Featured Application
This proposed method is suitable for the cooperative consensus control of various homogeneous Multiple Autonomous Unmanned linear systems, such as an underwater robot swarm and aerial UAV swarm.
Abstract
This paper addresses the distributed optimal decoupling synchronous control of multiple autonomous unmanned linear systems (MAUS) subject to complex network dynamic coupling. The leader–follower mechanism based on neighborhood error dynamics is established and the network coupling term is regarded as the external disturbance to realize the decoupling cooperative control of each agent. The Bounded L2-Gain problem for the network coupling term is formulated into a multi-player zero-sum differential game. It is shown that the solution to the multi-player zero-sum differential game requires the solution to coupled Hamilton–Jacobi (HJ) equations. The coupled HJ equations are transformed into an algebraic Riccati equation (ARE), which can be solved to obtain the Nash equilibrium of a multi-player zero-sum game. It is shown that the bounded L2-Gain for coupling attenuation can be realized by applying the zero-sum game solution as the control protocol and the ultimately uniform boundedness (UUB) of a local neighborhood error vector under conservative conditions is proved. A simulation example is provided to show the effectiveness of the proposed method.
1. Introduction
In the field of multi-agent distributed control, synchronous cooperative control is one of the most popular research topics because of its wide application prospects in many engineering systems, such as the cooperative control of autonomous underwater vehicles, wind farm and unmanned aerial vehicles. A great deal of research has been developed on the distributed control methods for multi-agent synchronization [1,2,3,4]. The purpose of distributed synchronous control is to design a control protocol for each agent, depending only on the states of neighboring agents, to ensure that the states of all agents in the communication digraph finally achieve synchronization. A leader–follower mechanism is the most popular one for distributed synchronous control because of its simplicity and scalability. The basic idea is that a leader agent is set as the reference node, and other agents are set as the follower nodes whose goal is to track the reference node to achieve the ultimate synchronization of the entire communication network.
On the basis of this mechanism, ref. [5] defines the local neighborhood error of each agent and deduces that this is a dynamical system with multiple control inputs, from itself and all of its neighbors. This means that the local neighborhood error of each agent is the result of coupling from adjacent node agents, which brings considerable complexity to the design of the control protocol. Ref. [6] formulated this intricate relationship as a differential game, namely, a multi-agent differential graphical game, by defining a local performance index for each agent. Optimal control and game theory [7,8] has been successful utilized to formulate strategic behavior, where the dynamic of each agent relies on the actions of itself and its neighbors. In an optimal control and differential graphical game, each agent minimizes the performance objective (cost value function) by adjusting its control strategy to optimal. In [9], the finite-time optimal coordination problem of multi-agent systems (MASs) is investigated. The authors in [10] addressed the centralized optimal coordination problem under tree formation constraints. In [11], the robust optimal formation control of heterogeneous MASs is studied. These published graphical games and optimal control methods for consensus and synchronization are achieved based on the solution of coupled Hamilton–Jacobi–Isaacs (HJI) equations and Hamilton–Jacobi–Bellman (HJB) equations, respectively. In practice, coupled HJI and coupled HJB equation are difficult to be solved by analytical methods due to their inherent nonlinearity and uncertainty.
The reinforcement learning (RL) method is often regarded as the effective method to solve the coupled HJI and coupled HJB equation. RL is the branch of machine learning concerned with how to methodically adjust the control strategy of agents based on the rewards from the environment [12,13,14,15]. In [16], an online distributed optimal adaptive algorithm is proposed for a differential graphical game, the intelligent identifier is designed to find the unknown dynamic and the neural actor–critic network structure is introduced to find the solutions of the Nash equilibrium. In [17], the bounded L2-gain consensus problem for the MASs with external disturbance is formulated into the zero-sum differential game by introducing a specific performance index and a policy iteration (PI) algorithm-based RL is provided to find the solution to the coupled HJI equations. In [18], the optimal synchronization control problem is studied for homogeneous MASs with input saturation by using the RL methods. This research utilizes the neural network as an approximator and a design-specific update law so that the neural network approximates the optimal value function and optimal control strategy with certain precision. However, the strict asymptotic convergence proof of the neural network is not given in these works, and only the boundedness of approximate errors is guaranteed. In addition, the neural network approximator-based RL needs to satisfy the persistence of the excitation condition (PE) [19,20,21,22,23], which also limits the practical engineering application of these methods.
The quadratic optimal control problem of a linear single system can be solved by solving an algebraic Riccati equation (ARE) [24], but the optimal control problem of MASs is far more complicated than that of a single system owing to the state coupling in the control design. At present, some optimal control methods of MASs are accompanied by a huge amount of calculations and strong assumptions.
Motivated by the above discussion, this paper focuses on the optimal cooperative control of Multiple Autonomous Unmanned linear systems (MAUS) from a new perspective, i.e., the adjacent nodes’ input coupling part is regarded as the external disturbance. Thus, the complex distributed multi-agent error dynamics are decoupled into centralized multi-input dynamics. Inspired by the idea of a zero-sum game in [17], this paper formulates these centralized multi-input dynamics into multiple independent multi-player zero-sum differential games. The motivation is to realize the decoupled optimal synchronous control of MASs and the main contributions of this paper are listed in the following:
- (1)
- The coupling among the distributed multi-agents is equivalent to the disturbance from different channels, and the local neighborhood error dynamics of each agent are modeled as an independent centralized multi-player game.
- (2)
- The bounded L2-gain problem for coupling attenuation is introduced and is formulated into a multi-player zero-sum game by defining a modified performance index. Different from the L2-gain problem of [17], concerning disturbance rejection, the motive of the bounded L2-gain for the coupling attenuation studied here is to suppress the coupling effect on the performance.
- (3)
- It is proved that the solution of the zero-sum game requires the solution of the coupled Hamilton–Jacobi (HJ) equation. The coupled HJ equation of each agent is transformed into an independent equivalent algebraic Riccati equation, which simplifies the solution process effectively.
This paper is organized as follows. Section 2 provides the mathematical background and derives the local error dynamics of each node that is coupled by its own control protocol and those of its neighbors. Section 3 proposes the problem formulation of the bounded L2-gain for coupling attenuation and its equivalent multi-player zero-sum differential game. Section 4 transforms this zero-sum differential game into the solution of an algebraic Riccati equation and proves the ultimately uniform boundedness of the local neighborhood error, conservatively. The simulation results and conclusion is presented in Section 5 and Section 6, respectively.
2. Preliminaries and Problem Formulation
2.1. Graph Theory
In this paper, the multi-agent directed communication network is depicted. A directed connected graph is defined as , where represents a finite non-empty set of nodes, is the ordered set of nodes pairs and is the adjacency matrix. If node can receive the information from node , then the node pairs , and node is called a neighbor of node . The neighbor set of node is represented by . Correspondingly, the adjacency matrix element when , otherwise . The graph Laplacian matrix is defined as , whose row sums are equal to zero [25]. Diagonal matrix is the in-degree matrix, where is the in-degree of node .
Definition 1.
A directed graph is called as strongly connected if there is a directed path for any a pair of distinct nodes, where the directed path is the edge sequence, ,...,.
Definition 2 [17].
A directed tree is a connected graph where every node except the root node, has an in-degree equal to one. The graph is called to have a spanning tree if a subset of the node pairs constructs a directed tree.
In this paper, and represent the maximum and minimum singular values of the matrix , respectively.
2.2. Problem Formulation
Considering the Multiple Autonomous Unmanned linear systems (MAUS) constructed by the directed communication graph having N agents, the dynamics of each agent is described in the following:
where are states and control inputs of node i, respectively. The cooperative control of homogeneous systems is investigated in this paper and the leader node is set to satisfy the following dynamic
The problem of MAUS synchronization is designing control protocols for each agent so that states of each node track the leader node, i.e., .
The neighborhood error for each node is defined as [26]
where denotes the pinning gain and there is at least one node that has a link to the leader node.
For the neighborhood error (3), the overall neighborhood error vector of graph is given by
where and denote the global state vector and global error vector, respectively. Moreover, for with , denotes the n dimensional identity matrix and denotes the N-vector of ones. The symbol is the Kronecker product [27]. as a diagonal matrix represents the connection between all agents and the leader node.
The overall synchronization error is
Assumption 1.
The communication graph is strongly connected, i.e., there is a directed path for any a pair of distinct nodes.
On the basis of Assumption 1, if , then for at least one. In this case, the matrix is non-singular and the real parts of all eigenvalues are positive [26]. The following lemma can be obtained, which shows that the overall neighborhood error vector is positively correlated with the overall synchronization error .
Lemma 1.
If the communication graph is strongly connected and, the synchronization errors are bounded, as follows
Furthermore, if and only if all nodes are synchronized, i.e.,
The dynamics of the local neighborhood tracking errors are given as
Substituting (1) and (2) into the above equation, it can be obtained that
It can be seen that the dynamics of the local neighborhood error of each agent i is affected by multiple control inputs from node i and its adjacent nodes. The whole MAUS with the communication graph presents a complex coupling relationship. It is quite intricate to solve the optimal control problem of dynamic (9) affected by multi-coupling.
3. Multi-Player Zero-Sum Differential Game for Decoupled Multi-Agent System
3.1. The Bounded L2-Gain Problem for Coupling Attenuation of Multi-Agent System
For decoupling, the inputs from adjacent nodes in the dynamics (9) are replaced by the virtual coupling actions which is regarded as the external disturbances. The performance output is defined as . It is desired to designed the control protocol to achieve synchronization while satisfying the follow bounded L2-gain condition for the coupling actions with a given
where, is a bounded function such that , . is defined as the minimum value of while the bounded L2-gain condition (10) is satisfied.
3.2. Multi-Player Zero-Sum Differential Game
The following equation is used to define the following performance index function for each agent.
where denotes the virtual coupling control inputs from neighboring nodes, i.e., . It should be noted that the main difference from [17] is that the coupling control inputs from neighboring nodes are regarded as the virtual external disturbances directly, which greatly simplifies the design of the control protocol .
The solution for the bounded L2-gain problem for coupling attenuation depicted in Section 3.1 can be equivalent to the Nash equilibrium solution of the multi-player zero-sum game-base on the performance index function (11). That is
In this multi-player zero-sum game, the goal of is to minimize the value . On the contrary, the virtual coupling inputs are assumed to maximize the value. This game has a unique solution if a game-theoretic saddle point exists, i.e.,
Accordingly, the value in the above equation is the value of the zero-sum game and satisfies the following Nash equilibrium condition for all policies
When the policies are selected, the value function of node i can yield
Differential equivalents to each value function are given as
where denotes the gradient vector. The Hamiltonian functions are defined as follows,
Under certain policies , the partial differential equation has a unique solution . The principle of optimality gives
If the is the Nash equilibrium solution of the multi-player zero-sum game, that is
we can obtain
Substituting the optimal strategy determined by (18) into (20), the coupled Hamilton–Jacobi (HJ) equations yield
For a given solution , in order to define and in the same way as (18), (21) can be written as
Lemma 2.
For any policies, the following equation holds
Proof of Lemma 2.
Substituting for in (22)
Substituting into (24), we can obtain
Completing the squares in (25) gives (23) upon the relationship between and . □
Remark 1.
The polices in Section 3 are not the real policies of neighboring nodes. These are only defined as the virtual coupling input from neighboring nodes, which are regarded as the external disturbances and have the same channels as the control inputs of neighboring nodes. In this way, the bounded L2-gain attenuation for the real coupling inputs from neighboring nodes can be realized. In addition, the complex relationships among agents are decoupled virtually during the control protocol design process, and the solving process of zero-sum game is effectively simplified. The coupled HJ equation of each agent is independent of each other.
4. Solution to Bounded L2-Gain Problem for the Coupling Attenuation and the Equivalent Algebraic Riccati Equation
4.1. Solution to Bounded L2-Gain Problem for Coupling Attenuation
In this subsection, the control policy is found to guarantee the condition (10) holds for a prescribed and . The following Theorem 1 shows that the solution of a coupled HJ equation (22) is actually the solution to the bounded L2-gain problem for coupling attenuation.
Theorem 1.
Let. Suppose the coupled HJ equation (22) has a smooth positive definite solution . The control policy is selected as , given by (18) in terms of. The bounded L2-gain condition (10) holds for all .
Proof of Theorem 1.
Selecting , we can obtain that
Integrating (27) yields,
is a smooth positive definite solution, i.e., , one has
Hence, the bounded L2-gain condition (10) for coupling attenuation is satisfied. □
According to Lemma 2
4.2. The Equivalent Algebraic Riccati Equation
It can be seen from the above results that the Nash equilibrium solution can be obtained by solving the coupled HJ equation (22). In this subsection, it will be shown that the coupled HJ equation (22) can be equivalent to an Algebraic Riccati equation (ARE).
Defining the optimal value function , the corresponding optimal and can be obtained as
Substituting (30) and into (21) yields
The above equation can be equivalent to
Defining the integrated matrix as
Then, (32) can be rewritten as the ARE
Theorem 2.
Selecting the first equation of (30) as the control policies, based on the solution of ARE (34). The local neighborhood error vector will ultimately and uniformly enter the following bounded invariant set
wheredenotes the Euclidean norm ofandis the positive definite matrix as.
Assume that all the real control policies of neighboring agents satisfy the bounded condition as follows,
Proof of Theorem 2.
Selecting as the first equation of (30) yields
Let , we can realize that
Defining yields the bounded invariant set (35). □
Selecting the optimal positive value function , in terms of the solution of the coupled HJ equation (21), as the Lyapunov function. According to Lemma 2, the derivative of is
Remark 2.
Theorem 2 shows the ultimately uniform boundedness (UUB) of the local neighborhood error vector. According to the bounded invariant sets , the bound ofcan be arbitrarily small by presetting the matrix,andin the performance index function (11). In fact, this result is conservative because the terminis omitted. The real control inputs of adjacent agents differ greatly fromin fact, which guarantees the negative characterization of. Therefore, the simulation results in the next section show that the local neighborhood error vector can converge asymptotically and uniformly to the origin.
Remark 3.
In a practical application, matrix,andand parametercan be selected according to engineering performance requirements. If a high convergence speed and synchronization accuracy are required,can be selected to make its eigenvalues large; if a low control energy consumption is required,can be selected to make its eigenvalues large; the coupling attenuation level can be adjusted by adjusting matrixand. It should be noted that,,,andmust satisfy the condition in Theorem 1, so that the coupled HJ equation (22) has a smooth positive definite solution. That is, (33) has a positive definite solution.
5. Simulation Results
This section shows the effectiveness of the equivalent ARE approach described in Section 4 and Theorem 2. The simulation is realized in MATLAB/Simulink. Consider a class of Multiple Autonomous Unmanned homogeneous linear systems referring to [5] which is shown as follows
where , , , and , with the Leader dynamics . The communication digraph structure is shown in Figure 1. The edge weights and the pinning gains are taken equal to 1.
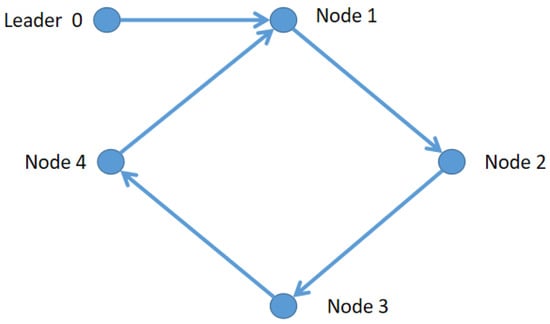
Figure 1.
The communication digraph structure.
The selected the weight matrices in (11) are , , , , , , , and . The bounded L2-gain coefficient in (11) for each agent are preset as , , and . The cooperative control protocol of each agent is implemented, as in Section 4.2, where the solution of ARE (33) is
Remark 4.
In the process of a simulation design, theshould be gradually reduced to search for a feasible and high coupling attenuation level under the premise that (33) has a positive definite solution . Using the ARE solver in MATLAB, it is very convenient to solve (33) and obtain. Then, the design of the coupling attenuation controller can be completed according to (30).
To elevate the Bounded L2-gain problem for the coupling attenuation, the following variable is introduced based on (29)
That is, , which means that the Bounded L2-gain condition (10) is satisfied.
The local neighborhood error vector of each agent is shown in Figure 2. Figure 3 is the 3-D phase plane plot of the system’s evolution for agents 1, 2, 3, 4 and leader 0. The of the node 1 agent is shown in Figure 4. As can be seen from Figure 2 and Figure 3, the neighborhood error vector can converge asymptotically and uniformly to the origin and all agents in the communication digraph are eventually synchronized, which is also consistent with Remark 2. Figure 4 shows that is always negative, which is equivalent to that the node 1 agent satisfies the bounded L2-gain condition with for the coupling attenuation. The effectiveness of the proposed method is thus verified.
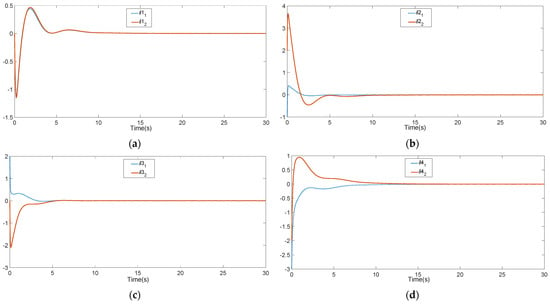
Figure 2.
The local neighborhood error vector of each agent: (a) The node 1 agent; (b) The node 2 agent; (c) The node 3 agent; (d) The node 4 agent.
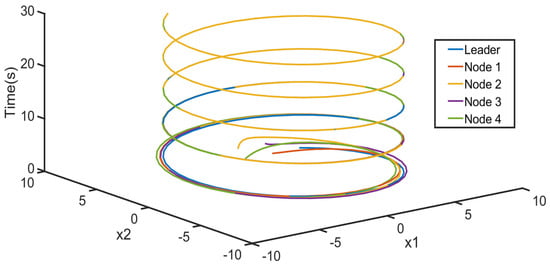
Figure 3.
The 3-D phase plane plot of the system’s evolution for agents 1, 2, 3, 4 and leader 0.
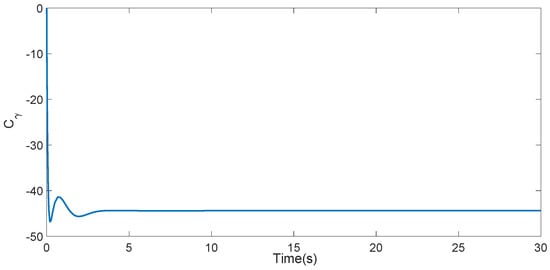
Figure 4.
The of node 1 agent.
6. Conclusions
This paper provides a novel idea for the synchronization control of Multiple Autonomous Unmanned linear systems, in which the local neighborhood error dynamic’s coupling part is considered as the virtual external disturbance, so as to decouple the multi-agent cooperative control problem into a relatively independent bounded L2-gain problem for coupling attenuation. The optimal control theory and differential game theory is utilized to formulate the bounded L2-gain problem into a centralized multi-player zero-sum game. It is shown that the solution to the multi-player zero-sum game is equivalent to the solution of a coupled HJ equation. It is also shown that the coupled HJ equation can be transformed into an algebraic Riccati equation (ARE) and the solution guarantees the ultimately uniform boundedness (UUB) of the local neighborhood error vector under conservative conditions. The law of parameters selection is summarized. The simulation results show that the proposed method can ensure that the local neighborhood error vectors converge asymptotically to the origin, that is, the multiple autonomous unmanned linear systems can achieve final synchronization, which demonstrates that the UUB of errors is conservative. Meanwhile, the bounded L2-gain condition for the coupling attenuation can be guaranteed.
This proposed method is suitable for the cooperative consensus control of various homogeneous multiple autonomous unmanned linear systems, such as an underwater robot swarm and aerial UAV swarm. Future work will focus on extending this method to nonlinear multi-agent systems and more serious models with uncertainties.
Author Contributions
Conceptualization, Y.L. and B.W.; methodology, Y.L.; software, Y.L.; validation, Y.L. and Y.C.; formal analysis, Y.C.; investigation, Y.L.; resources, B.W.; data curation, Y.L.; writing—original draft preparation, Y.L.; writing—review and editing, Y.L.; visualization, Y.L. and B.W.; supervision, B.W.; project administration, Y.C.; funding acquisition, B.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (NSFC), grant number 51777058, and in part by the Six Talent Peaks Project in the Jiangsu province, grant number XNY-010.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhou, Y.; Li, D.; Gao, F. Optimal synchronization control for heterogeneous multi-agent systems: Online adaptive learning solutions. Asian J. Control 2021. [Google Scholar] [CrossRef]
- Jing, G.; Zheng, Y.; Wang, L. Consensus of Multiagent Systems With Distance-Dependent Communication Networks. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2712–2726. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Dai, M.-Z.; Zhang, C.; Wu, J. Edge-Event-Triggered Synchronization for Multi-Agent Systems with Nonlinear Controller Outputs. Appl. Sci. 2020, 10, 5250. [Google Scholar] [CrossRef]
- Shi, H.; Hou, M.; Wu, Y. Distributed Control for Leader-Following Consensus Problem of Second-Order Multi-Agent Systems and Its Application to Motion Synchronization. Appl. Sci. 2019, 9, 4208. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Lewis, F.L.; Hudas, G.R. Multi-agent differential graphical games: Online adaptive learning solution for synchronization with optimality. Automatica 2012, 48, 1598–1611. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Lewis, F.L. Multi-agent differential graphical games. In Proceedings of the 30th Chinese Control Con-ference, Yantai, China, 22–24 July 2011. [Google Scholar]
- Liu, J.; Xu, F.; Lin, S.; Cai, H.; Yan, S. A Multi-Agent-Based Optimization Model for Microgrid Operation Using Dynamic Guiding Chaotic Search Particle Swarm Optimization. Energies 2018, 11, 3286. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-agent actor–critic for mixed cooperative-competitive environments. arXiv 2017, arXiv:1706.02275. [Google Scholar] [CrossRef]
- Liu, Y.; Geng, Z. Finite-time optimal formation control of multi-agent systems on the Lie group SE(3). Int. J. Control 2013, 86, 1675–1686. [Google Scholar] [CrossRef]
- Zhang, W.; Hu, J. Optimal multi-agent coordination under tree formation constraints. IEEE Trans. Autom. Control. 2008, 53, 692–705. [Google Scholar] [CrossRef][Green Version]
- Lin, W.; Zhao, W.; Liu, H. Robust Optimal Formation Control of Heterogeneous Multi-Agent System via Reinforcement Learning. IEEE Access 2020, 8, 218424–218432. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2017, 37, 421–436. [Google Scholar] [CrossRef]
- Tatari, F.; Vamvoudakis, K.G.; Mazouchi, M. Optimal distributed learning for disturbance rejection in networked non-linear games under unknown dynamics. IET Control Theory Appl. 2019, 13, 2838–2848. [Google Scholar] [CrossRef]
- Jiao, Q.; Modares, H.; Xu, S.; Lewis, F.L.; Vamvoudakis, K.G. Multi-agent zero-sum differential graphical games for disturbance rejection in distributed control. Automatica 2016, 69, 24–34. [Google Scholar] [CrossRef]
- Qin, J.; Li, M.; Shi, Y.; Ma, Q.; Zheng, W.X. Optimal Synchronization Control of Multiagent Systems With Input Saturation via Off-Policy Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 85–96. [Google Scholar] [CrossRef]
- Kamalapurkar, R.; Walters, P.; Dixon, W. Model-Based Reinforcement Learning for Approximate Optimal Regulation. Control. Complex Syst. 2016, 247–273. [Google Scholar] [CrossRef]
- Farrell, J.A. Persistence of excitation conditions in passive learning control. Automatica 1997, 33, 699–703. [Google Scholar] [CrossRef]
- Kamalapurkar, R.; Andrews, L.; Walters, P.; Dixon, W.E. Model-Based Reinforcement Learning for Infinite-Horizon Approximate Optimal Tracking. IEEE Trans. Neural Networks Learn. Syst. 2016, 28, 753–758. [Google Scholar] [CrossRef]
- Yasini, S.; Karimpour, A.; Sistani, M.-B.N.; Modares, H. Online concurrent reinforcement learning algorithm to solve two-player zero-sum games for partially unknown nonlinear continuous-time systems. Int. J. Adapt. Control Signal Process. 2014, 29, 473–493. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Lewis, F.L. Multi-player non-zero-sum games: Online adaptive learning solution of coupled Hamilton–Jacobi equations. Automatica 2011, 47, 1556–1569. [Google Scholar] [CrossRef]
- Bucolo, M.; Buscarino, A.; Fortuna, L.; Frasca, M. LQG control of linear lossless positive-real systems: The continuous-time and discrete-time cases. Int. J. Dyn. Control 2022, 10, 1075–1083. [Google Scholar] [CrossRef]
- Buscarino, A.; Fortuna, L.; Frasca, M.; Rizzo, A. Dynamical network interactions in distributed control of robots. Chaos: Interdiscip. J. Nonlinear Sci. 2006, 16, 015116. [Google Scholar] [CrossRef]
- Khoo, S.; Xie, L.; Man, Z. Robust Finite-Time Consensus Tracking Algorithm for Multirobot Systems. IEEE/ASME Trans. Mechatron. 2009, 14, 219–228. [Google Scholar] [CrossRef]
- Brewer, J. Kronecker products and matrix calculus in system theory. IEEE Trans. Circuits Syst. 1978, 25, 772–781. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).