
Hosted Cuckoo Optimization Algorithm with Stacked Autoencoder-Enabled Sarcasm Detection in Online Social Networks

 ,
,
Abstract
:1. Introduction
2. Literature Review
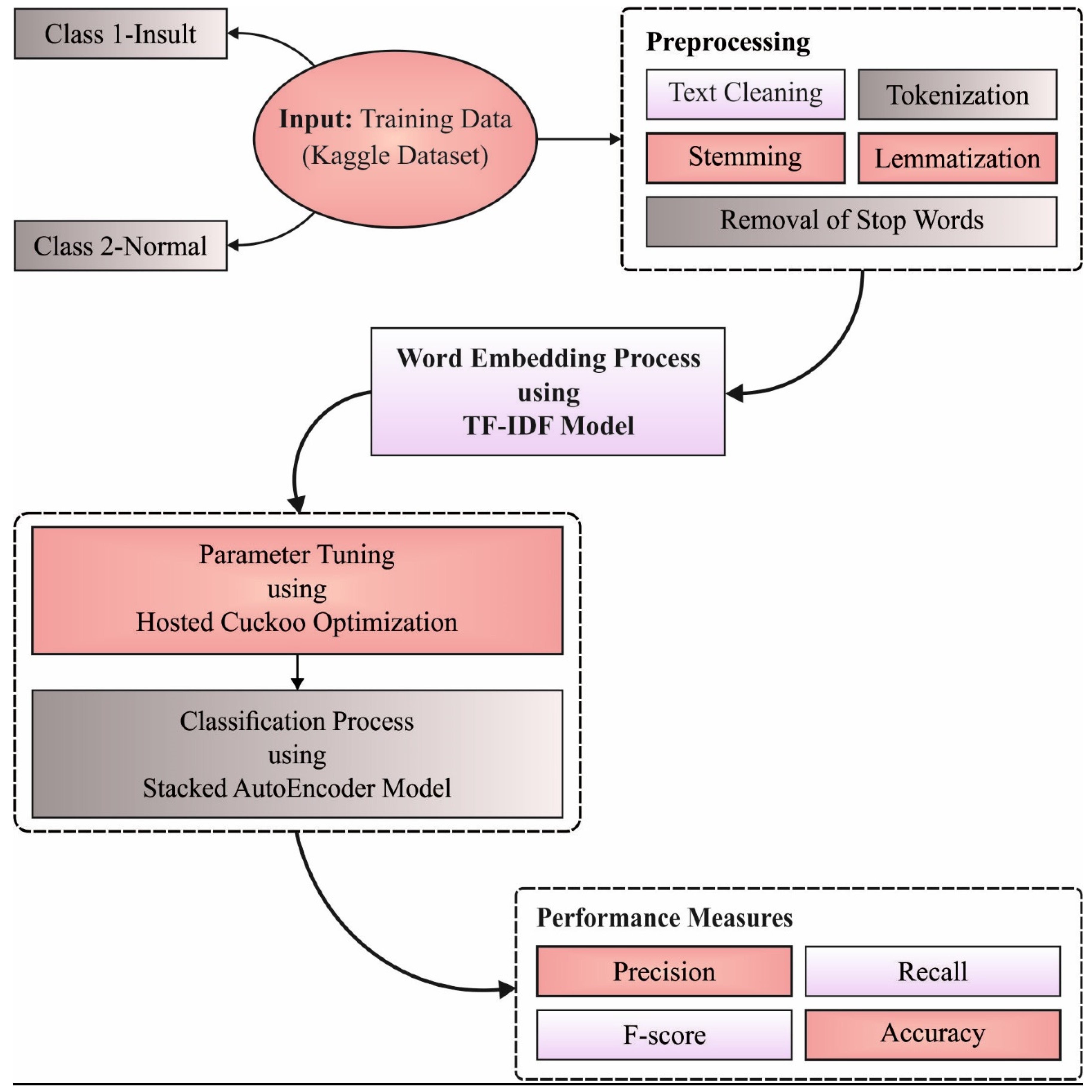
3. Design of HCOA-SACDC Model
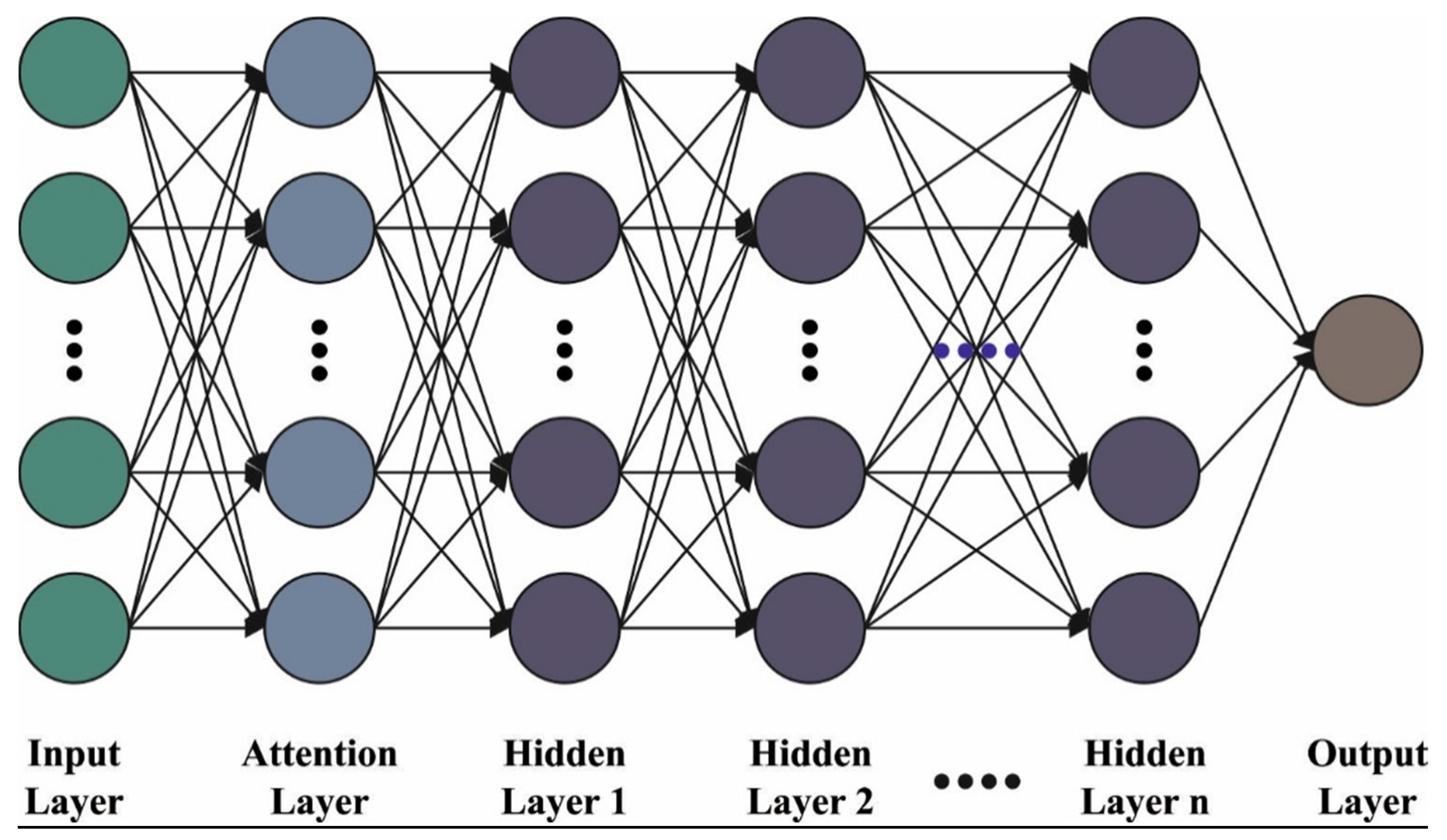
3.1. SAE-Based Classification
3.2. HCO-Based Parameter Optimization
| Algorithm 1: Pseudocode of HCO algorithm |
| Input: Parameter initialization: Begin While Produce the nests using Equation (5) Determine the fitness value Carry out the egg laying Carry out the chick stage Migrate cuckoos End while Output: Report optimal solutions End |
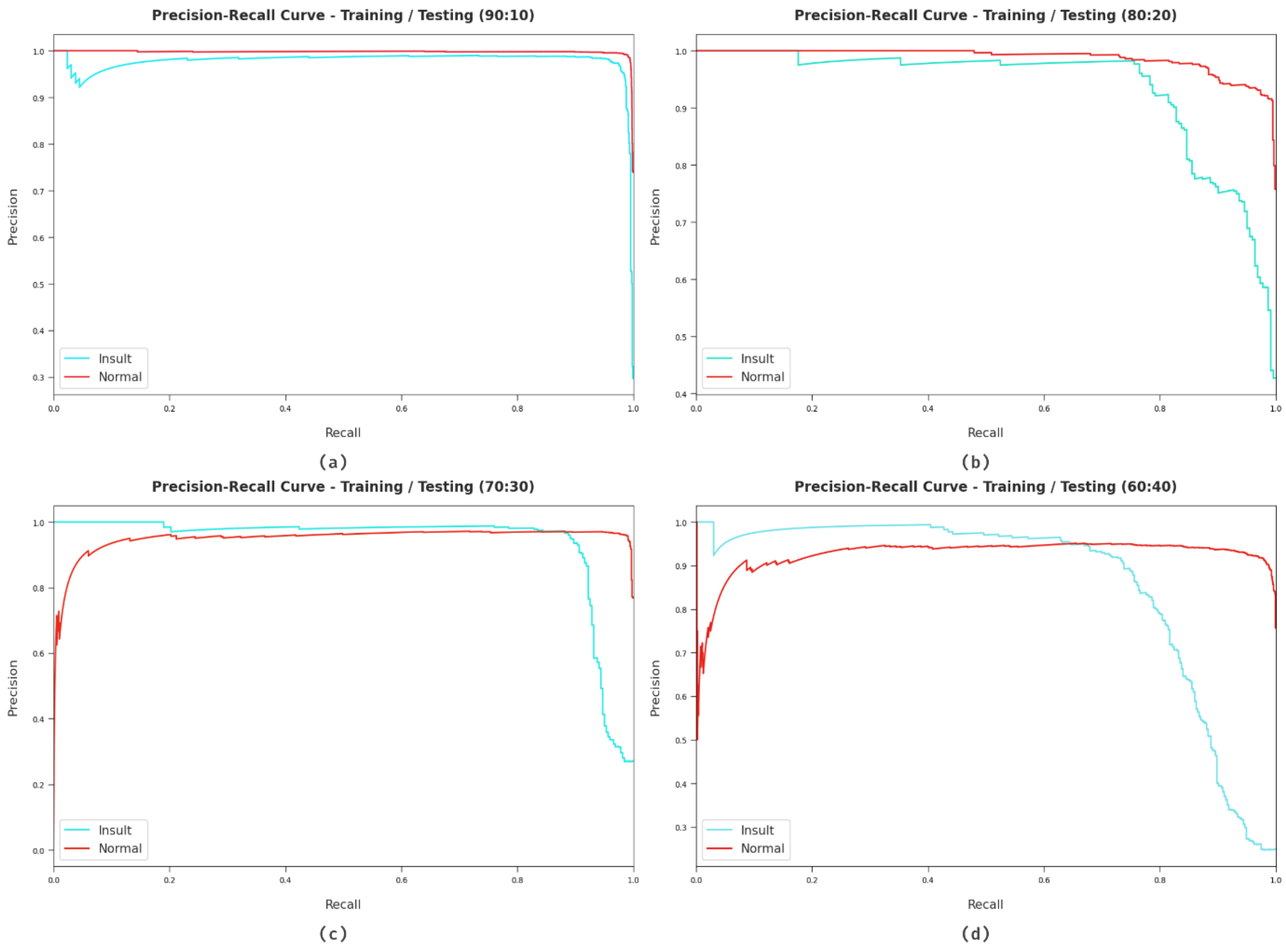
4. Experimental Validation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sarsam, S.M.; Al-Samarraie, H.; Alzahrani, A.I.; Wright, B. Sarcasm detection using machine learning algorithms in Twitter: A systematic review. Int. J. Mark. Res. 2020, 62, 578–598. [Google Scholar] [CrossRef]
- Kumar, A.; Narapareddy, V.T.; Srikanth, V.A.; Malapati, A.; Neti, L.B.M. Sarcasm Detection Using Multi-Head Attention Based Bidirectional LSTM. IEEE Access 2020, 8, 6388–6397. [Google Scholar] [CrossRef]
- Muaad, A.Y.; Davanagere, H.J.; Benifa, J.V.B.; Alabrah, A.; Saif, M.A.N.; Pushpa, D.; Al-Antari, M.A.; Alfakih, T.M. Artificial Intelligence-Based Approach for Misogyny and Sarcasm Detection from Arabic Texts. Comput. Intell. Neurosci. 2022, 2022, 7937667. [Google Scholar] [CrossRef] [PubMed]
- Banerjee, A.; Bhattacharjee, M.; Ghosh, K.; Chatterjee, S. Synthetic minority oversampling in addressing imbalanced sarcasm detection in social media. Multimed. Tools Appl. 2020, 79, 35995–36031. [Google Scholar] [CrossRef]
- Jaiswal, N. Neural sarcasm detection using conversation context. In Proceedings of the Second Workshop on Figurative Language Processing, Seattle, WA, USA, 9 July 2020; pp. 77–82. [Google Scholar]
- Dong, X.; Li, C.; Choi, J.D. Transformer-based context-aware sarcasm detection in conversation threads from social media. arXiv 2020, arXiv:2005.11424. [Google Scholar]
- Shrivastava, M.; Kumar, S. A pragmatic and intelligent model for sarcasm detection in social media text. Technol. Soc. 2020, 64, 101489. [Google Scholar] [CrossRef]
- Lou, C.; Liang, B.; Gui, L.; He, Y.; Dang, Y.; Xu, R. Affective dependency graph for sarcasm detection. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 July 2021; pp. 1844–1849. [Google Scholar]
- Gupta, R.; Kumar, J.; Agrawal, H. A statistical approach for sarcasm detection using Twitter data. In Proceedings of the 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 633–638. [Google Scholar]
- Yao, F.; Sun, X.; Yu, H.; Zhang, W.; Liang, W.; Fu, K. Mimicking the Brain’s Cognition of Sarcasm from Multidisciplines for Twitter Sarcasm Detection. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Potamias, R.A.; Siolas, G.; Stafylopatis, A.G. A transformer-based approach to irony and sarcasm detection. Neural Comput. Appl. 2020, 32, 17309–17320. [Google Scholar] [CrossRef]
- Pan, H.; Lin, Z.; Fu, P.; Qi, Y.; Wang, W. Modeling Intra and Inter-modality Incongruity for Multi-Modal Sarcasm Detection. In Findings of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1383–1392. [Google Scholar]
- Cai, Y.; Cai, H.; Wan, X. Multi-modal sarcasm detection in twitter with hierarchical fusion model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2506–2515. [Google Scholar]
- Akula, R.; Garibay, I. Interpretable Multi-Head Self-Attention Architecture for Sarcasm Detection in Social Media. Entropy 2021, 23, 394. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Li, T.; Pathan, M.S.; Teklehaimanot, H.K.; Yang, Z. An Effective Sarcasm Detection Approach Based on Sentimental Context and Individual Expression Habits. Cogn. Comput. 2021, 14, 78–90. [Google Scholar] [CrossRef]
- Kamal, A.; Abulaish, M. Cat-bigru: Convolution and attention with bi-directional gated recurrent unit for self-deprecating sarcasm detection. Cogn. Comput. 2022, 14, 91–109. [Google Scholar] [CrossRef]
- Sultana, A.; Bardalai, A.; Sarma, K.K. Salp Swarm-Artificial Neural Network Based Cyber-Attack Detection in Smart Grid. Neural Process. Lett. 2022, 1–23. [Google Scholar] [CrossRef]
- Soleymanzadeh, R.; Aljasim, M.; Qadeer, M.W.; Kashef, R. Cyberattack and Fraud Detection Using Ensemble Stacking. AI 2022, 3, 22-36. [Google Scholar] [CrossRef]
- Sagheer, A.; Kotb, M. Unsupervised Pre-training of a Deep LSTM-based Stacked Autoencoder for Multivariate Time Series Forecasting Problems. Sci. Rep. 2019, 9, 19038. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, M.; Quan, T.; Peng, Q.; Yu, X.; Liu, L. A model-based collaborate filtering algorithm based on stacked AutoEncoder. Neural Comput. Appl. 2021, 34, 2503–2511. [Google Scholar] [CrossRef]
- Mellal, M.A.; Al-Dahidi, S.; Williams, E.J. System reliability optimization with heterogeneous components using hosted cuckoo optimization algorithm. Reliab. Eng. Syst. Saf. 2020, 203, 107110. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/c/detecting-insults-in-social-commentary/data (accessed on 12 March 2022).
- Albraikan, A.A.; Hassine, S.B.H.; Fati, S.M.; Al-Wesabi, F.N.; Hilal, A.M.; Motwakel, A.; Hamza, M.A.; Al Duhayyim, M. Optimal Deep Learning-based Cyberattack Detection and Classification Technique on Social Networks. Comput. Mater. Contin. 2022, 72, 907–923. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
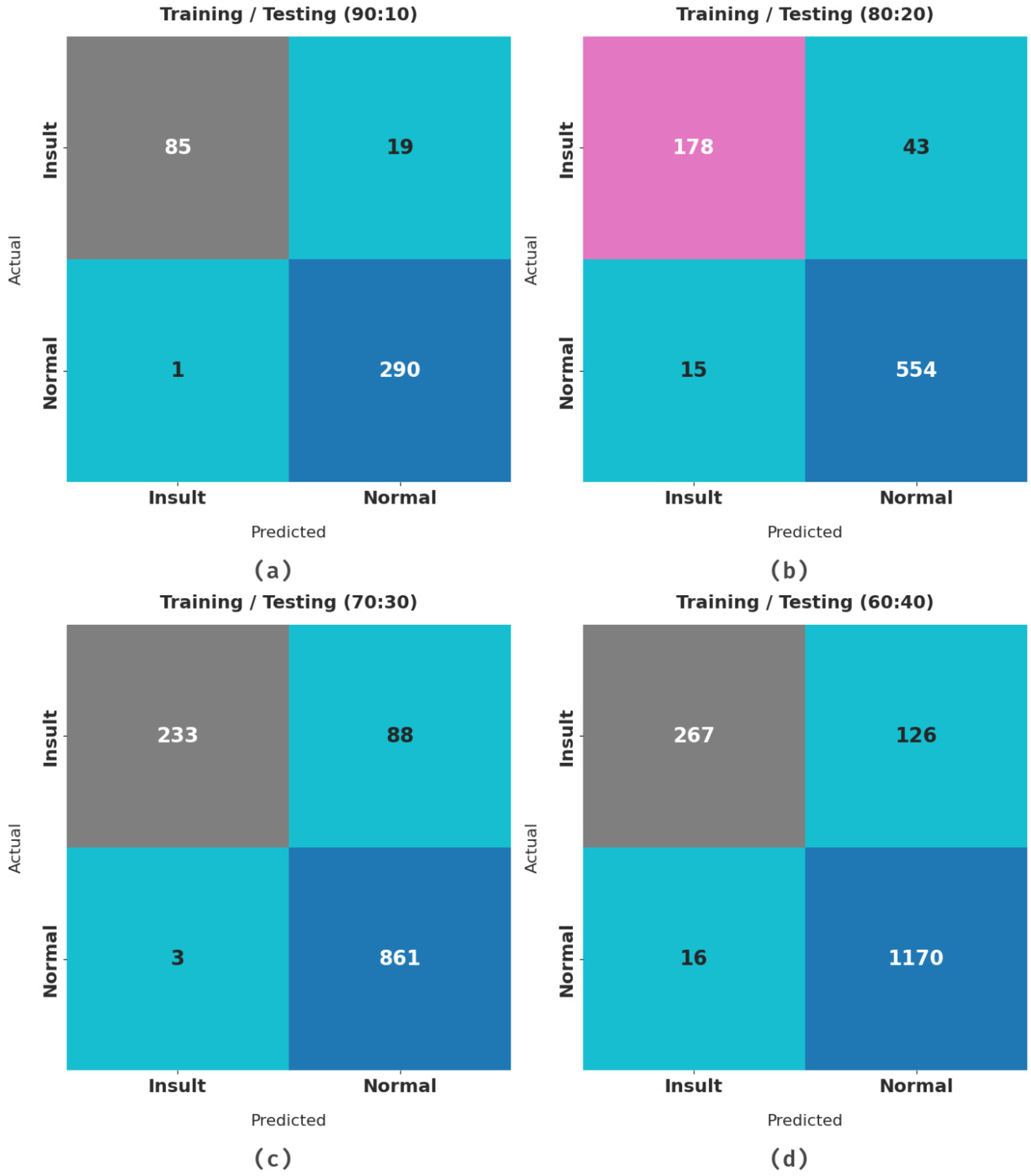
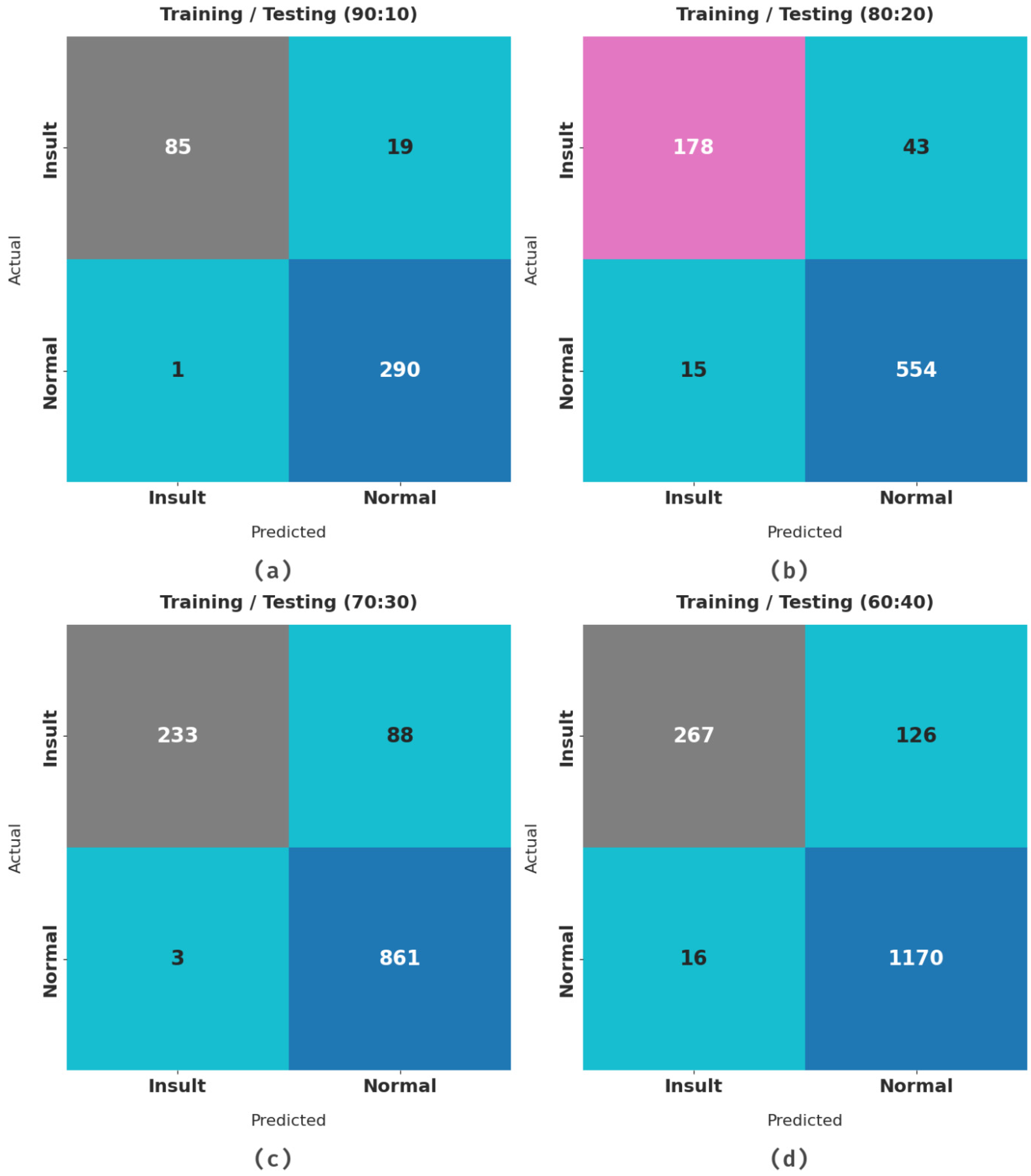
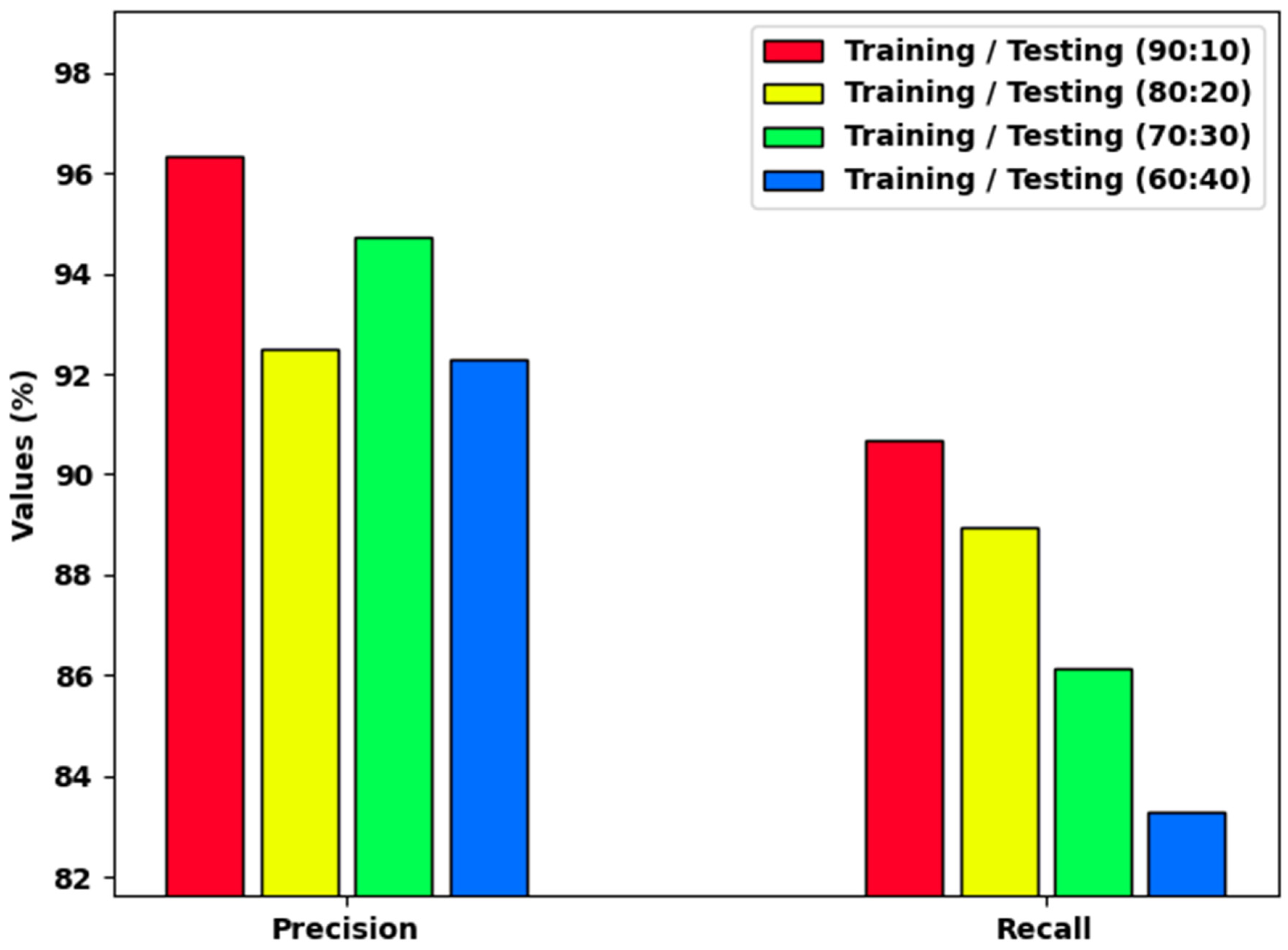
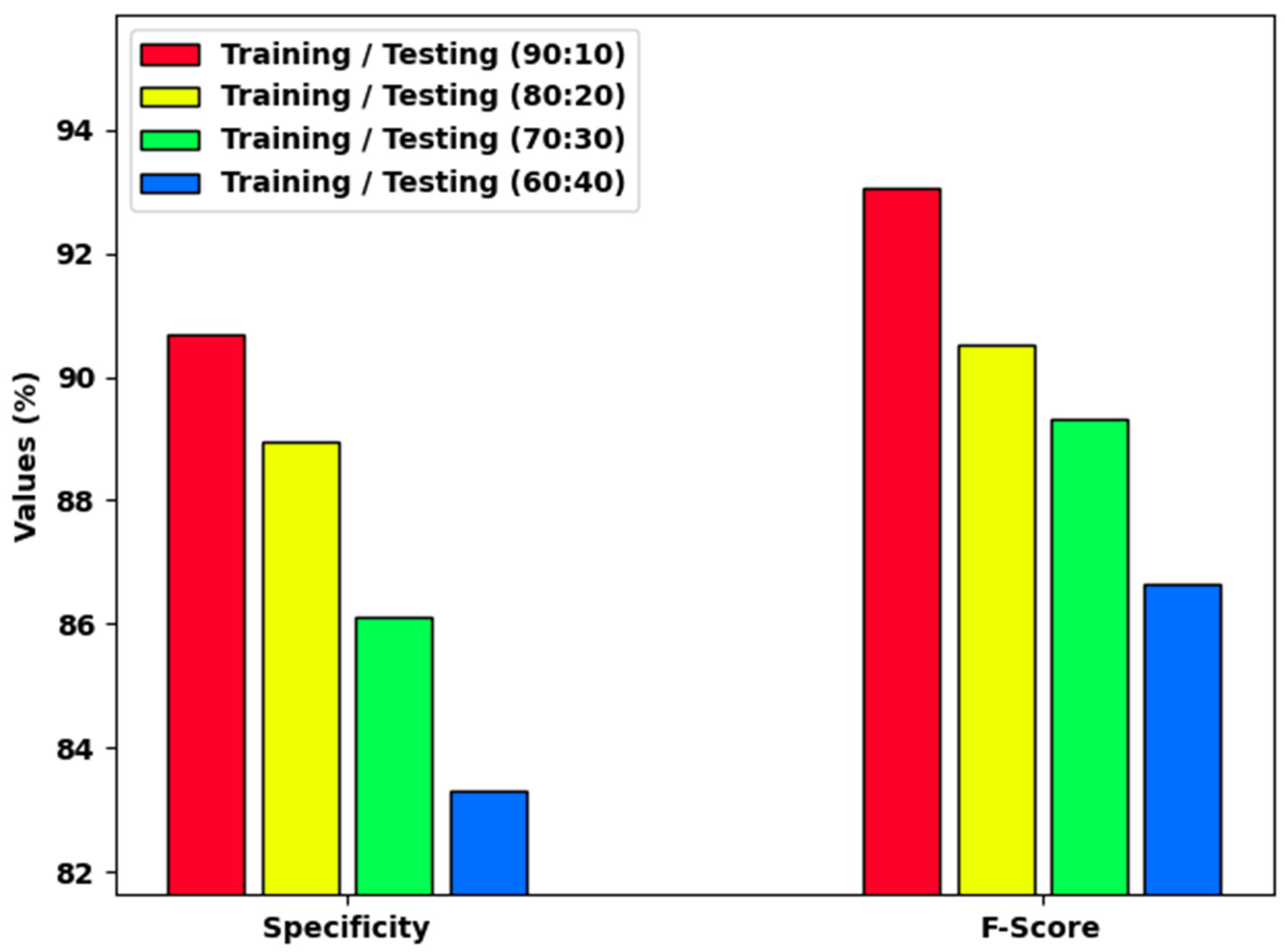
| Class Labels | Accuracy | Precision | Recall | Specificity | F-Score |
|---|---|---|---|---|---|
| Training/Testing (90:10) | |||||
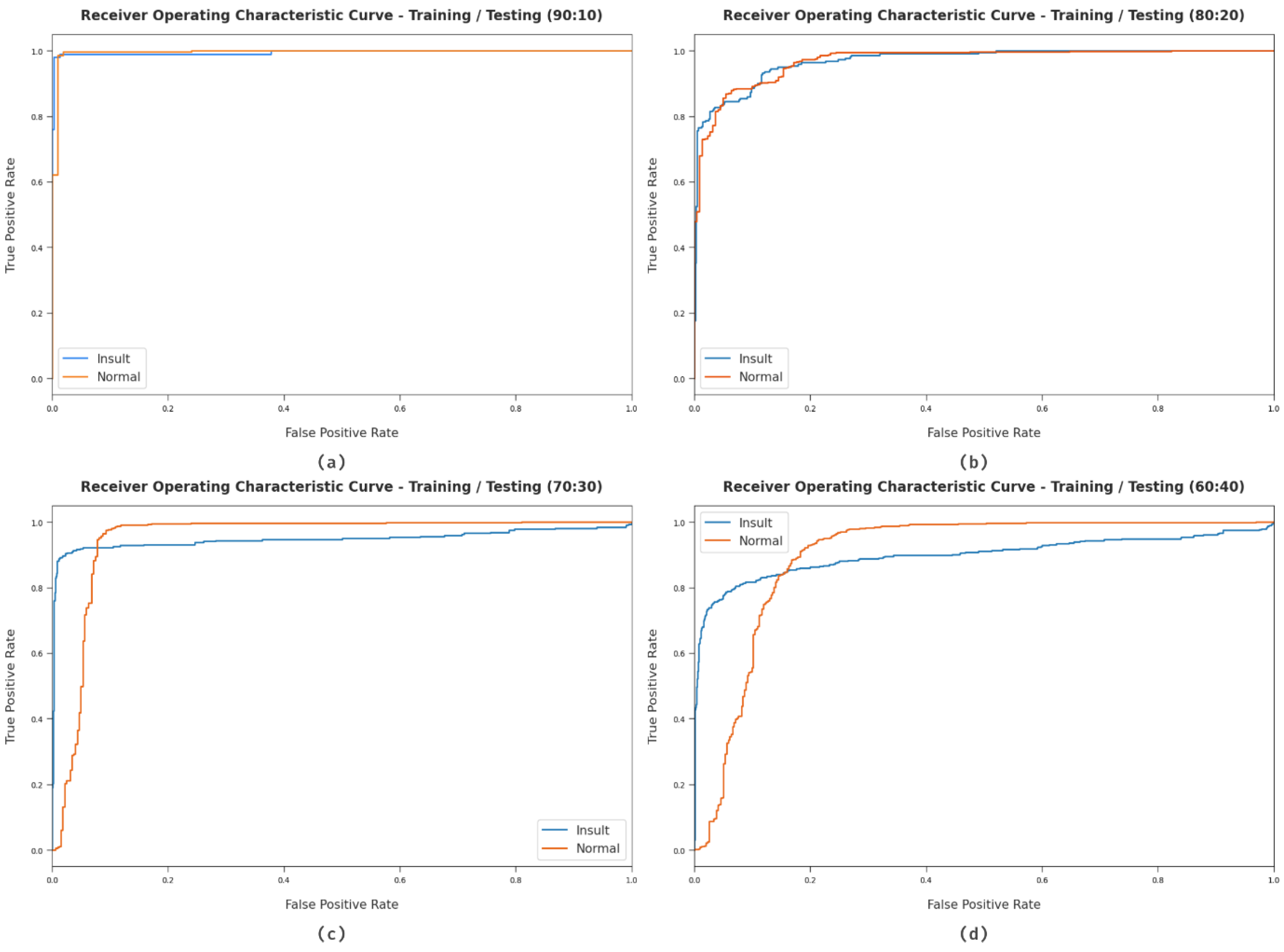
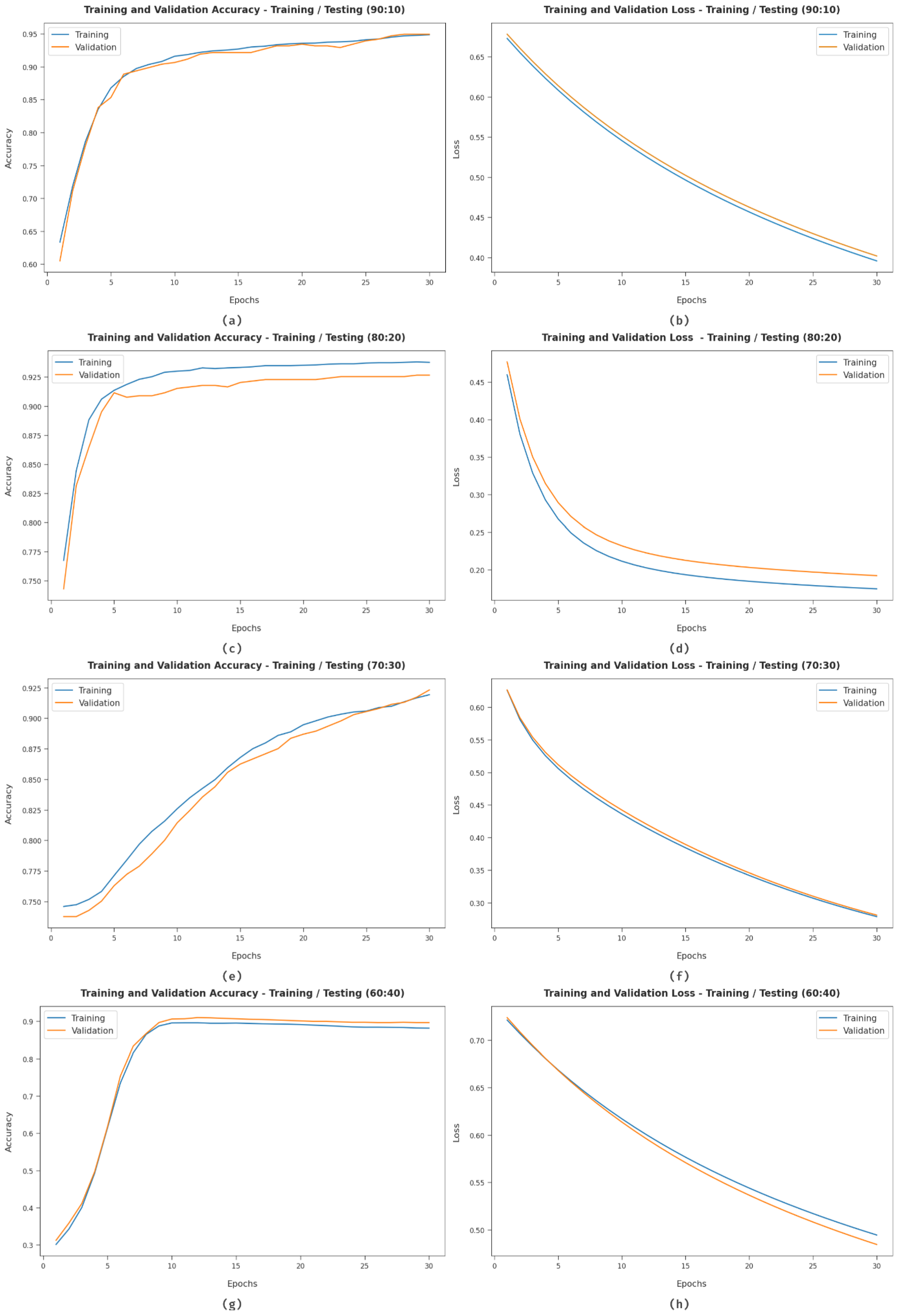
| Insult | 94.94 | 98.84 | 81.73 | 99.66 | 89.47 |
| Normal | 94.94 | 93.85 | 99.66 | 81.73 | 96.67 |
| Average | 94.94 | 96.34 | 90.69 | 90.69 | 93.07 |
| Training/Testing (80:20) | |||||
| Insult | 92.66 | 92.23 | 80.54 | 97.36 | 85.99 |
| Normal | 92.66 | 92.80 | 97.36 | 80.54 | 95.03 |
| Average | 92.66 | 92.51 | 88.95 | 88.95 | 90.51 |
| Training/Testing (70:30) | |||||
| Insult | 92.32 | 98.73 | 72.59 | 99.65 | 83.66 |
| Normal | 92.32 | 90.73 | 99.65 | 72.59 | 94.98 |
| Average | 92.32 | 94.73 | 86.12 | 86.12 | 89.32 |
| Training/Testing (60:40) | |||||
| Insult | 91.01 | 94.35 | 67.94 | 98.65 | 78.99 |
| Normal | 91.01 | 90.28 | 98.65 | 67.94 | 94.28 |
| Average | 91.01 | 92.31 | 83.29 | 83.29 | 86.64 |
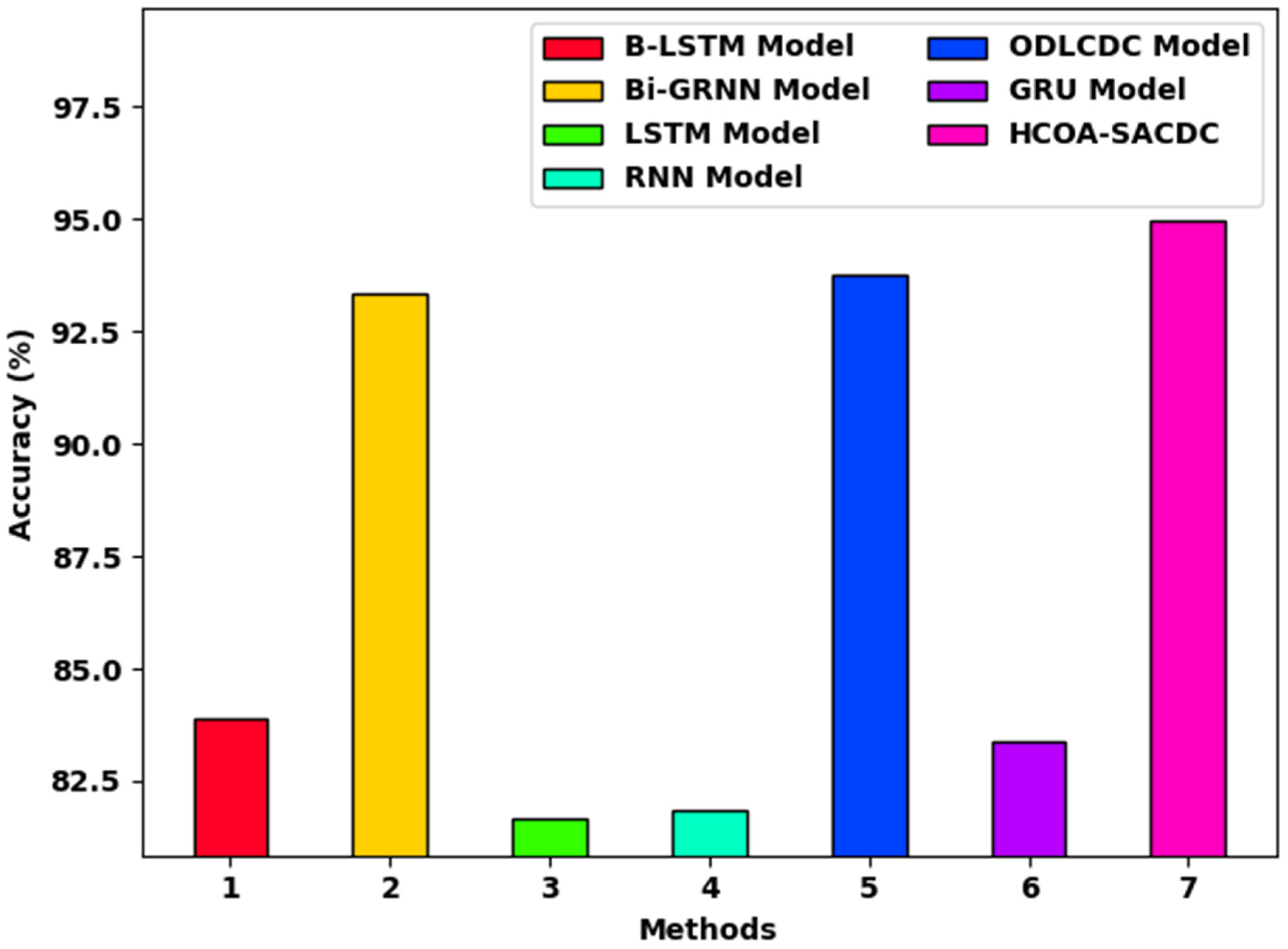
| Methods | Testing Accuracy |
|---|---|
| B-LSTM Model | 83.89 |
| Bi-GRNN Model | 93.33 |
| LSTM Model | 81.66 |
| RNN Model | 81.84 |
| ODLCDC Model | 93.76 |
| GRU Model | 83.36 |
| HCOA-SACDC | 94.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elkamchouchi, D.H.; Alzahrani, J.S.; Asiri, M.M.; Al Duhayyim, M.; Mohsen, H.; Motwakel, A.; Zamani, A.S.; Yaseen, I. Hosted Cuckoo Optimization Algorithm with Stacked Autoencoder-Enabled Sarcasm Detection in Online Social Networks. Appl. Sci. 2022, 12, 7119. https://doi.org/10.3390/app12147119
Elkamchouchi DH, Alzahrani JS, Asiri MM, Al Duhayyim M, Mohsen H, Motwakel A, Zamani AS, Yaseen I. Hosted Cuckoo Optimization Algorithm with Stacked Autoencoder-Enabled Sarcasm Detection in Online Social Networks. Applied Sciences. 2022; 12(14):7119. https://doi.org/10.3390/app12147119
Chicago/Turabian StyleElkamchouchi, Dalia H., Jaber S. Alzahrani, Mashael M. Asiri, Mesfer Al Duhayyim, Heba Mohsen, Abdelwahed Motwakel, Abu Sarwar Zamani, and Ishfaq Yaseen. 2022. "Hosted Cuckoo Optimization Algorithm with Stacked Autoencoder-Enabled Sarcasm Detection in Online Social Networks" Applied Sciences 12, no. 14: 7119. https://doi.org/10.3390/app12147119
APA StyleElkamchouchi, D. H., Alzahrani, J. S., Asiri, M. M., Al Duhayyim, M., Mohsen, H., Motwakel, A., Zamani, A. S., & Yaseen, I. (2022). Hosted Cuckoo Optimization Algorithm with Stacked Autoencoder-Enabled Sarcasm Detection in Online Social Networks. Applied Sciences, 12(14), 7119. https://doi.org/10.3390/app12147119