
Research on Traditional Mongolian-Chinese Neural Machine Translation Based on Dependency Syntactic Information and Transformer Model


Abstract
1. Introduction
- The syntactic-assisted learning unit M in the encoder can take into account the abilities of local and global information learning and is used in each encoder sublayer, expanding the hypothesis space of the model;
- The addition of the Chinese dependency syntax matrix (DP) to the decoder provides an intuitive, effective, and interpretable result;
- The combination of CNNs and MMHDPA enhances translation performance with only a few additional parameters.
2. Related Works
2.1. Traditional Mongolian-Chinese Machine Translation
2.2. Transformer
3. Baseline Model
3.1. Activation Functions
3.2. Optimizer
3.3. Learning Rate Adjustment Strategy
4. The Proposed Model
4.1. Improvement of the Self-Attention Mechanism in the Encoder
4.2. Masked Multi-Head Dependency Parsing Attention (MMHDPA)
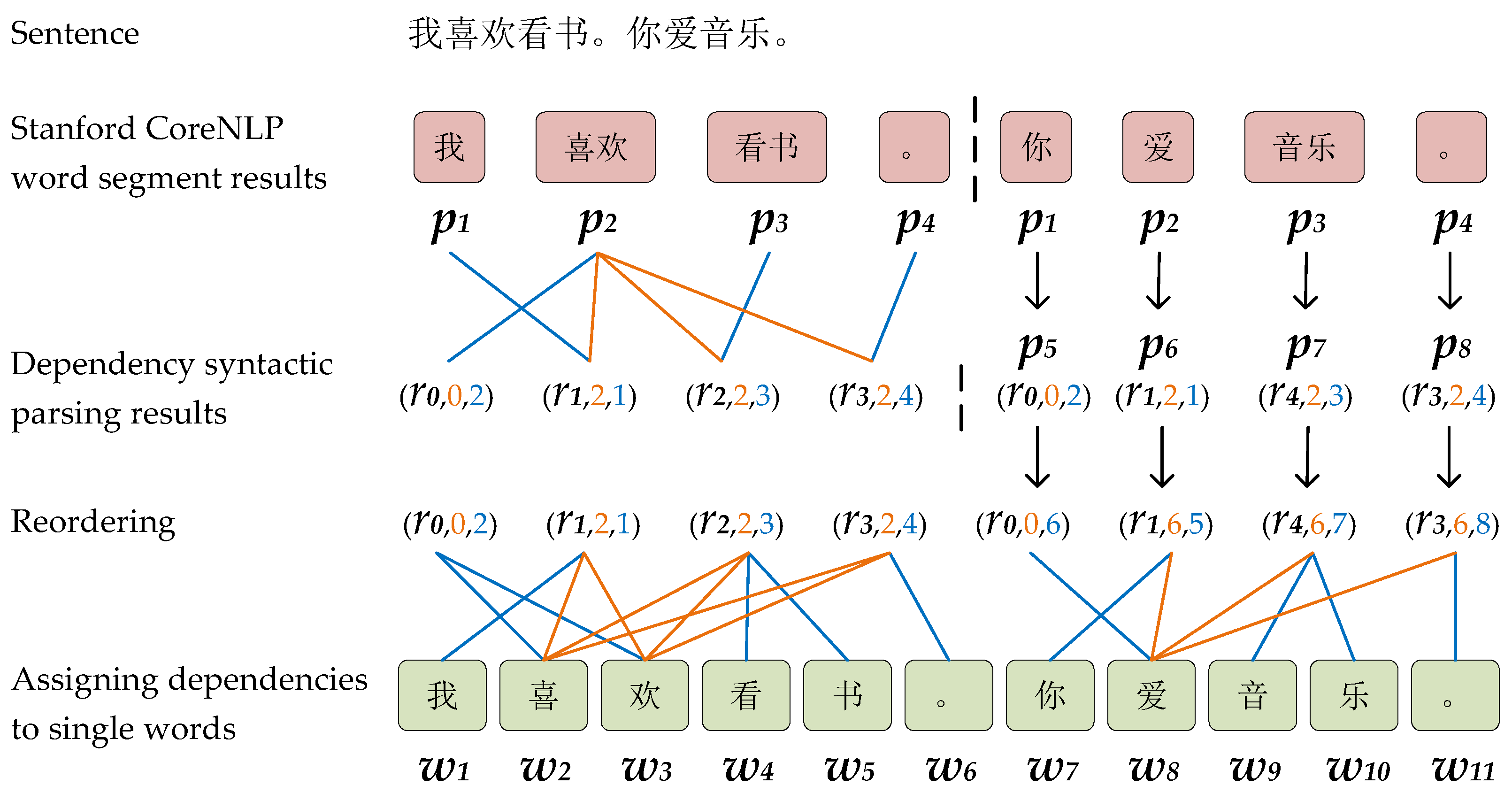
4.3. The Construction of the DP Matrix
5. Experiment
5.1. Word Segmentation
5.2. Datasets and Settings
5.3. Experimental Results and Discussion
5.3.1. Experimental Results of the Six-Layer Models
- Transformer_Enc_Dec_Imp + Syn did not have the highest average BLEU score, being lower than Transformer_Enc_Imp 1.161;
- Transformer_Dec_Imp + Syn performed the worst in the experiment and had lower BLEU values than the baseline model for each random seed, obtaining the two lowest scores in all the experimental results.
- The large disparity in the proportion of model parameters to the total increase in the parameters brought about by the improved encoder and improved decoder resulted in not having enough neural network units on the decoder side to fit the amount of data brought about by the dependent syntax matrix;
- The information extraction of the Chinese dependency syntax by MMHDPA was not sufficient, and the structure of MMHDPA should continue to be improved to better learn the target language’s grammar.
5.3.2. Experimental Results of the Five-Layer Models
6. Integration of Primer-EZ Methods Based on Improved Models
6.1. Primer-EZ
6.2. Experimental Results and Discussion
6.3. Comparison with Other Methods
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Neco, R.P.; Forcada, M.L. Asynchronous translations with recurrent neural nets. In Proceedings of the International Conference on Neural Networks (ICNN’97), Houston, TX, USA, 12 June 1997; pp. 2535–2540. [Google Scholar]
- Castano, A.; Casacuberta, F. A connectionist approach to machine translation. In Proceedings of the Fifth European Conference on Speech Communication and Technology, Rhodes, Greece, 22–25 September 1997; pp. 91–94. [Google Scholar]
- Forcada, M.L.; Ñeco, R.P. Recursive hetero-associative memories for translation. In Proceedings of the International Work-Conference on Artificial Neural Networks, Berlin, Germany, 4–6 June 1997; pp. 453–462. [Google Scholar]
- Pollack, J.B. Recursive distributed representations. Artif. Intell. 1990, 46, 142–149. [Google Scholar] [CrossRef]
- Chrisman, L. Learning recursive distributed representations for holistic computation. Connect. Sci. 1991, 3, 345–366. [Google Scholar] [CrossRef]
- Hinton, G.E. Learning distributed representations of concepts. In Proceedings of the Eighth Annual Conference of the Cognitive Science Society, Amherst, MA, USA, 15–17 August 1986; pp. 1–12. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7 May 2015. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing EMNLP, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the 2017 Conference on Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. arXiv 2021, arXiv:2106.04554. [Google Scholar]
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A survey of visual transformers. arXiv 2021, arXiv:211106091. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient transformers: A survey. arXiv 2020, arXiv:2009.06732. [Google Scholar] [CrossRef]
- Susanto, R.H.; Chollampatt, S.; Tan, L. Lexically Constrained Neural Machine Translation with Levenshtein Transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5 July 2020; pp. 3536–3543. [Google Scholar]
- Chen, K.; Wang, R.; Utiyama, M.; Sumita, E. Content word aware neural machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5 July 2020; pp. 358–364. [Google Scholar]
- Yang, J.; Ma, S.; Zhang, D.; Li, Z.; Zhou, M. Improving neural machine translation with soft template prediction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5 July 2020; pp. 5979–5989. [Google Scholar]
- Zheng, Z.; Huang, S.; Tu, Z.; Dai, X.; Chen, J. Dynamic Past and Future for Neural Machine Translation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3 November 2019; pp. 931–941. [Google Scholar]
- Li, F.; Zhu, J.; Yan, H.; Zhang, Z. Grammatically Derived Factual Relation Augmented Neural Machine Translation. Appl. Sci. 2022, 12, 6518. [Google Scholar] [CrossRef]
- Shi, L.; Niu, C.; Zhou, M.; Gao, J. A DOM tree alignment model for mining parallel data from the web. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 17–21 July 2006; pp. 489–496. [Google Scholar]
- Sennrich, R.; Haddow, B. Linguistic Input Features Improve Neural Machine Translation. In Proceedings of the First Conference on Machine Translation, Berlin, Germany, 11–12 August 2016; pp. 83–91. [Google Scholar]
- Eriguchi, A.; Tsuruoka, Y.; Cho, K. Learning to parse and translate improves neural machine translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 72–78. [Google Scholar]
- Chen, H.; Huang, S.; Chiang, D.; Chen, J. Improved Neural Machine Translation with a Syntax-Aware Encoder and Decoder. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1936–1945. [Google Scholar]
- Chen, K.; Wang, R.; Utiyama, M.; Sumita, E.; Zhao, T. Syntax-directed attention for neural machine translation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 4792–4799. [Google Scholar]
- Yang, B.; Tu, Z.; Wong, D.F.; Meng, F.; Chao, L.S.; Zhang, T. Modeling Localness for Self-Attention Networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4449–4458. [Google Scholar]
- Bugliarello, E.; Okazaki, N. Enhancing machine translation with dependency-aware self-attention. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5 July 2020; pp. 1618–1627. [Google Scholar]
- Wu, J.; Hou, H.X.; Monghjaya, M.; Bao, F.L.; Xie, C.J. Introduction of Traditional Mongolian-Chinese Machine Translation. In Proceedings of the 2015 International Conference on Electrical, Automation and Mechanical Engineering, Phuket, Thailand, 26–27 July 2015; pp. 357–360. [Google Scholar]
- Wu, J.; Hou, H.; Bao, F.; Jiang, Y. Template-Based Model for Mongolian-Chinese Machine Translation. J. Adv. Comput. Intell. Intell. Inform. 2016, 20, 893–901. [Google Scholar] [CrossRef]
- Wang, S.R.G.L.; Si, Q.T.; Nasun, U. The Research on Reordering Rule of Chinese-Mongolian Statistical Machine Translation. Adv. Mater. Res. 2011, 268, 2185–2190. [Google Scholar] [CrossRef]
- Yang, Z.; Li, M.; Chen, L.; Wei, L.; Wu, J.; Chen, S. Constructing morpheme-based translation model for Mongolian-Chinese SMT. In Proceedings of the 2015 International Conference on Asian Language Processing (IALP), Suzhou, China, 24 October 2015; pp. 25–28. [Google Scholar]
- Wu, J.; Hou, H.; Shen, Z.; Du, J.; Li, J. Adapting attention-based neural network to low-resource Mongolian-Chinese machine translation. In Proceedings of the Natural Language Understanding and Intelligent Applications, Kunming, China, 2–6 December 2016; pp. 470–480. [Google Scholar]
- Li, H.; Hou, H.; Wu, N.; Jia, X.; Chang, X. Semantically Constrained Document-Level Chinese-Mongolian Neural Machine Translation. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Ji, Y.; Hou, H.; Chen, J.; Wu, N. Adversarial training for unknown word problems in neural machine translation. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2019, 19, 1–12. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 30. [Google Scholar]
- Xu, J.; Li, Z.; Du, B.; Zhang, M.; Liu, J. Reluplex made more practical: Leaky ReLU. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. 2018. Available online: https://arxiv.org/abs/1711.05101v2 (accessed on 30 August 2022).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the 685 Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; (Long and Short Papers). Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The stanford corenlp natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22 June 2014; pp. 55–60. [Google Scholar]
- Zipf, G.K. Human Behaviour and the Principle of Least-Effort: An Introduction to Human Ecology; Martino Fine Books: Eastford, CT, USA, 1949. [Google Scholar]
- Li, X.; Meng, Y.; Sun, X.; Han, Q.; Yuan, A.; Li, J. Is Word Segmentation Necessary for Deep Learning of Chinese Representations? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 3242–3252. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- So, D.; Mańke, W.; Liu, H.; Dai, Z.; Shazeer, N.; Le, Q.V. Primer: Searching for Efficient Transformers for Language Modeling. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, Online, 6–14 December 2021; pp. 6010–6022. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corpus | MN-CH |
|---|---|
| Training Set | 479,163 |
| Validation Set | 9979 |
| Test Set | 9779 |
| Model | Number of Parameters |
|---|---|
| Transformer_Base | 48,787,909 |
| Transformer_Enc_Imp | 50,046,181 |
| Transformer_Dec_Imp + Syn | 49,051,077 |
| Transformer_Enc_Dec_Imp | 50,309,349 |
| Transformer_Enc_Dec_Imp + Syn | 50,309,349 |
| Model | 100 | 6421 | 2169 | 500 | 256 | Avg. BLEU |
|---|---|---|---|---|---|---|
| Transformer_Base | 38.377 | 38.280 | 38.566 | 38.362 | 38.588 | 38.435 |
| Transformer_Enc_Imp | 46.158 | 45.661 | 46.994 | 46.161 | 46.535 | 46.302 |
| Transformer_Dec_Imp + Syn | 37.183 | 28.481 | 36.939 | 35.264 | 16.351 | 30.844 |
| Transformer_Enc_Dec_Imp | 41.337 | 44.774 | 35.002 | 45.556 | 41.341 | 41.602 |
| Transformer_Enc_Dec_Imp + Syn | 46.195 | 44.892 | 45.273 | 46.170 | 43.176 | 45.141 |
| Model | Number of Parameters |
|---|---|
| Transformer_Base | 45,894,085 |
| Transformer_Enc_Imp | 46,942,645 |
| Transformer_Dec_Imp + Syn | 46,157,253 |
| Transformer_Enc_Dec_Imp | 47,205,813 |
| Transformer_Enc_Dec_Imp + Syn | 47,205,813 |
| Model | 100 | 6421 | 2169 | 500 | 256 | Avg. BLEU |
|---|---|---|---|---|---|---|
| Transformer_Base | 36.575 | 36.686 | 36.533 | 36.711 | 36.099 | 36.521 (↓1.914) |
| Transformer_Enc_Imp | 44.049 | 43.758 | 44.765 | 44.797 | 44.610 | 44.396 (↓1.906) |
| Transformer_Dec_Imp + Syn | 36.244 | 36.374 | 25.571 | 35.433 | 35.382 | 33.801 (↑2.957) |
| Transformer_Enc_Dec_Imp | 41.068 | 42.649 | 36.973 | 43.258 | 32.996 | 39.389 (↓2.213) |
| Transformer_Enc_Dec_Imp + Syn | 45.758 | 44.197 | 37.822 | 37.973 | 43.901 | 41.930 (↓3.211) |
| Model | 100 | 6421 | 2169 | 500 | 256 | Avg. BLEU |
|---|---|---|---|---|---|---|
| Transformer_Base + EZ (Squared Leaky ReLU) | 37.275 | 37.607 | 37.135 | 37.409 | 37.021 | 37.289 |
| Transformer_Enc_Imp + EZ (Squared Leaky ReLU) | 43.866 | 44.795 | 45.236 | 45.251 | 44.933 | 44.816 |
| Transformer_Dec_Imp + Syn + EZ (Both) | 37.556 | 37.183 | 37.622 | 37.283 | 36.102 | 37.149 |
| Transformer_Enc_Dec_Imp + EZ (Both) | 45.966 | 46.005 | 44.840 | 44.722 | 45.698 | 45.446 |
| Transformer_Enc_Dec_Imp + Syn + EZ (Both) | 45.569 | 46.081 | 45.597 | 45.264 | 45.658 | 45.634 |
| Model | Conditions | Avg. BLEU |
|---|---|---|
| Transformer_Base | N = 6, EPOCHS = 40 | 38.435 |
| Transformer_Base | N = 5, EPOCHS = 35 | 36.521 |
| Transformer_Base + EZ (Squared Leaky ReLU) | N = 5, EPOCHS = 35 | 37.289 |
| Transformer_Enc_Imp | N = 6, EPOCHS = 40 | 46.302 |
| Transformer_Enc_Imp | N = 5, EPOCHS = 35 | 44.396 |
| Transformer_Enc_Imp + EZ (Squared Leaky ReLU) | N = 5, EPOCHS = 35 | 44.816 |
| Transformer_Dec_Imp + Syn | N = 6, EPOCHS = 40 | 30.844 |
| Transformer_Dec_Imp + Syn | N = 5, EPOCHS = 35 | 33.801 |
| Transformer_Dec_Imp + Syn + EZ (Both) | N = 5, EPOCHS = 35 | 37.149 |
| Transformer_Enc_Dec_Imp | N = 6, EPOCHS = 40 | 41.602 |
| Transformer_Enc_Dec_Imp | N = 5, EPOCHS = 35 | 39.389 |
| Transformer_Enc_Dec_Imp + EZ (Both) | N = 5, EPOCHS = 35 | 45.446 |
| Transformer_Enc_Dec_Imp + Syn | N = 6, EPOCHS = 40 | 45.141 |
| Transformer_Enc_Dec_Imp + Syn | N = 5, EPOCHS = 35 | 41.930 |
| Transformer_Enc_Dec_Imp + Syn + EZ (Both) | N = 5, EPOCHS = 35 | 45.634 |
| Model | BLEU | Training Set | Validation Set | Test Set | Max. Sentence Length |
|---|---|---|---|---|---|
| Wu et al. [31] | 21.09 | 58,900 | 1000 | 1000 | - |
| Wu et al. [34] | 31.18 | 63,000 | 1000 | 1000 | 50 |
| Li et al. [35] | 19.4 | 421 | 52 | 52 | - |
| Our Approach | 45.634 | 479,163 | 9979 | 9779 | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qing-dao-er-ji, R.; Cheng, K.; Pang, R. Research on Traditional Mongolian-Chinese Neural Machine Translation Based on Dependency Syntactic Information and Transformer Model. Appl. Sci. 2022, 12, 10074. https://doi.org/10.3390/app121910074
Qing-dao-er-ji R, Cheng K, Pang R. Research on Traditional Mongolian-Chinese Neural Machine Translation Based on Dependency Syntactic Information and Transformer Model. Applied Sciences. 2022; 12(19):10074. https://doi.org/10.3390/app121910074
Chicago/Turabian StyleQing-dao-er-ji, Ren, Kun Cheng, and Rui Pang. 2022. "Research on Traditional Mongolian-Chinese Neural Machine Translation Based on Dependency Syntactic Information and Transformer Model" Applied Sciences 12, no. 19: 10074. https://doi.org/10.3390/app121910074
APA StyleQing-dao-er-ji, R., Cheng, K., & Pang, R. (2022). Research on Traditional Mongolian-Chinese Neural Machine Translation Based on Dependency Syntactic Information and Transformer Model. Applied Sciences, 12(19), 10074. https://doi.org/10.3390/app121910074