Pavement Surface Defect Detection Using Mask Region-Based Convolutional Neural Networks and Transfer Learning


 , ,
, , 
Abstract
:1. Introduction
2. Experiment and Methods
2.1. Experimental Setup and Performance Evaluation
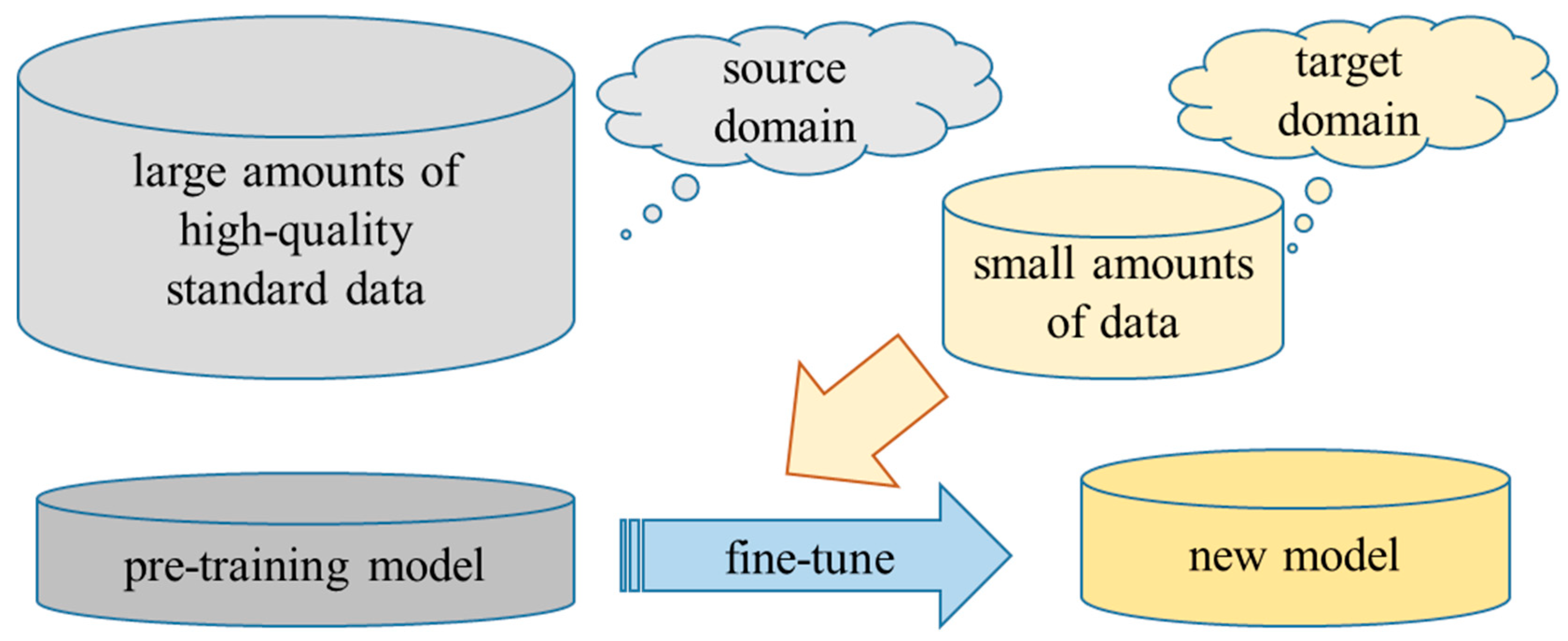
2.2. Transfer Learning
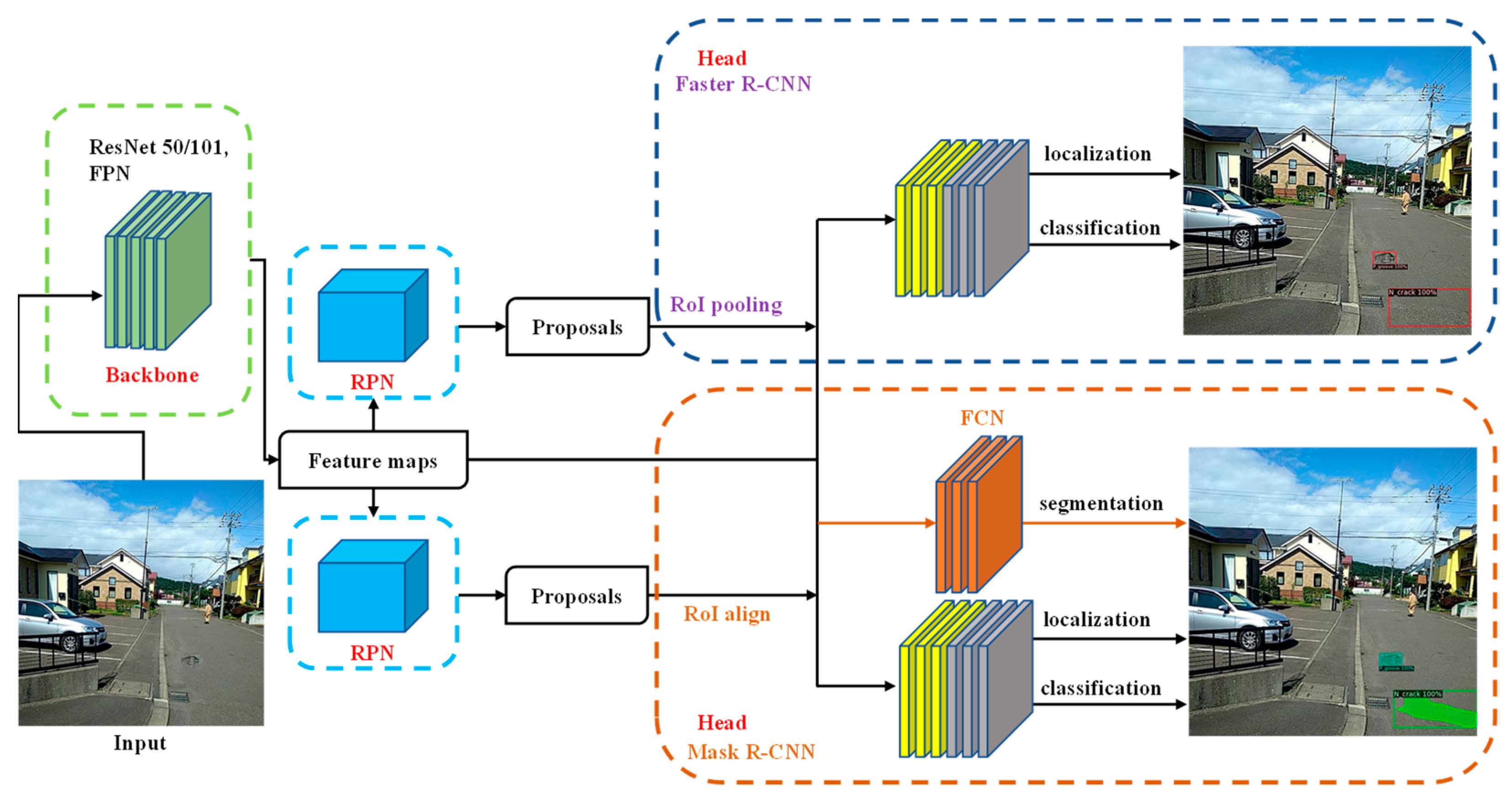
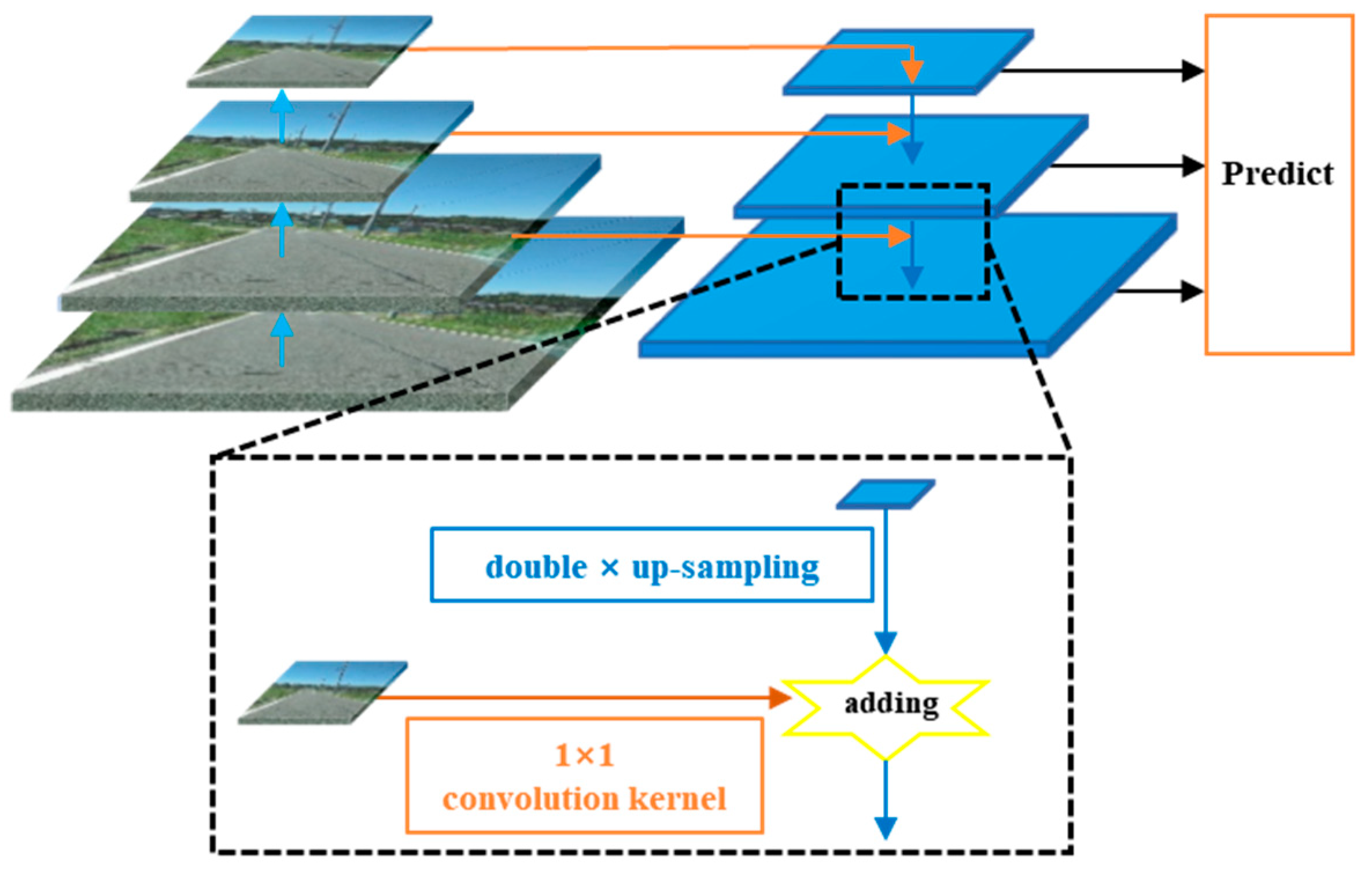
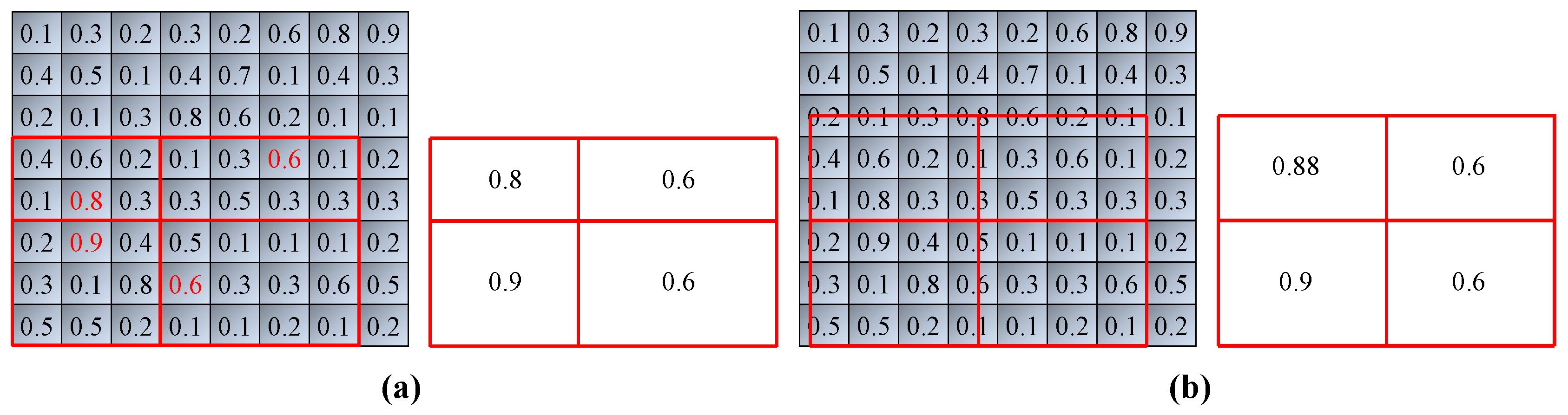
2.3. Structure of Faster R-CNN and Mask R-CNN
3. Results and Discussions
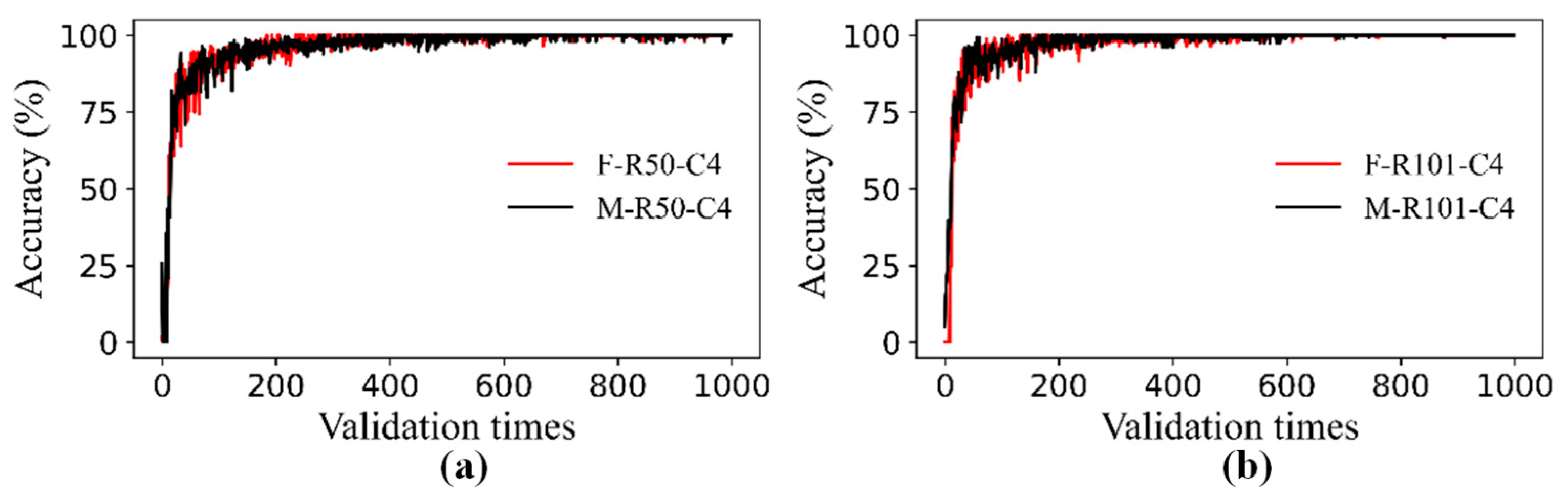
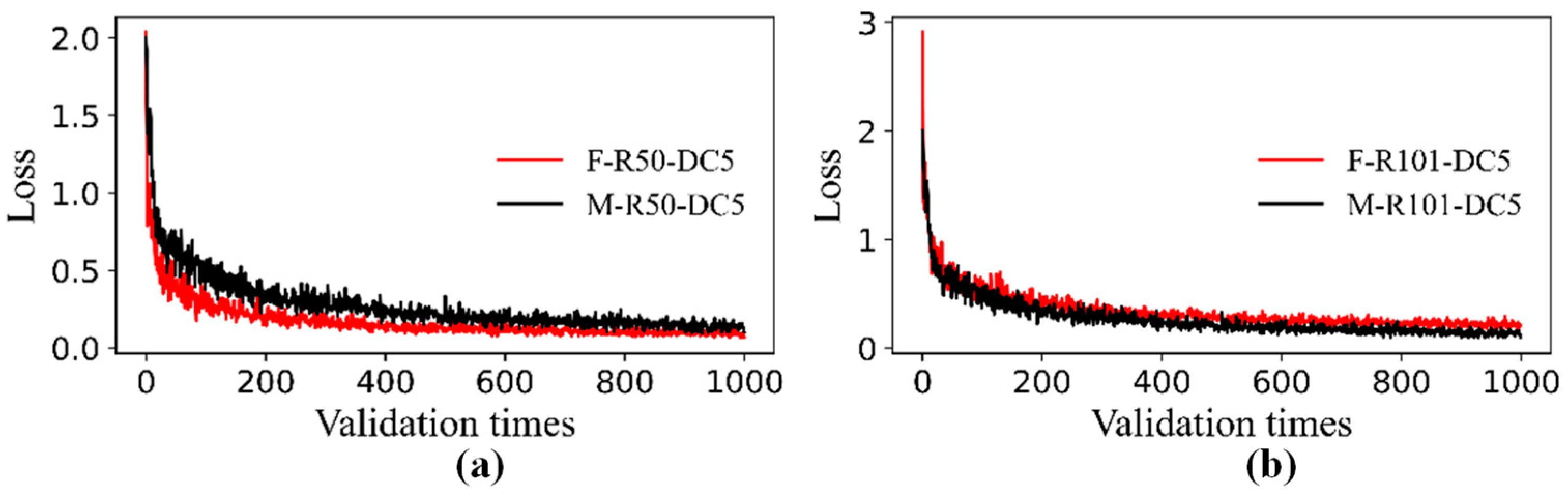
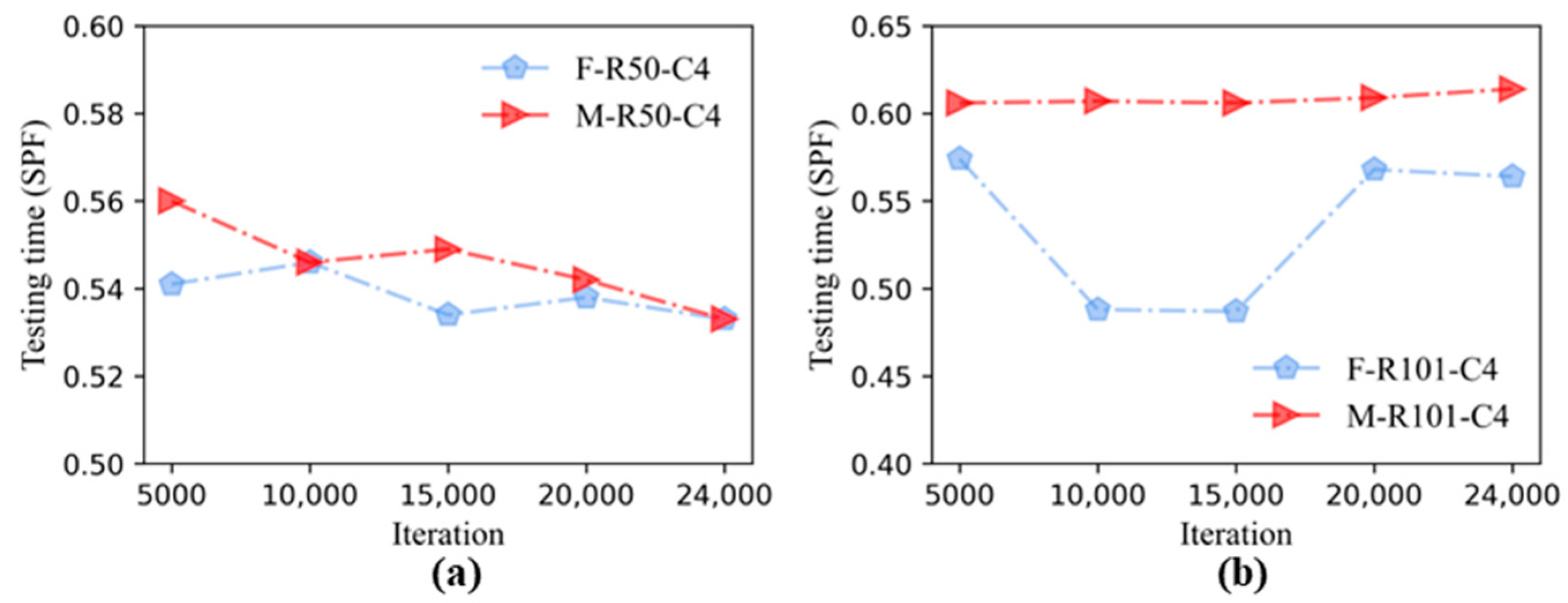
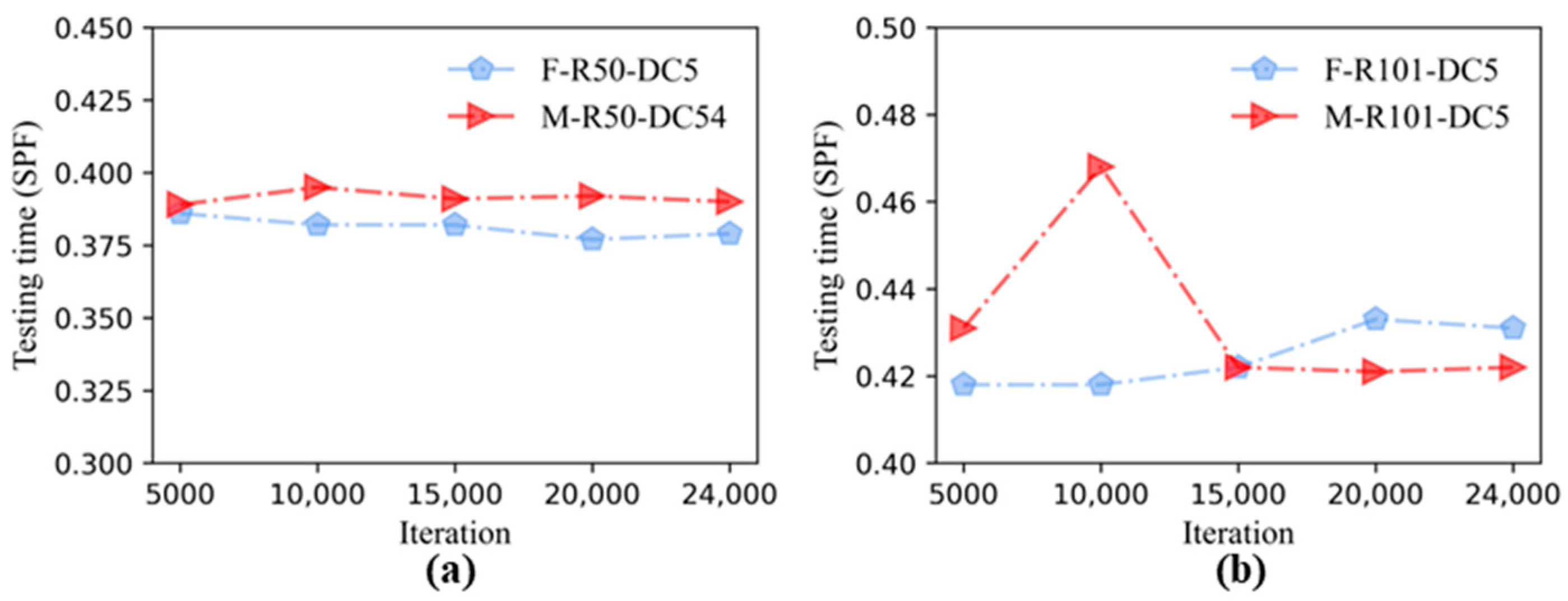
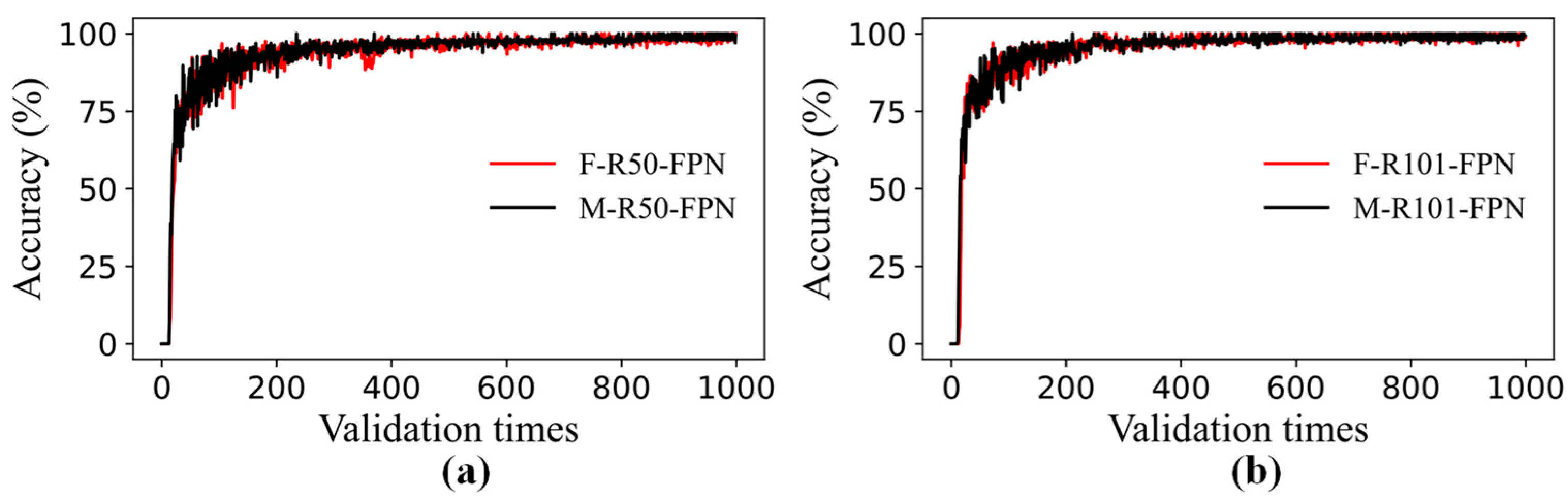
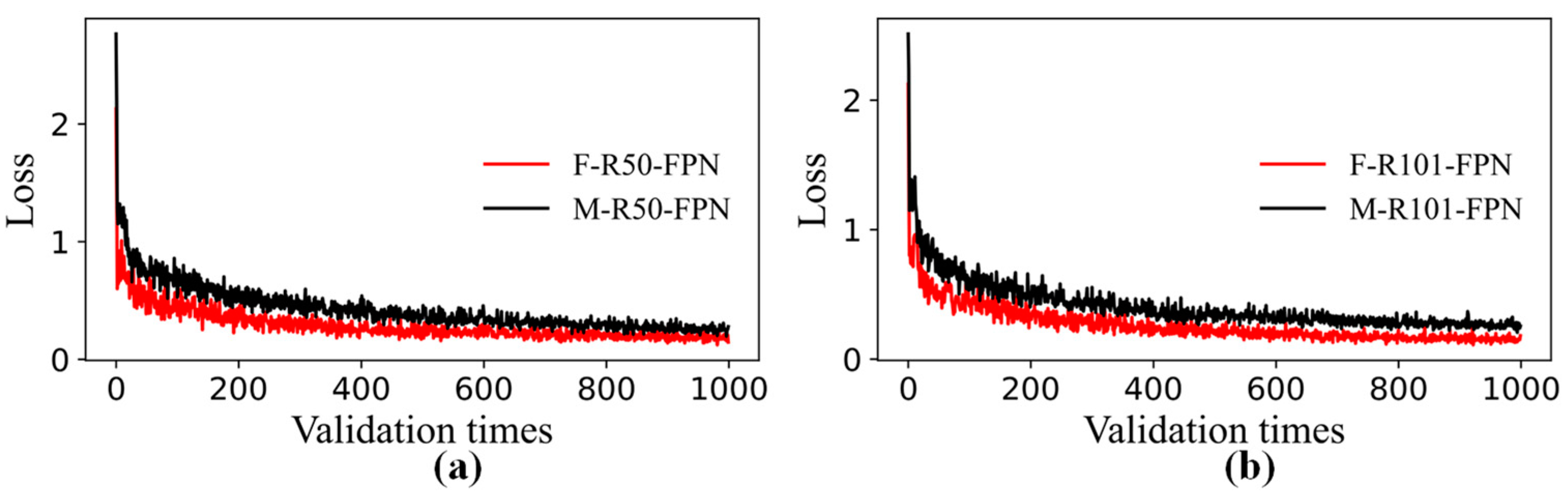
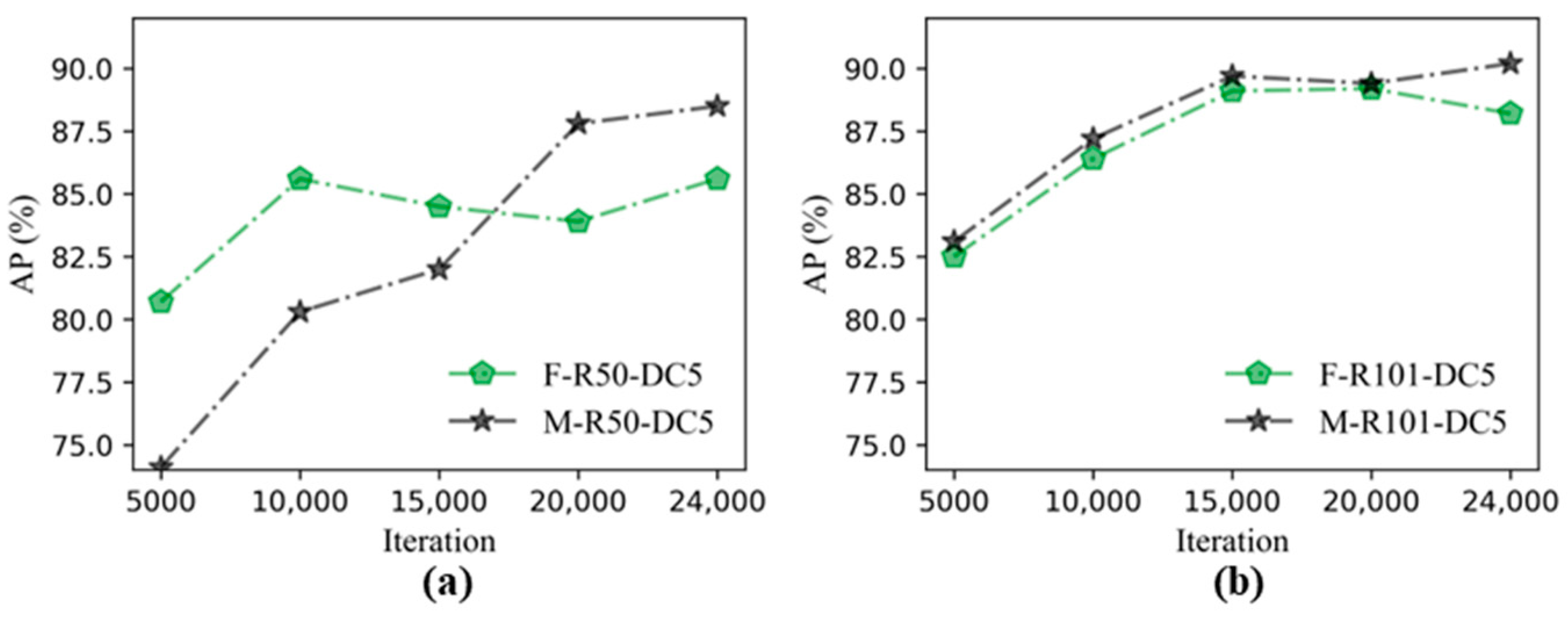
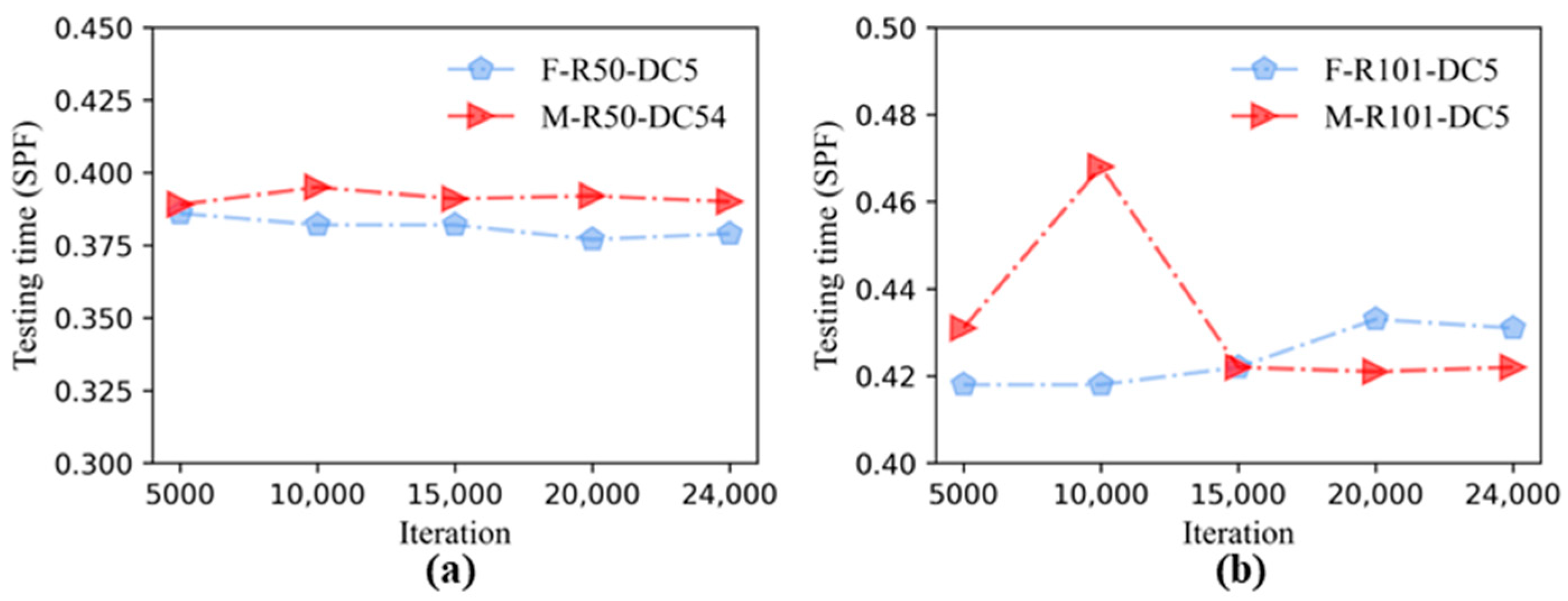
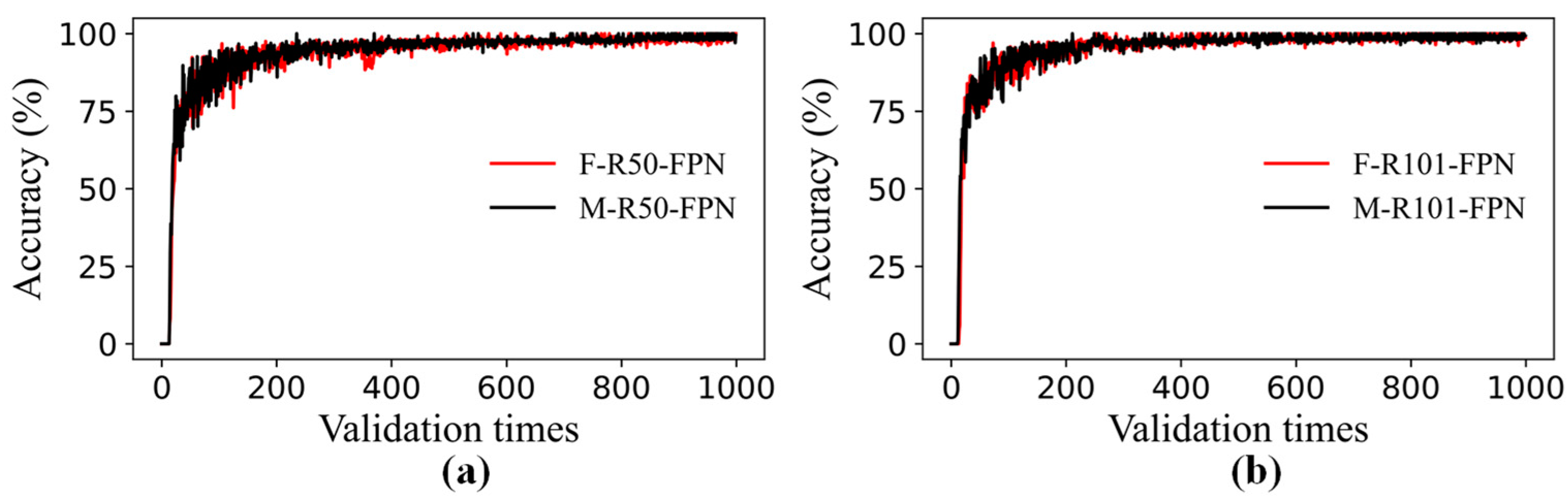
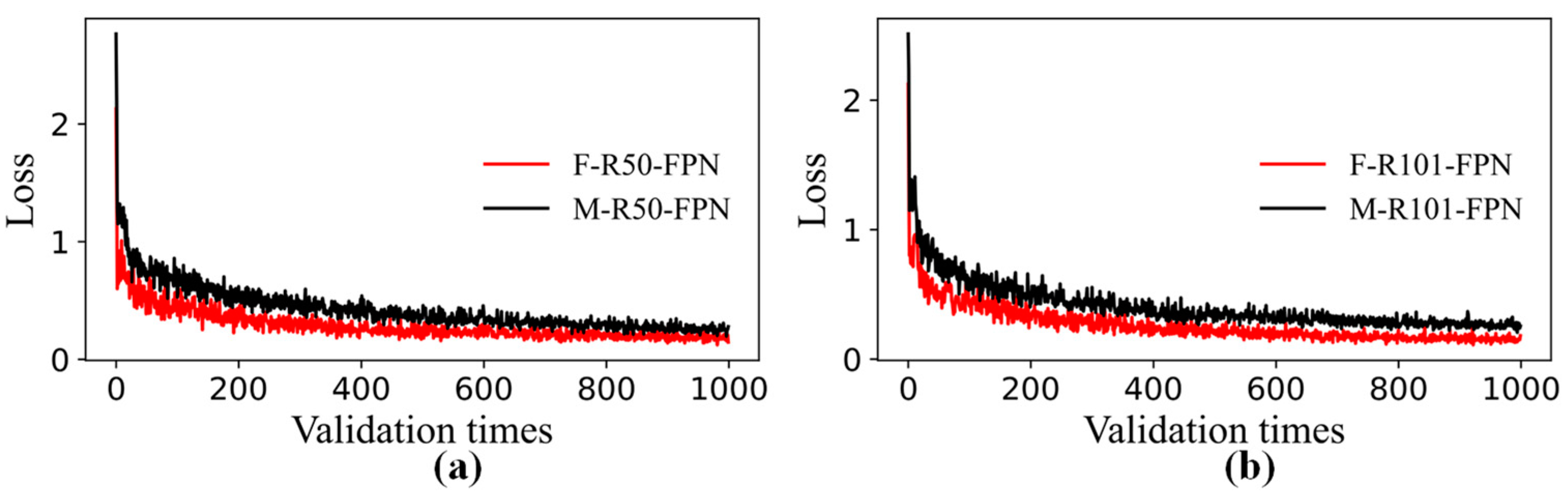
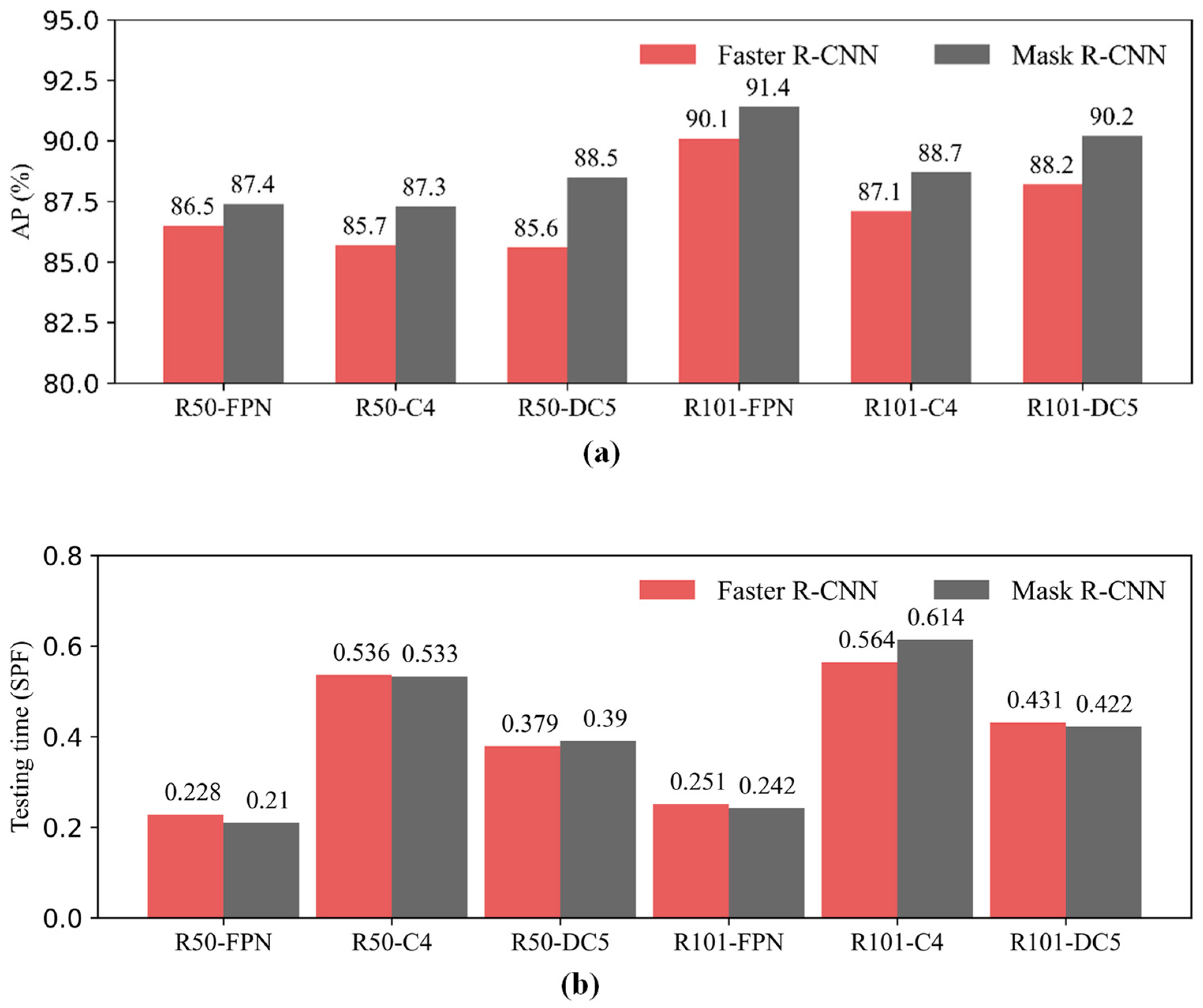
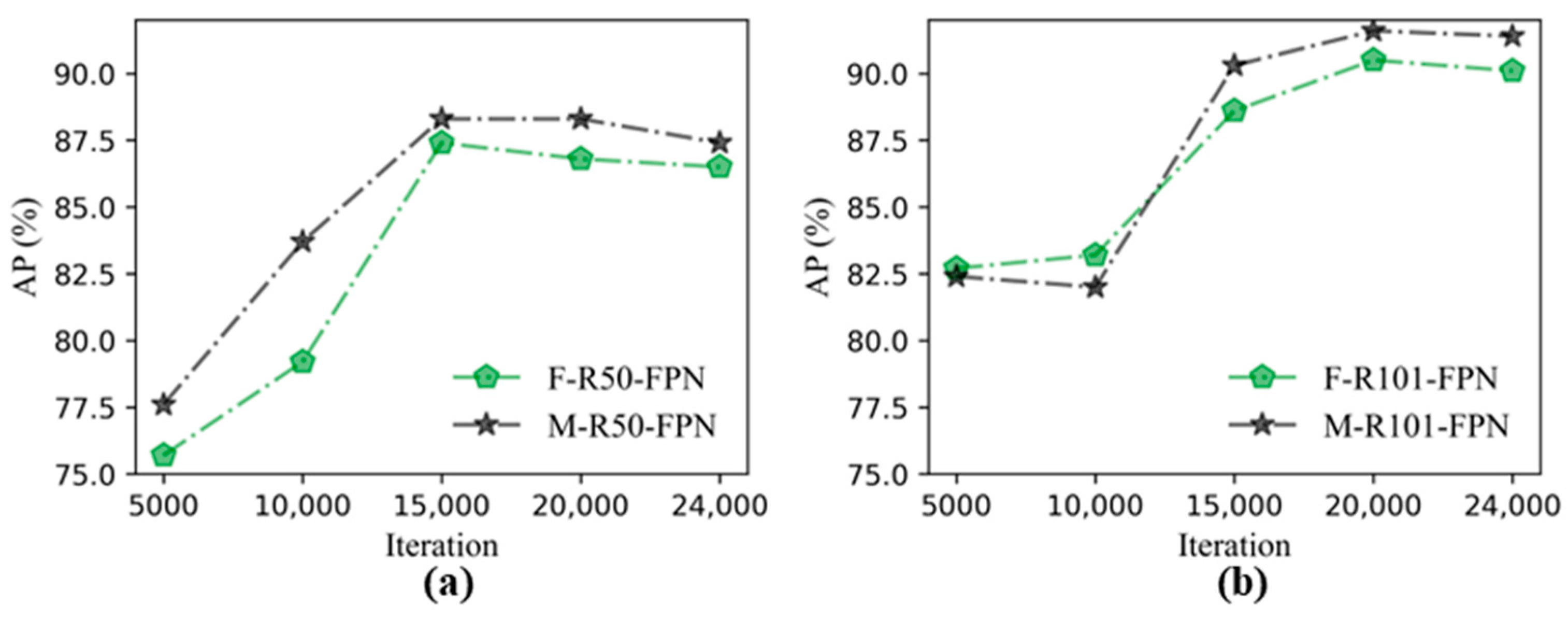
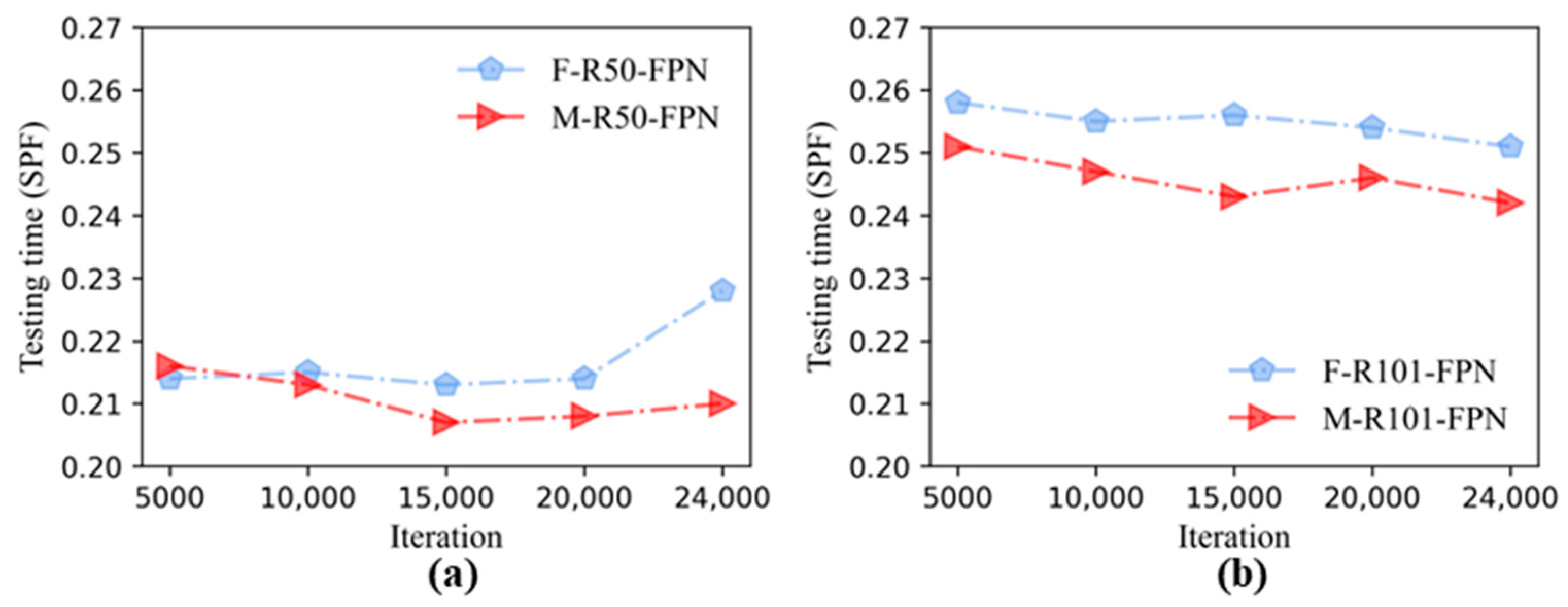
3.1. Performance Comparisons of Faster R-CNN and Mask R-CNN
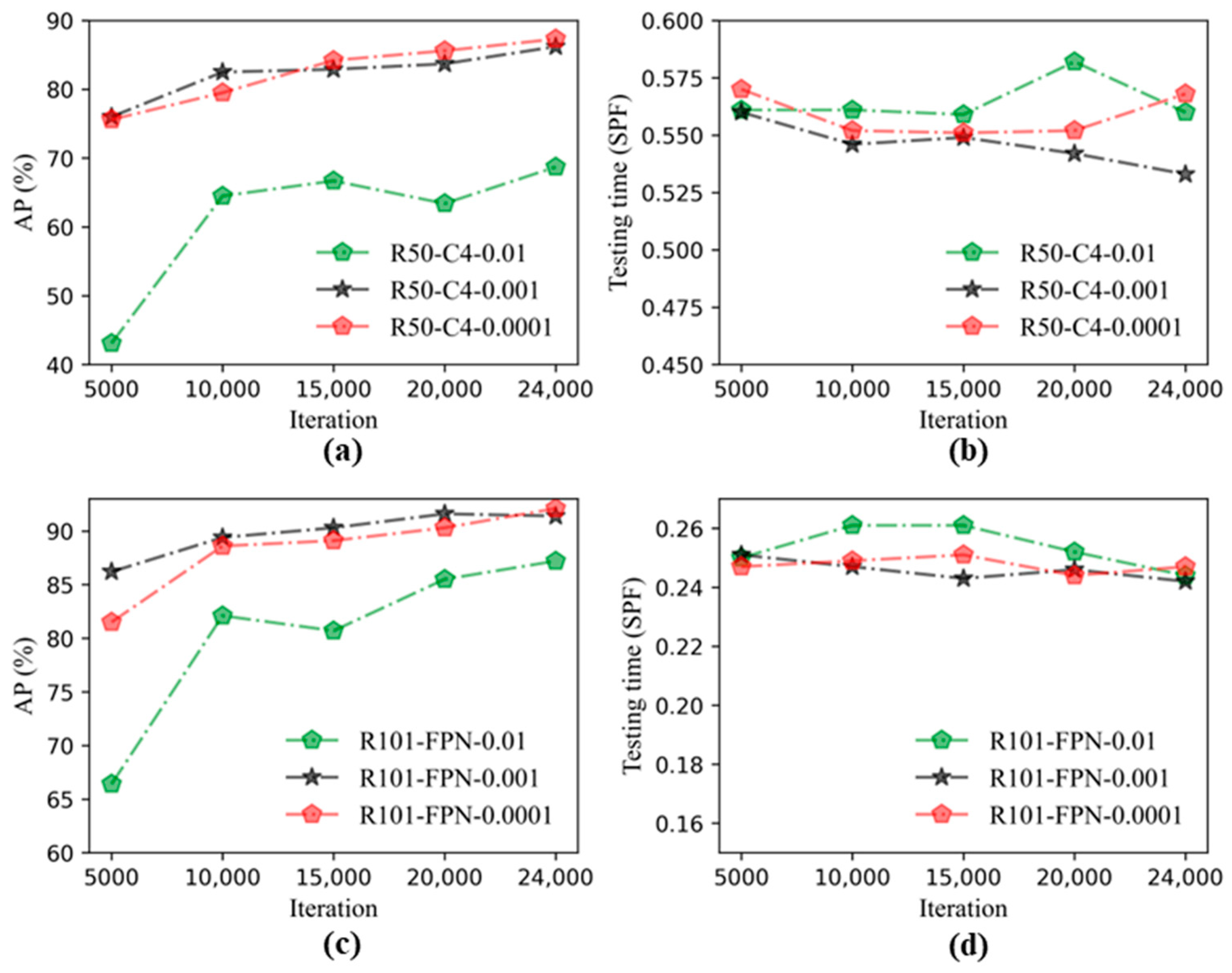
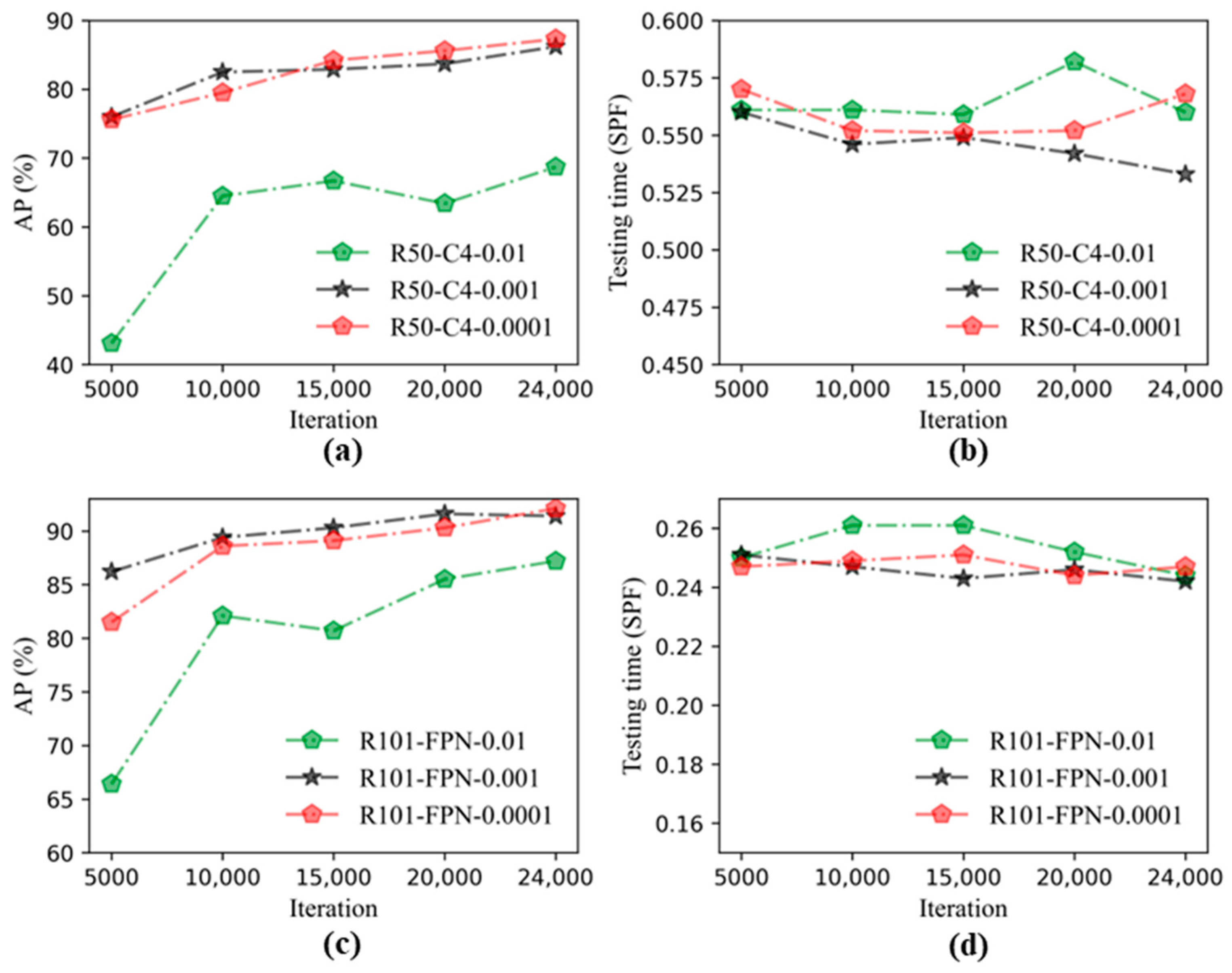
3.2. Performance Comparisons of Mask R-CNN at Different Learning Rates
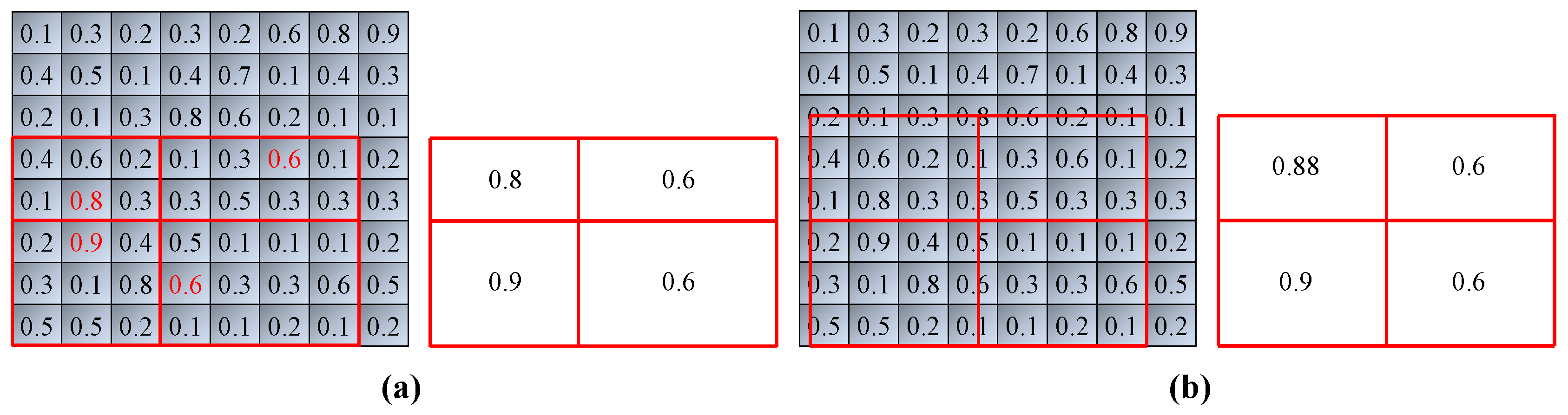
3.3. Quantified Results of Relative Optimal Model
4. Conclusions
- By using transfer learning, the performance results of the Faster R-CNN and Mask R-CNN combined with six backbone structures, it could be seen that the detection accuracy of the two algorithms was close, and the AP under each backbone structure of the Mask R-CNN was higher than that of the corresponding Faster R-CNN. The models containing FPN were faster than others in testing time.
- Through comparing the performance of the Mask R-CNN under three different LRs, the result could be obtained that the M-R101-FPN was the relatively optimal model when the learning rate was 0.0001, and the AP could reach 92.1%, and the detection effect was best.
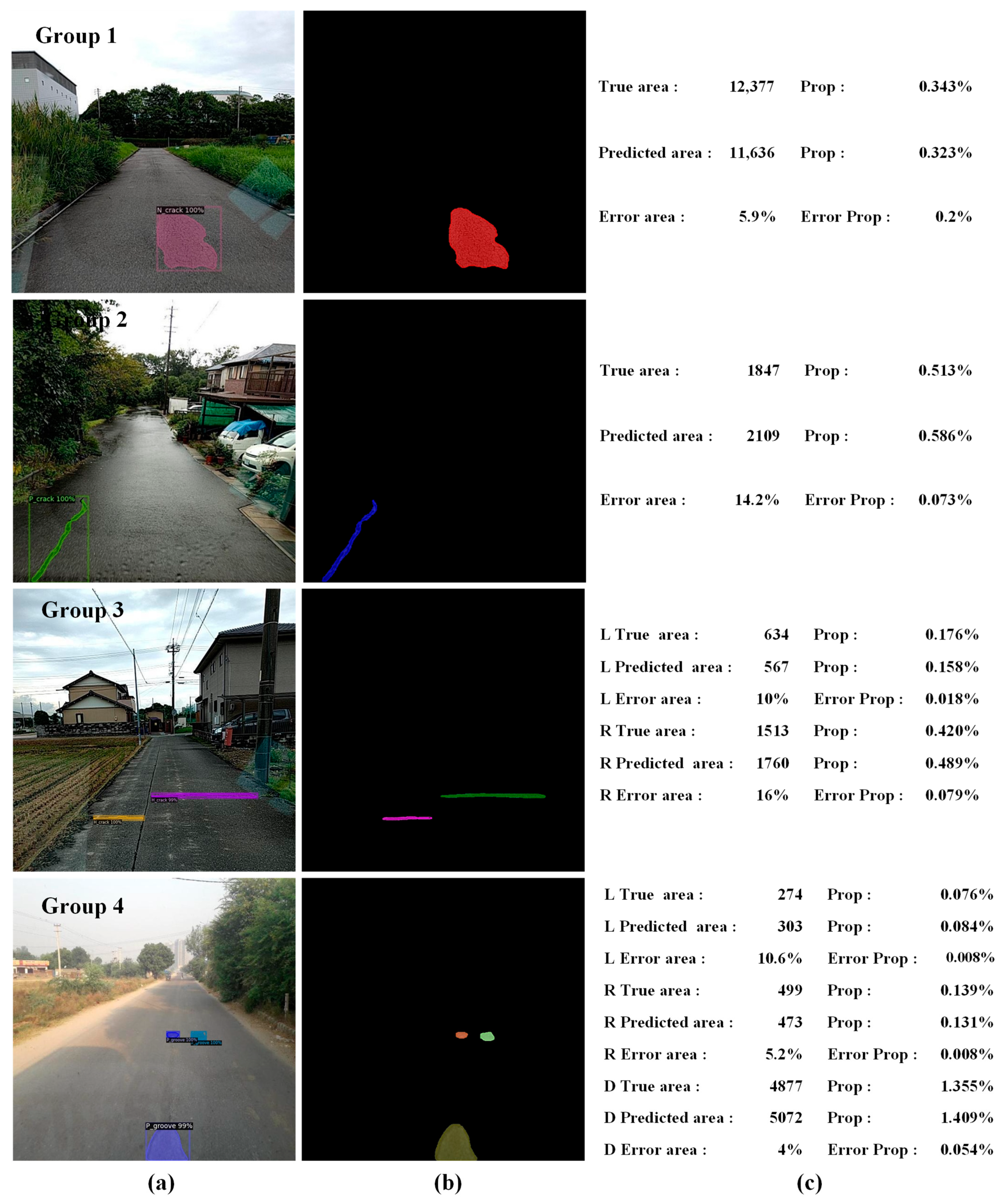
- The testing results of M-R101-FPN showed that the model had certain capabilities in the detection of multiple defects of complex pavements, and the quantification error was within a certain acceptable range.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone Structures | Precision (%) | Recall (%) | F1 (%) | AP (%) | Time (SPF) | ||
|---|---|---|---|---|---|---|---|
| Mask R-CNN | FPN | 89.1 | 84.3 | 85.2 | 83.6 | 0.206 | |
| ResNet50 | C4 | 73.5 | 80.1 | 76.7 | 68.7 | 0.560 | |
| DC5 | 87.6 | 89.4 | 88.5 | 85.1 | 0.382 | ||
| FPN | 90.2 | 91.5 | 90.9 | 87.2 | 0.244 | ||
| ResNet101 | C4 | 70.1 | 78.7 | 74.2 | 66.4 | 0.623 | |
| DC5 | 90.3 | 89.5 | 89.9 | 88.6 | 0.244 | ||
References
- Cao, W.M.; Liu, Q.F.; He, Z.Q. Review of Pavement Defect Detection Methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.Q.; Mao, Q.Z.; Wang, S. Crack Tree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Hamrat, M.; Boulekbache, B.; Chemrouk, M.; Amziane, S. Flexural cracking behavior of normal strength, high strength and high strength fiber concrete beams, using Digital Image Correlation technique. Constr. Build. Mater. 2016, 106, 678–692. [Google Scholar] [CrossRef]
- Rimkus, A.; Podviezko, A.; Gribniak, V. Processing digital images for crack localization in reinforced concrete members. Procedia Eng. 2015, 122, 239–243. [Google Scholar] [CrossRef]
- Li, L.; Wang, Q.; Zhang, G.; Shi, L.; Dong, J.; Jia, P. A method of detecting the cracks of concrete undergo high-temperature. Constr. Build. Mater. 2018, 162, 345–358. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Cho, S.; Shin, M.; Sim, S.H. Comparative analysis of image binarization methods for crack identification in concrete structures. Cem. Concr. Res. 2017, 99, 53–61. [Google Scholar] [CrossRef]
- Abdel-Qader, L.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civil. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Dollar, P.; Zitnick, C.L. Fast Edge Detection Using Structured Forests. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1558–1570. [Google Scholar] [CrossRef] [Green Version]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Wang, K.C.P.; Li, Q.; Gong, W.G. Wavelet-based pavement distress image edge detection with a trous algorithm. Transp. Res. Record 2007, 2024, 73–81. [Google Scholar] [CrossRef]
- Ying, L.; Salari, E. Beamlet Transform-Based Technique for Pavement Crack Detection and Classification. Comput.-Aided Civil Infrastruct. Eng. 2010, 25, 572–580. [Google Scholar] [CrossRef]
- Ebrahimkhanlou, A.; Farhidzadeh, A.; Salamone, S. Multifractal analysis of crack patterns in reinforced concrete shear walls. Struct. Health Monit. 2016, 15, 81–92. [Google Scholar] [CrossRef]
- Oh, J.K.; Jang, G.; Oh, S.; Lee, J.H.; Yi, B.J.; Moon, Y.S.; Lee, J.S.; Choi, Y. Bridge inspection robot system with machine vision. Autom. Constr. 2009, 18, 929–941. [Google Scholar] [CrossRef]
- Lim, R.S.; La, H.M.; Sheng, W.H. A Robotic Crack Inspection and Mapping System for Bridge Deck Maintenance. IEEE Trans. Autom. Sci. Eng. 2014, 11, 367–378. [Google Scholar] [CrossRef]
- Talab, A.M.A.; Huang, Z.C.; Xi, F.; Liu, H.M. Detection crack in image using Otsu method and multiple filtering in image processing techniques. Optik 2016, 127, 1030–1033. [Google Scholar] [CrossRef]
- Jahanshahi, M.R.; Masri, S.F. Adaptive vision-based crack detection using 3D scene reconstruction for condition assessment of structures. Autom. Constr. 2012, 22, 567–576. [Google Scholar] [CrossRef]
- Chen, F.C.; Jahanshahi, M.R.; Wu, R.T.; Joffe, C. A texture-Based Video Processing Methodology Using Bayesian Data Fusion for Autonomous Crack Detection on Metallic Surfaces. Comput.-Aided Civil Infrastruct. Eng. 2017, 32, 271–287. [Google Scholar] [CrossRef]
- Jahanshahi, M.R.; Masri, S.F.; Padgett, C.W.; Sukhatme, G.S. An innovative methodology for detection and quantification of cracks through incorporation of depth perception. Mach. Vis. Appl. 2013, 24, 227–241. [Google Scholar] [CrossRef]
- Zhang, J.Q.; Zhang, J.W.; Teng, S.; Chen, G.F.; Teng, Z.Q. Structural Damage Detection Based on Vibration Signal Fusion and Deep Learning. J. Vib. Eng. Technol. 2022, 10, 1205–1220. [Google Scholar] [CrossRef]
- Zihan, J.; Shuai, T.; Jiqiao, Z.; Gongfa, C. Structural Damage Recognition Based on Filtered Feature Selection and Convolutional Neural Network. Int. J. Struct. Stab. Dyn. 2022, 2250134. [Google Scholar] [CrossRef]
- Mohan, A.; Poobal, S. Crack detection using image processing: A critical review and analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Zakeri, H.; Moghadas Nejad, F.; Fahimifar, A. Image Based Techniques for Crack Detection, Classification and Quantification in Asphalt Pavement: A Review. Arch. Comput. Method Eng. 2017, 24, 935–977. [Google Scholar] [CrossRef]
- Chaiyasarn, K.; Buatik, A.; Mohamad, H.; Zhou, M.L.; Kongsilp, S.; Poovarodom, N. Integrated pixel-level CNN-FCN crack detection via photogrammetric 3D texture mapping of concrete structures. Autom. Constr. 2022, 140, 17. [Google Scholar] [CrossRef]
- Yu, B.; Meng, X.; Yu, Q. Automated Pixel-Wise Pavement Crack Detection by Classification-Segmentation Networks. J. Transp. Eng. Part B-Pavements 2021, 147, 04021005. [Google Scholar] [CrossRef]
- Liu, F.; Liu, J.; Wang, L. Deep learning and infrared thermography for asphalt pavement crack severity classification. Autom. Constr. 2022, 140, 104383. [Google Scholar] [CrossRef]
- Wang, G.; Xiang, J. Railway sleeper crack recognition based on edge detection and CNN. Smart Struct. Syst. 2021, 28, 779–789. [Google Scholar] [CrossRef]
- Tong, Z.; Gao, J.; Zhang, H. Recognition, location, measurement, and 3D reconstruction of concealed cracks using convolutional neural networks. Constr. Build. Mater. 2017, 146, 775–787. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Abu Talip, M.S.; Mokhtar, N.; Shoaib, M.A. Structural crack detection using deep convolutional neural networks. Autom. Constr. 2022, 133, 103989. [Google Scholar] [CrossRef]
- Wang, K.C.P.; Zhang, A.; Li, J.Q.; Fei, Y.; Chen, C.; Li, B.X. Deep Learning for Asphalt Pavement Cracking Recognition Using Convolutional Neural Network. In Airfield and Highway Pavements; American Society of Civil Engineers: Reston, VA, USA, 2017; pp. 166–177. [Google Scholar]
- Cha, Y.J.; Choi, W.; Buyukozturk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput.-Aided Civil Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Wu, L.J.; Lin, X.; Chen, Z.C.; Lin, P.J.; Cheng, S.Y. Surface crack detection based on image stitching and transfer learning with pretrained convolutional neural network. Struct. Control. Health Monit. 2021, 28, e2766. [Google Scholar] [CrossRef]
- Zhuang, F.Z.; Qi, Z.Y.; Duan, K.Y.; Xi, D.B.; Zhu, Y.C.; Zhu, H.S.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Du, Y.C.; Pan, N.; Xu, Z.H.; Deng, F.W.; Shen, Y.; Kang, H. Pavement distress detection and classification based on YOLO network. Int. J. Pavement Eng. 2021, 22, 1659–1672. [Google Scholar] [CrossRef]
- Majidifard, H.; Adu-Gyamfi, Y.; Buttlar, W.G. Deep machine learning approach to develop a new asphalt pavement condition index. Constr. Build. Mater. 2020, 247, 118513. [Google Scholar] [CrossRef]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Teng, S.; Liu, Z.C.; Chen, G.F.; Cheng, L. Concrete Crack Detection Based on Well-Known Feature Extractor Model and the YOLO_v2 Network. Appl. Sci. 2021, 11, 813. [Google Scholar] [CrossRef]
- Deng, L.; Chu, H.H.; Shi, P.; Wang, W.; Kong, X. Region-Based CNN Method with Deformable Modules for Visually Classifying Concrete Cracks. Appl. Sci. 2020, 10, 2528. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Buyukozturk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civil Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Ju, H.Y.; Li, W.; Tighe, S.S.; Xu, Z.C.; Zhai, J.Z. CrackU-net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control. Health Monit. 2020, 27, 19. [Google Scholar] [CrossRef]
- Zhang, Z.X.; Liu, Q.J.; Wang, Y.H. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.W.; Li, Q.T.; Zhang, D.M. Deep learning based image recognition for crack and leakage defects of metro shield tunnel. Tunn. Undergr. Space Technol. 2018, 77, 166–176. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; Zhang, L.; Yu, S.J.; Prokhorov, D.; Mei, X.; Ling, H.B. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef] [Green Version]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Li, S.Y.; Zhao, X.F.; Zhou, G.Y. Automatic pixel-level multiple damage detection of concrete structure using fully convolutional network. Comput.-Aided Civil Infrastruct. Eng. 2019, 34, 616–634. [Google Scholar] [CrossRef]
- He, K.M.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Huang, H.W.; Zhao, S.; Zhang, D.M.; Chen, J.Y. Deep learning-based instance segmentation of cracks from shield tunnel lining images. Struct. Infrastruct. Eng. 2022, 18, 183–196. [Google Scholar] [CrossRef]
- Wu, Z.Y.; Kalfarisi, R.; Kouyoumdjian, F.; Taelman, C. Applying deep convolutional neural network with 3D reality mesh model for water tank crack detection and evaluation. Urban Water J. 2020, 17, 682–695. [Google Scholar] [CrossRef]
- Taghanaki, S.A.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2021, 54, 137–178. [Google Scholar] [CrossRef]
- Wen, S.P.; Liu, W.W.; Yang, Y.; Zhou, P.; Guo, Z.Y.; Yan, Z.; Chen, Y.R.; Huang, T.W. Multilabel Image Classification via Feature/Label Co-Projection. IEEE Trans. Syst. Man Cybern.-Syst. 2021, 51, 7250–7259. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, Q.; Wang, Y.M.; Yang, T.; Zhang, X.Y.; Cheng, J.; Sun, J.; Ieee Comp, S.O.C. You Only Look One-level Feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, 19–25 June 2021; pp. 13034–13043. [Google Scholar] [CrossRef]


| Class | H_crack | P_crack | N_crack | P_groove |
|---|---|---|---|---|
| Numbers | 497 | 518 | 541 | 487 |
| Backbone Structures | |||||
|---|---|---|---|---|---|
| ResNet-50 | ResNet-101 | ||||
| Faster R-CNN Mask R-CNN | FPN | F-R50-FPN | M-R50-FPN | F-R101-FPN | M-R101-FPN |
| C4 | F-R50-C4 | M-R50-C4 | F-R101-C4 | M-R101-C4 | |
| DC5 | F-R50-DC5 | M-R50-DC5 | F-R101-DC5 | M-R101-DC5 | |
| Backbone Structures | ||||||
|---|---|---|---|---|---|---|
| ResNet-50 | ResNet-101 | |||||
| FPN | C4 | DC5 | FPN | C4 | DC5 | |
| Faster R-CNN | 100% | 100% | 100% | 98.7% | 100% | 100% |
| Mask R-CNN | 99.4% | 100% | 100% | 99.3% | 100% | 100% |
| Backbone Structures | Precision (%) | Recall (%) | F1 (%) | AP (%) | Time (SPF) | ||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | FPN | 90.6 | 92.4 | 91.5 | 86.5 | 0.228 | |
| ResNet50 | C4 | 87.1 | 90.6 | 88.8 | 85.7 | 0.536 | |
| DC5 | 88.1 | 90.2 | 89.1 | 85.6 | 0.379 | ||
| FPN | 84.5 | 90.4 | 87.4 | 90.1 | 0.251 | ||
| ResNet101 | C4 | 88.7 | 84.5 | 86.5 | 87.1 | 0.564 | |
| DC5 | 89.1 | 90.4 | 89.7 | 88.2 | 0.431 | ||
| Mask R-CNN | FPN | 92.4 | 93.6 | 92.9 | 87.4 | 0.210 | |
| ResNet50 | C4 | 91.7 | 92.5 | 92.1 | 87.3 | 0.533 | |
| DC5 | 90.3 | 89.7 | 90.0 | 88.5 | 0.390 | ||
| FPN | 92.7 | 93.1 | 92.9 | 91.4 | 0.242 | ||
| ResNet101 | C4 | 91.3 | 92.4 | 91.8 | 88.7 | 0.614 | |
| DC5 | 90.6 | 90.1 | 90.3 | 90.2 | 0.422 | ||
| Backbone Structures | Precision (%) | Recall (%) | F1 (%) | AP (%) | Time (SPF) | ||
|---|---|---|---|---|---|---|---|
| Mask R-CNN | FPN | 91.3 | 93.6 | 92.4 | 88.4 | 0.210 | |
| ResNet50 | C4 | 88.5 | 92.1 | 90.3 | 86.2 | 0.568 | |
| DC5 | 85.7 | 90.4 | 90.0 | 85.8 | 0.391 | ||
| FPN | 94.8 | 95.3 | 95.0 | 92.1 | 0.247 | ||
| ResNet101 | C4 | 92.3 | 93.5 | 92.9 | 88.5 | 0.595 | |
| DC5 | 90.6 | 91.2 | 90.9 | 89.7 | 0.426 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Jin, Z.; Zhang, J.; Teng, S.; Chen, G.; Sun, X.; Cui, F. Pavement Surface Defect Detection Using Mask Region-Based Convolutional Neural Networks and Transfer Learning. Appl. Sci. 2022, 12, 7364. https://doi.org/10.3390/app12157364
He Y, Jin Z, Zhang J, Teng S, Chen G, Sun X, Cui F. Pavement Surface Defect Detection Using Mask Region-Based Convolutional Neural Networks and Transfer Learning. Applied Sciences. 2022; 12(15):7364. https://doi.org/10.3390/app12157364
Chicago/Turabian StyleHe, Yang, Zihan Jin, Jiqiao Zhang, Shuai Teng, Gongfa Chen, Xiaoli Sun, and Fangsen Cui. 2022. "Pavement Surface Defect Detection Using Mask Region-Based Convolutional Neural Networks and Transfer Learning" Applied Sciences 12, no. 15: 7364. https://doi.org/10.3390/app12157364
APA StyleHe, Y., Jin, Z., Zhang, J., Teng, S., Chen, G., Sun, X., & Cui, F. (2022). Pavement Surface Defect Detection Using Mask Region-Based Convolutional Neural Networks and Transfer Learning. Applied Sciences, 12(15), 7364. https://doi.org/10.3390/app12157364