
Surface Defect Detection Model for Aero-Engine Components Based on Improved YOLOv5


Abstract
:1. Introduction
2. Methods and Principles
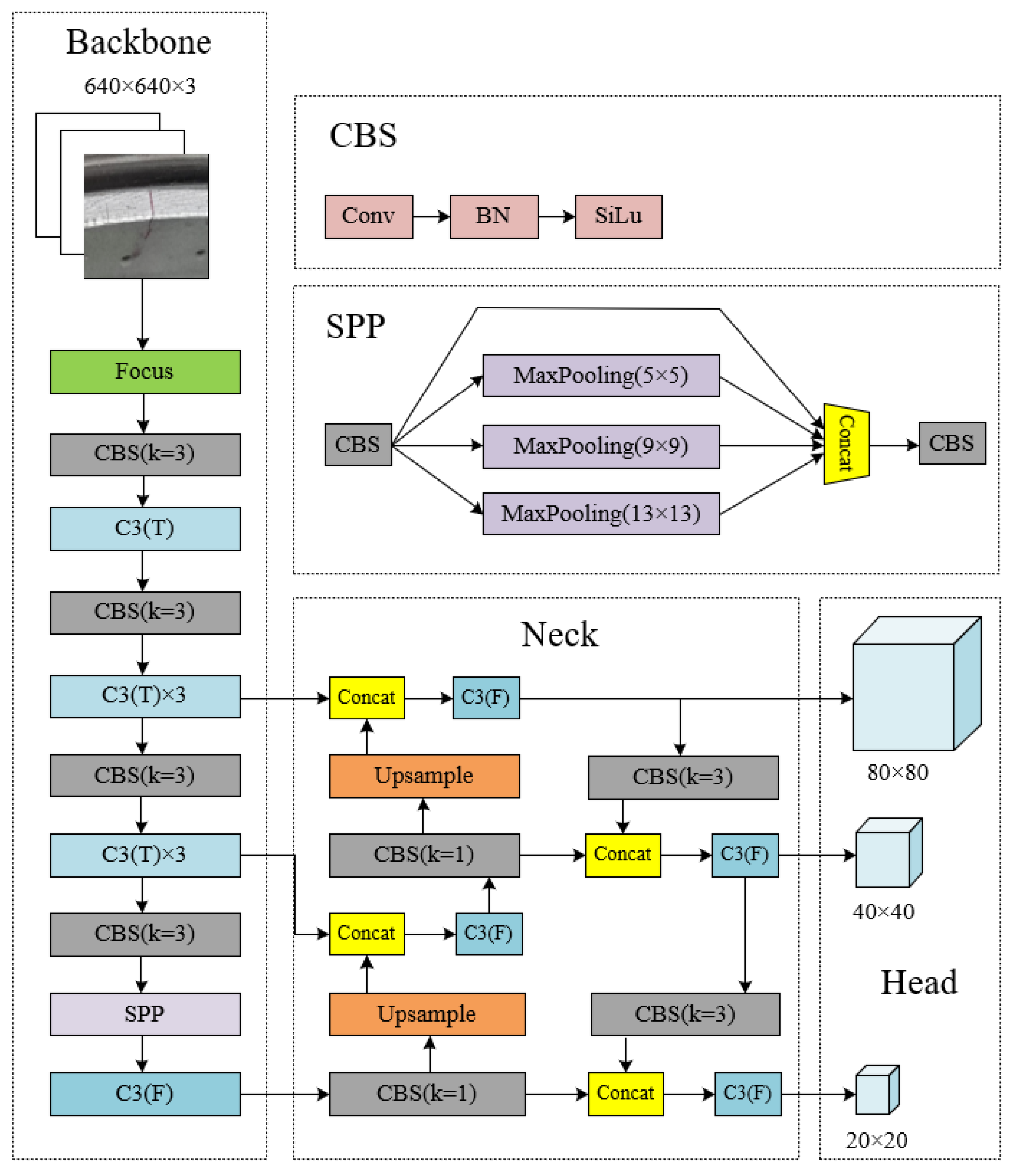
2.1. YOLOv5 Algorithm
2.2. YOLOv5 Improvement
2.2.1. K-Means Clustering Algorithm
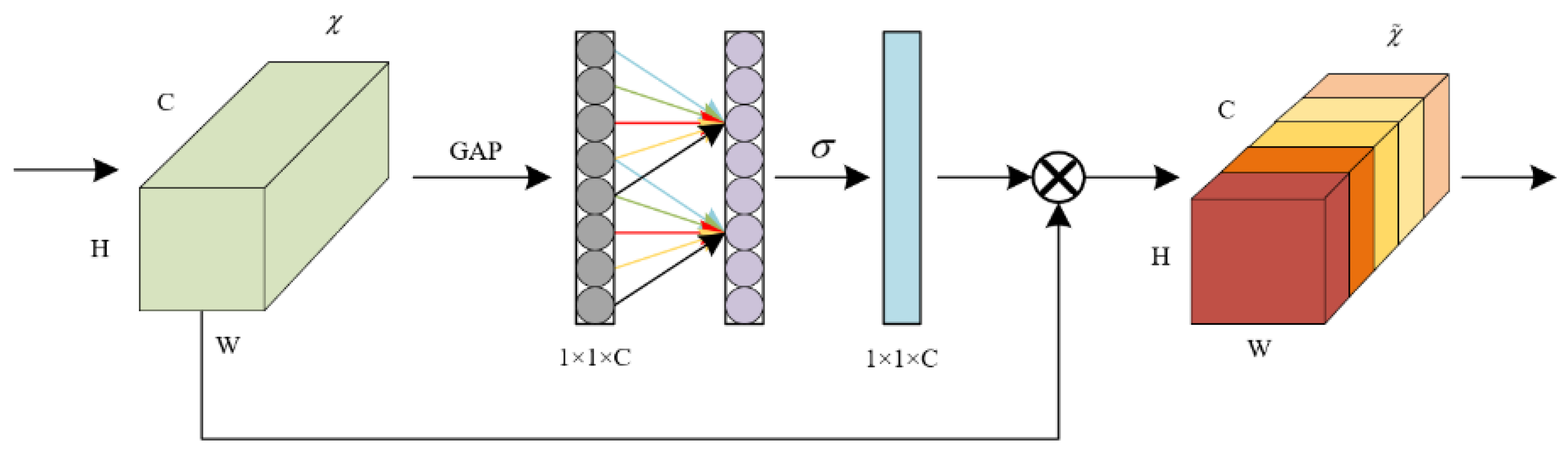
2.2.2. ECA-Net Mechanism
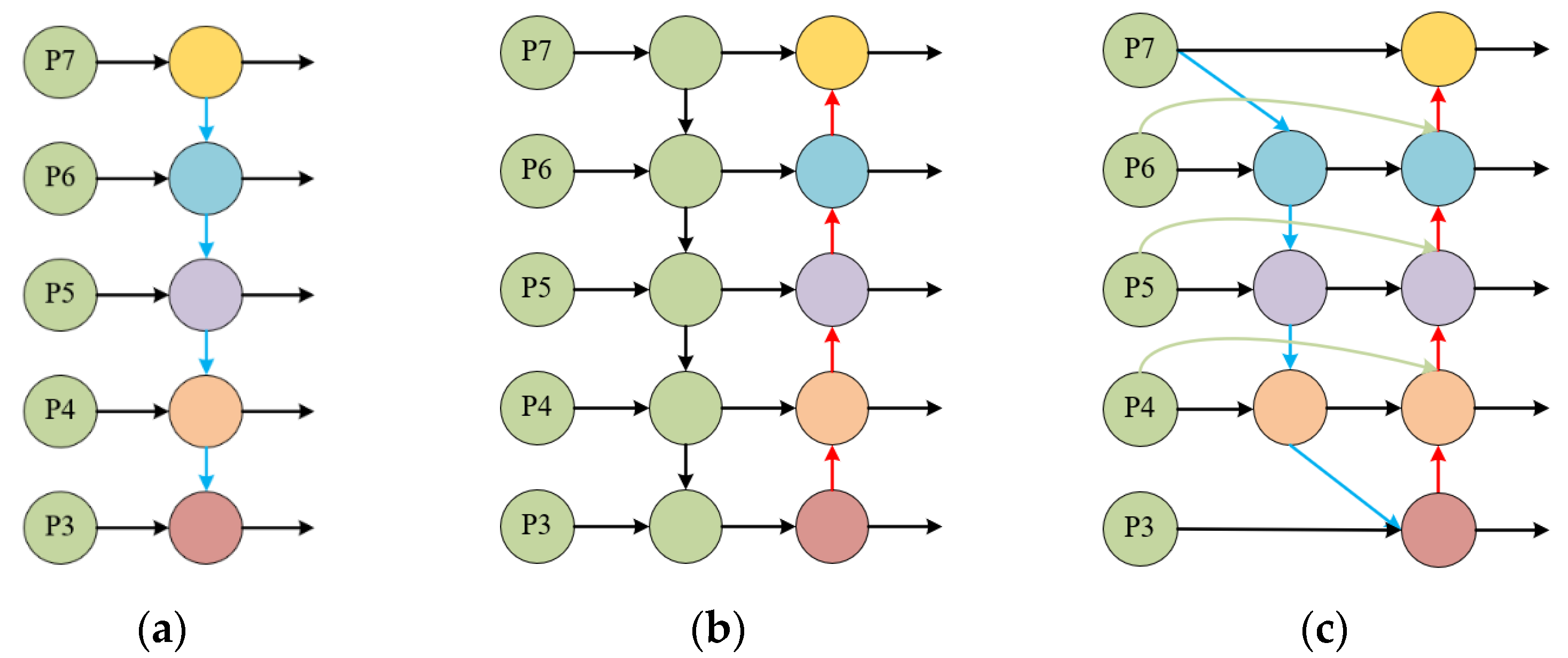
2.2.3. BiFPN Module
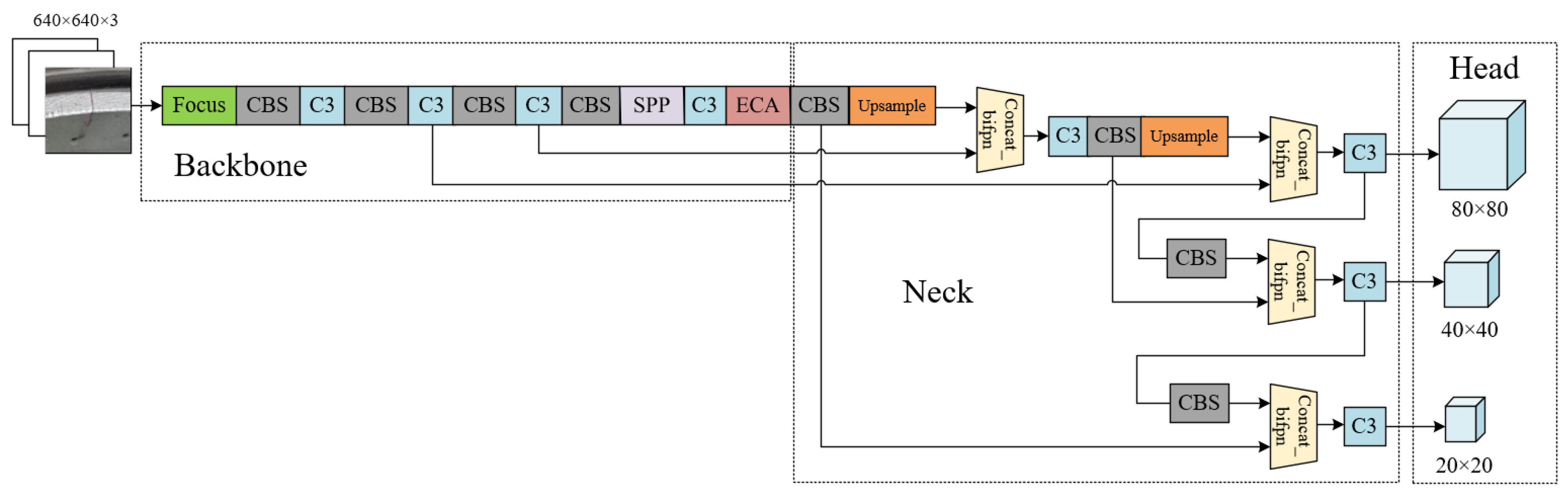
2.3. Improved YOLOv5
3. Experiment and Results
3.1. Experimental Environment
3.2. Dataset
3.3. Training Parameter Setting
3.4. Evaluation Indicators
3.5. Ablation Studies
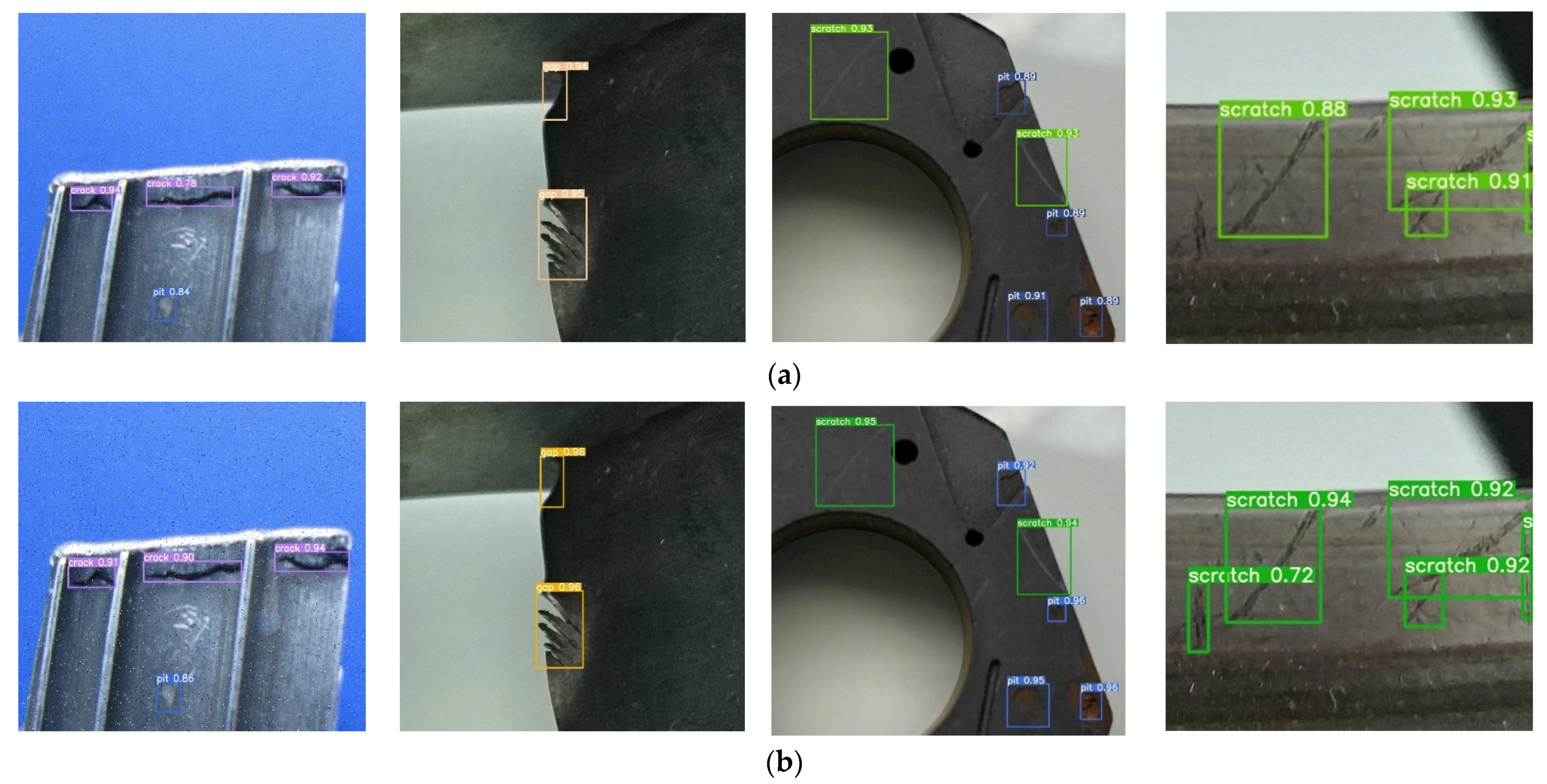
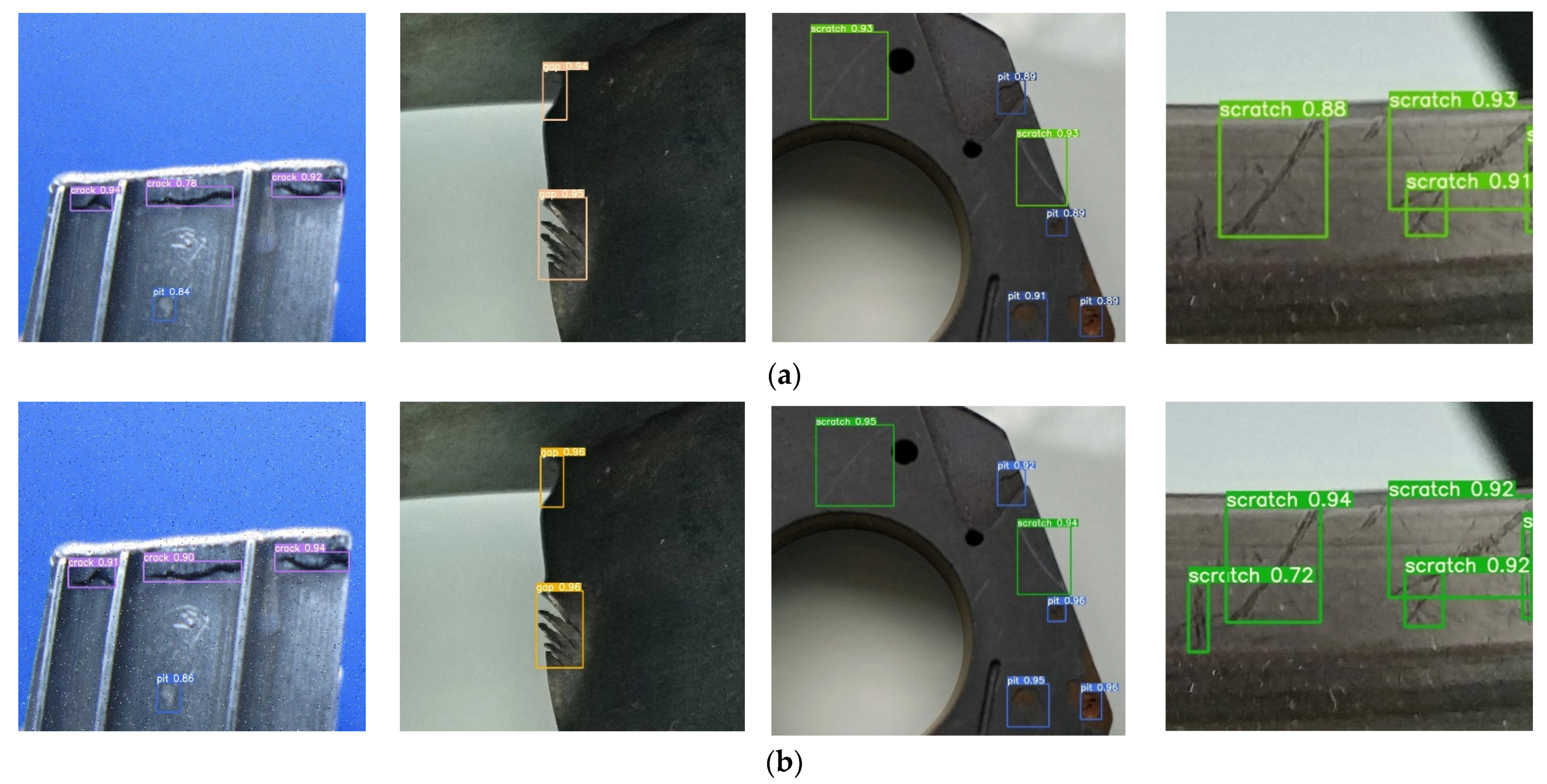
3.6. Comparison of Actual Detection Effects
3.7. Comparison of Different Object Detection Algorithms
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shang, H.; Sun, C.; Liu, J.; Chen, X.; Yan, R. Deep learning-based borescope image processing for aero-engine blade in-situ damage detection. Aerosp. Sci. Technol. 2022, 123, 107473. [Google Scholar] [CrossRef]
- Yilmaz, O.; Gindy, N.; Gao, J. A repair and overhaul methodology for aeroengine components. Rob. Comput. Integr. Manuf. 2010, 26, 190–201. [Google Scholar] [CrossRef]
- Li, D.; Li, Y.; Xie, Q.; Wu, Y.; Yu, Z.; Wang, J. Tiny defect detection in high-resolution aero-engine blade images via a coarse-to-fine framework. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. FasterR-CNN: Towards Real-time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 12 December 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Andriyanov, N.A.; Dementiev, V.E.; Tashlinskii, A.G. Detection of objects in the images: From likelihood relationships towards scalable and efficient neural networks. Comput. Opt. 2022, 46, 139–159. [Google Scholar] [CrossRef]
- Ramchandran, A.; Sangaiah, A.K. Unsupervised anomaly detection for high dimensional data—An exploratory analysis. In Computational Intelligence for Multimedia Big Data on the Cloud with Engineering Applications; Academic Press: Salt Lake City, UT, USA, 2018; pp. 233–251. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Kou, X.; Liu, S.; Cheng, K.; Qian, Y. Development of a YOLO-V3-based model for detecting defects on steel strip surface. Measurement 2021, 182, 109454. [Google Scholar] [CrossRef]
- Andriyanov, N.; Khasanshin, I.; Utkin, D.; Gataullin, T.; Ignar, S.; Shumaev, V.; Soloviev, V. Intelligent system for estimation of the spatial position of apples based on YOLOv3 and real sense depth camera D415. Symmetry 2022, 14, 148. [Google Scholar] [CrossRef]
- Tulbure, A.A.; Tulbure, A.A.; Dulf, E.H. A review on modern defect detection models using DCNNs–Deep convolutional neural networks. J. Adv. Res. 2022, 35, 33–48. [Google Scholar] [CrossRef] [PubMed]
- Du, X.; Chen, J.; Zhang, H.; Wang, J. Fault detection of aero-engine sensor based on inception-CNN. Aerospace 2022, 9, 236. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- GitHub. YOLOv5-Master. Available online: https://github.com/ultralytics/yolov5.git/ (accessed on 1 March 2021).
- Wang, C.-Y.; Mark Liao, H.-Y.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1571–1580. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, K.; Qin, L.; Li, Q.; Zhao, F.; Xu, Z.; Liu, K. Improved edge lightweight YOLOv4 and its application in on-site power system work. Glob. Energy Interconnect. 2022, 5, 168–180. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Du, F.J.; Jiao, S.J. Improvement of lightweight convolutional neural network model based on YOLO algorithm and its research in pavement defect detection. Sensors 2022, 22, 3537. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Anchor1 | Anchor2 | Anchor3 |
|---|---|---|---|
| COCO | (10, 13) | (30, 61) | (116, 90) |
| (16, 30) | (62, 45) | (156, 198) | |
| (33, 23) | (59, 119) | (373, 326) | |
| Ours | (7, 12) (14, 59) (16, 18) | (34, 74) (47, 30) (62, 161) | (130, 54) (167, 257) (380, 153) |
| Hyperparameters | Value |
|---|---|
| lr0 | 0.001 |
| lrf | 0.2 |
| momentum | 0.937 |
| weight_decay | 0.0005 |
| Model | K-Means | ECA | BiFPN | Weight | Inference Time 1 |
|---|---|---|---|---|---|
| YOLOv5s | × 2 | × | × | 14.4 MB | 2.9 ms |
| A | √ | × | × | 14.4 MB | 2.3 ms |
| B | × | √ | × | 14.4 MB | 2.9 ms |
| C | × | × | √ | 16.5 MB | 2.8 ms |
| YOLOv5s-KEB | √ | √ | √ | 16.5 MB | 2.6 ms |
| Model | AP | mAP | FPS | |||
|---|---|---|---|---|---|---|
| Crack | Gap | Pit | Scratch | |||
| YOLOv5s | 94.9% | 99.5% | 98.4% | 96.5% | 97.3% | 47.98 |
| A | 95.7% | 99.6% | 99.2% | 97.9% | 98.1% | 50.12 |
| B | 95.6% | 99.5% | 98.9% | 96.5% | 97.6% | 49.33 |
| C | 95.0% | 99.5% | 98.9% | 97.2% | 97.7% | 46.37 |
| YOLOv5s-KEB | 96.9% | 99.5% | 99.2% | 97.6% | 98.3% | 46.50 |
| Model | AP | mAP% | FPS | Weight | |||
|---|---|---|---|---|---|---|---|
| Crack | Gap | Pit | Scratch | ||||
| Faster R-CNN | 75.4% | 78.1% | 58.7% | 83.1% | 73.8% | 14.29 | 109 MB |
| YOLOv3 | 82.1% | 89.8% | 85.1% | 76.1% | 83.3% | 22.63 | 235 MB |
| YOLOv4 | 90.0% | 93.2% | 86.6% | 79.0% | 87.2% | 18.55 | 244 MB |
| YOLOv4-tiny | 64.3% | 48.8% | 45.5% | 41.7% | 50.1% | 85.08 | 22.4 MB |
| YOLOv5s-KEB | 96.9% | 99.5% | 99.2% | 97.6% | 98.3% | 46.50 | 16.5 MB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Wang, C.; Ju, H.; Li, Z. Surface Defect Detection Model for Aero-Engine Components Based on Improved YOLOv5. Appl. Sci. 2022, 12, 7235. https://doi.org/10.3390/app12147235
Li X, Wang C, Ju H, Li Z. Surface Defect Detection Model for Aero-Engine Components Based on Improved YOLOv5. Applied Sciences. 2022; 12(14):7235. https://doi.org/10.3390/app12147235
Chicago/Turabian StyleLi, Xin, Cheng Wang, Haijuan Ju, and Zhuoyue Li. 2022. "Surface Defect Detection Model for Aero-Engine Components Based on Improved YOLOv5" Applied Sciences 12, no. 14: 7235. https://doi.org/10.3390/app12147235
APA StyleLi, X., Wang, C., Ju, H., & Li, Z. (2022). Surface Defect Detection Model for Aero-Engine Components Based on Improved YOLOv5. Applied Sciences, 12(14), 7235. https://doi.org/10.3390/app12147235