

DRUNet: A Method for Infrared Point Target Detection
Abstract
:1. Introduction
- An effective CNN-based infrared small target detection algorithm is proposed, containing a feature extraction module and a prediction head module, where the feature extraction part can be used for other infrared small target vision tasks.
- For the problem of a sparse infrared small target dataset, the publicly available infrared small target dataset is expanded by selecting images with large target variations from the infrared tracking dataset using the frame extraction method.
- An evaluation method for keypoint detection and a fair method to measure the inference speed of the network are proposed.
2. Related Work
2.1. Infrared Single-Frame Small Target Detection by CNN-Based Method
2.2. Object Detection by Keypoint Estimation
3. Proposed Network
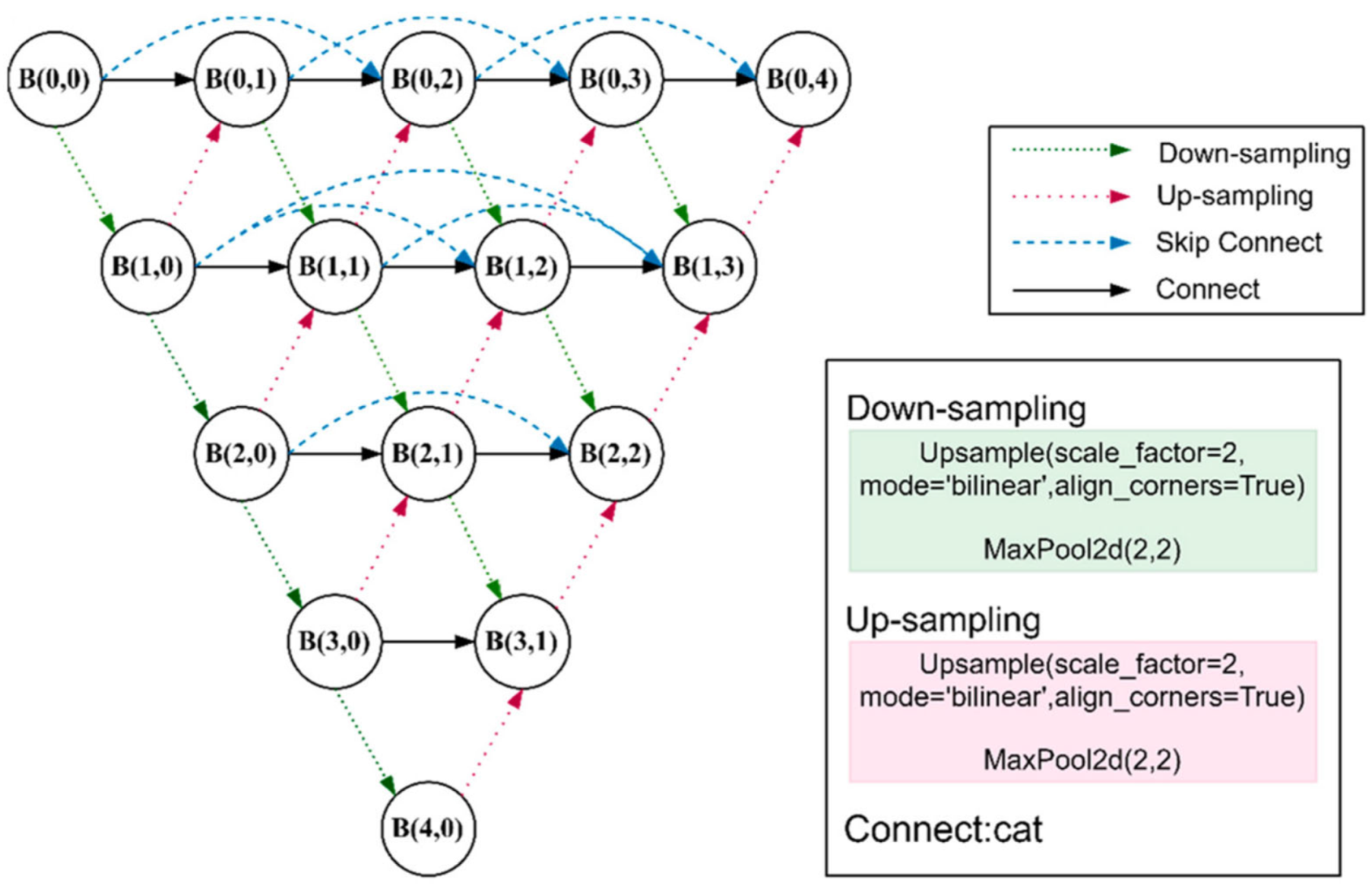
3.1. Network Architecture
- Unlike visible images, infrared images lack information, such as color, texture, and contours, especially in deep networks, where small targets are easily overwhelmed by complex environments or confused with pixel-level impulse noise.
- Resolution and semantics conflict. A complex low SNR ratio background often obscures small infrared targets. Deep networks learn more semantic representations by gradually shrinking feature sizes, which is inherently counterintuitive because they are learning more semantic representations by gradually decaying the feature size. To detect these small targets with a low false alarm rate, the network must have a high-level semantic understanding of the whole IR image.
- Down-sampling scheme: Many studies emphasize that the acceptance domain of predictors should match the target scale range when designing CNNs. If the down-sampling scheme is not recustomized, it is difficult to retain the features of small IR targets as the network goes deeper [26]. Therefore, our proposed method maintains an up-sampling rate of 2 and a down-sampling rate of 0.5 when performing feature extraction.
- Suitable image attention enhancement module: Since ordinary visible image targets are relatively large and the pixels occupied by the targets are more widely distributed in the graph, the existing attention modules tend to aggregate global or long-term contexts. However, infrared small targets occupy fewer pixels, so it is necessary to choose the appropriate module when using attention modules; otherwise, it is impossible to optimize the network performance while increasing the model complexity.
- Feature fusion methods: Feature fusion is mostly studied in a one-way, top–down manner to fuse cross-layer features and to select appropriate low-level features based on high-level semantics. However, only using top-down modulation may not work because small targets may already be overwhelmed by the background.
3.2. ECA-Rest Block
3.3. Target Extraction Module
3.4. Prediction Head
4. Training Method
4.1. Dataset
4.2. Loss Function
4.3. Training Setting
5. Experiments
5.1. Evaluation Metrics
5.2. Inference Speed Performance Metrics
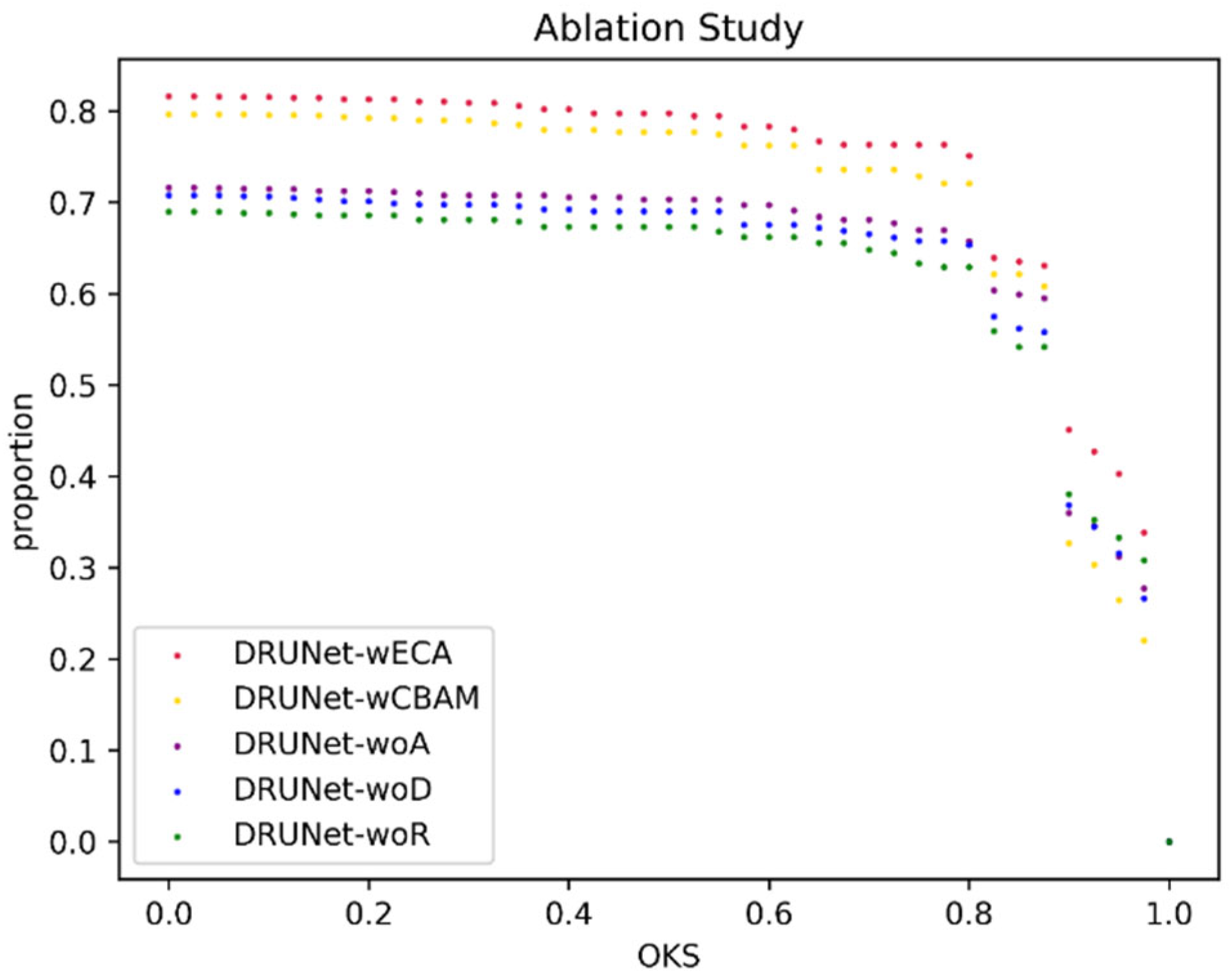
5.3. Ablation Study
- Question 1: Is the attention enhancement module effective, and how much can it improve performance?
- Question 2: Is the ECA module more suitable than other more complex attention enhancement modules for the detection of weak IR targets?
- Question 3: How much performance optimization can be achieved by using only the residual module for each block without using any attention enhancement module?
- Question 4: Does deep supervision result in improved network performance?
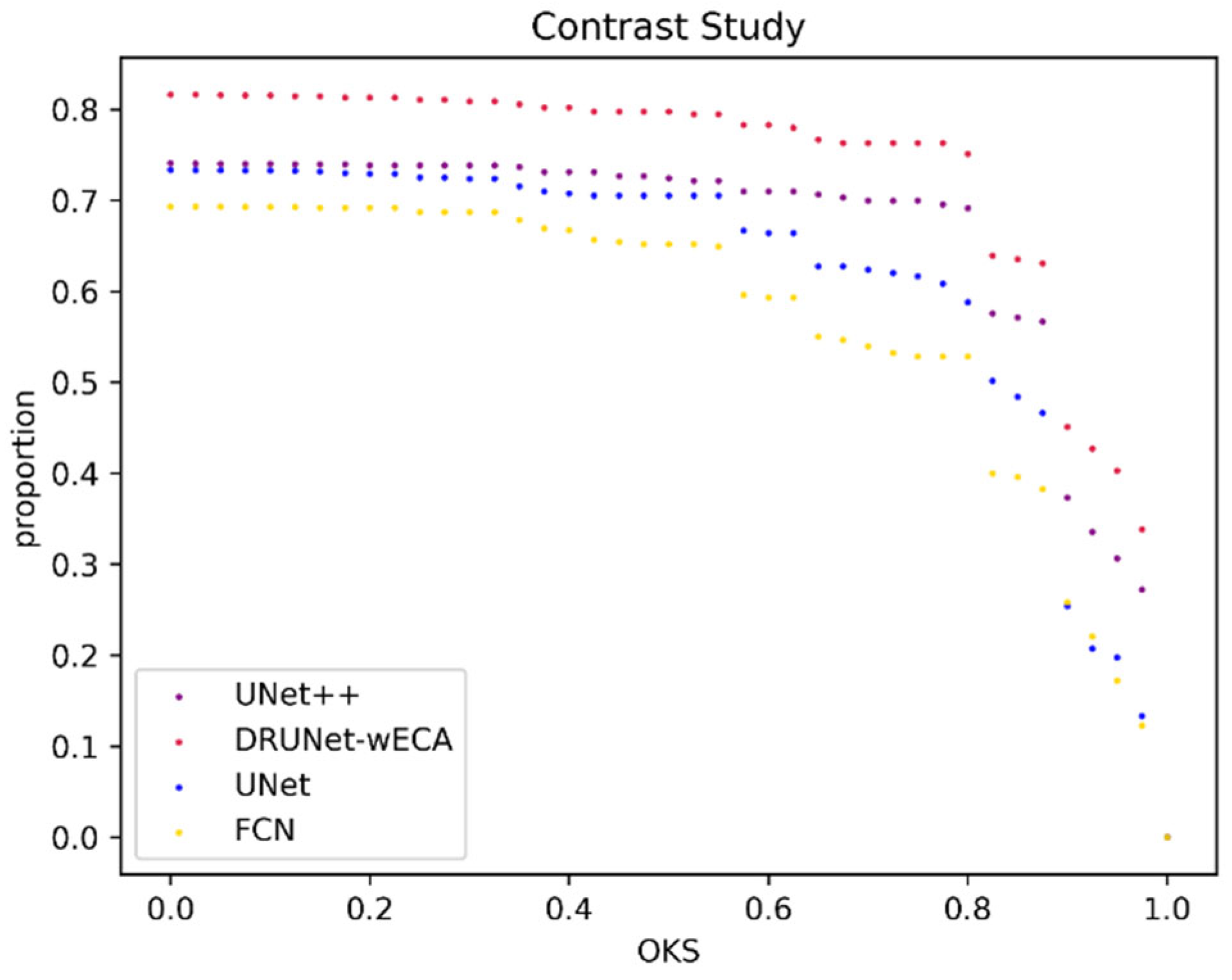
5.4. Contrast Experiment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, D.P.; Wu, C.; Li, Z.J.; Pan, W. Research and Progress of Infrared Imaging Technology in the Safety Field. Infrared Technol. 2015, 6, 528–535. [Google Scholar]
- Zhang, H.; Luo, C.; Wang, Q.; Kitchin, M.; Parmley, A.; Monge-Alvarez, J.; Casaseca-De-La-Higuera, P. A novel infrared video surveillance system using deep learning based techniques. Multimed. Tools Appl. 2018, 77, 26657–26676. [Google Scholar] [CrossRef]
- Eysa, R.; Hamdulla, A. Issues On Infrared Dim Small Target Detection And Tracking. In Proceedings of the International Conference on Smart Grid and Electrical Automation (ICSGEA), Xiangtan, China, 10–11 August 2019. [Google Scholar]
- Zhang, W.; Cong, M.; Wang, L. Algorithms for optical weak small targets detection and tracking: Review. In Proceedings of the International Conference on Neural Networks and Signal Processing, Nanjing, China, 14–17 December 2003. [Google Scholar]
- Liu, Z.; Yang, D.; Li, J.; Hang, C. A review of infrared single-frame dim small target detection algorithms. Laser Infrared 2022, 52, 154–162. [Google Scholar]
- Zhao, M.; Li, W.; Li, L.; Hu, J.; Ma, P.; Tao, R. Single-Frame Infrared Small-Target Detection. IEEE Geosci. Remote Sens. Mag. 2022, 10, 87–119. [Google Scholar] [CrossRef]
- Wang, H.X.; Dong, H.; Zhou, Z.Q. Review on Dim Small Target Detection Technologies in Infrared Single Frame Images. Laser Optoelectron. Prog. 2019, 56, 154–162. [Google Scholar]
- Da Cunha, A.L.; Zhou, J.; Do, M.N. The nonsubsampled contourlet transform: Theory, design, and applications. IEEE Trans. Image Process. 2006, 15, 3089–3101. [Google Scholar] [CrossRef] [PubMed]
- Comaniciu, D. An algorithm for data-driven bandwidth selection. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 281–288. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Hadhoud, M.M.; Thomas, D.W. The two-dimensional adaptive LMS (TDLMS) algorithm. IEEE Trans. Circuits Syst. 1988, 35, 485–494. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 574–581. [Google Scholar] [CrossRef]
- Qin, Y.; Li, B. Effective Infrared Small Target Detection Utilizing a Novel Local Contrast Method. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1890–1894. [Google Scholar] [CrossRef]
- Han, J.; Liu, S.; Qin, G.; Zhao, Q.; Zhang, H.; Li, N. A Local Contrast Method Combined With Adaptive Background Estimation for Infrared Small Target Detection. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1442–1446. [Google Scholar] [CrossRef]
- Davey, S.J.; Rutten, M.G.; Cheung, B. A comparison of detection performance for several track-before-detect algorithms. Eurasip J. Adv. Signal Process. 2007, 2008, 1–10. [Google Scholar] [CrossRef]
- Zhao, B.; Wang, C.; Fu, Q.; Han, Z. A Novel Pattern for Infrared Small Target Detection With Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4481–4492. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric Contextual Modulation for Infrared Small Target Detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Electr Network, Virtual, 5–9 January 2021. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional Local Contrast Networks for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense Nested Attention Network for Infrared Small Target Detection. IEEE Trans. Image Process. 2022; Early Access. [Google Scholar] [CrossRef]
- Zuo, Z.; Tong, X.; Wei, J.; Su, S.; Wu, P.; Guo, R.; Sun, B. AFFPN: Attention Fusion Feature Pyramid Network for Small Infrared Target Detection. Remote Sens. 2022, 14, 3412. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, H.Y.; Fan, J.L.; Gong, Y.C.; Li, Y.H.; Wang, F.P.; Lu, J. A Survey of Research and Application of Small Object Detection Based on Deep Learning. Acta Electonica Sin. 2020, 48, 590–601. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. CornerNet-Lite: Efficient Keypoint Based Object Detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up Object Detection by Grouping Extreme and Center Points. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet plus plus: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the 4th International Workshop on Deep Learning in Medical Image Analysis (DLMIA)/8th International Workshop on Multimodal Learning for Clinical Decision Support (ML-CDS), Granada, Spain, 20 September 2018. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. arXiv 2019, arXiv:1910.03151. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, H.; Zhou, L.; Wang, L. Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019.
- Hui, B.W.; Song, Z.Y.; Fan, H.Q.; Zhong, P.; Hu, W.D.; Zhang, X.F.; Ling, J.G.; Su, H.Y.; Jin, W.; Zhang, Y.J.; et al. A dataset for dim-small target detection and tracking of aircraft in infrared image sequences [DB/OL]. Sci. Data Bank 2019. under review. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiments | Model | Threshold 0.5 | Threshold 0.75 | Threshold 0.95 | Accuracy Rate | FPS (f/s) | Model Size (MB) |
|---|---|---|---|---|---|---|---|
| 1 | DRUNet-wECA | 0.7976 | 0.7633 | 0.403 | 0.8247 | 133 | 10.5 |
| 2 | DRUNet-wCBAM | 0.7771 | 0.7286 | 0.2646 | 0.8041 | 53 | 10.6 |
| 3 | DRUNet-woA | 0.7032 | 0.6696 | 0.3121 | 0.7319 | 182 | 10.5 |
| 4 | DRUNet-woR | 0.6735 | 0.6332 | 0.3328 | 0.6907 | 184 | 10.5 |
| 5 | DRUNet-woD | 0.6901 | 0.6577 | 0.316 | 0.7268 | 183 | 10.5 |
| Experiments | Model | Threshold 0.5 | Threshold 0.75 | Threshold 0.95 | Accuracy Rate | FPS (f/s) | Model Size (MB) |
|---|---|---|---|---|---|---|---|
| 1 | DRUNet-wECA | 0.7976 | 0.7633 | 0.403 | 0.8247 | 133 | 10.5 |
| 2 | UNet++ | 0.7242 | 0.6995 | 0.3067 | 0.7577 | 146 | 36.8 |
| 3 | UNet | 0.7054 | 0.6165 | 0.1977 | 0.6855 | 730 | 3.2 |
| 4 | FCN | 0.652 | 0.5285 | 0.1722 | 0.5876 | 327 | 44.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, C.; Li, Q.; Xu, J.; Yang, J.; Jiang, S. DRUNet: A Method for Infrared Point Target Detection. Appl. Sci. 2022, 12, 9299. https://doi.org/10.3390/app12189299
Wei C, Li Q, Xu J, Yang J, Jiang S. DRUNet: A Method for Infrared Point Target Detection. Applied Sciences. 2022; 12(18):9299. https://doi.org/10.3390/app12189299
Chicago/Turabian StyleWei, Changan, Qiqi Li, Ji Xu, Jingli Yang, and Shouda Jiang. 2022. "DRUNet: A Method for Infrared Point Target Detection" Applied Sciences 12, no. 18: 9299. https://doi.org/10.3390/app12189299
APA StyleWei, C., Li, Q., Xu, J., Yang, J., & Jiang, S. (2022). DRUNet: A Method for Infrared Point Target Detection. Applied Sciences, 12(18), 9299. https://doi.org/10.3390/app12189299