
Enhanced Context Learning with Transformer for Human Parsing



Abstract
:1. Introduction
- (1)
- We propose an enhanced context learning with Transformer for the human parsing method, which can improve the accuracy in the current field of human parsing both locally and globally.
- (2)
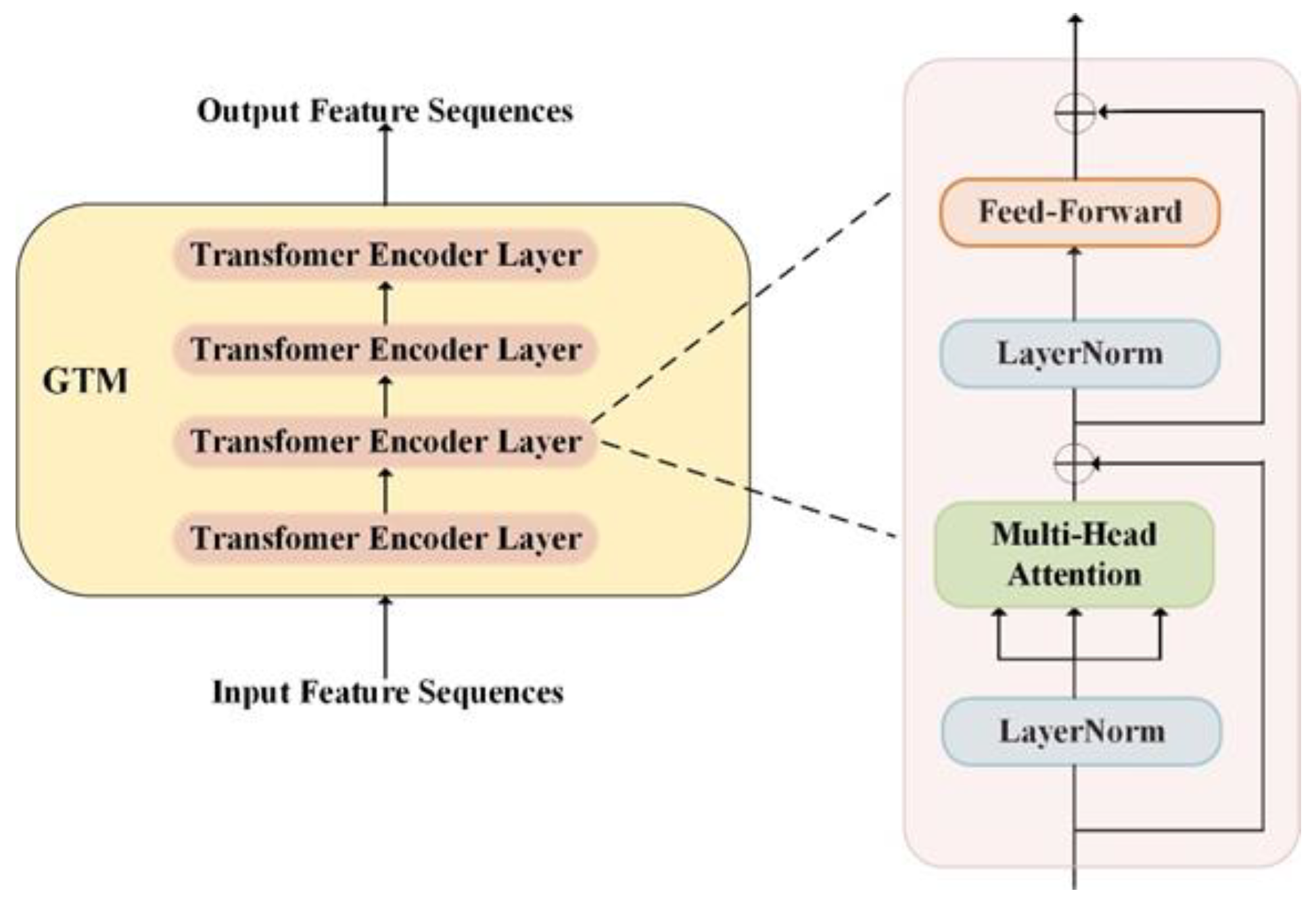
- We design a GTM architecture to explore long-range global information through the self-attention mechanism.
- (3)
- To capture fine-grained local information effectively, we design the DFE module to integrate information between the GTM and edge detection module, which learns rich and discriminative detailed features.
2. Related Work
2.1. Human Parsing
2.2. Context Information Extraction
2.3. Transformer in Vision
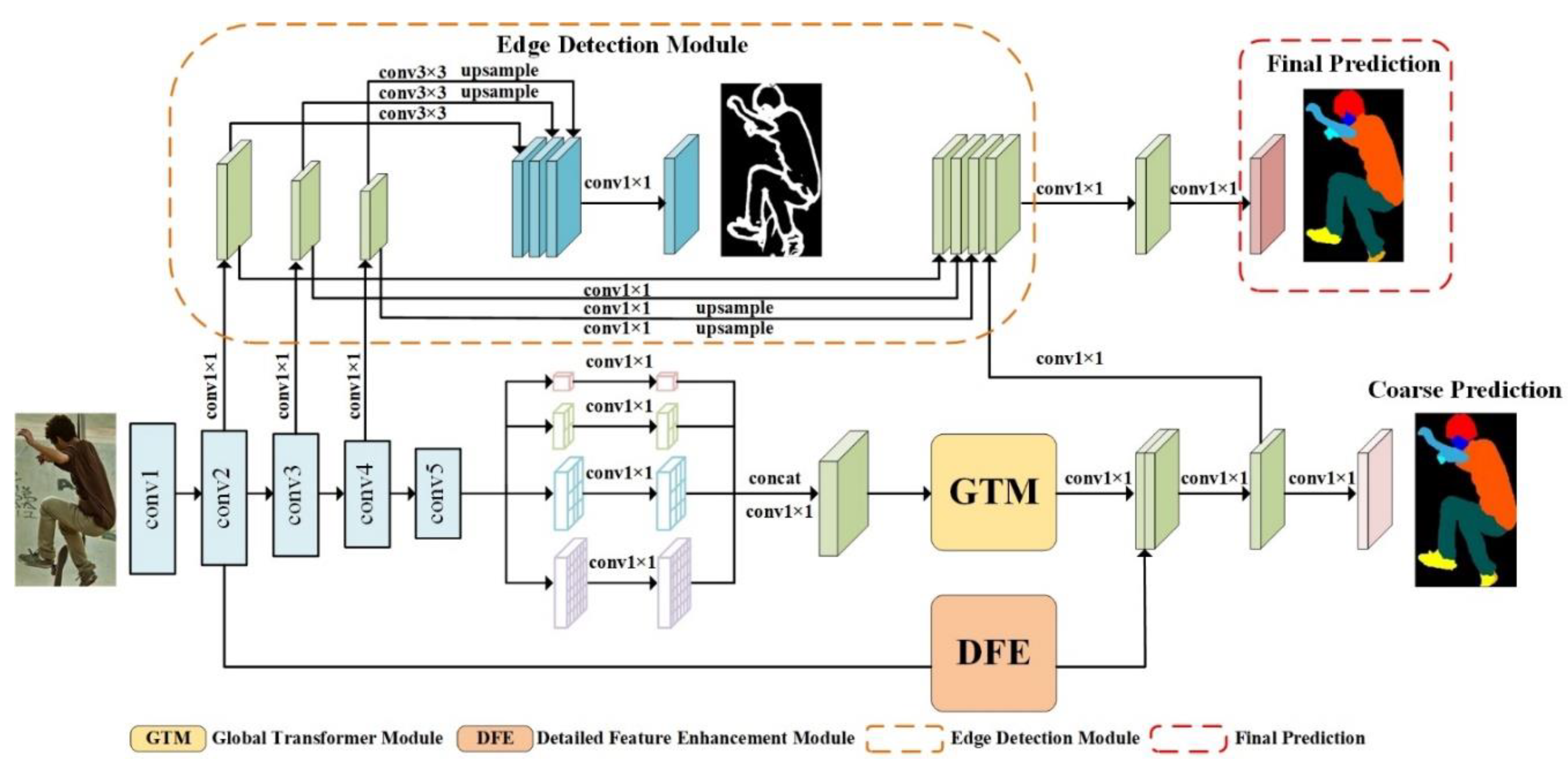
3. Method
3.1. Global Transformer Module
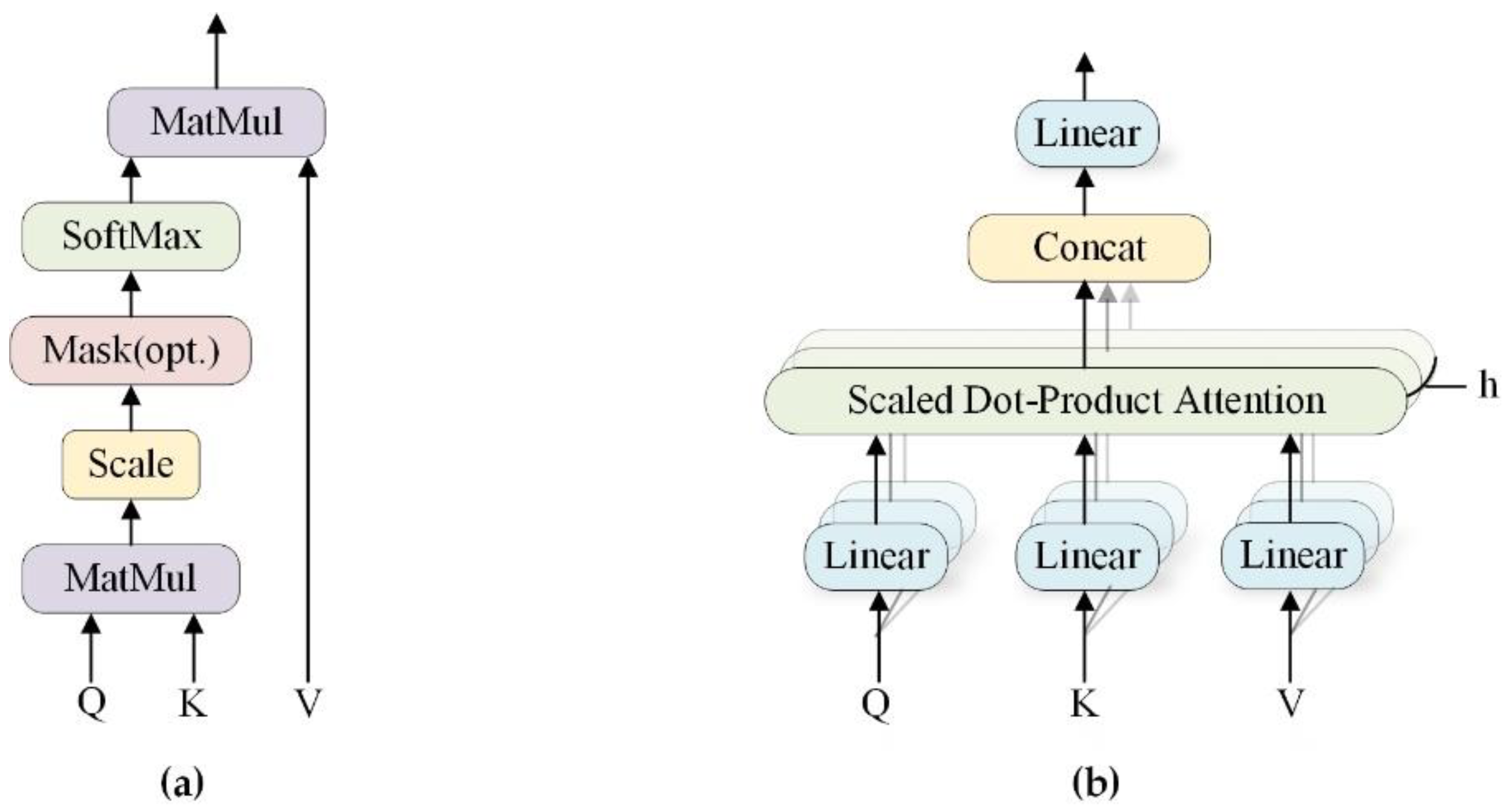
3.1.1. Self-Attention Mechanism
| Algorithm 1: Self-Attention for Transformer |
| Input: Sequence = (, …,), initialized q, k, v |
| Output: Vector sequence = (, …,) |
| Step 1. Obtain q, k, v for each input x; , , |
| Step 2. Calculate the attention scores of input x, |
| Step 3. Perform Scaled Dot-Product operation, |
| Step 4. Compute softmax, |
| Step 5. Multiply the score with the values and weight the sum, Z |
3.1.2. Positional Encoding
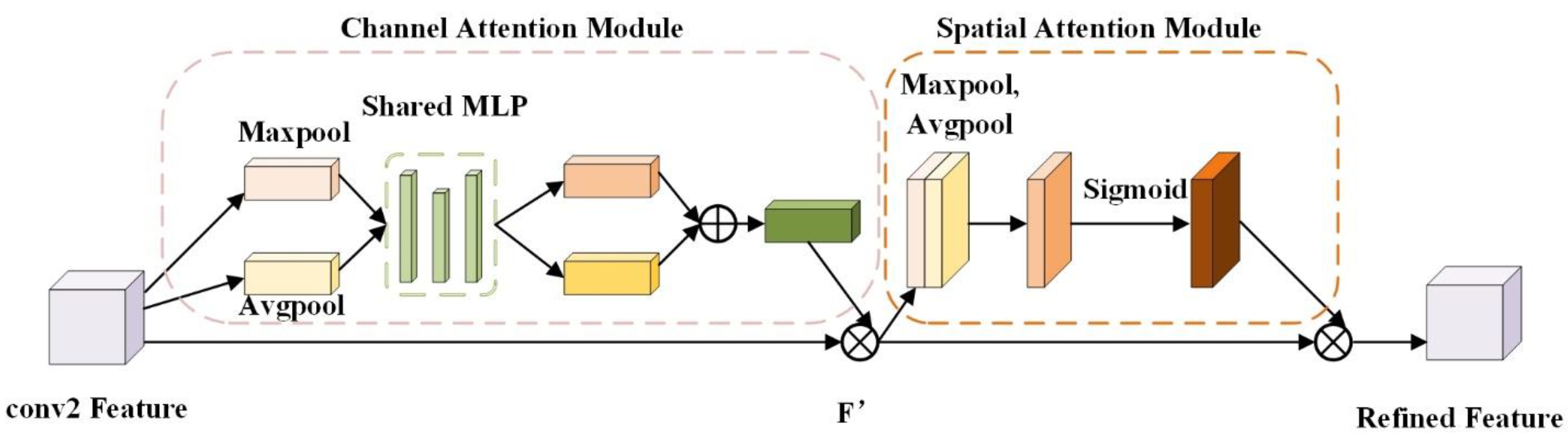
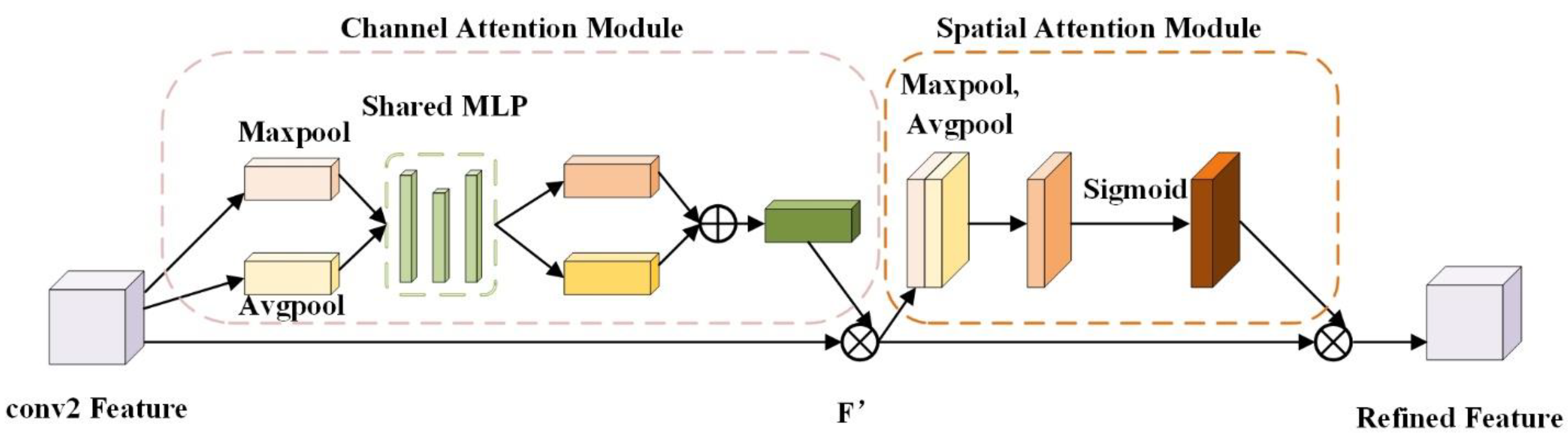
3.2. Detailed Feature Enhancement Module
3.3. Edge Detection Module
3.4. Loss Function
4. Experiments
4.1. Datasets and Metrics
4.2. Implement Details
4.3. Quantitative Results
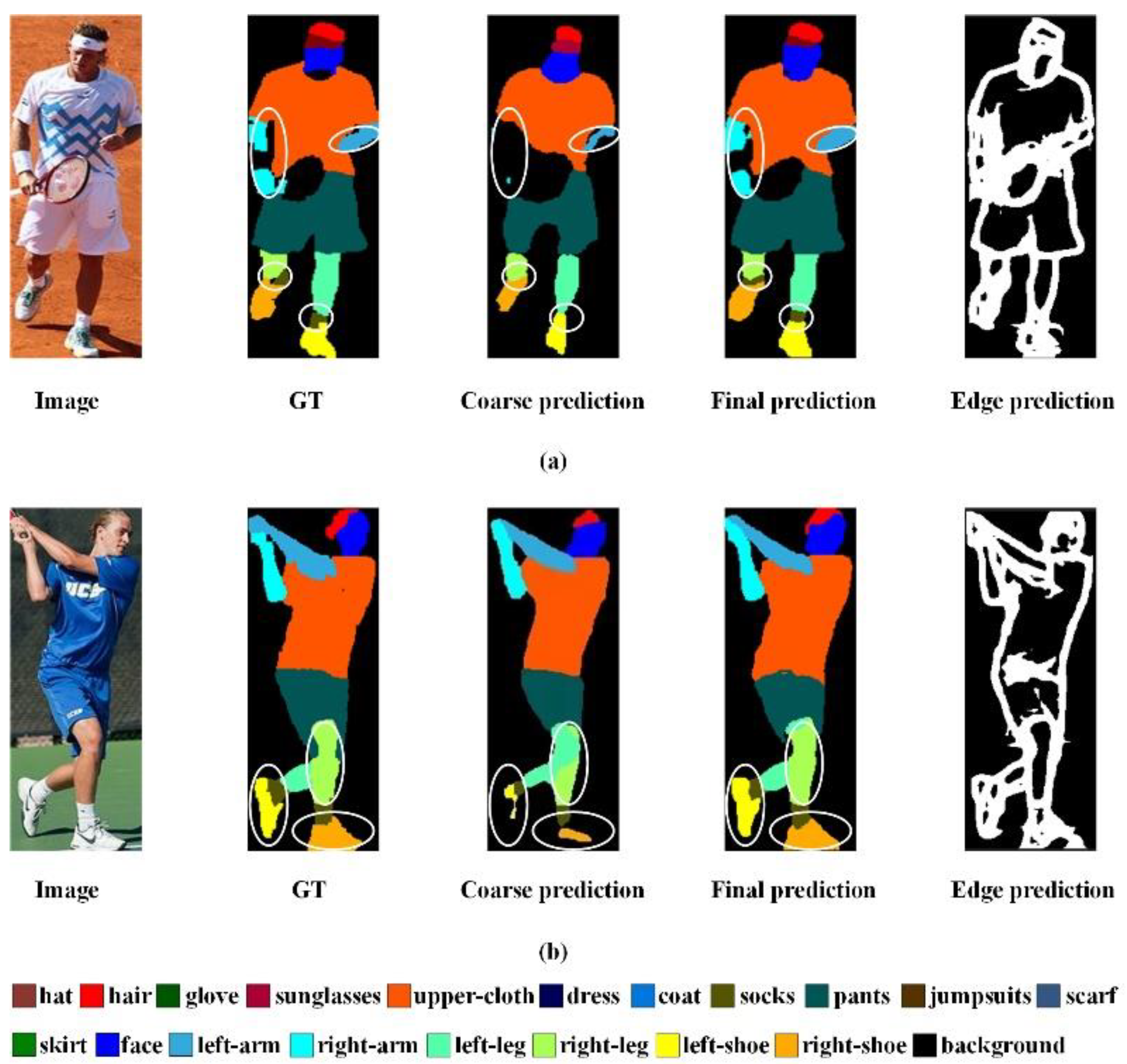
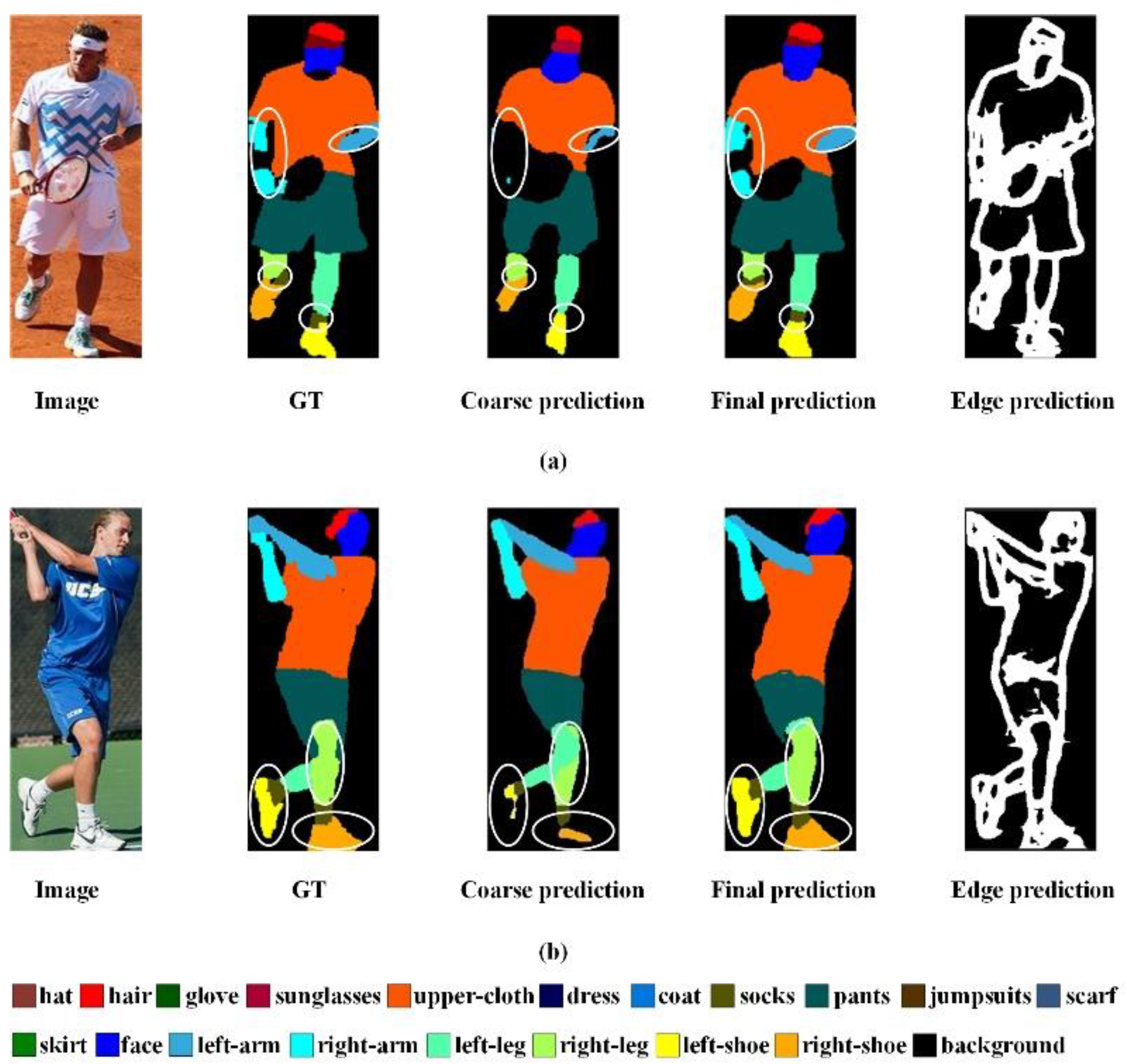
4.4. Qualitative Comparison
4.5. Ablation Study
4.5.1. The Effect of GTM
4.5.2. The Effect of DFE
4.5.3. The Effect of Edge Detection Module
4.5.4. The Effect of Auxiliary Loss
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, Y.; Boukharouba, K.; Boonært, J.; Fleury, A.; Lecoeuche, S. Application of an incremental SVM algorithm for online human recognition from video surveillance using texture and color features. Neurocomputing 2014, 126, 132–140. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Kalayeh, M.M.; Basaran, E.; Gökmen, M.; Kamasak, M.E.; Shah, M. Human semantic parsing for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1062–1071. [Google Scholar]
- Qi, S.; Wang, W.; Jia, B.; Shen, J.; Zhu, S.C. Learning human-object interactions by graph parsing neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 401–417. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image seg-mentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ruan, T.; Liu, T.; Huang, Z.; Wei, Y.; Wei, S.; Zhao, Y. Devil in the details: Towards accurate single and multiple human parsing. In Proceedings of the AAAI Conference on Artificial Intelligence, Hanolulu, HI, USA, 27 January–1 February 2019; pp. 4814–4821. [Google Scholar]
- Liang, X.; Xu, C.; Shen, X.; Yang, J.; Liu, S.; Tang, J.; Lin, L.; Yan, S.; Sun Yat-sen University; National University of Singapore; et al. Human parsing with contextualized convolutional neural network. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1386–1394. [Google Scholar]
- Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 6–10 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Liang, X.; Gong, K.; Shen, X.; Lin, L. Look into person: Joint body parsing & pose estimation network and a new benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 871–885. [Google Scholar]
- Nie, X.; Feng, J.; Yan, S. Mutual learning to adapt for joint human parsing and pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 502–517. [Google Scholar]
- Chen, L.C.; Barron, J.T.; Papandreou, G.; Murphy, K.; Yuille, A.L. Semantic image segmentation with task-specific edge detection using cnns and a discriminatively trained domain transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4545–4554. [Google Scholar]
- Gong, K.; Liang, X.; Li, Y.; Chen, Y.; Yang, M.; Lin, L. Instance-level human parsing via part grouping network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 770–785. [Google Scholar]
- Li, P.; Xu, Y.; Wei, Y.; Yang, Y. Self-correction for human parsing. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Su, C.; Zheng, L.; Xie, X. Correlating edge, pose with parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8900–8909. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y. Adaptive pyramid context network for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7519–7528. [Google Scholar]
- Yuan, Y.; Chen, X.; Chen, X.; Wang, J. Segmentation transformer: Object-contextual representations for semantic seg-mentation. arXiv 2019, arXiv:1909.11065. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning. PMLR, Stockholm Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Zhang, L.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Luo, X.; Su, Z.; Guo, J.; Zhang, G.; He, X. Trusted guidance pyramid network for human parsing. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 654–662. [Google Scholar]
- Liang, X.; Liu, S.; Shen, X.; Yang, J.; Liu, L.; Dong, J.; Lin, L.; Yan, S. Deep human parsing with active template regression. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2402–2414. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; Feng, J.; Domokos, C.; Xu, H.; Huang, J.; Hu, Z.; Yan, S. Fashion parsing with weak color-category labels. IEEE Trans. Multimed. 2013, 16, 253–265. [Google Scholar] [CrossRef]
- Yamaguchi, K.; Kiapour, M.H.; Ortiz, L.E.; Berg, T.L. Parsing clothing in fashion photographs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3570–3577. [Google Scholar]
- Yang, W.; Luo, P.; Lin, L. Clothing co-parsing by joint image segmentation and labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3182–3189. [Google Scholar]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Pixel Acc. | Mean Acc. | mIoU |
|---|---|---|---|
| DeepLab [9] | 82.66 | 51.64 | 41.64 |
| Attention [37] | 83.43 | 54.39 | 42.92 |
| DeepLab (ResNet-101) | 84.09 | 55.62 | 44.80 |
| MuLA [14] | 88.50 | 60.50 | 49.30 |
| JPPNet [13] | 86.39 | 62.32 | 51.37 |
| CE2P [6] | 87.37 | 63.20 | 53.10 |
| Ours | 87.66 | 66.09 | 54.50 |
| Method | Bkg | Hat | Hair | Glove | Glass | u-Cloth | Dress | Coat | Socks | Pants | j-Suits | Scarf | Skirt | Face | l-Arm | r-Arm | l-Leg | r-Leg | l-Shoe | r-Shoe | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SegNet [5] | 70.62 | 26.60 | 44.01 | 0.01 | 0.00 | 34.46 | 0.00 | 15.97 | 3.59 | 33.56 | 0.01 | 0.00 | 0.00 | 52.38 | 15.30 | 24.23 | 13.82 | 13.17 | 9.26 | 6.47 | 18.17 |
| DeepLab [9] | 83.25 | 57.94 | 66.11 | 28.50 | 18.40 | 60.94 | 23.17 | 47.03 | 34.51 | 64.00 | 22.38 | 14.29 | 18.74 | 69.70 | 49.44 | 51.66 | 37.49 | 34.60 | 28.22 | 22.41 | 41.64 |
| Attention [37] | 84.00 | 58.87 | 66.78 | 23.32 | 19.48 | 63.20 | 29.63 | 49.70 | 35.23 | 66.04 | 24.73 | 12.84 | 20.41 | 70.58 | 50.17 | 54.03 | 38.35 | 37.70 | 26.20 | 27.09 | 42.92 |
| DeepLab101 | 84.09 | 59.76 | 66.22 | 28.76 | 23.91 | 64.95 | 33.68 | 52.86 | 37.67 | 68.05 | 26.15 | 17.44 | 25.23 | 70.00 | 50.42 | 53.89 | 39.36 | 38.27 | 26.95 | 28.36 | 44.80 |
| JPPNet [13] | 86.26 | 63.55 | 70.20 | 36.16 | 23.48 | 68.15 | 31.42 | 55.65 | 44.56 | 72.19 | 28.39 | 18.76 | 25.14 | 73.36 | 61.97 | 63.88 | 58.21 | 57.99 | 44.02 | 44.09 | 51.37 |
| CE2P [6] | 87.67 | 65.29 | 72.54 | 39.09 | 32.73 | 69.46 | 32.52 | 56.28 | 49.67 | 74.11 | 27.23 | 14.19 | 22.51 | 75.50 | 65.14 | 66.59 | 60.10 | 58.59 | 46.63 | 46.12 | 53.10 |
| Ours | 87.87 | 67.28 | 72.11 | 42.24 | 33.70 | 70.46 | 37.82 | 57.07 | 50.55 | 75.21 | 32.16 | 17.67 | 28.73 | 74.84 | 65.54 | 67.83 | 59.60 | 58.81 | 45.28 | 45.42 | 54.50 |
| Method | Pixel Acc. | F.G.Acc | Avg.P. | Avg.R. | Avg.F-1 |
|---|---|---|---|---|---|
| DeepLab [9] | 87.68 | 56.08 | 35.35 | 39.00 | 37.09 |
| Attention [37] | 90.58 | 64.47 | 47.11 | 50.35 | 48.68 |
| Ours | 92.00 | 66.16 | 54.40 | 56.01 | 55.19 |
| Method | Pixel Acc. | F.G.Acc | Avg.P. | Avg.R. | Avg.F-1 |
|---|---|---|---|---|---|
| ATR [33] | 91.11 | 71.04 | 71.69 | 60.25 | 64.38 |
| DeepLab [9] | 94.42 | 82.93 | 78.48 | 69.24 | 73.53 |
| PSPNet [11] | 95.20 | 80.23 | 79.66 | 73.79 | 75.84 |
| Attention [37] | 95.41 | 85.71 | 81.30 | 73.55 | 77.23 |
| Co-CNN [7] | 96.02 | 83.57 | 84.95 | 77.66 | 80.14 |
| Ours | 96.10 | 84.02 | 84.87 | 80.89 | 80.26 |
| Method | Bkg | Hat | Hair | Glove | Glass | u-Cloth | Dress | Coat | Socks | Pants | j-Suits | Scarf | Skirt | Face | l-Arm | r-Arm | l-Leg | r-Leg | l-Shoe | r-Shoe | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | 87.22 | 65.34 | 72.13 | 36.18 | 31.97 | 68.86 | 31.02 | 55.81 | 47.35 | 73.23 | 26.91 | 12.28 | 20.58 | 74.49 | 62.95 | 65.18 | 56.31 | 55.59 | 43.49 | 43.80 | 51.54 |
| B + T | 87.70 | 65.87 | 71.77 | 40.08 | 29.76 | 69.46 | 36.48 | 56.39 | 46.69 | 74.51 | 33.14 | 20.07 | 27.83 | 74.68 | 64.07 | 67.00 | 57.77 | 57.69 | 44.40 | 45.68 | 53.55 |
| B + D | 86.72 | 63.72 | 70.41 | 40.00 | 27.87 | 66.84 | 34.03 | 53.00 | 44.98 | 72.37 | 26.33 | 15.56 | 27.37 | 73.54 | 62.48 | 64.80 | 56.82 | 55.96 | 42.88 | 43.65 | 51.47 |
| B + T + D | 87.63 | 65.68 | 71.77 | 39.90 | 28.95 | 69.19 | 34.66 | 55.48 | 47.31 | 74.73 | 34.22 | 21.06 | 28.40 | 74.38 | 64.19 | 66.77 | 57.90 | 57.58 | 44.48 | 45.20 | 53.47 |
| B + T + E | 87.86 | 66.84 | 71.72 | 42.72 | 30.81 | 69.95 | 36.62 | 56.90 | 49.46 | 74.97 | 31.50 | 18.76 | 25.26 | 74.81 | 65.26 | 67.37 | 58.34 | 57.95 | 44.45 | 45.26 | 53.84 |
| B + T + E + D | 87.86 | 67.15 | 71.70 | 43.45 | 32.40 | 70.08 | 38.10 | 56.59 | 50.08 | 74.80 | 31.50 | 17.50 | 27.21 | 74.83 | 64.97 | 67.57 | 58.79 | 58.36 | 44.55 | 45.43 | 54.14 |
| B + T + E + D (auxiliary) loss) | 87.87 | 67.28 | 72.11 | 42.24 | 33.70 | 70.46 | 37.82 | 57.07 | 50.55 | 75.21 | 32.16 | 17.67 | 28.73 | 74.84 | 65.54 | 67.83 | 59.60 | 58.81 | 45.28 | 45.42 | 54.50 |
| Method | Bkg | Hat | Hair | Glove | Glass | u-Cloth | Dress | Coat | Socks | Pants | j-Suits | Scarf | Skirt | Face | l-Arm | r-Arm | l-Leg | r-Leg | l-Shoe | r-Shoe | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B + T + SA | 87.69 | 66.45 | 71.96 | 41.14 | 28.25 | 69.38 | 35.28 | 56.71 | 47.93 | 74.84 | 32.8 | 20.07 | 27.38 | 74.53 | 63.78 | 66.26 | 57.51 | 57.27 | 44.95 | 45.39 | 53.48 |
| B + T + SA + CA | 87.63 | 65.68 | 71.77 | 39.90 | 28.95 | 69.19 | 34.66 | 55.48 | 47.31 | 74.73 | 34.22 | 21.06 | 28.40 | 74.38 | 64.19 | 66.77 | 57.90 | 57.58 | 44.48 | 45.20 | 53.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, J.; Shi, Q.; Li, Y.; Yang, F. Enhanced Context Learning with Transformer for Human Parsing. Appl. Sci. 2022, 12, 7821. https://doi.org/10.3390/app12157821
Song J, Shi Q, Li Y, Yang F. Enhanced Context Learning with Transformer for Human Parsing. Applied Sciences. 2022; 12(15):7821. https://doi.org/10.3390/app12157821
Chicago/Turabian StyleSong, Jingya, Qingxuan Shi, Yihang Li, and Fang Yang. 2022. "Enhanced Context Learning with Transformer for Human Parsing" Applied Sciences 12, no. 15: 7821. https://doi.org/10.3390/app12157821
APA StyleSong, J., Shi, Q., Li, Y., & Yang, F. (2022). Enhanced Context Learning with Transformer for Human Parsing. Applied Sciences, 12(15), 7821. https://doi.org/10.3390/app12157821