

Multi-Objective Hybrid Flower Pollination Resource Consolidation Scheme for Large Cloud Data Centres



Abstract
:1. Introduction
- The main contributions of this article are as follows:
- Some mathematical models for the objective functions of energy-efficiency and SLA violation are derived.
- Incorporation of LNS into FPA for addressing entrapment at both the local and global search levels.
- Integration of clustering strategies with robust migration mechanisms into the FPA-LNS to minimize the violation of SLA while satisfying minimum energy consumption.
2. Motivation of the Study
3. Literature Review
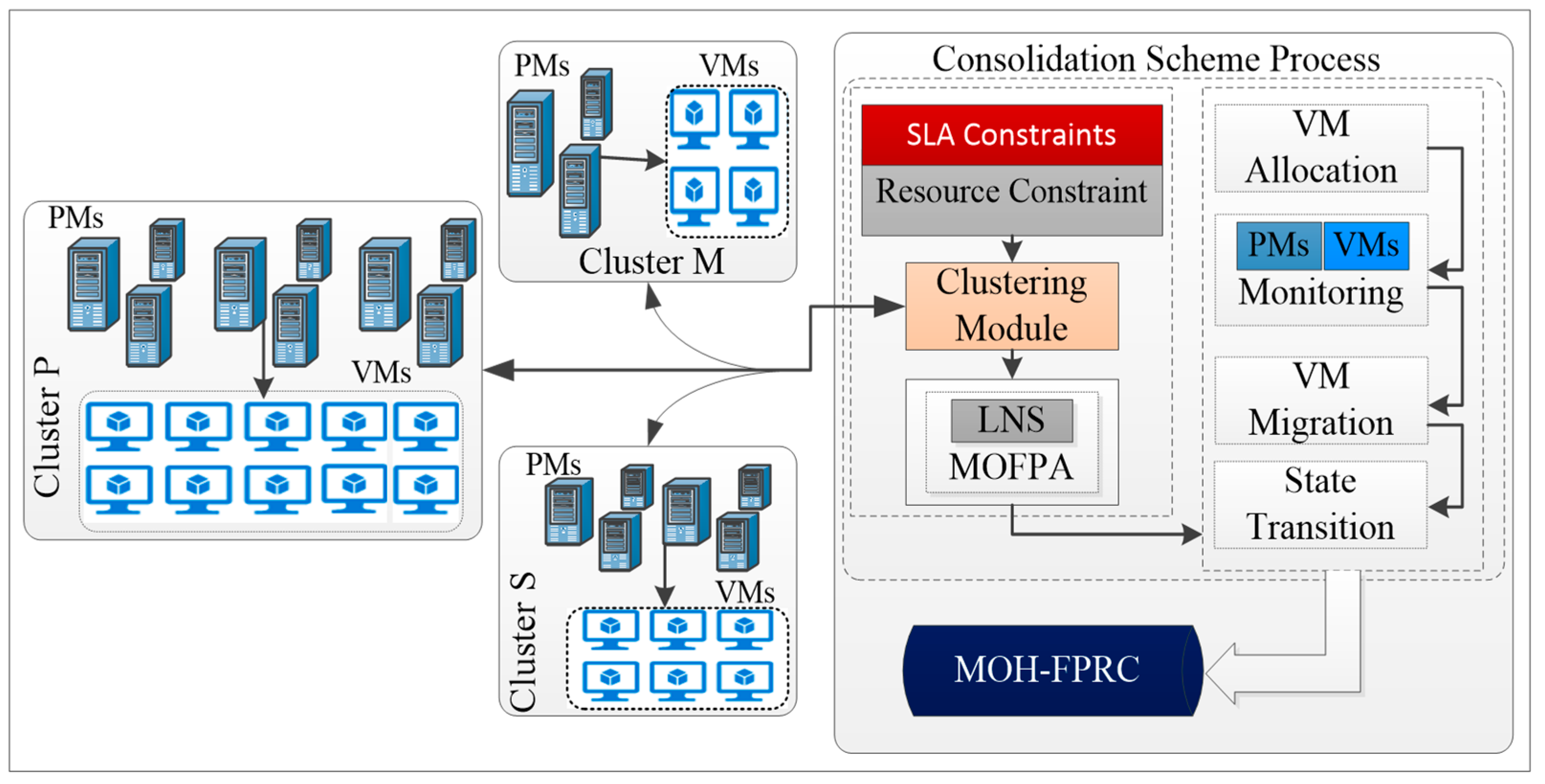
4. Multi-Objective Hybrid Resource Consolidation Algorithm
4.1. Mathematical Modelling of Objectives Functions
4.1.1. Service Level Agreement Model
4.1.2. Resource Consolidation Model
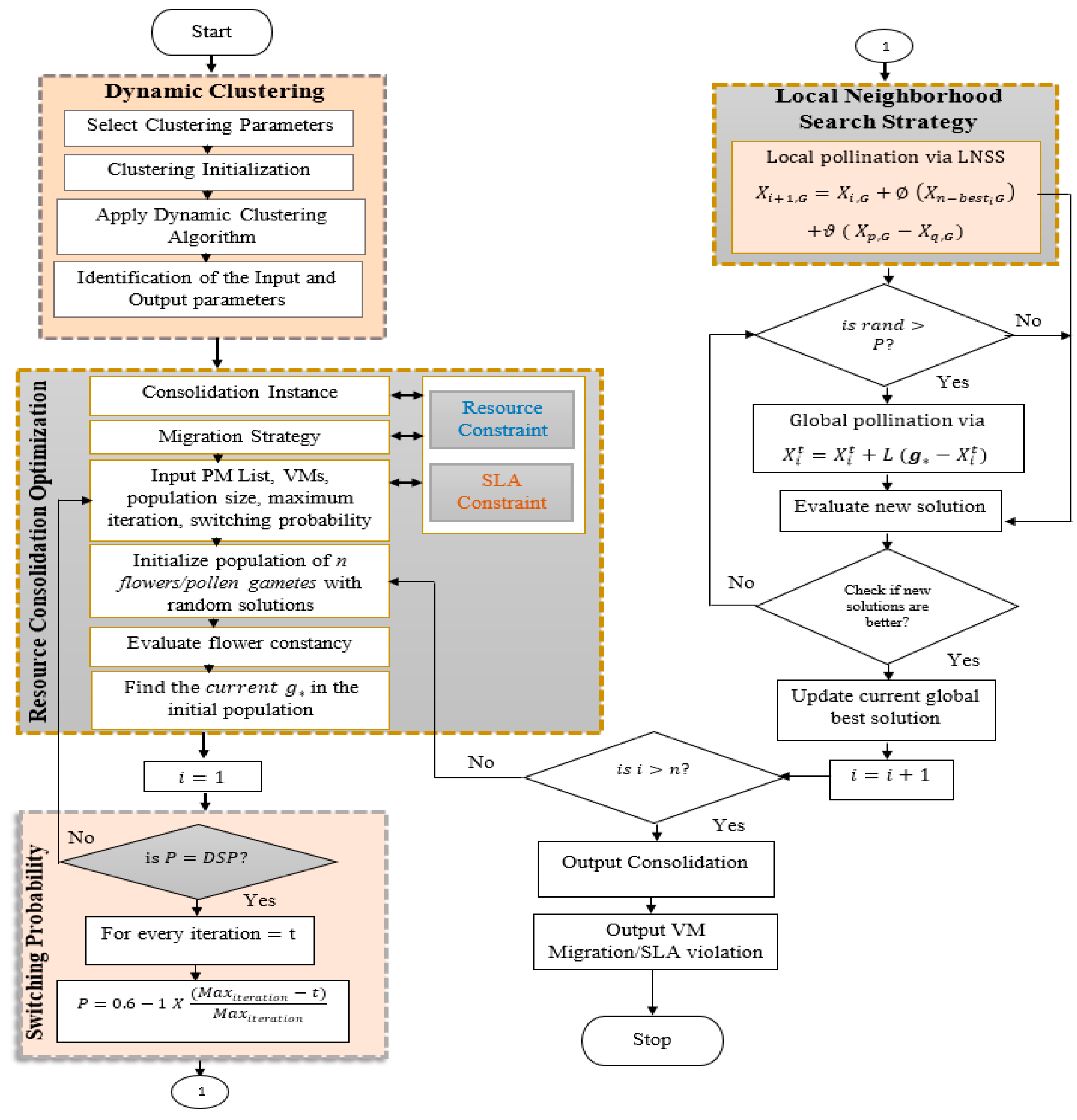
4.2. Hybrid Flower Pollination Resource Consolidation Algorithm
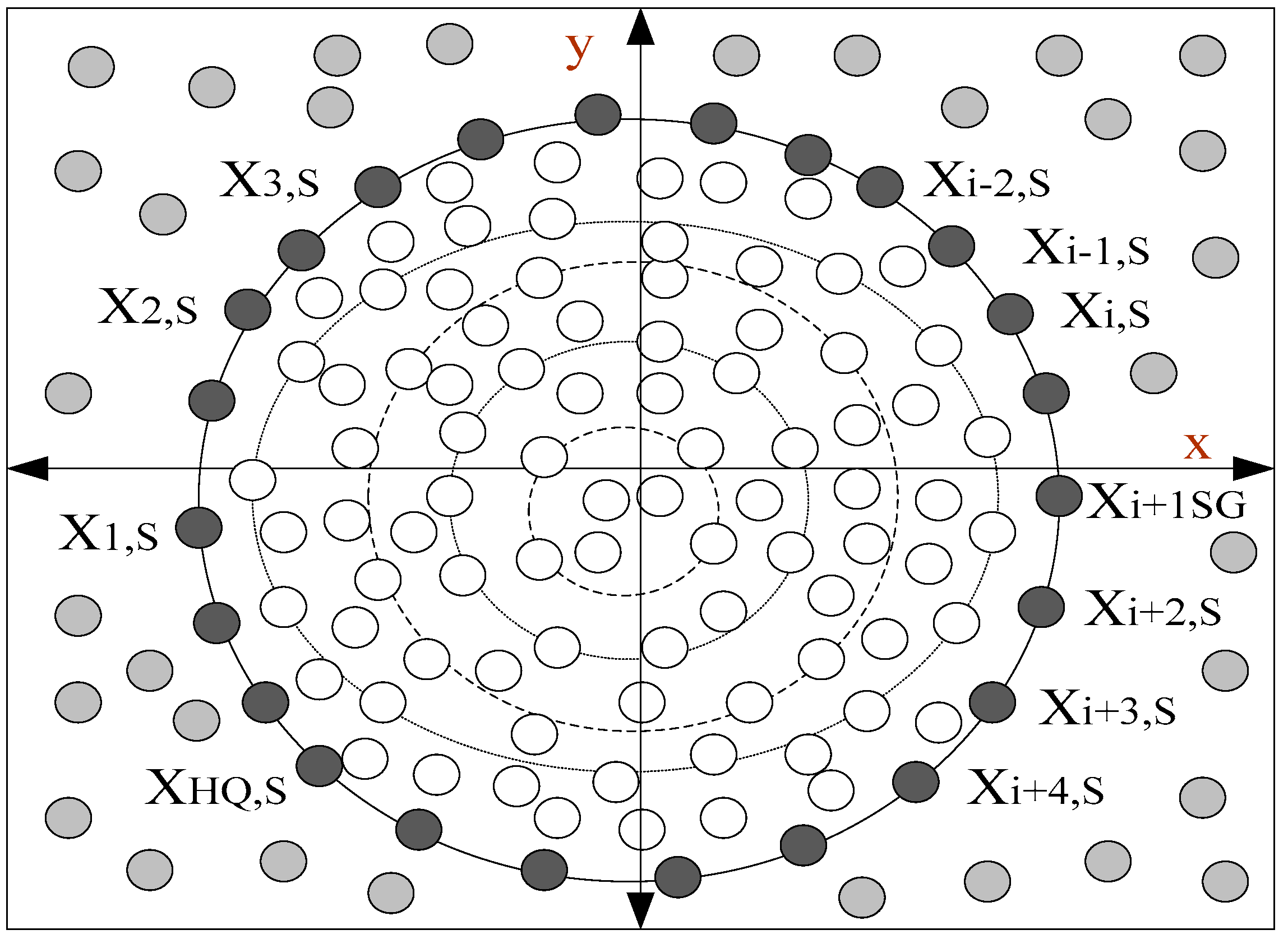
4.2.1. Flower Pollination Algorithm
4.2.2. Local Neighborhood Search Strategy Phase
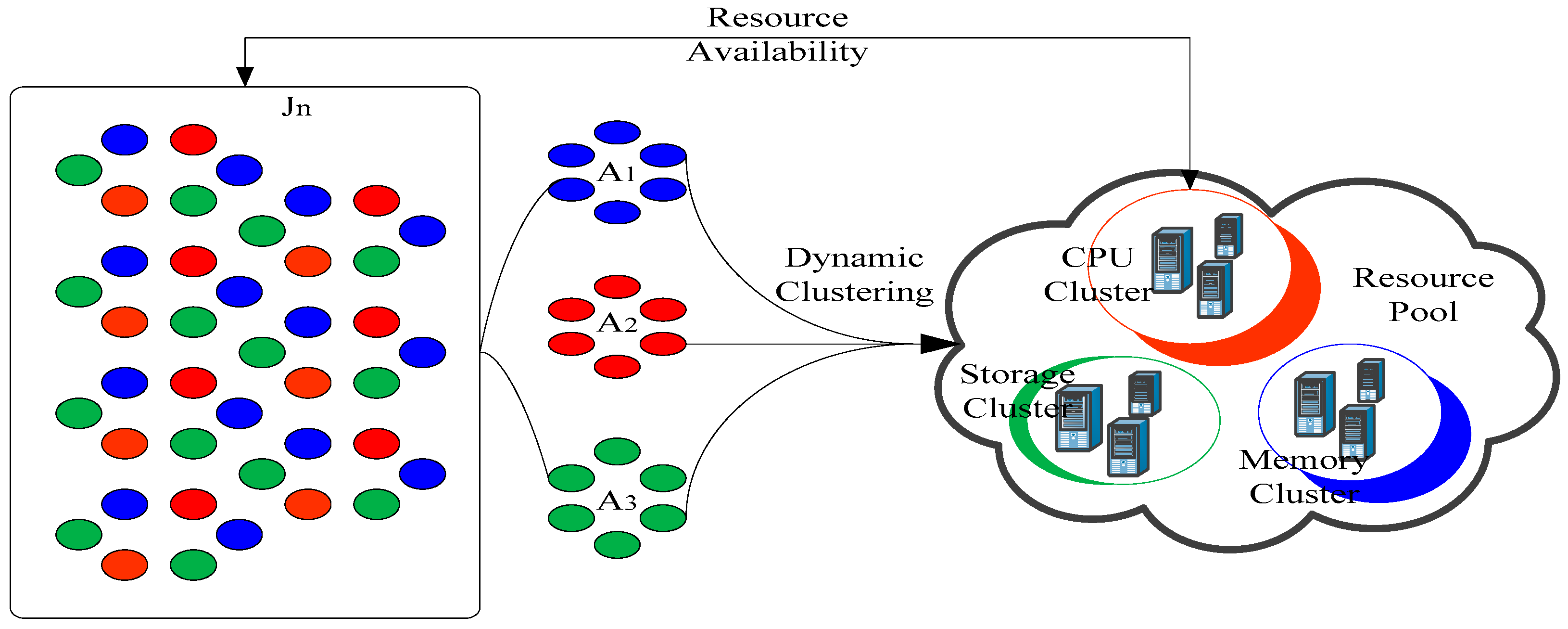
4.2.3. Clustering Phase
| Algorithm 1 Dynamic Clustering Algorithm | |
| Require: Combination of resource request Ensure: CPU Cluster, Memory Cluster, and Storage Cluster | |
| 1: | Initialization |
| 2: | Getn from the Cloud management system |
| 3: | |
| 4: | |
| 5: | |
| 6: | Let |
| 7: | Current Step: |
| 8: | While |
| 9: | Select |
| 10: | |
| 11: | |
| 12: | Get current from Cloud management system |
| 13: | End While |
4.2.4. Virtual Machine Migration Phase
| Algorithm 2 VM Migration Algorithm | |
| Require: Active PMs in n cluster, VM migration , Migration time, Migration data Ensure: SLA violation due to PM migration | |
| 1: | Initialization |
| 2: | For each PM in PM list do |
| 3: | For each data of PM component (CPU, memory, storage) do |
| 4: | Select best VM migration strategy |
| 5: | Estimate the |
| 6: | Compute the predicted resource utilization of PM |
| 7: | If utilization then |
| 8: | Repeat step 2–step 7 Else |
| 9: | VM is migrated |
| 10: | Migration time  VM get allocated VM get allocated |
| 11: | VM started on targeted PM |
| 12: | PM state change according to current utilization |
| 13: | End |
| 14: | End |
| 15: | Return (Number of VMs migration) |
| 16: | SLAV |
4.2.5. Implementation of Hybrid Resource Consolidation Algorithm
| Algorithm 3 Multi-Objective Hybrid Flower Pollination Algorithm | |
| Require: Set of population of n flowers/pollen gametes with random solutions Find the best solution g∗ in the initial population Ensure: Define a switch probability | |
| 1: | Initializing: use Algorithm 1 // Resource are clustered into CPU, memory, storage |
| 2: | Each Cluster is a single resource demand |
| 3: | VMs are classified based on requirement |
| 4: | Input:PM list, VM, set of parameters |
| 5: | Migration Strategy: use Algorithm 2 // Resource and SLA violation constraint |
| 6: | Output:Consolidation |
| 7: | Objective//Equation (5) |
| 8: | Initialize: a population of n flowers/pollen gametes with random solutions |
| 9: | Find the best solution in the initial population |
| 10: | Define a switch probability P |
| 11: | While (t ) |
| 12: | For |
| 13: | If |
| 14: | distribution |
| 15: | |
| 16: | Else |
| 17: | |
| 18: | |
| 19: | ; |
| 20: | end if |
| 21: | Evaluate new solutions |
| 22: | If new solutions are better, update them in the population |
| 23: | end for |
| 24: | Find the current best solution |
| 25: | End while |
| 25: | Termination criteria: If the stopping criterion is satisfied, then output the content of archive as the optimal solutions otherwise Move to line 8. |
5. Performance Evaluation
Result Analysis of MOH-FPRC
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Meaning |
| CC | Cloud Computing |
| IaaS | Infrastructure as a Service |
| PaaS | Platform as a Service |
| SaaS | Software as a service |
| PM | Physical Machine |
| VMs | Virtual Machines |
| PMs | Physical Machines |
| CPU | central processing unit |
| FPA | Flower Pollination Algorithm |
| LNS | Local Neighborhood Search |
| SLA | Service Level Agreement |
| FPRC | Flower Pollination Resource Consolidation |
| MOH-FPRC | Multi-Objective Hybrid Flower Pollination Resource Consolidation |
| ACO | Ant Colony Optimization |
| QoS | Quality of service |
| PSO | Particle Swarm Optimization |
| CSO | Cuckoo Search Optimization |
| SFLA | Shuffled Frog Leaping Algorithm |
| ACS-VMC | Ant Colony System-based VM Consolidation |
| MO-CSOA | Multi-Objective CSO Algorithm |
| VMC-ACO | VM Consolidation in Cloud data centers using ACO metaheuristics |
| MPSO | Modified PSO |
| UP-POD | utilization of resources through the host over-load detection |
| UP-PUD | host under-load detection |
| RL | Reinforcement Learning |
| DC | Dynamic clustering |
| SLAV | SLA violation |
| EU(t)j | energy consumption |
| SVM(Ai, Bj) | SLA violation |
| Rc | resource consolidation |
| MOH-FPRC | Multi-Objective Hybrid Flower Pollination Resource Consolidation |
| DC | Dynamic Clustering |
| IQR | Inter Quartile Range |
| ST | Static Threshold |
| MOACS | Multi-Objective Ant Colony System |
| ICT | Information and Communication Technology |
References
- Foster, I.; Zhao, Y.; Raicu, I.; Lu, S. Cloud computing and grid computing 360-degree compared. In Proceedings of the 2008 Grid Computing Environments Workshop, Austin, TX, USA, 12–16 November 2008. [Google Scholar]
- Xavier, T.C.; Santos, I.L.; Delicato, F.C.; Pires, P.F.; Alves, M.P.; Calmon, T.S.; Oliveira, A.C.; Amorim, C.L. Collaborative resource allocation for Cloud of Things systems. J. Netw. Comput. Appl. 2020, 159, 102592. [Google Scholar] [CrossRef]
- Fister, I., Jr.; Yang, X.-S.; Fister, I.; Brest, J. A Brief Review of Nature-Inspired Algorithms for Optimization. arXiv 2013, arXiv:1307.4186. [Google Scholar]
- Srinivasan, J.; Dhas, C.S.G. Cloud management architecture to improve the resource allocation in cloud IAAS platform. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 5397–5404. [Google Scholar] [CrossRef]
- Lee, Y.C.; Zomaya, A.Y. Energy efficient utilization of resources in cloud computing systems. J. Supercomput. 2012, 60, 268–280. [Google Scholar] [CrossRef]
- Gao, X.; Liu, R.; Kaushik, A. Hierarchical Multi-Agent Optimization for Resource Allocation in Cloud Computing. arXiv 2020, arXiv:2001.03929. [Google Scholar] [CrossRef]
- Chen, X.; Zhu, F.; Chen, Z.; Min, G.; Zheng, X.; Rong, C. Resource Allocation for Cloud-Based Software Services Using Prediction-Enabled Feedback Control With Reinforcement Learning. IEEE Trans. Cloud Comput. 2020, 10, 1117–1129. [Google Scholar] [CrossRef]
- Zhao, Q.; Xiong, C.; Yu, C.; Zhang, C.; Zhao, X. A new energy-aware task scheduling method for data-intensive applications in the cloud. J. Netw. Comput. Appl. 2016, 59, 14–27. [Google Scholar] [CrossRef]
- Usman, M.J.; Ismail, A.S.; Abdul-Salaam, G.; Chizari, H.; Kaiwartya, O.; Gital, A.Y.; Abdullahi, M.; Aliyu, A.; Dishing, S.I. Energy-efficient Nature-Inspired techniques in Cloud computing datacenters. Telecommun. Syst. 2019, 71, 275–302. [Google Scholar] [CrossRef]
- Beloglazov, A.; Buyya, R. Optimal online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in Cloud data centers. Concurr. Comput. Pract. Exp. 2012, 24, 1397–1420. [Google Scholar] [CrossRef]
- Lovász, G.; Niedermeier, F.; de Meer, H. Performance tradeoffs of energy-aware virtual machine consolidation. Clust. Comput. 2013, 16, 481–496. [Google Scholar] [CrossRef]
- Gong, S.; Yin, B.; Zheng, Z.; Cai, K.-Y. Adaptive Multivariable Control for Multiple Resource Allocation of Service-Based Systems in Cloud Computing. IEEE Access 2019, 7, 13817–13831. [Google Scholar] [CrossRef]
- Mandal, A.K.; Kahar, M.N.B.M. An Energy-aware resource management scheme of Data Centres for eco-friendly cloud computing. J. Adv. Appl. Sci. 2015, 3, 107–112. [Google Scholar]
- Devarasetty, P.; Reddy, S. Genetic algorithm for quality of service based resource allocation in cloud computing. Evol. Intell. 2019, 14, 381–387. [Google Scholar] [CrossRef]
- Wei, J.; Zeng, X.-F. Optimal computing resource allocation algorithm in cloud computing based on hybrid differential parallel scheduling. Clust. Comput. 2019, 22, 7577–7583. [Google Scholar] [CrossRef]
- Make IT Green. Cloud Computing and Its Contribution to Climate Change; Greenpeace International Annual Report; Greenpeace International: Amsterdam, The Netherlands, 2010. [Google Scholar]
- Muthulakshmi, B.; Somasundaram, K. A hybrid ABC-SA based optimized scheduling and resource allocation for cloud environment. Clust. Comput. 2019, 22, 10769–10777. [Google Scholar] [CrossRef]
- Kwon, S. Ensuring renewable energy utilization with quality of service guarantee for energy-efficient data center operations. Appl. Energy 2020, 276, 115424. [Google Scholar] [CrossRef]
- Usman, M.J.; Ismail, A.S.; Chizari, H.; Abdul-Salaam, G.; Usman, A.M.; Gital, A.Y.; Kaiwartya, O.; Aliyu, A. Energy-efficient Virtual Machine Allocation Technique Using Flower Pollination Algorithm in Cloud Datacenter: A Panacea to Green Computing. J. Bionic Eng. 2019, 16, 354–366. [Google Scholar] [CrossRef]
- Usman, M.J.; Ismail, A.S.; Gital, A.Y.; Aliyu, A.; Abubakar, T. Energy-Efficient Resource Allocation Technique Using Flower Pollination Algorithm for Cloud Datacenters. In Proceedings of the International Conference of Reliable Information and Communication Technology, Kuala Lumpur, Malaysia, 23–24 July 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Joda, U.M.; Ismail, A.S.; Gital, A.Y.; Aliyu, A. Energy-Aware Distributed Multi-Cloud Flower Pollination Optimization Scheme. In Proceedings of the 2018 Seventh ICT International Student Project Conference (ICT-ISPC), Nakhon, Thailand, 11–13 July 2018. [Google Scholar]
- Saber, T.; Ventresque, A.; Gandibleux, X.; Murphy, L. Genepi: A Multi-Objective Machine Reassignment Algorithm for Data Centres. In Proceedings of the International Workshop on Hybrid Metaheuristics, Hamburg, Germany, 11–13 June 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Farahnakian, F.; Ashraf, A.; Pahikkala, T.; Liljeberg, P.; PLoSila, J.; Porres, I.; Tenhunen, H. Using Ant Colony System to Consolidate VMs for Green Cloud Computing. IEEE Trans. Serv. Comput. 2015, 8, 187–198. [Google Scholar] [CrossRef]
- Ashraf, A.; Porres, I. Multi-objective dynamic virtual machine consolidation in the cloud using ant colony system. Int. J. Parallel Emergent Distrib. Syst. 2018, 33, 103–120. [Google Scholar] [CrossRef]
- Liu, X.-F.; Zhan, Z.-H.; Zhang, J. An Energy Aware Unified Ant Colony System for Dynamic Virtual Machine Placement in Cloud Computing. Energies 2017, 10, 609. [Google Scholar] [CrossRef]
- Gupta, P.; Goyal, U.; Verma, V. Cost-Aware ant colony optimization for resource allocation in cloud infrastructure. Recent Adv. Comput. Sci. Commun. 2020, 13, 326–335. [Google Scholar] [CrossRef]
- Shooli, R.G.; Javidi, M.M. Using gravitational search algorithm enhanced by fuzzy for resource allocation in cloud computing environments. SN Appl. Sci. 2020, 2, 195. [Google Scholar] [CrossRef] [Green Version]
- Durgadevi, P.; Srinivasan, S. Resource Allocation in Cloud Computing Using SFLA and Cuckoo Search Hybridization. Int. J. Parallel Program. 2020, 48, 549–565. [Google Scholar] [CrossRef]
- Chen, X.; Wang, H.; Ma, Y.; Zheng, X.; Guo, L. Self-adaptive resource allocation for cloud-based software services based on iterative QoS prediction model. Futur. Gener. Comput. Syst. 2020, 105, 287–296. [Google Scholar] [CrossRef]
- Praveenchandar, J.; Tamilarasi, A. Dynamic resource allocation with optimized task scheduling and improved power management in cloud computing. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 4147–4159. [Google Scholar] [CrossRef]
- Sait, S.M.; Bala, A.; El-Maleh, A.H. Cuckoo search based resource optimization of datacenters. Appl. Intell. 2016, 44, 489–506. [Google Scholar] [CrossRef]
- Ferdaus, M.H.; Murshed, M.; Calheiros, R.N.; Buyya, R. Virtual machine consolidation in cloud data centers using ACO metaheuristic. In Proceedings of the European Conference on Parallel Processing, Porto, Portugal, 25–29 August 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Li, H.; Zhu, G.; Cui, C.; Tang, H.; Dou, Y.; He, C. Energy-efficient migration and consolidation algorithm of virtual machines in data centers for cloud computing. Computing 2016, 98, 303–317. [Google Scholar] [CrossRef]
- Hsieh, S.-Y.; Liu, C.-S.; Buyya, R.; Zomaya, A.Y. Utilization-prediction-aware virtual machine consolidation approach for energy-efficient cloud data centers. J. Parallel Distrib. Comput. 2020, 139, 99–109. [Google Scholar] [CrossRef]
- Haghshenas, K.; Mohammadi, S. Prediction-based underutilized and destination host selection approaches for energy-efficient dynamic VM consolidation in data centers. J. Supercomput. 2020, 76, 10240–10257. [Google Scholar] [CrossRef]
- Shaw, R.; Howley, E.; Barrett, E. Applying reinforcement learning towards automating energy efficient virtual machine consolidation in cloud data centers. Inf. Syst. 2022, 107, 101722. [Google Scholar] [CrossRef]
- Yang, X.S. Flower pollination algorithm for global optimization. In Proceedings of the International Conference on Unconventional Computing and Natural Computation, Orléans, France, 3–7 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 240–249. [Google Scholar]
- Huang, Y.; Cheng, L.; Xue, L.; Liu, C.; Li, Y.; Li, J.; Ward, T. Deep Adversarial Imitation Reinforcement Learning for QoS-Aware Cloud Job Scheduling. IEEE Syst. J. 2021, 10, 1–11. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, H.; Deng, X.; Li, K.; Li, K. A scheduling scheme in the cloud computing environment using deep Q-learning. Inf. Sci. 2020, 512, 1170–1191. [Google Scholar] [CrossRef]
- Chen, X.; Cheng, L.; Liu, C.; Liu, Q.; Liu, J.; Mao, Y.; Murphy, J. A WOA-Based Optimization Approach for Task Scheduling in Cloud Computing Systems. IEEE Syst. J. 2020, 14, 3117–3128. [Google Scholar] [CrossRef]
- Tran, M.N.; Kim, Y. A Cloud QoS-driven Scheduler based on Deep Reinforcement Learning. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 15–19 October 2021; IEEE: New York, NY, USA, 2021; pp. 1823–1825. [Google Scholar]
- Askarizade Haghighi, M.; Maeen, M.; Haghparast, M. An energy-efficient dynamic resource management approach based on clustering and meta-heuristic algorithms in cloud computing IaaS platforms. Wirel. Pers. Commun. 2019, 104, 1367–1391. [Google Scholar] [CrossRef]
- Vaneet, G.; Jindal, B. Energy efficient virtual machine migration approach with SLA conservation in cloud computing. J. Cent. South Univ. 2021, 28, 760–770. [Google Scholar]
- Bloch, T.A.; Rajagopal, S.; Ranga, P.C. IAGA: Interference Aware Genetic Algorithm based VM Allocation Policy for Cloud Systems. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 754–765. [Google Scholar] [CrossRef]
- Forestiero, A.; Papuzzo, G. Agents-Based Algorithm for a Distributed Information System in Internet of Things. IEEE Internet Things J. 2021, 8, 16548–16558. [Google Scholar] [CrossRef]
- Gul, F.; Mir, I.; Abualigah, L.; Sumari, P.; Forestiero, A. A Consolidated Review of Path Planning and Optimization Techniques: Technical Perspectives and Future Directions. Electronics 2021, 10, 2250. [Google Scholar] [CrossRef]
- Lin, W.; Xu, S.; He, L.; Li, J. Multi-resource scheduling and power simulation for cloud computing. Inf. Sci. 2017, 397, 168–186. [Google Scholar] [CrossRef]
- Skendžić, A.; Kovačić, B.; Tijan, E. Effectiveness analysis of using Solid State Disk technology. In Information and Communication Technology, Electronics and Microelectronics (MIPRO), Proceedings of the 2016 39th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 30 May–3 June 2016; IEEE: New York, NY, USA, 2016. [Google Scholar]
- Ferdaus, M.H. Multi-objective, Decentralized Dynamic Virtual Machine Consolidation using ACO Metaheuristic in Computing Clouds. arXiv 2017, arXiv:1706.06646. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) | ||
| Cloud Entity | Parameter | Value |
| Datacenter | Number | 1 |
| PM | RAM | 2,048,000 MB |
| Disk | 10,000,000 MB | |
| Operating System | Linux | |
| Bandwidth | 1,000,000,000 MB | |
| Architecture | x86 | |
| VM Manager | Xen | |
| CPU Power Model | PowerModelSpecPowerX3550XeonX5675 | |
| Storage Power Model | PowerModelStorageSimple | |
| MemoryPower Model | PowerModelMemorySimple | |
| VM | RAM | 2,048,000 MB |
| Bandwidth | 0.1 GB/s | |
| MIPS | 367 MHz | |
| Storage | 1,000,000 MB | |
| (b) | ||
| Algorithms | Parameter | Value |
| MOH-FPRC | Population size | 50, 100, 150, 200 |
| Standard gamma function β | 1.5 | |
| Random walk L | ∈ [0, 1] | |
| Switching Probability p [0, 1] | 0.6–1.0 | |
| Maximum iteration | 1000 | |
| FPA | Population size | 50, 100, 150, 200 |
| Standard gamma function β | 1.5 | |
| Random walk L | ∈ [0, 1] | |
| Switching Probability p [0, 1] | 0.9 | |
| Maximum iteration | 1000 | |
| MOACS/ACS-VMC | Population size | 50, 100, 150, 200 |
| Crossover rate | 0.5 | |
| Pheromone tracking weight α | 0.3 | |
| Heuristic information weight β | 1 | |
| Pheromone updating constant Q | 100 | |
| Maximum iteration | 1000 | |
| Algorithm | MOH-FPRC | ACS-VMC | MOACS | |||
|---|---|---|---|---|---|---|
| VM Request | Energy Consumption (kWh) | SLA Violation % | Energy Consumption (kWh) | SLA Violation % | Energy Consumption (kWh) | SLA Violation % |
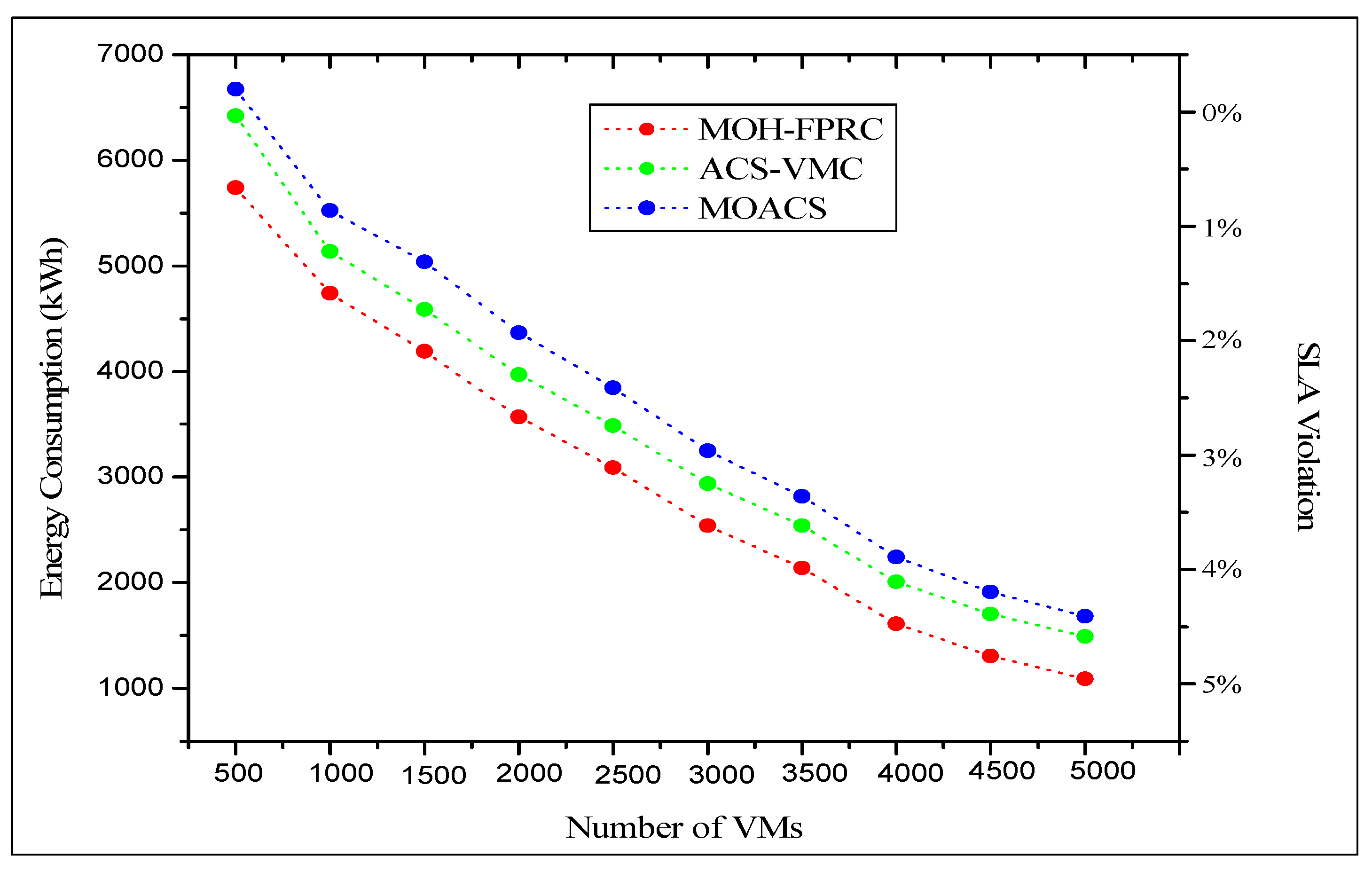
| 500 | 1089.25 | 0.00 | 1489.35 | 0.201 | 1589.45 | 0.220 |
| 1000 | 1304.05 | 0.00 | 1704.18 | 0.252 | 1804.11 | 0.251 |
| 1500 | 1609.32 | 0.15 | 2009.97 | 0.304 | 2109.76 | 0.312 |
| 2000 | 2139.84 | 0.20 | 2539.47 | 0.305 | 2639.34 | 0.325 |
| 2500 | 2539.21 | 0.25 | 2939.53 | 0.308 | 3039.62 | 0.339 |
| 3000 | 3089.59 | 0.30 | 3489.48 | 0.319 | 3589.46 | 0.339 |
| 3500 | 3569.35 | 0.35 | 3969.36 | 0.301 | 4069.64 | 0.342 |
| 4000 | 4189.87 | 0.40 | 4589.95 | 0.318 | 4689.89 | 0.342 |
| 4500 | 4739.65 | 0.42 | 5139.54 | 0.41 | 5139.41 | 0.401 |
| 5000 | 5739.14 | 0.48 | 6420.25 | 0.50 | 6200.96 | 0.50 |
| Algorithm | MOH-FPRC | ACS-VMC | MOACS | |||
|---|---|---|---|---|---|---|
| PM Utilization | Energy Consumption (kWh) | SLA Violation % | Energy Consumption (kWh) | SLA Violation % | Energy Consumption (kWh) | SLA Violation % |
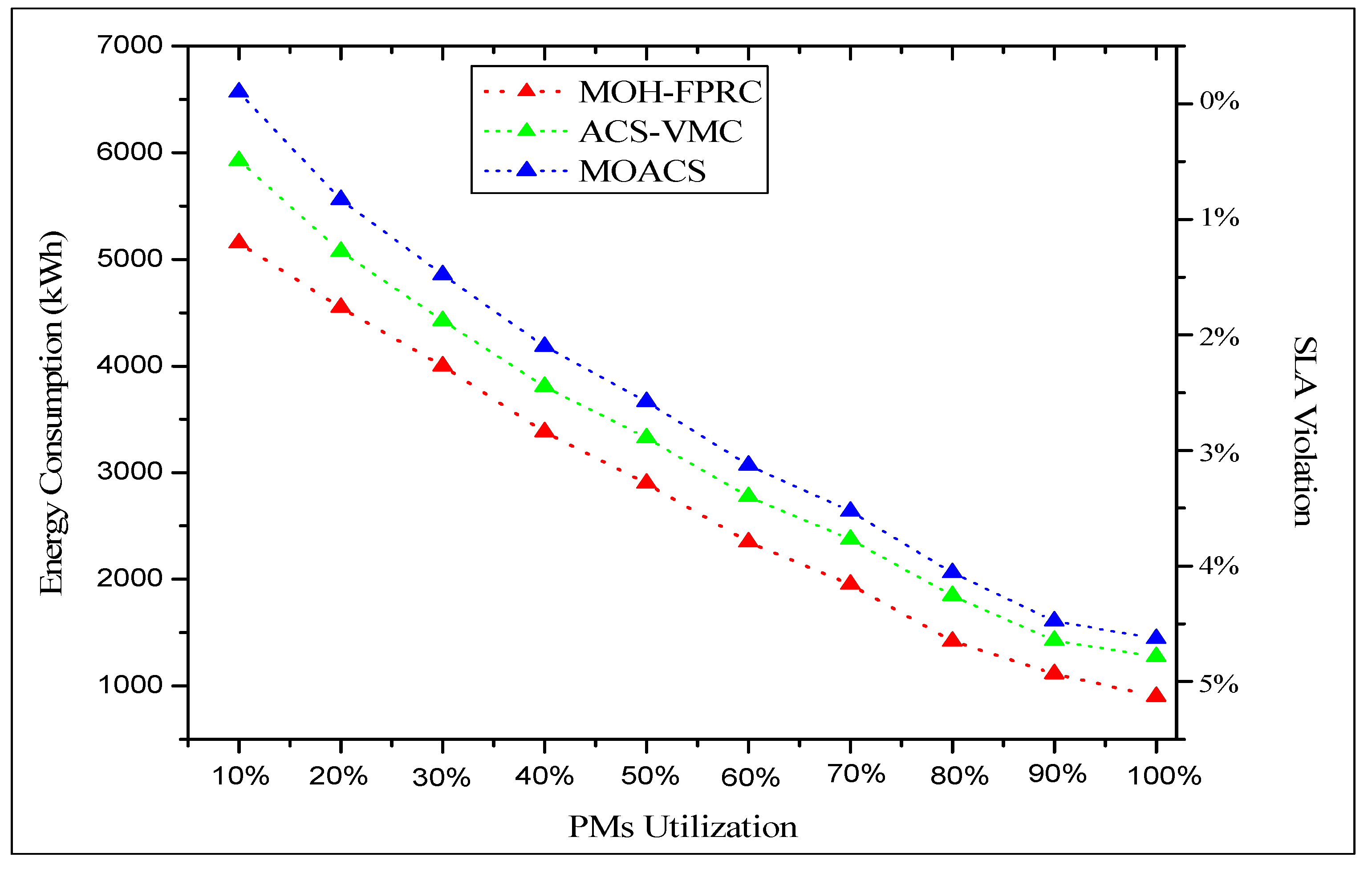
| 10 | 900.021 | 0.00 | 1275.25 | 0.21 | 1370.59 | 0.22 |
| 20 | 1115.50 | 0.01 | 1427.05 | 0.25 | 1522.36 | 0.25 |
| 30 | 1420.11 | 0.15 | 1845.32 | 0.34 | 1940.21 | 0.32 |
| 40 | 1950.01 | 0.20 | 2375.84 | 0.35 | 2470.58 | 0.35 |
| 50 | 2350.27 | 0.25 | 2775.21 | 0.38 | 2870.98 | 0.39 |
| 60 | 2900.14 | 0.31 | 3325.59 | 0.31 | 3420.74 | 0.39 |
| 70 | 3380.89 | 0.33 | 3805.11 | 0.38 | 3900.51 | 0.32 |
| 80 | 4010.22 | 0.37 | 4425.23 | 0.38 | 4520.45 | 0.32 |
| 90 | 4550.82 | 0.40 | 5075.87 | 0.41 | 5170.67 | 0.41 |
| 100 | 5150.42 | 0.43 | 5925.64 | 0.50 | 6100.07 | 0.50 |
| MOH-FPRC | ACS-VMC | MOACS | |
|---|---|---|---|
| Total average energy consumption and SLA violation | 5150.42 | 5925.64 | 6100.07 |
| 0.43 | 0.50 | 0.50 | |
| PI over ACS-VMC and MOACS (kWh) | -- | 14.54% | 29.48% |
| PI over ACS-VMC and MOACS (SLA violation) | -- | 13.57% | 13.57% |
| Algorithms | MOH-FPRC | ACS-VMC | MOACS | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number of PM | Number of VM | MAD Number of Migration | ST Number of Migration | IQR Number of Migration | MAD Number of Migration | ST Number of Migration | IQR Number of Migration | MAD Number of Migration | IQR Number of Migration | ST Number of Migration |
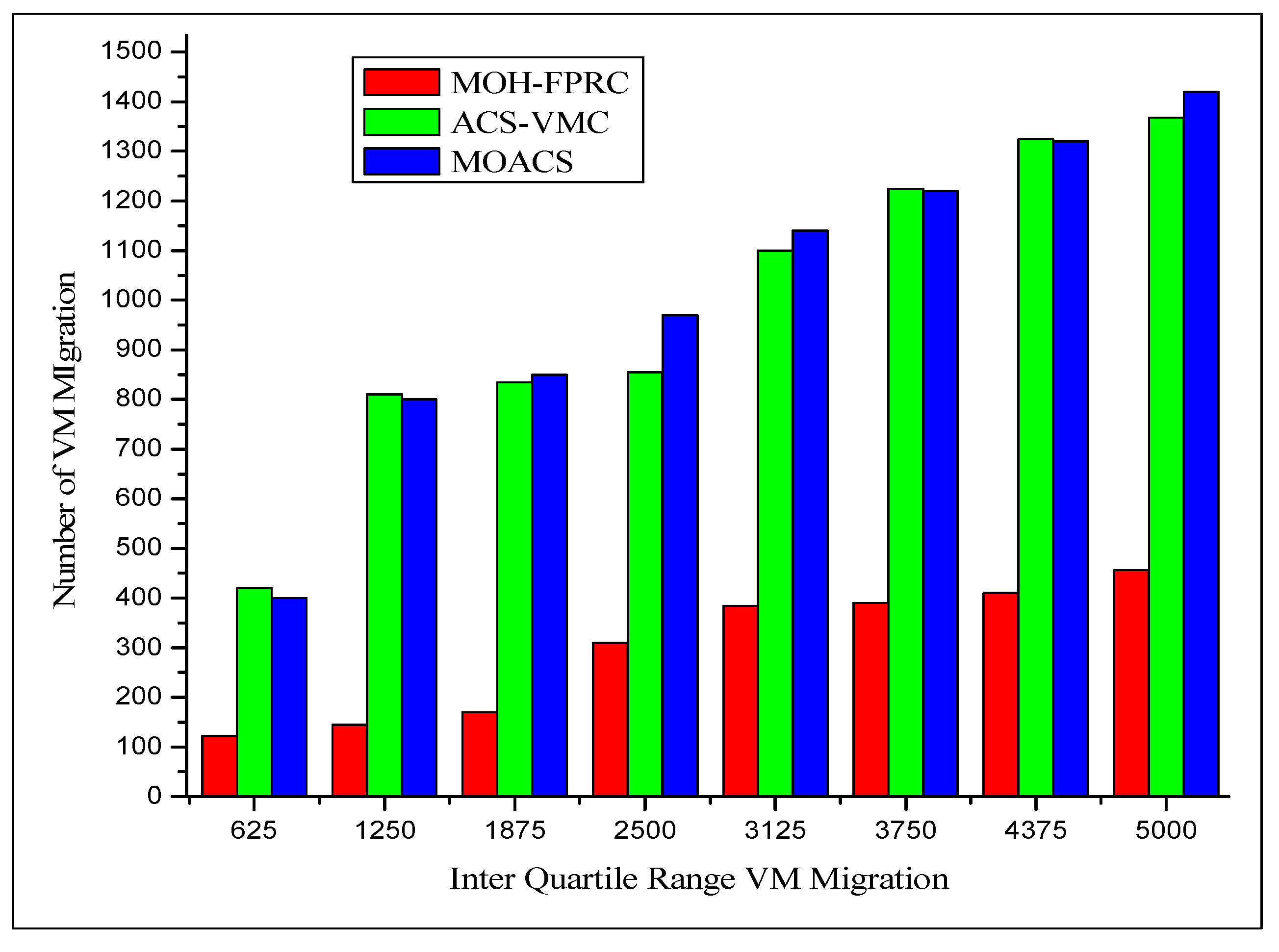
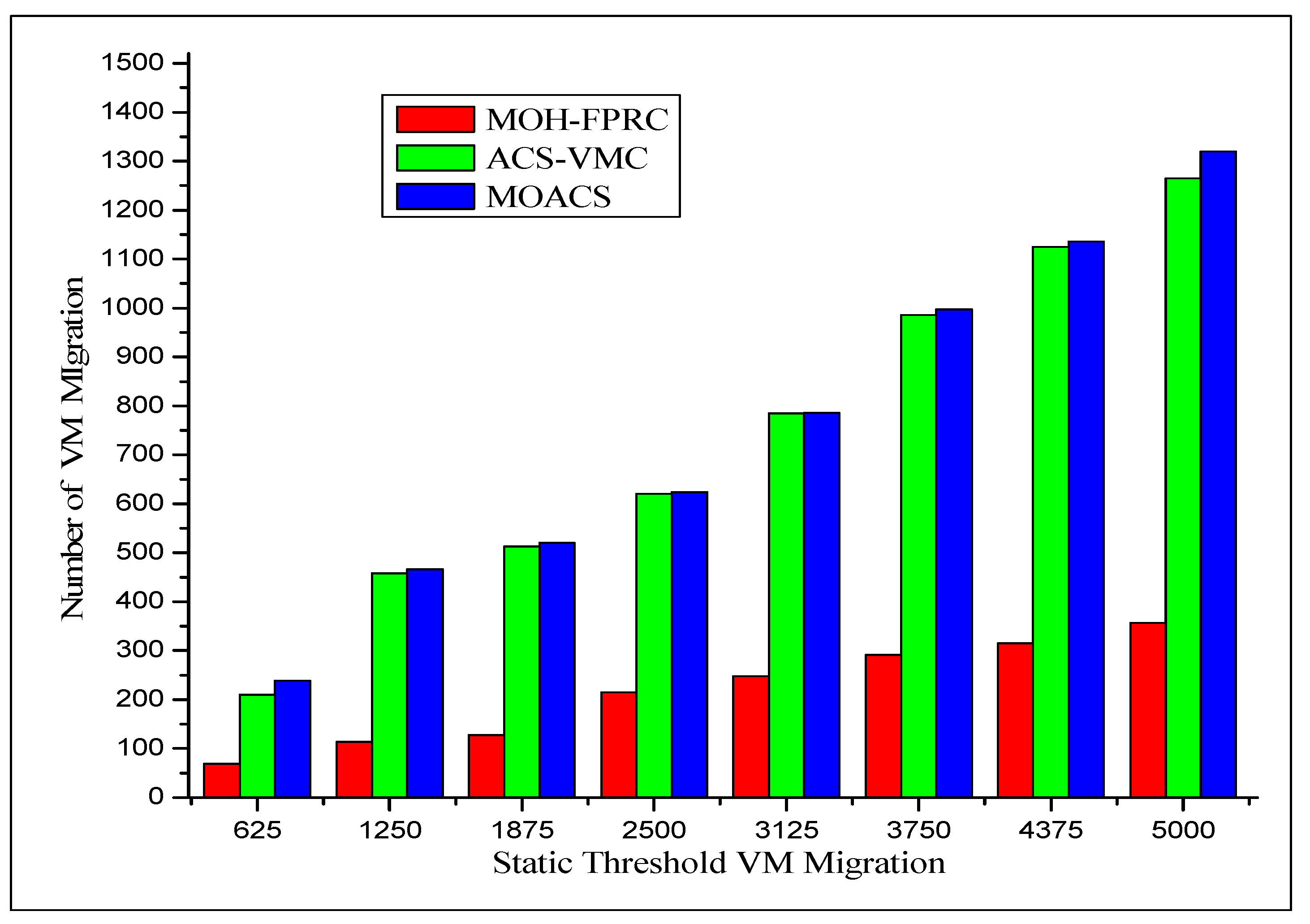
| 100 | 625 | 287 | 69 | 122 | 300 | 210 | 420 | 323 | 400 | 239 |
| 200 | 1250 | 520 | 114 | 145 | 535 | 458 | 810 | 540 | 800 | 466 |
| 300 | 1875 | 754 | 128 | 170 | 760 | 513 | 835 | 761 | 850 | 520 |
| 400 | 2500 | 805 | 215 | 310 | 810 | 621 | 855 | 810 | 970 | 624 |
| 500 | 3125 | 973 | 248 | 384 | 985 | 785 | 1100 | 982 | 1140 | 786 |
| 600 | 3750 | 1222 | 291 | 390 | 1240 | 986 | 1225 | 1238 | 1220 | 997 |
| 700 | 4375 | 1298 | 315 | 410 | 1310 | 1125 | 1324 | 1312 | 1320 | 1136 |
| 800 | 5000 | 1356 | 357 | 456 | 1400 | 1265 | 1368 | 1405 | 1420 | 1329 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Usman, M.J.; Gabralla, L.A.; Aliyu, A.; Gabi, D.; Chiroma, H. Multi-Objective Hybrid Flower Pollination Resource Consolidation Scheme for Large Cloud Data Centres. Appl. Sci. 2022, 12, 8516. https://doi.org/10.3390/app12178516
Usman MJ, Gabralla LA, Aliyu A, Gabi D, Chiroma H. Multi-Objective Hybrid Flower Pollination Resource Consolidation Scheme for Large Cloud Data Centres. Applied Sciences. 2022; 12(17):8516. https://doi.org/10.3390/app12178516
Chicago/Turabian StyleUsman, Mohammed Joda, Lubna A. Gabralla, Ahmed Aliyu, Danlami Gabi, and Haruna Chiroma. 2022. "Multi-Objective Hybrid Flower Pollination Resource Consolidation Scheme for Large Cloud Data Centres" Applied Sciences 12, no. 17: 8516. https://doi.org/10.3390/app12178516
APA StyleUsman, M. J., Gabralla, L. A., Aliyu, A., Gabi, D., & Chiroma, H. (2022). Multi-Objective Hybrid Flower Pollination Resource Consolidation Scheme for Large Cloud Data Centres. Applied Sciences, 12(17), 8516. https://doi.org/10.3390/app12178516