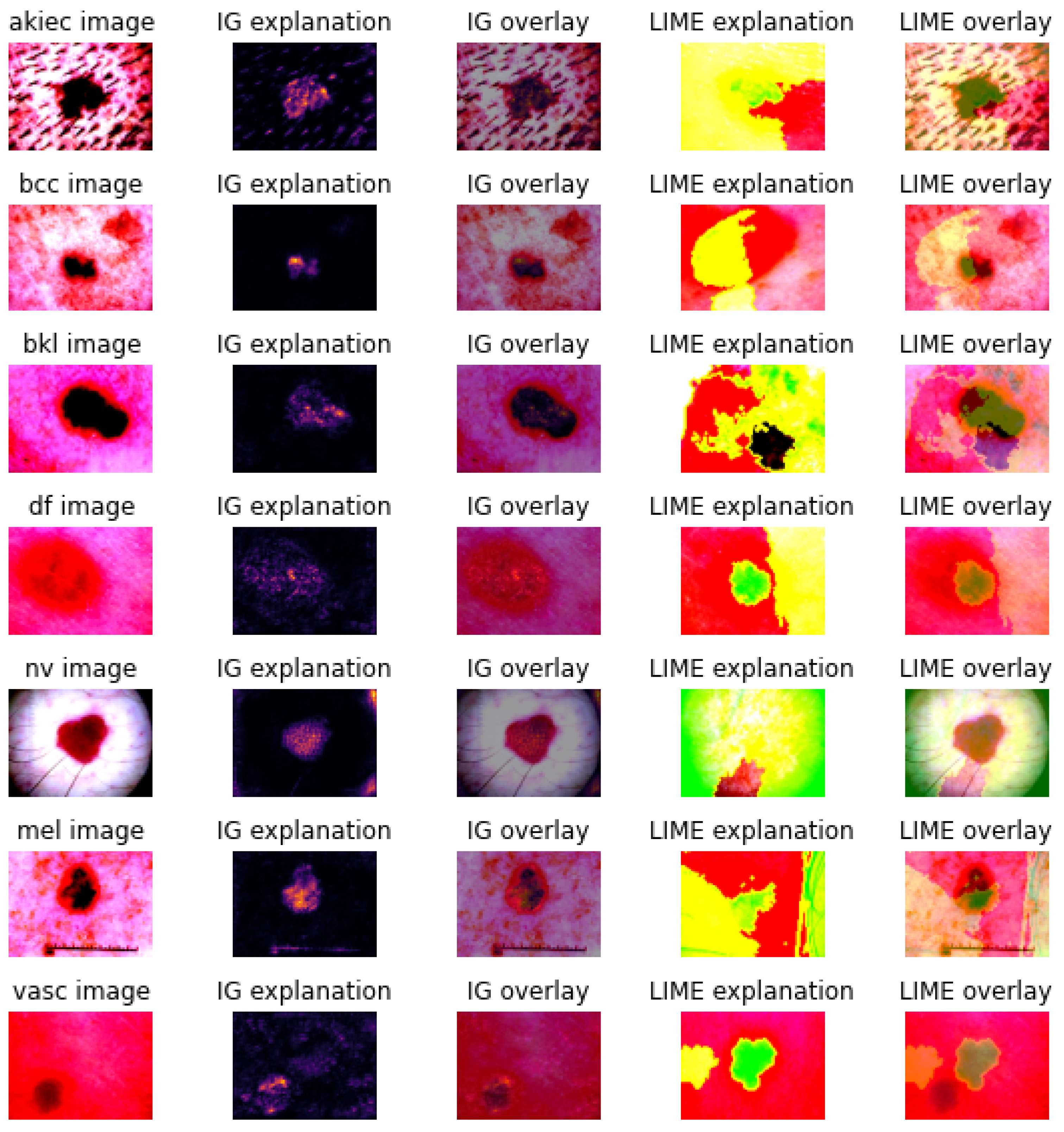
2.2.2. Explanation Techniques
- Intrinsic versus post hoc;
- Global versus local;
- Model-specific versus model-agnostic;
- Perturbation- or occlusion-based versus gradient-based.
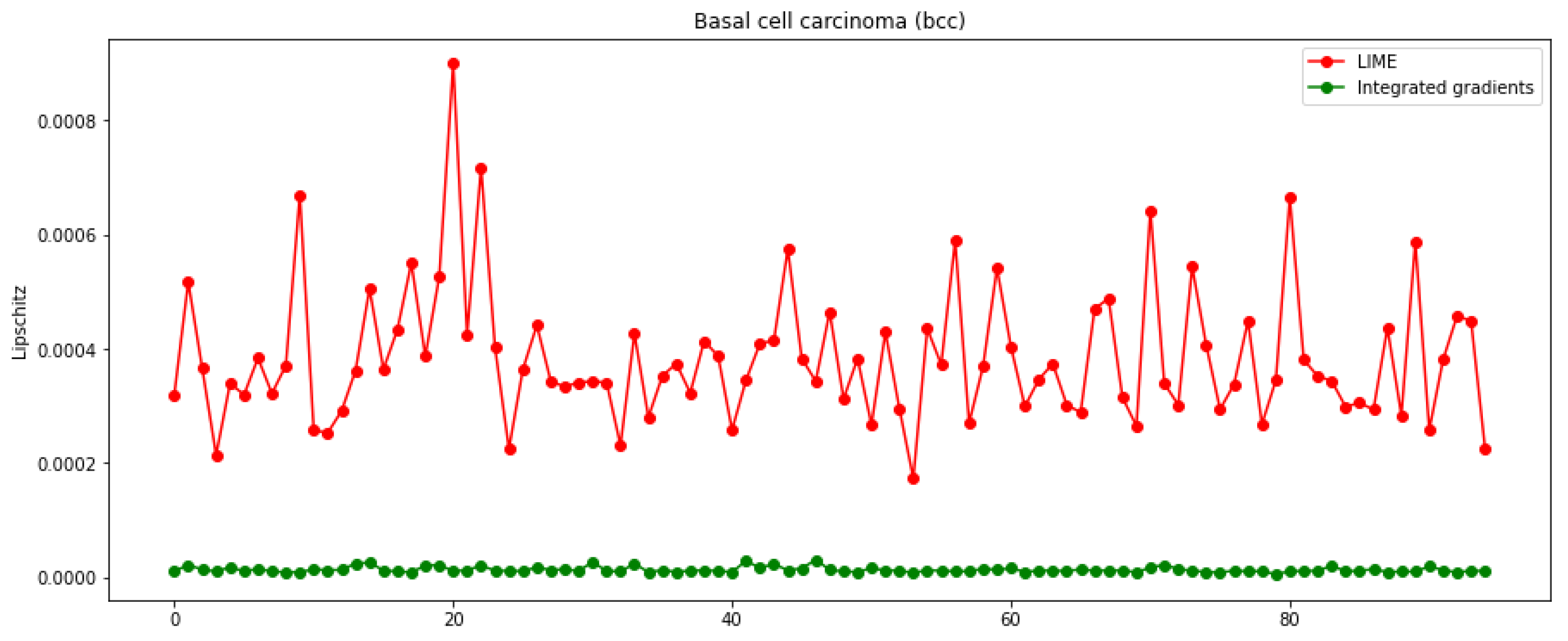
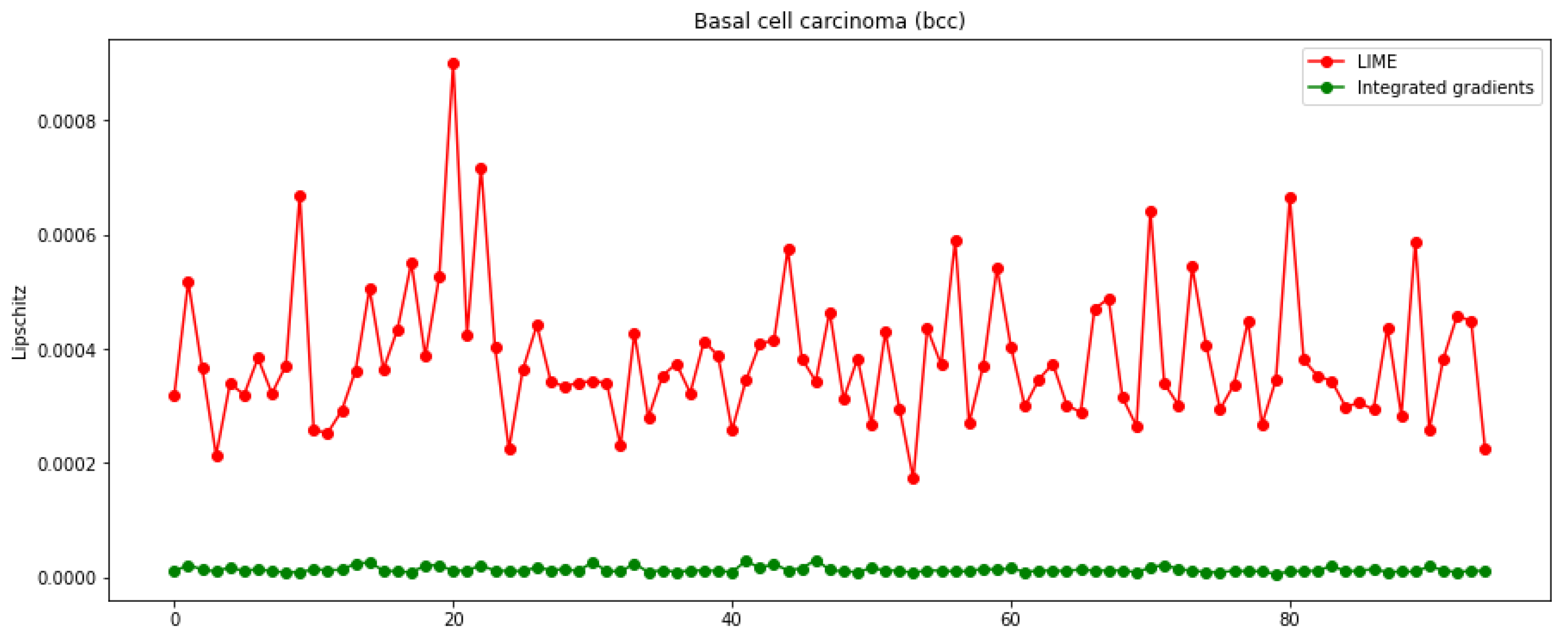
2.2.3. Metrics
3. Experimental Results
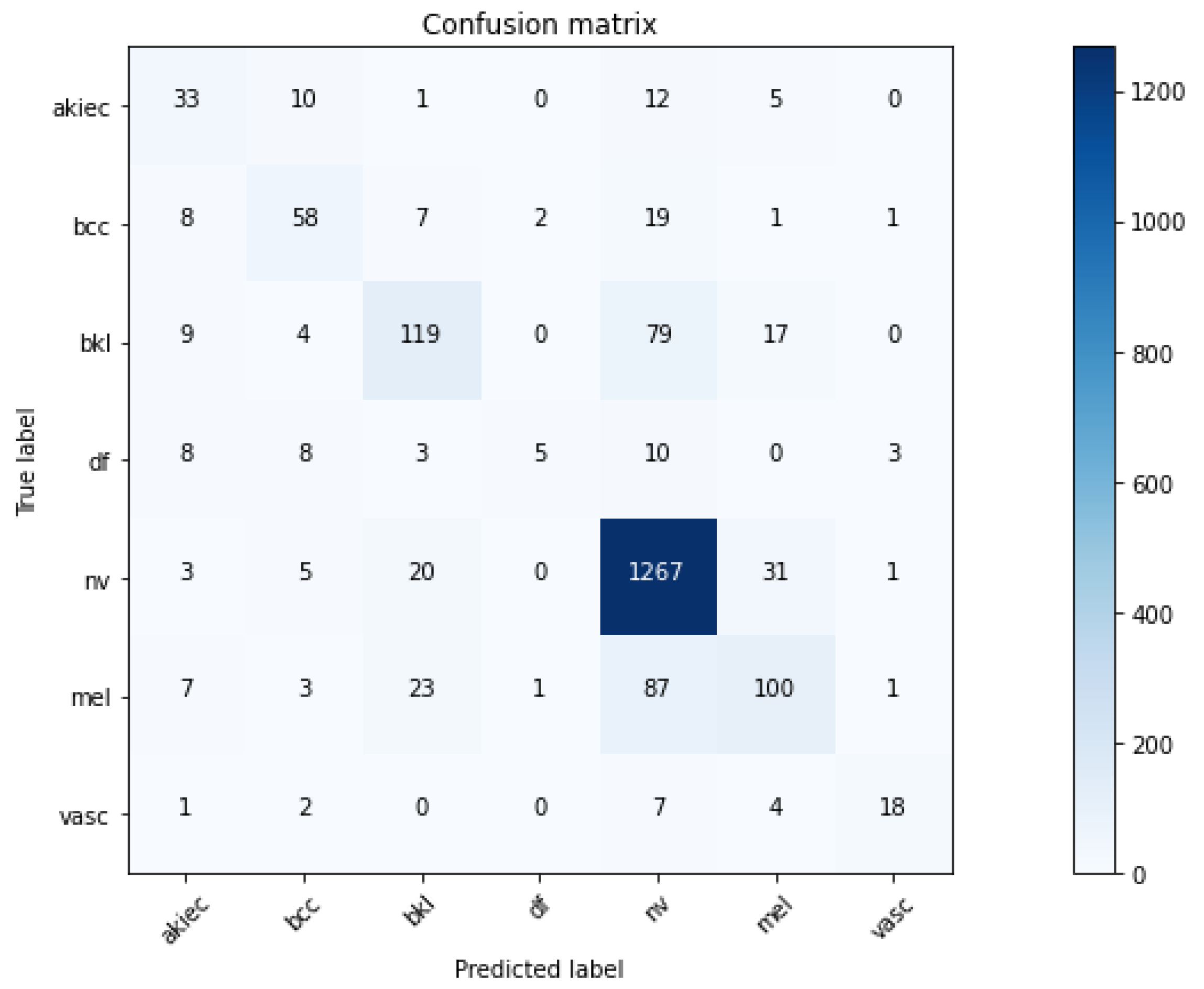
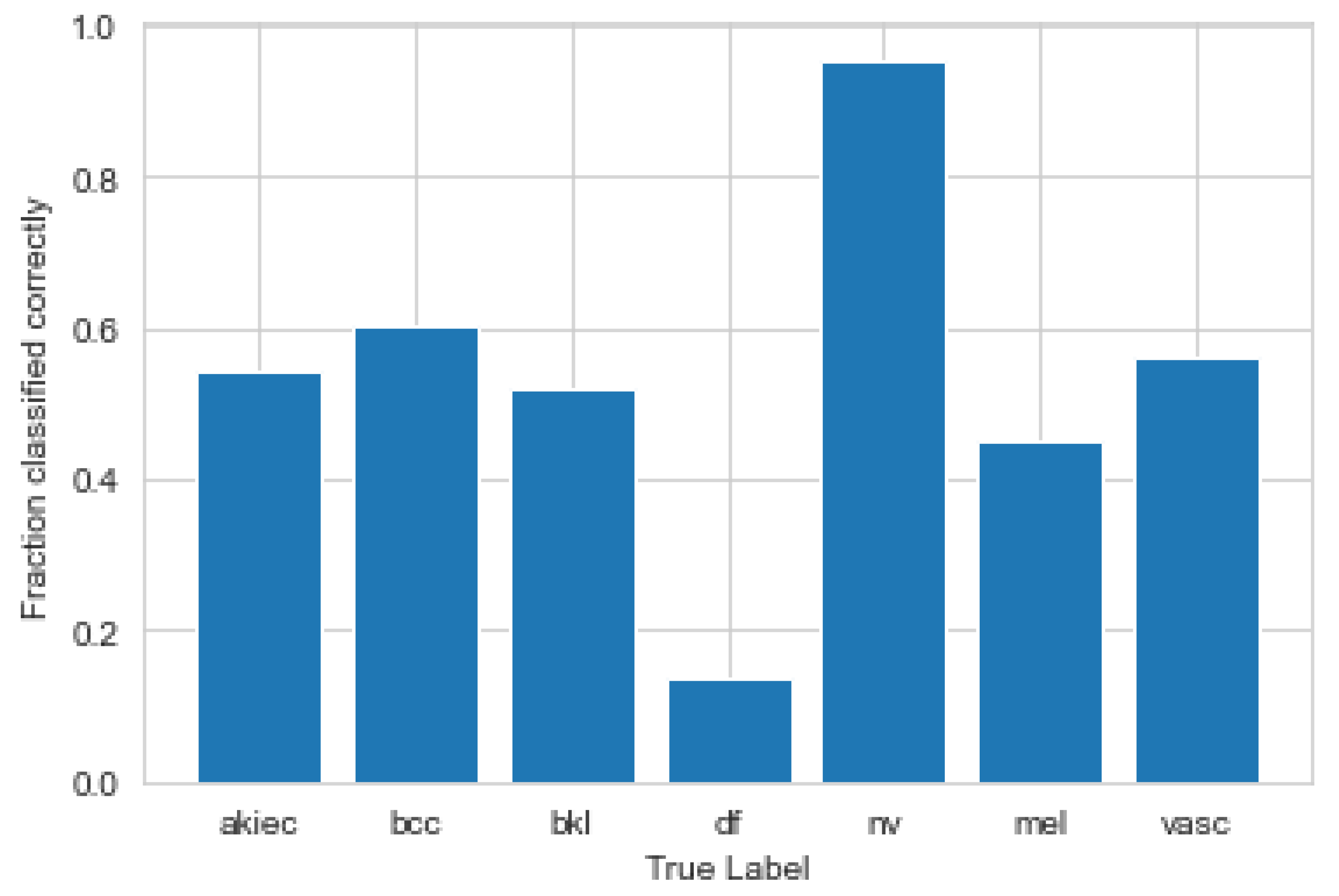
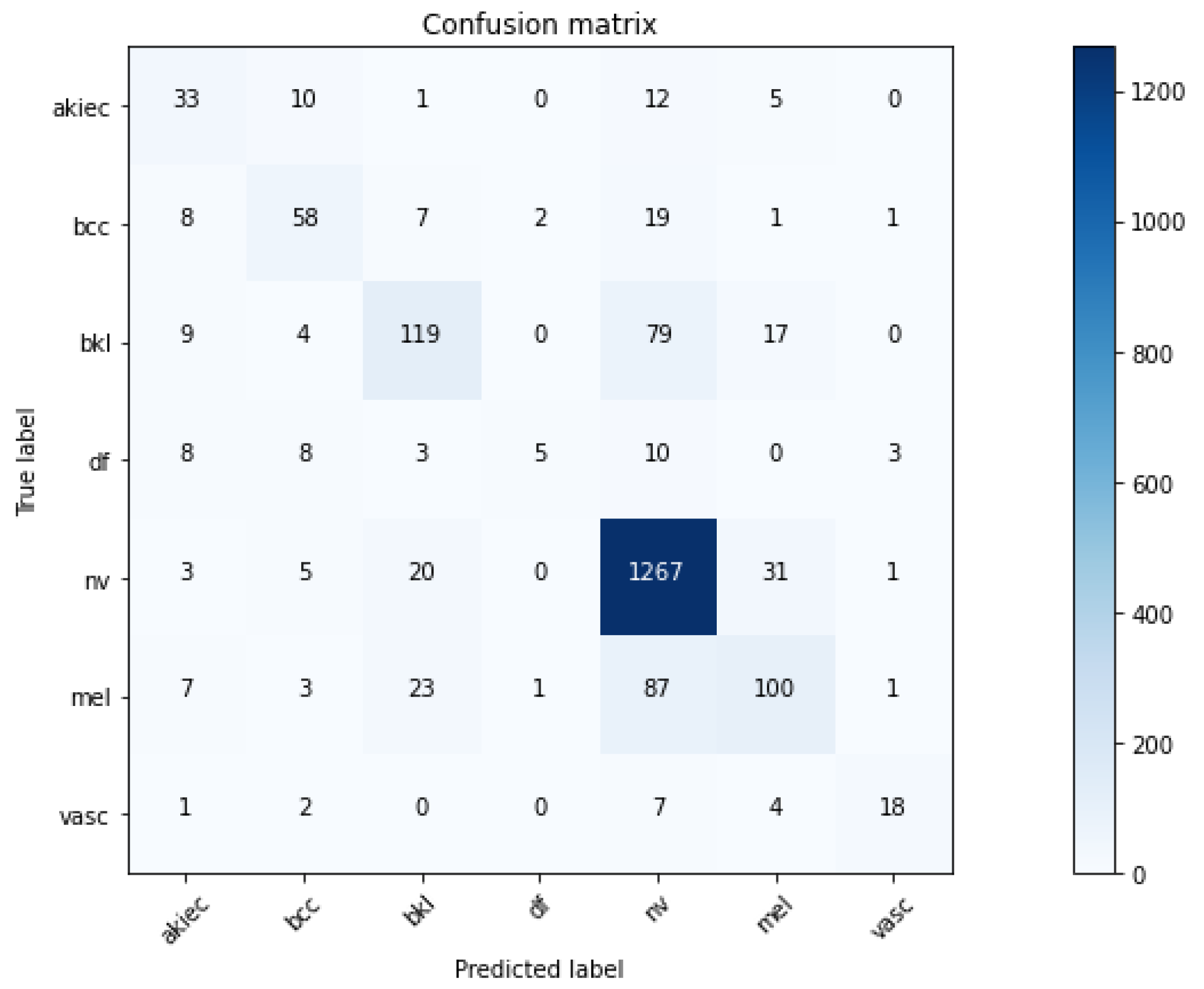
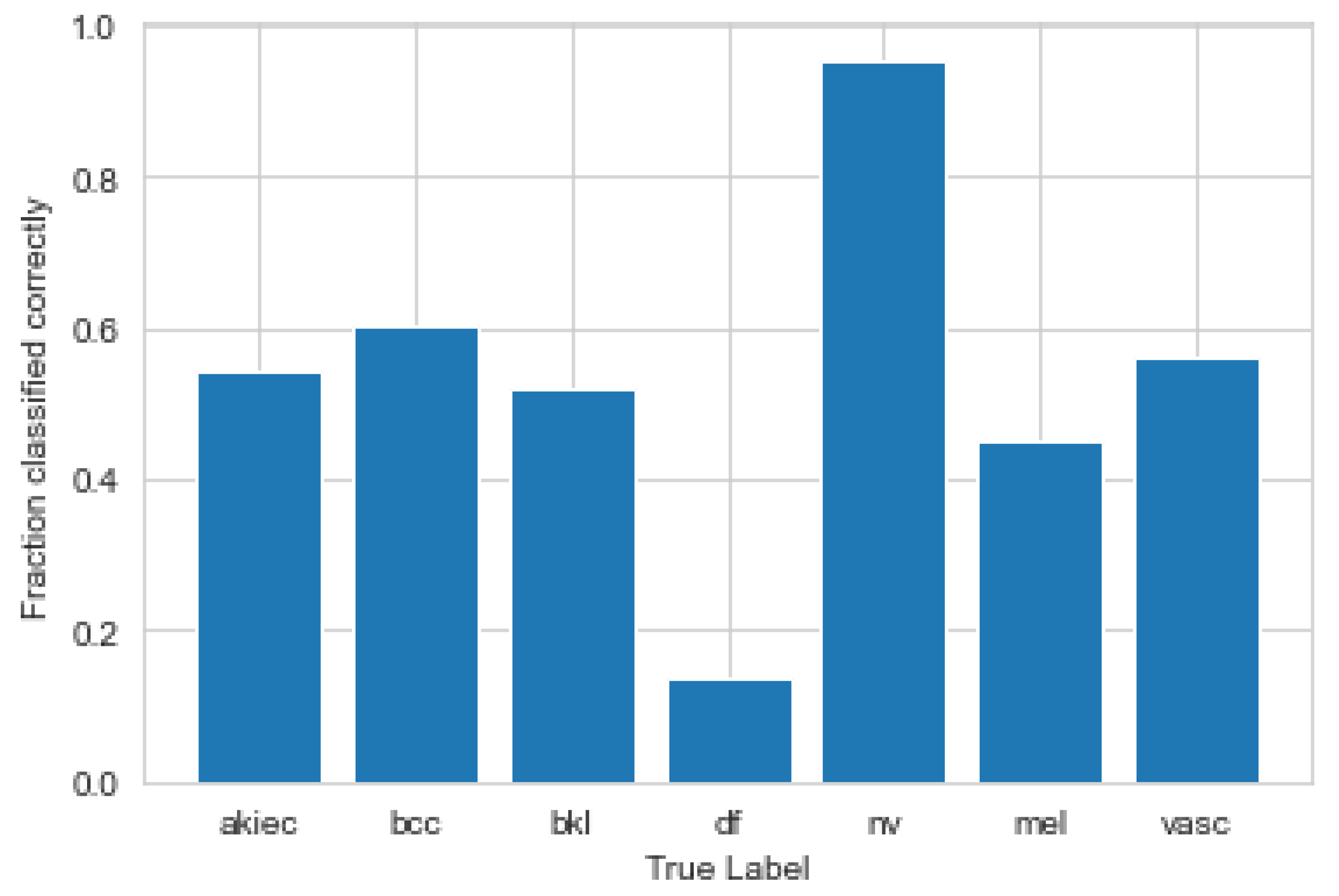
3.1. Convolutional Neural Network
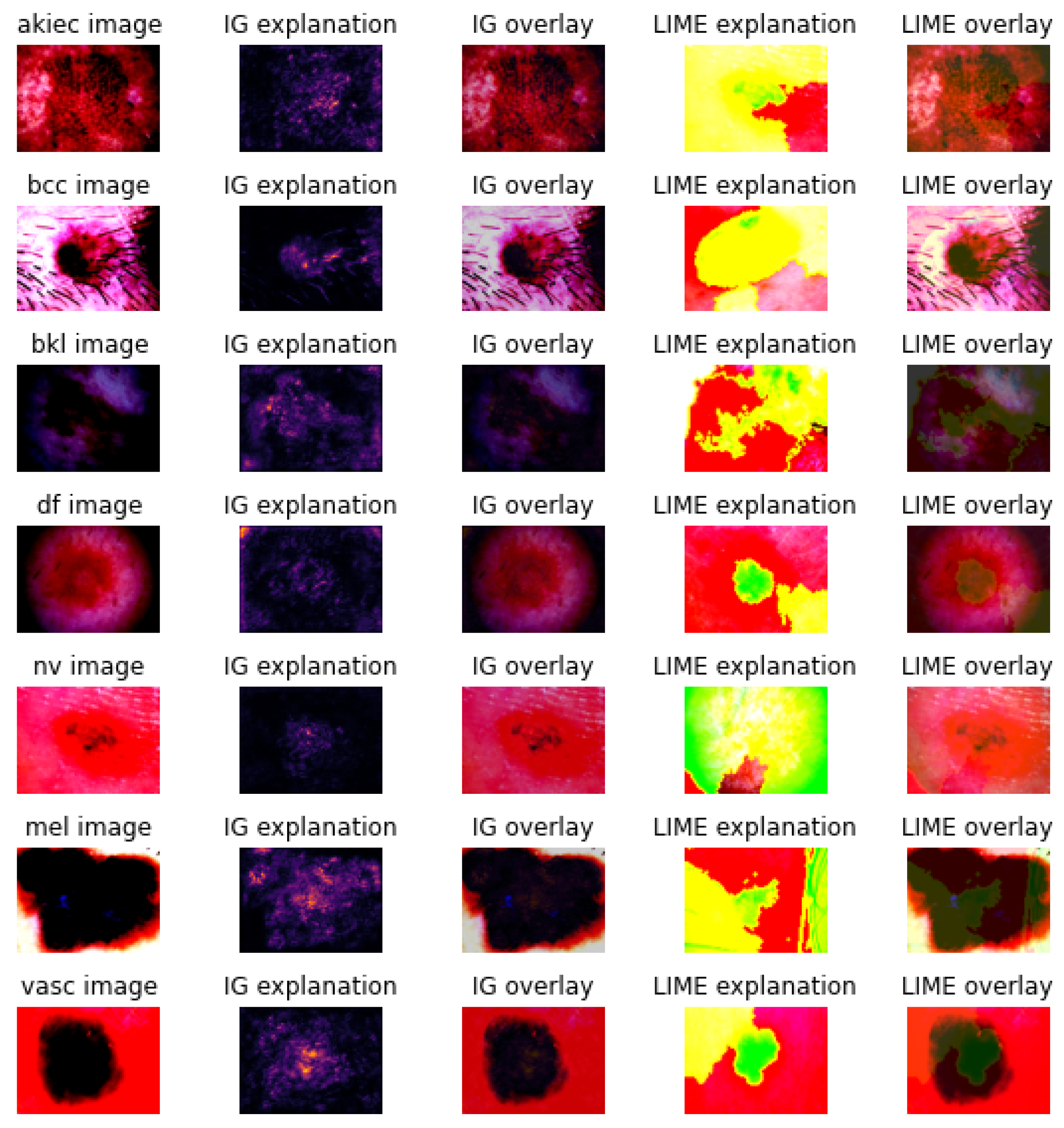
3.2. Explanations
3.3. Metrics and Axioms
4. Discussion and Conclusions
Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AKIEC | Actinic Keratoses |
| BCC | Basal Cell Carcinoma |
| BKL | Benign Keratosis-like Lesions |
| CNN | Convolutional Neural Networks |
| DF | Dermatofibroma |
| IML | Interpretable Machine Learning |
| IG | Integrated Gradients |
| IMDRF | International Medical Devices Regulator Forum |
| ISIC | International Skin Imaging Collaboration |
| LIME | Local Interpretable Model-agnostic Explanations |
| ML | Machine Learning |
| MEL | Melanoma |
| NV | Melanocytic Nevi |
| SVM | Support Vector Machine |
| XAI | Explainable Artificial Intelligence |
| VASC | Vascular lesions |
References
- Cassidy, B.; Kendrick, C.; Brodzicki, A.; Jaworek-Korjakowska, J.; Yap, M.H. Analysis of the ISIC image datasets: Usage, benchmarks and recommendations. Med. Image Anal. 2022, 75, 102305. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Holland, K. What Is a Dermatologist and How Can They Help You? Healthline. 2020. Last Medically Reviewed on 24 June 2020. Available online: https://www.healthline.com/find-care/articles/dermatologists/what-is-a-dermatologist (accessed on 22 September 2022).
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221. [Google Scholar] [CrossRef]
- Barata, C.; Celebi, M.E.; Marques, J.S. Explainable skin lesion diagnosis using taxonomies. Pattern Recognit. 2021, 110, 107413. [Google Scholar] [CrossRef]
- Thurnhofer-Hemsi, K.; Domínguez, E. A convolutional neural network framework for accurate skin cancer detection. Neural Process. Lett. 2021, 53, 3073–3093. [Google Scholar] [CrossRef]
- Brinker, T.J.; Hekler, A.; Enk, A.H.; Klode, J.; Hauschild, A.; Berking, C.; Schilling, B.; Haferkamp, S.; Schadendorf, D.; Fröhling, S.; et al. A convolutional neural network trained with dermoscopic images performed on par with 145 dermatologists in a clinical melanoma image classification task. Eur. J. Cancer 2019, 111, 148–154. [Google Scholar] [CrossRef]
- Tschandl, P.; Rinner, C.; Apalla, Z.; Argenziano, G.; Codella, N.; Halpern, A.; Janda, M.; Lallas, A.; Longo, C.; Malvehy, J.; et al. Human–computer collaboration for skin cancer recognition. Nat. Med. 2020, 26, 1229–1234. [Google Scholar] [CrossRef]
- Haggenmüller, S.; Maron, R.C.; Hekler, A.; Utikal, J.S.; Barata, C.; Barnhill, R.L.; Beltraminelli, H.; Berking, C.; Betz-Stablein, B.; Blum, A.; et al. Skin cancer classification via convolutional neural networks: Systematic review of studies involving human experts. Eur. J. Cancer 2021, 156, 202–216. [Google Scholar] [CrossRef]
- Codella, N.C.; Lin, C.C.; Halpern, A.; Hind, M.; Feris, R.; Smith, J.R. Collaborative human-AI (CHAI): Evidence-based interpretable melanoma classification in dermoscopic images. In Understanding and Interpreting Machine Learning in Medical Image Computing Applications; Springer: Cham, Germany, 2018; pp. 97–105. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Maron, R.C.; Schlager, J.G.; Haggenmüller, S.; von Kalle, C.; Utikal, J.S.; Meier, F.; Gellrich, F.F.; Hobelsberger, S.; Hauschild, A.; French, L.; et al. A benchmark for neural network robustness in skin cancer classification. Eur. J. Cancer 2021, 155, 191–199. [Google Scholar] [CrossRef] [PubMed]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef]
- Gaube, S.; Suresh, H.; Raue, M.; Merritt, A.; Berkowitz, S.J.; Lermer, E.; Coughlin, J.F.; Guttag, J.V.; Colak, E.; Ghassemi, M. Do as AI say: Susceptibility in deployment of clinical decision-aids. NPJ Digit. Med. 2021, 4, 31. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef]
- Samek, W.; Montavon, G.; Lapuschkin, S.; Anders, C.J.; Müller, K.R. Explaining deep neural networks and beyond: A review of methods and applications. Proc. IEEE 2021, 109, 247–278. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (XAI): Toward medical XAI. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Saarela, M.; Jauhiainen, S. Comparison of feature importance measures as explanations for classification models. SN Appl. Sci. 2021, 3, 272. [Google Scholar] [CrossRef]
- Saarela, M.; Kärkkäinen, T. Can we automate expert-based journal rankings? Analysis of the Finnish publication indicator. J. Inf. 2020, 14, 101008. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Y.; Xia, Y.; Shen, C. Attention residual learning for skin lesion classification. IEEE Trans. Med. Imaging 2019, 38, 2092–2103. [Google Scholar] [CrossRef]
- Höhn, J.; Hekler, A.; Krieghoff-Henning, E.; Kather, J.N.; Utikal, J.S.; Meier, F.; Gellrich, F.F.; Hauschild, A.; French, L.; Schlager, J.G.; et al. Integrating patient data into skin cancer classification using convolutional neural networks: Systematic review. J. Med. Internet Res. 2021, 23, e20708. [Google Scholar] [CrossRef]
- Gulzar, Y.; Khan, S.A. Skin Lesion Segmentation Based on Vision Transformers and Convolutional Neural Networks—A Comparative Study. Appl. Sci. 2022, 12, 5990. [Google Scholar] [CrossRef]
- Ali, M.S.; Miah, M.S.; Haque, J.; Rahman, M.M.; Islam, M.K. An enhanced technique of skin cancer classification using deep convolutional neural network with transfer learning models. Mach. Learn. Appl. 2021, 5, 100036. [Google Scholar] [CrossRef]
- Ali, K.; Shaikh, Z.A.; Khan, A.A.; Laghari, A.A. Multiclass skin cancer classification using EfficientNets—A first step towards preventing skin cancer. Neurosci. Inform. 2021, 2, 100034. [Google Scholar] [CrossRef]
- Ali, R.; Hardie, R.C.; Narayanan, B.N.; De Silva, S. Deep learning ensemble methods for skin lesion analysis towards melanoma detection. In Proceedings of the 2019 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 July 2019; pp. 311–316. [Google Scholar]
- Klaise, J.; Van Looveren, A.; Vacanti, G.; Coca, A. Alibi Explain: Algorithms for Explaining Machine Learning Models. J. Mach. Learn. Res. 2021, 22, 181-1. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Qin, Z.; Yu, F.; Liu, C.; Chen, X. How convolutional neural network see the world-A survey of convolutional neural network visualization methods. Math. Found. Comput. 2018, 1, 149–180. [Google Scholar] [CrossRef]
- Khan, S.A.; Gulzar, Y.; Turaev, S.; Peng, Y.S. A Modified HSIFT Descriptor for Medical Image Classification of Anatomy Objects. Symmetry 2021, 13, 1987. [Google Scholar] [CrossRef]
- Valueva, M.V.; Nagornov, N.; Lyakhov, P.A.; Valuev, G.V.; Chervyakov, N.I. Application of the residue number system to reduce hardware costs of the convolutional neural network implementation. Math. Comput. Simul. 2020, 177, 232–243. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the IEEE 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, 2nd ed.; Lulu Press: Morrisville, NC, USA, 2022. [Google Scholar]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine learning interpretability: A survey on methods and metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Koh, P.W.; Liang, P. Understanding black-box predictions via influence functions. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70. [Google Scholar]
- Yeh, C.K.; Kim, J.; Yen, I.E.H.; Ravikumar, P.K. Representer point selection for explaining deep neural networks. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Li, O.; Liu, H.; Chen, C.; Rudin, C. Deep Learning for Case-Based Reasoning through Prototypes: A Neural Network that Explains Its Predictions. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual Explanations without Opening the Black Box: Automated Decisions and the GDPR. Harv. J. Law Technol. 2017, 31, 841. [Google Scholar] [CrossRef]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing higher-layer features of a deep network. Univ. Montr. 2009, 1341, 1. [Google Scholar]
- Towell, G.G.; Shavlik, J.W. Extracting refined rules from knowledge-based neural networks. Mach. Learn. 1993, 13, 71–101. [Google Scholar] [CrossRef]
- Castro, J.L.; Mantas, C.J.; Benitez, J.M. Interpretation of artificial neural networks by means of fuzzy rules. IEEE Trans. Neural Netw. 2002, 13, 101–116. [Google Scholar] [CrossRef] [PubMed]
- Mitra, S.; Hayashi, Y. Neuro-fuzzy rule generation: Survey in soft computing framework. IEEE Trans. Neural Netw. 2000, 11, 748–768. [Google Scholar] [CrossRef] [PubMed]
- Fisher, A.; Rudin, C.; Dominici, F. All Models are Wrong, but Many are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously. J. Mach. Learn. Res. 2019, 20, 1–81. [Google Scholar]
- Fong, R.C.; Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zintgraf, L.M.; Cohen, T.S.; Adel, T.; Welling, M. Visualizing deep neural network decisions: Prediction difference analysis. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; pp. 1–12. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Wojtas, M.; Chen, K. Feature Importance Ranking for Deep Learning. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2020), Virtual, 6–12 December 2020; Volume 33, pp. 5105–5114. [Google Scholar]
- Burkart, N.; Huber, M.F. A Survey on the Explainability of Supervised Machine Learning. J. Artif. Intell. Res. 2021, 70, 245–317. [Google Scholar] [CrossRef]
- Dimopoulos, Y.; Bourret, P.; Lek, S. Use of some sensitivity criteria for choosing networks with good generalization ability. Neural Process. Lett. 1995, 2, 1–4. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3145–3153. [Google Scholar]
- Vilone, G.; Longo, L. Notions of explainability and evaluation approaches for explainable artificial intelligence. Inf. Fusion 2021, 76, 89–106. [Google Scholar] [CrossRef]
- Alvarez-Melis, D.; Jaakkola, T.S. On the robustness of interpretability methods. In Proceedings of the 35th International Conference on Machine Learning (ICML 2018), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Honegger, M. Shedding light on black box machine learning algorithms: Development of an axiomatic framework to assess the quality of methods that explain individual predictions. arXiv 2018, arXiv:1808.05054. [Google Scholar]
- Saarela, M.; Ryynänen, O.P.; Äyrämö, S. Predicting hospital associated disability from imbalanced data using supervised learning. Artif. Intell. Med. 2019, 95, 88–95. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Dindorf, C.; Konradi, J.; Wolf, C.; Taetz, B.; Bleser, G.; Huthwelker, J.; Werthmann, F.; Bartaguiz, E.; Kniepert, J.; Drees, P.; et al. Classification and automated interpretation of spinal posture data using a pathology-independent classifier and explainable artificial intelligence (XAI). Sensors 2021, 21, 6323. [Google Scholar] [CrossRef] [PubMed]
- IMDRF SaMD Working Group. Software as a Medical Device(SaMD): Clinical Evaluation—Guidance for Industry and Food and Drug Administration Staff; International Medical Device Regulators Forum, Food and Drug Administration (FDA): Rockville, MD, USA, 2017.
- Ali, R.; Hardie, R.C.; Narayanan, B.N.; Kebede, T.M. IMNets: Deep Learning Using an Incremental Modular Network Synthesis Approach for Medical Imaging Applications. Appl. Sci. 2022, 12, 5500. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Output Shape | Number of Parameters |
|---|---|---|---|
| conv2d | Conv2D | (None, 200, 150, 32) | 896 |
| conv2d_1 | Conv2D | (None, 200, 150, 32) | 9248 |
| max_pooling2d | Max_Pooling2D | (None, 100, 75, 32) | 0 |
| dropout | Dropout | (None, 100, 75, 32) | 0 |
| conv2d_2 | Conv2D | (None, 100, 75, 64) | 18,496 |
| conv2d_3 | Conv2D | (None, 100, 75, 64) | 36,928 |
| max_pooling2d_1 | Max_Pooling2D | (None, 50, 37, 64) | 0 |
| dropout_1 | Dropout | (None, 50, 37, 64) | 0 |
| flatten | Flatten | (None, 118,400) | 0 |
| dense | Dense | (None, 128) | 15,155,328 |
| dropout_2 | Dropout | (None, 128) | 0 |
| dense_1 | Dense | (None, 7) | 903 |
| Integrated Gradients | |||||||
|---|---|---|---|---|---|---|---|
| akiec | bcc | bkl | df | nv | mel | vasc | |
| Lipschitz Robustness | |||||||
| mean (±std) | |||||||
| Stability % | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Local Fidelity % | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| LIME | |||||||
| Lipschitz Robustness | |||||||
| mean (±std) | |||||||
| Stability % | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Local Fidelity % | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saarela, M.; Geogieva, L. Robustness, Stability, and Fidelity of Explanations for a Deep Skin Cancer Classification Model. Appl. Sci. 2022, 12, 9545. https://doi.org/10.3390/app12199545
Saarela M, Geogieva L. Robustness, Stability, and Fidelity of Explanations for a Deep Skin Cancer Classification Model. Applied Sciences. 2022; 12(19):9545. https://doi.org/10.3390/app12199545
Chicago/Turabian StyleSaarela, Mirka, and Lilia Geogieva. 2022. "Robustness, Stability, and Fidelity of Explanations for a Deep Skin Cancer Classification Model" Applied Sciences 12, no. 19: 9545. https://doi.org/10.3390/app12199545
APA StyleSaarela, M., & Geogieva, L. (2022). Robustness, Stability, and Fidelity of Explanations for a Deep Skin Cancer Classification Model. Applied Sciences, 12(19), 9545. https://doi.org/10.3390/app12199545