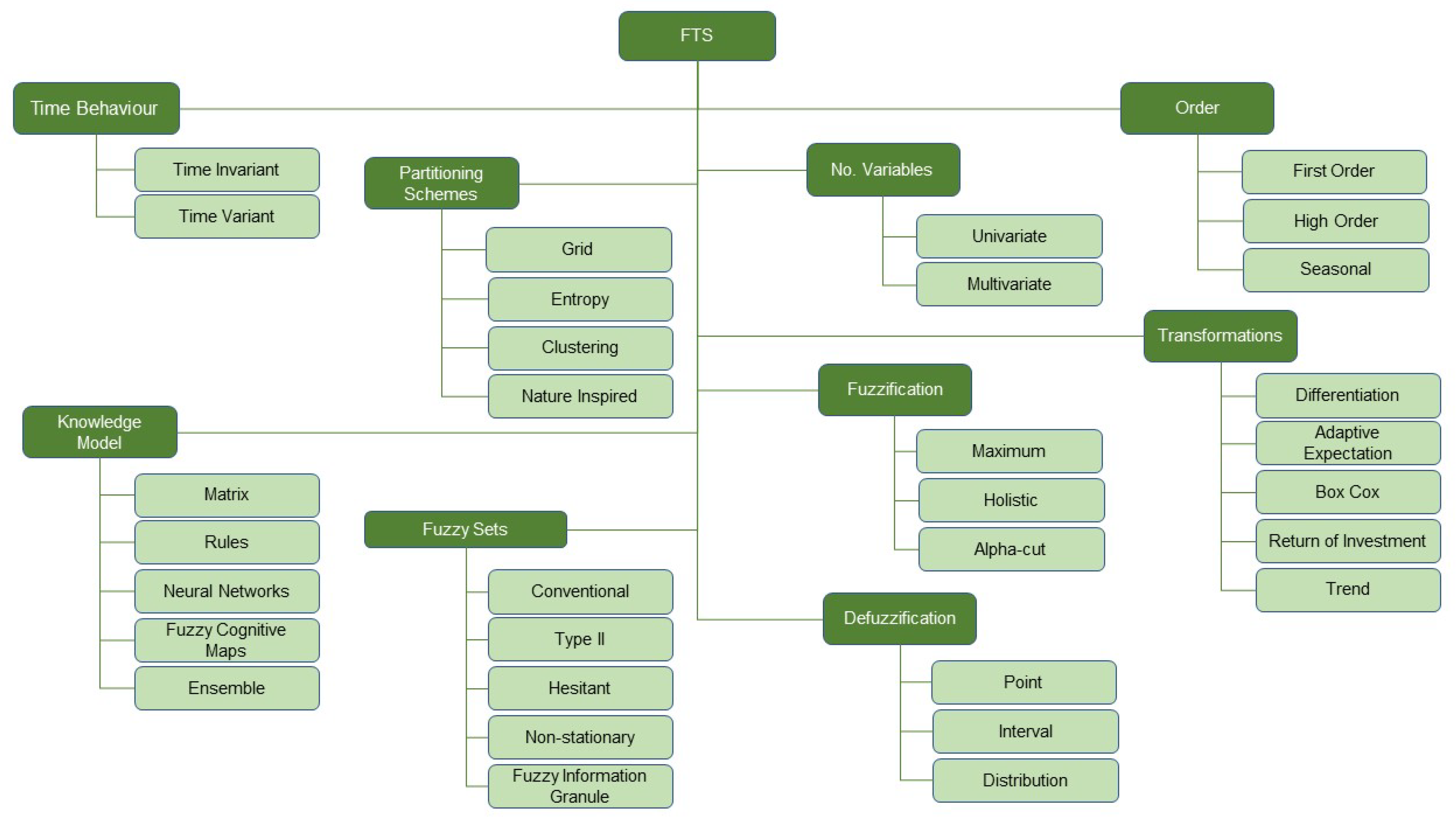
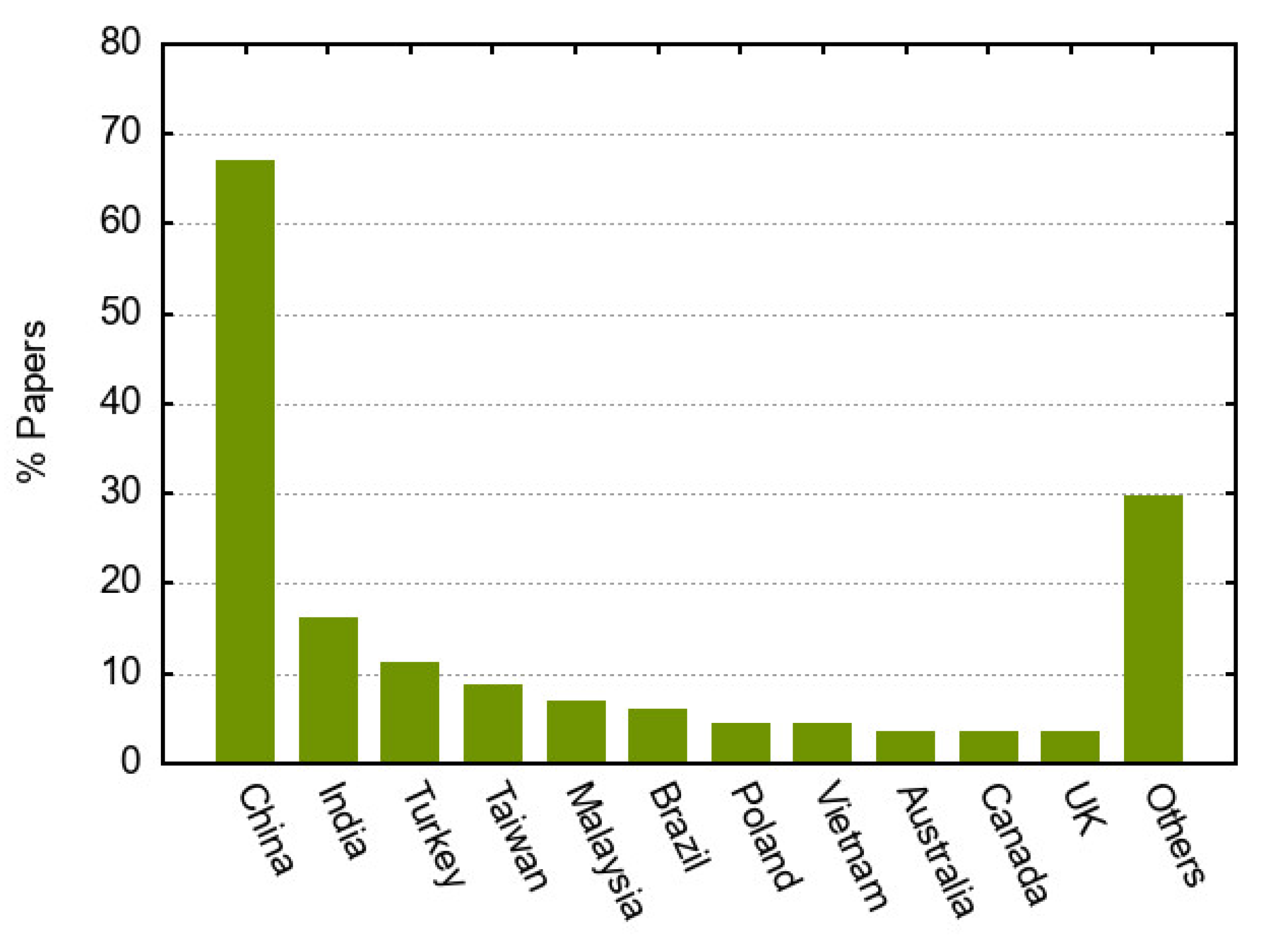
For the last research question, we intended to identify works considered important by other researchers, assuming that citations indicate relevance. To this end, a bibliometric indicator based on a relative weighted citation index was applied to evaluate the impact of an article. The relative weighted citation index
of an article
i was calculated as follows:
where
is the number of times that article
i was cited,
is the year of the present systematic review (i.e., 2022) and
refers to the publication year of article
i.
Note that this relative index weights the number of citations by the article age, thus not penalizing the young publications. Otherwise, by using the absolute number of citations, the old articles would likely be ranked at the top of the most influential works, since a longer time would allow them to accumulate more citations than recent publications.
Table 6 provides the top 10 most cited papers according to the relative weighted citation index
. The work by Sadaei et al. [
39] published in the
Energy journal was the most cited article, with 80 citations and a relative weighted citation index of 26.67, followed by the paper by Jiang et al. [
40] in Applied Energy and the paper by Castillo and Melin [
41] in
Chaos, Solitons & Fractals with 73 and 43 citations and scores of 24.33 and 23.00, respectively. It is also worth remarking that five of the most cited articles were published in journals that belong to Computer Science, and other four research areas (Energy and Fuels, Mathematics, Engineering and Automation and Control Systems) were represented by two papers each.
A Technical Overview of the Most Cited Articles
Using the list of papers given in
Table 6, this section highlights some technical subjects, including the proposed development, the time series data used in the experiments and the metrics applied to evaluate the performance in each article.
Sadaei et al. proposed a hybrid model based on FTS and convolutional neural networks for short-term load forecasting [
39], in which multi-variate time series were converted into multi-channel images to be processed by the deep neural network and FTS was used to apply regularization in the input layer to decrease the effect of overfitting. The algorithm was applied to temperature time series data and hourly load data of the power supply company of the city of Johor in Malaysia in the years 2009 and 2010. The metrics used to evaluate the performance of the model were absolute percentage error (APE), mean absolute percentage error (MAPE), root mean squared error (RMSE) and median relative absolute error (MdRAE).
Jiang et al. developed a three-stage system for wind speed time series, which comprised a data preprocessing module, an optimisation module and a forecasting module [
40]. In the data preprocessing phase, ensemble empirical mode decomposition [
49] was used to split the wind speed data into several intrinsic mode functions, eliminate the highest-frequency signal to reduce volatility and assemble the remaining signals to provide a new time series for forecasting. A multi-objective differential evolution algorithm and weighted FTS were applied in the optimisation and forecasting modules to achieve both accurate and stable results. The experiments were carried out over three short-term wind speed datasets from local wind farms in Penglai (China) and the performance was evaluated with mean absolute error (MAE), RMSE, MAPE, Theil’s inequality coefficient (TIC), variance of the forecasting error and direction accuracy of forecasting results (DA). This work presented compared different optimization algorithms (particle swarm optimisation, cuckoo search, harmony search and firefly algorithm) and several prediction models (three different neural network architectures, support vector regression, ARIMA and double exponential smoothing). In addition, hypothesis testing was used to verify statistically significant differences between the proposed forecasting system and the other models.
In the article by Castillo and Melin, a hybrid model based on fractal theory and fuzzy logic was applied to COVID-19 time series forecasting [
41]. The model was built with fuzzy rules that employed the fractal dimensions as input values and produced the predictions. The approach was evaluated over time series data related to confirmed, recovered and fatal cases of COVID-19 from 22 January 2020 to 31 March 2020 in 10 countries, taken from the Humanitarian Data Exchange website. The only metric used to assess the performance of the model was the forecasting error (the difference between the actual and predicted values).
Luo et al. introduced an evolving recurrent interval type-2 intuitionistic fuzzy neural network for time series forecasting and regression [
42]. In this model, the antecedent part of each fuzzy rule was defined using intuitionistic interval type-2 fuzzy sets, while the consequent rested upon the TSK-type FIS. The proposed model also employed a modified density-based clustering algorithm that allowed self-evolution of the intuitionistic fuzzy rules and adjustment of the network structure. The performance was compared to various variants of type-1 and type-2 fuzzy neural networks (both recurrent and feed-forward structures) using seven well-known benchmark databases and some high-frequency financial price prediction problems. The metrics used for performance evaluation were MAE, RMSE and MAPE.
Hybridisation of granular computing and bio-inspired computing for M-factors time series data forecasting was proposed by Singh and Dhiman [
43]. Granular computing was employed to discretize M-factors time series data set and obtain granular intervals, which were also used to fuzzify the time series data set; on the other hand, a bio-inspired algorithm was used to adjust the lengths of the intervals (both granular and non-granular) in the UoD. The proposed method was empirically compared to 12 existing models using the mean, standard deviation, RMSE and TIC to forecast the stock index prices of various companies obtained from
https://in.finance.yahoo.com/, accessed on 20 October 2016.
Zhang et al. presented a method based on two primary steps [
44]. First, the time series data were converted into a visibility graph (network) [
50] and an initial forecasting was made using link prediction [
51]. Then, the second step enhanced the initial predictions with the support of fuzzy logic (defining the fuzzy sets and fuzzy rules according to inter-relationship among the historical data). The method was applied to forecast three time series databases: the construction cost index, the Taiwan stock exchange index (TAIEX) and historical enrolment of the University of Alabama. The performance evaluation metrics used in the experiments were mean absolute difference (MAD), MAPE, symmetric mean absolute percentage error (SMAPE) and normalised root mean square error (NRMSE).
Wang et al. developed a hybrid air quality forecasting and early warning system consisting of a deterministic prediction module and an uncertainty analysis module [
45]. On the one hand, the deterministic prediction module defined the UoD and the fuzzy sets, fuzzified the observed rules, identified the FLRs, built a trend-weighted matrix where each row was for the occurrence frequency of the FLRs and predicted the output values by multiplying the defuzzified matrix and the trend-weighted matrix. On the other hand, the uncertainty analysis module applied interval forecasting based on the deterministic prediction to forecast the uncertainty of pollution concentrations. Two air pollution datasets from two cities in the Jing-Jin-Ji region (China) were used in the experiments and the performance of the forecasting system was assessed with MAPE, MAE, RMSE, median absolute percentage error, DA, fractional bias of forecasting results, index of agreement of forecasting results, Pearson’s correlation coefficient and interval forecasting average width.
A probabilistic intuitionistic fuzzy time series forecasting model using support vector machine to cope with both uncertainty and non-determinism associated with real-world time series was introduced by Pattanayak et al. [
46]. In addition, this work also proposed a new trend-based discretization method to determine the UoD and the number of intervals. The FLRs were identified by using the ratio trend variation of crisp observations and the mean of aggregated membership values, which were modelled through a support vector machine. The experiments were carried out over 16 benchmark time series datasets and the performance of the new method was compared to seven FTS models using RMSE, SMAPE and MAE.
Guler and Akkus proposed an FTS based on the fuzzy K-medoid clustering algorithm for the fuzzification step to remove outliers and abnormal observations [
47]. The new method was compared to two existing FTS models based on the fuzzy C-means and Gustafson–Kessel [
52] clustering algorithms to predict air pollution time series data consisting of weekly SO
2 concentrations measured at 65 monitoring stations in Turkey. RMSE and percent bias were used to assess the performance of the forecasting models.
Soto et al. designed a method for multiple time series forecasting using many inputs/many outputs (MIMO) fuzzy aggregation models (FAM) with modular neural networks [
48]. In this work, different MIMO-FAM approaches were used: (i) one based on the use of ANFIS with subtractive clustering and fuzzy C-means; (ii) one based on type-1 FIS of Mamdani type; and (iii) one based on interval type-2 FIS. The experiments were carried out over the Mexican stock exchange index, TAIEX and data from the National Association of Securities Dealers Automated Quotation and the performance was evaluated with MAE, RMSE and mean squared error.
From these articles, some comments can be made: (i) most works focused on proposing some kind of hybridisation to improve the performance of the FTS model; (ii) the most practical works corresponded to ad hoc solutions for specific problems, ranging from air pollution data to stock index prices and COVID-19 time series; (iii) the most used benchmark datasets were TAIEX and the University of Alabama enrolment; and (iv) many different metrics were applied to performance assessment.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}