
MST-VAE: Multi-Scale Temporal Variational Autoencoder for Anomaly Detection in Multivariate Time Series


Abstract
:1. Introduction
- To the best of our knowledge, our proposed method is the first that explores short-scale and long-scale kernels in 1D CNN combining with VAE for anomaly detection in multivariate time series.
- We conducted extensive experiments on five public datasets to evaluate the performance of the approach. The evaluation results demonstrate that our proposed method can not only enhance F1-Score but also reduce training and prediction times.
- For the sake of the reproducibility, we publish our code on GitHub repository.
2. Related Works
3. Background
3.1. Multivariate Time Series
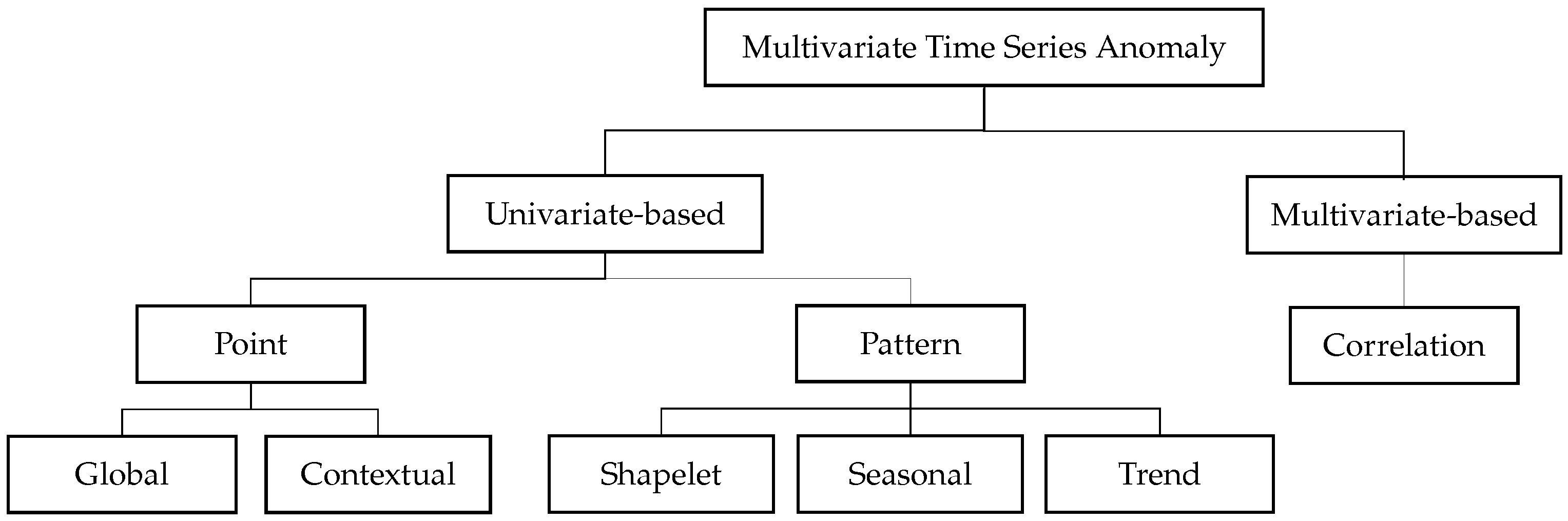
3.2. Anomaly Types
3.3. Convolutional Neural Network
3.4. Variational Autoencoder
4. Proposed Method
4.1. Proposed Architecture
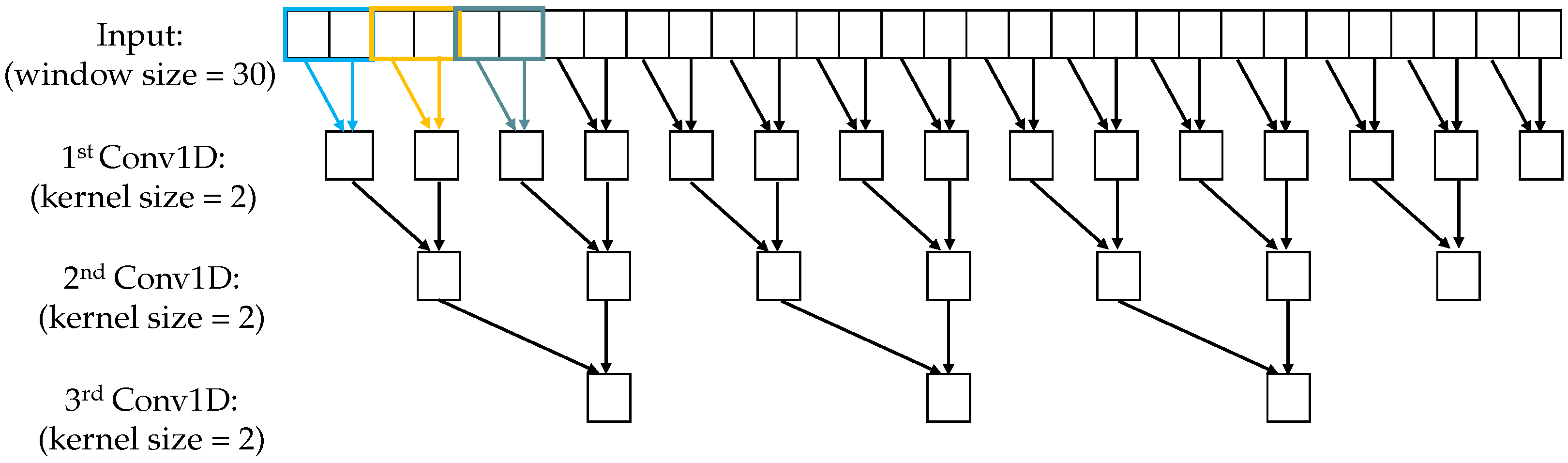
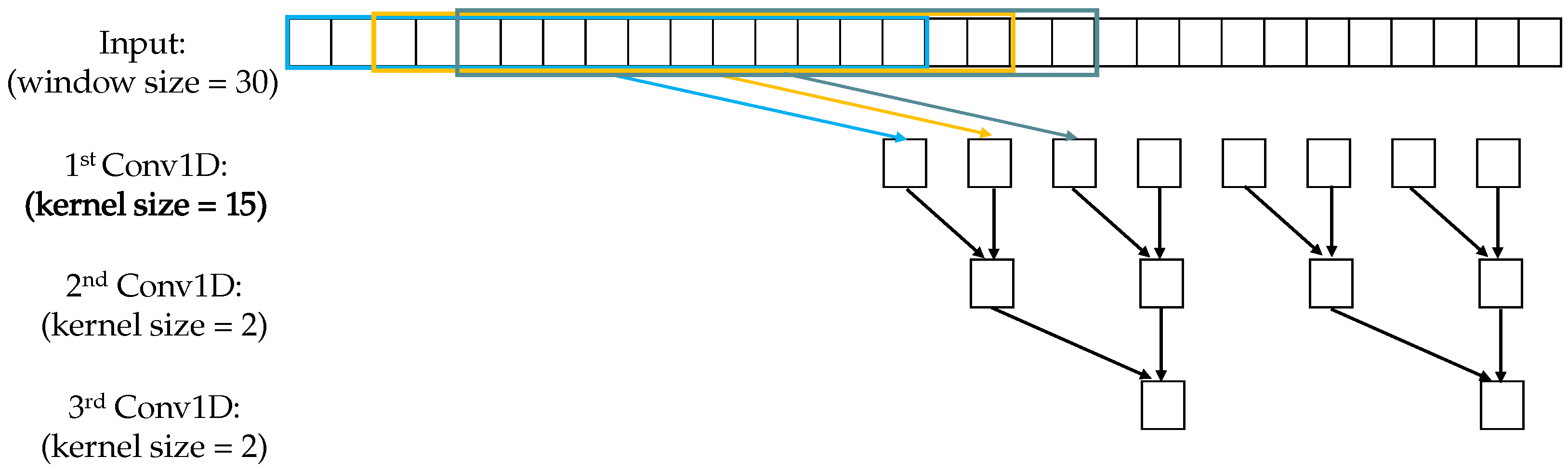
4.2. Multi-Scale Convolutional Kernels
4.3. Model Training and Inference
5. Experiment
5.1. Datasets
5.2. Experiment Setup
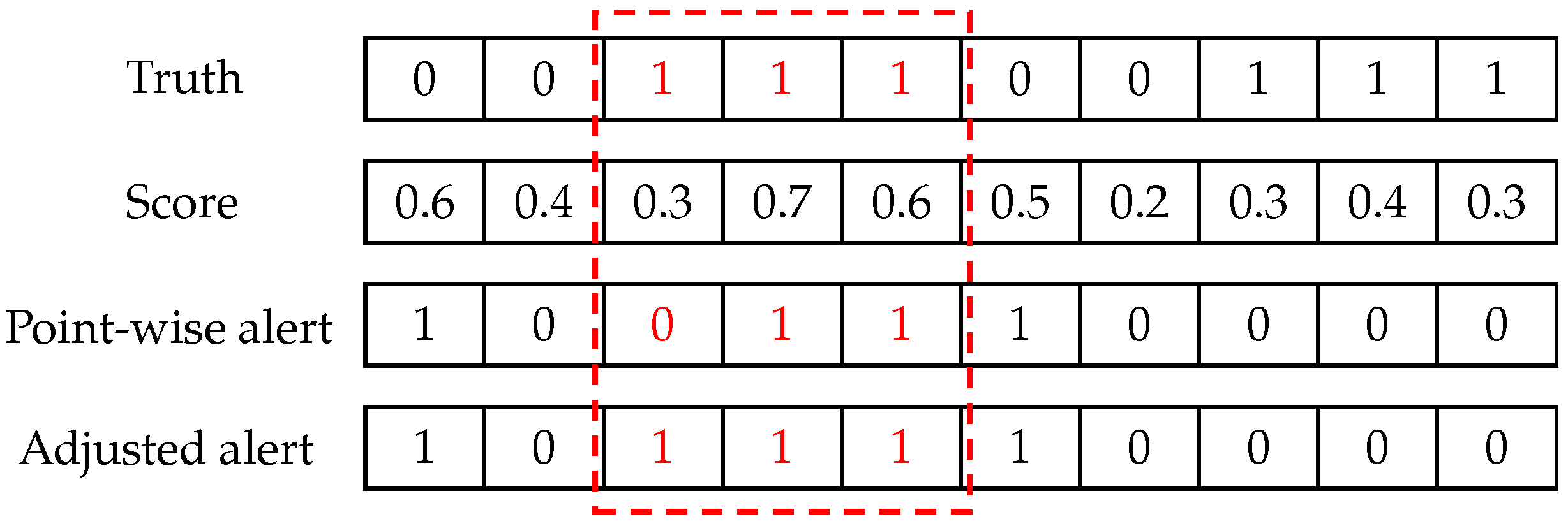
5.3. Evaluation Metrics
5.4. Performance Evaluation
5.4.1. Anomaly Detection Results
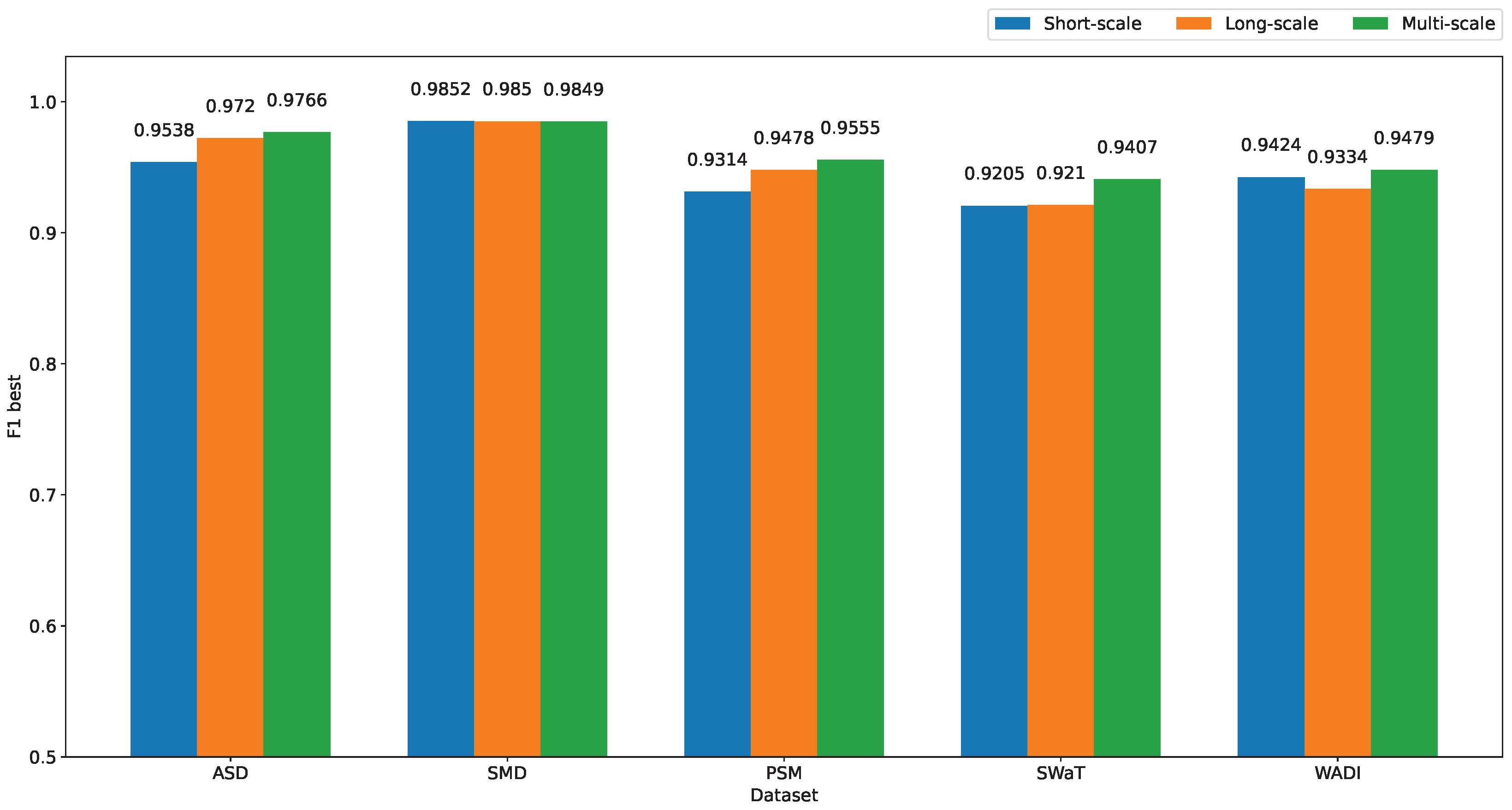
5.4.2. Effect of Multi-Scale Kernels on the Model Performance
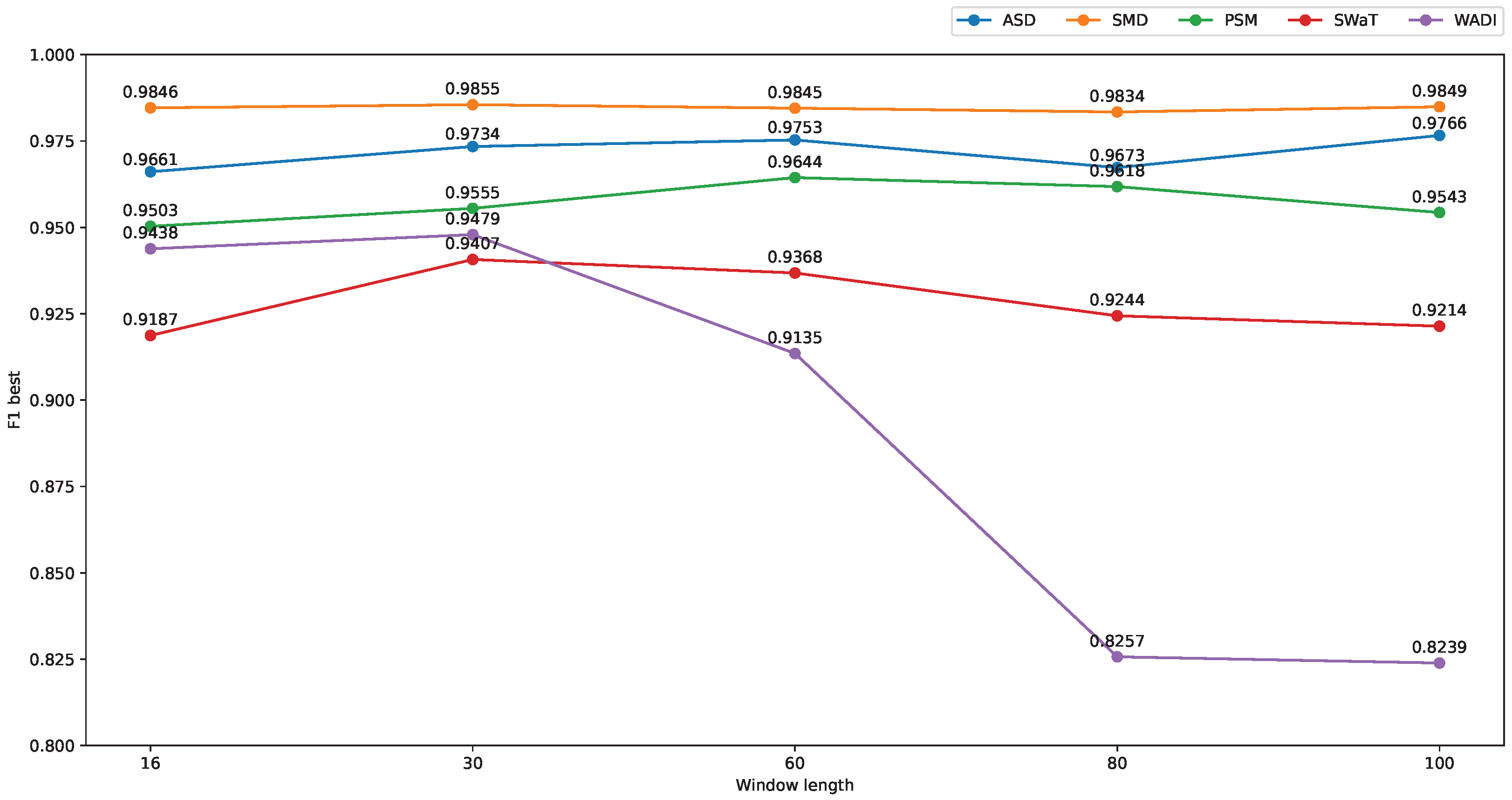
5.4.3. Effect of Window Lengths on the Model Performance
5.4.4. Training Time
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z.; Liu, Y.; Zhao, Y.; Pei, D.; Feng, Y.; et al. Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications. In Proceedings of the 2018 World Wide Web Conference on World Wide Web, Lyon, France, 23–27 April 2018; pp. 187–196. [Google Scholar]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust Anomaly Detection for Multivariate Time Series through Stochastic Recurrent Neural Network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2828–2837. [Google Scholar]
- Zhang, C.; Song, D.; Chen, Y.; Feng, X.; Lumezanu, C.; Cheng, W.; Ni, J.; Zong, B.; Chen, H.; Chawla, N.V. A Deep Neural Network for Unsupervised Anomaly Detection and Diagnosis in Multivariate Time Series Data. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 1409–1416. [Google Scholar]
- Sánchez-Fernández, A.; Baldán, F.J.; Sainz-Palmero, G.I.; Benítez, J.M.; Fuente, M.J. Fault detection based on time series modeling and multivariate statistical process control. Chemom. Intell. Lab. Syst. 2018, 182, 57–69. [Google Scholar] [CrossRef]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 387–395. [Google Scholar]
- Blázquez-Gacía, A.; Conde, A.; Mori, U.; Lozano, J.A. A Review on Outlier/Anomaly Detection in Time Series Data. ACM Comput. Surv. 2022, 54, 1–33. [Google Scholar] [CrossRef]
- Garg, A.; Zhang, W.; Samaran, J.; Savitha, R.; Foo, C.S. An Evaluation of Anomaly Detection and Diagnosis in Multivariate Time Series. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 2508–2517. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Qin, R.; Xu, H.; Sadiq, S.; Yu, Y. A Data Quality Control Method for Seafloor Observatories: The Application of Observed Time Series Data in the East China Sea. Sensors 2018, 18, 2628. [Google Scholar] [CrossRef] [Green Version]
- Carrera, D.; Rossi, B.; Fragneto, P.; Boracchi, G. Online anomaly detection for long-term ECG monitoring using wearable devices. Pattern Recognit. 2019, 88, 482–492. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Han, J.; Su, Y.; Jiao, R.; Wen, X.; Pei, D. Multivariate Time Series Anomaly Detection and Interpretation using Hierarchical Inter-Metric and Temporal Embedding. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Washington, DC, USA, 14–18 August 2021; pp. 3220–3230. [Google Scholar]
- Audibert, J.; Michiardi, P.; Guyard, F.; Marti, S.; Zuluaga, M.A. USAD: UnSupervised Anomaly Detection on Multivariate Time Series. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery Data Mining, New York, NY, USA, 6–10 July 2020; pp. 3395–3404. [Google Scholar]
- Zhao, Y.; Zhang, X.; Shang, Z.; Cao, Z. A Novel Hybrid Method for KPI Anomaly Detection Based on VAE and SVDD. Symmetry 2021, 13, 2104. [Google Scholar] [CrossRef]
- Braei, M.; Wagner, S. Anomaly Detection in Univariate Time-Series: A Survey on the State-of-the-Art. arXiv 2020, arXiv:2004.00433. [Google Scholar]
- Choi, K.; Yi, J.; Park, C.; Yoon, S. Deep Learning for Anomaly Detection in Time-Series Data: Review, Analysis, and Guidelines. IEEE Access 2021, 9, 120043–120065. [Google Scholar] [CrossRef]
- Pan, D.; Song, Z.; Nie, L.; Wang, B. Satellite Telemetry Data Anomaly Detection Using Bi-LSTM Prediction Based Model. In Proceedings of the 2020 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Dubrovnik, Croatia, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based encoder-decoder for multi-sensor anomaly detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Nguyen, H.D.; Tran, K.P.; Thomassey, S.; Hamad, M. Forecasting and Anomaly Detection approaches using LSTM and LSTM Autoencoder techniques with the applications in supply chain management. Int. J. Inf. Manag. 2020, 57, 102282. [Google Scholar] [CrossRef]
- Thill, M.; Konen, W.; Wang, H.; Bäck, T. Temporal convolutional autoencoder for unsupervised anomaly detection in time series. Appl. Soft Comput. 2021, 112, 107751. [Google Scholar] [CrossRef]
- An, J.; Cho, S. Variational Autoencoder Based Anomaly Detection Using Reconstruction Probability; Technical Report; SNU Data Mining Center: Seoul, Korea, 2015. [Google Scholar]
- Li, L.; Yan, J.; Wang, H.; Jin, Y. Anomaly Detection of Time Series With Smoothness-Inducing Sequential Variational Auto-Encoder. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1177–1191. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Song, X.; Wen, Q.; Wang, P.; Sun, L.; Xu, H. Robusttad: Robust time series anomaly detection via decomposition and convolutional neural networks. arXiv 2020, arXiv:2002.09535. [Google Scholar]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 93–104. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 8th IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Li, D.; Chen, D.; Goh, J.; Ng, S.-K. MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks. In Proceedings of the 28th International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; pp. 703–716. [Google Scholar]
- Park, D.; Hoshi, Y.; Kemp, C.C. A multimodal anomaly detector for robot-assisted feeding using an lstm-based variational autoencoder. IEEE Robot. Autom. Lett. 2018, 3, 1544–1551. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, C.C. An introduction to outlier analysis. In Outlier Analysis; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–34. [Google Scholar]
- Lai, K.H.; Zha, D.; Xu, J.; Zhao, Y.; Wang, G.; Hu, X. Revisiting Time Series Outlier Detection: Definitions and Benchmarks. In Proceedings of the Thirtyfifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), Online, 7–10 December 2021. [Google Scholar]
- Xu, J.; Wu, H.; Wang, J.; Long, M. Anomaly Transformer: Time series anomaly detection with association discrepancy. In Proceedings of the Tenth International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. arXiv 2019, arXiv:1905.03554. [Google Scholar] [CrossRef]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. In Proceedings of the 2nd International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Geweke, J. Bayesian Inference in Econometric Models Using Monte Carlo Integration. Econometrica 1989, 57, 1317–1339. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 Computer Vision and Pattern Recognition IEEE, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, S.; Li, Z.; Wang, J.; Xiong, N.N. Intelligent Detection for Key Performance Indicators in Industrial-Based Cyber-Physical Systems. IEEE Trans. Ind. Inform. 2021, 17, 5799–5809. [Google Scholar] [CrossRef]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-vae: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Wang, Y.; Blei, D.M.; Cunningham, J.P. Posterior collapse and latent variable non-identifiability. In Proceedings of the Neural Information Processing Systems 34 (NeurIPS 2021), Online, 6–14 December 2021. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In Proceedings of the 31st International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Abdulaal, A.; Liu, Z.; Lancewicki, T. Practical Approach to Asynchronous Multivariate Time Series Anomaly Detection and Localization. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD’21), New York, NY, USA, 14–18 August 2021; pp. 2485–2494.

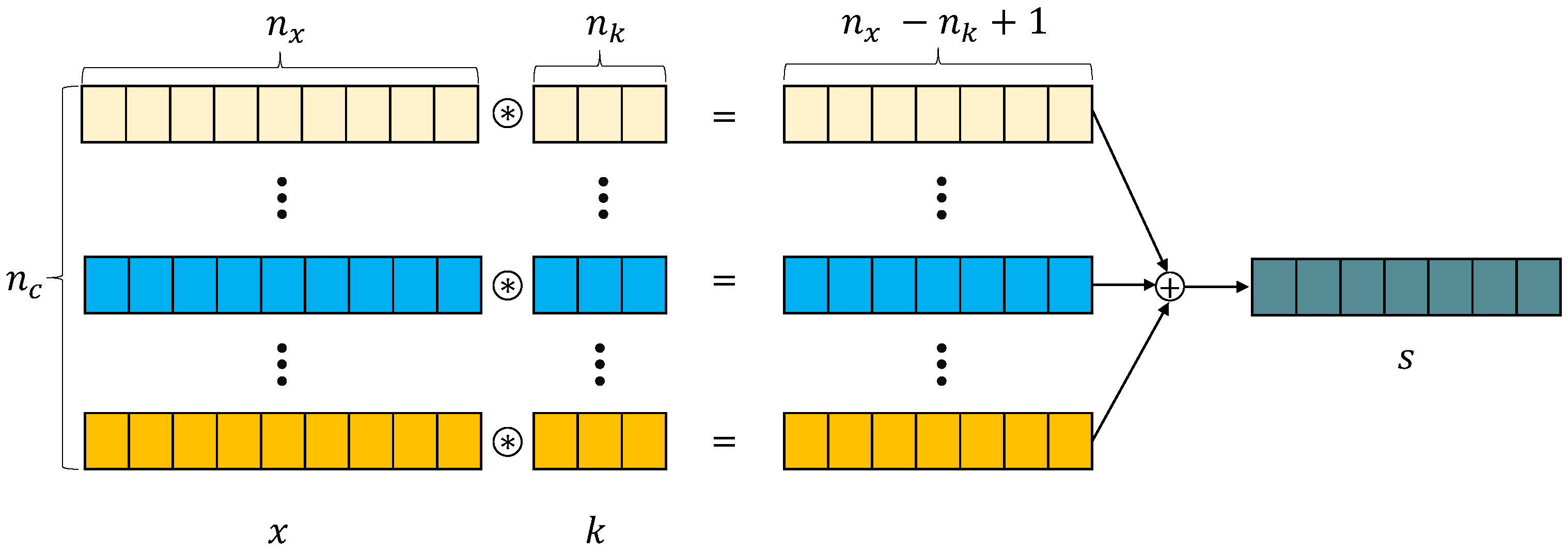


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | No. Entities | No. Metrics | Train | Test | Anomaly Rate |
|---|---|---|---|---|---|
| ASD | 12 | 19 | 102,331 | 51,840 | 4.61 |
| SMD | 12 | 38 | 304,168 | 304,174 | 5.84 |
| PSM | N/A | 25 | 132,841 | 87,841 | 11.07 |
| SWaT | 1 | 51 | 475,200 | 449,919 | 12.13 |
| WADI | 1 | 118 | 789,371 | 172,801 | 5.85 |
| Hyperparameter | Value |
|---|---|
| Window length | 100 for ASD, SMD; 30 for PSM, SWaT, and WADI |
| No. Conv1D layers in hidden layers | 3 for window length = 100, 2 for window length = 30 |
| Activation function | ReLU is applied for Conv1D in hidden layers |
| L2 regularization | 1 × 10 |
| Clip values for log std | min = −5, max = 2 |
| Batch size | 100 |
| Train validaion split | 7:3 for ASD, SMD; 9:1 for PSM, SWaT, and WADI |
| Number of z samples for Monte Carlo integration | 100 |
| No. MCMC iterations | 10 |
| Baselines | ASD | SMD | PSM | SWaT | WADI | Average |
|---|---|---|---|---|---|---|
| LOF | 0.7954 | 0.8954 | 0.7609 | 0.8167 | 0.4689 | 0.7475 |
| DAGMM | 0.7436 | 0.9528 | 0.9399 | 0.7997 | 0.4306 | 0.7733 |
| Isolation Forest | 0.7115 | 0.9516 | 0.9200 | 0.8413 | 0.6674 | 0.8184 |
| LSTM-NDT | 0.4061 | 0.7687 | 0.8319 | 0.8133 | 0.5067 | 0.6653 |
| MAD-GAN | 0.6325 | 0.8966 | 0.6158 | 0.8431 | 0.7085 | 0.7393 |
| LSTM-VAE | 0.5964 | 0.9501 | 0.7951 | 0.8223 | 0.5452 | 0.7418 |
| USAD | 0.7987 | 0.9024 | 0.7606 | 0.8227 | 0.4275 | 0.7424 |
| OmniAnomaly | 0.8344 | 0.9628 | 0.9076 | 0.7344 | 0.7927 | 0.8464 |
| MSCRED | 0.5948 | 0.8252 | 0.7468 | 0.8346 | 0.5469 | 0.7097 |
| InterFusion | 0.9531 | 0.9817 | 0.9511 | 0.9280 | 0.9103 | 0.9448 |
| MST-VAE | 0.9766 | 0.9849 | 0.9555 | 0.9407 | 0.9479 | 0.9611 |
| Baselines | ASD | SMD | PSM | SWaT | WADI |
|---|---|---|---|---|---|
| InterFusion | 15.38 | 49.39 | 111.92 | 499.2 | 611.07 |
| MST-VAE | 1.76 | 7.12 | 10 | 92.93 | 151.2 |
| Acceleration factor | 8.74 | 6.94 | 11.19 | 5.37 | 4.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pham, T.-A.; Lee, J.-H.; Park, C.-S. MST-VAE: Multi-Scale Temporal Variational Autoencoder for Anomaly Detection in Multivariate Time Series. Appl. Sci. 2022, 12, 10078. https://doi.org/10.3390/app121910078
Pham T-A, Lee J-H, Park C-S. MST-VAE: Multi-Scale Temporal Variational Autoencoder for Anomaly Detection in Multivariate Time Series. Applied Sciences. 2022; 12(19):10078. https://doi.org/10.3390/app121910078
Chicago/Turabian StylePham, Tuan-Anh, Jong-Hoon Lee, and Choong-Shik Park. 2022. "MST-VAE: Multi-Scale Temporal Variational Autoencoder for Anomaly Detection in Multivariate Time Series" Applied Sciences 12, no. 19: 10078. https://doi.org/10.3390/app121910078
APA StylePham, T.-A., Lee, J.-H., & Park, C.-S. (2022). MST-VAE: Multi-Scale Temporal Variational Autoencoder for Anomaly Detection in Multivariate Time Series. Applied Sciences, 12(19), 10078. https://doi.org/10.3390/app121910078