


Multiple-Stage Knowledge Distillation

 ,
,
Abstract
:1. Introduction
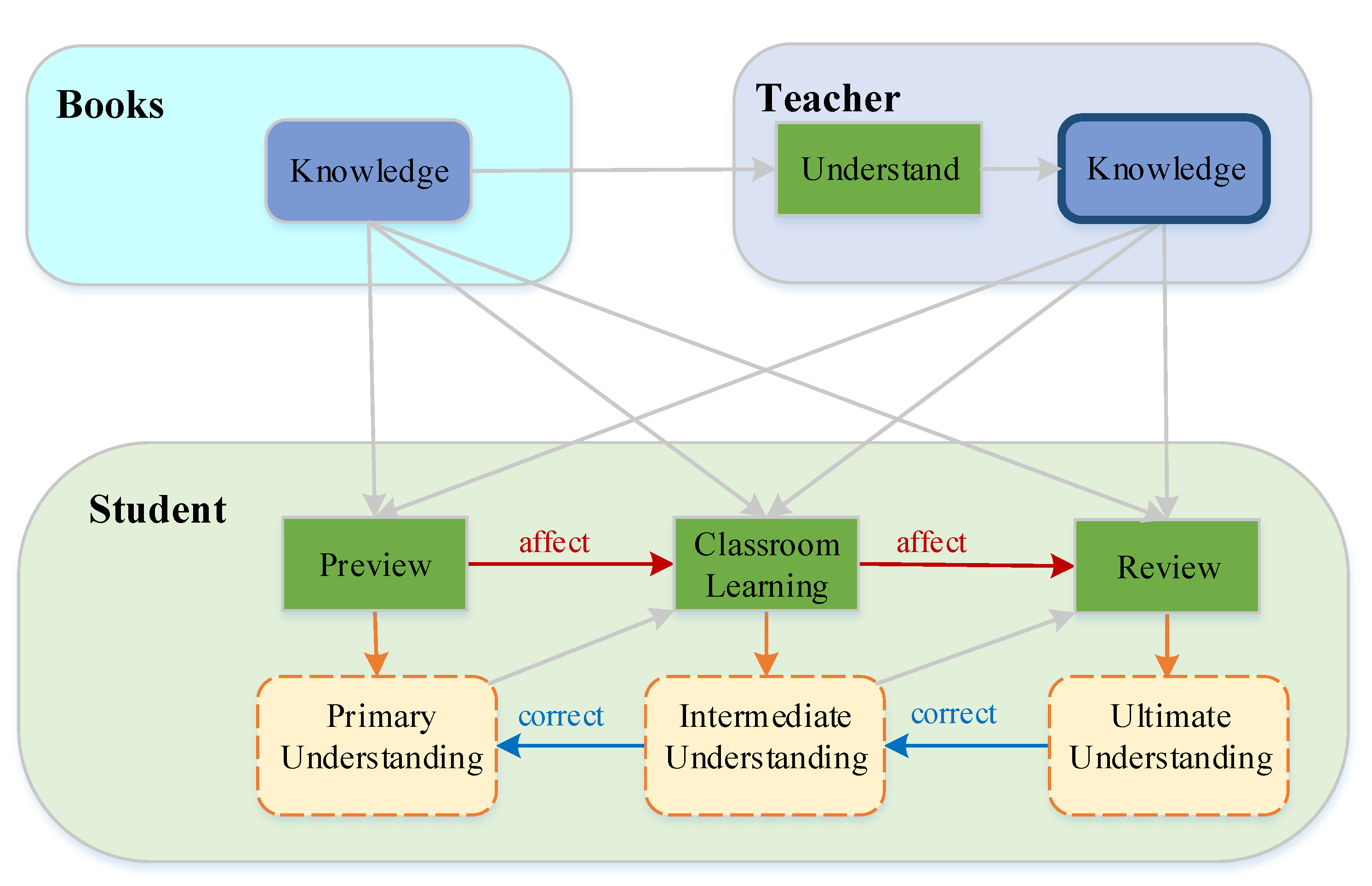
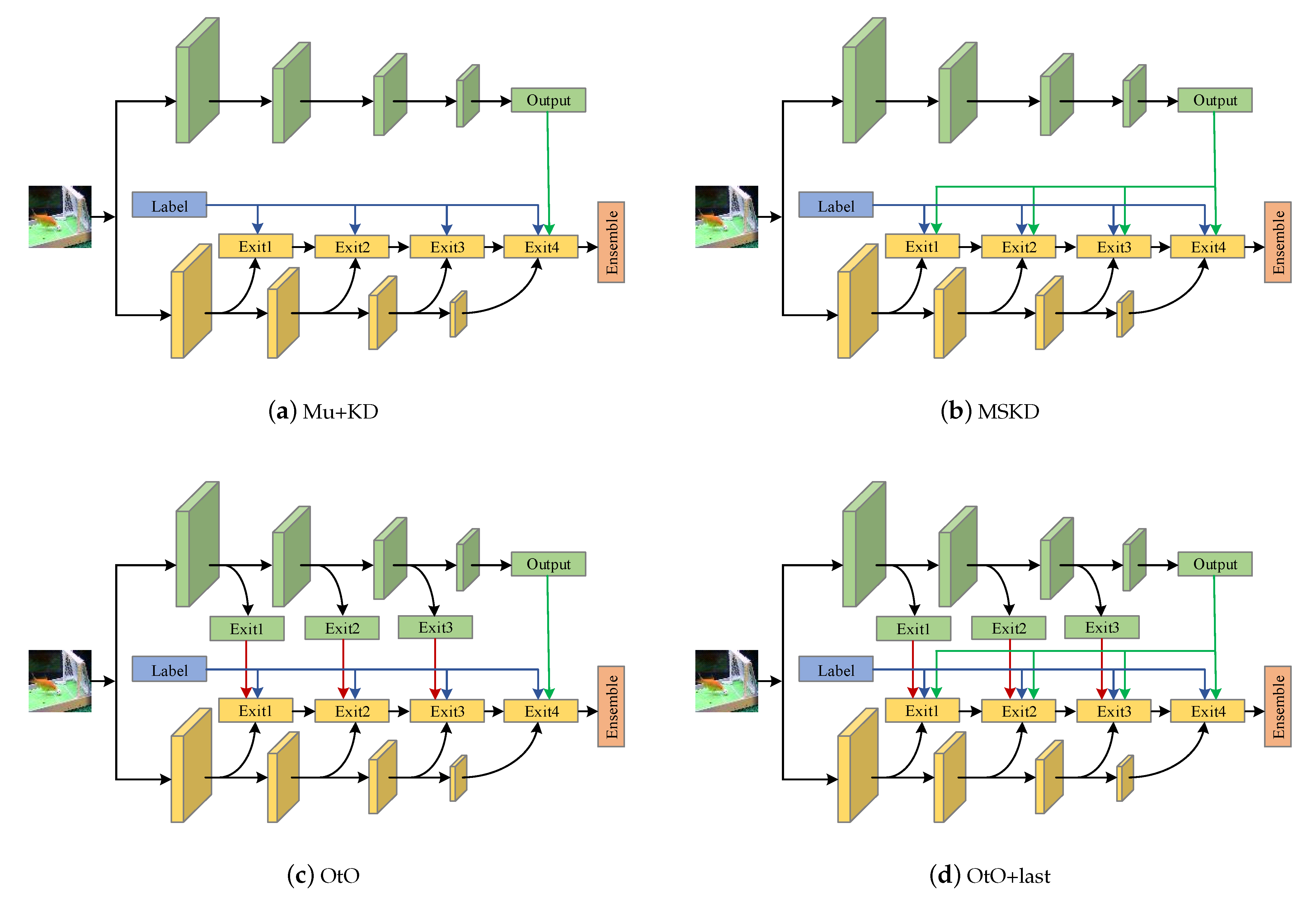
- We propose a multi-stage learning approach where the student can learn the teacher’s understanding of the original knowledge at different stages and the student is able to gradually get an identical understanding with the teacher, even becoming superior to the teacher.
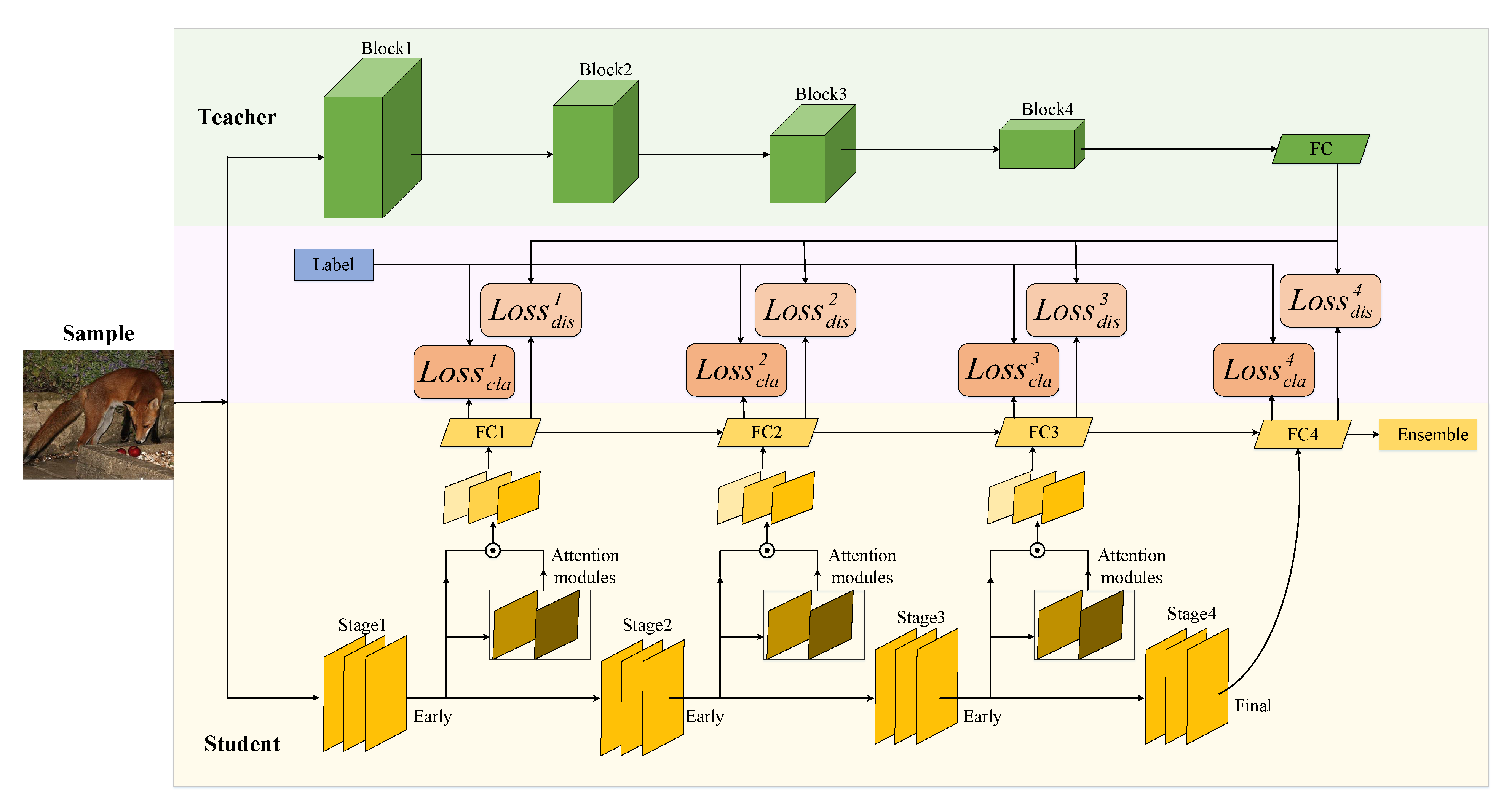
- We propose a multiple-stage KD (MSKD) method for the supervised training of different stages of a multi-exit network. In the MSKD, the output of the teacher network is used to guide the different stages of the student network, and the trained early stage network is trained later in the training process, thereby resulting in phased recursive training.
- We extend the MSKD method to a one-to-one MSKD (OtO) method that allows a multi-exit teacher network to provide one-to-one targeted instruction to a multi-exit student network.
- Extensive experiments were conducted using CIFAR100 and Tiny ImageNet to test different teacher–student network architectures and verify the effectiveness of the proposed method.
2. Related Work
2.1. KD
2.2. Multi-Exit Architectures
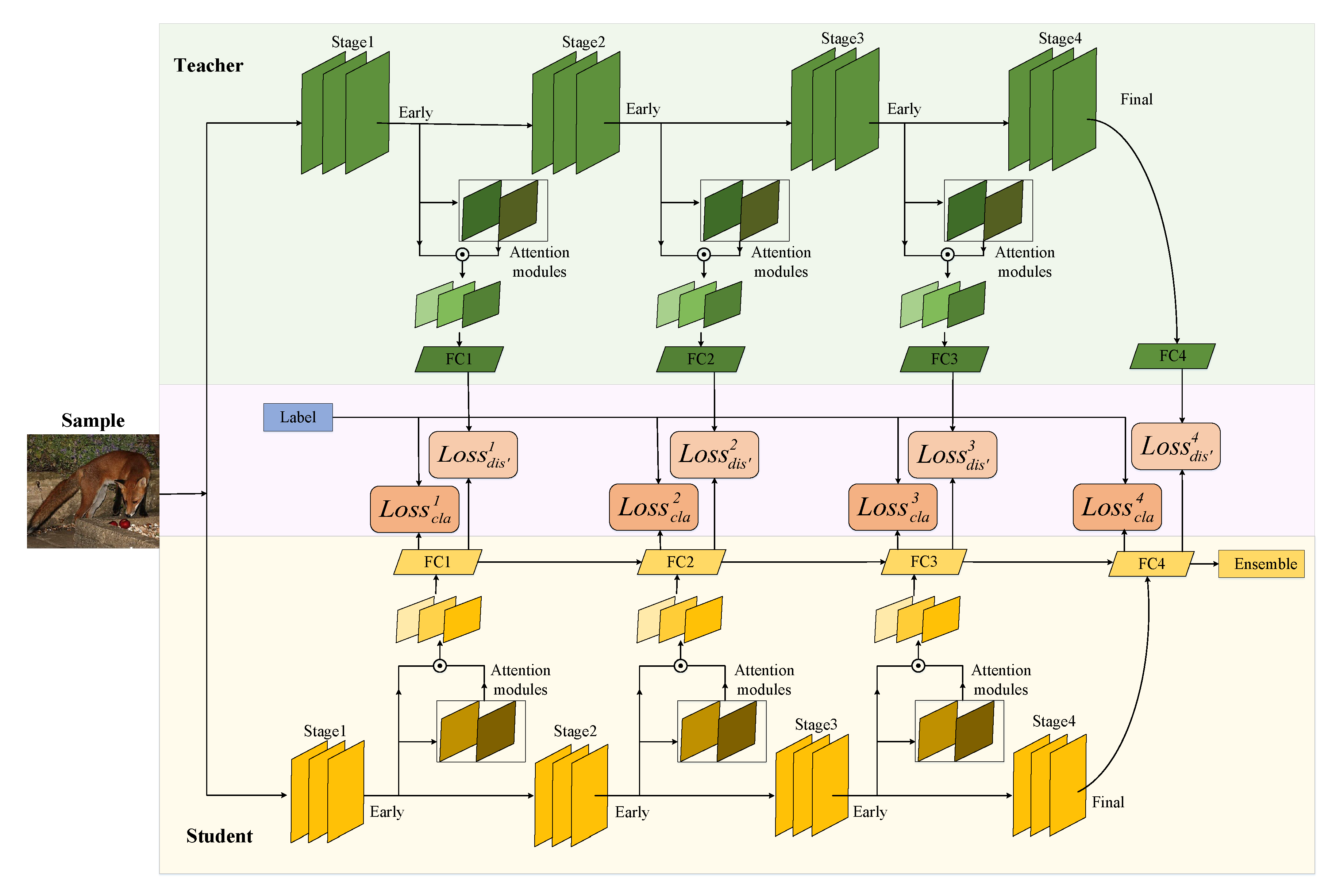
3. Proposed Method
3.1. KD
3.2. MSKD
| Algorithm 1: Multiple-Stage Knowledge Distillation | |||
Given: Dataset , Model t, Multi-exit Model s | |||
| 1 | for | indo | |
| 2 |  | = | |
| // s | |||
| 3 | = | ||
| // | |||
| 4 | |||
| 5 | forkindo | ||
| 6 |  | ||
| 7 | end | ||
| 8 | |||
| 9 | |||
| 10 | end | ||
3.3. OtO Method
4. Experiments
4.1. Experimental Setup
4.2. Comparison with the Benchmark Method
4.3. Comparison with Other KD Methods
5. Analysis
5.1. Ablation Study
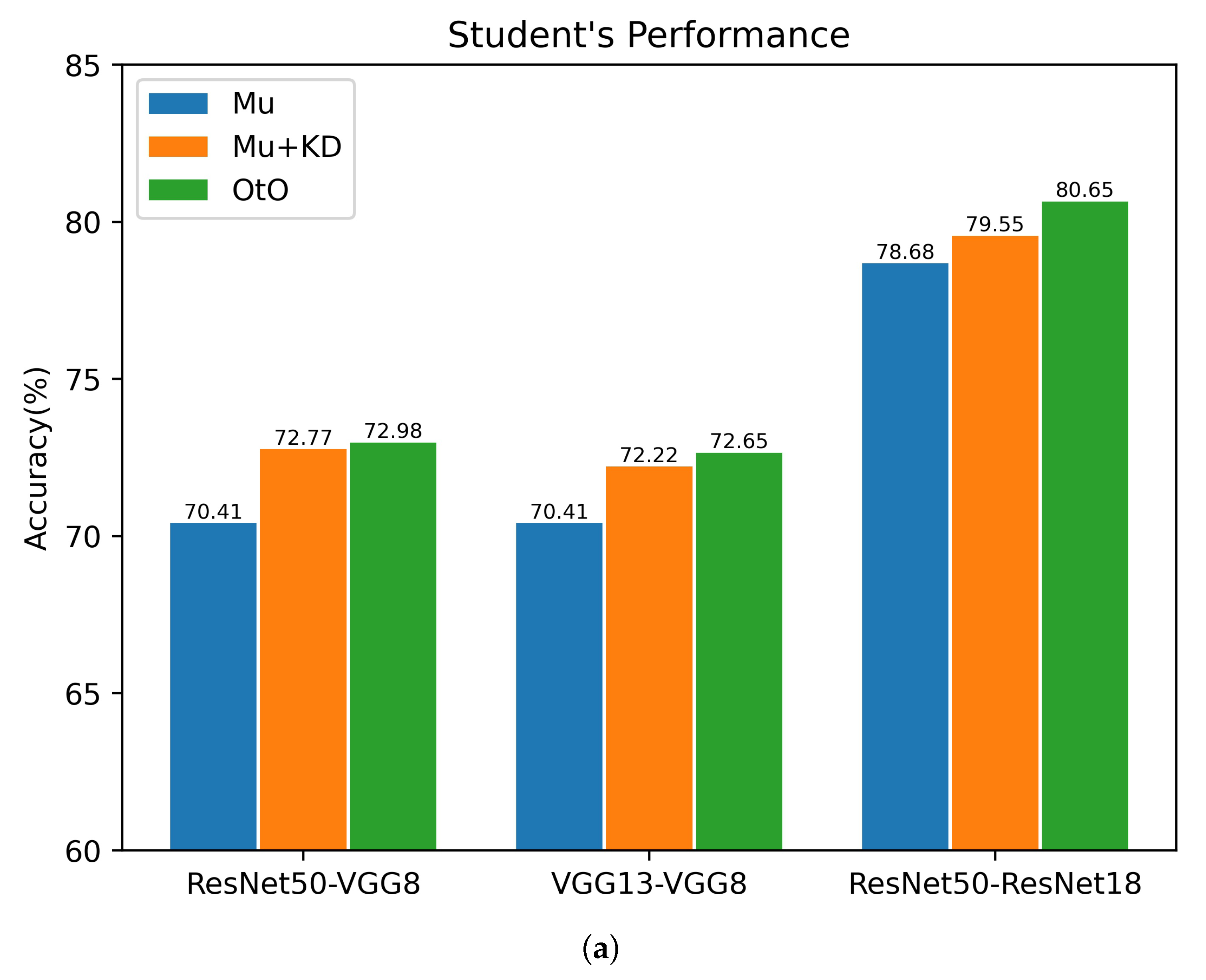
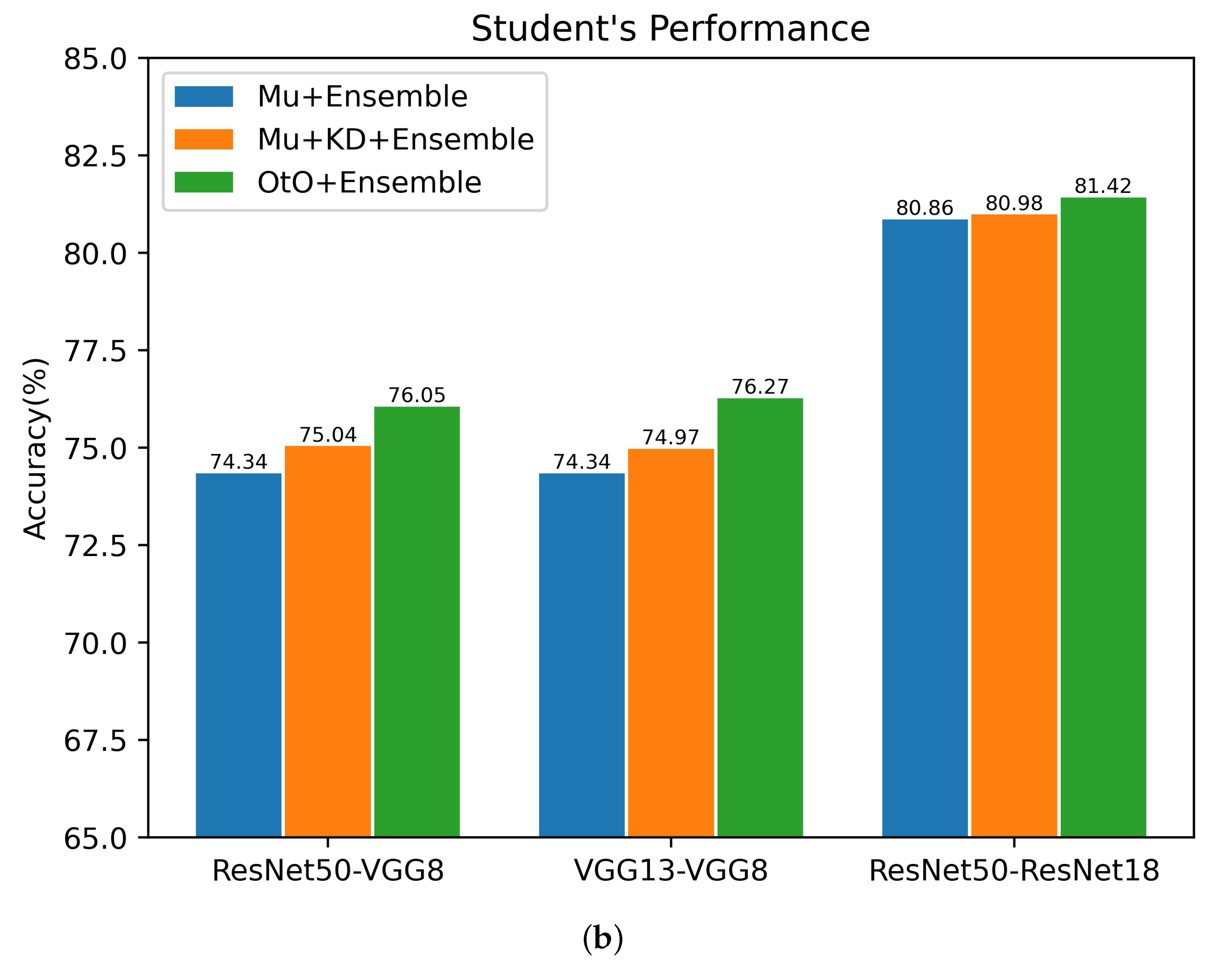
5.2. Ensemble Effectiveness of the Proposed Method
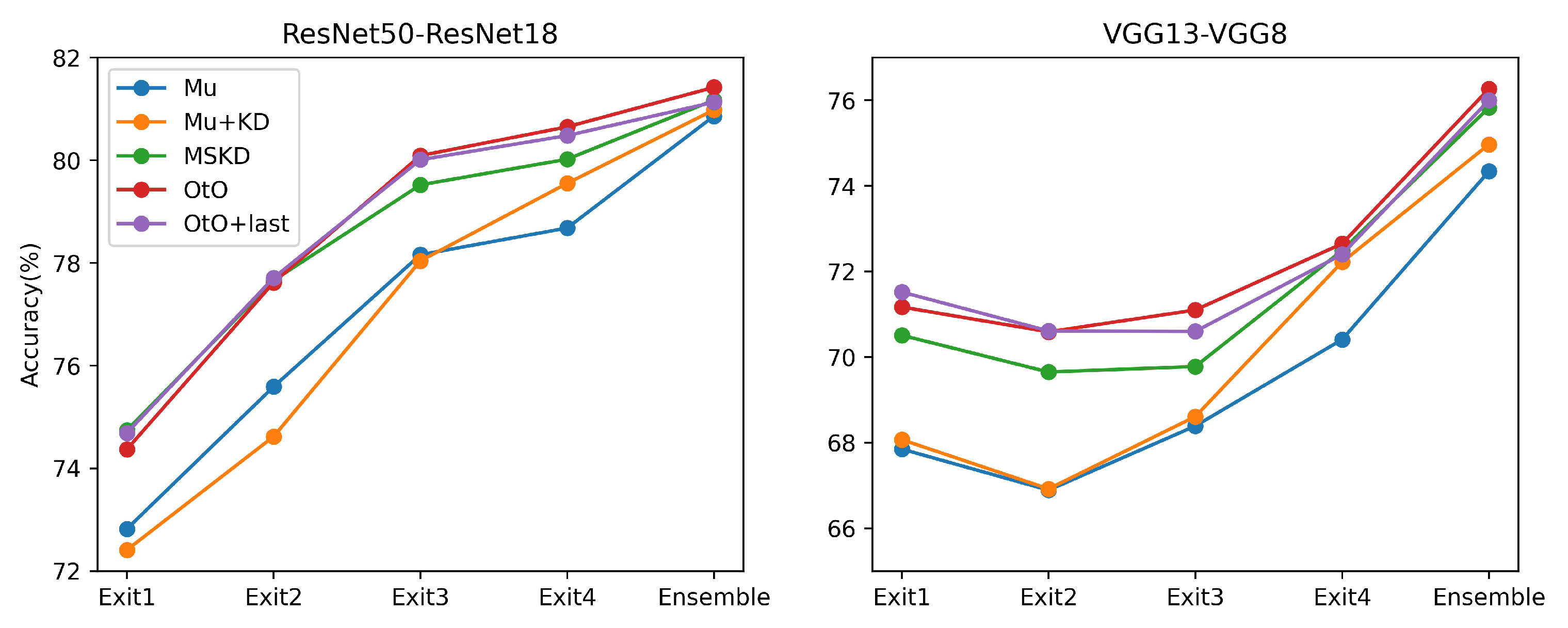
5.3. Exploratory Experiments
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Aggarwal, K.; Mijwil, M.M.; Al-Mistarehi, A.H.; Alomari, S.; Gök, M.; Alaabdin, A.M.Z.; Abdulrhman, S.H. Has the Future Started? The Current Growth of Artificial Intelligence, Machine Learning, and Deep Learning. IRAQI J. Comput. Sci. Math. 2022, 3, 115–123. [Google Scholar]
- Komodakis, N.; Zagoruyko, S. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Liu, Y.; Zhang, W.; Wang, J. Adaptive multi-teacher multi-level knowledge distillation. Neurocomputing 2020, 415, 106–113. [Google Scholar] [CrossRef]
- Aguilar, G.; Ling, Y.; Zhang, Y.; Yao, B.; Fan, X.; Guo, C. Knowledge distillation from internal representations. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7350–7357. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Wang, L.; Yoon, K.J. Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3048–3068. [Google Scholar] [CrossRef] [PubMed]
- Yuan, L.; Tay, F.E.; Li, G.; Wang, T.; Feng, J. Revisiting knowledge distillation via label smoothing regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3903–3911. [Google Scholar]
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Levine, N.; Matsukawa, A.; Ghasemzadeh, H. Improved knowledge distillation via teacher assistant. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5191–5198. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Tront, Toronto, ON, Canada, 2009. [Google Scholar]
- Deng, J. A large-scale hierarchical image database. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Stat 2015, 1050, 9. [Google Scholar]
- Cheng, X.; Rao, Z.; Chen, Y.; Zhang, Q. Explaining knowledge distillation by quantifying the knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12925–12935. [Google Scholar]
- Mobahi, H.; Farajtabar, M.; Bartlett, P. Self-distillation amplifies regularization in hilbert space. Adv. Neural Inf. Process. Syst. 2020, 33, 3351–3361. [Google Scholar]
- Phuong, M.; Lampert, C. Towards understanding knowledge distillation. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5142–5151. [Google Scholar]
- Allen-Zhu, Z.; Li, Y. Towards understanding ensemble, knowledge distillation and self-distillation in deep learning. arXiv 2020, arXiv:2012.09816. [Google Scholar]
- Fukuda, T.; Suzuki, M.; Kurata, G.; Thomas, S.; Cui, J.; Ramabhadran, B. Efficient Knowledge Distillation from an Ensemble of Teachers. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 3697–3701. [Google Scholar]
- Beyer, L.; Zhai, X.; Royer, A.; Markeeva, L.; Anil, R.; Kolesnikov, A. Knowledge distillation: A good teacher is patient and consistent. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–23 June 2022; pp. 10925–10934. [Google Scholar]
- Li, J.; Guo, J.; Sun, X.; Li, C.; Meng, L. A Fast Identification Method of Gunshot Types Based on Knowledge Distillation. Appl. Sci. 2022, 12, 5526. [Google Scholar] [CrossRef]
- Chen, L.; Ren, J.; Mao, X.; Zhao, Q. Electroglottograph-Based Speech Emotion Recognition via Cross-Modal Distillation. Appl. Sci. 2022, 12, 4338. [Google Scholar] [CrossRef]
- Passalis, N.; Tefas, A. Learning deep representations with probabilistic knowledge transfer. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 268–284. [Google Scholar]
- Liu, L.; Huang, Q.; Lin, S.; Xie, H.; Wang, B.; Chang, X.; Liang, X. Exploring inter-channel correlation for diversity-preserved knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 8271–8280. [Google Scholar]
- Wen, T.; Lai, S.; Qian, X. Preparing lessons: Improve knowledge distillation with better supervision. Neurocomputing 2021, 454, 25–33. [Google Scholar] [CrossRef]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Representation Distillation. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Xu, G.; Liu, Z.; Li, X.; Loy, C.C. Knowledge distillation meets self-supervision. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin, Germany, 2020; pp. 588–604. [Google Scholar]
- Yang, C.; An, Z.; Cai, L.; Xu, Y. Hierarchical Self-supervised Augmented Knowledge Distillation. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI), Montreal, QC, Canada, 19–27 August 2021; pp. 1217–1223. [Google Scholar]
- Fu, S.; Li, Z.; Liu, Z.; Yang, X. Interactive knowledge distillation for image classification. Neurocomputing 2021, 449, 411–421. [Google Scholar] [CrossRef]
- Teerapittayanon, S.; McDanel, B.; Kung, H.T. Branchynet: Fast inference via early exiting from deep neural networks. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2464–2469. [Google Scholar]
- Huang, G.; Chen, D.; Li, T.; Wu, F.; van der Maaten, L.; Weinberger, K. Multi-Scale Dense Networks for Resource Efficient Image Classification. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Li, H.; Zhang, H.; Qi, X.; Yang, R.; Huang, G. Improved techniques for training adaptive deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1891–1900. [Google Scholar]
- Zhang, L.; Tan, Z.; Song, J.; Chen, J.; Bao, C.; Ma, K. Scan: A scalable neural networks framework towards compact and efficient models. Adv. Neural Inf. Process. Syst. 2019, 32, 1–10. [Google Scholar]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3713–3722. [Google Scholar]
- Phuong, M.; Lampert, C.H. Distillation-based training for multi-exit architectures. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1355–1364. [Google Scholar]
- Wang, X.; Li, Y. Harmonized dense knowledge distillation training for multi-exit architectures. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 10–218. [Google Scholar]
- Duan, K.; Keerthi, S.S.; Chu, W.; Shevade, S.K.; Poo, A.N. Multi-category classification by soft-max combination of binary classifiers. In Proceedings of the International Workshop on Multiple Classifier Systems, Guilford, UK, 11–13 June 2003; Springer: Berlin, Germany, 2003; pp. 125–134. [Google Scholar]
- Johnson, D.; Sinanovic, S. Symmetrizing the kullback-leibler distance. IEEE Trans. Inf. Theory 2001, 57, 5455–5466. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the British Machine Vision Conference, York, UK, 19–22 September 2016; British Machine Vision Association: York, UK, 2016. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation policies from data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2015, arXiv:1412.6550. [Google Scholar]
- Tung, F.; Mori, G. Similarity-preserving knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1365–1374. [Google Scholar]
- Peng, B.; Jin, X.; Liu, J.; Li, D.; Wu, Y.; Liu, Y.; Zhou, S.; Zhang, Z. Correlation congruence for knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5007–5016. [Google Scholar]
- Ahn, S.; Hu, S.X.; Damianou, A.; Lawrence, N.D.; Dai, Z. Variational information distillation for knowledge transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9163–9171. [Google Scholar]
- Park, W.; Kim, D.; Lu, Y.; Cho, M. Relational knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3967–3976. [Google Scholar]
- Heo, B.; Lee, M.; Yun, S.; Choi, J.Y. Knowledge transfer via distillation of activation boundaries formed by hidden neurons. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3779–3787. [Google Scholar]
- Kim, J.; Park, S.; Kwak, N. Paraphrasing complex network: Network compression via factor transfer. Adv. Neural Inf. Process. Syst. 2018, 31, 2760–2769. [Google Scholar]
- Xu, C.; Gao, W.; Li, T.; Bai, N.; Li, G.; Zhang, Y. Teacher-student collaborative knowledge distillation for image classification. Appl. Intell. 2022, 1–13. [Google Scholar] [CrossRef]
- Ji, M.; Heo, B.; Park, S. Show, attend and distill: Knowledge distillation via attention-based feature matching. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 7945–7952. [Google Scholar]
- Scardapane, S.; Scarpiniti, M.; Baccarelli, E.; Uncini, A. Why should we add early exits to neural networks? Cogn. Comput. 2020, 12, 954–966. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Total | Category | Size | Data Augmentation |
|---|---|---|---|---|
| CIFAR100 | 60 k | 100 | 32 × 32 | random cropping and horizon flipping |
| Tiny ImageNet | 120 k | 200 | 64 × 64 | random rotation |
| Teacher | Baseline | Student | Baseline | Exit1 | Exit2 | Exit3 | Exit4 | Ensemble |
|---|---|---|---|---|---|---|---|---|
| ResNet152 | 80.88 | ResNet50 | 79.34 | 79.32 | 80.80 | 81.78 | 81.74 | 83.20 |
| ResNet152 | 80.88 | ResNet18 | 78.47 | 75.06 | 77.40 | 80.15 | 80.50 | 81.73 |
| ResNet152 | 80.88 | ResNet10 | 76.19 | 73.19 | 75.12 | 77.52 | 78.02 | 79.74 |
| ResNet50 | 79.34 | ResNet18 | 78.47 | 74.37 | 77.62 | 80.09 | 80.65 | 81.42 |
| ResNet50 | 79.34 | VGG8 | 70.36 | 71.20 | 69.79 | 70.95 | 72.98 | 76.05 |
| VGG13 | 74.64 | VGG8 | 70.36 | 71.17 | 70.59 | 71.10 | 72.65 | 76.27 |
| Teacher | Baseline | Student | Baseline | Exit1 | Exit2 | Exit3 | Exit4 | Ensemble |
|---|---|---|---|---|---|---|---|---|
| ResNet34 | 66.40 | ResNet34 | 66.40 | 59.52 | 63.80 | 68.65 | 70.38 | 71.38 |
| ResNet34 | 66.40 | ResNet18 | 64.40 | 59.86 | 62.30 | 65.30 | 68.04 | 69.86 |
| Teacher | ResNet152 | ResNet152 | ResNet152 | ResNet50 | ResNet50 | VGG13 | WRN40-2 |
|---|---|---|---|---|---|---|---|
| Student | ResNet50 | ResNet18 | ResNet10 | ResNet18 | VGG8 | VGG8 | WRN16-2 |
| KD [14] | 79.69 | 79.86 | 77.85 | 79.72 | 73.81 | 72.98 | 74.92 |
| FitNet [41] | 80.51 | 79.24 | 78.02 | 76.27 | 73.24 | 73.22 | 73.07 |
| AT [5] | 80.41 | 80.19 | 78.45 | 78.28 | 74.01 | 73.48 | 73.97 |
| SP [42] | 80.72 | 79.87 | 78.25 | 79.32 | 73.52 | 73.49 | 74.34 |
| CC [43] | 79.89 | 79.82 | 78.06 | 77.42 | 73.48 | 73.04 | 73.18 |
| VID [44] | 79.24 | 79.67 | 77.80 | 76.79 | 73.46 | 72.97 | 74.07 |
| RKD [45] | 80.22 | 79.60 | 77.90 | 78.75 | 73.51 | 73.19 | 73.36 |
| PKT [23] | 80.57 | 79.44 | 78.41 | 78.89 | 73.61 | 73.25 | 74.42 |
| AB [46] | 81.21 | 79.50 | 78.18 | 76.77 | 73.65 | 73.35 | 72.65 |
| FT [47] | 80.37 | 79.26 | 77.53 | 76.29 | 72.98 | 73.44 | 73.33 |
| CRD [26] | 80.53 | 79.81 | 78.60 | 74.58 | 74.58 | 74.29 | 75.79 |
| SSKD [27] | 80.29 | 80.36 | 78.60 | 79.72 | 75.36 | 75.27 | 76.14 |
| HSAKD [28] | 83.33 | 82.17 | 79.75 | 81.22 | 75.20 | 75.07 | 78.20 |
| TSKD [48] | 83.09 | 81.27 | 79.34 | 81.28 | 75.63 | 75.42 | 78.31 |
| MSKD (ours) | 82.37 | 81.32 | 79.38 | 81.17 | 75.74 | 75.83 | 77.58 |
| OtO (ours) | 83.20 | 81.73 | 79.74 | 81.42 | 76.05 | 76.27 | 78.57 |
| OtO* (ours) | 83.47 | 82.63 | 80.52 | 82.10 | 76.19 | 76.36 | 78.72 |
| Teacher | ResNet34 | ResNet34 |
|---|---|---|
| Student | ResNet18 | ResNet34 |
| Teacher | 66.40 | 66.40 |
| Student | 64.40 | 66.40 |
| KD [14] | 67.90 | 68.80 |
| FitNet [41] | 64.44 | 66.18 |
| AT [5] | 66.54 | 67.16 |
| SP [42] | 67.06 | 68.36 |
| VID [44] | 66.92 | 68.08 |
| RKD [45] | 65.90 | 67.80 |
| PKT [23] | 65.76 | 68.18 |
| CRD [26] | 67.94 | 68.96 |
| AFD [49] | 68.56 | 69.58 |
| MSKD (ours) | 69.04 | 70.78 |
| OtO (ours) | 69.86 | 71.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Bai, N.; Gao, W.; Li, T.; Li, M.; Li, G.; Zhang, Y. Multiple-Stage Knowledge Distillation. Appl. Sci. 2022, 12, 9453. https://doi.org/10.3390/app12199453
Xu C, Bai N, Gao W, Li T, Li M, Li G, Zhang Y. Multiple-Stage Knowledge Distillation. Applied Sciences. 2022; 12(19):9453. https://doi.org/10.3390/app12199453
Chicago/Turabian StyleXu, Chuanyun, Nanlan Bai, Wenjian Gao, Tian Li, Mengwei Li, Gang Li, and Yang Zhang. 2022. "Multiple-Stage Knowledge Distillation" Applied Sciences 12, no. 19: 9453. https://doi.org/10.3390/app12199453
APA StyleXu, C., Bai, N., Gao, W., Li, T., Li, M., Li, G., & Zhang, Y. (2022). Multiple-Stage Knowledge Distillation. Applied Sciences, 12(19), 9453. https://doi.org/10.3390/app12199453