
Multigranularity Syntax Guidance with Graph Structure for Machine Reading Comprehension


Abstract
:1. Introduction
- A new network structure, MgSG, is proposed. Based on the use of PrLMs to represent the text, combined with the graph structure, word and sentence granularities are used to obtain a text representation with richer semantics.
- Two graph structure construction methods are designed using dependencies and named entities, and a filtering mechanism is proposed to integrate them to improve the accuracy of the overall text representation.
- The role of the dependencies and named entities in reading comprehension tasks is analyzed, and it is demonstrated through experiments that both word and sentence granularities affect model performance. In addition, the two granularity representations are modularized to make them compatible with more models.
2. Related Work
2.1. Machine Reading Comprehension
2.2. Syntactic Representation
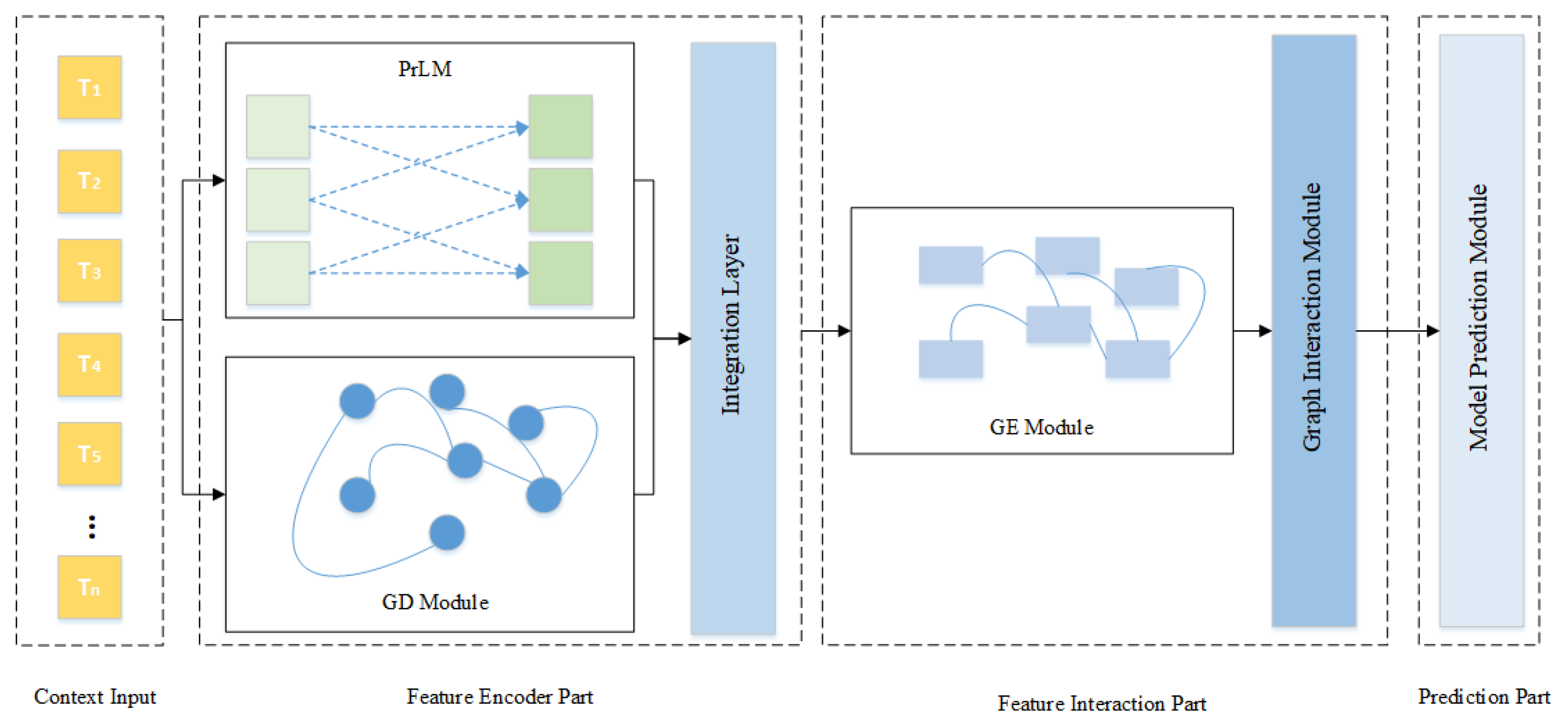
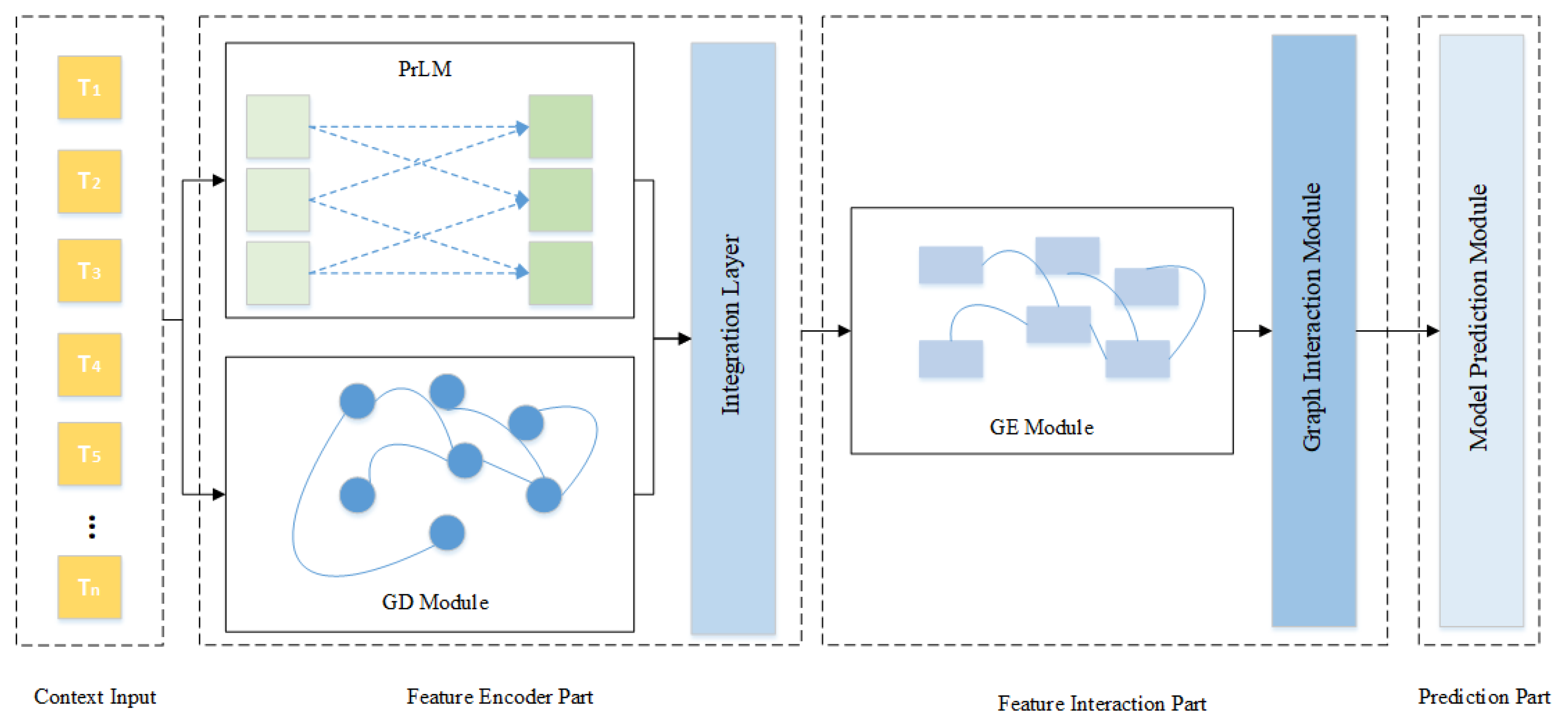
3. Methodology
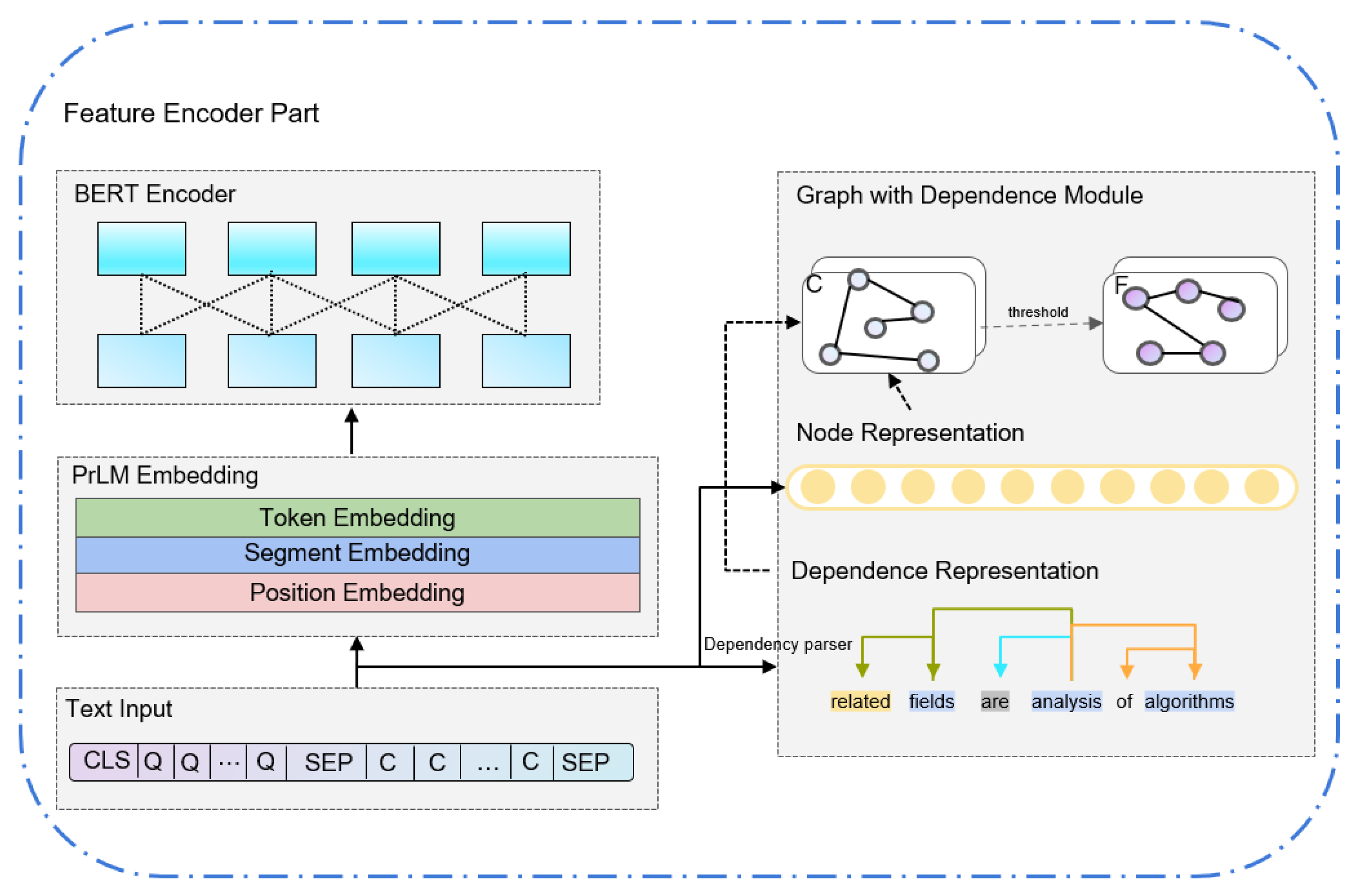
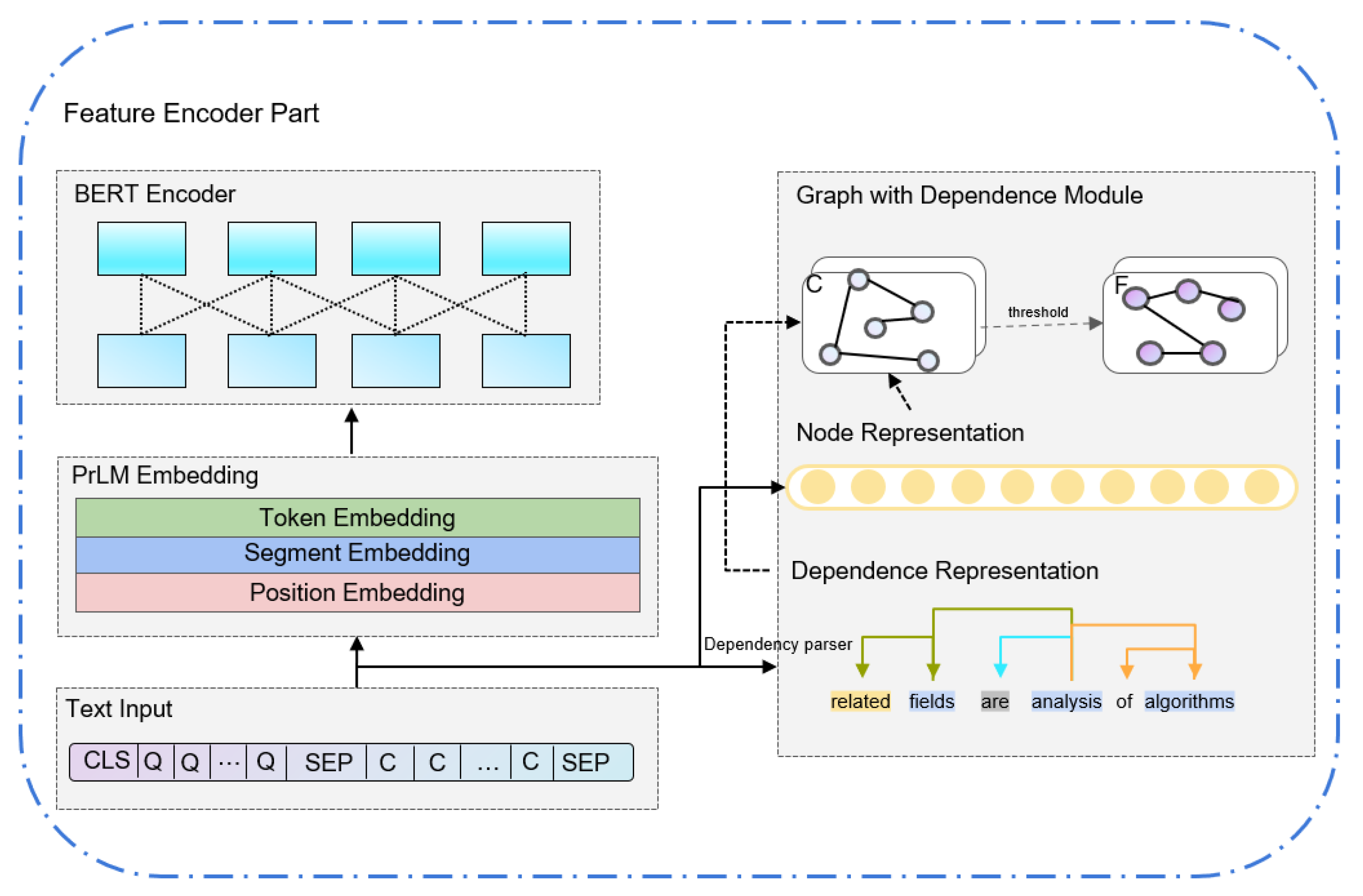
3.1. Feature Encoder Part
BERT Encoder
3.2. Graph with Dependence Module
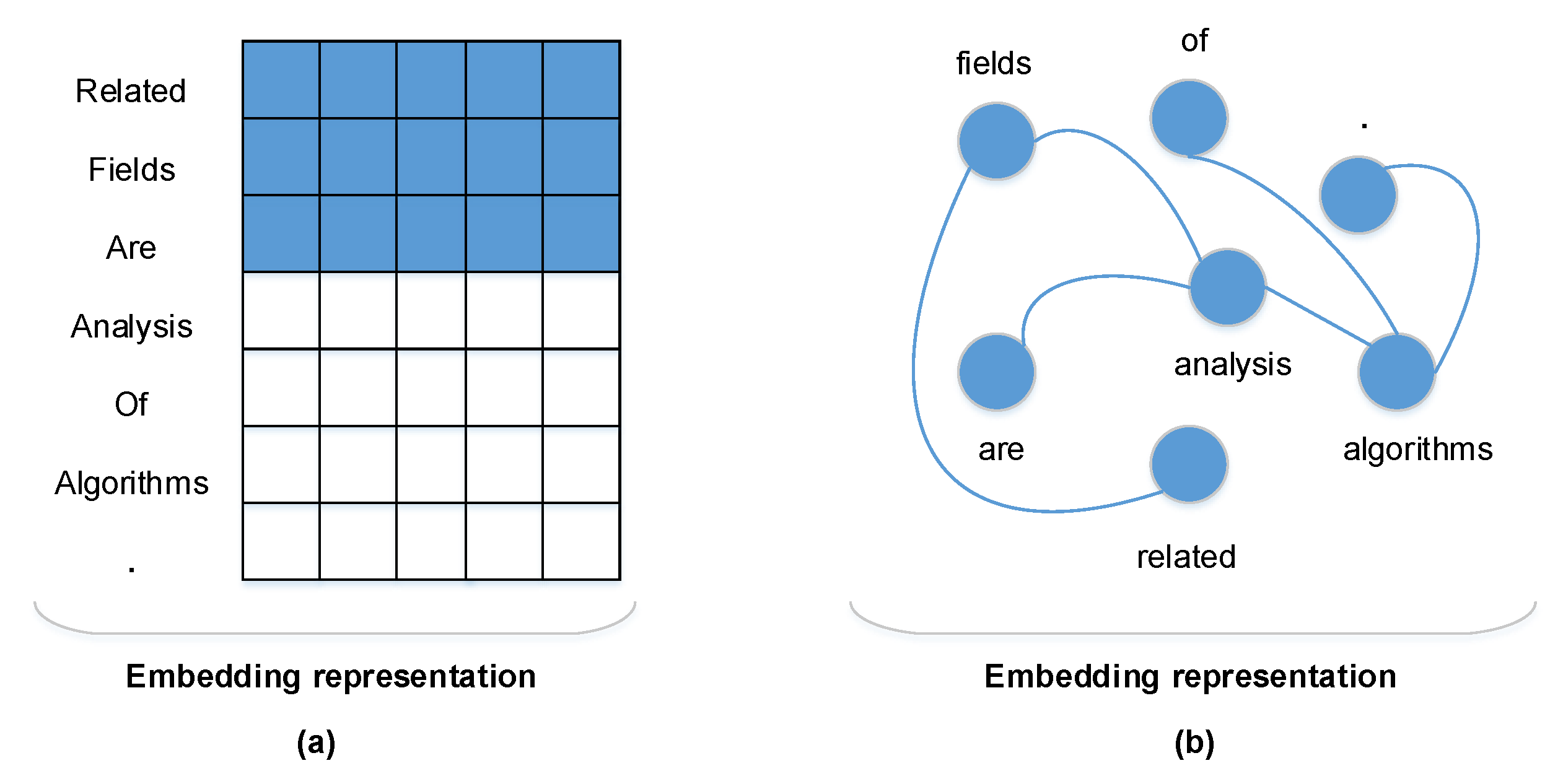
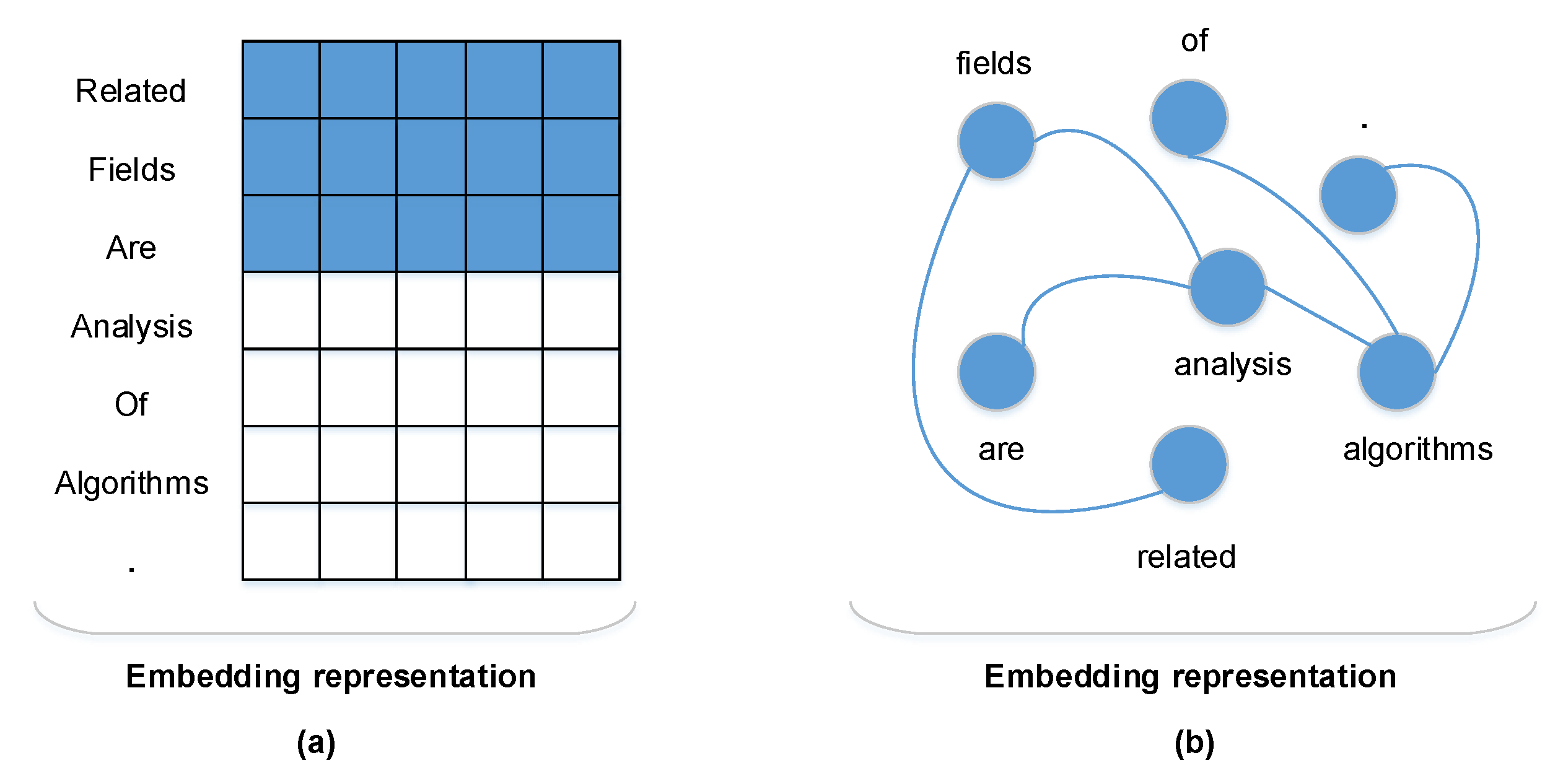
3.2.1. Dependence Relation
3.2.2. Graph Attention Network
3.3. Integration Layer
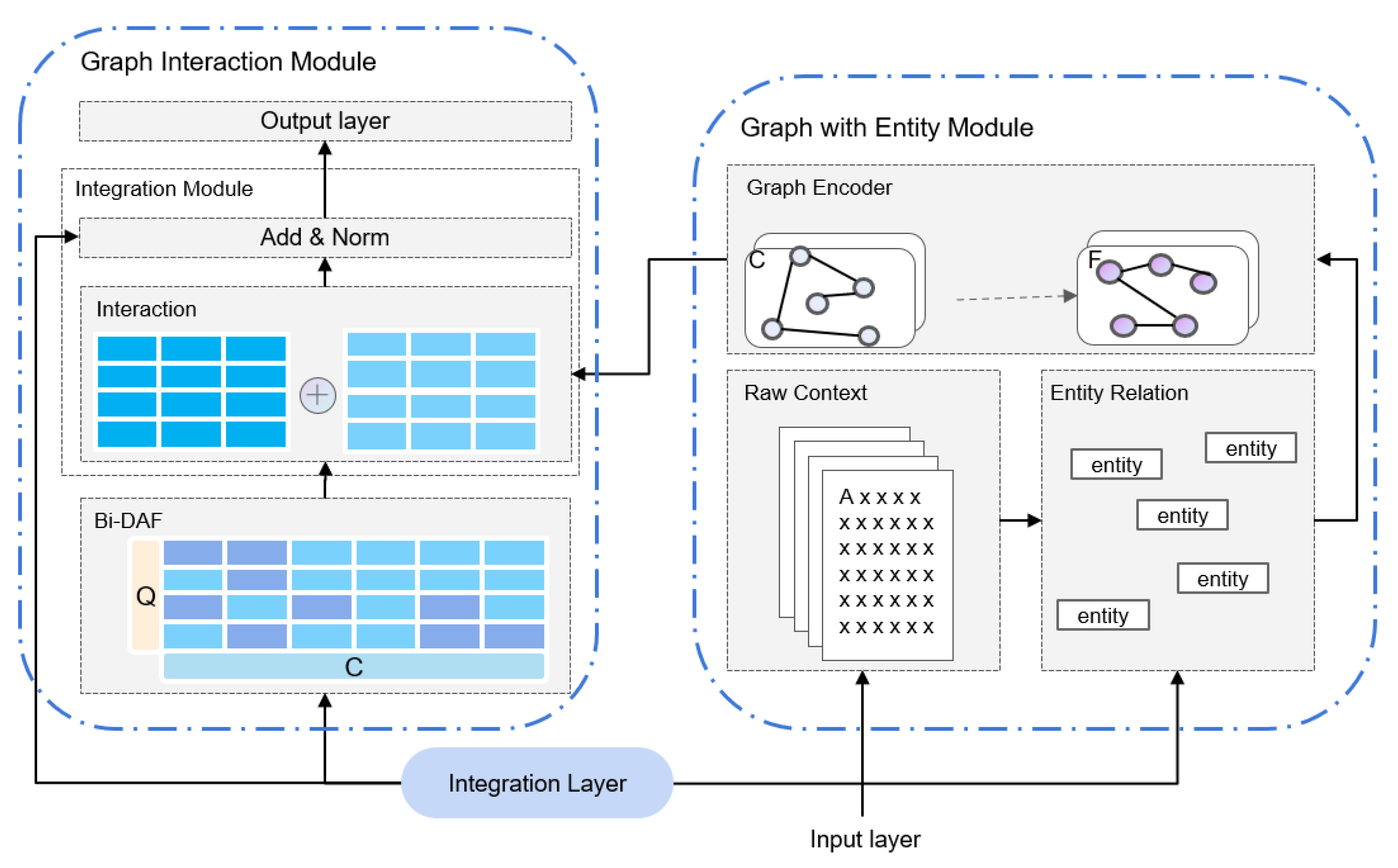
3.4. Feature Interaction Part
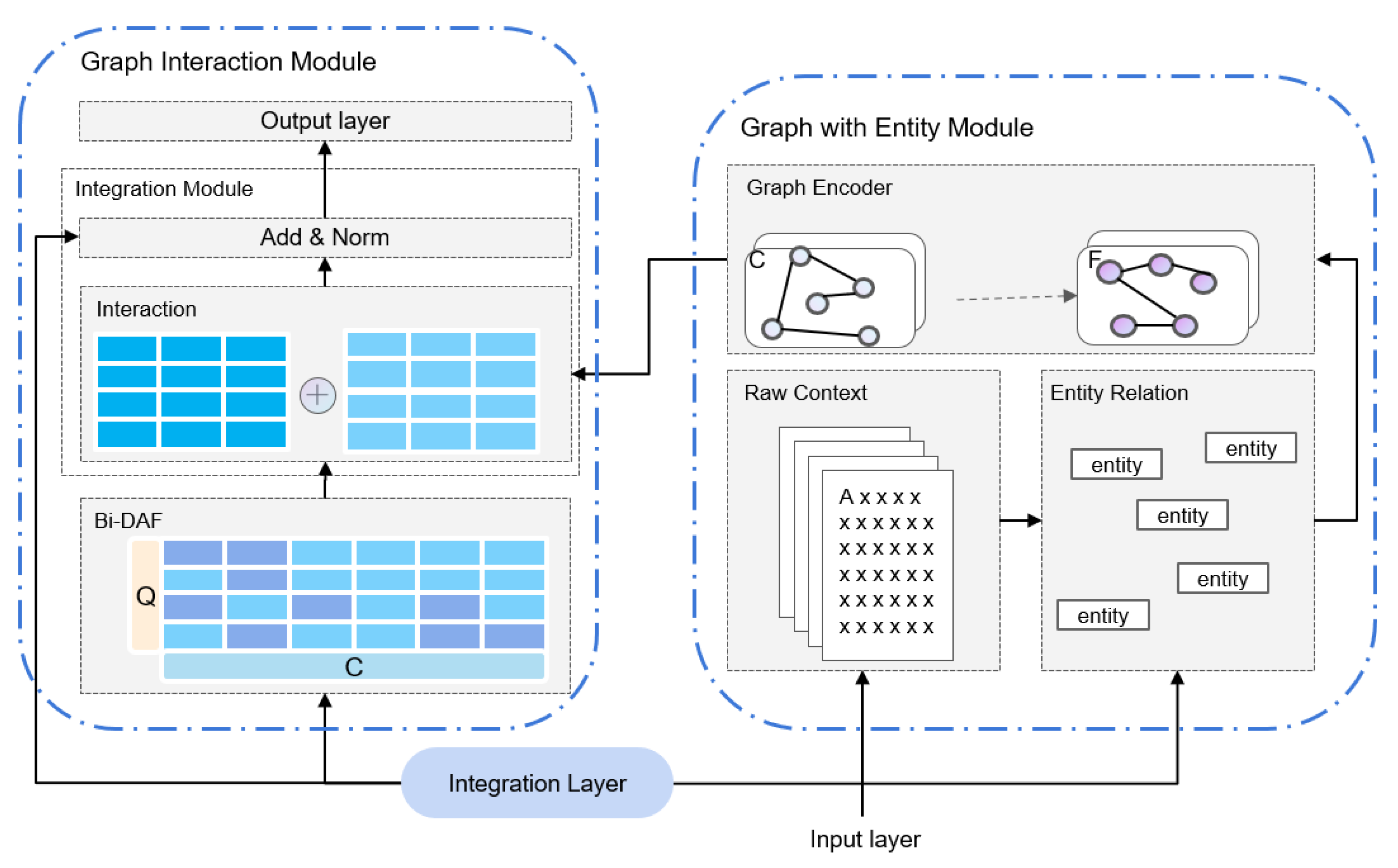
3.4.1. Graph with Entity Module
3.4.2. Graph Interaction Module
3.5. Prediction Module
4. Experiment
4.1. Setup
4.2. Datasets
4.3. Evaluation
5. Results and Discussion
5.1. Experiment Results
5.2. Ablation Study
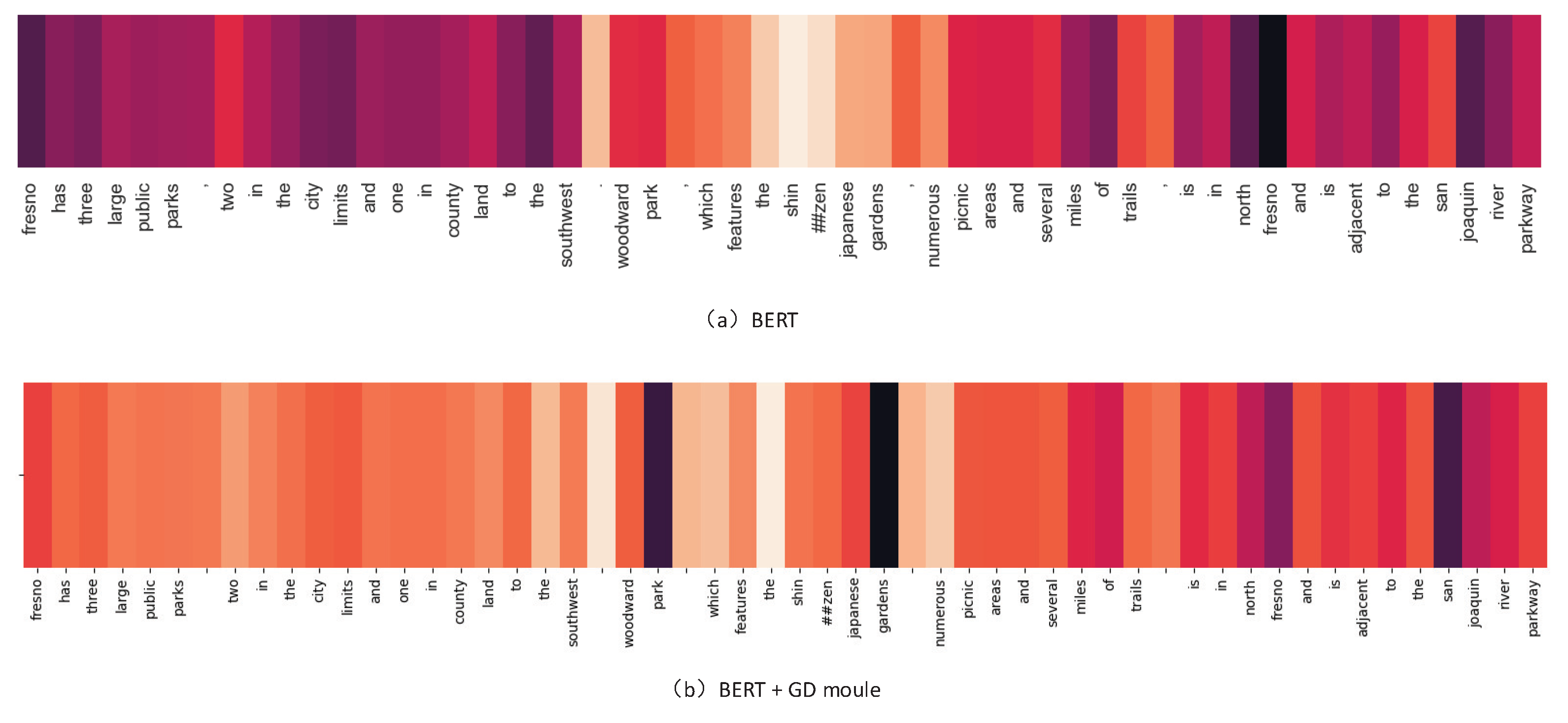
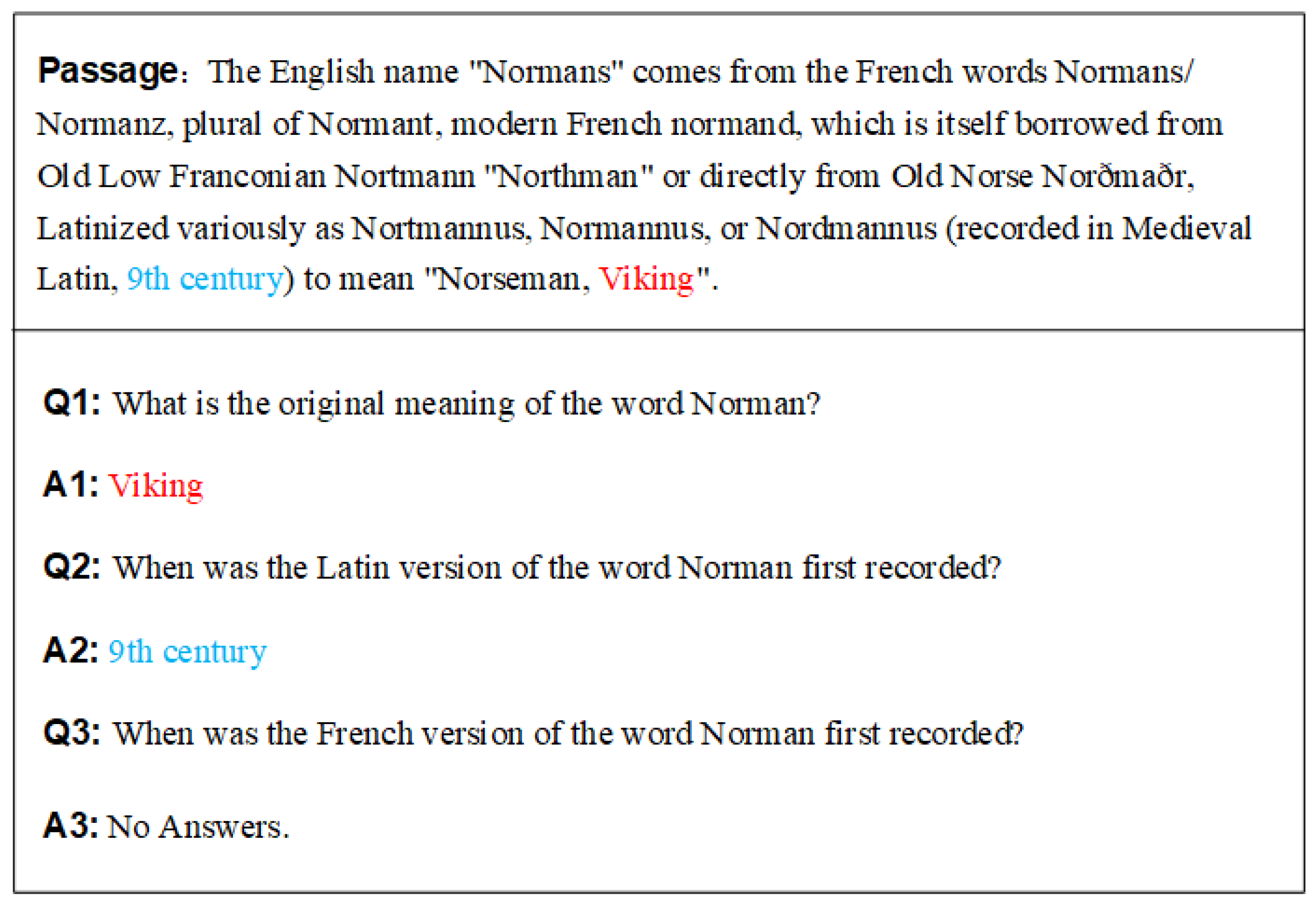
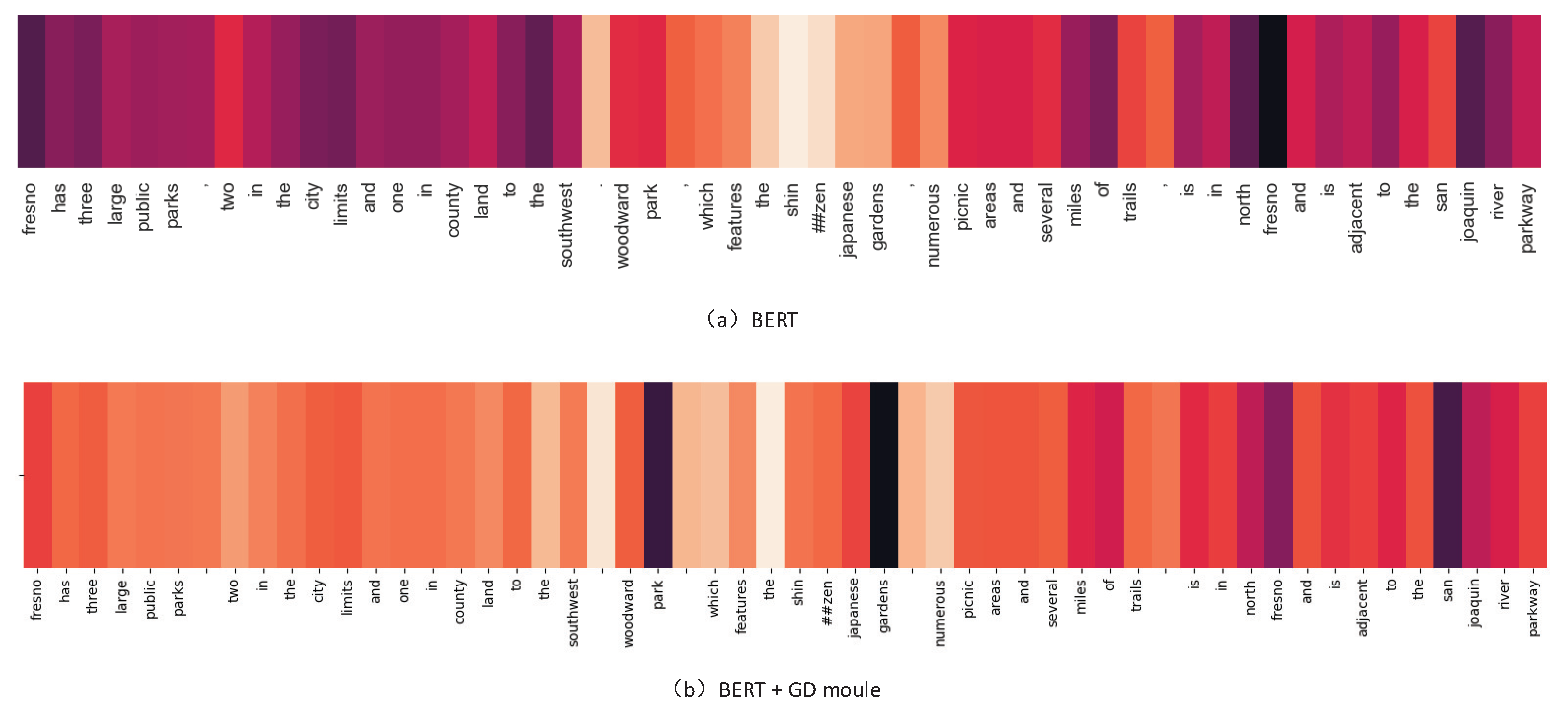
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, Y.; Zhao, H.; Zhang, Z. Topicaware multi-turn dialogue modeling. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Virtual, 2–9 February 2021. [Google Scholar]
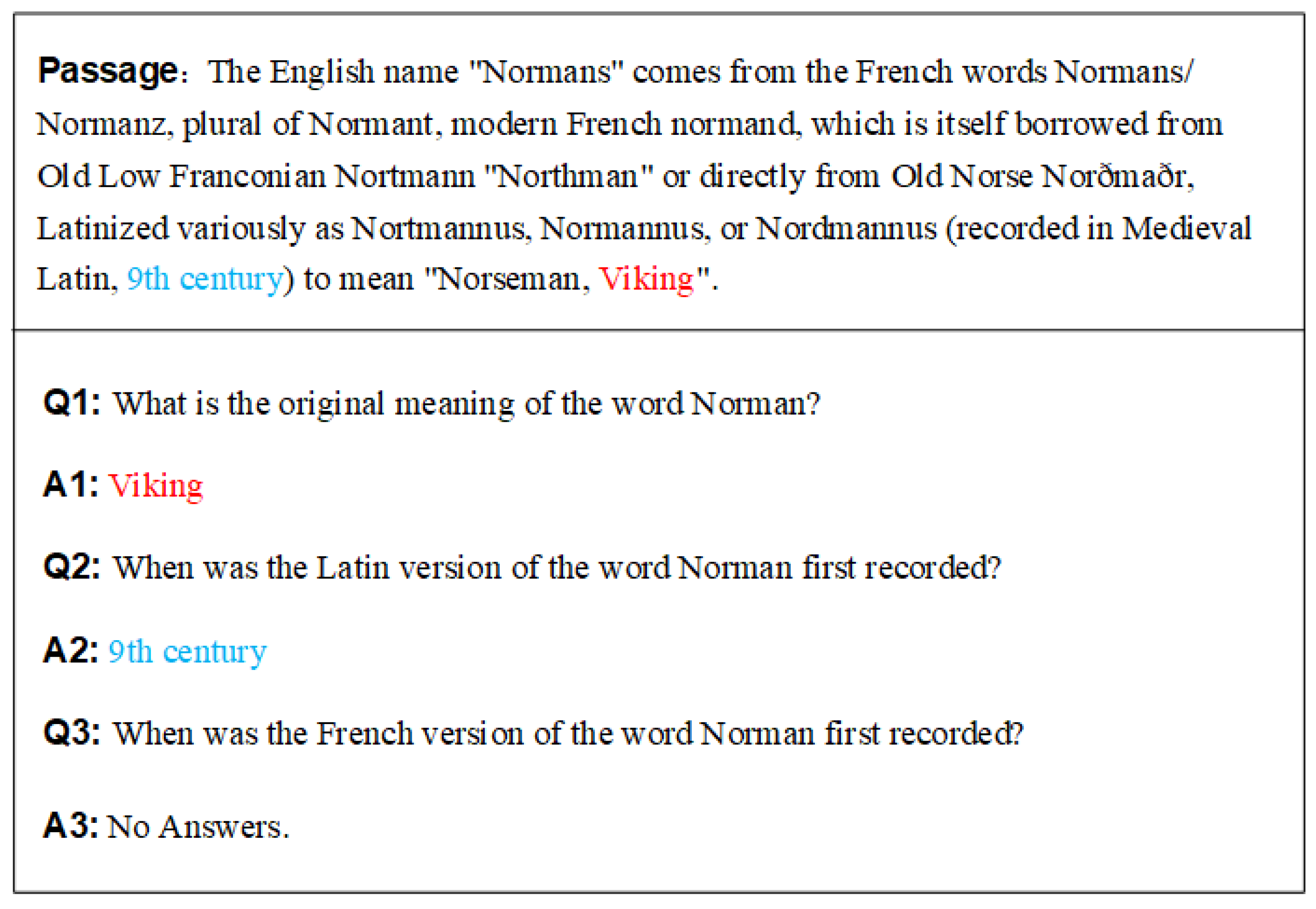
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Melbourne, Australia, 2016; pp. 2383–2392. [Google Scholar]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 784–789. [Google Scholar]
- Seo, M.J.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional Attention Flow for Machine Comprehension. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Cui, Y.; Chen, Z.; Wei, S.; Wang, S.; Liu, T.; Hu, G. Attention-over-Attention Neural Networks for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Melbourne, Australia, 2017; pp. 593–602. [Google Scholar]
- Wang, W.; Yang, N.; Wei, F.; Chang, B.; Zhou, M. Gated self-matching networks for reading comprehension and question answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 189–198. [Google Scholar]
- Yu, A.W.; Dohan, D.; Luong, M.T.; Zhao, R.; Chen, K.; Norouzi, M.; Le, Q.V. Qanet: Combining local convolution with global self-attention for reading comprehension. arXiv 2018, arXiv:1804.09541. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 7 May 2022).
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In Proceedings of the International Conference on Learning Representations, Virtual, 26 April–1 May 2020. [Google Scholar]
- Zhang, Z.; Wu, Y.; Zhao, H.; Li, Z.; Zhang, S.; Zhou, X.; Zhou, X. Semantics-aware BERT for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 9628–9635. [Google Scholar]
- Dai, Y.; Fu, Y.; Yang, L. A Multiple-Choice Machine Reading Comprehension Model with Multi-Granularity Semantic Reasoning. Appl. Sci. 2021, 11, 7945. [Google Scholar] [CrossRef]
- Duan, S.; Zhao, H.; Zhou, J.; Wang, R. Syntax-aware transformer encoder for neural machine translation. In Proceedings of the 2019 International Conference on Asian Language Processing (IALP), Shanghai, China, 15–17 November 2019; pp. 396–401. [Google Scholar]
- Zhou, J.; Li, Z.; Zhao, H. Parsing All: Syntax and Semantics, Dependencies and Spans. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics: Melbourne, Australia, 2020; pp. 4438–4449. [Google Scholar]
- Zhu, F.; Tan, L.Y.; Ng, S.K.; Bressan, S. Syntax-informed Question Answering with Heterogeneous Graph Transformer. arXiv 2022, arXiv:2204.09655. [Google Scholar]
- Zhou, J.; Zhao, H. Head-Driven Phrase Structure Grammar Parsing on Penn Treebank. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Melbourne, Australia, 2019; pp. 2396–2408. [Google Scholar]
- Zhang, Z.; Wu, Y.; Zhou, J.; Duan, S.; Zhao, H.; Wang, R. SG-Net: Syntax-guided machine reading comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 9636–9643. [Google Scholar]
- Zhang, J.; Hua, Y.; Qi, G.; Qi, D. Semantic Parsing for Multiple-relation Chinese Question Answering. In Proceedings of the CCKS Tasks, Tianjin, China, 14–17 August 2018; pp. 101–106. [Google Scholar]
- Fan, T.; Wang, H.; Wu, P. Negative Sentiment Analysis of Internet Users Based on Graph Convolutional Neural Network and Dependent Syntax Analysis. Data Anal. Knowl. Discov. 2021, 5, 97. [Google Scholar]
- Yin, Y.; Zheng, X.; Hu, B.; Zhang, Y.; Cui, X. EEG emotion recognition using fusion model of graph convolutional neural networks and LSTM. Appl. Soft Comput. 2021, 100, 106954. [Google Scholar] [CrossRef]
- Zheng, B.; Wen, H.; Liang, Y.; Duan, N.; Che, W.; Jiang, D.; Zhou, M.; Liu, T. Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension. In Proceedings of the ACL 2020, Online, 5–10 July 2020; Association for Computational Linguistics: Melbourne, Australia, 2020. [Google Scholar]
- Wu, S.; Chen, J.; Xu, T.; Chen, L.; Wu, L.; Hu, Y.; Chen, E. Linking the Characters: Video-Oriented Social Graph Generation via Hierarchical-Cumulative GCN. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 4716–4724. [Google Scholar]
- Lv, S.; Guo, D.; Xu, J.; Tang, D.; Duan, N.; Gong, M.; Shou, L.; Jiang, D.; Cao, G.; Hu, S. Graph-based reasoning over heterogeneous external knowledge for commonsense question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8449–8456. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In Proceedings of the ICLR, Virtual, 26 April–1 May 2020. [Google Scholar]
- Sultan, M.A.; Chandel, S.; Astudillo, R.F.; Castelli, V. On the importance of diversity in question generation for QA. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5651–5656. [Google Scholar]
- Zhu, P.; Hai Zhao, X.L. Dual Multi-head Co-attention for Multi-choice Reading Comprehension. arXiv 2020, arXiv:2001.09415. [Google Scholar]
- Zhuang, Y.; Wang, H. Token-level Dynamic Self-Attention Network for Multi-Passage Reading Comprehension. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Melbourne, Australia, 2019; pp. 2252–2262. [Google Scholar]
- Marcheggiani, D.; Bastings, J.; Titov, I. Exploiting Semantics in Neural Machine Translation with Graph Convolutional Networks. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers); Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 486–492. [Google Scholar]
- Song, L.; Zhang, Y.; Wang, Z.; Gildea, D. N-ary Relation Extraction using Graph-State LSTM. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 2226–2235. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 2205–2215. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Melbourne, Australia, 2020; pp. 3229–3238. [Google Scholar]
- Ding, M.; Zhou, C.; Chen, Q.; Yang, H.; Tang, J. Cognitive Graph for Multi-Hop Reading Comprehension at Scale. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 2694–2703. [Google Scholar]
- De Cao, N.; Aziz, W.; Titov, I. Question Answering by Reasoning Across Documents with Graph Convolutional Networks. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 2306–2317. [Google Scholar]
- Cao, Y.; Fang, M.; Tao, D. BAG: Bi-directional Attention Entity Graph Convolutional Network for Multi-hop Reasoning Question Answering. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 357–362. [Google Scholar]
- Bhargav, G.S.; Glass, M.; Garg, D.; Shevade, S.; Dana, S.; Khandelwal, D.; Subramaniam, L.V.; Gliozzo, A. Translucent answer predictions in multi-hop reading comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 7700–7707. [Google Scholar]
- Li, Z.; Zhao, H.; Parnow, K. Global greedy dependency parsing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8319–8326. [Google Scholar]
- Ma, X.; Hu, Z.; Liu, J.; Peng, N.; Neubig, G.; Hovy, E. Stack-Pointer Networks for Dependency Parsing. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 1403–1414. [Google Scholar]
- Chen, K.; Wang, R.; Utiyama, M.; Sumita, E.; Zhao, T. Syntax-directed attention for neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Wang, Y.; Lee, H.Y.; Chen, Y.N. Tree Transformer: Integrating Tree Structures into Self-Attention. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 1061–1070. [Google Scholar]
- Kasai, J.; Friedman, D.; Frank, R.; Radev, D.; Rambow, O. Syntax-aware Neural Semantic Role Labeling with Supertags. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 701–709. [Google Scholar]
- Strubell, E.; Verga, P.; Andor, D.; Weiss, D.; McCallum, A. Linguistically-Informed Self-Attention for Semantic Role Labeling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 5027–5038. [Google Scholar]
- Jawahar, G.; Sagot, B.; Seddah, D. What Does BERT Learn about the Structure of Language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 3651–3657. [Google Scholar]
- Kuncoro, A.; Kong, L.; Fried, D.; Yogatama, D.; Rimell, L.; Dyer, C.; Blunsom, P. Syntactic Structure Distillation Pretraining for Bidirectional Encoders. Trans. Assoc. Comput. Linguist. 2020, 8, 776–794. [Google Scholar] [CrossRef]
- Vashishth, S.; Bhandari, M.; Yadav, P.; Rai, P.; Bhattacharyya, C.; Talukdar, P. Incorporating Syntactic and Semantic Information in Word Embeddings using Graph Convolutional Networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 3308–3318. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhou, J.; Zhao, H. Head-driven phrase structure grammar parsing on Penn treebank. arXiv 2019, arXiv:1907.02684. [Google Scholar]
- Cui, Y.; Liu, T.; Che, W.; Xiao, L.; Chen, Z.; Ma, W.; Wang, S.; Hu, G. A Span-Extraction Dataset for Chinese Machine Reading Comprehension. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 5883–5889. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | EM(%) | F1(%) | EM(%) for MgSG | F1(%) for MgSG |
|---|---|---|---|---|
| Human performance | 86.8 | 89.5 | ||
| QANet | 62.6 | 66.7 | ||
| SAN | 68.2 | 70.9 | ||
| Match-LSTM | 60.3 | 63.5 | ||
| BERT-base | 75.8 | 79.2 | 77.2 | 81.1 |
| BERT-large | 80.4 | 83.3 | 80.9 | 84.0 |
| ALBERT-base | 77.1 | 80.1 | 81.5 | 84.8 |
| ALBERT-large | 79.4 | 82.3 | 81.8 | 85.6 |
| ALBERT-xxlarge | 85.6 | 88.1 | 85.9 | 88.2 |
| XLNET-base | 77.6 | 80.3 | 79.5 | 82.1 |
| PERT-base | 76.3 | 80.1 | 76.9 | 80.5 |
| PERT-large | 82.8 | 86.1 | 82.5 | 86.0 |
| ELECTRA-base | 79.5 | 82.5 | 80.2 | 83.6 |
| Model | EM(%) | F1(%) | EM(%) for MgSG | F1(%) for MgSG |
|---|---|---|---|---|
| Human performance | 75.8 | 79.2 | ||
| P-Reader (single model) | 76.7 | 80.6 | ||
| Z-Reader (single model) | 76.3 | 80.5 | ||
| BERT-base | 63.6 | 83.9 | 64.3 | 84.4 |
| BERT-wwm-ext | 64.6 | 84.8 | 64.8 | 84.8 |
| RoBERTa-wwm-ext | 65.5 | 85.5 | 65.1 | 85.6 |
| ELECTRA-base | 66.9 | 83.5 | 67.5 | 84.7 |
| ELECTRA-large | 67.6 | 83.8 | 67.9 | 85.4 |
| PERT-base | 64.1 | 84.5 | 64.8 | 85.1 |
| MacBERT-base | 66.3 | 85.4 | 66.1 | 85.4 |
| ERNIE 2.0-base | 67.8 | 87.5 | 67.7 | 87.3 |
| Model | EM (%) | F1 (%) |
|---|---|---|
| BERT | 75.8 (±0.2) | 79.2 (±0.2) |
| BERT + GD | 76.7 (±0.1) | 80.6 (±0.2) |
| BERT + GE | 76.5 (±0.1) | 80.5 (±0.2) |
| BERT + GD + GE | 77.2 (±0.1) | 81.1 (±0.2) |
| Num of Layers | EM (%) | F1 (%) |
|---|---|---|
| 1 | 76.1 | 80.1 |
| 2 | 75.5 | 80.2 |
| 3 | 76.8 | 80.8 |
| 4 | 77.2 | 81.1 |
| 5 | 76.5 | 80.8 |
| 6 | 76.4 | 80.5 |
| Threshold | EM (%) | F1 (%) |
|---|---|---|
| 0 | 75.5 | 78.8 |
| 1 | 76.8 | 80.2 |
| 2 | 76.9 | 80.5 |
| 3 | 76.6 | 80.1 |
| 4 | 76.1 | 79.5 |
| Type | EM (%) | F1 (%) |
|---|---|---|
| Noun | 76.5 | 80.4 |
| Noun + Pron | 76.1 | 80.2 |
| Noun + Time | 76.6 | 80.5 |
| Noun + Num | 76.7 | 80.5 |
| Noun + Num + Time | 76.7 | 80.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Liu, Z.; Li, G.; Zhu, C.; Zhang, Y. Multigranularity Syntax Guidance with Graph Structure for Machine Reading Comprehension. Appl. Sci. 2022, 12, 9525. https://doi.org/10.3390/app12199525
Xu C, Liu Z, Li G, Zhu C, Zhang Y. Multigranularity Syntax Guidance with Graph Structure for Machine Reading Comprehension. Applied Sciences. 2022; 12(19):9525. https://doi.org/10.3390/app12199525
Chicago/Turabian StyleXu, Chuanyun, Zixu Liu, Gang Li, Changpeng Zhu, and Yang Zhang. 2022. "Multigranularity Syntax Guidance with Graph Structure for Machine Reading Comprehension" Applied Sciences 12, no. 19: 9525. https://doi.org/10.3390/app12199525
APA StyleXu, C., Liu, Z., Li, G., Zhu, C., & Zhang, Y. (2022). Multigranularity Syntax Guidance with Graph Structure for Machine Reading Comprehension. Applied Sciences, 12(19), 9525. https://doi.org/10.3390/app12199525