


Artificial Intelligence-Assisted Diagnosis for Early Intervention Patients

Abstract
:1. Introduction
2. Methology
2.1. Problem Understanding
- 1.
- Cognitive, also known as neurocognitive disorders (NCDs). This category covers mental health disorders which fundamentally affect cognitive skills such as learning, memory, perception, and problem solving.
- 2.
- Communication and language disorders, communication disorders which hinder learning and the use of any type of spoken language, written language, sign language, etc.
- 3.
- Sensory-motor disorders which display physical symptoms such as pain, poor strength, and lack of mobility.
- 4.
- Socio-communicative disorders which are often linked to behavioral disorders.
2.2. Data Understanding
- 1.
- Basic questionnaire with different options, completed by the early care physician and easily processed using an automatic learning algorithm.
- 2.
- Fields completed in natural language by a qualified specialist who interviews the child’s family during the first visit to the primary care center. These fields are not consistent in terms of format, units, number of registers completed or other concepts for structuring information. Therefore, these data must be transformed prior to their use in artificial intelligence techniques.
2.3. Data Preparation
- 1.
- Medical Report field: ACOIDPEAMTFAMILIARES is the identifier of the field chosen as an example.
- 2.
- Field description: This value is an interpretation of the meaning of the field in question.
- 3.
- Data type: The possible values are: Categorical, Numerical, Free text (equivalent to natural language), or Not relevant.
- 4.
- Completness: Percentage of values completed in this field.
- 5.
- Transformation: Expresses where a transformation has been carried out.
- 6.
- Final variable: Contains the final variable type after transformation.
- 7.
- Comment: Specifies whether there are any additional aspects to be taken into consideration, i.e., No comment.
- 8.
- S (selected): Value is 1 if this field was chosen as an explanatory variable to train the model.
2.4. Modeling
2.4.1. Random Forest
2.4.2. Linear Regression or Adjustment
2.4.3. Linear Support Vector Machine (LSVM)
2.4.4. C5 Classifier
2.4.5. CHAID: Chi-Square Automatic Interaction Detection
2.4.6. XGBOOST or eXtreme Gradient Boosting
3. Results and Discussion
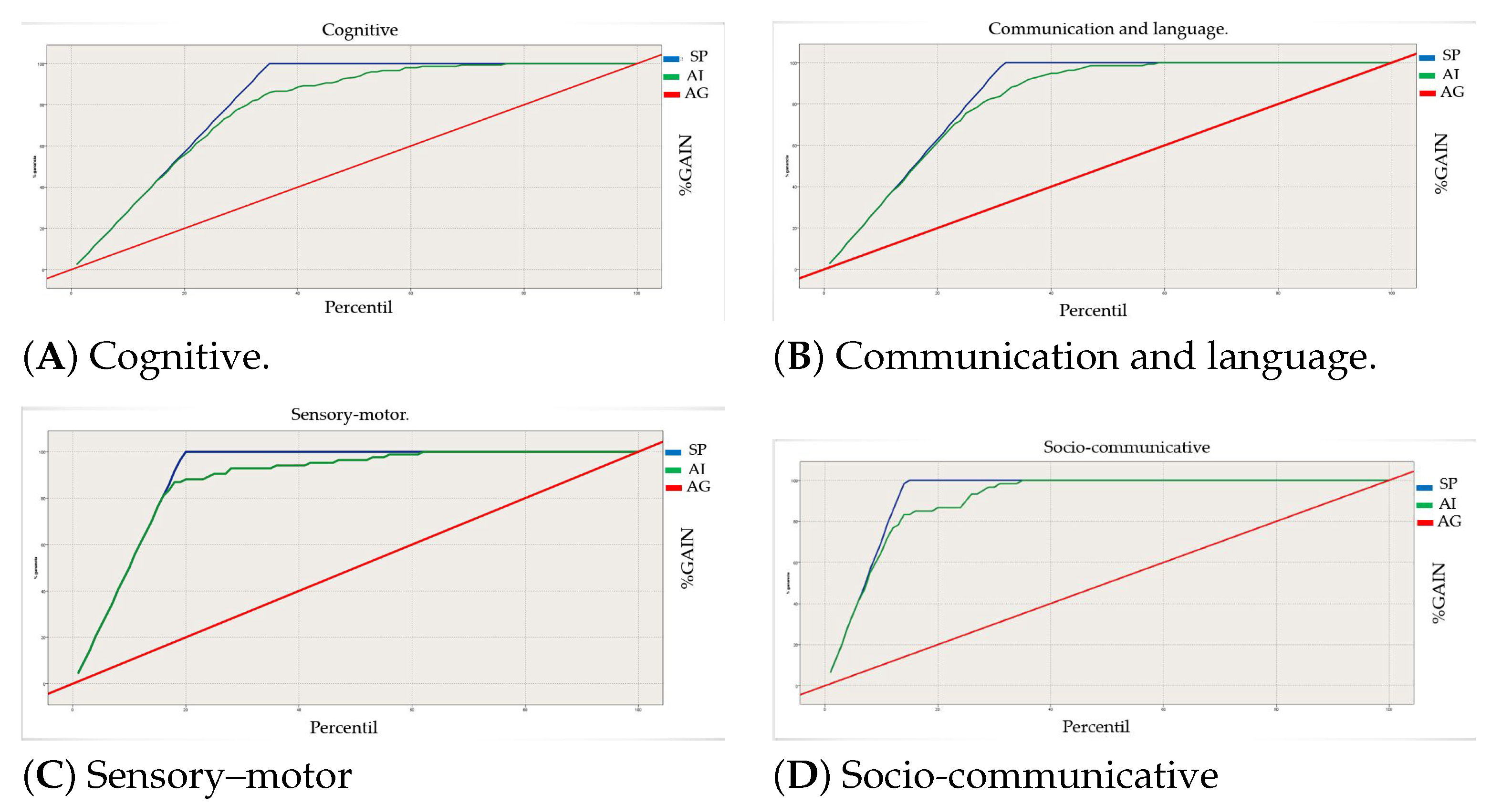
- The thick diagonal red line is the at-chance model.
- The blue line is the perfect classifier.
- The green line in the middle is our current model.
- The area under the green curve represents how well our system is behaving.
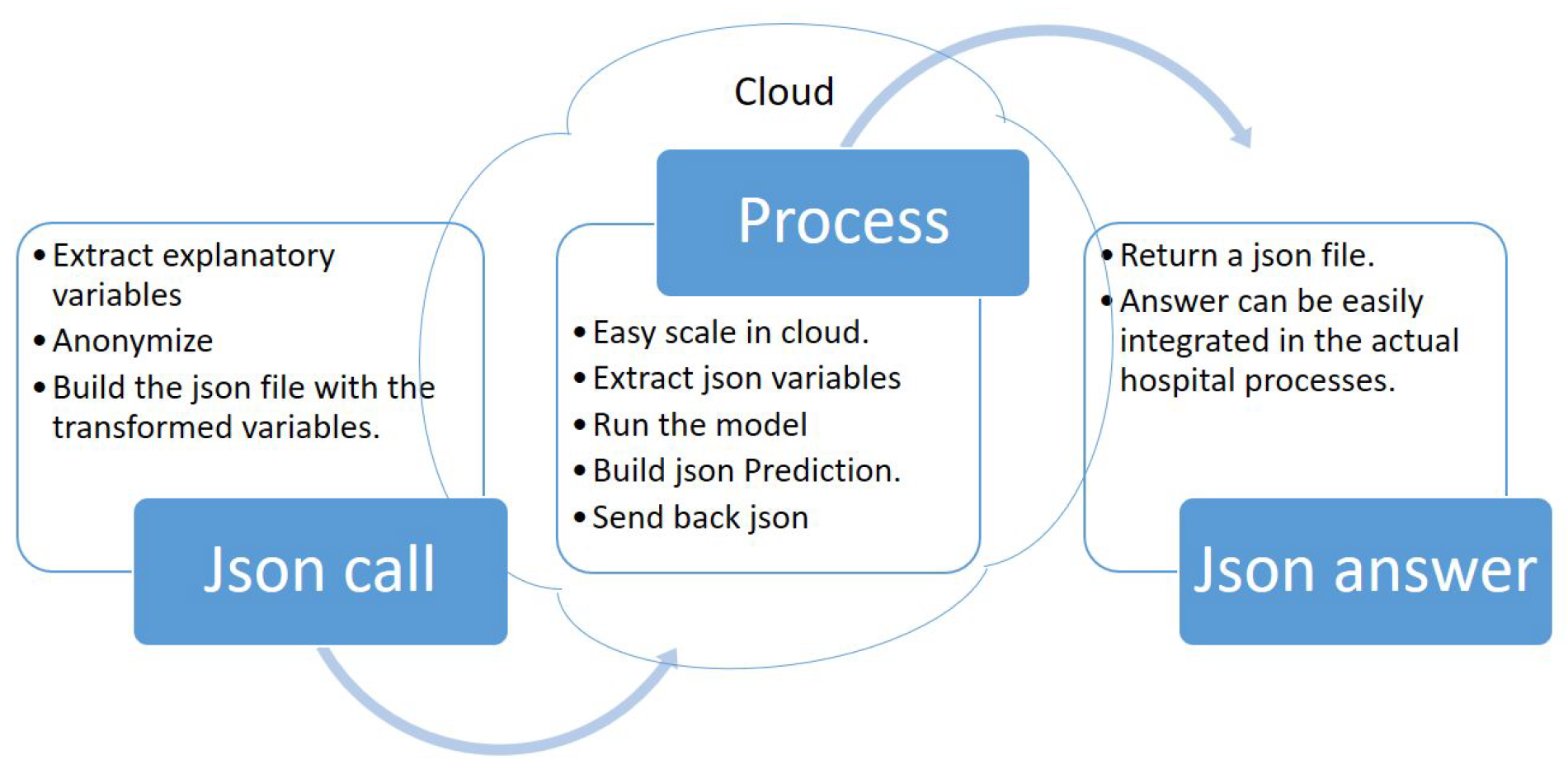
Deployment
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Ministry of Education and Science of Spain. Declaración de Salamanca y Marco de Acción Sobre Necesidades Educativas Especiales. In Proceedings of the World Conference on Special Needs Education: Access and Quality, Salamanca, Spain, 7–10 June 1994; Available online: https://unesdoc.unesco.org/ark:/48223/pf0000098427_spa (accessed on 1 December 2021).
- Soriano, V.; Alonso Gutierrez, M.V. Atención Temprana Análisis de la Situación en Europa Aspectos clave y Recomendaciones; European Agency for Development in Special Needs Education: Brussels, Belgium, 2005; Available online: https://www.european-agency.org/sites/default/files/early-childhood-intervention-analysis-of-situations-in-europe-key-aspects-and-recommendations_eci_es.pdf (accessed on 1 December 2021).
- Monsalve González, A.; Núñez Batalla, F. La importancia del diagnóstico e intervención temprana para el desarrollo de los niños sordos. Los programas de detección precoz de la hipoacusia. Psychosoc. Interv. 2006, 15, 7–28. [Google Scholar] [CrossRef]
- Liu, G.D.; Li, Y.C.; Zhang, W.; Zhang, L. A Brief Review of Artificial Intelligence Applications and Algorithms for Psychiatric Disorders. Engineering 2020, 6, 462–467. [Google Scholar] [CrossRef]
- Rajula, H.S.R. Comparison of Conventional Statistical Methods with Machine Learning in Medicine: Diagnosis, Drug Development, and Treatment. Med. J. 2020, 8, 455. [Google Scholar] [CrossRef] [PubMed]
- Tai, A.M.; Albuquerque, A.; Carmona, N.E.; Subramanieapillai, M.; Cha, D.S.; Sheko, M.; Lee, Y.; Mansur, R.; McIntyre, R.S. Machine learning and big data: Implications for disease modeling and therapeutic discovery in psychiatry. Artif. Intell. Med. 2019, 9, 101704. [Google Scholar] [CrossRef] [PubMed]
- Xu, W. Risk prediction of type II diabetes based on random forest model. In Proceedings of the 2017 Third International Conference on Advances in Electrical, Electronics, Information, Communication and Bio-Informatics (AEEICB), Chennai, India, 27–28 February 2017. [Google Scholar] [CrossRef]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Davenport, T.; Kalakota, R. The potential for artificial intelligence in healthcare. Future Healthc. J. 2019, 6, 94–98. [Google Scholar] [CrossRef] [PubMed]
- Azevedo, A.; Santos, M.F. KDD, SEMMA and CRISP-DM: A parallel overview. In Proceedings of the IADIS European Conference Data Mining, Amsterdam, The Netherlands, 24–26 July 2008; Abraham, A., Ed.; IADIS: Lisbon, Portugal, 2008; pp. 182–185. [Google Scholar]
- Ponce Rodriguez, L.; Carrasco Villalon, R. Propuesta y aplicación de una gestión por procesos para la intervención y atención temprana. In Proceedings of the VXII Jornadas de Atención Temprana en Andalucía, Andalucía, Spain, 19 February 2021. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 57. [Google Scholar] [CrossRef]
- Weisberg, S. Applied Linear Regression, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Newman, A.B.; Foster, G.; Givelber, R.; Nieto, F.J.; Redline, S.; Young, T. Progression and Regression of Sleep-Disordered Breathing with Changes in Weight: The Sleep Heart Health Study. Arch. Intern. Med. 2005, 165, 2408–2413. Available online: https://jamanetwork.com/journals/jamainternalmedicine/articlepdf/486784/ioi50103.pdf (accessed on 14 November 2021). [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Ahmadi, E.; Weckman, G.R.; Masel, D.T. Decision making model to predict presence of coronary artery disease using neural network and C5.0 decision tree. J. Ambient Intell. Humaniz. Comput. 2018, 9, 999–1011. [Google Scholar] [CrossRef]
- Kass, G.V. An Exploratory Technique for Investigating Large Quantities of Categorical Data. J. R. Stat. Soc. Ser. Appl. Stat. 1980, 29, 119–127. [Google Scholar] [CrossRef]
- Kuráňová, P. Evaluation of the Phadiatop test results using CHAID algorithm and logistic regression. In Proceedings of the 2015 International Conference on Information and Digital Technologies, Zilina, Slovakia, 7–9 July 2015; pp. 178–182. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. J. R. Stat. Soc. Ser. Appl. Stat. 2016, 785–794. [Google Scholar] [CrossRef]
- Liu, P.; Fu, B.; Yang, S.X.; Deng, L.; Zhong, X.; Zheng, H. Optimizing Survival Analysis of XGBoost for Ties to Predict Disease Progression of Breast Cancer. IEEE Trans. Biomed. Eng. 2021, 68, 148–160. [Google Scholar] [CrossRef] [PubMed]
- Wei, L.; Mooney, C. Epileptic Seizure Detection in Clinical EEGs Using an XGboost-based Method. In Proceedings of the 2020 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), Philadelphia, PA, USA, 5 December 2020; pp. 1–6. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Early Care Doctor Report Fields | Fields Description | Data Type | %Completness | Transformation | Final variable | Comment | S |
|---|---|---|---|---|---|---|---|
| ACO_CK_P_DERIVAR | Transfer | Boolean | 85 | Boolean | |||
| ACO_CK_P_REALIZAR_VI | Make diagnosis | Boolean | 85 | Boolean | |||
| ACO_CK_P_SEGUIMIENTO | Follow-up | Boolean | 85 | Boolean | |||
| ACO_CK_PAÑAL_24 | Diaper | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_PAÑAL_NOCHE | Night diaper | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_PAÑAL_SUCIO | Dirty diaper | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_RET_MADURATIVO_LENGUA | Language delay disorder | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_RETRASO_COGNITIVO | Cognitive | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_RETRASO_MOTOR | Motor delay disorder | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_RETRASO_PSICO | Psychological | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_SEÑALES_DE_ALERTA | Warning sign | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_TRASTORNO_COGNITIVO | Cognitive disorder | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_TRASTORNO_LENGUA | Language disorder | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_TRASTORNO_COMUNICA | Comunication disorder | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_TRASTORNO_MOTOR | Motor disorder | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_TRASTORNO_PSICO | Psychological disorder | Boolean | 85 | Boolean | 1 | ||
| ACO_CK_TRASTORNO_SENSORIAL | Sensory disorder | Boolean | 85 | Boolean | 1 | ||
| ACO_CMB_MEDICOS_SERVICIO | Doctors | Non-Relevant | 85 | Non-Relevant | |||
| ACO_ID_ALERGIAS | Allergies | Non-Relevant | 0.1 | Barely filled | |||
| ACO_ID_AP_ALIMENTACION | Feeding | Natural Language | 57 | True (Eats well)False (Eats Badly) | Boolean | 1 | |
| ACO_ID_AP_COMPLICA | Birth Complications | Free text | 67 | Respiratory(itis) | Three boolean variables | 1 | |
| Convul | 1 | ||||||
| Cardio | 1 | ||||||
| Other | 1 | ||||||
| ACO_ID_AP_HISTORIA_FAMI | Family background | Free text | 8 | Separation | Boolean | 1 | |
| ACO_ID_AP_HOSPITALIZA | Hospitalization | Free text | 56 | Boolean | Boolean | 1 | |
| ACO_ID_AP_TIPO_LACTANCIA | Lactation | Free text | 68 | Breastfeeding | Numeric | Until when, Numeric | 1 |
| ACO_ID_CENTRO_SALUD | Family hospital | Categorical | 85 | Categorical | 1 | ||
| ACO_ID_DF_ACTITUD_DIAG | Attitude toward diagnosis | Non-Relevant | 1 | Barely filled | |||
| ACO_ID_DF_COINCIDENC_PROB | Problem awareness | Non-Relevant | 10 | Barely filled | |||
| ACO_ID_DF_MOTIVA_COLABORAR | Collaboration | Non-Relevant | 1 | Barely filled | |||
| ACO_ID_DF_NECES_APOYO | Need help | Non-Relevant | 0.2 | Barely filled | |||
| ACO_ID_DF_REL_FAMI | Family Relationship | Free text | 23 | Good/Bad | Boolean | 1 | |
| ACO_ID_EMBARAZO | Pregnancy | Free text | 76 | With/without problems | Boolean | 1 | |
| ACO_ID_FECHA_ACOGIDA | Admission date | Non-Relevant | 82 | Non-Relevant | |||
| ACO_ID_FECHA_DERIVACION | Derivation date | Non-Relevant | 70 | Non-Relevant | |||
| ACO_ID_HE_CEFALICO | Head diameter | Free text | 13 | Unit consistency | Numeric | Barely filled | |
| ACO_ID_HE_BIPEDESTA | Stand up | Free text | 4 | Unit consistency | Numeric | Barely filled | |
| ACO_ID_HE_ESFINTERES | Sphincters | Free text | 18 | Unit consistency | Numeric | Barely filled | |
| ACO_ID_HE_FRASE | First sentence | Free text | 6 | Unit consistency | Numeric | Barely filled | |
| ACO_ID_HE_GATEO | Crawl | Free text | 38 | Unit consistency | Numeric | Barely filled | |
| ACO_ID_HE_INI_MARCHA | Begin Walking | Free text | 42 | Unit consistency | Numeric | Barely filled | |
| ACO_ID_HE_PRI_PALABRA | First word | Free text | 45 | Unit consistency | Numeric | Barely filled | |
| ACO_ID_HE_MARCHA | Walk | Free text | 15 | Unit consistency | Numeric | Barely filled | |
| ACO_ID_HE_SEDESTACION | Seat | Free text | 11 | Unit consistency | Numeric | Barely filled | |
| ACO_ID_MEDICO_FAMILIA | Family Doctor | Non-Relevant | 77 | Non-Relevant | |||
| ACO_ID_P_A_TERMINO | End of the process | Non-Relevant | 14 | Non-Relevant | |||
| ACO_ID_P_CON_ANR | Birth weight | Non-Relevant | 2 | Non-Relevant | |||
| ACO_ID_P_DERIVAR_A | Change to | Non-Relevant | 0 | Non-Relevant | |||
| ACO_ID_P_MOTIVO_ALTA | Reason medical discharge | Non-Relevant | 0 | Non-Relevant | |||
| ACO_ID_P_MULTIPLE | Multiple birth | Non-Relevant | 0 | Non-Relevant | |||
| ACO_ID_P_OBSERVACIONES | Observations | Difficult to extract | 0 | Non-Relevant | Non-Relevant | ||
| ACO_ID_P_PREMATURO | Premature | Free text | 17 | True/False | Boolean | 1 |
| Model | Precision | VN |
|---|---|---|
| XGBoost | 86.45 | 40 |
| Random Forest | 79.44 | 40 |
| Linear Regresion | 73.83 | 40 |
| LSVM | 68.46 | 40 |
| C5 | 61.45 | 9 |
| CHAID | 68.46 | 10 |
| NEURAL NETWORK | 48.131 | 40 |
| Predicted | I | II | III | IV |
|---|---|---|---|---|
| Actual | ||||
| I (Cognitive) | 129 | 18 | 1 | 1 |
| II (Communication and language) | 8 | 121 | 2 | 4 |
| III (Sensory–motor) | 10 | 1 | 73 | 0 |
| IV (Socio-communicative) | 6 | 7 | 0 | 47 |
| Process | Distribution |
|---|---|
| I (Cognitive) | 34.81 |
| II (Communication and Language) | 31.54 |
| III (Sensory–Motor) | 19.63 |
| IV (Socio-Communicative) | 14.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sierra, I.; Díaz-Díaz, N.; Barranco, C.; Carrasco-Villalón, R. Artificial Intelligence-Assisted Diagnosis for Early Intervention Patients. Appl. Sci. 2022, 12, 8953. https://doi.org/10.3390/app12188953
Sierra I, Díaz-Díaz N, Barranco C, Carrasco-Villalón R. Artificial Intelligence-Assisted Diagnosis for Early Intervention Patients. Applied Sciences. 2022; 12(18):8953. https://doi.org/10.3390/app12188953
Chicago/Turabian StyleSierra, Ignacio, Norberto Díaz-Díaz, Carlos Barranco, and Rocío Carrasco-Villalón. 2022. "Artificial Intelligence-Assisted Diagnosis for Early Intervention Patients" Applied Sciences 12, no. 18: 8953. https://doi.org/10.3390/app12188953
APA StyleSierra, I., Díaz-Díaz, N., Barranco, C., & Carrasco-Villalón, R. (2022). Artificial Intelligence-Assisted Diagnosis for Early Intervention Patients. Applied Sciences, 12(18), 8953. https://doi.org/10.3390/app12188953