


Enhancing Channelized Feature Interpretability Using Deep Learning Predictive Modeling


Abstract
:1. Introduction
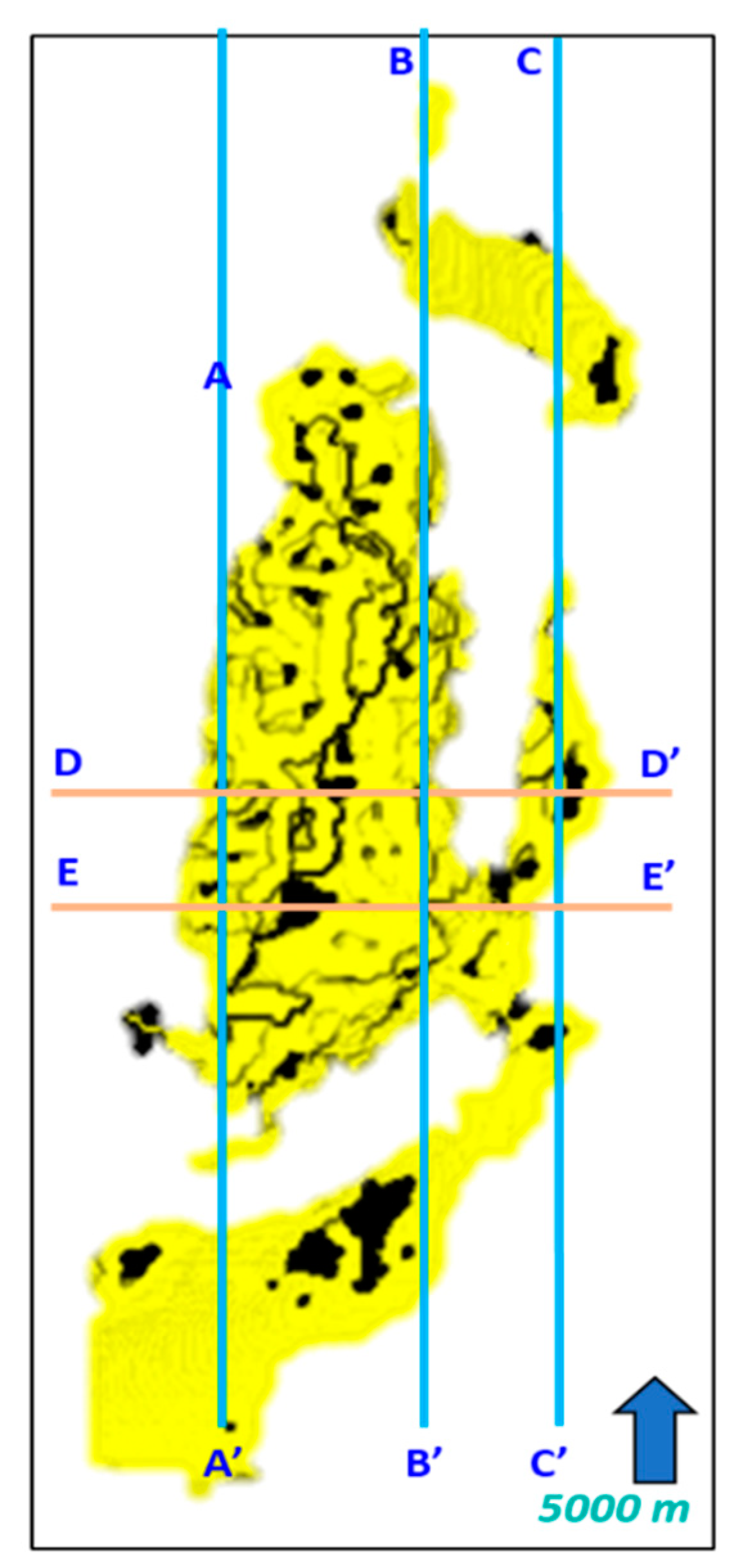
1.1. SEG Advanced Modeling (SEAM) Dataset
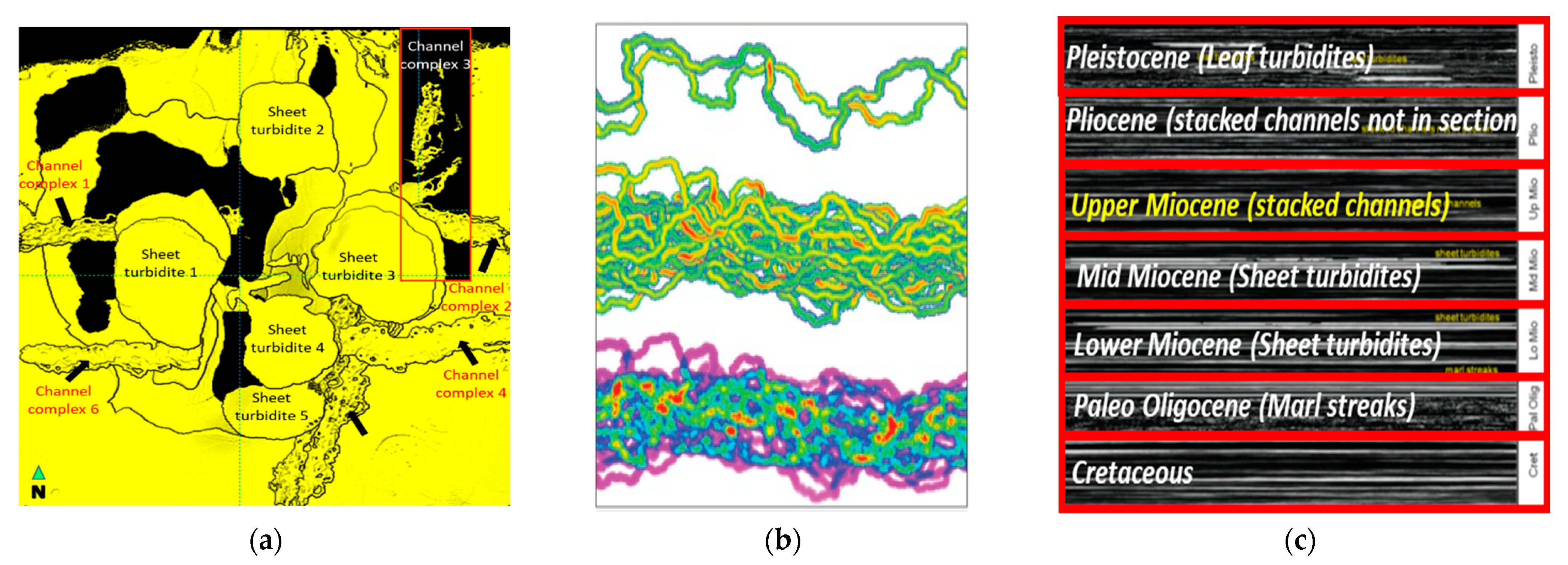
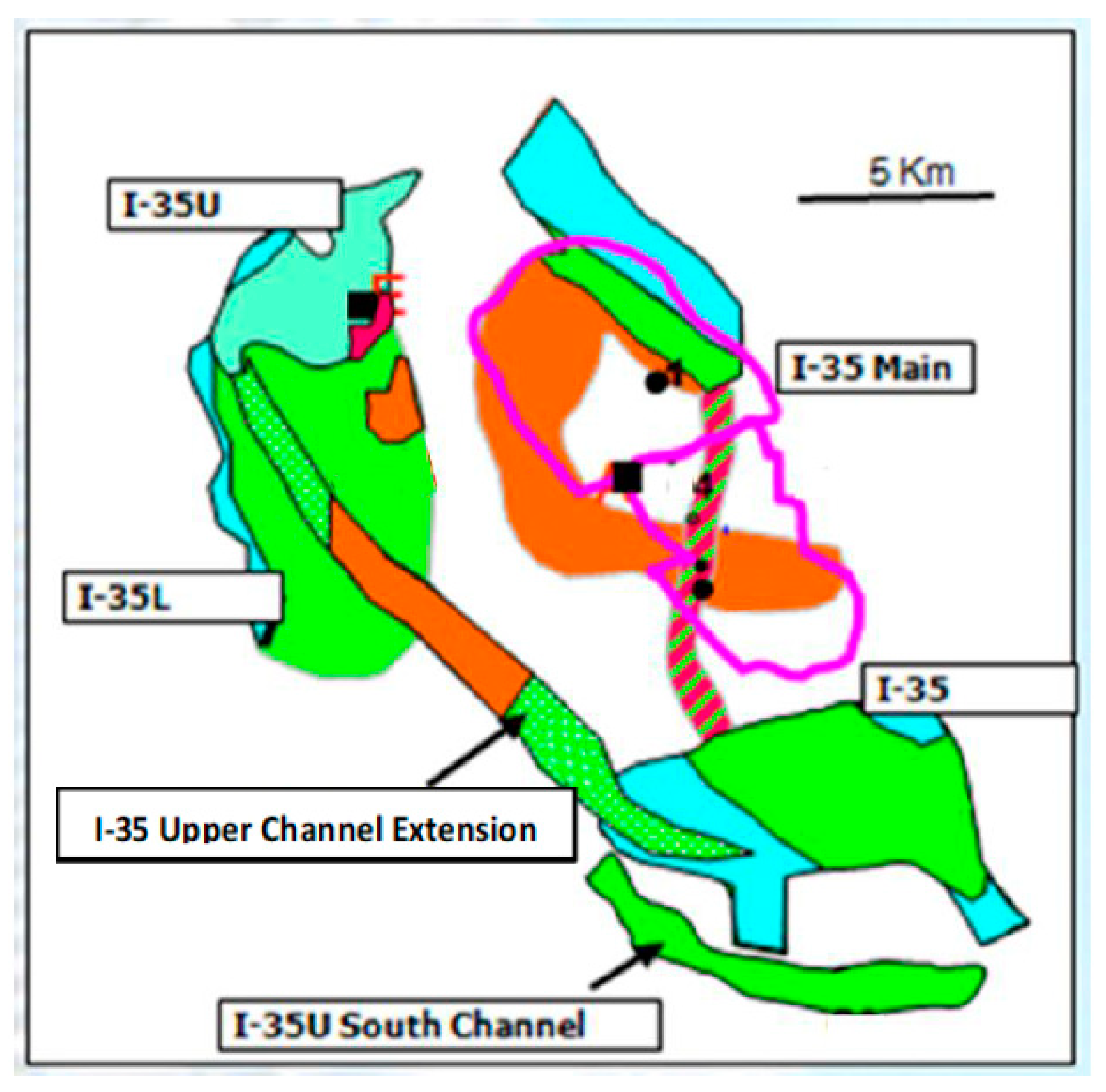
1.2. Geological Settings of A Field
1.3. Overview of Neural Network-Based Technology
1.4. Application of Neural Network in Geological Feature Identification
2. Methodology
- (a)
- We extract sixteen types of seismic attributes (Figure 4) and normalize the dataset into Gaussian scale during Exploratory Data Analysis (EDA).
- (b)
- Preparing the label data. We use two ground truth scenarios to fit into the requirements of the data availability from an expert’s perspectives.
2.1. Blob-Based Method
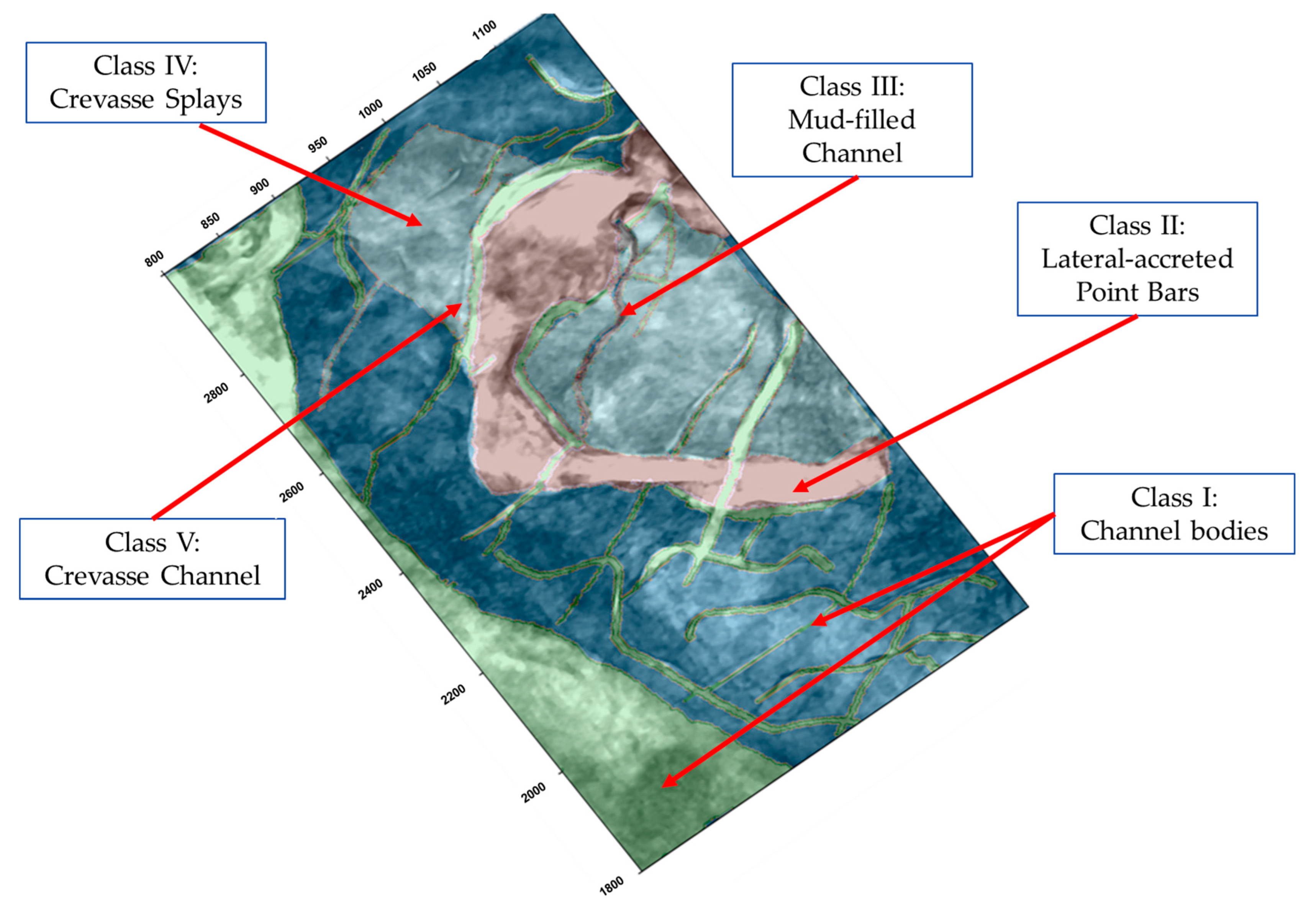
2.2. Python-Based Labeling Tool
- (c)
- We define the network architectures using Pytorch, an open-source machine learning framework. The major process that needs to be highlighted in a deep learning-based project is the training stage; hence, we choose a varied selection of loss functions:
- (d)
- The final outcome will be automated into binary or multi-facies geobodies and integrated with another dataset.
3. Results
3.1. Applied Network Architecture
- Contraction path (also known as encoder with four convolutional layers to extract important features from the input image.
- Bottleneck (which acts as a bridge when propagating input from encoder), and
- Expansion path (known as decoder).
3.2. Imbalanced Facies Classes during Training Stage
3.3. Data Augmentation
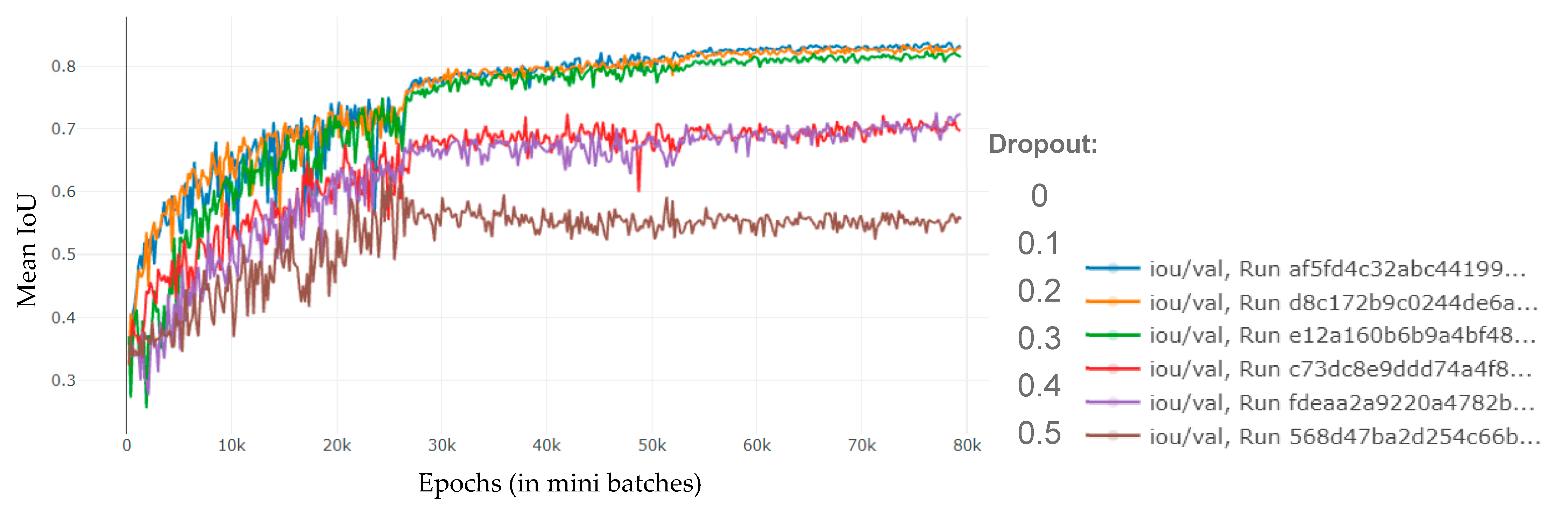
3.4. Dropout as Adaptive Training Regularization
4. Discussion
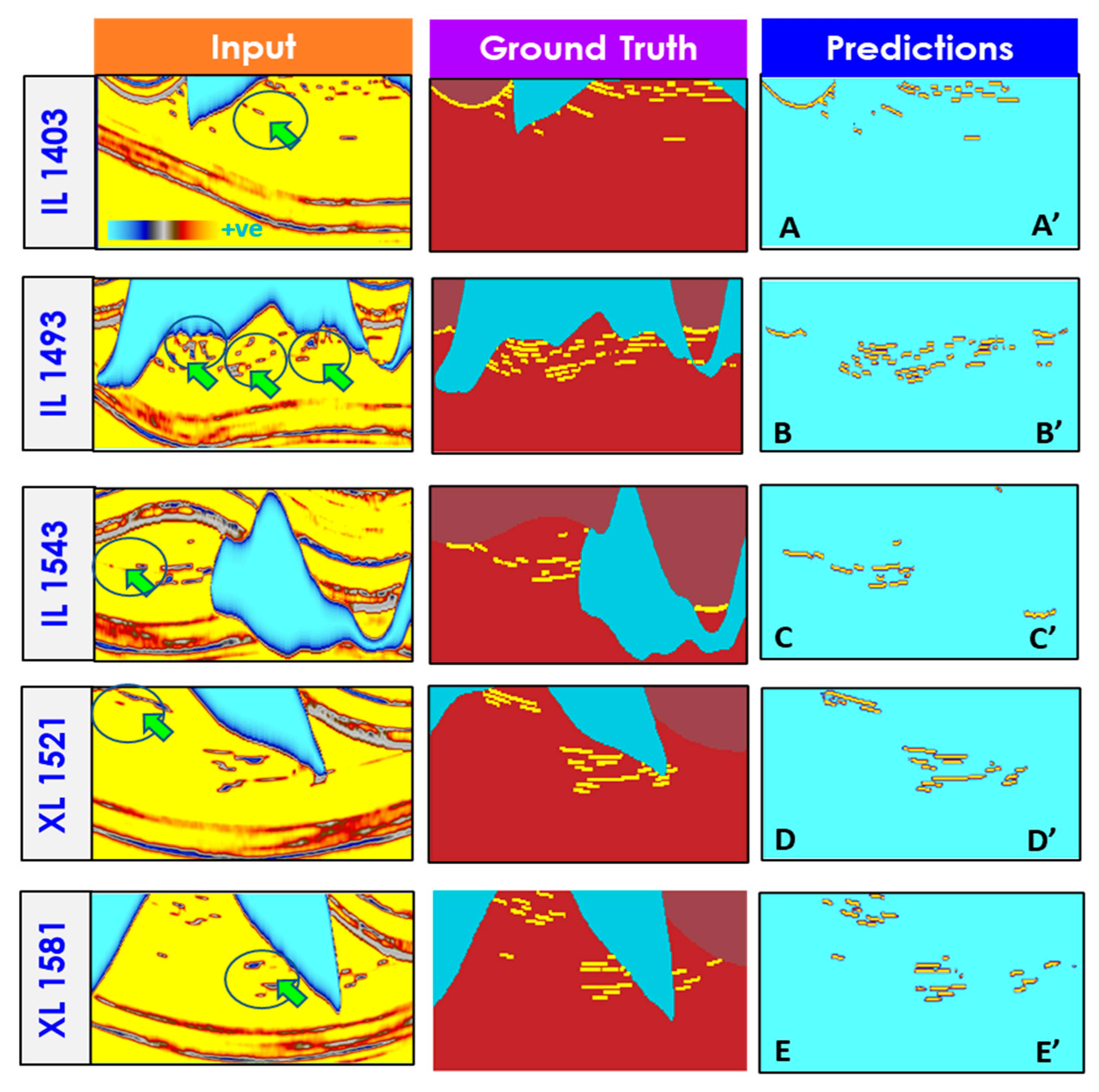
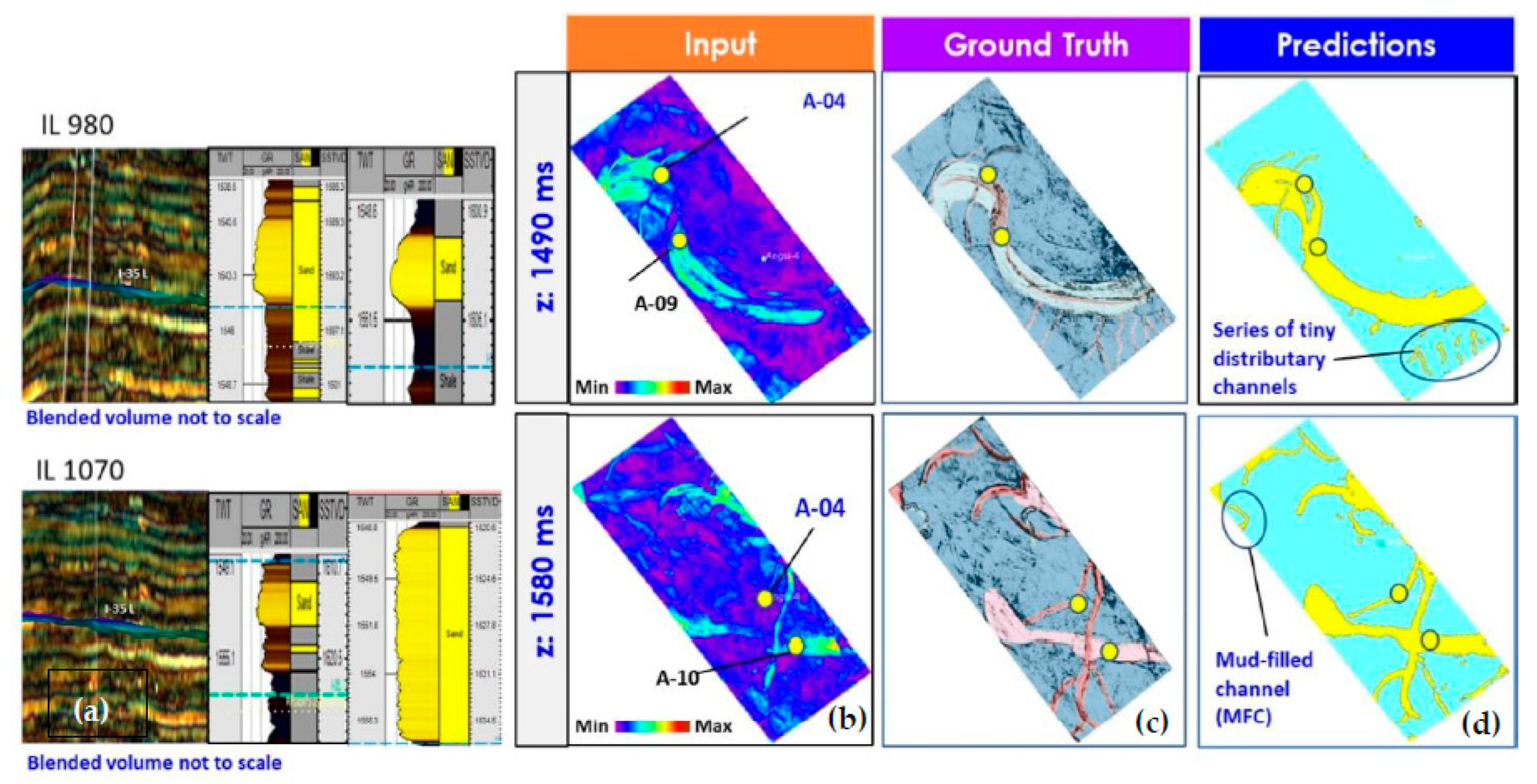
4.1. Binary Classification Using Synthetic Model
- Binary case.
- Multi-facies case.
4.2. Channel Detection Using U-Net (Binary Case)
4.3. Channel Detection Using U-Net (Multi-Facies Case)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bridge, J.S. Description and interpretation of fluvial deposits: A critical perspective. Sedimentology 1993, 40, 801–810. [Google Scholar] [CrossRef]
- Allen, G.P.; Posamentier, H.W. Transgressive facies and sequence architecture in mixed tide and wave-dominated incised valleys: Example from the Gironde estuary, France. Spec. Publ. 1994, 51, 225–240. [Google Scholar]
- Barnes, A. Seismic attributes in your facies. CSEG Rec. 2001, 26, 41–47. [Google Scholar]
- Marfurt, K.; Chopra, S. Emerging and future trends in seismic attributes. Lead. Edge 2008, 27, 298–318. [Google Scholar]
- Hart, B.S. Channel detection in 3-D seismic data using sweetness. AAPG Bull. 2008, 92, 733–742. [Google Scholar] [CrossRef]
- Chopra, S.; Marfurt, K. Seismic Attributes for Prospect Identification and Reservoir Characterization; Society of Exploration Geophysicists: Tulsa, OK, USA, 2007. [Google Scholar]
- Roden, R.; Smith, T.; Sacrey, D. Geologic pattern recognition from seismic attributes. Interp 2015, 3, 59–83. [Google Scholar]
- Fehler, M.; Keliher, P.J. SEAM Phase I: Challenges of Subsalt Imaging in Tertiary Basins, with Emphasis on Deepwater Gulf of Mexico; Society of Exploration Geophysicists: Tulsa, OK, USA, 2011. [Google Scholar]
- Marfurt, K.J.; Chopra, S. Seismic discontinuity attributes and Sobel filtering. CSEG Rec. 2014, 39, 4. [Google Scholar]
- LeCun, Y. Learning process in an asymmetric threshold network. In Ecole Superieure D’Lng (Mieurs en Electrotechnique ET Electronique); Springer: Berlin/Heidelberg, Germany, 1985; p. 20. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern. Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Fomel, S.; Wu, X. SaltSeg: Automatic 3D salt segmentation using a deep convolutional neural network. Interpretation 2019, 7, SE113–SE122. [Google Scholar] [CrossRef]
- Waldeland, A.; Jensen, A.; Gelius, L.-J.; Solberg, A. Convolutional neural networks for automated seismic interpretation. Lead. Edge 2018, 37, 529–537. [Google Scholar] [CrossRef]
- Dunham, M.W.; Welford, K.; Malcolm, A.E. Improved well-log classification using semisupervised label propagation and self- training, with comparisons to popular supervised algorithms. Geophysics 2020, 85, O1–O15. [Google Scholar] [CrossRef]
- Dramsch, J.S.; Mikael, L. Deep-learning seismic facies on state-of-the-art CNN architectures. In SEG Technical Program Expanded Abstracts 2018; Society of Exploration Geophysicists: Tulsa, OK, USA, 2018; pp. 2036–2040. [Google Scholar]
- Csáji, B.C. Approximation with Artificial Neural Networks. Master’s Thesis, Eotvos Loránd University, Budapest, Hungary, 2001. [Google Scholar]
- Di, H.; Alregib, G.; Wang, Z. Why using CNN for seismic interpretation? An investigation. In SEG Technical Program Expanded Abstracts 2018; Society of Exploration Geophysicists: Tulsa, OK, USA, 2018; pp. 2216–2220. [Google Scholar]
- Wang, W.; Yang, F.; Ma, J. Automatic salt detection with machine learning. In 80th EAGE Conference and Exhibition Extended Abstracts 2018; European Association of Geoscientists & Engineers: Houten, The Netherlands, 2018; pp. 1–5. [Google Scholar]
- Pham, N.; Fomel, S.; Dunlap, D. Automatic channel detection using deep learning. Interpretation 2019, 7, 43–50. [Google Scholar] [CrossRef]
- Wu, X.; Guo, Z. Detecting faults and channels while enhancing seismic structural and stratigraphic features. Interpretation 2019, 7, T155–T166. [Google Scholar] [CrossRef]
- Malik, F. Understanding Neural Network Neurons. 2019. Available online: Medium.com (accessed on 14 August 2022).
- Schelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern. Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net:Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580, arXiv:1207.0580. [Google Scholar]
- Radovich, B.J.; Oliveros, R.B. 3-D sequence interpretation of seismic instantaneous attributes from the Gorgon field. Lead. Edge 1998, 17, 1286–1293. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Class | Type | |
|---|---|---|---|
| Instantaneous Attributes | I | Reflection Strength, Instantaneous Phase, Instantaneous Frequency, Quadrature, Instantaneous Q | Lithology Contrasts, Bedding Continuity, Porosity, DHIs, Stratigraphy, Thickness |
| Geometric Attributes | II | Semblance and Eigen-Based Coherency/Similarity, Curvature (Maximum, Minimum, Most Positive, Most Negative, Strike, Dip) | Faults, Fractures, Folds Anisotropy, Regional Stress Fields |
| Amplitude-Accentuating Attributes | III | RMS Amplitude, Relative Acoustic Impedance, Sweetness, Average Energy | Porosity, Stratigraphic and Lithologic Variations, DHIs |
| AVO Attributes | IV | Intercept, Gradient, Intercept/Gradient Derivatives Fluid Factor, Lambda–Mu-Rho, Far–Near, (Far–Near) Far | Pore Fluid, Lithology, DHIs |
| Seismic Inversion Attributes | V | Colored Inversion, Sparse Spike, Elastic Impedance Extended Elastic Impedance, Prestack Simultaneous Inversion, Stochastic Inversion | Lithology, Porosity, Fluid Effects |
| Spectral Decomposition | VI | Continuous Wavelet Transform, Matching Pursuit Exponential Pursuit | Layer Thicknesses, Stratigraphic Variations |
| Class I (Channel) | Class II (Point Bar) | Class III (Mud-Filled Channel) | Class IV and V (Crevasse Splays and Crevasse Channel) |
|---|---|---|---|
| 7.12 | 4.15 | 0.16 | 88.57 |
| InputAttributes | Dropout | Facies Accuracy: | Overall Mean IoU | |||
|---|---|---|---|---|---|---|
| Class I | Class II | Class III | Class IV and V | |||
| 16 Features | 0.0 | 0.671 | 0.762 | 0.344 | 0.904 | 0.670 |
| 0.1 | 0.688 | 0.652 | 0.254 | 0.907 | 0.650 | |
| 0.2 | 0.652 | 0.785 | 0.328 | 0.905 | 0.667 | |
| 0.3 | 0.640 | 0.682 | 0.310 | 0.893 | 0.631 | |
| 9 Features | 0.0 | 0.681 | 0.766 | 0.322 | 0.905 | 0.668 |
| 0.1 | 0.702 | 0.757 | 0.302 | 0.907 | 0.651 | |
| 0.2 | 0.615 | 0.700 | 0.256 | 0.872 | 0.611 | |
| 0.3 | 0.666 | 0.668 | 0.293 | 0.882 | 0.631 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mad Sahad, S.; Tan, N.W.; Sajid, M.; Jones, E.A., Jr.; Abdul Latiff, A.H. Enhancing Channelized Feature Interpretability Using Deep Learning Predictive Modeling. Appl. Sci. 2022, 12, 9032. https://doi.org/10.3390/app12189032
Mad Sahad S, Tan NW, Sajid M, Jones EA Jr., Abdul Latiff AH. Enhancing Channelized Feature Interpretability Using Deep Learning Predictive Modeling. Applied Sciences. 2022; 12(18):9032. https://doi.org/10.3390/app12189032
Chicago/Turabian StyleMad Sahad, Salbiah, Nian Wei Tan, Muhammad Sajid, Ernest Austin Jones, Jr., and Abdul Halim Abdul Latiff. 2022. "Enhancing Channelized Feature Interpretability Using Deep Learning Predictive Modeling" Applied Sciences 12, no. 18: 9032. https://doi.org/10.3390/app12189032
APA StyleMad Sahad, S., Tan, N. W., Sajid, M., Jones, E. A., Jr., & Abdul Latiff, A. H. (2022). Enhancing Channelized Feature Interpretability Using Deep Learning Predictive Modeling. Applied Sciences, 12(18), 9032. https://doi.org/10.3390/app12189032