
Deep Active Learning for Computer Vision Tasks: Methodologies, Applications, and Challenges

Abstract
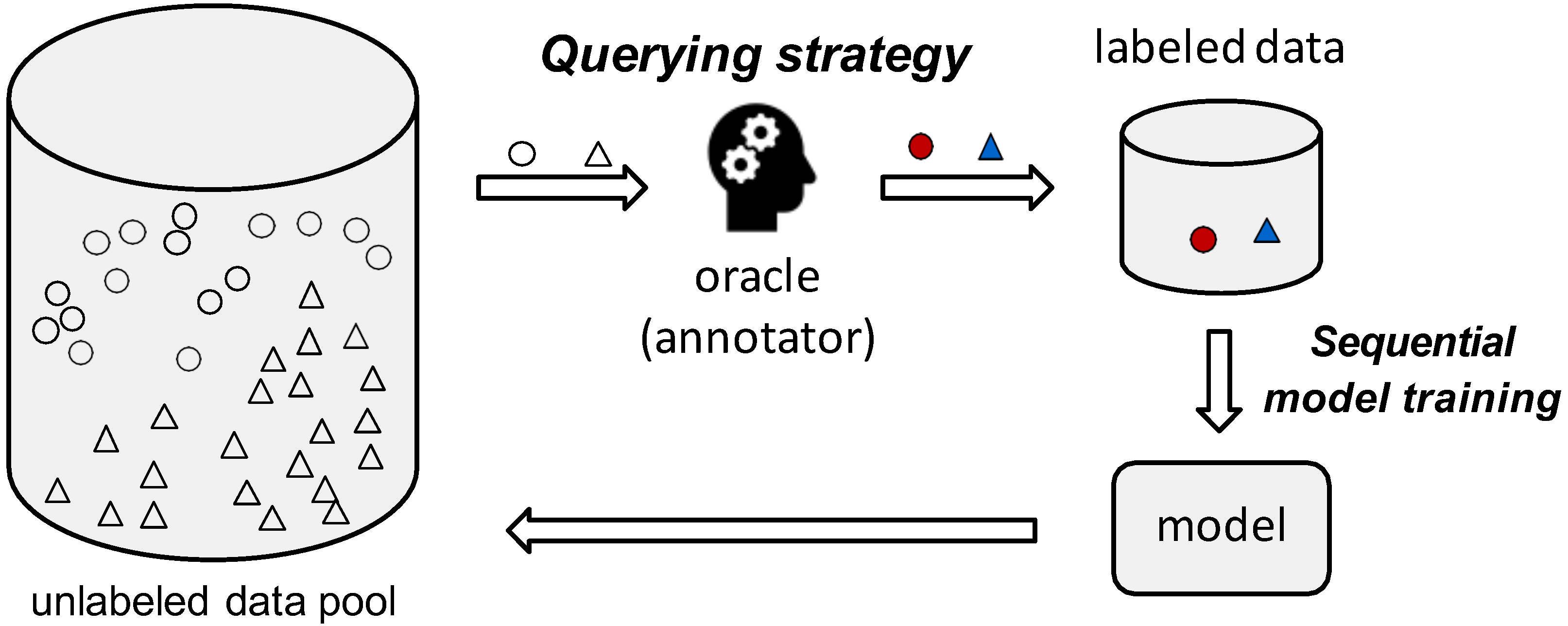
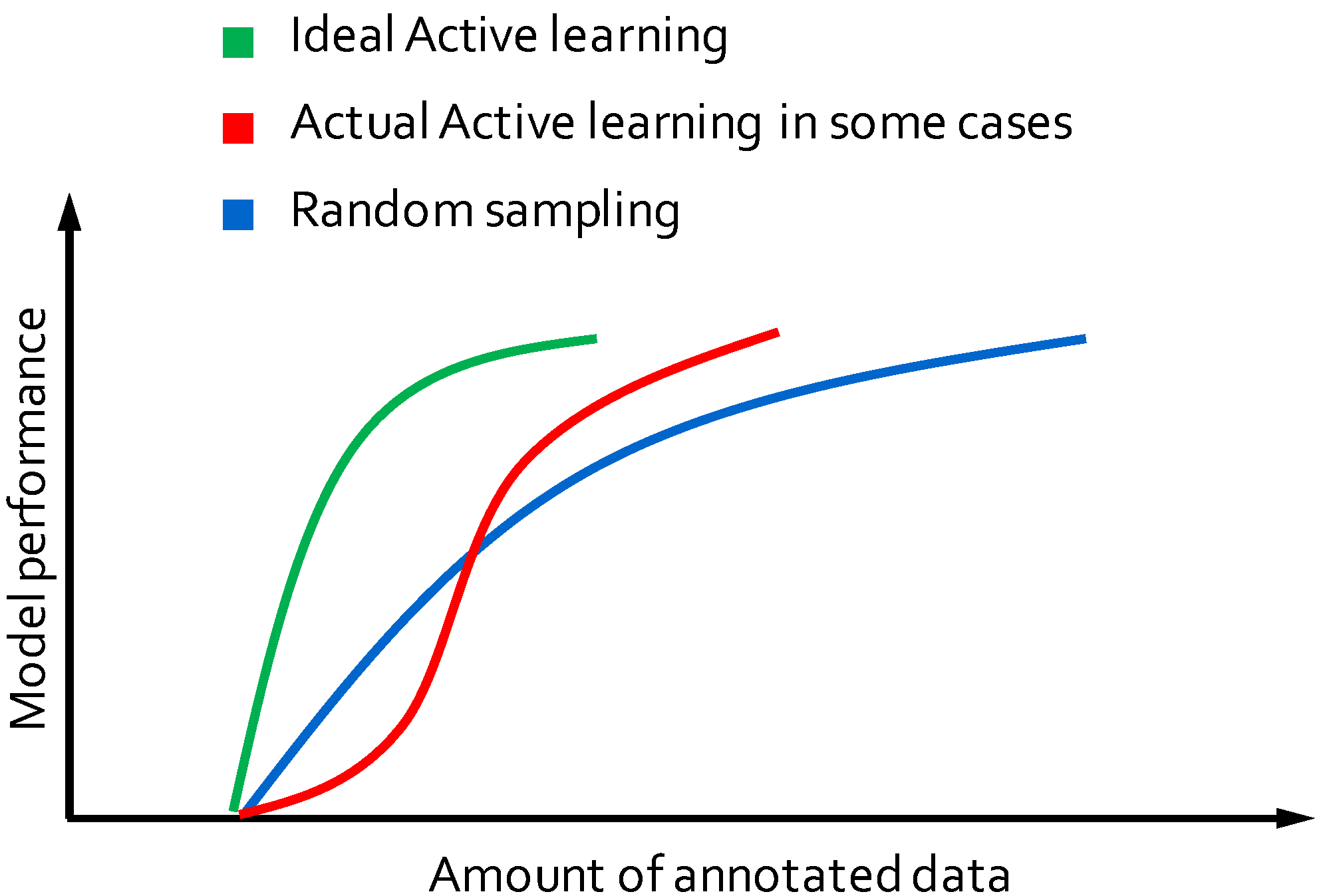
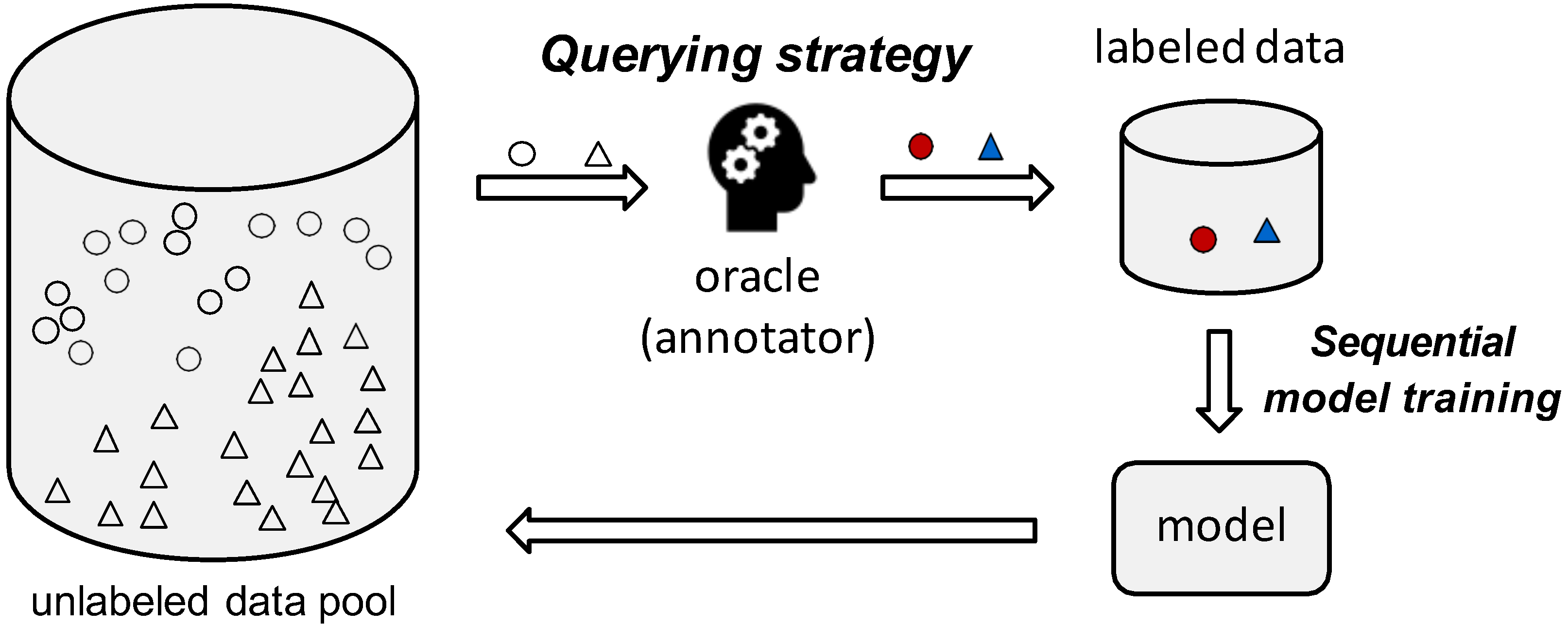
:1. Introduction
| Algorithm 1: The pool-based active learning workflow |
 |
2. Candidate Selection Strategies in Active Learning
2.1. Random Selection Strategies
2.2. Uncertainty-Based Selection Strategies
2.3. Diversity-Based Selection Strategy
2.4. Committee-Based Selection Strategy
- Multiple models are used to construct a committee for voting, i.e., .
- The models in the committee are then trained on the labeled dataset L and get different parameters.
- All models in the committee make predictions separately on unlabeled samples from . The samples with the richest information are voted.
- The samples which obtain the most disagreements are selected as candidates for labeling.
3. Common Querying Scenarios in Active Learning
4. Deep Active Learning Methods
4.1. Deep Active Learning for CNNs
4.2. Generative Adversarial Active Learning
| Algorithm 2: The synthesis-based active learning method workflow |
 |
4.3. Semi-Supervised Active Learning
| Algorithm 3: The workflow of basic self-training algorithm |
 |
4.4. Active Contrastive Learning
| Algorithm 4: The workflow of basic contrastive active learning algorithm |
 |
4.5. Other Deep Active Learning
5. Applications
5.1. Deep Learning-Based Autonomous Driving
5.2. Intelligent Medical Assisted Diagnosis
6. Challenges
6.1. Inefficient Serial Human-in-the-Loop Collaboration
6.2. Dirty Data and Noisy Oracle
6.3. Difficult to Cross-Domain Transfer
6.4. Unstable Performance
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Ma, J.; Zhang, Y.; Gu, S.; Zhu, C.; Ge, C.; Zhang, Y.; An, X.; Wang, C.; Wang, Q.; Liu, X.; et al. AbdomenCT-1K: Is Abdominal Organ Segmentation A Solved Problem. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2021. [Google Scholar] [CrossRef] [PubMed]
- Settles, B. Active Learning Literature Survey; Computer Sciences Technical Report 1648; University of Wisconsin–Madison: Madison, WI, USA, 2004. [Google Scholar]
- Netzer, E.; Geva, A.B. Human-in-the-loop active learning via brain computer interface. Ann. Math. Artif. Intell. 2020, 88, 1191–1205. [Google Scholar] [CrossRef]
- Budd, S.; Robinson, E.C.; Kainz, B. A survey on active learning and human-in-the-loop deep learning for medical image analysis. Med. Image Anal. 2021, 71, 102062. [Google Scholar] [CrossRef] [PubMed]
- Kumar, P.; Gupta, A. Active learning query strategies for classification, regression, and clustering: A survey. J. Comput. Sci. Technol. 2020, 35, 913–945. [Google Scholar] [CrossRef]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Chen, X.; Wang, X. A survey of deep active learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Zhan, X.; Wang, Q.; Huang, K.H.; Xiong, H.; Dou, D.; Chan, A.B. A comparative survey of deep active learning. arXiv 2022, arXiv:2203.13450. [Google Scholar]
- Li, M.; Sethi, I.K. Confidence-based active learning. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1251–1261. [Google Scholar]
- Agrawal, A.; Tripathi, S.; Vardhan, M. Multicore based least confidence query sampling strategy to speed up active learning approach for named entity recognition. Computing 2021, 1–19. [Google Scholar] [CrossRef]
- Agrawal, A.; Tripathi, S.; Vardhan, M. Active learning approach using a modified least confidence sampling strategy for named entity recognition. Prog. Artif. Intell. 2021, 10, 113–128. [Google Scholar] [CrossRef]
- Joshi, A.J.; Porikli, F.; Papanikolopoulos, N. Multi-class active learning for image classification. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2372–2379. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, S. Improved margin sampling for active learning. In Proceedings of the Chinese Conference on Pattern Recognition, Changsha, China, 17–19 November 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 120–129. [Google Scholar]
- Gu, Y.; Jin, Z.; Chiu, S.C. Active learning combining uncertainty and diversity for multi-class image classification. IET Comput. Vis. 2015, 9, 400–407. [Google Scholar] [CrossRef]
- Yang, Y.; Ma, Z.; Nie, F.; Chang, X.; Hauptmann, A.G. Multi-class active learning by uncertainty sampling with diversity maximization. Int. J. Comput. Vis. 2015, 113, 113–127. [Google Scholar] [CrossRef]
- Yu, D.; Varadarajan, B.; Deng, L.; Acero, A. Active learning and semi-supervised learning for speech recognition: A unified framework using the global entropy reduction maximization criterion. Comput. Speech Lang. 2010, 24, 433–444. [Google Scholar] [CrossRef]
- Ozdemir, F.; Peng, Z.; Tanner, C.; Fuernstahl, P.; Goksel, O. Active learning for segmentation by optimizing content information for maximal entropy. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 183–191. [Google Scholar]
- Brinker, K. Incorporating diversity in active learning with support vector machines. In Proceedings of the 20th International Conference on Machine Learning, Washington, DC, USA, 21 August 2003; pp. 59–66. [Google Scholar]
- Kukar, M. Transductive reliability estimation for medical diagnosis. Artif. Intell. Med. 2003, 29, 81–106. [Google Scholar] [CrossRef]
- Chakraborty, S.; Balasubramanian, V.; Sun, Q.; Panchanathan, S.; Ye, J. Active batch selection via convex relaxations with guaranteed solution bounds. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2015, 37, 1945–1958. [Google Scholar] [CrossRef]
- Zhou, Z.; Shin, J.Y.; Gurudu, S.R.; Gotway, M.B.; Liang, J. Active, continual fine tuning of convolutional neural networks for reducing annotation efforts. Med. Image Anal. 2021, 71, 101997. [Google Scholar] [CrossRef]
- Seung, H.S.; Opper, M.; Sompolinsky, H. Query by Committee. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 1 July 1992; pp. 287–294. [Google Scholar]
- Yan, Y.; Rosales, R.; Fung, G.; Dy, J. Active Learning from Crowds. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June 2011; Getoor, L., Scheffer, T., Eds.; ACM: New York, NY, USA, 2011; pp. 1161–1168. [Google Scholar]
- Dagan, I.; Engelson, S.P. Committee-based sampling for training probabilistic classifiers. In Machine Learning Proceedings 1995, Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 150–157. [Google Scholar]
- Zhou, Z.; Shin, J.; Zhang, L.; Gurudu, S.; Gotway, M.; Liang, J. Fine-tuning convolutional neural networks for biomedical image analysis: Actively and incrementally. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7340–7351. [Google Scholar]
- Angluin, D. Queries and Concept Learning. Mach. Learn. 1988, 2, 319–342. [Google Scholar] [CrossRef]
- Schumann, R.; Rehbein, I. Active learning via membership query synthesis for semi-supervised sentence classification. In Proceedings of the 23rd Conference on Computational Natural Language Learning, Hong Kong, China, 3–4 November 2019; pp. 472–481. [Google Scholar]
- Alabdulmohsin, I.; Gao, X.; Zhang, X. Efficient active learning of halfspaces via query synthesis. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Atlas, L.; Cohn, D.; Ladner, R. Training Connectionist Networks with Queries and Selective Sampling. In Advances in Neural Information Processing Systems; Touretzky, D., Ed.; Morgan-Kaufmann: Burlington, MA, USA, 1989; Volume 2. [Google Scholar]
- Balasubramanian, V.; Chakraborty, S.; Panchanathan, S. Generalized query by transduction for online active learning. In Proceedings of the IEEE 12th International Conference on Computer Vision (ICCV) Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1378–1385. [Google Scholar]
- Ho, S.S.; Wechsler, H. Query by transduction. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2008, 30, 1557–1571. [Google Scholar]
- Monteleoni, C.; Kaariainen, M. Practical online active learning for classification. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Lewis, D.D.; Gale, W.A. A Sequential Algorithm for Training Text Classifiers. In Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 3–6 July 1994; pp. 3–12. [Google Scholar]
- Wu, D. Pool-based sequential active learning for regression. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1348–1359. [Google Scholar] [CrossRef]
- Zhan, X.; Liu, H.; Li, Q.; Chan, A.B. A Comparative Survey: Benchmarking for Pool-based Active Learning. In Proceedings of the 30th International Joint Conference on Artificial Intelligence (IJCAI 2021), Virtual, 19–27 August 2021; pp. 4679–4686. [Google Scholar]
- Sugiyama, M.; Nakajima, S. Pool-based active learning in approximate linear regression. Mach. Learn. 2009, 75, 249–274. [Google Scholar] [CrossRef]
- Gal, Y.; Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1050–1059. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Bayesian convolutional neural networks with Bernoulli approximate variational inference. arXiv 2015, arXiv:1506.02158. [Google Scholar]
- Gal, Y.; Islam, R.; Ghahramani, Z. Deep bayesian active learning with image data. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, NSW, Australia, 6–11 August 2017; pp. 1183–1192. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Codella, N.C.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.W.; Kalloo, A.; Liopyris, K.; Mishra, N.; Kittler, H.; et al. Skin lesion analysis toward melanoma detection: A challenge at the 2017 International Symposium on Biomedical Imaging (ISBI), hosted by the International Skin Imaging Collaboration (ISIC). In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 168–172. [Google Scholar]
- Houlsby, N.; Huszár, F.; Ghahramani, Z.; Lengyel, M. Bayesian active learning for classification and preference learning. arXiv 2011, arXiv:1112.5745. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef]
- Beluch, W.H.; Genewein, T.; Nürnberger, A.; Köhler, J.M. The power of ensembles for active learning in image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9368–9377. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 10 July 2022).
- Sener, O.; Savarese, S. Active Learning for Convolutional Neural Networks: A Core-Set Approach. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 16 December 2011; p. 5. [Google Scholar]
- Janz, D.; van der Westhuizen, J.; Hernández-Lobato, J.M. Actively learning what makes a discrete sequence valid. arXiv 2017, arXiv:1708.04465. [Google Scholar]
- Kirsch, A.; Van Amersfoort, J.; Gal, Y. Batchbald: Efficient and diverse batch acquisition for deep bayesian active learning. In Proceedings of the NIPS’19: Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Yoo, D.; Kweon, I.S. Learning loss for active learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 93–102. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. (IJCV) 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- François, D. High-dimensional data analysis. From Optimal Metric to Feature Selection. Ph.D. Thesis, Université Catholique de Louvain, Ottignies-Louvain-la-Neuve, Belgium, 2008; pp. 54–55. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, USA, 8–13 December 2014; Volume 27. [Google Scholar]
- Zhu, J.; Bento, J. Generative Adversarial Active Learning. arXiv 2017, arXiv:1702.07956. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Tran, T.; Do, T.T.; Reid, I.; Carneiro, G. Bayesian generative active deep learning. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 6295–6304. [Google Scholar]
- Mayer, C.; Timofte, R. Adversarial Sampling for Active Learning. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020; pp. 3060–3068. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar] [CrossRef]
- Yu, F.; Zhang, Y.; Song, S.; Seff, A.; Xiao, J. LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Sinha, S.; Ebrahimi, S.; Darrell, T. Variational Adversarial Active Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October 2019; pp. 5971–5980. [Google Scholar] [CrossRef]
- Griffin, G.; Holub, A.; Perona, P. Caltech-256 Object Category Dataset. Available online: https://data.caltech.edu/records/20087 (accessed on 10 July 2022).
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]
- Huijser, M.; Gemert, J.C.v. Active Decision Boundary Annotation with Deep Generative Models. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5296–5305. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, NSW, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 1558–1566. [Google Scholar]
- Li, C.; Chen, W.; Luo, X.; He, Y.; Tan, Y. Adaptive Pseudo Labeling for Source-Free Domain Adaptation in Medical Image Segmentation. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 1091–1095. [Google Scholar]
- McCallum, A.; Nigam, K. Employing EM and Pool-Based Active Learning for Text Classification. In Proceedings of the Fifteenth International Conference on Machine Learning (ICML), Madison, WI, USA, 24–27 July 1998; pp. 350–358. [Google Scholar]
- Muslea, I.; Minton, S.; Knoblock, C.A. Active + semi-supervised learning = robust multi-view learning. In Proceedings of the Fifteenth International Conference on Machine Learning (ICML), Sydney, NSW, Australia, 8–12 July 2002; Volume 2, pp. 435–442. [Google Scholar]
- Zhou, Z.H.; Chen, K.J.; Jiang, Y. Exploiting unlabeled data in content-based image retrieval. In Proceedings of the European Conference on Machine Learning (ECML), Pisa, Italy, 20–24 September 2004; pp. 525–536. [Google Scholar]
- Blum, A.; Mitchell, T. Combining Labeled and Unlabeled Data with Co-Training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory (COLT), Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Zhou, Z.H.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef]
- Han, W.; Coutinho, E.; Ruan, H.; Li, H.; Schuller, B.; Yu, X.; Zhu, X. Semi-supervised active learning for sound classification in hybrid learning environments. PLoS ONE 2016, 11, e0162075. [Google Scholar] [CrossRef] [PubMed]
- Tomanek, K.; Hahn, U. Semi-supervised active learning for sequence labeling. In Proceedings of the 47th Annual Meeting of the Association of Computational Linguistics (ACL), Singapore, 2–7 August 2009; pp. 1039–1047. [Google Scholar]
- Tur, G.; Hakkani-Tür, D.; Schapire, R.E. Combining active and semi-supervised learning for spoken language understanding. Speech Commun. 2005, 45, 171–186. [Google Scholar] [CrossRef]
- Song, S.; Berthelot, D.; Rostamizadeh, A. Combining mixmatch and active learning for better accuracy with fewer labels. arXiv 2019, arXiv:1912.00594. [Google Scholar]
- Guo, J.; Shi, H.; Kang, Y.; Kuang, K.; Tang, S.; Jiang, Z.; Sun, C.; Wu, F.; Zhuang, Y. Semi-supervised active learning for semi-supervised models: Exploit adversarial examples with graph-based virtual labels. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 2896–2905. [Google Scholar]
- Van den Oord, A.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Poole, B.; Ozair, S.; Van Den Oord, A.; Alemi, A.; Tucker, G. On variational bounds of mutual information. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 5171–5180. [Google Scholar]
- McAllester, D.; Stratos, K. Formal limitations on the measurement of mutual information. In Proceedings of the International Conference on Artificial Intelligence and Statistics (PMLR), Palermo, Italy, 3–5 June 2020; pp. 875–884. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Chen, X.; Xie, S.; He, K. An Empirical Study of Training Self-Supervised Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9640–9649. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning (ICML), PMLR, Vienna, Austria, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G.E. Big self-supervised models are strong semi-supervised learners. Adv. Neural Inf. Process. Syst. (NIPS) 2020, 33, 22243–22255. [Google Scholar]
- Saunshi, N.; Plevrakis, O.; Arora, S.; Khodak, M.; Khandeparkar, H. A theoretical analysis of contrastive unsupervised representation learning. In Proceedings of the International Conference on Machine Learning (ICML), PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 5628–5637. [Google Scholar]
- Ma, S.; Zeng, Z.; McDuff, D.; Song, Y. Active Contrastive Learning of Audio-Visual Video Representations. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 3–7 May 2021. [Google Scholar]
- Du, P.; Zhao, S.; Chen, H.; Chai, S.; Chen, H.; Li, C. Contrastive coding for active learning under class distribution mismatch. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 8927–8936. [Google Scholar]
- Zhu, Y.; Xu, W.; Liu, Q.; Wu, S. When contrastive learning meets active learning: A novel graph active learning paradigm with self-supervision. arXiv 2020, arXiv:2010.16091. [Google Scholar]
- Krishnan, R.; Ahuja, N.; Sinha, A.; Subedar, M.; Tickoo, O.; Iyer, R. Improving robustness and efficiency in active learning with contrastive loss. arXiv 2021, arXiv:2109.06873. [Google Scholar]
- Gao, B.; Zhao, X.; Zhao, H. An Active and Contrastive Learning Framework for Fine-Grained Off-Road Semantic Segmentation. arXiv 2022, arXiv:2202.09002. [Google Scholar]
- Li, C.; Luo, X.; Chen, W.; He, Y.; Wu, M.; Tan, Y. AttENT: Domain-Adaptive Medical Image Segmentation via Attention-Aware Translation and Adversarial Entropy Minimization. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9–12 December 2021; pp. 952–959. [Google Scholar]
- Li, C.; Chen, W.; Wu, M.; Luo, X.; He, Y.; Tan, Y. Tri-Directional Tasks Complementary Learning for Unsupervised Domain Adaptation of Cross-modality Medical Image Semantic Segmentation. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9–12 December 2021; pp. 1406–1411. [Google Scholar]
- Chattopadhyay, R.; Fan, W.; Davidson, I.; Panchanathan, S.; Ye, J. Joint transfer and batch-mode active learning. In Proceedings of the International Conference on Machine Learning (ICML), PMLR, Atlanta, GA, USA, 16–21 June 2013; pp. 253–261. [Google Scholar]
- Huang, S.J.; Zhao, J.W.; Liu, Z.Y. Cost-effective training of deep cnns with active model adaptation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), London, UK, 19–23 August 2018; pp. 1580–1588. [Google Scholar]
- Ning, M.; Lu, D.; Wei, D.; Bian, C.; Yuan, C.; Yu, S.; Ma, K.; Zheng, Y. Multi-anchor active domain adaptation for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9112–9122. [Google Scholar]
- He, Y.; Zhang, L.; Chen, W.; Luo, X.; Jia, X.; Li, C. CenterRepp: Predict Central Representative Point Set’s Distribution For Detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8960–8967. [Google Scholar]
- Jia, X.; Chen, W.; Li, C.; Liang, Z.; Wu, M.; Tan, Y.; Huang, L. Multi-scale cost volumes cascade network for stereo matching. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), New Orleans, LA, USA, 3–7 May 2021; pp. 8657–8663. [Google Scholar]
- He, Y.; Chen, W.; Li, C.; Luo, X.; Huang, L. Fast and Accurate Lane Detection via Graph Structure and Disentangled Representation Learning. Sensors 2021, 21, 4657. [Google Scholar] [CrossRef]
- Chen, W.; Luo, X.; Liang, Z.; Li, C.; Wu, M.; Gao, Y.; Jia, X. A Unified Framework for Depth Prediction from a Single Image and Binocular Stereo Matching. Remote Sens. 2020, 12, 588. [Google Scholar] [CrossRef]
- Jia, X.; Chen, W.; Liang, Z.; Luo, X.; Wu, M.; Li, C.; He, Y.; Tan, Y.; Huang, L. A joint 2D-3D complementary network for stereo matching. Sensors 2021, 21, 1430. [Google Scholar] [CrossRef]
- He, Y.; Chen, W.; Liang, Z.; Chen, D.; Tan, Y.; Luo, X.; Li, C.; Guo, Y. Fast and Accurate Lane Detection via Frequency Domain Learning. In Proceedings of the 29th ACM International Conference on Multimedia (MM), Virtual, 20–24 October 2021; pp. 890–898. [Google Scholar]
- Hussein, A.; Gaber, M.M.; Elyan, E. Deep active learning for autonomous navigation. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Aberdeen, UK, 2–5 September 2016; Springer: Cham, Switzerland, 2016; pp. 3–17. [Google Scholar]
- Dhananjaya, M.M.; Kumar, V.R.; Yogamani, S. Weather and light level classification for autonomous driving: Dataset, baseline and active learning. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 2816–2821. [Google Scholar]
- Ajayi, G. Multi-Class Weather Dataset for Image Classification. 2018. Available online: https://data.mendeley.com/datasets/4drtyfjtfy/1 (accessed on 11 July 2022).
- Zhao, B.; Li, X.; Lu, X.; Wang, Z. A CNN–RNN architecture for multi-label weather recognition. Neurocomputing 2018, 322, 47–57. [Google Scholar] [CrossRef]
- Liang, Z.; Xu, X.; Deng, S.; Cai, L.; Jiang, T.; Jia, K. Exploring Diversity-based Active Learning for 3D Object Detection in Autonomous Driving. arXiv 2022, arXiv:2205.07708. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11621–11631. [Google Scholar]
- Peng, F.; Wang, C.; Liu, J.; Yang, Z. Active Learning for Lane Detection: A Knowledge Distillation Approach. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 15152–15161. [Google Scholar]
- Chen, Z.; Liu, Q.; Lian, C. Pointlanenet: Efficient end-to-end cnns for accurate real-time lane detection. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2563–2568. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra fast structure-aware deep lane detection. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 276–291. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Behrendt, K.; Soussan, R. Unsupervised labeled lane markers using maps. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Ranjan, V.; Wang, B.; Shah, M.; Hoai, M. Uncertainty estimation and sample selection for crowd counting. In Proceedings of the Asian Conference on Computer Vision (ACCV), Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Idrees, H.; Tayyab, M.; Athrey, K.; Zhang, D.; Al-Maadeed, S.; Rajpoot, N.; Shah, M. Composition loss for counting, density map estimation and localization in dense crowds. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 532–546. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 25–27 June 2013; pp. 2547–2554. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 589–597. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Li, X. NWPU-crowd: A large-scale benchmark for crowd counting and localization. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2020, 43, 2141–2149. [Google Scholar] [CrossRef]
- Zhao, Z.; Shi, M.; Zhao, X.; Li, L. Active crowd counting with limited supervision. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 565–581. [Google Scholar]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature Mining for Localised Crowd Counting. In Proceedings of the British Machine Vision Conference (BMVC), Guildford, UK, 3–7 September 2012; pp. 21.1–21.11. [Google Scholar] [CrossRef]
- Guerrero-Gómez-Olmedo, R.; Torre-Jiménez, B.; López-Sastre, R.; Maldonado-Bascón, S.; Onoro-Rubio, D. Extremely overlapping vehicle counting. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis (IbPRIA), Santiago, Spain, 17–19 June 2015; pp. 423–431. [Google Scholar]
- Marsden, M.; McGuinness, K.; Little, S.; Keogh, C.E.; O’Connor, N.E. People, penguins and petri dishes: Adapting object counting models to new visual domains and object types without forgetting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8070–8079. [Google Scholar]
- Li, C.; Chen, W.; Luo, X.; Wu, M.; Jia, X.; Tan, Y.; Wang, Z. Application of U-Shaped Convolutional Neural Network Based on Attention Mechanism in Liver CT Image Segmentation. In Proceedings of the International Conference on Medical Imaging and Computer-Aided Diagnosis, Oxford, UK, 20–21 January 2020; Springer: Singapore, 2020; pp. 198–206. [Google Scholar]
- Ze-Huan, Y.; Wei, C.; Chen, L.; Hao-Yi, Y.; Yu-Lin, H.; Yu-Song, T.; Fei, L. Automatic Diagnosis of Vaginal Microecological Pathological Images Based on Deep Learning. Prog. Biochem. Biophys. 2021, 48, 1348–1357. [Google Scholar]
- Li, C.; Chen, W.; Tan, Y. Point-sampling method based on 3D U-net architecture to reduce the influence of false positive and solve boundary blur problem in 3D CT image segmentation. Appl. Sci. 2020, 10, 6838. [Google Scholar] [CrossRef]
- Li, C.; Tan, Y.; Chen, W.; Luo, X.; He, Y.; Gao, Y.; Li, F. ANU-Net: Attention-based Nested U-Net to exploit full resolution features for medical image segmentation. Comput. Graph. 2020, 90, 11–20. [Google Scholar] [CrossRef]
- Li, C.; Tan, Y.; Chen, W.; Luo, X.; Gao, Y.; Jia, X.; Wang, Z. Attention unet++: A nested attention-aware u-net for liver ct image segmentation. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 345–349. [Google Scholar]
- Li, C.; Chen, W.; Tan, Y. Render u-net: A unique perspective on render to explore accurate medical image segmentation. Appl. Sci. 2020, 10, 6439. [Google Scholar] [CrossRef]
- Liu, L.; Lei, W.; Wan, X.; Liu, L.; Luo, Y.; Feng, C. Semi-supervised active learning for COVID-19 lung ultrasound multi-symptom classification. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Virutal, 9–11 November 2020; pp. 1268–1273. [Google Scholar]
- Hao, R.; Namdar, K.; Liu, L.; Khalvati, F. A transfer learning–based active learning framework for brain tumor classification. Front. Artif. Intell. 2021, 4, 635766. [Google Scholar] [CrossRef]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging (TMI) 2014, 34, 1993–2024. [Google Scholar] [CrossRef]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing the cancer genome atlas glioma MRI collections with expert segmentation labels and radiomic features. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef]
- Bakas, S.; Reyes, M.; Jakab, A.; Bauer, S.; Rempfler, M.; Crimi, A.; Shinohara, R.T.; Berger, C.; Ha, S.M.; Rozycki, M.; et al. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv 2018, arXiv:1811.02629. [Google Scholar]
- Ahsan, M.A.; Qayyum, A.; Qadir, J.; Razi, A. An Active Learning Method for Diabetic Retinopathy Classification with Uncertainty Quantification. arXiv 2020, arXiv:2012.13325. [Google Scholar] [CrossRef]
- Lam, C.; Yi, D.; Guo, M.; Lindsey, T. Automated detection of diabetic retinopathy using deep learning. AMIA Summits Transl. Sci. Proc. 2018, 2018, 147. [Google Scholar]
- Li, W.; Li, J.; Wang, Z.; Polson, J.; Sisk, A.E.; Sajed, D.P.; Speier, W.; Arnold, C.W. PathAL: An Active Learning Framework for Histopathology Image Analysis. IEEE Trans. Med. Imaging 2021, 41, 1176–1187. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning (ICML), PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Huang, J.; Qu, L.; Jia, R.; Zhao, B. O2u-net: A simple noisy label detection approach for deep neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3326–3334. [Google Scholar]
- Guo, S.; Huang, W.; Zhang, H.; Zhuang, C.; Dong, D.; Scott, M.R.; Huang, D. Curriculumnet: Weakly supervised learning from large-scale web images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 135–150. [Google Scholar]
- Bulten, W.; Kartasalo, K.; Chen, P.H.C.; Ström, P.; Pinckaers, H.; Nagpal, K.; Cai, Y.; Steiner, D.F.; van Boven, H.; Vink, R.; et al. Artificial intelligence for diagnosis and Gleason grading of prostate cancer: The PANDA challenge. Nat. Med. 2022, 28, 154–163. [Google Scholar] [CrossRef]
- Shen, Y.; Ke, J. Representative Region Based Active Learning For Histological Classification Of Colorectal Cancer. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 1730–1733. [Google Scholar]
- The Cancer Genome Atlas Research Network. Comprehensive molecular profiling of lung adenocarcinoma. Nature 2014, 511, 543–550. [Google Scholar] [CrossRef]
- Kather, J.N.; Krisam, J.; Charoentong, P.; Luedde, T.; Herpel, E.; Weis, C.A.; Gaiser, T.; Marx, A.; Valous, N.A.; Ferber, D.; et al. Predicting survival from colorectal cancer histology slides using deep learning: A retrospective multicenter study. PLoS Med. 2019, 16, e1002730. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Wang, J.; Yan, Y.; Zhang, Y.; Cao, G.; Yang, M.; Ng, M.K. Deep reinforcement active learning for medical image classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Lima, Peru, 4–8 October 2020; pp. 33–42. [Google Scholar]
- Smit, A.; Vrabac, D.; He, Y.; Ng, A.Y.; Beam, A.L.; Rajpurkar, P. MedSelect: Selective Labeling for Medical Image Classification Combining Meta-Learning with Deep Reinforcement Learning. arXiv 2021, arXiv:2103.14339. [Google Scholar]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 590–597. [Google Scholar]
- Shen, Y.; Ke, J. Su-Sampling Based Active Learning For Large-Scale Histopathology Image. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 116–120. [Google Scholar]
- Younesian, T.; Zhao, Z.; Ghiassi, A.; Birke, R.; Chen, L.Y. QActor: Active Learning on Noisy Labels. In Proceedings of the Asian Conference on Machine Learning, PMLR, Virtual, 17–19 November 2021; pp. 548–563. [Google Scholar]
- Guan, H.; Liu, M. Domain adaptation for medical image analysis: A survey. IEEE Trans. Biomed. Eng. 2021, 69, 1173–1185. [Google Scholar] [CrossRef] [PubMed]
- Choudhary, A.; Tong, L.; Zhu, Y.; Wang, M.D. Advancing medical imaging informatics by deep learning-based domain adaptation. Yearb. Med. Inform. 2020, 29, 129–138. [Google Scholar] [CrossRef] [PubMed]
- Prabhu, V.; Chandrasekaran, A.; Saenko, K.; Hoffman, J. Active domain adaptation via clustering uncertainty-weighted embeddings. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 8505–8514. [Google Scholar]
- Xie, B.; Yuan, L.; Li, S.; Liu, C.H.; Cheng, X.; Wang, G. Active learning for domain adaptation: An energy-based approach. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Virtual, 24–27 February 2022; Volume 36, pp. 8708–8716. [Google Scholar]
- Fu, B.; Cao, Z.; Wang, J.; Long, M. Transferable query selection for active domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 7272–7281. [Google Scholar]
- Zhou, Z.; Sodha, V.; Pang, J.; Gotway, M.B.; Liang, J. Models genesis. Med. Image Anal. 2021, 67, 101840. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
| Title | Main Contents | Publication |
|---|---|---|
| Samuel Budd et al. A survey on active learning and human-in-the-loop deep learning for medical image analysis [6] | ⊳ Investigate the active learning in the medical image analysis. ⊳ Propose the considerations in the deep learning–based active learning, including noisy oracles, weakly supervised learning, multi-task learning, annotation interface, and variable learning costs. ⊳ Discuss the future prospective and unanswered questions in the medical image analysis. | Medical Image Analysis. 2021, 71, 102062 |
| Punit Kumar et al. Active Learning Query Strategies for Classification, Regression, and Clustering: A Survey [7] | ⊳ Summarize the active learning query strategies for three tasks, including classification, regression, and clustering. ⊳ Classify the query strategies under classification into: informative-based, representative-based, informative-and-representative-based, and others. ⊳ Summarize the empirical evaluation of active learning query strategies. ⊳ Present the implementation, application, and challenges of the active learning in brief. | Journal of Computer Science and Technology. 2020, 35, 913–945. |
| Pengzhen Ren et al. A Survey of Deep Active Learning [8] | ⊳ Classify the existing works in the deep active learning. ⊳ Summarize the deep active learning applications, including vision and NLP. ⊳ Especially, in the visual data processing tasks, it discusses image classification and recognition, object detection and semantic segmentation, and video processing. | ACM Computing Surveys. 54.9 (2021): 1–40. |
| Xueying Zhan et al. A Comparative Survey of Deep Active Learning [9] | ⊳ Categorize deep active learning sampling methods and querying strategies. ⊳ Compare deep active learning algorithms across common used datasets. ⊳ Conduct experiments to explore influence factors of deep active learning ⊳ Release a deep active learning toolkit, named DeepAL+. | arXiv:2203.13450, 2022. |
| Strategies | Methodologies | Typical Works |
|---|---|---|
| Random selection | ⊳ Random sampling is to use random numbers to select samples from the unlabeled dataset for labeling. | N.A. |
| ⊳ | ||
| Uncertainty-based selection | ⊳ Least confidence is to select the sample with the smallest probability of the top1 predicted class. In practice, the opposite of the maximum predicted probability is often taken as the uncertainty score of the sample. | Li et al. [10] |
| ⊳ | Agrawal et al. [11,12] | |
| ⊳ Margin sampling is to calculate the difference between the probabilities of the top1 and the top2 predicted class.Then the samples with the smallest difference are defined as hard-to-classify samples for labeling. | Ajay J. et al. [13] | |
| ⊳ | Zhou et al. [14] | |
| ⊳ Multi-class level uncertainty is to select the two samples that are the farthest from the classification hyperplane of multi-class and take their distance difference as the score. | Gu et al. [15] | |
| ⊳ | Yang et al. [16] | |
| ⊳ Maximize entropy is to utilize the methodology that larger entropy denotes higher uncertainty. The sample with the largest entropy is selected as candidate. | Yu et al. [17] | |
| ⊳ | Ozdemir et al. [18] | |
| Diversity-based selection | ⊳ Angle-based measurement is to to measure diversity by calculating the undirected angles between the induced hyper-planes. | Brinker et al. [19] |
| ⊳ | ||
| ⊳ Redundancy-based measurement is to measure the diversity as the redundancy between unlabeled points via symmetric KL divergence [20] between the two vectors of probability values. | Shayok et al. [21] | |
| ⊳ | Zhou et al. [22] | |
| Committee-based selection [23] | ⊳ Vote entropy–based measurement is to select the hard sample voted by the Committee. The models in the committee distinguish samples into different classes. The predicted results toward one sample with the largest entropy is classified as hard sample and needs to vote for labeling. | Yan et al. [24] |
| ⊳ | Dagan et al. [25] | |
| ⊳ Average KL divergence–based measurement is to measure the deviation of those unlabeled samples via calculating the average KL divergence of the committee . | Dagan et al. [25] | |
| Scenarios | Concepts | Limitations | Publications |
|---|---|---|---|
| Membership query synthesis | ⊳ The membership query synthesis is to generate new unlabeled instances for querying by itself instead of selecting samples from the real-world distribution [27]. | ⊳ It may encounter troubles when the generated data is too arbitrary for the annotator to recognize or does not contains any semantic information. | [28,29] |
| Stream-based sampling | ⊳ The stream-based scenario [30] is to sample from the natural distribution instead of the synthesized one. ⊳ In this scenario, the selection process is similar to a pipeline. The unlabeled sample is firstly input into the model one by one. ⊳ Then, the active learning strategy needs to decide whether to pass it to the annotator for labeling or reject it directly. | ⊳ It is necessary for the model to immediately decide based on a single input rather than the comprehensive consideration of this batch. ⊳ The active learning system may suffer from the absence of knowledge of unseen areas. | [31,32,33] |
| Pool-based sampling | ⊳ The pool-based sampling scenario is to selects the most valuable samples from an unlabeled data pool for labeling according to the informativeness [34]. ⊳ The unlabeled data pool is sampled from the natural distribution instead of synthesized samples. | ⊳ It is computationally expensive because every iteration requires the informativeness evaluation for the whole pool. | [35,36,37] |
| Type | Methodology | Equation |
|---|---|---|
| MC dropout | ⊳ In practice, the MC dropout usually trains the CNN with the labeled data pool L with dropout. ⊳ After training, it generates a new dropout mask for the model parameters and performing T forward inference. ⊳ The output is the average of T results. | |
| Deep Ensembles | ⊳ The ensemble-based approaches design N neural networks at first. ⊳ These networks share same architecture but initialized from different weights. ⊳ Then networks are trained with the labeled data pool L. ⊳ The average of the outputs of the N networks is the final output. |
| Methods | Innovation | Architecture | Comments |
|---|---|---|---|
| GAAL [57] | ⊳ The first novel query synthesis-based active learning method GAAL fused with GAN. ⊳ GAAL combined query synthesis with the uncertainty sampling principle and adaptively synthesized training instances for querying to increase learning speed. ⊳ The DCGAN was implemented to replace the unlabeled pool in previous work. | ⊳ Generator: CNN ⊳ Discriminator: CNN ⊳ Predictor: SVM ⊳ Score-function: Uncertainty | ⊳ GAAL was the first work integrated active learning and generative methods. ⊳ GAAL provided rich representation training samples for active learning via GAN. ⊳ GAAL was limited by the generated abnormal instances if the GAN was not optimized correctly. ⊳ GAAL is limited by the binary classification setting. |
| BGAL [59] | ⊳ BGAL integrated deep active learning and data augmentation methods to generate informative samples and expand the labeled data set to improve the accuracy of model classification. ⊳ BGAL also integrated ACGAN [67] and VAE-GAN [68] into a novel generative model named VAE-ACGAN, where the VAE decoder was the generator of the GAN. ⊳ VAE-ACGAN generated new synthetic instances on the query samples. ⊳ The learner and the VAE-ACGAN were jointly trained in this work. | ⊳ Generator: VAE ⊳ Discriminator: Bayesian CNN ⊳ Predictor: Resnet18 ⊳ Score-function: MC-dropout | ⊳ BGAL extended the GAAL by combined more robust data augmentation techniques. ⊳ The combination of data augmentation and active learning obtained consistent improvement on classification than single methods. ⊳ The computation efficiency need to be improved due to the computational cost is high. |
| ASAL [60] | ⊳ ASAL consists of uncertainty sampling, adversarial sample generation, and sample matching. ⊳ In order to approximate the underlying data distribution from the unlabeled data pool, ASAL utilized a GAN to generate adversarial samples. ⊳ ASAL designed an efficient matching algorithm, where an uncertainty score was calculated to measure the similarity between the unlabeled samples and the generated samples. ⊳ ASAL selected the most similar samples from the pool and performs annotation. | ⊳ Generator: CNN with matching ⊳ Discriminator: CNN ⊳ Predictor: CNN ⊳ Score-function: Entropy | ⊳ ASAL was the first pool-based generative active learning method. ⊳ The main contribution of ASAL was to select the most similar sample from pool instead of directly annotating it via a matching algorithm. ⊳ ASAL utilized the entropy for uncertainty estimation and was applied in the multi-label classification. |
| VAAL [63] | ⊳ VAAL utilized adversarial learning to promote active learning. ⊳ A variational autoencoder (VAE) was used to extract image features, and then a discriminator decided whether the image was labeled or unlabeled. ⊳ The VAE hoped to trick the discriminator into judging all samples as labeled data, but the discriminator hoped to accurately distinguish unlabeled samples in the data pool. ⊳ The annotator labeled the unlabeled samples selected based on this method. | ⊳ Generator: VAE ⊳ Discriminator: MLP ⊳ Predictor: VGG16 ⊳ Score-function: Confidence | ⊳ VAAL provided a computational efficient sampling method with the best accuracy and time cost. |
| Applications | Comments | Implementation | Evaluation |
|---|---|---|---|
| Autonomous navigation [105] | ⊳ Proposed a framework for learning autonomous policies for navigation tasks from demonstrations. | ⊳ Network: 3 × (Conv + Pool) + FC. ⊳ Score-function Entropy: | ⊳ Reach the flag: error rate = 2.48%. ⊳ Follow the line: error rate = 4.06%. ⊳ Reach the correct object: error rate = 0.86%. ⊳ Eat all disks: error rate = 1.70% |
| Weather and light classification [106] | ⊳ Released the first public dataset for weather and light level classification focused on autonomous driving. | ⊳ Target network: Resnet18 ⊳ Loss-prediction module [52]: 4 × (GAP + FC + ReLU) + Concat + FC. ⊳ Selection strategy: High loss samples. | ⊳ Weather1 [107]: accuracy = 98.80% ⊳ Weather2 [108]: F1 score = 0.872 ⊳ Proposed dataset [106]: F1 score = 0.772 |
| 3D object detection [109] | ⊳ The first work that introduced active learning into 3D object detection in autonomous driving. | ⊳ 3D Detector: VoxelNet ⊳ Score-function: Diversity: | ⊳ nuScenes [110]: mAP = 45.02. |
| Lane detection [111] | ⊳ The first work that introduced active learning into lane detection in autonomous driving. | ⊳ Student model: ResNet-122 (for PLN [112]) ResNet-18 (for UFLD [113]) ⊳ Teacher model: SENet-154 (for PLN [112]) ResNet-101 (for UFLD [113]) ⊳ Score-function: Combined the uncertainty and diversity metrics. | ⊳ CULane [114] and LLAMAS [115]. (F1 score not reported) |
| Crowd counting [116] | ⊳ The first work that used predictive uncertainty for sample selection pertaining to crowd counting task. | ⊳ Local feature block: VGG16 ⊳ Non-local feature block: Transformer ⊳ Score-function: Informativeness difference: | ⊳ UCF-QNRF [117]: MAE = 86; MSE = 146. ⊳ UCF CC [118]: MAE = 210; MSE = 305.4. ⊳ ShanghaiTech-A [119]: MAE = 61.5; MSE = 103.4. ⊳ ShanghaiTech-B [119]: MAE = 7.5; MSE = 11.9. ⊳ NWPU [120]: MAE = 78; MSE = 448. |
| Crowd counting [121] | ⊳ Proposed a partition-based sample selection with weights (PSSW) strategy to actively select and annotate both diverse and dissimilar samples for network training. | ⊳ Backbone: VGG16 pretrained by imagenet ⊳ Score-function: Diverse in density and dissimilar to previous selections. | ⊳ ShanghaiTech-A [119]: MAE = 80.4; MSE = 138.8. ⊳ ShanghaiTech-B [119]: MAE = 12.7; MSE = 20.4. ⊳ UCF CC [118]: MAE = 318.7; MSE = 421.6. ⊳ Mall [122]: MAE = 3.8; MSE = 5.4. ⊳ TRANCOS [123]: MAE = 7.5. ⊳ DCC [124]: MAE = 4.5. |
| Applications | Comments | Implementation | Evaluation |
|---|---|---|---|
| Medical image detection and classification [22,26] | ⊳ Combined active learning, incremental fine-tuning, and transfer learning. | ⊳ Network: AlexNet pretrained by imagenet ⊳ Selection strategy: Entropy: Diversity: | ⊳ polyp detection: ↓ 86% labels. ⊳ pulmonary embolism detection: ↓ 80% labels. ⊳ colonoscopy frame classification: ↓ 82% labels. ⊳ scene classification: ↓ 35% labels. |
| COVID-19 Lung Ultrasound Multi-symptom Classification [131] | ⊳ The first work that introduced active learning into ultrasound classification for COVID-19-assisted diagnosis. | ⊳ Backbone: ResNet50 pretrained by imagenet ⊳ Score-function: Least confidence: t Multi-label entropy: | ⊳ COVID19-LUSMS v1: ↓ 80% labels. |
| Brain tumor Classification [132] | ⊳ Sampling candidates by discarding subsets of training samples with the highest and lowest uncertainty scores. | ⊳ Network: AlexNet pretrained by imagenet ⊳ Score-function: Combined entropy and Kullback–Leibler (KL) divergence: | ⊳ MICCAI BRATS [133,134,135]: ↓ 40% labels. |
| Diabetic retinopathy classification [136] | ⊳ The first work that introduced active learning into lane detection in autonomous driving. | ⊳ Bayesian convolutional neural network (BCNN): Monte-Carlo drop-out ⊳ Teacher model: SENet-154 (for PLN [112]) ResNet-101 (for UFLD [113]) ⊳ Score-function: entropy. | ⊳ APTOS 2019 [137]: AUC = 0.99 (multi-class classification) Accuracy = 92% (multi-class classification) Accuracy = 85% (BCNN in Active Learning) |
| Histo-pathology image analysis [138] | ⊳ The first work that proposed an AL framework (PathAL) to dynamically identify important samples to annotate and to distinguish noisy from hard samples in the training set. | ⊳ Backbone: EfficientNet-B0 [139] ⊳ Noisy sample detector: O2U-Net [140] Curriculum Sample Classification: CurriculumNet [141] ⊳ Score-function: Distinguished noisy samples from hard ones, and selected the most informative samples to be annotated. | ⊳ PANDA [142]: quadratic weighted kappa = 89.5. |
| Gastric adenocarcinoma and colorectal cancer [143] | ⊳ The first work that explored the identification of the most informative region of patches and proposed a patch location system to select patches. | ⊳ Backbone: ResNet-18 ⊳ Loss-prediction module [52]: 4 × (GAP + FC + ReLU) + Concat + FC. ⊳ Score-function: | ⊳ TCGA [144,145]: AUC = 0.933. accuracy = 92.7%. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, M.; Li, C.; Yao, Z. Deep Active Learning for Computer Vision Tasks: Methodologies, Applications, and Challenges. Appl. Sci. 2022, 12, 8103. https://doi.org/10.3390/app12168103
Wu M, Li C, Yao Z. Deep Active Learning for Computer Vision Tasks: Methodologies, Applications, and Challenges. Applied Sciences. 2022; 12(16):8103. https://doi.org/10.3390/app12168103
Chicago/Turabian StyleWu, Mingfei, Chen Li, and Zehuan Yao. 2022. "Deep Active Learning for Computer Vision Tasks: Methodologies, Applications, and Challenges" Applied Sciences 12, no. 16: 8103. https://doi.org/10.3390/app12168103
APA StyleWu, M., Li, C., & Yao, Z. (2022). Deep Active Learning for Computer Vision Tasks: Methodologies, Applications, and Challenges. Applied Sciences, 12(16), 8103. https://doi.org/10.3390/app12168103