



Context-Aware Complex Human Activity Recognition Using Hybrid Deep Learning Models


Abstract
1. Introduction
- The article proposes a deep hybrid feature model capable of discriminating between simple and complex activity signal patterns by augmenting low-level inertial sensing signals with contextual data to improve recognition and generalization accuracy.
- An extensive review of state-of-the-art human activity recognition, context awareness, deep learning algorithms, and interclass similarity problems in human activity recognition.
- We demonstrate through extensive experiments the efficacy of the context-aware CNN–LSTM model for realizing state-of-the-art results using raw sensor signals without heuristic handcrafted features.
- We demonstrate the efficacy of smartphone-rich contextual data for solving interclass similarity problems of simple and complex activities.
2. Literature Review
2.1. Simple and Complex Human Activities
2.2. Context Awareness and Intersimilarity in Complex HAR
2.3. Machine Learning for Complex HAR
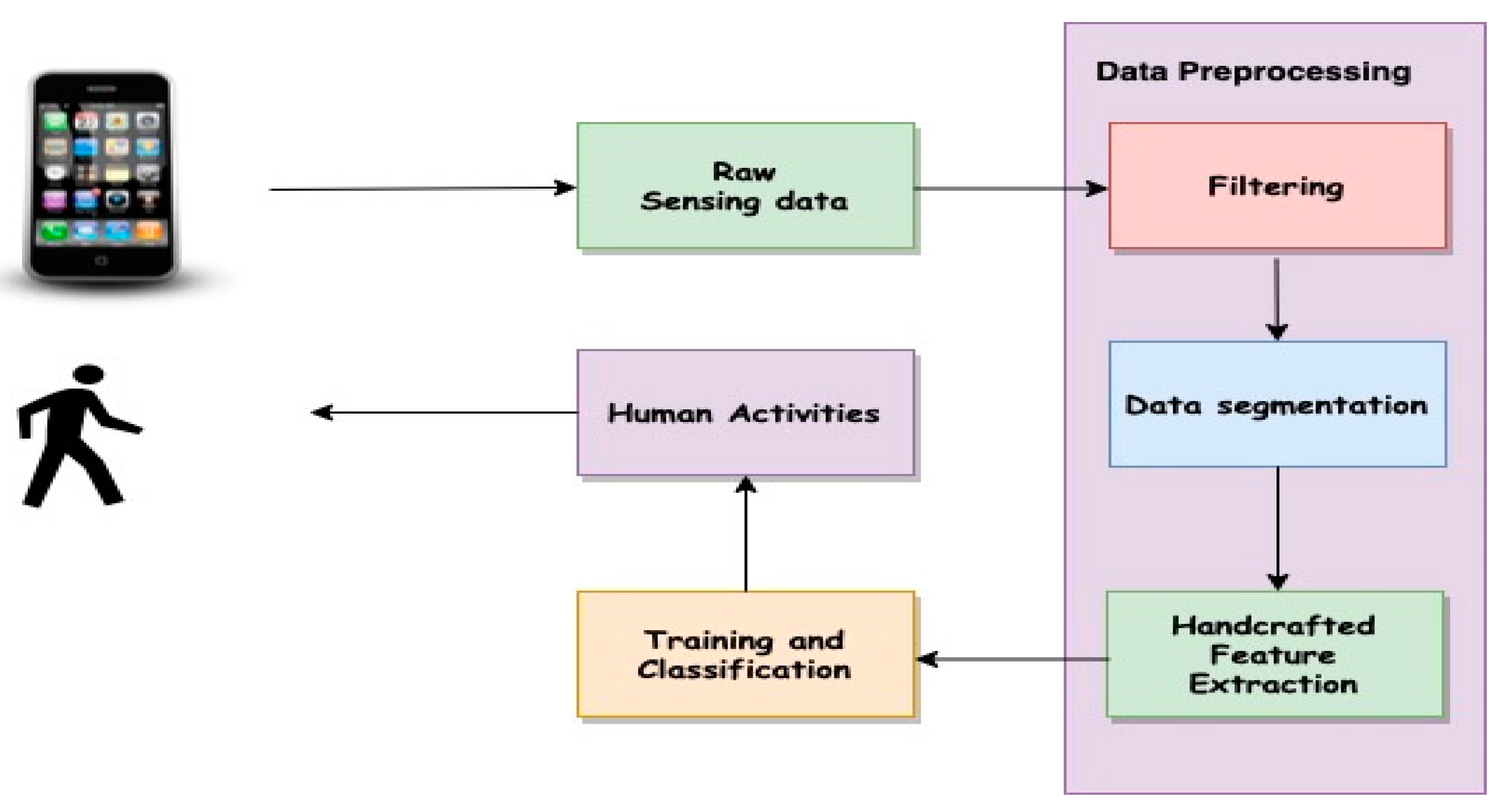
3. Methodology
3.1. Problem Definition
3.2. Inertial Sensor Signals
3.3. Environmental Contextual Signals
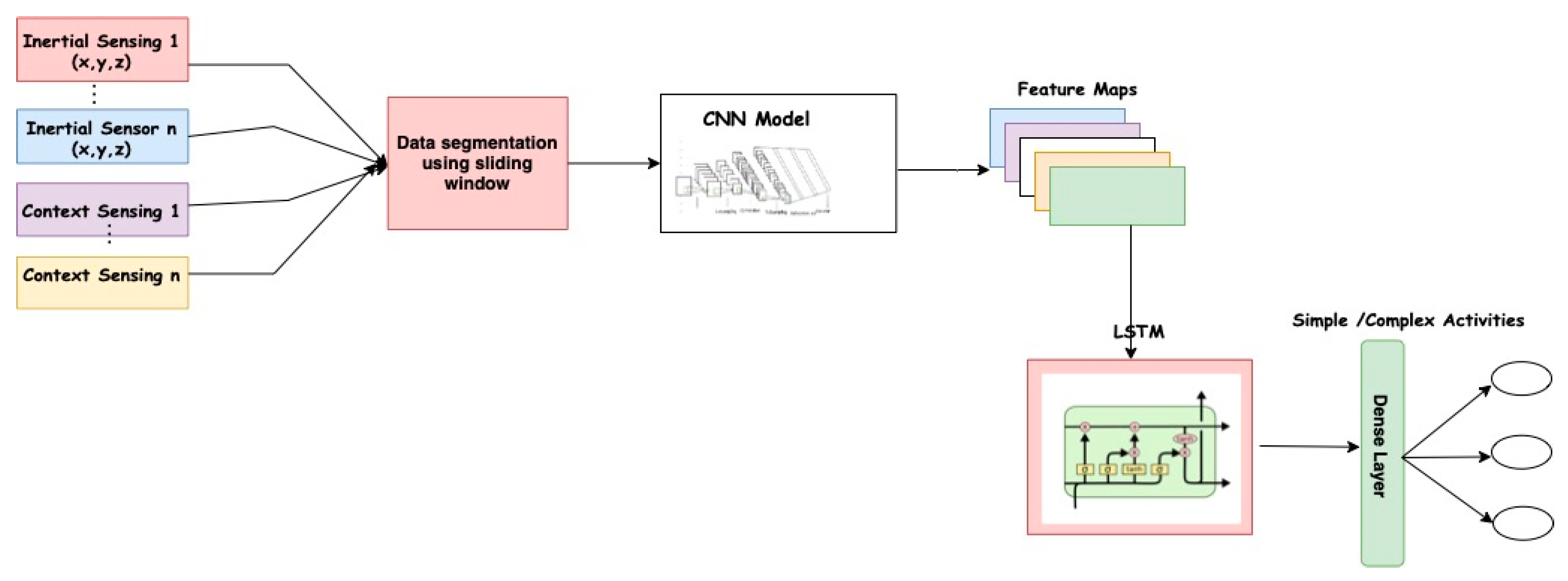
3.4. The CNN–LSTM Hybrid Model
3.4.1. The Convolutional Layer
- The Pooling layers
- The Flatten layer
- The LSTM Networks
3.4.2. The Fully Connected (FC) Layer
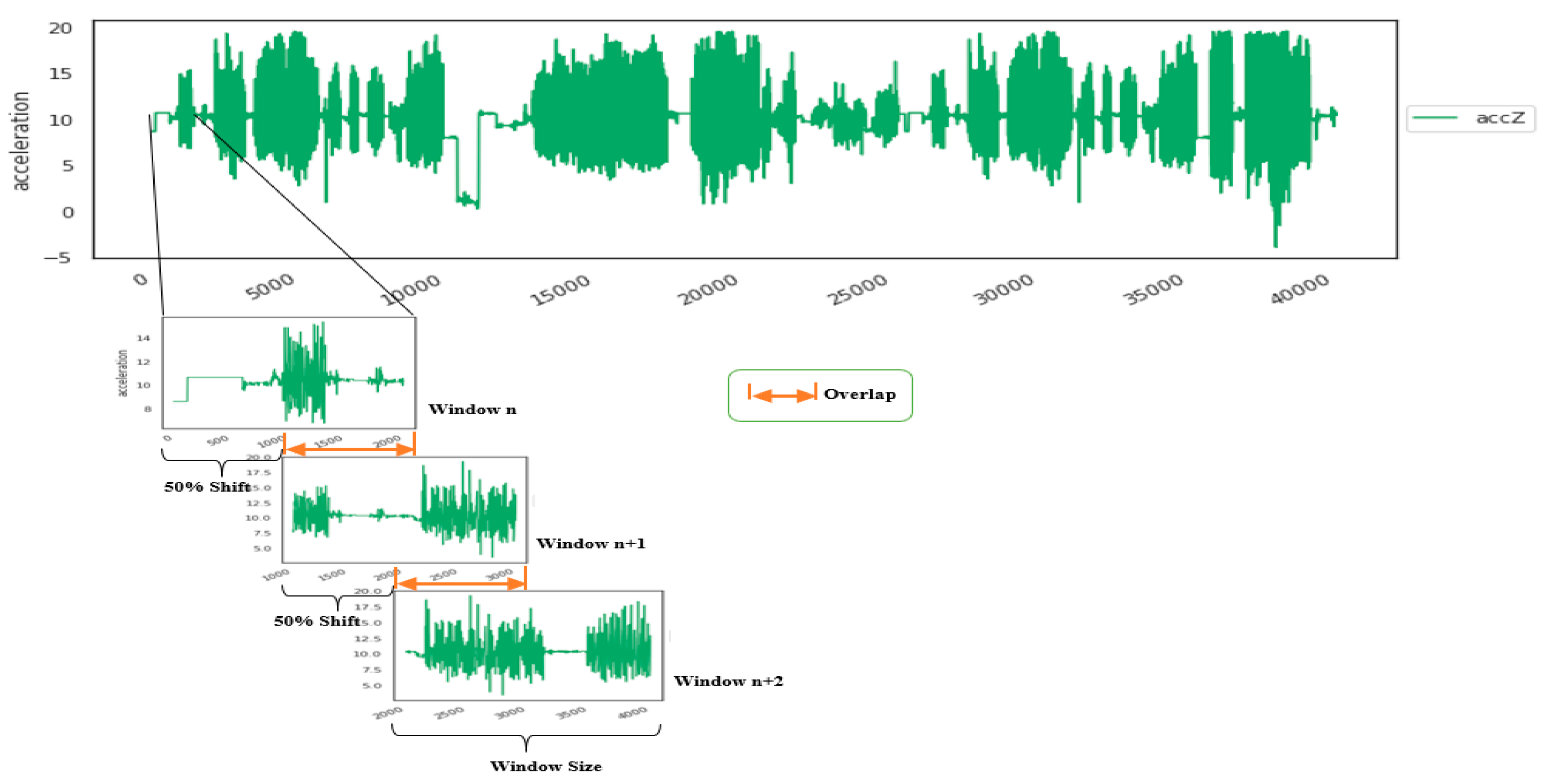
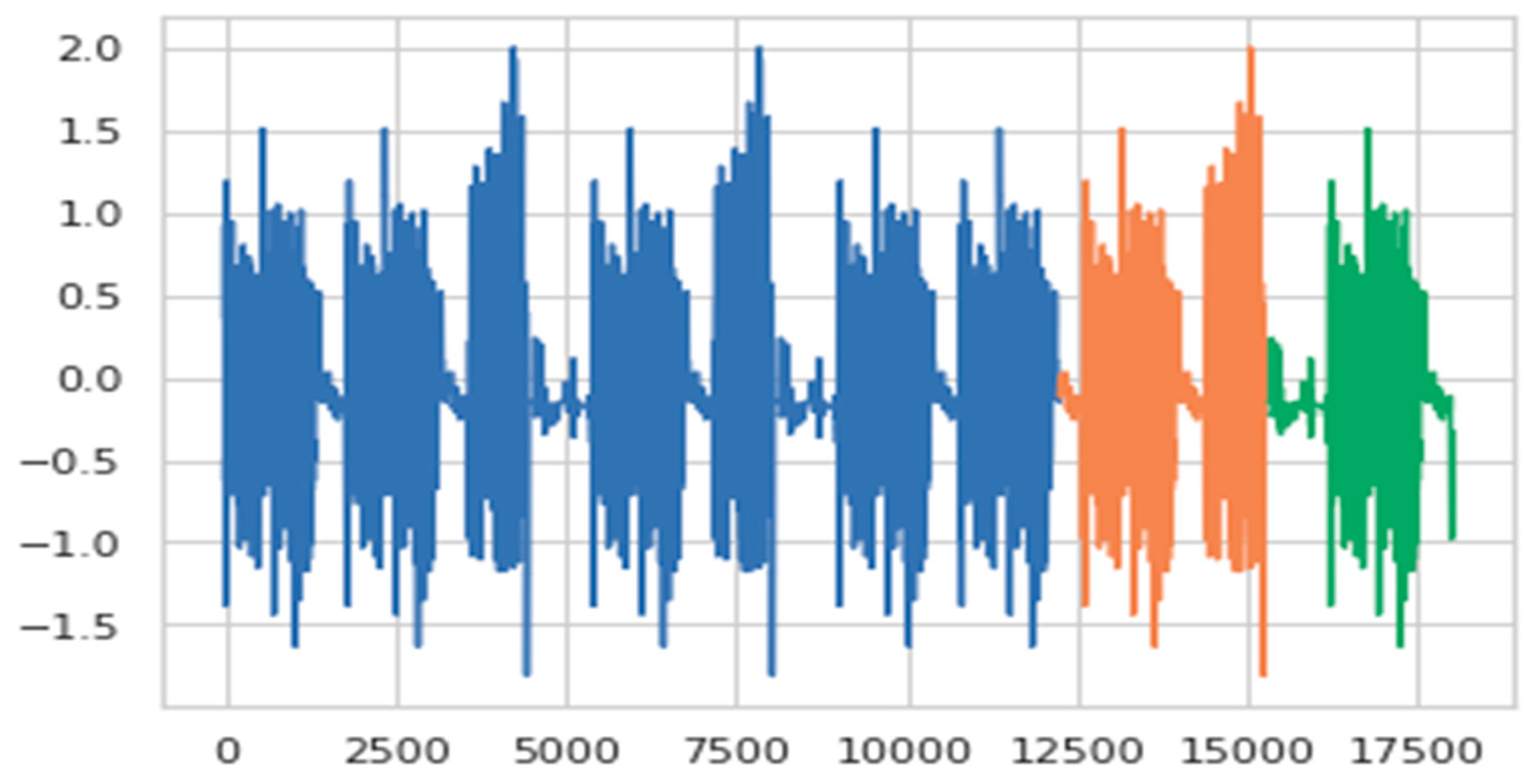
3.4.3. Data Preprocessing and Segmentation
3.4.4. Hyperparameter Tuning
4. Experiments and Results
4.1. Experimental Setup
4.1.1. Traditional Inertial Sensory Data
4.1.2. Inertial and Contextual Data
4.2. Simple and Complex Activity Taxonomy
4.3. Evaluation Metrics
4.4. Experiments and Performance Evaluation
4.5. Hyperparameter Tuning
4.5.1. Tuning the filter and kernel
4.5.2. Window Size Segmentation Tuning
4.5.3. Mitigating Overfitting
- Weight Decay
- Dropout Regularization
- Number of Epochs
- Tuning for Learning Rate
5. Result and Discussion
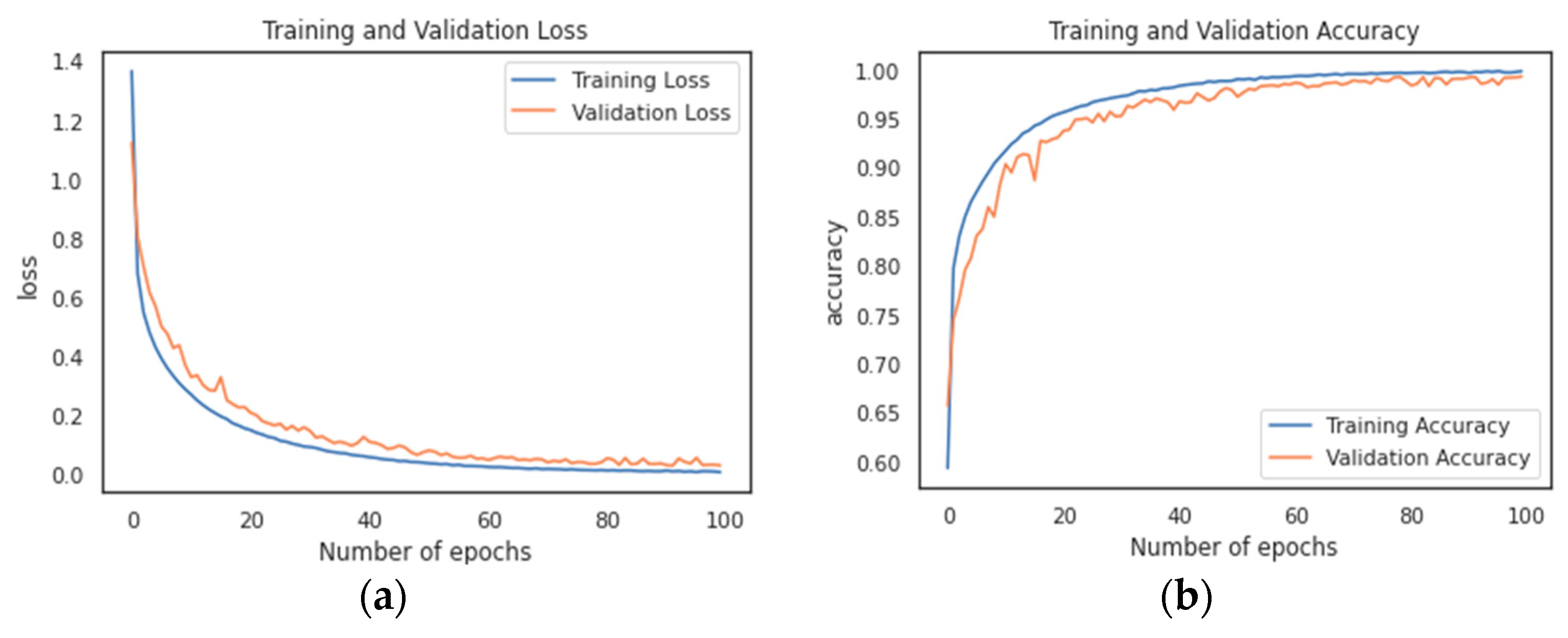
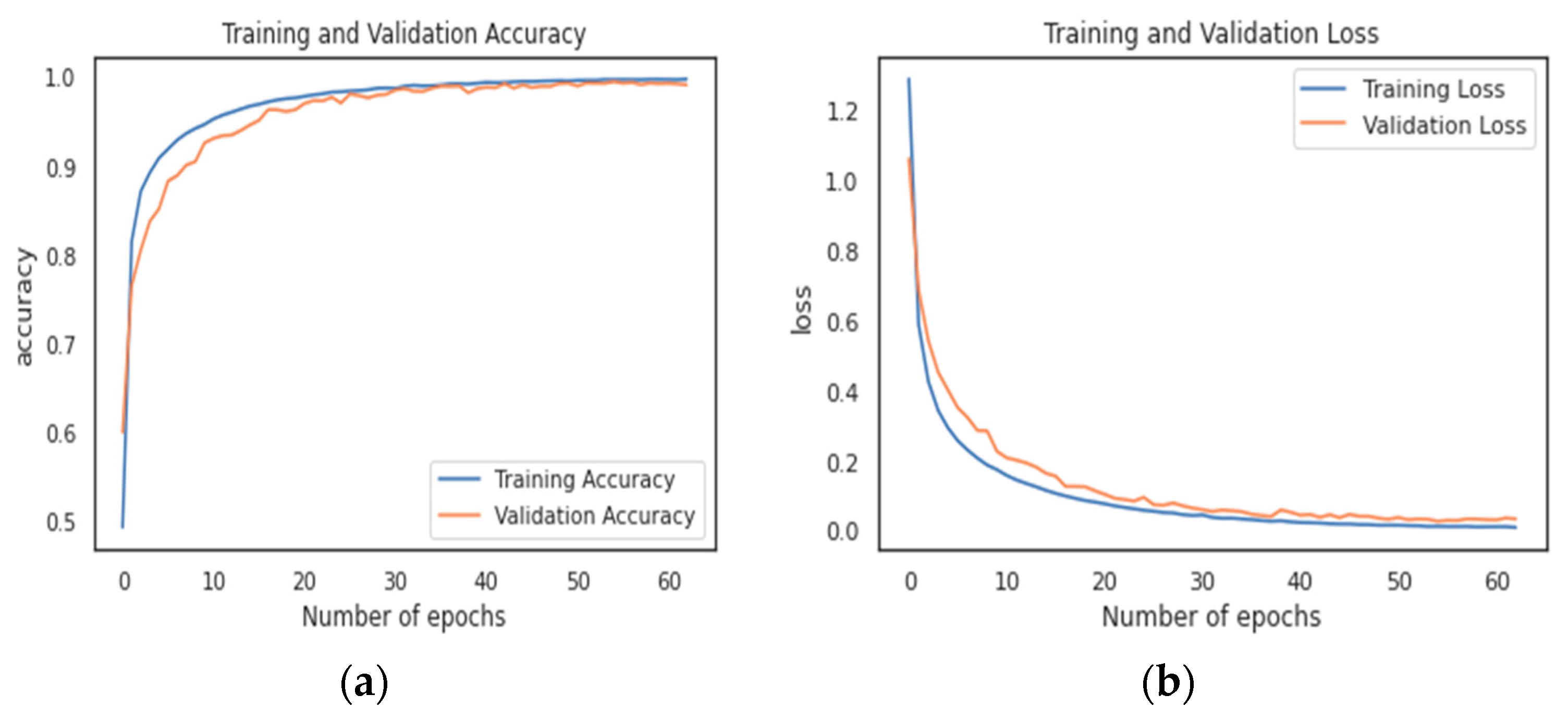
5.1. Analysis of Training and Validation Data
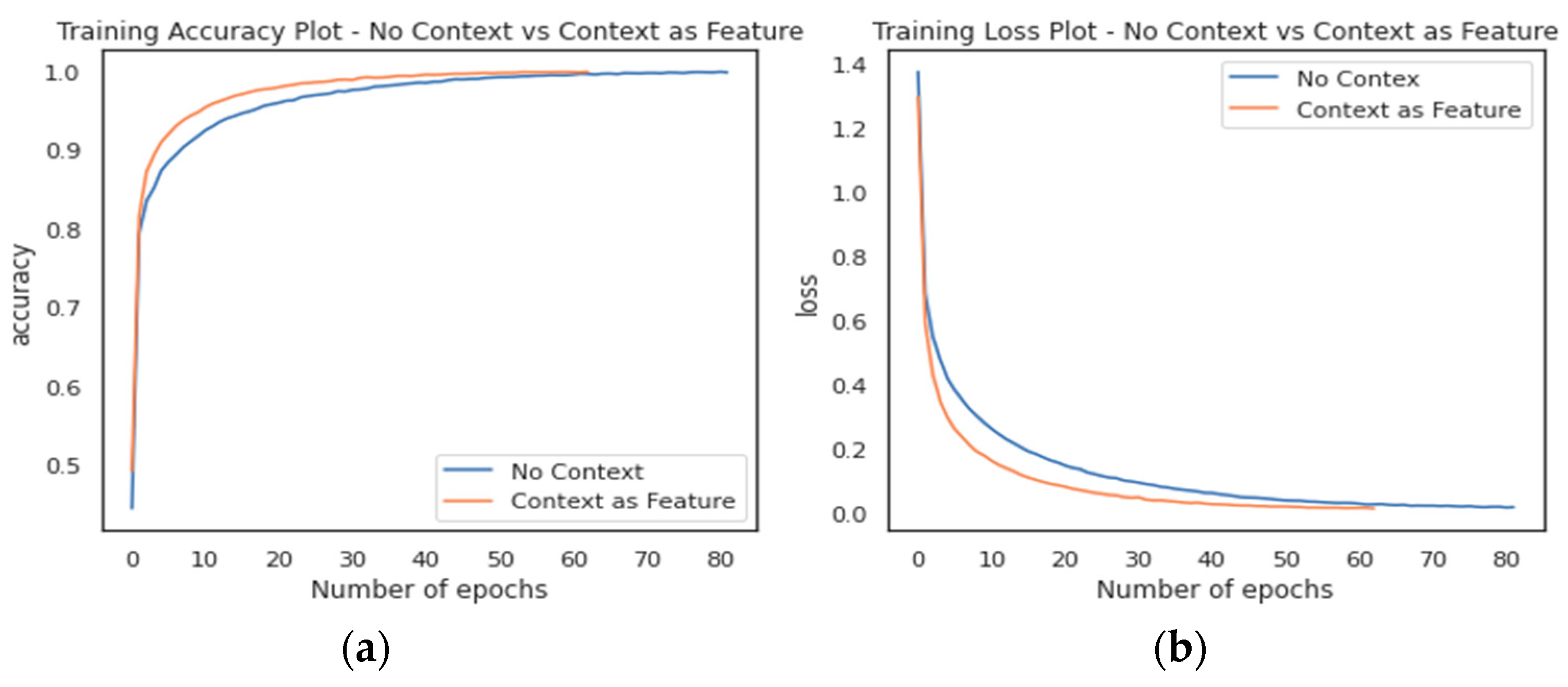
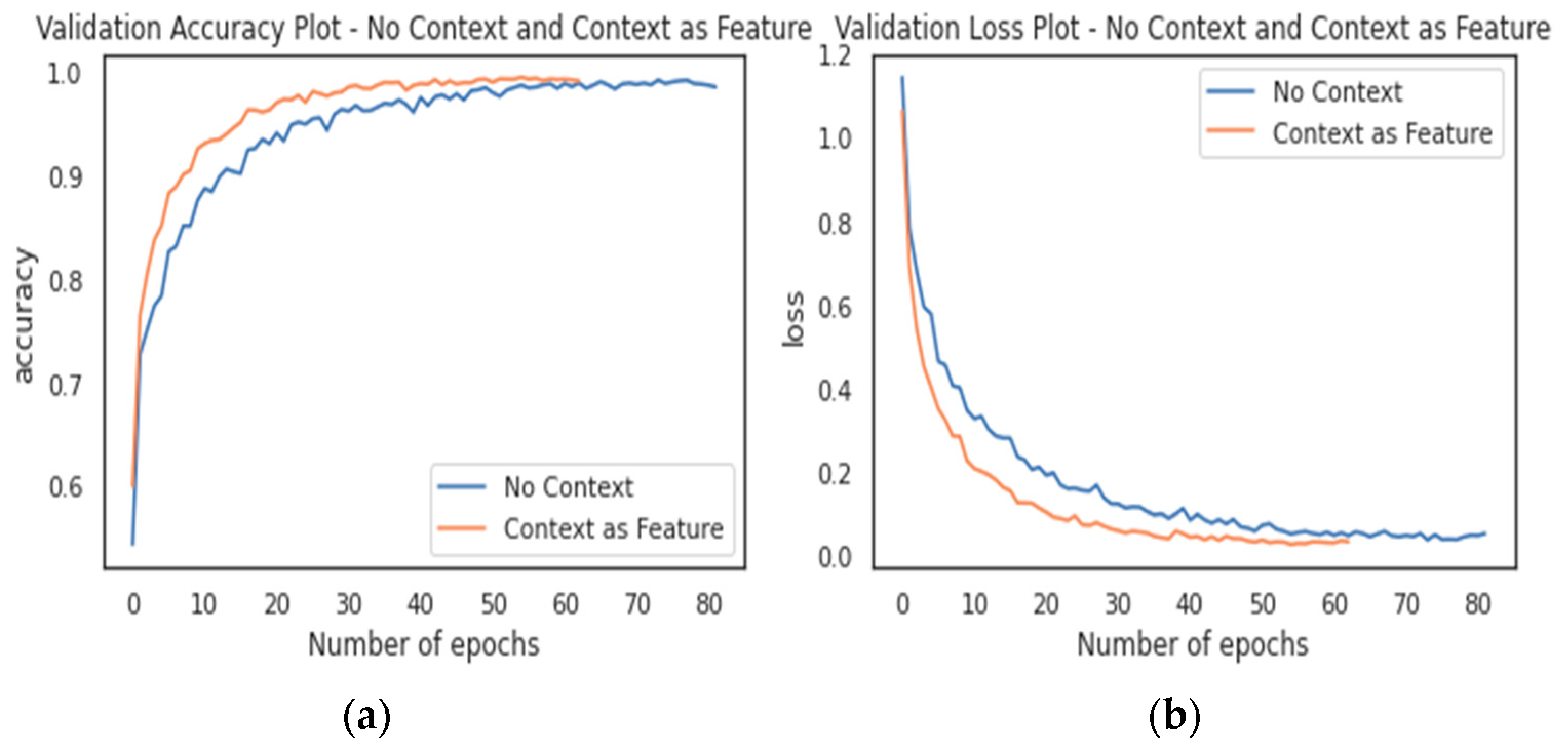
5.2. Recognition Accuracy for Simple and Complex Activities
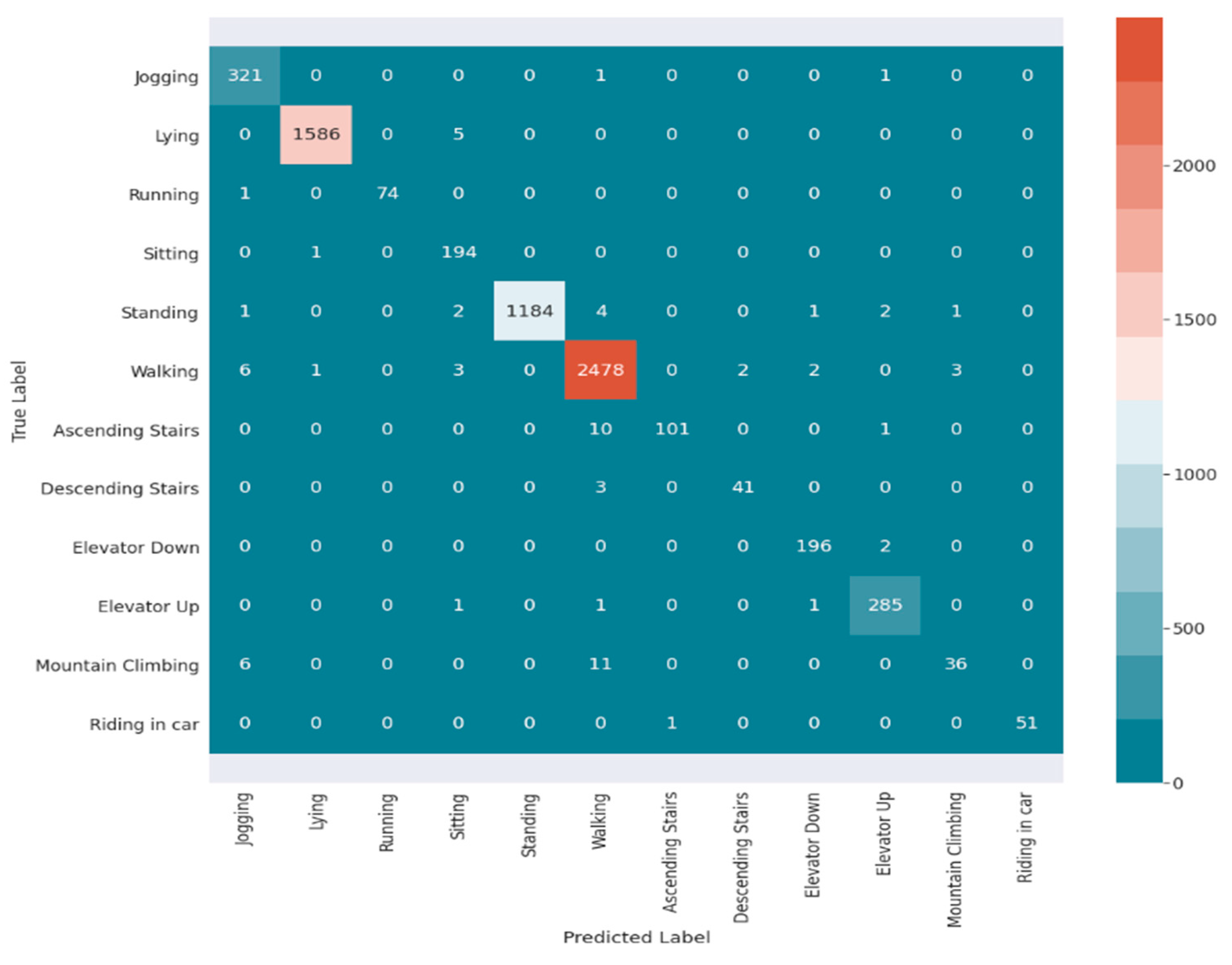
5.3. Interclass Similarity Analysis
6. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alawneh, L.; Al-Ayyoub, M.; Al-Sharif, Z.A.; Shatnawi, A. Personalized human activity recognition using deep learning and edge-cloud architecture. J. Ambient Intell. Humaniz. Comput. 2022. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep Learning for Sensor-based Human Activity Recognition: Overviews and Challenges and Opportunities. ACM Comput. Surv. 2022. [Google Scholar] [CrossRef]
- Number of Smartphone Subscriptions. Available online: https://www.statista.com/statistics/330695/number-of-smartphone-users-worldwide (accessed on 15 September 2022).
- Jalal, A.; Kim, J.T.; Kim, T. Development of a Life Logging System via Depth Imaging-based Human Activity Recognition for Smart Homes. In Proceedings of the 8th International Symposium on Sustainable Healthy Buildings, Seoul, Korea, 19 September 2012; pp. 91–104. [Google Scholar]
- Foubert, N.; McKee, A.M.; Goubran, R.A.; Knoefel, F. Lying and sitting posture recognition and transition detection using a pressure sensor array. In Proceedings of the 2012 IEEE International Symposium on Medical Measurements and Applications Proceedings, Budapest, Hungary, 18–19 May 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Gu, F.; Chung, M.H.; Chignell, M.; Valaee, S.; Zhou, B.; Liu, X. A Survey on Deep Learning for Human Activity Recognition. ACM Comput. Surv. 2022, 54, 1–34. [Google Scholar] [CrossRef]
- De Pessemier, T.; Dooms, S.; Martens, L. Context-aware recommendations through context and activity recognition in a mobile environment. Multimed. Tools Appl. 2014, 72, 2925–2948. [Google Scholar] [CrossRef]
- Otebolaku, A.M.; Andrade, M.T. Context-aware media recommendations for smart devices. J. Ambient Intell. Humaniz. Comput. 2015, 6, 13–36. [Google Scholar] [CrossRef]
- Thakur, D.; Biswas, S.; Ho, E.S.L.; Chattopadhyay, S. ConvAE-LSTM: Convolutional Autoencoder Long Short-Term Memory Network for Smartphone-Based Human Activity Recognition. IEEE Access 2022, 10, 4137–4156. [Google Scholar] [CrossRef]
- Grzeszick, R.; Lenk, J.M.; Rueda, F.M.; Fink, G.A.; Feldhorst, S.; Hompel, M.T. Deep neural network based human activity recognition for the order picking process. In Proceedings of the Proceedings of the 4th international Workshop on Sensor-based Activity Recognition and Interaction, Rostock, Germany, 21–22 September 2017. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Hasan, H.; Roy-Chowdhury, A.K. Context Aware Active Learning of Activity Recognition Models. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4543–4551. [Google Scholar] [CrossRef]
- Liu, Y.; Nie, L.; Han, L.; Zhang, L.; Rosenblum, D.S. Action2Activity: Recognizing complex activities from sensor data. In Proceedings of the International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1617–1623. [Google Scholar]
- Peng, L.; Chen, L.; Ye, Z.; Zhang, Y. AROMA: A Deep Multi-Task Learning Based Simple and Complex Human Activity Recognition Method Using Wearable Sensors. Proc. ACM Interact. Mobile Wearable Ubiquitous Technol. 2018. [Google Scholar] [CrossRef]
- Cheng, W.; Erfani, S.; Zhang, R.; Kotagiri, R. Predicting Complex Activities from Ongoing Multivariate Time Series. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3322–3328. [Google Scholar] [CrossRef]
- Dharaskar, V.; Thakare, V.M. PCA based optimal ANN classifiers for human activity recognition using mobile sensors data. In Proceedings of the First International Conference on Information and Communication Technology for Intelligent Systems: Volume 1; Springer: Berlin, Germany, 2016; pp. 429–436. [Google Scholar]
- Brownlee, J. Deep Learning for Time Series Forecasting: Predict the Future with MLPs, CNNs and LSTMs, Retrieved from Machine Learning Mastery. Available online: https://machinelearningmastery.com/deep-learning-for-time-series-forecasting (accessed on 20 October 2021).
- Yang, J.B.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Irfan, S.; Anjum, N.; Masood, N.; Khattak, A.S.; Ramzan, N. A Novel Hybrid Deep Learning Model for Human Activity Recognition Based on Transitional Activities. Sensors 2021, 21, 8227. [Google Scholar] [CrossRef]
- Khan, I.U.; Afzal, S.; Lee, J.W. Human Activity Recognition via Hybrid Deep Learning Based Model. Sensors 2022, 22, 323. [Google Scholar] [CrossRef] [PubMed]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Ryoo, M.S. Human Activity Analysis: A Review. ACM Comput. Surv. 2011. [CrossRef]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. A review of human activity recognition methods. Front. Robot. AI 2015. [Google Scholar] [CrossRef]
- Turaga, P.; Chellappa, R.; Subrahmanian, V.S.; Udrea, O. Machine Recognition of Human Activities: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1473–1488. [Google Scholar] [CrossRef]
- Dernbach, S.; Das, B.; Krishnan, N.C.; Thomas, B.L.; Cook, D.J. Simple and Complex Activity Recognition through Smart Phones. In Proceedings of the 2012 Eighth International Conference on Intelligent Environments, Washington, DC, USA, 26–29 June 2012; pp. 214–221. [Google Scholar] [CrossRef]
- Blanke, U.; Schiele, B.; Kreil, M.; Lukowicz, P.; Sick, B.; Gruber, T. All for one or one for all? Combining heterogeneous features for activity spotting. In Proceedings of the 2010 8th IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), Mannheim, Germany, 19 March–2 April 2010; pp. 18–24. [Google Scholar] [CrossRef]
- Vaizman, Y.; Ellis, K.; Lanckriet, G. Recognizing Detailed Human Context in the Wild from Smartphones and Smartwatches. IEEE Pervasive Comput. 2017, 16, 62–74. [Google Scholar] [CrossRef]
- Cruciani, F.; Vafeiadis, A.; Nugent, C.; Cleland, I.; McCullagh, P.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R. Feature learning for Human Activity Recognition using Convolutional Neural Networks. CCF Trans. Pervasive Comput. Interact. 2020, 2, 18–32. [Google Scholar] [CrossRef]
- Schrader, L.; Toro, A.V.; Konietzny, S.; Rüping, S.; Schäpers, B.; Steinböck, M.; Krewer, C.; Müller, F.; Güttler, J.; Bock, T. Advanced Sensing and Human Activity Recognition in Early Intervention and Rehabilitation of Elderly People. J. Popul. Ageing 2020, 13, 139–165. [Google Scholar] [CrossRef]
- Akila, K.; Chitrakala, S. Highly refined human action recognition model to handle intraclass variability & interclass similarity. Multimed. Tools Appl. 2019, 78, 20877–20894. [Google Scholar] [CrossRef]
- Bharti, P.; De, D.; Chellappan, S.; Das, S.K. HuMAn: Complex Activity Recognition with Multi-Modal Multi-Positional Body Sensing. IEEE Trans. Mobile Comput. 2019, 18, 857–870. [Google Scholar] [CrossRef]
- Niemann, F.; Lüdtke, S.; Bartelt, C.; ten Hompel, M. Context-Aware Human Activity Recognition in Industrial Processes. Sensors 2022, 22, 134. [Google Scholar] [CrossRef]
- Shoaib, M.; Scholten, H.; Havinga, P.J. Towards Physical Activity Recognition Using Smartphone Sensors. In Proceedings of the 2013 IEEE 10th International Conference on Ubiquitous Intelligence and Computing and 2013 IEEE 10th International Conference on Autonomic and Trusted Computing, Vietri sul Mare, Italy, 18–21 December 2013; pp. 80–87. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. Fusion of smartphone motion sensors for physical activity recognition. Sensors 2014, 14, 10146. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Ding, X.; Huang, K.; Ye, X.; Zhang, C. Changing health behaviors through social and physical context awareness. In Proceedings of the 2015 International Conference on Computing, Networking and Communications (ICNC), Garden Grove, CA, USA, 16–19 February 2015; pp. 663–667. [Google Scholar] [CrossRef]
- Ramos-Garcia, R.I.; Hoover, A.W. A Study of Temporal Action Sequencing during Consumption of a Meal. In Proceedings of the International Conference on Bioinformatics, Computational Biology and Biomedical Informatics, Washington, DC, USA, 22–25 September 2013; pp. 68–75. [Google Scholar] [CrossRef]
- Scholl, P.M.; van Laerhoven, K. A Feasibility Study of Wrist-Worn Accelerometer Based Detection of Smoking Habits. In Proceedings of the 2012 Sixth International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Washington, DC, USA, 4–6 July 2012; pp. 886–891. [Google Scholar] [CrossRef]
- Parate, A.; Chiu, M.C.; Chadowitz, C.; Ganesan, D.; Kalogerakis, E. RisQ: Recognizing Smoking Gestures with Inertial Sensors on a Wristband. In Proceedings of the 12th Annual International Conference on Mobile Systems, Applications, and Services, Bretton Woods, NH, USA, 16–19 July 2014; pp. 149–161. [Google Scholar] [CrossRef]
- Ha, S.; Yun, J.; Choi, S. Multi-modal Convolutional Neural Networks for Activity Recognition. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 3017–3022. [Google Scholar] [CrossRef]
- Lima, W.S.; Souto, E.; El-Khatib, K.; Jalali, R.; Gama, J. Human activity recognition using inertial sensors in a smartphone: An overview. Sensors 2019, 14, 3213. [Google Scholar] [CrossRef] [PubMed]
- Ignatov, A. Real-time human activity recognition from accelerometer data using convolutional neural networks. Appl. Soft Comput. J. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Hammerla, N.Y.; Halloran, S.; Ploetz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition using Wearables. In Proceedings of the IJCAI 2016, New York, NY, USA, 9–15 July 2016; pp. 1533–1540. [Google Scholar]
- Otebolaku, A.M.; Andrade, M.T. User context recognition using smartphone sensors and classification models. J. Netw. Comput. Appl. 2016, 66, 33–51. [Google Scholar] [CrossRef]
- Das, B.; Seelye, A.B.; Thomas, B.L.; Cook, D.J.; Holder, L.B.; Schmitter-Edgecombe, M. Using smart phones for context-aware prompting in smart environments. In Proceedings of the 2012 IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 14–17 January 2012; pp. 399–403. [Google Scholar] [CrossRef]
- Vaizman, Y.; Weibel, N.; Lanckriet, G. Context Recognition In-the-Wild: Unified Model for Multi-Modal Sensors and Multi-Label Classification. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018. [Google Scholar] [CrossRef]
- Edel, M.; Köppe, E. Binarized-BLSTM-RNN based Human Activity Recognition. In Proceedings of the 2016 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcalá de Henares, Spain, 4–7 October 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Inoue, M.; Inoue, S.; Nishida, T. Deep Recurrent Neural Network for Mobile Human Activity Recognition with High Throughput. Artif. Life Robot. 2018, 23, 173–185. [Google Scholar] [CrossRef]
- Guan, Y.; Ploetz, T. Ensembles of Deep LSTM Learners for Activity Recognition using Wearables. Proc. ACM Interact. Mobile Wearable Ubiquitous Technol. 2017. [Google Scholar] [CrossRef]
- Murad, A.; Pyun, J.-Y. Deep Recurrent Neural Networks for Human Activity Recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long Short-Term Memory Networks for Anomaly Detection in Time Series. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 22–24 April 2015. [Google Scholar]
- Alhussein, M.; Aurangzeb, K.; Haider, S.I. Hybrid CNN-LSTM Model for Short-Term Individual Household Load Forecasting. IEEE Access 2020, 8, 180544–180557. [Google Scholar] [CrossRef]
- umaei, A.; Hassan, M.M.; Alelaiwi, A.; Alsalman, H. A Hybrid Deep Learning Model for Human Activity Recognition Using Multimodal Body Sensing Data. IEEE Access 2019, 7, 99152–99160. [Google Scholar]
- Mohd Noor, M.H.; Tan, S.Y.; Ab Wahab, M.N. Deep Temporal Conv-LSTM for Activity Recognition. Neural Process Lett. 2022. [Google Scholar] [CrossRef]
- Yin, X.; Liu, Z.; Liu, D.; Ren, X. A Novel CNN-based Bi-LSTM parallel model with attention mechanism for human activity recognition with noisy data. Sci. Rep. 2022, 12, 7878. [Google Scholar] [CrossRef] [PubMed]
- Huan, R.; Jiang, C.; Ge, L.; Shu, J.; Zhan, Z.; Chen, P.; Chi, K.; Liang, R. Human Complex Activity Recognition with Sensor Data Using Multiple Features. IEEE Sens. J. 2022, 22, 757–775. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, Z.; Zhao, L.; Yang, P. Attention-Based Bi-LSTM Models for Personality Recognition from User-Generated Content. Inf. Sci. 2022, 596, 460–471. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Zhao, Y.; Yang, R.; Chevalier, G.; Xu, X.; Zhang, Z. Deep Residual Bidir-LSTM for Human Activity Recognition Using Wearable Sensors. Math. Probl. Eng. 2018, 2018, 7316954. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, Y.; Peng, L. METIER: A Deep Multi-Task Learning Based Activity and User Recognition Model Using Wearable Sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020. [Google Scholar] [CrossRef]
- Bragança, H.; Colonna, J.G.; Lima, W.S.; Souto, E. A Smartphone Lightweight Method for Human Activity Recognition Based on Information Theory. Sensors 2020, 20, 1856. [Google Scholar] [CrossRef]
- Gani, M.O.; Fayezeen, T.; Povinelli, R.J.; Smith, R.O.; Arif, M.; Kattan, A.J.; Ahamed, S.I. A lightweight smartphone based human activity recognition system with high accuracy. J. Netw. Comput. Appl. 2019, 141, 59–72. [Google Scholar] [CrossRef]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gen. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Otebolaku, A.; Enamamu, T.; Alfoudi, A.S.; Ikpehai, A.; Marchang, J.; Lee, G.M. Deep Sensing: Inertial and Ambient Sensing for Activity Context Recognition Using Deep Convolutional Neural Networks. Sensors 2020, 20, 3803. [Google Scholar] [CrossRef] [PubMed]
- Laguna, J.O.; Garc, A.; Borrajo, D. A Dynamic Sliding Window Approach for Activity Recognition. In Proceedings of the 19th International Conference on User modeling, Adaption, and Personalization, Girona, Spain, 11–15 July 2011; pp. 219–220. [Google Scholar]
- Almaslukh, B.; Artoli, A.M.; Al-Muhtadi, J. A Robust Deep Learning Approach for Position-Independent Smartphone-Based Human Activity Recognition. Sensors 2018, 18, 3726. [Google Scholar] [CrossRef] [PubMed]
- Chambers, R.D.; Yoder, N.C. FilterNet: A Many-to-Many Deep Learning Architecture for Time Series Classification. Sensors 2020, 20, 2498. [Google Scholar] [CrossRef] [PubMed]
- Masters, D.; Luschi, C. Revisiting Small Batch Training for Deep Neural Networks. arXiv 2018, arXiv:1804.07612. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 929–1958. [Google Scholar]
- Otebolaku, A.M.; Andrade, M.T. Recognizing High-Level Contexts from Smartphone Built-In Sensors for Mobile Media Content Recommendation. In Proceedings of the 2013 IEEE 14th International Conference on Mobile Data Management, Milan, Italy, 3–6 June 2013; pp. 142–147. [Google Scholar] [CrossRef]
- Bettini, C.; Civitarese, G.; Presotto, R. CAVIAR: Context-driven Active and Incremental Activity Recognition. Knowl. Based Syst. 2020, 196, 105816. [Google Scholar] [CrossRef]
- Weiss, G.M.; Yoneda, K.; Hayajneh, T. Smartphone and Smartwatch-Based Biometrics Using Activities of Daily Living. IEEE Access 2019, 7, 133190–133202. [Google Scholar] [CrossRef]
- Carneiro, T.; Medeiros Da NóBrega, R.V.; Nepomuceno, T.; Bian, G.B.; De Albuquerque, V.H.C.; Filho, P.P.R. Performance Analysis of Google Collaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access 2018, 6, 61677–61685. [Google Scholar] [CrossRef]
- Ward, J.A.; Lukowicz, P.; Gellersen, H.W. Performance metrics for activity recognition. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–23. [Google Scholar] [CrossRef]
- Agarwal, P.; Alam, M. A Lightweight Deep Learning Model for Human Activity Recognition on Edge Devices. Procedia Comput. Sci. 2020, 167, 2364–2373. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Activity | Category | Subactivity |
|---|---|---|---|
| 1 | Jogging | Simple | N/A |
| 2 | Lying | Simple | N/A |
| 3 | Running | Simple | N/A |
| 4 | Sitting | Simple | N/A |
| 5 | Standing | Simple | N/A |
| 6 | Walking | Simple | N/A |
| 7 | Ascending Stairs | Complex | Walking + in motion against gravity |
| 8 | Descending Stairs | Complex | Walking + in motion in line with gravity |
| 9 | Elevator Down | Complex | Standing + in motion in line with gravity |
| 10 | Elevator Up | Complex | Standing + in motion against gravity |
| 11 | Mountain Climbing | Complex | Walking + under high altitude |
| 12 | Riding in car | Complex | Sitting + in motion |
| kernel = 2: 97.674% (+/0.395) |
| kernel = 3: 97.900% (+/0.307) |
| kernel = 4: 97.703% (+/0.423) |
| kernel = 5: 97.514% (+/0.273) |
| kernel = 7: 97.099% (+/0.513) |
| Parameter | Recommended | Feasible | Tuned |
|---|---|---|---|
| CNN layers | 2 | No | |
| CNN—Kernel Size | 3 | 2 | Yes |
| CNN—Filter Size | 64 | 256 | Yes |
| LSTM Cells | 100 | No | |
| Optimizer | Adam | Yes | |
| Dropout | CNN = 0.1 | Yes | |
| Weight Decay | CNN = 1 × 10−6 LSTM = 1 × 10−5 | Yes | |
| Window Length (size of input vector) | 32 | 64 | Yes |
| Number of Input Channels | 9 | ||
| Batch Size | 64 | 32 | Yes |
| Subsequence Steps | 4 | No | |
| Learning Rate | 1 × 10−4 | 3 × 10−4 | Yes |
| Early Stopping | Patience: 10 epoch: 50–100 | Patience: 8 epoch: 40–80 | Yes |
| ModelCheckpoint | save_best_only: True | No |
| Model | Activity Category | |
|---|---|---|
| Simple | Complex | |
| Noncontextual | 98.7% | 93.7% |
| Contextual | 99.6% | 97.8% |
| # | Activity | F-Score | |
|---|---|---|---|
| Noncontextual | Contextual | ||
| 1 | Jogging | 0.976 | 0.992 |
| 2 | Lying | 0.998 | 1.000 |
| 3 | Running | 0.993 | 1.000 |
| 4 | Sitting | 0.970 | 0.990 |
| 5 | Standing | 0.995 | 0.997 |
| 6 | Walking | 0.991 | 0.996 |
| 7 | Ascending Stairs | 0.944 | 0.961 |
| 8 | Descending Stairs | 0.943 | 0.955 |
| 9 | Elevator Down | 0.985 | 0.992 |
| 10 | Elevator Up | 0.984 | 0.991 |
| 11 | Mountain Climbing | 0.774 | 0.981 |
| 12 | Riding in car | 0.990 | 0.990 |
| accuracy | 0.989 | 0.995 | |
| macro-average | 0.962 | 0.987 | |
| weighted average | 0.989 | 0.995 | |
| Model | Accuracy |
|---|---|
| Noncontextual | 96.19% |
| Contextual | 98.72% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Omolaja, A.; Otebolaku, A.; Alfoudi, A. Context-Aware Complex Human Activity Recognition Using Hybrid Deep Learning Models. Appl. Sci. 2022, 12, 9305. https://doi.org/10.3390/app12189305
Omolaja A, Otebolaku A, Alfoudi A. Context-Aware Complex Human Activity Recognition Using Hybrid Deep Learning Models. Applied Sciences. 2022; 12(18):9305. https://doi.org/10.3390/app12189305
Chicago/Turabian StyleOmolaja, Adebola, Abayomi Otebolaku, and Ali Alfoudi. 2022. "Context-Aware Complex Human Activity Recognition Using Hybrid Deep Learning Models" Applied Sciences 12, no. 18: 9305. https://doi.org/10.3390/app12189305
APA StyleOmolaja, A., Otebolaku, A., & Alfoudi, A. (2022). Context-Aware Complex Human Activity Recognition Using Hybrid Deep Learning Models. Applied Sciences, 12(18), 9305. https://doi.org/10.3390/app12189305