
A Novel Generative Model for Face Privacy Protection in Video Surveillance with Utility Maintenance


 ,
,
Abstract
:1. Introduction
- We present a new framework for facial privacy protection, called QM-VAE, which de-identifies the image first and then reconstructs its utility. We integrate vector quantization into the structure of the generative model, so that the model can generate high-quality face images. QM-VAE takes multiple groups of de-identified images as the input, which can make use of the advantages of existing technology to speed up the training and achieve the goal of maintaining service quality.
- We establish a service-oriented loss function by adding service quality loss to guide the generation of de-identified face images with utility maintenance. The proposed framework treats the service quality evaluator as a black box and can adjust the generated image automatically according to the different evaluation results, with wide applicability.
- We take facial expression service as an example and illustrate the viability of our model on the CelebA dataset. We find the most appropriate method configuration by adjusting the parameters. Experimental results show that our solution results in de-identified face images with significantly improved utility. Compared with the traditional methods of de-identification and AMT-GAN, the QM-VAE model has obvious advantages in maintaining specific service quality and increases the utility retention rate by at least 6.7%.
2. Related Work
3. Preliminary
3.1. Face De-Identification Methods
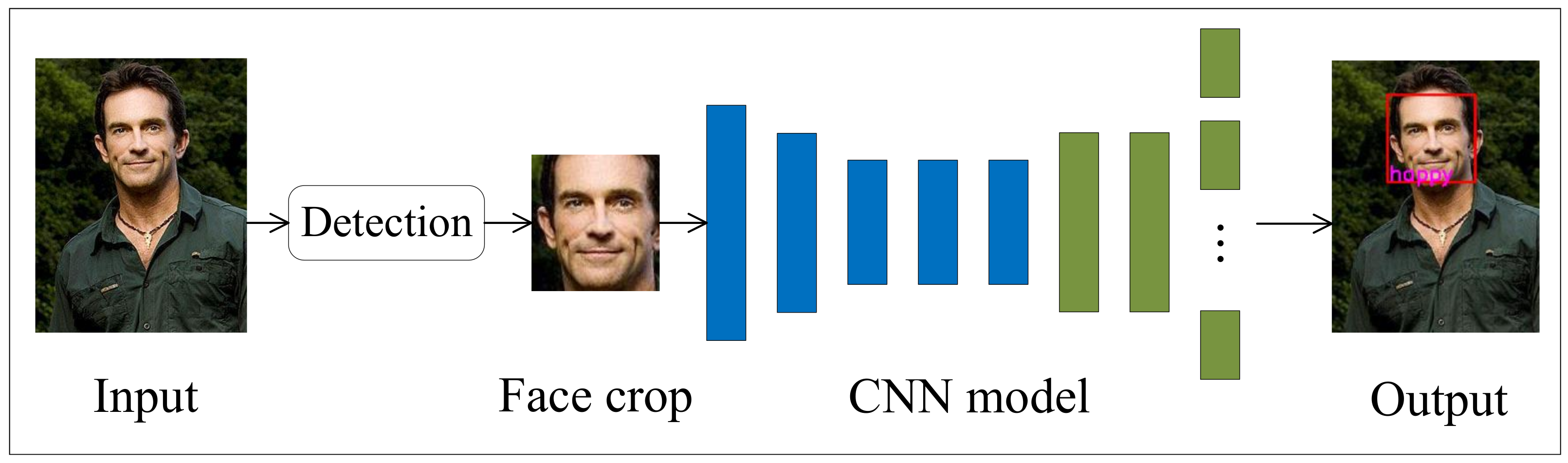
3.2. Facial Expression Recognition Module
4. Method
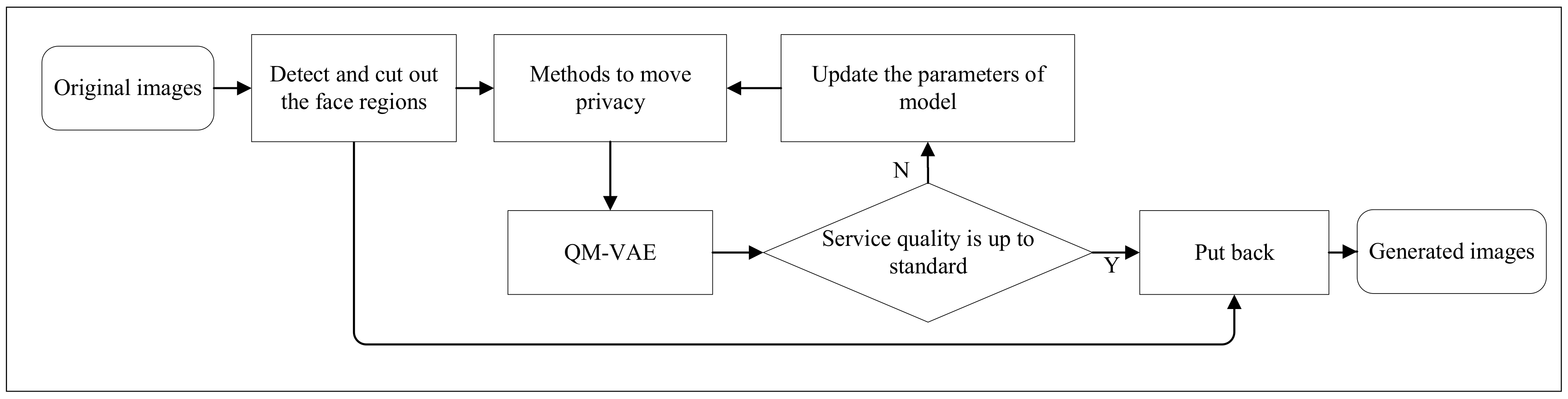
4.1. System Model
4.2. Architecture and Working
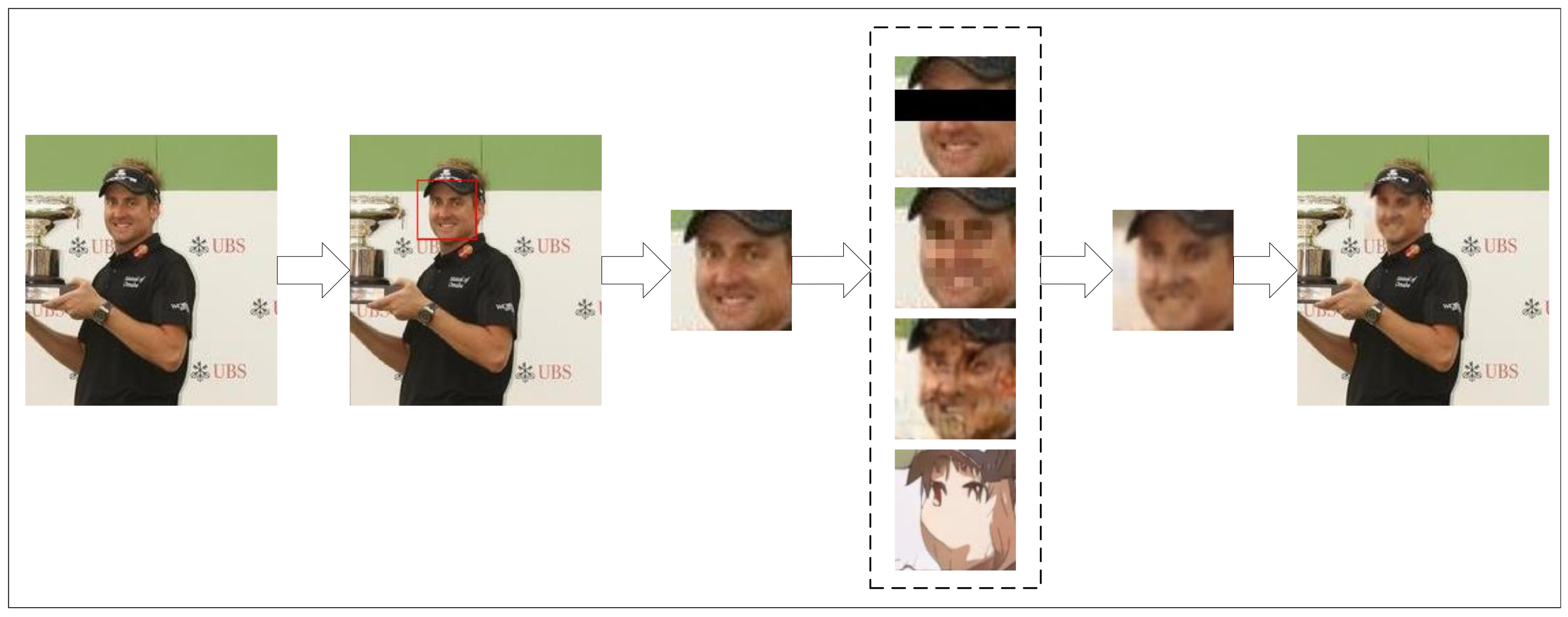
4.3. Method Execution Process
5. Experimentation and Results
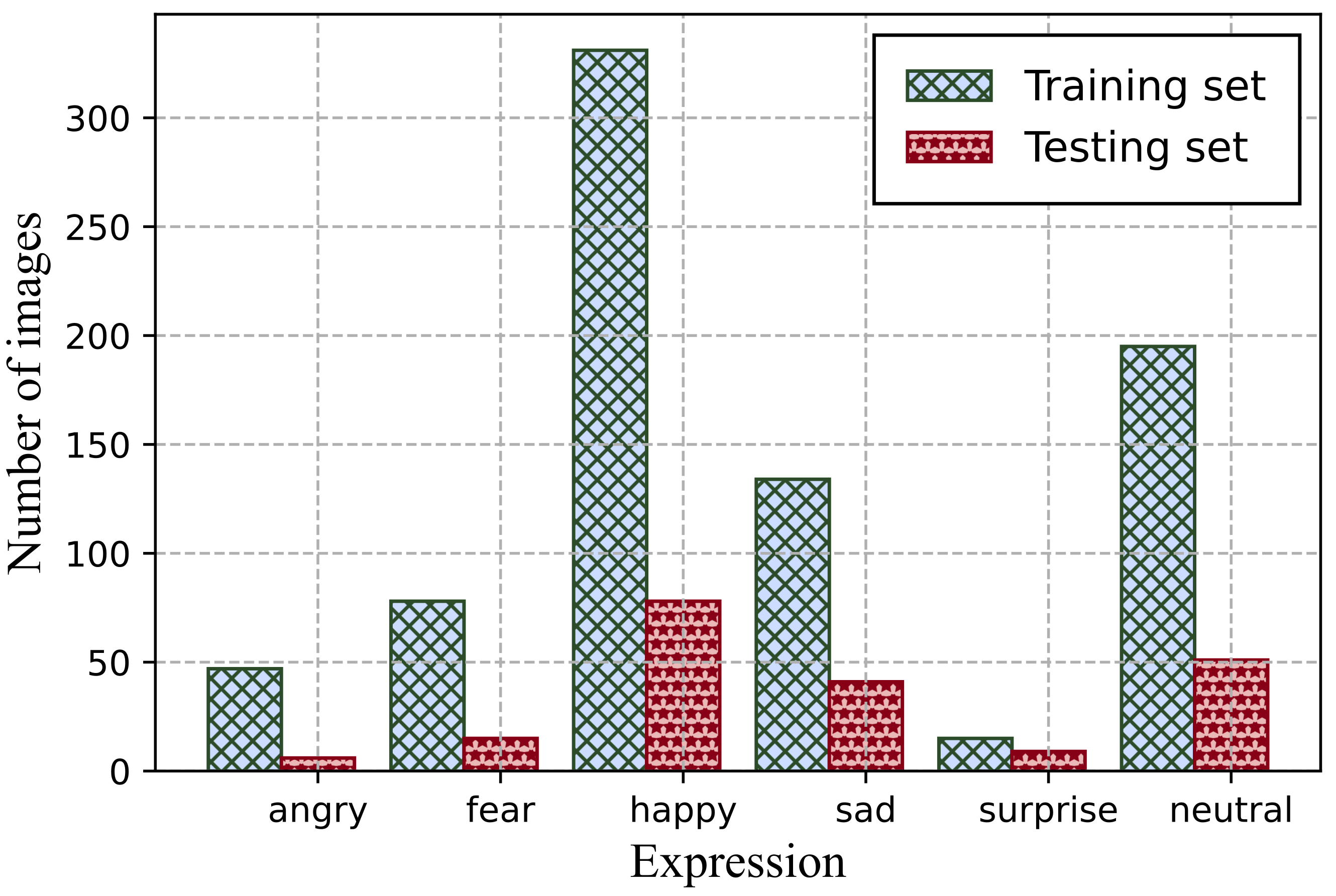
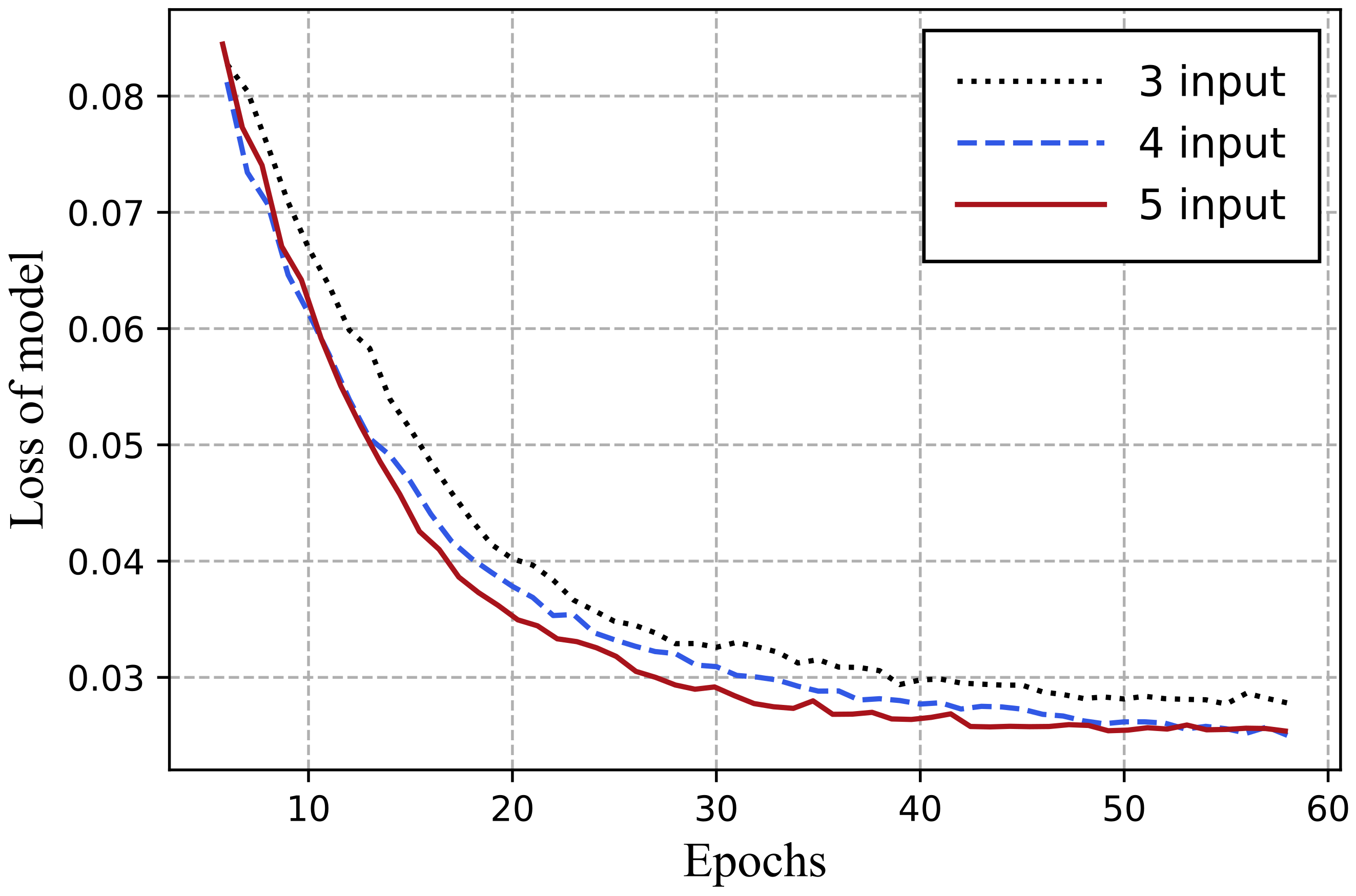
5.1. Experimental Setup
5.2. Face Image De-Identification
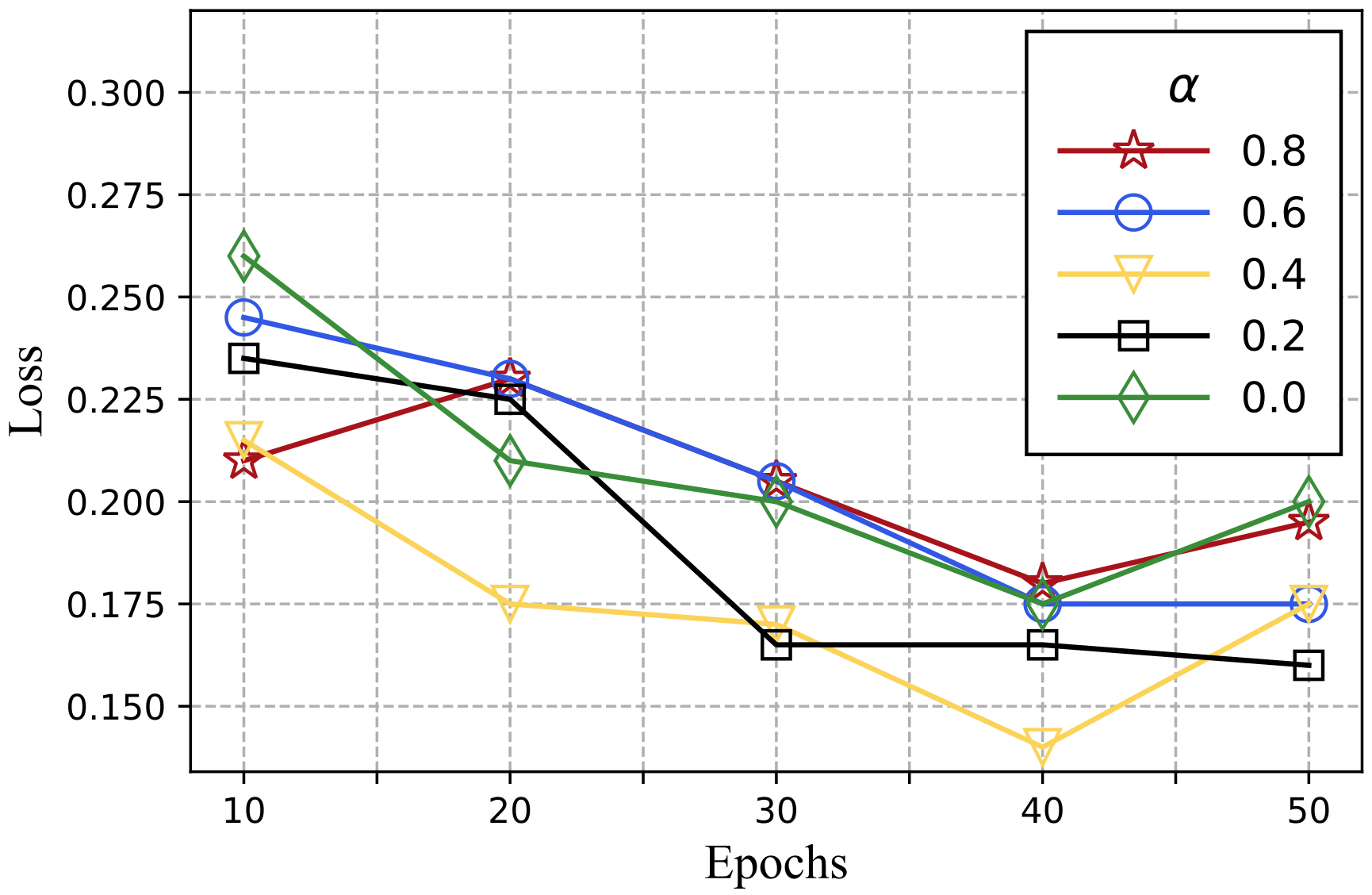
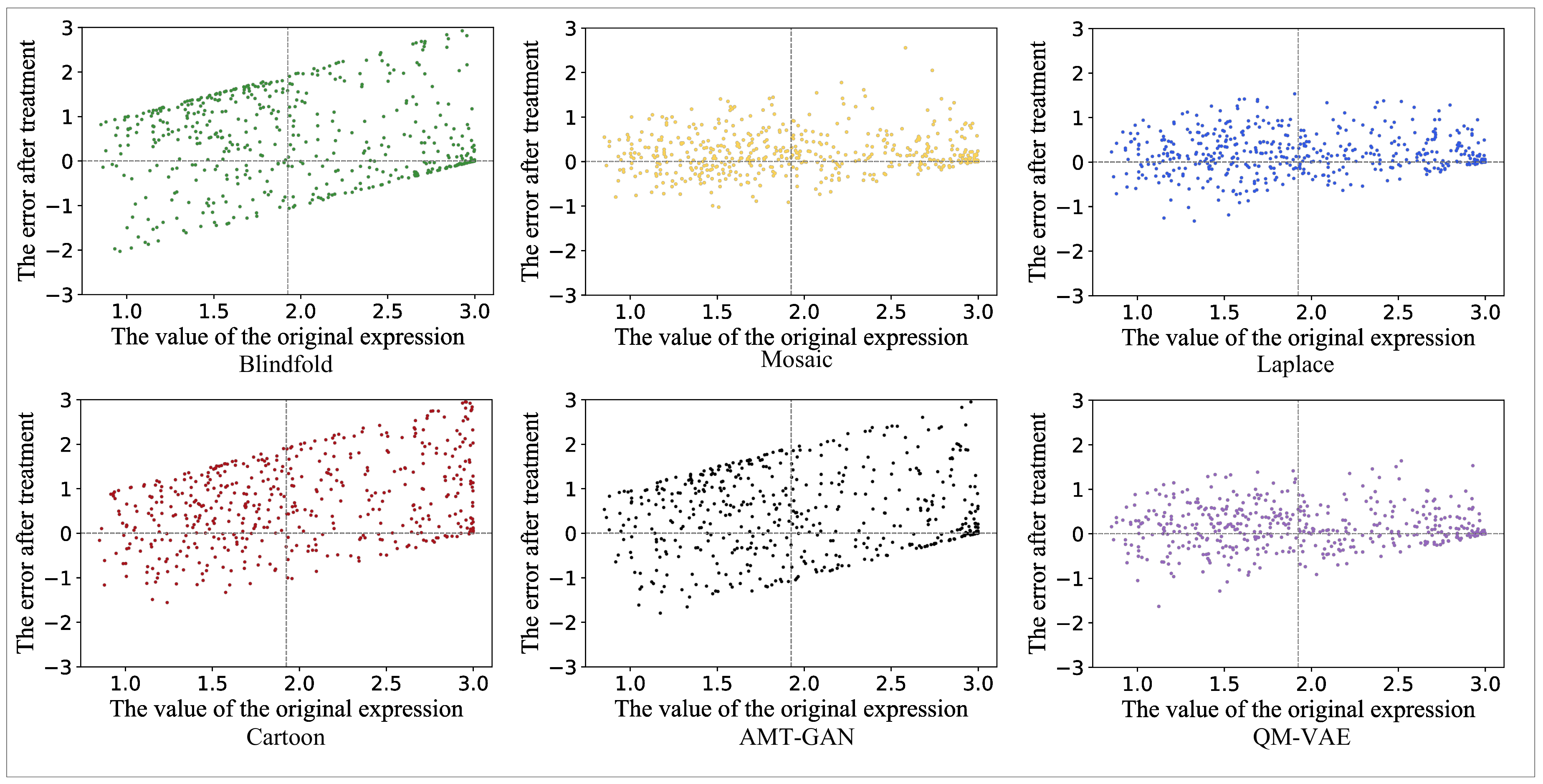
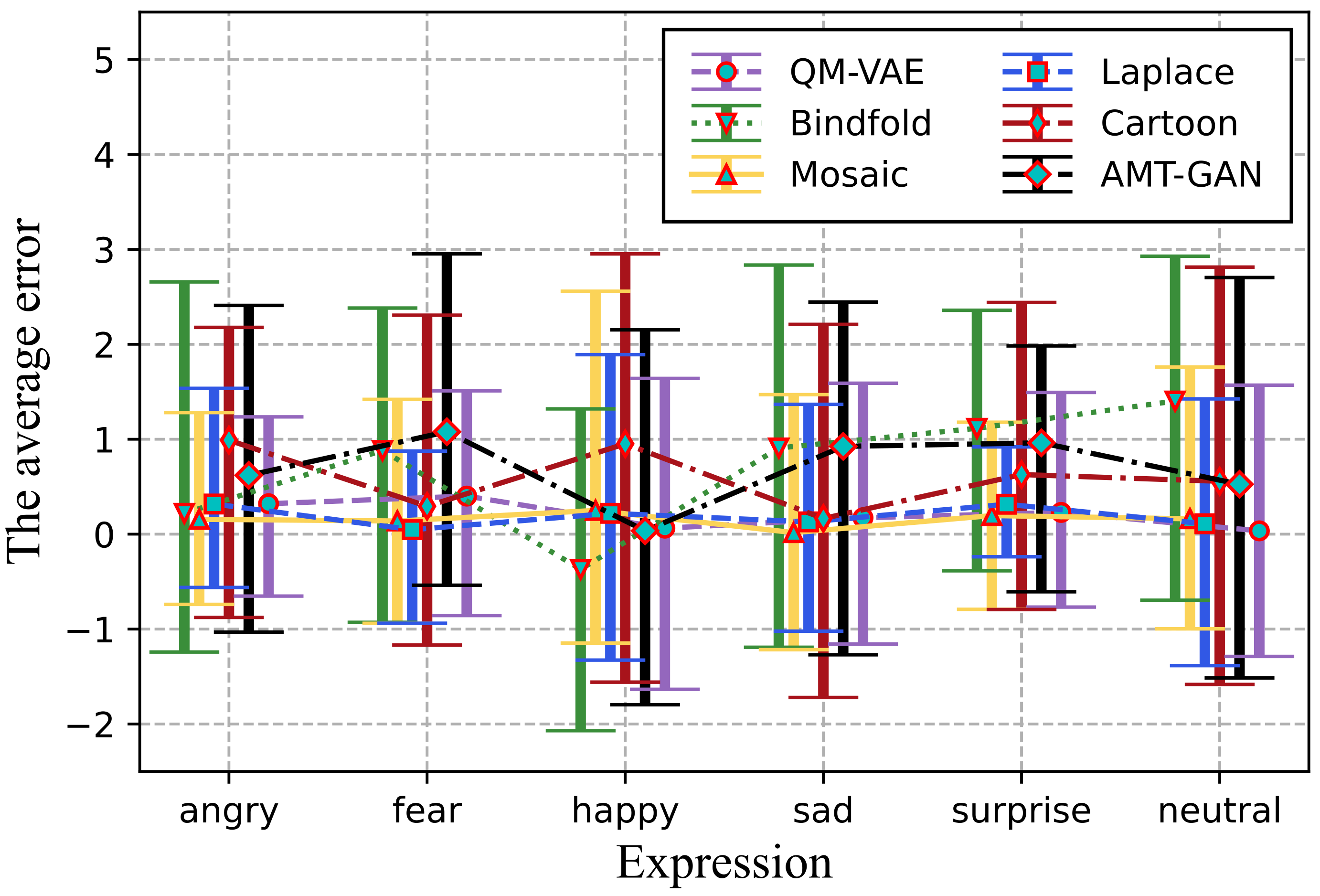
5.3. Images’ Utility Maintenance
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Agarwal, A.; Chattopadhyay, P.; Wang, L. Privacy preservation through facial de-identification with simultaneous emotion preservation. Signal Image Video Process. 2021, 15, 951–958. [Google Scholar] [CrossRef]
- Letournel, G.; Bugeau, A.; Ta, V.T.; Domenger, J.P. Face de-identification with expressions preservation. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4366–4370. [Google Scholar]
- Wu, Y.; Yang, F.; Xu, Y.; Ling, H. Privacy-protective-GAN for privacy preserving face de-identification. J. Comput. Sci. Technol. 2019, 34, 47–60. [Google Scholar] [CrossRef]
- Nousi, P.; Papadopoulos, S.; Tefas, A.; Pitas, I. Deep autoencoders for attribute preserving face de-identification. Signal Process. Image Commun. 2020, 81, 115699. [Google Scholar] [CrossRef]
- Brkić, K.; Hrkać, T.; Kalafatić, Z.; Sikirić, I. Face, hairstyle and clothing colour de-identification in video sequences. IET Signal Process. 2017, 11, 1062–1068. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Vinyals, O.; Kavukcuoglu, K. Neural discrete representation learning. arXiv 2017, arXiv:1711.00937. [Google Scholar]
- Pan, Z.; Yu, W.; Lei, J.; Ling, N.; Kwong, S. TSAN: Synthesized view quality enhancement via two-stream attention network for 3D-HEVC. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 345–358. [Google Scholar] [CrossRef]
- Peng, B.; Lei, J.; Fu, H.; Jia, Y.; Zhang, Z.; Li, Y. Deep video action clustering via spatio-temporal feature learning. Neurocomputing 2021, 456, 519–527. [Google Scholar] [CrossRef]
- Lei, J.; Li, X.; Peng, B.; Fang, L.; Ling, N.; Huang, Q. Deep spatial-spectral subspace clustering for hyperspectral image. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2686–2697. [Google Scholar] [CrossRef]
- Ribaric, S.; Ariyaeeinia, A.; Pavesic, N. De-identification for privacy protection in multimedia content: A survey. Signal Process. Image Commun. 2016, 47, 131–151. [Google Scholar] [CrossRef] [Green Version]
- Neustaedter, C.; Greenberg, S.; Boyle, M. Blur filtration fails to preserve privacy for home-based video conferencing. Acm Trans. -Comput.-Hum. Interact. (Tochi) 2006, 13, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Yu, J.; Zhang, B.; Kuang, Z.; Lin, D.; Fan, J. iPrivacy: Image privacy protection by identifying sensitive objects via deep multi-task learning. IEEE Trans. Inf. Forensics Secur. 2016, 12, 1005–1016. [Google Scholar] [CrossRef]
- Liu, J.; Yin, S.; Li, H.; Teng, L. A Density-based Clustering Method for K-anonymity Privacy Protection. J. Inf. Hiding Multim. Signal Process. 2017, 8, 12–18. [Google Scholar] [CrossRef]
- Gross, R.; Sweeney, L.; De La Torre, F.; Baker, S. Semi-supervised learning of multi-factor models for face de-identification. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Sun, Z.; Meng, L.; Ariyaeeinia, A. Distinguishable de-identified faces. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 4, pp. 1–6. [Google Scholar]
- Newton, E.M.; Sweeney, L.; Malin, B. Preserving privacy by de-identifying face images. IEEE Trans. Knowl. Data Eng. 2005, 17, 232–243. [Google Scholar] [CrossRef] [Green Version]
- Samarzija, B.; Ribaric, S. An approach to the de-identification of faces in different poses. In Proceedings of the 2014 37th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 26–30 May 2014; pp. 1246–1251. [Google Scholar]
- Gross, R.; Sweeney, L.; De la Torre, F.; Baker, S. Model-based face de-identification. In Proceedings of the 2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), New York, NY, USA, 17–22 June 2006; p. 161. [Google Scholar]
- Meden, B.; Emeršič, Ž.; Štruc, V.; Peer, P. k-Same-Net: k-Anonymity with generative deep neural networks for face deidentification. Entropy 2018, 20, 60. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dosovitskiy, A.; Springenberg, J.T.; Tatarchenko, M.; Brox, T. Learning to generate chairs, tables and cars with convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 692–705. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gross, R.; Airoldi, E.; Malin, B.; Sweeney, L. Integrating utility into face de-identification. In Proceedings of the 5th International Workshop on Privacy Enhancing Technologies, PET, Cavtat, Croatia, 30 May–1 June 2005; pp. 227–242. [Google Scholar]
- Xu, Y.; Shang, L.; Ye, J.; Qian, Q.; Li, Y.F.; Sun, B.; Li, H.; Jin, R. Dash: Semi-supervised learning with dynamic thresholding. In Proceedings of the International Conference on Machine Learning, Virtual Event. Vienna, Austria, 18–24 July 2021; pp. 11525–11536. [Google Scholar]
- Ning, X.; Wang, X.; Xu, S.; Cai, W.; Zhang, L.; Yu, L.; Li, W. A review of research on co-training. Concurr. Comput. Pract. Exp. 2021, 21, e6276. [Google Scholar] [CrossRef]
- Phillips, P.J.; Wechsler, H.; Huang, J. The FERET database and evaluation procedure for face–recognition algorithms. Image Vis. Comput. 1998, 16, 295–306. [Google Scholar] [CrossRef]
- Liu, C.; Wang, Y.; Chi, H.; Wang, S. Utility Preserved Facial Image De-identification Using Appearance Subspace Decomposition. Chin. J. Electron. 2021, 30, 413–418. [Google Scholar]
- Ian, G.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Cai, Z.; Xiong, Z.; Xu, H.; Wang, P.; Li, W.; Pan, Y. Generative adversarial networks: A survey towards and secure applications. arXiv 2021, arXiv:2106.03785. [Google Scholar] [CrossRef]
- Han, C.; Xue, R. Differentially private GANs by adding noise to Discriminator’s loss. Comput. Secur. 2021, 107, 102322. [Google Scholar] [CrossRef]
- Yang, R.; Ma, X.; Bai, X.; Su, X. Differential Privacy Images Protection Based on Generative Adversarial Network. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 9 February 2021; pp. 1688–1695. [Google Scholar]
- Hukkelås, H.; Mester, R.; Lindseth, F. Deepprivacy: A generative adversarial network for face anonymization. In Proceedings of the International Symposium on Visual Computing, Lake Tahoe, NV, USA, 7–9 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 565–578. [Google Scholar]
- Sun, Q.; Ma, L.; Oh, S.J.; Van Gool, L.; Schiele, B.; Fritz, M. Natural and effective obfuscation by head inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5050–5059. [Google Scholar]
- Li, Y.; Lu, Q.; Tao, Q.; Zhao, X.; Yu, Y. SF-GAN: Face De-identification Method without Losing Facial Attribute Information. IEEE Signal Process. Lett. 2021, 28, 1345–1349. [Google Scholar] [CrossRef]
- Chen, J.; Konrad, J.; Ishwar, P. Vgan-based image representation learning for privacy-preserving facial expression recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1570–1579. [Google Scholar]
- Louizos, C.; Swersky, K.; Li, Y.; Welling, M.; Zemel, R. The variational fair autoencoder. arXiv 2015, arXiv:1511.00830. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Yu, J.; Xue, H.; Liu, B.; Wang, Y.; Zhu, S.; Ding, M. GAN-Based Differential Private Image Privacy Protection Framework for the Internet of Multimedia Things. Sensors 2021, 21, 58. [Google Scholar] [CrossRef]
- Zhou, G.; Qin, S.; Zhou, H.; Cheng, D. A differential privacy noise dynamic allocation algorithm for big multimedia data. Multimed. Tools Appl. 2019, 78, 3747–3765. [Google Scholar] [CrossRef]
- Bu, Z.; Dong, J.; Long, Q.; Su, W.J. Deep learning with Gaussian differential privacy. Harv. Data Sci. Rev. 2020, 2, 3747–3765. [Google Scholar] [CrossRef]
- Dong, J.; Roth, A.; Su, W.J. Gaussian differential privacy. arXiv 2019, arXiv:1905.02383. [Google Scholar] [CrossRef]
- Kim, T.; Yang, J. Latent-Space-Level Image Anonymization With Adversarial Protector Networks. IEEE Access 2019, 7, 84992–84999. [Google Scholar] [CrossRef]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Croft, W.L.; Sack, J.R.; Shi, W. Obfuscation of images via differential privacy: From facial images to general images. Peer-to-Peer Netw. Appl. 2021, 14, 1705–1733. [Google Scholar] [CrossRef]
- Chamikara, M.A.P.; Bertók, P.; Khalil, I.; Liu, D.; Camtepe, S. Privacy preserving face recognition utilizing differential privacy. Comput. Secur. 2020, 97, 101951. [Google Scholar] [CrossRef]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 739–753. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Kim, T.; Yang, J. Selective feature anonymization for privacy-preserving image data publishing. Electronics 2020, 9, 874. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Liu, C.; Yang, J.; Zhao, W.; Zhang, Y.; Li, J.; Mu, C. Face Image Publication Based on Differential Privacy. Wirel. Commun. Mob. Comput. 2021, 2021, 6680701. [Google Scholar] [CrossRef]
- Carpentieri, B.; Castiglione, A.; De Santis, A.; Palmieri, F.; Pizzolante, R. Privacy-preserving Secure Media Streaming for Multi-user Smart Environments. ACM Trans. Internet Technol. (Toit) 2021, 22, 1–21. [Google Scholar] [CrossRef]
- Xu, H.; Cai, Z.; Takabi, D.; Li, W. Audio-visual autoencoding for privacy-preserving video streaming. IEEE Internet Things J. 2021, 9, 1749–1761. [Google Scholar] [CrossRef]
- Kim, J.; Kim, M.; Kang, H.; Lee, K. U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation. arXiv 2019, arXiv:1907.10830. [Google Scholar]
- Meng, L.; Sun, Z.; Ariyaeeinia, A.; Bennett, K.L. Retaining expressions on de-identified faces. In Proceedings of the 2014 37th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 26–30 May 2014. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ma, T.; Rong, H.; Hao, Y.; Cao, J.; Tian, Y.; Al-Rodhaan, M.A. A novel sentiment polarity detection framework for Chinese. IEEE Trans. Affect. Comput. 2019, 13, 60–74. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ma, T.; Wang, H.; Zhang, L.; Tian, Y.; Al-Nabhan, N. Graph classification based on structural features of significant nodes and spatial convolutional neural networks. Neurocomputing 2021, 423, 639–650. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Jeon, J.; Park, J.C.; Jo, Y.; Nam, C.; Bae, K.H.; Hwang, Y.; Kim, D.S. A real-time facial expression recognizer using deep neural network. In Proceedings of the 10th International Conference on Ubiquitous Information Management and Communication, Da Nang, Vietnam, 4–6 January 2016; pp. 1–4. [Google Scholar]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020, 11, 1. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.-H.; et al. Challenges in Representation Learning: A Report on Three Machine Learning Contests. In Proceedings of the International Conference on Neural Information Processing, Daegu, Korea, 3–7 November 2013. [Google Scholar]
- Viola, P.A.; Jones, M.J. Rapid Object Detection using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Large-Scale CelebFaces Attributes (CelebA) Dataset. Available online: http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html (accessed on 7 March 2001).
- Bock, S.; Weiß, M. A proof of local convergence for the Adam optimizer. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Epochs | |
|---|---|---|
| QM-VAE | 10 | from 0 to 1 in steps of 0.1 |
| QM-VAE | 20 | from 0 to 1 in steps of 0.1 |
| QM-VAE | 30 | from 0 to 1 in steps of 0.1 |
| QM-VAE | 40 | from 0 to 1 in steps of 0.1 |
| Blindfold | ∖ | ∖ |
| Mosaic | ∖ | ∖ |
| Cartoon | ∖ | ∖ |
| Type | Blindfold | Mosaic | Laplace | Cartoon |
|---|---|---|---|---|
| Quality loss rate | 0.462 | 0.207 | 0.207 | 0.465 |
| Loss Rate | Angry | Fear | Happy | Sad | Surprise | Neutral |
|---|---|---|---|---|---|---|
| QM-VAE | 0.167 | 0.4 | 0.064 | 0.171 | 0.33 | 0.117 |
| Blindfold | 0.396 | 0.701 | 0.039 | 0.726 | 0.75 | 0.870 |
| Mosaic | 0.226 | 0.290 | 0.196 | 0.149 | 0.208 | 0.232 |
| Laplace | 0.321 | 0.204 | 0.178 | 0.246 | 0.333 | 0.191 |
| Cartoon | 0.755 | 0.452 | 0.504 | 0.343 | 0.542 | 0.423 |
| AMT-GAN | 0.551 | 0.776 | 0.144 | 0.677 | 0.826 | 0.476 |
| The Coefficient of MSE | Epochs = 20 | Epochs = 40 |
|---|---|---|
| 0 | 0.740 | 0.825 |
| 0.2 | 0.23 | 0.18 |
| 0.5 | 0.205 | 0.150 |
| 0.8 | 0.225 | 0.165 |
| 1 | 0.210 | 0.175 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Y.; Niu, Z.; Song, B.; Ma, T.; Al-Dhelaan, A.; Al-Dhelaan, M. A Novel Generative Model for Face Privacy Protection in Video Surveillance with Utility Maintenance. Appl. Sci. 2022, 12, 6962. https://doi.org/10.3390/app12146962
Qiu Y, Niu Z, Song B, Ma T, Al-Dhelaan A, Al-Dhelaan M. A Novel Generative Model for Face Privacy Protection in Video Surveillance with Utility Maintenance. Applied Sciences. 2022; 12(14):6962. https://doi.org/10.3390/app12146962
Chicago/Turabian StyleQiu, Yuying, Zhiyi Niu, Biao Song, Tinghuai Ma, Abdullah Al-Dhelaan, and Mohammed Al-Dhelaan. 2022. "A Novel Generative Model for Face Privacy Protection in Video Surveillance with Utility Maintenance" Applied Sciences 12, no. 14: 6962. https://doi.org/10.3390/app12146962
APA StyleQiu, Y., Niu, Z., Song, B., Ma, T., Al-Dhelaan, A., & Al-Dhelaan, M. (2022). A Novel Generative Model for Face Privacy Protection in Video Surveillance with Utility Maintenance. Applied Sciences, 12(14), 6962. https://doi.org/10.3390/app12146962