
REX: General-Purpose CNL with Code Generation Support


Abstract
:1. Introduction
2. Background and Related Work
- Verification errors: ambiguity is removed (through a formal grammar), and automated verification is added (through code generation);
- Validation errors: the time/effort required to measure the realization value of requirements in practice is reduced (through code generation).
3. REX
3.1. Introduction
- Class declaration (one statement);
- Class composition (one statement);
- Subclassing (one statement);
- Function/pattern declaration, definition, and call (two statements, one phrase);
- Class/object instantiation (one phrase).
3.2. Hello, World!
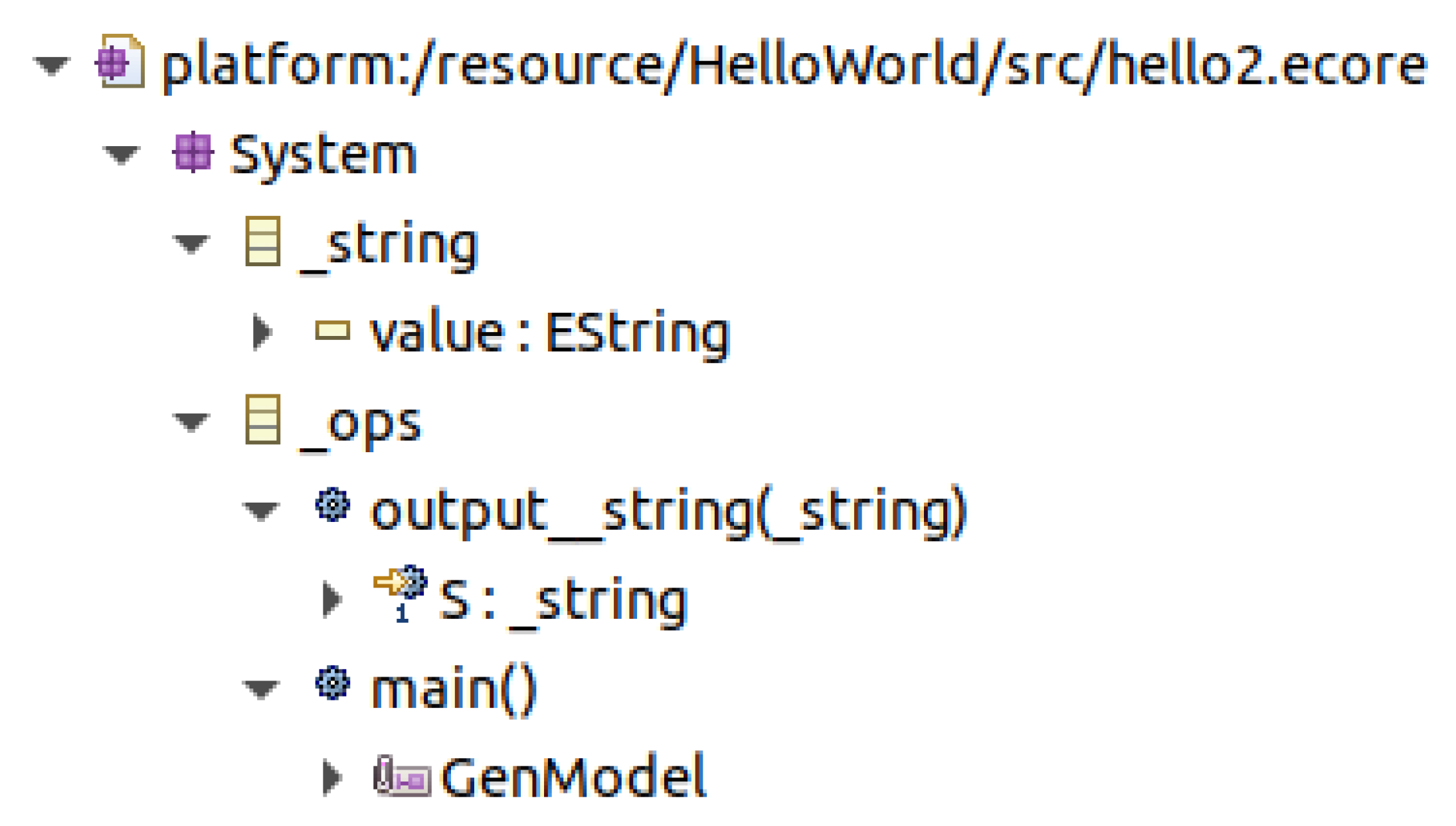
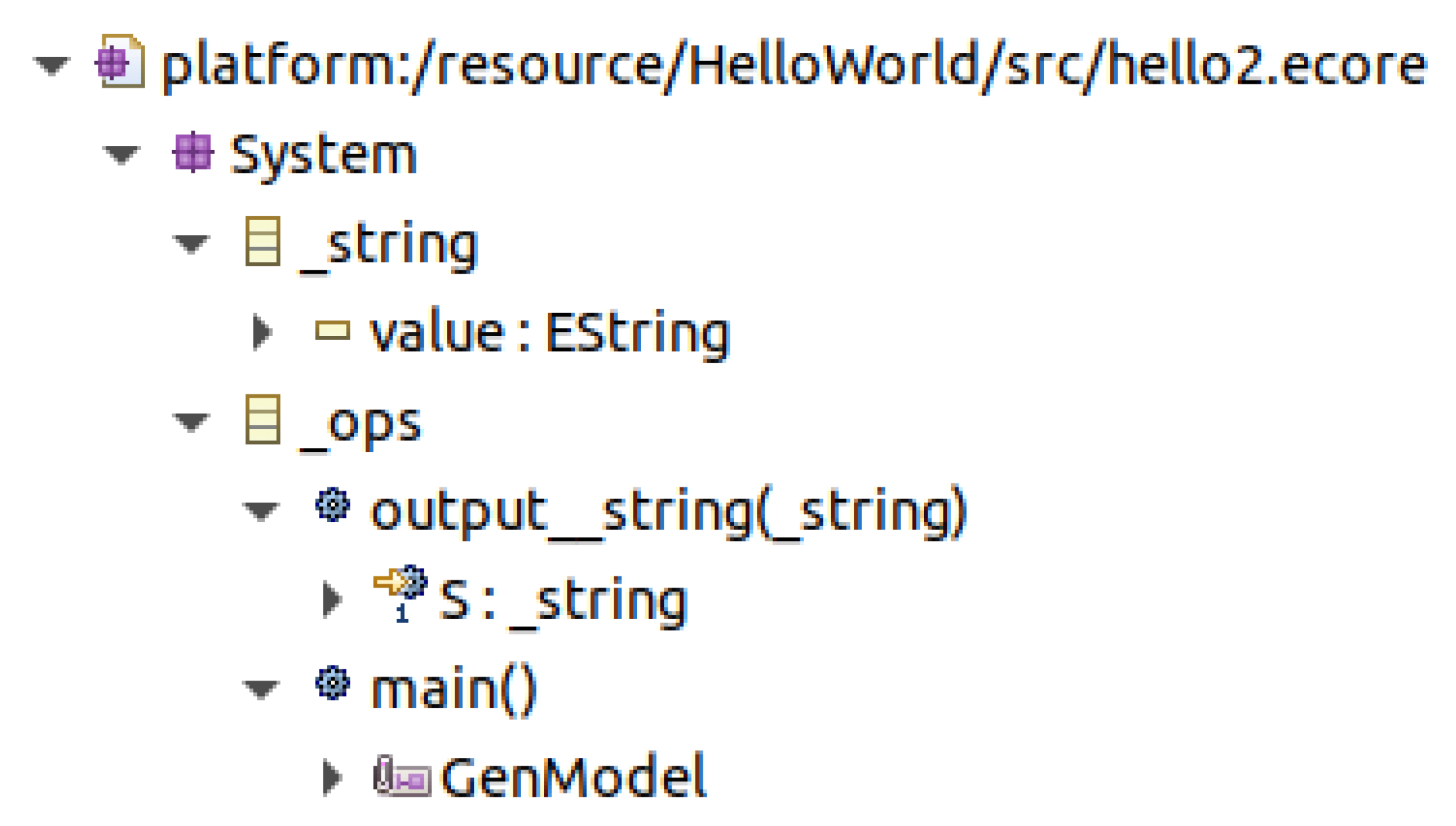
3.3. Hello, World! 2
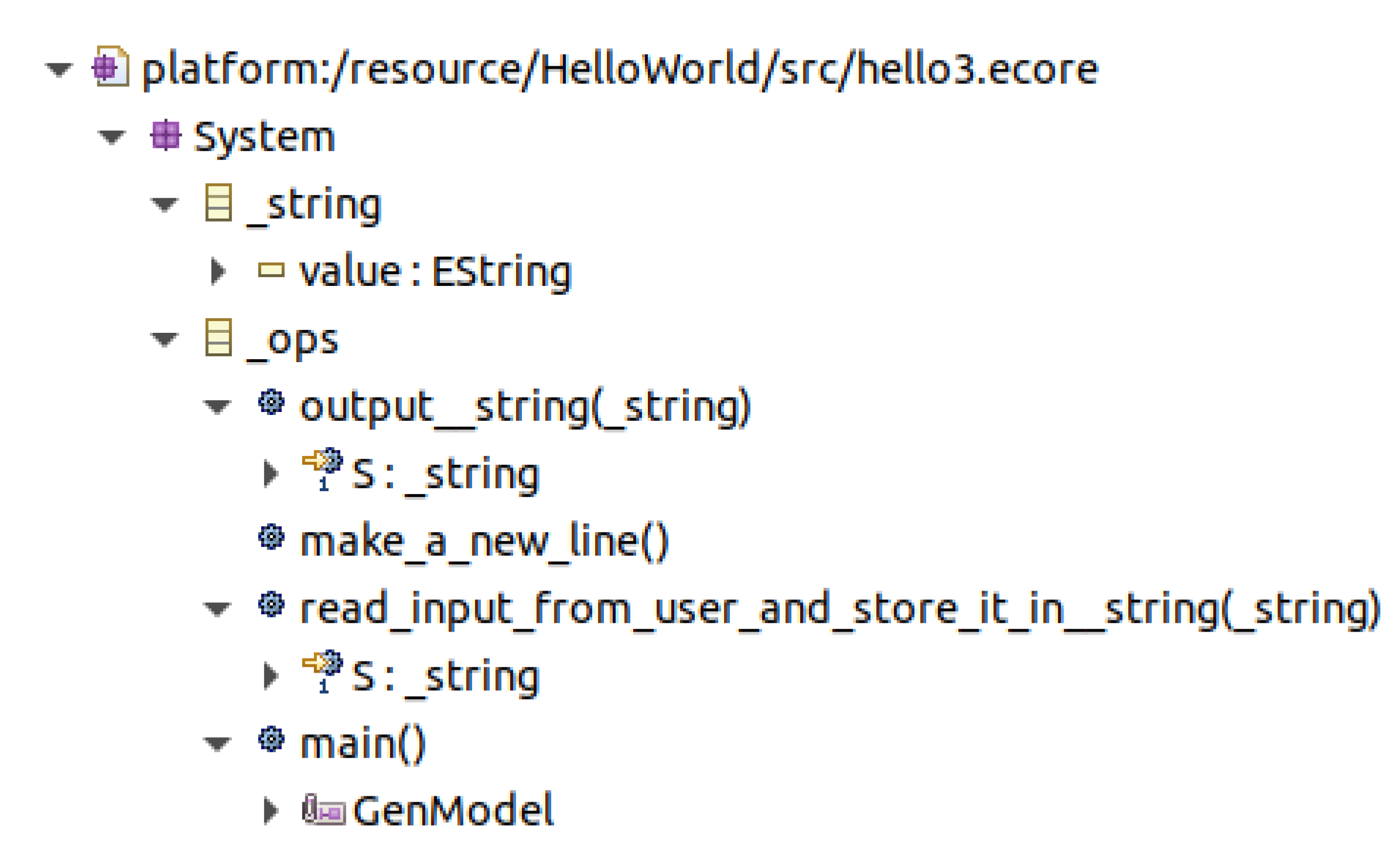
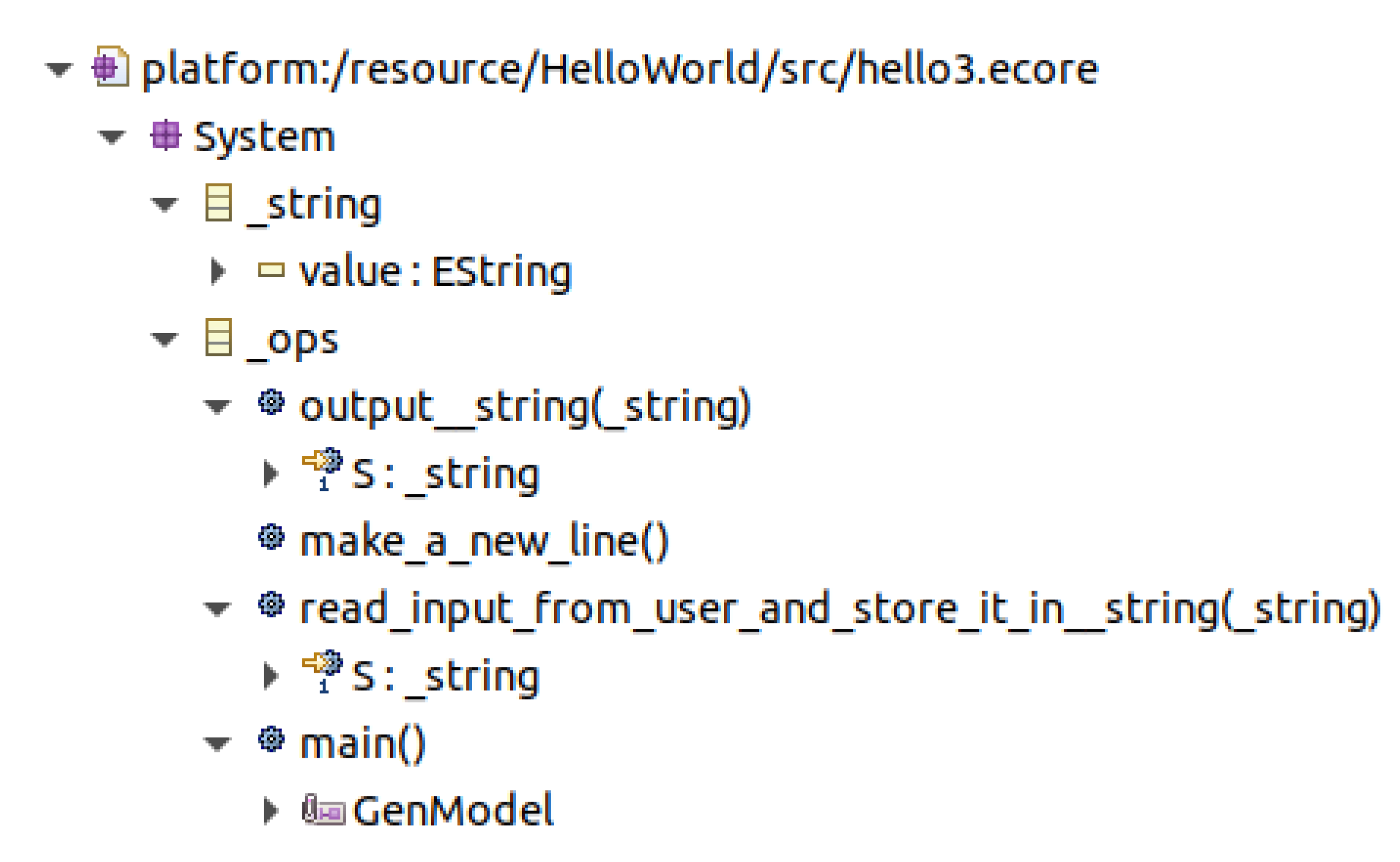
3.4. Hello, World! 3
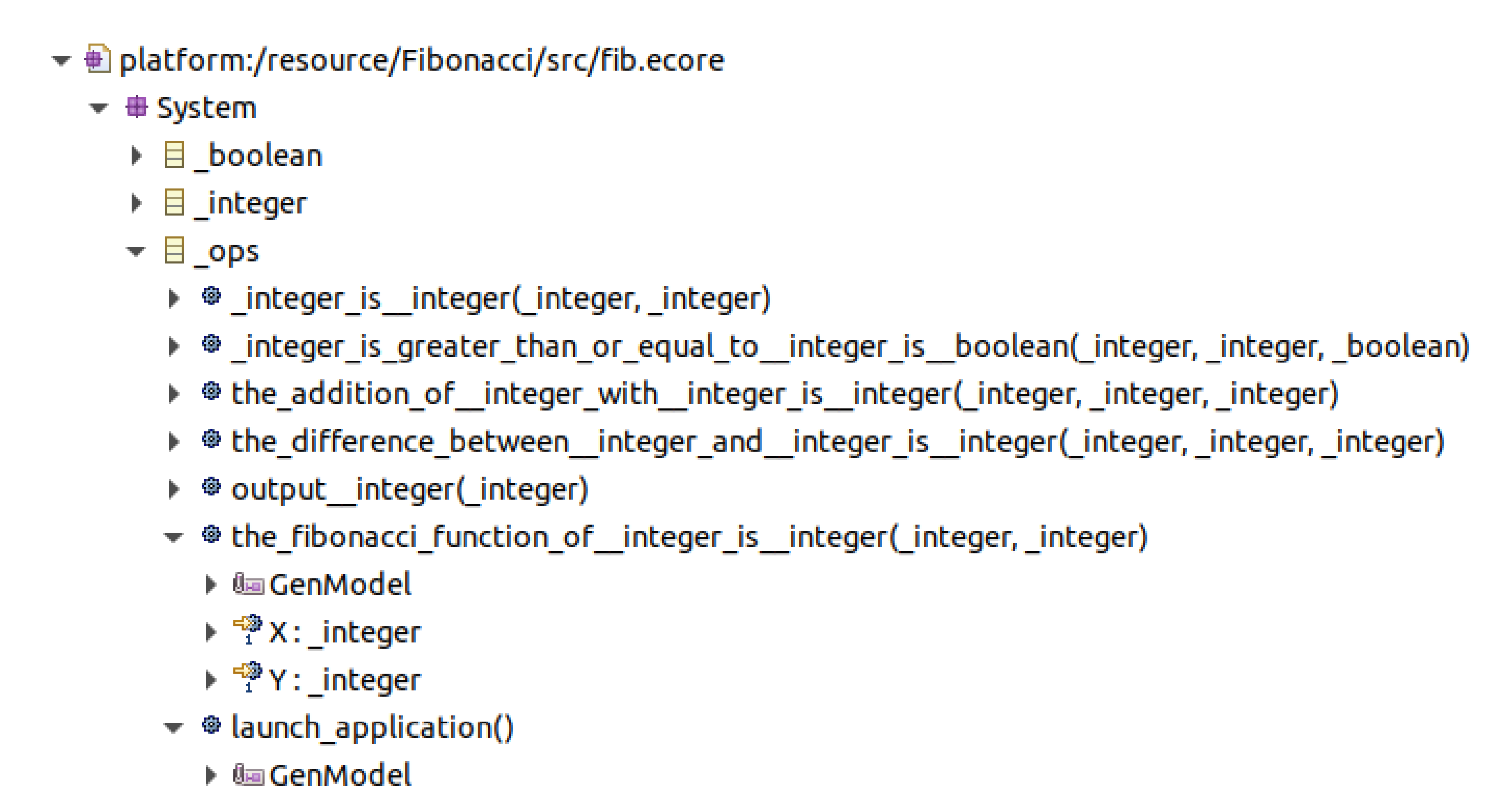
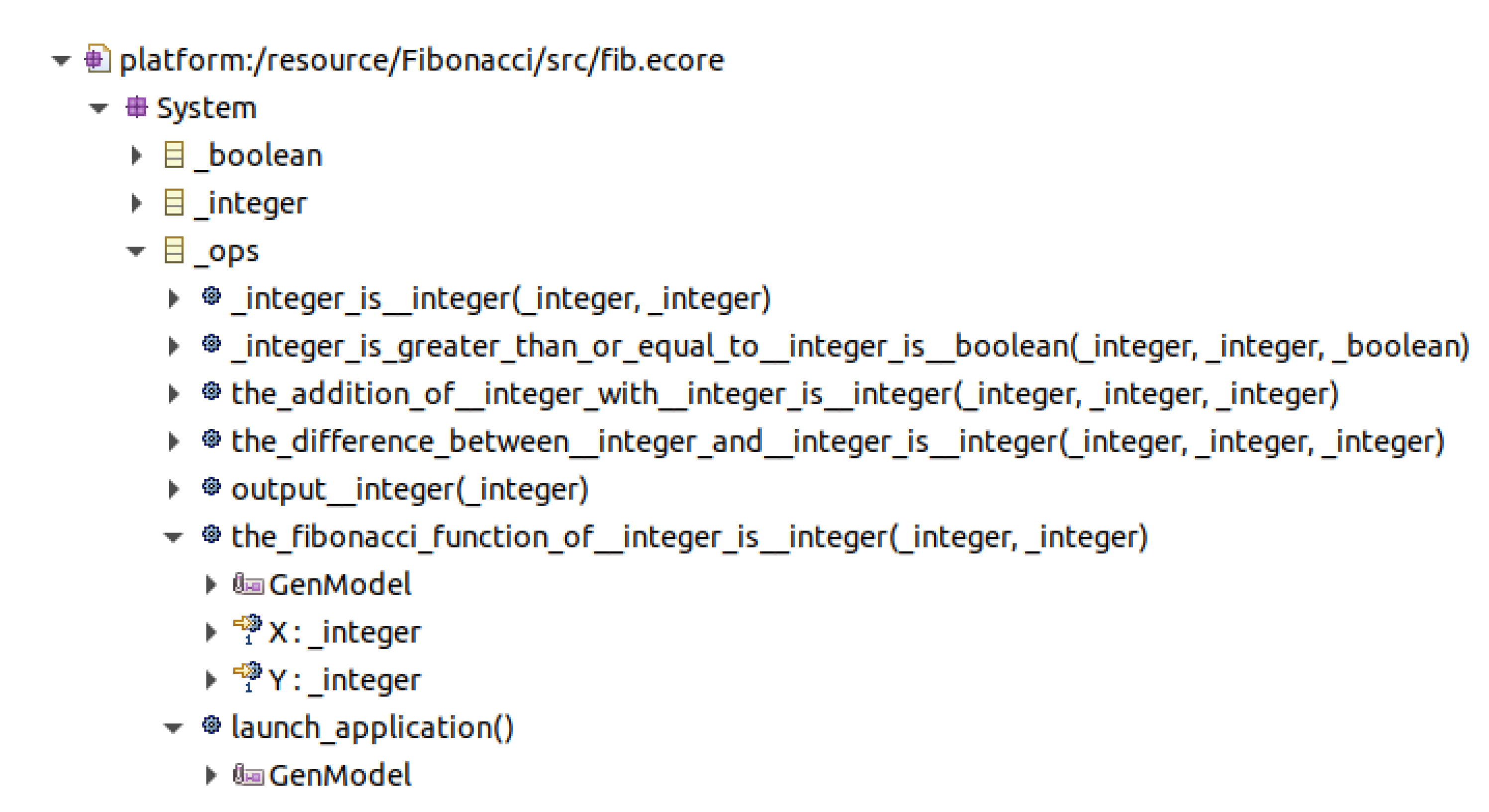
3.5. Fibonacci
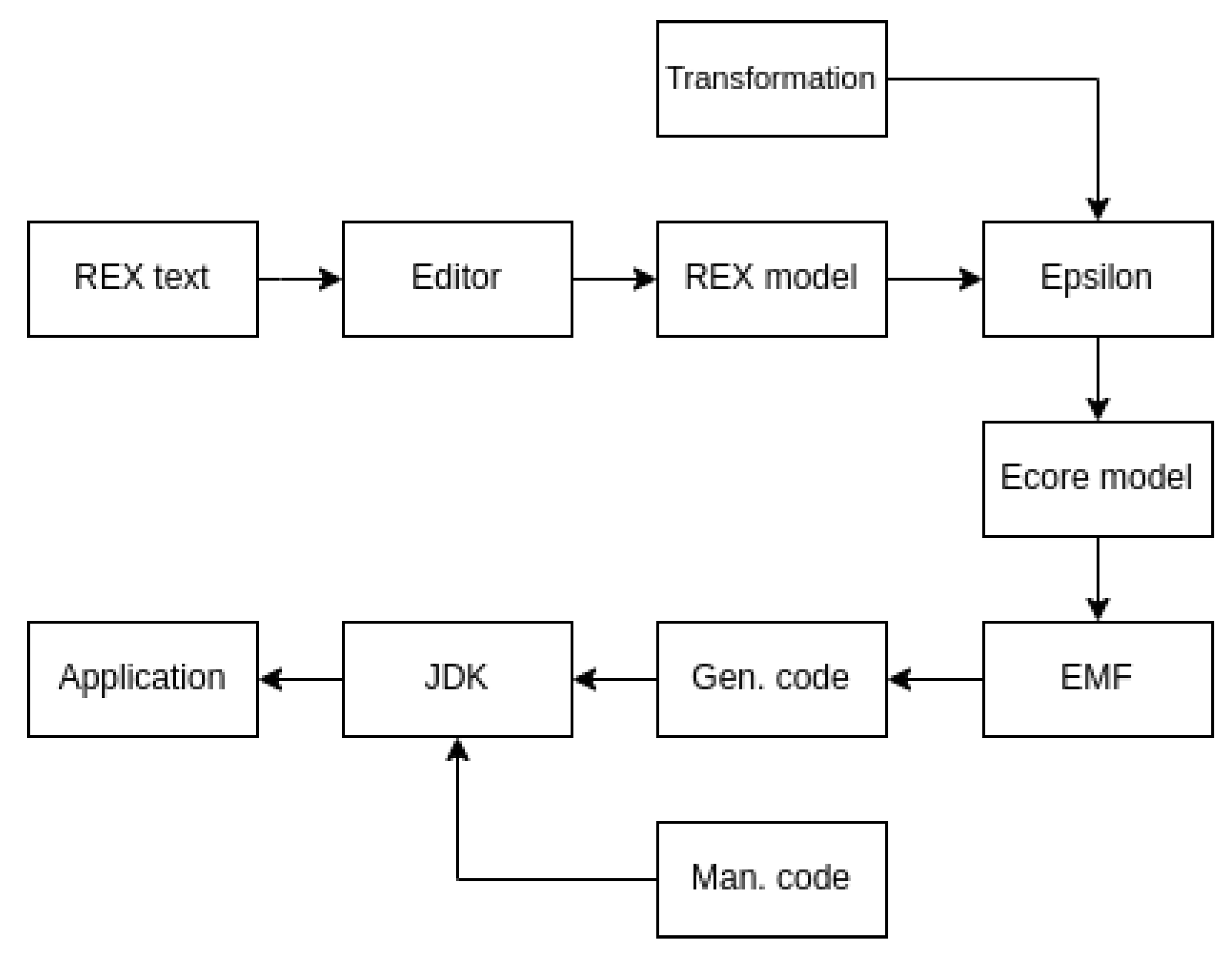
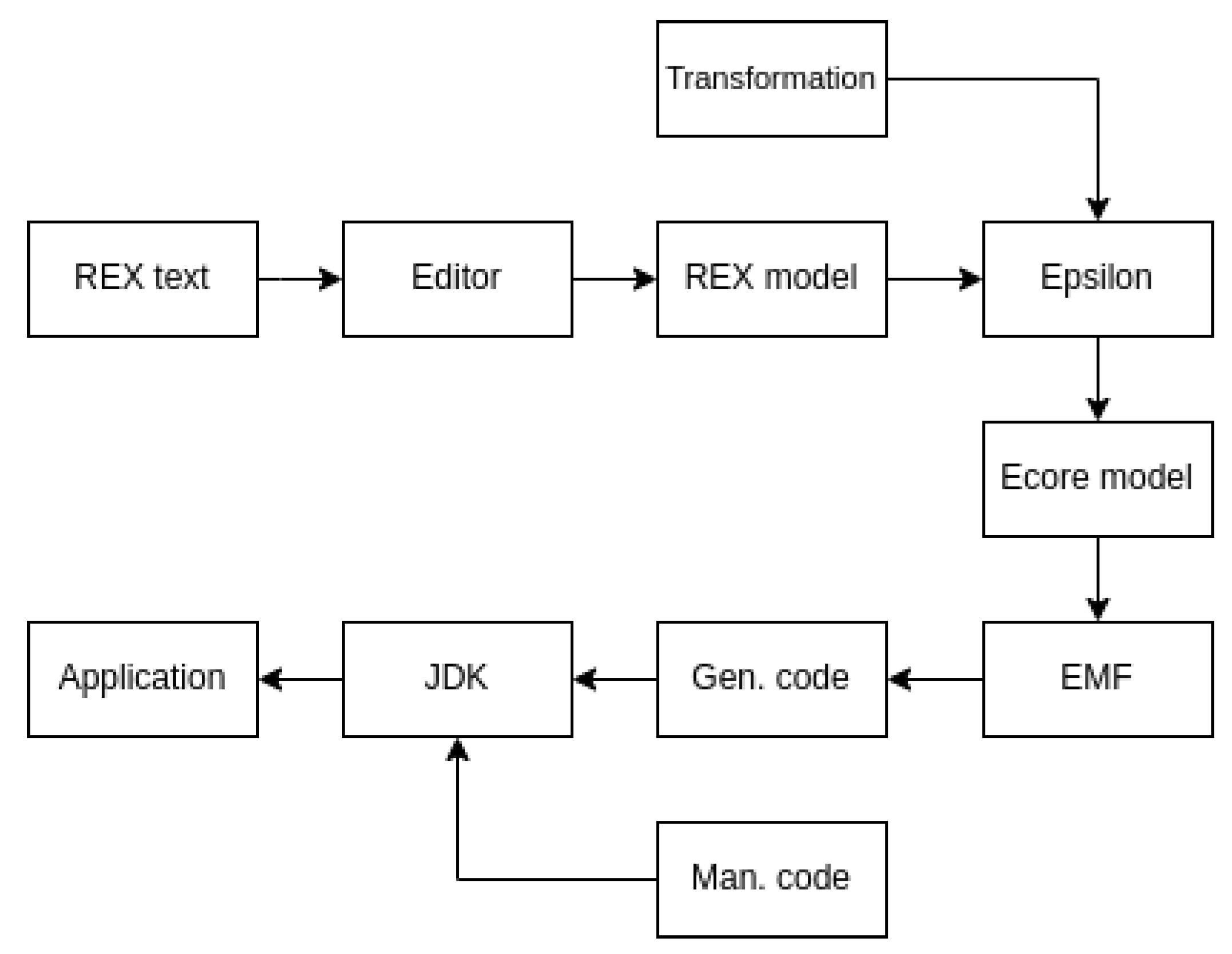
4. Implementation
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stecklein, J.M.; Dabney, J.; Dick, B.; Haskins, B.; Lovell, R.; Moroney, G. Error cost escalation through the project life cycle. In Proceedings of the 14th Annual International Symposium, Marseille, France, 15–18 July 2014. [Google Scholar]
- Yue, T.; Briand, L.C.; Labiche, Y. A systematic review of transformation approaches between user requirements and analysis models. Requir. Eng. 2011, 16, 75–99. [Google Scholar] [CrossRef] [Green Version]
- Tommila, T.; Pakonen, A. Controlled Natural Language Requirements in the Design and Analysis of Safety Critical I&C Systems; VTT Technical Research Centre of Finland: Espoo, Finland, 2014. [Google Scholar]
- Fuchs, N.E.; Kaljurand, K.; Kuhn, T. Attempto controlled english for knowledge representation. In Reasoning Web; Springer: Berlin/Heidelberg, Germany, 2008; pp. 104–124. [Google Scholar]
- Mohanani, R.; Ralph, P.; Turhan, B.; Mandic, V. How Templated Requirements Specifications Inhibit Creativity in Software Engineering. IEEE Trans. Softw. Eng. 2021. [Google Scholar] [CrossRef]
- Young, R.R. Effective Requirements Practices; Addison-Wesley Professional: Boston, MA, USA, 2001. [Google Scholar]
- Sadoun, D.; Dubois, C.; Ghamri-Doudane, Y.; Grau, B. Formal rule representation and verification from natural language requirements using an ontology. In Proceedings of the International Symposium on Rules and Rule Markup Languages for the Semantic Web, Prague, Czech Republic, 18–20 August 2014; pp. 226–235. [Google Scholar]
- Letsholo, K.J.; Zhao, L.; Chioasca, E.V. TRAM: A tool for transforming textual requirements into analysis models. In Proceedings of the 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 738–741. [Google Scholar] [CrossRef]
- Fifarek, A.W.; Wagner, L.G.; Hoffman, J.A.; Rodes, B.D.; Aiello, M.A.; Davis, J.A. Spear v2. 0: Formalized past LTL specification and analysis of requirements. In Proceedings of the 9th International Symposium, Moffett Field, CA, USA, 16–18 May 2017; pp. 420–426. [Google Scholar]
- Manaf, N.A.; Antoniades, A.; Moschoyiannis, S. SBVR2Alloy: An SBVR to Alloy Compiler. In Proceedings of the 2017 IEEE 10th Conference on Service-Oriented Computing and Applications (SOCA), Kanazawa, Japan, 22–25 November 2017; pp. 73–80. [Google Scholar] [CrossRef] [Green Version]
- Osmosian. Available online: https://github.com/Folds/osmosian (accessed on 24 June 2022).
- Kowalski, R. Logical english. In Proceedings of the Logic and Practice of Programming (LPOP), Oxford, UK, 18 July 2020. [Google Scholar]
- SWISH—Minicontract.pl. Available online: https://logicalenglish.logicalcontracts.com/p/minicontract.pl (accessed on 24 June 2022).
- Bugayenko, Y. Combining object-oriented paradigm and controlled natural language for requirements specification. In Proceedings of the 1st ACM SIGPLAN International Workshop on Beyond Code, Chicago, IL, USA, 17 October 2021; pp. 11–17. [Google Scholar] [CrossRef]
- Bugayenko, Y. yegor256/requs. Available online: https://github.com/yegor256/requs (accessed on 24 June 2022).
- Gherkin Syntax—Cucumber Documentation. Available online: https://cucumber.io/docs/gherkin/ (accessed on 24 June 2022).
- da Silva, A.R.; Savic, D. Linguistic Patterns and Linguistic Styles for Requirements Specification: Focus on Data Entities. Appl. Sci. 2021, 11, 4119. [Google Scholar] [CrossRef]
- About the Semantics of Business Vocabulary and Business Rules Specification Version 1.5. Available online: https://www.omg.org/spec/SBVR/About-SBVR/ (accessed on 24 June 2022).
- RuleSpeak®||Let the Business People Speak Rules! Available online: http://www.rulespeak.com/en/ (accessed on 24 June 2022).
- RuleXpress Overview. Available online: https://www.rulearts.com/rulearts-products/rulexpress-business-rules-software/rulexpress-overview/ (accessed on 24 June 2022).
- Trentelman, K. Processable English: The Theory Behind the PENG System; Defense Technical Information Center: Fort Belvoir, VA, USA, 2009. [Google Scholar]
- Mavin, A.; Wilkinson, P.; Harwood, A.; Novak, M. Easy Approach to Requirements Syntax (EARS). In Proceedings of the 2009 17th IEEE International Requirements Engineering Conference, Atlanta, GA, USA, 31 August–4 September 2009; pp. 317–322. [Google Scholar] [CrossRef]
- Mavin, A.; Wilkinson, P. Big Ears (The Return of “Easy Approach to Requirements Engineering”). In Proceedings of the 2010 18th IEEE International Requirements Engineering Conference, Sydney, NSW, Australia, 27 September–1 October 2010; pp. 277–282. [Google Scholar] [CrossRef]
- Eclipse Modeling Project|The Eclipse Foundation. Available online: https://www.eclipse.org/modeling/emf/ (accessed on 24 June 2022).
- Eclipse IDE for Java and DSL Developers|Eclipse Packages. Available online: https://www.eclipse.org/downloads/packages/release/2021-09/r/eclipse-ide-java-and-dsl-developers (accessed on 24 June 2022).
- Xtext—Language Engineering Made Easy! Available online: https://www.eclipse.org/Xtext/ (accessed on 24 June 2022).
- Epsilon. Available online: https://www.eclipse.org/epsilon/ (accessed on 24 June 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| it_is_possible_to print_hello_world. if launch_application, then print_hello_world. |
| FunDecl <-- "it_is_possible_to" FunDeclElem+ "." FunDeclElem <-- WORD Examples: it_is_possible_to show_UI. it_is_possible_to create_main_window. it_is_possible_to add_account. it_is_possible_to translate_to_portuguese. |
| FunDef <-- "if" FunDeclElem+ "," "then" FunCallElem+ "." FunDeclElem <-- WORD FunCallElem <-- FunDeclElem Examples: if show_UI, then create_main_window. if add_account_button_clicked, then add_account. If translate_button_clicked, then translate_to_portuguese. |
| public class _ops { public void print_hello_world() { throw new UnsupportedOperationException(); } public void launch_application() { print_hello_world(); } } |
| public class HelloApp extends _ops { public static void main(String[] args) { HelloApp hello = new HelloApp(); hello.launch_application(); } public void print_hello_world() { System.out.println(“Hello, World!”); } } |
| there_are strings (string). it_is_possible_to print a string S. if launch_application, then print “Hello, World!”. |
| ClassDecl <-- "there_are" ClassPlu "(" ClassSin ")" "." ClassPlu <-- WORD ClassSin <-- WORD Examples: there_are persons (person). There_are names (name). there_are clients (client). there_are banks (bank). |
| public class _string { protected String value; public String getValue() { return value; } public void setValue(String newValue) { value = newValue; } } |
| FunDecl <-- "it_is_possible_to" FunDeclElem+ "." FunDeclElem <-- WORD | (("a" | "an") ClassSin) Examples: it_is_possible_to show a UI X. it_is_possible_to show a widget W. it_is_possible_to add an account ACC. |
| FunDef <-- "if" FunDeclElem+ "," "then" FunCallElem+ "." FunDeclElem <-- WORD FunCallElem <-- WORD | STRING Examples: if show UI, then create main window named "App". if show UI, then add account named "savings". If translate button clicked, then translate "hello" to portuguese. |
| public class _ops { public void print__string(_string S) { throw new UnsupportedOperationException(); } public void launch_application() { SystemFactory factory = new SystemFactory(); _string _local__string0 = factory.create_string(); _local__string0.setValue(“Hello, World!”); print__string(_local__string0); } } |
| public class Hello2App extends _ops { public static void main(String[] args) { Hello2App hello2 = new Hello2App(); hello2.launch_application(); } public void print__string(_string S) { System.out.println(S.getValue()); } } |
| there_are strings (string). it_is_possible_to print a string S. it_is_possible_to start_a_new_line. it_is_possible_to read_input_from_user_and_store_it_in a string S. if launch_application, then there_is_one string S, print "Hey! What’s your name?", start_a_new_line, read_input_from_user_and_store_it_in S, print "Hello ", print S, print "! Welcome!", start_a_new_line. |
| ClassInst <-- "there_is_one" ClassSin WORD "." ClassSin <-- WORD Examples: there_is_one person ADA. There_is_one name N. there_is_one client C. |
| public void launch_application() { SystemFactory factory = new SystemFactory(); _string _local__string0 = factory.create_string(); _local__string0.setValue("Hey! What’s your name?"); _string _local__string1 = factory.create_string(); _local__string1.setValue("Hello "); _string _local__string2 = factory.create_string(); _local__string2.setValue("! Welcome!"); _string S = factory.create_string(); print__string(_local__string0); start_a_new_line(); read_input_from_user_and_store_it_in__string(S); print__string(_local__string1); print__string(S); print__string(_local__string2); start_a_new_line(); } |
| public class Hello3App extends _ops { public static void main(String[] args) { Hello3App hello3 = new Hello3App(); hello3.launch_application(); } public void print__string(_string S) { System.out.print(S.getValue()); // no new line. } public void start_a_new_line() { System.out.println(); // new line. } public void read_input_from_user_and_store_it_in__string(_string S) { Scanner scanner = new Scanner(System.in); S.setValue(scanner.nextLine()); } } |
| there_are booleans (boolean). there_are integers (integer). it_is_possible_that an integer X is an integer Y. it_is_possible_that an integer X is_greater_than_or_equal_to an integer Y is a boolean B. it_is_possible the_addition_of an integer A with an integer B is an integer X. it_is_possible the_difference_between an integer A and an integer B is an integer X. it_is_possible_to output an integer X. if the_fibonacci_function_of an integer X is an integer Y, then if X is_greater_than_or_equal_to 3, then there_is_one integer N1, there_is_one integer N2, the_difference_between X and 1 is N1, the_difference_between X and 2 is N2, there_is_one integer A, there_is_one integer B, the_fibonacci_function_of N1 is A, the_fibonacci_function_of N2 is B, the_addition_of A with B is Y; else Y is 1. if launch application, then there_is_one integer A, there_is_one integer B, there_is_one integer C, the_fibonacci_function_of 1 is A, the_fibonacci_function_of 2 is B, the_fibonacci_function_of 10 is C, output A, output B, output C. |
| public class FibApp extends _ops { public static void main(String[] args) { FibApp fib = new FibApp(); fib.launch_application(); } public void _integer_is__integer(_integer X, _integer Y) { X.setValue(Y.getValue());; } public void _integer_is_greater_than_or_equal_to__integer_is__boolean( _integer X, _integer Y, _boolean B) { B.setValue(X.getValue() >= Y.getValue()); } public void the_addition_of__integer_with__integer_is__integer( _integer A, _integer B, _integer X) { X.setValue(A.getValue() + B.getValue()); } public void the_difference_between__integer_and__integer_is__integer( _integer A, _integer B, _integer X) { X.setValue(A.getValue() - B.getValue()); } public void output__integer(_integer X) { System.out.println(X.getValue()); } } |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carvalho, A. REX: General-Purpose CNL with Code Generation Support. Appl. Sci. 2022, 12, 7700. https://doi.org/10.3390/app12157700
Carvalho A. REX: General-Purpose CNL with Code Generation Support. Applied Sciences. 2022; 12(15):7700. https://doi.org/10.3390/app12157700
Chicago/Turabian StyleCarvalho, Adriano. 2022. "REX: General-Purpose CNL with Code Generation Support" Applied Sciences 12, no. 15: 7700. https://doi.org/10.3390/app12157700
APA StyleCarvalho, A. (2022). REX: General-Purpose CNL with Code Generation Support. Applied Sciences, 12(15), 7700. https://doi.org/10.3390/app12157700