2.1. Study Area and Data
The background of this study stems from a need for activity-based analysis of travel behaviors as part of a Czech national project, “Smart City—Smart Region—Smart Community” [
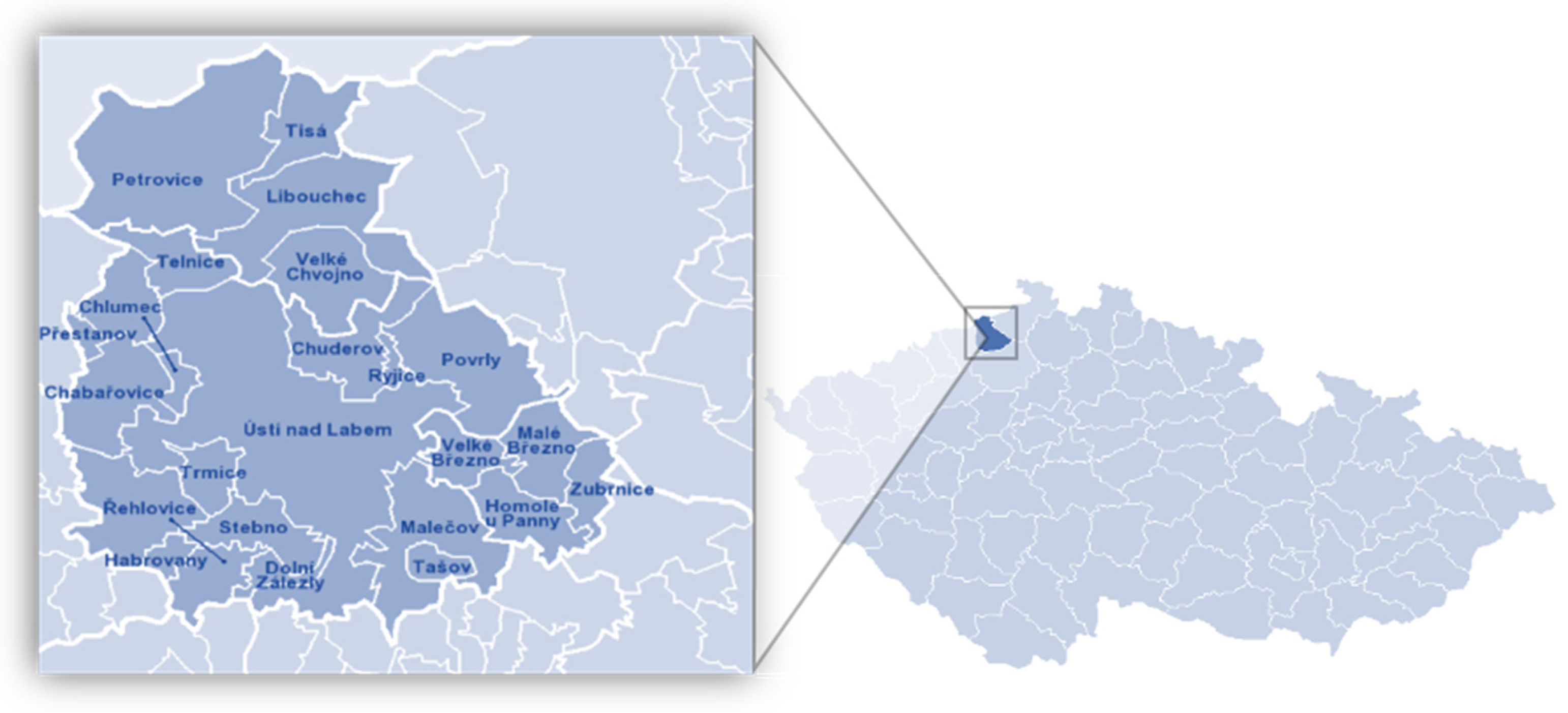
23]. The study focuses on the Ústí nad Labem catchment area, referred to as the district area. In general, a district area in the Czech Republic represents a functional region consisting of a central city and surrounding municipalities that are dependent on the central city in terms of jobs and services. The district of Ústí nad Labem is located in the northwest part of the Czech Republic, shown in
Figure 1. The main city (Ústí nad Labem) and its surrounding 23 municipalities are home to 90,378 and 26,538 inhabitants, respectively, for a total of 116,916 residents [
24] The Czech Land Survey Office provided zonal boundary data for the study area [
25]. In recent decades, the city of Ústí nad Labem had a dramatic transition from an industrial-based economy to service-oriented one. The city is a regional center with important administrative, cultural, and educational institutions, including a university. There is a complex railway junction connecting many national and international cities in the Ústí nad Labem city center, making the city an important transportation hub.
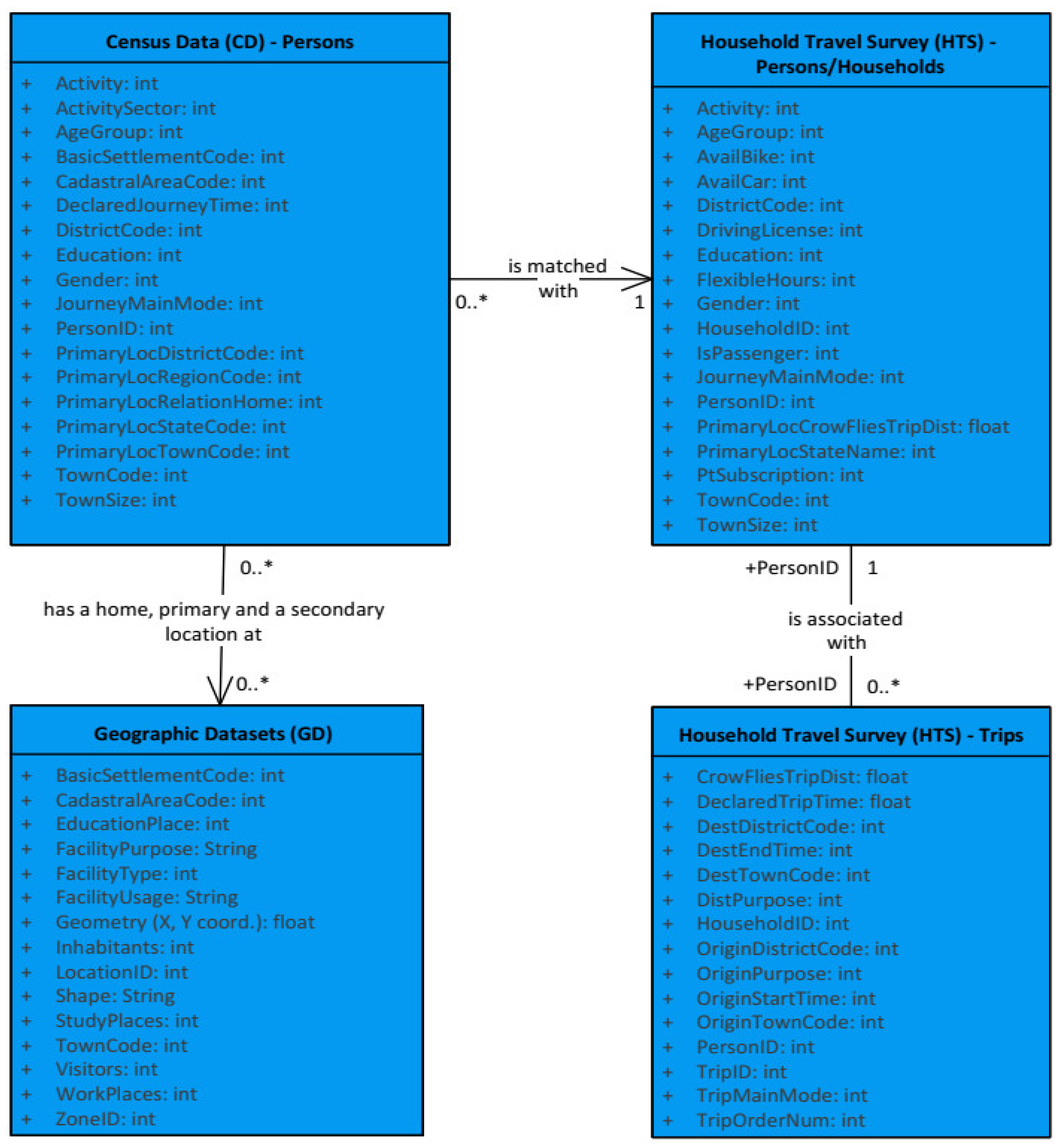
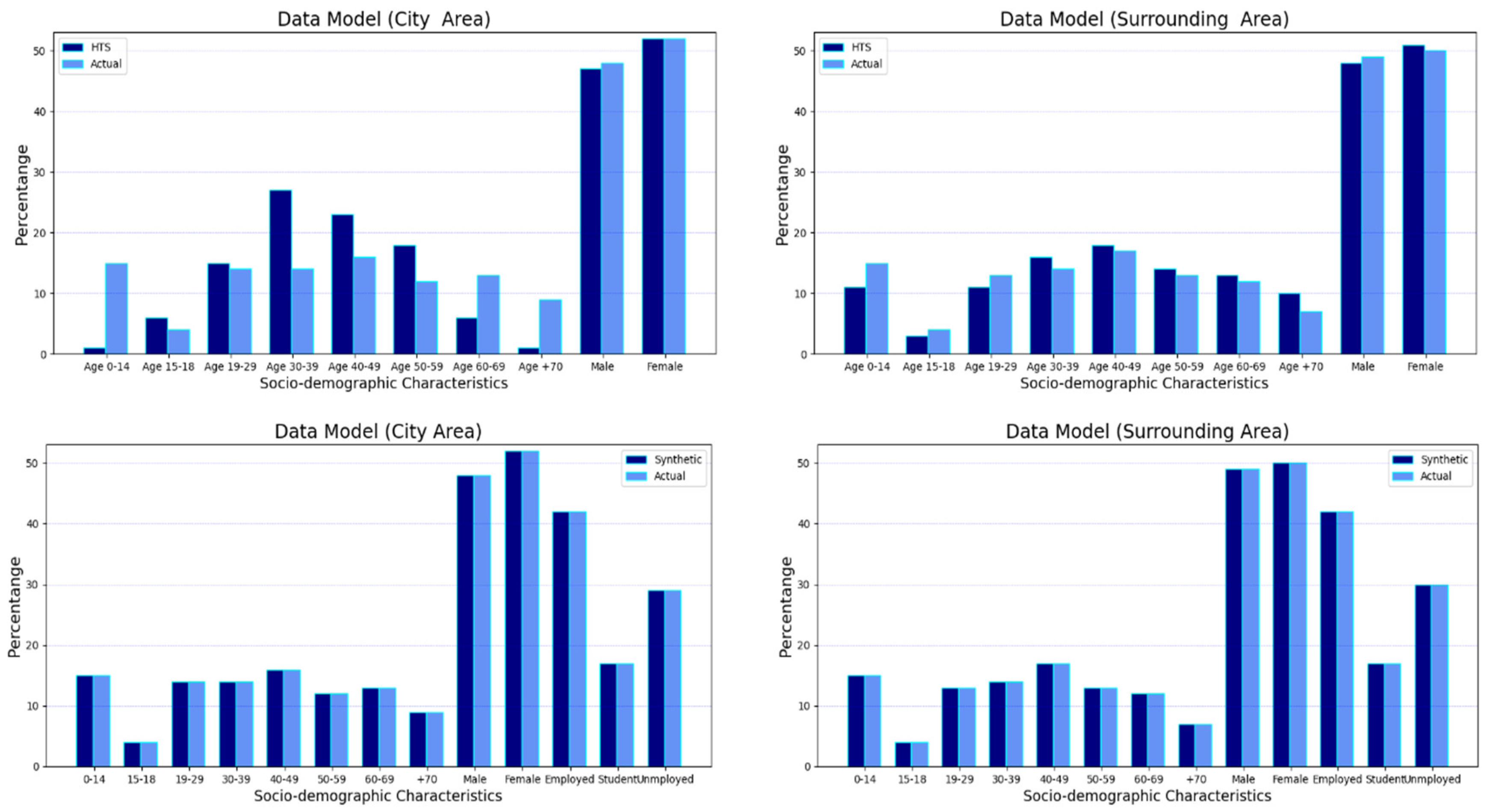
Census data (CD) provided by the Czech Statistical Office [
26] was used to generate a synthetic population for the study area together with household travel surveys (HTS) to reflect travel demand and geographic datasets (GD) containing useful information about the buildings, facilities, and land use of the study area in order to increase the realism of travel demand assignment. Census data are collected every ten years in the Czech Republic, and the latest available census was conducted in 2011 (CD-2011). The CD-2011 provides demographics, travel attitudes, housing conditions, and work and education locations relative to home locations (e.g., in the same municipality or in another municipality of the same district) for each inhabitant. A demographic transition algorithm was applied to this dataset to reflect a realistic sociodemographic structure for the year 2016, as explained in the next subsection. Demographic transition was implemented by utilizing a dataset provided by the Czech Statistical Office containing birth rates, mortality rates, and the information about the residential mobility of inhabitants [
27,
28,
29].
HTS represents travel data of a sample of the citizens containing transport mode preferences, daily activity purposes, daily activity chains, origins and destination (OD) points of trips, trip purposes, trip distances, and trip durations. Two household travel surveys were utilized here, one is at national level (Czech Republic HTS) and the other is at the city level (City HTS). The Czech Republic HTS was conducted by the Transport Research Center (CDV) in 2017, and this dataset is openly available [
30]. The City HTS survey was conducted in 2016 by the NMS Research Center [
31]. City HTS provided information about trips starting or ending in the city of Ústí nad Labem, while Czech Republic HTS was used to simulate travel demand for the remaining 23 municipalities. Czech Republic HTS and City HTS datasets provided travel behaviors of 21,209 and 2054 respondents, respectively. However, after some data filtering and cleaning (see the next subsection), the sample size was reduced to 12,397 and 937 respondents, respectively. The census and travel survey datasets do not contain weights showing how many respondents a specific entry represented. The weights of each sample were assigned based on their age and gender in the datasets. Furthermore, HTS datasets only provided information about inhabitants having trips on the day of the survey. Therefore, average trip frequencies from the “EU Survey on Issues Related to Transport and Mobility” [
32] were used in this study to estimate the distribution of the inhabitants staying at home based on their employment statuses, which were available in the HTS datasets to a large extent; the Czech Republic average was used when employment data were missing.
Both the CD and HTS datasets required some generalization to enable a matching process between them by transforming some attributes into common terms. This is a harmonization process; we use this term in the next section. The harmonization process is applied to 19 attributes; we briefly describe two of them (please see the open-code repository in
Supplementary Materials for the details). The activity types represented in daily chains (e.g., home–work–home) of the respondents in the HTS datasets were categorized into six activity purposes: home, work, education, free time, shopping, and errands. In order to apply harmonization to the activity purposes for City HTS, activities related to sports, culture, and leisure were unified into one “free time” category. The activity purposes called “workplace”, “business meeting”, and “entrepreneurship” were placed in a “work” category, and activity purposes called “services”, “visiting public institutions”, “doctor”, and “other” were categorized as “errands.” For Czech Republic HTS, activity purposes related to eating and shopping were united in one “shopping” category, while work and business trip activities were placed in the “work”, and errands and other activities into “errands” category. For the transportation modes of each journey (i.e., the mode of the main trip) in the CD and HTS surveys, we reference the transportation mode types from the Czech Republic HTS, which are walk, bicycle, public transport, regional bus, regional train, car driver, car passenger, and other. In this case, for the City HTS, taxi and passenger car were grouped together into “passenger car”, while traveling by motorcycle was placed in the “other” category to match with the Czech Republic HTS arrangement. The public transport category was used for “town bus” and “trolleybus” in both HTS, meanwhile Czech Republic HTS also has additional “tram” and “metro” possibilities that were also defined as public transport. For the CD, the harmonization process for the transportation modes was much more complex as it had dozens of possibilities; please check
Supplementary Materials for information.
Geographic datasets (GD) provided detailed information about the location of residential and work-related facilities in the study area. They were extracted from the RCDB (Register of Census Districts and Buildings) database provided by the Czech Statistical Office [
33] for a more precise location assignment. The facilities where free time, shopping, and errands activities took place were extracted according to OpenStreetMap (OSM) tags and sourced with the OSM 442324 reference. The data regarding the capacity of each facility (for work) and expected number of visitors for each facility (for free time, shopping, and errands activities) were estimated based on each building’s area building which is sourced from the RCDB [
33] together with the number of residents. Moreover, educational facilities (except for universities) and their capacities were sourced from the Register of Schools and Educational Facilities (RSEF) database [
34] provided by the Czech Ministry of Education Youth and Sports. University facilities and their capacities were manually added, based on information provided in university reports and annual reports of the municipalities.
The synthesis of the population with the data sources presented provided the most holistic approach to date ever considered in the Czech Republic in terms of presenting disaggregate characteristics and activities at an individual level.
Figure 2 shows the entity–relationship (E–R) diagram of the data model used in this study, representing which data are necessary from each data source and how they are related.
Nevertheless, there were some data management limitations in this study due to the extreme dependency on available data, which were not always complete. An important socioeconomic indicator, income, was not available in the CD, for example. However, the CD contained primary journey data for each person, including journey transport modes and average journey times, which was crucial for the demand synthesis process. Therefore, there were many undefined answers in the CD; for example, 72.3% of travel characteristics (average journey time, journey transport mode, etc.) for respondents were also missing in the CD dataset. As a result, a sampling process was conducted to complete missing values based on the attributes of defined subpopulations, explained in the following subsection. The City HTS dataset’s primary limitations were the low number of survey respondents, and some questions did not have responses. Because regional HTS data were not available for the study area, national HTS data were used, which generalized activity patterns to a certain extent. Therefore, both HTS data had to be considered as being limited in terms of their ability to illustrate actual behaviors. Data limitations for OpenStreetMaps in estimating the capacities of facilities and areas in terms of workers and visitors [
11,
19,
21] were resolved by using building registration datasets, which provided floor plan information and activity purposes for each certified building in the city area. This is important to note, because solid assignment of facilities data is critical for increasing a realistic foundation for activity-based scenarios. However, the building registration datasets were also missing information about the floors and categories for some facilities. Thus, some steps were conducted to complete the dataset, as explained in the following subsection. The following subsection presents the applied synthesis framework for generating a synthetic population for the study area.
2.2. Synthesis Framework
In this section, the steps leading to the creation of the synthetic population are presented. The synthetic population including travel demand of the study area was generated by modifying and extending the Eqasim framework used for the São Paulo case [
19]. This scenario served as a basis for the application of Eqasim for the district of Ústí nad Labem because the types of data available in both cases were similar. However, one major difference between the two cases is the binding of different algorithms. The São Paulo case utilizes the SYNPP package [
35] Python to bind different algorithms together in order to provide a large pipeline generating MATSim input files, which is also originally used in the Eqasim framework. There are some difficulties of code debugging and of some simplifications while parallelization in coding for the tqdm package [
36] of Python; therefore, we prefer to write codes by mimicking (partially) SYNPP functionalities to avoid these issues.
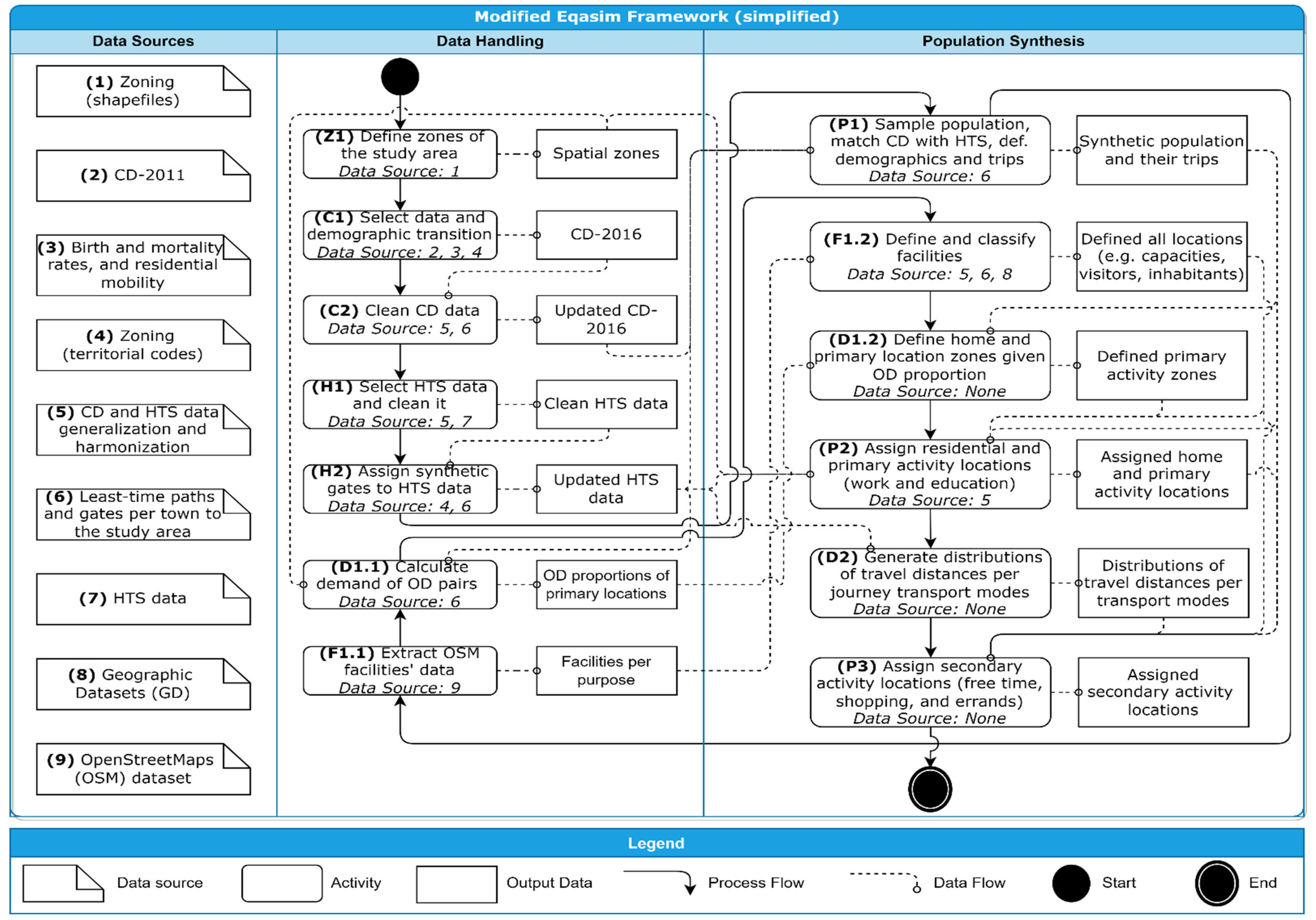
Figure 3 shows a simplified data and process flowchart of the applied framework, which is divided into data handling and population synthesis steps, including the additional data sources for each operation. The operations are described along with this subsection according to the order of the process flow.
First, the Czech zoning dataset was loaded in step Z1, which is includes the basic settlement units, cadastral area units, municipalities, and districts. In step C1, a demographic transition was conducted to mimic real population changes for the period from 2011 (when the census was conducted) to 2016 (when the City HTS was conducted). This mimicking process was generated with a stochastic simulation of several demographic transitions coded in Python. The demographic transition process was conducted based on age, gender, and geolocational data. The process utilized rates of birth and mortality and residential mobility data for the population. First, mortality of citizens was simulated for each year by converting mortality rates to the mortality probabilities assigned to each person based on age and gender. Deceased citizens were removed from the synthetic population at the end of each simulated year. Then, birth dates for the citizens were simulated for each year by converting birth rates to the birth probabilities assigned to each female, also considering the ages of the women in the study area. Genders for newborn citizens were probabilistically assigned with the ratio of 1.05 male to 1 female in the study area. Newborn citizens were included in the synthetic population at the end of each simulated year. Relocation of citizens between municipalities was performed based on the demographic database information provided by the Czech Statistical Office. The database provided the number of citizens relocating in each municipality each year, and it also contained information about the inbound and outbound migrations for the municipalities studied, including age and gender for previous and new residents. Citizens relocating to the outer part of the studied municipalities were assigned by justifying the distribution of age and gender of citizens in the database. Such citizens were consequently removed from the synthetic population. The missing values in personal attributes, i.e., family status, work sectors, places of education, travel characteristics, zones of residence, and housing types were completed by a sampling process performed on the original citizen records based on each subpopulation group categorized by gender and age characteristics in the dataset. If a defined subgroup did not have complete indicator values for each person, the missing values were completed by conducting a sampling process considering only three age subgroups: 0–14, 15–64, and 65+ years of age.
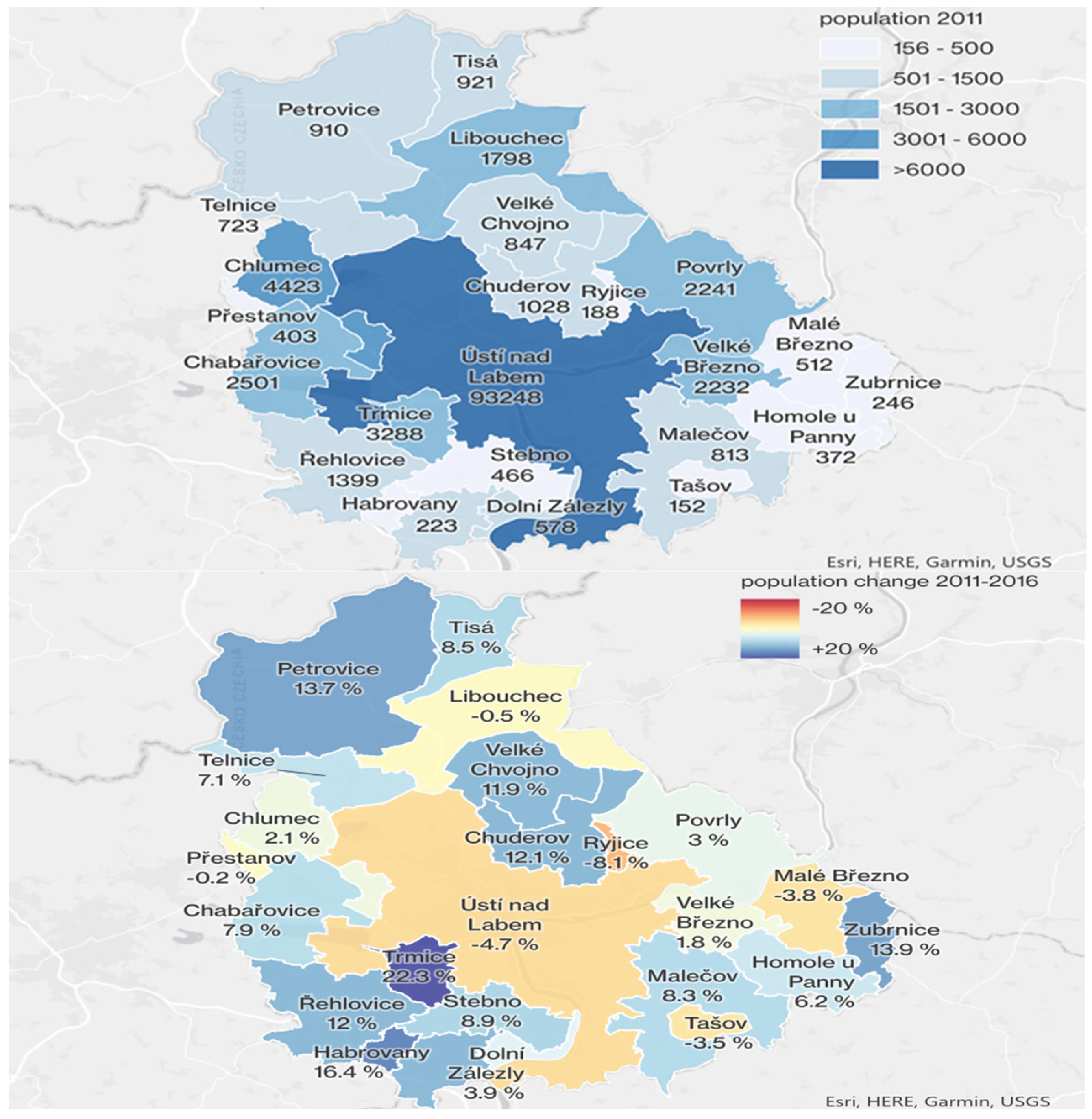
Figure 4 shows population changes in the study area (i.e., the district of Ústí nad Labem) from 2011 to 2016 as a result of the demographic transition procedure. The population of the city of Ústí nad Labem declined, while population growth was observed in its surrounding municipalities. This indicated that there was a suburbanization process taking place during the study period, and changes in the commuting patterns for the study area were to be expected. Step C2 cleaned the census data (CD-2016), extracting only citizens residing in the study area and harmonizing the CD-2016 data with both City HTS and Czech Republic HTS data according to the process described in the previous section.
Step H1 organized both City HTS and Czech Republic HTS data, in addition to also applying the harmonization process. Inconsistent data were removed, notably when some of attributes were unknown, such as average trip distances and the district codes for the origins or destinations of a trip, when trip purposes were missing, when activity chains did not start and end at home, and also when trips were repeated. Step H2 was originally intended to filter HTS trips that were totally carried outside the study area. This process is important to ensure more precise travel behavior, and it is also available in the open code in
Supplementary Materials; tough it removed too many samples. Therefore, we deactivated this step of Eqasim framework and focused on the assignment of synthetic gates for inbound and outbound trips of the study area based on the average travel times between the study area and any municipality in the Czech Republic. As the Czech Republic HTS have only OD data between certain municipalities, synthetic gates were assigned using weighted random with the population of the destination’s municipality as weight parameter. This step enabled us to model city visitors/residents traveling in and out of the city in the simulation.
Step P1 performed the statistical matching process applied in the São Paulo scenario [
19] for CD-2016, Czech Republic HTS, and City HTS datasets, which utilizes a simplified version of the hot-deck matching algorithm [
37]. The principle of this process relies on assigning travel behavior characteristics from an HTS sample to a sample in the CD-2016 based on the sociodemographic attribute values in both the CD and HTS datasets. It requires mandatory attributes, which represent attributes that must be same value in both CD-2016 and HTS samples and preferential attributes that are not required to be the same. Let
a be defined as an attribute, the sum of mandatory and preferential attributes as
N, and a sample from the CD dataset as
c, we can define the sample’s vector of its attribute values as follows:
Similarly, for a sample from the HTS dataset,
s:
First, the algorithm creates a vector with all possible combinations
k of mandatory attribute values with preferential attribute values, for instance:
Then, for every combination
k of attribute values, we define
β = {
s|as = ak} as the samples with same attribute values towards a combination and its size as the number of HTS samples matching with this combination, likewise
γ = {
c|ac = ak} while its size is the number of matching CD samples. Considering a minimum number of HTS samples to match with CD samples
M that exist with any matching CD sample, i.e., |
β| ≥
M and |
γ| > 0, then the algorithm randomly assigns HTS samples to CD-2016 samples. Afterward, if remaining CD samples need to be matched, the algorithm repeats the process by dropping one by one each preferential attribute; for example, for the last preferential attribute:
We used mostly preferential rather than mandatory attributes, and the minimum number of HTS samples to be matched with a CD-2016 sample is set to M = 3. These settings may lead to overfitting, but the main reason for these settings was the insufficiency of HTS data sample size for many groups of people with specific characteristics. The following attributes were used for preferential matching:
- (a)
gender;
- (b)
education;
- (c)
economic activity (e.g., student, employee, retired);
- (d)
main journey mode;
- (e)
primary activity location related to home;
- (f)
zone (the cadastral area unit for City HTS, and the region code for Czech Republic HTS).
The attributes used as a mandatory matching were:
- (a)
age;
- (b)
town size (only for the Czech Republic HTS dataset).
This configuration enabled us to match 100% of the CD-2016 persons. However, the inclusion of any attribute from preferential to mandatory resulted in the removal of 10~25% of the synthetic population, especially for the City HTS dataset. Therefore, retaining all citizens was preferred.
In step F1.1, OpenStreetMaps (OSM) data were imported by utilizing specific tags [
38] of OSM data, the values of building and amenity keywords were sufficient to import facilities related to almost each activity purpose (i.e., home, free time, shopping, work, education, errands), although some purposes such as free time also required other tag keys, such as “leisure”, “natural”, “tourism”, and “hiking” to capture especially the squares, parks, etc. Step D1.1 calculates the proportions of work- and education-related trips between zones by utilizing O–D pairs for each trip from the HTS datasets according to the weights of each respondent sample. In step F1.2, facility locations and their characteristics were defined by a complex combination of different datasets. Educational facilities were imported from the Register of Schools and Educational Facilities (RSEF), containing student capacity of the facilities and educational degrees granted by them (e.g., primary schools, high schools, universities). The Register of Census Districts and Buildings (RCDB) database was utilized for the location and shape of residential and commercial buildings with their characteristics linked with CD data. The building types in the RCDB dataset were harmonized based on their usage (e.g., home, work, home and work) and functionality (e.g., industry, agriculture, hospitality). The secondary facility locations were imported from OSM as a result from the F1.1 operation. The utilization purpose of each facility was carefully assigned; for example, a shopping mall may have shops, a post office, restaurants, doctor offices, and pharmacies, among others; thus, multiple activity purposes are considered during the assignment process. To achieve this, OSM data points matching the location of the building areas imported from RCDB were utilized.
Facility occupation was estimated based on the activity demands related to each facility’s purpose. The activity demand was estimated based on floorspace of facilities and their floorspace productivity (number of workers and visitors per floorspace unit). The RCDB included information about the number of floors in each building, and this information was integrated with building footprints provided in the ZABAGED digital map [
39] to estimate the floorspace of each building. The productivity of a floorspace unit was calculated in order to assign the number of workers and visitors based on facility purposes. The productivity of floorspaces was derived from the normative indicators provided by EDIP [
40], and by using various sources of information: legal prescriptions, normative guidelines, institutional annual records and sociodemographic statistics. The total number of workers and visitors for each facility was assigned by multiplying the total floorspace of each building with the productivity of a floorspace. It is important to note that open-air facilities were defined to have unlimited visitor capacity, and not to have residents and employees. Lastly, the results of the assignment operation for the residents, visitors, and facility capacities are visualized below by utilizing ArcGIS Pro.
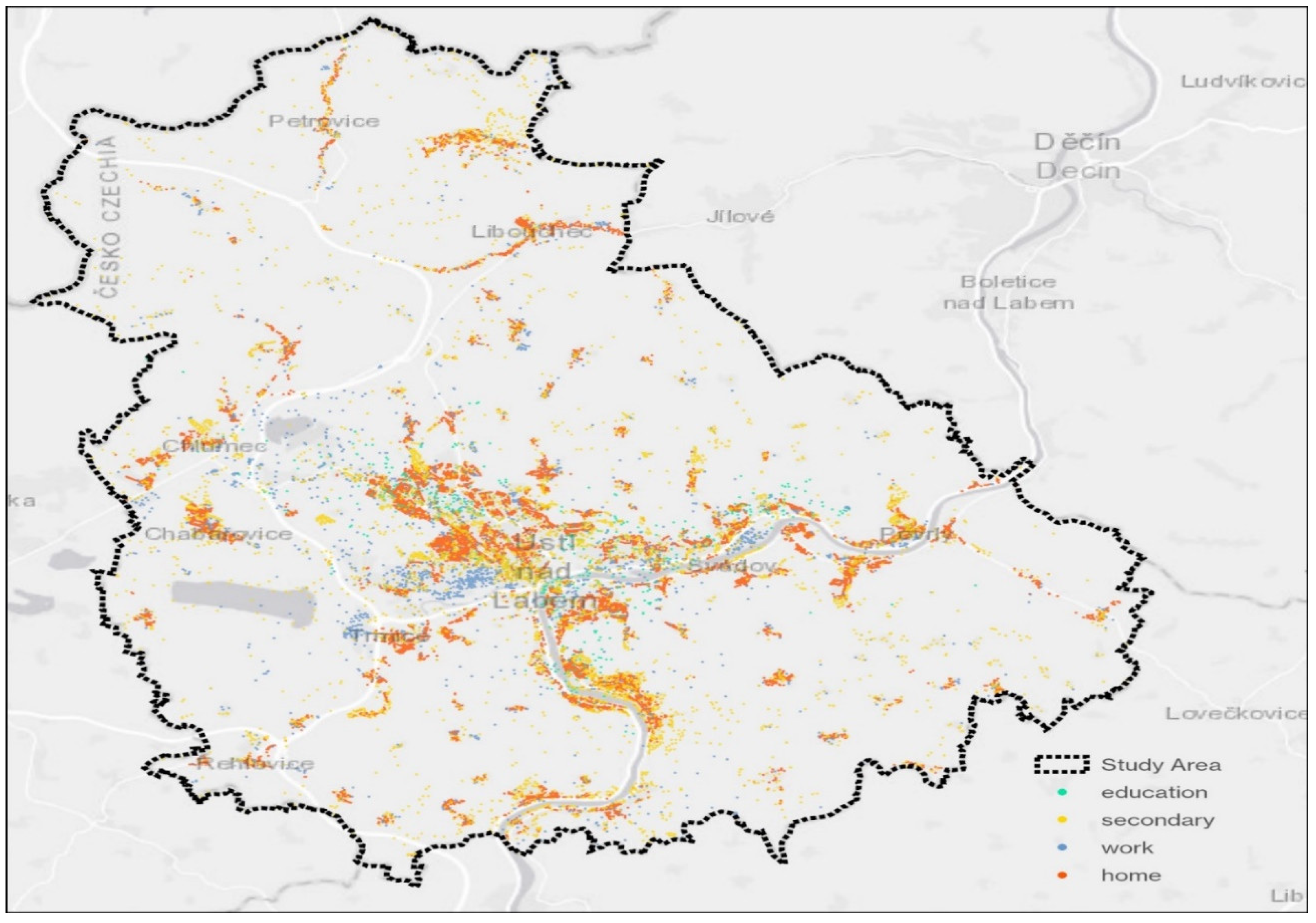
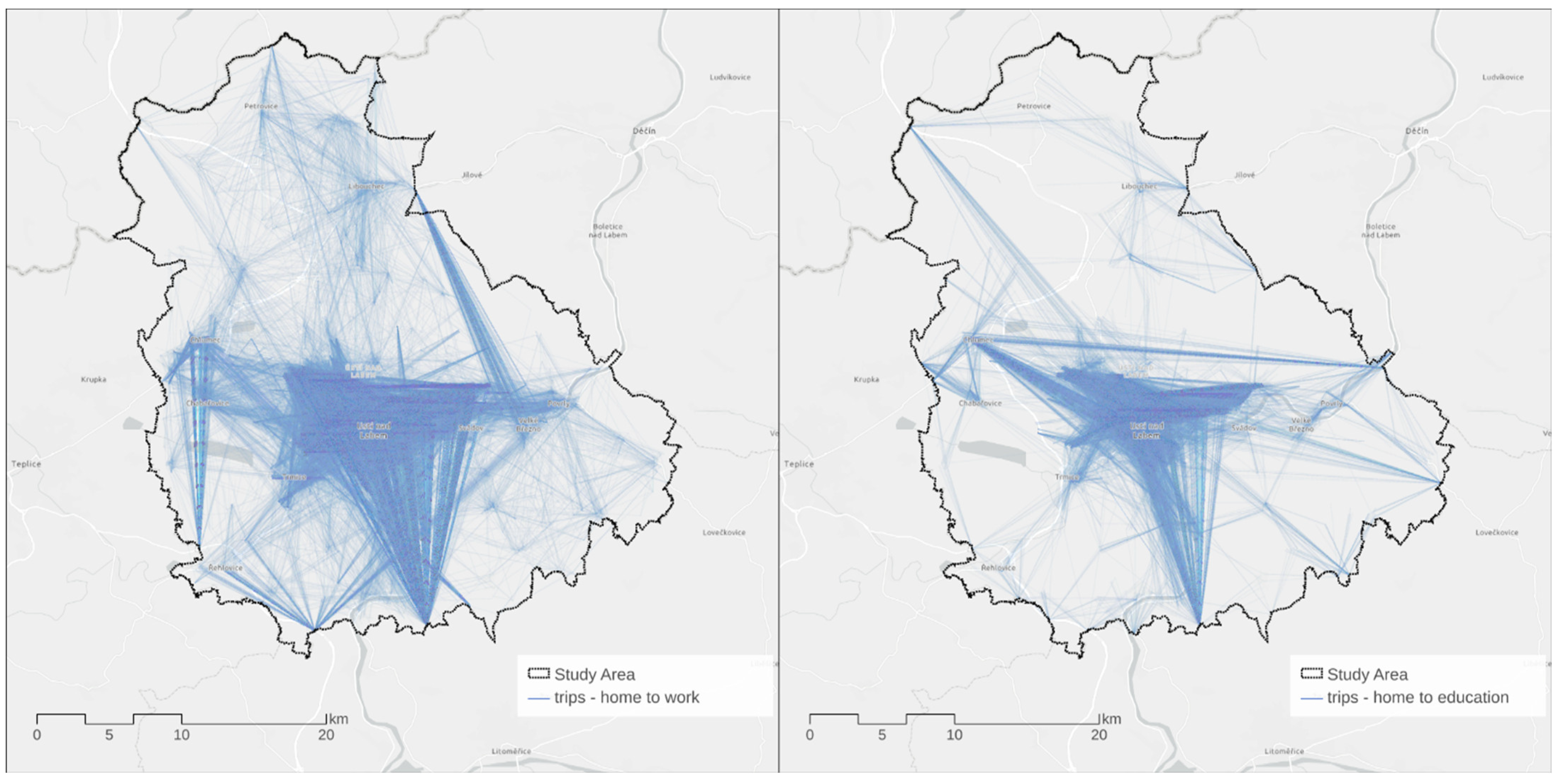
Figure 5 demonstrates the geoposition of all assigned locations in the study area based on home, work, educational, and secondary activity categories (free-time, shopping, errands).
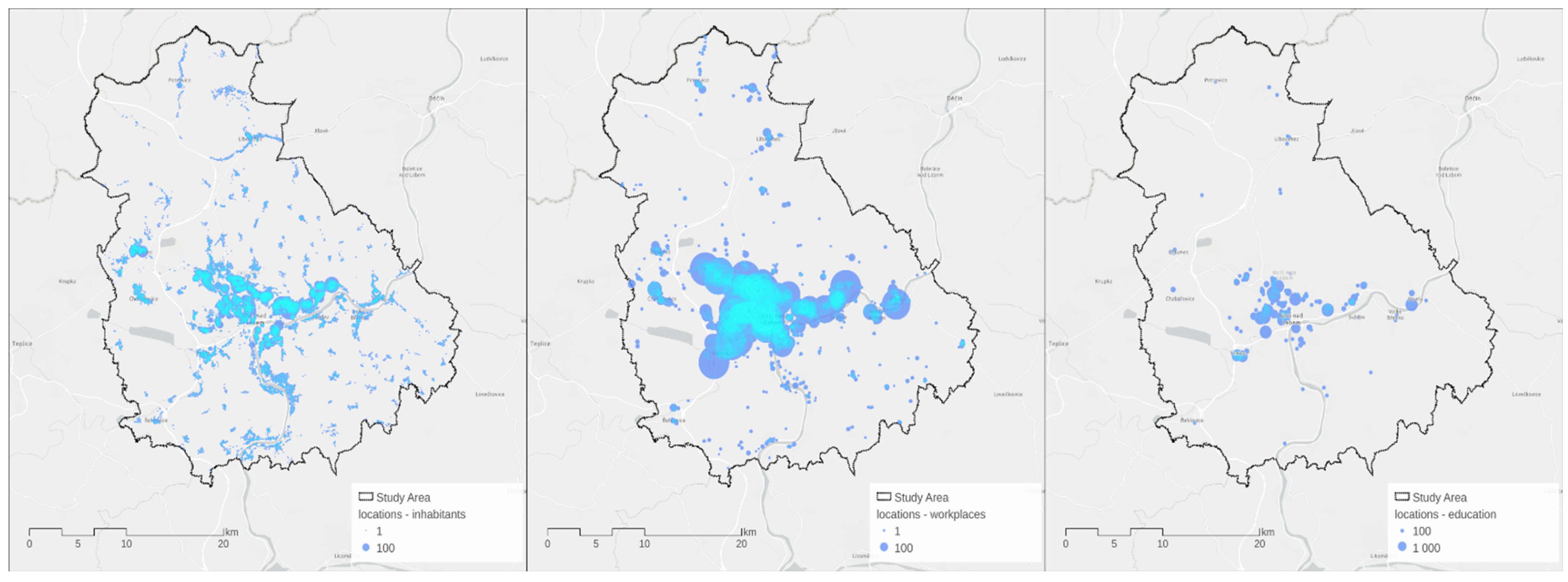
Figure 6 quantifies the number of residents in each building and the capacities of the work and educational facilities, while
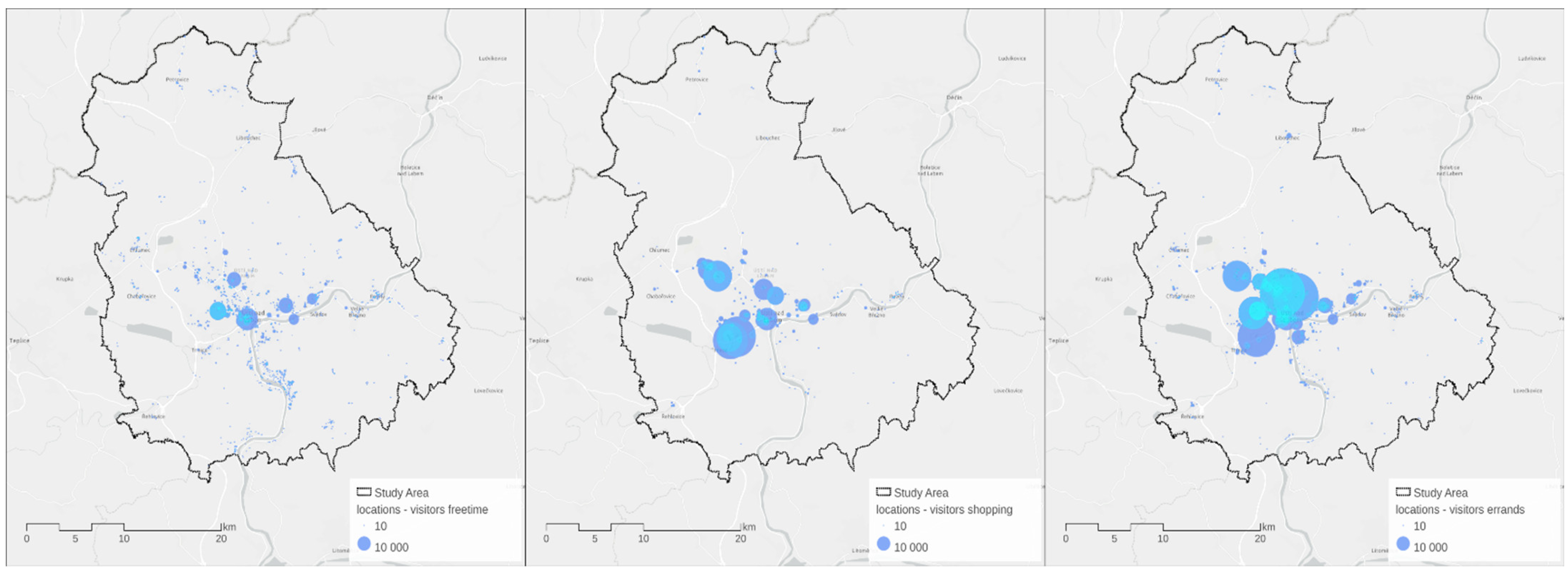
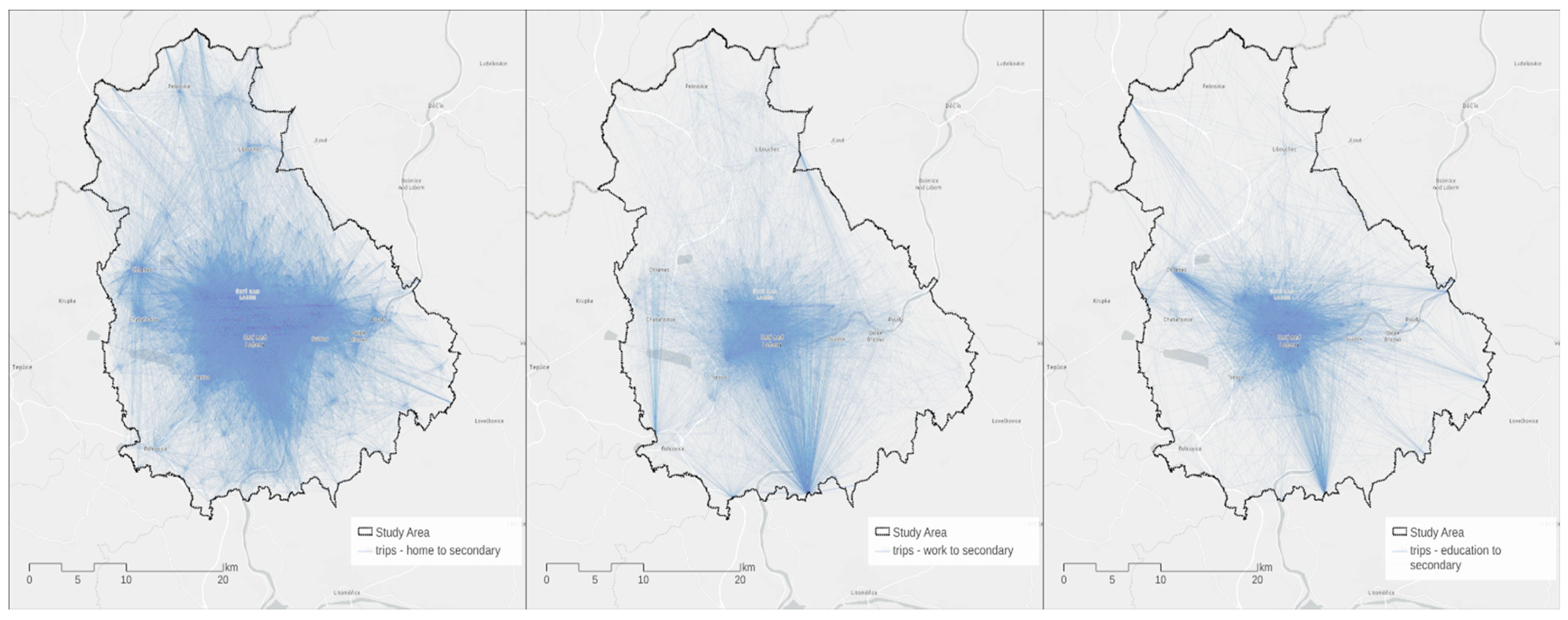
Figure 7 visualizes the number of visitors for the secondary activity locations (free-time, shopping, errands) in the study area.
Step D1.2 defines work and educational zones for each person in the synthetic population by utilizing the OD proportions outputted in the D1.1 operation, as in the São Paulo scenario [
19]. For each origin home zone
o and destination primary zone
d, we used multinomial distribution to estimate the quantity of trips
fod (and assigned citizens to these trips) until the last destination
D, based on the OD proportions
pod and the number of people traveling from the origin zone
no:
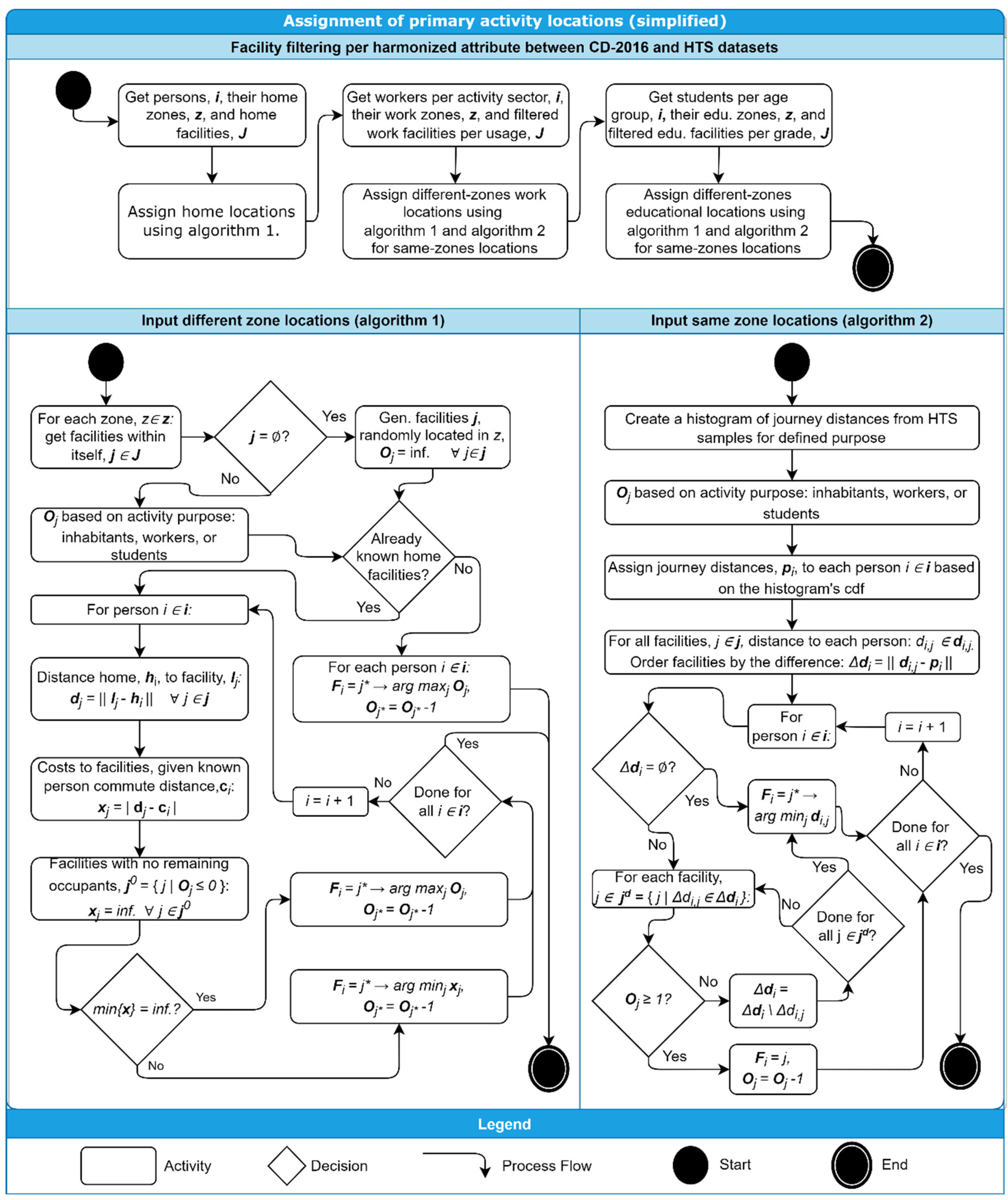
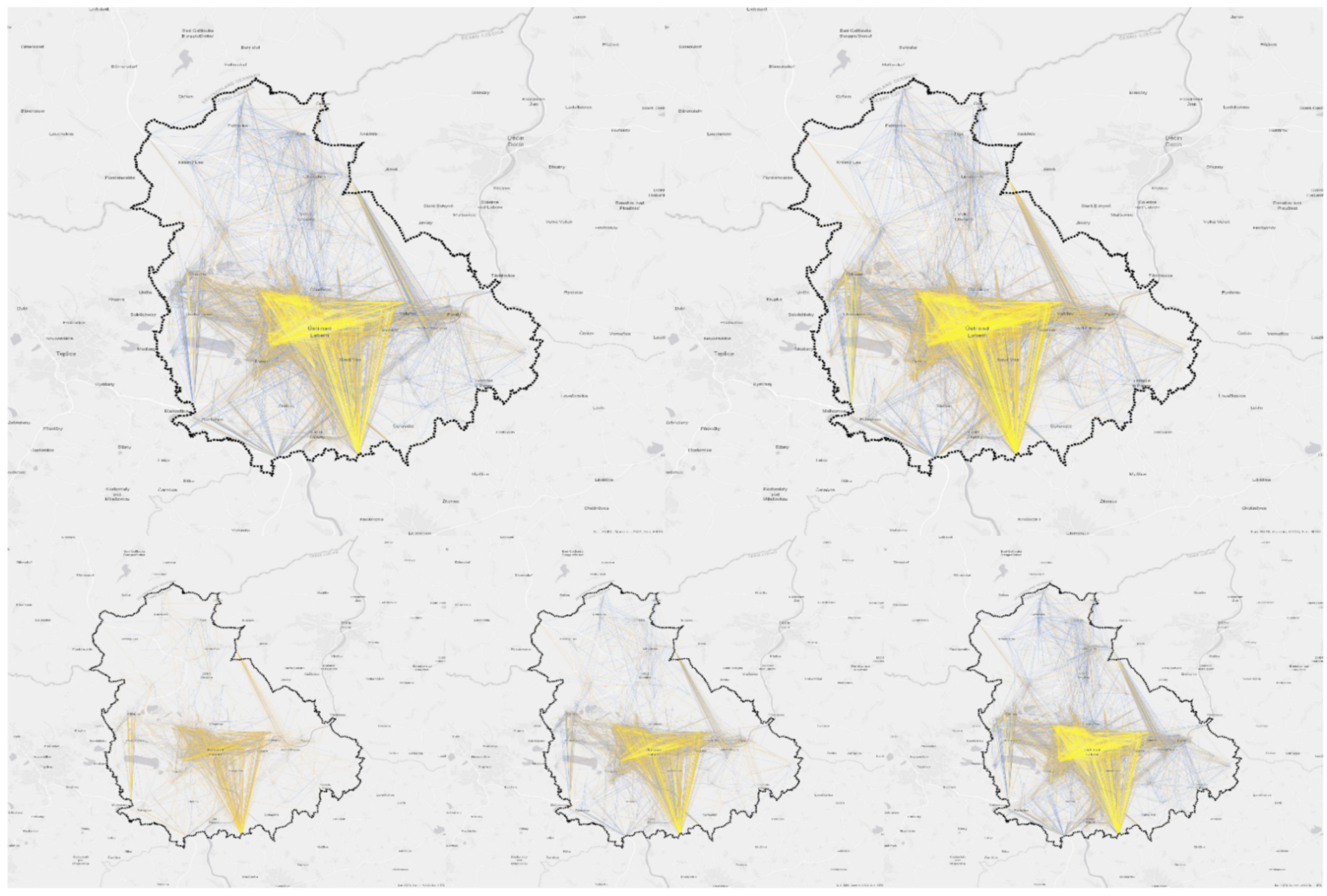
In step P2, residential and primary activity locations of the citizens are assigned by utilizing two different algorithms, as demonstrated in
Figure 8. First, the framework assigns the citizens by using algorithm 1 to the residential buildings located in the zone where they live according to CD-2016 data. Then, once the home location of every person is defined, the framework assigns the primary activity locations (i.e., work and educational) of the citizens by applying algorithm 1 if the home and primary activity location are in the same zone, and when the home location and primary activity are in different zones, then algorithm 2 is applied. The assignment process is conducted in order, where each arrangement corresponds to a portion of the population and a subset of facilities to be assigned. For instance, a citizen working in the retail sector based on the CD-2016 is to be considered for all possible work locations classified as either events, commercial, or multipurpose in the RCDB. For another example, students within the age group 8–14 have their educational locations filtered to schools offering the grades of a primary school. However, citizens over 29 years old were additionally placed in this category, because parents are likely to escort children to primary schools. Algorithm 1 runs several times, once for each zone and selecting only the facilities located inside the zone. Initially, the algorithm checks if any relevant facility
j is present in the zone with the attributes matching with a specific portion of the population (e.g., age group 8–14 for primary schools), and if not, random locations with unlimited occupancy
Oj in the zone are generated. The occupancy
Oj of a facility is defined according to the number of inhabitants (in the case of residential assignment), work places (in the case of worker assignment), and study places (in the case of student assignment). In the case of residential locations, the assigned facility is simply defined by the one with the maximum available occupancy, and then once a person
i is assigned to a building
j, then one unit of occupancy, i.e.,
Fi =
j, one unit of occupancy is dropped from
Oj. In the case of the assignment of primary locations, for every person
i, the distance between home and each facility
dj is calculated. A cost to each facility
xi is set as the absolute difference between the calculated commute distance and the declared commute distance of the inhabitants (straight-line distance to the primary location)
cj. Afterward, facilities with no remaining occupants are marked with infinity cost. If there are still facilities with finite cost, the algorithm chooses the one with the minimum cost. On the other hand, if all filtered facilities have infinite cost, the assigned facility is the one with the highest occupancy. Algorithm 2 runs only once, but separately for work and education locations. The first step assigns a radius to each person
pi based on the cumulative distribution function (cdf) of all trips in the HTS data (selected based on home location), and defines facility
j and occupancy
Oj as in Algorithm 1. The facility order is based on the proximity to the assigned radius
Δdi. If there is not a facility found within the given radius, the algorithm assigns the nearest facility available and reduces the capacity of the assigned facility. In the case of unavailability of the nearest facility because of full occupancy, the algorithm drops them from the search set and tries to find another one. In the case of an absent facility with available occupancy, the algorithm still assigns the citizen into the nearest facility.
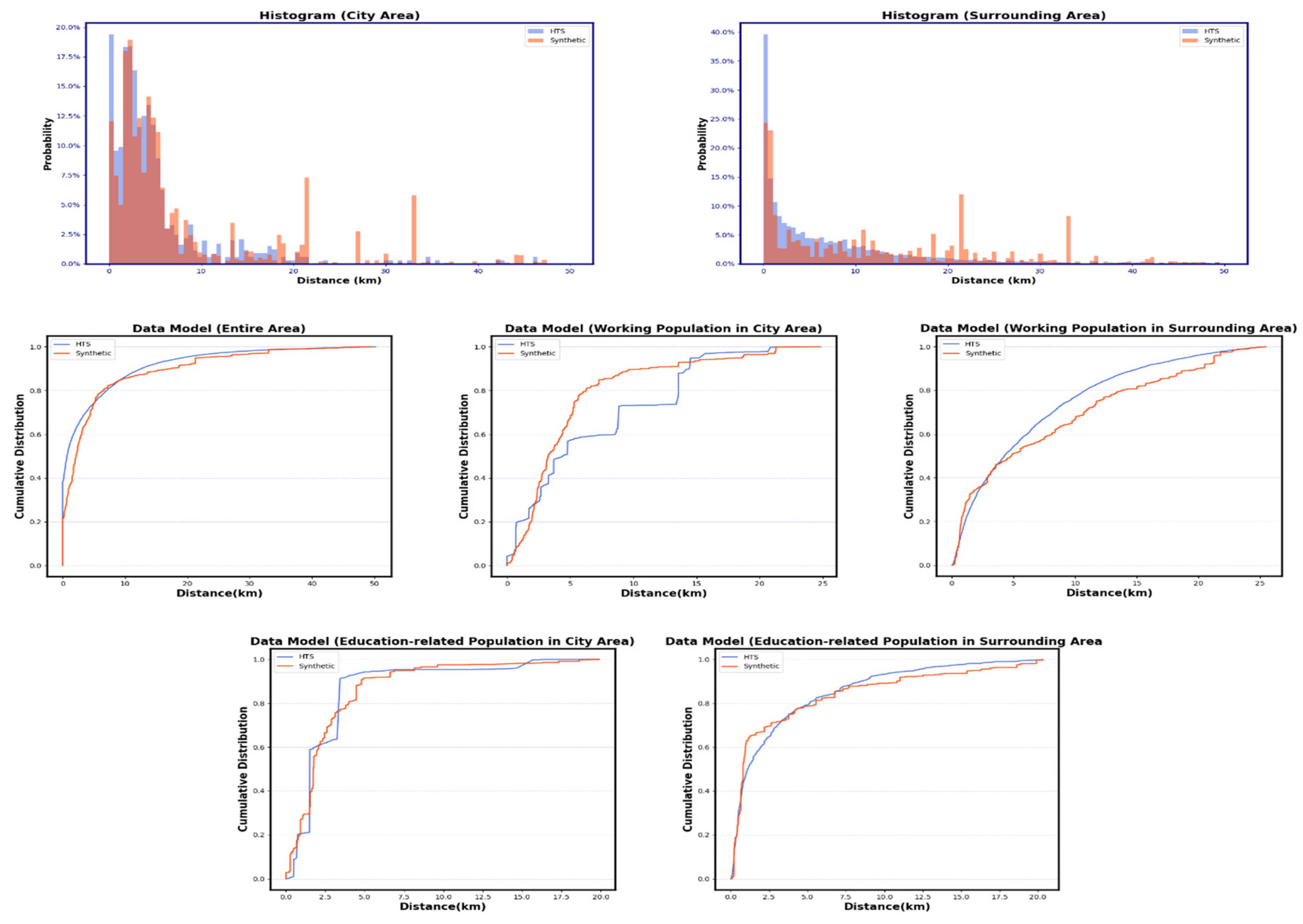
In step D2, travel-distance distributions from both HTS datasets were generated for each journey transport mode according to the weight of sample citizens and declared trip time. For some transport modes only used in several samples, a bin size of 20 is applied. In step P3, the relaxation–discretization algorithm [
41] was used as in the São Paulo scenario [
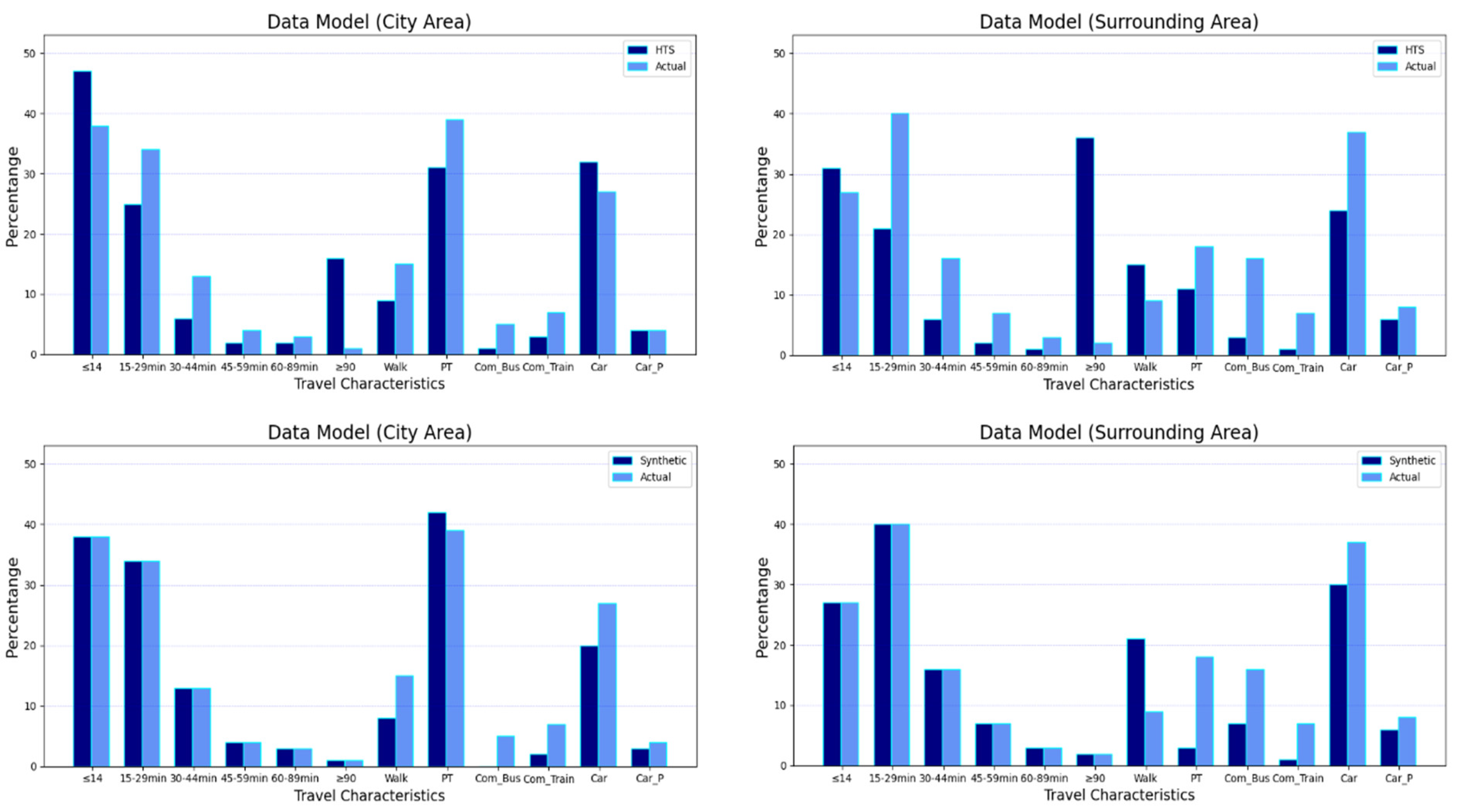
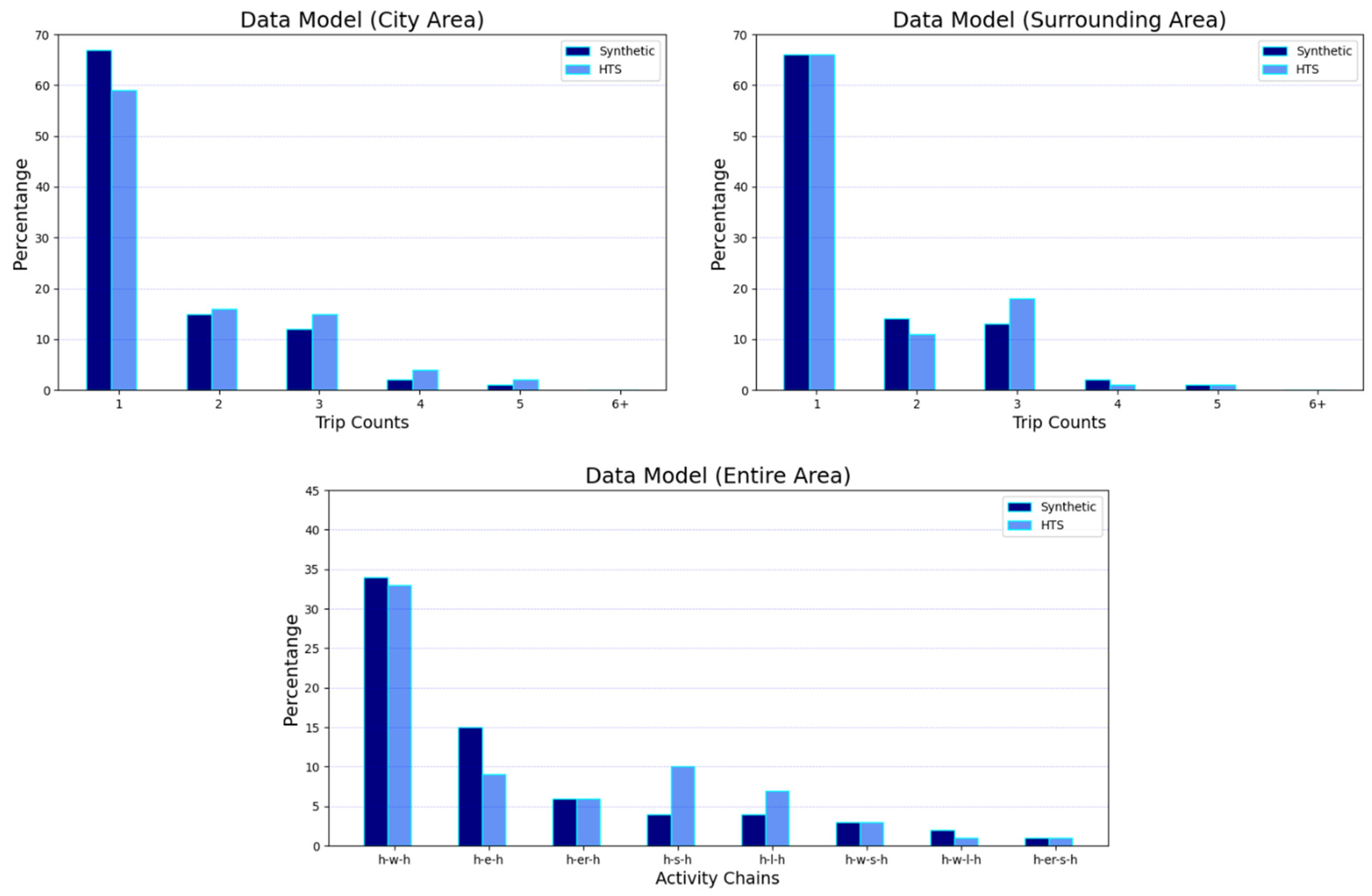
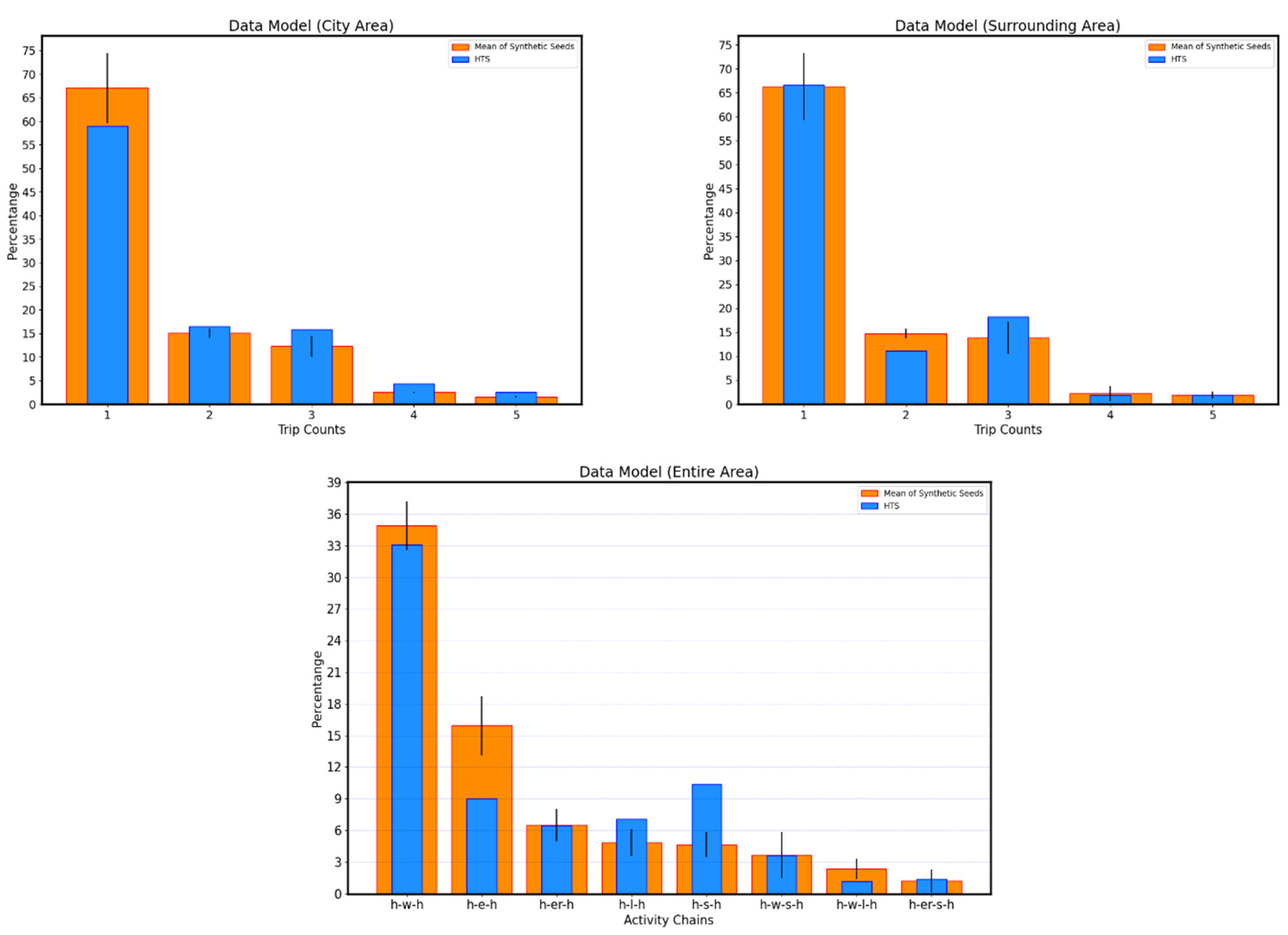
19] to assign the secondary activity locations for the citizens. We contributed here by removing facilities from the list of possible locations when they have no available capacity (similar to Algorithm 2 of P2 operation). At first, the algorithm finds the available secondary-activity facilities with at least occupied ones (the expected number of visitors for secondary locations is utilized here). After that, the algorithm selects all activity chains containing secondary trips. Then, sampling of travel distances for each trip is conducted based on declared travel time and journey transport mode. Afterward, possible destinations to assign secondary activity locations (from a primary activity location as origin) are determined to match travel distances between the activities based on the sampled distances. Following the order of possible destinations, if the assigned location is fully occupied, the algorithm removes it from the list of possible locations and tries to assign the next possible destination. This occurs until a facility is assigned to a person and the visitor capacity (i.e., occupancy) of this location is reduced by one after each successful assignment. Lastly, the final synthetic population files were created in MATSim format. The resulting synthetic population for the study area is presented.



 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















