
Link Pruning for Community Detection in Social Networks



Abstract
:1. Introduction
- We notice a different pattern between the attributes of links within a cluster (i.e., internal links) and those of links belonging to different clusters (i.e., external links).
- We develop a new community detection algorithm that removes less important links according to the different patterns of link attributes.
- We theoretically prove that link pruning effectively detects enhanced communities using a random graph model with planted clusters.
- We empirically show that the proposed algorithm achieves higher accuracy than the existing algorithms, especially when the pruning rate increases.
2. Related Work
2.1. Link Attributes
2.2. Community Detection
2.3. Graph Sparsification
3. Our Proposed Framework
3.1. Calculation of Link Attributes
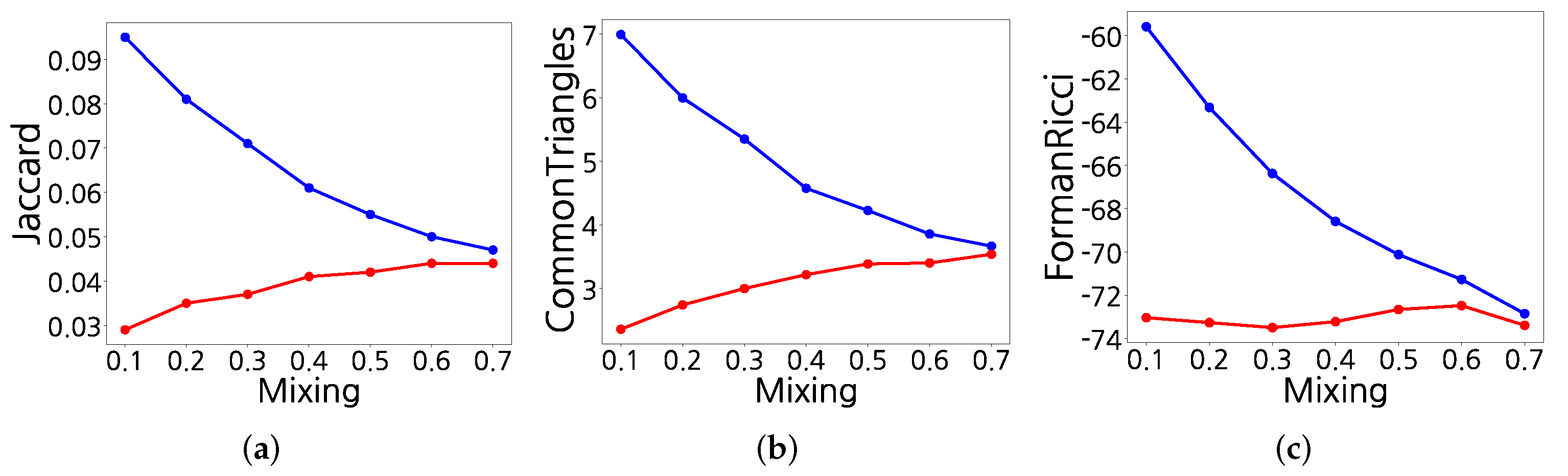
3.1.1. Jaccard’s Index
3.1.2. Number of Common Triangles
3.1.3. Forman–Ricci Curvature
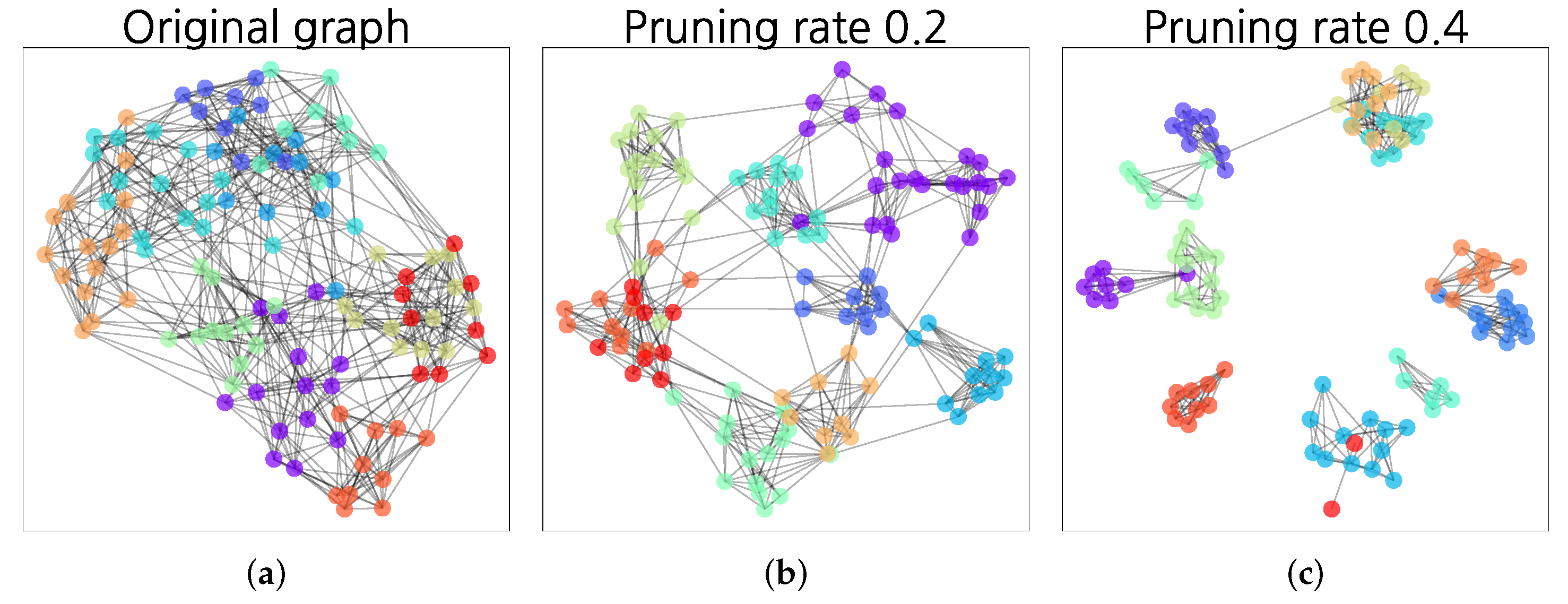
3.2. Algorithm for Clustering Using Link Pruning
3.2.1. Proposed Algorithm
| Algorithm 1: Clustering with Link Pruning. |
| input: (i) a graph ; (ii) a link attribute ; (iii) a pruning rate ; (iv) a clustering algorithm A; output: a set of clusters C of V; 1 /* Step 1: Calculate the link attributes */ 2 for do 3 | Calculate 4 /* Step 2: Sort the link attributes */ 5 Sort 6 /* Step 3: Prune low-value links */ 7 remove the smallest % links from G 8 /* Step 4: Detect communities in the transformed graph */ 9 apply A to 10 return C; |
3.2.2. Theoretical Analysis
4. Experiments
4.1. Datasets
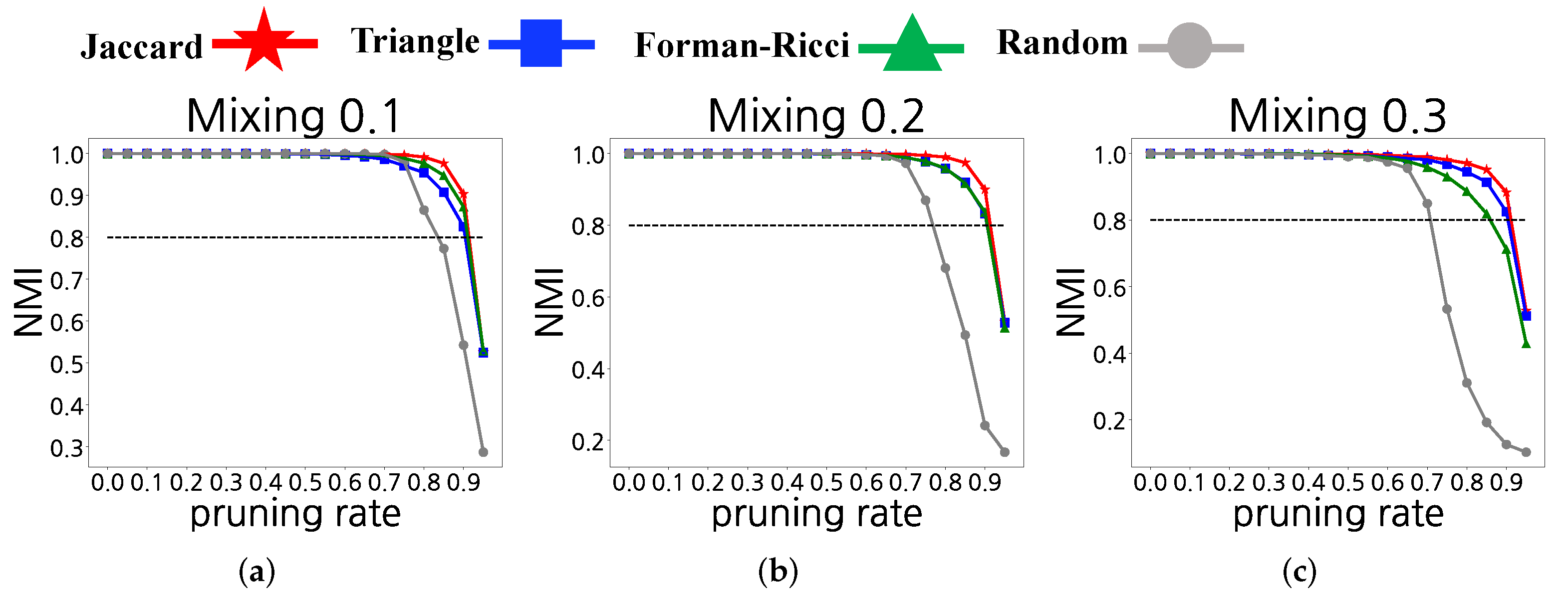
4.1.1. Synthetic Networks
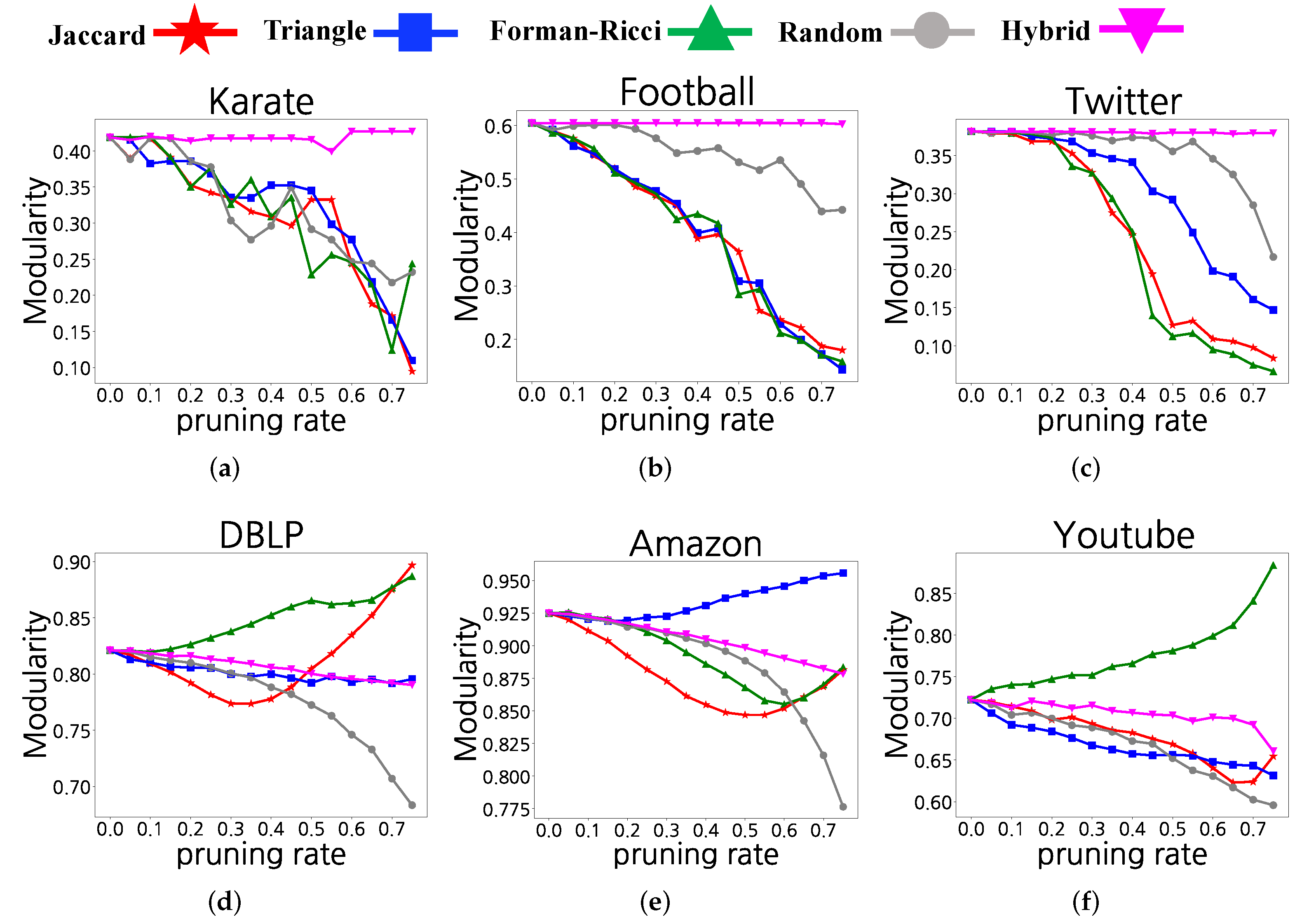
4.1.2. Real-World Networks
4.2. Link Attribute Distribution
4.2.1. Synthetic Networks
4.2.2. Real-World Networks
4.3. Community Detection
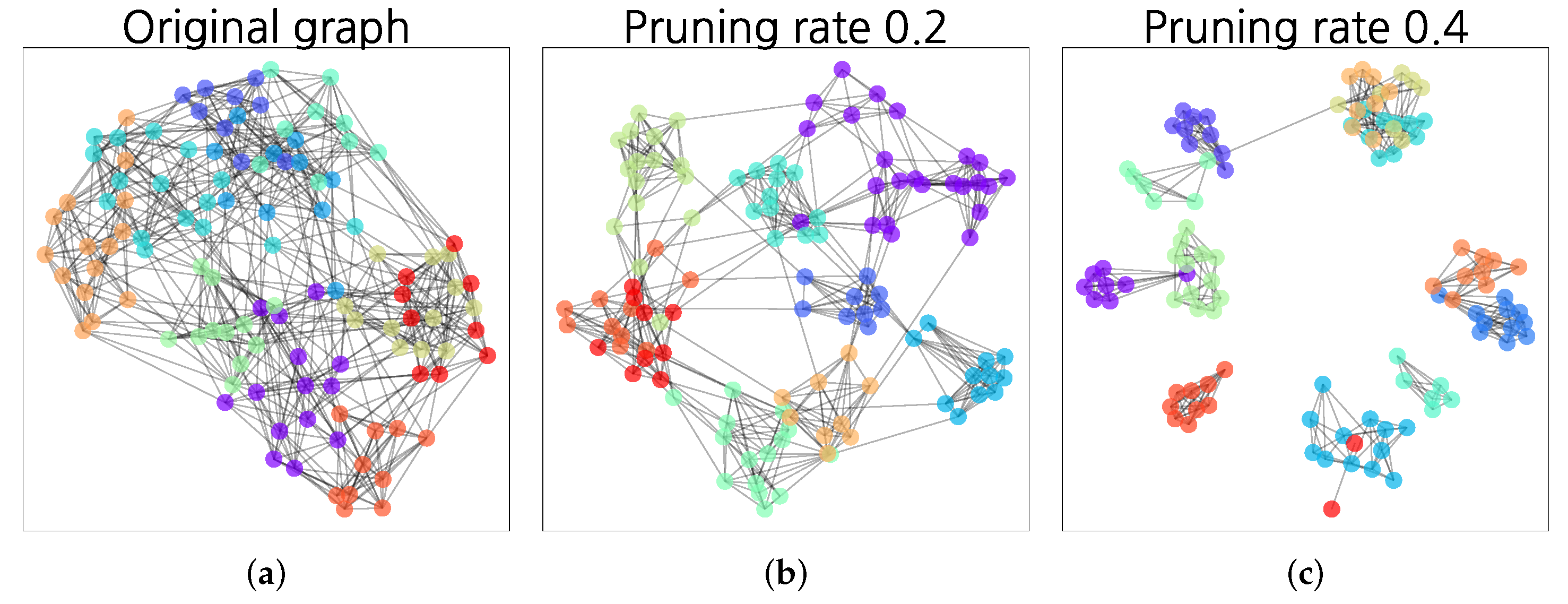
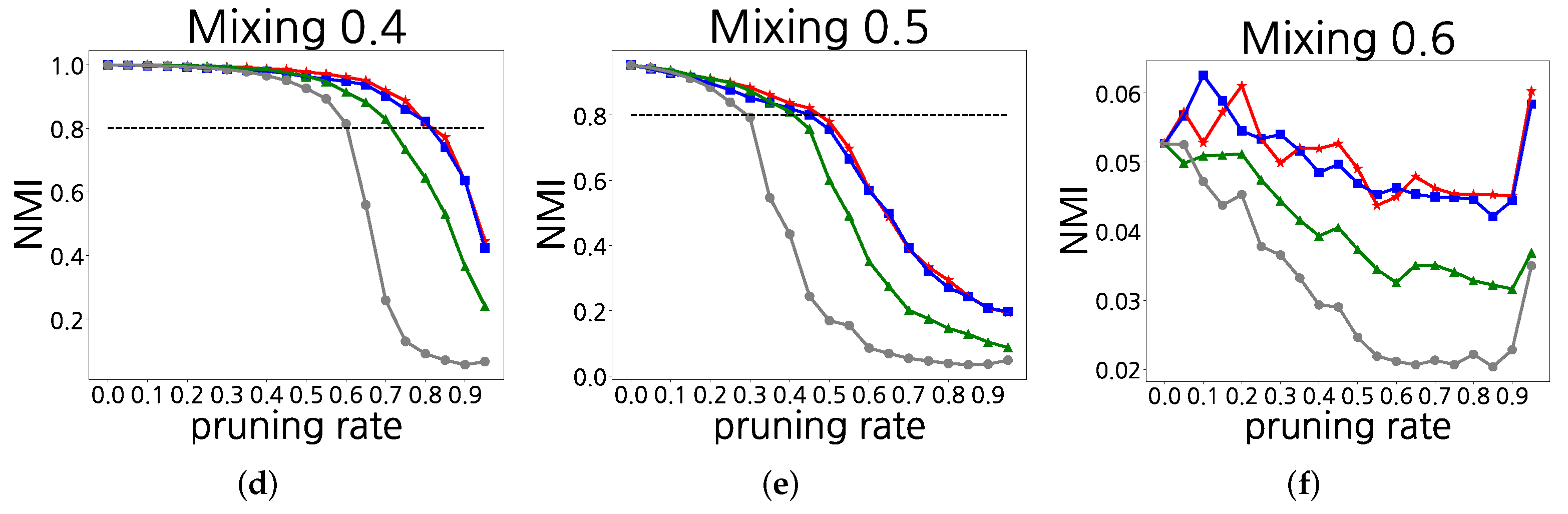
4.4. Synthetic Networks
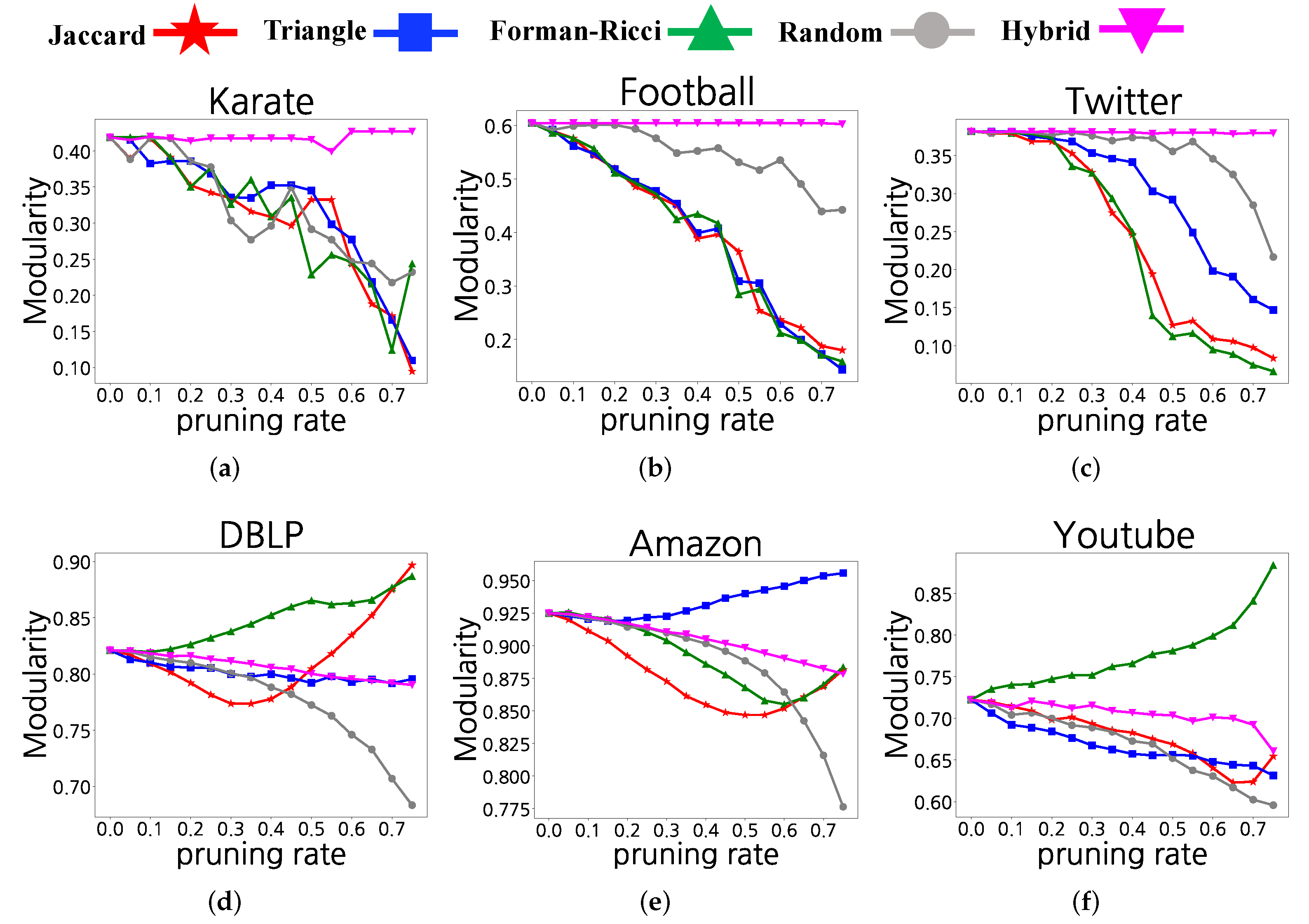
4.5. Real-World Networks
4.6. Hybrid Method
4.7. Verification of Efficiency
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kazienko, P.; Chawla, N. Applications of Social Media and Social Network Analysis; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Zhang, Z.; Cui, P.; Zhu, W. Deep Learning on Graphs: A Survey. IEEE Trans. Knowl. Data Eng. 2022, 34, 249–270. [Google Scholar] [CrossRef] [Green Version]
- Fortunato, S. Community Detection in Graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Strehl, A.; Ghosh, J. Cluster Ensembles—A Knowledge Reuse Framework for Combining Multiple Partitions. J. Mach. Learn. Res. 2002, 3, 583–617. [Google Scholar]
- Danon, L.; Diaz-Guilera, A.; Duch, J.; Arenas, A. Comparing Community Structure Identification. J. Stat. Mech. Theory Exp. 2005, 2005, P09008. [Google Scholar] [CrossRef]
- Newman, M.E.J. Fast Algorithm for Detecting Community Structure in Networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newman, M.E.J. Modularity and Community Structure in Networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [Green Version]
- Cai, H.; Zheng, V.W.; Chang, K.C.C. A Comprehensive Survey of Graph Embedding: Problems, Techniques, and Applications. IEEE Trans. Knowl. Data Eng. 2018, 30, 1616–1637. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Lim, S.; Lee, J.G. Motif-based Embedding for Graph Clustering. J. Stat. Mech. Theory Exp. 2016, 2016, P123401. [Google Scholar] [CrossRef]
- Liben-Nowell, D.; Kleinberg, J. The Link-Prediction Problem for Social Networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef] [Green Version]
- Sreejith, R.P.; Mohanraj, K.; Jost, J.; Saucan, E.; Samal, A. Forman Curvature for Complex Networks. J. Stat. Mech. Theory Exp. 2016, 2016, P063206. [Google Scholar] [CrossRef] [Green Version]
- Sia, J.; Jonckheere, E.; Bogdan, P. Ollivier-Ricci Curvature-Based Method to Community Detection in Complex Networks. Sci. Rep. 2019, 9, 9800. [Google Scholar] [CrossRef] [PubMed]
- Lancichinetti, A.; Fortunato, S. Community Detection Algorithms: A Comparative Analysis. Phys. Rev. E 2009, 80, 056117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fortunato, S.; Hric, D. Community Detection in Networks: A User Guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef] [Green Version]
- Yousuf, M.I.; Kim, S. Guided Sampling for Large Graphs. Data Min. Knowl. Discov. 2020, 34, 905–948. [Google Scholar] [CrossRef]
- Rozemberczki, B.; Kiss, O.; Sarkar, R. Little Ball of Fur: A Python Library for Graph Sampling. In Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM), Virtual Event, 19–23 October 2020. [Google Scholar]
- Krishnamurthy, V.; Faloutsos, M.; Chrobak, M.; Lao, L.; Cui, J.H.; Percus, A.G. Reducing Large Internet Topologies for Faster Simulations. In Proceedings of the International IFIP-TC6 Networking Conference (Networking), Waterloo, ON, Canada, 2–6 May 2005. [Google Scholar]
- Ahmed, N.K.; Neville, J.; Kompella, R. Network Sampling: From Static to Streaming Graphs. ACM Trans. Knowl. Discov. Data 2014, 8, 7. [Google Scholar] [CrossRef]
- Satuluri, V.; Parthasarathy, S.; Ruan, Y. Local Graph Sparsification for Scalable Clustering. In Proceedings of the ACM International Conference on Management of Data (SIGMOD), Athens, Greece, 12–16 June 2011. [Google Scholar]
- Sun, H.; Zanetti, L. Distributed Graph Clustering and Sparsification. ACM Trans. Parallel Comput. 2019, 6, 17. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lim, S.; Lee, J.G.; Lee, B.S. LinkBlackHole*: Robust Overlapping Community Detection Using Link Embedding. IEEE Trans. Knowl. Data Eng. 2019, 31, 2138–2150. [Google Scholar] [CrossRef]
- Lim, S.; Ryu, S.; Kwon, S.; Jung, K.; Lee, J.G. LinkSCAN*: Overlapping Community Detection Using the Link-Space Transformation. In Proceedings of the IEEE International Conference on Data Engineering (ICDE), Chicago, IL, USA, 31 March–4 April 2014. [Google Scholar]
- Zhou, F.; Mahler, S.; Toivonen, H. Network Simplification with Minimal Loss of Connectivity. In Proceedings of the IEEE International Conference on Data Mining (ICDM), Sydney, Australia, 13–17 December 2010; pp. 659–668. [Google Scholar]
- Salton, G.; McGill, M.J. Introduction to Modern Information Retrieval; McGrawHill: New York, NY, USA, 1983. [Google Scholar]
- Newman, M.E.J. Clustering and Preferential Attachment in Growing Networks. Phys. Rev. E 2001, 64, 025102(R). [Google Scholar] [CrossRef] [Green Version]
- Abbe, E. Community Detection and Stochastic Block Models: Recent Developments. J. Mach. Learn. Res. 2018, 18, 1–86. [Google Scholar]
- Karrer, B.; Newman, M.E. Stochastic Blockmodels and Community Structure in Networks. Phys. Rev. E 2011, 83, 016107. [Google Scholar] [CrossRef] [Green Version]
- Kunegis, J. KONECT: The Koblenz Network Collection. In Proceedings of the International World Wide Web Conference (WWW), Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1343–1350. [Google Scholar]
- Spielman, D.A.; Teng, S.H. Nearly-Linear Time Algorithms for Graph Partitioning. In Proceedings of the Annual ACM Symposium on Theory of Computing (STOC), Chicago, IL, USA, 13–15 June 2004; pp. 81–90. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast Unfolding of Communities in Large Networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Chamberlain, B.P.; Levy-Kramerand, J.; Humby, C.; Deisenrothe, M.P. Real-Time Community Detection in Full Social Networks on a Laptop. PLoS ONE 2018, 13, e0188702. [Google Scholar] [CrossRef] [Green Version]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near Linear Time Algorithm to Detect Community Structures in Large-Scale Networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef] [Green Version]
- Rosvall, M.; Bergstrom, C.T. Maps of Random Walks on Complex Networks Reveal Community Structure. Proc. Natl. Acad. Sci. USA 2008, 105, 1118–1123. [Google Scholar] [CrossRef] [Green Version]
- Pons, P.; Latapy, M. Computing Communities in Large Networks Using Random Walks. J. Graph Algorithms Appl. 2006, 10, 191–218. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Algesheimer, R.; Tessone, C.J. A Comparative Analysis of Community Detection Algorithms on Artificial Networks. Sci. Rep. 2016, 6, 30750. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # of Nodes | # of Links | Clustering Coefficient |
|---|---|---|---|
| Karate | 34 | 78 | 0.571 |
| Football | 115 | 613 | 0.403 |
| 348 | 4831 | 0.475 | |
| DBLP | 317,080 | 1,049,866 | 0.632 |
| Amazon | 334,863 | 925,872 | 0.397 |
| YouTube | 1,134,890 | 2,987,624 | 0.081 |
| Dataset | Link Type | |||
|---|---|---|---|---|
| Karate | intra | |||
| inter | ||||
| Football | intra | |||
| inter | ||||
| intra | ||||
| inter | ||||
| DBLP | intra | |||
| inter | ||||
| Amazon | intra | |||
| inter | ||||
| YouTube | intra | |||
| inter |
| Pruning Rate () | Louvain | LPA | Infomap | Fastgreedy | Walktrap |
|---|---|---|---|---|---|
| 0 | 4.94 | 28.31 | 1681.35 | 308.87 | 1495.25 |
| 0.1 | 4.59 | 22.49 | 1332.08 | 137.12 | 1398.27 |
| 0.2 | 4.42 | 14.81 | 903.47 | 32.16 | 1392.60 |
| 0.3 | 4.32 | 12.19 | 10504.02 | 63.47 | 1199.82 |
| Pruning Rate () | Louvain | LPA | Infomap | Fastgreedy | Walktrap |
|---|---|---|---|---|---|
| 0 | 0.926 | 0.786 | 0.825 | 0.867 | 0.849 |
| 0.1 | 0.911 | 0.760 | 0.803 | 0.889 | 0.811 |
| 0.2 | 0.892 | 0.741 | 0.782 | 0.886 | 0.793 |
| 0.3 | 0.873 | 0.725 | 0.767 | 0.868 | 0.783 |
| Pruning Rate () | Louvain | LPA | Infomap | Fastgreedy | Walktrap |
|---|---|---|---|---|---|
| 0 | 0.0012 | 0.0033 | 0.0029 | 0.0015 | 0.0028 |
| 0.1 | 0.0011 | 0.0033 | 0.0029 | 0.0011 | 0.0029 |
| 0.2 | 0.0012 | 0.0033 | 0.0031 | 0.0012 | 0.0031 |
| 0.3 | 0.0028 | 0.0033 | 0.0031 | 0.0028 | 0.0028 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Jeong, S.; Lim, S. Link Pruning for Community Detection in Social Networks. Appl. Sci. 2022, 12, 6811. https://doi.org/10.3390/app12136811
Kim J, Jeong S, Lim S. Link Pruning for Community Detection in Social Networks. Applied Sciences. 2022; 12(13):6811. https://doi.org/10.3390/app12136811
Chicago/Turabian StyleKim, Jeongseon, Soohwan Jeong, and Sungsu Lim. 2022. "Link Pruning for Community Detection in Social Networks" Applied Sciences 12, no. 13: 6811. https://doi.org/10.3390/app12136811
APA StyleKim, J., Jeong, S., & Lim, S. (2022). Link Pruning for Community Detection in Social Networks. Applied Sciences, 12(13), 6811. https://doi.org/10.3390/app12136811