

Deep Transfer Learning Model for Semantic Address Matching

 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Semantic Address Matching Definition
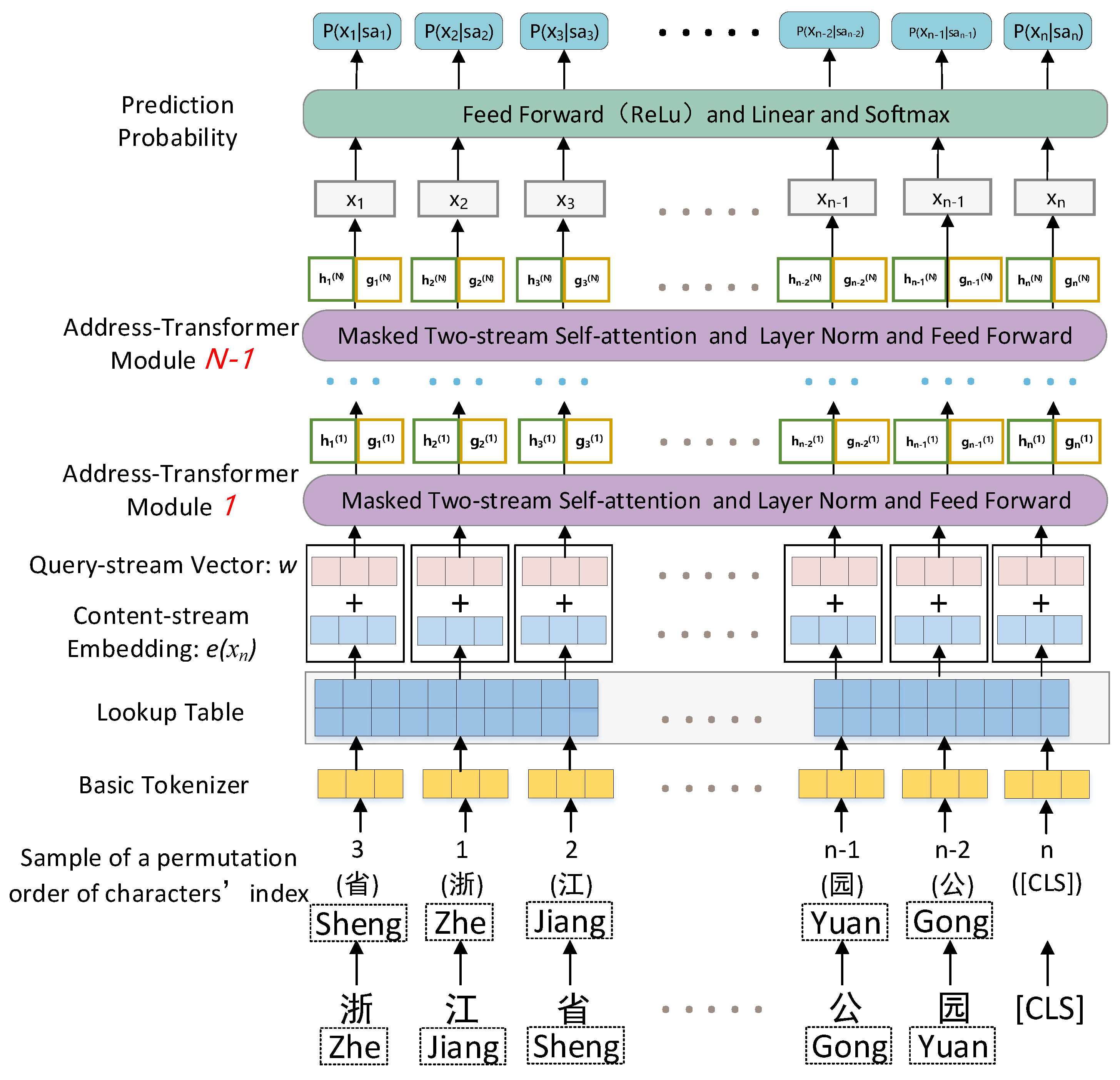
2.3. Pretraining Phase Using the Address Corpus Based on XLNet
2.3.1. Tokenization of Address Characters
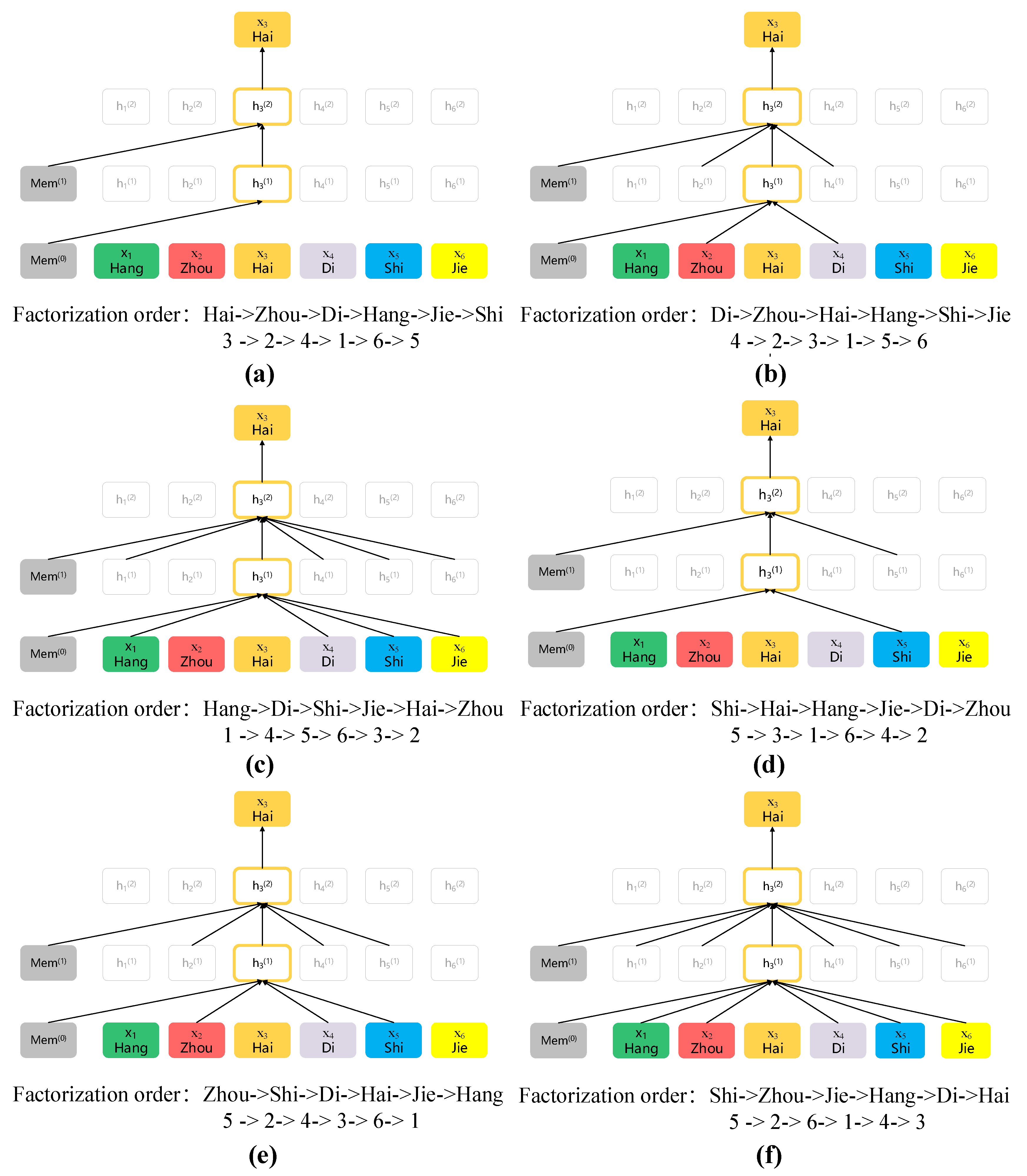
2.3.2. Objective of Permutation Unknown Character Prediction and Two-Stream Self-Attention Structure
2.4. Fine-Tuning for Semantic Address Matching
3. Results and Discussion
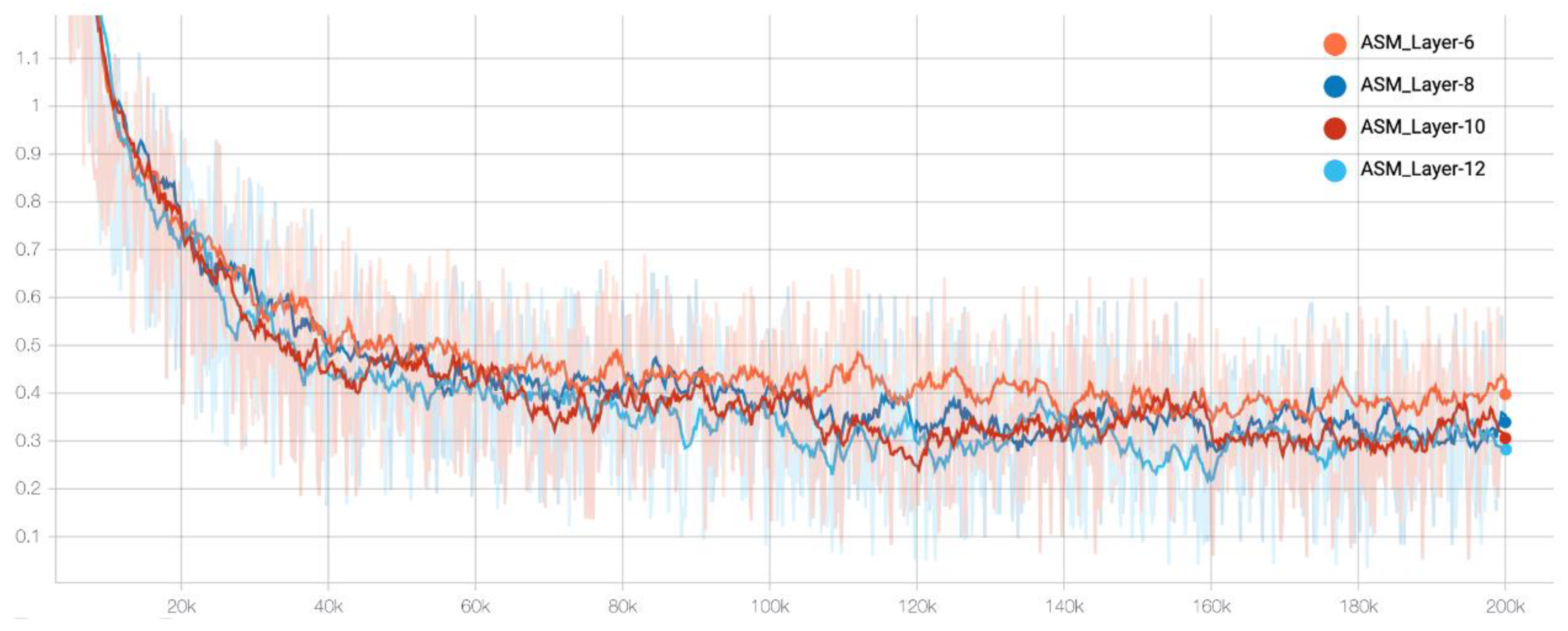
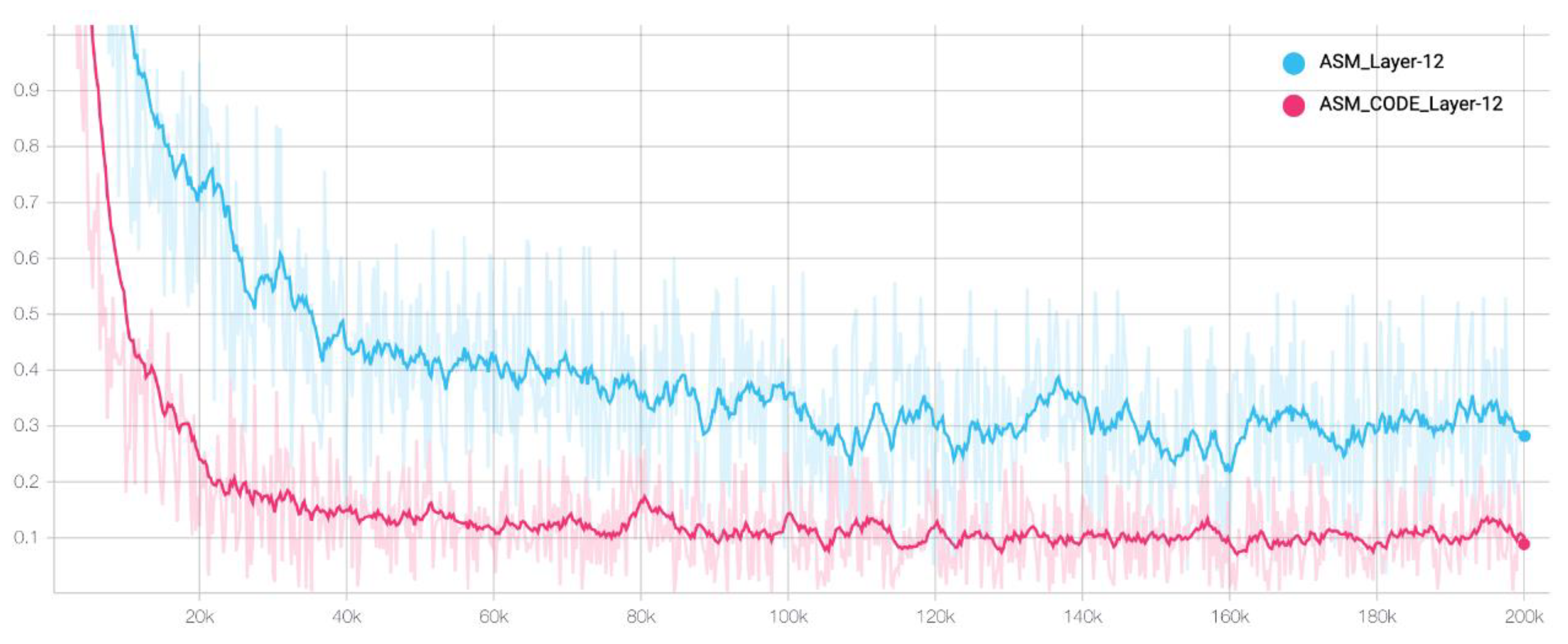
3.1. Address Semantic Model Pretraining
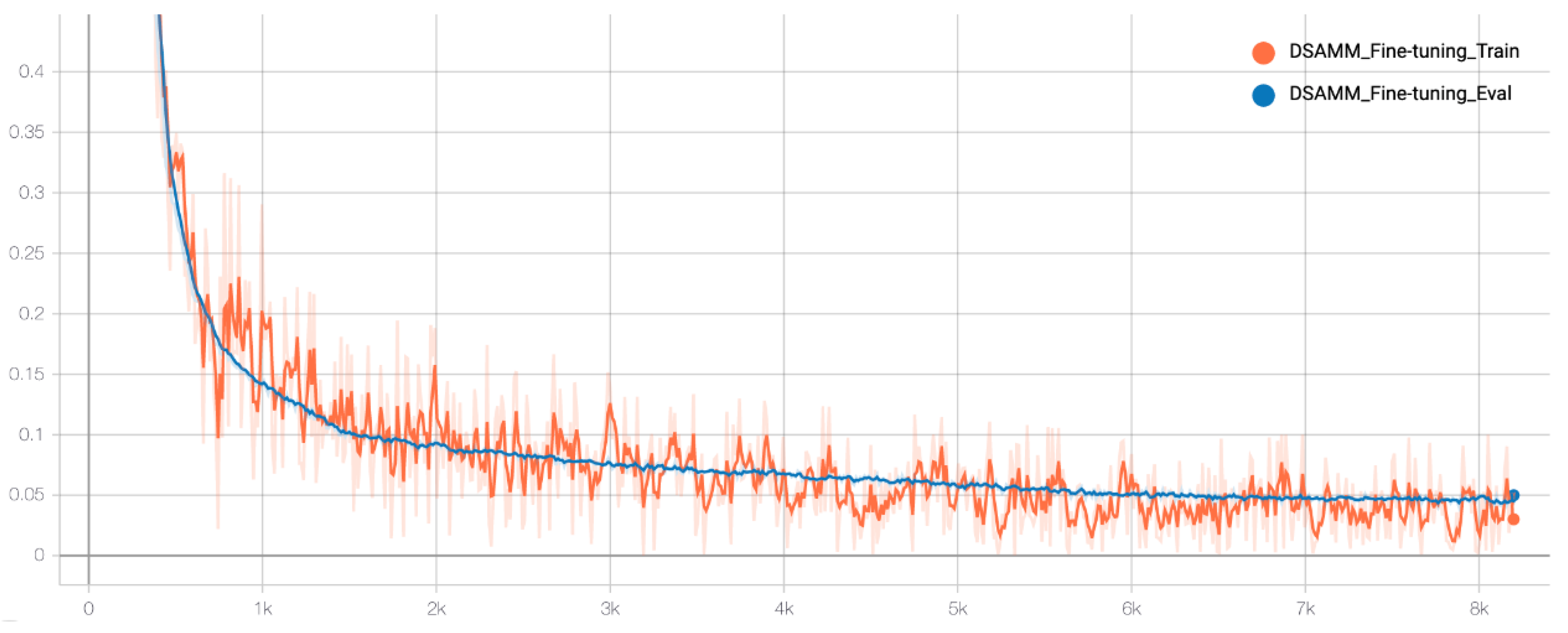
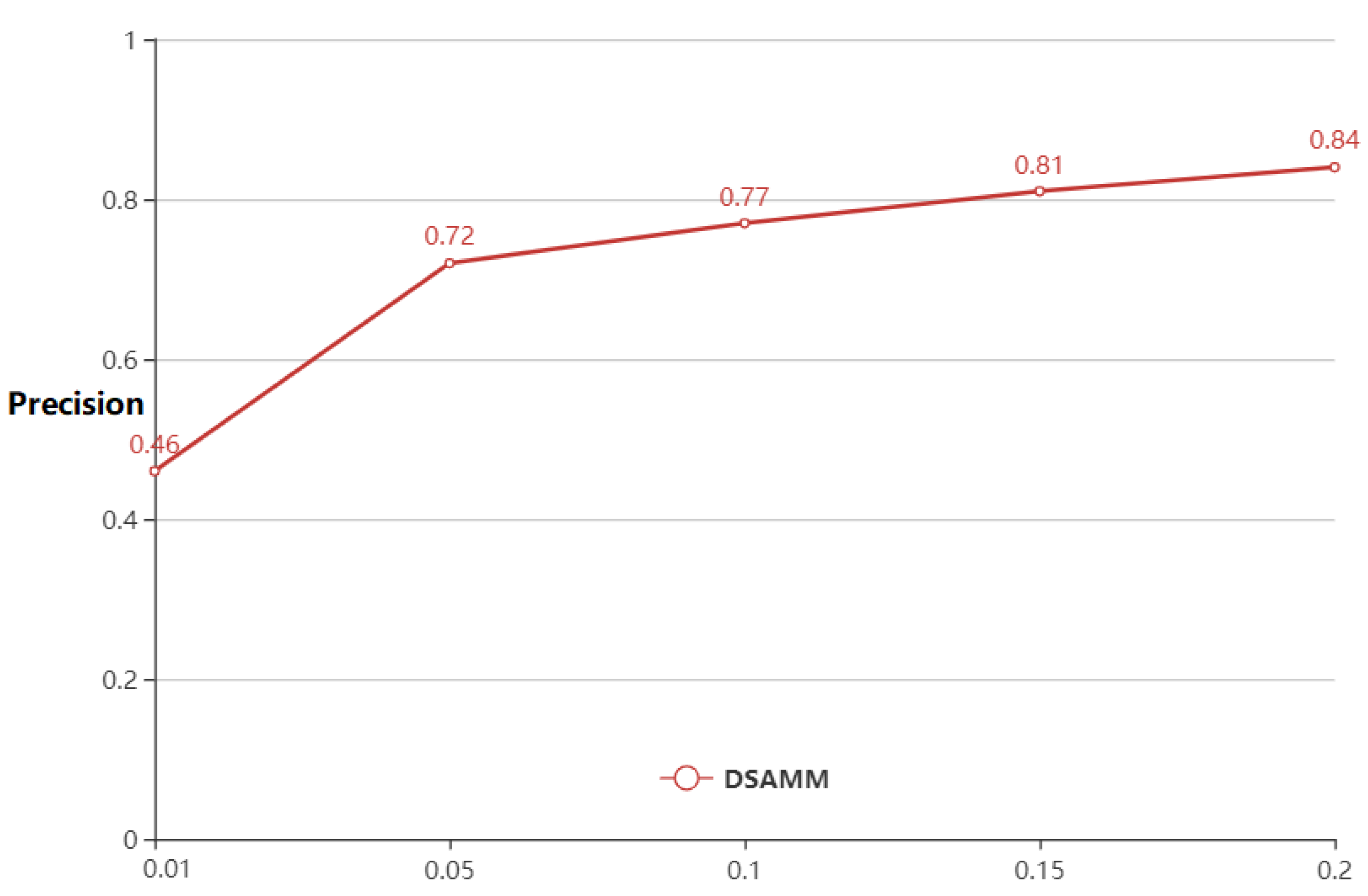
3.2. Fine-Tuning for Semantic Address Matching
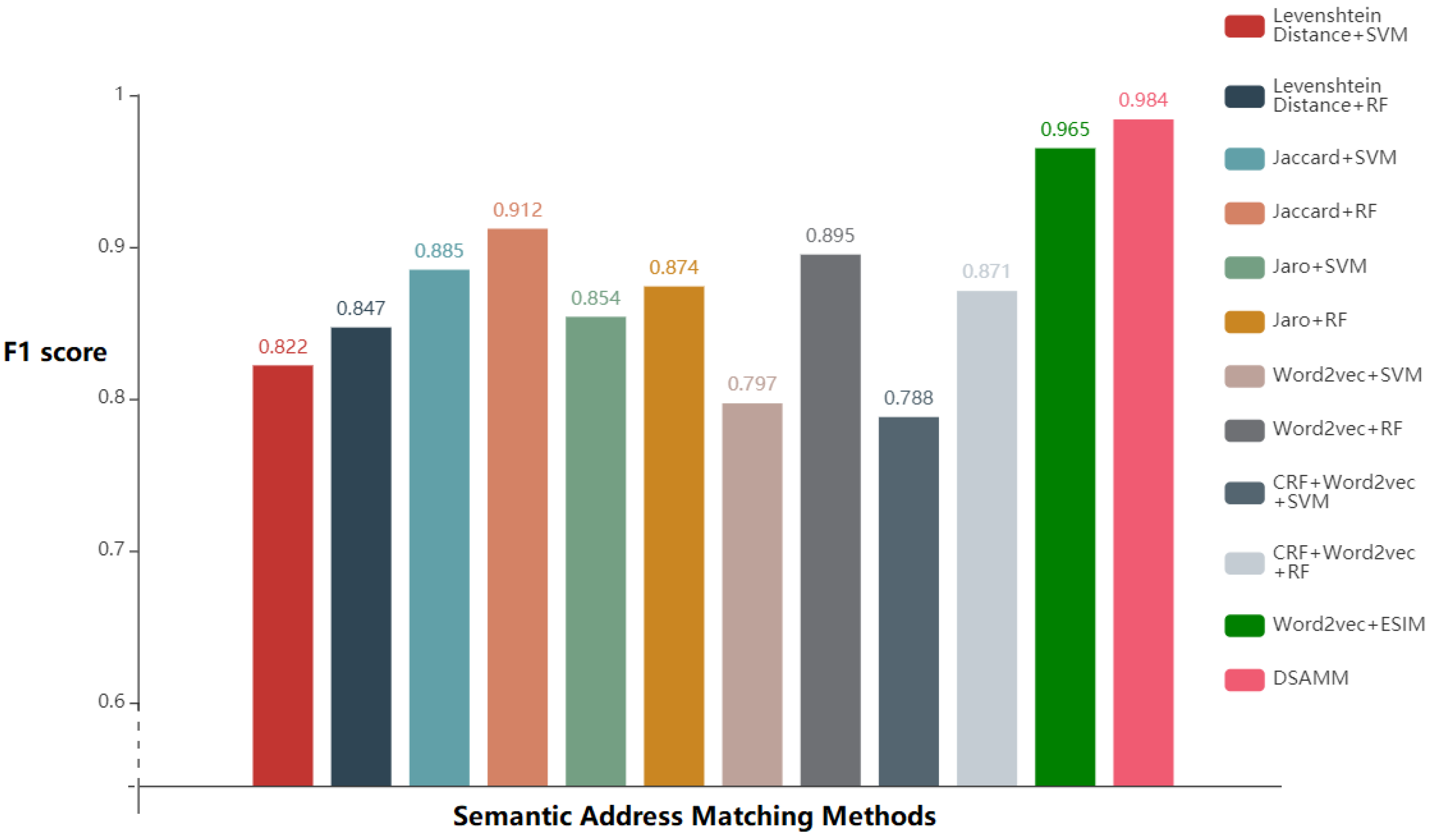
3.3. Comparative Experiment Analysis of the Address Matching
4. Conclusions
- The ASM was constructed using a self-supervised pretrained language model. The experimental results demonstrate that the ASM can achieve a high level of accuracy with the objective of predicting unknown characters.
- The DSAMM was constructed using the fine-tuning approach in deep transfer learning. The results of the comparison experiments showed that the DSAMM performed the best, with all the metrics above 0.98.
- It is shown that utilizing deep transfer learning, high address matching accuracy can be attained with only a few labelled training datasets.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Drummond, W.J. Address matching: GIS technology for mapping human activity patterns. J. Am. Plan. Assoc. 1995, 61, 240–251. [Google Scholar] [CrossRef]
- Longley, P.A.; Goodchild, M.F.; Maguire, D.J.; Rhind, D.W. Geographic Information Systems and Science; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Holtzheimer, P.E. Introduction to the GBF/DIME: A primer. Comp. Environ. Urban Syst. 1983, 8, 133–173. [Google Scholar] [CrossRef]
- Harada, Y.; Shimada, T. Examining the impact of the precision of address geocoding on estimated density of crime locations. Comput. GeoSci. 2006, 32, 1096–1107. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; She, X.; Mao, J.; Chen, G. Deep Contrast Learning Approach for Address Semantic Matching. Appl. Sci. 2021, 11, 7608. [Google Scholar] [CrossRef]
- Lee, B.H.; Waddell, P.; Wang, L.; Pendyala, R.M. Reexamining the influence of work and nonwork accessibility on residential location choices with a microanalytic framework. Environ. Plan. A 2010, 42, 913–930. [Google Scholar] [CrossRef]
- Sun, Z.; Qiu, A.G.; Zhao, J.; Zhang, F.; Zhao, Y.; Wang, L. Technology of fuzzy Chinese-geocoding method. In Proceedings of the 2013 International Conference on Information Science and Cloud Computing, Guangzhou, China, 7–8 December 2013; 2013; pp. 7–12. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Navarro, G. A guided tour to approximate string matching. ACM Comput. Surv. CSUR 2001, 33, 31–88. [Google Scholar] [CrossRef]
- Zhang, Z.; Hadjieleftheriou, M.; Ooi, B.C.; Srivastava, D. Bed-tree: An all-purpose index structure for string similarity search based on edit distance. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data, Indianapolis, IN, USA, 6–10 June 2010; pp. 915–926. [Google Scholar]
- Jaccard, P. Nouvelles recherches sur la distribution florale. Bull. Soc. Vaud. Sci. Nat. 1908, 44, 223–270. [Google Scholar]
- Jaro, M.A. Advances in record-linkage methodology as applied to matching the 1985 census of Tampa, Florida. J. Am. Stat. Assoc. 1989, 84, 414–420. [Google Scholar] [CrossRef]
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. In Proceedings of the Section on Survey Research Methods, American Statistical Association, Anaheim, CA, USA, 6–9 August 1990; pp. 354–359. [Google Scholar]
- Santos, R.; Murrieta-Flores, P.; Martins, B. Learning to combine multiple string similarity metrics for effective toponym matching. Int. J. Digit. Earth 2018, 11, 913–938. [Google Scholar] [CrossRef]
- Banerjee, S.; Pedersen, T. The design, implementation, and use of the ngram statistics package. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Mexico City, Mexico, 16–22 February 2003; Springer: Berlin/Heidelberg, Germany; pp. 370–381.
- Pedersen, T.; Banerjee, S.; McInnes, B.; Kohli, S.; Joshi, M.; Liu, Y. The Ngram statistics package (text:: nsp): A flexible tool for identifying ngrams, collocations, and word associations. In Proceedings of the workshop on multiword expressions: From parsing and generation to the real world, Oregon, Portland, 23 June 2011; pp. 131–133. [Google Scholar]
- Wang, Y.; Liu, J.; Guo, Q.; Luo, A. The standardization method of address information for pois from internet based on positional relation. Acta Geod. Cartogr. Sin. 2016, 45, 623. [Google Scholar]
- Xueying, Z.; Guonian, L.; Boqiu, L.; Wenjun, C. Rule-based approach to semantic resolution of Chinese addresses. J. Geo-Inf. Sci. 2010, 12, 9–16. [Google Scholar]
- Cheng, C.; Yu, B. A rule-based segmenting and matching method for fuzzy Chinese addresses. Geogr. Geo-Inf. Sci. 2011, 3. [Google Scholar]
- Li, L.; Wang, W.; He, B.; Zhang, Y. A hybrid method for Chinese address segmentation. Int. J. Geogr. Inf. Sci. 2018, 32, 30–48. [Google Scholar] [CrossRef]
- Lin, Y.; Kang, M.; Wu, Y.; Du, Q.; Liu, T. A deep learning architecture for semantic address matching. Int. J. Geogr. Inf. Sci. 2020, 34, 559–576. [Google Scholar] [CrossRef]
- Wu, D.; Fung, P. Improving Chinese tokenization with linguistic filters on statistical lexical acquisition. In Proceedings of the Fourth Conference on Applied Natural Language Processing, Stuttgart, Germany, 13–15 October 1994; pp. 180–181. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. 2001. Available online: https://repository.upenn.edu/cgi/viewcontent.cgi?article=1162&context=cis_papers (accessed on 6 August 2022).
- Bokaei, M.H.; Sameti, H.; Bahrani, M.; Babaali, B. Segmental HMM-based part-of-speech tagger. In Proceedings of the 2010 International Conference on Audio, Language and Image Processing, Shanghai, China, 23–25 November 2010; pp. 52–56. [Google Scholar] [CrossRef]
- Tian, Q.; Ren, F.; Hu, T.; Liu, J.; Li, R.; Du, Q. Using an optimized Chinese address matching method to develop a geocoding service: A case study of Shenzhen, China. ISPRS Int. J. Geo-Inf. 2016, 5, 65. [Google Scholar] [CrossRef]
- Koumarelas, I.; Kroschk, A.; Mosley, C.; Naumann, F. Experience: Enhancing address matching with geocoding and similarity measure selection. J. Data Inf. Qual. JDIQ 2018, 10, 1–16. [Google Scholar] [CrossRef]
- Kang, M.; Du., Q.; Wang, M. A new method of Chinese address extraction based on address tree model. Acta Geod. Cartogr. Sin. 2015, 44, 99. [Google Scholar]
- Luo, M.; Huang, H. New method of Chinese address standardization based on finite state machine theory. Comput. Appl. Res. 2016, 33, 3691–3695. (In Chinese) [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 6 August 2022).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced language representation with informative entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Xu, L.; Du, Z.; Mao, R.; Zhang, F.; Liu, R. GSAM: A deep neural network model for extracting computational representations of Chinese addresses fused with geospatial feature. Comput. Environ. Urban Syst. 2020, 81, 101473. [Google Scholar] [CrossRef]
- Cruz, P.; Vanneschi, L.; Painho, M.; Rita, P. Automatic Identification of Addresses: A Systematic Literature Review. ISPRS Int. J. Geo-Inf. 2021, 11, 11. [Google Scholar] [CrossRef]
- Comber, S.; Arribas-Bel, D. Machine learning innovations in address matching: A practical comparison of word2vec and CRFs. Trans. GIS 2019, 23, 334–348. [Google Scholar] [CrossRef]
- Zhang, C.; Guo, R.; Ma, X.; Kuai, X.; He, B. W-TextCNN: A TextCNN model with weighted word embeddings for Chinese address pattern classification. Comput. Environ. Urban Syst. 2022, 95, 101819. [Google Scholar] [CrossRef]
- Luo, A.; Liu, J.; Li, P.; Wang, Y.; Xu, S. Chinese address standardisation of POIs based on GRU and spatial correlation and applied in multi-source emergency events fusion. Int. J. Image Data Fusion 2021, 12, 319–334. [Google Scholar] [CrossRef]
- Liu, J.; Wang, J.; Zhang, C.; Yang, X.; Deng, J.; Zhu, R.; Nan, X.; Chen, Q. Chinese Address Similarity Calculation Based on Auto Geological Level Tagging. In Proceedings of the International Symposium on Neural Networks, Moscow, Russia, 10–12 July 2019; Springer: Cham, Switzerland; pp. 431–438. [Google Scholar]
- Li, H.; Lu, W.; Xie, P.; Li, L. Neural Chinese address parsing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 3421–3431. [Google Scholar]
- Li, P.; Luo, A.; Liu, J.; Wang, Y.; Zhu, J.; Deng, Y.; Zhang, J. Bidirectional gated recurrent unit neural network for Chinese address element segmentation. ISPRS Int. J. Geo-Inf. 2020, 9, 635. [Google Scholar] [CrossRef]
- Santos, R.; Murrieta-Flores, P.; Calado, P.; Martins, B. Toponym matching through deep neural networks. Int. J. Geogr. Inf. Sci. 2018, 32, 324–348. [Google Scholar] [CrossRef]
- Shan, S.; Li, Z.; Yang, Q.; Liu, A.; Zhao, L.; Liu, G.; Chen, Z. Geographical address representation learning for address matching. World Wide Web 2020, 23, 2005–2022. [Google Scholar] [CrossRef]
- Li, F.; Lu, Y.; Mao, X.; Duan, J.; Liu, X. Multi-task deep learning model based on hierarchical relations of address elements for semantic address matching. Neural. Comput. Appl. 2022, 34, 8919–8931. [Google Scholar] [CrossRef]
- Chen, Q.; Zhu, X.; Ling, Z.; Wei, S.; Jiang, H.; Inkpen, D. Enhanced LSTM for natural language inference. arXiv 2016, arXiv:1609.06038. [Google Scholar]
- Shan, S.; Li, Z.; Qiang, Y.; Liu, A.; Xu, J.; Chen, Z. DeepAM: Deep Semantic Address Representation for Address Matching. In Proceedings of the Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data, Chengdu, China, 1 August 2019; Springer: Cham, Switzerland; pp. 45–60.
- Zhang, H.; Ren, F.; Li, H.; Yang, R.; Zhang, S.; Du, Q. Recognition method of new address elements in Chinese address matching based on deep learning. ISPRS Int. J. Geo-Inf. 2020, 9, 745. [Google Scholar] [CrossRef]
- Gupta, V.; Gupta, M.; Garg, J.; Garg, N. Improvement in Semantic Address Matching using Natural Language Processing. In Proceedings of the 2021 2nd International Conference for Emerging Technology (INCET), Belagavi, India, 21–23 May 2021; pp. 1–5. [Google Scholar]
- Wei, J.; Zou, K. Eda: Easy data augmentation techniques for boosting performance on text classification tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Qian, C.; Yi, C.; Cheng, C.; Pu, G.; Liu, J. A coarse-to-fine model for geolocating Chinese addresses. ISPRS Int. J. Geo-Inf. 2020, 9, 698. [Google Scholar] [CrossRef]
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Dai, A.M.; Le, Q.V. Semi-supervised sequence learning. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; pp. 3079–3087. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. TIST 2011, 2, 1–27. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Address Sa | Address Sb | Label |
|---|---|---|
| Block 3, No. 15 Haiyue Road, Hangzhou City (杭州市海月路15号3幢) | Block 3, Haiyue Garden Residential Unit, Shangcheng District, Hangzhou (杭州上城区海月花园3幢) | 1 |
| Block 3, No. 15 Haiyue Road, Hangzhou City (杭州市海月路15号3幢) | Hangzhou Haiyue Bathing Centre (杭州海月洗浴中心) | 0 |
| Statistical Characteristics | Value |
|---|---|
| Total number of address pairs | 64,358 |
| Number of matching address pairs | 32,179 |
| Number of unmatched address pairs | 32,179 |
| Average length difference for all the address pairs | 4.76 |
| Average length difference for matching address pairs | 3.73 |
| Average length difference for unmatched address pairs | 5.79 |
| Average Levenshtein distance for all the address pairs | 12.16 |
| Average Levenshtein distance for matching address pairs | 7.28 |
| Average Levenshtein distance for unmatched address pairs | 17.05 |
| Average Jaccard similarity coefficient for all the address pairs | 0.46 |
| Average Jaccard similarity coefficient for matching address pairs | 0.68 |
| Average Jaccard similarity coefficient for unmatched address pairs | 0.24 |
| Hyperparameters | Are Numbers Replaced with “CODE|” | |
|---|---|---|
| Replaced | Not Replaced | |
| num_address_transformer_module | 12 | 6, 8, 10, 12 |
| batch_size | 32 | 32 |
| hidden_size | 768 | 768 |
| num_head | 4 | 4 |
| dim_head | 8 | 8 |
| FFN_hidden_size | 2048 | 2048 |
| Dropout | 0.1 | 0.1 |
| K | 3 | 3 |
| sequence_len | 32 | 32 |
| mem_len | 24 | 24 |
| 0.00005 | 0.00005 | |
| epoch | 4 | 4 |
| voc_size | 3491 | 9425 |
| Number of Address-Transformer Modules | Training Time | Training Loss | Mean Evaluation Loss | Accuracy |
|---|---|---|---|---|
| 6 | 6 h 19 m 36 s | 0.3864 | 0.3615 | 90.62% |
| 8 | 8 h 21 m 54 s | 0.3395 | 0.3258 | 90.98% |
| 10 | 10 h 23 m 5 s | 0.3016 | 0.3003 | 91.21% |
| 12 | 12 h 32 m 45 s | 0.2831 | 0.2793 | 91.47% |
| Prediction Accuracy | Without “CODE” Replacement | “CODE” Replacement |
|---|---|---|
| ALM [40] | 90.31% | 97.22% |
| ASM | 91.47% | 98.53% |
| Comparison Methods | Predictive Results | ||
|---|---|---|---|
| Precision | Recall | F1 Score | |
| Levenshtein distance + SVM | 0.849 | 0.795 | 0.822 |
| Levenshtein distance + RF | 0.875 | 0.819 | 0.847 |
| Jaccard similarity coefficient + SVM | 0.890 | 0.881 | 0.885 |
| Jaccard similarity coefficient + RF | 0.914 | 0.911 | 0.912 |
| Jaro similarity + SVM | 0.902 | 0.807 | 0.854 |
| Jaro similarity + RF | 0.891 | 0.858 | 0.874 |
| word2vec + SVM | 0.832 | 0.762 | 0.797 |
| word2vec + RF | 0.910 | 0.879 | 0.895 |
| CRF + word2vec + SVM | 0.826 | 0.751 | 0.788 |
| CRF + word2vec + RF | 0.895 | 0.846 | 0.871 |
| word2vec + ESIM | 0.969 | 0.961 | 0.965 |
| DSAMM | 0.987 | 0.982 | 0.984 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, L.; Mao, R.; Zhang, C.; Wang, Y.; Zheng, X.; Xue, X.; Xia, F. Deep Transfer Learning Model for Semantic Address Matching. Appl. Sci. 2022, 12, 10110. https://doi.org/10.3390/app121910110
Xu L, Mao R, Zhang C, Wang Y, Zheng X, Xue X, Xia F. Deep Transfer Learning Model for Semantic Address Matching. Applied Sciences. 2022; 12(19):10110. https://doi.org/10.3390/app121910110
Chicago/Turabian StyleXu, Liuchang, Ruichen Mao, Chengkun Zhang, Yuanyuan Wang, Xinyu Zheng, Xingyu Xue, and Fang Xia. 2022. "Deep Transfer Learning Model for Semantic Address Matching" Applied Sciences 12, no. 19: 10110. https://doi.org/10.3390/app121910110
APA StyleXu, L., Mao, R., Zhang, C., Wang, Y., Zheng, X., Xue, X., & Xia, F. (2022). Deep Transfer Learning Model for Semantic Address Matching. Applied Sciences, 12(19), 10110. https://doi.org/10.3390/app121910110