
A Compact Cat Swarm Optimization Algorithm Based on Small Sample Probability Model


Abstract
:1. Introduction
2. Related Work
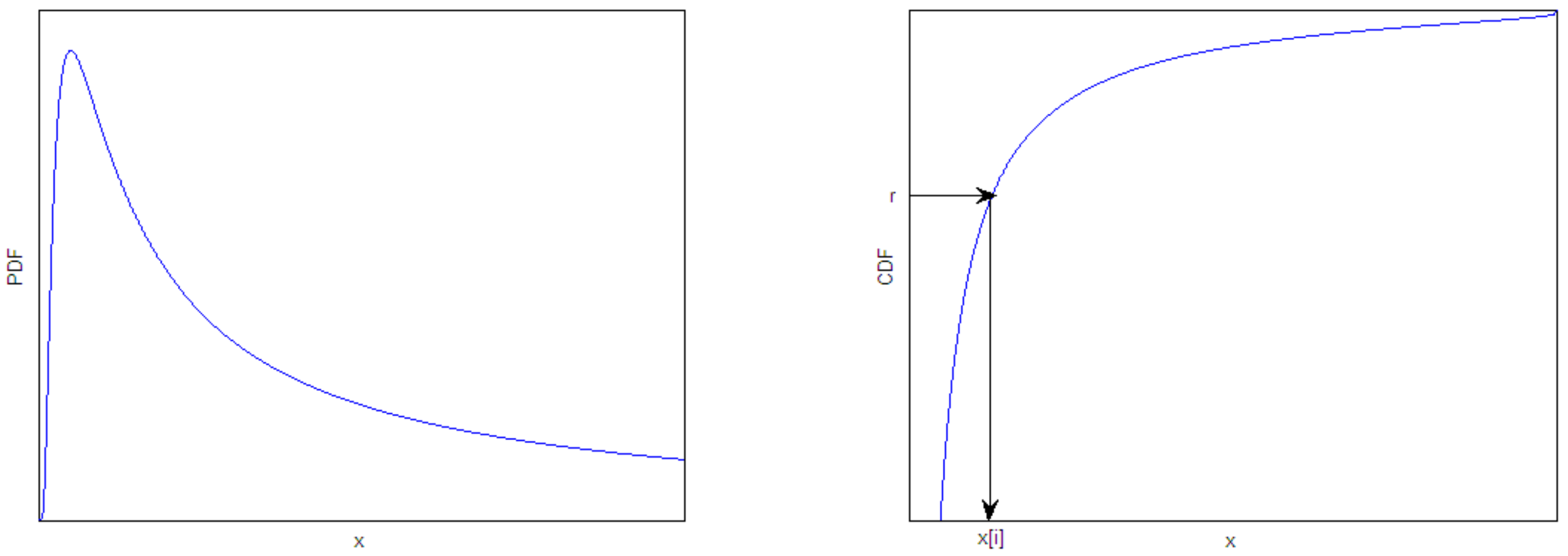
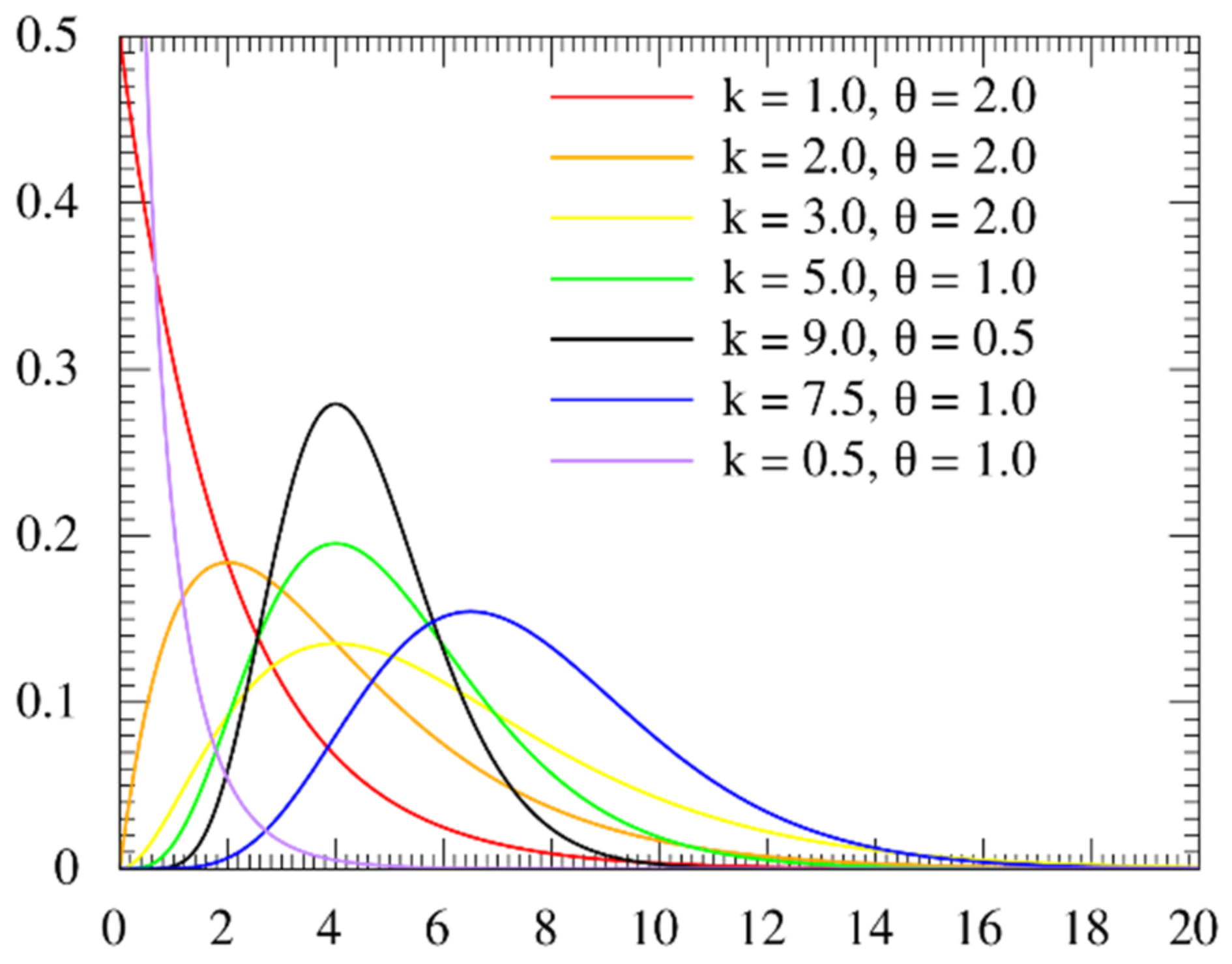
2.1. The Sampling Mechanism Based on Real-Valued
2.2. Cat Swarm Optimization (CSO)
2.2.1. Seeking Mode
2.2.2. Tracing Mode
3. The Proposed Compact Cat Swarm Optimization Scheme Based on Small Sample Probability Model (SSPCCSO)
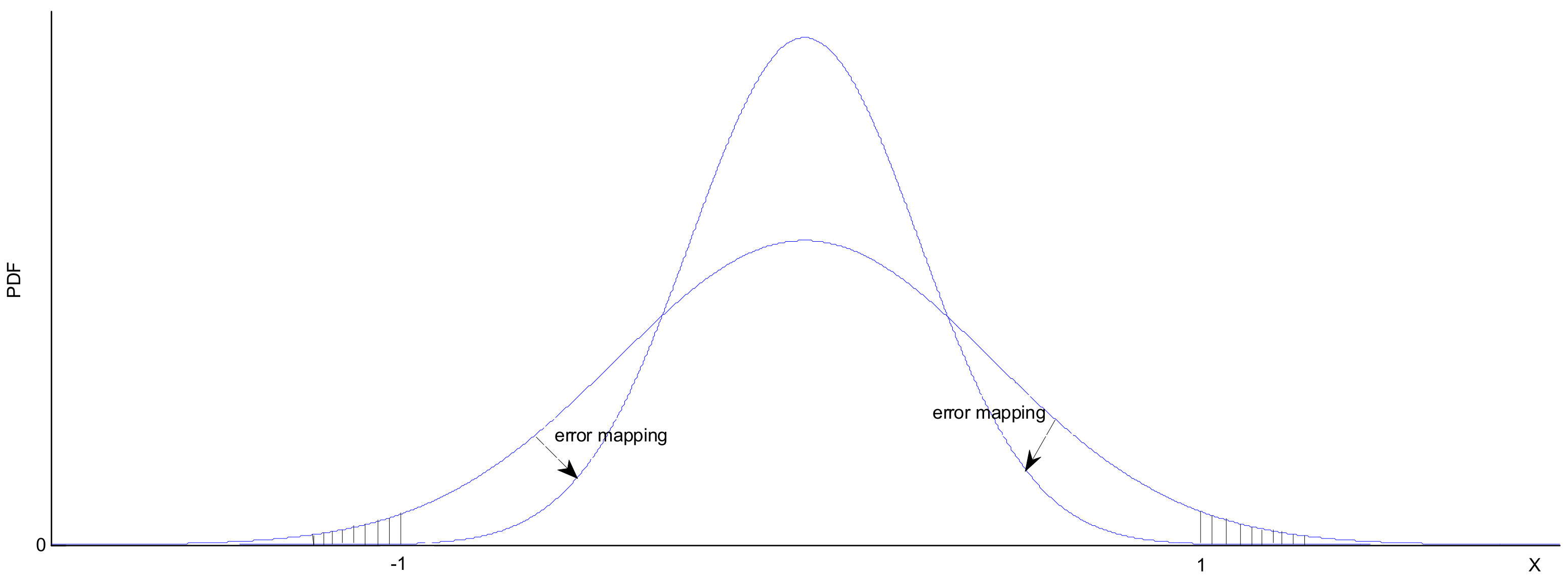
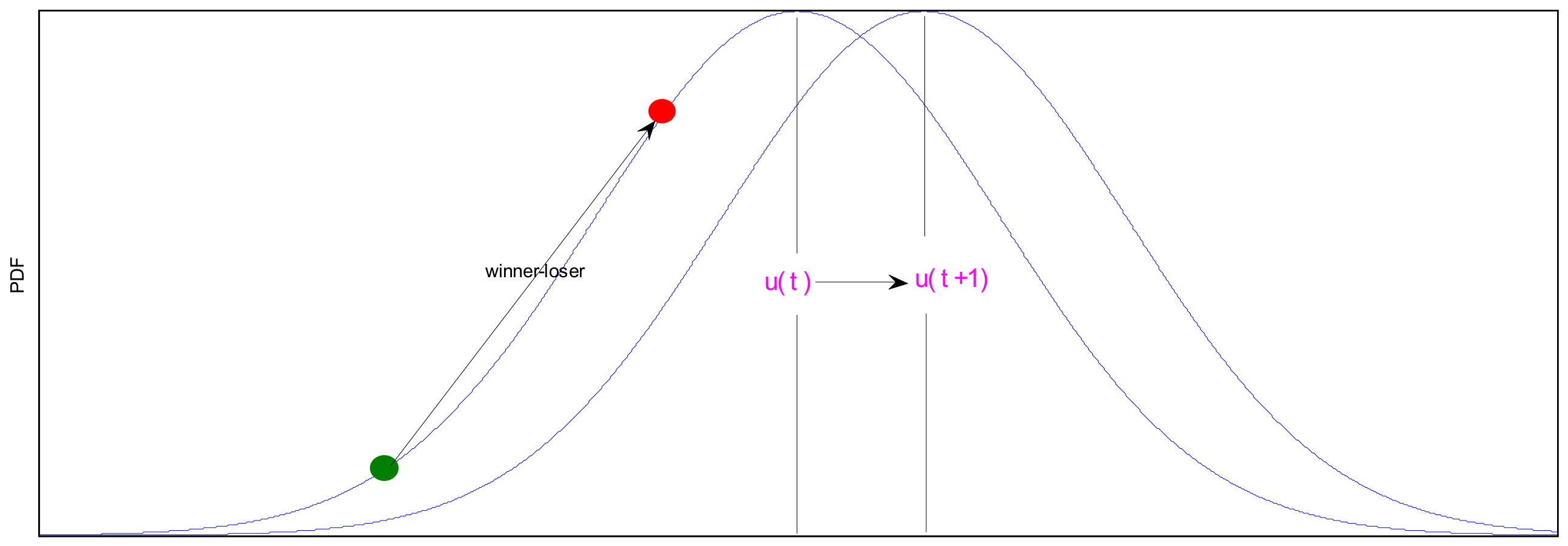
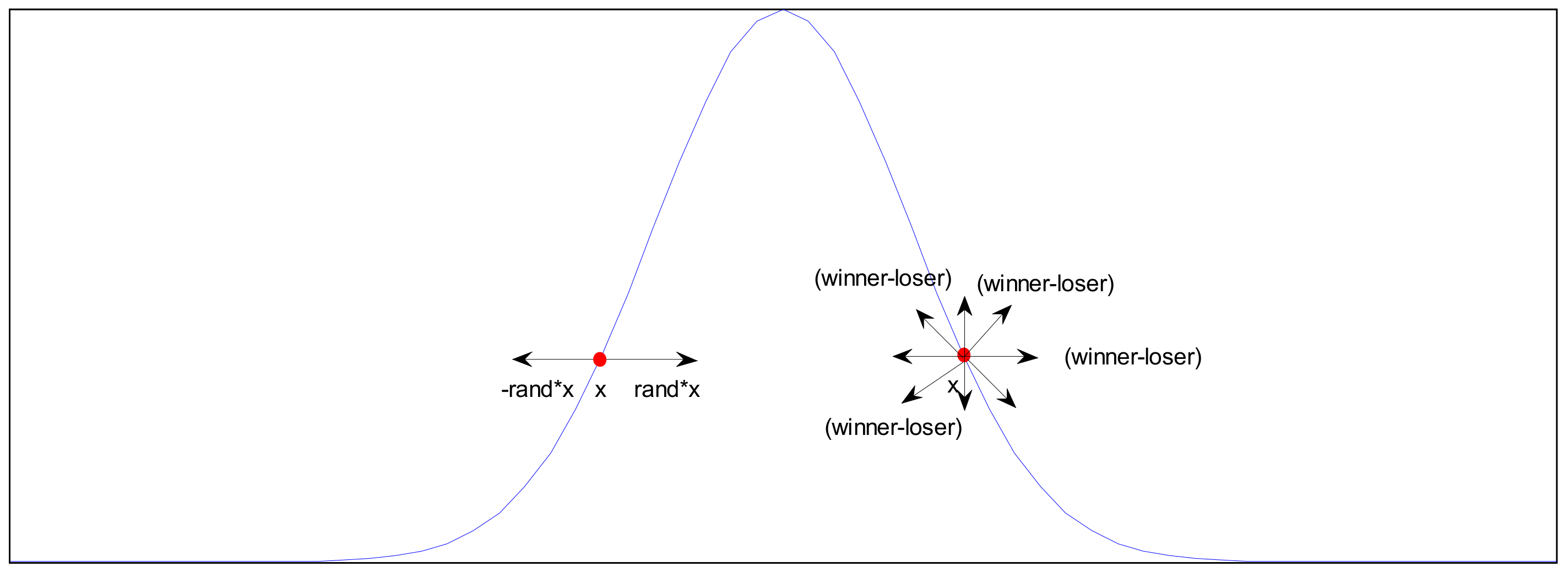
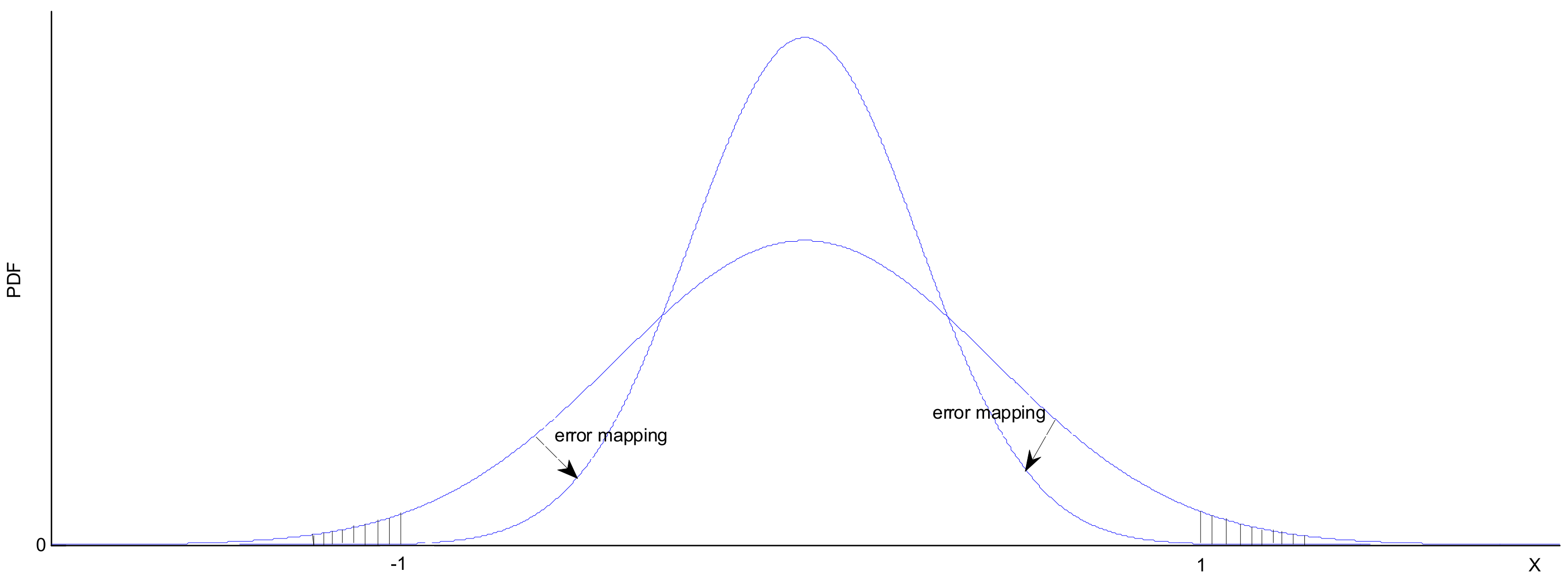
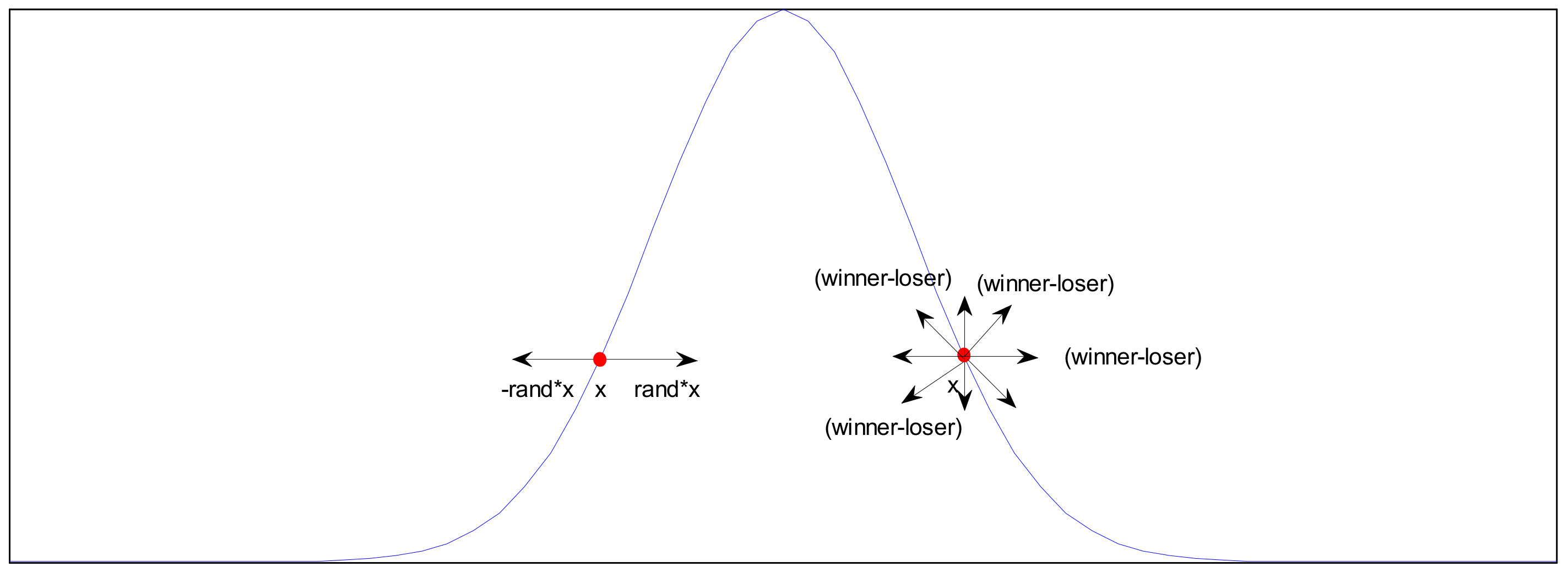
3.1. Virtual Population and Sampling Mechanism with Real-Valued
The Perturbation Vector Updating Rule
3.2. Seeking Mode
3.2.1. Differential Operator
3.2.2. Gradient Descent Method
3.3. Tracing Mode
3.4. The Procedure and Pseudo Code for SSPCCSO
4. Experimental Results and Analysis
4.1. Comparison for Memory Usage
4.2. Comparisons for Compact Optimization Algorithms
4.3. Comparison between the Corresponding Population-Based Algorithms and SSPCCSO
4.4. Comparison against Swarm-Based Version Algorithms Based on Iterations and Solution
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Harik, G.R.; Lobo, F.G.; Goldberg, D.E. The compact genetic algorithm. IEEE Trans. Evol. Comput. 1999, 3, 287–297. [Google Scholar] [CrossRef]
- Mininno, E.; Cupertino, F.; Naso, D. Real-valued compact genetic algorithms for embedded microcontroller optimization. IEEE Trans. Evol. Comput. 2008, 12, 203–219. [Google Scholar] [CrossRef]
- Mininno, E.; Neri, F.; Cupertino, F.; Naso, D. Compact differential evolution. IEEE Trans. Evol. Comput. 2011, 15, 32–54. [Google Scholar] [CrossRef]
- Neri, F.; Mininno, E.; Iacca, G. Compact Particle Swarm Optimization. Inf. Sci. 2013, 239, 96–121. [Google Scholar] [CrossRef]
- Zhao, M. A novel compact cat swarm optimization based on differential method. Enterp. Inf. Syst. 2020, 14, 196–220. [Google Scholar] [CrossRef]
- Muzaffar, E.; Kevin, L.; Fayzul, P. Shuffled frog-leaping algorithm: A memetic meta-heuristic for discrete optimization. Eng. Optim. 2001, 38, 129–154. [Google Scholar] [CrossRef]
- Li, L.X.; Shao, Z.J.; Qian, J.X. An optimizing method based on autonomous animals: Fish-swarm algorithm. Syst. Eng. Theory Pract. 2002, 22, 32–38. [Google Scholar]
- Luo, X.; Yang, Y.; Li, X. Modified shuffled frog-leaping algorithm to solve traveling salesman problem. J. Commun. 2009, 30, 130–135. [Google Scholar]
- Luo, J.; Li, X. Improved shuffled frog leaping algorithm for solving TSP. J. Shenzhen Univ. Sci. Eng. 2010, 27, 173–179. [Google Scholar]
- Chu, S.C.; Tsai, P.W.; Pan, J.S. Cat swarm optimization. In Proceedings of the 9th Pacific Rim International Conference on Artificial Intelligence, Guilin, China, 7–11 August 2006; pp. 854–858. [Google Scholar]
- Tsai, P.W.; Pan, J.S.; Chen, S.M.; Liao, B.Y.; Hao, S.P. Parallel cat swarm optimization. In Proceedings of the Seventh International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; pp. 3328–3333. [Google Scholar]
- Wang, Z.H.; Chang, C.C.; Li, M.C. Optimizing least-significant-bit substitution using cat swarm. Inf. Sci. 2012, 192, 98–108. [Google Scholar] [CrossRef]
- Available online: https://en.wikipedia.org/wiki/Gamma_distribution#/media/File:Gamma_distribution_pdf.svg (accessed on 1 March 2022).
- Panda, G.; Pradhan, P.M.; Majhi, B. IIR system identification using cat swarm optimization. Expert Syst. Appl. 2011, 38, 12671–12683. [Google Scholar] [CrossRef]
- Gautschi, W. Error Function and Fresnel Integrals. In Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables; Abramowitz, M., Stegun, I.A., Eds.; Dover Publications: Mineola, NY, USA, 1972; Chapter 7; pp. 297–309. [Google Scholar]
- Cody, W.J. Rational Chebyshev approximations for the error function. Math. Comput. 1969, 23, 631–637. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Luc, D. Non-Uniform Random Variate Generation; Springer: New York, NY, USA, 1986; Chapter 9, Section 3; pp. 401–428. [Google Scholar]
- Snyman, J.A. Practical Mathematical Optimization: An Introduction to Basic Optimization Theory and Classical and New Gradient-Based Algorithms; Springer: New York, NY, USA, 2005. [Google Scholar]
- Wang, H.; Xu, X. Stop Criterion Based on Convergence Properties of GA. J. Wuhan Univ. Technol. Transp. Sci. Eng. 2012, 36, 1091–1094. [Google Scholar]
- Tang, K.; Yao, X.; Suganthan, P.N.; MacNish, C.; Chen, Y.P.; Chen, C.M.; Yang, Z. Benchmark Functions for the CEC’ 2008 Special Session and Competition on Large Scale Global Optimization; Nature Inspired Computation and Applications Laboratory, USTC: Hefei, China, 2007. [Google Scholar]
- Liang, J.J.; Suganthan, P.N.; Deb, K. Novel Composition Test Functions for Numerical Global Optimization. In Proceedings of the 2005 IEEE Swarm Intelligence Symposium, Pasadena, CA, USA, 8–10 June 2005; pp. 68–75. [Google Scholar]
- Neri, F.; Tirronen, V. Recent advances in differential evolution: A review and experimental analysis. Artif. Intell. Rev. 2010, 33, 61–106. [Google Scholar] [CrossRef]
- Clerc, M. Particle Swarm Optimization Webpage. Available online: http://clerc.maurice.free.fr/pso/ (accessed on 1 March 2022).
- Zhou, J.; Ji, Z.; Shen, L. Simplified intelligence single particle optimization based neural network for digit recognition. In Proceedings of the Chinese Conference on Pattern Recognition, Beijing, China, 22–24 October 2008; pp. 1031–1847. [Google Scholar]
- Pedersen, M.E.H. Good Parameters for Particle Swarm Optimization; Technical Report no. HL1001; Hvass Lab.: Copenhagen, Denmark, 2010. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameters | Literature | Algorithm | Parameters | Literature |
|---|---|---|---|---|---|
| rcGA | [1] | DE | [23] | ||
| cDE | [2] | PSO | [24] | ||
| cPSO | [3] | ISPO | [25] | ||
| CSO | [10] | SSPCCSO |
| Algorithm | Components | Memory Slots |
|---|---|---|
| ISPO | Single individual, 1 global best | 2 |
| rcGA | One individual, persistent elitism, 1 sampling | 4 |
| cDE | 3 sampling, 1 global best | 4 |
| cPSO | 1 sampling, 5 persistent variables | 5 |
| SSPCCSO | The same to cPSO | 5 |
| PSO | Population-based, history and current individuals | 2NP |
| DE | Population-based, current individuals only | NP |
| CSO | Population-based, history and current individuals | 2NP |
| Function | rCGA | cDE | ISPO | cPSO | W | SSPCCSO |
|---|---|---|---|---|---|---|
| fu1 | 1.427 × 104 ± 9.27 × 103 | 8.73 × 10−28 ± 1.86 × 10−28 | 8.437 × 10−31 ± 3.31 × 10−31 | 6.471 × 101 ± 2.28 × 101 | + | 6.170 × 10−3 ± 1.05 × 10−3 |
| fu2 | 2.851 × 104 ± 6.58 × 103 | 3.778 × 103 ± 1.85 × 103 | 1.184 × 101 ± 5.92 × 100 | 2.560 × 103 ± 2.37 × 103 | + | 3.625 × 102 ± 7.02 × 102 |
| fu3 | 1.282 × 109 ± 1.58 × 109 | 1.291 × 102± 1.84 × 102 | 2.026 × 102 ± 3.28 × 102 | 1.320 × 105 ± 7.46 × 104 | + | 5.776 × 10−1 ± 7.01 × 100 |
| fu4 | 1.874 × 101 ± 3.59 × 10−1 | 8.694 × 10−2 ± 2.97 × 10−1 | 1.942 × 101 ± 1.57 × 10−1 | 3.728 × 100 ± 3.71 × 10−1 | + | 5.574 × 10−1 ± 3.07 × 10−2 |
| fu5 | 6.434 × 10−3 ± 1.31 × 10−2 | 4.289 × 10−3 ± 1.38 × 10−2 | 1.124 × 101 ± 1.77 × 101 | 9.63 × 10−8 ± 3.07 × 10−8 | − | 1.613 × 10−2 ± 2.37 × 10−3 |
| fu6 | 1.963 × 102 ± 2.85 × 101 | 7.944 × 101 ± 1.48 × 101 | 2.548 × 102± 4.23 × 101 | 2.94 × 101 ± 7.94 × 100 | + | 2.399 × 10−2 ± 4.09 × 10−3 |
| fu7 | 2.312 × 103 ± 2.47 × 103 | 4.983 × 103 ± 3.78 × 103 | 2.254 × 103 ± 8.62 × 102 | 4.614 × 102 ± 2.40 × 102 | + | 2.991 × 102 ± 1.75 × 10−1 |
| fu8 | 3.194 × 103 ± 8.01 × 102 | 1.673 × 103 ± 4.48 × 102 | 5.768 × 103 ± 5.38 × 102 | 3.160 × 103 ± 9.75 × 102 | + | 1.248 × 101 ± 1.90 × 100 |
| fu9 | 1.008 × 104 ± 2.35 × 103 | 8.548 × 103 ± 2.14 × 103 | 2.755 × 104 ± 6.08 × 103 | 1.344 × 104 ± 1.74 × 103 | − | 1.111 × 105 ± 5.29 × 104 |
| fu10 | 3.697 × 105 ± 1.78 × 105 | 4.265 × 104 ± 2.35 × 104 | 4.326 × 103± 4.54 × 103 | 1.040 × 106 ± 1.16 × 105 | + | 9.390 × 105 ± 1.13 × 104 |
| fu11 | 1.851 × 101 ± 4.37 × 10−1 | 1.708 × 100 ± 1.11 × 100 | 1.948 × 101 ± 1.89 × 10−1 | 3.699 × 100 ± 3.53 × 10−1 | + | 8.328 × 10−2 ± 8.23 × 10−2 |
| fu12 | 5.769 × 10−2 ± 1.05 × 10−1 | 2.395 × 10−1 ± 2.03 × 10−1 | 0.001 × 10−1± 0.01× 100 | 9.567 × 10−8 ± 2.69 × 10−8 | + | 1.018 × 10−8± 2.61 × 10−9 |
| fu13 | 2.154 × 102 ± 3.96 × 101 | 1.314 × 102 ± 1.87 × 101 | 2.566 × 102 ± 4.15 × 101 | 3.924 × 101 ± 2.31 × 101 | − | 2.70 × 102 ± 1.81 × 10−5 |
| fu14 | 3.246 × 101 ± 4.53 × 100 | 2.988 × 101 ± 3.47 × 100 | 4.777 × 101 ± 4.34 × 100 | 3.943 × 101 ± 1.15 × 100 | − | 7.142 × 102 ± 2.37 × 10−1 |
| fu15 | 5.251 × 100 ± 5.19 × 100 | 2.315 × 10−16 ± 5.65 × 10−16 | 1.184 × 10−6 ± 2.89 × 10−17 | 1.778 × 100 ± 4.27 × 10−1 | + | 9.427 × 10−3 ± 6.15 × 10−3 |
| fu16 | −1.001 × 102 ± 4.43 × 10−9 | −1.001 × 102 ± 1.63 × 10−9 | −1.001 × 102 ± 8.38 × 10−15 | −1.001 × 102 ± 8.45 × 10−5 | = | −1.001 × 102 ± 0.00 × 100 |
| fu17 | 1.452 × 100 ± 1.88 × 100 | 2.817 × 10−23 ± 3.16 × 10−23 | 9.994 × 10−1 ± 1.56 × 100 | 1.702 × 100 ± 7.08 × 10−1 | + | 9.518 × 10−5 ± 1.57 × 10−6 |
| fu18 | −5.485 × 10−1 ± 1.11 × 100 | −1.150 × 100 ± 4.98 × 10−16 | −2.258 × 10−1 ± 1.28 × 100 | −1.030 × 100± 7.56 × 10−1 | − | −4.104 × 10−1± 8.97 × 10−4 |
| fu19 | 4.338 × 102 ± 4.75 × 101 | 2.603 × 102 ± 3.04 × 101 | 4.044 × 102 ± 4.15 × 101 | 4.403 × 101 ± 3.44 × 101 | − | 4.500 × 102 ± 2.60 × 10−3 |
| fu20 | −1.517 × 101 ± 2.76 × 100 | −3.347 × 101 ± 1.87 × 100 | −3.348 × 101 ± 1.64 × 100 | −2.063 × 101 ± 2.33 × 100 | − | −1.988 × 101 ± 2.33 × 10−1 |
| fu21 | 8.372 × 103 ± 1.62 × 103 | 5.343 × 103 ± 8.47 × 102 | 9.679 × 103 ± 1.09 × 103 | 4.784 × 103 ± 1.09 × 103 | − | 1.42 × 100 ± 2.26 × 100 |
| fu22 | 2.014 × 101 ± 1.48 × 10−1 | 1.787 × 101 ± 2.89 × 10−1 | 1.951 × 101 ± 7.51 × 10−2 | 3.899 × 10−1 ± 5.19 × 10−1 | + | 7.139 × 10−2 ± 4.17 × 10−2 |
| fu23 | 1.645 × 102 ± 2.36 × 101 | 4.042 × 101 ± 1.41 × 101 | 1.247 × 10−13± 1.01 × 10−14 | 4.657 × 10−2± 2.39 × 10−2 | = | 7.319 × 10−2 ± 5.17 × 10−3 |
| fu24 | 8.488 × 104 ± 8.14 × 103 | 2.941 × 103 ± 1.59 × 103 | 1.252 × 10−30± 3.09 × 10−31 | 6.918 × 10−2 ± 2.54 × 10−2 | − | 8.961 × 10−3 ± 1.46 × 10−2 |
| fu25 | −6.349 × 10−3± 3.24 × 10−4 | −9.161 × 10−3 ± 6.27 × 10−4 | −4.551 × 10−3 ± 3.79 × 10−4 | −7.85 × 10−1 ± 1.60 × 10−14 | − | 0.000 × 100 ± 0.00 × 100 |
| fu26 | −2.178 × 101 ± 3.09 × 100 | −4.938 × 101 ± 3.54 × 100 | −6.556 × 101 ± 3.18 × 100 | −2.920 × 101 ± 2.53 × 100 | = | −3.970 × 101 ± 1.52 × 10−1 |
| fu27 | 2.524 × 105 ± 2.58 × 104 | 1.051 × 104 ± 6.31 × 103 | 3.498 × 10−30± 8.75 × 10−31 | 2.217 × 10−2 ± 4.04 × 10−3 | − | 1.033 × 10−2 ± 1.39 × 10−2 |
| fu28 | 1.166 × 103 ± 7.35 × 101 | 4.218 × 102 ± 3.72 × 101 | 7.942 × 102 ± 7.69 × 101 | 8.776 × 10−3 ± 2.88 × 10−3 | = | 6.631 × 10−3 ± 1.24 × 10−4 |
| fu29 | 6.906 × 1010 ± 1.38 × 1010 | 5.643 × 108 ± 4.98 × 108 | 3.503 × 102 ± 3.91 × 102 | 1.220 × 102 ± 2.81 × 101 | + | 1.286 × 100 ± 2.50 × 100 |
| fu30 | 1.297 × 1011 ± 2.63 × 1010 | 7.066 × 1010 ± 1.19 × 1010 | 9.702 × 109 ± 3.26 × 109 | 4.928 × 106 ± 6.56 × 105 | − | 1.109 × 108 ± 3.44 × 108 |
| fu31 | 2.148 × 104 ± 2.51 × 103 | 1.842 × 104 ± 1.29 × 103 | 1.971 × 104 ± 1.28 × 103 | 1.045 × 104 ± 2.94 × 103 | − | 4.989 × 104 ± 8.38 × 104 |
| fu32 | 1.591 × 103 ± 1.27 × 103 | 1.062 × 10−5 ± 9.78 × 10−6 | 2.684 × 10−30± 4.75 × 10−31 | 1.531 × 10−2 ± 3.80 × 10−3 | = | 1.774 × 10−2 ± 2.89 × 10−2 |
| fu33 | 1.258 × 102 ± 6.44 × 100 | 8.948 × 101 ± 6.18 × 100 | 1.773 × 102 ± 5.91 × 100 | 7.370 × 101 ± 3.32 × 100 | + | −9.9 × 101 ± 0.00 × 100 |
| fu34 | 5.331 × 1010 ± 3.51 × 1010 | 8.041 × 109± 4.88 × 109 | 2.476 × 102 ± 2.13 × 103 | 4.896 × 105 ± 2.21 × 105 | + | 1.790 × 100 ± 2.67 × 100 |
| fu35 | 9.384 × 102 ± 1.78 × 102 | 5.578 × 102 ± 8.53 × 101 | 1.612 × 103 ± 2.32 × 102 | 6.701 × 102 ± 6.36 × 101 | + | 1.046 × 10−2± 1.66 × 10−2 |
| fu36 | 7.462 × 102 ± 2.32 × 102 | 2.422 × 102 ± 8.72 × 101 | −1.273 × 102± 3.77 × 100 | −1.082 × 102 ± 4.21 × 100 | − | 3.137 × 10−2 ± 6.55 × 10−2 |
| fu37 | 5.5078 × 102 ± 1.83 × 10−1 | 5.478 × 102 ± 9.65 × 10−1 | 5.498 × 102 ± 4.64 × 10−2 | 5.492 × 102 ± 2.51 × 10−1 | + | 6.525 × 10−2 ± 4.01 × 10−2 |
| fu38 | −1.201 × 103 ± 4.77 × 101 | −1.407 × 103 ± 3.24 × 101 | −1.267 × 103 ± 5.18 × 101 | −1.284 × 103 ± 3.90 × 101 | − | 0.000 × 100 ± 0.00 × 100 |
| fu39 | 6.157 × 104 ± 1.54 × 104 | 4.98 × 10−27 ± 4.22 × 10−27 | 1.445 × 10−30± 5.58 × 10−31 | 4.314 × 10−3 ± 1.24 × 10−3 | − | 8.704 × 10−3 ± 2.16 × 10−4 |
| fu40 | 7.518 × 104 ± 1.08 × 104 | 3.316 × 104 ± 8.12 × 103 | 5.665 × 102 ± 2.19 × 102 | 4.375 × 100 ± 9.83 × 10−1 | + | 1.463 × 10−1 ± 2.02 × 10−1 |
| fu41 | 1.044 × 1010 ± 4.34 × 109 | 1.098 × 103 ± 1.86 × 103 | 2.575 × 102 ± 3.11 × 102 | 8.941 × 101 ± 5.26 × 101 | − | 1.397 × 100 ± 5.03 × 100 |
| fu42 | 1.949 × 101 ± 2.59 × 10−1 | 8.003 × 100 ± 4.31 × 100 | 1.949 × 101± 1.48 × 10−1 | 1.277 × 100 ± 3.68 × 10−1 | + | 7.812 × 10−2 ± 3.72 × 10−2 |
| fu43 | 2.978 × 10−1± 3.723 × 10−1 | 1.354 × 10−1 ± 2.31 × 10−1 | 6.857 × 100 ± 1.06 × 101 | 1.084 × 100 ± 3.16 × 10−1 | + | 2.039 × 10−2± 3.72 × 10−2 |
| fu44 | 4.707 × 10−3 ± 7.38 × 10−3 | 0.001 × 100 ± 0.01 × 100 | 0.001 × 100 ± 0.01 × 100 | 0.001 × 100 ± 0.01 × 100 | = | 0.001 × 100 ± 0.01 × 100 |
| fu45 | 4.258 × 104 ± 4.15 × 104 | 2.534 × 104 ± 6.28 × 103 | 4.066 × 103 ± 9.66 × 102 | 5.051 × 101 ± 4.28 × 101 | + | 1.433 × 101 ± 1.92 × 101 |
| fu46 | 2.368 × 104 ± 3.45 × 103 | 2.01 × 104 ± 3.04 × 103 | 3.776 × 104 ± 6.47 × 103 | 2.320 × 104 ± 3.38 × 103 | + | 3.577 × 103 ± 8.68 × 103 |
| fu47 | 2.087 × 106 ± 7.97 × 105 | 4.588 × 105 ± 1.69 × 105 | 1.589 × 104 ± 1.74 × 104 | 1.395 × 106 ± 1.14 × 106 | − | 3.749 × 106 ± 2.47 × 106 |
| Benmark | DE | PSO | W | CSO | W | SSPCCSO |
|---|---|---|---|---|---|---|
| fu1 | 8.269 × 101 ± 1.90 × 101 | 1.095 × 104 ± 2.30 × 103 | − | 0.000 × 100± 0.00 × 100 | − | 6.170 × 10−3 ± 1.05 × 10−3 |
| fu2 | 3.063 × 104 ± 3.70 × 103 | 4.232 × 104 ± 1.84 × 103 | + | 0.000 × 100± 0.00 × 100 | − | 3.625 × 102 ± 7.02 × 102 |
| fu3 | 2.715 × 100± 1.11 × 106 | 1.103 × 109 ± 5.07 × 108 | + | 2.890 × 101 ± 1.394 × 10−2 | − | 5.776 × 10−1 ± 7.01 × 100 |
| fu4 | 4.072 × 101 ± 1.98 × 10−1 | 1.639 × 101 ± 1.21 × 100 | + | 0.001 × 100± 0.00 × 100 | − | 5.574 × 10−1 ± 3.07 × 10−2 |
| fu5 | 7.195 × 101 ± 9.73 × 100 | 0.001 × 100± 0.001 × 100 | − | 0.001 × 100± 0.01 × 100 | − | 1.613 × 10−2 ± 2.37 × 10−3 |
| fu6 | 2.151 × 102± 9.08 × 100 | 2.887 × 102± 3.28 × 101 | + | 0.001 × 100± 0.00 × 100 | − | 2.399 × 10−2 ± 4.09 × 10−3 |
| fu7 | 2.408 × 105 ± 4.96 × 104 | 1.321 × 105 ± 1.03 × 104 | + | 2.990 × 102 ± 0.00 × 100 | = | 2.991 × 102 ± 1.75 × 10−1 |
| fu8 | 6.328 × 103 ± 2.36 × 102 | 6.677 × 103 ± 6.44 × 102 | − | 3.161 × 103 ± 9.76 × 102 | − | 1.248 × 100± 1.90 × 100 |
| fu9 | 1.633 × 104 ± 1.13 × 103 | 1.305 × 104 ± 3.17 × 103 | + | 1.344 × 104 ± 1.74 × 103 | + | 1.111 × 105 ± 5.29 × 104 |
| fu10 | 8.508 × 105± 9.24 × 104 | 9.716 × 105 ± 1.57 × 105 | − | 3.222 × 106 ± 1.68 × 105 | + | 9.390 × 105 ± 1.13 × 104 |
| fu11 | 4.217 × 100 ± 1.58 × 10−1 | 1.707 × 101± 1.73 × 100 | + | −1.84 × 10−6 ± 0.01 × 100 | − | 8.328 × 10−2 ± 8.23 × 10−2 |
| fu12 | 6.536 × 101± 1.02 × 101 | 1.139 × 101 ± 3.08 × 101 | + | 9.568 × 10−8± 2.68 × 10−8 | = | 1.018 × 10−8 ± 2.61 × 109 |
| fu13 | 2.586 × 102±1.12 × 101 | 3.155 × 102± 2.19 × 101 | + | 2.701 × 102 ± 0.01 × 100 | = | 2.70 × 102± 1.81 × 10−5 |
| fu14 | 4.003 × 101 ± 1.09 × 100 | 3.966 × 101± 1.18 × 100 | − | 7.049 × 102± 2.22 × 100 | = | 7.142 × 102 ± 2.37 × 10−1 |
| fu15 | 7.443 × 10−2 ± 1.89 × 10−5 | 4.083 × 100 ± 2.23 × 100 | + | 0.001 × 100± 0.01 × 100 | − | 9.427 × 10−3 ± 6.15 × 10−3 |
| fu16 | −9.942 × 10−8± 1.08 × 10−1 | −1.001 × 102± 0.01 × 100 | = | −1.001 × 102± 8.46 × 10−5 | = | −1.000 × 102± 0.00 × 100 |
| fu17 | 9.424 × 10−8± 5.16 × 10−8 | 1.046 × 101 ± 5.08 × 100 | − | 1.631 × 100 ± 5.84 × 10−1 | − | 9.518 × 10−5 ± 1.57 × 10−6 |
| fu18 | −1.151 × 100± 3.37 × 10−7 | 3.502 × 103 ± 9.85 × 103 | + | 5454 × 10−1 ± 3.27 × 10−1 | + | −4.104 × 10−1 ± 8.97 × 10−4 |
| fu19 | 4.701 × 102 ± 1.44 × 101 | 6.107 × 102 ± 3.43 × 101 | + | 4.501 × 102± 0.01 × 100 | = | 4.500 × 102 ± 2.60 × 10−3 |
| fu20 | −1.278 × 101 ± 4.28 × 10−1 | −1.936 × 101 ± 1.72 × × 100 | + | −1.103 × 101 ± 1.08 × 100 | + | −1.988 × 101 ± 2.33 × 10−1 |
| fu21 | 1.268 × 104 ± 3.62 × 102 | 9.691 × 103 ± 1.14 × 103 | − | 4.785 × 103 ± 1.48 × 102 | − | 1.42 × 100 ± 2.26 × 100 |
| fu22 | 1.828 × 101 ± 4.24 × 101 | 2.004 × 101 ± 3.75 × 10−1 | + | 0.001 × 100± 0.01 × 100 | − | 7.139 × 10−2 ± 4.17 × 10−2 |
| fu23 | 1.611 × 102 ± 6.39 × 100 | 1.815 × 101 ± 1.01 × 101 | + | 4.658 × 10−2± 2.38 × 10−2 | − | 7.319 × 10−2 ± 5.17 × 10−3 |
| fu24 | 2.386 × 104 ± 3.48 × 103 | 6.501 × 104 ± 9.68 × 103 | + | 0.001 × 100± 0.01 × 100 | − | 8.961 × 10−3 ± 1.46 × 10−2 |
| fu25 | −1.119 × 10−2± 1.29 × 10−3 | −7.493 × 10−3 ± 1.06 × 10−3 | − | 0.001 × 100 ± 0.01 × 100 | = | 0.000 × 100 ± 0.00 × 100 |
| fu26 | −1.589 × 101 ± 5.26 × 10−1 | −2.677 × 101 ± 2.01 × 100 | − | −1.978 × 101 ± 1.43 × 100 | = | −3.970 × 101 ± 1.52 × 10−1 |
| fu27 | 8.899 × 104 ± 8.79 × 103 | 1.925 × 104 ± 1.93 × 104 | + | 0.001 × 100± 0.01 × 100 | − | 1.033 × 10−2 ± 1.39 × 10−2 |
| fu28 | 1.177 × 103 ± 2.54 × 101 | 1.279 × 103± 4.45 × 101 | + | 0.001 × 100± 0.01 × 100 | − | 6.631 × 10−3 ± 1.24 × 10−4 |
| fu29 | 2.636 × 1010 ± 5.09 × 109 | 3.854 × 1010 ± 1.42 × 1010 | + | 9.899 × 101± 1.85 × 100 | − | 1.286 × 100 ± 2.50 × 100 |
| fu30 | 1.477 × 1011 ± 1.27 × 1010 | 1.017 × 1011 ± 1.96 × 1010 | + | 0.001 × 100± 8.36 × 100 | − | 1.109 × 108 ± 3.44 × 108 |
| fu31 | 3.026 × 104 ± 4.79 × 102 | 2.368 × 104 ± 1.89 × 103 | − | 1.046 × 104± 2.95 × 103 | − | 4.989 × 104 ± 8.38 × 104 |
| fu32 | 2.094 × 105 ± 1.64 × 104 | 1.138 × 104 ± 1.68 × 103 | + | 1.532 × 10−2± 3.81 × 10−3 | − | 1.774 × 10−2 ± 2.89 × 10−2 |
| fu33 | 1.186 × 102 ± 2.84 × 100 | 1.407 × 102 ± 1.28 × 101 | + | 7.371 × 103 ± 3.33 × 100 | + | −9.9 × 101 ± 0.00 × 100 |
| fu34 | 8.197 × 1010 ± 1.12 × 1010 | 7.765 × 1010 ± 2.17 × 1010 | + | 9.898 × 102 ± 2.25 × 10−2 | + | 1.790 × 100 ± 2.67 × 100 |
| fu35 | 1.398 × 103 ± 4.25 × 101 | 1.055 × 103 ± 1.48 × 102 | + | 0.001 × 100± 0.01 × 100 | − | 1.046 × 10−2 ± 1.66 × 10−2 |
| fu36 | 1.567 × 103 ± 1.34 × 102 | 1.242 × 103 ± 2.45 × 102 | + | 1.083 × 102 ± 4.22 × 100 | + | 3.137 × 10−2 ± 6.55 × 10−2 |
| fu37 | 5.507 × 102 ± 1.25 × 10−1 | 5.508 × 102 ± 1.71 × 10−1 | + | 5.493 × 102± 2.51 × 10−1 | + | 6.525 × 10−2 ± 4.01 × 10−2 |
| fu38 | −1.056 × 103 ± 1.09 × 101 | −1.283 × 103 ± 2.18 × 102 | − | −1.285 × 103± 3.91 × 101 | − | 0.000 × 100 ± 0.00 × 100 |
| fu39 | 8.338 × 103 ± 1.12 × 103 | 1.201 × 103 ± 2.18 × 102 | + | 0.001 × 100± 0.01 × 100 | − | 8.704 × 10−3 ± 2.16 × 10−4 |
| fu40 | 8.969 × 104 ± 7.75 × 103 | 1.701 × 104 ± 3.08 × 103 | + | 0.001 × 100± 0.01 × 100 | − | 1.463 × 10−1 ± 2.02 × 10−1 |
| fu41 | 2.142 × 109 ± 5.71 × 108 | 1.784 × 107 ± 5.52 × 106 | + | 4.898 × 101 ± 1.38 × 10−2 | − | 1.397 × 100± 5.03 × 100 |
| fu42 | 1.364 × 101 ± 4.46 × 10−1 | 6.878 × 100 ± 4.73 × 10−1 | + | 0.001 × 100± 0.01 × 100 | − | 7.812 × 10−2 ± 3.72 × 10−2 |
| fu43 | 3.711 × 10−2 ± 3.27 × 101 | 2.555 × 10−2 ± 4.98 × 101 | − | 0.001 × 100± 0.01 × 100 | − | 2.039 × 10−2 ± 3.72 × 10−2 |
| fu44 | 4.684 × 102 ± 1.35 × 101 | 0.001 × 100± 0.01 × 100 | = | 0.001 × 100± 0.01 × 100 | = | 0.001 × 100 ± 0.01 × 100 |
| fu45 | 2.539 × 106 ± 2.09 × 105 | 1.134 × 106 ± 2.17 × 103 | + | 0.001 × 100± 0.01 × 100 | − | 1.433 × 101 ± 1.92 × 101 |
| fu46 | 3.152 × 104 ± 1.18 × 103 | 1.888 × 104 ± 2.17 × 103 | + | 0.0010 × 100± 0.01 × 100 | − | 3.577 × 103 ± 8.68 × 103 |
| fu47 | 4.675 × 106 ± 2.19 × 105 | 2.183 × 106± 4.01 × 105 | − | 1.694 × 107 ± 4.31 × 106 | + | 3.749 × 106 ± 2.47 × 106 |
| Iterations | PSO | CSO | cPSO | SSPCCSO |
| I 100 | 8202.6317 | 0.000000 | 55.695 | 5.809 |
| I 200 | 3754.9483 | 0.000000 | 19.852 | 4.277 |
| I 1000 | 1417.4688 | 0.000000 | 0.61648 | 0.03692 |
| I 2000 | 1414.2868 | 0.000000 | 0.36894 | 0.000032 |
| Iterations | PSO | CSO | cPSO | SSPCCSO |
| I 100 | 14.38578 | 8.88 × 10−16 | 6.3458 | 10.602 |
| I 200 | 12.03479 | 8.88 × 10−16 | 4.6725 | 4.942 |
| I 500 | 10.31688 | 8.88 × 10−16 | 3.3370 | 3.824 |
| I 1000 | 9.05237 | 8.88 × 10−16 | 2.3393 | 1.427 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Zhao, M.; Luo, T.; Yang, Y. A Compact Cat Swarm Optimization Algorithm Based on Small Sample Probability Model. Appl. Sci. 2022, 12, 8209. https://doi.org/10.3390/app12168209
He Z, Zhao M, Luo T, Yang Y. A Compact Cat Swarm Optimization Algorithm Based on Small Sample Probability Model. Applied Sciences. 2022; 12(16):8209. https://doi.org/10.3390/app12168209
Chicago/Turabian StyleHe, Zeyu, Ming Zhao, Tie Luo, and Yimin Yang. 2022. "A Compact Cat Swarm Optimization Algorithm Based on Small Sample Probability Model" Applied Sciences 12, no. 16: 8209. https://doi.org/10.3390/app12168209
APA StyleHe, Z., Zhao, M., Luo, T., & Yang, Y. (2022). A Compact Cat Swarm Optimization Algorithm Based on Small Sample Probability Model. Applied Sciences, 12(16), 8209. https://doi.org/10.3390/app12168209