

Deep Reinforcement Learning for Vehicle Platooning at a Signalized Intersection in Mixed Traffic with Partial Detection


Abstract
1. Introduction
- We combined systems that work together, including platoon and DRL, with partial detection at a signalized intersection. DRL was the main solution to improve signal system optimization and traffic efficiency. We proposed a new state description for the mixed traffic (IMS only collected information from platoon vehicles (CVs)). Compared with two benchmark options, ATSC and MP, the proposed solution reduced the waiting time of all vehicles significantly.
- A set of hyperparameters was tested to identify the main influencing parameters in the learning process.
- We also considered the effect of platoon size (number of vehicles in the platoon) at the intersection to measure the average delay time, waiting time, speed of traffic, and travel time. The contribution of this paper increased the understanding of the influence of platoons at signal intersections.
- Finally, we evaluated the influence of CV penetration rate on the model results and recommended reasonable rates.
2. Research Methodology
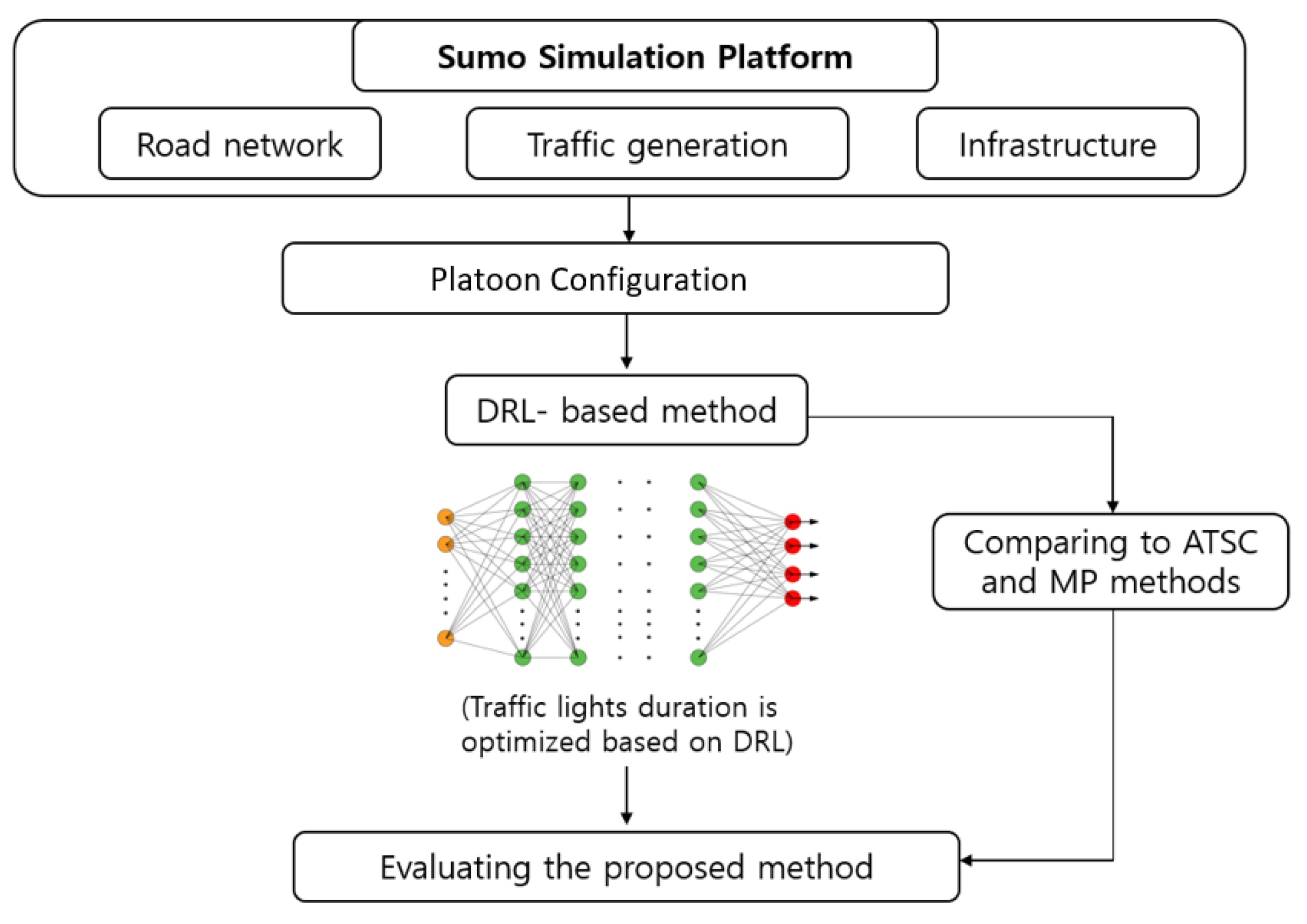
2.1. Research Architecture
2.2. Longitudinal Car-Following Models
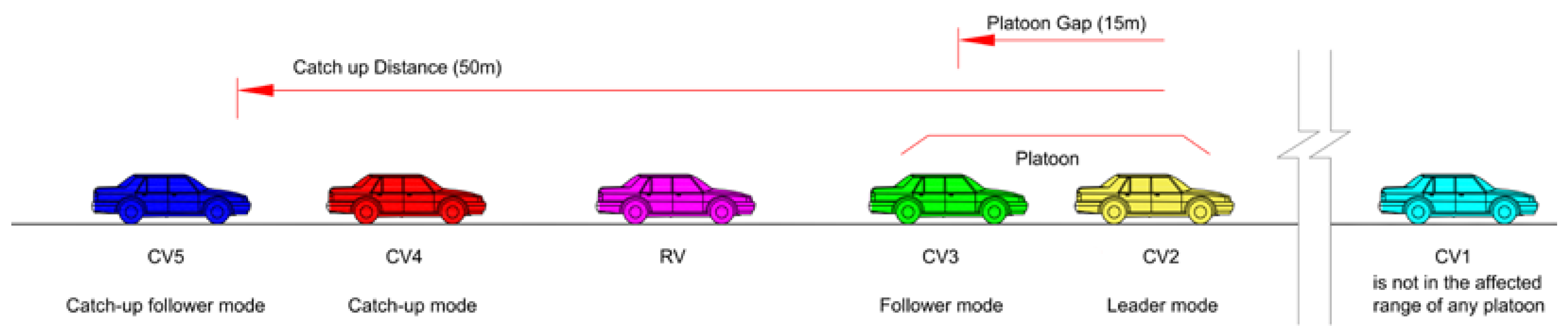
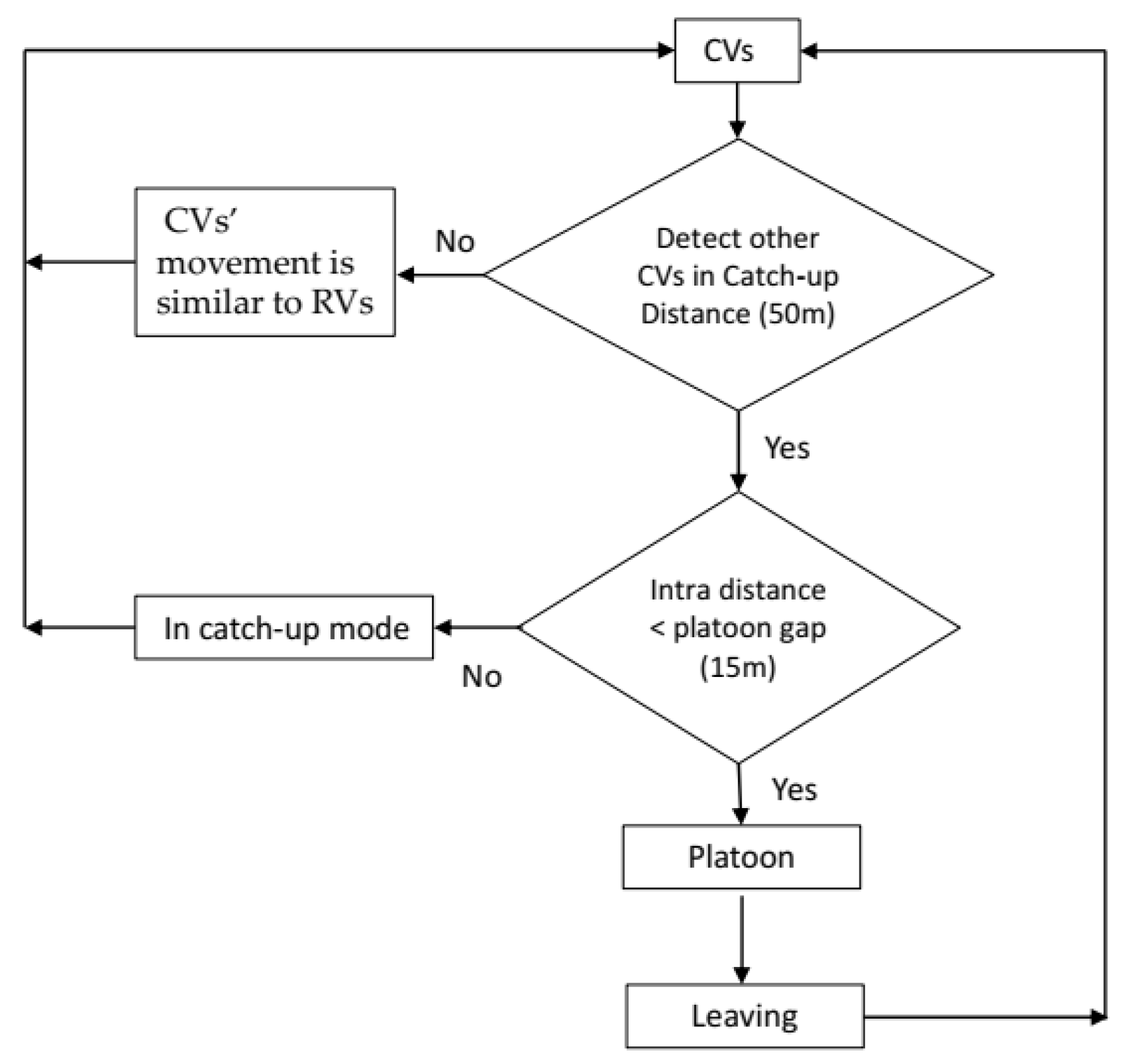
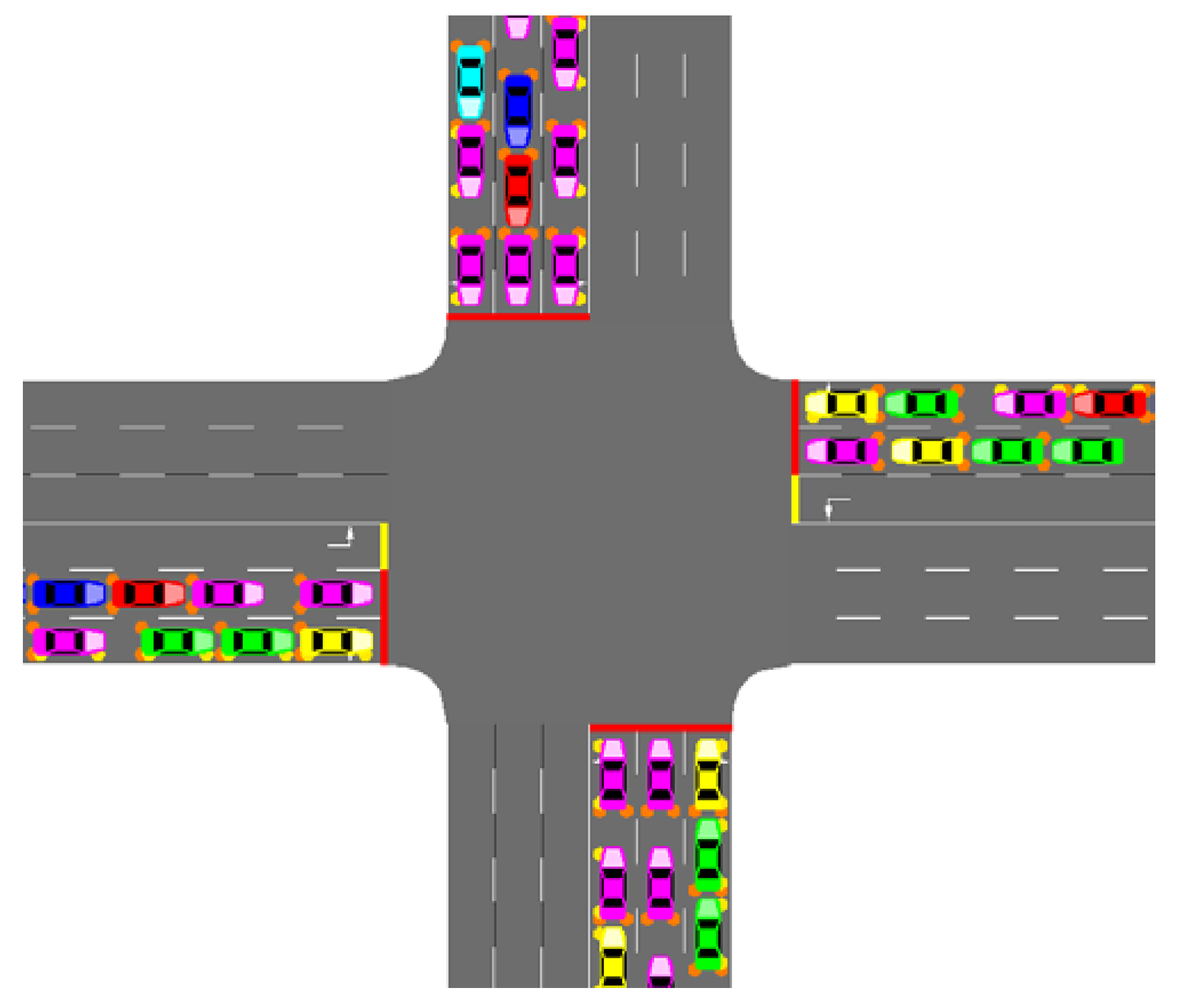
2.3. Car-Following Models with Platoons
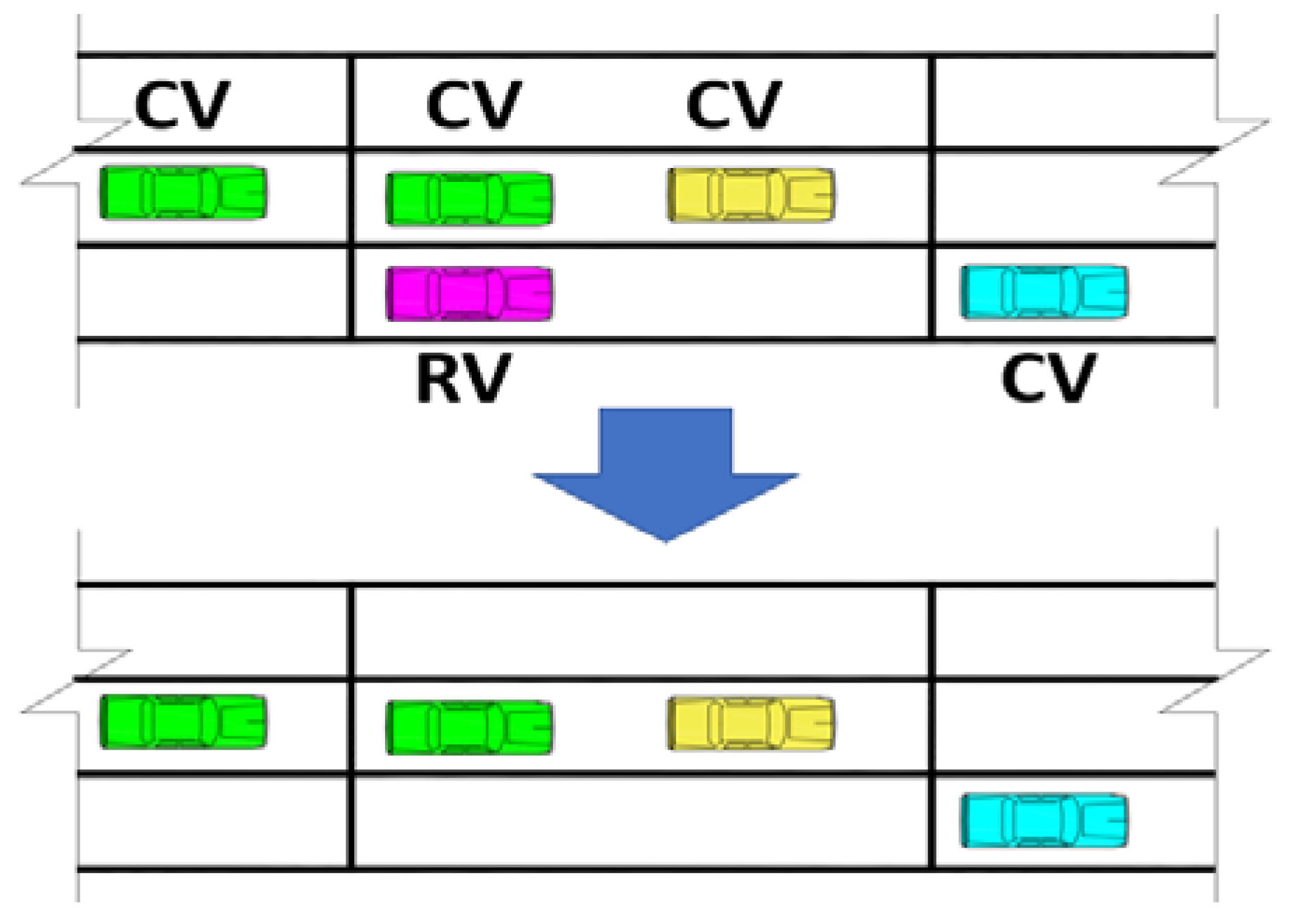
- When CVs are within the defined platoon range on the same lane, they can switch to 4 modes (platoon leader, platoon follower, catch-up, and catch-up follower mode), as shown in Figure 2. Platooning vehicles are considered as a platoon if the gap is smaller than 15 m (yellow and green vehicles). CVs switch their type to catch-up mode when the front platoon is closer to a given value of 50 m (red and blue vehicles). If the connection conditions are not met, CVs’ movement is similar to that of RVs (cyan vehicle).
- Changing lanes to join the platoon is not yet supported in Simpla. If the platoon leader changes lanes, other vehicles will try to change lanes.
- In the combined operation mode, when joining the platoon, CVs in the follower and catch-up modes can move at a speed greater than the maximum speed (speed_Factor equals 1.2). Other modes default to 1.
- A platoon leader has the ability to accelerate and switch to the follower mode if it is within range of another platoon in front.
- A platooning vehicle can switch to the manual mode if it is outside of the platooning range. It can accelerate and connect to form a platoon in a catch-up area.
- At the intersection area, due to the influence of traffic lights, CVs can be split from the platoon. The reforming of the platooning operation is shown in Figure 3.
2.4. Learning with DRL
- are the updated, old and optimum Q network value.
- are the learning rate and discount factor of the training network.
| Algorithm 1: Training of deep Q network with Experience Replay on a traffic light. |
| Input: neural network agent with random weights, replay memory size, minibatch size, epsilon (), learning rate (), and discount factor () |
| Initialize replay buffer B in Memory M |
| Initialize action-value function Q with |
| Initialize the action-value function with random parameters |
| while episode < Total Episodes: |
| Episode = 1, … E do |
| Start Simulation with first step J, observe initials state and action |
| For J = 1, … N do |
| Perform action and observe the reward r, next state |
| Store experiences () in B. |
| Sample random B experiences from M |
| Calculate the loss L |
| Update by minimizing the loss function |
| For every step |
| Reset Set end for |
| end while |
3. Experimental Setup
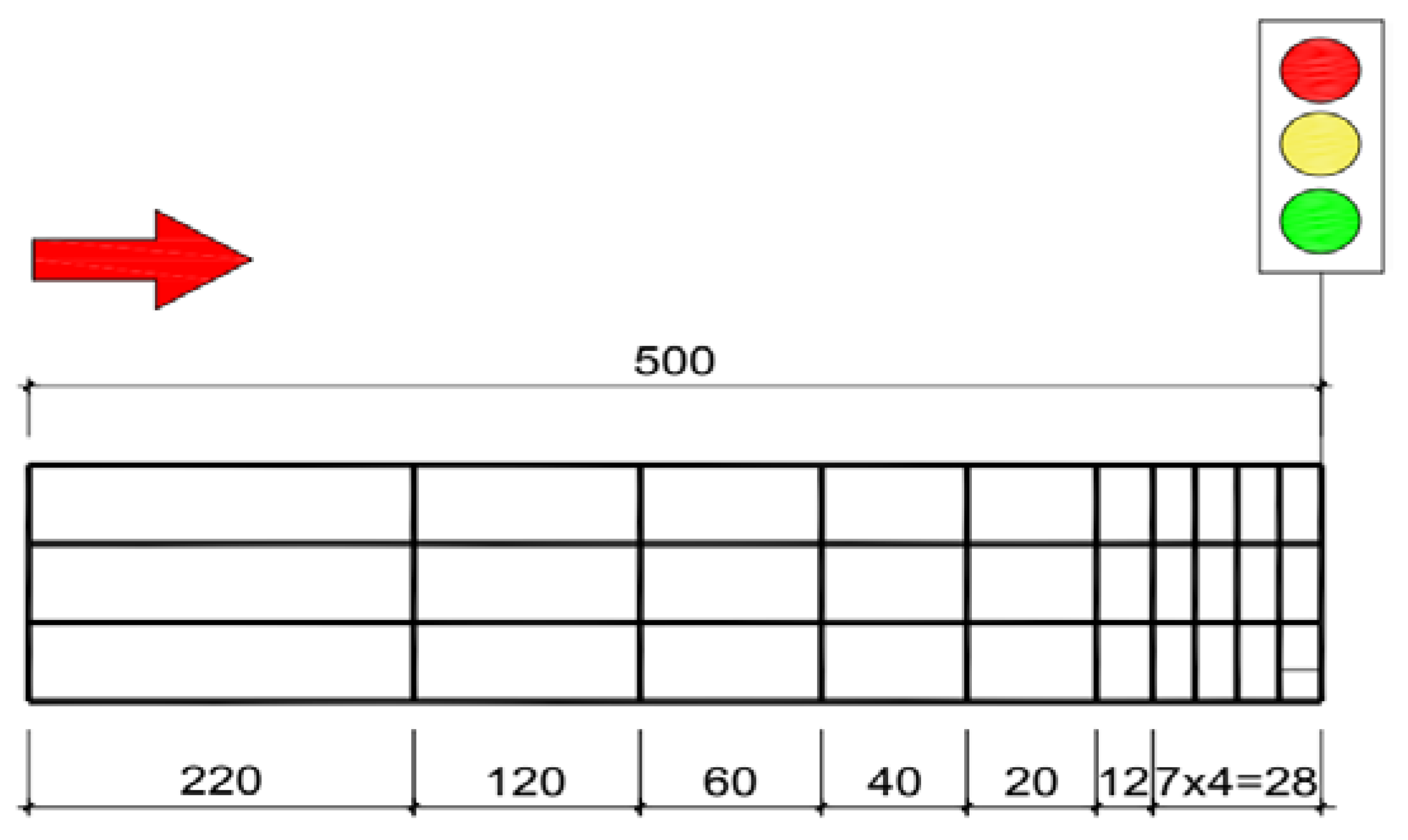
3.1. Road, Lane and Other Configuration
3.2. Scenario 1: DRL-Based Scenario at the Signalized Intersection
3.2.1. State Space
3.2.2. Action Space
3.2.3. Reward Definition
3.2.4. Parameters of the Training Process
- Activation functions
- Optimization function
- Experience replay
- Epsilon in Q-Learning Policy
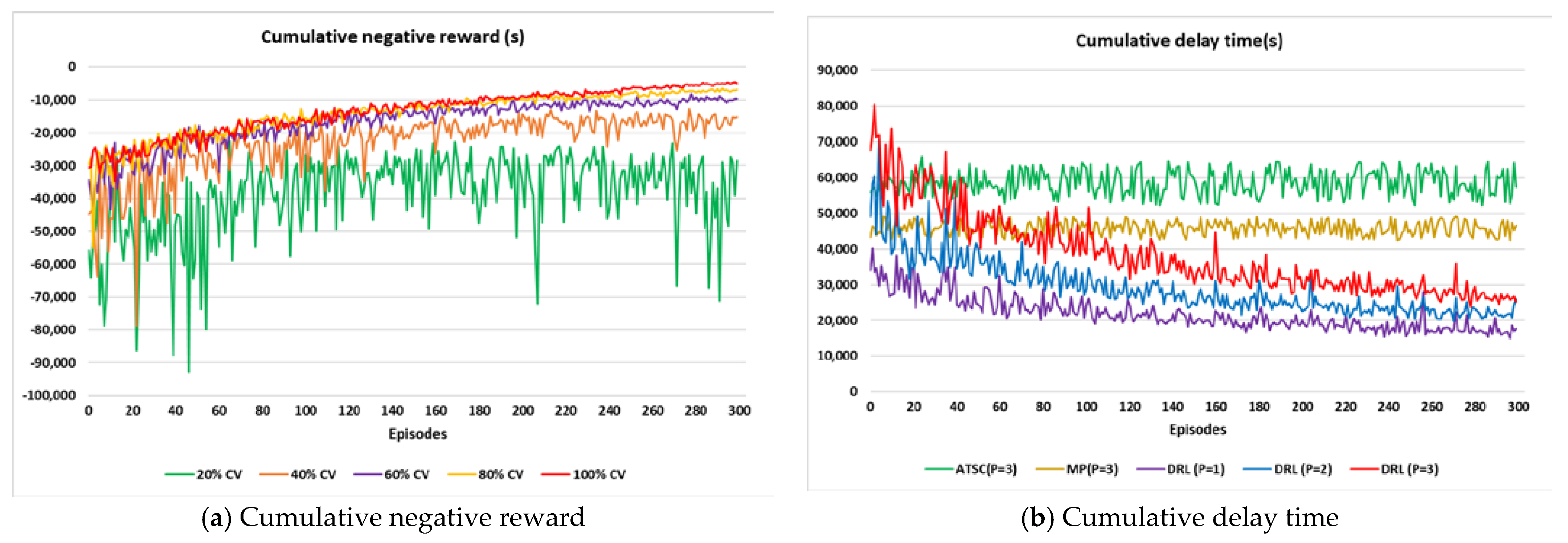
3.2.5. Determine the Hyperparameters
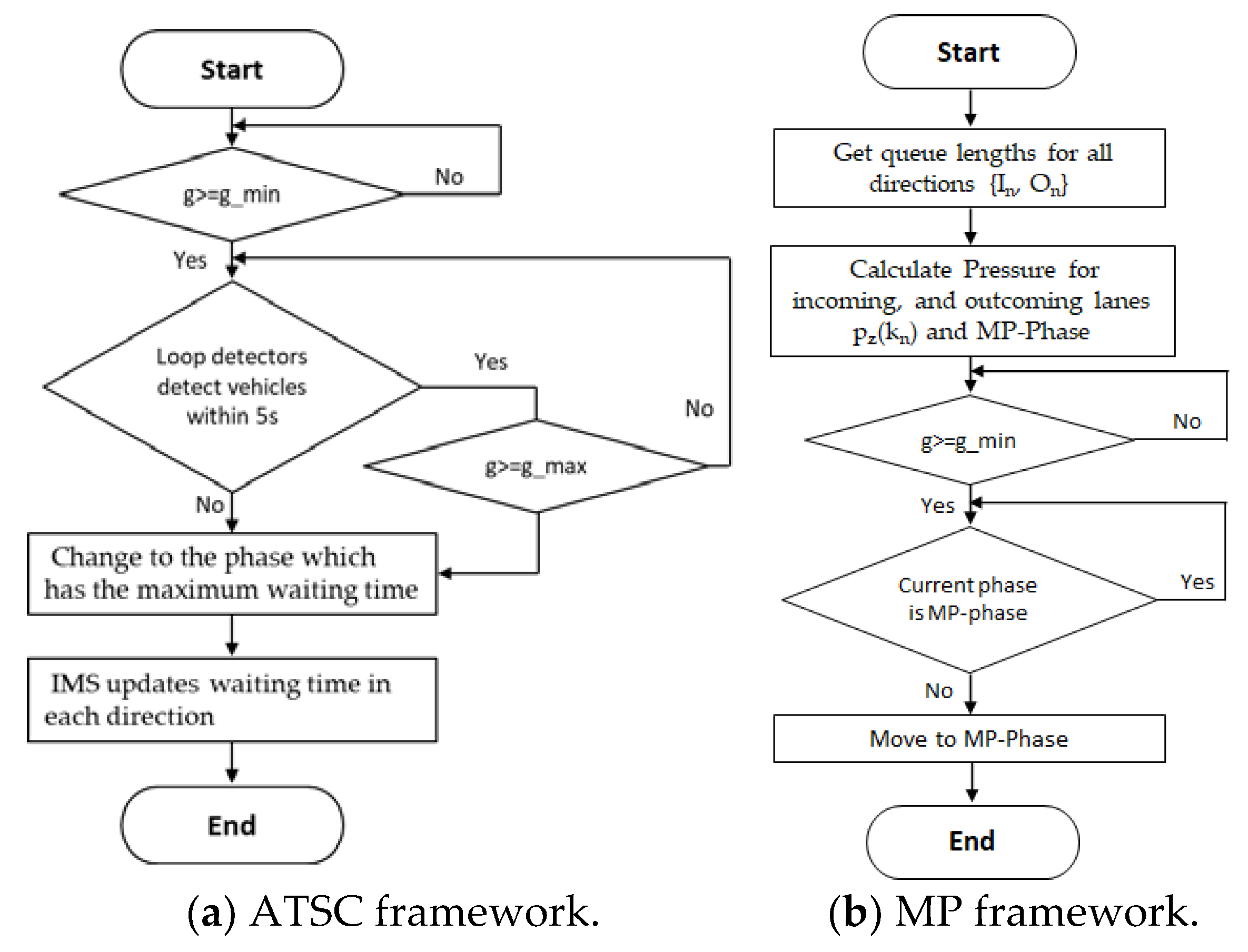
3.3. Scenario 2: ATSC-Based Scenario at the Signalized Intersection
3.4. Scenario 3: MP-Based Scenario at the Signalized Intersection
- is the number of vehicles in link z to link m at the end of the discrete-time t.
- are the inflow and outflow in the same period.
- are the demand and saturation flow in this link.
- are the storage capacity of link z and link w.
- is the turning movement rate with and .
- is the control discrete time index.
- is the green time of stage j.
3.5. Performance Evaluation Metric
4. Results and Evaluation
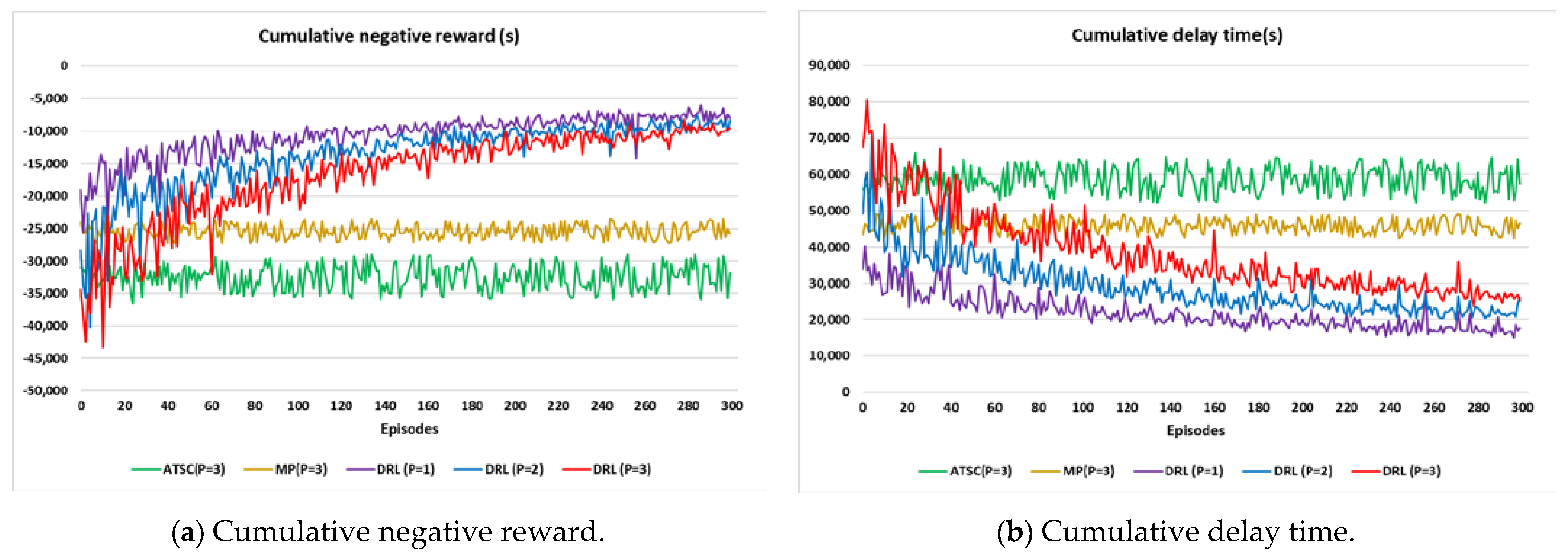
4.1. Performance of DRL, ATSC, and MP-Based Models
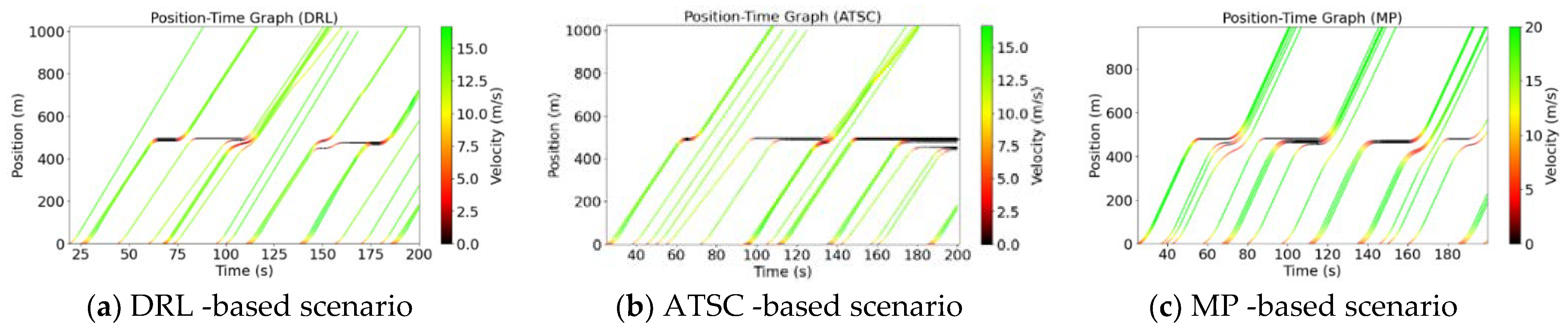
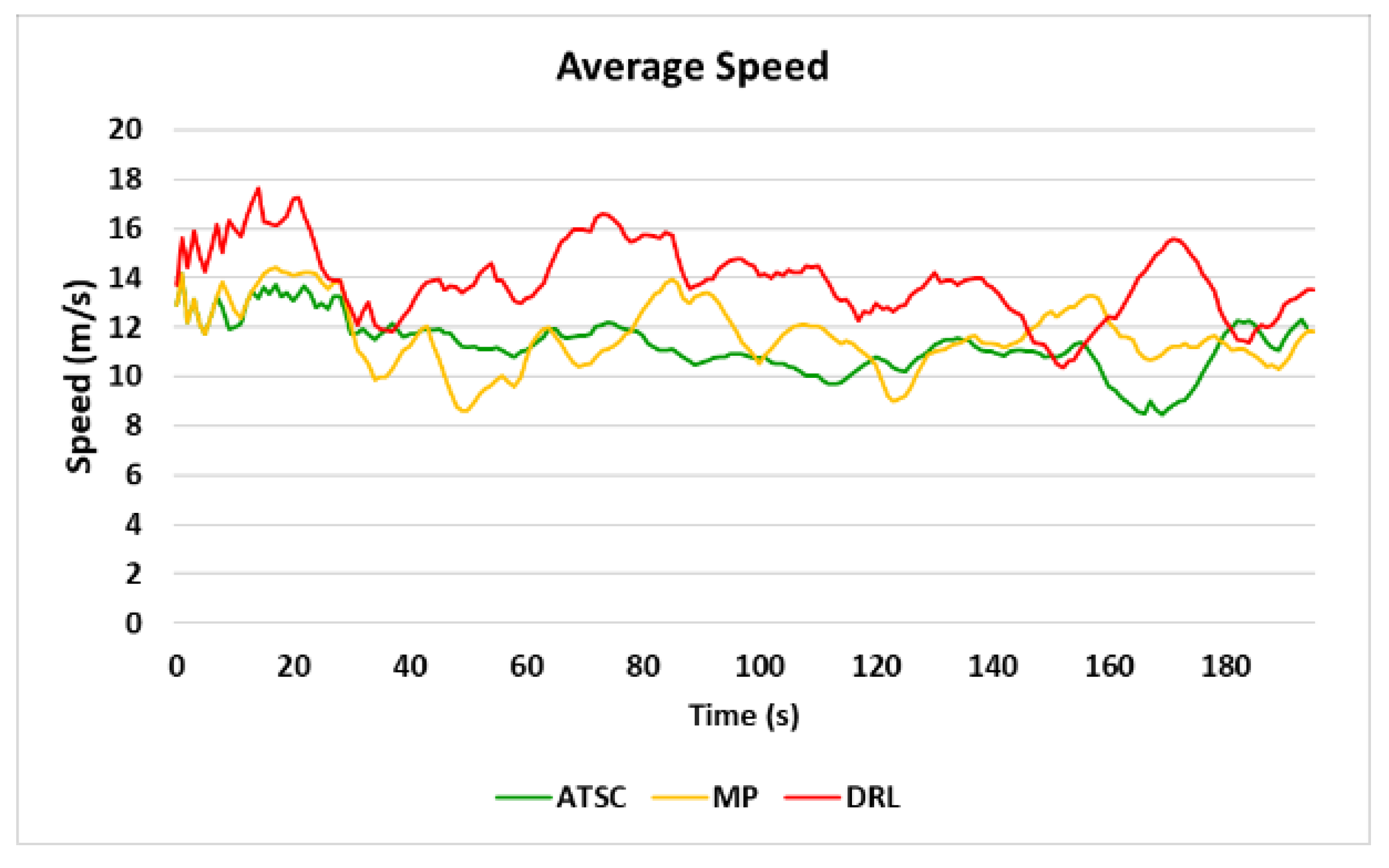
4.2. Trajectories and Average Speed of 3 Scenarios
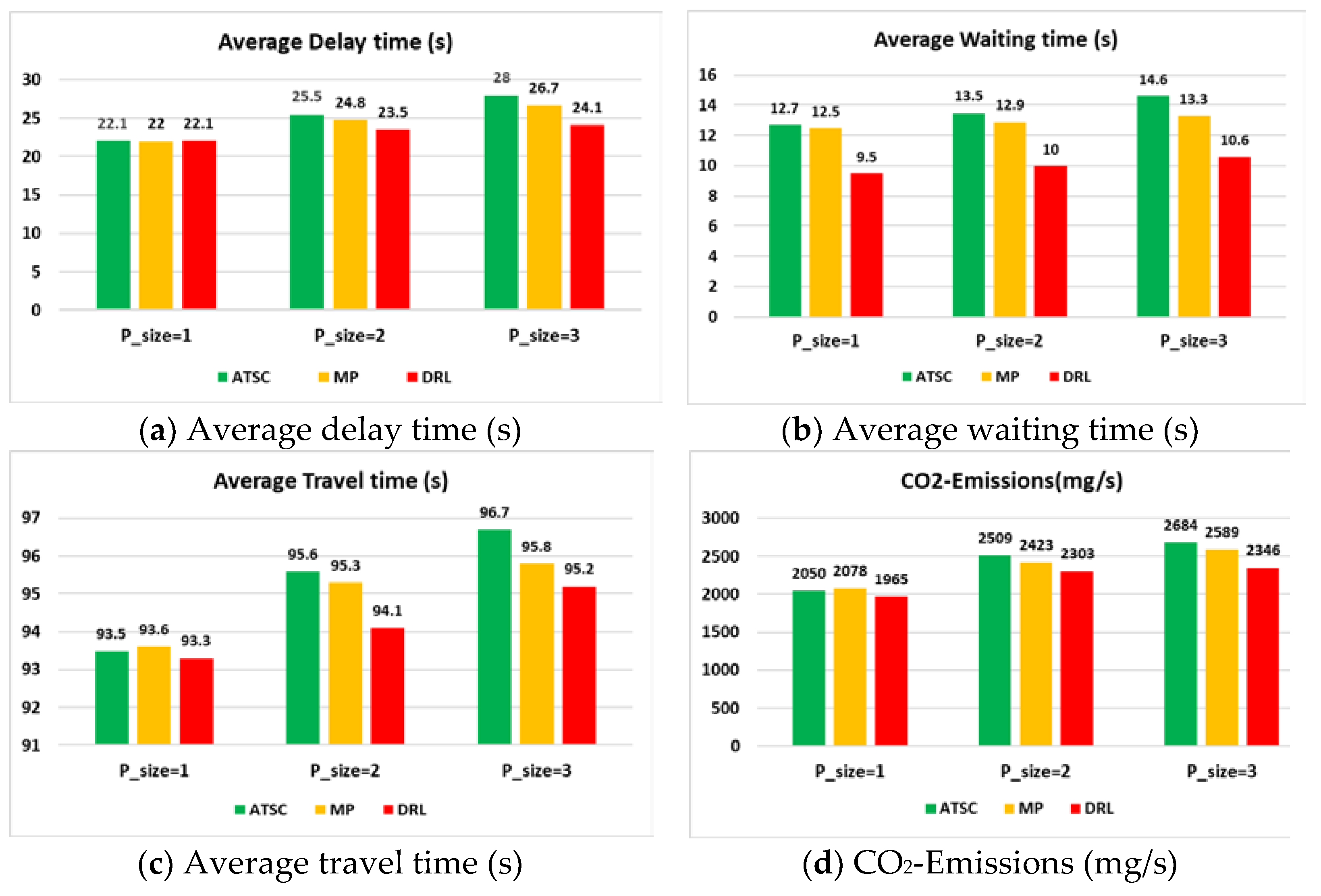
4.3. MOE Performance
4.4. Effect of Penetration Rate
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Howie, D. Urban traffic congestion: A search for new solutions. ITE J. 1989, 59, 13–16. [Google Scholar]
- Bivina, G.R.; Landge, V.; Kumar, V.S. Socio economic valuation of traffic delays. Transp. Res. Procedia 2016, 17, 513–520. [Google Scholar] [CrossRef]
- Hofer, C.; Jager, G.; Fullsack, M. Large scale simulation of CO2 emissions caused by urban car traffic: An agent-based network approach. J. Clean. Prod. 2018, 183, 1–10. [Google Scholar] [CrossRef]
- Dey, K.C.; Rayamajhi, A.; Chowdhury, M.; Bhavsar, P.; Martin, J. Vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) communication in a heterogeneous wireless network—Performance evaluation. Transp. Res. Part C Emerg. Technol. 2016, 68, 168–184. [Google Scholar] [CrossRef]
- Chen, L.; Englund, C. Cooperative intersection management: A survey. IEEE Trans. Intell. Transp. Syst. 2016, 17, 570–586. [Google Scholar] [CrossRef]
- Kuang, X.; Zhao, F.; Hao, H.; Liu, Z. Intelligent connected vehicles: The industrial practices and impacts on automotive value-chains in China. Asia Pac. Bus. Rev. 2017, 24, 1–21. [Google Scholar] [CrossRef]
- Traub, M.; Maier, A.; Barbehön, K.L. Future automotive architecture and the impact of IT trends. IEEE Softw. 2017, 34, 27–32. [Google Scholar] [CrossRef]
- Kopelias, P.; Demiridi, E.; Vogiatzis, K.; Skabardonis, A.; Zafiropoulou, V. Connected & autonomous vehicles—Environmental impacts—A review. Sci. Total Environ. 2020, 712, 135237. [Google Scholar]
- Olia, A.; Razavi, S.; Abdulhai, B.; Abdelgawad, H. Traffic capacity implications of automated vehicles mixed with regular vehicles. J. Intell. Transp. Syst. 2018, 22, 244–262. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, Y.; Li, K.; Li, Q.; Zheng, Q. Car-following model of connected and autonomous vehicles considering both average headway and electronic throttle angle. Mod. Phys. Lett. B 2021, 35, 2150257. [Google Scholar] [CrossRef]
- Fu, R.; Li, Z.; Sun, Q.; Wang, C. Human-like car-following model for autonomous vehicles considering the cut-in behavior of other vehicles in mixed traffic. Accid. Anal. Prev. 2019, 132, 105260. [Google Scholar] [CrossRef]
- Papadoulis, A.; Quddus, M.; Imprialou, M. Evaluating the safety impact of connected and autonomous vehicles on motorways. Accid. Anal. Prev. 2019, 124, 12–22. [Google Scholar] [CrossRef]
- Liu, H.; Kan, X.; Shladover, S.E.; Lu, X.Y.; Ferlis, R.E. Impact of cooperative adaptive cruise control on multilane freeway merge capacity. J. Intell. Transp. Syst. 2018, 22, 263–275. [Google Scholar] [CrossRef]
- Zohdy, I.H.; Rakha, H.A. Intersection management via vehicle connectivity: The intersection cooperative adaptive cruise control system concept. J. Intell. Transp. Syst. 2016, 20, 17–32. [Google Scholar] [CrossRef]
- Van Arem, B.V.; Van Driel, C.J.G.; Visser, R. The impact of cooperative adaptive cruise control on traffic-flow characteristics. IEEE Trans. Intell. Transp. Syst. 2006, 7, 429–436. [Google Scholar] [CrossRef]
- Segata, M. Platooning in SUMO: An open-source Implementation. In Proceedings of the SUMO User Conference 2017, Berlin, Germany, 8–10 May 2017; pp. 51–62. [Google Scholar]
- Segata, M.; Joerer, S.; Bloessl, B.; Sommer, C.; Dressler, F.; Cigno, R.L. Plexe: A Platooning Extension for Veins. In Proceedings of the 2014 IEEE Vehicular Networking Conference, Paderborn, Germany, 3–5 December 2014. [Google Scholar]
- Sturm, T.; Krupitzer, C.; Segata, M.; Becker, C. A Taxonomy of Optimization Factors for Platooning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6097–6114. [Google Scholar] [CrossRef]
- Haas, I.; Friedrich, B. An autonomous connected platoon-based system for city-logistics: Development and examination of travel time aspects. Transp. A Transp. Sci. 2018, 17, 151–168. [Google Scholar] [CrossRef]
- Liang, K.Y.; Martensson, J.; Johansson, K.H. Experiments on Platoon Formation of Heavy Trucks in Traffic. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 1–4 November 2016. [Google Scholar]
- Maiti, S.; Winter, S.; Sarkar, S. The impact of flexible platoon formation operations. IEEE Trans. Intell. Veh. 2020, 5, 229–239. [Google Scholar] [CrossRef]
- Heinovski, J.; Dressler, F. Platoon Formation: Optimized Car to Platoon Assignment Strategies and Protocols. In Proceedings of the 2018 IEEE Vehicular Networking Conference (VNC), Taipei, Taiwan, 5–7 December 2018. [Google Scholar]
- Mahbub, A.M.I.; Malikopoulos, A.A. A Platoon Formation Framework in a Mixed Traffic Environment. IEEE Control. Syst. Lett. 2022, 6, 1370–1375. [Google Scholar] [CrossRef]
- Woo, S.; Skabardonis, A. Flow-aware platoon formation of Connected Automated Vehicles in a mixed traffic with human-driven vehicles. Transp. Res. Part C Emerg. Technol. 2021, 133, 103442. [Google Scholar] [CrossRef]
- Amoozadeh, M.; Deng, H.; Chuah, C.; Zhang, H.M.; Ghosalc, D. Platoon management with cooperative adaptive cruise control enabled by VANET. Veh. Commun. 2015, 2, 110–123. [Google Scholar] [CrossRef]
- Zhao, L.; Sun, J. Simulation Framework for Vehicle Platooning and Car-following behaviors under Connected-Vehicle Environment. Procedia-Soc. Behav. Sci. 2013, 96, 914–924. [Google Scholar] [CrossRef]
- Zhou, J.; Zhu, F. Analytical analysis of the effect of maximum platoon size of connected and automated vehicles. Transp. Res. Part C Emerg. Technol. 2021, 122, 102882. [Google Scholar] [CrossRef]
- Branke, J.; Goldate, P.; Prothmann, H. Actuated Traffic Signal Optimisation Using Evolutionary Algorithms. In Proceedings of the 6th European Congress and Exhibition on Intelligent Transport Systems and Services (ITS07), Aalborg, Denmark, 18–20 June 2007. [Google Scholar]
- Taale, H. Optimising Traffic Signal Control with Evolutionary Algorithms. In Proceedings of the 7th World Congress on Intelligent Transport Systems, Turin, Italy, 6–9 November 2000. [Google Scholar]
- Varaiya, P. Max pressure control of a network of signalized intersections. Transp. Res. Part C Emerg. Technol. 2013, 36, 177–195. [Google Scholar] [CrossRef]
- Lioris, J.; Kurzhanskiy, A.; Varaiya, P. Adaptive max pressure control of network of signalized intersections. IFAC-Papers OnLine 2016, 49, 19–24. [Google Scholar] [CrossRef]
- Ferreira, M.; Fernandes, R.; Conceição, H.; Viriyasitavat, W.; Tonguz, O.K. Self-Organized Traffic Control. In Proceedings of the seventh ACM international workshop on Vehicular Internetworking, Chicago, IL, USA, 20–24 September 2010. [Google Scholar]
- Lowrie, P.R. SCATS: Sydney Co-Ordinated Adaptive Traffic System: A Traffic Responsive Method of Controlling Urban Traffic; Roads and Traffic Authority NSW: Darlinghurst, NSW, Australia, 1990. [Google Scholar]
- Hunt, P.; Robertson, D.I.; Bretherton, R.D.; Winton, R.I. SCOOT-a Traffic Responsive Method of Coordinating Signals; Transport and Road Research Laboratory (TRRL): Berkshire, UK, 1981. [Google Scholar]
- Luyanda, F.; Gettman, D.; Head, L.; Shelby, S. ACS-lite algorithmic architecture: Applying adaptive control system technology to closed-loop traffic signal control systems. Transp. Res. Rec. 2003, 1856, 175–184. [Google Scholar] [CrossRef]
- Mushtaq, A.; Haq, I.U.; Imtiaz, M.U.; Khan, A.; Shafiq, O. Traffic flow management of autonomous vehicles using deep reinforcement learning and smart rerouting. IEEE Access 2021, 9, 51005–51019. [Google Scholar] [CrossRef]
- Liang, X.; Du, X.; Wang, G.; Han, Z. A deep q learning network for traffic lights’ cycle control in vehicular networks. IEEE Trans. Veh. Technol. 2019, 68, 1243–1253. [Google Scholar] [CrossRef]
- Vidali, A.; Crociani, L.; Vizzari, G.; Bandini, S. A deep reinforcement learning approach to adaptive traffic lights management. In Proceedings of the WOA, Parma, Italy, 26–28 June 2019; pp. 42–50. [Google Scholar]
- Tran, Q.D.; Bae, S.H. Proximal policy optimization through a deep reinforcement learning framework for multiple autonomous vehicles at a non-signalized intersection. Appl. Sci. 2020, 10, 5722. [Google Scholar] [CrossRef]
- Li, M.; Cao, Z.; Li, Z. A reinforcement learning-based vehicle platoon control strategy for reducing energy consumption in traffic oscillations. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 5309–5322. [Google Scholar] [CrossRef]
- Bai, Z.; Hao, P.; Shangguan, W.; Cai, B.; Barth, M.J. Hybrid reinforcement learning-based eco-driving strategy for connected and automated vehicles at signalized intersections. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15850–15863. [Google Scholar] [CrossRef]
- Zhou, M.; Yu, Y.; Qu, X. Development of an efficient driving strategy for connected and automated vehicles at signalized intersections: A reinforcement learning approach. IEEE Trans. Intell. Transp. Syst. 2020, 21, 433–443. [Google Scholar] [CrossRef]
- Berbar, A.; Gastli, A.; Meskin, N.; Al-Hitmi, M.A.; Ghommam, J.; Mesbah, M.; Mnif, F. Reinforcement learning-based control of signalized intersections having platoons. IEEE Access 2022, 10, 17683–17696. [Google Scholar] [CrossRef]
- Lei, L.; Liu, T.; Zheng, K.; Hanzo, L. Deep reinforcement learning aided platoon control relying on V2X information. IEEE Trans. Veh. Technol. 2022, 71, 5811–5826. [Google Scholar] [CrossRef]
- Liu, T.; Lei, L.; Zheng, K.; Zhang, K. Autonomous platoon control with integrated deep reinforcement learning and dynamic programming. arXiv 2022, arXiv:2206.07536. [Google Scholar]
- Zhang, R.; Ishikawa, A.; Wang, W.; Striner, B.; Tonguz, O. Using reinforcement learning with partial vehicle detection for intelligent traffic signal control. IEEE Trans. Intell. Transp. Syst. 2021, 22, 404–415. [Google Scholar] [CrossRef]
- Ducrocq, R.; Farhi, N. Deep reinforcement Q-learning for intelligent traffic signal control with partial detection. arXiv 2021, arXiv:2109.14337. [Google Scholar]
- Lopez, P.A.; Behrisch, M.; Bieker-Walz, L.; Erdmann, J.; Flotterod, Y.P.; Hilbrich, R.; Lucken, L.; Rummel, J.; Wagner, P.; Wießner, E. Microscopic Traffic Simulation using SUMO. In Proceedings of the 2018 21st IEEE International Conference on Intelligent Transportation Systems, Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Institute of Transportation Systems of the German Aerospace Center. Traffic Control Interface-SUMO Documentation. Available online: https://sumo.dlr.de/docs/Simpla.html (accessed on 1 August 2021).
- Wegener, A.; Piorkowski, M.; Raya, M.; Hellbruck, H.; Fischer, S.; Hubaux, J.P. TraCI: An Interface for Coupling Road Traffic and Network Simulators. In Proceedings of the 11th Communications and Networking Simulation Symposium (CNS), Ottawa, ON, Canada, 14–17 April 2008. [Google Scholar]
- Krauss, S. Microscopic Modeling of Traffic Flow: Investigation of Collision Free Vehicle Dynamics. Ph.D. Thesis, University of Cologne, Köln, Germany, 1998. [Google Scholar]
- Genders, W.; Razavi, S. Using a deep reinforcement learning agent for traffic signal control. arXiv 2016, arXiv:1611.01142. [Google Scholar]
- Kingma Diederik, P.; Adam, J.B. A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Poole, D.; Mackworth, A. Artificial Intelligence: Foundations of Computational Agents; Section 12.6 Evaluating Reinforcement Learning Algorithms; Cambridge University Press: Cambridge, UK, 2017; Available online: https://artint.info/2e/html/ArtInt2e.Ch12.S6.html (accessed on 1 August 2021).
- Gettman, D.; Folk, E.; Curtis, E.; Ormand, K.K.D.; Mayer, M.; Flanigan, E. Measure of Effectiveness and Validation Guidance for Adaptive Signal Control Technologies; U.S. Department of Transportation, Federal Highway Administration: Washington, DC, USA, 2013.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Platoon size | 1, 2, and 3 vehicles |
| Vehicle length | 4 m |
| Initial speed | 5 m/s |
| Max_speed | 20 m/s |
| Max_acceleration | 2.5 m/s2 |
| Max_deceleration | 3 m/s2 |
| Platoon gap | 15 m |
| Catch_up distance | 50 m |
| Speed_factor | 1.2 only for follower and catch-up modes. 1 for other modes |
| tau (The desired minimum time headway) | 0.3 s for CVs and 1 s for RVs. |
| minGap | 0.5 m for CVs and 2.5 m for RVs |
| Parameter | Cumulative Negative Reward (s) | Cumulative Delay Time (s) |
|---|---|---|
| Hidden layers = 2, Neurons = 128 | −9947 | 25,677 |
| Hidden layers = 4, Neurons = 128 | −10,671 | 28,115 |
| Hidden layers = 8, Neurons = 128 | −11,974 | 29,652 |
| Hidden layers = 2, Neurons = 256 | −12,824 | 30,235 |
| Hidden layers = 2, Neurons = 512 | −11,508 | 30,654 |
| Parameter | Value |
|---|---|
| Gui | False |
| Total Episode | 300 |
| Max_steps | 3600 s |
| Green duration | 5 s |
| Yellow duration | 3 s |
| Learning rate | 0.001 |
| Batch_size | 100 |
| Training_epochs | 800 |
| Num_states | 120 |
| Num_actions | 4 |
| gama | 0.75 |
| Parameter | Value |
|---|---|
| Simulator | SUMO |
| Num_layers (Hidden layers) | 2 |
| Width_layers (Neurons) | 256 |
| Loss Function | Mean Squared Error |
| Activation Function | Relu |
| Optimization Function | Adam Optimizer |
| CV Penetration Rate | Platoons (Size = 3) | RVs | Cumulative Negative Reward | Average Speed (m/s) | Average Waiting Time (s) | Average Delay Time (s) |
|---|---|---|---|---|---|---|
| 20% | 160 | 1920 | −28,529 | 8.8 | 35.8 | 61.6 |
| 40% | 320 | 1440 | −15,144 | 10.19 | 18.8 | 35.2 |
| 60% | 480 | 960 | −9603 | 11.2 | 10.6 | 24.1 |
| 80% | 640 | 480 | −6987 | 11.7 | 8.0 | 21.2 |
| 1000% | 800 | 0 | −4886 | 12.1 | 5.6 | 19.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trinh, H.T.; Bae, S.-H.; Tran, D.Q. Deep Reinforcement Learning for Vehicle Platooning at a Signalized Intersection in Mixed Traffic with Partial Detection. Appl. Sci. 2022, 12, 10145. https://doi.org/10.3390/app121910145
Trinh HT, Bae S-H, Tran DQ. Deep Reinforcement Learning for Vehicle Platooning at a Signalized Intersection in Mixed Traffic with Partial Detection. Applied Sciences. 2022; 12(19):10145. https://doi.org/10.3390/app121910145
Chicago/Turabian StyleTrinh, Hung Tuan, Sang-Hoon Bae, and Duy Quang Tran. 2022. "Deep Reinforcement Learning for Vehicle Platooning at a Signalized Intersection in Mixed Traffic with Partial Detection" Applied Sciences 12, no. 19: 10145. https://doi.org/10.3390/app121910145
APA StyleTrinh, H. T., Bae, S.-H., & Tran, D. Q. (2022). Deep Reinforcement Learning for Vehicle Platooning at a Signalized Intersection in Mixed Traffic with Partial Detection. Applied Sciences, 12(19), 10145. https://doi.org/10.3390/app121910145