Abstract
Rankings are a well-established tool to evaluate the performance of actors in different sectors of the economy, and their use is increasing even in the context of the startup ecosystem, both on a regional and on a global scale. Although rankings meet the demand for measurability and comparability, they often provide an oversimplified picture of the status quo, which, in particular, overlooks the variability of the socio-economic conditions in which the quantified results are achieved. In this paper, we describe an approach based on constructing a network of world countries, in which links are determined by mutual similarity in terms of development indicators. Through the instrument of community detection, we perform an unsupervised partition of the considered set of countries, aimed at interpreting their performance in the StartupBlink rankings. We consider both the global ranking and the specific ones (quality, quantity, business). After verifying if community membership is predictive of the success of a country in the considered ranking, we rate country performances in terms of the expectation based on community peers. We are thus able to identify cases in which performance is better than expected, providing a benchmark for countries in similar conditions, and cases in which performance is below the expectation, highlighting the need to strengthen the innovation ecosystem.
1. Introduction
Rankings and indexes are currently employed to quantify different kinds of performances. Both their application range and their importance are increasing, both in the context of economics and politics [1,2] and in private matters [3]. Rankings significantly affect the process of decision-making, and their influence on the choices and reputation of private and public institutions is extensively proven in literature [4,5]. Among the aspects of development that are surveyed through rankings, there are the propensity and ability of an administrative region to create innovation ecosystems [6]. These ecosystems are formed by startup enterprises, along with all the specialised communities that organize around them.
A necessary condition for the innovation ecosystem to emerge and develop is the availability of resources, capital elements, and capacities, allowing to create a product and business model with the required growth potential [7], establishing, at the same time, a community able to support the cooperation and interaction with investors [8,9]. Accordingly, the governance structures can influence in a relevant way the ecosystem quality. Recent research [10,11] has been oriented to support the coordination of activities and objectives for different actors (entrepreneurs, firms, investors, governmental institutions, and universities) in order to improve the cooperation of stakeholders inside the innovation ecosystem. In particular, venture capital, which seeks profitability in the ecosystem, and funders, who face major risks and uncertainties, as well as public policy-makers, naturally require as much information as possible about the available resources and capital and about the possibility for a startup in a given area to survive and develop. Such an information request is satisfied both by specialized databases, including Crunchbase, PitchBook, and Dealroom [12,13,14]), and by rankings that measure individual ecosystem performances. StartupBlink and Startup Genome [15,16], introduced in 2016–2017 and published every year since then, were the first worldwide rankings of innovation ecosystems and are receiving increasing attention and diffusion in official press and social network media. In particular, the annual outcomes and rankings generate much interest in the startup community and among investors, as well as in government agencies, which often motivate their country’s success in the international media by mentioning improvements in these startup ecosystem rankings [17]. To the best of our knowledge, the scientific community has not yet devoted to innovation ecosystems an attention comparable to that shown, instead, by economic, communication, and political sectors. In this work we implement a framework for the investigation of innovation ecosystems, with the aim of identifying the multiple structural factors that condition their relevance and efficiency.
Country rankings represent a common tool to rate performances with respect to a specific indicator or a group of indicators [18]. Actually, even if indicators and rankings provide an over-simplified representation of the complexity underlying cultural, social and economic phenomena, they constitute one of the few quantitative means to explore the multifaceted aspects of social systems [19]. Therefore, the use of rankings and indicators to set up government policies requires great attention to avoid critical issues. First of all, aggregate indexes may be influenced by biases, arbitrariness, and inaccuracy in choosing and aggregating different indicators, which could even be partially inter-related to each other [20,21]. Second, interpreting a ranking could lead to ambiguities, since it provides a status quo snapshot, considering neither the degree of development nor the heterogeneous starting conditions of the context in which a result is achieved: these differences are generally emphasized by rankings, while country performance assessment should be driven, instead, by the idea of similarity [22]. Detailed information on the development status that allows comparisons with countries recognized as similar can be useful for analysts and decision-makers to assess the result obtained by a given country in a ranking. The advantages of this approach are twofold, since it provides an equity-oriented criterion for the evaluation of a country performance and exploits the concept of proximity of economic complexity, according to which capturing similarities among states is essential for identifying and promoting possible unexpressed potentialities [23,24].
Currently, the approach followed by the two most influential publicly-available rankings [25] (StartupBlink and Startup Genome) to assess innovation ecosystems performance is based on a weighted sum of various startup business indicators, such as the presence of unicorns (namely, private startup companies whose value exceeds 1 billion USD) in a given area and the ease of doing business based on technological infrastructures and bureaucracy. Nonetheless, these rankings do not fully take into account the economic peculiarities of each country or geographical area. In this work, we aim at establishing a robust, reproducible and insightful pipeline to evaluate country performances in innovation ecosystem rankings. In particular, we focus on the StartupBlink ranking, which provides information at both a country level and a metropolitan-area level, while Startup Genome only ranks the innovation ecosystems in metropolitan areas.
The proposed strategy, which follows the pipeline defined in Ref. [26] in the analysis of socio-economic rankings, represents, to the best of our knowledge, the first rethinking of innovation ecosystem rankings based on the idea of improving equity. The method relies on representing development conditions in a complex and multifaceted way, replacing individual proxies determined by the arbitrary aggregation of indexes. We shall adopt the machinery of complex network theory [27], which allows us to represent and characterize multi-fold interactions among constituents of a system by means of a graph, where constituents and their interactions are modeled as nodes and edges, respectively. The complex network approach has been extensively adopted in a large number of domains, such as economics [24,28,29,30], neuroscience [31,32,33,34], genetics [35,36], and sustainability [37], to mention a few. Moreover, the complex network theory framework has been recently enriched with new methodological tools, such as multilayer networks [38] and network potentials [39,40], of specific interest for applications. Complex networks have already been applied to analyze rankings in studies that involve specific subjects, such as sport teams [41], world countries [26] and universities [42,43], highlighting in some cases general phenomena as the dynamics of rankings [44] or the presence of biases and their removal [43].
A crucial step of our analysis will consist of identifying network communities [45,46], namely non-overlapping groups of nodes with a tendency to create stronger connections inside the group than with the rest of the network. The procedure defines a method to partition the set of countries based on their similarity, evaluated considering a wide range of development-related parameters, and paves the way for a formulation of equity-based evaluation criteria. While the World Bank subdivides, for statistical reasons, world countries in income groups [47], thus focusing on a very specific aspect of development [48], our method encompasses a wide range of development variables to provide an unsupervised partition of countries ranked in StartupBlink. Community detection actually keeps track of relevant similarities that in some cases can be hidden, unexpected and not deduced from merely geographical and economic considerations.
The work is organized as follows. In Section 2, we present the StartupBlink country ranking and the World Development Indicators (WDIs) database and describe the procedures to construct the corresponding network of countries and perform community detection. Results concerning community detection and ranking reinterpretation are reported in Section 3, while the inherent discussion is presented in Section 4.
2. Materials and Methods
In this section, we first present the indicators that determine the StartupBlink ranking and describe the World Bank database employed to set up the complex network. Then, we focus on network construction: StartupBlink-ranked countries, representing nodes, are mutually connected by links whose strength increases with similarity, measured by Pearson correlation coefficient among the corresponding WDI sets. We also discuss the steps of community detection, which provides a partition of the considered countries that will be used to interpret the StartupBlink ranking. Moreover, we present the outcomes of alternative paths to partition the country set based on clustering algorithms. A concise representation of the workflow followed in our research is reported in Figure 1.
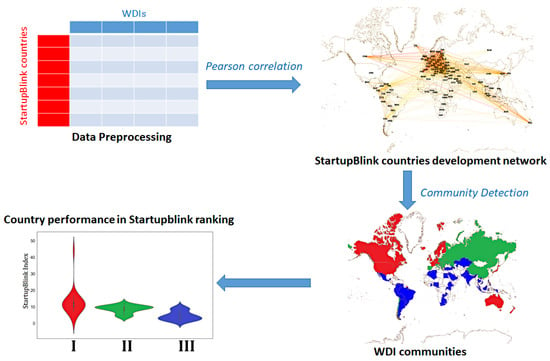
Figure 1.
Pipeline representation. First, data related to the StartupBlink countries were collected from the WDI database and preprocessed (top left); then, a similarity network was built, in which links between two countries were weighted by the Pearson correlation between their sets of WDIs, provided it was statistically significant (top right); finally, community detection was performed on the similarity network to detect homogeneous groups of countries (bottom right), which were used to reinterpret their achievements in the StartupBlink rankings (bottom left).
2.1. Ranking Innovation Ecosystems on a Global Scale: StartupBlink
Publicly available rankings about innovation ecosystems are an important and fairly recent instrument. StartupBlink, in particular, was one of the first rankings to be issued in 2016, and provides, nowadays, the most influential overview about the innovation ecosystems in the world [25], rating 100 world countries according to three main indicators:
- Quantity, determined not only by the number of startups in a country, but also by the presence of coworking spaces, accelerators (privately or publicly funded entities setting a fixed-term, cohort-based program including mentorship and educational components [49]), and startup events (pitch events in which startup founders present their ideas and services [50]).
- Quality, related to the impact of startups on their ecosystems. StartupBlink uses a variety of indicators to assess quality, such as startups’ customer base, number of monthly visits on websites, number of unicorns, number of global coworking brands and mass startup events.
- Business Environment, measuring, based on the World Bank Doing Business report [51], the ease of doing business in a given location, considering, e.g., technological infrastructures and bureaucracy.
We decided to consider the StartupBlink ranking referring to 2019, a pre-pandemic period, in order to avoid biasing effects on the ranking due to economic downturns triggered by the recent situation. The 2019 StartupBlink ranking, together with its component indexes, is reported in the Supplementary Material (Table S1). For simplicity, we will henceforth refer to the countries listed in this ranking as the StartupBlink countries.
2.2. Socio-Economic Factors Influencing Development of Countries: World Development Indicators
Network construction was based on the World Development Indicators (WDIs) database, “a compilation of relevant, high quality, and internationally comparable statistics about global development and the fight against poverty” [52], which collects yearly indicators starting, in the best case, from 1960, for 217 country’s economies (mostly belonging to the United Nations) and more than 40 economic or geographical country groups. Here, we will focus only on the 100 StartupBlink countries. The choice of basing our network on WDIs satisfies the need for a development representation that is as multidimensional as possible. The WDI database actually includes a wide variety of data: the indicators that will be used in this work are taken from the Environment, Economic Policy and Debt, Education, Financial Sector, Gender, Health, Infrastructure, Private Sector and Trade, Social Protection and Labor categories, which cover essentially all the aspects of the development of a country.
The bulk file that we used for this study was updated to 15th September 2021. The dataset records 1443 WDIs, but missing entries are present in a number that undergoes wide variations from one country to another. Data availability also changes with time, increasing, due to collection process improvements, in an overall monotonous way from 1960 to the 2005–2016 period (a maximum is reached in 2010), and dropping in the following years, due to the fact that some recent results are still unrecorded.
The choice to focus on 2019 indicators, motivated by the need to avoid pandemic biases, was also dictated by a tradeoff between recentness and data availability. Missing entries in 2019 were borrowed from 2018 data or, in case even the latter data are unavailable, from the 2017 dataset.
Then, 426 indicators, whose complete list is reported in the Supplementary Material (Table S2), were used to perform our analysis. Selection followed the criteria of data availability, consistency and information non-redundancy, comprising the following sequence of actions:
- Indicators with more than missing values were excluded.
- To mitigate the effect of outliers, indicator values exceeding the 99th percentile and below the 1st percentile were replaced by the reference percentiles.
- Each indicator was scaled in the interval in such a way that 0 corresponds to the minimum value and 1 to the maximum.
- To avoid redundancy, we calculated the Pearson correlation coefficient between all couples of indicators and identified the ones having a correlation value larger than . Then, for each of these couples, we selected the indicator having the smaller number of missing entries and excluded the other.
2.3. Building the StartupBlink Country Network
The 426 selected WDIs were employed to evaluate the pairwise Pearson correlations between countries. Then, we constructed a complex network constituted by 100 nodes, each representing a StartupBlink country. Pairs of nodes were connected by weighted edges, whose weight was determined by the pairwise Pearson correlation between the sets of WDIs associated to the corresponding countries. In particular, we retained those links whose Pearson correlation was statistically significant (at the significance level). We thus obtained a connected network of 100 nodes with 4782 weighted links. A geographical distributed version of the network is depicted in Figure 2.
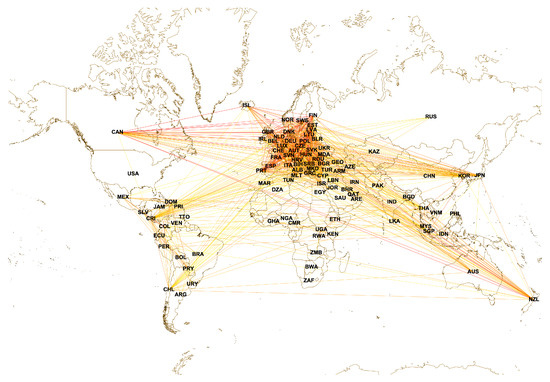
Figure 2.
Similarity network of StartupBlink countries based on the values of their WDIs. Link colors are related to their weight, in ascending order from yellow to red. Only edges whose weight is equal to or greater than are reported.
2.4. Unveiling Groups of Similar Countries
The process of community detection must consider the fact that both positive and negative edge weights are involved in the network. Therefore, we used algorithms that are suitable to handle signed weights [45], such as Spin Glass, based on concepts of statistical mechanics [53,54], and Leiden [55].
For both the considered algorithms, we performed a hierarchical community detection by recursive partitioning, following a procedure explored in Refs. [26,56,57]. In this multi-step process, we applied subsequent detection algorithms to find a subdivision of communities coming from the previous stage. The procedure stopped when an iteration condition, determined by the accordance between outputs of different runs of the algorithm, was no longer satisfied. The pipeline followed by each detection step was not entirely deterministic, thus providing, in general, different outputs when applied to the same network; however, when community detection is robust, the outcome should be as independent as possible from randomness. Moreover, the output of community detection also depends on the choice of the Spin Glass or Leiden algorithm parameters.
Accordingly, in order to choose the right parameters for the community detection algorithms and obtain consistent communities, we followed this criterion: we used one of the chosen algorithms to partition the network 100 times; if the same outcome occurred in at least of cases, that partition was accepted, and recursive partitioning proceeded to the next step; otherwise, the iteration stopped, and the partition found at the previous level was accepted as the final result. The method was performed with both community detection algorithms through an accurate exploration of the space of their parameters: the choice of parameters was determined by the request of output consistency and robustness with respect to parameter variations. In particular, the relevant parameters that were varied in the Spin Glass algorithm were the resolution and the cooling factor: we considered ranging in the interval , with a step, and cooling factor in with a step, besides the extreme values and . In the Leiden algorithm, we varied the resolution as well as the randomness . The resolution varied in the same range as for Spin Glass, while ranged in with a step, besides the extreme .
We analyzed the performance of the community detection algorithms upon varying parameters by monitoring the behaviour of three quantities:
- Percentage of agreement, computed, for a given set of parameters, as the ratio between the number of occurrences of the most common network partition and the total number of runs of the algorithm;
- Number of communities in the most common partition;
- the Inverse participation ratio (IPR) in the most common partition, defined, for a partition in K subsets of a network with N nodes, as
2.5. Benchmarking Community Detection against Clustering Methods
In the previous sections, we have described the data and the complex network methods we used to obtain groups of similar countries in an unsupervised way. Nonetheless, one might question the use of complex networks to model elements, such as countries in the StartupBlink ranking, represented by numerical features (WDIs) that do not describe proper interactions among them. In fact, clustering methods have been developed to find groups (or clusters) of similar objects in a set, representing data associated with each object as points in a multidimensional space. In order to show the advantage of the network model even with this kind of data, we applied different classical clustering algorithms, comparing their performances to those of the network methods based on community detection. We considered three of the most relevant algorithms in clustering problems: K-means, K-medoids and hierarchical clustering.
K-means is one of the most popular clustering algorithms and is widely used in both academic and industrial settings [58]. This algorithm can be seen as an optimization problem, in which the target is minimization, through an iterative process, of the sum of squared errors (SSE), determined by using the Euclidean distance among points:
where identifies the objects, k is the number of clusters, is the j-th cluster, is the data vector corresponding to the i-th object, is the centroid of the j-th cluster and denotes the Euclidean norm. It should be noted that K-means has two drawbacks:
- It is a stochastic algorithm, in which different runs generally provide different clustering results;
- The number of clusters, k, should be fixed a priori.
To tackle the first issue, we performed 100 different runs of K-means to check the statistical robustness of the minimization process. Concerning the second issue, the optimal number of clusters can be determined by considering the SSE and the mean Silhouette score [59] together. The latter is a measure of the clustering quality based on averaging over all objects the Silhouette score, defined for a given data vector as
where is the average distance between and all other points in the same cluster (cluster cohesion), while is the average distance between and all points in the nearest cluster (cluster separation). The optimal number of clusters should coincide with the elbow point of the SSE vs k curve [60] and, at the same time, with the maximum of the mean Silhouette score. If these two conditions are not satisfied together, one can conclude that K-means is not well suited for clustering the considered data.
The same reasoning on the clustering quality applies to K-medoids, an algorithm similar to K-means, in which actual data points, instead of centroids, are chosen as cluster centers. K-medoids can be used with arbitrary distances [61]; hence, we considered three common metrics to calculate SSE and mean Silhouette score: Euclidean, Cosine and Manhattan.
Hierarchical clustering algorithms take an alternative approach to group similar items [62], which entails the advantage of not needing to fix the number of clusters. In this work, we implemented an algorithm that starts with each data point considered as an individual cluster and iteratively merges the closest pairs of clusters until it ends up with a single cluster encompassing all data points. In order to avoid the effect of outliers and putting all points in clusters on a same ground, average linkage was applied: namely, cluster pairs were merged based on the minimum average distances between all group members in the two clusters. Additionally, in this case, we considered three metrics to calculate distances among clusters: Euclidean, Cosine and Manhattan. The described algorithm is deterministic and allows us to obtain dendrograms, which can help with the interpretation of the results. We remark that, since hierarchical clustering algorithms are not optimization problems, SSE and Silhouette are not reliable measures of the partition quality. Accordingly, we choose the IPR values at various levels of the dendrogram as a metric factor for each of the considered metrics.
2.6. Reinterpreting the Ranking: Resolution Ratio
As a quantifier of the connection between community membership of a country and the score it achieves in a StartupBlink ranking, we used the resolution ratio R, a quality factor that increases as the separation among index distributions related to different communities becomes larger [26]. The definition R takes into account the partition of a set elements …, to which values are assigned, in disjoint groups , each characterized by its cardinality .
One can associate with the full distribution an overall mean value and a variance . On the other hand, given the partition in groups , one can evaluate for each group the related mean and variance . The definition of R is based on the fact [63] that the overall variance can be viewes as composed of two positive contributions
Considering that is the weighted average (with weight ) of group variances, whereas is determined by the discrepancy between group means and the full distribution mean, the quantity
is an indicator of how much group distributions tend to separate.
In our case, groups coincide with network communities. When the distributions of a StartupBlink score corresponding to different communities have small overlap with each other, the resolution ratio tends to be much larger than 1, while it becomes very small if community distributions fully overlap. can be considered as an intermediate case, with mean values of neighboring community distributions separated by an amount that is close to the typical inter-community variation of the considered index. Therefore, we assume as a threshold value that separates cases in which reading country performances in the light of development communities is either meaningful or not.
3. Results
After the outline of the employed methods, we present in this section the relevant findings of our research. First, we show the results of partitioning the network of StartupBlink countries in communities. Then, the obtained subdivision is quantitatively compared with the well-established income-based country groupings employed by the World Bank. Finally, we reinterpret the performances of countries in the StartupBlink rankings (for both the global StartupBlink index and its three constituent indexes: quantity, quality and business) based on their community membership, provided the distribution of the corresponding index in communities satisfies .
3.1. WDI Country Communities
As described in Section 2.4, we use two different algorithms, exploring a wide range of the related parameter spaces, to obtain a hierarchical community detection. The robust partition of the StartupBlink countries’ WDI network found through this process consists of three communities that will be labeled henceforth as I, II, and III. The geographical distribution of countries in these communities is shown in Figure 3.
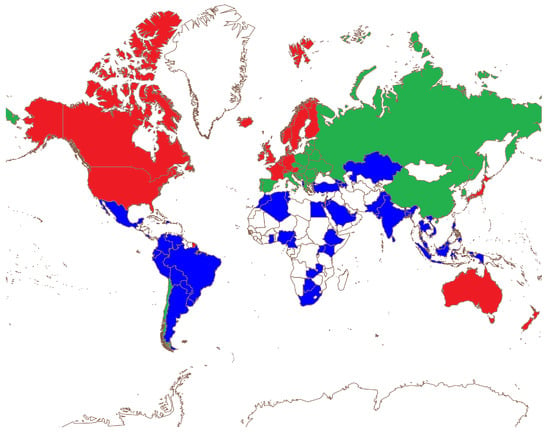
Figure 3.
StartupBlink network communities. Communities of StartupBlink countries determined from the similarity network based on WDI indicators. Community I (red) contains 22 countries; community II (green) contains 27 countries; community III (blue) contains 51 countries.
Both Spin Glass and Leiden algorithms stop after two iterations of the hierarchical pipeline described in the Section 2.4 and provide the same results in each step. In the first iteration, the algorithms return a network subdivision in two communities, comprising 49 and 51 countries, respectively. Then, in the second iteration, the first community splits in two sets, composed of 22 and 27 countries, while the second community, made of 51 nodes, is no longer divisible. Therefore, the final partition of the country network consists of three communities. Country membership to the three final communities is explicitly reported below, with countries identified according to their ISO-3166 alpha-3 code standard [64]:
- Community I (22 countries): USA, GBR, CAN, ISR, AUS, NLD, SWE, CHE, DEU, FRA, FIN, IRL, DNK, SGP, JPN, BEL, NZL, AUT, NOR, LUX, ISL, MLT;
- Community II (27 countries): ESP, EST, RUS, LTU, KOR, POL, CZE, ITA, CHN, PRT, CHL, UKR, BGR, SRB, ROU, HUN, GRC, LVA, SVN, SVK, HRV, BLR, MKD, MDA, CYP, PRI, BIH;
- Community III (51 countries): IND, MEX, THA, COL, BRA, ARE, IDN, TUR, ARG, MYS, ZAF, KEN, PHL, NGA, PER, EGY, PAK, GEO, ARM, RWA, MAR, AZE, KAZ, URY, VNM, JOR, TUN, GHA, ECU, LKA, DOM, SAU, UGA, LBN, IRN, CMR, ALB, CRI, BGD, JAM, BWA, SLV, ZMB, VEN, TTO, BHR, PRY, QAT, BOL, DZA, ETH.
Interestingly, as one can also observe from Figure 3, many states that are members of the same community share geographical proximity in addition to economic proximity. Comparison with the partitions determined by the the World Bank income groups [47] indicates, as reported in Figure 4, that communities are ordered in a descending manner from I to III in terms of income: therefore, we will use henceforth the expression wealth communities when referring to them.

Figure 4.
Composition of StartupBlink network communities in terms of World Bank income groups, highlighting an emerging hierarchy, in descending order from I to III, in terms of income.
3.2. Clustering Results for StartupBlink Countries
In the previous subsection, we partitioned the set of StartupBlink countries using a community detection algorithm based on a complex network model. We will now observe how the performance of classical clustering algorithms is not satisfying, thus making network methods necessary. In Figure 5, we show the SSE and mean Silhouette score of the K-means algorithm as a function of the number of clusters. There, one can observe the absence of an elbow-point in the SSE plot. Moreover, the maximum mean Silhouette value is obtained for , where SSE also reaches its maximum. As stated in Section 2.5, this implies that K-means is not well suited for an efficient partition of StartupBlink countries. In Figure 6, one can observe the same inconsistency in the case of SSE and mean Silhouette for K-medoids, with the Euclidean, Cosine and Manhattan metrics. Therefore, even K-medoids algorithms should be discarded when attempting to partition StartupBlink countries.
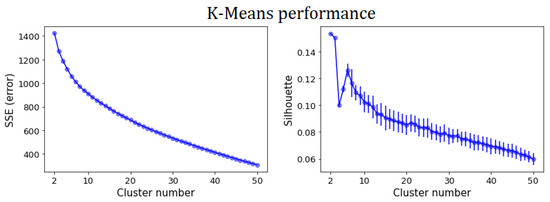
Figure 5.
SSE (left panel) and mean Silhouette value (right panel) of K-means clustering for StartupBlink countries at different fixed numbers of clusters. Error bars are determined by the variance of the considered quantities over 100 runs of the algorithm. The absence of an elbow-point in the SSE plot, along with the maximum mean Silhouette value obtained for , where SSE also reaches its maximum, implies that K-means is not well suited for an efficient partition of StartupBlink countries.
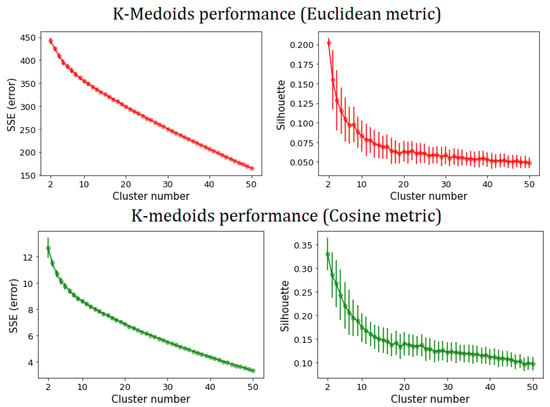
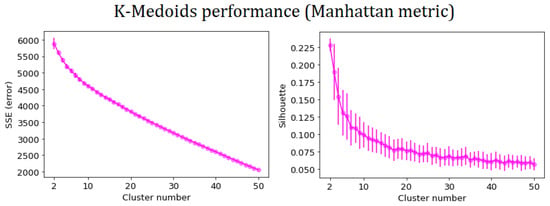
Figure 6.
SSE (panels in the left column) and mean Silhouette value (panels in the right column) of K-medoids clustering for StartupBlink countries, at different fixed numbers of clusters, with three kinds of metric. Error bars are determined by the variance of the considered quantities over 100 runs of the algorithm. The absence of an elbow-point in the SSE plots, along with the maximum mean Silhouette values obtained for , where SSE also reaches its maximum, implies that K-medoids algorithms, with the considered metrics, are not well suited for an efficient partition of StartupBlink countries.
Concerning hierarchical clustering algorithms, Figure 7 shows the obtained dendrograms. In order to measure the quality of clustering, as explained in Section 2.5, we consider the IPR values relative to the various partitions returned by the algorithms. In Table 1, we report the IPR values corresponding to a number of clusters going from to . There, we can notice a discrepancy, at all levels, between the number of groups and the IPR, indicating the presence of clusters with a very small number of elements. Actually, one can observe the tendency to create highly uneven partitions already in the dendrograms of Figure 7. On the other hand, such a fragmentation can be avoided in the network community detection process, as demonstrated both by the final partition reported in Section 3.1, and by the detailed results of the community detection algorithm (see figures in the Appendix A), where at each step, the optimal communities are characterized by IPR close to the partition cardinality.
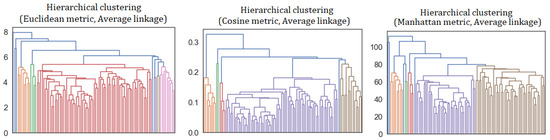
Figure 7.
Hierarchical clustering dendrograms, obtained using the Euclidean (left panel), Cosine (center) and Manhattan (right) metrics and the average linkage method. The vertical axes report the values of the metric. From these dendrograms, one can observe the tendency of the considered clustering algorithms to create highly uneven partitions at any cluster number.

Table 1.
IPR values of the partitions returned by hierarchical clustering algorithms, based on the Euclidean, Cosine and Manhattan metrics, at different cluster numbers k.
3.3. Rethinking StartupBlink Ranking in the Framework of Wealth Communities
The partition in communities constitutes both a way to group countries in terms of their development similarities and a tool that allows to reinterpret their achievements in the StartupBlink rankings. Based on the assumption that the wealth level inside a given community is essentially homogeneous, it is reasonable to expect a tendency of ranking values referred to the same community to cluster together and separate from the values related to other communities. With this picture in mind, one could point out, on one hand, those countries whose performances go beyond the expectations determined by community membership and, on the other hand, the ones that can potentially reach their community peers in the ranking, provided they increase their efforts towards the objective.
However, such an assumption can be considered valid only after being checked a posteriori. Figure 8 represents the distribution of the StartupBlink indexes using violin plots, with the vertical coordinates corresponding to the considered index values, while the horizontal coordinate is determined by country community membership. It can be observed that community distributions follow the ordering that one would expect from the wealth hierarchy, showing a partial overlap. Therefore, information provided by a community-based country performance evaluation can be considered reliable.

Figure 8.
Violin plots of the distributions in the three wealth communities of the overall StartupBlink index (top left panel), and of the specific business (top right), quantity (bottom left) and quality (bottom right) indexes. The plots related to the overall and the business index show a tendency of community distributions to separate from each other. This tendency, more pronounced in the overall case, is confirmed by the analysis of the resolution ratio.
We use the resolution ratio, defined in Equations (4)–(6), to quantify how much country performances in the considered rankings and community membership are related. We consider the global StartupBlink index, as well as its three components: the resolution ratio values of these indexes are reported in Table 2.
Table 2.
Resolution ratio values for the global StartupBlink index and its constituents. In bold, R values greater than 1.
Resolution ratios relative to the StartupBlink global index and business index are both above 1. This result means that wealth communities are well resolved with respect to both the index measuring the ease of doing business in a country (business index) and the indicator quantifying the global value of its innovation ecosystem (StartupBlink index).
Since for two indexes, we can make reasonable community-based predictions on country performances in the two related rankings and also critically evaluate those performances that deviate from the expected outcome. We focus the attention on countries whose score in a ranking is either above or below the expectations provided by the score of other countries, both in the same community and in other communities. In particular, we define top-of-the-class countries in a given ranking those whose score falls, at the same time
- Beyond the 75th percentile of the community to which they belong;
- Beyond the 25th percentile of at least one higher-wealth community.
An analogous criterion is applied to define room-for-improvement states, as those whose score is placed both
- Under the 25th percentile of the community to which they belong;
- Under the 75th percentile of at least one lower-wealth community.
We can consider top-of-the-class countries as reference cases that can be taken as models by states similar in terms of development that aim at improving their status in the considered ranking. The mismatch of their performances and the community-based expectation can be further characterized by assigning a symbol “↑” for each 25th percentile of a higher-wealth community that is overcome by its score. On the other hand, room-for-improvement countries are the ones that, given their wealth level, can potentially achieve better results in the ranking, possibly closing the gap with countries in similar development conditions. In this case, we provide a further characterization of performance by marking a country with a symbol “*” each time the score lies under the 75th percentile of one lower-wealth community. Countries having either the highest scores in community I or the lowest scores in III are not covered by the previous definitions, since it is not possible to compare their results with more or less developed communities, respectively. We thus introduce two specific categories to classify these remarkable performances. Benchmark countries are those belonging to community I, characterized by a score beyond the 75th percentile of that community: hence, they can be viewed by the rest of the world as best-practice. Trailing countries are those belonging to III, with their scores smaller than the 25th community percentile: trailing states could require specific support to improve their political and economic practices in boosting their innovation ecosystems. We report below the complete evaluation of country performances, as measured by StartupBlink index and business index, according to the aforementioned criteria:
StartupBlink index
- Community I. Benchmark: USA, GBR, CAN, ISR, AUS, NLD; Room for improvement: NZL (*), AUT (*), NOR (*), LUX (*), ISL (*), MLT (*).
- Community II. Top-of-the-class: ESP (↑), EST (↑), RUS (↑), LTU (↑), KOR (↑), POL (↑), CZE (↑); Room for improvement: BLR (*), MKD (*), MDA (*), CYP (*), PRI (*), BIH (*).
- Community III. Top-of-the-class: IND (↑), MEX (↑), THA (↑), COL (↑), BRA (↑), ARE (↑), IDN (↑), TUR (↑), ARG (↑), MYS (↑); Trailing: BGD, JAM, BWA, SLV, ZMB, VEN, TTO, BHR, PRY, QAT, BOL, DZA, ETH.
Business index
- Community I. Benchmark: USA, GBR, SWE, FIN, DNK, NZL; Room for improvement: ISR (*), BEL(*), NOR(*), LUX(*), ISL(*), MLT(*).
- Community II. Top-of-the-class: ESP (↑), EST (↑), LTU (↑), KOR (↑), POL (↑), CZE (↑), PRT (↑); Room for improvement: MKD (*), MDA (*), CYP (*), PRI (*), BIH (*).
- Community III. Top-of-the-class: IND (↑), MEX (↑), THA (↑), COL (↑), BRA (↑), ARE (↑), IDN (↑), TUR (↑), ARG (↑), MYS (↑); Trailing: BGD, JAM, BWA, SLV, ZMB, VEN, TTO, BHR, PRY, QAT, BOL, DZA, ETH.
4. Discussion
The described approach to evaluate country performances in the StartupBlink rankings (one for each StartupBlink index) is based on community detection, an unsupervised and data-driven method that provides, in our case, stable and reasonable results, not biased by human judgment. Only objective socio-economic factors (WDIs) are used to set up the country network and determine the corresponding wealth communities. In particular, since WDIs cover multiple aspects of the social and economic performance of countries, it is not surprising that the network communities are characterized by different wealth classes but by an homogeneous wealth level therein. This result enables us to relate the wealth level of a country with the quality of its innovation ecosystem and, above all, establish which countries need specific support or can be considered as examples of best practices in the technological innovation policies. The reliability of these results also rests on the robustness of the community detection, as both Spin Glass and Leiden algorithms give the same results. We also tested classical clustering algorithms to partition the set of StartupBlink countries, finding that they are not suitable to this task for different reasons, which corroborates the need for a network model and the related tools. The use of network communities as a tool to evaluate country performances is validated by a quantitative control to confirm the existence of a relation between community membership and expected rating: the resolution ratio R quantifies the tendency of the ranked index distributions related to different network communities to be separated in a relevant way. The resolution ratio associated to the global StartupBlink index shows a good separation between communities, which allows us to compare a country’s performance with the expectation based on its wealth conditions. Among the constituent indexes of StartupBlink, the only one associated with a value is Business Environment, which measures the ease of conducting business in the considered territory. This result is related to the presence, among the WDIs, of indicators associated with bureaucracy, bank loans to the private sector and other aspects affecting the efficiency of firms. Instead, the quantity index, related to the number of assets in the innovation ecosystem, and the quality index, which evaluates the impact of startups, seem not to be affected in a significant way by a territorial drift effect. India and Brazil, belonging to the least-wealthy community III, exhibit relevant discrepancies between the value of these indexes and general wealth conditions: India’s quantity index is larger than Canada, close to that of the United Kingdom, and larger than those of all states in Community II, indicating a very active innovation scene; Brazil, instead, in addition to a high quantity index, is also characterized by a quality index above all the ones in Community III and all but the highest 5 in Community II. The positive performance of India and Brazil with respect to the expectations is confirmed by the fact that they are labelled as top-of-the-class in both the global and the business index.
Deepening the analysis of the outcomes, it can be seen that, unsurprisingly, the United States are a benchmark country both from a global and an ease-of-business point of view. In fact, conditions offered by the United States startup ecosystem to both entrepreneurs and investors are excellent. The United States ecosystem mostly operates in the New York and San Francisco areas, with the technological center of the Silicon Valley representing a privileged choice to create products and initiatives that are appealing to the global market [65]. Much of the United Kingdom’s strength in the global startup ecosystem comes from its startup hub, London. In fact, in recent years, London has become the most successful startup ecosystem in Europe, producing the largest output of startups in the European Union and becoming a first-choice location for fast-growing US startups to establish their European headquarters [66].
Furthermore, it is worth noticing the role of Israel, which is, at the same time, a benchmark country for the global StartupBlink index and a room-for-improvement country for the business index. This two-fold outcome indicates that, although Israel plays a leading role among the world innovation ecosystems, its practices in boosting the startup environment should be improved. The apparent contradiction is related to the hierarchical nature of the Israel startup system, having just a single innovation hub in Tel Aviv, while the rest of the territory does not reach comparable performances [67]. An independent confirmation of our results is given by the fact that, since 2019, Israel has been committed to improving the quality of its political and social actions to increase the number of high-impact startups [68].
The approach developed in this work, based on a robust and data-driven procedure, can represent the quantitative basis to develop new methods for highlighting problematic scenarios and establish suitable policies in the innovation ecosystem. As a further improvement, we shall consider the possibility of using the proposed methodology to analyze the innovation ecosystems at the city level. Accordingly, we would be able, for each country, to identify the most effective local policies and territorial characteristics able to attract startups and investments, with an important impact on the local economy.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/app12189069/s1.
Author Contributions
Conceptualization, L.B.; methodology, F.D.N., A.M. and L.B.; software, F.D.N. and L.B.; validation, F.D.N., A.M., G.A., L.B., R.C., E.P., S.T., F.Z., N.A. and R.B.; investigation, F.D.N.; data curation, A.M.; writing—original draft preparation, F.D.N., L.B. and N.A.; writing—review and editing, F.D.N., A.M., G.A., L.B., R.C., E.P., S.T., F.Z., N.A. and R.B.; visualization, F.D.N. and A.M.; supervision, N.A. and R.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are either publicly available on databases cited in the bibliography, or available from the corresponding author on request.
Acknowledgments
Code development/testing and results were obtained on the IT resources hosted at ReCaS data center. ReCaS is a project financed by the italian MIUR (PONa3_00052, Avviso 254/Ric.).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| WDI(s) | World Development Indicator(s) |
| IPR | Inverse participation ratio |
| SSE | Sum of squared errors |
Appendix A
The heatmaps in Figure A1, Figure A2, Figure A3, Figure A4, Figure A5, Figure A6, Figure A7, Figure A8, Figure A9 and Figure A10 represent the performances of hierarchical Spin Glass and Leiden community detection algorithms at the different steps required to identify the most stable and reliable partition.
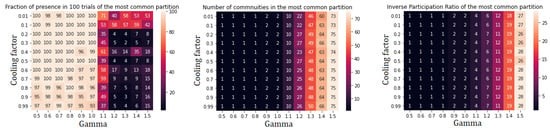
Figure A1.
Performance indicators for Spin Glass algorithm applied to the whole StartupBlink network. Two communities are found: community 0 (49 nodes) and community III (51 nodes).
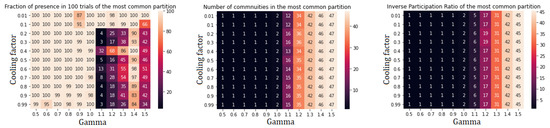
Figure A2.
Performance indicators for Spin Glass algorithm applied to community 0. Two subcommunities are found: community I (22 nodes) and community II (27 nodes).
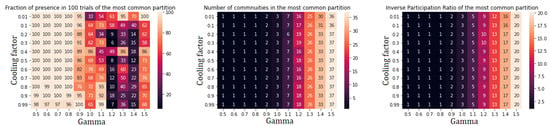
Figure A3.
Performance indicators for Spin Glass algorithm applied to community III. There is no further subdivision.
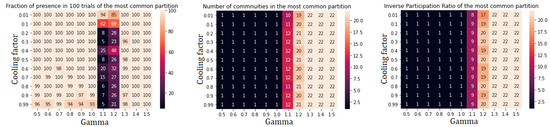
Figure A4.
Performance indicators for Spin Glass algorithm applied to community I. There is no further subdivision.
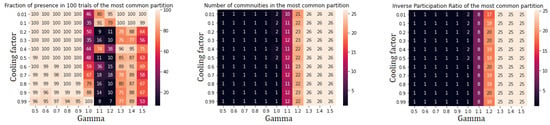
Figure A5.
Performance indicators for Spin Glass algorithm applied to community II. There is no further subdivision.
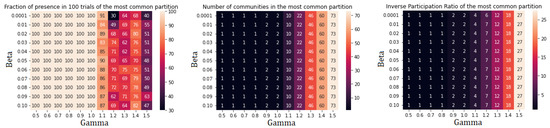
Figure A6.
Performance indicators for Leiden algorithm applied to the whole StartupBlink network. Two communities are found: community 0 (49 nodes) and community III (51 nodes).
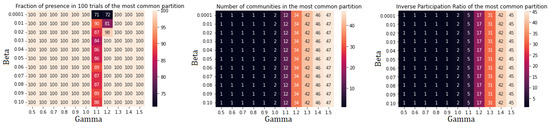
Figure A7.
Performance indicators for Leiden algorithm applied to community 0. Two subcommunities are found: community I (22 nodes) and community II (27 nodes).
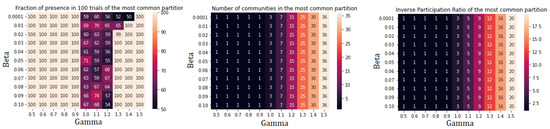
Figure A8.
Performance indicators for Leiden algorithm applied to community III. There is no further subdivision.
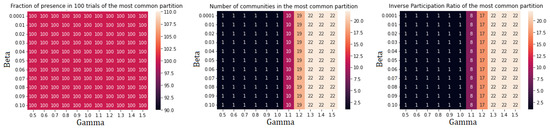
Figure A9.
Performance indicators for Leiden algorithm applied to community I. There is no further subdivision.
Figure A10.
Performance indicators for Leiden algorithm applied to community II. There is no further subdivision.
References
- Malito, D.V.; Umbach, G.; Bhuta, N. The Palgrave Handbook of Indicators in Global Governance; Springer: New York, NY, USA, 2018. [Google Scholar]
- Bukovansky, M.; Cooley, A.; Snyder, J. Ranking the World: Grading States as a Tool of Global Governance; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Muller, J.Z. The Tyranny of Metrics; Princeton University Press: Princeton, NJ, USA, 2019. [Google Scholar]
- Érdi, P. Ranking: The Unwritten Rules of the Social Game We All Play; Oxford University Press: Oxford, UK, 2019. [Google Scholar]
- Origgi, G. Reputation: What It Is and Why It Matters; Princeton University Press: Princeton, NJ, USA, 2019. [Google Scholar]
- Clark, J. Uneven Innovation: The Work of Smart Cities; Columbia University Press: New York, NY, USA, 2020. [Google Scholar]
- Feld, B. Startup Communities: Building an Entrepreneurial Ecosystem in Your City; John Wiley & Sons: Hoboke, NJ, USA, 2020. [Google Scholar]
- Fiorentino, S. Startup cities: Why only a few cities dominate the global startup scene and what the rest should do about it. Reg. Stud. 2020, 54, 280–281. [Google Scholar] [CrossRef]
- Gerli, F.; Calderini, M.; Chiodo, V. An ecosystemic model for the technological development of social entrepreneurship: Exploring clusters of social innovation. Eur. Plan. Stud. 2021, 1–23. [Google Scholar] [CrossRef]
- Cao, Z.; Shi, X. A systematic literature review of entrepreneurial ecosystems in advanced and emerging economies. Small Bus. Econ. 2021, 57, 75–110. [Google Scholar] [CrossRef]
- Amoroso, N.; Bellantuono, L.; Monaco, A.; De Nicolò, F.; Somma, E.; Bellotti, R. Economic Interplay Forecasting Business Success. Complexity 2021, 2021, 8861267. [Google Scholar] [CrossRef]
- Crunchbase: Discover Innovative Companies and the People behind Them. Available online: https://www.crunchbase.com (accessed on 2 September 2022).
- Dealroom.co: Identify Promising Companies before Everyone Else. Available online: http://www.dealroom.co (accessed on 2 September 2022).
- Pitchbook: Venture Capital, Private Equity and M&A Database. Available online: http://www.pitchbook.com. (accessed on 2 September 2022).
- StartupBlink Startup Ecosystem Rankings. 2017. Available online: https://www.startupblink.com/startups (accessed on 2 September 2022).
- StartupGenome Global Startup Ecosystem Report 2016. Available online: https://www.startupgenome.com/all-reports (accessed on 2 September 2022).
- Langville, A.N.; Meyer, C.D. Who’s #1?: The Science of Rating and Ranking; Princeton University Press: Princeton, NJ, USA, 2012. [Google Scholar]
- Kelley, J.G.; Simmons, B.A. The Power of Global Performance Indicators; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Esposito, E.; Stark, D. What’s observed in a rating? Rankings as orientation in the face of uncertainty. Theory Cult. Soc. 2019, 36, 3–26. [Google Scholar] [CrossRef]
- Kuc-Czarnecka, M.; Lo Piano, S.; Saltelli, A. Quantitative storytelling in the making of a composite indicator. Soc. Indic. Res. 2020, 149, 775–802. [Google Scholar] [CrossRef]
- Verma, A.; Angelini, O.; Di Matteo, T. A new set of cluster driven composite development indicators. EPJ Data Sci. 2020, 9, 8. [Google Scholar] [CrossRef]
- Høyland, B.; Moene, K.; Willumsen, F. The tyranny of international index rankings. J. Dev. Econ. 2012, 97, 1–14. [Google Scholar] [CrossRef]
- Tacchella, A.; Cristelli, M.; Caldarelli, G.; Gabrielli, A.; Pietronero, L. A new metrics for countries’ fitness and products’ complexity. Sci. Rep. 2012, 2, 723. [Google Scholar] [CrossRef]
- Hidalgo, C.A.; Klinger, B.; Barabási, A.L.; Hausmann, R. The product space conditions the development of nations. Science 2007, 317, 482–487. [Google Scholar] [CrossRef] [Green Version]
- Makai, A.L. Startup Ecosystems Rankings. Hung. Stat. Rev. 2021, 4, 70–94. [Google Scholar] [CrossRef]
- Bellantuono, L.; Monaco, A.; Tangaro, S.; Amoroso, N.; Aquaro, V.; Bellotti, R. An equity-oriented rethink of global rankings with complex networks mapping development. Sci. Rep. 2020, 10, 18046. [Google Scholar] [CrossRef] [PubMed]
- Newman, M. Networks; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Battiston, S.; Puliga, M.; Kaushik, R.; Tasca, P.; Caldarelli, G. DebtRank: Too Central to Fail? Financial Networks, the FED and Systemic Risk. Sci. Rep. 2012, 2, 541. [Google Scholar] [CrossRef] [PubMed]
- Bardoscia, M.; Battiston, S.; Caccioli, F.; Caldarelli, G. Pathways towards instability in financial networks. Nat. Commun. 2017, 8, 14416. [Google Scholar] [CrossRef] [PubMed]
- Bardoscia, M.; Barucca, P.; Battiston, S.; Caccioli, F.; Cimini, G.; Garlaschelli, D.; Saracco, F.; Squartini, T.; Caldarelli, G. The physics of financial networks. Nat. Rev. Phys. 2021, 3, 490–507. [Google Scholar] [CrossRef]
- Sporns, O. The human connectome: A complex network. Ann. N. Y. Acad. Sci. 2011, 1224, 109–125. [Google Scholar] [CrossRef]
- Bellantuono, L.; Marzano, L.; La Rocca, M.; Duncan, D.; Lombardi, A.; Maggipinto, T.; Monaco, A.; Tangaro, S.; Amoroso, N.; Bellotti, R. Predicting brain age with complex networks: From adolescence to adulthood. NeuroImage 2021, 225, 117458. [Google Scholar] [CrossRef]
- Amoroso, N.; La Rocca, M.; Bellantuono, L.; Diacono, D.; Fanizzi, A.; Lella, E.; Lombardi, A.; Maggipinto, T.; Monaco, A.; Tangaro, S.; et al. Deep learning and multiplex networks for accurate modeling of brain age. Front. Aging Neurosci. 2019, 11, 115. [Google Scholar] [CrossRef]
- Amoroso, N.; La Rocca, M.; Bruno, S.; Maggipinto, T.; Monaco, A.; Bellotti, R.; Tangaro, S. Multiplex networks for early diagnosis of Alzheimer’s disease. Front. Aging Neurosci. 2018, 10, 365. [Google Scholar] [CrossRef]
- Monaco, A.; Amoroso, N.; Bellantuono, L.; Lella, E.; Lombardi, A.; Monda, A.; Tateo, A.; Bellotti, R.; Tangaro, S. Shannon entropy approach reveals relevant genes in Alzheimer’s disease. PLoS ONE 2019, 14, e0226190. [Google Scholar] [CrossRef]
- Monaco, A.; Pantaleo, E.; Amoroso, N.; Bellantuono, L.; Lombardi, A.; Tateo, A.; Tangaro, S.; Bellotti, R. Identifying potential gene biomarkers for Parkinson’s disease through an information entropy based approach. Phys. Biol. 2020, 18, 016003. [Google Scholar] [CrossRef] [PubMed]
- Bellantuono, L.; Monaco, A.; Amoroso, N.; Aquaro, V.; Lombardi, A.; Tangaro, S.; Bellotti, R. Sustainable development goals: Conceptualization, communication and achievement synergies in a complex network framework. Appl. Netw. Sci. 2022, 7, 14. [Google Scholar] [CrossRef] [PubMed]
- Bianconi, G. Multilayer Networks: Structure and Function; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Amoroso, N.; Bellantuono, L.; Pascazio, S.; Lombardi, A.; Monaco, A.; Tangaro, S.; Bellotti, R. Potential energy of complex networks: A quantum mechanical perspective. Sci. Rep. 2020, 10, 18387. [Google Scholar] [CrossRef] [PubMed]
- Amoroso, N.; Bellantuono, L.; Pascazio, S.; Monaco, A.; Bellotti, R. Characterization of real-world networks through quantum potentials. PLoS ONE 2021, 16, e0254384. [Google Scholar]
- Criado, R.; García, E.; Pedroche, F.; Romance, M. A new method for comparing rankings through complex networks: Model and analysis of competitiveness of major European soccer leagues. Chaos 2013, 23, 043114. [Google Scholar] [CrossRef]
- Tuesta, E.F.; Bolaños-Pizarro, M.; Neves, D.P.; Fernández, G.; Axel-Berg, J. Complex networks for benchmarking in global universities rankings. Scientometrics 2020, 125, 405–425. [Google Scholar] [CrossRef]
- Bellantuono, L.; Monaco, A.; Amoroso, N.; Aquaro, V.; Bardoscia, M.; Demarinis Loiotile, A.; Lombardi, A.; Tangaro, S.; Bellotti, R. Territorial bias in university rankings: A complex network approach. Sci. Rep. 2022, 12, 4995. [Google Scholar] [CrossRef]
- Iñiguez, G.; Pineda, C.; Gershenson, C.; Barabási, A.L. Dynamics of rankings. Nat. Commun. 2022, 13, 1–7. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Newman, M.E. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef]
- How does the World Bank Classify Countries? Available online: https://datahelpdesk.worldbank.org/knowledgebase/articles/378834-how-does-the-world-bank-classify-countries.html (accessed on 2 September 2022).
- United Nations Development Policy Committee. Report on the 18th Session: The Role of Country Groupings for Development; United Nations: New York, NY, USA, 2014; pp. 24–27. [Google Scholar]
- Katila, R.; Chen, E.L.; Piezunka, H. All the right moves: How entrepreneurial firms compete effectively. Strateg. Entrep. J. 2012, 6, 116–132. [Google Scholar] [CrossRef]
- Cohen, S. What do accelerators do? Insights from incubators and angels. Innov. Technol. Gov. Glob. 2013, 8, 19–25. [Google Scholar] [CrossRef]
- Doing Business Report. 2019. Available online: https://archive.doingbusiness.org/ (accessed on 2 September 2022).
- World Development Indicators—Databank. Available online: https://databank.worldbank.org/source/world-development-indicators (accessed on 2 September 2022).
- Traag, V.A.; Bruggeman, J. Community detection in networks with positive and negative links. Phys. Rev. E 2009, 80, 036115. [Google Scholar] [CrossRef] [PubMed]
- Reichardt, J.; Bornholdt, S. Statistical mechanics of community detection. Phys. Rev. E 2006, 74, 016110. [Google Scholar] [CrossRef]
- Traag, V.A.; Waltman, L.; Van Eck, N.J. From Louvain to Leiden: Guaranteeing well-connected communities. Sci. Rep. 2019, 9, 5233. [Google Scholar] [CrossRef]
- Palla, G.; Tibély, G.; Mones, E.; Pollner, P.; Vicsek, T. Hierarchical networks of scientific journals. Palgrave Commun. 2015, 1, 15016. [Google Scholar] [CrossRef]
- Arenas, A.; Danon, L.; Diaz-Guilera, A.; Gleiser, P.M.; Guimera, R. Community analysis in social networks. Eur. Phys. J. B 2004, 38, 373–380. [Google Scholar] [CrossRef]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means algorithm: A comprehensive survey and performance evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Shahapure, K.R.; Charles, N. Cluster quality analysis using silhouette score. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, Australia, 6–9 October 2020; pp. 747–748. [Google Scholar]
- Nainggolan, R.; Perangin-angin, R.; Simarmata, E.; Tarigan, A.F. Improved the performance of the k-means cluster using the sum of squared error (SSE) optimized by using the Elbow method. J. Phys. Conf. Ser. 2019, 1361, 012015. [Google Scholar] [CrossRef]
- Budiaji, W.; Leisch, F. Simple k-medoids partitioning algorithm for mixed variable data. Algorithms 2019, 12, 177. [Google Scholar] [CrossRef]
- Roux, M. A comparative study of divisive and agglomerative hierarchical clustering algorithms. J. Classif. 2018, 35, 345–366. [Google Scholar] [CrossRef] [Green Version]
- Hoffmeister, O. Development status as a measure of development. Stat. J. IAOS 2020, 36, 1095–1128. [Google Scholar] [CrossRef]
- The International Standard for Country Codes and Codes for Their Subdivisions—ISO 3166 Country Codes. Available online: https://www.iso.org/iso-3166-country-codes.html (accessed on 2 September 2022).
- Geibel, R.C.; Manickam, M. Comparison of selected startup ecosystems in Germany and in the USA. Explorative analysis of the startup environments. GSTF J. Bus. Rev. 2016, 4, 66–71. [Google Scholar]
- del Palacio, I.; Chapman, D. United Kingdom: London’s tech startup boom. In Global Clusters of Innovation; Edward Elgar Publishing: Chelthenam, UK, 2014. [Google Scholar]
- StartupBlink Startup Ecosystem Rankings. 2019. Available online: https://www.startupblink.com/startups (accessed on 2 September 2022).
- Zahra, S.A.; Hashai, N. The effect of MNEs’ technology startup acquisitions on small open economies’ entrepreneurial ecosystems. J. Int. Bus. Policy 2022, 1–19. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).