
Underwater Sea Cucumber Identification Based on Improved YOLOv5


Abstract
:1. Introduction
- (1)
- Improve the structure of the YOLOv5s model, increase the number of upsampled in the Neck network, and increase the Detect layer in the Head network, so that small sea cucumber targets can be detected;
- (2)
- Add the CBAM module, which can save parameters and computing power, and ensure that it can be integrated into the existing network architecture as a plug-and-play module;
- (3)
- The image was pre-processed by MSRCR algorithm, which enhanced the differentiation of the sea participation environment and provided help for precise and rapid identification of sea cucumbers in the natural environment.
- (4)
- After modifying the YOLOv5s model, ablation study was conducted, and the feasibility of improvement was proved. Compared with YOLOv4 and Faster-RCNN, the experimental results showed that the improved YOLOv5s had a higher precision and recall rate.
2. Materials and Methods
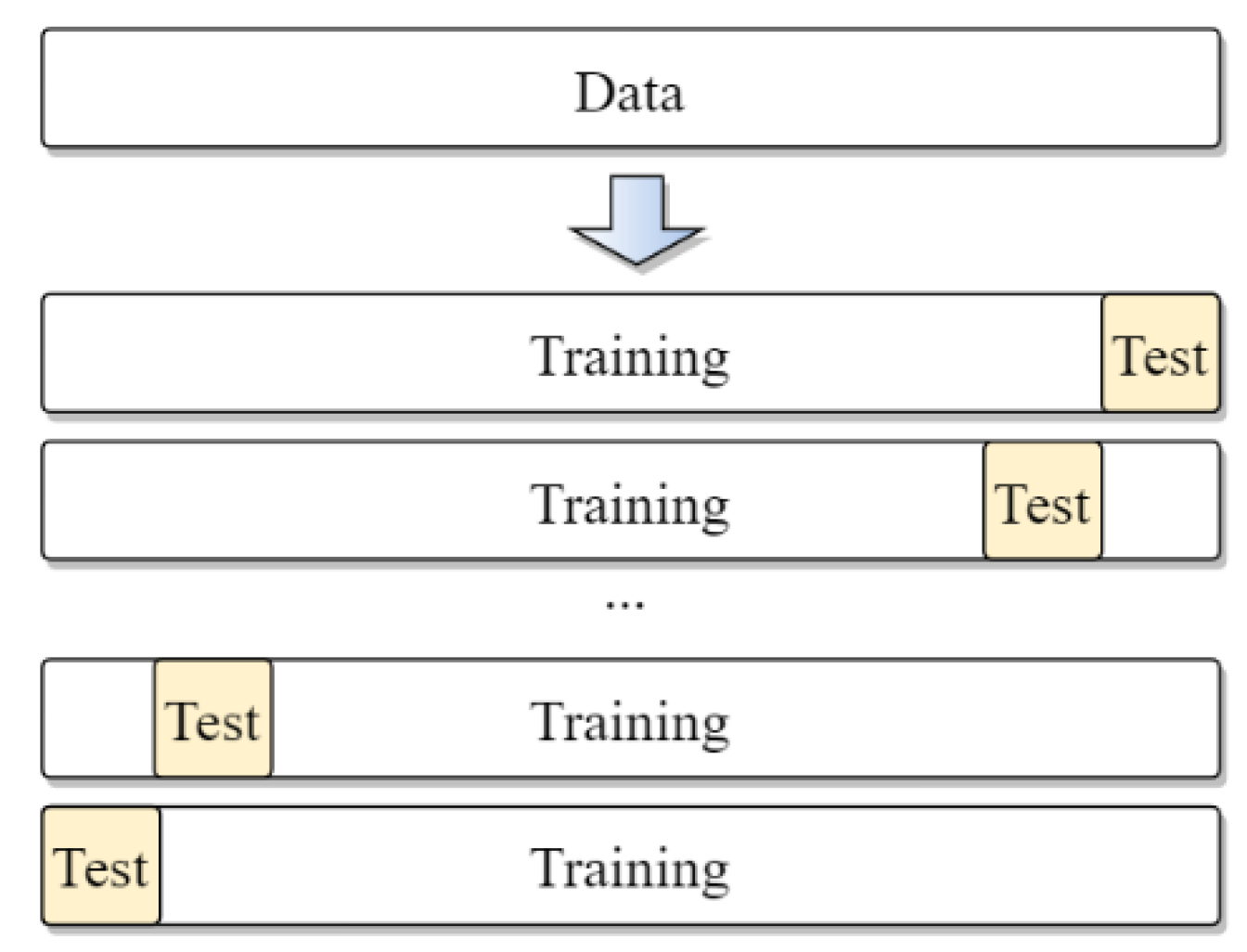
2.1. Experimental Data Acquisition
2.2. Image Preprocessing
2.3. Data Augmentation
2.4. Dataset Preparation
3. Sea Cucumber Identification Network
3.1. YOLOv5 Network Model
3.2. Loss Function
3.3. YOLOv5 Network Improvements
3.3.1. Add Convolutional Block Attention Module
3.3.2. Add Detect Layer
3.3.3. Ablation Study
4. Model Training and Testing
4.1. Experimental Platform
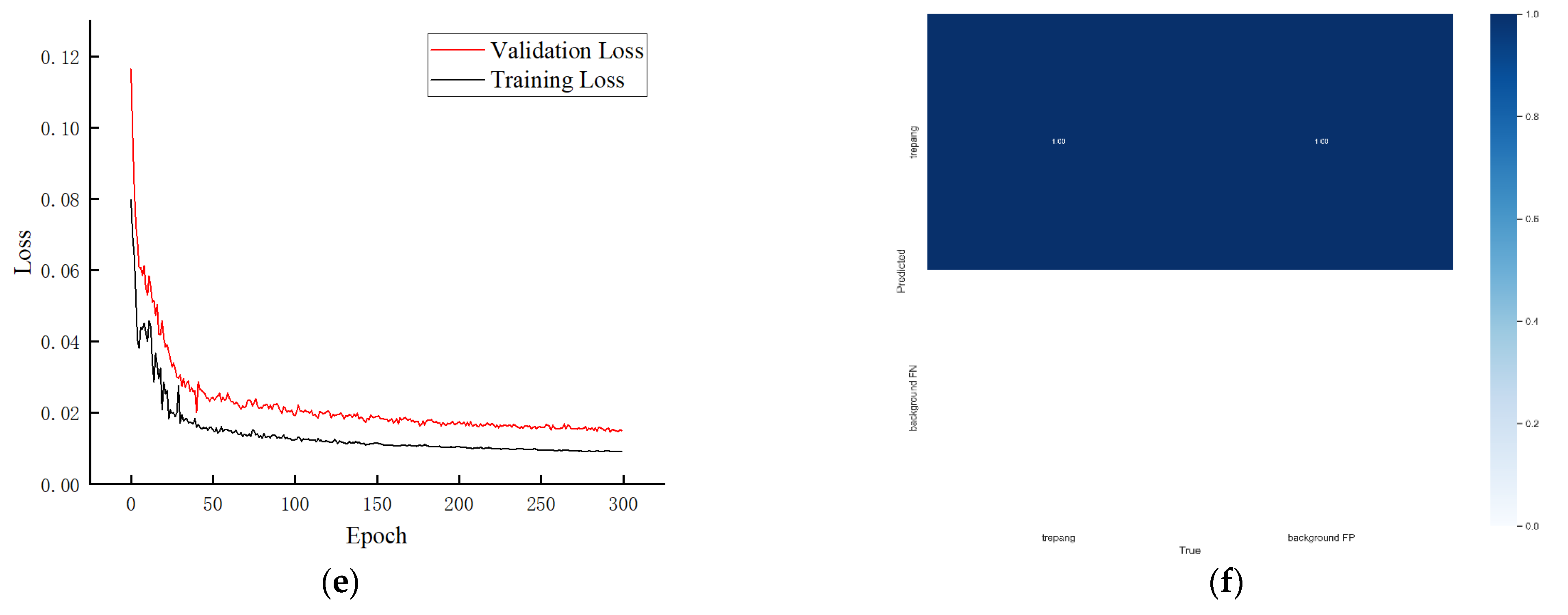
4.2. Model Testing
5. Results and Analysis
5.1. Sea Cucumber Identification for the Single Gallery
5.2. Sea Cucumber Identification for Mixed Image Gallery
5.3. Comparison of Test Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiwei, L.; Honglei, W.; Qichao, P.; Liran, X. Underwater sea cucumber target tracking algorithm based on correlation filtering. CAAI Trans. Intell. Syst. 2019, 14, 525–532. [Google Scholar] [CrossRef]
- Juan, L.; Xueyan, Z.; Fengli, G.; Haoran, B. Research on underwater sea cucumber identification based on computer vision. J. Chin. Agric. Mech. 2020, 41, 171–177. [Google Scholar]
- Wei, Q.; Yuyao, H.; Yujin, G.; Baoqi, L.; Lingjiao, H. Exploring Underwater Target Detection Algorithm Based on Improved SSD. J. Northwest. Polytech. Univ. 2020, 38, 747–754. [Google Scholar]
- Yu, L.; Shuiyuan, H. Improved Cascade RCNN underwater target detection. Electron. World 2022, 1, 105–108. [Google Scholar]
- Kongwei, M. Sea Cucumber Detection Based on CNN and Its Application in Underwater Vehicle. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2019. [Google Scholar]
- Lu, W.; Leiou, W.; Donghui, W. Exploring Underwater Target Detection Algorithm Based on Faster-RCNN. Netw. New Media Technol. 2021, 10, 43—51, 58. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 2016; pp. 779–788. [Google Scholar]
- Jiang, N.; Wang, J.; Kong, L.; Zhang, S.; Dong, J. Underwater target recognition and tracking method based on YOLO-V3 algorithm. J. Chin. Inert. Technol. 2020, 28, 129–133. [Google Scholar]
- Conghui, Z. The Design and Implementation of Sea Cucumber Target Recognition System Based on YOLO-v3. Master’s Thesis, Harbin Engineering University, Harbin, China, 2020. [Google Scholar]
- Shiwei, Z.; Renlong, H.; Qingshan, L. Underwater Object Detection Based on the Class-Weighted YOLO Net. J. Nanjing Norm. Univ. (Nat. Sci. Ed.) 2020, 43, 129–135. [Google Scholar]
- Qingzheng, W.; Shuai, L.; Hong, Q.; Hao, A. Super-resolution of multi-observed RGB—D images based on nonlocal regression and total variation. IEEE Trans. Image Process. 2016, 25, 1425–1440. [Google Scholar]
- Yiquan, W.; Yangdong, W.; Bing, Q. Study on UAV spray method of intercropping farmland based on Faster RCNN. J. Chin. Agric. Mech. 2019, 40, 76–81. [Google Scholar]
- Kaixing, Z.; Gaolong, L.; Hao, J.; Xiuyan, Z.; Xianxi, L. Maize leaf disease recognition based on image processing and BP neural network. J. Chin. Agric. Mech. 2019, 40, 122–126. [Google Scholar]
- Zhijun, S.; Hua, Z.; Cheng, Z.; Meng, L.; Qi, Z. Automatic orientation method and experiment of Fructus aurantii based on machine vision. J. Chin. Agric. Mech. 2019, 40, 119–124. [Google Scholar]
- ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite. Available online: https://github.com/ultralytics/yolov5 (accessed on 7 March 2022).
- Zhongzhi, H.; Jianhua, W.; Jie, L.; Shao, M.; Yue, G.; An, D. Multispectral Imaging Detection Using The Ultraviolet Fluorescence Characteristics of Oil. Chin. J. Lumin. 2015, 36, 1335–1341. [Google Scholar] [CrossRef]
- Chen, F.; Wang, C.; Gu, M.; Zhao, Y. Spruce Image Segmentation Algorithm Based on Fully Convolutional Networks. Trans. Chin. Soc. Agric. Mach. 2018, 49, 188–194. [Google Scholar]
- Jiahao, H.; Haiyang, Z.; Lin, W. Improved YOLOv3 Model for miniature camera detection. Opt. Laser Technol. 2021, 142, 75–79. [Google Scholar]
- Liu, S.; Xu, Y.; Guo, L.; Shao, M.; Yue, G.; An, D. Multi-scale personnel deep feature detection algorithm based on Extended-YOLOv3. J. Intell. Fuzzy Syst. 2021, 40, 773–786. [Google Scholar] [CrossRef]
- Jobson, D.; Rahman, Z.; Woodell, G. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Lei, W.; Wanjing, Z.; Zaibai, Q.; Shuling, H. Real-time Detection of Sea Surface Targets. J. Shanghai Jiaotong Univ. 2012, 46, 1421–1427. [Google Scholar]
- Yuan, H. Design and Implementation of an In-Car Life Detection System Based on Image. Master’s Thesis, Jiangxi Normal University, Nanchang, China, 2017. [Google Scholar]
- Han, G. The Illumination Compensation Algorithms in Pattern Recognition. Master’s Thesis, Beijing Insititute of Technology, Beijing, China, 2016. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T. Rich feature hierarchies for precise object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 28 June 2014; pp. 580–587. [Google Scholar]
- Hu, X.; Liu, Y.; Zhao, Z.; Liu, J.; Yang, X.; Sun, C.; Zhou, C. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved YOLO-V4 network. Comput. Electron. Agric. 2021, 185, 106135. [Google Scholar] [CrossRef]
- Lei, Z. Research of Image Enhancement Algorithm of Retinex and Implementation by Using FPGA. Master’s Thesis, Tsinghua University, Beijing, China, 2012. [Google Scholar]
- Qiujun, Z.; Junshan, L.; Yinghong, Z.; Jianhua, L.; Jiao, Z. Adaptive Infrared Thermal Image Enhancement Based on Retinex. Microelectron. Comput. 2013, 30, 22–25. [Google Scholar]
- Lei, F.; Tang, F.; Li, S. Underwater Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2022, 10, 310. [Google Scholar] [CrossRef]
- Qiao, X.; Bao, J.; Zhang, H.; Wan, F.; Li, D. fvUnderwater sea cucumber identification based on principal component analysis and support vector machine. Measurement 2019, 133, 444–455. [Google Scholar] [CrossRef]
- Zhang, L.; Xing, B.; Wang, W.; Xu, J. Sea Cucumber Detection Algorithm Based on Deep Learning. Sensors 2022, 22, 5717. [Google Scholar] [CrossRef] [PubMed]
- Xue, L.; Zeng, X.; Jin, A. A Novel Deep-Learning Method with Channel Attention Mechanism for Underwater Target Recognition. Sensors 2022, 22, 5492. [Google Scholar] [CrossRef] [PubMed]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Precision | Training Duration (Hour) | Weight (MB) | Detection Speed (ms/pic) |
|---|---|---|---|---|
| YOLOv5s | 83.6% | 4.4 | 13.5 | 17 |
| YOLOv5s + CBAM | 89.1% | 4.9 | 14.4 | 21 |
| YOLOv5s + detect | 87.4% | 5.0 | 14.8 | 23 |
| YOLOv5s + CBAM + detect | 92.9% | 5.5 | 15.6 | 25 |
| Configuration | Parameter |
|---|---|
| CPU | Intel Core i5-7300HQ |
| GPU | NVIDIA GeForce GTX1050Ti 4G |
| Operating system | Windows10 |
| Environment | Cuda11.2 |
| Development platform | PyCharm2021.3 |
| Others | OpenCV4.5.5, Numpy1.20.3 |
| Models | Precision | Recall | Detection Speed (ms/pic) |
|---|---|---|---|
| Improved YOLOv5s | 97.1% | 96.0% | 22 |
| YOLOv5s | 88.1% | 84.5% | 19 |
| YOLOv4 | 78.3% | 77.4% | 31 |
| Faster-RCNN | 82.4% | 80.9% | 25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhai, X.; Wei, H.; He, Y.; Shang, Y.; Liu, C. Underwater Sea Cucumber Identification Based on Improved YOLOv5. Appl. Sci. 2022, 12, 9105. https://doi.org/10.3390/app12189105
Zhai X, Wei H, He Y, Shang Y, Liu C. Underwater Sea Cucumber Identification Based on Improved YOLOv5. Applied Sciences. 2022; 12(18):9105. https://doi.org/10.3390/app12189105
Chicago/Turabian StyleZhai, Xianyi, Honglei Wei, Yuyang He, Yetong Shang, and Chenghao Liu. 2022. "Underwater Sea Cucumber Identification Based on Improved YOLOv5" Applied Sciences 12, no. 18: 9105. https://doi.org/10.3390/app12189105
APA StyleZhai, X., Wei, H., He, Y., Shang, Y., & Liu, C. (2022). Underwater Sea Cucumber Identification Based on Improved YOLOv5. Applied Sciences, 12(18), 9105. https://doi.org/10.3390/app12189105